Часть II: Навигация по блочному уровню
Данная часть представляет собой введение в ту роль, которую играет блочный уровень в ядре Linux. Блочный уровень выступает ключевой частью стека хранения ядра, поскольку те интерфейсы, которые реализуются на блочном уровне применяются приложениями пространства пользователя для выполнения доступа к имеющимся в распоряжении устройствам хранения данных. В данной части будет описан блочный уровень и его основные компоненты, такие как инфраструктура сопоставления устройств, блочные устройства, структуры данных блочного уровня, инфраструктура множества очередей и различные планировщики ввода/ вывода.
Эта часть составлена из следующих глав:
Глава 4. Разбираемся с Блочным уровнем, Блочными устройствами и Структурами данных
Содержание
- Глава 4. Разбираемся с Блочным уровнем, Блочными устройствами и Структурами данных
- Технические требования
- Раскрываем роль блочного уровня
- Определение блочных устройств
- Определение характеристик блочных устройств
- Взглянем на представление блочных устройств
- Взглянем на структуры данных блочного уровня
- Функция register_blkdev (регистрация блочного устройства)
- Структура block_device (представление блочных устройств)
- Структура gendisk (представление физических дисков)
- Структура buffer_head (представление блоков в памяти)
- Структура bio (представление активного ввода/ вывода блоков)
- Структура bio_vec (представление вектора ввода/ вывода)
- Запросы и очереди запросов (представление отложенных запросов ввода/ вывода)
- Путешествие запроса ввода/ вывода по блочному уровню
- Выводы
Первые три главы вертелись вокруг первого компонента иерархии ввода/ вывода ядра, коим выступает уровень VFS. Мы объяснили функции и назначение VFS, а также то, как она служит промежуточным слоем между общим интерфейсом системных вызовов и файловыми системами, а также их первичными структурами данных. Кроме того, ты также обсудили те файловые системы, которые пребывают на уровне VFS и предоставили некоторые важные относящиеся к ним понятия.
Теперь мы перенесём средоточие своего внимания на второй основной раздел в иерархии хранения ядра: на блочный уровень. Блочный уровень имеет дело с блочными устройствами и ответственен за обработку выполняемых в блочных устройствах операций ввода/ вывода. Все программы пространства пользователя пользуются интерфейсами блочного уровня для адресации и доступа к лежащим в основе устройствам хранения. За последнее десятилетие или около того носители информации претерпели существенную трансформацию: от более медленных механических к более быстрым флэш- устройствам. Следовательно, сам блочный уровень претерпел значительные изменения. Поскольку, когда речь идёт об оборудовании хранения данных, именно производительность выступает критическим фактором, в код ядра был внесён ряд улучшений, позволяющих дисковым устройствам полностью реализовывать свой потенциал. В данной главе мы намерены представить собственно блочный уровень, определить блочные устройства, а затем углубиться в основные структуры данных на этом блочном уровне.
Вот краткое изложение того что последует:
-
Пояснение роли блочного уровня
-
Определение блочных устройств
-
Определение характеристик блочных устройств
-
Представление блочных устройств
-
Просмотр основных структур данных на блочном устройстве
-
Путешествие по запросу на ввод/ вывод на блочном уровне
Блочный уровень ядра это слегка сложная тема. Хорошее понимание представленного в первых трёх главах материала поможет вам разобраться с взаимодействием между обсуждаемым блочным уровнем и различными файловыми системами. Навыки работы с языком программирования C помогут вам понять представленный в данной главе код. Кроме того, любые практические навыки работы с системой Linux помогут улучшат ваше понимание обсуждаемых здесь понятий.
Если вы желаете выгрузить исходный код ядра, вы можете скачать его с https://www.kernel.org.
Фрагменты кода, которые мы применяем в качестве справочных материалов в данной главе и книге взяты из ядра 5.19.9.
На блочный уровень возложена задача реализации интерфейсов ядра, которые делают возможным для файловых систем взаимодействовать со своими
устройствами хранения. В контексте доступа к физическому хранилищу приложения применяют блочные устройства и любые запросы на доступ к данным
этих устройств управляются блочным уровнем. Слегка выше блочного уровня ядро также содержит уровень отображения (соответствия, mapping). Этот
уровень представляет собой гибкий и мощный способ сопоставления одного блочного устройства с другим, допуская выполнение таких операций как
создание моментальных снимков, шифрование данных и создание логических томов, охватывающих несколько физических устройств. Реализованные на блочном
уровне интерфейсы играют центральную роль управления физическим хранением в Linux. Файлы самих устройств для блочных устройств создаются в каталоге
/dev.
Как и для VFS, центральной функцией блочного уровня выступает абстракция. Уровень VFS делает возможным для приложений выполнять общие запросы взаимодействия с файлами, при этом не беспокоясь о лежащей в основе файловой системе. Аналогичным образом, блочный уровень позволяет приложениям единообразно осуществлять доступ к устройствам хранения данных. Для самого приложения не является вопросом выбор внутреннего носителя данных.
Для выделения основных функций блочного уровня давайте выстроим иерархию хранения, которую мы определили при описании VFS. Следующий рисунок схематично отображает все основные компоненты блочного уровня:
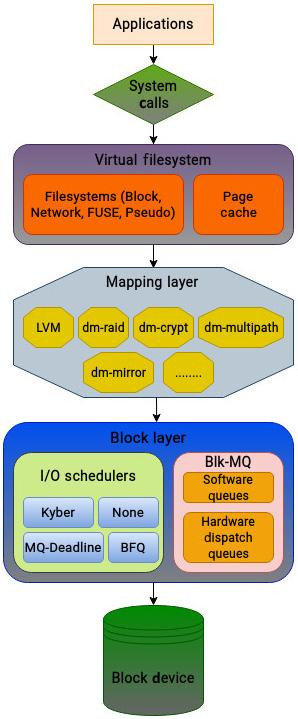
Давайте вкратце взглянем на эти функции:
-
Блочный уровень предоставляет идущий вверх интерфейс к файловым системам и позволяет им единообразно выполнять доступ к разнообразному диапазону устройств хранения, причём предоставляя их с единой точкой входа для всех приложений.
-
Как мы обнаружим в данной главе, блочный уровень заключает в себе весьма хитроумные структуры для универсального предоставления своих служб. Вероятно, наиболее важной из них всех выступает структура
bio. Уровень файловой системы создаёт структуруbioдля представления соответствующего запроса на ввод/ вывод и передаёт его на блочный уровень. Данная структураbioотвечает за транспортировку всех запросов на ввод/ вывод в надлежащий драйвер. Уровень отображения (mapping) ведает предоставлением инфраструктуры для сопоставления физических блочных устройств с логическими устройствами. Уровень отображения способен достигать этого пользуясь имеющейся в ядре структурой сопоставления. Такой сопоставитель устройств (device mapper) закладывает основу ряда технологий ядра. К ним относятся: управление томами, множественность путей (multipathing), динамичное выделение (thin provisioning), шифрование и программно определяемый RAID. Наиболее известным из них выступает LVM (logical volume management, управление логическими томами). Сопоставитель устройств (device mapper) создаёт все логические тома как обладающие отображением устройства. LVM предоставляет администраторам хранилищ великолепную гибкость и упрощает управление хранением. -
Инфраструктура
blk-mqстала важной частью блочного уровня, поскольку она решила ограничения производительности за счёт изоляции очередей запросов для каждого из ядер ЦПУ. Данная инфраструктура ведает присмотром за запросами блочного ввода/ вывода во множество очередей разгрузки. Более подробно структуруblk-mqмы рассмотрим в Главе 5. -
Блочный уровень также содержит различные планировщики для обработки запросов на ввод/ вывод. Такие планировщики обладают возможностью подключения и могут устанавливаться для индивидуальных блочных устройств. Не поддерживающие множество очередей планировщики рассматриваются устаревшими и больше не поддерживаются в современных ядрах. Как мы обнаружим в Главе 6, такие планировщики пользуются разнообразными методиками для принятия разумных решений относительно планирования ввода/ вывода.
-
Кроме того, блочный уровень реализует такие функции как обработку ошибок и сбор статистических данных операций ввода/ вывода для блочных устройств.
В самой сердцевине блочного уровня располагаются блочные устройства. Помимо передающих данные потоком, таких как ленточные устройства, большинство устройств хранения, таких как шпиндельные устройства и твердотельные накопители флеш- карт, рассматриваются в качестве блочных устройств. Давайте взглянем на определяющие особенности блочных устройств и то, как они представлены в Linux.
Для обмена данными ядра с внешними устройствами существует два основных способа. Один из методов состоит в обмене с устройством по одному символу за раз. Устройства, к которым обращаются такие методы, носят название символьных устройств. Символьные устройства адресуются при помощи потока последовательных данных. Для выполнения операций ввода и вывода программы могут обращаться к ним по одному символу за раз. По причине отсутствия методов произвольного доступа управление символьными устройствами для ядра проще. Примерами символьных устройств являются такие устройства, как клавиатуры, текстовые консоли и последовательные порты.
Когда объём данных невелик, скажем, при использовании последовательных портов или клавиатуры, взаимодействие по одному символу за раз приемлемо. Клавиатура получает за раз по одному символу, а потому имеет смысл применение символьного интерфейса. Однако такой подход превращается в несостоятельный при передаче больших объёмов данных. При выполнении записи на физические диски мы ожидаем что они будут обладать возможностью адресации за раз более одного символа и предоставлять произвольный доступ к данным. Ядро осуществляет адресацию к физическим дискам порциями фиксированного размера, носящими название блоков. Помимо традиционных дисков данный подход применяется в таких устройствах как CD-ROM и флеш- накопители. Подобные устройства именуются блочными устройствами. По сравнению с символьными устройствами, блочными устройствами сложнее управлять и со стороны ядра они требуют больше внимания. Ядру приходится принимать критически важные решения относительно адресации и организации блочных устройств, ибо они могут оказывать существенное воздействие не только на само блочное устройство, но и на общую производительность системы.
Блочные устройства могут присутствовать в оперативной памяти Этого можно достичь путём создания ramdisk (диска оперативной памяти). Одним из наиболее примечательных вариантов использования диска в оперативной памяти является его применение в последовательности запуска систем Linux. initrd (initial ramdisk) отвечает за загрузку временной корневой файловой системы в оперативную память с целью процесса запуска. {Прим. пер.: строго говоря, в настоящее собственно дисковое устройство в памяти не создаётся, а вместо этого, с целью экономии времени, применяется "на лету" непосредственно механизм кэширования подробнее об initramfs.} Файловая система может создаваться в диске памяти подобно любой обычной файловой системе. Значения скорости оперативной памяти невообразимо выше. Однако, по причине энергозависимой природы оперативной памяти всякий диск в памяти поддерживается только пока это устройство запитано.
Хотя диски оперативной памяти к тому же основываются на блоках, они применяются редко. Как вы обнаружите на протяжении данной книги, блочное устройство обычно рассматривается постоянным носителем хранения данных с некой файловой системой поверх него.
Все операции в блочных устройствах осуществляются самим ядром порциями фиксированного размера из N
байт, носящих название блоков. Реальное значение N
изменяется по всему стеку , поскольку различные уровни в иерархии ввода/ вывода ядра для адресации блочных устройств пользуются порциями разного
размера. По этой причине сам определяемый термин блока, в зависимости от своего местонахождения в стеке, определяется различными способами:
-
Приложения пространства пользователя: Раз приложения взаимодействуют с пространством ядра посредством системных вызовов, сам термин
блокав данном контексте определяет тот объём данных, который считывается или записывается через системные вызовы. -
Страница кэша: Для улучшения производительности операций чтения или записи ядро интенсивно пользуется кэшированием страниц VFS. Здесь фундаментальной единицей обмена данными выступает
страница, имеющая размер 4кБ {Прим. пер.: обычно}. -
Основанные на дисках файловые системы: Как уже пояснялось в Главе 3, некий блок представляет собой фиксированное число байт, которыми эти файловые системы выполняют операции ввода/ вывода. Хотя файловые системы допустимы и для бо́льших размеров блоков, зачастую вплоть до 64кБ, как правило, по причине размера страницы, величина размера блока обычно в пределах от 512 байт до 4кБ.
-
Физическое хранилище: На физических дисках наименьшие адресуемые элементы носят название сектора, который, как правило, составляет 512 байт. Такой сектор зачастую далее классифицируется как логический или физический.
В Главе 3 мы уже обсуждали блоки файловой системы. Не путайтесь; размер блока файловой системы
не является фундаментальным элементом блочного ввода/ вывода. Базовым элементом блочного ввода/ вывода выступает сектор. Структура данных на блочном
уровне определяет переменную с типом sector_t в коде ядра, которая представляет смещение или размер, который
умножается на 512. Такая переменная sector_t определена как тип целого без знака, которое достаточно велико
чтобы представлять максимальное число секторов, допустимое для адресации данным блочным устройством. Оно интенсивно применяется через блочный уровень
в подобных "bio" структурах для представления адресов и смещений диска.
Подводя итог, устройства, которые организованы и адресуются в терминах блоков носят название блочных устройств. Они допускают произвольный доступ и предоставляют повышенную производительность по сравнению с символьными устройствами. Для получения всех преимуществ блочных устройств, ядро обязано принимать грамотное решение относительно своей адресации и организации.
Давайте по- быстрому пройдёмся по некоторым ключевым функциональным возможностям, определяющим блочное устройство.
Как уже упоминалось ранее, блочные устройства допускают намного более развитые способы обработки запросов на ввод/ вывод. Вот некоторые из определяющих блочные устройства характеристик:
-
Произвольный доступ: Блочные устройства допускают произвольный доступ. Это подразумевает, что такие устройства способны выполнять позиционирование (seek) из одного положения в другое.
-
Размер блока: Блочные устройства осуществляют адресацию и обмен данным блоками фиксированного размера.
-
Построение стека: Блочные устройств способны выстраиваться в стек посредством применения инфраструктуры сопоставления устройств (device mapper). Это расширяет базовые функциональные возможности физических дисков и делает возможным масштабирование логических томов.
-
Буферированный ввод/ вывод: Блочные устройства пользуются буферированным вводом/ выводом, что означает, что данные записываются в некий буфер, прежде чем они будут записаны на само устройство. Операции считывания и записи в блочных устройствах интенсивно пользуются кэшированием страниц. Считываемые с самого блочного устройства данные загружаются в оперативную память и удерживаются в ней на протяжении некоторого периода времени. Аналогично, подлежащие записи в блочное устройство данные, сначала записываются в такой кэш.
-
Файловые системы/ разбиение на разделы: Блочные устройства могут делиться на разделы в элементы меньшего размера, причём поверх них создаются обособленные файловые системы.
-
Очереди запросов: Блочные устройства реализуют понятие очередей запросов, которые отвечают за предоставляемое блочному устройству управление запросами на ввод/ вывод.
Давайте рассмотрим как представлены в Linux блочные устройства.
При обсуждении VFS мы наблюдали, что в самой сердцевине стека ввода/ вывода ядра находятся абстракции. Блочный уровень не является исключением данного правила. Вне зависимости от отличий физического изготовления и модели ядро обязано иметь возможность единообразно работать с устройствами хранения. Для реализации стандартного взаимодействия всех устройств собственно операции должны быть независимы от свойств имеющихся у своего лежащего в основе устройства хранения.
Как уже пояснялось в Главе 1, почти всё представляется в виде файла, включая аппаратные
устройства. Блочное устройство это особый файл и он имеет как такое название по той причине, что ядро взаимодействует с ним посредством фиксированного
числа байт. В зависимости от природы самого устройства, представляемые им файлы создаются и хранятся в конкретных местах своей системы. Все
блочные устройства представлены в своей системе в каталоге /dev. Представляющие дисковые устройства в системе
названия файлов начинаются с sd, за которыми следует представляющая порядок обнаружения буква. Самое первое
устройство носит название sda и так далее. Аналогично, первый раздел в устройстве sda
представляется как sda1. Когда мы взглянем на устройства sd* в
/dev, мы обратим внимание что значением типа файла выступает b,
обозначая блочное устройство. Также вы можете перечислить блочные устройства при помощи команды lsblk, как
это отражено на следующем рисунке:

Непосредственно перед значением временной метки изменения обращают на себя внимание два разделяемых запятой числа. Само ядро представляет блочные устройства парой чисел. Эти числа носят название главного (major) и уточняющего (minor) номеров устройства. Главный номер указывает на ассоциируемой с данным устройством драйвер, в то время как уточняющий номер применяется для отличия индивидуальных устройств.
В нашем предыдущем рисунке все три устройства - sda, sda1 и
sda2 пользуются одним и тем же драйвером, а следовательно обладают одним и тем же главным номером,
8. Для указания значения экземпляра драйвера каждого из устройств используются уточняющие номера -
0, 1 и 2.
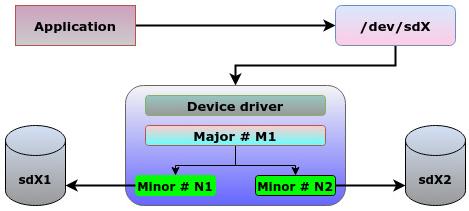
Все представленные в каталоге /dev файлы устройств для установления связи взаимодействия с реальным
оборудованием подключаются к соответствующим драйверам устройств. Когда некая программа взаимодействует со своим файлом блочного устройства,
ядро пользуется главным числом для выявления надлежащего драйвера данного устройства и отправляет свой запрос. Поскольку драйвер способен отвечать
за множество устройств, должен иметься способ, которым ядро способно различать устройства с одним и тем же главным номером. Для этой цели и
применяются уточняющие номера.
Теперь мы изучим необходимые первичные структуры данных, применяемые на блочном уровне.
Работа с блочными устройствами достаточно сложна, поскольку ядро обязано реализовывать такие функциональные возможности, как управление очередями, планирование и возможность произвольного доступа к данным. Значения скорости блочных устройств значительно выше нежели символьных. Это превращает блочные устройства в чрезвычайно чувствительные к производительности, причём для достижения максимальной производительности именно ядру приходится принимать осмысленные решения. Следовательно у этим двум типам устройств имеет смысл относиться по- разному. По этой причине существует целая подсистема ядра, целиком предназначенная для управления блочными устройствами. Всё это делает блочный уровень в наиболее сложный фрагмент кода ядра Linux.
На протяжении всей данной книги, чтобы вы могли знакомится с реализацией конкретных понятий, мы ссылались на соответствующие фрагменты кода. Если вы намерены заниматься разработкой ядра, это может казаться хорошей отправной точкой. Однако, если вы больше сосредоточены на теоретическом осмыслении, применение кода способно сбивать с толку. Однако важно получить общее представление о том как представлены в ядре определённые моменты. Конкретно, обсуждая блочный уровень, невозможно обсудить все составляющие его сложную конструкцию структуры. Тем не менее, нам следует выделить некоторые наиболее важные конструкции, которые дают нам чёткое понимание представления и организации в ядре блочного уровня.
Вот некоторые наиболее важные структуры данных, которые применяются для работы с блочными устройствами:
-
register_blkdev -
block_device -
gendisk -
buffer_head -
bio -
bio_vec -
request -
request_queue
Давайте рассмотрим их один за другим.
Чтобы превратить блочные устройства в доступные к применению, они вначале должны быть зарегистрированы в самом ядре. Данный процесс регистрации
осуществляется функцией register_blkdev(), которая определена в
include/linux/blkdev.h:
int __register_blkdev(unsigned int major, const char *name,
void (*probe)(dev_t devt))
Функция register_blkdev используется драйверами блочных устройств для самостоятельной регистрации и
является макросом, который перенаправляет в __register_blkdev. Эта функция
__register_blkdev осуществляет реальный процесс регистрации. Основная цель обладания обособленной внутренней
функцией состоит в предоставлении дополнительной обработки ошибок и признания допустимости перед внесением изменений в структурах данных своего
ядра.
Данная функция регистрации выполняет следующие задачи:
-
Она запрашивает старший номер из динамического пула распределения старших номеров. Значение старшего номера однозначно идентифицирует необходимый драйвер блочного устройства в данной системе.
-
После успешного получения основного номера, эта функция создаёт структуру
block_device, которая представляет соответствующий драйвер блочного устройства. Такая структура содержит такие сведения как значение старшего номера, названия своего драйвера, а также указатели функций на различные операции драйвера.
Подводя итог, функция register_blkdev действует в качестве дружественного интерфейса, посредством которого
драйверы блочных устройств способны инициировать свои процессы регистрации при помощи блочного уровня ядра. Она обрабатывает необходимые этапы для
получения основного номера, создания структуры block_device и установления необходимых соединений с
соответствующим блочным уровнем.
Собственно блочное устройство определяется в include/linux/blk_types.h посредством структуры
block_device из своего ядра:
struct block_device {
sector_t bd_start_sect;
sector_t bd_nr_sectors;
struct disk_stats __percpu *bd_stats;
unsigned long bd_stamp;
bool bd_read_only;
dev_t bd_dev;
atomic_t bd_openers;
struct inode * bd_inode;
[……..]
Конкретный экземпляр структуры block_device создаётся при открытии файла его устройства. Блочным
устройством может выступать диск целиком, либо отдельный раздел, а структура block_device способна представлять
любое из них. При использовании разделов, конкретные индивидуальные разделы идентифицируются через значение поля
bd_partno. Поскольку доступ к блочным устройствам происходит через уровень VFS, соответствующим файлам устройств
также назначается номер индексного дескриптора (inode). Значения индексных дескрипторов для блочных устройств являются виртуальными и хранятся в
виртуальной файловой системе bdev. Значение индексного дескриптора для блочного устройства также содержит
сведения относительно старшего и вспомогательного номеров.
Структура block_device также предоставляет сведения относительно самого устройства, такие как его имя,
размер и значение размера блока. Она также содержит указатель на структуру gendisk, которая представляет
сам диск, а также перечень структур request_queues для обработки запросов операций ввода/ вывода.
В определении структуры block_device важным полем выступает указатель
bd_disk, который ссылается на структуру gendisk. Эта структура
gendisk, которая определена в include/linux/blkdev.h, представляет
сведения о самом диске и используется для реализации собственно представления в своём ядре физического жёсткого диска.
Такая структура gendisk представляет необходимые свойства диска, а также методы доступа к нему. Она
используется для регистрации блочного устройства и и ассоциированных с ним операций ввода/ вывода своим ядром, делая возможным взаимодействие с
самим устройством:
struct gendisk {
int major;
int first_minor;
int minors;
char disk_name[DISK_NAME_LEN];
unsigned short events;
unsigned short event_flags;
[……]
gendisk может рассматриваться как упомянутая ранее связь между интерфейсами блоков и файловой системы с
аппаратным интерфейсом. Для представления определяемого в gendisk всего физического устройства будет
присутствовать структура block_device. Аналогично, будут иметься отдельные структуры
block_device, которые описывают внутри gendisk индивидуальные разделы.
Обратите внимание на то, что gendisk выделяется самим драйвером блочного устройства и управляется им же, а
регистрируется в своём ядре при помощи функции register_blkdev. После регистрации, соответствующий драйвер
блочного устройства может применять структуру gendisk для осуществления в данном устройстве операций
ввода/ вывода.
Давайте взглянем на наиболее важные поля этой структуры:
-
major: Данное поле определяет значение старшего числа, ассоциируемого со своей структуройgendisk. Как уже определялось ранее, значение старшего числа применяется ядром для идентификации того драйвера, который отвечает за обработку данного блочного устройства. -
first_minor: Это поле ссылается на самый меньший вспомогательный номер, который ассоциируется с данным блочным устройством. Оно может трактоваться как некое смещение, начиная с которого выделяются значения вспомогательных номеров для различных разделов данного устройства. -
minors: Это поле определяет общее число ассоциируемых с данной структуройgendiskвспомогательных номеров. -
fops: Данное поле указывает на структуры файловых операций, которые связаны с данной структуройgendisk. Эти файловые операции используются самим ядром для обработки считывания, записи и прочих файловых операций в данном устройстве. -
private_data: Это поле используется драйвером для хранения всех частных сведений, ассоциируемых со своей структуройgendisk, например, все специфичные для драйвера сведения. -
queue: Данное поле ссылается на ассоциируемую со своей структуройgendiskочередь запросов. Такая очередь запросов ответственна за управления всеми инициируемыми для её устройства запросами на ввод/ вывод. Это превращает данное поле в очень важное, ибо оно делает возможным ассоциацию ядра с конкретной очередью на ввод/ вывод, причём для каждого блочного устройства. Обладая обособленными очередями на ввод/ вывод, ядро способно независимым образом управлять множеством блочных устройств и более действенно обрабатывать их операции ввода/ вывода. Это позволяет ядру оптимизировать производительность, применять соответствующие политики планирования и избегать узких мест. -
disk_name: Это поле является строкой, которая определяет значение имени данного устройства. Данное имя применяется ядром для идентификации этого устройства и обычно отображается в журналах регистрации системы.
Давайте перейдём к нашей следующей структуре.
Одной из определяющих особенностей блочного устройства выступает широкое применение страничного кэша. Все операции чтения и записи блочного устройства осуществляются в таком кэше. Когда некое приложение впервые считывает блок, этот блок извлекается с физического устройства в оперативную память. Аналогично, когда какая- то программа хочет выполнить запись неких данных, эта операция записи сначала выполняется в кэше. На диск запись производится на более позднем этапе.
Считываемый с диска блок или подлежащий записи на диск блок сохраняются в неком буфере. Этот буфер представлен структурой
buffer_head, которая определена в самом ядре в include/linux/buffer_head.h.
Мы можем сказать, что этот буфер является представлением индивидуального блока в оперативной памяти:
struct buffer_head {
unsigned long b_state;
struct buffer_head *b_this_page;
struct page *b_page;
sector_t b_blocknr;
size_t b_size;
[………...]
Соответствующие поля в структуре buffer_head содержат сведения, необходимые для уникальной идентификации
конкретного блока в своём блочном устройстве. Имеющиеся в структуре buffer_head поля описываются
следующим образом:
-
b_data: Данное поле указывает на начало ассоциируемого сbuffer_headбуфера данных. размер самого буфера определяется величиной размера буфера в его файловой системе. -
b_size: Поле определяет размер буфера в байтах. -
b_page: Это указатель на ту страницу в оперативной памяти, где хранится данный блок. Данное поле обычно применяется совместно с такими полями какb_dataиb_sizeдля манипуляций собственно данными буфера. -
b_blocknr: Данное поле определяет значение числа логических блоков в своём буфере данной файловой системы. Всякому блоку файловой системы назначается уникальный номер, который носит название номера логического блока. Это число представляет устанавливаемый в данной файловой системе порядок, причём начинается он с0для самого первого блока. -
b_state: Это поле является побитовым и представляет значение состояния своего буфера. Оно может хранить несколько значений. Например, значениеBH_Uptodateуказывает, что его буфер содержит актуальные данные, в то время как значениеBH_Dirtyуказывает на то, что данный буфер содержит испорченные (dirty, изменённые) данные и необходима их запись на диск. -
b_count: Данное поле отслеживает значение числа пользователейbuffer_head. -
b_page: Поле указывает на страницу в кэше страниц, которая содержит данные, ассоциируемые с этой структуройbuffer_head. -
b_assoc_map: Это поле применяется некоторыми файловыми системами для отслеживания того какой именно блок в данный момент ассоциируется сbuffer_head. -
b_private: Данное поле это указатель на ассоциируемые сbuffer_headчастные данные. Оно может применяться своей файловой системой для хранения относящихся к этому буферу сведений. -
b_bdev: Это поле выступает указателем на то блочное устройство, к которому относится данный буфер. -
b_end_io: Это поле является функцией, которая определяет функция завершения операции ввода/ вывода в буфере и применяется для выполнения необходимых операций очистки.
По умолчанию, раз значение размера блока файловой системы равно величине размера страницы, отдельная страница в памяти способна хранить один блок. Когда размер блока меньше величины размера страницы, страница способна удерживать более одного блока.
Заголовок буфера поддерживает соответствие между некой страницей в оперативной памяти и её соответствующей версией на диске. Хотя всё ещё он
удерживает важные сведения, он был всё ещё более интегрированным компонентом ядра вплоть до его версии 2.6. В те времена, помимо сопровождения
сопоставления дисковых блоков страницам, он также служил контейнером для всех операций ввода/ вывода на блочном уровне. Имея дело с большим
запросом на блочный ввод/ вывод, ядру приходилось дробить его на более мелкие запросы, причём с каждым из них, в свою очередь, была связана
структура buffer_head.
По причине ограничений структуры buffer_head для представления текущей операции блочного ввода/ вывода
была создана структура bio.Данная структура bio стала фундаментальным
элементом ввода/ вывода на блочном уровне начиная с ядра 2.5. Когда некое приложение активирует запрос ввода/ вывода, лежащая в основе его файловая
система транслирует его в одну или несколько структур bio для выдачи запросов на ввод/ вывод своему
базовому блочному устройству. Сама структура bio определена в
include/linux/blk_types.h:
struct bio {
struct bio *bi_next;
struct block_device *bi_bdev;
unsigned int bi_opf;
……
unsigned short bi_max_vecs;
atomic_t __bi_cnt;
struct bio_vec *bi_io_vec;
[……….]
Вот некоторые представляющие практический интерес поля:
-
bi_next: Это указатель на идущую в списке следом структуруbioи он применяется для связи множества структурbio, представляющих отдельную операцию ввода/ вывода. Именно это важно осознать, так как отдельная операция ввода/ вывода может нуждаться в расщеплении на множество структурbio. -
bi_vcnt: Данное поле определяет значение числа структурbio_vec, которые будут применяться для описания своей операции ввода/ вывода. Всякая структураbio_vecв этом векторе описывает непрерывный блок оперативной памяти, который передаётся между соответствующим блочным устройством и активировавшей запрос программой пространства пользователя. -
bi_io_vec: Представляет собой указатель на массив структурbio_vec, который описывает значения местоположения и длины тех буферов данных, которые ассоциируются с данной операцией ввода/ вывода. Он закладывает основу для осуществления ввода/ выводаscatter-gather(накопления- рассеивания) - то есть эти данные могут быть распределены по множеству не смежных мест в оперативной памяти. -
bi_vcnt: Поле, определяющее значение числа буферов данных, ассоциируемых с данной операцией ввода/ вывода. Каждый буфер данных представлен некой структуройbio_vec, причём она содержит указатель на буфер оперативной памяти и значение длины этого буфера. -
bi_end_io: Это указатель на функцию, вызываемую по завершению данной операции ввода/ вывода. Эта функция предоставляется для очистки всех связанных с данной операцией ввода/ вывода и совершает проход по всем процессам, ожидающим завершения данной операции. -
bi_private: Представляет собой указатель на всякие связанные с данной операцией ввода/ вывода частные данные. -
bi_opf: Это маска бит, которая определяет все дополнительные возможности или флаги, относящиеся к данной операции ввода/ вывода. Она способна содержать такие варианты как force synchronous I/O (принудительная синхронизация ввода/ вывода) или disable write caching (запрет кэширования записи).
Когда активируется неким приложением пространства пользователя запрос на ввод/ вывод, отслеживание всех необходимых транзакций ввода/ вывода на
рассматриваемом нами блочном уровне продолжает осуществлять конкретная структура bio. После того как
такая структура bio была выстроена, она передаётся на наш уровень блочного ввода/ вывода через функцию
submit_bio. Такая функция submit_bio() применяется для поставки
в блочные устройства запросов на ввод/ вывод. Эта функция submit_bio() не будет дожидаться завершения
своего ввода/ вывода.
Можно сказать, что наша структура bio выступает в качестве моста между соответствующей файловой системой
и имеющимся уровнем блочного устройства, что делает возможным для файловой системы осуществлять операции ввода/ вывода в своём блочном устройстве.
Конкретная структура bio_vec определяет на блочном уровне операции ввода/ вывода векторные или
накопления- рассеивания.
Эта структура bio_vec определяется в include/linux/bvec.h:
struct request {
struct request_queue *q;
struct blk_mq_ctx *mq_ctx;
struct blk_mq_hw_ctx *mq_hctx;
[……..]
Её поля определены так:
-
bio_vec: Данное поле удерживает ссылку на ту структуру страницы (struct page), которая содержит подлежащие обмену данные. Как уже пояснялось в Главе 2, страница это блок в памяти фиксированного размера. -
bv_offset: Это поле содержит значение смещения внутри своей страницы, где начинается обмен соответствующими данными. -
bv_len: Содержит значение длины своих подлежащих обмену данных.
Ввод/ вывод накопления- рассеивания включает в себя обмен данными между неким
устройством и имеющейся оперативной памятью. Обычно данные считываются с и записываются в отдельный непрерывный буфер памяти. При операции
ввода/ вывода накопления- рассеивания, все данные делятся на сегменты меньшего размера и распределяются по множеству не смежных буферов в
памяти, носящих название списков рассеивания (scatter lists) для операций ввода.
Для операций вывода необходимые данные затем накапливаются из таких множественных не смежных буферов памяти. Для представления операций ввода/
вывода накопления- рассеивания применяется структура bio_vec. Блочный уровень способен строить отдельную
bio со множеством структур bio_vec, причём каждая представляет
различные физические страницы памяти и разные смещения внутри этих страниц.
Когда нашему блочному уровню gjlf`ncz некий запрос на ввод/ вывод, блочный уровень для представления такого запроса создаёт структуру
request.
Структуры request и request_queue определены, соответственно в
include/linux/blk-mq.h и в include/linux/blkdev.h:
struct request {
struct request_queue *q;
struct blk_mq_ctx *mq_ctx;
struct blk_mq_hw_ctx *mq_hctx;
[……..]
Здесь поясняются некоторые наиболее важные поля:
-
struct request_queue *q: В соответствующую очередь запросов блочного устройства добавляется запрос на ввод/ вывод. Здест именно полеqуказывает на такую очередь запросов. -
struct blk_mq_ctx *mq_ctx: Это полеblk_mq_ctx *mq_ctxна имеющиеся на этапе программного обеспечения очереди; такая структура выделяется в соответствии с принципом для каждого ядра ЦПУ. Для отслеживания текущего состояния представленного на обработку в данном ЦПУ запроса, каждый ЦПУ обладаетblk_mq_ctx. -
struct blk_mq_hw_ctx *mq_hctx: Данное поле представляет необходимый аппаратный контекст, с которым ассоциирована очередь запроса. Именно оно применяется для остлеживания того, с какой аппаратной очередью соотносится данный запрос. -
struct list_head queuelist: Связанный список запросов, которые дожидаются обработки. Когда на блочном уровне добавляется некий запрос, он добавляется в этот список. -
struct request *rq_next: Это указатель на следующий запрос в данной очереди. Он применяется для связывания запросов внутри своей очереди запросов. -
sector_t sector: Данное поле определяет значение номера стартового сектора своей операции ввода/ вывода. -
struct bio *bio:: Указывающее на структуруbioполе, которая содержит сведения относительно своей операции ввода/ вывода, например, её тип (считывание или запись). -
struct bio *biotail: Это поле указывает на самую последнюю в своей очереди структуруbio. Когда в эту очередь добавляется новаяbio, она привязывается к самому концу своего списка, на который и указываетbiotail.
Структура request_queue представляет собой связанную с блочным устройством очередь запросов. Эта очередь
запросов отвечает за управление всеми запросами на ввод/ вывод, которые активируются в данном блочном устройстве:
struct request_queue {
struct request *last_merge;
struct elevator_queue *elevator;
struct percpu_ref q_usage_counter;
[………..]
Давайте взглянем на некоторые наиболее важные поля:
-
struct request *last_merge: Данное поле применяется планировщиком ввода/ вывода для отслеживания самого последнего запроса, который был поглощён другим запросом. -
struct elevator_queue *elevator: Это поле указывает на планировщик ввода/ вывода для данной очереди запросов. Соответствующий планировщик запросов ввода/ вывода определяет тот порядок, коим обслуживаются запросы. -
struct percpu_ref q_usage_counter: Поле представляет счётчик числа применений для данной очереди запросов. Для отслеживания справочных сведений счётчика ресурсов на основе для каждого ЦПУ ядро пользуется счётчиком для каждого ЦПУ. -
struct rq_qos *rq_qos: Данное поле указывает на соглашение качества обслуживания очереди запросов, которое данная очередь запросов предоставляет своему блочному устройству. Оно применяется для приоритезации запросов на ввода/ вывод на основании различных критериев, например, величины приоритета конкретного запроса. -
const struct blk_mq_ops *mq_ops: Содержащая указатели функций структура, которые определяют необходимое поведение данной очереди запросов для планировщиков ввода/ вывода множества очередей. -
struct gendisk *disk: Это поле указывает на структуруgendisk, ассоциируемую с данной очередью запросов.gendiskпредставляет универсальное дисковое устройство.
Уф! Их слишком много. Давайте подведём черту значений роли каждой из структур и посмотрим как все они работают совместно.
Приводимая ниже таблица предоставляет краткий обзор тех структур, которые мы рассматривали в своём предыдущем разделе:
| Структура | Представляет | Описание |
|---|---|---|
|
Физический диск |
Применяется для представления физического диска целиком и содержит такие сведения, как значения ёмкости диска и геометрии. |
|
Блочное устройство |
Представляет определённый экземпляр устройства и содержит такие сведения как старший и вспомогательный номера, разделы и те очереди, которые обрабатывают запросы на ввод/ вывод. |
|
Блок данных в памяти |
Применяется для отслеживания считываемых с или записываемых в блочное устройство данных в оперативной памяти. |
|
Запрос на ввод/ вывод |
Содержит такие сведения, как тип операции ввода/ вывода и значение номера стартового блока. |
|
Очередь запросов на ввод/ вывод |
Содержит сведения относительно значения текущего состояния своей очереди, например, величины числа ожидающих обработки запросов. |
|
Блок ввода/ вывода |
Это запрос на ввод/ вывод верхнего уровня и он способен содержать множество структур запросов. |
|
Список буферов памяти накопления- распределения |
Применяется как часть своей структуры |
Давайте посмотрим на взаимодействие между этими структурами когда процесс активирует запрос ввода/ вывода:
-
Когда некое приложение записывает данные в буфер своего адресного пространства, для представления этих данных имеющийся блочный уровень создаёт структуру
buffer_head. -
Для представления запроса на ввод/ вывод блочный уровень строит структуру
bioи ставит в соответствие структуреbuffer_headсвою структуруbio_vec. Для каждойbioблочный уровень создаёт оду или более структурbio_vecпредставления данных подлежащих считыванию или записи. -
Затем к структуре
request_queueдля предполагаемого блочного устройства через структуруrequestдобавляется структураbio. -
Надлежащий драйвер устройства, который представлен через
register_blkdev, выполняет разбор очередиbioпланирует её к обработке. -
Затем на основании размера блока данного устройства
bioрасщепляется на одну или более структурrequest. -
Для обработки соответствующим драйвером устройства в надлежащую структуру
request_queueдалее добавляются все объектыrequest. -
После выполнения обработки данного запроса его драйвер устройства записывает данные в физическое хранилище.
-
По завершению операции ввода/ вывода её драйвер устройства выполняет уведомление своего блочного уровня.
-
Далее блочный уровень обновляет свой кэш буферов и ассоциированные структуры данных. Он помечает данный запрос как выполненный и уведомляет все ожидающие процессы о выполнении данной конкретной операции ввода/ вывода.
-
Для отражения надлежащего текущего состояния данных в своём блочном устройстве обновляются соответствующие структуры
buffer_head.
Для работы с блочными устройствами блочный уровень, совместно со всей своей сложной конструкцией применяет некоторые сложные структуры. Мы рассмотрели некоторые сложные структуры для работы с блочными устройствами для помощи вам в понимании того как всё это работает под капотом. Каждая структура задаёт в своём определении массу полей; для понимания сути вещей мы постарались выделить некоторые из них.
Важно отметить, что все очереди запросов в более старых ядрах представляли собой отдельные потоки и были не способны пользоваться возможностями
современной аппаратуры. Поддержку множества очередей ядро Linux добавило начиная с версии 3.13. Та
инфраструктура, которая реализована для поддержки множества очередей носит название blk-mq. В своей следующей
главе мы намерены рассмотреть эту инфраструктуру множества очередей.
Самая первая часть данной книги, содержащая Главы 1,
2 и 3. Имела дело с VFS и файловыми
системами. Наша вторая часть книги, составлена Главами 4,
5 и 6, причём все они посвящены
блочному уровню. Данная глава служит введением в собственно роль блочного уровня ядра Linux. Блочный
уровень это подсистема ядра, отвечающая за управление операциями ввода/ вывода, осуществляемыми в
блочных устройствах. Интерфейс блочных устройств ядра играет центральную роль в управлении
постоянным хранением Linux. Приложения пространства пользователя имеют возможность получения доступа к блочным устройствам через особые блочные
устройства каталога /dev. Работа с блочными устройствами намного сложнее работы с символьными устройствами,
которые способны работать только последовательно. Символьные устройства обладают лишь одной текущей позицией. Управление блочными устройствами намного
более сложная задача для ядра, поскольку блочные устройства должны обладать возможностью перемещения в любое положение для обеспечения произвольного
метода доступа к данным. По этой причине основной проблемой при работе с блочными устройствами выступает производительность. Для работы с блочными
устройствами ядро Linux представляет собой сложную экосистему структур на своём блочном уровне.
В своей следующей главе мы расширим своё понимание и рассмотрим как на блочном уровне обслуживаются запросы на ввод/ вывод. Также мы рассмотрим средство отображения устройств (device mapper) и инфраструктуру множества очередей в ядре.