Дополнение A. Управление памятью и безопасность (Полное руководство Rust, 2е изд)
Содержание
- Дополнение A. Управление памятью и безопасность (Полное руководство Rust, 2е изд)
- Программы и память
- Как программы используют память?
- Управление памятью и его виды
- Подходы к выделению памяти
- Ловушки управления памятью
- Безопасность памяти
- Триединство безопасности памяти
- Типы указателей в Rust
- Выводы
Перевод Главы 5 Управление памятью и безопасность из 2го издания Полного руководства Rust, Рауля Шармы и Везы Кайхлавирты, (с) 2019, Packt Publishing.
Управление памятью это фундаментальная концепция для понимания всем, кто работает с языком программирования нижнего уровня. Языки программирования нижнего уровня не поставляются с решениями автоматического восстановления памяти, такими как встроенные сборщики мусора и управление используемой его программой памятью это всецело ответственность самого программиста. Обладание знанием того как память применяется программой позволяет программистам строить действенные и безопасные программные системы. Большое число ошибок при программировании на нижнем уровне обусловлено ненадлежащей обработкой памяти. Порой это ошибка самого программиста. В других ситуациях это сторонний эффект собственно применяемого языка программирования, такого как C и C++, которые обладают позорной репутацией большого числа отчётов уязвимостей памяти в программном обеспечении. Rust предлагает лучшее решение времени компиляции для управления памятью. Это делает затруднительным написание программного обеспечения с утечками памяти, только если намеренно не добиваться этого! Выполнившие достаточное число разработок на Rust программисты в конечном итоге приходят к осознанию того, что он препятствует плохой практике программирования и направляет самого программиста к написанию программ, которые безопасно и действенно применяют память.
В данной главе мы углубимся в мельчайшие подробности того, как Rust приручает память, которая используется ресурсами в программе. Мы предоставим краткое введение в процессы, выделение памяти, управление памятью и в то, что мы понимаем под безопасностью памяти. Затем мы пройдёмся по тому как собственно модель безопасности памяти предоставляется Rust и пониманию тех понятий, которые позволяют отслеживать применение памяти во время компиляции. Мы также окунёмся в различные типы умных указателей, которые предоставляют абстракции для управления ресурсами в самой программе.
Вот вопросы, которые мы рассматриваем в данной главе:
-
Программы и память
-
Выделение памяти и безопасность
-
Управление памятью
-
Стек и куча
-
Триединство безопасности - владение, заимствование и времена жизни.
-
Типы умных указателей.
"Если вы желаете ограничить имеющуюся гибкость своего подхода, вы почти всегда можете сделать что- то лучше."
Джон Кармак
В качестве своей мотивации пониманию памяти и её управления, нам важно обладать общей идеей того как программы запускаются операционной системой и какие механизмы стоят за тем, что позволяет им использовать для своих потребностей память.
Всякая программа для запуска нуждается в памяти, будь то ваш любимый инструмент командной строки или сложная служба
обработки потока. В большинстве реализаций операционных систем исполняемая программа реализуется в качестве процесса. Процесс
это исполняемый экземпляр программы. Когда мы запускаем ./my_program в оболочке в Linux
или дважды кликаем по my_program.exe в Windows, соответствующая ОС загружает
my_program в качестве процесса в память и начинает исполнять её, помимо прочих процессов,
предоставляя ей разделение ЦПУ и памяти. Она назначает такому процессу его собственное виртуальное адресное пространство,
которое отличается от виртуальных адресных пространств прочих процессов и обладает своим собственным представлением
памяти.
На протяжении всего времени жизни процесса он пользуется большим числом системных ресурсов. Прежде всего, ему необходима
память для хранения своих собственных инструкций, далее ему требуется пространство для запрашиваемых во время исполнения
инструкций ресурсов, а также значение адреса для возвращения после самой последней активированной функции. Некоторые из таких
требований могут решаться заблаговременно во время компиляции, такие как сохранение примитивов типа в некоторой переменной,
в то время как прочие могут быть удовлетворены лишь во время исполнения, например, создание динамических данных, таких как
Vec<String>. По причине имеющегося разнообразия уровней требования памяти, а также
для целей безопасности, представление памяти процесса подразделяется на области, известные как схема памяти.
Здесь у нас имеется общее приблизительное представление схемы памяти процесса:
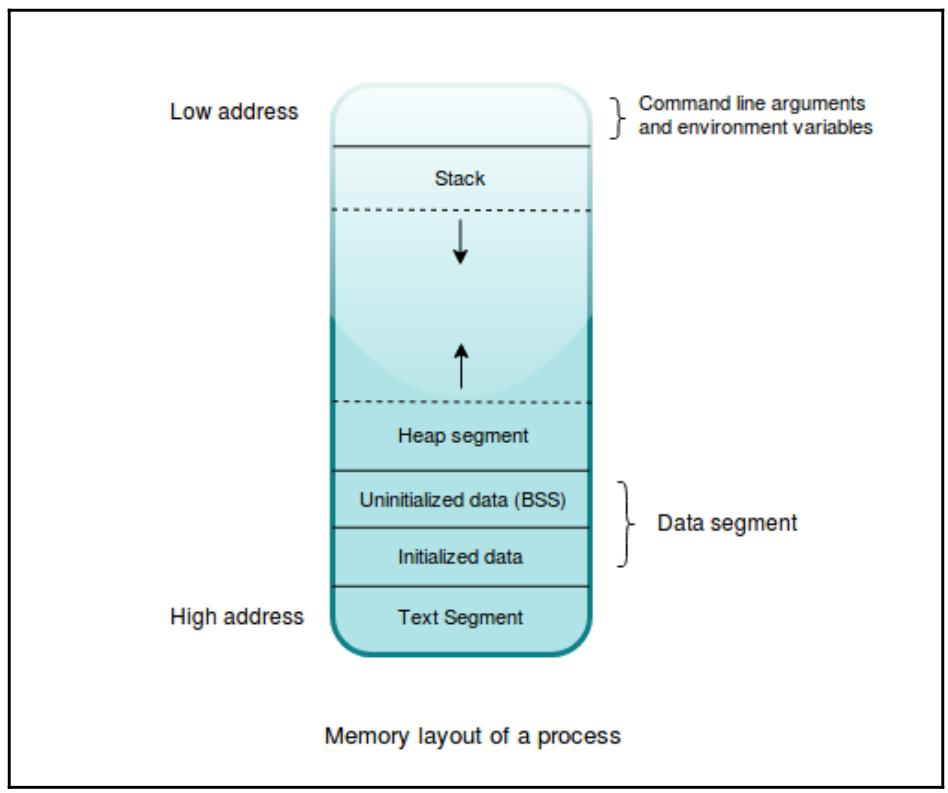
Эта схема делится на различные области на основании того вида данных, которые они хранят, а также предоставляемых ими функциональных возможностей. Основные рассматриваемые нами части таковы:
-
Сегмент текста: Этот раздел содержит реальный код, подлежащий исполнению в его откомпилированном двоичном файле. Такой текстовый сегмент является доступным только на чтение сегментом и любому коду пользователя запрещено изменять его. Осуществление такого может приводить к крушению самой программы.
-
Сегмент данных: Он и далее делится на подразделы, например, на сегмент инициализированных данных и сегмент не инициализированных данных, который исторически именуется Block Started by Symbol BSS (Bold, начинающийся с символа блок), и он содержит все глобальные и статические значения, объявляемые в самой программе. Не инициализированные значения вначале заполняются нулями при своей загрузке в память.
-
Сегмент стека: Этот сегмент используется для удержания всех локальных переменных и значений возвращаемых адресов функций. Все ресурсы, размер которых известен на будущее и все временные/ промежуточные создаваемые программой переменные в явном виде хранятся в стеке.
-
Сегмент кучи: Данный сегмент применяется для хранения всех динамически выделяемых данных, чей размер не известен наперёд и может изменяться во время исполнения в зависимости от имеющихся потребностей своей программы. Именно это место является идеальным, когда нам желательно чтобы значения жили дольше чем их определение внутри некоторой функции.
Итак, нам известно, что процесс обладает неким фрагментом памяти, выделенной для его исполнения. Однако как он получает доступ к этой памяти для осуществления своих задач? По причинам безопасности и для изоляции отказов, процессу запрещён прямой доступ к имеющейся физической памяти. Вместо этого он пользуется виртуальной памятью, которая ставится в соответствие реальной физической памяти самой ОС, при помощи структур данных в памяти, носящих название страниц, которые сопровождаются в таблицах страниц. Сам процесс обязан запрашивать память у своей ОС для её применения, а то что он получает, это виртуальные адреса, которым внутренним образом ставятся в соответствие физические адреса в оперативной памяти. По причинам производительности, такая память запрашивается и обрабатывается фрагментами. Когда доступ к виртуальной памяти осуществляется из её процесса, имеющееся устройство управления памятью выполняет реальное преобразование из виртуальной памяти в физическую.
Вся последовательность шагов, через которую память запрашивается процессом у своей ОС называется
выделением памяти. Процесс запрашивает фрагмент памяти у ОС
при помощисистемных вызовов, и сама ОС помечает такой фрагмент памяти используемым
данным процессом. когда процесс выполнил использование такой памяти, он обязан пометить такую память как свободную с тем,
чтобы ею могли применять прочие процессы. Это носит название освобождения
(de-allocation) памяти. Основные реализации операционных систем предоставляют абстракции через системные вызовы (например,
brk и sbrk в Linux), которые являются функциями,
которые общаются непосредственно с самим ядром ОС и способны выполнять выделение памяти, запрашиваемое соответствующим процессом.
Однако такие функции уровня ядра слишком низкоуровневые, а потому они и дальше абстрагируются системными библиотеками, такими как
библиотека glibc, которая является стандартной библиотекой C в
Linux, включающей необходимую реализацию API POSIX, обеспечивающего взаимодействие на нижнем уровне со своей ОС из языка
программирования C.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
POSIX это сокращение от Portable Operating System Interface, термина, введённого Ричардом Стэллманом. Это набор стандартов, который появился с потребностью для стандартизации той функциональности, которую должны предоставлять подобные Unix операционные системы, какие API нижнего уровня они должны выставлять в языки программирования, подобные C, какие утилиты командной строки они должны включать и многие прочие стороны. |
Glib также предоставляет API механизма распределения памяти, выставляя такие функции как
malloc, calloc и
realloc для выделения памяти и функцию free для
освобождения памяти. Даже хотя у нас имеется API достаточно высокого уровня для выделения/ освобождения памяти, нам всё ещё
приходится самостоятельно управлять памятью при программировании низкого уровня на языках программирования.
Оперативная память в вашем компьютере это ограниченный ресурс и он разделяется между всеми программами. Существует необходимость
того, чтобы когда программа закончила выполнять свои инструкции, она ожидает высвобождения всей применявшейся ею памяти с тем,
чтобы её ОС могла восстановить её и снабдить ею прочие процессы. Когда мы говорим об управлении памятью, заметной стороной этого
является то, как мы заботимся о восстановлении используемой памяти и как это происходит. Такой уровень управления, необходимый
для освобождения памяти, отличается в разных языках программирования. Вплоть до середины 1990-х основные языки программирования
полагались на управление памятью вручную, что требовало от программиста вызывать API механизма выделения памяти, такие как
malloc и free при кодировании для выделения и
освобождения памяти, соответственно. Примерно в 1959 году, Джон МакКарти,
создательLisp, предложил Сборщики
мусора (Garbage Collectors, GC), некую форму
автоматического управления памятью и Lisp был первым языком программирования, применявшим их. Сборщик мусора работает как
поток демона в виде части своей исполняемой программы и анализирует свою память, на которую больше нет ссылок ни из каких
переменных в его программе и автоматически освобождает их в определённые моменты времени по ходу исполнения своей программы.
Однако языки нижнего уровня не поставляются со сборщиками мусора, так как они вносят неопределённость и накладные расходы времени исполнения, по причине того, что сам сборщик мусора исполняется в фоновом режиме, что при некоторых обстоятельствах приостанавливает исполнение его программы. Такие паузы порой достигают латентности в миллисекунды. Это может жёстко нарушать согласованность времени и пространства системного программного обеспечения. Языки программирования нижнего уровня отдают это на откуп программисту для контроля распределения памятью вручную. Однако такие языки программирования как C++ и Rust снимают некое такое бремя с программистов через такие типы системной абстракции как умные указатели, которые мы обсудим в этой главе позднее.
Принимая во внимание имеющиеся отличия между языками программирования, мы можем классифицировать применяемые стратегии управления памятью в три ёмкости:
-
Вручную: C обладает такой формой управления памятью, когда именно в руках программиста всецело находится ответственность помещения вызовов
freeпосле того как код завершил применение памяти. C++ автоматизирует это до некоторой степени, применяя умные указатели, в которых такой вызовfreeпомещается в определение метода деструктора класса. Rust также обладает умными указателями, которые мы обсудим в этой главе позднее. -
Автоматически: Языки программирования с таким видом управления памяти содержат некий дополнительный поток времени исполнения, называемый Сборщиком мусора, который работает совместно с самой программой в качестве потока демона. Большинство динамических языков программирования, таких как Python, Java, C#, Ruby полагаются на автоматическое управление памятью. Автоматическое управление памятью одна из основных причин, по которой написание кода на таком языке простое.
-
Полу- автоматически: В эту категорию попадают такие языки программирования как Swift. Они не обладают выделенным Сборщиком мусора, собираемого как часть его времени исполнения, однако предлагает тип счётчиков ссылок, который автоматически управляет памятью на уровне некой грануляции. Rust также предоставляет типы счётчиков ссылок
Rc<T>иArc<T>. Мы вернёмся к ним позднее в этой главе, когда поясним умные счётчики.
Во время исполнения выделение памяти в процессе происходит либо через стек, либо через кучу. Это местоположения хранения, которые используются для хранения значений в процессе исполнения самой программы. В этом разделе мы рассмотрим оба эти подхода выделения памяти.
Стек применяется для значений с коротким временем хранения, чьи размеры известны в момент компиляции и является идеальным местоположением хранения для вызова функции и связанного с ней контекста, которые удаляются прочь после возврата из функции. Куча служит для всего, что должно выживать вне приделов вызова функций. Как упоминалось в Главе 1, Getting Your Feet Wet 2го издания Полного руководства Rust, Рауля Шармы и Везы Кайхлавирты, (с) 2019, Packt Publishing, Rust предпочитает по умолчанию выделения стека. Все значения или экземпляры некого типа, которые вы создали и привязали к переменной по умолчанию сохраняются в стеке. Сохранение в куче выполняется в явном виде и осуществляется с применением типов умного указателя, которые поясняются позднее в этой главе.
Каждый раз когда мы вызываем функцию или метод, для выделения пространства создаваемым внутри такой функции значениям
применяется стек. Все привязки let из вашей функции хранятся в стеке либо как значения
сами по себе, либо как указатели на расположения в памяти из кучи. Такие значения составляют свой
кадр стека для конкретной функции. Кадр стека это логический блок
памяти в стеке, который хранит весь контекст вызова функции. Такой контекст может содержать аргументы функции, локальные
переменные, возвращаемые адреса и все сохраняемые значения регистров, которые требуются для восстановления после возвращения из
такой функции. По мере того как вызывается всё больше и больше функций, их соответствующие кадры стека доставляются в общий стек.
После возврата из функции, такой соответствующий этой функции кадр стека уходит прочь, причём совместно со всеми объявленными
внутри этого кадра значениями.
Такие значения удаляются в обратном к их объявлению порядке, следуя порядку LIFO (Last In First Out, Последний пришедший обслуживается первым).
Выделения в памяти стека быстрые, поскольку выделение и очистка памяти в этом случае требует всего одной инструкции:
приращение/ вычитание значения указателя кадра стека. Такой указатель стека (esp)
это регистр ЦПУ, который всегда указывает на значение вершины своего стека. Значение указателя кадра стека продолжает
обновляться по мере вызова функции или после возврата из неё. Когда выполняется возврат из функции, её кадр стека отбрасывается
через возвращение значения указателя кадра стека в то место, в котором он пребывал до входа в эту функцию. Применение стека
это стратегия временного выделения памяти, однако она надёжна в плане высвобождения применяемой памяти по причине своей
простоты. Однако это же самое свойство стека превращает его в неприемлемое для случаев, при которых нам требуются значения с
более длительным временем жизни за рамками текущего кадра стека.
Вот фрагмент кода для точной иллюстрации того, как обновляется стек в процессе вызовов функций:
// stack_basics.rs
fn double_of(b: i32) -> i32 {
let x = 2 * b;
x
}
fn main() {
let a = 12;
let result = double_of(a);
}
Мы будем представлять значение состояния своего стека для этой программы неким пустым массивом
[]. Давайте поясним значение содержимого стека выполняя холостой пробег этой
программы. Мы будем применять [] также для представления кадров стека внутри
нашего родительского стека. При выполнении данной программы, вот последовательность происходящих шагов:
-
При активации функции
mainсоздаётся необходимый кадр стека, который содержитaиresult(инициализированный нулями). Этот стек теперь[[a=12, result=0]]. -
Затем вызывается функция
double_ofи в наш стек помещается новый кадр стека для хранения её локальных значений. Значение содержимого стека теперь[[a=12, result=0], [b=12, temp_double=2*x, x=0]].temp_doubleэто временная переменная, которая создаётся самим компилятором для хранения значения результата2 * x, которое затем назначается значениюxтой переменной, которая создаётся внутри самой функцииdouble_of. Этаxзатем возвращается вызывающей стороне, которой выступает наша функцияmain. -
После возврата из
double_ofеё кадр стека выдавливается из общего стека и стек теперь это[[a=12, result=24]. -
Вслед за этим завершается
mainи выталкивается её кадр стека, оставляя стек пустым:[].
Однако, для этого имеются дополнительные подробности. Мы прошлись лишь по очень верхнему уровню вызова функции и её взаимодействия со стеком памяти. Теперь, если бы всё что у нас имелось, было бы локальными значениями, остающимися действительными только на время жизни вызова самой функции, это было бы слишком ограниченным. Хотя стек прост и мощен для своей практичности, программе также требуются переменные с более длительным временем жизни, а для этого нам необходима куча.
Куча служит для более сложных и динамических требований выделения памяти. программа способны выделять память в куче в
определённый момент времени и способна высвобождать её в иной момент, причём нет необходимости строгих границ между этими
моментами, как это присутствует в случае со стеком памяти. Кроме того, некое значение в такой куче может жить вне самой
функции, в которой произошло выделение и оно позднее может быть отозвано какой- то другой функцией. В такой ситуации данный
код закончится неудачно при вызове free, а потому он не сможет отозвать её, что будет
наихудшим вариантом.
Различные языки программирования пользуются кучей по- разному. В динамических языках программирования, таких как Python,
всё является объектами, а они по умолчанию размещаются в куче. В C мы выделяем память в куче при помощи применения
malloc вручную, в то время как в C++ мы осуществляем выделение при помощи ключевого
слова new. Для отзыва выделения памяти нам требуется вызывать
free в C и delete в C++. В C++ во избежание
применения вызовов delete программисты часто пользуются умными указателями, такими как
unique_ptr или shared_ptr. Такие умные указатели
обладают методами деструктора, которые активируются, когда они выходят за рамки области действия, внутренним образом вызывая
delete. Такая парадигма управления памятью носит название принципа RAII, который и
получил популярность из C++.
|
| Замечание |
|---|---|
|
RAII это сокращение для Resource Acquisition Is Initialization (Получение ресурса инициализацией); парадигмы, которая предполагает, что ресурсы должны получаться при инициализации объектов и высвобождаются при их освобождении или при вызове их деструкторов. |
Rust также обладает аналогичные абстракции того как C++ управляет кучей памяти. Здесь единственный способ для выделения
памяти в имеющейся куче пролегает через типы умных указателей. Типы умных указателей в Rust реализуют признак (trait)
Drop, который определяет как именно используемая этим значением память должна
отзываться и семантически он аналогичен методам деструкторов в C++. Пока некто не напишет свой собственный индивидуальный
тип умного указателя, вам никогда не потребуется реализовывать свой собственный Drop
в ваших типах. Дополнительно о признаке Drop в отдельном разделе.
Для выделения памяти в своей куче, языки программирования полагаются на посвящённые этому механизмы выделения, которые скрывают все подробности нижнего уровня, такие как выделение памяти с её выравниванием, а также снижение фрагментации при выделении памяти и прочие оптимизации. Для компиляции программы компилятор rustc сам по себе применяет механизм выделения jemalloc, в то время как имеющиеся библиотеки и исполняемые файлы, строящиеся из Rust пользуются имеющимся механизмом выделения системы. В Linux это были бы API механизма выделения памяти glibc. Jemalloc это действенная библиотека механизма выделения памяти для применения в многопоточных средах и она значительно снижает время построения в программах Rust. В то время как jemalloc применяется самим компилятором, он не применяется никакими приложениями, которые собираются пр помощи Rust, потому как это увеличивает размер исполняемого файла. Итак, скомпилированные исполняемые файлы и библиотеки по умолчанию пользуются системным механизмом выделения памяти.
Rust к тому же обладает архитектурой подключаемого механизма выделения памяти, и он способен применять системный механизм
выделения памяти или любой иной механизм выделения памяти, который реализован в признаке GlobalAlloc
из модуля std::alloc. Он часто реализуется при помощи атрибута
#[global_allocator], который может быть помещён в любой тип его объявления в качестве
механизма выделения памяти.
|
| Замечание |
|---|---|
|
Когда у вас имеется вариант применения, при котором вы пользуетесь для создания своих программ также и jemalloc, вы можете воспользоваться корзиной (crate) https://crates.io/crates/jemallocator. |
В Rust большинство типов с заранее неизвестным размером размещаются в куче. Отсюда исключаются типы примитивов. Например,
создание String внутренним образом выполняет выделение в куче:
let s = String::new("foo");
String::new выполняет выделение в куче
Vec<u8> м возвращает ссылку на него. Эта ссылка связывается с переменной
s, которая выделяется в соответствующем стеке. Сама строка в куче живёт до тех пор,
пока s пребывает в области действия. Как только s
выходит из области действия, её Vec<u8> освобождается из своей кучи и вызывается
её метод drop как часть общей реализации Drop.
Для редких вариантов, когда вам необходимо размещать в куче тип примитива, вы можете воспользоваться типом
Box<T>, который является общим типом умного указателя.
В своём следующем разделе мы рассмотрим подводные камни при использовании такого языка программирования как C, который не обладает всеми удобствами автоматического управления памятью.
В языках программирования со сборщиками мусора работа с памятью абстрагирована от самого программиста. Вы объявляете переменные в своём коде и пользуетесь ими, а как они освобождают память, это подробности реализации, о которых вам не стоит беспокоиться. Системные языки программирования нижнего уровня, такие как C/C++, с другой стороны, ничего не делают для сокрытия таких подробностей от своего программиста и не предоставляют практически никакой безопасности. В таком случае программистам даётся на откуп ответственность за освобождение памяти через вызовы освобождения вручную. Теперь, если мы взглянем на CVEs (Common Vulnerabilities & Exposure, Распространённые уязвимости и подверженности внешнему воздействию) в программном обеспечении относительно управления памятью, они показывают, что все мы люди и не слишком сильны в этом! Программисты запросто создают сложные в отладке ошибки путём выделения памяти и её освобождения в неверном порядке, или даже способны забывать освобождать использованную память, либо незаконно выравнивать указатели. В C ничто не препятствует вам в создании указателей через некое целое значение и повторно ссылаться на него где- нибудь ещё, и лишь позднее обращать внимание на крах программы. Кроме того, в C достаточно просто создавать уязвимости по причине минимальности проверок компилятором.
Наиболее важным случаем является освобождение выделенных в куче данных. Памятью кучи надлежит пользоваться с осторожностью.
Значения в куче имеют возможность обитать непрерывно на протяжении всего жизненного цикла программы, когда они не освобождаются,
а в конечном итоге это может приводить к убийству самой программы уничтожителем Out
Of Memory (OOM, нехватки памяти) ядра. В время
выполнения ошибка в коде или заблуждение программиста способны приводить к тому, что программа либо забудет освободить память,
либо получит доступ к той части памяти, которая находится вне пределов её схемы памяти, либо разыменует адрес памяти в
защищённом сегменте кода. Когда это происходит, такой процесс получает инструкцию ловушки из самого ядра, которая состоит в том
что вы наблюдаете сообщение ошибки segmentation fault (нарушения сегментации), за чем
следует останов данного процесса. Раз это так, мы обязаны обеспечивать безопасность процессов и их взаимодействия с памятью!
Либо нам, как программистам, надлежит критически относиться к своим вызовам malloc и
free, либо применять безопасный для памяти язык программирования, чтобы обрабатывать эти
подробности за нас.
Однако, что мы подразумеваем под безопасной для памяти программой? Безопасность памяти это основная мысль относительно того, что ваша программа никогда не касается того расположения памяти, для которой она не предназначена, а также что все объявленные в вашей программе переменные не способны указывать на недопустимую память и остаются действительными во всех путях кода. Иначе говоря, безопасность сводится в основном к тому, чтобы указатели обладали допустимыми ссылками в вашей программе и чтобы все операции с указателями не приводили к неопределённому поведению. Неопределённое поведение это такое состояние программы, при котором она попадает в обстоятельства, которые не были учтены в её компиляторе, поскольку имеющаяся спецификация компилятора не уточняет что происходит в подобном случае.
Неким примером неопределённого поведения в C являются выход за границы массива и элементы массива без инициализации:
// uninitialized_reads.c
#include <stdio.h>
int main() {
int values[5];
for (int i = 0; i < 5; i++)
printf("%d ", values[i]);
}
В своём предыдущем коде мы имеем массив из 5 элементов и обход в цикле с выводом на печать имеющихся в этом массиве
значений. Запуск этой программы при помощи gcc -o main uninitialized_reads.c &&
./main приводит к следующему выводу:
4195840 0 4195488 0 609963056
На вашем компьютере это может приводить к выводу любого иного значения, или даже адреса инструкции, чем можно воспользоваться. Это непредвиденное поведение, когда может происходить всё что угодно. Ваша программа может немедленно выйти из строя, что является наилучшим вариантом, поскольку вы об этом узнаете сразу и там где нужно. Она также может продолжить свою работу, стирая любое внутреннее состояние программы, что впоследствии приводить к ошибочному выводу из этого приложения.
Другим образцом нарушения безопасности выступает проблема недостоверности итератора в C++:
// iterator_invalidation.cpp
#include <iostream>
#include <vector>
int main() {
std::vector <int> v{1, 5, 10, 15, 20};
for (auto it=v.begin();it!=v.end();it++)
if ((*it) == 5)
v.push_back(-1);
for (auto it=v.begin();it!=v.end();it++)
std::cout << (*it) << " ";
return 0;
}
В данном коде C++ мы создаём вектор целых значений v и мы пытаемся выполнить итерации
при помощи итератора с названием it в своём цикле for.
Основная проблема с нашим предыдущим кодом состоит в том, что у нас имеется итератор it,
указывающий на v, в то время как мы выполняем итерации по
v и доставляем его значения.
Теперь, по причине реализации нашего вектора, он внутренним образом размещается в неком ином месте, от того, в котором
своей ёмкости достигает его размер. Когда это происходит, это приводит к тому, что наш указатель
it указывает на некое мусорное значение, что носит название проблемы недостоверности
итератора по той причине, что наш указатель теперь наводит на не верную память.
Ещё одним примером нарушения безопасности памяти выступает переполнение буфера в C. Эту мысль демонстрирует приводимый ниже фрагмент кода:
// buffer_overflow.c
int main() {
char buf[3];
buf[0] = 'a';
buf[1] = 'b';
buf[2] = 'c';
buf[3] = 'd';
}
Это отлично компилируется и даже работает без ошибок, однако самое последнее присваивание выходит за пределы выделенного
буфера и способно переписать по данному адресу прочие данные или инструкции. Кроме того, особым образом сконструированные
вредоносные входные данные, приспособленные под конкретную архитектуру и среду, способны выдавать исполнение произвольного
кода. Такой вид ошибок происходит в реальном коде менее очевидным образом и приводит к уязвимостям, оказывающим воздействие на
компании по всему миру. В последних версиях компилятора gcc это определяется как атака взлома стека, при которой gcc
отправляет сигнал SIGABRT (прекращения).
Ошибки безопасности памяти приводят к утечкам памяти, краху аппаратных средств в виде отказов или отказов сегментации или,
в наихудшей ситуации, уязвимостям безопасности. Для создания правильных и безопасных программ на C, программисту приходится
дискретным образом верно расставлять вызовы free после завершения применения памяти.
Современные C++ выполняет защиту против некоторых проблем, вызываемых управлением памяти вручную, за счёт предоставления типов
умных указателей, однако это не окончательно прекращает их. Основывающиеся на виртуальных машинах языки программирования
(наиболее ярким представителем выступает JVM Java) пользуются сборкой мусора для прекращения всего класса проблем безопасности
памяти. Хотя Rust и не обладает встроенной сборкой мусора, он полагается на тот же самый RAII, встраиваемый в сам язык
программирования, и превращающий для нас освобождение памяти в автоматическое на основании установленной области действия
переменных и намного большей безопасности чем в C и C++. Это снабжает нас некоторыми абстракциями тонкой грануляции, которые вы
можете выбирать в соответствии со своими потребностями и оплачивать лишь то, чем вы пользуетесь. Чтобы увидеть как всё это
работает в Rust, давайте изучим те принципы, которые способствуют предоставлению программистам со стороны Rust управление
памятью времени компиляции.
Те понятия, которые мы рассмотрим далее, являются центральными догматами безопасности памяти Rust и его принципом абстракции с нулевой стоимостью. Они позволяют Rust выявлять нарушения безопасности памяти во время компиляции, обеспечивают автоматическое высвобождение ресурсов при достижения конца их областей действия, а также многое иное. Мы называем эти понятия владением (ownership), заимствованием (borrowing) и временами жизни (lifetimes). Владение выступает чем- то, подобным основному принципу, в то время как заимствование и времена жизни являются расширениями системы типов для самого языка программирования, применяя, а порой ослабляя свой принцип владения в различных контекстах кода для обеспечения управления памятью во время компиляции. Давайте уточним эти идеи.
Само понятие истинного владельца ресурса разнится в зависимости от языка программирования. Здесь под ресурсом мы собирательно понимаем любую переменную, содержащую некое значение в куче или стеке, либо переменную, содержащую дескриптор открытого файла, сокет подключения к базе данных, сетевой сокет и тому подобное. Всё это занимает некий объём памяти с момента их существования до того момента, когда они перестают использоваться своей программой. Важной обязанностью владельца ресурса является благоразумное освобождение той памяти, которое применялось ими, поскольку неспособность выполнять освобождение в нужном месте и в нужное время способно приводить к утечке памяти.
При программировании на динамических языках программирования, таких как Python, хорошо обладать множеством владельцев или
псевдонимов для объекта list, когда вы можете добавлять или удалять элементы из такого
списка, применяя одну из многих указывающих на этот объект переменных. Этим переменным нет нужды беспокоиться об освобождении
памяти, применяемым таким объектом, потому как имеющийся Сборщик мусора позаботится об этом и освободит память, как только
исчезнут все ссылки на данный объект.
Для языков программирования с компиляцией, таких как C/C++, прежде чем появились умные указатели, библиотеки обладали самоуверенным взглядом на то, будет ли API вызывающей или вызываемой стороны нести ответственность за освобождение памяти после выполнения кода с неким ресурсом. Такие мнения имелись по той причине, что в таких языках программирования право владения не обеспечивалось их компилятором. В C++ всё ещё существует возможность ошибки, не применяя умные указатели. В C++ совершенно обыденно обладать более чем одной переменной, указывающей на значение в куче (хотя мы и не советуем делать этого), и это носит название псевдонимов (aliasing). Допускающий это программист сталкивается со всевозможными неприятными последствиями подобной гибкости обладания множеством указателей или псевдонимов некого ресурса, одним из которых выступает проблема недостоверности итератора в C++, которую мы поясняли ранее. В частности, проблемы возникают, когда имеется хотя бы один изменяемый псевдоним на ресурс среди прочих неизменных псевдонимов в заданной области действия.
С другой стороны, Rust старается вносит верную семантику в отношении владения значениями в программе. Такое правило владения устанавливает следующие принципы:
-
Когда вы создаёте ресурс ил значение при помощи оператора
letи присваиваете его некой переменной, такая переменная превращается во владельца данного ресурса -
Когда это значение повторно присваивается из одной переменной в другую, такое владение этим значением перемещается в другую переменную, а его более старая переменная превращается в недейственную для последующего применения
-
Само значение и его переменная освобождаются в самом конце области их действия
Привносимый этим эффект состоит в том, что у значений Rust имеется единственный владелец, то есть те переменные, которые его создали. Этот принцип достаточно прост, однако его последствия поражают тех программистов, которые пришли из прочих языков программирования. Рассмотрим приводимый ниже код, демонстрирующий поясняемый принцип владения в его самом простом виде:
// ownership_basics.rs
#[derive(Debug)]
struct Foo(u32);
fn main() {
let foo = Foo(2048);
let bar = foo;
println!("Foo is {:?}", foo);
println!("Bar is {:?}", bar);
}
Мы создали две переменные, foo и bar,
которые указывают на экземпляр Foo. Для всех, кто знаком с повелениями основного
направления языков программирования, это допускает множество владельцев для некого значения, причём мы ожидаем, что данная
программа скомпилируется просто замечательно. Однако в Rust в процессе компиляции мы получаем следующую ошибку:
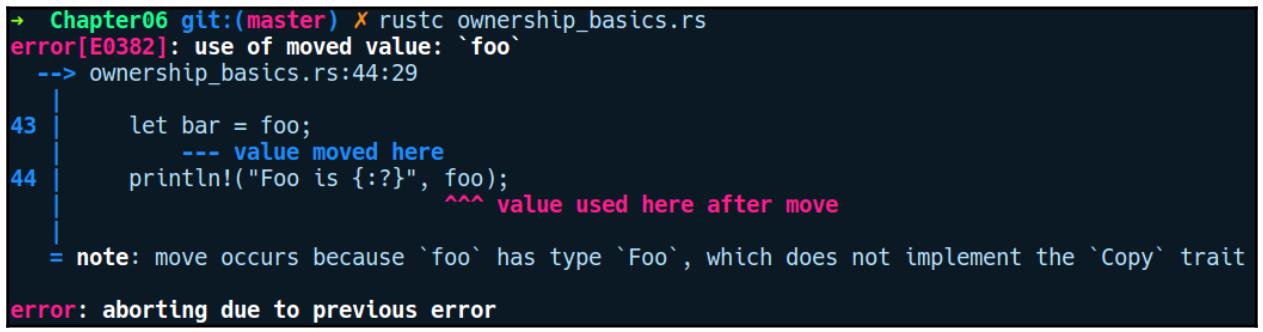
В данном случае мы создали некий экземпляр Foo и присвоили его своей переменной
foo. Согласно нашему правилу владения, foo
теперь владеет этим экземпляром Foo. В своей следующей строке мы затем присваиваем
foo в bar. По выполнению этой второй строки в
main, новым владельцем нашего экземпляра Foo
становится bar, а наша переменная foo теперь
брошенная переменная, которая более нигде не может применяться после своего перемещения. Это становится очевидным после вызова
println! в нашей третьей строке. Rust по умолчанию перемещает указатели на значения
для некой переменной всякий раз, когда мы присваиваем её какой- то другой переменной или выполняем считывание из этой
переменной. Имеющееся правило владения препятствует вам владеть множеством точек доступа для изменения своего значения, что
способно приводить к ситуации использования после освобождения, причём даже в контексте с единственным потоком для языков
программирования, которые запрещают множественные изменяемые псевдонимы для значений. Основным классическим примером выступает
проблема недействительного итератора в C++. Теперь, чтобы проанализировать случай когда некое значение выходит за рамки
сферы действия, наше правило владения также принимает во внимание саму область действия переменных. Давайте далее разберёмся с
областями действия.
Вкратце об областях действия
Прежде чем мы двинемся далее в понятии владения, нам необходимо вкратце разобраться с идеей областей действия, которая может
быть вам уже известна, если вы знакомы с C, однако мы повторим её здесь в контексте Rust, ибо владение работает в тандеме с
областями действия. Области действия в коде представляются фигурными скобками {}.
Некая область действия создаётся всякий раз, когда вы пользуетесь каким- то выражением
блока, то есть, неким выражением, которое начинается и заканчивается фигурной скобкой
{}. Кроме того, области действия способны вкладываться внутри друг друга и способны
выполнять доступ к области действия своего предка, но при этом никоим иным образом.
Вот некий образец кода, представляющего множество областей действия и значений:
// scopes.rs
fn main() {
let level_0_str = String::from("foo");
{
let level_1_number = 9;
{
let mut level_2_vector = vec![1, 2, 3];
level_2_vector.push(level_1_number); // можем выполнять доступ
} // здесь level_2_vector покидает свою область действия
level_2_vector.push(4); // более не существует
} // здесь level_1_number выходит за пределы области действия
} // здесь покидает область действия level_0_str
Чтобы помочь пояснить это, мы предположим, что наши области действия пронумерованы, начиная с 0.
Придерживаясь данного предположения, мы создали переменные, которые обладают в своём названии префиксом
level_x. Давайте пройдёмся строка за строкой по этому коду. Раз функция способна создавать
новые области действия, наша функция main вводит корневой уровень области действия
0, с определённой внутри неё level_0_str.
Внутри своей области действия уровня 0 мы создаём при помощи блока фигурных скобок
новую область действия, 1, которая содержит нашу переменную
level_1_number. Внутри уровня 1 мы создаём другое
блоковое выражение, которое превращается в область действия уровня 2. На уровне
2 мы объявляем ещё одну переменную, level_2_vector,
в которую мы доставляем level_1_number, которое поставляется из родительской области
действия, то есть с уровня 1. Наконец, когда наш код достигает конца
}, все его значения удаляются и соответствующие области действия подходят к концу.
Когда область действия завершена, мы не можем пользоваться никакими определёнными в её рамках значениями.
Области действия выступают важным свойством, которое надлежит учитывать в ходе рассуждений относительно своего правила
владения. Они также применяются в рассуждениях относительно заимствований и времён жизни, как мы это обнаружим позднее. Когда
некая область действия заканчивается, все переменные, которые владели неким значением исполняют код для удаления своего значения
и сами по себе становятся недействительными для применения вне своей области действия. В частности, для размещённых в куче
значений, сразу после конца области действия } помещается метод
drop. Это так же как и вызов функции free в C,
однако здесь это в неявном виде и уберегает своего программиста от того чтобы он забывал удалять значения. Данный
метод drop поступает из признака (trait) Drop,
который реализуется для большинства типов выделения в куче для Rust и автоматизирует с ветерком высвобождение ресурсов.
Ознакомившись с областями действия, давайте взглянем на некий пример, аналогичный тому, который мы видели ранее в
ownership_basics.rs, однако на этот раз давайте воспользуемся неким значением
примитива:
// ownership_primitives.rs
fn main() {
let foo = 4623;
let bar = foo;
println!("{:?} {:?}", foo, bar);
}
Попробуем скомпилировать и исполнить эту программу. Вы можете слегка удивиться, поскольку данная программа компилируется
и выполняется отлично. Но что произошло? В этой программе владение 4623 не переместилось
от foo к bar, а вместо этого,
bar получила отдельную копию 4623.
Это происходит по той причине, что типы примитивов трактуются в Rust особым образом, при котором они копируются вместо своего
перемещения. Это означает, что имеются различные семантики владения в зависимости от того, какие типы используются в Rust,
что приводит нас к понятию семантик перемещения и копирования.
Семантики перемещения и копирования
В Rust по умолчанию привязка переменной обладает семантикой перемещения. Однако что это означает в реальности? Чтобы разобраться с этим, нам необходимо подумать о том, как переменные применяются в программе. Мы создаём значения или ресурсы и присваиваем их переменным для упрощения ссылок на них позднее в своей программе. Такие переменные это имена, которые указывают на место в памяти, в котором расположено это значение. Теперь, операции с переменными, такие как считывание, присваивание, добавление, передача их функциям, и тому подобные, способны обладать различными семантиками или смыслом относительно того, как выполняется указание на это значение при доступе к данной переменной. В языках программирования со статическими типами эти семантики классифицируются как семантику перемещения и семантику копирования. Давайте определим обе.
Семантика перемещения: Значение, которое перемещается в принимающий элемент при доступе через переменную или переназначении переменной, демонстрирует семантику перемещения. По умолчанию Rust обладает семантикой перемещения по причине своей системы афинных типов. Отличительной чертой системы афинных типов является то, что значения и ресурсы можно применять только один раз и Rust демонстрирует это свойство при помощи своего правила владения.
Семантика копирования: По умолчанию копируемое значение (как при побитном копировании) при назначении, или доступе через переменную, или при передаче в/ возврате из функции, демонстрирует семантику копирования. Это означает, что такое значение может применяться любое количество раз и каждое значение является совершенно новым.
Такие семантики знакомы участникам сообщества C++. C++ по умолчанию обладает семантикой копирования. Семантика перемещения добавилась позднее в выпуске 11 C++.
Семантика перемещения в Rust порой может быть ограничивающей. К счастью, поведение типа можно изменять чтобы оно следовало семантике
копирования, реализуя признак (trait) Copy. Это по умолчанию реализовано для примитивов
и прочих типов, применяемых только в стеке, и это именно та причина, по которой работает наш предыдущий код, применяющий
примитивы. Рассмотрим следующий фрагмент кода, пытающийся создать в явном виде тип Copy:
// making_copy_types.rs
#[derive(Copy, Debug)]
struct Dummy;
fn main() {
let a = Dummy;
let b = a;
println!("{}", a);
println!("{}", b);
}
При его компиляции мы получаем следующую ошибку:
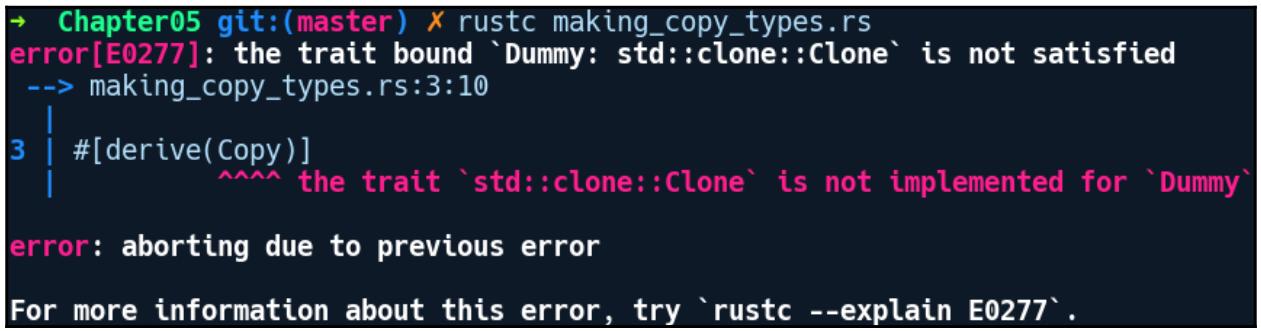
Занятно! Похоже, что Copy зависит от признака Clone.
Это обусловлено тем, что в своей стандартной библиотеке Copy определяется так:
pub trait Copy: Clone { }
Clone является перекрывающим признаком для Copy,
а потому всякий реализующий Copy тип обязан также реализовывать
Clone. Мы можем превратить свой пример в компилируемый, добавляя в аннотации наследования
признак Clone наряду с Copy:
// making_copy_types_fixed.rs
#[derive(Copy, Clone, Debug)]
struct Dummy;
fn main() {
let a = Dummy;
let b = a;
println!("{}", a);
println!("{}", b);
}
Теперь эта программа работает. Однако не совсем ясна разница между Clone и
Copy. Давайте далее проведём это разграничение.
Признаки (trait) Copy и Clone передают
основную мысль того, как именно дублируются типы при их применении в коде.
Копирование
Признак (trait) Copy обычно реализуется для типов, которые могут целиком
представляться в стеке. Это означает, что у них нет какой- то собственной части, обитающей в куче. Если бы это было так,
операция Copy была бы сложной, так как ей приходилось бы опускаться вниз по куче для
копирования своих значений. Это напрямую влияет на то, как работает оператор присваивания
=. Когда некий тип реализует Copy, присваивание
одной переменной другой приводит к копированию данных в неявном виде.
Copy это автоматический признак, который непреднамеренно реализуется в большинстве
типов данных стека, таких как примитивы и неизменные ссылки, то есть &T. Тот
способ, которым Copy дублирует типы очень схож с тем, как работает в C функция
memcpy, которая применяется для побитного копирования значений. Для определяемых
пользователем типов Copy не реализован по умолчанию, поскольку Rust желает чтобы
копирование проводилось в явном виде и сам разработчик обязан принять участие в реализации такого признака. Когда кто- то
желает реализовать в своих типах Copy, Copy
также зависит от признака Clone.
Не реализующими Copy типами выступают Vec<T>
String и изменяемые ссылки. Для выполнения копирования этих значений мы пользуемся
более явным признаком Clone.
Клонирование
Признак (trait) Clone служит для дублирования в явном виде и поступает в методе
clone, который может реализовывать тип для собственного копирования. Такой признак
Clone определяется следующим образом:
pub trait Clone {
fn clone(&self) -> Self;
}
Он обладает методом с названием clone, который получает неизменную ссылку на своего
получателя, то есть &self, и возвращает некое новое значение того же самого типа.
Определяемые пользователем типы, или любые типы обёрток, которым требуется предоставлять такую возможность дублирования
самого себя, обязаны реализовывать признак Clone через реализацию соответствующего
метода clone.
Однако в отличие от типов Copy, в которых присваивание неявно копирует значение,
для дублирования значения Clone мы обязаны в явном виде вызывать соответствующий
метод clone. Сам метод clone является более
общим механизмом дублирования, а Copy лишь его частный случай, который всегда
является побитовым копированием. Такие элементы, как String и
Vec, которые тяжело копировать, реализуют лишь признак
Clone. Типы умных указателей также реализуют признак Clone,
в котором они просто копируют сам указатель и дополнительные метаданные, такие как значение счётчика ссылок и в то же время
указывают на те же самые данные в куче.
Именно это один из тех примеров, когда мы можем решать как мы желаем копировать типы, а признак
Clone делает для нас возможной такую гибкость.
Вот программа, которая демонстрирует применение Clone для дублирования типа:
// explicit_copy.rs
#[derive(Clone, Debug)]
struct Dummy {
items: u32
}
fn main() {
let a = Dummy { items: 54 };
let b = a.clone();
println!("a: {:?}, b: {:?}", a, b);
}
В свой производящий атрибут мы добавили Clone. При этом мы можем вызывать
clone для a, чтобы получать его новую копию.
Теперь вы, вероятно, поинтересуетесь когда следует реализовывать любой из таких типов. Ниже приводится ряд рекомендаций.
При реализации Copy некого типа:
Для малых значений, которые могут представляться исключительно в стеке это выглядит так:
-
Когда тип зависит только от тех типов, которые обладают в себе реализованным
Copy; для него в неявном виде реализуется признакCopy. -
Сам признак
Copyнеявно влияет на то, как именно реализуется оператор присваивания=. Само решение о том, создавать ли ваши собственные видимые извне типы при помощи признакаCopy, требует неких соображений по причине того, как это повлияет на сам оператор присваивания. если на ранней стадии разработки ваш тип этоCopy, а затем вы отмените это, такое действие окажет влияние на все моменты, в которых выполняется присваивание значений данного типа. Таким образов вы запросто можете разрушить API.
При реализации типа Clone:
-
Сам признак
Cloneвсего лишь определяет методclone, который требуется для его вызова в явном виде. -
Когда ваш тп также содержит значение в куче как часть своего представления, тогда избирайте реализацию
Clone, что превращает его в явный для пользователей, которые также будут клонировать данные кучи. -
Когда вы реализуете тип умного указателя, например тип со счётчиком ссылок, вы обязаны реализовывать для своего типа
Clone, чтобы в стеке копировать только сами указатели.
Теперь, когда мы ознакомились с основами Copy и
Clone, давайте двинемся далее, чтобы ознакомиться с тем, как владение оказывает
воздействие на прочие места в коде.
Владение в действии
Помимо нашего примера с привязкой let, имеются и прочие места, в которых мы
можем в действии обнаружить владение и это важно распознавать и это выдаёт нам ошибки при компиляции.
Функции: Когда вы передаёте в функции параметры, вступает в действие то же самое правило владения:
// ownership_functions.rs
fn take_the_n(n: u8) { }
fn take_the_s(s: String) { }
fn main() {
let n = 5;
let s = String::from("string");
take_the_n(n);
take_the_s(s);
println!("n is {}", n);
println!("s is {}", s);
}
Наша компиляция завершается неудачно неким аналогичным образом:
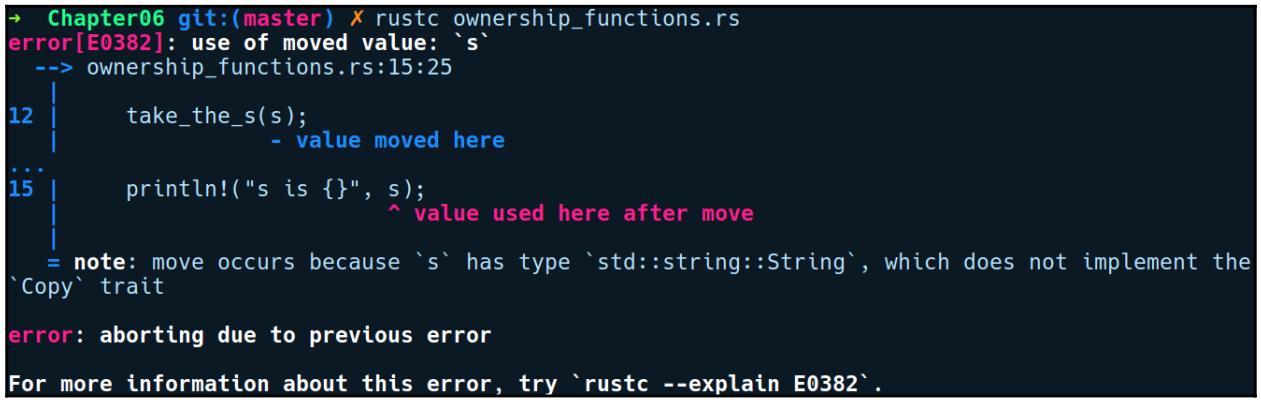
String не реализует признак (trait) Copy, а
потому владение его значением перемещается внутри самой функции take_the_s. Когда
происходит возврат из этой функции, область действия данного значения заканчивается и для
s вызывается drop, что приводит к освобождению
занимавшейся s памяти кучи. Более того, s вовсе
не может применяться после вызова самой функции. Однако, поскольку String реализует
Clone, мы способны заставить свой код работать, добавляя вызов
.clone() на площадке вызова самой функции:
take_the_s(s.clone());
Наша take_the_n отрабатывает прекрасно, поскольку
u8 (тип примитива) реализует Copy.
Именно это и означает, что после передачи в функцию перемещаемых типов, мы не можем позднее пользоваться этим выражением.
Если вы хотите пользоваться этим значением, мы должны вместо этого клонировать его тип и отправить некую копию в свою
функцию. Теперь, если нам требуется лишь доступ к переменной s, другой способ, которым
мы можем заставить работать этот код заключается в передаче значения строки s
обратно в main. Это выглядит как- то так:
// ownership_functions_back.rs
fn take_the_n(n: u8) { }
fn take_the_s(s: String) -> String {
println!("inside function {}", s);
s
}
fn main() {
let n = 5;
let s = String::from("string");
take_the_n(n);
let s = take_the_s(s);
println!("n is {}", n);
println!("s is {}", s);
}
Мы добавили в свою функцию take_the_s тип возвращаемого значения и вернули
передаваемую строку s обратно своей вызывающей стороне. В
main мы получаем её в s. При помощи этого
работает наша самая последняя строка кода main.
Выражения соответствия: Внутри некого выражения соответствия тип перемещения также осуществляет по умолчанию перемещение, как это показано в нашем следующем коде:
// ownership_match.rs
#[derive(Debug)]
enum Food {
Cake,
Pizza,
Salad
}
#[derive(Debug)]
struct Bag {
food: Food
}
fn main() {
let bag = Bag { food: Food::Cake };
match bag.food {
Food::Cake => println!("I got cake"),
a => println!("I got {:?}", a)
}
println!("{:?}", bag);
}
В своём предыдущем коде мы создали некий экземпляр Bag и назначили его в
bag. Далее мы устанавливаем соответствие его полю
food и выводим на печать некий текст. Позднее мы при помощи
println! выводим на печать bag.
Мы получаем следующую ошибку компиляции:
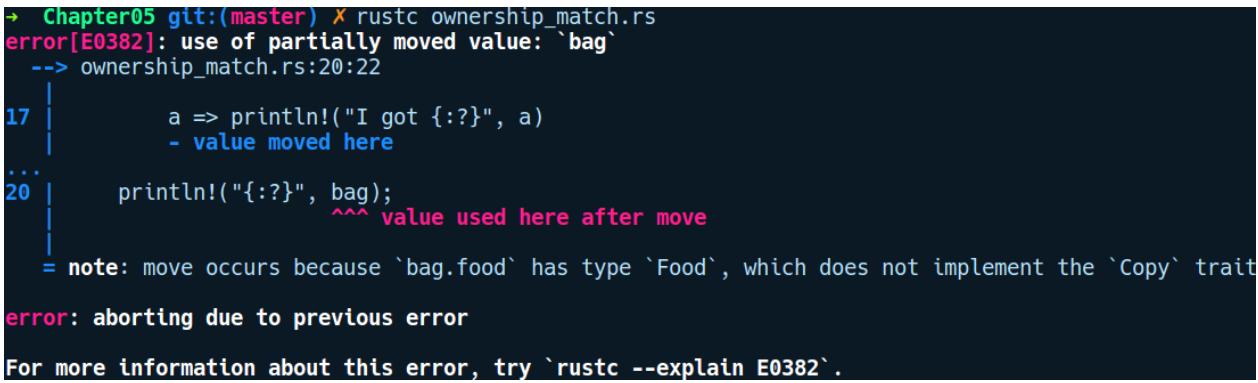
Как вы можете отчётливо прочесть, данное сообщение об ошибке говорит, что bag уже
была перемещена и употреблена соответствующей переменной a в выражении установления
соответствия. Это делает несостоятельной переменную bag для последующего использования.
Мы увидим как превратить этот код в работающий когда мы приступим к понятию заимствования.
Методы: Внутри некого блока impl
всякий метод с self в качестве самого первого параметра получает владение тем значением,
для которого вызван данный метод. Это отображает приводимый ниже код:
// ownership_methods.rs
struct Item(u32);
impl Item {
fn new() -> Self {
Item(1024)
}
fn take_item(self) {
// не делается ничего
}
}
fn main() {
let it = Item::new();
it.take_item();
println!("{}", it.0);
}
В процессе компиляции мы получаем такую ошибку:
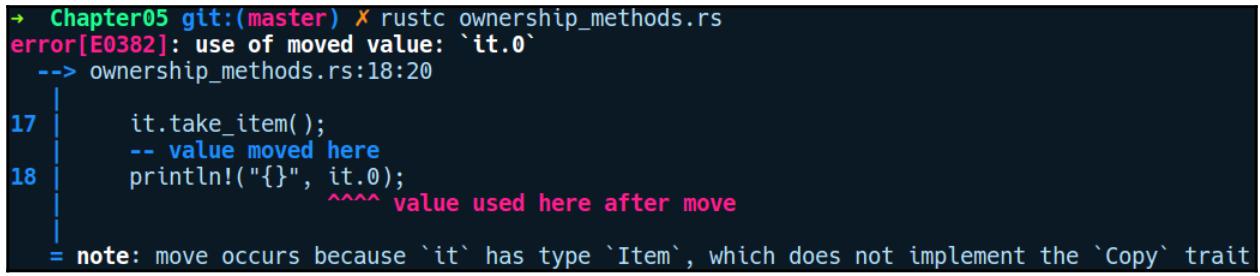
take_item это метод экземпляра, который получает self
в качестве самого первого параметра. После его активации, it перемещается внутри данного
метода и удаляется когда заканчивается область действия данной функции. Позднее мы не сможем воспользоваться
it снова. Мы превратим этот код в рабочий когда мы приступим к понятию заимствования.
Владение замыканиями: То же самое происходит и в случае замыканий. Рассмотрим такой фрагмент кода:
// ownership_closures.rs
#[derive(Debug)]
struct Foo;
fn main() {
let a = Foo;
let closure = || {
let b = a;
};
println!("{:?}", a);
}
Как вы могли догадаться, обладание Foo по умолчанию переместилось к
b внутри данного замыкания при присвоении, и мы не можем снова получать доступ к
a. При компиляции своего предыдущего кода мы получаем такую ошибку:
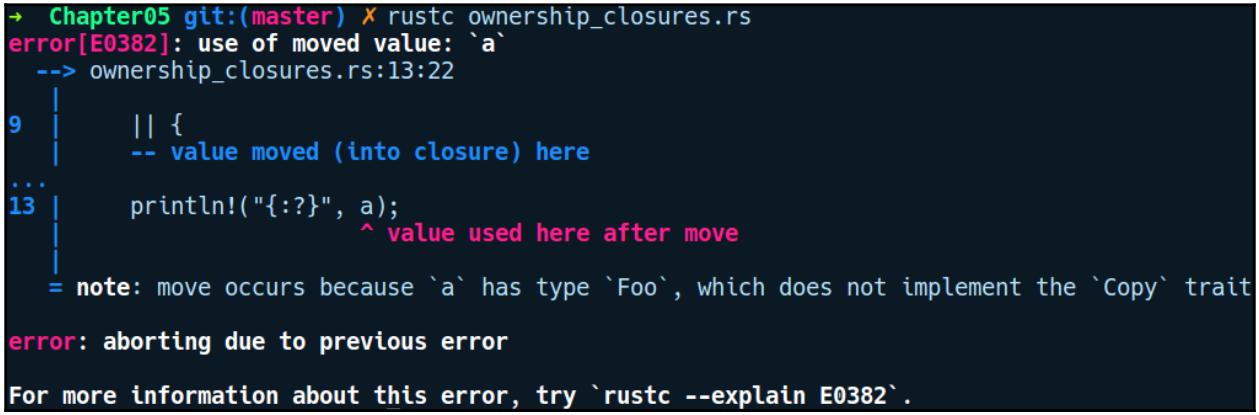
Чтобы обладать копией a мы можем вызвать a.clone()
внутри своего замыкания и назначить его в b или поместить перед данным замыканием
ключевое слово move, например так:
let closure = move || {
let b = a;
};
Это превращает нашу программу в компилируемую.
|
| Замечание |
|---|---|
|
Замыкания по- разному получают значения в зависимости от того как переменная используется внутри этого замыкания. |
Благодаря данным наблюдениям мы уже способны видеть, что наше правило владения способно быть достаточно ограничительным,
ибо оно допускает нам пользоваться типом всего лишь раз. Когда функции требуется доступ исключительно на чтение значения,
тогда нам требуется либо снова вернуть это значение из функции, либо клонировать его перед передачей в данную функцию.
Последнее может оказаться невозможным когда данный тип не реализует Clone. Клонирование
такого типа может показаться простым способом обхода нашего принципа владения, но это лишает смысла обещания нулевой
стоимости, поскольку Clone всегда дублирует типы, возможно, вызывая API распределения
памяти, что является дорогостоящей операцией с привлечением системных вызовов.
Благодаря семантике перемещения и правилу владения вскоре становится громоздким написание программ на Rust. К счастью, у нас имеются понятие заимствования и ссылочные типы, которые ослабляют налагаемые нашими правилами имеющиеся ограничения, но при этом сохраняются гарантии владения в момент компиляции.
Концепция заимствования предназначена для того, чтобы обходить ограничения нашего правила владения. При заимствовании вы
не принимаете на себя владение значениями, а всего лишь одалживаете данные на то время, которое требуется вам. Это достигается
через заимствование значений, то есть получения ссылки на значение. Для заимствования значения мы помещаем перед необходимой
переменной оператор &. & это
оператор адреса (address of). В Rust мы можем заимствовать значения двумя способами.
Неизменное заимствование: Когда мы помещаем свой оператор
& перед типом, мы создаём не изменяемую ссылку на неё. Наш предыдущий пример из
раздела владения можно переписать с применением заимствования:
// borrowing_basics.rs
#[derive(Debug)]
struct Foo(u32);
fn main() {
let foo = Foo;
let bar = &foo;
println!("Foo is {:?}", foo);
println!("Bar is {:?}", bar);
}
На этот раз наша программа компилируется, поскольку вторая строка внутри main
изменена следующим образом:
let bar = &foo;
Обратите внимание на & перед нашей переменной foo.
Мы заимствуем foo и присваиваем это заимствование bar.
bar обладает типом &Foo, который является
типом ссылки. Будучи неизменной ссылкой, мы не можем модифицировать своё значение внутри
Foo из bar.
Изменяемое заимствование: Изменяемое заимствование значения
может браться при помощи оператора &mut. При изменяемом заимствовании мы способны
модифицировать такое значение. Рассмотрим такой код:
// mutable_borrow.rs
fn main() {
let a = String::from("Owned string");
let a_ref = &mut a;
a_ref.push('!');
}
Здесь у нас имеется экземпляр String, объявленный как
a. Также мы создаём изменяемую ссылку на неё при помощи
b, применяя &mut a. Это не перемещает
a в b, всего лишь заимствует его с возможностью
изменения. Затем мы доставляем в эту строку символ '!'. Давайте скомпилируем эту
программу:
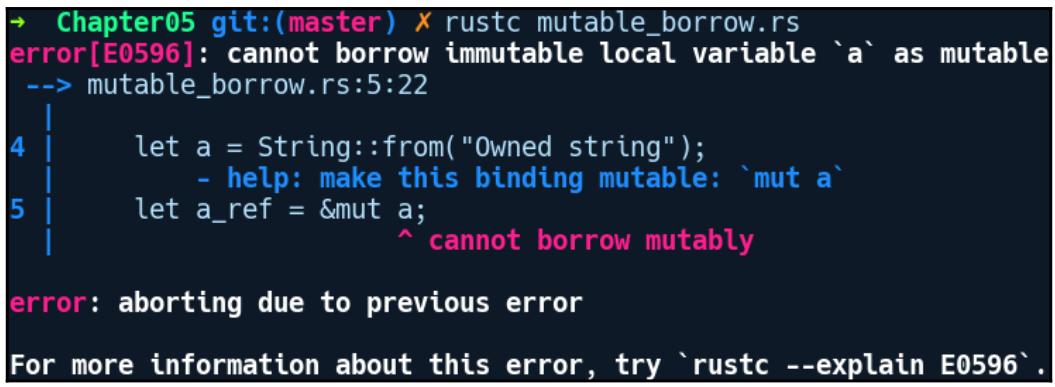
Мы получаем ошибку. наш компилятор сообщает, что мы не можем заимствовать a с
возможностью изменения. Это обусловлено тем, что заимствование с изменением требует для себя владение такой переменной для
её объявления в ключевом слове mut. Это должно быть достаточно очевидным, так как мы
не можем изменять нечто, что стоит за неизменной привязкой. Соответственно, мы изменим своё объявление на такое:
let mut a = String::from("Owned string");
Это превращает нашу программу в компилированную. Здесь a это переменная стека,
которая указывает на выделенное в куче значение, а a_ref это изменяемая ссылка на
то значение, которым владеет a. a_ref способна
изменять своё значение String, однако она не способна отбрасывать само значение,
поскольку она не владеет им. Заимствование становится несостоятельным если a
отбрасывается до того как её строка получает ссылку.
Теперь, для вывода на печать своего модифицированного a, мы добавляем в конец своей
предыдущей программы println!:
// exclusive_borrow.rs
fn main() {
let mut a = String::from("Owned string");
let a_ref = &mut a;
a_ref.push('!');
println!("{}", a);
}
Компиляция выдаёт нам такую ошибку:
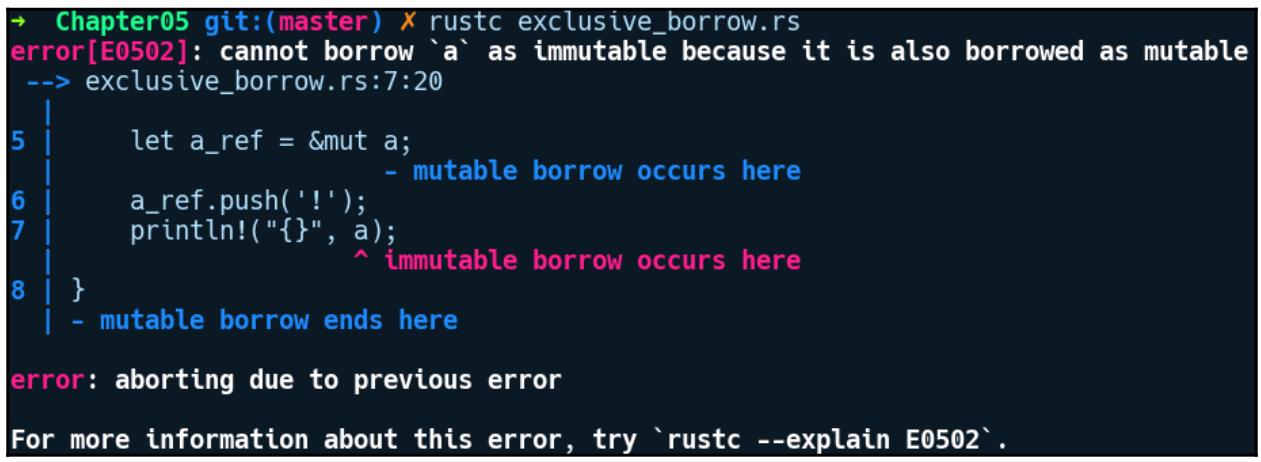
Rust запрещает это, таким образом, заимствование этого значения неизменным в качестве заимствования с возможностью
изменения при помощи a_ref уже представлено в нашей области действия. Это выделяет
ещё одно важное правило заимствования. Как только некое заимствованное значение становится допускает изменения, у нас не
может быть никаких иных заимствований его. Даже неизменного заимствования. Ознакомившись с заимствованием, давайте выделим
точные правила заимствования в Rust.
Правила заимствования
Аналогично правилу владения, у нас также имеются правила заимствования, которые фактически поддерживают семантику единственного владения для ссылок. Вот эти правила:
-
Ссылка не может существовать дольше того на что она указывает. Это очевидно, потому как если бы это было не так, она бы ссылалась на некое мусорное значение.
-
КОгда имеется ссылка на значение с возможностью изменения, в этой области действия на то же самое значение не допустимы никакие иные ссылки, не изменяемые, не неизменные. Ссылки с возможностью изменения являются исключительным заимствованием.
-
Когда нет никаких ссылок с возможностью изменения на нечто, в данной области действия на одно и то же значение допускается любое число ссылок без возможности изменения.
|
| Замечание |
|---|---|
|
Все правила заимствования в Rust подвергаются анализу компонентом компилятора с названием блока проверки заимствования. Сообщество Rust забавно именует ведение дел с проверкой заимствования битвой с блоком проверки заимствований. |
Теперь, когда мы ознакомились с этими правилами, давайте посмотрим что произойдёт если мы пойдём против такого блока проверки заимствования, нарушая его.
Заимствование в действии
Диагностика ошибок Rust для имеющихся правил заимствования в действительности полезна когда мы идём вразрез с установленной проверкой заимствования. В приводимых далее примерах мы рассмотрим их в различных контекстах.
Заимствование в функциях: Как вы уже наблюдали ранее, перемещение владения при выполнении вызова функции не имеет существенного значения когда вы только считываете само значение, и оно очень ограничивающее, вы не получите возможности применять такое значение после вызова функции. Вместо получения параметров по значению, мы можем пользоваться ими по ссылке. Мы можем поправить свой предыдущий пример кода, который был представлен в нашем разделе владения для передачи его без клонирования подобно следующему:
// borrowing_functions.rs
fn take_the_n(n: &mut u8) {
*n += 2;
}
fn take_the_s(s: &mut String) {
s.push_str("ing");
}
fn main() {
let mut n = 5;
let mut s = String::from("Borrow");
take_the_n(&mut n);
take_the_s(&mut s);
println!("n changed to {}", n);
println!("s changed to {}", s);
}
В нашем приводимом выше коде take_the_s и take_the_n
теперь это ссылки с возможностью изменения. Для этого нам необходимо изменить в своём коде три момента. Прежде всего должны
быть превращены в изменяемые привязки к соответствующим переменным:
let mut s = String::from("Borrow");
Во- вторых, изменения наших функций таковы:
fn take_the_s(n: &mut String) {
s.push_str("ing");
}
В- третьих, сторона вызова также требует изменения следующего вида:
take_the_s(&mut s);
И снова, мы можем наблюдать что всё в Rust делается в явном виде. По очевидным причинам изменяемость очень заметна в Rust, в особенности когда в игру вступает множество потоков.
Заимствование в выражениях соответствия: В выражениях
соответствия, по умолчанию, значение перемещается в руки соответствия, только если это не тип
Copy. Наш приводимый далее код, который был представлен в нашем предыдущем разделе о
владении, компилируется через заимствование в руках выражения соответствия:
// borrowing_match.rs
#[derive(Debug)]
enum Food {
Cake,
Pizza,
Salad
}
#[derive(Debug)]
struct Bag {
food: Food
}
fn main() {
let bag = Bag { food: Food::Cake };
match bag.food {
Food::Cake => println!("I got cake"),
ref a => println!("I got {:?}", a)
}
println!("{:?}", bag);
}
В свой предыдущий код мы внесли небольшие изменения, с которыми вы можете быть знакомы из нашего раздела владения.
Для второго выражения соответствия мы воспользовались префиксом ref. Наше ключевое
слово ref это то ключевое слово, которое способно устанавливать соответствие элементам,
получая ссылку на них вместо их перехвата по значению. При данном изменении наш код компилируется.
Возврат ссылки из функции: В приводимом ниже примере кода у нас имеется функция, которая предпринимает попытку возврата ссылки на объявленное в рамках этой функции значение:
// return_func_ref.rs
fn get_a_borrowed_value() -> &u8 {
let x = 1;
&x
}
fn main() {
let value = get_a_borrowed_value();
}
Данный код завершается отказом при передаче блоку проверки заимствования и мы сталкиваемся со следующей ошибкой:

Данная ошибка сообщает что мы упустили спецификатор времени жизни. Это не сильно помогло нам с тем чтобы понять что не так в данном коде. И это именно то место, в котором нам необходимо ознакомиться с понятием времён жизни, которое будет пояснено в идущем далее разделе. Перед этим, давайте разъясним те виды функций, которые мы можем иметь на основании правил заимствования.
Имеющиеся правила заимствования также диктуют как определяются в типах наследуемые методы, а также в методах экземпляра из признаков (trait). Ниже приводится как они получают свой экземпляр, представляемые от наименее ограничительных к наиболее ограничительным:
-
Методы
&self: Данные методы обладают для своих участников только доступом без изменений -
Методы
&mut self: Эти методы заимствуют экземпляр self с возможностью изменений -
Методы
self: Такие методы получают владение тем экземпляром, для которого они вызываются и этот тип не доступен для вызова позднее
В случае определяемых пользователем типов точно такой же вид заимствования применяется к его элементам полей.
|
| Замечание |
|---|---|
|
До тех пор пока вы намеренно не пишите метод, который должен переместить или отбросить в самом конце
|
Третьим фрагментом в мозаике безопасности памяти времени компиляции Rust выступает идея времён жизни и соответствующая относящаяся к определению времён жизни в коде синтаксическая аннотация. В данном разделе мы поясним времена жизни, разбирая их вниз до самых основ.
Когда мы объявляем некую переменную, инициализируя её значением, такая переменная обладает определённым временем жизни,
вне которого не допустимо её применение. При обычном стиле изложения программирования значением времени жизни переменной
выступает некая область кода, в которой эта переменная указывает на допустимую память. Если вы уже программировали на C,
вы должны прекрасно осознавать о таком варианте с временами жизни переменных: всякий раз когда вы выделяете память переменной
при помощи malloc, она должна обладать неким владельцем и этот владелец обязан
основательно принимать решение когда истекает время жизни данной переменной и когда освобождается её память. Однако хуже
всего то, что сам компилятор C не принуждает к этому; вместо этого, всё это отдаётся на откуп программисту.
Для размещённых в стеке данных мы способны запросто сделать выводы рассмотрев сам код и придя к выводу состоятельна эта переменная или нет. для размещаемых в куче значений, однако, это не столь очевидно. Времена жизни в Rust это основательная конструкция, а не концептуальная идея как в C. Здесь выполняется тот же самый анализ, который программист выполняет вручную, то есть изучение области действия значения и всех ссылающихся на него переменных.
При обсуждении времён жизни в Rust вам следует иметь с ними дело когда у вас имеются ссылки. Все ссылки обладают подключёнными к ним в неявном виде сведениями о времени жизни. Некое время жизни определяет насколько долго эта ссылка живёт относительно своего первоначального владельца её значения а также до какой степени области действия этой ссылки. В большинстве случаев это выражено неявно и сам компилятор выводит значение времени жизни соответствующей переменной, просматривая соответствующий код. Однако в некоторых ситуациях компилятор не способен на это и, таким образом, ему требуется наша помощь или, лучше сказать, он просит вас определить свои намерения.
До сих пор мы имели дело со ссылками и заимствование было достаточно простым в наших предыдущих образцах кода, однако давайте посмотрим что произойдёт когда мы пытаемся откомпилировать такой код:
// lifetime_basics.rs
struct SomeRef<T> {
part: &T
}
fn main() {
let a = SomeRef { part: &43 };
}
Этот код очень простой. У нас имеется структура SomeRef, которая хранит ссылку на
некий общий тип, T. В main мы создаём
экземпляр этой структуры, инициализируем её поле part при помощи ссылки на некую
i32, а именно, &43.
В процессе компиляции это предоставляет нам следующую ошибку:
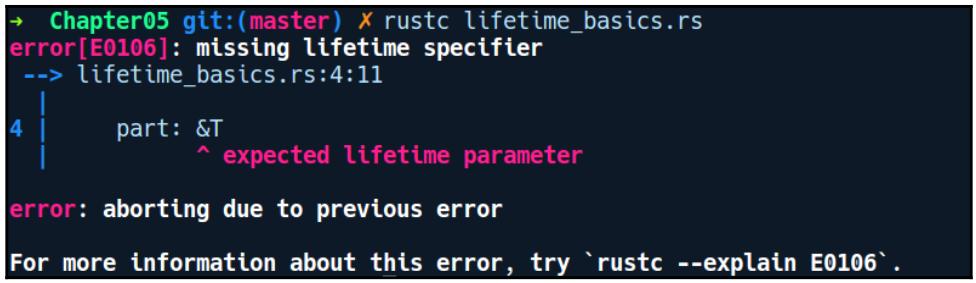
В данном случае наш компилятор просит нас поместить нечто с названием параметра времени жизни. Параметр времени жизни
очень похож на параметр общего типа. В то время как общий тип T обозначает любой
тип, параметры времени жизни определяют ту область или тот срок, когда соответствующую ссылку допустимо применять. Здесь
это всего лишь для того, чтобы компилятор позднее выполнил заполнение значением сведений о реальной области, когда данный код
анализируется блоком проверки заимствования.
Время жизни это в чистом виде конструкция времени компиляции, которая способствует компилятору в определении той степени, до которой ссылка может применяться внутри некой области действия и обеспечивает что она следует правилам заимствования. Оно способно отслеживать такие моменты как собственно появление ссылок, а также переживут ли они своё заимствованное значение. Времена жизни в Rust обеспечивают то, что ссылка не способна жить дольше указываемого ею значения. Времена жизни это вовсе не то, чем вы, как разработчик, будете пользоваться, однако они служат для применения компилятором и рассуждений относительно допустимости ссылок.
Параметры времени жизни
Для тех ситуаций, при которых сам компилятор не способен вычислить значение времени жизни значений изучая свой код,
нам требуется сообщить его Rust при помощи неких аннотаций в коде. Чтобы отличать их от идентификаторов, аннотации времени
жизни обозначается причудливым символом префикса, буквой '. Итак, чтобы превратить
наш предыдущий пример в компилируемый с неким параметром, мы добавили в свою структуру StructRef
аннотацию времени жизни следующим образом:
// using_lifetimes.rs
struct SomeRef<'a, T> {
part: &'a T
}
fn main() {
let _a = SomeRef { part: &43 };
}
Время жизни обозначается ', за которым следует любая последовательность допустимых
идентификаторов. Однако, в соответствии с соглашением, большинство применяемых в Rust кодов используют в качестве параметров
времён жизни 'a, 'b b
'c. Если в вашем типе имеется множество времён жизни, вы можете применять более
длинные описательные имена времени жизни, например, 'ctx,
'reader, 'writer и так далее. Оно объявляется
в том же самом месте и тем же самым способом, как и параметры общего типа.
Мы видели образцы, в которых наши времена жизни действовали как общий параметр для разрешения позднее допустимых ссылок, однако существует время жизни, которое обладает конкретным значением. Это показано в приводимом ниже коде:
// static_lifetime.rs
fn main() {
let _a: &'static str = "I live forever";
}
Значение времени жизни static означает, что эти ссылки допустимы на протяжении всей
данной программы. Все литеральные строки в Rust обладают временем жизни 'static и они
следуют в сегмент данных компилируемого объектного кода.
Элизия времени жизни и правила
Всякий раз когда имеется определение ссылки в функции или в типе, вовлекается время жизни. В большинстве случаев вам не требуется применять аннотацию времени жизни в явном виде своего кода, поскольку сам компилятор достаточно разумен чтобы догадаться за вас, поскольку на момент компиляции относительно ссылок уже доступен большой объём сведений.
Иными словами, данные две подписи функций идентичны:
fn func_one(x: &u8) → &u8 { .. }
fn func_two<'a>(x: &'a u8) → &'a u8 { .. }
В обычном случае сам компилятор имеет умалчиваемое значение параметра времени жизни для
func_one и нам не нужно прописывать его как в случае с
func_two.
Однако наш компилятор способен подразумевать времена жизни лишь в ограниченном числе мест и для элизии (пропуска) имеются правила. Прежде чем мы обсудим эти правила, нам требуется обсудить времена жизни входящих и исходящих данных. Они обсуждаются только когда вовлечены функции, получающие ссылки.
Время жизни входных данных: Аннотации времён жизни в параметрах, которые являются ссылками, носят название времён жизни входных данных.
Время жизни данных вывода: Аннотации времён жизни в являющихся ссылками возвращаемых функциями значениях именуются временами жизни данных вывода.
Важно отметить, что любые времена жизни данных вывода происходят от времён жизни входных данных. Мы не можем иметь время жизни данных вывода, которые независимы и отличаются от времени жизни входных данных. Оно может быть временем жизни, которое меньше или равно значению времени жизни данных вывода.
Ниже приводятся правила, которым надлежит следовать при элизии времён жизни:
-
Когда время жизни входных данных содержит лишь одну ссылку, значение времени жизни данных вывода предполагается тем же самым.
-
Для методов с вовлечёнными в них
selfи&mut self, значение времени жизни входных данных подразумевается как для значения параметра&self.
Однако порой в не очевидных ситуациях наш компилятор не пытается полагаться на нечто. Рассмотрим такой код:
// explicit_lifetimes.rs
fn foo(a: &str, b: &str) -> &str {
b
}
fn main() {
let a = "Hello";
let b = "World";
let c = foo(a, b);
}
В нашем предыдущем коде RefItem хранит ссылку на любой тип,
T. В такой ситуации значение времени жизни нашего возвращаемого значения не очевидно,
поскольку имеются вовлечёнными две ссылки входных данных. Однако порой компилятор не способен вывести значение времени жизни
ссылок, и тогда ему требуется помощь и он попросит нас определить параметры времени жизни. Рассмотрим следующий код, который
не компилируется:

Наша предыдущая программа не компилируется по той причине, что Rust не способен определить значение времени жизни возвращаемого значения и здесь ему нужно помочь.
Теперь, имеются различные места, в которых мы должны определять времена жизни, когда Rust не способен вычислять их за нас:
-
Подписи функции
-
Структуры и поля структур
-
Блоки impl
Время жизни в определяемых пользователем типах
Если определение структуры обладает полями, которые ссылаются на любой тип, нам необходимо в явном виде задавать продолжительность жизни таких ссылок. Этот синтаксис аналогичен синтаксису подписей функции: сначала мы определяем имена времён жизни в самой строке структуры, а затем применяем их в этих полях.
Вот как выглядит этот синтаксис в самом простом виде:
// lifetime_struct.rs
struct Number<'a> {
num: &'a u8
}
fn main() {
let _n = Number {num: &545};
}
Такое определение Number продолжает существовать столько же сколько присутствует
ссылка для num.
Время жизни в блоках impl
Когда мы создаём блоки impl для структур со ссылками, нам необходимо повторять
имеющиеся заявления и определения времён жизни снова. Например, если мы выполнили некую реализацию для структуры
Foo, которую мы определяли ранее, наш синтаксис выглядел бы так:
// lifetime_impls.rs
#[derive(Debug)]
struct Number<'a> {
num: &'a u8
}
impl<'a> Number<'a> {
fn get_num(&self) -> &'a u8 {
self.num
}
fn set_num(&mut self, new_number: &'a u8) {
self.num = new_number
}
}
fn main() {
let a = 10;
let mut num = Number { num: &a };
num.set_num(&23);
println!("{:?}", num.get_num());
}
В большинстве таких случаев это выводится из самих типов, а затем мы можем опустить подписи с синтаксисом
<'_>.
Множественность времени жизни
Как и в случае с параметрами универсального типа, мы можем указать несколько сроков жизни, когда у нас имеется более
одной ссылки с разными временами жизни. Однако может быстро превратиться в неприятную необходимость жонглирования в вашем коде
более чем одним сроком жизни. В большинстве случаев мы можем выкрутиться всего с одним срок жизни в ваших структурах или в
любой из ваших функций. Но бывают обстоятельства, при которых вам потребуется более одной аннотации времени жизни. Например,
допустим, мы создаём библиотеку декодера, которая способна анализировать двоичные файлы в соответствии со схемой и заданным
закодированным потоком байт. У нас имеется объект Decoder, который обладает ссылкой на
объект Schema и ссылкой на тип Reader. Наше
определение Decoder будет выглядеть так:
// multiple_lifetimes.rs
struct Decoder<'a, 'b, S, R> {
schema: &'a S,
reader: &'b R
}
fn main() {}
В нашем предыдущем определении вполне вероятно, что мы получаем Reader из
сетевой среды,в то время как Schema локальна, а потому их сроки жизни будут разными.
Когда мы предоставляем реализации для такого Decoder, мы способны определить
отношения с ним по срокам жизни подтипов, которые мы поясняем далее.
Подтипы времени жизни
Мы можем определить отношение между сроками жизни , которые определяют можно ли будет использовать две ссылки в одном и
том же месте. Продолжая с нашим примером структуры Decoder, мы можем определить
необходимые отношения сроков жизни друг с другом в своём блоке impl примерно так:
// lifetime_subtyping.rs
struct Decoder<'a, 'b, S, R> {
schema: &'a S,
reader: &'b R
}
impl<'a, 'b, S, R> Decoder<'a, 'b, S, R>
where 'a: 'b {
}
fn main() {
let a: Vec<u8> = vec![];
let b: Vec<u8> = vec![];
let decoder = Decoder {schema: &a, reader: &b};
}
Мы определили взаимоотношения в своём блоке impl при помощи выражения where как
'a:'b. Это читается как значение срока жизни 'a
переживёт 'b, иными словами, 'b никогда не
живёт дольше 'a.
Определение границ времени жизни в общих типах
Помимо применения признаков (trait) для построения тех типов, которые могут приниматься обычной функцией, применяя аннотацию
сроков жизни мы также способны ограничивать параметры общего. Например, рассмотрим ситуацию при которой у нас имеется библиотека
регистрации, в которой объект Logger определяется следующим образом:
// lifetime_bounds.rs
enum Level {
Error
}
struct Logger<'a>(&'a str, Level);
fn configure_logger<T>(_t: T) where T: Send + 'static {
// configure the logger here
}
fn main() {
let name = "Global";
let log1 = Logger(name, Level::Error);
configure_logger(log1);
}
В своём предыдущем коде у нас имеется структура Logger со своим названием и
перечисление Level. У нас также имеется общая функция с названием
configure_logger, которая получает тип
T, который составляется при помощи Send + 'static.
В main мы создаём регистрационную запись с 'static, строкой
"Global" и вызываем configure_logger,
передавая её.
Наряду с привязкой к Send, которая сообщает что этот поток может быть отправлен в
потоки, мы также сообщаем что этот тип должен существовать столько же, каков срок жизни у
'static. Допустим, мы должны были применять Logger,
который ссылается на строку с более коротким сроком существования, например так:
// lifetime_bounds_short.rs
enum Level {
Error
}
struct Logger<'a>(&'a str, Level);
fn configure_logger<T>(_t: T) where T: Send + 'static {
// configure the logger here
}
fn main() {
let other = String::from("Local");
let log2 = Logger(&other, Level::Error);
configure_logger(&log2);
}
Это завершается отказом с такой ошибкой:
Это сообщение об ошибке ясно сообщает, что такое заимствуемое значение должно быть допустимым для статического срока
существования, однако мы передаём в нём строку, которая обладает сроком существования с названием
'a из main, что короче времени жизни 'static.
Получив на пояс инструментов понятие времени жизни, давайте повторим типы ссылок в Rust.
Наше повествование относительно управления памятью осталось бы незавершённым, если бы мы не включили в обсуждение указатели, которые являются самым первым способом манипуляции памятью в любом языке программирования нижнего уровня. Указатели это просто переменные, которые указывают на местоположения памяти в адресном пространстве процесса. В Rust мы имеем дело с тремя видами указателей.
Такие указатели уже знакомы вам из раздела заимствования. Ссылки подобны указателям в C, однако они проверяются на
правильность. Они никогда не должны быть null и всегда указывают на те же самые данные, коими владеют все переменные. Те
данные, на которые они указывают могут пребывать или в стеке или в куче, либо в сегменте данных самого исполняемого файла.
Они создаются при помощи оператора & или
&mut. Такие операторы, когда за ними следует префикс
T, создают тип ссылки, который обозначается &T
для ссылок без возможности изменения или &mut T для ссылок с изменением. Давайте
повторим это снова:
-
&T: это неизменная ссылка на типT. Указатель&Tимеет типCopy, что просто означает, что вы можете обладать множеством ссылок на значениеT. Если вы назначаете этот указатель другой переменной, вы получаете копию такого указателя, который указывает на те же самые данные. Также нормально иметь ссылку на ссылку, например&&T. -
&mut: это указатель с возможностью изменения на типT. Внутри некой области действия вы не имеете возможности обладать двумя изменяемыми ссылками на значениеTиз- за правила заимствования. Это означает, что типы&mutне реализуют признакCopy. Они также не могут отправляться в потоки.
Такие указатели обладают причудливым видом подписи, будучи снабжаемыми префиксом *,
который к тому же выступает оператором разыменования. В целом, они применяются в небезопасном коде. Для их разыменования
необходим небезопасный блок. В Rust имеется два вида сырых указателей:
-
*const T: это некий сырой указатель без возможности изменения на типT. Они также обладают типомCopy. Они схожи с&T, просто*const Tтакже может иметь значение null. -
*mut T: это сырой указатель с возможностью изменения на типT, который к тому же неCopy.
В качестве дополнительного примечания можно привести ссылку к сырому указателю как это показано в приводимом ниже коде:
let a = &56;
let a_raw_ptr = a as *const u32;
// или
let b = &mut 5634.3;
let b_mut_ptr = b as *mut T;
Хотя мы не способны привести &T к *mut T,
поскольку это нарушало бы имеющиеся правила заимствования, которые допускают только заимствование с изменением.
Для ссылок с возможностью изменения мы можем приводить их тип к *mut T или даже к
*const T, что носит название ослабления указателя, когда мы переходим от более
ёмкого указателя &mut T к менее ёмкому указателю
*const T. Для ссылок без возможности изменения мы можем приводить их только к
*const T.
Однако разыменование сырого указателя является небезопасной операцией. Когда мы дойдём до Главы 10, Небезопасный Rust и интерфейсы внешних функций 2го издания Полного руководства Rust, Рауля Шармы и Везы Кайхлавирты, (с) 2019, Packt Publishing.
Управление сырыми указателями крайне небезопасно и разработчикам необходимо быть аккуратными со множеством подробностей при их применении. Неосведомлённое применение способно приводить к таким проблемам как утечка памяти, оборванные ссылки и двойное освобождение в больших базах кода не очевидным образом. Для решения этих проблем мы можем применять умные ссылки, которые получили популярность в C++.
Rust также обладает большим числом умных указателей. Они носят название умных по той причине, что также обладают дополнительными метаданными и связываемым с ними кодом, исполняемым при их создании или удалении. Обладание способностью автоматического освобождения лежащих в основе ресурсов при выходе некого умного указателя за область действия выступает одной из самых основных причин применения умных указателей.
Наибольшая часть интеллекта умных указателей исходит из двух признаков (trait), носящих название признака Drop и признака Deref. Прежде чем мы рассмотрим доступные типы умных указателей, давайте подробно разберёмся с этими признаками.
Drop
Это именно тот признак, который мы достаточно часто упоминали и который выполняет всю магию автоматического освобождения
используемых ресурсов при выходе значения за область действия. Такой признак Dropпохож
на то, что бы вы в других языках программирования называли бы методом object destructor
(деструктора объекта). Он содержит единственный метод drop, который вызывается когда
объект выходит за пределы области видимости. В качестве параметра такой метод принимает &mut
self. Освобождение значений при отбрасывании выполняется по принципу
последний принятый удаляется первым (LIFO, last in, first out).
То есть построенное последним отбрасывается первым. Это иллюстрирует приводимый ниже код:
// drop.rs
struct Character {
name: String,
}
impl Drop for Character {
fn drop(&mut self) {
println!("{} went away", self.name)
}
}
fn main() {
let steve = Character {
name: "Steve".into(),
};
let john = Character {
name: "John".into(),
};
}
Это снабжает нас следующим выводом:
Такой метод drop это идеальное место для помещения кода очистки ваших собственных
структур, в случае такой необходимости. Это в особенности подходит для типов, в которых такая очистка менее определённа,
например, когда применяются значения счётчиков ссылок или сборщики мусора. Когда мы иллюстрируем примером любое реализованное
значение Drop (любой размещённый в куче тип), сам компилятор Rust вставляет после
компиляции вызовы метода drop по окончанию каждой области действия. Поэтому нам не
требуется вызывать drop вручную для таких экземпляров. Такой основанный на областях
видимости вид автоматического восстановления вдохновлён принципом RAII C++.
Deref и DerefMut
Для предоставления аналогичного обычным указателям поведения, то есть способности разыменования самих вызовов методов в
лежащем в их основе типе для указания, типы умных указателей часто реализуют признак Deref,
который позволяет нам применять для этих типов оператор разыменования *. В то время как
Deref предоставляет нам доступ только на чтение, также имеется
DerefMut, который способен нам предоставлять ссылку с возможностью изменения для
лежащего в основе типа. Deref обладает таким типом подписи (сигнатуры):
pub trait Deref {
type Target: ?Sized;
fn deref(&self) -> &Self::Target;
}
При определении отдельного метода с названием Deref, он получает
self по ссылке и возвращает для лежащего в основе типа некую ссылку без возможности
изменения. В сочетании с функциональной возможностью приведения типа Rust это сокращает объём кода, который вам приходится
составлять. Приведение типа deref это когда некий тип автоматически преобразуется в
какую- то другую ссылку. Это рассматривается в Главе 7, Дополнительные понятия
2го издания Полного руководства Rust, Рауля Шармы и Везы Кайхлавирты, (с) 2019, Packt Publishing.
Типы умных указателей
Вот некоторые типы умных указателей из стандартной библиотеки:
-
Box<T>: Предоставляет самый простой вид размещения в куче. ТипBoxвладеет необходимым значением внутри него и тем самым способен удерживать значения внутри структур или к их возврату из функций. -
Rc<T>: Служит для подсчёта ссылок. Увеличивает на единицу счётчик при каждом новом обращении к ссылке и уменьшает на единицу при всяком освобождении ссылки. Когда этот счётчик достигает нуля, данное значение отбрасывается. -
Arc<T>: Это атомарный подсчёт ссылок (Atomic Reference Counting). Он аналогичен предыдущему типу, но с атомарностью для безопасности при многопоточности. -
Cell<T>: Снабжает нас внутренней возможностью изменения для реализующихCopyтипов. Иными словами, мы получаем возможность получения множества ссылок с возможностью изменения на нечто. -
RefCell<T>: Предоставляет внутреннюю возможность изменения для типов без необходимости признакаCopy. Для безопасности применяет блокировку времени выполнения.
Box<T>
Представленный в стандартной библиотеке общий тип Box снабжает нас самым
простым способом выделения в куче значений. Его проще определить как структуру кортежа в самой стандартной библиотеке и
оболочки всех приданных ему типов и помещающих их в кучу. Если вы знакомы с понятиями упаковки (boxing) и распаковки
(unboxing) из прочих языков программирования, например из Java, где Boxed integers выступают классом
Integer, это предоставляет аналогичную абстракцию. Собственно семантика типа
Box зависит от своего обёртываемого типа. Когда лежащий в основе тип это
Copy, его экземпляр Box становится копируемым,
в противном случае он по умолчанию перемещается.
Для создания выделяемого в куче значения с типом T при помощи
Box мы просто вызываем связанный с ним метод new,
передавая само значение. Создание обёртки такого значения Box с типом
T отдаёт назад собственно сам экземпляр Box,
который является указателем в стеке, указывающим на размещаемый в куче T. Ниже
приводится пример того как пользоваться Box:
// box_basics.rs
fn box_ref<T>(b: T) -> Box<T> {
let a = b;
Box::new(a)
}
struct Foo;
fn main() {
let boxed_one = Box::new(Foo);
let unboxed_one = *boxed_one;
box_ref(unboxed_one);
}
В своей функции main мы создали значение с выделением в куче в boxed_one посредством
вызова Box::new(Foo).
Наш тип Box может применяться при следующих обстоятельствах:
-
Он может применяться для создания определений рекурсивного типа. Например, вот тип
Node, который представляет узел в неком однонаправленном списке:// recursive_type.rs struct Node { data: u32, next: Option<Node> } fn main() { let a = Node { data: 33, next: None }; }При компиляции мы получаем такую ошибку:
Мы не можем обладать таким определением типа
Nodeпо той причине, чтоnextобладает типом, который ссылается на себя самого. Если допустить такое определение, анализ нашим компилятором нашего определенияNodeникогда не достигнет конца, поскольку он продолжит оценку до тех пор пока не достигнет предела памяти. Это лучше проиллюстрировать таким фрагментом кода:struct Node { data: u32, next: Some(Node { data: u32, next: Node { data: u32, next: ... } }) }Данная оценка определения
Nodeпродолжит подсчёт пока наш компилятор не исчерпает память. К тому же, всякий кусочек данных необходимо хранить статически с известным на момент компиляции размером, а это не представленный в Rust тип. Мы можем осуществить это поместивnextпозади указателя по той причине, что указатели всегда имеют фиксированный размер. Если вы наблюдаете такое сообщение об ошибке компилятора, мы воспользуемся определением типаBoxсвоего новогоNode, например так:struct Node { data: u32, next: Option<Box<Node>> }Тип
Boxтакже применяется при определении рекурсивных типов, которые должны быть скрыты за косвенной адресациейSized. Таким образом, составленное из вариантов со ссылками на себя перечислений может применять типBoxдля употребления разночтений в таких ситуациях: -
Когда вам требуется хранить типы объектов признаков (trait)
-
Если вам нужно хранить функции в некой коллекции
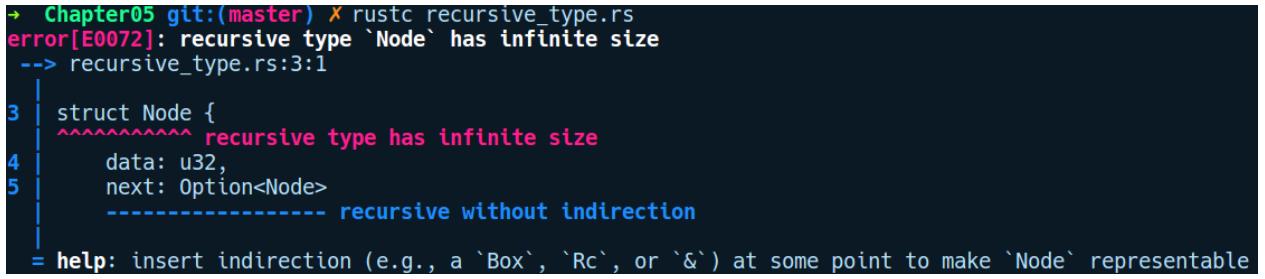
Установленное правило владения допускает в некий момент времени в данной области действия существовать только одному
владельцу. Однако имеются случаи, когда вам требуется разделять свой тип со множеством переменных. Например, в некой
библиотеке графического интерфейса всякий дочерний виджет должен обладать ссылкой на свой родительский контейнер виджета
для таких моментов как взаимодействие для компоновки дочернего виджета на основе события изменения размера от своего
пользователя. Хотя время действия и позволяет вам ссылаться на соответствующий родительский узел из своих дочерних узлов,
сохраняя этого предка как (допустим) &'a Parent, это часто ограничено сроком
действия (временем жизни) значения &'a. Как только заканчивается его область
действия, ваша ссылка не действительна. В таких ситуациях требуются более гибкие подходы, а это требует применения типов с
подсчётом ссылок. Такие типы умных указателей обеспечивают в программе совместное владение значениями.
Типы с подсчётом ссылок допускают сборку мусора на гранулированном уровне. При таком подходе тип умного указателя делает
для вас возможным обладать множеством ссылок на обёртываемое ими значение. Внутри себя, подобный умный указатель ведёт
подсчёт того, сколько ссылок задано и имеются ли активные, применяя счётчик ссылок (в данном случае refcount), который
просто является целым значением. По мере того, как ссылающиеся на обёртываемое умным указателем значение выходят за пределы
области действия, значение счётчика ссылок уменьшается. Как только исчезнут все ссылки, а значение счётчика достигнет
0, обёртываемое значение освобождается. Именно так в целом работают указатели с
подсчётом ссылок.
Rust снабжает нас двумя видами типов указателей с подсчётом ссылок:
-
Rc<T>: В основном служат для применения в средах с единственным потоком -
Arc<T>подразумевают использование в окружениях со множеством потоков
Давайте здесь рассмотрим вариант с единственным потоком. Вариант с его противоположностью для множества потоков мы посетим в Главе 8, Одновременность 2го издания Полного руководства Rust, Рауля Шармы и Везы Кайхлавирты, (с) 2019, Packt Publishing.
Rc<T>
Когда мы взаимодействуем с неким типом Rc, внутренним образом происходят следующие
изменения:
-
Когда вы получаете новую ссылку на
Rcчерез вызовClone(), образом увеличивает внутренний счётчик ссылокRc. Внутри себяRcприменяет типCellдля своих счётчиков ссылок. -
Когда соответствующая ссылка выходит за область действия, он уменьшается
-
Когда все разделяемые ссылки покидают область действия, значение счётчика ссылок становится равным нулю. В этот момент самый последний отбрасывающий вызов для
Rcосуществляет удаление его размещения.
Применение контейнеров со счётчиками ссылок даёт нам большую гибкость при реализации: мы можем выдавать копии своего значения, как если бы они были новой копией без необходимости отслеживания в точности когда эти ссылки покидают область действия. Это не означает, что мы можем изменять альтернативные названия своих внутренних значений.
Rc<T> в основном используется в двух методах:
-
Статический метод
Rc::newсоздаёт новый контейнер с подсчётом ссылок. -
Метод
cloneувеличивает сильных ссылок и выдаёт новыйRc<T>.
Внутри себя Rc удерживает два вида ссылок: сильные
(Rc<T>) и слабые (Weak<T>).
Оба хранят счётчик того, сколько было выдано ссылок каждого типа, однако обёрнутые значения будут удалены из памяти только
когда достигает нуля значение счётчика сильных ссылок. Основная мотивация для этого состоит в том, что реализации структуры
данных может потребоваться учёт одного и того же момента несколько раз. Например, реализация дерева может обладать ссылками
как на свои дочерние узлы, так и на свои родительские, однако приращение значения счётчика для каждой из ссылок не было бы
верным и повлекло бы к зацикливанию ссылок. Ситуацию с зацикливанием ссылок иллюстрирует следующая схема:
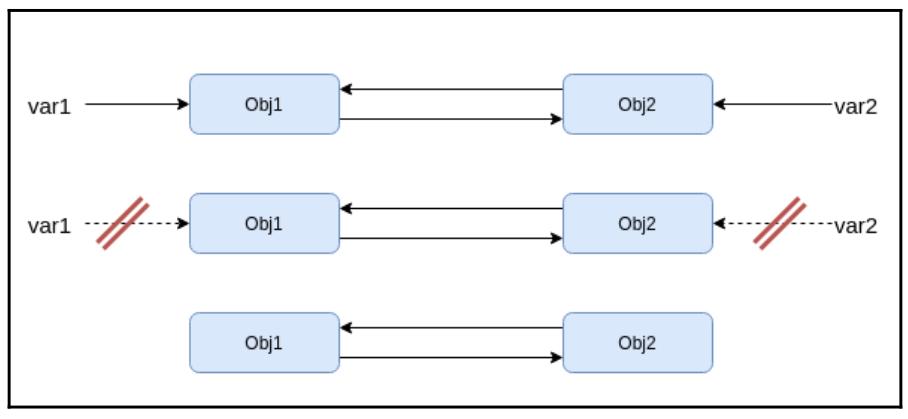
В предыдущей схеме у нас имеются две переменные, var1 и
var2, которые ссылаются на два ресурса, Obj1 и
Obj2. Помимо этого, Obj1 также
обладает ссылкой на Obj2, а Obj2 имеет ссылку на
Obj1. И Obj1, и
Obj2 при выходе var1 и
var2 из области действия обладают счётчиком 2, а
значение счётчиков Obj1 и Obj2 достигают
1. Они не могут быть высвобожденными, поскольку они всё ещё ссылаются друг на друга.
Такое зацикливание ссылок может быть разорвано при помощи слабых ссылок. В качестве иного примера, связный список может быть реализован таким образом, что он поддерживает ссылки через подсчёт ссылок как для следующего элемента, так и для предыдущего. Лучше всего выполнить это воспользовавшись сильными ссылками в одном направлении и слабыми в другом.
Давайте покажет как это может работать. Вот минимальная из возможных реализаций, быть может, и не самой практичной, но наилучшей для целей обучения структуры данных, односвязного списка:
// linked_list.rs
use std::rc::Rc;
#[derive(Debug)]
struct LinkedList<T> {
head: Option<Rc<Node<T>>>
}
#[derive(Debug)]
struct Node<T> {
next: Option<Rc<Node<T>>>,
data: T
}
impl<T> LinkedList<T> {
fn new() -> Self {
LinkedList { head: None }
}
fn append(&self, data: T) -> Self {
LinkedList {
head: Some(Rc::new(Node {
data: data,
next: self.head.clone()
}))
}
}
}
fn main() {
let list_of_nums = LinkedList::new().append(1).append(2);
println!("nums: {:?}", list_of_nums);
let list_of_strs = LinkedList::new().append("foo").append("bar");
println!("strs: {:?}", list_of_strs);
}
Этот связный список формируется двумя структурами: LinkedList предоставляет ссылку
на самый первый элемент этого списка и значение общедоступного API списка, а Node
содержит реальные элементы. Обратите внимание на то, как мы применяем Rc и
как клонируем свой следующий указатель при каждом добавлении в конец. Давайте пройдёмся по тому, что происходит в варианте
добавления в конец:
-
LinkedList::new()предоставляет нам новый список. Голова установлена вNone. -
В конец этого списка мы добавляем
1. Голова теперь это узел, который содержит1, а следующим становится предыдущая голова:None. -
В конец этого списка мы добавляем
2. Головой теперь выступает тот узел, который содержит в качестве данных2, а следующим выступает наша предыдущая голова, содержащий1узел.
Это подтверждает отладочный вывод из println!:
nums: LinkedList { head: Some(Node { next: Some(Node { next: None, data: 1 }), data: 2 }) }
strs: LinkedList { head: Some(Node { next: Some(Node { next: None, data: "foo" }), data: "bar" }) }
Это весьма функциональный вид данной структуры; всякое добавление в конец работает просто как добавление данных в саму голову, что означает, что нам не приходится воспроизводить ссылки и реальный список ссылок может оставаться без возможности изменения. Если мы пожелаем оставить данную структуру столь же простой, но в то же время обладающей двусвязным списком, это потребует небольшого изменения, поскольку тогда нам на практике потребуется вносить в имеющуюся структуру изменения.
Вы можете понизить тип Rc<T> до Weak<T>
при помощи метода downgrade и аналогично тип
Weak<T> может быть возвращён в Rc<T>
с применением метода upgrade. Метод понижения работает всегда. В противоположность
этому, при вызове повышения слабой ссылки, её реальное значение может оказаться уже сброшенным, и в этом случае вы получите
None.
Итак, давайте добавим в свой предыдущий узел слабый указатель:
// rc_weak.rs
use std::rc::Rc;
use std::rc::Weak;
#[derive(Debug)]
struct LinkedList<T> {
head: Option<Rc<LinkedListNode<T>>>
}
#[derive(Debug)]
struct LinkedListNode<T> {
next: Option<Rc<LinkedListNode<T>>>,
prev: Option<Weak<LinkedListNode<T>>>,
data: T
}
impl<T> LinkedList<T> {
fn new() -> Self {
LinkedList { head: None }
}
fn append(&mut self, data: T) -> Self {
let new_node = Rc::new(LinkedListNode {
data: data,
next: self.head.clone(),
prev: None
});
match self.head.clone() {
Some(node) => {
node.prev = Some(Rc::downgrade(&new_node));
},
None => {
}
}
LinkedList {
head: Some(new_node)
}
}
}
fn main() {
let list_of_nums = LinkedList::new().append(1).append(2).append(3);
println!("nums: {:?}", list_of_nums);
}
Наш метод append слегка вырос; теперь нам необходимо обновлять свой предыдущий узел
для своей текущей головы перед возвратом вновь созданной головы. Это почти вполне неплохо, но не совсем. Наш компилятор не
позволит нам выполнять неверные операции:

Мы могли бы заставить append принимать ссылку на
self с возможностью изменения, но это бы означало, что вы бы были способны добавлять
в конец своего списка только когда все привязки узлов обладали бы возможностью изменения, что заставило бы всю структуру
превратить в обладающую возможностью к изменениям и, к счастью, мы можем осуществить это при помощи единственного
RefCell.
-
Для своего
RefCellдобавьтеuseuse std::cell::RefCell; -
Оберните в
RefCellсвоё предыдущее поле изLinkedListNode:// rc_3.rs #[derive(Debug)] struct LinkedListNode<T> { next: Option<Rc<LinkedListNode<T>>>, prev: RefCell<Option<Weak<LinkedListNode<T>>>>, data: T } -
Для создания нового
RefCellмы изменили методappendи обновили свою предыдущую ссылку через заимствование с возможностью изменения этогоRefCell:// rc_3.rs fn append(&mut self, data: T) -> Self { let new_node = Rc::new(LinkedListNode { data: data, next: self.head.Clone(), prev: RefCell::new(None) }); match self.head.Clone() { Some(node) => { let mut prev = node.prev.borrow_mut(); *prev = Some(Rc::downgrade(&new_node)); }, None => { } } LinkedList { head: Some(new_node) } } }
При каждом применении заимствований RefCell хорошим практическим приёмом является
тщательное продумать что мы используем их безопасным образом, поскольку ошибки могут приводить к ситуации паники времени
исполнения. Однако при данной реализации легко заметить, что у нас имеется лишь одно borrow
и что наш закрывающий блок немедленно его прекращает.
Воспользовавшись понятием внутренней возможности изменения Rust, помимо совместного владения мы также способны получать разделяемую возможность внесения изменений времени выполнения, которая моделируется особыми типами умных обёртывающих указателей.
Внутренняя изменчивость
Как мы наблюдали ранее, во время компиляции Rust защищает нас от проблемы совмещения имён нашего указателя, допуская в любой заданной области действия лишь одну ссылку с возможностью изменения. Однако имеются ситуации, при которых это становится слишком ограничительным, превращая код, который, как мы знаем, не содержит ошибок, в не проходящий компилятором по причине проверки строгости заимствования. Для подобных случаев одним из решений является перемещение такой проверки заимствования со времени компиляции на время исполнения, что достигается при помощи внутренней изменчивости. Прежде чем мы обсудим те типы, которые делают возможной внутреннюю изменчивость, нам необходимо разобраться с самим понятием внутренней изменчивости и наследуемой изменчивости:
-
Наследуемая изменчивость: Это устанавливаемая по умолчанию возможность внесения изменений когда берёте на некую структуру ссылку
&mut. Это также подразумевает, что вы способны модифицировать все имеющиеся в этой структуре поля. -
Внутренняя изменчивость: При данном виде возможности изменений, даже когда у вас имеется ссылка
&SomeStructна некий тип, вы способны вносить изменения в его поля, когда эти поля обладают типомCell<T>илиRefCell<T>.
Внутренняя изменчивость делает возможным слегка изменять правила заимствования, но также и возлагает на самого
программиста бремя обеспечения того, чтобы во время исполнения не существовало двух заимствований с возможностью изменения.
Эти типы переносят выявление множественности ссылок с возможностью изменения со времени компиляции на время исполнения и
претерпевают ситуацию паники когда имеются две ссылки с возможностью изменения на некое значение. Внутренняя изменчивость
часто применяется когда вы желаете предоставить пользователям API без возможности изменений, несмотря на то, что внутри самого
API имеются части с возможностью внесения изменений. В стандартной библиотеки имеются два общих типа умных указателей, которые
предоставляют возможность совместного изменения: Cell и
RefCell.
Cell<T>
Рассмотрим эту программу, в которой у нас имеется требование видоизменить bag двумя
ссылками на него с возможностью изменения:
// without_cell.rs
use std::cell::Cell;
#[derive(Debug)]
struct Bag {
item: Box<u32>
}
fn main() {
let mut bag = Cell::new(Bag { item: Box::new(1) });
let hand1 = &mut bag;
let hand2 = &mut bag;
*hand1 = Cell::new(Bag {item: Box::new(2)});
*hand2 = Cell::new(Bag {item: Box::new(2)});
}
Однако, естественно, это не компилируется по причине правил проверки заимствования:
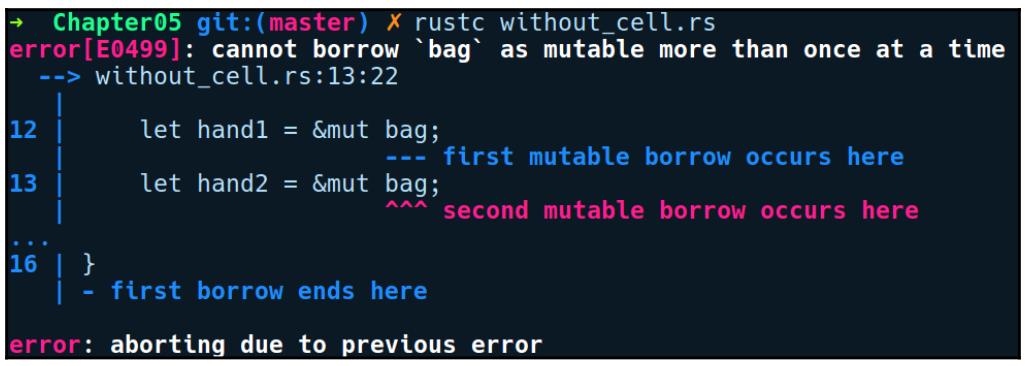
Мы можем заставить это работать, инкапсулируя своё значение bag внутри некого
Cell наш код обновляется так:
// cell.rs
use std::cell::Cell;
#[derive(Debug)]
struct Bag {
item: Box<u32>
}
fn main() {
let bag = Cell::new(Bag { item: Box::new(1) });
let hand1 = &bag;
let hand2 = &bag;
hand1.set(Bag { item: Box::new(2)});
hand2.set(Bag { item: Box::new(3)});
}
Это работает ожидаемым образом и единственной добавляемой затратой является то, что вам приходится писать чуть больше. Стоимость дополнительного времени исполнения равна нулю, а следовательно, все наши имеющие возможность изменения моменты остаются неизменными.
Собственно тип Cell<T> это тип умного указателя, который позволяет изменять
значения, даже позади ссылок без возможности изменения. Он предоставляет такую возможность с чрезвычайно минимальными
накладными расходами и обладает минимальным API:
-
Vtnjl
Cell::newпозволяет вам создавать новые экземпляры своего типаCell, передавая ему любой типT. -
get: Этот методgetделает для вас возможным копирование своего значения в ячейке. Данный метод доступен только когда обёртывающий его типTэтоCopy. -
set: Допускает изменение своего внутреннего значения вами, даже позади ссылки без возможности изменения.
RefCell<T>
Когда вам требуются подобные Cell функциональные возможности для типов, не
являющихся Copy, существует тип RefCell.
Он применяет шаблон чтения/ записи аналогично тому, как работает заимствование, однако перемещает проверку на время
исполнения, что удобно, однако обладает ненулевой стоимостью. RefCell выдаёт ссылки
на необходимое значение вместо возвращения вещей по значению, как это имеет место в случае с типом
Cell. Вот образец такой программы:
// refcell_basics.rs
use std::cell::RefCell;
#[derive(Debug)]
struct Bag {
item: Box<u32>
}
fn main() {
let bag = RefCell::new(Bag { item: Box::new(1) });
let hand1 = &bag;
let hand2 = &bag;
*hand1.borrow_mut() = Bag { item: Box::new(2)};
*hand2.borrow_mut() = Bag { item: Box::new(3)};
let borrowed = hand1.borrow();
println!("{:?}", borrowed);
}
Как вы можете наблюдать, мы способны заимствовать bag, причём с возможностью
изменения, из hand1 и hand2, даже хотя они
объявлены как переменные без возможности изменения. Для изменения самих элементов в bag,
мы вызываем из hand1 и hand2
borrow_mut. Позднее мы заимствуем его возможность изменения и выводим на печать
получаемое содержимое.
Соответствующий тип RefCell снабжает нас двумя следующими методами заимствования:
-
Метод
borrowполучает новую неизменную ссылку -
Метод
borrow_mutполучает новую ссылку с возможностью изменения
Теперь мы попробуем вызвать оба этих метода в одной и той же области действия: изменяя самую последнюю строку в своём предыдущем коде так:
println!("{:?} {:?}", hand1.borrow(), hand1.borrow_mut());
После выполнения своей программы мы получаем следующее:
thread 'main' panicked at 'already borrowed: BorrowMutError', src/libcore/result.rs:1009:5
note: Run with `RUST_BACKTRACE=1` for a backtrace.
Ситуация паники времени исполнения! Она произошла по причине всё того же самого правила владения по обладанию исключительным
доступом на изменение. Однако, для RefCell это проверяется вместо прежнего, на момент
исполнения. Для подобных данной ситуаций для разделения заимствований следует применять голые блоки в явном виде или пользоваться
методом drop для удаления соответствующей ссылки.
|
| Замечание |
|---|---|
|
Типы |
В нашем предыдущем разделе примеры использования Cell и RefCell
были упрощены, и вам скорее всего не потребуется применять из в таком виде в своём коде. Давайте рассмотрим некоторые реальные
преимущества, которые могли бы предоставить нам эти типы.
Как мы уже упоминали ранее, сама возможность изменения привязок не обладает тонкой настройкой; всякое значение может либо
изменяться, либо нет, причём это относится ко всем его полям, когда это структура или нечто перечисляемое.
Cell и RefCell способны превращать некую вещь без
возможности изменения в нечто изменяемое, позволяя нам определять части некой неизменной структуры как обладающие возможностью
изменения.
Следующий фрагмент кода дополняет некую структуру двумя целыми числами и методом sum
для кэширования получаемого ответа значения sum и возвращения такого кэшированного значения
в случае его наличия:
// cell_cache.rs
use std::cell::Cell;
struct Point {
x: u8,
y: u8,
cached_sum: Cell<Option<u8>>
}
impl Point {
fn sum(&self) -> u8 {
match self.cached_sum.get() {
Some(sum) => {
println!("Got from cache: {}", sum);
sum
},
None => {
let new_sum = self.x + self.y;
self.cached_sum.set(Some(new_sum));
println!("Set cache: {}", new_sum);
new_sum
}
}
}
}
fn main() {
let p = Point { x: 8, y: 9, cached_sum: Cell::new(None) };
println!("Summed result: {}", p.sum());
println!("Summed result: {}", p.sum());
}
Ниже приводится вывод данной программы:
Rust применяет подход системного программирования нижнего уровня для управления памятью, обещая подобную C производительность, а порой даже и лучше. Благодаря применению семантике владения, времени существования и заимствования, он делает это, не требуя специального сборщика мусора. Мы рассмотрели здесь большое число вопросов по предмету, который является самым сложным для новичка Растасина. Так любят именовать себя знакомые с Rust люди, а вы близки к тому, чтобы стать одним из них! Чтобы свободно овладеть таким мышлением о собственности во время компиляции, потребуется какое- то время, но инвестиции в изучение подобных понятий окупаются в виде надёжного программного обеспечения при небольшом объёме памяти.
Наша следующая глава из 2го издания Полного руководства Rust, Рауля Шармы и Везы Кайхлавирты, (с) 2019, Packt Publishing будет рассматривать как в Rust обрабатываются ситуации с отказами. Встретимся там!