Глава 5. Разбираемся с Блочным уровнем, Множественной очередью и Сопоставлением устройств
Содержание
"Я чувствую жажду... жажду скорости," Мэверик в Лучшем стрелке
Глава 4 сделала для нас введение в роль блочного устройства в ядре. Мы получили возможность рассмотреть что составляет блочное устройство и изучить основные структуры данные на самом блочном уровне. Данная глава, по мере того как мы будем продолжать разбираться с блочным уровнем, продолжит основывается на этом.
Эта глава представит нам два основных понятия: механизм блочного ввода/ вывода со множеством очередей и инфраструктуру сопоставления устройств. Собственно блочный уровень ядра за последние годы для решения проблем с производительностью претерпел значительные изменения. Важной вехой в этом направлении стало внедрение инфраструктуры множества очередей, что обсуждается в Глава 4. При работе с блочными устройствами производительность выступает критически важным фактором, а потому в ядре для улучшения производительности дисков реализованы различные улучшения. В Главе 4 мы рассмотрим структуры очередей запросов и откликов собственно на блочном уровне, которые и обрабатывают запросы на ввод/ вывод для блочного устройства. В данной главе мы начинаем с представления очереди с одиночными запросами, её ограничениями в отношении производительности, а также проблем, с которыми сталкивается наш блочный уровень при работе с современными высокопроизводительными накопителями, такими как NVMe и SSD. Также мы поясним как на производительность систем со множеством ядер влияет модель очереди с одиночными запросами.
Второй важной темой данной главы будет инфраструктура соответствия в ядре, именуемая также device mapper (Сопоставлением устройств). Инфраструктура сопоставления устройств в ядре работает совместно с самим блочным уровнем и отвечает со соответствие физических блочных устройств логическим блочным устройствам. Как мы обнаружим, эта инфраструктура сопоставления устройств служит в качестве основы для реализации разнообразных технологий, таких как управление логическими томами, RAID, шифрование и динамическое выделение (thin provisioning). В самом конце мы также кратко обсудим механизмы кэширования на блочном уровне.
Мы обсудим такие основные вопросы:
-
Основная проблема с очередями одиночных запросов
-
Механизм блочного ввода/ вывода со множеством очередей
-
Инфраструктура Сопоставления устройств
-
Многоуровневое кэширование на блочном уровне
Дополнительно к рассмотренным нами ранее понятиям операционной системы Linux, обсуждаемые в данной главе вопросы требуют основ понимания технологий современных процессоров и хранилищ. Всякие практические навыки администрирования хранилищ Linux значительно улучшают понимание вами определённых моментов.
Все представленные в этой главе команды и примеры не зависят от дистрибутива и мы можем выполнять их в любой операционной системе Linux, например,
в Debian, Ubuntu, Red Hat, Fedora и прочих. Присутствует ряд ссылок на исходный код ядра. Если вы пожелаете выгрузить исходный код ядра, вы можете
выполнить это с https://www.kernel.org. Те фрагменты кода, на которые ссылается наша
глава, взяты из ядра 5.19.9.
Наша операционная система обязана обрабатывать блочные устройства так, чтобы они оперировали со всем своим потенциалом. Некое приложение может требовать выполнения операций ввода/ вывода в произвольных местах блочного устройства, что требуете выполнения позиционирования (seeking) во множестве местоположений на диске и способно продлевать продолжительность определённой операции. В случае шпиндельных устройств (с механическим вращением), постоянное выполнение доступа случайным образом способно не только приводить к деградации производительности, но и воспроизводить заметный шум. Хотя в наши дни мы всё ещё продолжаем пользоваться такие интерфейсы как SATA (Serial Advanced Technology Attachment, последовательного интерфейса обмена с накопителями данных) продолжают оставаться применяемыми для механических дисков протоколами. Изначальная архитектура блочного уровня ядра была предназначена для того времени, когда именно механические приводы применялись в качестве используемой среды носителей. Это изменили два момента: появление процессоров со множеством ядер и достижения в технологиях приводов. Именно благодаря этим изменениям узкое место в общем стеке хранения данных переместилось с физического оборудования на уровни программного обеспечения в сомом ядре.
В наследуемой архитектуре имеющийся блочный уровень ядра обрабатывает запросы на ввод/ вывод одним из следующих способов:
-
Для обработки запросов на ввод/ вывод сам блочный уровень осуществляет поддержку очереди с одиночных запросом, структуру связанного списка. Новые запросы вставлялись в конец такой очереди. Перед их передачей соответствующему драйверу существовавший блочный уровень реализовывал такие механизмы как слияние и объединение (которые мы поясняем в своём следующем разделе).
-
При некоторых обстоятельствах, поступающие запросы на ввод/ вывод обязаны обходить имеющиеся очереди запросов и непосредственно загружаться в драйвер устройства. Это подразумевает, что вся выполняемая в такой очереди запросов обработка будет осуществляться самим драйвером устройства. Как правило, в результате это приводит к отрицательному воздействию на производительность.
Даже в случае применения современных твердотельных накопителей такая архитектура обладает серьёзными ограничениями. Такой подход дополнительно приводит к тройственной проблеме:
-
Существующая содержащая запросы на ввод/ вывод очередь запросов не масштабируется для обработки потребностей современных процессоров. В системах со множеством ядер очередь одиночных запросов должна совместно использоваться множеством ядер. Тем самым, для доступа к такой очереди запросов применялся механизм блокировок. Подобная глобальная блокировка использовалась для синхронизации совместного доступа к очереди запросов блочного уровня. Для реализации различных механизмов обработки ввода/ вывода ядро ЦПУ обязано осуществлять блокирование всей очереди запросов. Это подразумевает, что когда другому ядру требуется работа с данной очередью запросов, он вынужден определённое время выполнять ожидание. Для блокирования единственной очереди запросов вся ядра ЦПУ продолжают пребывать в состоянии конкуренции. Нетрудно понять, что подобная архитектура превращает одну очередь запросов в единственную точку конкуренции в системах со множеством ядер.
-
Очередь одиночных запросов к тому же создаёт проблемы с согласованностью кэширования. Каждое ядро ЦПУ обладает своим собственным кэшем L1/ L2, причём они способны содержать некую копию разделяемых данных. Когда ядро ЦПУ изменяет некие данные после овладения глобальной блокировкой в единственной очереди запросов, и обновляет обсуждаемые данные в своём кэше, имеющиеся прочие ядра могут всё ещё содержать в своих кэшах устаревшие копии тех же самых данных. В результате, внесённые одним из ядер изменения не могут немедленно распространяться в кэши прочих ядер. Это приводит к несогласованному представлению совместных данных в различных ядрах. После высвобождения глобальной блокировки ядром, владение ею передаётся иному ожидающему блокировке ядру. Хотя и существует ряд протоколов согласования кэша, которые обеспечивают поддержку согласованности представления совместных данных кэшами, суть состоит в том, что сама архитектура с одиночными запросами, по своей идее, не поддерживает механизмов синхронизации кэшей различных ядер ЦПУ. Это увеличивает общую рабочую нагрузку, необходимую для обеспечения согласованности кэша.
-
Столь частое переключение блокировок очереди запросов между ядрами в результате приводит к росту числа прерываний.
В целом, применение множества ядер подразумевало, что множество исполняемых потоков будут одновременно конкурировать за одну и ту же совместную блокировку. Чем больше значение числа процессоров/ ядер в нашей системе, тем выше вероятность состязательности за блокировку единственной очереди запросов. По причине связанных с получением необходимой блокировки обращений и конфликтов, впустую тратится значительное число циклов ЦПУ. Это существенно снижает значение числа IOPs (операций ввода/ вывода в секунду) для систем со множеством процессоров.
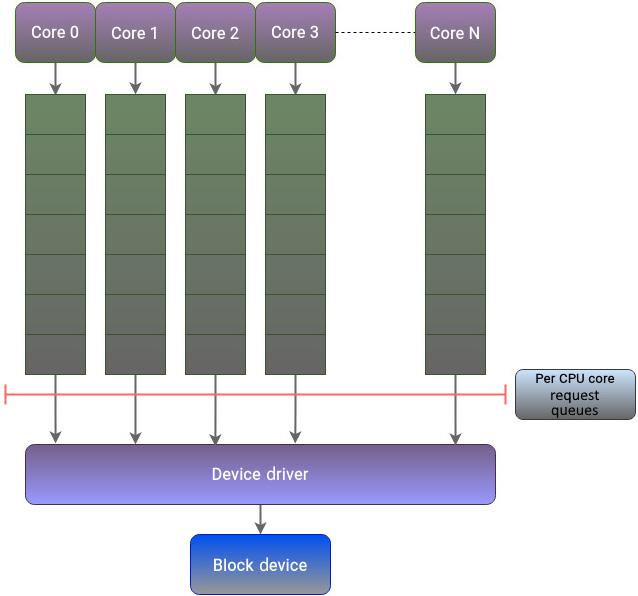
Рисунок 5.1 обозначает имеющиеся ограничения использования модели с единственной очередью:

Из Рисунка 5.1 становится совершенно ясно, что вне зависимости от числа ядер ЦПУ и типа лежащего в основе хранилища архитектура блочного уровня с единственной очередью не имеет возможности масштабирования для соответствия их требованиям производительности.
За последнее десятилетие или около того, корпоративные среды испытали сдвиг в сторону твердотельных накопителей и энергонезависимой памяти. Такие устройства не обладают механическими частями и способны одновременно обрабатывать запросы на ввод/ вывод. Архитектура подобных устройств обеспечивает отсутствие отрицательных последствий при рассмотрении вариантов выполнения доступа случайным образом. С появлением флеш- накопителей в качестве предпочтительного постоянного носителя информации применявшиеся на блочном уровне для работы с жёсткими дисками традиционные методы превратились в устаревшие. Для применения в полной мере расширенных возможностей твердотельных накопителей необходимо надлежащим образом усовершенствовать имеющуюся архитектуру блочного уровня.
В своём следующем разделе мы пронаблюдаем за тем, как для решения данной задачи эволюционировал блочный уровень.
Организация иерархии хранения в Linux обладает неким сходством с сетевым стеком в Linux. Оба представляют множество уровней и строго определяют роль каждого уровня в своём стеке. Задействованы определяющие общую производительность драйверы устройств и физические интерфейсы. Подобно блочному уровню, как только сетевой пакет готов к передаче, он помещался в единую очередь. Такой подход применялся на протяжении ряда лет, пока сетевой оборудование не эволюционировало на поддержку множества очередей. Таким образом, для устройств со множеством очередей данный подход устарел.
Данная проблема вполне аналогична той, с которой позднее столкнулся блочный уровень в ядре. Сетевой стек разрешил эту задачу в ядре Linux намного раньше нежели стек хранения. Таким образом, стек хранения ядра взял это на вооружение, что привело к созданию новой инфраструктуры для блочного уровня Linux, носящей название механизма организации очередей блочного ввода/ вывода со множеством очередей, сокращённо blk-mq.
Инфраструктура со множеством очередей разрешает имеющееся на блочном уровне ограничение изолируя очереди запросов для каждого из ядер. Рисунок 5.2 иллюстрирует как этот подход исправляет все три ограничения архитектуры инфраструктуры с очередью одиночных запросов:
Применяя данный подход, ядро ЦПУ способно сосредоточиться на исполнении своего потока не заботясь относительно запущенных в прочих ядрах потоках. Этот подход разрешает те ограничения, которые вызываются совместной глобальной блокировкой и к тому же минимизируют применение прерываний и потребность в согласовании кэшей.
Инфраструктура blk-mq для обработки запросов на ввод/ вывод реализует следующую архитектуру очередей с
двумя уровнями:
-
Очереди подготовки программного обеспечения: Такие представляемые подготовительные очереди программного обеспечения составляются одной или более структурой
bio. Блочное устройство будет обладать множеством очередей программного обеспечения отправки ввода/ вывода, как правило, по одной для каждого ядра ЦПУ, причём каждая очередь будет обладать блокировкой. Система сMсокетами иNядрами будет минимально обладатьM, а максимальноNочередями. Каждое ядро отправляет запросы на ввод/ вывод в собственную очередь и не взаимодействует с прочими ядрами. В конечном счёте все эти очереди объединяются в одну очередь для соответствующего драйвера устройства. Планировщики ввода/ вывода способны обрабатывать необходимые запросы в надлежащей подготовительной очереди для изменения их порядка или слияния. Однако такое переупорядочение не имеет значения, ибо накопителям SSD и NVMe не важно является ли запрос на ввод/ вывод произвольным или последовательным. Подобное планирование производится только между запросами в одной и той же очереди, а потому не требует механизма блокировки. -
Очереди аппаратной отправки: Значение числа поддерживаемых очередей зависит от общего числа поддерживаемых оборудованием и соответствующим драйвером контекстов аппаратных средств. Величина числа промежуточных очередей программного обеспечения может быть меньше, больше или равно количеству аппаратных очередей. Очереди аппаратной отправки являют собой последний этап блочного уровня и действуют в качестве некого посредника перед передачей всех запросов своему драйверу устройства для их окончательного исполнения. Когда некий запрос на ввод/ вывод поступает на блочный уровень, а с этим блочным уровнем не связан планировщик ввода/ вывода,
blk-mqотправит такой запрос непосредственно в надлежащую аппаратную очередь.
Для указания того какой именно запрос был выполнен, API множества очередей пользуется тегами. Всякий запрос идентифицируется неким тегом, представляющим собой целое значение в диапазоне от нуля до величины размера очереди отправки. Сам блочный уровень вырабатывает тег, который впоследствии применяется надлежащим драйвером устройства, что избавляет от необходимости дублирования идентификатора. Как только соответствующий драйвер завершает обработку своего запроса, этот тег возвращается на блочный уровень с тем, чтобы сигнализировать о завершении его операции. В нашем следующем разделе освещены некоторые наиболее важные структуры данных, играющие важную роль в реализации блочного уровня со множеством очередей.
Вот некоторые первейшие структуры данных, которые существенны для реализации блочного уровня со множеством очередей:
-
Самой первой относящейся к делу структурой, которая применяется инфраструктурой множества очередей является структура
blk_mq_register_dev, которая содержит все необходимые сведения, которые требуются при регистрации нового блочного устройства на блочном уровне. Она содержит различные поля, предоставляющие подробности относительно возможностей и требований его драйвера. -
Структура данных
blk_mq_opsслужит в качестве справочника блочного уровня со множеством очередей для доступа к конкретным подпрограммам драйвера. Данная структура служит в качестве интерфейса для взаимодействия между самим драйвером и уровнемblk-mq, делая возможной для этого драйвера бесшовную интеграцию в общей инфраструктуре обработки множества очередей. -
Структурой
blk_mq_ctxпредставляются очереди подготовки программного обеспечения. Данная структура распределяется исходя из выделения для каждого ядра. -
Структура
blk_mq_hw_ctxопределяет соответствующие конструкции для очередей аппаратной отправки. Она представляет необходимый контекст оборудования с которым ассоциируется очередь запросов. -
Задача установления соответствия между очередями подготовки программного обеспечения и очередями аппаратной отправки осуществляется структурой
blk_mq_queue_map. -
Сами запросы создаются и отправляются в надлежащее блочное устройство через функцию
blk_mq_submit_bio.
На нашем следующем рисунке показано как эти функции связаны между собой:
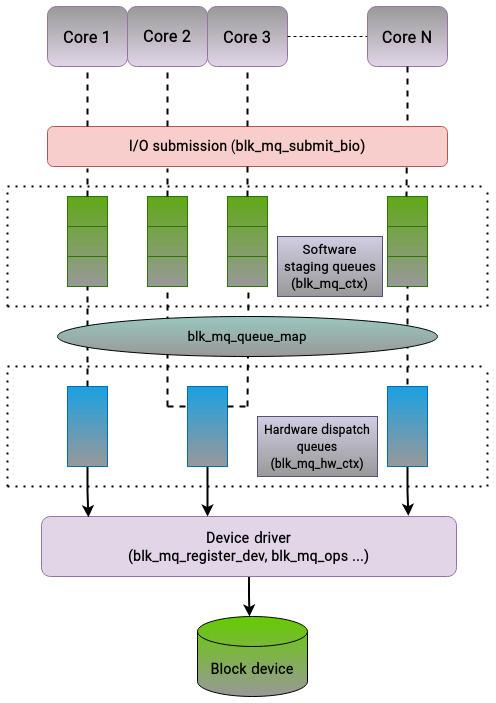
Суммируя, наш интерфейс множества очередей решает ограничения, с которыми сталкивается блочный уровень при работе с современными устройствами хранения , обладающими большим числом очередей. Исторически вне зависимости от имеющихся возможностей лежащих в основе физических носителей информации для обработки запросов на ввод/ вывод блочный уровень поддерживает очередь одиночных запросов. В системах со множеством ядер это быстро становится узким местом. Поскольку такая очередь запросов разделяется между всеми ядрами ЦПУ посредством глобальной блокировки, существенный промежуток времени тратится каждым ядром ЦПУ на ожидание высвобождения блокировки другим ядром. Для обхода такого вызова была разработана новая инфраструктура для удовлетворения имеющихся требований современных процессоров и устройств хранения. Данная инфраструктура множества очередей разрешает имеющиеся ограничения блочного уровня разделяя очереди запросов для каждого ядра ЦПУ. Эта инфраструктура пользуется архитектурой двойной очереди, которая представлена очередями подготовки программным обеспечением и очередями аппаратной отправки.
На этом мы считаем выполненным анализ инфраструктуры со множеством очередей блочного уровня. Теперь мы сдвинем центр своего внимания и изучим инфраструктуру Сопоставления устройств.
По умолчанию управление физическими блочными устройствами неизменно, поскольку приложение может пользоваться ими лишь несколькими способами.
При работе с блочными устройствами необходимо принимать обоснованные решения относительно разбиения диска и управления пространством чтобы
гарантировать оптимальное применение доступных ресурсов. В прошлом такие функциональные возможности как динамическое выделение, моментальные снимки,
управление томами и шифрование были доступны лишь корпоративным массивам хранения. Однако ос временем эти функциональные возможности превратились
в важнейшие компоненты любой инфраструктуры локального хранилища. При работе с физическими устройствами ожидается, что верхние уровни его
операционной системы будут обладать необходимыми возможностями для реализации и сопровождения таких свойств. Для реализации данных понятий ядро Linux
предоставляет среду Сопоставления устройств (device mapper). Сопоставление устройств применяется ядром для соотнесения физических блочных устройств с
виртуальными блочными устройствами верхнего уровня. Первейшая цель среды Сопоставления устройств заключается в создании слоя абстракции верхнего
уровня поверх физических устройств. Сопоставитель устройств предоставляет механизм изменения структур bio при
транспортировке и соотнесения их с блочными устройствами. Применение инфраструктуры Сопоставление устройств закладывает основу для реализации таких
функциональных возможностей как управление логическими томами.
Сопоставление устройств предоставляет общий способ создания виртуальных уровней блочных устройств поверх физических устройств и реализации таких функциональных возможностей как чередование, зеркалирование, моментальные снимки и множественность путей. Как и большинство вещей в Linux, функциональные возможности инфраструктуры Сопоставления устройств делится на пространство ядра и пространство пользователя. Связанная с политикой работа, например, определение соотнесения физических устройств с логическими, содержится в пространстве пользователя, в то время как собственно реализующие эти политики функции установления подобного соотнесения лежат в пространстве ядра.
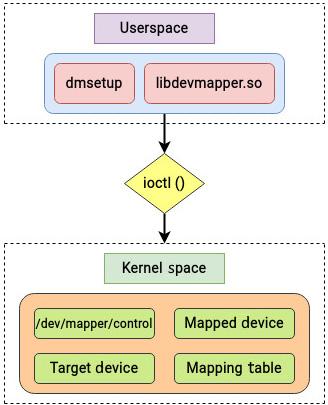
Прикладным интерфейсом Сопоставления устройств выступают системные вызовы ioctl. Такой системный вызов
выравнивает параметры специального файла лежащего в основе устройства. Пользующиеся инфраструктурой Сопоставления устройств логические устройства
управляются при помощи команды dmsetup и библиотеки libdevmapper, которые
реализуют соответствующий интерфейс пользователя, как это отражено на нашем следующем рисунке:
Когда в команде dmsetup мы исполним strace, мы обнаружим, что она
пользуется библиотекой libdevmapper и интерфейсом ioctl:
root@linuxbox:~# strace dmsetup ls
execve("/sbin/dmsetup", ["dmsetup", "ls"], 0x7fffbd282c58 /* 22 vars */) = 0
[..................]
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libdevmapper.so.1.02.1", O_RDONLY|O_CLOEXEC) = 3
[...............…]
stat("/dev/mapper/control", {st_mode=S_IFCHR|0600, st_rdev=makedev(10, 236), ...}) = 0
openat(AT_FDCWD, "/dev/mapper/control", O_RDWR) = 3
openat(AT_FDCWD, "/proc/devices", O_RDONLY) = 4
[...............…]
ioctl(3, DM_VERSION, {version=4.0.0, data_size=16384, flags=DM_EXISTS_FLAG} => {version=4.41.0, data_size=16384, flags=DM_EXISTS_FLAG}) = 0
ioctl(3, DM_LIST_DEVICES, {version=4.0.0, data_size=16384, data_start=312, flags=DM_EXISTS_FLAG} => {version=4.41.0, data_size=528, data_start=312, flags=DM_EXISTS_FLAG, ...}) = 0
[..................]
Устанавливающие соотнесение устройств приложения, такие как LVM, взаимодействуют с инфраструктурой Соответствия устройств через библиотеку
libdevmapper. Данная библиотека libdevmapper пользуется командами
ioctl для передачи сведений в устройство /dev/mapper/control. Это
приспособление /dev/mapper/control является специализированным устройством, которое функционирует в качестве
механизма инфраструктуры Сопоставления устройств.
На Рисунке 5.4 мы можем наблюдать что инфраструктура Сопоставления устройств в пространстве ядра для управления хранилищами реализует модульную архитектуру. Функциональность инфраструктуры Сопоставления устройств составлена из трёх следующих основных компонентов:
-
Сопоставляемого устройства
-
Таблицы сопоставлений
-
Целевого устройства
Кратко взглянем на соответствующие им роли.
Взглянем на Сопоставляемое устройство
Некое блочное устройство, скажем, диск целиком или индивидуальный раздел, могут быть поставлены в соответствие
другому устройству. Сопоставляемое устройство это это логическое устройство, предоставляемое драйвером Сопоставления устройств (device mapper) и
обычно присутствует в каталоге /dev/mapper. Примерами сопоставляемых устройств выступают логические тома в LVM.
Собственно устройство сопоставления определено в drivers/md/dm-core.h. Если мы взглянем на это определение,
мы обнаружим знакомую структуру:
struct mapped_device {
[……..]
struct gendisk *disk;
[………..]
Как пояснялось в Главе 4, структура gendisk
представляет в ядре понятие физического жёсткого диска.
Взглянем на Таблицу сопоставлений
Соответствие устройств определяется как Таблица сопоставлений. Такая Таблица сопоставлений представляет соответствие между Сопоставляемым
устройством и Целевыми устройствами. Сопоставляемое устройство определяется таблицей, которая описывает как каждый диапазон логических секторов
в этом устройстве должен соответствовать при помощи Таблицы сопоставлений, которая поддерживается собственно инфраструктурой Сопоставления
устройств. Такая определяемая в каталоге drivers/md/dm-core.h Таблица сопоставлений содержит некий
указатель на необходимое Сопоставляемое устройство:
struct dm_table {
struct mapped_device *md;
[……………..]
Данная структура позволяет создавать, изменять и удалять соответствия в общем стеке Сопоставления устройств. Подробности Таблицы сопоставлений
можно просматривать выполняя команду dmsetup.
Взглянем на Целевое устройство
Как уже пояснялось ранее, среда Сопоставления устройств создаёт виртуальные блочные устройства определяя соответствие с физическими блочными устройствами.
Логические устройства создаются с применением "целей", которые мы способны представлять себе как модульные подключаемые элементы. При помощи таких
целей могут создаваться разнообразные типы соответствий, такие как линейные, зеркальные, моментальных снимков и так далее. Данные передаются от виртуального
блочного устройства через данные соответствия. Собственно структура целевого устройства определяется в
include/linux/device-mapper.h. Вот применяемый для установления соответствия сектора элемент:
struct dm_target {
struct dm_table *table;
sector_t begin;
sector_t len;
[………….]
Сопоставление устройств может оказаться слегка запутанным для его понимания, а потому давайте проиллюстрируем пример использования тех строительных
блоков, которые мы поясняли ранее. Мы намерены воспользоваться линейной целью, которая лежит в основе управления
логическими томами. Как уже обсуждалось ранее, мы собираемся воспользоваться для этой цели командой dmsetup, поскольку
она реализует функциональные возможности Сопоставления устройств пространстве пользователя. Мы хотим создать линейное целевое соответствие с названием
dm_disk. Если вы планируете выполнить следующую команду, убедитесь что вы запускаете её на чистом диске. Здесь мы
воспользуемся двумя дисками, sdc и sdd (для данного упражнения можно воспользоваться
любым диском, лишь бы он был пуст!). Обратите внимание на то, что после того как после команд dmsetup create
вы нажмёте Enter, она запросит у вас ввод. Ссылки на диски sdc и
sdd используют для своего применения свои соответствующие главные и уточняющие номера. Вы можете определить значения
главного и уточняющего номеров своих дисков при помощи lsblk. Для sdc
главным и уточняющим номерами выступают 8 и 32 и они отражаются как
8:32. Аналогично, такая комбинация для sdd выражается как
8:48. Остальные поля ввода мы поясним чуть позднее. После ввода всех необходимых данных для выхода воспользуйтесь
Ctrl + D. Наш следующие пример создаст линейную цель размером 5 GiB:
[root@linuxbox ~]# dmsetup create dm_disk
dm_disk: 0 2048000 linear 8:32 0
dm_disk: 2048000 8192000 linear 8:48 1024
[root@linuxbox ~]#
[root@linuxbox ~]# fdisk -l /dev/mapper/dm_disk
Disk /dev/mapper/dm_disk: 4.9 GiB, 5242880000 bytes, 10240000 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
[root@linuxbox ~]#
Вот что мы тут сотворили:
-
Мы создали логическое устройство с названием
dm_disk, воспользовавшись конкретными разделами или диапазонами физических дисковsdcиsdd. -
Первый выполненный нами ввод,
dm_disk: 0 2048000 linear 8:32 0означает, что самые первые2048000секторов (0 - 2047999 linear 8:32 0)dm_diskвоспользуются секторами/dev/sdcначиная с сектора 0. Таким образом,dm_diskпользуется первыми2048000 (0 - 2047999)секторамиsdc. -
Наша вторая строка,
dm_disk: 2048000 8192000 linear 8:48 1024, означает, что следующие8192000секторовdm_diskвыделяются сsdd. Эти8192000секторов изsddбудут выделены начиная с сектора1024и далее. Если наши диски не содержат никаких данных, здесь мы можем пользоваться любыми номерами секторов. Когда присутствуют данные, необходимые сектора надлежит выделять из не используемого диапазона. -
Общее число секторов в
dm_diskсоставит8192000 + 2048000 = 10240000. -
При размере секторов в
512байт размерdm_diskбудет равен(8192000 x 512) + (2048000 x 512) ≈ 5 GiB.
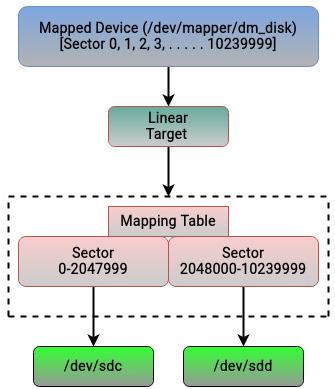
Первые номера секторов dm_disk, 0-2047999 соответствуют
sdc, в то время как сектора 2048000-10239999 сопоставляются с
sdd. Обсуждённый нами пример достаточно прост, но должно быть очевидным, что мы способны составлять соответствие
для любого числа устройств и реализовывать разнообразные концепции.
Приводимый ниже рисунок суммирует пояснённое ранее:
Имеющаяся инфраструктура Сопоставления устройств поддерживает широкий диапазон целей. Поясним здесь некоторые из них:
-
Linear (Линейный): Как мы уже видели ранее, цель может соответствовать непрерывному диапазону блоков для другого блочного устройства. Это основной строительный блок управления логическими томами.
-
Raid (Дисковый массив): Подобная цель дискового массива применяется для реализации понятия программно определяемого дискового массива. Она способна поддерживать различные типы дисковых массивов.
-
Crypt (Шифрование): Шифруемая цель используется для шифрования данных в блочных устройствах.
-
Stripe (Чередование): Цель чередования служит для создания дисков, носящих название чередующихся (
raid 0) по множеству составляющих основу дисков. -
Multipath (Множественность путей): Цель зо множеством путей применяется в средах хранения, в которых хост обладает множеством путей к устройству хранения. Она делает возможным сопоставление устройств со множеством путей.
-
Thin (Динамическая): Такая динамическая цель используется для динамического выделения, создавая устройства большего размера, нежели лежащие в основе физические устройства. Собственно физическое пространство выделяется только при записи в него.
Как мы неустанно повторяли ранее, наиболее широко применяемыми в LVM выступают линейные цели. Для выделения пространства по умолчанию и разбиения разделов большинство дистрибутивов Linux пор умолчанию пользуются LVM. Для широкой публики LVM, скорее всего, наиболее известная функциональная возможность в Linux. Не трудно увидеть как в этом отношении может применяться в LVM упоминавшийся ранее пример или любая иная цель.
Как должно быть известно большинству из вас, LVM подразделяется на три основных логических элемента:
-
Physical volume (Физический том): Подобный физический том составляет самый нижний уровень. Физическим томом выступает лежащий в основе физический диск или его раздел.
-
Volume group (Группа томов): Такая группа томов делит доступное в физическом томе пространство на последовательность фрагментов, носящих название физических экстентов. Некий физический экстент представляет собой какой- то непрерывный диапазон блоков. Именно он выступает самым маленьким элементом дискового пространства, который способен индивидуально управляться LVM. По умолчанию применяется размер экстента в 4МБ.
-
Logical volume (Логический том): Из доступного в группе томов пространства могут создаваться логические тома. Логические тома обычно делятся на меньшие фрагменты данных, причём каждый из них носит название логического экстента. Поскольку LVM пользуется линейным сопоставлением цели, существует непосредственное соотнесение между физическими и логическими экстентами. Таким образом, логический том может рассматриваться как сопоставление, которое устанавливается LVM, которая ассоциирует логические экстенты с физическими. Это можно визуально представить таким рисунком :
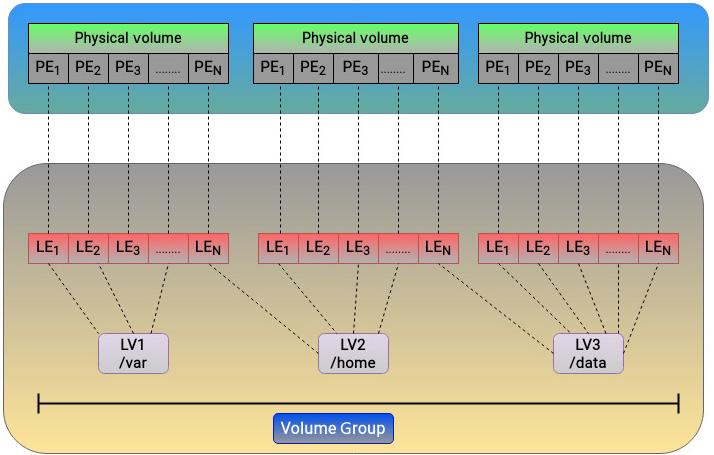
Как нам всем хорошо известно, такие логические тома можно рассматривать как любое обычное блочное устройство, а поверх него можно создавать файловые системы.
Отдельный логический том, который распространяется на множество физических дисков аналогичен RAID-0. Значение применяемого
типа сопоставления между физическими и логическими экстентами определяется его целью. Поскольку LVM основывается на линейной цели, между физическими и
логическими экстентами существует взаимосвязь сопоставления один- к- одному. Допустим, мы применяем свою цель dm-raid
и настраиваем RAID-1 для выполнения зеркалирования между множеством блочных устройств. В такой ситуации множество
физических экстентов будет сопоставлено единственному логическому экстенту.
Давайте свернём своё обсуждение среды Сопоставления устройств установив в памяти соответствие некоторых ключевых моментов. Наша инфраструктура Сопоставления
устройств играет жизненно важную роль в ядре и отвечает за реализацию ряда ключевых принципов в общей иерархии хранения. Ядро пользуется средой Сопоставления
устройств для установления соответствия физических блочных устройств виртуальным блочным устройствам более верхнего уровня. Все функциональные возможности
среды Сопоставления устройств расщепляются на пространство пользователя и пространство ядра. Интерфейс пространства пользователя составляется библиотекой
libdevmapper и утилитой dmsetup. Основная часть ядра составляется из трёх
главных компонентов: Сопоставляемого устройства, Таблицы сопоставлений и Целевого устройства. Именно среда Сопоставления устройств предоставляет всю основу
для различных важных технологий Linux, таких как LVM. LVM снабжает тонкий уровень абстракций поверх физических дисков и разделов. Такой уровень абстракций
делает возможным для администраторов хранилищ запросто изменять размеры файловых систем на основе своих требований пространства, предоставляя им гибкость
верхнего уровня. Прежде чем покончить с этой главой, давайте слегка затронем механизм кэширования, который реализуется на нашем блочном уровне.
Обычно производительность физического хранилища на несколько порядков ниже производительности процессоров и памяти. Ядро Linux достаточно осведомлено об этом ограничении. Вследствие этого оно пользуется доступной оперативной памятью в качестве кэша и перед записью всех данных на лежащие в основе диски осуществляет все действия в оперативной памяти. Такой механизм кэширования выступает в качестве установленного по умолчанию поведения и играет центральную роль при улучшении производительности блочных устройств. К тому же это оказывает позитивное воздействие на улучшение общей производительности системы.
Хотя в большинстве инфраструктур хранения твердотельные накопители и устройства NVMe в наши дни являются обычным явлением, традиционные шпиндельные накопители по прежнему применяются в тех случаях, когда требуется ёмкость и производительность не выступает в качестве серьёзной задачи. Когда мы обсуждаем производительность дисков, именно нагрузки с произвольным доступом выступают Ахиллесовой пятой шпиндельных механических дисков. В противоположность им, значение производительности флэш - накопителей не страдает подобными ограничениями, но они существенно дороже механических устройств. В идеале было бы недурно воспользоваться преимуществами обоих типов носителей. Большинство сред хранения являются гибридными и стараются действенно применять оба типа дисков. Одной из наиболее распространённых методик является размещение горячих или часто используемых данных на самом быстром физическом носителе и перемещение холодных данных на более медленные механические устройства. Большинство корпоративных массивов хранения предлагает встроенные функциональные возможности многоуровневого хранения данных, которые реализуют подобную функциональность кэширования.
Такое решение кэширования также способно предоставлять само ядро Linux. Для сочетания предлагаемой шпиндельными устройствами ёмкости с доставляемой
твердотельными дисками скоростью доступа ядро предоставляет ряд вариантов. Как мы уже видели ранее, инфраструктура Сопоставления устройств предлагает широкое
разнообразие целей, которое добавляет функциональность поверх блочных устройств. Одной из таких целей выступает dm-cache.
Цель dm-cache может применяться для улучшения производительности механических устройств путём миграции части своих
данных на более быстрые носители, например, на твердотельные. Такой подход слегка противоречит устанавливаемому по умолчанию механизму кэширования ядра,
но в некоторых ситуациях он может оказываться весьма полезным.
Большинство механизмов кэширования предлагают следующие режимы работы:
-
Write-back (отложенная запись): Данный режим выполняет кэширование вновь записываемых данных, однако не переносит их немедленно на целевой устройство.
-
Write-through (сквозная запись): В этом режиме новые данные записываются в свою цель и при этом сохраняя их в кэше для последующих считываний.
-
Write-around (обходная запись): При данном режиме реализуется кэширование только для считывания. Записываемые в накопитель данные непосредственно передаются в более медленное механическое устройство и не записываются на быстрый твердотельный диск.
-
Pass-through (сквозной режим): Для включения сквозного режима кэш должен быть очищен. Считывание выполняется с исходного устройства в обход кэширования. Запись пересылается на исходное устройство и превращает блок кэширование в не действующий.
Цель dm-cache поддерживает все вышеупомянутые режимы кроме обходной записи. Необходимые функциональные возможности
реализуются следующими тремя устройствами:
-
Origin device (Исходное устройство): Им всегда выступает медленное основное устройство хранения.
-
Cache device (Устройство кэширования): Это высокопроизводительный диск, как правило твердотельный.
-
Metadata device (Устройство метаданных): Хотя оно и не обязательно, и эти сведения также могут храниться на устройстве быстрого кэширования, данное устройство применяется для отслеживания всех сведений метаданных, к примеру, какие именно блоки содержатся в кэше, какие блоки грязные (dirty, перезаписаны) и так далее.
Иным аналогичным решением кэширования выступает dm-writecache, которое также является целью Сопоставления устройств.
Как это следует из его названия, в основном dm-writecache сосредотачивается на строгом отложенном кэшировании. Оно
кэширует исключительно операции записи и не выполняет никакого считывания или обходного кэширования. Основная мысль отказа от кэширования считывания состоит
в том, что данные считывания уже должны пребывать в кэше страниц. Операции записи кэшируются в более быстром устройстве, а затем переносятся в фоновом
режиме на более медленный диск.
Другим достойным упоминания, получающим широкое распространение, становится bcache. Данное решение
bcache поддерживает все четыре ранее определённых режима кэширования. bcache
пользуется более сложным подходом и по умолчанию допускает выполнение всех последовательных операций на механических устройствах. Поскольку твердотельные диски
превосходно справляются с операциями произвольного доступа, кэширование больших последовательных операций на твердотельных накопителях, как правило, не сулит
больших преимуществ. Следовательно, bcache выявляет последовательные операции и пропускает их. Записи в
bcache сопоставимы с ARC
( adaptive replacement cache, кэшированием адаптивной замены) L2 в ZFS. Данный проект
bcache также привёл к разработке файловой системы Bcachefs.
Данная глава стала второй главой в нашем изучении блочного уровня ядра. Двумя основными обсуждавшимися вопросами являлись инфраструктуры множества очередей и Соответствия устройств. В самом начале этой главы мы мы рассмотрели наследуемую модель очереди одиночных запросов блочного уровня, её ограничения и её отрицательное воздействие на производительность при работе с современными устройствами хранения и в системах со множеством ядер. Исходя из этого мы ввели в своё ядро инфраструктуру множества очередей. Мы пояснили каким образом множество очередей разрешает ограничения очереди одиночных запросов улучшает общую производительность современных устройств хранения, которые обладают способностью поддержки большого числа аппаратных очередей.
У нас также была возможность взглянуть на среду Сопоставления устройств в ядре. Инфраструктура Сопоставления устройств также выступает важной частью ядра и отвечает за реализацию ряда технологий, таких как управление несколькими маршрутами, логические тома, шифрование и построение массивов. Наиболее заметным из них выступает управление логическими томами. Мы обнаружили как Сопоставление устройств способно реализовывать эти мощные функциональные возможности при помощи методик соотнесения.
В своей следующей главе мы завершим обсуждение блочного уровня после изучения различных планировщиков ввода/ вывода ядра.