Глава 2. Поясняем структуры данных VFS
Содержание
В первой части этой книги мы получили хороший обзор VFS (virtual filesystem, Виртуальной файловой системы), её наиболее распространённых функций, почему она необходима, а также каким образом она выполняет ключевую роль в понятии "Все является файлом" в Linux. Также мы объяснили интерфейс системных вызовов в Linux и каким образом приложения пространства пользователя могут применять универсальные системные вызовы и взаимодействовать с VFS. VFS является сэндвичем между программами пространства пользователя и реальными файловыми системами, а также реализуют общую файловую модель с тем, чтобы приложения могли пользоваться единообразными методами доступа для выполнения своих операций, причём вне зависимости от того какая файловая система применяется.
При обсуждении применяемых разнообразных файловых систем мы упоминали, что VFS применяет такие структуры как индексные дескрипторы (inodes), суперблоки и записи каталога для представления общего вида соответствующих файловых систем. Эти структуры критически важны, поскольку они обеспечивают чёткое разделение между метаданными и реальными данными файла.
Данная глава сделает для вас введение в такие различные структуры данных VFS ядра. Вы узнаете как само ядро пользуется такими структурами как индексные дескрипторы и записи каталога для хранения метаданных о файлах. Вы также изучите как ядро способно записывать необходимые характеристики соответствующей файловой системы через свою структуру суперблока. В самом конце мы поясним механизмы кэширования в VFS.
Мы намерены рассмотреть следующие основные вопросы:
-
Индексные дескрипторы (inodes)
-
Суперблоки
-
Записи каталога
-
Объекты файлов
-
Страницы кэша
Было бы полезно обладать хорошим представлением о концепциях операционной системы Linux. Они включают в себя знакомство с файловыми системами, процессами и управление памятью. В данной книге мы не намерены создавать какой бы то ни было новый код, но если вы желаете более детально изучать ядро Linux, для понимания структур данных VFS решающее значение имеет знакомство с понятием программирования на C. Как правило, вам следует получить привычку обращаться к официальной документации ядра, поскольку она способна предоставлять подробные сведения относительно внутренней работы ядра.
Представленные в данной главе команды и примеры не зависят от дистрибутива и могут запускаться в любой операционной системе Linux, такой как Debian, Ubuntu, Red Hat, Fedora {Rocky} и т.п.. На исходный код ядра имеется несколько ссылок. Если вы желаете выгрузить исходный код ядра, вы можете выполнить это с https://www.kernel.org. Упоминающиеся в данных главе и книге сегменты кода взяты из ядра 5.19.9.
Для реализации универсальных методов абстракции во всех файловых системах и предоставления необходимого интерфейса файловой системы программам пространства пользователя VFS пользуется различными структурами данных. Эти структуры обеспечивают определённую общность между архитектурой и работой файловых систем. Важно помнить, что все определённые в VFS методы не применяются к файловым системам. Да, файловые системы обязаны соответствовать определяемым в VFS структурам и основываются на них для обеспечения общности между ними. Но в этих структурах может иметься множество методов и полей, не применимых к конкретной файловой системе. В подобных ситуациях файловые системы придерживаются соответствующих полей в соответствии с их архитектурой и исключают лишние сведения. Поскольку мы намерены пояснять общие структуры данных VFS, крайне важно чтобы мы взглянули на соответствующие фрагменты кода ядра для некоторых пояснений. Тем не менее, я изо всех сил старался представить материал в самом общем виде с тем, чтобы с основными понятиями можно было бы разобраться даже без глубокого понимания кода ядра.
Древние греки верили, что всё состоит из четырёх элементов: земли, воды, воздуха и огня. Аналогично, VFS составлен из следующих структур, ну, по большей части:
-
Индексные дескрипторы
-
Записи каталога
-
Файловые объекты
-
Суперблоки
При сохранении данных на диск Linux следует одному строгому правилу: все выходящие за пределы упаковки сведения обязаны храниться отдельно от содержимого внутри упаковки. Иными словами, описывающие файл данные изолированы от реальных данных в файле. Содержащая эти сведения структура носит название индексного узла (index node) , сокращённо inode (индексный дескриптор). Такая структура индексного дескриптора содержит метаданные для файлов и каталогов в Linux. Имя файла или каталога - это просто указатель на некий индексный дескриптор, причём каждый файл или каталог обладает ровно одним индексным дескриптором.
В качестве аналогии возьмём Карту Мародёров (кто- нибудь из Гарри Поттера?). На карте показано местонахождение каждого человека в школе. Все люди представлены точками на карте, а когда вы нажимаете на эту точку, отображаются сведения об этом человеке, такие как его имя, местоположение и состояние. Представьте себе эту Карту Мародёров в качестве файловой системы, а сопоставляющие людей точки в качестве индексных дескрипторов, отображающих метаданные.
Но что представляют собой метаданные фала? Когда вы осуществляете простой просмотр файла при помощи команды ls, вы
обнаруживаете кучу сведений, таких как права доступа к файлу, владельца файла, временные отметки и тому подобное. Все эти подробности составляют метаданные файла,
поскольку они описывают некоторые свойства этого файла, а не его фактическое содержимое.
Некоторые из метаданных этого файла могут проверяться простой командой ls. Хоте несколько лучшей командой для отображения
имеющихся метаданных файлов является stat, поскольку она предоставляет намного больше сведений относительно атрибутов фала.
Например, она показывает метки времени доступа, модификации, изменения, устройство, на котором находится этот файл, количество зарезервированных на диске под файл
блоков, а также номер индексного дескриптора файла.
Если вы хотите получить подробные сведения о метаданных файла, скажем, /etc/hosts, мы можем таким образом
воспользоваться командой stat:
stat /etc/hosts
Обратите внимание но номер индексного дескриптора (67118958) для /etc/hosts в
получаемом от команды stat вывода:
[root@linuxbox ~]# stat /etc/hosts
File: /etc/hosts
Size: 220 Blocks: 8 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 67118958 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2022-11-20 04:00:38.054988422 -0500
Modify: 2022-06-15 22:30:32.755324938 -0400
Change: 2022-06-15 22:30:32.755324938 -0400
Birth: 2022-06-15 22:30:32.755324938 -0400
[root@linuxbox ~]#
Номер индексного дескриптора это уникальный идентификатор для файла. Рассмотрим пример DNS
(Domain Name System). Мы пользуемся читаемыми человеком именами вебсайта, дабы нам не приходилось
запоминать значение IP адреса для каждого вебсайта. Аналогично, имена файла или каталога обеспечивают нас тем, что нам нет нужды запоминать значение номера
индексного дескриптора. Ядро отслеживает каждый файл или каталог по его индексному дескриптору. Некий индексный может рассматриваться в качестве имени нижнего
уровня для файла. Например, существует возможность определить местоположение файла по его номеру индексного дескриптора. Команда
find предоставляет параметр inode для поиска файла по его индексному дескриптору:
find / -inum 67118958 -exec ls -l {} \;
Если мы найдём полученный при помощи команды stat номер индексного дескриптора, мы сможем получить соответствующий
файл:
[root@linuxbox ~]# find / -inum 67118958 -exec ls -l {} \;
-rw-r--r-- 1 root root 220 Jun 15 22:30 /etc/hosts
[root@linuxbox ~]#
Индексный дескриптор уникален только в рамках файловой системы. Если каталог вашей системы (такой как /home или
/tmp) находятся в обособленных дисковых разделах или файловых системах, один и тот же номер индексного дескриптора может
быть назначен различным файлам в различных файловых системах:
[root@linuxbox ~]# ls -li /home/pokemon/pikachu
134460858 -rw-r--r-- 1 root root 1472 Oct 11 05:10 /home/pokemon/pikachu
[root@linuxbox ~]#
[root@linuxbox ~]# ls -li /tmp/bulbasaur
134460858 -rw-r--r-- 1 root root 259 Nov 20 04:36 /tmp/bulbasaur
[root@linuxbox ~]#
Уникальность номеров индексных дескрипторов в рамках файловой системы связана с понятием связывания (linking). Поскольку один и тот же номер индексного дескриптора может применяться в различных файловых системах, жёсткие ссылки (hard links) не пересекают границы файловой системы.
В исходном коде ядра определение индексного дескриптора представлен в linux/fs.h. В этом определении бесчисленное
число полей. Обратите внимание, что данное определение struct inode является универсальным и
всеобъемлющим. Некий индексный дескриптор это специфичное для файловой системы свойство. В определении своего файлового дескриптора файловой системе не обязательно
определять все эти поля. Определение индексного дескриптора очень длинное, поэтому мы ограничимся некоторыми базовыми полями:
struct inode {
umode_t i_mode;
unsigned short i_opflags;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
const struct inode_operations *i_op;
struct super_block *i_sb;
[………………………...]
Здесь определены некоторые представляющие интерес поля:
-
i_mapping: Это указатель значения структуры адресного пространства, которое хранит значение соответствия для соответствующих блоков данных индексного дескриптора. Это поле инициализируется самой файловой системой когда создаётся индексный дескриптор или когда он считывается с диска. Например, когда процесс записывает данные в файл, ядро применяет это поле для установления соответствия соответствующим страницам памяти для блоков данных этого файла. (Блоки данных объясняются в наших следующих разделах.) -
i_uidиi_gid: Служат, соответственно для владельцев пользователя и группы. -
i_flags: Определяет специфические для файловой системы флаги. -
i_acl: Служит для списков контроля доступа (ACL) файловых систем. -
i_op: Это указатели на структуру операций индексного дескриптора, которые определяют все те операции, которые могут выполняться в индексном дескрипторе, такие как создание, чтение, запись и изменение значение атрибутов файла. -
i_sb: Указывает на структуру суперблока лежащей в основе файловой системы, в которой располагаются эти индексные дескрипторы (Для объяснения суперблока имеется отдельная тема.) -
i_rdev: Это поле хранит значение номера устройства для некоторых специфичных файлов. К примеру, ядро создаёт специальный файл для представления жёстких дисков или прочих устройств в данной системе. Когда специальный файл создан, ядро назначает ему уникальный номер устройства, создаёт индексный дескриптор для этого устройства, а также набор полей для указания на значение идентификатора устройства. -
i_atime,i_mtimeиi_ctime: Это временные метки доступа, модификации и изменения, соответственно. -
i_bytes: Значение числа байт в данном файле. -
i_blkbits: Это поле хранит значение числа бит, необходимых для представления размера блока той файловой системы, к которой относится данный индексный дескриптор. -
i_blocks: Данное поле хранит значение общего числа блоков, применяемых для представления своего файла данным индексным дескриптором. -
i_fop: Это указатель на структуру операций файла, ассоциированную с этим индексным дескриптором. Например, когда процесс открывает файл, ядро пользуется этим полем для получения указателя на соответствующую структуры операций файла для этого файла. Оно может применять определённые в данной структуре операций файла функции для осуществления операций с этим файлом, такие как чтение или запись. -
i_count: Используется для значения числа активных ссылок на данный индексный дескриптор. Всякий раз, когда новый процесс выполняет доступ к файлу, данный счётчик для этого файла увеличивается на единицу. Когда это поле достигает значения ноль, это означает, что более нет никаких ссылок на данный индексный дескриптор и он может быть безопасно освобождён. -
i_nlink: Это поле ссылается на значение числа жёстких ссылок на данный индексный дескриптор. -
i_io_list: Данный список применяется для отслеживания индексных дескрипторов, которые обладают отложенными запросами на ввод/ вывод. Когда ядро добавляет некий запрос на ввод/ вывод в очередь для какого- то индексного дескриптора, такой индексный дескриптор добавляется в данный список. После завершения соответствующей операции ввода/ вывода, этот индексный дескриптор удаляется из данного списка.
В определении структуры индексного дескриптора около 50 полей, поэтому здесь мы лишь едва коснулись её поверхности. Но это должно дать нам некое представление
о том, что индексный дескриптор определяет гораздо больше чем просто поверхностные сведения для некого файла. Не волнуйтесь если вы запутались. Мы намерена пояснить
более подробно индексные дескрипторы. Существует два типа применимых к структуре индексного дескриптора операций, которые определяются структурами
file_operations и inode_operations. По структуре
file_operations мы пройдёмся слегка позднее, когда мы будем рассматривать файловые объекты в разделе
Объекты файлов - представление открытых файлов.
Структура операций индексного дескриптора содержит множество указателей на функции, которые определяют как данная файловая система взаимодействует с индексными дескрипторами. Каждая файловая система обладает своим собственной структурой операций индексного дескриптора, которая регистрируется в VFS при монтировании этой файловой системы.
Ссылка на структуру inode_operations выполняется указателем i_op. Помните,
когда в Главе 1, Откуда всё начинается - Виртуальная файловая системамы поясняли
"Все является файлом", хотя и разного типа, каждому из них назначается индексный дескриптор. Дисковые устройства,
дисковые разделы, обычные текстовые файлы, документы, конвейеры, а также сокеты, все они обладают назначенными им индексными дескрипторами. Также индексный дескриптор
имеется для каждого каталога. Однако все эти файлы имеют разную природу и представляют собой в вашей системе различные
логические элементы. Например, доступные для каталога операции индексного дескриптора отличны от операций для обычного текстового файла. Структура
inode_operations предоставляет все те функции, которые требуются индексным дескрипторам для реализации каждого типа файлов,
с тем чтобы управлять данными индексного дескриптора.
Каждый индексный дескриптор ассоциирован с неким экземпляром структуры inode_operations, предоставляющая набор
операций, которые используются для манипуляций индексными дескрипторами:
struct inode_operations {
struct dentry * (*lookup) (struct inode *,struct dentry *, unsigned int);
const char * (*get_link) (struct dentry *, struct inode *, struct delayed_call *);
int (*permission) (struct user_namespace *, struct inode *, int);
struct posix_acl * (*get_acl)(struct inode *, int, bool);
int (*readlink) (struct dentry *, char __user *,int);
int (*create) (struct user_namespace *, struct inode *,struct dentry *, umode_t, bool);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct user_namespace *, struct inode *,struct dentry *,
[……………………………………….]
Здесь мы поясним некоторые наиболее важные операции, которые могут выполняться при помощи этой структуры:
-
lookup: Применяется для поиска записи индексного дескриптора в каталоге. Она получает в качестве параметров индексный дескриптор каталога и имя файла и возвращает указатель на значение индексного дескриптора, который соответствует указанному имени файла. -
create: Данная функция вызывается когда создаются новый файл или каталог и она отвечает за инициализацию такого индексного дескриптора с соответствующими метаданными, таким как владелец и полномочия. Он применяется для построения объекта индексного дескриптора в ответ на системный вызовopen (). -
get_link: Используется для работы с символическими ссылками. Некая символическая ссылка это указатель на иной индексный дескриптор. -
permission: Когда файл подлежит доступу, VFS активирует эту функцию для проверки прав для такого файла. -
link: Активируется как отклик на системный вызовlink (), который создаёт некую новую жёсткую ссылку. Она увеличивает на единицу значения счётчика link соответствующего индексного дескриптора и обновляет его метаданные. -
symlink: Активируется как отклик на системный вызовsymlink (), который создаёт некую новую символическую (мягкую) ссылку. -
unlink: Активируется как отклик на системный вызовunlink (), который удаляет имеющуюся ссылку на файл. Она уменьшает на единицу счётчик link соответствующего индексного дескриптора и удаляет этот индексный дескриптор с его диска, когда данный счётчик link достигает нуля. -
mkdirиrmdir: Активируют отклик на системные вызовыmkdir ()иrmdir ()для создания и удаления каталогов, соответственно.
Поскольку всякий файл в своей системе намерен обладать некими метаданными, он всегда обладает в точности одним ассоциируемым с ним индексным дескриптором.
Так как каждый индексный дескриптор хранит некие сведения, файловым системам требуется резервировать под них какое- то пространство, обычно всего несколько байт.
Например, файловая система Ext4 по умолчанию пользуется 256 байтами под один индексный дескриптор. Для отслеживания
используемых и свободных индексных дескрипторов файловые системы поддерживают inode table (таблицу
индексных дескрипторов).
Присутствующие в структуре индексного дескриптора поля предоставляют следующие два типа сведений относительно файла:
-
Атрибуты файлов: Подробности относительно владельцев, полномочий, временных меток, ссылок, а также значения числа используемых блоков.
-
Блоки данных: Указатели на блоки данных на диске, в которых хранятся реальные данные.
Дополнительно к файловым полномочиям, владельцам и временным меткам, другим важным фрагментом предоставляемых индексным дескриптором сведений выступает значение местоположения реальных данных на диске. Файл может захватывать множество дисковых блоков, в зависимости от своего размера. Для отслеживания этих сведений структура индексного дескриптора применяет указатели. Зачем это нужно? Такое отслеживание дисковых блоков требуется поскольку нет никаких гарантий того, что имеющиеся в файле данные будут храниться и доступными неким последовательным или непрерывным образом. Применяемые индексным дескриптором указатели обычно имеют размер в 4 байта и могут классифицироваться как прямые или косвенные указатели. Для файлов меньшего размера индексный дескриптор содержит прямые (непосредственные) указатели на его блоки данных файла. Всякий непосредственный указатель указывает значение адреса диска, по которому хранятся данные.
Применение непосредственных указателей для обращения к адресам диска всегда обладало серьёзными ограничениями. Основным вопросом было: сколько непосредственных указателей достаточно? Применение в структуре 15 непосредственных указателей означало бы, что для блока размером в 4кБ мы могли бы указывать только на 60кБ данных. Естественно, это не сработает на в каком измерении, поскольку даже небольшие текстовые файлы обычно обладают размером более 60кБ. Это отображено на Рисунке 2.1:
Рисунок 2.1
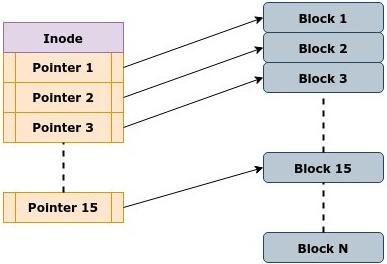
Ограничения при использовании непосредственных указателей: для блока размером в 4кБ могут быть адресованы только 60кБ данных
Чтобы совладать с этой задачей, используются косвенные указатели. Структура индексного дескриптора содержит 12 непосредственных и 3 косвенных указателя. В отличии от прямого указателя, indirect pointer (косвенный указатель) это указатель на блок указателей. Когда исчерпаны все непосредственные указатели, файловая система пользуется неким блоком данных для хранения дополнительных указателей. Не счастливый 13-й или единичный косвенный указатель в индексном дескрипторе указывает на такой блок данных. Все указатели внутри этого блока указывают на блоки данных, которые в действительности содержат данные файла. Когда имеющийся размер файла не способен адресоваться с использованием единичного косвенного указателя, используется двойной косвенный указатель. Double indirect pointers (двойные косвенные указатели) указывают на блок, который содержит указатели на косвенные блоки, причём каждый из них содержит указатели на адреса на диске. Аналогично, когда файл дорастает выше пределов двойного косвенного указателя - да, вы угадали, - используются triple indirect pointers (тройные косвенные указатели).
На данный момент вы, скорее всего, полагаете что объелись белены и считаете что в этом нет никакой сути (указателей {игра слов: point - смысл, pointer- указатель}). Излишне говорить, что вся такая иерархия достаточно сложна. Некоторые современные файловый системы для хранения файлов большого размера пользуются понятием, носящим название экстентов. Мы рассмотрим его когда будем изучать блочные файловые системы в Главе 3, Изучаем реальные файловые системы под VFS.
А пока давайте упрости всё это и двинемся в верном направлении. Мы намерены воспользоваться элементарной математикой чтобы пояснить как косвенные указатели помогают хранить большие файлы. Мы собираемся рассмотреть блок с размером в 4кБ, поскольку именно он по умолчанию используется в большинстве файловых систем:
-
Общее число указателей в индексном дескрипторе = 15
-
Число непосредственных указателей = 12
-
Число косвенных указателей = 1
-
Число двойных косвенных указателей = 1
-
Число тройных косвенных указателей = 1
-
Размер каждого указателя (непосредственного или косвенного) = 4 байта
-
Число указателей в блоке = (размер блока / размер указателя) = (4кБ / 4) = 1 024 указателя
-
Максимальный размер файла, который может быть организован непосредственными указателями = 12 x 4кБ = 48кБ
-
Максимальный размер файла, который может быть организован 12 непосредственными и одним косвенным указателями = [(12 x 4кБ) + (1 024 x 4кБ)] ≈ 4МБ
-
Максимальный размер файла, который может быть организован 12 непосредственными, одним косвенным и одним двойным косвенным указателями = [(12 x 4кБ) + (1 024 x 4кБ) + (1 024 x 1 024 x 4кБ)] ≈ 4ГБ
-
Максимальный размер файла, который может быть организован 12 непосредственными, одним косвенным, одним двойным косвенным и одним тройным косвенным указателями = [(12 x 4кБ) + (1 024 x 4кБ) + (1 024 x 1 024 x 4кБ) + (1 024 x 1 024 x 1 024 x 4кБ)] ≈ 4ТБ
Наш следующий рисунок показывает как применение косвенных указателей способно помогать при адресации фалов большого размера:
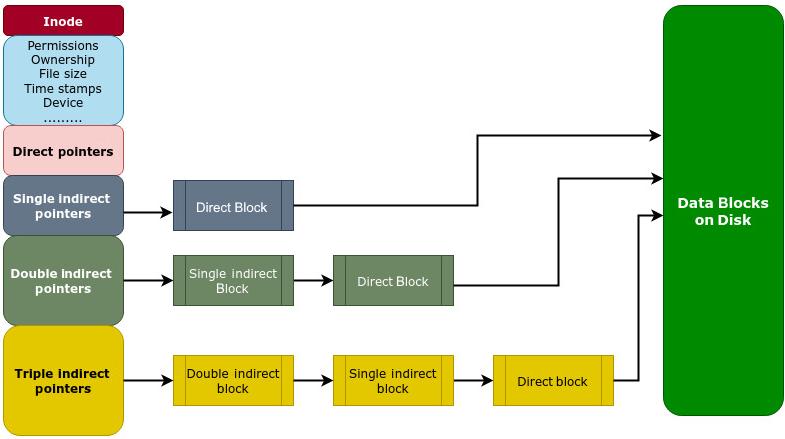
Как отражено на Рисунке 2.2, файловые системы могут пользоваться одноуровневыми косвенными указателями для файлов меньшего размера, а затем переключаться на косвенные блоки двойного уровня для файлов большего размера. Применение косвенных указателей предлагает множество преимуществ. Прежде всего, они прекращают потребность в непрерывном выделении хранилища для размещения файлов большого размера, тем самым, позволяя файловой системе действенно обрабатывать подобные файлы. Во- вторых, это способствует более эффективному применению пространства, поскольку блоки могут выделяться для файла на основании потребности вместо упреждающего резервирования значительного объёма памяти. Каждый индексный дескриптор обычно обладает 12 непосредственными, 1 одинарным, 1 двойным и 1 тройным косвенными указателями.
Когда мы управляем хранилищем, основным вопросом является способность удерживать доступное пространство. Исчерпание дискового пространства это распространённая
ситуация. Некий индексный дескриптор назначается всем файлам и каталогам в конкретной файловой системе, однако что если было выделено всё число индексных
дескрипторов? Это крайне маловероятно, поскольку, ак правило, файловые системы обладают несколькими миллионами доступных индексных дескрипторов. Но да, имеется
возможность исчерпания индексных дескрипторов. И если это произойдёт, общий объём свободного пространства на диске станет бесполезным, ибо файловая система не будет
способна создать новый файл. После создания файловой системы количество индексных дескрипторов не может быть увеличено, а поэтому единственным вариантом останется
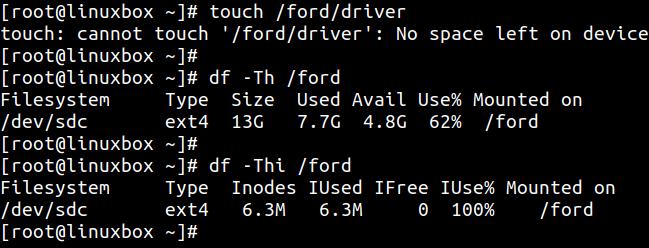
резервное копирование. Вы можете проверить загруженность индексных дескрипторов смонтированных файловых систем при помощи команды
df:
df -Thi
Данная ситуация иллюстрируется на Рисунке 2.3. Смонтированная в /ford файловая система близка к наличию свободным
40% пространства, однако поскольку все 6.3 миллиона индексных дескрипторов исчерпаны, нет возможности создавать и далее никакие файлы:
Давайте подведём к концу своё обсуждение несколькими ключевыми моментами про указатели индексных дескрипторов:
-
Помимо метаданных, индексные дескрипторы также хранят сведения относительно того где хранится файл на своём физическом диске. Для отслеживания физического местоположения файла индексные дескрипторы пользуются рядом непосредственных и косвенных указателей.
-
Индексные дескрипторы хранятся в структурах файловой системы на диске в таблице индексных дескрипторов. Когда требуется открытие файла, его соответствующий индексный дескриптор загружается в память.
-
Для тем файловых систем, которые только в оперативной памяти вырабатывают своё содержимое, например, для
procfsиsysfs, их индексные дескрипторы присутствуют только в памяти. -
Хотя индексные дескрипторы хранят большое число метаданных о файле, они не хранят значение имени этого файла. Итак, двумя моментами, которые не являются частью структуры индексного дескриптора выступают содержимое файла и его название.
-
Индексные дескрипторы пользуются 15 указателями для отслеживания на диске файловых блоков. Первые 12 указателей являются непосредственными (прямыми) указателями, и способны выполнять адресацию файлов только до 48кБ. Остающиеся три указателя предоставляют одиночный, двойной и тройной уровни косвенной адресации. С помощью таких косвенных указателей можно выполнять адресацию файлов большого размера.
-
Когда файловая система исчерпала индексные дескрипторы, в ней не может быть создан никакой новый файл. Это очень редкая ситуация, поскольку обычно файловая система обладает большим количеством индексных дескрипторов, исчисляемых миллионами.
Каталог действует как список или контейнер пользовательских файлов. Применяемые к каталогу операции отличаются от операций с обычными файлами. Для работы с каталогами существуют различные команды. Файл всегда будет находиться внутри некоторого каталога и для доступа к этому файлу вам необходимо в терминах каталогов указать абсолютный или относительный путь. Тем не менее, как и большинство вещей в Linux, каталоги также рассматриваются в качестве файлов. Итак, как же всё это работает?
Естественные файловые системы Linux трактуют каталоги как файлы и хранят их как файлы. как и все обычные файлы, каталогу также назначается индексный дескриптор. Нет никакой разницы между индексными дескрипторами каталога и файла. В случае каталога поле type в индексном дескрипторе это directory. Вспомните из нашего обсуждения индексных дескрипторов, что некий индексный дескриптор содержит множество метаданных относительно файла, но не содержит самого названия этого файла. Значение имени файла представлено в каталоге. Каталог можно рассматривать как некий особый файл, содержащий таблицу. эта таблица составлена из названий файлов и соответствующих им номеров индексных дескрипторов.
При попытке доступа к файлу процесс должен пройтись по иерархической структуре каталога. Каждый уровень в этой структуре определяет путь, который может быть
либо абсолютным, либо относительным. Абсолютные имена пути, также носящие название
полных путей (fully qualified pathnames), начинающихся с корневого каталога, например,
/etc/ssh/sshd_config. Наоборот, относительные имена путей
начинаются с текущего рабочего каталога данного процесса или пользователя, например, ssh/sshd_config. В относительных именах
путей в имени пути нет начального /.
Полное имя пути, сопоставляющее имена числам, заметьте, что это слегка напоминает понятию разрешению имён. При описании индексных дескрипторов мы воспользовались аналогией с DNS и будем её придерживаться. Точно так же, как обычные записи DNS сопоставляют названия веб- сайтов с IP- адресами, каталог ставит в соответствие все имена файлов с надлежащими номерами индексных дескрипторов. Такое сочетание имён файлов с индексными дескрипторами носит название связывания (linking). Данное понятие связывания поясняется ближе к концу данной главы.
Если вы предпочитаете аналогии из поп- культуры, вспомните про звёздные карты из франшизы Звёздных войн. Для отправки на конкретную планету, дабы отыскать подходящее место, персонажи сверяются со звёздной картой. Представьте себе звёздную карту в качестве каталога, а каждую планету как файл или подкаталог. На карте указано точное местоположение и координаты каждой планеты, во многом подобно каталогу, в котором указано значение номера индексного дескриптора и местоположение каждого файла.
Такое соответствие помогает при осуществлении операций поиска. Поиск названий путей это ориентированная на каталог операция, поскольку файлы всегда находятся
внутри некого каталога. Для поиска путей VFS пользуется записями каталога, которые носят название dentry objects. Такие
dentry objects отвечают за представление каталога в памяти. При проходе по пути каждым рассматриваемым компонентом является
dentry objects. Если в качестве примера мы возьмём /etc/hosts, и
/etc, и hosts, оба файла рассматриваются в качестве
dentry objects и им установлено соответствие в памяти. Это способствует кэшированию результатов операций
lookup, что в свою очередь общую производительность при просмотре названий путей.
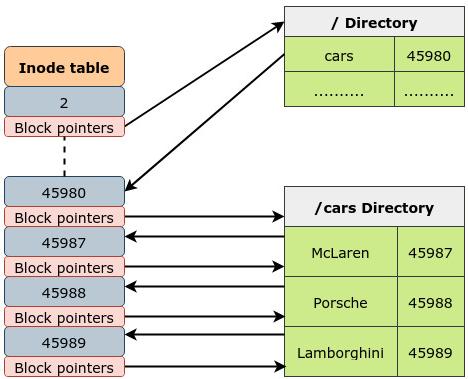
Рассмотрим простой пример: в разделе / имеется каталог /cars, который содержит
три файла: McLaren, Porsche и Lamborghini.
В нашей упрощённой версии имевших место событий когда некий процесс хочет получить доступ к файлу McLaren в каталоге
/cars:
-
VFS реконструирует соответствующий путь как
dentry objects. -
Для каждого компонента из названия пути будет создан
dentry objects. VFS проследует по каждой из записей каталога для разрешения пути. При просмотре/cars/McLaren, отдельныеdentry objectsбудут созданы для/,/carsи/McLaren. -
Поскольку наш процесс определил значение абсолютного пути, VFS начнёт с самого первого компонента в этом пути, то есть с
/cars, а затем продолжит по дочерним объектам. -
VFS сверится с относящимися к делу полномочиями в соответствующем индексном дескрипторе чтобы убедиться, что вызывающий процесс обладает всеми необходимыми полномочиями.
-
VFS также вычислит значение хэша для
dentry objectsи сопоставит его со значениями в своей таблице хэшей. -
Наш каталог
/содержит значения соответствий файлов и каталогов их надлежащим номерам индексных дескрипторов. По достижению индексного дескриптора/cars, ядро может воспользоваться его указателями на блоки для просмотра содержимого на диске этого каталога. -
Каталог
/carsбудет содержать соответствия для трёх файлов (McLaren,PorscheиLamborghini) их номерам индексных дескрипторов. Отсюда мы можем воспользоваться значением индексного дескриптора дляMcLaren, который будет указывать нам на располагающиеся на диске блоки данных, содержащие сведения этого файла.
Важно знать, что представление некого каталога через dentry objects присутствует только в памяти. Сами они не хранятся
на диске. Эти объекты создаются VFS на лету:
Обладающий орлиным глазом читатель мог бы удивиться: как мы узнали значение индексного дескриптора для своего каталога /?
Большинство файловых систем начинают выделение значений индексных дескрипторов с 2. Номер индексного дескриптора
0 не используется. Номер 1 индексного дескриптора применяется для отслеживании
плохих или сбойных блоков на своём физическом диске. Таким образом, выделение в файловой системы начинается с 2 и нашему
корневому каталогу в файловой системе всегда назначается индексный дескриптор с номером 2.
С точки зрения производительности обход по имени пути и поиск каталога могут быть затратными операциями, в особенности, когда имеется множество подлежащих разрешению рекурсивных путей. После разрешения некого пути и когда некому процессу потребуется доступ к этому же пути снова, VFS придётся выполнять всю эту операцию снова, что затратно. Также имеется зависимость от лежащего в основе носителя: насколько быстро он выполняет выборку необходимых сведений. Это тормозит данную операцию.
Мы снова хотим воспользоваться подходяще здесь аналогией, то есть DNS. Когда клиент DNS выполняет один и тот же запрос, локальный DNS сервер кэширует получаемые для этого запроса результаты. Это сделано с тем, чтобы при любом идентичном запросе DNS серверу не пришлось бы снова проводить путешествие по всей необходимой иерархии DNS серверов. Аналогичным образом, для ускорения процесса поиска имён путей, ядро пользуется кэшированием записей каталога. Для ускорения нашего процесса поиска часто используемые названия пути сохраняются в памяти. Это избавляет от большого числа не нужных операций ввода/ вывода к лежащей в основе файловой системе. В операции поиска имени файла ключевую роль играет кэш dentry.
Каталог ставит в соответствие имена файлов индексным дескрипторам. Вы обязаны спросить: раз объекты dentry создаёт
представление каталогов в оперативной памяти и результаты поиска кэшируются, это означает что и соответствующие индексные дескрипторы также кэшируются?
Ответ утвердительный. Нет смысла кэшировать одно без другого. Если кэшируется запись каталога, также кэшируется и соответствующий индексный дескриптор.
Объекты dentry закрепляют соответствующие индексные дескрипторы и они остаются в памяти пока там имеются объекты
dentry.
Объекты dentry определены в файле include/linux/dcache.h:
struct dentry_operations {
int (*d_revalidate)(struct dentry *, unsigned int);
int (*d_weak_revalidate)(struct dentry *, unsigned int);
int (*d_hash)(const struct dentry *, struct qstr *);
int (*d_compare)(const struct dentry *, unsigned int, const char *, const struct qstr *);
int (*d_delete)(const struct dentry *);
int (*d_init)(struct dentry *);
void (*d_release)(struct dentry *);
void (*d_prune)(struct dentry *);
[……………………….]
Здесь приводятся некоторые наиболее часто применяемые термины:
-
d_name: Это поле содержит указатель на объектstruct qstr, который представляет название соответствующих файла или каталога. Объектqstr, это структура, которая используется самим ядром для представления строки или последовательности символов. -
d_parent: Данное поле содержит указатель на родительский каталог того файла или каталога, с которым ассоциирована данная запись каталога. -
d_inode: Указывающее на объектstruct inodeфайла или каталога поле указателя. -
d_lock: Поле содержит взаимную блокировку (spinlock), применяемую для защиты доступа к объектуstruct dentry. Довольно часто объектыdentryinodeиспользуются несколькими процессами, открывающими один и тот же файл или каталог. Данное полеd_lockвыполняет защиту этих объектов от одновременных изменений, которые способны повлечь за собой противоречивые или повреждённые данные файловой системы. -
d_op: Данное поле содержит указатель на структуруstruct dentry_operations, которая содержит набор указателей функций, определяющих те операции, которые могут выполняться над данным объектомdentry. -
d_sb: Это указатель на структуруstruct super_block, которая определяет суперблок той файловой системы, к которой относится запись данного каталога.
Представленный в оперативной памяти хэш пользуется таблицей хэшей. Каждая запись в этой структуре таблице хэширования указывает на список записей кэша каталога, обладающих тех же самым значением хэша. Когда некий процесс предпринимает попытку доступа к файлу или каталогу, ядро выполняет поиск значения кэша для соответствующей записи каталога, применяя в качестве ключа название файла или каталога. Если в этом кэше найдена необходимая запись, она возвращается вызывавшему поиск процессу. Когда запись не обнаружена, ядру придётся возвращаться на диск и выполнять операции ввода/ вывода для считывания необходимой записи каталога из его файловой системы.
Объекты dentry имеют тенденцию пребывать в одном из трёх следующих состояний:
-
Used: Используемая
dentryуказывает на то, что объектdentryв настоящий момент применяется VFS и отображает, что существует допустимая структура индексного дескриптора, ассоциируемого с ним. Это означает, что некий процесс активно пользуется данной записью. -
Unused: Не используемая запись также обладает ассоциированным с нею индексным дескриптором, но он не используется VFS. Если операция поиска имени пути (относящаяся к данной записи) выполняется снова, такая операция может выполняться при помощи данной кэшированной записи. Когда возникает потребность в освобождении памяти, от данной записи можно избавиться.
-
Negative: Отрицательное состояние слегка уникально в том, что оно представляет неудачную операцию поиска. Например, когда файл, к которому осуществляется доступ, уже удалён, или значение такого пути не существует изначально, вызывающему процессу типично возвращается сообщение No such file or directory (нет такого файла или каталога). В результате такого неудачного поиска VFS создаст отрицательную (Negative)
dentry. Слишком большое число неудачных операций поиска способно приводить к созданию ненужных отрицательныхdentryи способно неблагоприятно влиять на производительность.
Различные относящиеся к файловой систем операции, которые могут выполняться с объектами dentry определяются в
соответствующей структуре dentry_operations:
struct dentry_operations {
int (*d_revalidate)(struct dentry *, unsigned int);
int (*d_weak_revalidate)(struct dentry *, unsigned int);
int (*d_hash)(const struct dentry *, struct qstr *);
int (*d_compare)(const struct dentry *, unsigned int, const char *, const struct qstr *);
int (*d_delete)(const struct dentry *);
int (*d_init)(struct dentry *);
void (*d_release)(struct dentry *);
void (*d_prune)(struct dentry *);
[……………………….]
Здесь приводятся описания некоторых важных операций:
-
d_revalidate: Часто может так происходить, что объектыdentryв кэше могут утрачивать синхронизацию с данными на диске. Это часто имеет место в случае сетевых файловых систем. Ядро зависит от своей сетевой среды для получения сведений относительно структур на диске. В подобных ситуациях VFS применяет операциюd_revalidateдля подтвержденияdentry. -
d_weak_revalidate: После того как операция поиска пути завершаетсяdentry, которая не получена после просмотра в своём родительском каталоге, VFS вызывает операциюd_weak_revalidate. -
d_hash: Она применяется для вычисления значения хэшаdentry. Она получает на входdentryи возвращает значение хэша, который применяется для поиска даннойdentryв кэше каталога. -
d_compare: Используется для сопоставления значений имён файлов двухdentry. Она получает двеdentryв качестве параметров и возвращаетtrueесли они ссылаются на один и тот же файл или каталог иfalseкогда они отличаются. -
d_init: Вызывается при инициализации объектаdentry. -
d_release: Вызывается когдаdentryподлежит освобождению. Она высвобождает используемую даннойdentryпамять и все ассоциированные с нею ресурсы, например, кэшированные данные. -
d_iput: Активируется когда объектdentryтеряет свой индексный дескриптор. Она просто вызываетd_release. -
d_dname: Используется для выработки имён путей для псевдо файловых систем, таких какprocfsиsysfs.
Давайте суммируем своё обсуждение записей каталога:
-
Linux трактует каталоги как файлы. Каталоги также обладают назначенными им индексными дескрипторами. В таком каталоге хранятся имена файлов.
-
Единственное отличие между индексным дескриптором файла и каталога заключается в содержимом соответствующих дисковых блоков. Данные каталога на диске содержат сопоставление имён файлов и номеров их индексных дескрипторов.
-
В памяти каталоги представлены через объекты
dentry. Объектыdentryсоздаются VFS в оперативной памяти и не хранятся на физическом диске. -
Для оптимизации операций поиска используется кэширование
dentry. Такой кэшdentryотслеживает в оперативной памяти имена путей, к которым недавно осуществлялся доступ, и их индексные дескрипторы.
Аналогично объектам dentry, объекты файлов это представление в оперативной памяти открытых файлов. Такой объект файла олицетворяет представление процессом открытого файла. Как и объекты dentry, объекты файлов также не соответствуют никаким структурам на диске. Когда в Главе 1 мы рассматривали системные вызовы, упоминалось, что программы пространства пользователя осуществляют взаимодействие через интерфейс системных вызовов. Такие системные вызовы представляют собой универсальные функции для выполнения общих операций, таких как считывание и запись. Основная идея всего этого состоит в том, чтобы программам пространства пользователя не приходилось беспокоиться относительно файловых систем и их структур данных.
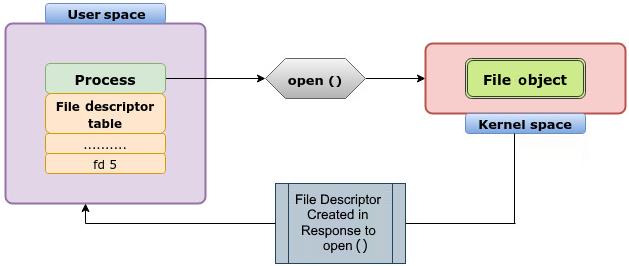
Когда приложения вырабатывают системный вызов доступа к файлу, такой как open (), в оперативной памяти создаётся объект
файла. Аналогично, когда этому приложению больше не требуется доступ к данному файлу и оно решает закрыть его при помощи close (),
такой объект файла освобождается. Важно отметить, что VFS способна создавать множество объектов файла для определённого файла. Это обусловлено тем, что определённый
файл не ограничен единственным процессом; файл может одновременно открываться множеством процессов. По этой причине конкретный объект файла частным образом
используется каждым процессом.
Ниже приводятся в тех способах, коими применяются ядром индексные дескрипторы и объекты файлов:
-
Когда процессу необходим доступ к файлу, используются объекты файлов совместно с индексными дескрипторами.
-
Для доступа к надлежащему индексному дескриптору конкретного файла, процессу потребуется объект файла, указывающий на индексный дескриптор этого файла. Объекты файлов относятся к некому отдельному процессу, в то время как индексный дескриптор может использоваться множеством процессов.
-
Объект файла создаётся при каждом открытии файла. Когда другой процесс желает выполнить доступ к тому же самому файлу, будет создан новый файловый объект, причём персональный для этого объекта.
-
Когда процесс закрывает файл, соответствующий ему объект файла уничтожается, однако его индексный дескриптор может всё ещё сохраняться в кэше.
Существует некоторая путаница между объектами файлов и другими логическими элементами, которые применяются для доступа к файлам,
файловыми дескрипторами. Системный вызов open () процесса
часто возвращает файловый дескриптор, который используется данным процессом для доступа к файлу. В некотором смысле, файловый дескриптор также иллюстрирует
взаимосвязь между процессом и файлом. Так в чём же разница? Дабы поиграть словами, объект файла предоставляет дескриптор открытого файла. Файловый объект будет
содержать все относящиеся к файловому дескриптору данные. Файловые дескрипторы это ссылки пространства пользователя на объекты ядра. Объект файла будет содержать
такие сведения, как указатель файла, указывающий на на текущую позицию в файле и о том как был открыт этот файл:
Определение объекта файла представлено в include/linux/fs.h. Эта структура хранит сведения относительно взаимосвязи
соответствующего процесса с открытым файлом. Значение указателя f_inode указывает на конкретный индексный дескриптор данного
файла:
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
[……..]
Здесь описаны некоторые важные поля:
-
f_path: Данное поле представляет значение пути каталога к тому файлу, с которым ассоциирован данный объект файла. При открытии файла VFS создаёт новый объектstruct fileи инициализирует его полеf_pathдля указание на значение пути каталога данного файла. -
f_inode: Это указатель на объектstruct inode, который представляет файл, ассоциируемый с объектом даннойstruct file. -
f_op: Указатель на объектstruct file_operations, содержащий набор указателей на функции для файловых операций для ассоциируемого файла. -
f_lock: Данное поле применяется для обеспечения синхронизации между различными потоками, которые осуществляют доступ к одному и тому же объекту файла.
Как и для прочих структур, применяемых для конкретных объектов файлов методы файловой системы определены в таблице file_operations.
Значение указателя f_op показывает на такую таблицу file_operations. Собственно VFS
реализует общий интерфейс для всех файловых систем, которые подключают реальные механизмы лежащих в основе файловых систем:
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iopoll)(struct kiocb *kiocb, struct io_comp_batch *, unsigned int flags);
int (*iterate) (struct file *, struct dir_context *);
int (*iterate_shared) (struct file *, struct dir_context *);
__poll_t (*poll) (struct file *, struct poll_table_struct *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
[………………]
Определяемые здесь операции выглядят во многом аналогично описанным в Главе 1 универсальным системным вызовам:
-
llseek: Вызывается когда VFS требуется переместить положение индекса данного файла. -
read: Вызываетсяread()и родственными системными вызовами. -
open: Вызывается когда требуется открытие файла (индексного дескриптора). -
write: Вызываетсяwrite()и родственными вызовами. -
release: Вызывается когда открытый файл подлежит закрытию. -
map: Вызывается когда процесс желает установить соответствие файлу в памяти при помощи системного вызоваmmap().
Это универсальные операции. Не все они могут применяться к некому отдельному файлу. В конце концов, выбор из данного набора операций зависит от конкретной
файловой системы. Если конкретный метод не применим к файловой системе, для него можно просто установить значение NULL.
Ядро устанавливает ограничения на максимальное число одновременно открытых процессов. Такие ограничения могут применяться на уровне пользователя, группы или
глобально для системы. Когда были выделены все файловые дескрипторы, соответствующий процесс не способен открывать дополнительные файлы. Многим большим приложениям
требуется намного больше дескрипторов, чем разрешённое по умолчанию для процесса количество дескрипторов. В подобных ситуациях ограничения для отдельных
пользователей можно настраивать в файле /etc/security/limits.conf. Для настроек на всю систему можно применять команду
sysctl:
Давайте суммируем наше обсуждение, прежде чем мы достигнем своего предела открытых файлов:
-
Объект файла это представление в оперативной памяти некого открытого файла и оно не обладает соответствующим ему образом на диске.
-
Объект файла создаётся в ответ на системный вызов процессом
open(). -
Объект файла является частным для процесса. Раз более чем один процесс способен выполнять доступ к конкретному файлу, VFS будет создавать множество объектов файлов для определённого файла.
Если вы когда- либо создавали файловую систему запуская на блочном устройстве mkfs, скорее всего, в получаемом выводе
вы наблюдали термин суперблок (superblock). Суперблок это одна из наиболее знакомых обычным
пользователям структура Linux. Вы могли обратить внимание на то, что применяемые в VFS структуры очень похожи друг на друга. Dentry и файловые объекты хранят
в памяти представления каталогов и открытых файлов, соответственно. Обе структуры не обладают образом на диске и присутствуют только в оперативной памяти.
Аналогичным образом, структура суперблок обладает многим общим с индексными дескрипторами. Индексные дескрипторы хранят метаданные о файлах, тогда как суперблоки
содержат метаданные о файловых системах.
Рассмотрим пример системы каталога библиотеки, которая отслеживает книги, включая их названия, авторов и расположения на полках. Когда система каталогов утеряна ил повреждена, найти и получить конкретные книги в этой библиотеке может оказаться проблематично. Точно так же, когда в ядре повреждена структура суперблока, это может приводить к утрате данных или к ошибкам файловой системы.
Точно так же как каждый файл обладает назначенным ему индексным дескриптором, всякая файловая система обладает соответствующей структурой суперблока. Как и
индексные дескрипторы, суперблок также обладает образом на диске. Для вырабатывающих "на лету" своё содержимое файловых систем, таких как
procfs и sysfs, структуры суперблоков хранятся только в оперативной памяти. Когда
некая файловая система подлежит монтированию, относящиеся к монтированию этой файловой системы сведения сохраняются в её суперблоке.
Суперблок файловой системы содержит запутанные сведения относительно своей файловой системы, такие как общее число блоков, их используемое число, значения не используемых и свободных блоков, состояние и тип файловой системы, индексные дескрипторы и многое иное. По мере внесения изменений в файловую систему хранимая в данном суперблоке информация обновляется. Поскольку суперблок считывается при монтировании файловой системы, мы должны задаться вопросом что произойдёт если хранимые в её суперблоке сведения уничтожены или разрушены. Проще говоря, без суперблока невозможно смонтировать файловую систему. Учитывая его критически важную природу, во множестве мест на диске сохраняются несколько копий суперблока. В случае нарушений в первичной копии суперблока файловая система может быть смонтирована при помощи любой имеющейся резервной копии суперблока.
Структура суперблока определена в include/linux/fs.h. s_list содержит
указатели на монтированные суперблоки, а s_list идентифицирует его устройство. Операции суперблока определены в таблице
super_operations, на которую ссылается указатель s_op:
struct super_block {
struct list_head s_list; /* Keep this first */
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size */
struct file_system_type *s_type;
const struct super_operations *s_op;
const struct dquot_operations *dq_op;
const struct quotactl_ops *s_qcop;
const struct export_operations *s_export_op;
[…………………………]
Ниже пояснены некоторые важные поля суперблока:
-
s_list: Данное поле применяется для поддержки списка всех смонтированных на данный момент файловых систем. -
s_dev: Это поле определяет значение номера устройства, которое соответствует индексному дескриптору корневого каталога файловой системы. -
s_type: Поле указывает на определение конкретной файловой системы, которая применяется для интерпретации хранимых в этой файловой системе данных. Например, если оно указывает на файловую систему XFS, ядро знает, что для взаимодействия с этой файловой системой ему требуется пользоваться специфичными для XFS функциями. -
s_root: Данное поле используется ядром для определения местоположения корневого каталога этой файловой системы при её монтировании. После токо как значение корневого каталога идентифицировано, для доступа к прочим файлам в этой файловой системе можно перемещаться по её дереву каталогов. -
s_magic: Это поле применяется для идентификации типа данной файловой системы в конкретном устройстве или разделе.
И снова, полей великое множество, а потому все их пояснить невозможно. Некоторые поля представляют собой простые целые числа, тогда как иные обладают гораздо более сложными структурами данных и указателями функций.
Как и для всех структур VFS, все операции над суперблоками из include/linux/fs.h не являются обязательными для файловой
системы. Ядро удерживает копию суперблока файловой системы в оперативной памяти. Когда в файловую систему вносятся изменения, в памяти обновляются сведения о
суперблоке. Тем самым, данная копия суперблока помечается как dirty (изменённая), поскольку ядру надлежит обновить суперблок
на диске изменёнными данными:
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
void (*free_inode)(struct inode *);
void (*dirty_inode) (struct inode *, int flags);
int (*write_inode) (struct inode *, struct writeback_control *wbc);
int (*drop_inode) (struct inode *);
void (*evict_inode) (struct inode *);
void (*put_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
int (*freeze_super) (struct super_block *);
[………………………..]
Ниже определены некоторые важные методы:
-
alloc_inode: Этот метод вызывается для инициализации и выделения памяти подstruct inode. -
destroy_inode: Данный метод вызываетсяdestroy_inode()для освобождения выделенныхstruct inodeресурсов. -
dirty_inode: Метод, вызываемый VFS для пометки некого индексного дескриптора какdirty. -
write_inode: Данный метод вызывается когда VFS требуется выполнить запись индексного дескриптора на диск. -
delete_inode: Вызывается когда VFS хочет удалить индексный дескриптор. -
sync_fs: Вызывается когда VFS записываетdirtyданные, ассоциируемые с суперблоком. -
statfs: Вызывается когда VFS требуется получить статистические данные файловой системы, такие как её размер, свободное пространство и число индексных дескрипторов. -
umount_begin: Вызывается при демонтаже файловой системы.
Давайте суммируем:
-
Структура суперблока записывает все характеристики файловой системы.
-
Структура суперблока считывается при монтировании и демонтаже файловой системы. Файловые системы поддерживают копии суперблоков во множестве мест на диске.
В своём обсуждении записей каталога мы упоминали операцию привязки (linking). Ссылки (привязки) имеются двух типов: символические (или программные, мягкие, soft) и жёсткие (hard), как могло бы знать большинство пользователей. Символические ссылки ведут себя как ярлыки, хотя и имеются небольшие отличия. Символические ссылки (soft links) указывают на значение пути, содержащего данные, в то время как жёсткие ссылки (hard links) ссылаются собственно на данные.
Вернёмся слегка обратно, конкретный индексный дескриптор не содержит названия своего файла. Значение названия файла содержится внутри его каталога. Это означает, что что в списке некоторого каталога может иметься множество названий файлов, причём все они могут указывать на один и тот же индексный дескриптор. Данной логикой пользуются жёсткие ссылки. Жёсткая ссылка указывает на значение индексного дескриптора файла. Это подразумевает, что такая ссылка и файл не отличимы, поскольку они оба указывают на один и тот же индексный дескриптор. Спустя какое- то время вы даже можете не понимать что именно было первоначальным файлом:
Рисунок 2.7

Невозможно сказать какой из файлов первоначальный, поскольку оба обладают одним и тем же индексным дескриптором
Напротив, символические ссылки обладают номерами индексных дескрипторов, отличающимися от значений и оригинального файла. Обратите внимание, что такая
символическая ссылка указывает на изначальный файл и обозначается значением l в разделе разрешений данного файла:

Применение одного и того же номера индексного дескриптора для множества файлов имеет результатом некие ограничения. Поскольку номера индексных дескрипторов уникальны только внутри некой файловой системы, жёсткие ссылки не могут выходить за границы файловой системы. Они существуют только внутри какой- то файловой системы. Это препятствует нарушениям в структуре такой файловой системы. Жёсткие ссылки на каталог способны создавать бесконечные зацикленные структуры.
Некоторые из тех понятий, которые мы обсуждали здесь станут намного яснее когда мы обсудим блочные структуры в Главе 3, Изучаем реальные файловые системы под VFS. Но мы получили представление о том, как VFS плетёт данную паутину абстракции.
Как обсуждалось в Главе 1, архитектура VFS пристрастна в отношении возникших внутри клана Linux файловых систем. Большинство не натуральных Linux файловых систем не общаются в терминах объектов индексных дескрипторов, суперблоков, файлов и каталогов. Для реализации под них общей файловой модели VGS создаёт такие структуры в оперативной памяти. Тем самым, такие объекты, как индексные дескрипторы и суперблоки, которые для естественных Linux файловых систем присутствуют на диске и в оперативной памяти, для пришлых файловых систем могут присутствовать только в оперативной памяти. По причине различий в самой архитектуре пришлых файловых систем, они могут не поддерживать некоторые распространённые в Linux операции, например, символические ссылки.
Приводимая ниже таблица кратко суммирует основные структуры VFS:
| Структура | Описание | Хранение на диске/ в памяти |
|---|---|---|
|
Содержит все метаданные файла за исключением его названия |
На диске и в памяти |
|
Представляет взаимосвязь между записями каталога и файлами |
Только в памяти |
file object
Хранит сведения относительно взаимосвязи определённого процесса с каким- то открытым файлом
Только в памяти
superblock
Содержит характеристики и метаданные файловой системы
На диске и в памяти
Приводимая далее схема представляет как циркулирует открытие файла на диске процессом:
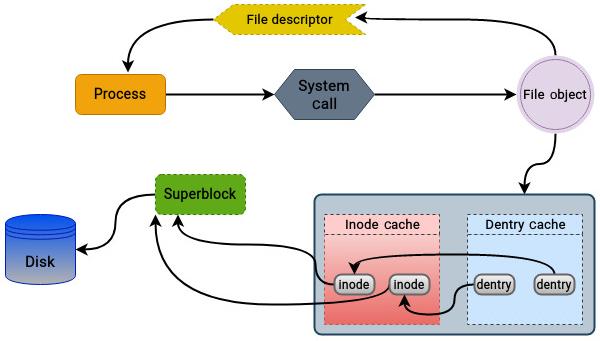
Помните, что структура суперблока создаётся и инициализируется в процессе монтирования файловой системы и содержит указатель на dentry (запись каталога) своего корня, которая, в свою очередь, содержит указатель на индексный дескриптор, представляющий значение корневого каталога данной файловой системы.
Когда для открытия файла процесс делает системный вызов open () VFS создаёт объект
struct file для представления этого файла в адресном пространстве процесса и инициализирует поле
f_path для указания на значение пути файла для этого файла. Объект struct dentry
содержит указатель на объект struct inode, который представляет индексный дескриптор файла на диске.
Объект struct inode ассоциирован с объектом struct super_block, который
представляет значение struct super_block файловой системы на диске. Объект struct
super_block содержит указатели на специфичные для файловой системы функции определяемые в структуре struct
super_operations, которая при меняется в VFS для взаимодействия с этой файловой системой.
Применяемая для определения различных понятий и терминов в Linux терминология слегка странная. Системные вызовы для создания файла именуются
creat. Создатель Unix, Кен Томпсон однажды в шутку сказал, что отсутствие e
в creat стало самым большим сожалением архитектуры Unix. При описании некоторых операций со структурами VFS
применялось слово dirty (грязные). Как и почему этот термин применяется в Linux остаётся лишь догадываться.
В этом случае термин грязные относится к уже изменённым страницам памяти, которые пока не были
сброшены (flushed) на диск.
Для улучшения производительности общим применяемым на практике приёмом как в аппаратных устройствах, так и в программных приложениях является кэширование. В плане аппаратных средств скорости и производительность ЦПУ, подсистемы памяти и физических дисков имеется взаимосвязь. Центральный процессор намного быстрее подсистемы оперативной памяти, которая, в свою очередь, быстрее физических дисков. Такое несоответствие в скорости способно приводить к напрасной трате ресурсов ЦПУ при ожидании отклика от оперативной памяти или диска.
Для решения этой проблемы к ЦПУ для хранения данных с частым доступом из основной памяти были добавлены уровни кэширования. Это делает возможным для ЦПУ работать на его естественной скорости до тех пор пока в таком кэше доступны необходимые данные. Аналогичным образом программные приложения также пользуются кэшированием для хранения данных или инструкций с частым доступом в более быстром и более доступном местоположении чтобы улучшать производительность.
Архитектура Linux ориентирована на производительность, причём в обеспечении этого жизненно важную роль играет кэш. Основная цель страничного кэша
заключается в уменьшении задержки операций read и write, обеспечивая
хранение в оперативной памяти (при условии её достаточности) с тем, чтобы можно было избегать частых обращений к лежащим в основе физическим дискам.
Всё это содействует повышению производительности, ибо доступ к диску осуществляется намного медленнее нежели к оперативной памяти.
Операционные системы взаимодействуют с оборудованием на более низком уровне и для управления и использования доступных ресурсов применяют различные элементы. Например, файловые системы разбивают имеющееся дисковое пространство на блоки, которые выступают абстракцией более высокого уровня чем индивидуальные байты и биты. Фундаментальным элементов в оперативной памяти ядра выступает страница и она по умолчанию имеет размер в 4кБ. Именно это является существенным, так как все операции ввода/ вывода выравниваются на некое число страниц. Приводимый ниже рисунок подводит итог тому как данные считываются с диска и записываются на него при помощи кэша страниц:
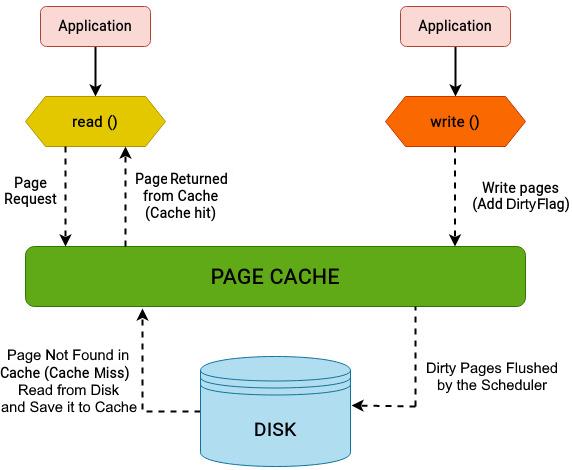
Рисунок 2.10 выделяют то как кэширование страниц служит для улучшения производительности считывания и записи путём кэширования часто применяемых данных в оперативной памяти, тем самым снижая доступ к дискам и благотворно сказываясь на производительности системы.
Перечисляемые далее моменты предоставляют краткое суммирование того что происходит когда некий запущенный в пространстве пользователя процесс запрашивает считывание данных с диска:
-
Само ядро изначально проверяет доступны ли уже в его кэше необходимые данные. Если данные обнаруживаются в его кэше, ядро имеет возможность избежать осуществления каких бы то ни было дисковых операций и предоставляет напрямую в процесс запрошенные данные. Такая ситуация носит название попадания в кэш (cache hit).
-
Когда запрашиваемые данные не могут быть обнаружены в кэше, ядро должно обращаться к лежащему в основе диску. Это именуется промахом кэша (cache miss). Перед этим ему приходится удостовериться достаточно ли имеется свободной оперативной памяти. После этого ядро составляет расписание операций
read, осуществляет выборку запрошенных данных с соответствующего диска, сохраняет их в имеющийся кэш и далее обрабатывает их для вызывающего процесса. -
Если для доступа к этой странице выполняются какие- то последующие запросы, они могут пополняться из данных кэшированных страниц.
-
В случае когда запрошенные данные обнаружены в кэше, но уже были помечены как
dirty, ядро сначала запишет их обратно на диск прежде чем продолжать обозначенную выше процедуру.
Аналогично, когда процессу необходимо выполнить запись на диск, происходит следующее:
-
Ядро обновляет соответствующий этому файлу страничный кэш и помечает данные как
грязные. Те страницы, которые пока не были записаны на диск носят название dirty pages. -
Ядро не будет немедленно записывать все грязные данные на диск. Такие грязные данные будут сбрасываться на соответствующий диск в зависимости от настроек потока сброса ядра.
По завершению запроса write ядро отправляет некое подтверждение вызывавшему процессу. Тем не менее, оно
не информирует этот процесс относительно того чтобы соответствующие грязные данные в действительности будут записаны на диск. Занятно отметить, что
подобный асинхронный подход превращает операции записи в намного более быстрые операции по сравнению с операциями считывания, поскольку ядро
маневрирует неким путём по лежащему в основе физическому диску. Возникает также вопрос: раз мои запросы на ввод/
вывод обслуживаются из оперативной памяти, что произойдёт в случае внезапного отключения питания?. Все грязные страницы в оперативной
памятив действительности сбрасываются на необходимые физические диски через определённый интервал; это носит название
обратной записи (writeback). Насколько часто сбрасываются или как долго данные хранятся
в памяти зависит от определённых факторов. Когда приложение продолжает кэшировать данные это может создавать проблемы для прочих процессов
в системе. Общий объём памяти системы намного меньше ёмкости физического диска, поэтому следует постоянно очищать кэш. Для предотвращения утраты
критически важных данных некоторым приложениям, к примеру базам данных, необходимы гарантии того, что данные были записаны на постоянное хранение.
В таких ситуациях имеет смысл немедленно сбрасывать грязные данные на диск. Ядро (через sysctl) предлагает
некоторые настройки, которые могут применяться для управления таким поведением кэширования
страниц.
Несмотря на связанные с кэшированием страниц риски, оно несомненно повышает производительность. Значение размера кэширования страниц не фиксировано; по своей природе он динамичен. Страничный кэш способен пользоваться всеми доступными ресурсами оперативной памяти. Однако как только величина доступной системе свободной оперативной памяти падает ниже порогового значения срабатывают планировщики очистки и они приступают к выгрузке страничного кэша на диск.