- Использование "ip a" для проверки состояний интерфейса
- Визуализация сетевого обмена nova-network в облаке
- Визуализация потоков данных сетевых служб OpenStack в облаке
- Поиск неисправностей в пути
- tcpdump
- iptables
- Настройка сети в базе данных для nova-network
- Отладка проблем DHCP с применением nova-network
- Проблемы отладки DNS
- Поиск неисправностей Open vSwitch
- Операции с сетевым пространством имен
- Резюме
К сожалению, поиск и устранение неисправностей сети может быть очень сложной и
запутанной процедурой. Вопросы с сетью могут вызывать проблемы в различных местах
облака. Использование процедуры логического устранения неполадок может уменьшить беспорядок
и более быстро изолировать именно то место, где есть проблема сети.
Цель данной главы- предоставить вам информацию, которая необходима для определения
любой проблемы для либоnova-network или
сетевого ресурса OpenStack (neutron) с Linux Bridge or Open vSwitch.
Используйте следующую команду на вычислительных узлах и узлах, с работающими
nova-network, чтобы увидеть информацию об интерфейсах,
включая информацию об IP-адресах, VLAN и работают ли ваши интерфейсы:
# ip a
Если вы испытываете любой вид проблем с сетью, одна хорошая начальная здравая проверка заключается в том, чтобы убедиться, что ваши интерфейсы работают. Например:
$ ip a | grep state 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master br100 state UP qlen 1000 4: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN 5: br100: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
Вы можете спокойно игнорировать состояние virbr0, который
является мостом (bridge) по умолчанию созданным libvirt и не используемым OpenStack.
Если вы вошли в систему экземпляра и выполняете ping на внешний хост, например Google — пакеты ping имеют маршрутизацию показанную на Рисунке 12.1, “Маршрутизация обмена для ping-а пакетов”.
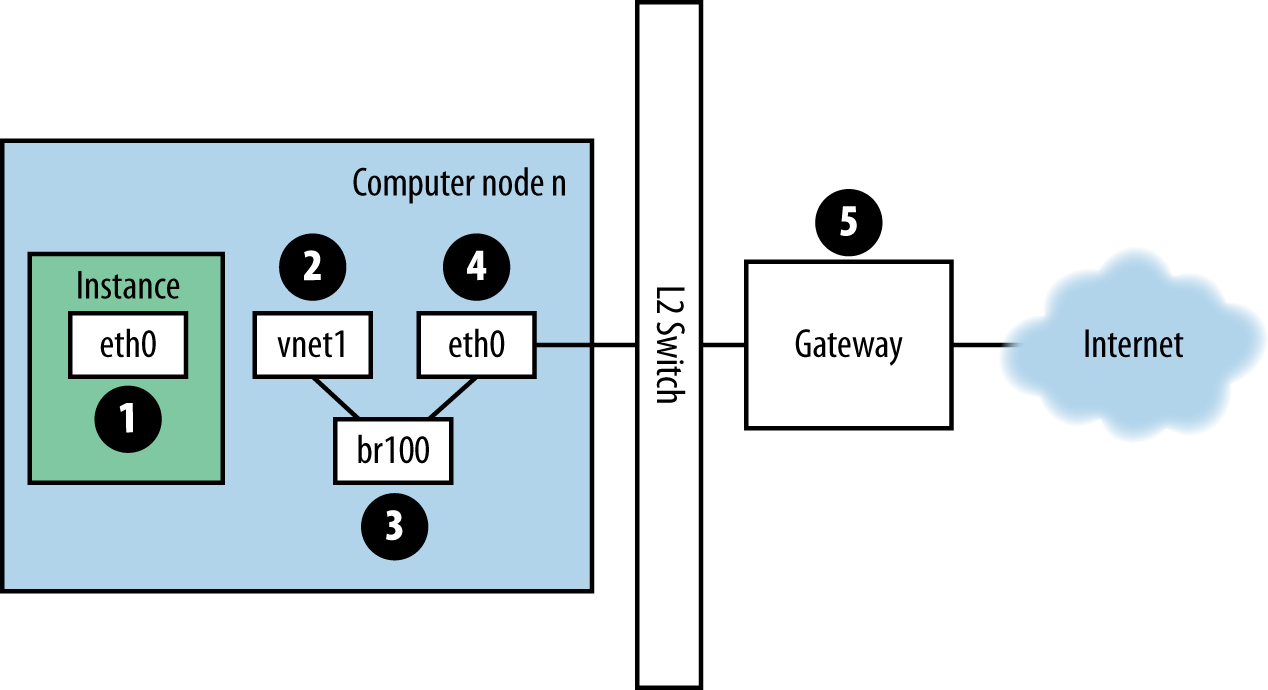
-
Экземпляр генерирует пакет и помещает его в виртуальную сетевую плату (virtual NIC) внутри экземпляра, например, такую, как,
eth0. -
Пакет передается виртуальной сетевой плате вычислительного хоста, например,
vnet1. Вы можете узнать какой именно сетевой адаптер (vnet NIC) используется, просмотрев файл/etc/libvirt/qemu/instance-xxxxxxxx.xml. -
Из vnet NIC пакет передается в мост вычислительного узла, например
br100.Если у вас выполняется FlatDHCPManager, на вычислительном узле присутствует один мост. Если у вас выполняется VlanManager, по одному мосту существует для каждой VLAN.
Чтобы найти какой мост будет использовать пакет, выполните команду:
$ brctl show
Найдите vnet NIC. Вы также можете воспользоваться
nova.confи найти параметрflat_interface_bridge. -
Пакеты перемещается в главную сетевую плату вычислительного узла. Вы опять можете найти эту сетевую плату в выводе результата
brctl, или вы можете найти ее с помощью ссылки на параметрflat_interfaceвnova.conf. -
После того, как пакет попадает в этот сетевой адаптер, он передается в шлюз по умолчанию для данного вычислительного узла. Наиболее вероятно, что теперь пакет находится вне вашего контроля в данной точке. Диаграмма изображает внешний шлюз. Тем не менее, в конфигурации по умолчанию с многими хостами, хост вычислительного узла является шлюзом.
Чтобы увидеть путь ответа ping, измените направление. Из рассмотренного пути вы можете увидеть, что один пакет проходит через четыре различных сетевых адаптера. Если возникает проблема с любой из этих сетевых плат, возникает проблема с сетью.
Сетевая служба OpenStack, neutron, имеет гораздо больше степеней свободы чем
предоставляет nova-network своими подключаемыми
внутренними серверами. Она может быть настроена на работу с плагинами с открытым
кодом или собственного производства поставщиков, которые управляют оборудованием
сетей, определяемым программным обеспечением (SDN, software defined networking) или
плагинами, которые используют имеющиеся у Linux функции на ваших хостах, таких как
Open vSwitch или Linux Bridge.
Глава сетевых ресурсов OpenStack Руководства администратора облака описывает разнообразие сетевых сценариев и способов их подключений. Цель данного раздела заключается в предоставлении вам инструментов для устранения неисправностей различных компонентов, которые, однако, совместно работают по вертикали в вашей среде.
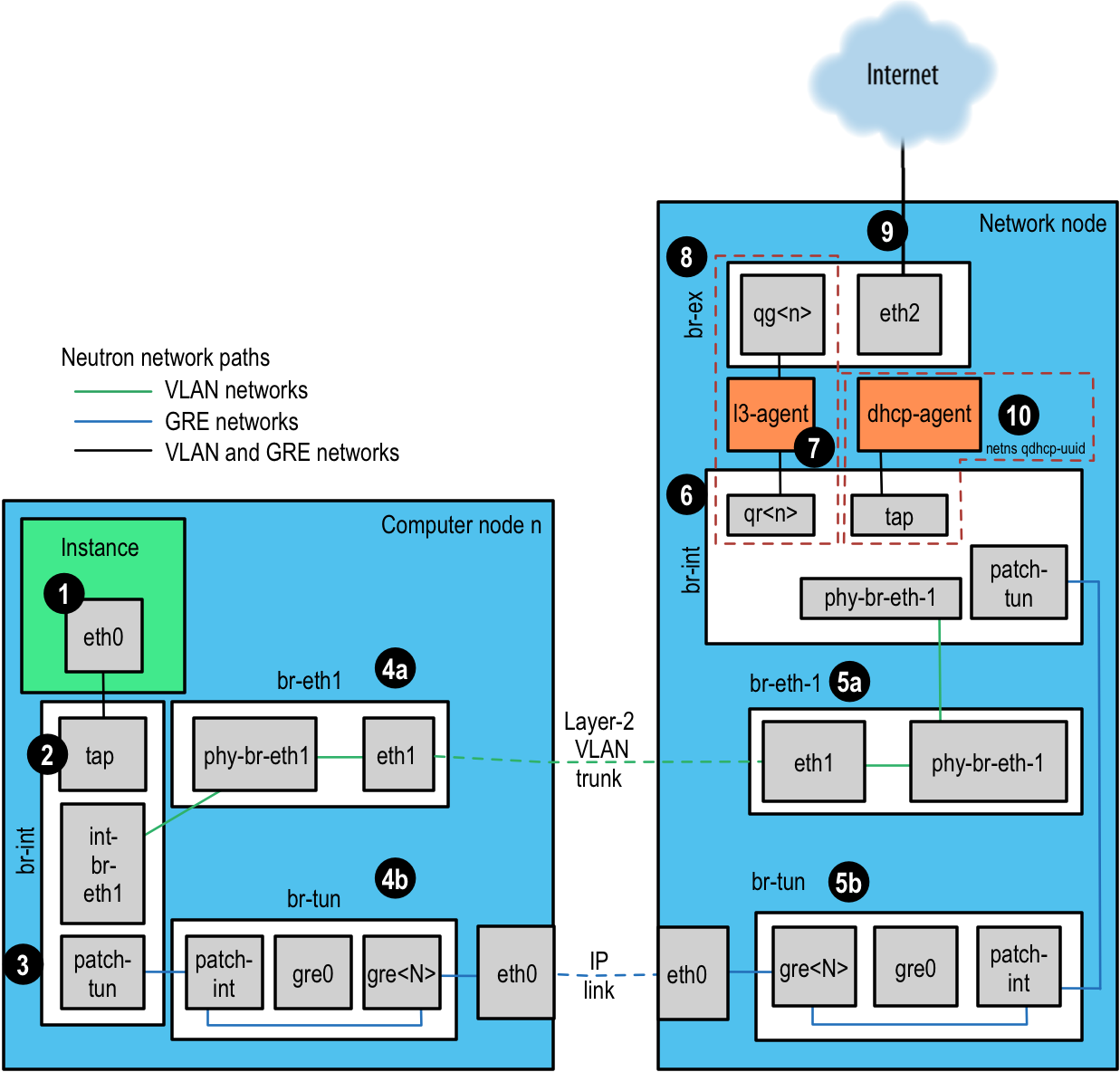
Для данного примера мы используем внутренние сервера Open vSwitch (OVS). Другие плагины будут иметь очень отличные потоки данных. Согласно опросу пользователей OpenStack в октябре 2013, OVS является наиболее популярным драйвером развертывания сети, более чем с 50 процентами сайтов, использующими его по сравнению с занявшим второе место драйвером Linux Bridge driver. Для справки, мы опишем все этапы в кругообороте при помощи Рисунка 12.2, “Сетевые пути Neutron”.
-
Экземпляр формирует пакет и помещает его в виртуальный NIC внутри экземпляра, например, eth0.
-
Пакет передается в устройство тест-порта (TAP, Test Access Point) в вычислительном хосте, например, tap690466bc-92. Просмотрев файл
/etc/libvirt/qemu/instance-xxxxxxxx.xml, вы можете определить какой тест- порт (TAP) используется.Имя устройства тест- порта (TAP) строится с использованием первых 11 символов ID порта (10 шестнадцатеричных цифр плюс входящий в их состав символ дефиса '-'), следовательно, если вы увидите построенное иначе имя устройства, это будет означать использование команды
neutron. Она возвращает список конвейера с разделителями, первым элементом которого будет ID порта. Например, для получения ID порта, связанного с IP адресом 10.0.0.10, выполните:# neutron port-list | grep 10.0.0.10 | cut -d \| -f 2 ff387e54-9e54-442b-94a3-aa4481764f1d
Взяв первые 11 символов, мы сможем построить имя устройства tapff387e54-9e из результата вывода.
{kind=link}
{kind=link}
-
Устройство тест-порта (TAP) присоединяется к объединяющему (integration) мосту,
br-int. Этот мост соединяет все устройства тест- портов (TAP) экземпляра и все остальные мосты системы. В данном примере у нас имеетсяint-br-eth1иpatch-tun.int-br-eth1является первой половиной пары veth, присоединенной к мостуbr-eth1, который обрабатывает сеть VLAN, создающую магистральную линию сквозь физические устройства Etherneteth1.patch-tunявляется внутренним портом Open vSwitch, который соединяет мостbr-tunс сетями GRE.Устройства тест-порта (TAP) и устройства veth являются обычными устройствами Linux и могут обследованы при помощи обычных инструментов, таких как
ipиtcpdump. Внутренние устройства Open vSwitch, например,patch-tun, видны только в рамках среды Open vSwitch. Если вы попробуете выполнитьtcpdump -i patch-tun, это вызовет ошибку с сообщением, что такое устройство не существует.Существует возможность просмотра пакетов во внутренних интерфейсах, однако это требует некоторой сетевой акробатики. Вначале вы должны создать фиктивное (dummy) сетевое устройство, которое могут видеть обычные инструменты Linux. Затем вам необходимо добавить его в мост, содержащий внутренние интерфейсы, которые вы хотите отслеживать. Наконец, вы должны запросить Open vSwitch зеркалировать весь обмен к- или от- внутреннего порта на этот фиктивный порт. После всего этого вы можете выполнить
tcpdumpна фиктивном интерфейсе и увидеть трафик внутреннего порта.Для перехвата пакетов из внутреннего интерфейса
patch-tunв объединяющем (integration) мостуbr-int:-
Создайте и настройте фиктивный интерфейс,
snooper0:# ip link add name snooper0 type dummy
# ip link set dev snooper0 up
-
Добавьте устройство
snooper0к мостуbr-int:# ovs-vsctl add-port br-int snooper0
-
Создайте зеркало
patch-tunнаsnooper0(возвращает UUID порта зеркала):# ovs-vsctl -- set Bridge br-int mirrors=@m -- --id=@snooper0 \ get Port snooper0 -- --id=@patch-tun get Port patch-tun \ -- --id=@m create Mirror name=mymirror select-dst-port=@patch-tun \ select-src-port=@patch-tun output-port=@snooper0
-
Польза. Теперь вы можете просматривать обмен в
patch-tunвыполнивtcpdump -i snooper0. -
Проведите очистку, очистив все зеркала в
br-intи удалиы фиктивные интерфейсы:# ovs-vsctl clear Bridge br-int mirrors
# ovs-vsctl del-port br-int snooper0
# ip link delete dev snooper0
В объединенном (integration) мосте сети разделяются при помощи внутренних VLANs в зависимости от определенных на них служб. Это позволяет экземплярам на одном хосте взаимодействовать напрямую без перекачки остатка виртуальной или физической сети. ID таких внутренних VLAN основаны на порядке их создания в узле и могут различаться между узлами. Подобные ID не имеют никакой связи с ID сегментации, используемыми при определении сети и в физических соединениях.
Метки (tags) VLAN транслируются между внешними метками, определенными при создании сети и внутренними метками в различных местах. В
br-int, пакеты, приходящие отint-br-eth1транслируются их внешних меток во внутренние. Другие трансляции также происходят в других мостах и будут обсуждаться в своих разделах.Чтобы обнаружить какая внутренняя метка VLAN используется для данного внешнего VLAN при помощи команды
ovs-ofctl:-
Найдите метку внешней VLAN интересующей вас сети. Это будет
provider:segmentation_id, возвращаемые сетевой службой:# neutron net-show --fields provider:segmentation_id <network name> +---------------------------+--------------------------------------+ | Field | Value | +---------------------------+--------------------------------------+ | provider:network_type | vlan | | provider:segmentation_id | 2113 | +---------------------------+--------------------------------------+
-
В данном случае выполните grep для
provider:segmentation_id, 2113, в выводе результатаovs-ofctl dump-flows br-int:# ovs-ofctl dump-flows br-int|grep vlan=2113 cookie=0x0, duration=173615.481s, table=0, n_packets=7676140, \ n_bytes=444818637, idle_age=0, hard_age=65534, priority=3, \ in_port=1,dl_vlan=2113 actions=mod_vlan_vid:7,NORMAL
Здесь вы можете увидеть,что принимающиеся в порт ID 1 пакеты с меткой VLAN 2113 модифицируются таким образом, чтобы иметь метку внутренней VLAN, равной 7. Погрузившись немного глубже, вы можете убедиться, что порт 1 фактически является
int-br-eth1:# ovs-ofctl show br-int OFPT_FEATURES_REPLY (xid=0x2): dpid:000022bc45e1914b n_tables:254, n_buffers:256 capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS \ ARP_MATCH_IP actions: OUTPUT SET_VLAN_VID SET_VLAN_PCP STRIP_VLAN SET_DL_SRC \ SET_DL_DST SET_NW_SRC SET_NW_DST SET_NW_TOS SET_TP_SRC \ SET_TP_DST ENQUEUE 1(int-br-eth1): addr:c2:72:74:7f:86:08 config: 0 state: 0 current: 10GB-FD COPPER speed: 10000 Mbps now, 0 Mbps max 2(patch-tun): addr:fa:24:73:75:ad:cd config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max 3(tap9be586e6-79): addr:fe:16:3e:e6:98:56 config: 0 state: 0 current: 10MB-FD COPPER speed: 10 Mbps now, 0 Mbps max LOCAL(br-int): addr:22:bc:45:e1:91:4b config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max OFPT_GET_CONFIG_REPLY (xid=0x4): frags=normal miss_send_len=0
-
-
Следующий этап зависит от того настроена ли виртуальная сеть на использование меток (tags) 802.1q VLAN или GRE:
-
Сети на основе VLAN покидают объединяющий мост через интерфейс veth
int-br-eth1, а приходят в него черезbr-eth1другого участника пары vethphy-br-eth1. Пакеты в этом интерфейсе приходят с внутренними метками (tags) VLAN и транслируются во внешние метки (tags) в порядке, обратном описанному выше:# ovs-ofctl dump-flows br-eth1|grep 2113 cookie=0x0, duration=184168.225s, table=0, n_packets=0, n_bytes=0, \ idle_age=65534, hard_age=65534, priority=4,in_port=1,dl_vlan=7 \ actions=mod_vlan_vid:2113,NORMAL
Пакеты теперь помечаются метками внешнего VLAN, затем выходят в физическую сеть через
eth1. Коммутирующий эти интерфейсы Layer2 соединен таким образом, чтобы быть настроенным на прием трафика с используемым ID VLAN. Следующий интервал связи (hop) для этого пакета должен происходить также в сети layer-2. -
Сети на основе GRE проходят через
patch-tunв мост туннеляbr-tunв интерфейсеpatch-int. Этот мост также содержит один порт для каждого однорангового (peer) участника туннеля GRE, т.е. по одному для каждого вычислительного узла и сетевого узла в вашей сети. Порты нумеруются последовательно отgre-1и так далее.Соответствие интерфейсов
gre-<n>конечным точкм туннеля можно установить просмотрев состояние Open vSwitch:# ovs-vsctl show |grep -A 3 -e Port\ \"gre- Port "gre-1" Interface "gre-1" type: gre options: {in_key=flow, local_ip="10.10.128.21", \ out_key=flow, remote_ip="10.10.128.16"}В данном случае
gre-1является туннелем из IP 10.10.128.21, который должен соответствовать внутреннему интерфейсу данного узла, к IP 10.10.128.16 на удаленной стороне.Такие туннели используются в обычных таблицах маршрутизации в хосте для переправки получающихся в результате пакетов GRE, следовательно, не существует требования для конечных точек GRE присутствовать в одной и той же сети layer-2, в отличие от инкапсуляции VLAN.
Все интерфейсы в
br-tunявляются внутренними по отношению к Open vSwitch. Дляотслеживания трафика в нем вы должны установить порт зеркала, как это было описано выше дляpatch-tunв мостеbr-int.Все трансляции туннеля GRE в- и из- внутренних VLAN происходят в мосте.
Чтобы обнаружить какие метки (tags) внутренних VLAN используются для туннеля GRE при помощи команды
ovs-ofctl:-
Найдите
provider:segmentation_idинтересующей вас сети. Это то же поле, которое используется для ID VLAN в сетях на основе VLAN:# neutron net-show --fields provider:segmentation_id <network name> +--------------------------+-------+ | Field | Value | +--------------------------+-------+ | provider:network_type | gre | | provider:segmentation_id | 3 | +--------------------------+-------+
-
В данном случае осуществите grep для 0x<
provider:segmentation_id>, 0x3, в выдаче результатаovs-ofctl dump-flows br-tun:# ovs-ofctl dump-flows br-tun|grep 0x3 cookie=0x0, duration=380575.724s, table=2, n_packets=1800, \ n_bytes=286104, priority=1,tun_id=0x3 \ actions=mod_vlan_vid:1,resubmit(,10) cookie=0x0, duration=715.529s, table=20, n_packets=5, \ n_bytes=830, hard_timeout=300,priority=1, \ vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:a6:48:24 \ actions=load:0->NXM_OF_VLAN_TCI[], \ load:0x3->NXM_NX_TUN_ID[],output:53 cookie=0x0, duration=193729.242s, table=21, n_packets=58761, \ n_bytes=2618498, dl_vlan=1 actions=strip_vlan,set_tunnel:0x3, \ output:4,output:58,output:56,output:11,output:12,output:47, \ output:13,output:48,output:49,output:44,output:43,output:45, \ output:46,output:30,output:31,output:29,output:28,output:26, \ output:27,output:24,output:25,output:32,output:19,output:21, \ output:59,output:60,output:57,output:6,output:5,output:20, \ output:18,output:17,output:16,output:15,output:14,output:7, \ output:9,output:8,output:53,output:10,output:3,output:2, \ output:38,output:37,output:39,output:40,output:34,output:23, \ output:36,output:35,output:22,output:42,output:41,output:54, \ output:52,output:51,output:50,output:55,output:33
Здесь вы видите три потока, связанных с туннелем GRE. Первый является трансляцией из входящих в этот туннель пакетов с ID данного туннеля в ID 1 внутренней VLAN. Второй показывает поток одноадресной передачи в порт вывода 53 для пакетов, предназначенных MAC адресу fa:16:3e:a6:48:24. Третий отображает трансляцию из внутреннего представления VLAN в ID туннеля GRE лавинно маршрутизирующиеся во все выводящие порты. Для более подробного ознакомления с особенностями описания потока обратитесь к оперативной странице руководства для
ovs-ofctl. Каки в предыдущем примере VLAN, соответствие численных ID портов с их именами может быть установлено путем просмотра результата выводаovs-ofctl show br-tun.
-
-
Затем пакет получается на сетевом узле. Обратите внимание, что любое перемещение в L3-агенте или DHCP -агенте будут видны только в пределах их сетевого пространства имен. Просмотр любых интерфейсов за пределами этих пространств имен, даже тех, которые осуществляют сетевой трафик, покажет только широковещательные пакеты, такие как протоколы разрешения адресов (ARP), а одноадресный трафик к маршрутизатору или DHCP адрес не будет виден. См. Работа с сетевыми пространствами имен для подробностей о том, как выполнять команды внутри этих пространств имен.
Кроме того, можно настроить сети на основе VLAN на использование внешних маршрутизаторов вместо L3-агента, показанного здесь, при условии, что внешний маршрутизатор находится в той же VLAN:
-
Сети на основе VLAN воспринимаются как помеченные пакеты в физическом сетевом интерфейсе, в данном примере,
eth1. Так же, как на вычислительном узле, этот интерфейс является членом мостаbr-eth1. -
Сети на основе GRE будут переданы в туннель моста
br-tun, который ведет себя так же, как интерфейсы GRE на вычислительном узле.
-
-
Далее, пакеты из любого входа проходят объединяющий мост, снова в точности как на вычислительном узле.
-
Затем пакет изготавливается для L3-агента. Это на самом деле другое устройство тест-порта (TAP) в пространстве имен сети маршрутизатора. Пространство имен маршрутизатора именуется в форме
qrouter-<router-uuid>. Запускip a, в рамках пространства имен покажет имя устройства тест-порта (TAP), QR-e6256f7d-31 в нашем примере:# ip netns exec qrouter-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5 ip a|grep state 10: qr-e6256f7d-31: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue \ state UNKNOWN 11: qg-35916e1f-36: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 \ qdisc pfifo_fast state UNKNOWN qlen 500 28: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN -
Интерфейс
qg-<n>в L3-агенте пространства имен маршрутизатора пересылает пакет своему следующему интервалу связи (hop) через устройствоeth2во внешней мостаbr-ex. Этот мост построен так же, какbr-eth1и может быть проверен таким же образом. -
Этот внешний мост также включает в себя физический сетевой интерфейс, в нашем примере
eth2, который, наконец, выгружает пакет во внешнюю сеть, определенную для внешнего маршрутизатора или получателя. -
Агенты DHCP, оперирующие в сети OpenStack работают в пространствах имен, подобных L3-агентам. DHCP пространства имен именуются как
qdhcp-<uuid>и имеют устройство тест-порта (TAP) в объединяющем мосте. Отладка проблем DHCP обычно включает в себя работу внутри пространства имен этой сети.
Используйте команду ping, чтобы быстро найти где существует отказ в сетевом пути. В экземпляре вначале убедитесь, можете ли вы проверить связь (ping) с внешним хостом, например, google.com. Если да, то вообще не должно быть проблемы с сетью.
Если нет, попробуйте выполнить ping к IP адресу вычислительного узла, на котором располагается экземпляр. Если ping к этому IP выполняется, то проблема находится где- то между вычислительным узлом и его шлюзом по умолчанию.
Если ping на IP адрес данного вычислительного узла не выполняется, проблема между экземпляром и вычислительным узлом. Она может заключаться и в мосте, соединяющем основную сетевую плату вычислительного узла и vnet NIC экземпляра.
И последний тест заключается в запуске второго экземпляра и проверке того, что оба экземпляра могут осуществлять ping друг к другу. Если да, то проблема может быть связана с брандмауэром (firewall) на данном вычислительном узле.
Один замечательный, хотя и чересчур глубокий, способ устранения неполадок сети заключается
в использовании tcpdump. Мы рекомендуем использовать
tcpdump в различных точках сетевого пути, чтобы
провести корреляцию того, где может быть проблема. Если вы предпочитаете работать с графическим интерфейсом (GUI),
либо напрямую или с использованием перехвата tcpdump попробуйте в обоих случаях
Wireshark.
Например, выполните следующую команду:
tcpdump -i any -n -v \ 'icmp[icmptype] = icmp-echoreply or icmp[icmptype] = icmp-echo'
Выполните ее из командной строки в следующих областях:
-
На внешнем сервере за пределами облака
-
На вычислительном узле
-
В экземпляре, запущенном на вычислительном узле
В нашем примере эти местоположения имеют следующие IP-адреса:
Instance
10.0.2.24
203.0.113.30
Compute Node
10.0.0.42
203.0.113.34
External Server
1.2.3.4
Затем откройте новую оболочку на экземпляре и потом выполните ping к внешнему
хосту, на котором работает tcpdump.
Если сетевой путь к внешнему серверу и обратно полностью работоспособен, вы видите нечто вроде
следующего:
На внешнем сервере:
12:51:42.020227 IP (tos 0x0, ttl 61, id 0, offset 0, flags [DF], \
proto ICMP (1), length 84)
203.0.113.30 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.020255 IP (tos 0x0, ttl 64, id 8137, offset 0, flags [none], \
proto ICMP (1), length 84)
1.2.3.4 > 203.0.113.30: ICMP echo reply, id 24895, seq 1, \
length 64
На вычислительном узле:
12:51:42.019519 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], \
proto ICMP (1), length 84)
10.0.2.24 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019519 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], \
proto ICMP (1), length 84)
10.0.2.24 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019545 IP (tos 0x0, ttl 63, id 0, offset 0, flags [DF], \
proto ICMP (1), length 84)
203.0.113.30 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019780 IP (tos 0x0, ttl 62, id 8137, offset 0, flags [none], \
proto ICMP (1), length 84)
1.2.3.4 > 203.0.113.30: ICMP echo reply, id 24895, seq 1, length 64
12:51:42.019801 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none], \
proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
12:51:42.019807 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none], \
proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
В экземпляре:
12:51:42.020974 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none], \ proto ICMP (1), length 84) 1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
Здесь внешний сервер получил запрос ping и послал ping-ответ.
На вычислительном узле вы можете увидеть, что и сам ping и ping ответ
успешно выполнены. Вы также должны увидеть дублированные пакеты на
вычислительном узле, как показано выше, потому что
С использованием nova-network вычислительная среда
OpenStack автоматически управляет iptables, в том числе пересылкой пакетов к экземпляру и от
него на вычислительном узле, переадресацию (forwarding) трафика плавающих IP и
управление правилами безопасности группы.
Выполните следующую команду, чтобы посмотреть текущую конфигурацию iptables:
# iptables-save
![[Замечание]](../common/images/admon/note.png) | Замечание |
|---|---|
|
Если вы измените конфигурацию, она вернется в следующий раз, когда вы
перезагрузите |
При использовании nova-network база данных nova
содержит несколько таблиц с сетевой информацией:
fixed_ips-
Содержит все возможные IP-адреса для подсети (подсетей) добавленных в вычислительную среду. Эта таблица связана с таблицей
instances(экземпляров) посредством столбца (Прим. пер.: более правильно с точки зрения баз данных: атрибута, поля)fixed_ips.instance_uuid. floating_ips-
Содержит все плавающие IP адреса, которые были добавлены в вычислительную среду. Эта таблица связана с таблицей
fixed_ipsчерез столбецfloating_ips.fixed_ip_id. instances-
Не совсем характерна для сети, но она содержит информацию об экземпляре, который использует
fixed_ipи не обязательныеfloating_ip.
Из этих таблиц вы можете увидеть, что плавающие IP технически никогда напрямую не связаны с экземпляром; соединение всегда должно проходить через фиксированный IP.
Иногда экземпляр завершается, но плавающий IP не был правильно отсоединен от этого экземпляра. Поскольку база данных находится в несогласованном состоянии, обычные инструменты для отсоединения IP больше не работают. Чтобы исправить это, необходимо вручную обновить базу данных.
Сначала найдите UUID экземпляра выполнив запрос:
mysql> select uuid from instances where hostname = 'hostname';
Далее, найдите запись фиксированного IP для этого UUID:
mysql> select * from fixed_ips where instance_uuid = '<uuid>';
Теперь вы можете получить соответствующую запись плавающего IP:
mysql> select * from floating_ips where fixed_ip_id = '<fixed_ip_id>';
И, наконец, вы можете отсоединить плавающий IP:
mysql> update floating_ips set fixed_ip_id = NULL, host = NULL where
fixed_ip_id = '<fixed_ip_id>';
При необходимости также можно освободить IP из пула пользователя:
mysql> update floating_ips set project_id = NULL where
fixed_ip_id = '<fixed_ip_id>';
Одна из распространенных проблем сети заключается в том, что экземпляр успешно стартует,
но не доступен, потому что не удается получить IP-адрес от
dnsmasq, который является сервером DHCP, запускаемым службой
nova-network.
Самый простой способ выяснить, что эта проблема связана с вашим экземпляром, заключается в просмотре вывода консоли вашего экземпляра. Если отказал DHCP, вы можете получить журнал консоли, выполнив:
$ nova console-log <instance name or uuid>
Если ваш экземпляр не получил IP через DHCP, в консоли должны появиться какие-то сообщения. Например, для образа Cirros вы увидите вывод результатов, выглядящий следующим образом:
udhcpc (v1.17.2) started Sending discover... Sending discover... Sending discover... No lease, forking to background starting DHCP forEthernet interface eth0 [ [1;32mOK[0;39m ] cloud-setup: checking http://169.254.169.254/2009-04-04/meta-data/instance-id wget: can't connect to remote host (169.254.169.254): Network is unreachable
После того, как вы установите, что экземпляр загрузился правильно, задача состоит в том, чтобы выяснить, где происходит отказ.
Проблема DHCP может быть вызвана некорректно работающим процессом dnsmasq.
Во-первых, выполните отладку, проверив журналы и перезагрузите процессы dnsmasq только
для этого проекта (владельца, tenant). В режиме VLAN существует по процессу dnsmasq для
каждого владельца. После перезагрузки целевых процессов dnsmasq,
самый простой способ исключить причины dnsmasq, состоит в том, чтобы уничтожить все dnsmasq
процессы на машине, и перезапустить nova-network.
В крайнем случае, выполните это с правами root:
# killall dnsmasq # restart nova-network
|
| Замечание |
|---|---|
|
Используйте |
Спустя несколько минут после того, как nova-network запущена повторно,
вы должны увидеть новое выполнение процессов dnsmasq:
# ps aux | grep dnsmasq
nobody 3735 0.0 0.0 27540 1044 ? S 15:40 0:00 /usr/sbin/dnsmasq --strict-order \
--bind-interfaces --conf-file= \
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid \
--listen-address=192.168.100.1 --except-interface=lo \
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s \
--dhcp-lease-max=256 \
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf \
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
root 3736 0.0 0.0 27512 444 ? S 15:40 0:00 /usr/sbin/dnsmasq --strict-order \
--bind-interfaces --conf-file= \
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid \
--listen-address=192.168.100.1 --except-interface=lo \
--dhcp-range=set:'novanetwork',192.168.100.2,static,120s \
--dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf
--dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
Если ваши экземпляры все еще не в состоянии получить IP-адреса,
следующая задача заключается в проверке того, видны ли запросы DHCP dnsmasq из
экземпляра. На машине, на которой выполняется процесс dnsmasq и которая является
вычислительным хоcтом при работе в режиме с многими хостами, найдите
/var/log/syslog, чтобы увидеть вывод результатов dnsmasq. Если dnsmasq
видит запросы правильно и раздает IP, результат выглядит таким обазом:
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPDISCOVER(br100) fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPOFFER(br100) 192.168.100.3
fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPREQUEST(br100) 192.168.100.3
fa:16:3e:56:0b:6f
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPACK(br100) 192.168.100.3
fa:16:3e:56:0b:6f test
Если вы не видите DHCPDISCOVER, существует
проблема с получением пакетов от экземпляра к машине с запущенным
dnsmasq. Если вы видите все приводимые выше выводы, а экземплярам
до сих пор не удалось получить IP-адреса, то пакеты доходят от экземпляра к хосту
с запущенным dnsmasq, но они не в состоянии выполнить обратный путь.
Вы также должны видеть сообщение, подобное такому:
Feb 27 22:01:36 mynode dnsmasq-dhcp[25435]: DHCPDISCOVER(br100)
fa:16:3e:78:44:84 no address available
Это может быть проблема, вызванная Dnsmasq и / или nova-network.
(Для предыдущего примера, если бы случилась проблема, что dnsmasq не имеет больше
IP-адресов для выдачи, поскольку больше нет фиксированных IP-адресов в базе данных в
вычислительной среде OpenStack).
Если есть подозрительные сообщения журнала dnsmasq, взгляните на аргументы командной строки для процессов dnsmasq чтобы убедиться, что они выглядят правильно:
$ ps aux | grep dnsmasq
Вывод результатов выглядит примерно следующим образом:
108 1695 0.0 0.0 25972 1000 ? S Feb26 0:00 /usr/sbin/dnsmasq -u libvirt-dnsmasq \ --strict-order --bind-interfaces --pid-file=/var/run/libvirt/network/default.pid --conf-file= --except-interface lo --listen-address 192.168.122.1 --dhcp-range 192.168.122.2,192.168.122.254 --dhcp-leasefile=/var/lib/libvirt/dnsmasq/default.leases --dhcp-lease-max=253 --dhcp-no-override nobody 2438 0.0 0.0 27540 1096 ? S Feb26 0:00 /usr/sbin/dnsmasq --strict-order --bind-interfaces --conf-file= --domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid --listen-address=192.168.100.1 --except-interface=lo \ --dhcp-range=set:'novanetwork',192.168.100.2,static,120s --dhcp-lease-max=256 --dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf --dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro root 2439 0.0 0.0 27512 472 ? S Feb26 0:00 /usr/sbin/dnsmasq --strict-order --bind-interfaces --conf-file= --domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid --listen-address=192.168.100.1 --except-interface=lo --dhcp-range=set:'novanetwork',192.168.100.2,static,120s --dhcp-lease-max=256 --dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf --dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
Вывод результатов показывает три различных процесса dnsmasq. Процесс dnsmasq,
который имеет диапазон подсети DHCP 192.168.122.0, относящийся к libvirt
и может быть проигнорирован. Другие два процесса dnsmasq принадлежат
nova-network. Эти два процесса на самом деле
связаны — один просто является порождающим процессом второго. Аргументы
процессов dnsmasq должны соответствовать реквизитам, с которыми вы настроили
nova-network.
Если проблема не кажется связанной с самим dnsmasq, в данном
месте используйте tcpdump в интерфейсах для определения точки,
в которой теряются пакеты.
DHCP трафик использует UDP. Клиент отправляет пакеты из порта 68 в порт 67 на
сервере. Попробуйте загрузить новый экземпляр, а затем систематически прослушивать
сетевой адаптер, пока вы не идентифицируете тот, который не видит трафик. Чтобы
использовать tcpdump для прослушивания портов 67 и 68 на br100, вы могли
бы выполнить:
# tcpdump -i br100 -n port 67 or port 68
Вы должны выполнять проверку готовности к работе интерфейсов,
например, с помощью команд, подобных ip a и
brctl show для того, чтобы убедиться, что
интерфейсы действительно работают и настроены таким образом, что вы полагаете, что они
существуют.
Если вы в состоянии пробросить ssh к экземпляру, но получение приглашения занимает очень много времени (порядка минуты), то, возможно, у вас проблемы с DNS. Причина проблемы с DNS может быть вызвана тем, что сервер ssh не осуществляет обратный DNS поиск IP-адреса, с которого вы подключаетесь. Если поиск DNS не работает на вашем экземпляре, то вы должны ожидать выполнение тайм-аута обратного просмотра DNS для выполнения процесса авторизации ssh.
При отладке проблем DNS, начните с удостоверения того, что хост, на котором работает процесс dnsmasq для этого экземпляра способен правильно разрешать адреса. Если хост не может разрешать адреса, тогда и экземпляры не смогут выполнять это.
Быстрый способ проверить, работает ли DNS заключается в разрешении имени хоста
внутри вашего экземпляра с использованием команды host. Если DNS
работает, вы должны увидеть:
$ host openstack.org openstack.org has address 174.143.194.225 openstack.org mail is handled by 10 mx1.emailsrvr.com. openstack.org mail is handled by 20 mx2.emailsrvr.com.
Если вы работаете с образом Cirros, он не имеет установленной программы "host", в этом случае вы можете использовать ping, чтобы попытаться получить доступ к машине по имени хоста и чтобы убедиться в способности разрешать имена. Если DNS работает, первая строка ping будет::
$ ping openstack.org PING openstack.org (174.143.194.225): 56 data bytes
Если экземпляр не может разрешить имя хоста, у вас имеется проблема с DNS. Например:
$ ping openstack.org ping: bad address 'openstack.org'
В облаке OpenStack, процесс dnsmasq выступает в качестве DNS- сервера
для экземпляров в дополнение к работе в качестве DHCP-сервера. Некорректно
работающий процесс dnsmasq может быть источником проблем, связанных с DNS внутри
экземпляра. Как уже упоминалось в предыдущем разделе, самый простой способ исключения
плохого поведения процесса dnsmasq, заключается в уничтожении (kill) всех dnsmasq процессов на
машине, и перезапуске nova-network. Однако следует помнить,
что эта команда влияет на все работающие на данном узле экземпляры,
в том числе на процессы владельцев (tenant), которые не испытывают данной проблемы. В крайнем случае,
выполните с правами root:
# killall dnsmasq # restart nova-network
После того, как dnsmasq снова стартует, убедитесь что DNS работает.
Если перезапуск процесса dnsmasq не решил проблему, вам, возможно,
потребуется использовать tcpdump для просмотра пакетов, чтобы проследить, где
они теряются. Сервер DNS прослушивает UDP порт 53. Вы должны увидеть запрос DNS
в мосте (например, br100) вашего вычислительного узла. Если вы
запустили прослушивание tcpdump на вычислительном узле:
# tcpdump -i br100 -n -v udp port 53 tcpdump: listening on br100, link-type EN10MB (Ethernet), capture size 65535 bytes
Тогда, если вы прокинете ssh в экземпляр и попытаетесь выполнить
ping openstack.org, вы должны увидеть нечто вроде:
16:36:18.807518 IP (tos 0x0, ttl 64, id 56057, offset 0, flags [DF], proto UDP (17), length 59) 192.168.100.4.54244 > 192.168.100.1.53: 2+ A? openstack.org. (31) 16:36:18.808285 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto UDP (17), length 75) 192.168.100.1.53 > 192.168.100.4.54244: 2 1/0/0 openstack.org. A 174.143.194.225 (47)
Использовавшийся в предыдущих примерах сетевых служб OpenStack Open vSwitch
является многоуровневым виртуальным коммутатором с полным набором характеристик,
лицензируемый согласно лиценизии Apache 2.0 для систем с открытым кодом.
Полная документация может быть найдена на
веб-сайте проекта.
На практике, после выполнения предыдущих настроек, наиболее общие проблемы связаны с тем,
существуют ли необходимые мосты (br-int,
br-tun, br-ex и т.п.)
и подключены ли к ним соответствующие порты.
Драйвер Open vSwitch должен это выполнять автоматически, и обычно так и происходит,
однако полезно знать как это сделатьвручнуюс помощью команды
ovs-vsctl. Эта команда имеет большое
количество подмножеств команд, которые мы будем использовать здесь;
изучите оперативные страницы руководства (man page) или воспользуйтесь
ovs-vsctl --help для получения полного списка.
Для получения пеоечня мостов в системе воспользуйтесь
ovs-vsctl list-br. Данный пример показывает
вычислительные узлы, которые имеют внутренние мосты и мосту туннелей.
Сети VLAN собираются в магистраль (trunked) через сетевой интерфейс
eth1:
# ovs-vsctl list-br
br-int
br-tun
eth1-br
Оперируя изнутри физических интерфейсов, мы можемувидеть цепочку
портов и мостов. Во-первых, мост eth1-br,
который содержит физический сетевой интерфейс eth1
и виртуальный интерфейс phy-eth1-br:
# ovs-vsctl list-ports eth1-br
eth1
phy-eth1-br
Далее, внутренний мост, br-int, содержащий
int-eth1-br, который идет в паре с phy-eth1-br
для присоединения к физической сети, показанной в предыдущем мосте,
patch-tun, который используется для соединения
моста туннеля GRE и устройства тест-порта (TAP), который присоединяет к
экземпляру, работающему в настоящее время в системе:
# ovs-vsctl list-ports br-int
int-eth1-br
patch-tun
tap2d782834-d1
tap690466bc-92
tap8a864970-2d
Мост туннеля, br-tun, содержит интерфейс
patch-int и интерфейс gre-<N>
для каждого одорангового участника, к которому он подключается через GRE,
причем,по одному для каждого вычислительного и сетевого узла в вашем кластере:
# ovs-vsctl list-ports br-tun
patch-int
gre-1
.
.
.
gre-<N>
Если какое- либо из этихсоединений пропущено или некорректно,
это означает ошибку настройки. Мосты могут добавляться при помощи
ovs-vsctl add-br, а порты могут добавляться к
мостам с использованием ovs-vsctl add-port.
При ручном запуске полезно будет воспользоваться отладкой,
важно, чтобы изменения, внесенные вручную и которые вы собираетесь сохранить
были отражены в ваших файлах настройки.
Сетевые пространства имен Linux являются функцией ядра, которую сетевые службы используют для поддержки множественных изолированных сетей уровня 2 с перекрывающимися диапазонами алресов. Поддержкаможет быть запрещена, однако по умолчанию она присутствует. Если она разрешена в вашей среде, ваши сетвые узлы будут выполнять своих агентов dhcp и агентов 3 уровня в изолированных пространствах имен. Сетевые интерфейсы и обмен в этих интерфейсах будут не видны в пространстве имен по умолчанию.
Для просмотра того,используете ли вы пространство имен, выполните
ip netns:
# ip netns
qdhcp-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5
qdhcp-a4d00c60-f005-400e-a24c-1bf8b8308f98
qdhcp-fe178706-9942-4600-9224-b2ae7c61db71
qdhcp-0a1d0a27-cffa-4de3-92c5-9d3fd3f2e74d
qrouter-8a4ce760-ab55-4f2f-8ec5-a2e858ce0d39
Пространство имен маршрутизатора агента 3 уровня именуется
qrouter-,
а пространство имен агента dhcp именуется
<router_uuid>qdhcp-<net_uuid>neutron net-list
с полномочиями администратора.
Когда вы определите, вкаком пространстве имен вам необходимо работать,
выможете использовать любое средство отладки, обсуждавшееся ранее, предваряемое
префиксом команды с ip netns exec <namespace>.
Например, для просмотра того, какие сетевые интерфейсы существуют в первом
пространстве имен qdhcp namespace, возвращавшемся ранее, выполните следующее:
# ip netns exec qdhcp-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5 ip a
10: tape6256f7d-31: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN
link/ether fa:16:3e:aa:f7:a1 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.100/24 brd 10.0.1.255 scope global tape6256f7d-31
inet 169.254.169.254/16 brd 169.254.255.255 scope global tape6256f7d-31
inet6 fe80::f816:3eff:feaa:f7a1/64 scope link
valid_lft forever preferred_lft forever
28: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
Отсюда вы видите что сервер DHCP в данной сети использует устройство tape6256f7d-31
и имеет IP адрес 10.0.1.100. Просмотрев адрес 169.254.169.254, вы также
можете увидеть, что агент dhcp выполняет службу прокси метаданных.
Люьые упоминавшиеся ранее в ланной главе команды могут быть выполнены аналогично.
Также возможно запустить оболочку, например, такую как bash,
и получить интерактивный сеанс в рамках заданного пространства имен.
В последнем случае, существующая оболочка вернет вас в пространство имен верхнего
уровня,заданное по умолчанию.
Авторы затратили очень много времени на просмотр дампов пакетов с целью извлечения приведенной информации вам. Мы верим, что следуя приведенным в данной главе методам, вы легко проведете время! Отклоняясь в сторону от работы с приведенными выше инструментами и рекомендованными этапами, не забывайте, что иногда дополнительная пара глаз пройдет длинный путь помощи.