Часть I: Окунаемся в Виртуальную файловую систему
Данная часть предлагает подробное введение в уровень VFS (virtual filesystem, виртуальной файловой системы) и находящиеся под ней реальные файловые системы. Вы изучите VFS, её основные структуры данных, семейство расширенной файловой системы, а также основные понятия, связанные с различными файловыми системами в Linux.
Эта часть содержит следующие главы:
Глава 1. Откуда всё начинается - Виртуальная файловая система
Содержание
Даже несмотря на астрономические успехи в разработке программного обеспечения, ядро Linux остаётся одним из самых сложных фрагментов кода. Разработчики, программисты и потенциальные хакеры ядра постоянно стремятся погрузиться в сам код ядра и предложить новые функции, тогда как любители и энтузиасты пытаются понять и разгадать эти тайны.
Естественно, о Linux и его внутренней работе написано очень много, начиная с общего администрирования и до программирования ядра. За десятилетия были опубликованы сотни книг, охватывающих широкий спектр важных вопросов операционных систем, таких как создание процессов, многопоточность, управление памятью, виртуализация, реализации файловых систем и расписания ЦПУ. Эта книга, которую вы взяли в руки (спасибо вам!), будет посвящена стеку хранения данных в Linux и его многоуровневой организации.
Мы начнём с представления собственно Виртуальной файловой системы в ядре Linux и её ключевой роли в предоставлении программам конечного пользователя доступа к данным в файловых системах. Более глубокое понимание Виртуальной файловой системы чрезвычайно важно, поскольку в этой книге мы намерены охватить весь стек хранилища сверху вниз, а также ибо она является отправной точкой запроса ввода/ вывода в ядре. Мы представим понятия пространства пользователя и пространства ядра, разберёмся с системными вызовами и обнаружим, как философия "Все является файлом" в Linux связана с Виртуальной файловой системой.
В данной главе мы намерены рассмотреть следующие важные вопросы:
-
Понимание хранилища в современном Центре обработки данных (ЦОД)
-
Определение системных вызовов
-
Пояснение необходимости Виртуальной файловой системы
-
Описание Виртуальной файловой системы
-
Объяснение философии "Все является файлом"
Прежде чем следовать далее, я полагаю, важно признать, что некоторые технические вопросы могут оказаться более сложными для понимания новичками, нежели прочие. Поскольку здесь целью основной является понимание внутренней работы ядра Linux и его основных подсистем, будет полезно иметь хорошее базовое понимание понятий операционной системы в целом и Linux в частности. Прежде всего, важно подходить к этим вопросам с терпением, любопытством и желанием учиться.
Представленные в данной главе команды и примеры не зависят от дистрибутива и могут быть запущены в любой операционной системе Linux, таких как Debian, Ubuntu, Red Hat {Rocky Linux} и Fedora. Существует ряд ссылок на исходный код ядра Linux. Если вы желаете выгрузить исходный код ядра, вы можете выполнить это по ссылке https://www.kernel.org. Относящиеся к данной главе пакеты можно установить следующим образом:
-
Для Ubuntu/Debian:
-
sudo apt install strace -
sudo apt install bcc
-
-
Для систем на основе Fedora/CentOS/Red Hat {Rocky}:
-
sudo yum install strace -
sudo yum install bcc-tools
-
Теоретизировать, не обладая данными, это серьёзная ошибка. Незаметно человек начинает искажать факты, подгоняя их под теории, вместо того чтобы теории соответствовали фактам. - Сэр Артур Конан Дойл
Основой любой инфраструктуры выступают вычисления, хранилища и сетевые среды. Насколько хорошо работают ваши приложения, зачастую зависит от совместной производительности этих трёх слоёв. Выполняемые в современном ЦОД (Центре обработки данных) рабочие нагрузки разнятся от потоковых служб до приложений машинного обучения. Совместно со стремительным ростом и внедрением платформ облачных вычислений все основные строительные блоки теперь абстрагированы от конечного пользователя. Превращается в норму добавление дополнительных аппаратных ресурсов в ваше приложение по мере того, как оно превращается в требовательное к ресурсам. Устранение проблем производительности часто игнорируется в пользу миграции приложений на более совершенные аппаратные платформы.
Из этих трёх строительных блоков, вычислений, хранилищ и сетевой среды, в большинстве ситуаций именно хранилища зачастую рассматриваются как узкое место. Для таких приложений как базы данных, значение производительности лежащего в основе хранилища имеет первейшую важность. В случаях, когда инфраструктура размещает критически важные и чувствительные ко времени приложения, например, OLTP (Online Transaction Processing, оперативная обработка транзакций), именно производительность хранилищ зачастую попадает под радары. Малейшие задержки при обслуживании запросов ввода/ вывода способны оказывать воздействие на общий отклик всего приложения.
Наиболее распространённой метрикой, применяемой для замеров производительности хранилища выступает задержка (латентность). Обычно, время отклика запоминающих устройств измеряется миллисекундами. Сопоставьте это со средними значениями процессора или памяти, где такие показатели измеряются в наносекундах и вы поймёте как производительность слоя хранения может оказывать воздействие на общую работу вашей системы. В результате это приводит к несоответствию между требованиями вашего приложения и тем, что на самом деле способно обеспечивать базовое хранилище. За последние несколько лет большинство достижений в области современных накопителей было ориентировано на размер - область значения ёмкости. Однако повышение производительности оборудования хранения данных не происходило теми же темпами. По сравнению с вычислительными функциями, производительность хранилища выглядит бледно. По этим причинам его зачастую именуют трёхногой собакой ЦОД.
Говоря о выборе носителя информации, уместно заметить, что насколько мощным он бы не являлся, в своих функциональных возможностях аппаратные средства всегда будут обладать ограничениями. Не менее важно, чтобы приложение и операционная система настраивались в соответствии с имеющимся оборудованием. Точная настройка параметров вашего приложения, операционной системы и файловой системы способна значительно повысить общую производительность. Чтобы пользоваться всем потенциалом базового оборудования, все уровни вашей иерархии ввода/ вывода должны функционировать действенно.
Ядро Linux проводит чёткое разграничение между процессами пространства пользователя и пространства ядра. Все доступные аппаратные ресурсы, такие как ЦПУ, оперативная память и хранилище лежат в пространстве ядра. Любое желающее получить доступ к ресурсам пространства ядра приложение обязано выработать системный вызов (system call), как это показано на Рисунке 1.1:
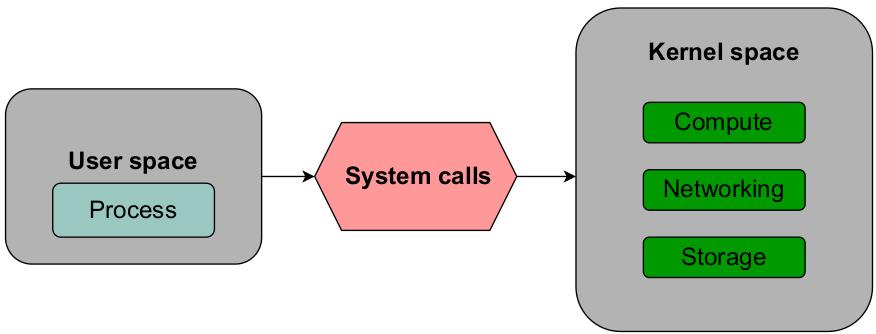
Пространство пользователя (User space) относится ко всем приложениям и процессам, обитающим вне своего ядра. Пространство ядра содержит такие программы как драйверы устройств, которые обладают доступом к лежащему в основе оборудованию без ограничений. Такое пространство пользователя может рассматриваться в виде песочницы для ограничения программам пользователя изменений критически важных функций.
Понятие пространства пользователя и ядра глубоко укоренилось в архитектуре современных процессоров. Традиционные ЦПУ x86 пользуются понятием защищённых областей, носящих название колец (ring), для совместного и ограниченного доступа к аппаратным ресурсам. Процессоры предлагают четыре кольца или режима, которые пронумерованы от 0 до 3. Современные процессоры спроектированы под работу в двух из этих режимов, кольца 0 и кольца 3. Приложения пространства пользователя обрабатываются в кольце 3, которое обладает ограниченным доступом к ресурсам ядра. Само ядро занимает кольцо 0. Именно здесь исполняется код ядра и осуществляется взаимодействие с лежащими в основе аппаратными ресурсами.
Когда процессам требуется выполнить считывание или запись в некий файл, им придётся взаимодействовать со структурами файловой системы поверх своего физического диска. Для организации данных на соответствующем физическом диске всякая файловая система пользуется различными методами организации данных. Сам запрос от такого процесса не достигает непосредственно своих файловой системы или физического диска. Для того, чтобы соответствующий запрос на ввод/ вывод такого процесса был обслужен своим физическим диском, ему приходится проходить через всю иерархию в своём ядре. Самый первый уровень в этой иерархии носит название Виртуальной файловой системы (VFS, Virtual Filesystem). Наш следующий Рисунок, Рисунок 1.2, высвечивает основные компоненты такой Виртуальной файловой системы:
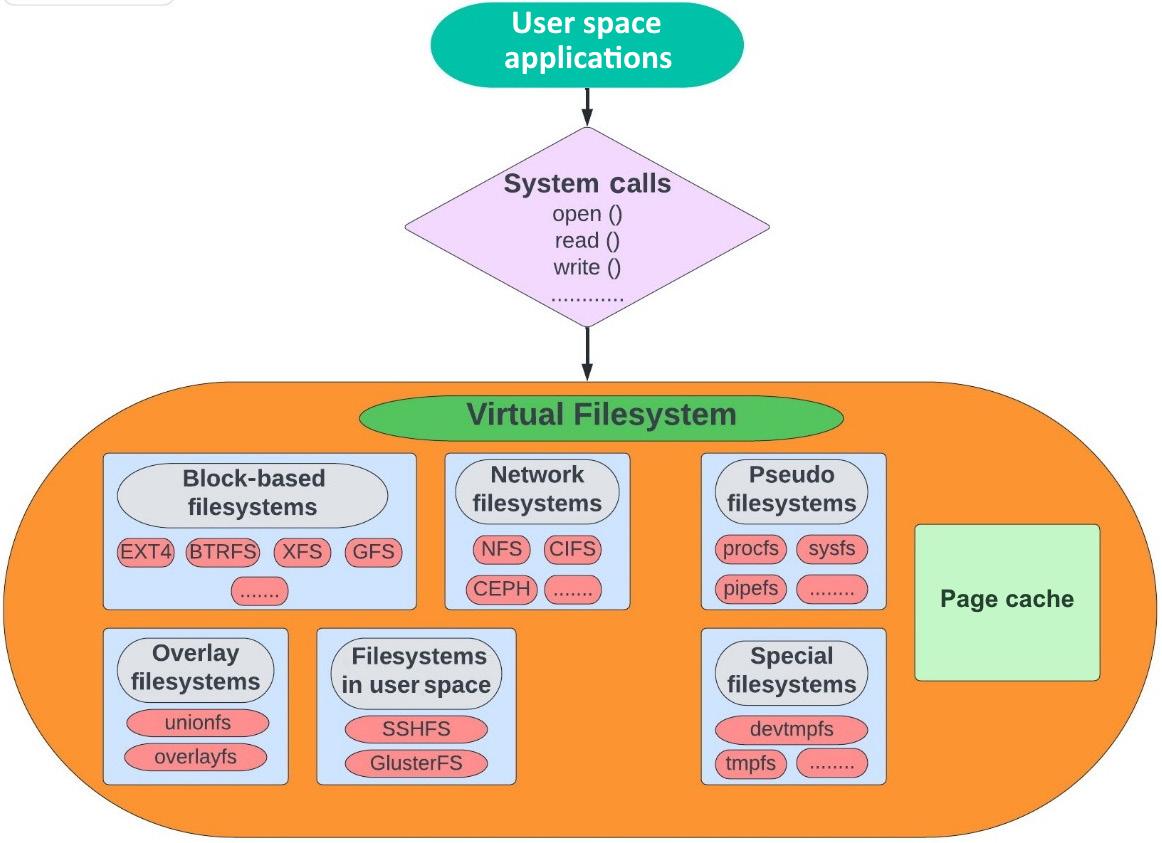
Имеющийся стек хранения в Linux состоит из большого числа составляющих единое целое уровней, причём все они гарантируют что собственно доступ к носителю физического хранилища абстрагирован посредством единообразного интерфейса. По мере нашего продвижения вперёд, мы намерены выполнять построение этой структуры и добавлять дополнительные уровни. Мы попробуем погрузиться поглубже в каждый из них и рассмотреть как они работают в гармонии.
Данная глава будет сосредоточена исключительно на самой Виртуальной файловой системе и её различных функциональных возможностях. В последующих главах мы намерены пояснить и раскрыть некую происходящую под капотом работу для наиболее широко применяемых в Linux файловых системах. Тем не менее, учитывая насколько часто здесь будет применяться термин файловая система, я полагаю разумным кратко классифицировать различные типы файловых систем просто во избежание путаницы:
-
Блочная файловая система: Файловые системы на основании блоков или дисков это наиболее распространённый способ хранения пользовательских данных. В качестве обычного пользователя операционной системы, именно с этими файловыми системами чаще всего взаимодействуют пользователи. Такие файловые системы, как Extended filesystem version 2/3/4 (Ext 2/3/4), Extent filesystem (XFS), Btrfs, FAT и NTFS, все они относятся к категории основанных на дисках, или блочных файловых систем. Эти файловые системы общаются в терминах блоков. Значение размера блока это свойство соответствующей файловой системы и оно может быть установлено только при создании файловой системы в устройстве. Значение размера блока указывает какой размер этой файловой системы будет применяться при считывании или записи данных. Мы можем рассматривать его в качестве логического элемента размещения и выборки хранилища для файловой системы. Устройство, к которому может выполняться доступ в терминах блоков является, таким образом, носящим название блочного устройства. Всякое подключаемое к компьютеру устройство хранения, будь то жёсткий диск или некое внешнее USB, может классифицироваться в качестве блочного устройства. Обычно блочные файловые системы монтируются в единичном хосте и не допускают совместного применения множеством хостов.
-
Кластерные файловые системы: Кластерные файловые системы также являются блочными файловыми системами и для считывания или записи данных они применяют методы доступа на основе блоков. Основное отличие состоит в том, что они допускают одной файловой системе одновременно выполнять монтирование и использование множеством хостов. Кластерные файловые системы основываются на понятии совместного хранилища (shared storage), что означает, что множество хостов способно одновременно выполнять доступ к одному и тому же блочному устройству. Распространёнными файловыми системами в Linux являются GFS2 Global File System 2 в Red Hat и OCFS (Oracle Clustered File System).
-
Сетевые файловые системы (NFS, Network filesystems): Это протокол, который делает возможным удалённое совместное использование файла. В отличии от обычных блочных файловых систем, NFS основывается на понятии совместного применения данных множеством хостов. NFS работает с понятиями клиента и сервера. Основа хранилища предоставляется сервером NFS. Те системы хостов, в которых монтируется такая файловая система NFS носят название клиентов. Необходимое соединение между такими клиентом и сервером достигается при помощи обычного Ethernet. Все клиенты NFS совместно используют единственную копию файла в своём сервере NFS. NFS не предлагает ту же самую производительность что и блочные файловые системы, однако они всё ещё применяются в корпоративных средах, в основном, для долговременного хранения резервных копий и совместного применения общих данных.
-
Псевдо файловые системы: Псевдо файловые системы присутствуют в самом ядре и динамически производят своё содержимое. Они не применяются для постоянного хранения данных. Их поведение отличается от таких обычных дисковых файловых систем как Ext4 или XFS. основная цель псевдо файловой системы состоит во взаимодействии со своим ядром. Под эту категорию подпадают такие каталоги как
/proc(procfs) и/syssysfs. Эти каталоги содержат виртуальные или временные файлы, которые содержат сведения относительно различных подсистем ядра. Такие псевдо файловые системы также часть ландшафта Виртуальной файловой системы, как мы обнаружим это в разделе всё является файлом.
Теперь, когда мы уяснили основную идею пространства пользователя, пространства ядра и различных типов файловых систем, давайте поясним как приложение способно запрашивать ресурсы в пространстве ядра через системные вызовы.
Рассматривая рисунок, поясняющий взаимодействие между приложениями и Виртуальной файловой системой, возможно, вы заметили промежуточный уровень между программами пространства пользователя и Виртуальной файловой системой; этот слой именуется интерфейсом системных вызовов. Для запроса у своего ядра какую бы то ни было услугу, программы пространства пользователя выполняют активацию интерфейса системного вызова. Такие системные вызовы предоставляют приложениям конечных пользователей средства доступа к ресурсам в пространстве ядра, например, к процессору, памяти и хранилищу. Интерфейс системного вызова служит трём основным целям:
-
Гарантия безопасности: Системные вызовы препятствуют приложениям пространства пользователя напрямую изменять ресурсы пространства ядра.
-
Абстракция: Приложениям нет необходимости самостоятельно иметь дело с лежащими в основе спецификациями оборудования.
-
Переносимость: Программы пользователей могут корректно запускаться во всех ядрах, которые реализуют некий набор интерфейсов.
Зачастую встречается путаница различий между системными вызовами (system calls) и API (application programming interface, интерфейсом прикладного программирования). Некий API это набор программного интерфейса, применяемого программой. Такие интерфейсы определяют метод взаимодействия между двумя компонентами. API реализуется в пространстве пользователя и в выступает эскизом получения конкретной службы. Системный вызов это механизм намного более низкого уровня, который пользуется прерываниями для осуществления в явном виде запроса к своему ядру. В Linux интерфейс системного вызова предоставляется стандартной библиотекой C.
Когда выработанный вызывающим процессом системный вызов успешен, возвращается файловый дескриптор. Файловый
дескриптор (file descriptor) это некое применяемое для доступа к файлам целое число. Например, при открытии файла с помощью системного вызова
open (), в вызвавший процесс возвращается файловый дескриптор. После открытия файла программы пользуются этим дескриптором
для выполнения операций с данным файлом. При помощи этого файлового дескриптора выполняются все операции считывания, записи и прочих действий.
Всякий процесс, как минимум, обладает тремя открытыми файлами - стандартным вводом, стандартным выводом и стандартной ошибкой - представляемыми, соответственно,
значениями дескрипторов 0,1 и 2. Следующему открываемому файлу будет назначен дескриптор со значением 3. Если мы выполняем просмотр перечня файлов через
1 секунду и запустим strace, системный вызов open вернёт значение
3, которое выступает файловым дескриптором, представляющим файл - в данной ситуации
/etc/hosts. После этого, для осуществления последующих операций, значение данного файлового дескриптора применяется
вызовами fstat и close:
strace ls /etc/hosts
root@linuxbox:~# strace ls /etc/hosts
execve("/bin/ls", ["ls", "/etc/hosts"], 0x7ffdee289b48 /* 22 vars */) = 0
brk(NULL) = 0x562b97fc6000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=140454, ...}) = 0
mmap(NULL, 140454, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7fbaa2519000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libselinux.so.1", O_RDONLY|O_CLOEXEC) = 3
[Остальной код опущен для краткости.]
В системах x86 существует около 360 системных вызовов. Это число может отличаться для различных архитектур. Всякий системный вызов представлен уникальным
целым числом. Вы можете перечислить в вашей системе при помощи команды ausyscall. Это выведет список системных вызовов и
их соответствующих численных значений:
ausyscall –dump
root@linuxbox:~# ausyscall --dump
Using x86_64 syscall table:
0 read
1 write
2 open
3 close
4 stat
5 fstat
6 lstat
7 poll
8 lseek
9 mmap
10 mprotect
[Остальной код опущен для краткости.]
root@linuxbox:~# ausyscall --dump|wc -l
334
root@linuxbox:~#
Следующая таблица перечисляет некоторые распространённые системные вызовы:
| Системный вызов | Описание |
|---|---|
|
Открывает и закрывает файлы |
|
Создаёт файл |
|
Изменяет каталог |
|
Монтирует и демонтирует файловую систему |
|
Изменяет значение положения указателя в файле |
|
Выполняет считывание и запись в файл |
|
Получает состояние файла |
|
Получает статистические сведения файла |
|
Исполняет конкретную программу по ссылке имени пути |
|
Проверяет способен ли вызывающий процесс выполнять доступ по указанному имени пути |
|
Создаёт новое соответствие в виртуальном адресном пространстве данного вызывающего процесса |
Итак, какую роль системные вызовы играют во взаимодействии с файловыми системами? Как мы увидим в последующих разделах, когда некое пространство пользователя вырабатывает системный вызов для доступа к ресурсу в пространстве ядра, именно Виртуальная файловая система выступает самым первым компонентом, с которым он взаимодействует. Такой системный вызов сначала обрабатывается соответствующим обработчиком системного вызова в самом ядре, а после подтверждения запрошенной операции этот обработчик выполняет вызов к соответствующей функции на уровне VFS. Данный уровень VFS передаёт значение запроса в надлежащий модуль драйвера файловой системы, который и выполняет реальные операции с необходимым файлом.
Нам следует здесь понять зачем - почему наш процесс взаимодействует с Виртуальной файловой системой, а не с реальной файловой системой на диске? В идущем далее разделе мы выясним это.
Чтобы суммировать, рассматриваемый интерфейс системных вызовов в Linux реализует общие методы, которые могут применяться приложениями в пространстве пользователей для доступа к ресурсам пространства ядра.
Некая стандартная файловая система это набор структур данных, который определяет как организованы на диске данные пользователя. Конечный пользователь способен взаимодействовать с такой стандартной файловой системой посредством обычных методов файлового доступа и решать общие задачи. Всякая операционная система (как Linux, так и не- Linux) предоставляют по крайней мере одну такую файловую систему, и, естественно, каждая из них претендует на то, чтобы быть лучше, быстрее и более безопасной нежели прочие. Основное большинство современных дистрибутивов Linux в качестве файловой системы по умолчанию применяют XFS или Ext4. Эти файловые системы обладают некоторыми функциональными возможностями и рассматриваются как стабильные и надёжные для повседневного применения.
Тем не менее, поддержка файловых систем в Linux не ограничена лишь этими двумя. Одним из основных преимуществ применения Linux является то, что она предлагает поддержку большого числа файловых систем, причём все они могут рассматриваться как в точности приемлемые альтернативы для XFS и Ext4. По этой причине Linux способна свободно сосуществовать с прочими операционными системами. Некоторые из наиболее часто применяемых файловых систем включают более старые версии Ext4, такие как Ext2 и Ext3, а также Btrfs, ReiserFS, OpenZFS, FAT и NTFS. При использовании множества разделов пользователи обладают возможностью выбора из длинного списка доступных файловых систем и создавать различные файловые системы в каждом из разделов диска в соответствии со своими потребностями.
Наименьшим адресуемым элементом физического жёсткого диска выступает сектор. Для файловых систем наименьший записываемый элемент носит название блока. Блок может рассматриваться как некая группа последовательных секторов. Все операции файловой системы осуществляются в терминах блоков. Не существует единого способа адресации и организации таких блоков в разных файловых системах. Каждая файловая система имеет возможность применять свой собственный набор структур данных для размещения и хранения данных в этих блоках. Может оказываться сложным управлять наличием различных файловых систем в каждом из разделов хранилища. Принимая во внимание широкий спектр поддерживаемых в Linux файловых систем представьте себе, что приложениям требуется разбираться с подробностями каждой имеющейся файловой системы. Чтобы быть совместимой с некой файловой системой, приложению необходимо реализовать уникальный метод доступа для каждой применяемой файловой системы. Это превратило бы разработку приложения в почти не практичную.
Абстрактные интерфейсы играют критически важную роль в ядре Linux. В Linux, вне зависимости от используемой файловой системы, конечные пользователи или приложения способны взаимодействовать с конкретной файловой системой при помощи универсальных методов доступа. Всё это достигается через слой Виртуальной файловой системы, который скрывает реализации файловой системы под учитывающим всё интерфейсом.
Чтобы гарантировать что приложения не сталкиваются с подобными препятствиями (о которых мы упоминали ранее) при работе с различными файловыми системами, ядро
Linux реализует некий слой между приложениями конечного пользователя и имеющейся файловой системой, в которой подлежат хранению данные. Этот уровень носит название
VFS (Virtual Filesystem, Виртуальной
файловой системы). Такая VFS это не стандартная файловая система, подобная Ext4 или XFS. (Не существует команды mkfs.vfs!)
По этой причине кое- кто предпочитает термин Virtual Filesystem Switch (Коммутатор Виртуальной
файловой системы).
Вспомните волшебный шкаф из "Хроник Нарнии". На самом деле этот шкаф является портал в магический мир Нарнии. Пройдя через этот шкаф, вы сможете исследовать этот мир и взаимодействовать с его обитателями. Аналогичным образом VFS предоставляет доступ к разнообразным файловым системам.
VFS определяет общий интерфейс, который делает возможным сосуществовать в Linux большому числу файловых систем. Стоит ещё раз отметить, что в случае VFS мы не говорим о стандартной блочной файловой системе. Мы обсуждаем некий уровень абстракции, который обеспечивает связь между приложениями конечного пользователя и реальными блочными файловыми системами. Посредством реализуемой в VFS стандартизации, предложения способны выполнять операции считывания и записи, причём без забот относительно лежащей в основе файловой системы.
Как отражено на Рисунке 1.3, наша VFS помещается между программами пространства пользователя и реальными файловыми системами:
Рисунок 1.3
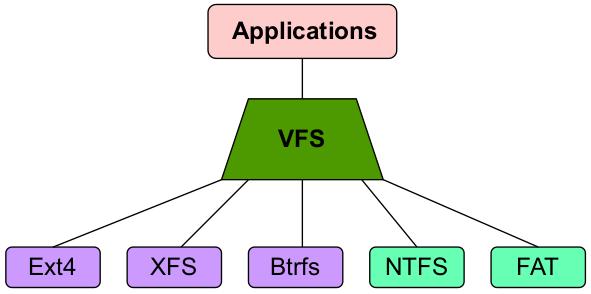
VFS действует в качестве моста между программами пространства пользователя и файловыми системами
Чтобы VFS предоставляла услуги обеим частям должно быть применимо следующее:
-
Все приложения конечного пользователя обязаны определять свои операции файловой системы в терминах предоставляемого VFS стандартного интерфейса.
-
Всем файловым системам требуется предоставлять некую реализацию общего интерфейса, предоставляемого VFS.
Мы поясняли, что приложениям пространства пользователя, когда они желают получать доступ к ресурсам пространства пользователя, требуется вырабатывать системные
вызовы. Посредством предоставляемого VFS уровня абстракции, такие системные вызовы, как read() и
write() работают как положено, причём вне зависимости от используемой файловой системы. Эти системные вызовы работают за
пределами границ файловой системы. Нам не требуется специальный механизм для перемещения данных в иную или не естественную файловую систему. Например, мы можем
просто перемещать данные из файловой системы Ext4 в XFS и наоборот. На самом верхнем уровне, когда процесс активирует системный вызов
read() или write() для считывания или записи файла, наша VFS будет находить необходимый
для применения драйвер файловой системы и передавать такие системные вызовы в данный драйвер.
Первейшая цель VFS состоит в представлении множество разнообразных файловых систем в ядре при минимальных накладных расходах. Когда некий процесс запрашивает в файле операцию считывания или записи, само ядро подставляет его специфической функцией файловой системы, в которой тот расположен. Для достижения этого каждая файловая система обязана приспосабливаться в терминах VFS.
Для лучшего понимания давайте рассмотрим следующий конкретный пример.
Воспользуемся следующим примером команды cp (copy) в Linux. Допустим, что мы
пытаемся скопировать файл из Ext4 в файловую систему XFS. Как совершается данная операция? Как команда cp взаимодействует
с этими двумя файловыми системами? Взгляните на Рисунок 1.4:
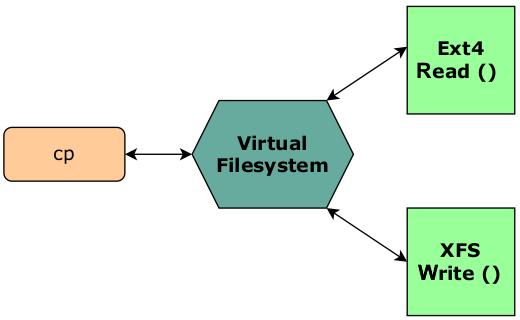
С самого начала команда cp не заботится о применяемой файловой системе. Мы определили именно уровень VFS в качестве
слоя, реализующего абстракцию. Итак, наша команда cp не имеет потребности рассматривать самостоятельно подробности
соответствующей файловой системы. А именно, она активирует системные вызовы open () и
read () для открытия и считывания того файла, который подлежит копированию. Открытие файла представляется соответствующей
структурой данных в самом ядре (как мы изучим это в нашей следующей Главе 2, Поясняем структуры данных VFS).
Когда cp вырабатывает эти универсальные системные вызовы, само ядро отправит данные вызовы в соответствующую функцию
необходимой файловой системы через указатель по которому располагается данный файл. Для копирования этого файла в файловую систему XFS системный вызов
write () передаётся в VFS. Он снова перенаправляется в соответствующую функцию файловой системы XFS, которая реализует
данную функциональную возможность. Через активируемые в VFS системные вызовы наш процесс cp может выполнять операцию
копирования пользуясь методом read () Ext4 и методом write () XFS. В точности как
коммутатор, VFS будет переключать соответствующие общие методы доступа между обозначенными ей реализациями файловых
систем.
Такие чтение, запись и любая иная функция в этом отношении не обладает в ядре определением по умолчанию- отсюда и название - virtual (виртуальная). Конкретная интерпретация этих функций зависит от лежащей в основе файловой системы. Подобно пользующимся преимуществами данной предлагаемой VFS абстракции программам пользователей, файловые системы также получают выгоду от данного подхода. Общие методы доступа к файлам не требуют предопределения файловыми системами.
Это достаточно круто, не так ли? Но что если мы пожелаем выполнить копирование чего- то из Ext4 в не родную файловую систему? Такие файловые системы как Ext4, XFS и Btrfs были намеренно разработаны под Linux. Но что если одна из участвующих в данной операции файловых систем это FAT или NTFS?
Следует признать, что архитектура VFS ориентирована на файловые системы, пришедшие из клана Linux. Для конечного пользователя существует чёткое различие между файлом и каталогом. В философии Linux же, всё является файлом, включая и каталоги. Встроенные в Linux файловые системы, такие как Ext4 и XFS, были разработаны с учётом таких нюансов. Из- за отличий в реализации, пришлые файловые системы наподобие FAT и NTFS не поддерживают все операции VFS. Для общего представления файловой системы VFS в Linux применяет такие структуры, как индексные дескрипторы, суперблоки и записи каталогов. Пришлые для Linux файловые системы не общаются в этих структурах. К примеру, возьмём файловую систему FAT. Файловая система FAT пришла из иного мира и для представления файлов и каталогов не пользуется такими структурами. Она не рассматривает каталоги в качестве файлов. Итак, как же VFS взаимодействует с файловой системой FAT?
Все относящиеся к файловой системе операции ядра прочно интегрированы со структурами данных VFS. Для применения в Linux пришлых файловых систем ядро динамически создаёт соответствующие необходимые структуры данных. Например, чтобы удовлетворять общей модели файлов для подобных FAT файловых систем, соответствующие каталогам файлы будут создаваться в памяти "на лету". Эти файлы являются виртуальными и присутствуют только в памяти. В собственных файловых системах структуры, подобные индексным дескрипторам и суперблокам не только присутствуют в памяти, но и хранятся на самом физическом носителе. И наоборот, не- Linux файловые системы, просто обязаны обязаны вводить в действие подобные структуры в памяти.
Если мы заглянем в исходный код ядра, предоставляемые его VFS разнообразные функции присутствуют в каталоге fs. Все
исходные файлы, заканчивающиеся на .c, содержат реализации различных методов VFS. Как отражено на Рисунке 1.5, конкретные
подкаталоги содержат реализации определённых файловых систем:
Вы можете обратить внимание на такие исходные файлы как open.c и read_write.c,
которые являются теми функциями, которые активируются при выработке в пространстве пользователя таких системных вызовов как open (),
read () и write (). Эти файлы содержат гигантский объём кода, а поскольку мы не
намерены здесь создавать никакого нового кода, это просто куча примеров. Тем не менее, в данных файлах имеется некоторое число важных фрагментов кода, которые
подчёркивают то, что мы поясняли ранее. Давайте по- быстрому рассмотрим функции чтения и записи.
Соответствующий макрос SYSCALL_DEFINE3 это стандартный способ определения системного вызова и он получает название
системного вызова в качестве одного из имеющихся параметров.
Для системного вызова write это определение выглядит следующим образом. Обратите внимание на то, что один из параетров
является файловым дескриптором:
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf, size_t, count)
{
return ksys_write(fd, buf, count);
}
Аналогично, вот как выглядит его определение для системного вызова read:
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
return ksys_read(fd, buf, count);
}
Оба вызывают соответствующие функции ksys_write () и ksys_read (). Давайте
рассмотрим код для этих двух функций:
ssize_t ksys_read(unsigned int fd, char __user *buf, size_t count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
******* Skipped *******
ret = vfs_read(f.file, buf, count, ppos);
******* Skipped *******
return ret;
}
ssize_t ksys_write(unsigned int fd, const char __user *buf, size_t count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
******* Skipped *******
ret = vfs_write(f.file, buf, count, ppos);
******* Skipped *******
return ret;
}
Присутствие функций vfs_read () и vfs_write () указывает на то, что мы переносимся
в VFS. Эти функции отыскивают структуру file_operations для базовой файловой системы и активирует соответствующие методы
read () и write ():
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
******* Skipped *******
if (file->f_op->read)
ret = file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
ret = new_sync_read(file, buf, count, pos);
******* Skipped *******
return ret;
}
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
******* Skipped *******
if (file->f_op->write)
ret = file->f_op->write(file, buf, count, pos);
else if (file->f_op->write_iter)
ret = new_sync_write(file, buf, count, pos);
******* Skipped *******
return ret;
}
Каждая файловая система определяет собственную структуру file_operations указателей поддерживаемых операций. В исходном
коде ядра существует множество определений структуры file_operations, уникальных для каждой из файловых систем. Определяемые
в этой структуре операции определяют как будут выполняться операции чтения и записи:
root@linuxbox:/linux-5.19.9/fs# grep -R "struct file_operations" * | wc -l
453
root@linuxbox:/linux-5.19.9/fs# grep -R "struct file_operations" *
9p/vfs_dir.c:const struct file_operations v9fs_dir_operations = {
9p/vfs_dir.c:const struct file_operations v9fs_dir_operations_dotl = {
9p/v9fs_vfs.h:extern const struct file_operations v9fs_file_operations;
9p/v9fs_vfs.h:extern const struct file_operations v9fs_file_operations_dotl;
9p/v9fs_vfs.h:extern const struct file_operations v9fs_dir_operations;
9p/v9fs_vfs.h:extern const struct file_operations v9fs_dir_operations_dotl;
9p/v9fs_vfs.h:extern const struct file_operations v9fs_cached_file_operations;
9p/v9fs_vfs.h:extern const struct file_operations v9fs_cached_file_operations_dotl;
9p/v9fs_vfs.h:extern const struct file_operations v9fs_mmap_file_operations;
9p/v9fs_vfs.h:extern const struct file_operations v9fs_mmap_file_operations_dotl;
[Остальной код опущен для краткости.]
Как вы можете видеть, структура file_operations используется для широкого диапазона типов файлов, включая обычные файлы,
каталоги, файлы устройств и сетевые сокеты. В целом, данная структура обязана охватывать все типы файлов, которые могут открываться стандартными операциями ввода/
вывода и над которыми могут производится манипуляции.
В Linux Представлено достаточно много механизмов трассировки, которые способны дать представление о том, как всё устроено под капотом. Одним из них является
инструментарий BCC (BPF Compiler Collection).
Данный инструментарий предлагает широкий спектр сценариев, которые способны записывать события для различных подсистем ядра. Следуя инструкциям в разделе
Technical requirements (Технические требования) вы можете установить эти инструменты для своей операционной системы. Сейчас мы
просто намерены воспользоваться одной из программ данного набора инструментов с названием funccount. Как следует из её
названия, функция funccount подсчитывает количество вызовов функций:
root@linuxbox:~# funccount --help
usage: funccount [-h] [-p PID] [-i INTERVAL] [-d DURATION] [-T] [-r] [-D]
[-c CPU]
pattern
Count functions, tracepoints, and USDT probes
Просто чтобы проверить и подтвердить своё понимание того, о чём мы говорили ранее, мы собираемся запустить простой процесс копирования в фоновом режиме и
воспользоваться программой funccount для отслеживания вызываемых в результате исполнения cp
функций VFS. Поскольку мы намерены подсчитывать вызовы VFS только для процесса cp, нам необходимо воспользоваться флагом
-p для указания необходимого процесса. Наш параметр vfs_* будет отслеживать все
функции VFS для указанного процесса. Вы обнаружите, что процессом cp вызываются функции
vfs_read () и vfs_write (). Значение столбца
COUNT определяет число вызовов соответствующей функции:
funccount -p process_ID 'vfs_*'
[root@linuxbox ~]# nohup cp myfile /tmp/myfile &
[1] 1228433
[root@linuxbox ~]# nohup: ignoring input and appending output to 'nohup.out'
[root@linuxbox ~]#
[root@linuxbox ~]# funccount -p 1228433 "vfs_*"
Tracing 66 functions for "b'vfs_*'"... Hit Ctrl-C to end.
^C
FUNC COUNT
b'vfs_read' 28015
b'vfs_write' 28510
Detaching...
[root@linuxbox ~]#
Давайте запустим это снова и посмотрим какие системные вызовы применяются когда мы выполняем простую операцию копирования. Как и ожидалось, при выполнении
cp, наиболее часто используемыми системными вызовами являются read и
write:
funccount 't:syscalls:sys_enter_*' -p process_ID
[root@linuxbox ~]# nohup cp myfile /tmp/myfile &
[1] 1228433
[root@linuxbox ~]# nohup: ignoring input and appending output to 'nohup.out'
[root@linuxbox ~]#
[root@linuxbox ~]# /usr/share/bcc/tools/funccount -p 1228433 "vfs_*"
Tracing 66 functions for "b'vfs_*'"... Hit Ctrl-C to end.
^C
FUNC COUNT
b'vfs_read' 28015
b'vfs_write' 28510
Detaching...
[root@linuxbox ~]#
Давайте суммируем рассмотренное нами в данном разделе. Linux предлагает поддержку для широкого диапазона файловых систем, а уровень VFS в его ядре обеспечивает то, что этого можно достигать без каких бы то ни было преград. VFS предоставляет стандартный способ взаимодействия с различными файловыми системами процессам конечных пользователей. Такая стандартизация достигается за счёт реализации общего режима файла. VFS определяет некоторые виртуальные функции для распространённых файловых операций. В результате данного подхода приложения способны универсальным образом выполнять операции обычных файлов. Когда некий процесс вырабатывает системный вызов, VFS перенаправит такие вызовы в соответствующую функцию необходимой файловой системы.
В Linux все следующее рассматривается как файлы:
-
Каталоги
-
Дисковые устройства и их разделы
-
Сокеты
-
Конвейеры
-
CD-ROM
Фраза всё является файлом подразумевает, что все предыдущие логические элементы в Linux представлены файловыми дескрипторами, абстрагируемыми поверх VFS. Вы также можете сказать что всё обладает дескриптором файла, но давайте не вдаваться в эту дискуссию.
Характеризующая архитектуру Linux идеология всё является файлом также реализована благодаря VFS. Ранее мы определили псевдофайловые системы как вырабатывающие "на лету" содержимое файловые системы. Эти файловые системы также относятся к VFS и играют важную роль в данной концепции.
Вы можете осуществить выборку перечня зарегистрированных в настоящий момент времени в ядре файловых систем через псевдо файловую систему
procfs. Когда мы просматриваем данный список, обратите внимание на nodev
напротив некоторых файловых систем в самом первом столбце. nodev указывает что это псевдо файловая система и она не обладает
в своей сонове блочным устройством. Такие файловые системы как Ext2, Ext3 и Ext4 создаются в блочном устройстве, в своём первом столбце они не имеют записи
nodev:
cat /proc/filesystems
[root@linuxbox ~]# cat /proc/filesystems
nodev sysfs
nodev tmpfs
nodev bdev
nodev proc
nodev cgroup
nodev cgroup2
nodev cpuset
nodev devtmpfs
nodev configfs
nodev debugfs
nodev tracefs
nodev securityfs
nodev sockfs
nodev bpf
nodev pipefs
nodev ramfs
[Остальной код опущен для краткости.]
Чтобы разузнать об установленных в данный момент псевдо файловых системах, вы также можете воспользоваться командой
mount:
mount | grep -v sd | grep -ivE ":/|mapper"
[root@linuxbox ~]# mount | grep -v sd | grep -ivE ":/|mapper"
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
devtmpfs on /dev type devtmpfs (rw,nosuid,size=1993552k,nr_inodes=498388,mode=755)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,nodev,mode=755)
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
pstore on /sys/fs/pstore type pstore (rw,nosuid,nodev,noexec,relatime)
efivarfs on /sys/firmware/efi/efivars type efivarfs (rw,nosuid,nodev,noexec,relatime)
[Остальной код опущен для краткости.]
Давайте предпримем путешествие в свой каталог /proc. Вы обнаружите длинный перечень пронумерованных каталогов; эти
номера представляют значения идентификаторов (ID) всех имеющихся процессов, которые исполняются в настоящий момент в вашей системе:
[root@linuxbox ~]# ls /proc/
1 1116 1228072 1235 1534 196 216 30 54 6 631 668 810 ioports scsi
10 1121 1228220 1243 1535 197 217 32 55 600 632 670 9 irq self
1038 1125 1228371 1264 1536 198 218 345 56 602
633 673 905 kallsyms slabinfo
1039 1127 1228376 13 1537 199 219 347 570 603
634 675 91 kcore softirqs
1040 1197 1228378 14 1538 2 22 348 573 605 635 677 947 keys stat
1041 12 1228379 1442 16 20 220 37 574 607
636 679 acpi key-users swaps
1042 1205 1228385 1443 1604 200 221 38 576 609
637 681 buddyinfo kmsg sys
1043 1213 1228386 1444 1611 201 222 39 577 610 638 684 bus
[Остальной код опущен для краткости.]
Файловая система procfs предлагает нам мельком взглянуть на исполняемое состояние ядра. Когда мы желаем просмотреть
эти сведения, вырабатывается содержимое /proc. Эти сведения не присутствуют постоянно на вашем диске. Всё это происходит
в оперативной памяти. Как видно из команды ls, размер /proc на диске равен нулю
байт:
[root@linuxbox ~]# ls -ld /proc/
dr-xr-xr-x 292 root root 0 Sep 20 00:41 /proc/
[root@linuxbox ~]#
/proc предоставляет оперативное представление запущенных в системе процессов. Рассмотрим файл
/proc/cpuinfo. В данном файле отображаются сведения о процессоре вашей системы. Если мы проверим это файл, он будет показан
как empty:
[root@linuxbox ~]# ls -l /proc/cpuinfo
-r--r--r-- 1 root root 0 Nov 5 02:02 /proc/cpuinfo
[root@linuxbox ~]#
[root@linuxbox ~]# file /proc/cpuinfo
/proc/cpuinfo: empty
[root@linuxbox ~]#
Однако, когда вы просматриваете содержимое данного файла через cat, выводится большой объём сведений:
root@linuxbox ~]# cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU E5-2683 v4 @ 2.10GHz
stepping : 1
microcode : 0xb00003e
cpu MHz : 2099.998
cache size : 40960 KB
physical id : 0
siblings : 1
core id : 0
cpu cores : 1
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 20
wp : yes
[Остальной код опущен для краткости.]
В VFS Linux абстрагируется от всех таких объектов как процессы, каталоги, сетевые сокеты и устройства хранения. Через VFS мы имеем возможность получать сведения
из самого ядра. Большинство дистрибутивов Linux предлагает различные инструменты для мониторинга потребления ресурсов хранения, вычислений и памяти. Все эти
инструменты собирают статистические данные по различным показателям при помощи доступных в procfs сведений. Например,
команда mpstat, предоставляющая статистику обо всех процессорах в системе, извлекает сведения из файла
/proc/stat. Затем для лучшего понимания она представляет эту информацию в удобочитаемом формате:
[root@linuxbox ~]# cat /proc/stat
cpu 5441359 345061 4902126 1576734730 46546 1375926 942018 0 0 0
cpu0 1276258 81287 1176897 394542528 13159 255659 280236 0 0 0
cpu1 1455759 126524 1299970 394192241 13392 314865 178446 0 0 0
cpu2 1445048 126489 1319450 394145153 12496 318550 186289 0 0 0
cpu3 1264293 10760 1105807 393854806 7498 486850 297045 0 0 0
[Остальной код опущен для краткости.]
Если мы воспользуемся в команде mpstat утилитой strace, она покажет, что
у себя под капотом mpstat пользуется файлом /proc/stat для отображения статистических
данных процессора:
strace mpstat 2>&1 |grep "/proc/stat"
[root@linuxbox ~]# strace mpstat 2>&1 |grep "/proc/stat"
openat(AT_FDCWD, "/proc/stat", O_RDONLY) = 3
[root@linuxbox ~]#
Аналогично, такие популярные команды как top, ps и free
получают относящиеся к памяти сведения из файла /proc/meminfo:
[root@linuxbox ~]# strace free -h 2>&1 |grep meminfo
openat(AT_FDCWD, "/proc/meminfo", O_RDONLY) = 3
[root@linuxbox ~]#
Точно так же как и /proc, применяется другая псевдо файловая система sysfs,
которая монтируется в /sys. Эта файловая система sysfs в основном
содержит сведения об аппаратных устройствах в вашей системе. Например, чтобы отыскать сведения относительно дисковых устройствах в вашей системе, скажем о его модели,
вы можете активировать следующую команду:
cat /sys/block/sda/device/model
[root@linuxbox ~]# cat /sys/block/sda/device/model
SAMSUNG MZMTE512
[root@linuxbox ~]#
Даже светодиод клавиатуры обладает соответствующим файлом в /sys:
[root@linuxbox ~]# ls /sys/class/leds
ath9k-phy0 input4::capslock input4::numlock input4::scrolllock
[root@linuxbox ~]#
Философия всё является файлом это одна из определяющих особенностей ядра Linux. Она означает, что всё в системе, включая обычные текстовые файлы, каталоги и устройства, всё это можно абстрагировать в ядре через уровень VFS. В результате, все эти логические элементы могут быть представлены в виде файловых объектов через слой VFS. В Linux присутствует несколько псевдо файловых систем, которые содержат сведения о различных подсистемах своего ядра. Содержимое таких псевдо файловых систем присутствует только в памяти и вырабатывается динамически.
Стек хранения Linux представляет собой сложную архитектуру и состоит из множества уровней, причём все они согласованы. Как и прочие аппаратные ресурсы, хранилище
пребывает в пространстве ядра. Когда программа пространства пользователя желает получить доступ к любому из этих ресурсов, она обязана активировать некий системный
вызов. Интерфейс системных вызовов в Linux позволяет программам пространства пользователя получать доступ к ресурсам в пространстве ядра. Когда программа пространства
пользователя хочет получить к чему бы то ни было на диске, именно подсистема VFS является самым первым компонентом, с которым она взаимодействует. VFS предоставляет
некую абстракцию относящегося к файловой системе взаимодействия и отвечает за размещение в ядре множества файловых систем. Через свой общий интерфейс файловой системы
VFS перехватывает универсальные системные вызовы (такие как read () и write ()) из
программ пространства пользователя и перенаправляет их в соответствующие интерфейсы на уровне необходимой файловой системы. Благодаря такому подходу программам
пространства пользователя не требуется заботиться о применяемых файловых системах и они способны единообразно выполнять операции с файловой системой.
Данная глава служит введением в самую основную подсистему Linux, Виртуальную файловую систему, а также в её первичные функции в ядре Linux. VFS предоставляет общий интерфейс для всех файловых систем через такие структуры данных как индексные деcкрипторы (inodes), суперблоки и записи каталогов. В своей следующей главе мы взглянем на эти структуры данных и поясним как они способствуют VFS управлять множеством файловых систем.