Глава 4. 20 библиотек Asyncio, которые вы не применяете (Но... Да ладно, не берите в голову)
Содержание
В этой главе мы рассмотрим примеры использования новых свойств Python для асинхронного программирования. Мы будем применять некоторые библиотеки сторонних разработчиков и это важно показать, так как в ваших собственных проектах вы в основном будете применять библиотеки.
Название этой главы, 20 библиотек Asyncio, которые вы не применяете..., обыгрывает заголовок моей предыдущей книги
20 библиотек Python, которые вы не применяете
(а следовало бы). Многие из этих библиотек также будут полезны вам в приложениях на основе asyncio, однако в
данной главе мы будем применять библиотеки, намеренно спроектированные под обсуждаемую новую функциональность Python.
Сложно представлять код на основе asyncio в коротких фрагментах. Как вы уже видели во всех предыдущих образцах
кода в этой книге, я пытаюсь сделать всякий пример завершённой, запускаемой программой, так как управление жизненным циклом является сердцевиной
рассмотрения проблем для правильного применения асинхронного программирования.
По этой причине большинство примеров из этой главы будут чем- то большим в терминах строк кода, чем это бывает обычно в подобных книгах. Моя цель состоит в применении данного подхода состояла в том, чтобы сделать данные примеры более полезными, предоставляя вам "полное представление" какой- то асинхронной программы вместо того чтобы оставить вас с необходимостью самостоятельно размышлять как соединять фрагменты воедино.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Порой образцы кода в этой главе будут компромиссом со стилем кода для экономии места. Мне нравится PEP8, так же как и Pythonista, но практичность одерживает верх над безукоризненностью! |
Прежде чем пускаться во все тяжкие со сторонними библиотеками, давайте начнём со стандартной. Streams API является интерфейсом верхнего уровня предлагаемого для асинхронного программирования сокетов и, как покажет наш следующий пример, его достаточно просто применять; тем не менее, проектирование приложения остаётся сложным просто из- за самой природы этой области.
Наш следующий пример показывает некую реализацию посредника (брокера) сообщений и вначале демонстрирует некий безыскусный подход, за которым последует рассмотрение более сложной архитектуры. Ни один из них не является готовым к промышленному применению, но моя цель состоит в том чтобы помочь вам задуматься о различных сторонах параллельного сетевого программирования, которые следует принимать во внимание при построении подобных приложений.
Некая служба очередей сообщений является промежуточным ПО, ориентированным на сообщения (MOM, messageoriented middleware), развёртываемом в вычислительном облачном решении при помощи программного обеспечения в виде модели службы. Подписавшиеся на службу осуществляют доступ к очередям или темам для обмена данными применяя топологию точка- точка или шаблоны издателя и подписчика. [1].
-- Wikipedia: "Message queuing service"
Я только что работал в некотором проекте, который привлекал использование ActiveMQ в качестве посредника обмена сообщениями для взаимодействия микрослужб. На базовом уровне такой брокер (сервер):
-
поддерживал постоянные соединения со множеством клиентов,
-
получал сообщения от клиентов с каким- то целевым "названием канала",
-
доставлял эти сообщения всем прочим клиентам, подписанным на канал с тем же самым названием.
Я помню как трудно было создать такое приложение. В качестве дополнительного штриха, ActiveMQ способен выполнять разные модели распространения сообщений, причём имеющиеся две модели обычно отличаются своими названиями каналов:
-
Каналы с префиксом
/topicв названии, например,/topic/customer/registrationуправляются при помощи шаблона Издатель-подписчик (все подписчики канала получают все сообщения) -
Каналы именуемые с префиксом
/queueобрабатываются в соответствии с моделью точка-точка {P2P, одноранговой}, при которой сообщения в канале распространяются между подписчиками канала неким карусельным манером: каждый подписчик получает какое- то уникальное сообщение.
В нашем примере мы сконструируем игрушечного брокера сообщений при помощи таких базовых функций. Самой первой проблемой, которую нам предстоит решить, является то, что TCP не является протоколом, основанным на сообщениях: мы просто получаем потоки байт в какой- то сети. Нам требуется создать свой собственный протокол для требуемой структуры сообщений, причём самым простым протоколом является установка префикса с неким размером заголовка, за которым следует какая- то полезная нагрузка с этим размером. Для такого рода сообщений приводимая ниже утилита библиотеки предоставляет read и write:
Пример 4-1. Протокол обмена сообщениями: чтение и запись
# msgproto.py
import asyncio
from asyncio import StreamReader, StreamWriter
async def read_msg(reader: StreamReader) > bytes:
# Возбуждает asyncio.streams.IncompleteReadError
size_bytes = await reader.readexactly(4) (1)
size = int.from_bytes(size_bytes, byteorder='big') (2)
data = await reader.readexactly(size) (3)
return data
async def send_msg(writer: StreamWriter, data: bytes):
writer.write(len(data).to_bytes(4, byteorder='big')) (4)
writer.write(data) (5)
await writer.drain() (6)
def run_server(client, host='127.0.0.1', port=25000): (7)
loop = asyncio.get_event_loop()
coro = asyncio.start_server(client, '127.0.0.1', 25000)
server = loop.run_until_complete(coro)
try:
loop.run_forever()
except KeyboardInterrupt:
print('Bye!')
server.close()
loop.run_until_complete(server.wait_closed())
tasks = asyncio.Task.all_tasks()
for t in tasks:
t.cancel()
group = asyncio.gather(*tasks, return_exceptions=True
loop.run_until_complete(group)
loop.close()
-
(1) Получаем самые первые четыре байта. Это префикс размера.
-
(2) Эти четыре байта необходимо преобразовать в целое значение.
-
(3) Теперь, когда мы знаем размер полезной нагрузки, считываем её из имеющегося потока.
-
(4) Запись обратна к чтению: вначале мы отправляем значение длины своих данных, кодируя их в 4 байтах.
-
(5) Затем отправляем собственно данные.
-
(6)
drain()гарантирует то что необходимые данные отправлены полностью. Безdrain()какие- то данные всё ещё могут дожидаться своей очереди в имеющемся буфере отправки в то время как выполнен выход из данной сопрограммы. -
(7) Это здесь не существенно, но я снабдил функцию под запуск некоего сервера TCP. Данная последовательность останова уже обсуждалась ранее в нашем предыдущем разделе и я включаю это здесь исключительно для экономии места в последующих примерах кода. Останов сервера начинается через
SIGINTили Ctrl-C.
Теперь, когда у нас имеется примитивный протокол обмена сообщениями, мы можем сосредоточиться на приложении посредника обмена сообщениями:
Пример 4-2. Некий прототип в 35 строк
# mq_server.py
import asyncio
from asyncio import StreamReader, StreamWriter, gather
from collections import deque, defaultdict
from typing import Deque, DefaultDict
from msgproto import read_msg, send_msg, run_server (1)
SUBSCRIBERS: DefaultDict[bytes, Deque] = defaultdict(deque) (2)
async def client(reader: StreamReader, writer: StreamWriter):
peername = writer.transport.get_extra_info('peername') (3)
subscribe_chan = await read_msg(reader) (4)
SUBSCRIBERS[subscribe_chan].append(writer) (5)
print(f'Remote {peername} subscribed to {subscribe_chan}')
try:
while True:
channel_name = await read_msg(reader) (6)
data = await read_msg(reader) (7)
print(f'Sending to {channel_name}: {data[:19]}...')
writers = SUBSCRIBERS[channel_name]
if writers and channel_name.startswith(b'/queue'):
writers.rotate() (8)
writers = [writers[0]] (9)
await gather(*[send_msg(w, data) for w in writers]) (10)
except asyncio.CancelledError: (11)
print(f'Remote {peername} closing connection.') (12)
writer.close()
except asyncio.streams.IncompleteReadError:
print(f'Remote {peername} disconnected')
finally:
print(f'Remote {peername} closed')
SUBSCRIBERS[subscribe_chan].remove(writer) (13)
if __name__ == '__main__':
run_server(client)
-
(1) Импорт из нашего модуля
msgproto.py. -
(2) Некая общая коллекция активных в настоящее время подписчиков. При каждом подключении какого- то клиента, тот обязан вначале отправить некое название канала, на который он подписывается.
Очередь с двусторонним доступом(deque) удержит всех имеющихся подписчиков в каком- то определённом канале. -
(3) Данная функция сопрограммы
client()произведёт какую- то долгоживущую сопрограмму для каждого нового соединения. Представляйте себе её как некий обратный вызов того сервера TCP, который запускается вrun_server(). В этой строке я показал как можно получить адрес хоста и порт удалённого однорангового партнёра, например, для регистрации. -
(4) Наш протокол для клиентов состоит в следующем:
-
При первом подключении некий клиент обязан отправить какое- то сообщение, содержащее тот канал, на который он подписывается (в данном случае,
subscribe_chan). -
После этого, для обеспечения собственно жизни данного соединения клиент отправляет какое- то сообщение в канал вначале отправляя какое- то сообщение, содержащее имя своего целевого канала, за которым следует сообщение с данными. Наш брокер отправит такие сообщения с данными каждому клиенту, который подписан на данный канал.
-
-
(5) Добавляем необходимый экземпляр
StreamWriterв имеющуюся общую коллекцию подписчиков. -
(6) В бесконечном цикле ожидаем данные от этого клиента. Самое первое сообщение от какого- то клиента должно быть названием целевого канала.
-
(7) Далее переходим к реальным данным для распространения в конкретном канале.
-
(8) Получаем определённую очередь с двусторонним доступом (deque) подписчиков в своём целевом канале.
-
(9) Некая особая обработка если данное название канала начинается с магического слова "
/queue": в таком случае мы отправляем свои данные только одному из всех подписчиков, а не всем им. Это можно применять для разделения работы между каким- то пакетом исполнителей, вместо того чтобы следовать обычной схеме уведомлений pub-sub, при которой все подписчики в некотором канале получают все сообщения. -
(10) Именно по этой причине мы используем двустороннюю очередь, а не список: вращение по нашей
dequeэто то как мы отслеживаем своего следующего клиента в строке для распространения "/queue". Это кажется затратным, пока вы не поймёте, что однократное обращение по двусторонней очереди является операцией O(1). -
(11) Целевым является всякий идущий первым клиент; это изменяется после каждого кругового обхода.
-
(12) Создаём некий список сопрограмм для отправки данного сообщения каждому записывающему, а затем распаковываем его в
gather()с тем, чтобы мы могли дождаться завершения всех этих отсылок.Замечание Эта строка является негодной брешью в нашей программе, но может быть не очевидно почему: хотя может быть и правильным дождаться отправки всем подписчикам, которая происходит одновременно, что произойдёт если у нас имеется очень медленный клиент? В таком случае наш
gather()завершится только когда самый тормозной подписчик получит свои данные. Мы не можем получать никакие иные данные от отправляющих их клиентов пока не завершатся все этиsend_msg(). Это замедляет распространение всех сообщений до значения скорости самого медленного подписчика. -
(13) Когда мы покидаем сопрограмму
client(), не забудьте удалить себя из имеющейся общей коллекцииSUBSCRIBERS. К сожалению, это операция с O(n), которая может быть затратной при больших значенияхn. Некая иная структура исправит это, но в данный момент мы утешаем себя пониманием того что соединения рассматриваются как обладающие большим временем жизни, следовательно события отключения единичны; аnвряд ли будет слишком большим (скажем ~ 10 000 в качестве грубой оценки); и в таком коде достаточно просто разобраться!
Итак, у нас есть сервер; теперь нам нужны клиенты, а после этого мы сможем продемонстрировать некий вывод. Для целей демонстрации мы создадим два вида клиентов: "отправителя" и "получателя". Наш сервер не изменяется? для него клиенты одни и те же. Данное отличие между поведением "отправителя" и "получателя" служит лишь цели обучения.
Пример 4-3. Сторона ожидания: некий инструментарий для ожидания сообщений в нашем брокере сообщений
# mq_client_listen.py
import asyncio
import argparse, uuid
from msgproto import read_msg, send_msg
async def main(args):
me = uuid.uuid4().hex[:8] (1)
print(f'Starting up {me}')
reader, writer = await asyncio.open_connection(
args.host, args.port) (2)
print(f'I am {writer.transport.get_extra_info("sockname")}')
channel = args.listen.encode() (3)
await send_msg(writer, channel) (4)
try:
while True:
data = await read_msg(reader) (5)
if not data:
print('Connection ended.')
break
print(f'Received by {me}: {data[:20]}')
except asyncio.streams.IncompleteReadError:
print('Server closed.')
if __name__ == '__main__':
parser = argparse.ArgumentParser() (6)
parser.add_argument('host', default='localhost')
parser.add_argument('port', default=25000)
parser.add_argument('listen', default='/topic/foo')
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(main(parser.parse_args()))
except KeyboardInterrupt:
print('Bye!')
loop.close()
-
(1) Наш стандартный модуль
uuidявляется удобным способом создания какй- то "уникальности" для данного ожидающего. Если вы при помощи этого вы запускаете множество экземпляров, каждый из них будет иметь свй собственный идентификатор и у вас будет возможность отслеживать в соответствующих журналах что происходит. -
(2) Открываем соединение со своим сервером.
-
(3) Название канала для подписки является неким входным параметром, которые выбирается из
args.listen. Перед отправки кодируем его вbytes. -
(4) По правилам нашего протокола (которые описаны в анализе кода нашего брокера ранее), самое первое, что мы должны сделать сразу после подключения, так это отправит то название канала, на который требуется подписка.
-
(5) Этот цикл ничего не делает кроме того что ждёт появления данных в своём сокете.
-
(6) Параметры командной строки для данной программы чтобы сделать более простым указание хоста, порта и названия канала, в котором следует выполнять ожидание.
Структура нашего другого клиента, программы "отправителя", аналогична уже обсуждённому модулю стороны ожидания.
Пример 4-4. Наилучшая практика использования потоков
# mq_client_sender.py
import asyncio
import argparse, uuid
from itertools import count
from msgproto import send_msg
async def main(args):
me = uuid.uuid4().hex[:8] (1)
print(f'Starting up {me}')
reader, writer = await asyncio.open_connection(
host=args.host, port=args.port) (2)
print(f'I am {writer.transport.get_extra_info("sockname")}')
channel = b'/null' (3)
await send_msg(writer, channel) (4)
chan = args.channel.encode() (5)
for i in count(): (6)
await asyncio.sleep(args.interval) (7)
data = b'X'*args.size or f'Msg {i} from {me}'.encode()
try:
await send_msg(writer, chan)
await send_msg(writer, data) (8)
except ConnectionResetError:
print('Connection ended.')
break
writer.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser() (9)
parser.add_argument('host', default='localhost')
parser.add_argument('port', default=25000, type=int)
parser.add_argument('channel', default='/topic/foo')
parser.add_argument('interval', default=1, type=float)
parser.add_argument('size', default=0, type=int)
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(main(parser.parse_args()))
except KeyboardInterrupt:
print('Bye!')
loop.close()
-
(1) Как и для стороны ожидания, требуется некая идентичность.
-
(2) Как и для стороны ожидания, добиваемся выполнения подключения.
-
(3) В соответствии с правилами нашего протокола, самый первый момент, который следует выполнить сразу после подключения, состоит в получении самого названия канала для подписки; однако, так как мы являемся стороной отправки, мы на самом деле не озабочены подпиской на какие- либо каналы; тем не менее, так как наш протокол того требует, поэтому просто предоставляем некий нулевой канал для подписки (на самом деле нам не требуется ничего ожидать).
-
(4) Отправляем значение канала для подписки.
-
(5) Получаемый из командной строки параметр
args.channelпредоставляет тот канал, в который мы желаем отправлять сообщения. Отметим, что его следует преобразовать в байты перед отправкой. -
(6) Применение
itertools.count()похоже на циклwhile True, за исключением того что вы получаете для использования некую переменную итераций. Мы применяем это при отладке обмена сообщениями, так как таким образом проще отслеживать какое сообщение откуда отправлено. -
(7) Значение задержки между отправляемыми сообщениями является неким получаемым на входе параметром,
args.interval. Наша следующая строка вырабатывает полезную нагрузку данного сообщения. Это либо строка байт предписанного размера (args.size), либо некое описательное сообщение. Такая гибкость служит исключительно для проверки. -
(8) Отправляем! Заметим, что здесь присутствуют два сообщения: самым первым является название целевого канала, а второе представляет собственно полезную нагрузку.
-
(9) Как и в случае стороны ожидания, имеется некий пакет параметров командной строки для регулировок нашего отправителя: "channel" определяет целевой канал для отправки, в то время как "interval" управляет значение задержки между отправками. Значение параметра "size" управляет размером полезной нагрузки каждого сообщения.
Теперь у нас имеются некие брокер, сторона ожидания и отправитель; настало время ознакомиться с выводом. Для того чтобы воспроизвести следующие фрагменты кода я запустил свой сервер, после этого двух клиентов ожидания и затем отправителя; а после этого были отправлены несколько сообщений, я остановил свой сервер при помощи Ctrl-C:
Пример 4-5. Вывод брокера обмена сообщениями (сервера)
$ python mq_server.py
Remote ('127.0.0.1', 55382) subscribed to b'/queue/blah'
Remote ('127.0.0.1', 55386) subscribed to b'/queue/blah'
Remote ('127.0.0.1', 55390) subscribed to b'/null'
Sending to b'/queue/blah': b'Msg 0 from 6b5a8e1d'...
Sending to b'/queue/blah': b'Msg 1 from 6b5a8e1d'...
Sending to b'/queue/blah': b'Msg 2 from 6b5a8e1d'...
Sending to b'/queue/blah': b'Msg 3 from 6b5a8e1d'...
Sending to b'/queue/blah': b'Msg 4 from 6b5a8e1d'...
Sending to b'/queue/blah': b'Msg 5 from 6b5a8e1d'...
^CBye!
Remote ('127.0.0.1', 55382) closing connection.
Remote ('127.0.0.1', 55382) closed
Remote ('127.0.0.1', 55390) closing connection.
Remote ('127.0.0.1', 55390) closed
Remote ('127.0.0.1', 55386) closing connection.
Remote ('127.0.0.1', 55386) closed
Пример 4-6. Вывод отправителя (клиента)
$ python mq_client_sender.py channel /queue/blah
Starting up 6b5a8e1d
I am ('127.0.0.1', 55390)
Connection ended.
Пример 4-7. Вывод получателя 1 (клиента)
$ python mq_client_listen.py listen /queue/blah
Starting up 9ae04690
I am ('127.0.0.1', 55382)
Received by 9ae04690: b'Msg 1 from 6b5a8e1d'
Received by 9ae04690: b'Msg 3 from 6b5a8e1d'
Received by 9ae04690: b'Msg 5 from 6b5a8e1d'
Server closed.
Пример 4-8. Вывод получателя 2 (клиента)
$ python mq_client_listen.py listen /queue/blah
Starting up bd4e3baa
I am ('127.0.0.1', 55386)
Received by bd4e3baa: b'Msg 0 from 6b5a8e1d'
Received by bd4e3baa: b'Msg 2 from 6b5a8e1d'
Received by bd4e3baa: b'Msg 4 from 6b5a8e1d'
Server closed.
Наш игрушечный брокер обмена сообщениями работает! Полученный код достаточно просто понять, принимая во внимание насколько сложна область изучения, однако к сожалению полученное построение данного кода брокера само по себе имеет проблемы.
Основная проблема в том, что для какого- то определённого клиента мы отправляем сообщения подписчикам в той же самой
подпрограмме, в которой мы получили новые сообщения. Это означает, что если какой- то подписчик является медленным для того чтобы
потреблять то, что ему отсылается, он может тратить много времени на выполнение строки await gather(...)
и мы не можем ничего более получать и обрабатывать пока не дождёмся его.
Вместо этого нам требуется отвязать получение сообщений от отправки сообщений. В своём следующем примере мы переработаем наш код именно с этой целью.
В этом примере мы изменим имеющуюся архитектуру своего игрушечного брокера обмена сообщениями. Наши программы "стороны ожидания" и "отправителя" останутся прежними. Основная цель для этого нового проекта посредника состоит в разъединении отправки и приёма. Данный код слегка длиннее, но также не страшный.
Пример 4-9. Брокер обмена сообщениями: улучшенная архитектура
# mq_server_plus.py
import asyncio
from asyncio import StreamReader, StreamWriter, Queue
from collections import deque, defaultdict
from contextlib import suppress
from typing import Deque, DefaultDict, Dict
from msgproto import read_msg, send_msg, run_server
SUBSCRIBERS: DefaultDict[bytes, Deque] = defaultdict(deque)
SEND_QUEUES: DefaultDict[StreamWriter, Queue] = defaultdict(Queue)
CHAN_QUEUES: Dict[bytes, Queue] = {} (1)
async def client(reader: StreamReader, writer: StreamWriter):
peername = writer.transport.get_extra_info('peername')
subscribe_chan = await read_msg(reader)
SUBSCRIBERS[subscribe_chan].append(writer) (2)
loop = asyncio.get_event_loop()
send_task = loop.create_task(
send_client(writer, SEND_QUEUES[writer])) (3)
print(f'Remote {peername} subscribed to {subscribe_chan}')
try:
while True:
channel_name = await read_msg(reader)
data = await read_msg(reader)
if channel_name not in CHAN_QUEUES: (4)
CHAN_QUEUES[channel_name] = Queue(maxsize=10) (5)
loop.create_task(chan_sender(channel_name)) (6)
await CHAN_QUEUES[channel_name].put(data) (7)
except asyncio.CancelledError:
print(f'Remote {peername} connection cancelled.')
except asyncio.streams.IncompleteReadError:
print(f'Remote {peername} disconnected')
finally:
print(f'Remote {peername} closed')
await SEND_QUEUES[writer].put(None) (8)
await send_task (9)
del SEND_QUEUES[writer] (10)
SUBSCRIBERS[subscribe_chan].remove(writer)
async def send_client(writer: StreamWriter, queue: Queue): (11)
while True:
with suppress(asyncio.CancelledError):
data = await queue.get()
if not data:
writer.close()
break
await send_msg(writer, data)
async def chan_sender(name: bytes):
with suppress(asyncio.CancelledError):
while True:
writers = SUBSCRIBERS[name]
if not writers:
await asyncio.sleep(1)
continue (12)
if name.startswith(b'/queue'): (13)
writers.rotate()
writers = [writers[0]]
msg = await CHAN_QUEUES[name].get() (14)
if not msg:
break
for writer in writers:
if not SEND_QUEUES[writer].full():
print(f'Sending to {name}: {msg[:19]}...')
await SEND_QUEUES[writer].put(msg) (15)
if __name__ == '__main__':
run_server(client)
-
(1) В нашей предыдущей реализации имелся только один
SUBSCRIBERS; теперь в глобальном наборе присуствуютSEND_QUEUESиCHAN_QUEUES. Именно это является результатом полного разделения приёма и отправления данных.SEND_QUEUESимеет одну запись очереди для каждого соединения с клиентом: все подлежащие отправке этому клиенту данные должны помещаться в эту очередь. (Если вы быстро заглянете вперёд, сопрограммаsend_client()выгрузитSEND_QUEUESи отправит её.) -
(2) До текущего момента в нашей функции сопрограммы
client()весь код был в точности тем же, что и в нашем образце сервера: принималось название канала подписчика и мы добавляли соответствующий экземплярStreamWriterдля такого нового клиента в свою глобальную коллекциюSUBSCRIBERS. -
(3) А вот это новинка: мы создаём некую задачу с долгим временем жизни которая будет выполнять всю отправку данных такому клиенту. Эта задача будет исполняться независимо в виде какой- то отдельной сопрограммы и будет выгружать для отправки сообщения поддерживаемой ею очереди,
SEND_QUEUES[writer] -
(4) Теперь мы находимся внутри того цикла, в котором мы принимаем данные. Помните, что мы всегда получаем два сообщения: одно для своего названия целевого канала, а второе собственно для данных. Мы намерены создать каую- то новую, выделенную
Queueдля каждого целевого канала, и именно этому служитCHAN_QUEUES: всякий раз, когда клиент желает поместить данные в какой- то канал, мы обираемся размещать такие данные в соответствующей очереди, а затем немедленно возвращаемся к ожиданию дополнительных данных. Такой подход отсоединяет имеющееся распределение обмена сообщениями от необходимого приёма сообщений этим же клиентом. -
(5) Если уже имеется некая очередь для данного целевого канала, пользуемся ею.
-
(6) Для этого канала создаём некую выделенную задачу с длительным временем жизни. Данная сопрограмма,
chan_sender(), будет отвечать за забор данных из очереди этого канала и распространения этих данных подписчикам. -
(7) Помещаем свои вновь полученные данные в очередь некого специфического канала. Отметим, что если данная очередь заполнится, мы будем выполнять здесь ожидание пока не освободится место для наших новых данных. В процессе ожидания в этом месте мы не будем считывать никакие новые данные из своего сокета, что означает, что нашему клиенту придётся со своей стороны выполнять ожидание отправки новых данных в соответствующий сокет. Это не обязательно плохой момент, так как он сообщает данному клиенту о так называемом противодавлении - back pressure. (В противном случае вы можете здесь выбрать сброс сообщений, если это подходит для вашего варианта применения.)
-
(8) После того как это соединение закрывается, самое время для его очистки! Та долгоиграющая задача, которую мы создавали для отправки данных этому клиенту,
send_task, может быть остановлена помещениемNoneв её очередь,SEND_QUEUES[writer](проверьте соответствующий код дляsend_client()). Существенно применять какое- то значение в данной очереди вместо того чтобы полностью прекращать её, так как в этой очереди уже могут иметься данные и мы хотим отправки этих данных прежде чем завершитьsend_client(). -
(9) Ожидаем завершения данной задачи отправителя.
-
(10) Удаляем соответствующую запись в своей коллекции
SEND_QUEUES(а в своей следующей строке мы также удаляем соответствующийsockиз своей коллекцииSUBSCRIBERS, как и ранее). -
(11) Наша функция сопрограммы
send_client()очень похожа на пример из текста данной книги по извлечению исполнителя из очереди. Отметим как данная сопрограмма выполнит выход если поместитьNoneв соответствующую очередь. Также укажем на то как мы гасимCancelledErrorвнутри данного цикла: именно поэтому мы желаем чтобы данная задача закрывалась исключительно по получениюNoneв своей очереди. Таким образом все придерживаемые в этой очереди данные могут быть отправлены до её останова. -
(12)
chan_sender()является некоторой необходимой логикой распространения для какого- то канала: она отправляет данные из какого- то выделенного экземпляраQueueканала всем своим подписчикам в этом канале. Но что произойдёт если пока ещё нет никаких подписчиков для этого канала? Мы всего лишь немного подождём и повторим попытку вновь (Заметим, что соответствующая очередь этого канала, то естьCHAN_QUEUES[name], тем не менее продолжит заполняться.) -
(13) Как и ранее в своей предыдущей реализации брокера, мы делаем нечто особенное для каналов, название которых начинается с "/deque": мы вращаем свою
deque(двустороннюю очередь, колоду) и отправляем только самую первую запись. Это действует как некая недоделанная система балансировки нагрузки, так как каждый подписчик получает различные сообщения из той же самой очереди. Для всех прочих каналов все подписчики получают все имеющиеся сообщения. -
(14) Здесь мы выполняем ожидание данных этой очереди. В своей следующей строке мы выполняем выход в случае получения
None. В настоящее время это не является предметом переключения где бы то ни было (следовательно, данная сопрограммаchan_sender()живёт постоянно); однако если впоследствии была добавлена логика очистки задач этого канала, скажем, в случае отсутствия активности на протяжении какого- то времени, именно здесь это следует делать. -
(15) Данные были получены, поэтому настало время их отправки подписчикам. Отметим что мы здесь не выполняем отправку: мы помещаем соответствующие данные в собственную очередь отправки каждого подписчика. Дакое разъединение необходимо чтобы гарантировать то, что какой- то медленный подписчик не будет замедлять получение данных кому- то ещё. И более того, если соответствующий подписчик настолько медленный, что его очередь отправки переполняется, мы не помещаем эти данные в его очередь, т.е. они теряются.
Приведённая архитектура производит тот же самый вывод что и более ранняя, упрощённая реализация, но теперь мы можем гарантировать что некая медленная сторона ожидания не будет воздействовать при помощи распределения обмена сообщениями на прочие стороны ожидания.
Эти два варианта применения показывают некий прогресс в понимании относительно необходимой архитектуры распределённой системы обмена сообщениями. Неким ключевым моментом была та реализация, при которой отправка и получение данных могут лучше обрабатываться в отдельных сопрограммах в зависимости от варианта применения. При таких обстоятельствах для перемещения данных между различными сопрограммами, а также для предоставления буферизации с целью их разделения могут очень полезными оказаться очереди.
Самой важной целью данных примеров было показать то как API Streams из asyncio упрощает построение приложений
на основе сокетов.
Проект Twisted предшествовал - причём впечатляющим образом -
нашей стандартной библиотеке asyncio и вывешивался как основной флаг асинхронного программирования на Python
на протяжении почти 14 лет до текущего времени. Этот проект предоставлял не только основные строительные блоки, такие как цикл событий, но также и
примитивы наподобие deferreds (отложенных операций), которые слегка похожи на
futures (фьючерсы) asyncio. Само построение
asyncio испытало сильное воздействие со стороны Twisted, а также громадного опыта его лидеров и групп
поддержки.
Отметим, что asyncio не заменяет Twisted[2]. Twisted содержит реализации высочайшего уровня
гигантского числа протоколов Internete, включающих в себя не только HTTP, но также и XMPP, NNTP, IMAP, SSH, IRC и FTP (как серверы, так и клиенты).
А в последнее время также ждите прибавок: DNS? Проверьте. SMTP? Проверьте. POP3? Проверьте.
На уровне самого кода основное различие между Twisted и asyncio, помимо истории и исторического контекста,
состоит в том, что на протяжении длительного времени Python испытывал недостаток языковой поддержки для
сопрограмм, а это означало, что Twisted и подобные ему проекты вынуждены были предлагать пути работы с асинхронностью, которые бы работали с
имеющимся стандартным синтаксисом Python. На протяжении большей части истории Twisted обратные вызовы
(callback) выступали тем средством, при помощи которого выполнялось асинхронное программирование, причём со всею нелинейной сложностью, которую
они влекли за собой.
Как только стало возможным применять генераторы в качестве временной замены сопрограмм, это неожиданно сделало возможным размещать в Twisted
код линейным образом применяя его декоратор defer.inlineCallbacks:
@defer.inlineCallbacks (1)
def f():
yield
defer.returnValue(123) (2)
@defer.inlineCallbacks
def my_coro_func():
value = yield f() (3)
assert value == 123
-
(1) Первоначально Twisted требовал создания экземпляров
Deferred, а также добавления обратных вызовов к такому экземпляру в качестве своего метода построения асинхронных программ. Несколько лет назад был добавлен соответствующий декоратор@inlineCallbacks, который видоизменил генераторы в качестве сопрограмм. -
(2) Хотя
@inlineCallbacksпозволил нам писать код, который был линейным при своём возникновении (в отличии от обратных вызовов), всё же требовался некий хак, например, вызовdefer.returnValue(), который был именно тем способом, которым возвращались значения из сопрограмм@inlineCallbacks. -
(3) Здесь мы можем обнаружить
yield(оператор производства), который делает эту функцию неким генератором. Для того чтобы работал@inlineCallbacks, должен иметься по крайней мере одинyieldдля осуществления декорации данной функции.
После появления в Python 3.5 сопрограмм, команда Twisted (в частности, Amber
Brown) выполнила работу по добавлению поддержки в запущенном Twisted соответствующего цикла событий asyncio.
Эти усилия предпринимаются и в настоящее время и моя цель в данном разделе не в том чтобы убедить вас создавать все ваши приложения в виде некоего гибрида Twistedasyncio, а вместо этого ознакомит вас с тем, что такая работа в настоящее время выполняется с тем, чтобы предоставить значительное взаимодействие между Twisted и asyncio.
Для тех из вас, кто обладает существенным опытом относительно Twisted, следующий пример может вызвать раздражение:
Пример 4-10. Наилучшая практика использования потоков
from time import ctime
from twisted.internet import asyncioreactor
asyncioreactor.install() (1)
from twisted.internet import reactor, defer, task (2)
async def main(): (3)
for i in range(5):
print(f'{ctime()} Hello {i}')
await task.deferLater(reactor, 1, lambda: None) (4)
defer.ensureDeferred(main()) (5)
reactor.run() (6)
-
(1) Именно таким образом вы сообщаете Twisted о необходимости применять соответствующий цикл событий
asyncioв качестве его основногоreactor. Отметим, что данная строка обязана предшествовать самому импортуreactorизtwisted.internetв нашей следующей строке. -
(2) Всякий знакомый с программированием Twisted распознает эти импорты. У нас нет места пояснять их здесь, но в своей сердцевине наш
reactorявляется соответствующей версиейTwistedнеобходимого циклаasyncio, аdeferиtaskявляются пространствами имён для инструментов по работе с составлением расписаний сопрограмм. -
(3) Увидеть
async defздесь, в некоторой программе Twistes, выглядит как ужасно неуместное, но это именно то, что в конечном итоге даёт нам наша новая поддержка дляasync/await: возможность применять естественные сопрограммы непосредственно в программах Twisted! -
(4) В нашм более древнем мире
@inlineCallbacks, вам пришлось бы применять здесьyield, но теперь мы можем тут воспользоватьсяawait, точно также как и в кодеasyncio. Оставшаяся часть данной строки,deferLater, является неким альтернативным способом того же самого, чем являетсяasyncio.sleep(1). Мы выполняемawaitнекоего фьючерса, в котором через 1 секунду будет зажжён некий ничего не выполняющий обратный вызов. -
(5)
ensureDeferred()выступает в роли версии Twisted планирования какой- то сопрограммы. Это аналогичноloop.create_task()илиasyncio.ensure_future(). -
(6) Запуск необходимого reactor в точности тот же что и для
loop.run_forever()вasyncio.
Вывод:
$ python twisted_asyncio.py
Mon Oct 16 16:19:49 2017 Hello 0
Mon Oct 16 16:19:50 2017 Hello 1
Mon Oct 16 16:19:51 2017 Hello 2
Mon Oct 16 16:19:52 2017 Hello 3
Mon Oct 16 16:19:53 2017 Hello 4
Имеется намного больше тем для изучения Twisted и в особенности стоит потратить своё время на просмотр перечня реализованных в Twisted сетевых
протоколов. Ещё имеется определённая работа, которую следует осуществить, но общее будущее выглядит очень ярким для взаимодействия Twisted м
asyncio.
Имеющаяся архитектура asyncio была настроена таким образом, что мы имеем возможность заглянуть в будущее,
в котором будет возможен объединённый код множества различных асинхронных инфраструктур, таких как Twisted и Tornado в некотором отдельном приложении,
причём весь код запускается в одном и том же цикле событий.
Наша Очередь Janus (устанавливаемая при помощи pip install janus) предоставляет некое решение для взаимодействия
между потоками и сопрограммами. В нашей стандартной библиотеке существуют такие виды очередей:
-
queue.Queue: некая очередь с ",блокировкой", обычно применяемая для взаимодействия и буферизации между потоками (threads) -
asyncio.Queue: некая совместимая сasyncioочередь, обычно используемая при взаимодействии и буферизации между сопрограммами (coroutines)
К несчастью ничего нет полезного для взаимодействия между потоками и сопрограммами! Именно тут на помощь приходит Janus: это некая отдельная Очередь, которая выставляет оба API: один с блокировкой, и второй асинхронный. В нашем следующем образце кода данные вырабатываются внутри некоего потока, помещаются в какую- то очередь, а заетм потребляются из некоторой сопрограммы.
Пример 4-11. Наилучшая практика использования потоков
import asyncio, time, random, janus
loop = asyncio.get_event_loop()
queue = janus.Queue(loop=loop) (1)
async def main():
while True:
data = await queue.async_q.get() (2)
if data is None:
break
print(f'Got {data} off queue') (3)
print('Done.')
def data_source():
for i in range(10):
r = random.randint(0, 4)
time.sleep(r) (4)
queue.sync_q.put(r) (5)
queue.sync_q.put(None)
loop.run_in_executor(None, data_source)
loop.run_until_complete(main())
loop.close()
-
(1) Создаём некую очередь Janus. Отметим, что точно так же как и в случае с
asyncio.Queue, очередь Janus будет связана с неким определённым циклом событий. Как обычно, если вы не предоставляете предписанный параметрloop, внутренним образом будет применяться соответствующий стандартный вызовget_event_loop(). -
(2) Наша функция сопрограммы
main()просто выполняет ожидание данных в какой- то очереди. Данная строка подвешивается до тех пор, пока нет данных, в точности как и дляasyncio.Queue. Данный объект очереди имеет два "лица" {в точном соответствии с названием}: это именуетсяasync_q, и оно предоставляет API очереди, совместимый с асинхронными приложениями. -
(3) Выводим некое сообщение.
-
(4) Внутри нашей функции
data_source()вырабатывается некое случайное целое значение, которое применяется как некая продолжительность сна, а также как какое- то значение данных. Отметим, что вызовtime.sleep()является блокирующим, поэтому данная функция должна исполняться в каком- то потоке. -
(5) Помещаем полученные данные в имеющуюся очередь Janus. Это отображает второе "лицо" нашей очереди Janus:
sync_q, которое предоставляет наш стандартный APIQueueс блокировкой.
Вывод:
Got 2 off queue
Got 4 off queue
Got 4 off queue
Got 2 off queue
Got 3 off queue
Got 4 off queue
Got 1 off queue
Got 1 off queue
Got 0 off queue
Got 4 off queue
Done.
Если у вас есть такая возможность, лучше ориентироваться на короткие задания на исполнение и в таких случаях очередь (для взаимодействия) не понадобится. Однако это не всегда возможно, и в таких ситуациях наличие очереди Janus может быть наиболее подходящим решением для буферизации и распространения данных между потоками и сопрограммами.
aiohttp привносит в asyncio все моменты HTTP, в том числе
поддержку для клиентов и серверов HTTP, а также сопровождение вебсокетов. Давайте перепрыгнем сразу в примеры кодирования начиная далее с
простейшего самого по себе: &qout;hello world&qout;:
Следующий пример демонстрирует минимальный веб сервер при помощи aiohttp:
from aiohttp import web
async def hello(request):
return web.Response(text="Hello, world")
app = web.Application() (1)
app.router.add_get('/', hello) (2)
web.run_app(app, port=8080) (3)
Обратим внимание что в данном коде не упоминаются никакие циклы, задачи или фьючерсы : разработчики инфраструктуры
aiohttp скрыли всё это от нас, оставив очень чистый API. Такой подход рассматривается как общий в
большинстве инфраструктур поверх asyncio, который разрабатывается с тем, чтобы позволить
проектировщикам инфраструктур выбирать только самое существенное из того что необходимо и заключать
это в предпочитаемом ими API.
aiohttp может применяться как в качестве сервера, так и как какая- то библиотека клиента, как и очень
популярная (на применяющая блокировку!) библиотека requests.
Я бы хотел показать демонстрацию aiohttp применяя некий пример, который объединяет обе функциональности.
В данном примере мы реализуем некий вебсайт, который за сценой выполняет вытаскивание веб содержимого (scraping). Это приложение будет выполнять выскребание новостей с двух вебсайтов и объединять полученные заголовки в одну страницу результатов. Вот наша стратегия:
-
Некий клиент браузера выполняет веб запрос к
http://localhost:8080/news -
Наш веб сервер получает этот запрос, а затем в своём сервере делает выборку данных с множества новостных вебсайтов
-
Со всех страниц данных вытаскиваются заголовки
-
Полученные заголовки сортируются и форматируются в соответствующий HTML отклика, который отправляется обратно в соответствующий клиент браузера
Рисунок 4-1 отображает наш вывод:
Рисунок 4-1

Окончательная продукция нашей программы вытаскивания новостей: заголовки из CNN на синем, из Al Jazeera на жёлтом.
Выдёргивание веб содержимого в наши дни достаточно сложное, так как многие вебсайты интенсивно применяют JavaScript для загрузки своего содержимого.
К примеру, если вы попробуете requests.get('http://edition.cnn.com'), вы обнаружите что этот
отклик содержит очень мало полезных данных! Становится со всё возрастающей необходимостью иметь способность исполнять JavaScript локально чтобы
получать данные, так как многие сайты применяют JavaScript для загрузки своего реального содержимого. Сам процесс исполнения такого JavaScript
для воспроизводства такого окончательного вывода HTML именуется рендерингом (построением образа).
Для осуществления построения образа мы применяем отличный проект с названием Splash, который описывает самого себя как "Службу рендеринга JavaScript". Он способен запускаться в каком- то контейнере
docker и предоставлять некий API для построения образа прочих сайтов. Внутри
себя он применяет некий механизм WebKit (JavaScript- совместимый) для полной выгрузки и построения образа какого- то вебсайта. Именно его мы будем
применять для получения данных вебсайта. Наш сервер aiohttp будет вызывать этот API Splash для получения
данных необходимой страницы.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Чтобы получить и запустить необходимый контейнер Splash, в своей оболочке выполните следующие команды: Наша серверная основа будет вызывать API Splash в |
from asyncio import get_event_loop, gather
from string import Template
from aiohttp import web, ClientSession
from bs4 import BeautifulSoup
async def news(request): (1)
sites = [
('http://edition.cnn.com', cnn_articles), (2)
('http://www.aljazeera.com', aljazeera_articles),
]
loop = get_event_loop()
tasks = [loop.create_task(news_fetch(*s)) for s in sites] (3)
await gather(*tasks) (4)
items = { (5)
text: ( (6)
f'<div class="box {kind}">'
f'<span>'
f'<a href="{href}">{text}</a>'
f'</span>'
f'</div>'
)
for task in tasks for href, text, kind in task.result()
}
content = ''.join(items[x] for x in sorted(items))
page = Template(open('index.html').read()) (7)
return web.Response(
body=page.safe_substitute(body=content), (8)
content_type='text/html',
)
async def news_fetch(url, postprocess):
proxy_url = (
f'http://localhost:8050/render.html?' (9)
f'url={url}&timeout=60&wait=1'
)
async with ClientSession() as session:
async with session.get(proxy_url) as resp: (10)
data = await resp.read()
data = data.decode('utf8')
return postprocess(url, data) (11)
def cnn_articles(url, page_data): (12)
soup = BeautifulSoup(page_data, 'lxml')
def match(tag):
return (
tag.text and tag.has_attr('href')
and tag['href'].startswith('/')
and tag['href'].endswith('.html')
and tag.find(class_='cd__headlinetext')
)
headlines = soup.find_all(match) (13)
return [(url + hl['href'], hl.text, 'cnn')
for hl in headlines]
def aljazeera_articles(url, page_data): (14)
soup = BeautifulSoup(page_data, 'lxml')
def match(tag):
return (
tag.text and tag.has_attr('href')
and tag['href'].startswith('/news')
and tag['href'].endswith('.html')
)
headlines = soup.find_all(match)
return [(url + hl['href'], hl. text, 'aljazeera')
for hl in headlines]
app = web.Application()
app.router.add_get('/news', news)
web.run_app(app, port=8080)
-
(1) Наша функция
news()является соответствующим обработчиком для URL/newsв нашем сервере. Она возвращает окончательную страницу HTML, отображающую все имеющиеся заголовки. -
(2) Здесь у нас имеется толлько два новостных вебсайта для выдёргивания: CNN и Al Jazeera. Легко можно добавить дополнительные, но затем также потребуется добавить дополнительные обработчики данных, подобные представленным функциям
cnn_articles()иaljazeera_articles(), каждая из которых имеет индивидуальные настройки извлечения данных заголовков. -
(3) Для каждого новостного сайта мы создаём некую задачу для извлечения и обработки данных соответствующей страницы HTML для их передовиц. Отметим, что мы распаковываем соответствующие кортежи
((*s)), так как наша функция сопрограммыnews_fetch()получает оба URL и функцию обработки данных в качестве параметров. Каждыйnews_fetch()будет возвращать перечень кортежей в виде(<article URL>, <article title>). -
(4) Все задачи собираются воедино в отдельный
Future(gather()возвращает некий фьючерс, представляющий значение состояния всех подлежащих выработке задач), а затем мы немедленно выполняемawaitотносительно завершения такого фьючерса. Данная строка будет в подвешенном состоянии пока не завершится соответствующий фьючерс. -
(5) Так как все имеющиеся задачи
news_fetch()теперь завершены, мы собираем все полученные результаты в некий словарь. Отметим как вложенные содержания понятий применяются для выполнения итераций по задачам, а затем и по списку кортежей, возвращаемых каждой задачей. Мы также используемf- строкидля непосредственной подстановки данных, в том числе и сам "вид" страницы, что будет применяться в CSSS для обозначения цветом фона соответствующегоdiv. -
(6) В этом словаре значением
ключаявляется сам заголовок, а егозначениемнекая строка HTML для какого- тоdiv, которая будет отображаться в нашей странице результата. -
(7) Наш веб сервер собирается вернуть HTML. Мы выгружаем данные HTML из некоторого локального файла с названием
index.html, этот файл предоставляется в наших Дополнениях, если вы пожелаете восстановить данный пример самостоятельно. -
(8) Мы подставляем собранные DIV заголовков в общий шаблон и возвращаем полученную страницу в браузер своего клиента. Созданная страница отображена на Рисунке 4-1.
-
(9) Здесь, внутри соответствующей функции сопрограммы
news_fetch(), у нас имеется крошечный шаблон для попадания в свой API Splash (в моём случае он исполняется в некотором локальном контейнере docker с портом 8050). Здесь мы демонстрируем какaiohttpможет применяться в качестве некоторого клиента HTPP. -
(10) Самый стандартный путь состоит в создании некоего экземпляра
ClientSession()и последующем применении методаget()в имеющемся экземпляре сеанса для выполнения необходимого вызова REST. В нашей следующей строке получаются данные отклика. Отметим, что поскольку мы всегда оперируем в сопрограммах, причём применяяasync withиawait, эти сопрограммы никогда не выполняют блокировку: у нас будет иметься возможность обрабатывать многие тысячи таких запросов, даже хотя эти операции, т.е.news_fetch(), могут быть относительно медленными, поскольку мы выполняем веб вызовы внутренним образом. -
(11) После получения необходимых данных вызываем требуемую функцию обработки данных. Возвращаясь назад, вспоминаем, что для CNN это будет
cnn_articles(), а для Al Jazeeraaljazeera_articles(). -
(12) У нас очень мало места для краткого обзора обработки данных. После получения данных соответствующей страницы мы применяем библиотеку Beautiful Soup 4 для выделения заголовков.
-
(13) Наша функция
match()возвратит все имеющие соответствие теги (я вручную проверил соответствующие исходные коды HTML исходные коды этих новостных вебсайтов чтобы вывести какие комбинации фильтров выделяют наилучшие теги), а затем мы возвращаем какой- то список кортежей, соответствующий установленному формату (<article URL>, <article title>). -
(14) Это аналогично обработке данных для Al Jazeera. Соответствующее условие
match()слегка другое, но иным способом выдаёт то же самое из CNN.
В общем случае вы обнаружите, что aiohttp имеет достаточно простой API и "остаётся на вашем пути"
при разработке вами своих приложений.
В своём следующем разделе мы рассмотрим применение ZeroMQ с помощью asyncio, который имеет достаточно
приятным свой любопытный эффект программирования сокета.
Программирование является наукой одеваться, как и в искусстве, потому что большинство из нас не понимает физики программного обеспечения и её редко преподают, если вообще когда-то это делают. Собственно физика программного обеспечения это вовсе не алгоритмы, структуры данных, языки и абстракции. Это всего лишь инструменты, которые мы изготавливаем, используем и выбрасываем прочь. В действительности физика программного обеспечения это физика персонала. В частности, когда дело доходит до сложности и нашего желания совместно работать для решения больших проблем по частям, речь идёт о наших ограничениях. Именно в этом состоит наука программирования: изготовление строительных блоков, с которыми люди способны с лёгкостью разобраться и запросто могут их применять, причём персонал будет работать совместно над решением очень сложных проблем.
-- Питер Хинтджентс, ZeroMQ: Обмен сообщениям для множества приложений
ZeroMQ (or even ØMQ!) является популярной безразличной к языкам программирования
библиотекой для сетевых приложений: она предоставляет "умные" сокеты. Когда вы создаёте сокеты ZeroMQ в виде кода они напоминают
обычные сокеты с хорошо узнаваемыми названиями методов наподобие recv() и
send() и тому подобных, однако внутри себя эти сокеты обрабатывают некоторые из наиболее раздражающих и
утомительных задач, требующихся при работе с обычными сокетами.
Одной из таких функций является управление передачей сообщений, следовательно вам не приходится внедрять свой собственный протокол и отсчитывать байты в кабеле для определения того когда доставлены все необходимые байты для конкретного сообщения - вы просто отправляете нечто, что вы рассматриваете как служащее неким "сообщением" и вся эта штука появляется неповреждённой на другой стороне!
Другим величайшим свойством является автоматическое распознавание логики. Если ваш сервер падает и возвращается обратно в строй позднее, ваш клиент сокета ØMQ автоматически восстановит соединение. И, что ещё лучше, отправленные вашим кодом в этот сокет сообщения будут собираться в буфер на протяжении всего периода отключения, следовательно все они всё же будут отправлены когда их сервер вернётся к жизни. Имеется ряд причин, по которым ØMQ порой именуется как обмен сообщениями без брокера[3]: он предоставляет некоторые из необходимых функций программного обеспечения посредника обмена сообщениями непосредственно в самих своих объектах сокетов.
Сокеты ØMQ уже реализуются внутри самих себя как асинхронные (поэтому они могут поддерживать многие тысячи одновременных соединений, даже при использовании в коде с потоками), однако это скрыто от нас за API ØMQ; тем не менее в привязку Python PyZMQ к библиотеке ØMQ была добавлена поддержка Asyncio и в данном разделе мы намерены взглянуть на некоторые примеры того как эти умные сокеты могут встраиваться в ваши приложения Python.
Относительно вытаскивания заголовков: если ØMQ предоставляет сокеты, которые уже являются асинхронными неким способом, который применяется с
потоками, в чём соль применения ØMQ совместно с Code? Ответ такой: код очистки.
Для демонстрации давайте взглянем на некий крошечный пример в котором вы используете множество сокетов ØMQ в одном и том же приложении. Для начала мы покажем версию с блокировкой (этот пример взят из the zguide, официального руководства по ØMQ):
Пример 4-12. Традиционный подход
# poller.py
import zmq
context = zmq.Context()
receiver = context.socket(zmq.PULL) (1)
receiver.connect("tcp://localhost:5557")
subscriber = context.socket(zmq.SUB) (2)
subscriber.connect("tcp://localhost:5556")
subscriber.setsockopt_string(zmq.SUBSCRIBE, '')
poller = zmq.Poller() (3)
poller.register(receiver, zmq.POLLIN)
poller.register(subscriber, zmq.POLLIN)
while True:
try:
socks = dict(poller.poll()) (4)
except KeyboardInterrupt:
break
if receiver in socks:
message = receiver.recv_json()
print(f'Via PULL: {message}')
if subscriber in socks:
message = subscriber.recv_json()
print(f'Via SUB: {message}')
-
(1) Сокеты ØMQ имеют типы! Это некий сокет
PULL. Вы можете представлять себе его как некий вид сокета "доступного только на получение", который будет запитываться неким иным сокетом "только для отправки", который будетсокетом типаPUSH. -
(2) Данный сокет с типом
SUBявляется иным видом сокета "доступного только на получение", и он будет питаться сокетом типаPUB, который служит "только для отправки". -
(3) Если вам необходимо перемещать данные между множеством сокетов в каком- то приложении ØMQ потока, вам понадобится некое средство опроса (poller). Это происходит по причине того, что такие сокеты не сберегают поток, поэтому вы не можете выполнять
recv()в различных сокетах из разных потоков [4: На самом деле вы можете делать это пока ваши подлежащие использованию в различных потоках сокеты создаются, применяются и целиком уничтожаются в своих собственных потоках. Это возможно, но трудно сделать, причём многие люди пытаются добиться этого. Именно по этой причине настолько сильна рекомендация применять единый поток и механизм опроса.] -
(4) Это работает аналогично системному вызову
select(). Данная система опроса не будет блокирована когда имеются данные готовыми на приём в одном из своих зарегистрированных сокетов и затем она поднимается для вас чтобы выгрузить эти данные и сделать с ними что- то. Этот большой блокifявляется тем как вам приходится обнаруживать правильный сокет.
Применение некоего цикла опроса плюс какой- то блок выбора сокета в явном виде делают его выглядящим слегка неуклюжим. Иным вариантом может быть
.recv() в каждом сокете в различных потоках - но тогда вам придётся иметь дело с большим числом потенциальных
проблем относительно сохранности потоков. К примеру: сокеты ØMQ не сохраняют потоки и поэтому один и тот же
сокет не должен применяться в различных потоках. Отображённый выше код является намного более безопасным, так как вам не приходится беспокоиться о
каких бы то ни было проблемах сохранности потока.
Так или иначе, прежде чем мы продолжим обсуждение, давайте рассмотрим код своего сервера и некий небольшой вывод:
Пример 4-13. Код сервера
# poller_srv.py
import zmq, itertools, time
context = zmq.Context()
pusher = context.socket(zmq.PUSH)
pusher.bind("tcp://*:5557")
publisher = context.socket(zmq.PUB)
publisher.bind("tcp://*:5556")
for i in itertools.count():
time.sleep(1)
pusher.send_json(i)
publisher.send_json(i)
Данный код сервера не важен для нашего обсуждения, но вкратце: имеется некий сокет PUSH и какой- то сокет PUB, как мы и говорили ранее, а также
цикл внутри, который отправляет данные в оба сокета каждую секунду. Вот некий вывод из poller.py
(Отметим, должны быть запущены обе программы):
$ python poller.py
Via PULL: 0
Via SUB: 0
Via PULL: 1
Via SUB: 1
Via PULL: 2
Via SUB: 2
Via PULL: 3
Via SUB: 3
Наш код работает. Однако наш интерес здесь не в том работает ли этот код, а в том что может предложить
asyncio для самой структуры этого кода
poller.py. Ключевым моментом для понимания является то, что наш код
asyncio предназначен для запуска в некотором отдельном потоке, что означает, что будет луше обрабатывать
различные сокеты в разных сопрограммах - и действительно, именно это мы и сделаем.
Конечно, кому- то пришлось взять на себя тяжёлый труд добавления
поддержки сопрограмм в pyzmq (нашей библиотеке клиента Python для ØMQ) самостоятельно выполнив эту работу,
так что это было не бесплатно! Но теперь, когда этот тяжкий труд выполнен, мы можем слегка улучшить структуру своего "традиционного"
кода:
|
| Замечание |
|---|---|
|
Для последующих примеров кода необходимо использовать |
Пример 4-14. Чистое разделение с asyncio
# poller_aio.py
import asyncio
import zmq
from zmq.asyncio import Context
context = Context()
async def do_receiver():
receiver = context.socket(zmq.PULL) (1)
receiver.connect("tcp://localhost:5557")
while True:
message = await receiver.recv_json() (2)
print(f'Via PULL: {message}')
async def do_subscriber():
subscriber = context.socket(zmq.SUB) (3)
subscriber.connect("tcp://localhost:5556")
subscriber.setsockopt_string(zmq.SUBSCRIBE, '')
while True:
message = await subscriber.recv_json() (4)
print(f'Via SUB: {message}')
loop = asyncio.get_event_loop()
loop.create_task(do_receiver()) (5)
loop.create_task(do_subscriber())
loop.run_forever()
-
(1) Этот образец кода делает то же самое что и ранее, за исключением того, что теперь мы пользуемся преимуществами сопрограмм чтобы поменять всё. Теперь мы можем иметь дело с каждым сокетом по отдельности. Мы создали две функции сопрограмм, одну для каждого сокета, а вторую для имеющегося сокета
PULL. -
(2) В
pyzmqмы пользуемся поддержкойasyncio, что означает, что всеsend()иrecv()обязаны применять соответствующее ключевое словоawait. НашPollerбольше не появляется где бы то ни было, так как он интегрирован в сам цикл событийasyncio. -
(3) Именно это обработчик для нашего сокета
SUB. Его структура очень похожа на соответствующий обработчик сокетаPULL, но тот не является предметом в этом случае. Если бы потребовалась более сложная логика, мы могли бы запросто добавить его тут, причём полностью заключив только внутри кода обработчика данногоSUB. -
(4) И вновь: совместимые с
asyncioсокеты требуют такого ключевого словаawaitпри отправке и приёме. -
(5) Для запуска необходимого цикла событий
asyncioи создания задач для каждого сокета требуются эти дополнительные строки. Я срезал здесь несколько углов и опустил всю обработку ошибо и очистку, так как хочу выделить само воздействие на компоновку кода в дальнейшем.
Получаемый вывод в точности тот же, что был показан ранее.
Такое использование сопрограмм, по моему мнению, оказывает невероятно положительное воздействие на структуру кода в данных примерах. В реальном промышленном коде с большим числом сокетов ØMQ, такие сопрограммы обработчики для каждого могут также даже располагаться в отдельных файлах, предоставляя дополнительные возможности для лучшей структуры кода. И даже для программ с единственным сокетом чтения- записи очень просто применять отдельные сопрограммы для чтения и записи в случае такой потребности.
Наш улучшенный код выглядит во многом похожим на код потока и действительно, для данного конкретного отображённого выше примера тот же самый
refactor будет работать и для потоков: запустите функции do_receiver() и
do_subscriber() с блокировкой в отдельных потоках. Но вы и правда желаете иметь дело даже с
потенциальными условиями для состязательности, в особенности когда ваше приложение растёт со временем в
отношении особенностей и сложности?
Здесь ешё множество возможностей для изучения и, как я уже говорил ранее, эти волшебные сокеты полны потех на забаву! В своём следующем примере мы рассмотрим более практичное применение ØMQ нежели то, которое преложено выше.
В современной, упакованной в контейнеры, базирующейся на развёртывании микрослужб практике сегодняшнего для некоторые моменты, применение которых
обязано быть тривиальным, например мониторинг применения вашими прикладными программами ЦПУ и памяти стало чем- то более сложным нежели простой запуск
top. Для заполнения этой пустоты на протяжении последних нескольких лет появился ряд коммерческих продуктов,
однако остаётся тот вариант, когда стоимость может выступать запретом для небольших команд стартапов и тех для кого это составляет хобби.
В данном примере мы приспособим ØMQ и asyncio для построения игрушечного прототипа распределённого
мониторинга приложений. Наш проект имеет три части:
-
Уровень приложения
Этот уровень содержит все наши приложения. Примерами могут служить "индивидуальные" микрослужбы, микрослужбы "резервирования", некая микруслужба "электронной почты" и тому подобное. Мы добавляем некий "передающий" сокет ØMQ в каждое из своих приложений. Этот сокет будет отправлять измерения производительности в какой- то центральный сервер.
-
Уровень сбора информации
Наш центральный сервер выставит какой- то сокет ØMQ для сбора необходимых данных от всех запущенных экземпляров приложений. Этот сервер также будет обслуживать некуб веб страницу для показа графиков производительности во времени, а также наш сервер будет в реальном времени выдавать потоком те данные, которые приходят к нему!
-
Уровень виртуализации
Это сама веб страница подлежащая обслуживанию. Мы будем отображать все собираемые данные в каком- то наборе графиков и эти диаграммы будут в живую обновляться в реальном масштабе времени. Для упрощения примеров нашего кода мы воспользуемся библиотекой JavaScript Smoothie Charts, которая предоставляет все необходимые функции стороны клиента.
Пример 4-15. Уровень приложения: производство измерений
import argparse
from asyncio import get_event_loop, gather, sleep, CancelledError
from random import randint, uniform
from datetime import datetime as dt
from datetime import timezone as tz
from contextlib import suppress
import zmq, zmq.asyncio, psutil
from signal import SIGINT
# zmq.asyncio.install() (1)
ctx = zmq.asyncio.Context()
async def stats_reporter(color: str): (2)
p = psutil.Process()
sock = ctx.socket(zmq.PUB) (3)
sock.setsockopt(zmq.LINGER, 1)
sock.connect('tcp://localhost:5555') (4)
with suppress(CancelledError): (5)
while True: (6)
await sock.send_json(dict( (7)
color=color,
timestamp=dt.now(tz=tz.utc).isoformat(), (8)
cpu=p.cpu_percent(),
mem=p.memory_full_info().rss / 1024 / 1024
))
await sleep(1)
sock.close() (9)
async def main(args):
leak = []
with suppress(CancelledError):
while True:
sum(range(randint(1_000, 10_000_000))) (10)
await sleep(uniform(0, 1))
leak += [0] * args.leak
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('color', type=str) (11)
parser.add_argument('leak', type=int, default=0)
args = parser.parse_args()
loop = get_event_loop()
loop.add_signal_handler(SIGINT, loop.call_soon, loop.stop) (12)
tasks = gather(main(args), stats_reporter(args.color)) (13)
loop.run_forever()
print('Leaving...')
for t in asyncio.Task.all_tasks():
t.cancel() (14)
loop.run_until_complete(tasks)
ctx.term() (15)
-
(1) В версиях
pyzmq, предшествующих 17.0.0, требовалось применять в явном виде данную командуzmq.asyncio.install()чтобы разрешить поддержку Asyncio. На момент написания версия 17 находилась в бета версии {Прим. пер.: однако на момент перевода всё уже хорошо.} -
(2) Эта функция сопрограммы запустит некую сопрограмму с долгим временем жизни, последовательно отправляющую данные в свой процесс сервера.
-
(3) Создаём некий сокет ØMQ! Имеются различные разновидности сокетов. Именно этот имеет тип
PUB, и он допускает отправку сообщений в одном направлении в другой сокет ØMQ. Этот сокет имеет - как об этом гласит руководство ØMQ - суперсилу. Он будет автоматически обрабатывать все повторные подключения и буферировать логику для вас. -
(4) Подключаемся к своему серверу.
-
(5) Наша последовательность останова управляется
KeyboardInterrupt, впоследствии останавливаясь. Когда принимается соответствующий сигнал мы прекращаем все свои задачи. Здесь мы обрабатываем соответствующий возбуждённуюCancelledErrorпри помощи удобного диспетчера контекстаsuppress()из модуля стандартной библиотекиcontextlib. -
(6) Выполняем итерации на постоянной основе, отправляя данные в свой сервер.
-
(7) Так как ØMQ знает как работать с целыми сообщениями, а не просто с обрезками какого- то потока данных, он открывает свою дверь для стопки полезных обёрток вокруг обычной идиомы
sock.send(): в данном случае мы применяем один из таких вспомогательных методов,send_json(), который автоматически выстраивает все аргументы в JSON. Это позволяет нам напрямую применятьdict(). -
(8) Надёжный способ передачи информации даты и времени состоит в следовании формата ISO 8601. Это в особенности справедливо если вы обмениваетесь данными даты и времени между программным обеспечением, написанным на различных языках программирования, так как подавляющее большинство реализаций языков способно работать с данным стандартом.
-
(9) Чтобы закончить здесь мы должны получить исключительную ситуацию
CancelledError, приводящую в результате к прекращению задачи. Наш сокет ØMQ должен быть закрыт чтобы позволить останов программы. -
(10) Эта функция
main()символизирует самое настоящее приложение микрослужбы. Данное суммирование произвольных чисел производит поддельную работу, просто чтобы выдавать нам некие ненулевые данные для просмотра на нашем уровне виртуализации слегка позднее. -
(11) Мы собираемся создать множество экземпляров данного приложения, поэтому будет удобно иметь возможность различать их (позднее на диаграммах) при помощи некоего параметра
color. -
(12) При получении сигнала
SIGINT(например, при нажатии CtrlC), планировщик вызывает останов данного цикла. -
(13) Создаём и собираем задачи для каждой из имеющихся функций сопрограммы.
-
(14) Получив соответствующий сигнал останова прекращаем все задачи. Это возбуждает некую
CancelledErrorвнутри всех тех сопрограмм, которые представлены в нашей группеtasks. После завершения, всё ещё требуется запускать эти задачи для их окончания, предоставляя им возможность обработать надлежащим образом такое завершение. К примеру, мы обязаны закрыть имеющийся сокет ØMQ чтобы выполнить окончательное завершение. -
(15) Наконец может быть прекращён контекст соответствующего ØMQ.
Представляющей наибольший интерес является наша функция stats_reporter(). Именно она отправляет поток
данных измерений (собираемых очень полезной библиотекой psutil). Оставшийся код предполагается выступающим
в качестве обычного приложения микрослужбы.
Теперь мы рассмотрим код своего сервера, в котором собираются все получаемые данные и обслуживаются неким веб клиентом.
Пример 4-16. Уровень сбора данных: этот сервер собирает результаты статистик
# metricserver.py
import asyncio
from contextlib import suppress
import zmq
import zmq.asyncio
import aiohttp
from aiohttp import web
from aiohttp_sse import sse_response
from weakref import WeakSet
import json
# zmq.asyncio.install()
ctx = zmq.asyncio.Context()
connections = WeakSet() (1)
async def collector():
sock = ctx.socket(zmq.SUB) (2)
sock.setsockopt_string(zmq.SUBSCRIBE, '') (3)
sock.bind('tcp://*:5555') (4)
with suppress(asyncio.CancelledError):
while True:
data = await sock.recv_json() (5)
print(data)
for q in connections:
await q.put(data) (6)
sock.close()
async def feed(request): (7)
queue = asyncio.Queue()
connections.add(queue) (8)
with suppress(asyncio.CancelledError):
async with sse_response(request) as resp: (9)
while True:
data = await queue.get() (10)
print('sending data:', data)
resp.send(json.dumps(data)) (11)
return resp
async def index(request): (12)
return aiohttp.web.FileResponse('./charts.html')
async def start_collector(app): (13)
app['collector'] = app.loop.create_task(collector())
async def stop_collector(app):
print('Stopping collector...')
app['collector'].cancel() (14)
await app['collector']
ctx.term()
if __name__ == '__main__':
app = web.Application()
app.router.add_route('GET', '/', index)
app.router.add_route('GET', '/feed', feed)
app.on_startup.append(start_collector) (15)
app.on_cleanup.append(stop_collector)
web.run_app(app, host='127.0.0.1', port=8088)
-
(1) Одна половина этой программы будет получать данные от прочих приложений, а другая половина будет предоставлять данные браузерам клиентов через SSE (serversent events , события отправки сервером). Мы применяем
WeakSet()для отслеживания всех подключённых в настоящее время веб клиентов. Каждый подключённый клиент будет иметь некий связанный с ним экземплярQueue(), поэтому такой идентификаторconnectionsна самом деле некий набор очередей. -
(2) Повторно вызывая это на своём уровне приложения мы применяем некий сокет
zmq.PUB; здесь, на уровне сбора информации мы пользуемся его партнёром, с соответствующим типом сокетаzmq.PUB. Этот сокет ØMQ может выполнять только приём, и при этом не выполняет никакой отправки. -
(3) Для данного типа сокета
zmq.SUBтребуется предоставлять некое имя подписки, но для своих целей мы просто проверяем что всё идёт своим чередом, поэтому тут у нас пустой название темы. -
(4) Тут мы подвязываемся к своему сокету
zmq.SUB. Задумайтесь на мгновение об этом! В конфигурациях "pubsub" вам обычно приходится делать сторону публикации своего сервера (bind()) и сторону подписки соответствующего клиента (connect()). ØMQ применяет иной подход: любая сторона может выступать в качестве такого сервера. Для нашего случая применения это важно, так как каждый из экземпляров нашего уровня приложения будет подключаться к одному и тому доменному имени сервера соединения и нет никакого иного обходного пути. -
(5) Имеющаяся в
pyzmqподдержкаasyncioпозволяет нам выполнятьawaitданных со стороны наших подключённых прикладных программ. И не только это, так как все входящие данные будут автоматически распаковываться из JSON (да, это означает, чтоdataпредставлены в видеdict()). -
(6) Повторный вызов этого нашего набора
connectionsудержит какую- то очередь для каждого веб клиента? Теперь, когда данные были получены, самое время отправить их всем клиентам: эти данные помещаются в каждую из очередей. -
(7) Наша функция сопрограммы
feed()создаст сопрограммы для каждого подключённого веб клиента. Для активной доставки данных соответствующему клиенту внутри применяются события отправки сервером. -
(8) Как уже описывалось ранее, каждый веб клиент будет иметь свой собственный экземпляр
queueдля приёма данных из соответствующей сопрограммыcollector(). Такой экземплярqueueдобавляется в имеющийся наборconnections, но посколькуconnectionsявляется неким неустойчивым набором, соответствующая запись будет автоматически удаляться изconnectionsкогда соответствующая очередь покидает сферу, т.е. когда отключается некий веб клиент. Неустойчивые ссылки (weakrefs) великолепны для упрощения таких видов задач резервирования. -
(9) Имеющийся пакет
aiohttp_sseпредоставляет необходимый диспетчер контекстаsse_response(). Он предоставляет нам некую сферу внутри тех данных, для которых мы выполняем активную доставку своему веб клиенту. -
(10) Мы остаёмся подключёнными к соответствующему веб клиенту и ожидаем данные для очереди этого конкретного клиента.
-
(11) Как только поступают необходимые данные (внутри
collector()), они отправляются необходимому подключённому веб клиенту. Отметим, что здесь мы повторно инициализируем соответствующийdict данных. Некая оптимизация в показанном здесь коде позволит избежать распаковки JSON в (collector() и вместо этого воспользоваться (sock.recv_string чтобы обойти потребность упорядочения в обо конца. Конечно, в каком- то реальном сценарии вы можете пожелать в любом случае выполнять распаковку в своём средстве сбора информации и выполнять некую проверку этих данных прежде чем отправлять их в браузер своего клиента. Так много возможностей! -
(12) Оконечная точка
index()является самой первой загружаемой страницей и здесь мы обслуживаем некий файл со статистическими данными с названиемcharts.html. -
(13) Наша библиотека
aiohttpпредоставляет возможности для вас подхватывать дополнительные сопрограммы с длительным временем жизни, которые вам могут понадобиться. При помощи соответствующей сопрограммыcollector() у нас имеется именно такое положение дел, поэтому мы создаём некую сопрограмму запускаstart_collector() и какую- то сопрограмму останова. Они будут вызываться на протяжении определённых этапов последовательностей запуска и остановаaiohttp. Отметим, что мы добавили необходимую задачу средства сбора информации в саму нашуapp, которая реализует какой- то протокол установки соответствия с тем, чтобы вы могли применять его в видеdict. -
(14) Здесь вы можете увидеть что мы получаем свою сопрограмму
collector()из соответствующего идентификатораappи вызываем в нейcancel(). -
(15) Наконец, вы можете увидеть где прицепляются необходимые индивидуальные сопрограммы запуска и останова: соответствующий экземпляр
appпредоставляет особые точки входа дополнительного ПО, к которым в конец могут быть добавлены ваши персональные сопрограммы.
Всё что нам осталось, это соответствующий уровень виртуализации. Мы применяем библиотеку Smoothie Charts для выработки диаграмм с прокруткой и законченным HTML для нашей основной (и не только!) веб страницы,
charts.html, который представлен в наших Дополнениях целиком. В нём имеется слишком много HTML, CSS и JavaScript чтобы представлять их в данном разделе, но я на всё же
хочу выделить несколько моментов относительно того как наши события отправки сервером (SSE) обрабатываются
в JavaScript соответствующего клиента браузера.
Пример 4-17. Уровень визуализации, который является воображаемым способом высказываться "соответствующему браузеру"
<обрез>
var evtSource = new EventSource("/feed"); (1)
evtSource.onmessage = function(e) {
var obj = JSON.parse(e.data); (2)
if (!(obj.color in cpu)) {
add_timeseries(cpu, cpu_chart, obj.color);
}
if (!(obj.color in mem)) {
add_timeseries(mem, mem_chart, obj.color);
}
cpu[obj.color].append(
Date.parse(obj.timestamp), obj.cpu); (3)
mem[obj.color].append(
Date.parse(obj.timestamp), obj.mem);
};
<обрез>
-
(1) Создаём некий новый экземпляр
EventSourceв соответствующем URL/feed. Соответствующий браузер подключится к/feedв нашем сервере,metricserver.py. Заметим, что этот браузер автоматически попытается выполнить повторное подключение в случае утраты такого подключения. События отправки сервером (SSE) часто остаются недооценёнными, но имеется множество случаев в которых такая простота SSE может быть предпочтительной для веб сокетов. -
(2) Это событие
onmessage()зажигается всякий раз когда наш сервер отправляет данные. Здесь наши данные подвергаются синтаксическому разбору в качестве JSON. -
(3) Повторный вызов данного идентификатора
cpuявляется некоторой установкой соответствия цвета экземпляруTimeSeries(). В данном случае мы получаем некую временную последовательность и помещаем в её конец данные. Мы также получаем соответствующий временной штамп и выполняем его разбор для получения правильного формата, необходимого нашей диаграмме.
Теперь мы собираемся запустить свой код. Чтобы получить всё отображение в движении требуется некий пакет инструкций командной строки:
Пример 4-18. Запуск нашего средства сбора информациии
$ python metricserver.py
======== Running on http://127.0.0.1:8088 ========
(Press CTRL+C to quit)
Это стартует наш коллектор. Своим следующим шагом мы запускаем все необходимые экземпляры микрослужб. Они отправляют свои измерения ЦПУ и памяти в наше средство сбора информации. Каждое будет снабжено идентификацией отличительного цвета, что определяется в соответствующей командной строке:
Пример 4-19. Запуск необходимых приложений мониторинга
$ python backendapp.py color red &
$ python backendapp.py color blue leak 10000 &
$ python backendapp.py color green leak 100000 &
Рисунок 4-2 отображает наш окончательный продукт! Вы должны поверить мне на слово, что графики на самом деле оживают. Вы можете отметить в приведённом выше листинге, что я добавил некую утечку памяти для синего и ещё более высокую для зелёного. Мне даже пришлось перезапускать свою зелёную службу несколько раз чтобы предотвратить её восхождение выше 100 МБ.
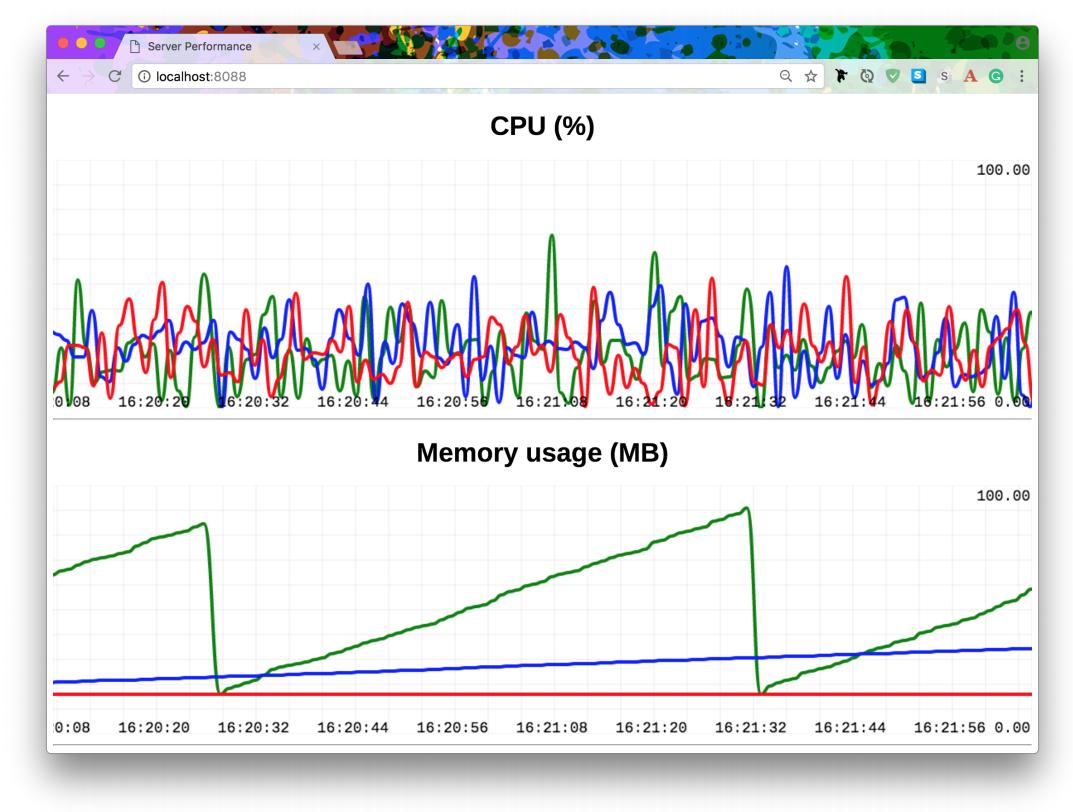
Что особенно интересно относительно данного проекта, так это: любой из запущенных экземпляров в любой
части данного стека может быть перезапущен и не требуется никакой код обработки повторного подключения! Наши сокеты ØMQ совместно с имеющимся
экземпляром JavaScript EventSource в соответствующем браузере, волшебным образом выполняет повтороное
соединение и подхватывается в том месте, в котором оно было утрачено.
В своём следующем разделе мы переключим своё внимание на базы данных и то как asyncio может применяться
при проектировании системы прекращения кэширования.
Библиотека asyncpg предоставляет клиентский доступ к базе данных
PostgreSQL, но отличается сама по себе от прочих библиотек клиентов Postgres тем что сосредоточена на скорости.
asyncpg является авторским продуктом
Юрия Селиванова, одного из коренных разработчиков
asyncio, который также является автором проекта uvloop. Кроме того,
asyncpg не имеет зависимостей от сторонних разработок, хотя всё же требуется
Cython, если вы выполняете установку из исходного кода.
asyncpg достигает своей скорости за счёт работы напрямую с соответствующим двоичным протоколом PostgreSQL,
а также прочих преимуществ своего подхода нижнего уровня, включая поддержку предварительно подготавливаемых операторов и
курсоров с прокруткой.
Мы рассмотрим пример использования asyncpg для признания недействительным кэширования, но для начала было
бы полезным получить базовые знания о том что предоставляет имеющийся API asyncpg. Для всего кода в
данном разделе нам потребуется запущенный экземпляр PostgreSQL и проще всего это сделать при помощи Docker:
Отмечу, что я выставил порт 55432 вместо устанавливаемого по умолчанию, 5432, просто на тот случай если у вас уже и меется некий запущенный
экземпляр такой базы данных с этим портом по умолчанию. Приводимый ниже код демонстрирует каким образом
asyncpg общается с PostgreSQL.
Пример 4-21. Базовая демонстрация asyncpg
import asyncio
import asyncpg
import datetime
from util import Database (1)
async def main():
async with Database('test', owner=True) as conn: (2)
await demo(conn)
async def demo(conn: asyncpg.Connection):
await conn.execute('''
CREATE TABLE users(
id serial PRIMARY KEY,
name text,
dob date
)'''
) (3)
pk = await conn.fetchval( (4)
'INSERT INTO users(name, dob) VALUES($1, $2) '
'RETURNING id', 'Bob', datetime.date(1984, 3, 1)
)
async def get_row(): (5)
return await conn.fetchrow( (6)
'SELECT * FROM users WHERE name = $1',
'Bob'
)
print('After INSERT:', await get_row()) (7)
await conn.execute(
'UPDATE users SET dob = $1 WHERE id=1',
datetime.date(1985, 3, 1) (8)
)
print('After UPDATE:', await get_row())
await conn.execute(
'DELETE FROM users WHERE id=1'
)
print('After DELETE:', await get_row())
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
-
(1) Я скрыл некоторые инструменты подготовки в небольшом модуле
utilдля упрощения вещей и сохранении самых центральных сообщений. -
(2) Наш класс
Databaseдаёт нам некий диспетчер контекста, который создаст для нас некую новую базу данных - в данном случае с наименованиемtest- и уничтожит эту базу данных при покидании этого диспетчера контекста. Это становится очень полезным при экспериментах с идеями в коде. Так как никакое состояние не переносится между экспериментами, вы всякий раз начинаете с чистой базой данных. Отметим, что данный диспетчер контекста являетсяasync with; мы рассмотрим это подробнее впоследствии, но в данный момент основной областью нашего фокуса в данной демонстрации является то, что происходит внутри нашей сопрограммыdemo(). -
(3) Yfi lbcgtnxth rjyntrcnf
Databaseснабжает нас неким экземпляромConnection, который незамедлительно применяется для создания новой таблицы,users. -
(4) Вставляем новую запись. Хотя мы и можем применять для выполнения данной вставки
.execute(), основным преимуществом использованияfetchval()является то, что мы можем получать соответствующийidвновь вставляемой записи, который будет сохраняться в нашем идентификатореpk.Замечание Мы применяем параметры (
$1и$2) для проброса данных в свой запрос SQL. Никогда не пользуйтесь интерполяцией строк или конкатенацией при построении запросов, так как это создаёт риск для безопасности! -
(5) При извлечении данных, намного более полезным будет применять методы на основе
fetch, так как они возвратят объектыRecord.asyncpgавтоматически приводит в соответствие большинство типов данных в надлежащие типы данных для Python. -
(6) Мы немедленно применяем вспомогательную функцию
get_row()для отображения вновь вставленной записи. -
(7) Мы изменили данные воспользовавшись соответствующей командой
UPDATEдля SQL. Это достаточно незначительная модификация: значение года в дате рождения изменяется на один год. Как и ранее, это осуществляется при помощи метода соединенияexecute(). Оставшаяся часть данного кода демонстрирует далее те же самые структуры, которые мы видели ранее, а такжеDELETE, за которым следует другойprint(), происходящий несколькими строками позднее. -
(8)
Он производит следующий вывод:
$ python asyncpgbasic.py
After INSERT: <Record id=1 name='Bob' dob=datetime.date(1984, 3, 1)>
After UPDATE: <Record id=1 name='Bob' dob=datetime.date(1985, 3, 1)>
After DELETE: None
В этом выводе отметим как мы выполняем выборку необходимого значения даты из своего объекта Record,
подлежащего преобразованию в некий объект date Python: asyncpg
автоматически преобразует этот тип данных из типа SQL в свои замены в Python. Имеется большая таблица
преобразования типов в документации
asyncpg, которая описывает все имеющиеся соответствия типов, которые уже встроены в
asyncpg.
Приведённый выше код является очень простым; возможно даже слишком грубым, поэтому, если вы если вы применяете удобство ORM
(objectrelational mapper, соответствий реляционных объектов), таких как SQLAlchemy
или веб инфраструктуру Django со встроенным ORM. В конце
данной главы я упомяну некоторые библиотеки сторонних разработчиков, которые предоставляют доступ к ORM или функциональности подобной ORM для
asyncpg.
Давайте быстро взглянем на мой инструментарий готовки объекта Database в секретном модуле
utils; вы можете найти его полезным для изготовления нечто подобного в своих собственных
экспериментах:
Пример 4-22. Полезный инструментарий для экспериментов с asyncpg
# util.py
import argparse, asyncio, asyncpg
from asyncpg.pool import Pool
DSN = 'postgresql://{user}@{host}:{port}'
DSN_DB = DSN + '/{name}'
CREATE_DB = 'CREATE DATABASE {name}'
DROP_DB = 'DROP DATABASE {name}'
class Database:
def __init__(self, name, owner=False, **kwargs):
self.params = dict(
user='postgres', host='localhost',
port=55432, name=name) (1)
self.params.update(kwargs)
self.pool: Pool = None
self.owner = owner
self.listeners = []
async def connect(self) > Pool:
if self.owner:
await self.server_command(
CREATE_DB.format(**self.params)) (3)
self.pool = await asyncpg.create_pool( (4)
DSN_DB.format(**self.params))
return self.pool
async def disconnect(self):
"""Destroy the database"""
if self.pool:
releases = [self.pool.release(conn)
for conn in self.listeners]
await asyncio.gather(*releases)
await self.pool.close() (5)
if self.owner:
await self.server_command( (6)
DROP_DB.format(**self.params))
async def __aenter__(self) > Pool: (2)
return await self.connect()
async def __aexit__(self, *exc):
await self.disconnect()
async def server_command(self, cmd): (7)
conn = await asyncpg.connect(
DSN.format(**self.params))
await conn.execute(cmd)
await conn.close()
async def add_listener(self, channel, callback): (8)
conn: asyncpg.Connection = await self.pool.acquire()
await conn.add_listener(channel, callback)
self.listeners.append(conn)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('cmd', choices=['create', 'drop'])
parser.add_argument('name', type=str)
args = parser.parse_args()
loop = asyncio.get_event_loop()
d = Database(args.name, owner=True)
if args.cmd == 'create':
loop.run_until_complete(d.connect())
elif args.cmd == 'drop':
loop.run_until_complete(d.disconnect())
else:
parser.print_help()
-
(1) Наш класс
Databaseвсего лишь некий предполагаемый диспетчер контекста для создания и удаления какой- то базы данных из экземпляра PostgreSQL. Необходимое название базы данных передаётся в имеющийся конструктор. -
(2) (Примечание: Данная последовательность сносок в коде намеренно отличается от данного списка.) Данные диспетчер контекста является именно асинхронным. Вместо обычных методов
__enter__()и__exit__()у нас имеются их заменители__aenter__()и__aexit__(). Здесь, на стороне входа, мы создадим необходимую базу данных и вернём подключение к этой новой базе данных. -
(3)
server_command()является другим вспомогательным методом, определяемым несколькими строками позднее. Мы применяем его для запуска необходимых команд при создании своей новой базы данных. -
(4) Для вновь созданной базы данных делается некое соединение. Отметим, что я жёстко закодировал определённые подробности о данном подключении: это сделано умышленно, так как я стараюсь сохранять данный образец кода небольшим. Вы запросто можете сделать его универсальным введя такие поля как имя пользователя, название хоста и номер порта.
-
(5) На стороне выхода из своего диспетчера контекста мы закрываем текущее подключение и ...
-
(6) ... уничтожаем базу данных.
-
(7) Для завершённости решения, именно этот метод утилиты служит для запуска команд в самом сервере PostgreSQL. Для данной цели он создаёт некое подключение, запускает все определённые команды и выполняет выход.
-
(8) Это сюрприз и он будет гвоздём программы в нашем следующем примере!
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
В приводимом выше пункте 8 мы создали некое выделенное соединение для каждого канала, в котором мы желаем выполнять ожидание. Это очень затратно, так как это означает, что некий исполнитель PostgreSQL будет целиком привязан к каждому каналу, в котором он выполняет ожидание. Намного лучший подход применял бы одно подключение ко множеству каналов. После того как вы проработаете данный пример, попробуйте изменить данный код для использования единого соединения для ожидания во множестве каналов! |
Теперь, когда у нас имеется базовое понимание имеющихся строительных блоков asyncpg, мы можем
изучить реально замечательный пример: использование встроенной поддержки PostgreSQL для отправки уведомлений осуществления выполнения несостоятельности
кэширования!
В науке вычислений имеются пара сложных вещей: установка несостоятельности кэширования, хорошая хэш- функция и ошибки одна за другой.
-- Фил Карлтон
В веб службах и веб приложениях распространённым является то, что на уровне перманентности, т.е. сами серверы баз данных (DB), становятся узким местом производительности быстрее нежели все прочие части общего стека. Имеющийся прикладной уровень обычно может масштабироваться горизонтально, т.е. запускать дополнительные экземпляры, в то время как проделывать с базой данных это затруднительно.
Именно по этой причине распространённой практикой является рассмотрение вариантов архитектуры, которые могут ограничить избыточное общение с общей базой данных. Наиболее распространённым вариантом является применение кэширования для "запоминания" выбранных ранее результатов базы данных и повторного воспроизведения при их запросе с тем чтобы избегать последовательных вызовов имеющейся DB относительно одной и той же информации.
Однако: что произойдёт если одна из экземпляров ваших прикладных программ запишет новые данные в эту базу данных, в то время как другой экземпляр прикладного приложения всё ещё возвращает свои старые, устаревшие данные из их внутреннего кэша? Именно это составляет классическую задачу несостоятельности кэширования (cache invalidation - устаревания кэширования), причём это очень сложно решить каким- то надёжным путём.
Наша стратегия наступления такова:
-
Каждый экземпляр прикладной программы имеет некий кэш запросов к базе данных в оперативной памяти.
-
Когда в эту базу данных выполняется запись, сама база данных выставляет оповещения во все экземпляры подключённых приложений о таких новых данных.
-
Каждый экземпляр прикладного приложения затем обновляет соответствующим образом свой внутренний кэш.
Данный пример выделяет как встроенная поддержка обновления событий PostreSQL посредством своих команд LISTEN и NOTIFY может просто сообщать нам о том когда изменены данные.
asyncpg уже имеет поддержку для такого API LISTEN/NOTIFY. Данная функциональность PostgreSQL позволяет вашей
прикладной программе подписаться на события в каком- то именованном канале, а также отправлять события в именованные каналы. Это практически аналогично
тому что PostreSQL становится облегчённой версией RabbitMQ
или ActiveMQ!
Данный пример имеет больше подвижных частей чем обычно, а это делает затруднительным его представления в обычном линейном формате. Вместо этого мы начнём с рассмотрения окончательного продукта и отрабатывать в обратную сторону относительно лежащей в основе реализации.
Наше прикладное приложение предоставляет некий сервер API на основе JSON для управления любимыми блюдами покровителей в нашем роботизированном
ресторане. Наша лежащая в основе база данных будет иметь всего одну таблицу, patron, причём всего с двумя полями:
name и fav_dish. Наш API делает возможными для нас обычный набор из
четырёх операций: create, read,
update и delete (CRUD).
Вот как выглядит взаимодействие с нашим API при помощи curl для создания какого- то нового элемента в
нашей базе данных:
Пример 4-23. Создание записи нового покровителя
curl d '{"name": "Carol", "fav_dish": "SPAM Bruschetta"}' \
H "ContentType: application/json" \
X POST \
http://localhost:8000/patron
Вывод:
{"msg":"ok","id":37}
Значение параметра d предназначено для данных (Здесь можно найти рецепт этого блюда и рецепты для прочих
замечательных трат на основе SPAM), значение H служит для необходимых заголовков HTTP, а
X для соответствующих методов HTTP запросов (альтернативами являются
GET, DELETE и PUT, а также
несколько прочих), а URL предназначен для нашего сервера API. Мы вскорости получим код для этого.
Из своего вывода мы видим, что наше создание было "OK", и что в качестве первичного ключа этой новой записи в нашей базе данных был возвращён
соответствующий id.
В наших последующих нескольких фрагментах мы проследуем запуску трёх прочих операций: read,
update и delete.
Вывод:
{"id":37,"name":"Carol","fav_dish":"SPAM Bruschetta"}
Чтение имеющихся данных достаточно прямолинейное и заметим, что в его URL должен быть представлен id
нужной нам записи.
Пример 4-25. Обновление записи какого- то имеющегося покровителя (а также некая проверка!)
curl d '{"name": "Eric", "fav_dish": "SPAM Bruschetta"}' \
H "ContentType: application/json" \
X PUT \
http://localhost:8000/patron/37
curl X GET http://localhost:8000/patron/37
Вывод:
{"msg":"ok"}
{"id":37,"name":"Eric","fav_dish":"SPAM Bruschetta"}
Обновление некоего ресурса, как показано выше, очень похоже на его создания, за исключением двух ключевых отличий:
-
Методом запроса HTTP (
X) являетсяPUT, а неPOST. -
Наш URL теперь нуждается в соответствующем поле
id.
Нам также придётся вызвать другой GET сразу после чтобы убедиться в применении своего изменения.
Наконец, удаление:
Пример 4-26. Удаление записи какого- то имеющегося покровителя (а также некая проверка!)
curl X DELETE http://localhost:8000/patron/37
curl X GET http://localhost:8000/patron/37
Вывод:
{"msg":"ok"}
null
Этот приведённый выше пример также показывает возврат null при попытке получения несуществующей записи.
До сих пор всё выглядело достаточно обычным; однако нашим предметом является не только сделать некий API CRUD - мы желаем посмотреть на признание недейственным кэширования, поэтому давайте переключим наше внимание на само кэширование. Теперь, когда у нас имеется понимание API наших прикладных программ, мы можем взглянуть на журнал регистраций приложения чтобы посмотреть на данные времён для каждого из запросов: это сообщит нам какие какие приложения были кэшированы, а какие попадали в саму DB.
Когда наш сервер запускается впервые, имеющийся кэш является пустым; кроме всего прочего это кэш в оперативной памяти. Мы намерены запустить свой
сервер, а затем в отдельной оболочке запустить два запроса GET в быстрой последовательности:
curl X GET http://localhost:8000/patron/29
curl X GET http://localhost:8000/patron/29
Вывод:
{"id":29,"name":"John Cleese","fav_dish":"Gravy on Toast"}
{"id":29,"name":"John Cleese","fav_dish":"Gravy on Toast"}
мы ожидаем что самый первый раз при извлечении нашей записи выше имеется промах в кэшировании, а во второй раз попадание. Мы можем ясно убедиться в этом из записей регистрации для самого сервера API:
$ python sanic_demo.py
20170929 16:20:33 (sanic)[DEBUG]:
▄▄▄▄▄
▀▀▀██████▄▄▄ _______________
▄▄▄▄▄ █████████▄ / \
▀▀▀▀█████▌ ▀▐▄ ▀▐█ | Gotta go fast! |
▀▀█████▄▄ ▀██████▄██ | _________________/
▀▄▄▄▄▄ ▀▀█▄▀█════█▀ |/
▀▀▀▄ ▀▀███ ▀ ▄▄
▄███▀▀██▄████████▄ ▄▀▀▀▀▀▀█▌
██▀▄▄▄██▀▄███▀ ▀▀████ ▄██
▄▀▀▀▄██▄▀▀▌████▒▒▒▒▒▒███ ▌▄▄▀
▌ ▐▀████▐███▒▒▒▒▒▐██▌
▀▄▄▄▄▀ ▀▀████▒▒▒▒▄██▀
▀▀█████████▀
▄▄██▀██████▀█
▄██▀ ▀▀▀ █
▄█ ▐▌
▄▄▄▄█▌ ▀█▄▄▄▄▀▀▄
▌ ▐ ▀▀▄▄▄▀
▀▀▄▄▀
20170929 16:20:33 (sanic): Goin' Fast @ http://0.0.0.0:8000
20170929 16:20:33 (sanic): Starting worker [10366]) (1)
20170929 16:25:27 (perf): id=37 Cache miss (2)
20170929 16:25:27 (perf): get Elapsed: 4.26 ms (3)
20170929 16:25:27 (perf): get Elapsed: 0.04 ms (4)
-
(1) Всё вплоть до этой строки является установленным по умолчанию запуском регистрации сообщений
sanic. -
(2) Как это уже пояснялось, самый первый
GETимеет результатом промах кэшировнаия, так как наш сервер только что запущен. -
(3) Это получено из
curl X GET. Я добавил некую функциональность определения времён в свои оконечные точки API. В данном случае соответствующая обработка данного запросаGETтребует ~4 мс. -
(4) Второй
GETвозвращает данные из своего кэша, и намного быстрое время, ~100х, указывает что эти данные теперь возвращаются из кэша.
До сих пор ничего необычного. Многие веб страницы применяют кэширование таким образом.
Давайте запустим некое второе приложение с портом 8001 (первый экземпляр работал по порту 8000):
$ python sanic_demo.py port 8001
<разрыв>
20171002 08:09:56 (sanic): Goin' Fast @ http://0.0.0.0:8001
20171002 08:09:56 (sanic): Starting worker [385]
Оба экземпляра, конечно, подключены к одной и той же базе данных. Теперь, когда запущены оба экземпляра сервера API, давайте свои видоизменим
имеющиеся данные для своего попечителя Джона, который предпочитает, ясен пень, достаточно Спама в своей диете.
Мы сделаем это выполнив некий UPDATE, допустим, в первом экземпляре своей прикладной программы по порту 8000:
curl d '{"name": "John Cleese", "fav_dish": "SPAM on toast"}' \
H "ContentType: application/json" \
X PUT \
http://localhost:8000/patron/29
{"msg":"ok"}
Сразу после данного события обновления только в одном экземпляре прикладной программы, оба сервера API, 8000 и 8001, сообщают следующие события в их журналах:
Пример 4-27. Сообщения в журналах обоих серверов, 8000 и 8001
20171002 08:35:49 (perf)[INFO]: Got DB event:
{
"table": "patron",
"id": 29,
"type": "UPDATE",
"data": {
"old": {
"id": 29,
"name": "John Cleese",
"fav_dish": "Gravy on Toast"
},
"new": {
"id": 29,
"name": "John Cleese",
"fav_dish": "SPAM on toast"
},
"diff": {
"fav_dish": "SPAM on toast"
}
}
}
Наша база данных сообщила имеющиеся события обновлений обратно в наши экземпляры прикладного приложения! Мы даже ещё не сделали никаких запросов к экземпляру 8001 прикладного приложения. Означает ли это что наши новые данные уже кэшированы здесь?
Чтобы проверить это, теперь мы делаем некий GET в своём втором
сервере 8001, и информация о времени показывает что мы на самом деле получаем свои данные напрямую из имеющегося кэша, даже хотя никакой
GETне вызывался ранее в этом экземпляре прикладной программы:
Пример 4-28. Самый первый GET для id=29 в сервере 8001
curl X GET http://localhost:8001/patron/29
{"id":29,"name":"John Cleese","fav_dish":"SPAM on toast"}
Пример 4-29. Журнал регистрации сервера 8001: Самый первый GET производящий кэшируемые данные
20171002 08:46:45 (perf)[INFO]: get Elapsed: 0.04 ms
Кульминационный момент: при изменениях базы данных все подключённые экземпляры прикладного приложения получают уведомления, что позволяет им обновить свои кэши.
Чтобы пояснить чего мы пытаемся достичь, было необходимо тщательно прорабботанное введение. Пройдя этот длинный путь, теперь мы можем взглянуть на
свою реализацию кода asyncpg, который заставляет на самом деле работать нашу установку недейственности
кэширования.
Основа проекта данного кода заключается в следующем:
-
Некий простой веб API, использующий наш новый, совместимый с
asyncioвеб- инструментарий Sanic. -
Все данные храняться в некотором экземпляре сервера PostreSQL, однако наш API будет обслуживаться через множество экземпляров своих серверов прикладного приложения веб API.
-
Наши серверы прикладного приложения будут кэшировать данные из общей базы данных.
-
Все серверы прикладного приложения будут подписаны на события через
asyncpgв конкретных таблицах нашей DB и будут получать уведомления об обновлениях когда соответствующие данные в производной таблице DB были изменены. Это делает возможным для имеющихся серверов прикладного приложения обновлять их персональные кэши в оперативной памяти.
Пример 4-30. API при помощи Sanic
# sanic_demo.py
import argparse
from sanic import Sanic
from sanic.views import HTTPMethodView
from sanic.response import json
from util import Database (1)
from perf import aelapsed, aprofiler (2)
import model
app = Sanic() (3)
@aelapsed
async def new_patron(request): (4)
data = request.json (5)
id = await model.add_patron(app.pool, data) (6)
return json(dict(msg='ok', id=id)) (7)
class PatronAPI(HTTPMethodView, metaclass=aprofiler): (8)
async def get(self, request, id):
data = await model.get_patron(app.pool, id) (9)
return json(data)
async def put(self, request, id):
data = request.json
ok = await model.update_patron(app.pool, id, data)
return json(dict(msg='ok' if ok else 'bad')) (10)
async def delete(self, request, id):
ok = await model.delete_patron(app.pool, id)
return json(dict(msg='ok' if ok else 'bad'))
@app.listener('before_server_start') (11)
async def db_connect(app, loop):
app.db = Database('restaurant', owner=False) (12)
app.pool = await app.db.connect() (13)
await model.create_table_if_missing(app.pool) (14)
await app.db.add_listener('chan_patron', model.db_event) (15)
@app.listener('after_server_stop') (16)
async def db_disconnect(app, loop):
await app.db.disconnect()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('port', type=int, default=8000)
args = parser.parse_args()
app.add_route(
new_patron, '/patron', methods=['POST']) (17)
app.add_route(
PatronAPI.as_view(), '/patron/') (18)
app.run(host="0.0.0.0", port=args.port)
-
(1) Вспомогательная утилита
Databaseописывалась ранее. Она предоставляет те методы, которые требуются для подключения к нашей базе данных. -
(2) Два дополнительных инструмента я на скорую руку смастерил воедино для регистрации значения прошедшего времени для каждого оконечного пункта API. Мы применяли его в предыдущем обсуждении при выявлении того, когда некий
GETвозвращался из своего кэша. Сами реализации дляaelapsed()иaprofiler()не важны для данного примера, но вы можете получить их в наших Дополнениях. -
(3) Создан необходимый основной экземпляр прикладного приложения Sanic.
-
(4) Данная функция сопрограммы служит для создания новых записей покровителей. В некотором вызове
add_route(), далее вниз по нашему коду,new_patron()связывается с соответствующей оконечной точкой/patron, причём только для надлежащего методаPOST. Наш декоратор@aelapsedне является частью основного API Sanic: он является моим собственным новшеством, в основном с целью регистрации значений времён для каждого вызова. -
(5) Sanic предоставляет немедленный разбор получаемых данных
.jsonпри помощи соответствующего атрибута в получаемом объектеrequest. -
(6) Наша модель
model, которую мы импортировали ранее, является основной моделью для нашей таблицы покровителей в общей базе данных. Мы рассмотрим её подробнее в своём следующем листинге кода. А на текущий момент просто уясните, что все наши запросы и SQL к базе данных находятся в этом модулеmodel. Здесь мы пробрасываем соответствующий пул соединений для своей базы данных, и именно они являются одним и тем же шаблоном для всех наших операций с нашей моделью базы данных в данной функции и в нашем классеPatronAPIниже. -
(7) Будет создан новый первичный ключ,
id, и именно он возвращается обратно вызывающей стороне в виде JSON. -
(8) В то время как создание обрабатывается в нашей функции
new_patron(), все прочие взаимодействия обрабатываются в данном представлении на основе класса, который удобно предоставляется Sanic. Все имеющиеся в данном классе методы ассоциируются с одним и тем же URL,/patron/<id:int>, который вы можете увидеть далее вниз по коду в соответствующейadd_route()ближе к концу. Отметим, что необходимый параметр URLidбудет передаваться во всякий вызываемый метод, причём этот параметр требуется для всех трёх оконечных точек.Вы можете не опасаться проигнорировать соответствующий аргумент
metaclass: всё что он выполняет, это обёртка вокруг каждого метода при помощи декоратора@aelapsedс тем чтобы значения времени выводились в нашем журнале регистраций. Это не является частью API Sanic, и опять- таки является моим собственным нововведением для регистрации данных времени. -
(9) Как и ранее, модель взаимодействия выполняется внутри нашего модуля
model. -
(10) Если наша модель выдаёт отчёт об отказе для осуществления необходимого обновления, мы изменяем соответствующие данные отклика. Я включил это для тех читателей, которые ещё пока не знакомы с версией трёхместного оператора Python.
-
(11) Применяемые декораторы
@app.listenerявляются предоставляемыми Sanic точками входа, которые дают вам какое- то место для добавления дополнительных действий в процессе последовательностей запуска и останова. Конкретно эта, before_server_start, вызывается перед тем как будет запущен наш сервер API. Она выглядит как подходящее место для инициализации нашего подключения к базе данных. -
(12) Мы применяем своего помощника
Databaseдля создания какого- то соединения с нашим экземпляром PostgreSQL. Той DB, к которой мы выполняем подключение, являетсяrestaurant. -
(13) Получаем некий пул подключений к нашей базе данных.
-
(14) Применяем свою модель (к соответствующей таблице
patron) чтобы создать необходимую таблицу если она отсутствует. -
(15) Применяем свою модель для создания некоей выделенной стороны ожидания для событий базы данных, причём ожидание мы выполняем в канале
chan_patron. Соответствующей функцией обратного вызова для данных событий являетсяmodel.db_event(), которую мы изучим в своём следующем листинге. Этот обратный вызов будет вызываться всякий раз, когда наша база данных обновляет соответствующий канал. -
(16)
after_server_stopявляется той точкой входа, которая должна появиться в процессе останова. В этом месте мы отключаемся от своей базы данных. -
(17) Этот
add_route()отправляет запросыPOSTдля соответствующего URL/patronв нашу функцию сопрограммыnew_patron(). -
(18) Данный
add_route()отправляет все запросы для соответствующего URL/patron/<id:int>>в представление на основе классаPatronAPI. Все названия методов в этом классе определяют именно то что они вызывают. Поэтому некий запросGETвызовет соответствующий методPatronAPI.get()и так далее.
Приводимый выше код содержит всю необходимую обработку HTTP для нашего сервера, а также задачи запуска и останова в виде настройки некоего
пула соединений с нашей базой данных, а также, что является критически важным, установку стороны ожидания событий DB в имеющемся канале
chan_patron в нашем сервере DB.
Теперь мы намерены рассмотреть свою модель для обсуждаемой таблицы patron из общей базы данных:
Пример 4-31. Модель DB для таблицы "patron"
# model.py
import logging
from json import loads, dumps
from triggers import (
create_notify_trigger, add_table_triggers) (1)
from boltons.cacheutils import LRU (2)
logger = logging.getLogger('perf')
CREATE_TABLE = ('CREATE TABLE IF NOT EXISTS patron(' (3)
'id serial PRIMARY KEY, name text, '
'fav_dish text)')
INSERT = ('INSERT INTO patron(name, fav_dish) '
'VALUES ($1, $2) RETURNING id')
SELECT = 'SELECT * FROM patron WHERE id = $1'
UPDATE = 'UPDATE patron SET name=$1, fav_dish=$2 WHERE id=$3'
DELETE = 'DELETE FROM patron WHERE id=$1'
EXISTS = "SELECT to_regclass('patron')"
CACHE = LRU(max_size=65536) (4)
async def add_patron(conn, data: dict) > int: (5)
return await conn.fetchval(
INSERT, data['name'], data['fav_dish'])
async def update_patron(conn, id: int, data: dict) > bool:
result = await conn.execute( (6)
UPDATE, data['name'], data['fav_dish'], id)
return result == 'UPDATE 1'
async def delete_patron(conn, id: int): (7)
result = await conn.execute(DELETE, id)
return result == 'DELETE 1'
async def get_patron(conn, id: int) > dict: (8)
if id not in CACHE:
logger.info(f'id={id} Cache miss')
record = await conn.fetchrow(SELECT, id) (9)
CACHE[id] = record and dict(record.items())
return CACHE[id]
def db_event(conn, pid, channel, payload): (10)
event = loads(payload) (11)
logger.info('Got DB event:\n' + dumps(event, indent=4))
id = event['id']
if event['type'] == 'INSERT':
CACHE[id] = event['data']
elif event['type'] == 'UPDATE':
CACHE[id] = event['data']['new'] (12)
elif event['type'] == 'DELETE':
CACHE[id] = None
async def create_table_if_missing(conn): (13)
if not await conn.fetchval(EXISTS):
await conn.fetchval(CREATE_TABLE)
await create_notify_trigger(
conn, channel='chan_patron')
await add_table_triggers(
conn, table='patron')
-
(1) Чтобы быть способными получать уведомления при изменениях базы данных вам придётся добавить триггеры в свою базу данных. Я разработал эти полезные вспомогательные функции для создания необходимых функций триггера самих по себе (при помощи
create_notify_trigger), а также для добавления такого триггера в некую определённую таблицу (посредствомadd_table_triggers). Необходимый для этого язык SQL является чем- то выходящим за рамки данной книги, тем не менее, это критически важно для понимания того как работает данный пример. Я включил соответствующий код с аннотациями для данных триггеров в соответствующее Дополнение. -
(2) Пакет стороннего разработчика
boltonsпредоставляет некую пачку полезных инструментов, не последним из которых является собственно кэшLRU, более многостороннюю версию нежели наш декоратор@lru_cacheиз стандартного библиотечного модуляfunctools[Получитеboltonsвоспользовавшисьpip install boltons]. -
(3) Данный блок текста содержит все необходимые SQL для наших стандартных операций CRUD. Отметим, что мы применяем стандартный синтаксис PostgreSQL для его параметров:
$1,$2 и так далее. Здесь нет никакой новизны, ну и нечего обсуждать более. -
(4) Создаём необходимый кэш для данного экземпляра прикладного приложения.
-
(5) Данная функция сопрограммы
add_patron()является тем, что мы вызываем из своего модуля Sanic внутри соответствующей оконечной точкиnew_patron()для добавления новых покровителей. Внутри этой функции мы применяем для вставки новых данных методfetchval()почему "fetchval", а не "fetchval"? Потому что "fetchval" возвращает значение первичного ключа вновь вставляемой записи! [Тем не менее, вам также потребуется соответствующая часть SQLRETURNING id!] -
(6) Обновляем некую имеющуюся запись. В случае успеха PostgreSQL возвратит
UPDATE 1, следовательно мы используем это для проверки успешности данного обновления. -
(7) Удаление очень похоже на обновление.
-
(8) Это операция "чтения". Именно она является той частью нашего интерфейса CRUD, которая требует позаботиться относительно состояния кэша. Задумайтесь об этом на мгновение: мы не обновляем значение кэша при осуществлении вставки, обновления или удаления. Это происходит потому, что мы полагаемся на существующие асинхронные уведомления от своей базы данных (через установленные триггеры) относительно обновлений значения кэширования в том случае когда изменяются любые данные.
-
(9) Безусловно, мы всё ещё желаем применять кэширование после самого первого
GET. -
(10) Наша функция
db_event()является необходимым обратным вызовом, которыйasyncpgбудет осуществлять когда имеются события в нашем канале уведомлений DB,chan_patron. Этот особый параметр списка требуемый со стороныasyncpg.connявляется тем подключением, в которое были отправлены необходимые события,pidявляется значением идентификатора самого процесса того экземпляра PostgreSQL, который отправил данное событие,channelпредставляет собственно название нашего канала (и в нашем случае этоchan_patron), аpayloadявляются подлежащими отправке в этом канале данными. -
(11) Выполняем разбор полученных данных JSON в некий
dict. -
(12) Само заполнение кэша является достаточно прямолинейным, однако заметим, что события "обновления" содержат как новые, так и старые данные, поэтому нам необходимо гарантировать, что мы выполняем кэширование только новых данных.
-
(13) Это небольшая функция утилиты, которую я создал для простого повторного создания таблицы при её отсутствии. Это действительно полезно ксли вам требуется часто выполнять данную операцию - например в случае написания примеров кода для данной книги! Именно в этом месте также создаются соответствующие коды триггеров уведомления нашей базы данных и добавляются в нашу таблицу
patron. Относительно листинга этих функция с пояснениями обратитесь к нашему Дополнению.
Это подводит нас к самому концу данного примера. Мы рассмотрели как Sanic делает очень простым создание
некоего сервера API, а также мы ознакомились с тем как применять asyncpg для осуществления запросов через
некий пул подключений, а также как использовать функциональность асинхронных уведомлений PostgerSQL для приёма обратных вызовов поверх
некоего выделенного подключения к базе дынных с длительным временем жизни.
Многие люди предпочитают применять для работы с базами данных ORM (objectrelational mapper - соответствий реляционных объектов), и это именно та
отрасль, в которой лидером выступает SQLAlchemy. Существует растущая поддержка
применения SQLAlchemy совместно с asyncpg в библиотеках сторонних разработчиков, таких как
asyncpgsa и
GINO. Другой популярный ORM,
peewee поддерживается под
asyncio через пакет aiopeewee.
Для asyncio существует множество прочих библиотек, не охватываемых данной книгой. Для дополнительного
поиска вы можете воспользоваться проектом aio-libs, который управляет примерно
сорока различными библиотеками, а также проектом Awesome asyncio,
который сопровождает закладки большого числа прочих проектов для asyncio.
Одна из тех библиотек, которую будет не лишним отметить: aiofiles.
Если вы вернётесь к более раннему обсуждению, в котором мы сказали, что для достижения выской степери параллельности в
asyncio жизненно важно чтобы наш цикл никогда не "блокировался". В данном контексте мы концентрируемся
на блокирующих операциях, которые исключительно относились к вводу/ выводу на сетевой основе, но в свою очередь и доступ к дискам также некая операция
с блокировкой, которая оказывает воздействие на производительность на очень высоких уровнях распараллеливания. Решением для этого являются
aiofiles, которые предоставляют удобную обёртку для выполнения доступа к диску в некотором потоке. Это
работает потому что Python высвобождает GIL [global interpreter lock] в процессе файловых операций, следовательно ваш основной поток (исполняющий
соответствующий цикл asyncio) не затрагивается.
Наиболее важной областью для asyncio намерена выступать сетевое программирование. По этой причине неплохой мыслью
будет слегка подучить программирование сокета, и даже по прошествии лет Socket Programming HOWTO Гордона МакМиллана, включённый в стандартную документацию Python является одним из самых лучших введений в
эту тему из тех что можно найти.
Я изучал asyncio из очень разнообразных источников, которые я уже упоминал в боле ранних разделах. Люди по
разному обучаются из различных источников, а мои учебные материалы, которые я ещё не упоминал такие:
-
Безусловно, наилучший рассказ относительно
asyncio, с которым мне удалось познакомиться на YouTube, это Getting To Grips With Asyncio Роберта Смолшира, представленного на NDC в январе 2017 в Лондоне. Это выступление может быть достаточно сложным для начинающих, но на самом деле представляет ясное описание того как спроектированasyncio. -
Слайды Николая Новика, представленные на PyCon UA 2016: Building Apps With Asyncio. Эта информация очень плотная, но в этих слайдах содержится гигантский практический опыт.
-
Нескончаемые сеансы в Python REPL, в которых выполняются пробы м "наблюдается что происходит"!
Наконец, я побуждаю вас продолжать обучение и если какое- то понятие не "клеится", продолжать искать новые источники, пока вы не отыщете объяснение, которое сработает в вашем случае.