Глава 6. Разбираемся с обработкой ввода/ вывода и планированием на блочном уровне
Содержание
"Главное - не расставлять приоритеты в своём расписании, а планировать свои приоритеты," Стивен Кови
Глава 4 и Глава 5 этой книги были сосредоточены на роли блочного уровня в ядре. Мы имели возможность рассмотреть что составляет блочное устройство, основные структуры данных блочного уровня инфраструктуру блочного ввода/ вывода со множеством очередей, а также Сопоставление устройств.Данная глава сосредоточится на другой важной функции блочного уровня - планировании.
Планирование это чрезвычайно критичный компонент любой системы, ибо принимаемое планировщиком решение способны обладать решающим значением для определения общей производительности всей системы. Планирование ввода/ вывода на блочном уровне не является исключением из данного правила. Планировщик ввода/ вывода играет важную роль в определении способа и времени доставки на более нижние уровни запроса на ввод/ вывод. принимая это во внимание, становится крайне важным тщательный анализ шаблонов ввода/ вывода приложения, поскольку некоторые запросы требуют определённых приоритетов над прочими.
Эта глава предоставляет нам введение в различные доступные на блочном уровне планировщики ввода/ вывода и их образ действия. Каждый планировщик пользуется различным набором методик отправки запросов на ввод/ вывод к более нижним уровням. Как мы неустанно повторяем, при работе с блочными устройствами ключевым вопросом выступает производительность. Для возможности получения от дисковых устройств максимальной производительности сам блочный уровень претерпел ряд улучшений. Они также включают в себя разработку планировщиков для работы с современными и высокопроизводительными устройствами хранения.
Мы начнём с введения в распространённые методики, применяемые для большей действенности различными планировщиками при обработке запросов на ввода/ вывод. Хотя эти методики и разрабатывались для традиционных шпиндельных устройств, они всё ещё считаются приемлемыми для современных флеш- дисков. Первейшая цель данных методик состояла в снижении времени операций позиционирования на диске для механических устройств, ибо таковые обладают отрицательным воздействием на их производительность. Большинство планировщиков пользуются по умолчанию такими методиками, причём вне зависимости от лежащего в основе оборудования хранения.
Основной обсуждаемой в данной главе темой будут различные доступные в ядре варианты планирования. Старые дисковые планировщики были разработаны для устройств, доступ к которым осуществляется с применением очереди одиночных доступов и они устарели, поскольку не способны масштабироваться для обеспечения производительности современных дисков. За последние несколько лет в ядро были интегрированы четыре планировщика со множеством очередей ввода/ вывода. Данные планировщики обладают возможностью установления соответствия со множеством очередей на ввод/ вывод.
В этой главе мы намерены обсудить следующие основные вопросы:
-
Понимание основных методик ввода/ вывода на блочном уровне
-
Поясниние планировщиков ввода/ вывода в Linux:
-
Планировщик с предельными сроками MQ - гарантированное время начала обслуживания
-
Бюджетно справедливая организация очередей - обеспечение пропорциональной доли диска
-
Kyber - приоритет пропускной способности
-
None - минимальные накладные расходы на планирование
-
-
Обсуждаем головоломку планирования
Будет полезным обладать некими знаниями относительно основ ввода/ вывода для понимания представленных в данной главе понятий. Обладание неким пониманием различных типов носителей хранения и таких понятий как время позиционирования окажут содействие в постижении представленных в данной главе материалов.
Все представленные в этой главе команды и примеры не зависят от дистрибутива и могут исполняться в любой операционной системе Linux, например, в
Debian, Ubuntu, Red Hat и Fedora. Присутствуют всего лишь несколько ссылок на исходный код ядра. Если вы пожелаете выгрузить исходный код ядра, вы
можете выполнить это с https://www.kernel.org. Все справочные фрагменты кода в данной главе
и книге относятся к ядру 5.19.9.
При изучении блочного уровня в Главе 4 и Главе 5, мы часто упоминали о чувствительности производительности блочных устройств и о том как блочный уровень должен принимать обоснованные и разумные решения для полного раскрытия своего потенциала. До сих пор мы не обсуждали какие бы то ни было методы способствующие повышению производительности блочных устройств.
Возвращаясь в прошлое к шпиндельным устройствам, производительность устройств хранения была основным узким местом в общем стеке ввода/ вывода. Механические диски предлагали пристойную производительность при осуществлении последовательных операций ввода/ вывода. Тем не менее, для рабочих нагрузок с произвольным доступом их производительность весьма драматично деградировала. Это вполне объяснимо, ибо механические диски обладают позиционированием (seek), запрашивающим местоположение на вращающемся диске и устанавливающим головку чтения- записи в конкретное место. Чем больше число случайных позиционирований, тем выше штрафная плата производительностью. Создаваемые поверх блочных устройств файловые системы пытаются реализовывать некоторые практические приёмы, предпринимающие попытку оптимизации производительности диска, однако невозможно совсем избегать операций произвольного доступа.
С учётом гигантского времени позиционирования механических приводов крайне важно применять какую- то оптимизацию для сокращения времени позиционирования перед передачей запросов на вводы/ вывод в базовое хранилище. Примитивным подходом кажется простая передача их в лежащее в основе хранилище. Именно здесь на передний край выходят планировщики ввода/ вывода. Имеющиеся планировщики ввода/ вывода блочного уровня пользуются некоторыми общими методами для гарантии минимальности накладных расходов, происходящих по причине произвольного доступа. Данные методы решают ряд задач производительности шпиндельных накопителей, хотя они могут не обладать существенным эффектом при применении флеш- накопителей, поскольку те не подвержены воздействию операций произвольного доступа.
Большинство планировщиков для оптимизации производительности дисков пользуется сочетанием следующих методик:
-
Сортировка (Sorting)
-
Слияние (Merging)
-
Сращивание (Coalescing)
-
Подключение (Plugging)
Давайте обсудим их подробнее.
Допустим, получены четыре запроса на ввод/ вывод, A, B, C и D, соответственно, для секторов 2, 3, 1 и 4, причём именно в таком порядке, что отражено на Рисунке 6.1. Если данные запросы будут переданы в лежащий в основе шпиндельный диск именно таким образом, они будут обработаны в таком порядке:
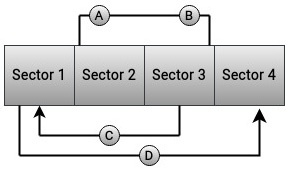
Это означает, что послы выполнения запросов A и B последовательным образом, для запроса C головка чтения- записи диска должна быть возвращена обратно в сектор 1. После завершения запроса C, ей придётся осуществить другое позиционирование и перейти вперёд к сектору 4. нетрудно заметить неэффективность подобного результата при таком подходе. Когда запросы обрабатываются в соответствии с порядком принятия, пострадает производительность диска.
Для шпиндельных дисков операции произвольного доступа убивают производительность, поскольку такой диск осуществляет большое число операций позиционирования. Когда поступающие запросы просто вставляются в конец очереди пришедший- первым- обслуживается- первым (FIFO), каждый запрос вовлекается в отдельную обработку и возрастают накладные расходы, вызываемые произвольным доступом. Таким образом, большинство планировщиков поддерживают очередь в упорядоченном виде и пытаются вставлять новые поступающие запросы отсортированным образом. Такая очередь запросов сортируется по секторам. Это гарантирует последовательное выполнение операций над соседними секторами.
Слияние действует в качестве дополнения к механизму сортировки и пытается ещё снижать произвольность доступа. Его можно осуществлять двумя методами: в прямом и в обратном порядке. Два запроса можно соединять когда они предназначены для смежных секторов. Когда некий запрос поступает в планировщик и присоединяется к уже поставленному в очередь запросу, он рассматривается в качестве претендента на переднее или реверсивное слияние. Если приходящий запрос соединяется с уже имеющимся запросом, это носит название реверсивного (back) слияния. Понятие реверсивного слияния демонстрируется на рисунке 6.2:
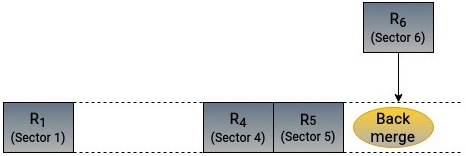
Аналогичным образом, когда вновь создаваемый запрос сочетается с уже имеющимся, он носит название переднего (front) слияния как это отражено на Рисунке 6.3:
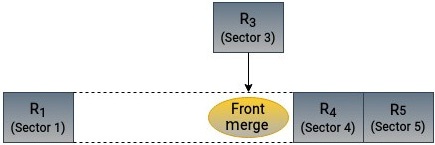
Основная мысль проста - избегать непрерывных перемещений в произвольные места. Это наиболее действенно для шпиндельных механических устройств. По умолчанию, большинство планировщиков блочного уровня пытаются выполнять слияние входящего запроса с уже имеющимся.
Операция сращивания (coalescing) включает в себя и переднее и реверсивное слияния. Сращивание происходит когда новый запрос на ввод/ вывод закрывает промежуток между двумя имеющимися запросами, что показано на следующем рисунке:
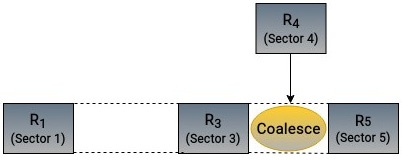
Сращивание используется для снижения накладных расходов , вызываемых небольшими и частыми операциями ввода/ вывода, в особенности для шпиндельных устройств жёстких дисков. Путём сращивания множества запросов диск способен выполнять последовательные чтение и запись, в результате получая более быстрые операции ввода/ вывода и снижая число перемещений головок диска.
Для прекращения обработки запросов в очереди ядро пользуется понятием перекрытия (plugging). Здесь мы обсуждаем улучшение производительности, так как же поможет помещение очереди в приостановленное состояние? Как мы уже изучали, слияние обладает весьма положительным воздействием на производительность диска. Однако, чтобы запросы на ввод/ вывод меньшего размера сливались в единообразный запрос большего размера, для выравнивания секторов в существующей очереди уже должны присутствовать имеющиеся запросы. Тем самым, для осуществления слияния ядру сначала требуется выстроить очередь из какого то числа запросов с тем чтобы вероятность слияния стала большей. Перекрытие очереди способствует группировке запросов для операций слияния и сортировки.
Перекрытие это методика, применяемая для гарантии того, что в нашей очереди имеется достаточное число запросов для потенциальных операций слияния. Она вовлекает в себя ожидание дополнительных запросов для заполнения очереди запросов и оказания содействия в регулировании скорости отправки запросов в очередь устройства. Основная задача перекрытия состоит в контроле скорости отправки запросов в соответствующую очередь запросов. Когда нет отложенных запросов или в очереди блочного устройства их слишком мало, поступающие запросы не отправляются в драйвер устройства немедленно. В результате это приводит к переходу устройства в состояние перекрытого. Данное понятие демонстрирует наш следующий рисунок:
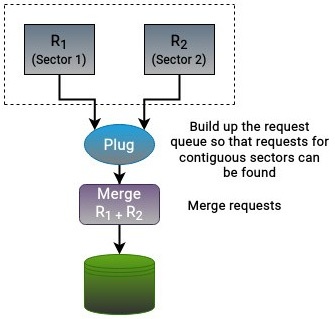
Вместо того чтобы исполнять его на уровне устройства, перекрытие выполняется на уровне своего процесса. При осуществлении процессом операций ввода/ вывода, ядро инициирует последовательность перекрытия. После того как этот процесс завершил отправку своих запросов на ввод/ вывод в соответствующую очередь, эти запросы передаются на блочный уровень, а затем отправляются драйверу устройства. Устройство рассматривается отключённым как только данный процесс завершил отправку запросов ввода/ вывода. Если приложение заблокировано в период последовательности перекрытия, планировщик приступает к обработке уже находящихся в его очереди запросов.
Обсудив наиболее часто встречающиеся в планировщиках ввода/ вывода методов планирования ввода/ вывода, давайте теперь углубимся в рассуждения и принципы, лежащие в основе принятия решений, наиболее широко применяемых планировщиками ввода/ вывода Linux.
Дисковые планировщики интересная тема. Они служат мостом между блочным уровнем и драйверами устройства нижнего уровня. Выдаваемые блочному устройству запросы видоизменяются планировщиком ввода/ вывода и передаются надлежащим драйверам устройств. В задачу планировщика входит выполнение таких операций как слияние, сортировка и перекрытие поступающих запросов на ввод/ вывод, а также разделение ресурсов хранения между поставленными в очередь запросами на ввод/ вывод. Одним из стоящих упоминания преимуществ планировщиков Linux выступает их возможность Plug and Play, допускающая их подключение в реальном масштабе времени. Кроме того, в зависимости от характеристик применяемых аппаратных средств хранения данных, всякому блочному устройству в общей системе может назначаться отдельный планировщик. Выбор дискового планировщика это зачастую ускользающий из поля зрения момент, если только вы не попытаетесь выжимать максимум из своей системы. Планировщик ввода/ вывода отвечает за определение того порядка, в котором запросы на ввод/ вывод будут доставляться в соответствующий драйвер устройства. Устанавливаемый порядок принимается при помощи приоритета по следующим задачам:
-
Снижение времени позиционирования на диске
-
Обеспечение справедливости между запросами на ввод/ вывод
-
Максимизация пропускной способности диска
-
Снижение задержек для чувствительных ко времени задач
Найти баланс между этими целями непростая задача. Для достижения данных целей различные планировщики пользуются множеством очередей. Такие операции как слияние и сортировка осуществляются в очередях запросов. Согласно собственным внутренним алгоритмам планировщики также выполняют в этих очередях дополнительную обработку. Как только запросы подготовлены, они передаются в управляемую драйверами устройств очередь отправки.
Основная оптимизация производительности в более ранних архитектурах блочного уровня была направлена на жёсткие диски. Это особенно справедливо в отношении алгоритмов планирования таких дисков. Большинство обсуждавшихся до сих пор методов обработки ввода/ вывода наиболее полезны когда лежащий в основе носитель данных составлен из вращающихся механических устройств. Как мы обнаружим в Главе 7, твердотельные накопители и устройства NVMe это твари совершенно иной природы и на них не распространяются присущие механическим устройствам ограничения.
Соответствующий планировщик управляет поведением лежащих в его основе дисков и, тем самым, играет жизненно важную роль в определении производительности приложения. Подобно тому как различаются типы физических хранилищ, всякое приложение также устроено по своему. Крайне важно знать тип рабочей нагрузки для подлежащей настройке рабочей среды. Не существует единого планировщика, который можно было бы считать достаточно подходящим для соответствия разнообразным характеристикам ввода/ вывода для всех приложений. Привыборе планировщика надлежит задаваться следующими вопросами:
-
Какого типа система хоста - то есть, это ноутбук, настольный компьютер, виртуальная машина или сервер?
-
Какого вида рабочая нагрузка будет выполняться? Какой тип имеет приложение? База данных, интерфейс рабочего стола множества пользователей, игры или видео?
-
Является ли размещаемое приложение процессором или связано с вводом/ выводом?
-
Какой тип у лежащих в основе носителей? Жёсткие диски, твердотельные накопители или NVMe?
-
Является ли хранилище локальным для своего хоста? Либо оно предоставляется из большой корпоративной сети хранения данных (SAN)?
Вырабатываемые приложением реального времени запросы на ввод/ вывод должны быть выполнены на протяжении определённого срока. К примеру, при передаче потокового видео через мультимедийный проигрыватель необходимо обеспечивать своевременное считывание кадров дабы это видео воспроизводилось без каких бы то ни было сбоев. С другой стороны, интерактивным приложениям приходится дожидаться завершения задачи прежде чем переходить к следующей. Например, при написании в редакторе документов конечный пользователь ожидает, что редактор немедленно реагирует на нажатие клавиши. Кроме того, вводимый текст обязан появляться именно в том порядке, в котором он набирается.
Для отдельных систем выбор планировщика может не иметь большого значения и может оказаться достаточно настроек по умолчанию. Для выполняющих корпоративные рабочие нагрузки серверов допустимые пределы намного меньше и то, каким образом планировщик обрабатывает запросы на ввод/ вывод вполне способно определять общую производительность конкретного приложения. Как мы уже неоднократно упоминали в этой книге, операции дискового ввода/ вывода намного медленнее подсистем процессора и памяти. По этой причине любое решение относительно выбора дискового планировщика должно сопровождаться тщательными анализом и тестированием производительности.
Планирование дисковых операций не следует путать с планированием ЦПУ. Для обработки любого запроса требуются как операции ввода/ вывода, так и время процессора. Проще говоря, процесс запрашивает время у ЦПУ, после чего он имеет возможность исполнения (когда это время выделено). Такой процесс может выдавать запросы на считывание или запись на диске. Далее задача дисковых планировщиков состоит в упорядочении и направлении этих запросов к лежащим в основе дискам.
Планировщики ввода/ вывода в Linux также носят название подъёмных устройств (elevators). Алгоритм подъёма, также именуемый
SCAN сравнивает все операции наследуемых механических накопителей с подъёмниками или лифтами. Когда лифты поднимаются
или опускаются, они продолжают перемещаться в том же направлении и останавливаются для высадки людей по пути. При дисковом планировании соответствующая
головка чтения- записи диска стартует с одной из сторон диска и перемещается к другой, одновременно обслуживая запросы. Продолжая эту аналогию, механическим
приводам требуется считывать (pick up, прихватывать) и записывать (drop off,
высаживать) запросы (people, людей) в различные места диска (floors, этажи).
Различные доступные из ядра планировщики ввода/ вывода подходят для конкретных вариантов применения, причём некоторые больше чем иные. Как мы узнали в Главе 5, структура с одной очередью не масштабируется чтобы соответствовать уровням производительности современных устройств хранения данных. Прогресс технологии устройств и системы со множеством ядер повлекли за собой разработку инфраструктуры блочного ввода/ вывода со множеством очередей. Даже после реализации этой среды в ядре по- прежнему отсутствовал важный компонент работы с современными накопителями - планировщик ввода/ вывода, предназначенный для работы с устройствами со множеством очередей. Разработанные для работы с единственной очередью планировщики, к тому же предназначенные для применения с устройствами с одной очередью, с современными устройствами не работают оптимально.
Рисунок 6.6 выделяет различные типы планировщиков ввода/ вывода, доступных в средах как с единственной очередью, так и со множеством очередей:
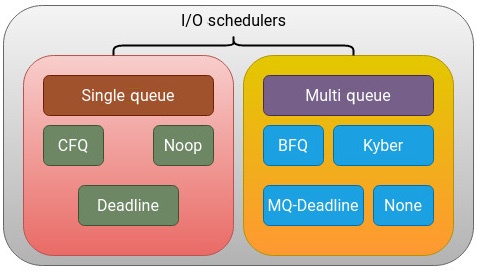
Планировщики с единственной очередью признаны устаревшими и не являются частью ядра начиная с его версии 5.0. Хотя вы и имеете возможность отключения этого и возврата обратно к планировщикам с единственной очередью, самые последние ядра по умолчанию выпускаются с планировщиками множества очередей, а раз так, мы продолжим сосредотачиваться на планировщиках множества очередей, которые выступают частью имеющегося ядра. В этой категории присутствует четыре основных игрока. Эти планировщики устанавливают соответствие запросов на ввод/ вывод множеству очередей, которые обрабатываются потоками ядра, распределяемыми по множеству ядер ЦПУ:
-
MQ-deadline, Время жизни MQ
-
BFQ (Budget Fair Queuing), Бюджетно справедливая организация очередей
-
Kyber
-
None
Давайте взглянем на логику работы этих планировщиков.
Планировщик времени жизни (deadline), как следует из его названия, устанавливает крайний срок для обслуживания запросов на ввод/ вывод. Благодаря своей ориентированной на задержку архитектуре он часто применяется для чувствительных к латентности рабочих нагрузок. Благодаря своей высокой производительности он также был приспособлен для устройств со множеством очередей. Его реализация для устройств со множеством очередей (multi-queue) носит название mq-deadline - времени жизни для множества очередей.
Наипервейшая цель планировщика времени жизни состоит в обеспечении запросам назначенного времени обслуживания. Это достигается за счёт принудительного установления сроков для всех операций ввода/ вывода, что способствует предотвращению оставления запросов без внимания. Планировщик времени жизни пользуется такими очередями:
-
Sorted (отсортированная): Операции считывания и записи в этой очереди сортируются по номерам подлежащих обращению секторов.
-
Deadline: Очередь крайних сроков это стандартная очередь FIFO (First-In-First-Out FIFO, пришедший первым обслуживается первым), которая содержит отсортированные по срокам запросы. Во избежания зависания запросов, планировщик сроков пользуется отдельными экземплярами очереди крайних сроков назначая каждому запросу на ввод/ вывод времени его истечения.
Планировщик времени жизни помещает все запросы на ввод/ вывод в обе очереди, и в отсортированную, и в очередь крайних сроков. Перед принятием решения о том какой именно запрос обрабатывать, планировщик времени жизни (крайних сроков) отдаёт предпочтение очереди, из которой выполняется выбор запроса на считывание или запись. Когда запросы присутствую и в очереди на считывание и очереди на запись, предпочтение отдаётся очередям на чтение. Что обусловлено тем, что запросы на запись способны истощать операции на считывание. Это превращает планировщики времени жизни в чрезвычайно действенные для рабочих нагрузок с интенсивным считыванием.
Логика действий планировщика времени жизни отображена на следующем рисунке:
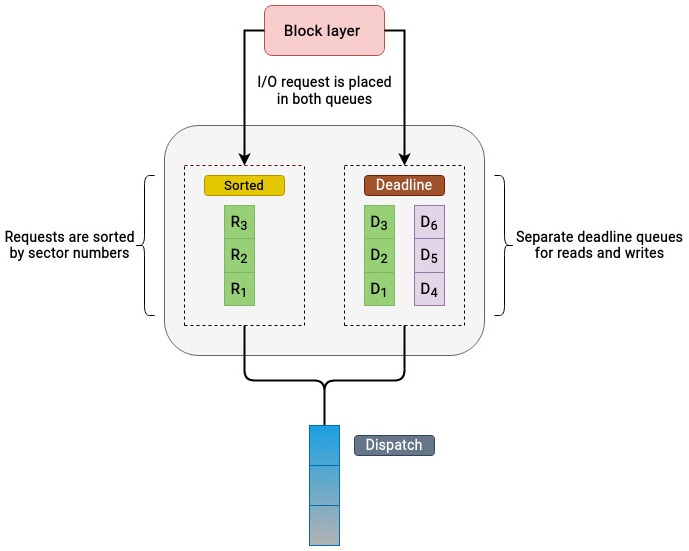
Решение о подлежащих обслуживанию запросах на ввод/ вывод принимается следующим образом:
-
Допустим, наш планировщик принял решение обслуживать запросы на чтение. Он проверит самый первый запрос в очереди крайних сроков. Когда истекает время действия связанного с этим запросом таймера, он будет передан в очередь отправки и вставлен в конец её хвоста. Этот планировщик далее переключает свой фокус на отсортированную очередь и выбирает пакет запросов (по умолчанию 16 запросов), следующих за выбранным запросом. Это осуществляется для роста числа последовательных операций. Представляйте себе это как то, как лифт высаживает людей на различных этажах на своём пути в пункт назначения. Значения числа запросов в пакете это настраиваемый параметр и его можно изменять.
-
Может так случиться, что в очереди крайних сроков нет никаких запросов с истекающим временем жизни. В подобной ситуации наш планировщик изучит самый последний обслуженный в отсортированной очереди запрос и выберет следующий запрос в этой последовательности. Затем планировщик выберет пакет из 16 запросов, следующих за этим выбранным запросом.
-
После обработки каждого пакета запросов, планировщик крайних сроков проверяет не задерживаются ли слишком долго запросы в очереди крайнего срока на запись, после чего принимает решение запускать ли новый пакет операций считывания или записи.
Поясняет этот процесс наш следующий рисунок. Когда получен запрос на считывание с диска сектора номер 19, ему назначается время жизни и он вставляется в конец хвоста очереди крайних сроков для операций на чтение. На основании номера своего сектора этот запрос также помещается в отсортированную по секторам очередь, сразу за запросом для сектора 11. Весь поток действий для планировщика времени жизни относительно обработки запросов показан на Рисунке 6.8:
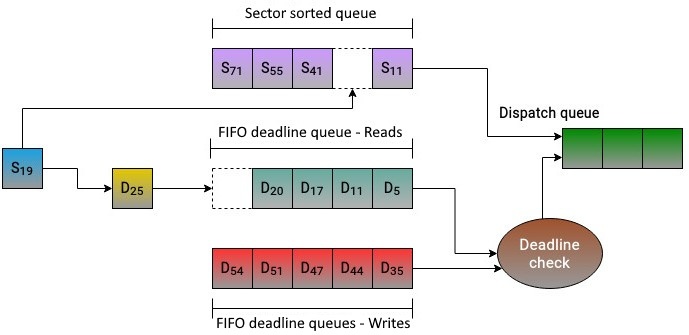
Приводимый ниже фрагмент кода mq-deadline из block/mq-deadline предписывает некое проиллюстрированное предыдущим рисунком
поведение. Истечение времени жизни запросов на считывание (HZ/2) равно 500 миллисекундам, в то время как для записей оно составляет 5 секунд (5*HZ).
Величина элемента HZ представлена значением числа вырабатываемых в секунду тактов. Определение
writes_starved указывает что считывание способно истощать записи. Необходимые записи обслуживаются лишь один раз
после двух этапов считывания. fifo_batch устанавливает значения числа запросов, которые могут соединяться в один пакет:
[……….]
static const int read_expire = HZ / 2;
static const int write_expire = 5 * HZ;
static const int writes_starved = 2;
static const int fifo_batch = 16;
[……….]
Подводя итог, планировщик времени жизни стремится сократить задержку ввода/ вывода, реализуя времена начала обслуживания для каждого поступающего запроса. Всякому новому поступающему запросу назначается таймер крайнего срока. По истечению срока действия запроса планировщик принудительно обслужит данный запрос для предотвращения зависания запросов.
BFQ (Budget Fair Queuing, Бюджетно справедливый планировщик) это относительный новичок в мире дисковых планировщиков, но он приобрёл значительную популярность. Он создан по образцу планировщика CFQ (Completely Fair Queuing, абсолютно справедливой очереди). Предоставляет достаточное хорошее время отклика и считается в особенности подходящим для медленных устройств. Благодаря своим богатым и исчерпывающим методам планирования BFQ зачастую рассматривается в качестве одного из наиболее совершенных дисковых планировщиков, хотя его сложная архитектура превращает его в наиболее сложный из всех планировщиков.
BFQ является планировщиком с пропорциональным совместным применением диска. Первичная цель BFQ состоит в справедливом отношении ко всем запросам на ввод/
вывод. Для достижения подобной справедливости он пользуется некоторыми замысловатыми методами. Внутри BFQ применяется алгоритм
B-WF2Q+ (Worst-case Fair Weighted Fair Queuing+, честно взвешиваемой справедливой
очереди для наихудшей ситуации+), способствующий принятию решений планирования.
Планировщик BFQ обеспечивает пропорциональное совместное владение дисковыми ресурсами для всех процессов в своей системе. Он собирает поступающие запросы на ввод/ вывод в следующие очереди:
-
Per-process queues (очереди для каждого процесса): Планировщик BFQ для каждого процесса выделяет очередь. Всяка очередь для процесса содержит синхронные запросы на ввод/ вывод.
-
Per-device queue (очередь для устройства): Все асинхронные запросы на ввод/ вывод собираются в очереди для устройства. Эта очередь совместно используется процессами.
При каждом создании некой очереди ей назначается некий изменяемый бюджет. В отличии от большинства планировщиков, которые выделяют кванты времени, данный бюджет реализуется в виде значения числа секторов которое допускается всякому процессу передавать когда он планируется в следующий раз на доступ к ресурсам диска. Такая величина данного бюджета это именно то, что в конечном счёте определяет долю полосы пропускания каждого из процессов. Раз так, её вычисление является сложным и основывается на большом числе факторов. Самыми основными составляющими в данном вычислении выступают вес ввода/ вывода и самая последняя активность ввода/ вывода данного процесса. Основываясь на этих результатах наблюдений, наш планировщик назначает пропорциональный активности ввода/ вывода бюджет. Величина веса ввода/ вывода процесса обладает значением по умолчанию, однако его можно изменять. Распределение бюджета таково, что один процесс не обладает возможностью заграбастать всю полосу пропускания доступного ресурса хранения. Рисунок 6.9 отображает различные применяемые планировщиком BFQ очереди:
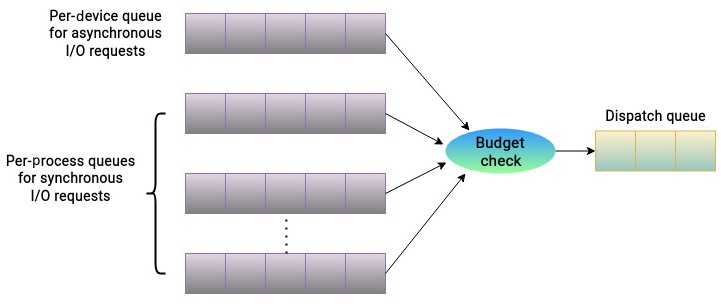
Когда речь заходит об обслуживании запросов на ввод/ вывод, вот некоторые из моментов, которые оказывают влияние на принятие решений планирования:
-
Посредством алгоритма C-LOOK BFQ выбирает подлежащую обслуживанию очередь. В избранной очереди он подхватывает самый первый запрос и вручает его соответствующему драйверу. Величина бюджета уменьшается на значение размера данного запроса. По окончанию данного обсуждения это поясняется слегка более подробно. За раз BFQ обслуживает исключительно одну очередь.
-
Планировщик BFQ отдаёт приоритет процессам планирования с меньшими бюджетами ввода/ вывода. Обычно это процессы, обладающие небольшим, но произвольным набором запросов на ввод/ вывод. Напротив, процессам с интенсивным вводом/ выводом и большим количеством последовательных запросов на ввод/ вывод выделяется бо́льший бюджет. При избрании очереди процесса на обслуживание планировщик BFQ выбирает очередь с наименьшим бюджетом ввода/ вывода, предоставляя монопольный доступ к дисковым ресурсам. Такой подход достигает двух целей. Во-первых, процессы с меньшими бюджетами обслуживаются быстро и им не приходится слишком долго ожидать. Во-вторых, связанные с вводом-выводом процессы бо́льшего бюджета получают пропорционально бо́льшую долю дисковых ресурсов, что способствует операциям последовательного ввода/ вывода и тем самым повышает производительность диска. Для увеличения пропускной способности диска планировщик BFQ применяет несколько оригинальный подход, а именно выполняет простой диска путём проверки наличия синхронных запросов на ввод/ вывод. Когда приложение генерирует запросы синхронного ввода/ вывода, оно переходит в состояние блокировки и ожидает завершения такой операции. В основном это запросы на чтение, ибо операции записи асинхронны и могут выполняться непосредственно в кэше. Процесс переходит в состояние ожидания если последний запрос в очереди процесса является синхронным. Такой запрос не отправляется сразу на диск, поскольку планировщик BFQ позволяет процессу выработать иной запрос. На протяжении этого периода времени диск остаётся бездействующим. Чаще всего, прежде чем выдавать новые запросы, процесс генерирует ещё один запрос, поскольку он ожидает завершения текущего синхронного запроса. Новый запрос обычно находится рядом с последним запросом, что повышает вероятность последовательных операций. Порой такой подход может иметь неприятные последствия и не всегда оказывать положительное влияние на производительность.
-
Когда два процесса работают в двух соседних областях диска, есть смысл в сочетании их запросов с тем, чтобы могло вырасти число последовательных операций. В таком случае BFQсливает эти очереди обоих процессов воедино дабы допустить консолидацию запросов. Все входящие запросы сопоставляются со следующим запросом в обслуживаемой очереди и, если два запроса близки, эти очереди запросов объединяются в одну.
В ситуации, когда выполняющее на считывание запросы приложение исчерпает свою очередь, при этом сохраняя бюджет избыточным, диск будет непродолжительно ожидать, чтобы предоставить этому процессу возможность выполнения ещё одного запроса на ввод/ вывод.
Наш планировщик продолжает обслуживать свою очередь выбранную очередь пока не произойдёт одно из следующих событий:
-
Исчерпан бюджет этой очереди
-
Были завершены все запросы данной очереди
-
В процессе ожидания новых запросов от своего процесса истекло значение таймера ожидания
-
В процессе обслуживания данной очереди было истрачено слишком много времени
При изучении найденного в block/bfq-iosched.c кода BFQ вы обнаружите заслуживающую внимания концепцию с названием
charge factor (множитель издержек) для асинхронных запросов:
static const int bfq_async_charge_factor = 3;
Ранее уже упоминалось, что когда обслуживается выбранный из очереди запрос, значение бюджета этой очереди уменьшается на величину данного запроса, то есть
на величину секторов в таком запросе. Именно это справедливо для синхронных запросов, однако для асинхронных запросов такая стоимость намного выше. Это к тому
же один из вариантов повышения приоритета считывания над записью. Для асинхронных запросов их очередь нагружается числом секторов в обслуживаемом запросе,
помноженном на значение bfq_async_charge_factor, равное трём. В соответствии с документацией ядра, текущее значение
величины параметра множителя издержек определено путём процесса настроек, в который вовлекались различные конфигурации аппаратных и программных средств.
Подводя итог, можно сказать, что планировщик BFQ пользуется равноправными подходами к организации очередей, пропорционально распределяя общей пропускной способности ввода/ вывода на каждый процесс. Он применяет по одной очереди для синхронных запросов, а для асинхронных запросов по очереди для каждого устройства. Данный бюджет вычисляется на основе значения приоритета ввода/ вывода и величины переданных секторов с момента последнего распределения. Хотя данный планировщик BFQ сложен и требует несколько бо́льших накладных расходов по сравнению с прочими планировщиками, он широко применим, поскольку улучшает времена отклика системы и минимизирует задержки для требовательных ко времени приложений.
Планировщик Kyber также относительно новое явление в мире дисковых планировщиков. Хотя планировщик BFQ и старее планировщика Kyber, они оба стали частью ядра версии 4.12. Планировщик Kyber специально спроектирован для современных высокопроизводительных устройств хранения.
Исторически сложилось так, что конечной целью дисковых планировщиков было сокращение времён позиционирования механических дисков дабы уменьшать вызываемые операциями произвольного доступа накладные расходы. Следовательно, имевшиеся различные дисковые планировщики пользовались сложными и изощрёнными методами для достижения этой общей цели. Каждый планировщик по- своему задаёт приоритеты определённых сторон производительности, что приводит к дополнительным накладным расходам при обработке запросов на ввод/ вывод. Поскольку такие современные устройства как твердотельные диски и NVMe накопители, не страдают от операций с произвольным доступом, некоторые применяемые рядом планировщиков искушённые методы могут оказываться неприемлемыми для таких устройств. К примеру, планировщик BFQ обладает слегка завышенными накладными расходами на каждый запрос, а потому не рассматривается как идеальный для обладающих дисками с высокой пропускной способностью систем. Вот тут-то и пригодится планировщик Kyber.
Планировщик Kyber не обладает сложными внутренними алгоритмами планирования. Он предназначен для применения в содержащих высокопроизводительные устройства
хранения данных средах. Он применяет крайне непосредственный подход и для выстраивания запросов на ввод/ вывод реализует некоторые базовые политики. Планировщик
Kyber расщепляет лежащее в основе устройство на множество областей. Основная мысль состоит в сопровождении очередей для различных типов запросов на ввода/
вывод. Когда мы просматриваем находящийся в block/kyber-iosched.c код, мы можем наблюдать наличие следующих типов
запросов:
[…….]
static const char *Kyber_domain_names[] = {
[KYBER_READ] = "READ",
[KYBER_WRITE] = "WRITE",
[KYBER_DISCARD] = "DISCARD",
[KYBER_OTHER] = "OTHER",
};
[…….]
Планировщик Kyber разбивает все запросы на следующие категории - процессы чтения, записи, отброса и прочие. Запрос отброса (discard) применяется для подобных твердотельным устройств. Имеющаяся поверх такого устройства файловая система способна активировать этот запрос для отброса не используемых этой файловой системой блоков. Для всех упомянутых выше типов запросов данный планировщик реализует некий предел соответствующего числа операций в своей очереди устройства:
[…...]
static const unsigned int Kyber_depth[] = {
[KYBER_READ] = 256,
[KYBER_WRITE] = 128,
[KYBER_DISCARD] = 64,
[KYBER_OTHER] = 16,
};
[…...]
Основная суть подхода Kyber состоит в ограничении значения размера очередей отправки. Оно напрямую коррелирует со значением затрачиваемого на ожидание запросов в очереди на ввод/ вывод времени. Планировщик посылает в очередь отправки лишь ограниченное число операций, что гарантирует не слишком большое переполнение этой очереди отправки. Это влечёт за собой быструю обработку запросов очереди отправки. Тем самым, операции ввода/ вывода очередей запросов не должны ожидать обслуживания слишком долго. Такой подход приводит к снижению латентности. Приводимый ниже рисунок иллюстрирует логику планирования Kyber:
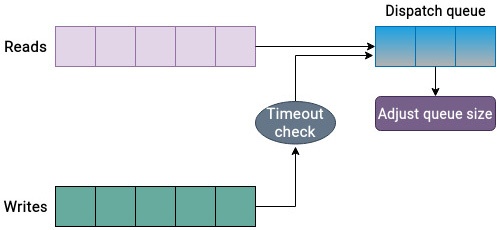
Для определения значения числа запросов, которое допустимо в очереди отправки, планировщик Kyber использует простой, но действенный подход. Он вычисляет время исполнения каждого запроса и на основе данной обратной связи он выравнивает общее число запросов в очереди отправки. Далее, значения целевых задержек для считываний и синхронных записей являются регулируемыми параметрами и могут быть изменяемыми. На основании их значений наш планировщик дросселирует запросы по порядку чтобы приводить в соответствие данные целевые задержки.
Планировщик Kyber отдаёт приоритет запросам в очереди на считывание над запросами из очереди записи, если только запрос на запись не пребывает в обработке слишком долго, что означает нарушение величины целевой задержки.
Планировщик Kyber выступает мощным источником производительности когда речь идёт о современных устройствах хранения данных. Он предназначен для высокопроизводительных устройств хранения, таких как твердотельные и NVMe и отдаёт предпочтение операциям ввода/ вывода с малой задержкой. Данный планировщик динамически подстраивается, тщательно анализируя запросы на ввод/ вывод и позволяет выставлять целевые задержки как для синхронной записи, так и для считывания. Тем самым для достижения заданных целей он регулирует запросы на ввод/ вывод.
Планирование запросов ввода/ вывода это многогранная проблема. Такому планировщику приходится заботиться о множестве сторон, таких как изменение порядка запросов в своей очереди, выделение части дисковых ресурсов каждому процессу, контроль продолжительности каждого запроса, а также обеспечение того, чтобы отдельные запросы не монополизировали все доступные ресурсы хранения. Каждый планировщик предполагает, что его хост сам по себе не способен оптимизировать запросы. А потому он действует быстро и энергично применяя сложные методы в попытке максимально действенно применять доступные ресурсы хранения. Чем более изощрённый метод планирования, тем больше накладные расходы на его обработку. При оптимизации запросов планировщики, как правило, исходят из некоторых предположений относительно лежащего в основе устройства. Это достойно работает, только если более нижние уровни стека не обладают лучшей видимостью доступных ресурсов хранения и не способны самостоятельно принимать решение по планированию, например, такие:
-
В настройках высокопроизводительных систем хранения, таких как сети хранения данных, массивы хранения данных зачастую сами содержат собственную логику планирования ибо они обладают более глубоким пониманием всех нюансов лежащих в основе устройств. В результате, собственно планирование запросов на ввод/ вывод обычно происходит на самом нижнем уровне. При использовании RAID контроллеров их хост система не обладает полными сведениями относительно лежащих в основе дисках. Даже когда планировщик применяет некую оптимизацию к запросам на ввод/ вывод, это может не иметь большого значения, ибо самой системе хоста не хватает видимости для точного переупорядочения запросов для снижения времени позиционирования. В подобных случаях имеет смысл простая отправка запросов рейд- контроллеру.
-
Большинство оптимизаций планировщика направлено на медленные механические приводы. Когда ваша среда состоит их твердотельных дисков и накопителей NVMe, связанные с оптимизацией планирования затраты на обработку могут показаться чрезмерными.
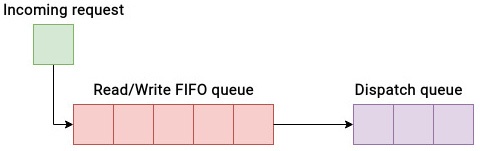
В подобных обстоятельствах уникальным, но действенным решением является применение планировщика none. Планировщик none это планировщик ввода/ вывода no-op (холостых команд). Для устройств с единственной очередью те же самые функциональные возможности достигаются через планировщик no-op (холостых команд).
Планировщик none это наиболее простой из всех планировщиков, поскольку он не выполняет оптимизаций планирования. Всякий входящий запрос на ввод/ вывод помещается в конец очереди FIFO и делегируется для обработки в само блочное устройство. Данная стратегия оказывается полезной, когда установлено, что сам хост не должен пытаться переупорядочивать запросы в соответствии в соответствии с включаемыми в них номерами секторов. Планировщик none обладает единой очередью запросов, которая содержит как запросы ввода/ вывода на считывание, так и на запись. Благодаря своему элементарному подходу, несмотря на минимальные накладные расходы, планировщик ввода/ вывода none не обеспечивает никакого особенного качества обслуживания. Планировщик none, к тому же, не осуществляет никакого переупорядочения запросов. Он лишь запрашивает слияние для сокращения времени позиционирования и улучшения пропускной способности. В отличие от всех прочих планировщиков, планировщик none не обладает возможностями регулировок и настройками для оптимизации. Вся его сложность состоит в операции слияния. По этой причине планировщик none применяет минимальное число инструкций ЦПУ на запрос ввода/ вывода. Работа планировщика none основывается на предположении, что устройства нижнего уровня, такие как RAID- контроллеры или контроллеры хранения сами будут оптимизировать производительность ввода/ вывода.
Простая логика работы планировщика none показана на Рисунке 6.11:
Хотя всякая среда, в зависимости от режима работы, обладает множеством переменных, по- видимому, планировщик none является предпочтительным для корпоративных сетей хранения данных (SAN), ибо он не выполняет никаких предположений относительно лежащих в основе физических устройствах и не реализует никаких решений относительно планирования, которые были бы способны соперничать или противоречить логике контроллеров ввода/ вывода более нижнего уровня.
Принимая во внимание обилие вариантов выбора, может оказаться сложным определить, какой именно планировщик наиболее соответствует вашим потребностям. В своём следующем разделе мы опишем общие сценарии применения тех планировщиков, которые мы рассмотрели в данной главе.
Мы обсудили и дали пояснения того, как работают различные варианты планирования ввода/ вывода, однако выбор планировщика всегда должен сопровождаться собираемых в результате реальных рабочих нагрузок результатами эталонных тестов. Как уже упоминалось ранее, в большинстве ситуаций может оказываться достаточным наличие настроек по умолчанию. Лишь когда вы пытаетесь достигать максимальной эффективности, вы предпринимаете попытку и варганите нечто с настройками по умолчанию.
Сама природа подключаемости этих планировщиков подразумевает, что мы обладаем возможностью замены установленного планировщика ввода/ вывода для блочного
устройства на лету. Осуществить это можно двумя способами. Активный в настоящее время планировщик для конкретного дискового устройства можно проверить
посредством sysfs. В нашем следующем примере активный планировщик настроен на
mq-deadline:
[root@linuxbox ~]# cat /sys/block/sda/queue/scheduler
[mq-deadline] none bfq kyber
[root@linuxbox ~]#
Для изменения своего активного планировщика запишите значение имени желаемого планировщика в файл планировщиков. Например, для установки устройству
sda планировщика BFQ воспользуйтесь такой командой:
echo bfq > /sys/block/sda/queue/scheduler
Наш предыдущий метод установит планировщик лишь временно и возвратится обратно к настройкам по умолчанию после перезапуска. Для превращения данного
изменения в постоянное, отредактируйте файл /etc/default/grub и добавьте в строку
GRUB_CMDLINE_LINUX_DEFAULT параметр elevator=bfq. Затем сгенерируйте
соответствующую конфигурацию GRUB и перезапустите свою систему.
Простая замена планировщика не даст в результате двукратного прироста производительности. Как правило, показатели улучшения будут в пределах 10 - 20%.
Хотя всякая среда имеет отличия и производительность планировщика может варьироваться в зависимости от нескольких переменных, в качестве основы можно привести следующие варианты применения обсуждавшихся в данной главе планировщиков:
| Вариант применения | Рекомендуемый планировщик ввода/ вывода |
|---|---|
Графический интерфейс рабочего стола, интерактивные приложения, а также программные приложения реального времени, такие как аудио и видео проигрыватели |
BFQ, поскольку он обеспечивает хороший отклик системы и низкие задержки для чувствительных ко времени приложений |
Традиционные механические устройства |
BFQ или MQ-deadline - оба рассматриваются как подходящие для медленных устройств. Kyber/none отдают предпочтение быстрым устройствам. |
Высокопроизводительные устройства SSD и NVMe |
Предпочтителен none, однако в некоторых ситуациях хорошей альтернативой может быть Kyber. |
Корпоративные массивы хранения |
None, ибо большинство массивов хранения обладают более действенной встроенной логикой планирования ввода/ вывода. |
Среды виртуализации |
Хорошим вариантом является MQ-deadline. Когда сам уровень гипервизора обладает собственным планированием ввода/ вывода, тогда может сулить преимущества применение планировщика none. |
Будьте добры иметь в виду, что это не строгие варианты применения, зачастую могут накладываться друг на друга некоторые условия. Тип приложения, рабочая нагрузка, система хоста и носитель хранения это всего лишь часть факторов, которые следует принимать во внимание перед принятием решения о планировании. Как правило, по причине небольшой нагрузки на ЦПУ, универсальным выбором считается планировщик времени жизни. BFQ достойно работает в настольных средах, тогда как None и Kyber лучше подходят для высокопроизводительных устройств хранения данных.
Данная глава предоставила обзор планирования ввода/ вывода, что является критически важной функцией блочного уровня. Когда запросы на считывание и запись передаются через все имеющиеся уровни общей виртуальной файловой системы, в конечном счёте они появляются на блочном уровне. Данная глава изучает различные виды планировщиков ввода/ вывода и их характеристики, включая преимущества и недостатки. Блочный уровень содержит большое число планировщиков ввода/ вывода, которые подходят под конкретные варианты использования. Собственно выбор планировщика ввода/ вывода играет жизненно важную роль в определении того каким образом запросы на ввод/ вывод будут обрабатываться на своём нижнем уровне. Для принятия более ориентированных на производительность решений большинство планировщиков пользуется рядом общих методик, которые имеют целью улучшение общей производительности диска. Обсуждавшимися нами в данной главе методиками были слияние, сращивание, сортировка и перекрытие.
Мы также дали пояснения различным доступным в ядре вариантам планирования. Ядро обладает отдельными наборами планировщиков ввода/ вывода для устройств с единой очередью или со множеством очередей. Планировщики с единственной очередью рассматриваются как устаревшие начиная с версии 5.0 ядра. Варианты планирования со множеством очередей включают в свой состав планировщики времени жизни со множеством очередей, BFQ, Kyber и None. Каждый из этих планировщик является подходящим для конкретного варианта применения, причём не существует единой рекомендации, применимой ко всем обстоятельствам. Планировщик времени жизни MQ обладает хорошей общей производительностью. Планировщик BFQ больше ориентирован на интерактивные приложения, в то время как Kyber и None ориентированы на устройства хранения данных высокой производительности. Чтобы выбрать планировщик, необходимо знать подробные сведения о самой среде, включая такие детали, как тип рабочей нагрузки, приложение, хост-система и лежащий в основе физический носитель.
Эта глава завершает вторую часть нашей книги, в которой мы погружались в блочный уровень. В своей следующей главе мы рассмотрим различные доступные в наши дни носители хранения и поясним отличия между ними.