Глава 3. Изучаем реальные файловые системы под VFS
Содержание
- Глава 3. Изучаем реальные файловые системы под VFS
- Технические требования
- Галерея файловых систем Linux
- Дневник файловой системы- понятие ведения журнала
- Занятный вариант файловых систем CoW
- Расширенная файловая система
- Сетевая файловая система
- FUSE - уникальный метод создания файловых систем
- Выводы
"Не все корни зарыты в земле, некоторые растут на верхушках деревьев" - Джинвирле
Стек ввода/ вывода ядра может быть разбит вниз на три основных раздела: VFS (виртуальную файловую систему), уровень блоков и физический уровень. В качестве завершающей части уровня VFS можно рассматривать различные варианты файловых систем. Наши первые две главы предоставили нам хорошее понимание роли VFS, основных применяемых VFS структур и того, как она способствует процессам конечного пользователя во взаимодействии с разнообразными файловыми системами через общую файловую модель. Это означает, что на данный момент мы имеем возможность применять само понятие "файловая система" в его общепринятом контексте. Наконец.
В Главе 2 мы определили и пояснили некоторые важные структуры данных, применяемые VFS для задания универсальной инфраструктуры под различные файловые системы. Чтобы конкретная файловая система поддерживалась ядром, она обязана оперировать в рамках такой инфраструктуры. Однако не обязательна поддержка файловой системой всех определённых в VFS методов. Файловые системы обязаны придерживаться определяемых VFS структур и основываться на них для обеспечения их универсальности, но поскольку каждая файловая система пользуется своим собственным подходом к организации данных, в этих файловых системах может присутствовать масса методов и полей, которые не применимы к конкретной файловой системе. В подобных ситуациях файловые системы определяют надлежащие поля в соответствии со своей собственной архитектурой и исключают несущественные сведения.
Как мы уже наблюдали, VFS представляет собой бутерброд между программами пространства пользователя и реальными файловыми системами, а также реализует унифицированную файловую модель с тем, чтобы эти приложения могли пользоваться единообразными методами доступа для выполнения своих операций, причём независимо о лежащей в основе применения файловой системы. Теперь мы намерены сместить свой фокус на одну конкретную часть этого бутерброда, которым выступает файловая система, содержащая данные пользователя.
Данная глава представит вам некоторые наиболее распространённые применяемые в Linux файловые системы. Наиболее подробно мы рассмотрим файловую систему extended, поскольку на наиболее широко используется. Мы прольём некоторый свет на сетевые файловые системы и рассмотрим некоторые относящиеся к файловым системам важные понятия, такие как журналирование, файловые системы пространства пользователя и механизмы CoW (записи копированием, copy-on-write).
Мы собираемся рассмотреть следующие основные темы:
-
Понятие журналирования
-
Механизмы CoW (записи копированием)
-
Семейство extended файловых систем
-
Сетевые файловые системы
-
Файловые системы в пространстве пользователя
Данная глава полностью сосредоточена на на файловых системах и связанных с ними понятиями. Если у вас имеется опыт решения задач администрирования хранилища в Linux, но вы не вникали во внутреннюю работу файловых систем, данная глава послужит ценным упражнением. Рассматриваемое в данной главе содержание улучшит ваше понимание предварительное знакомство с понятиями файловой системы.
Представленные в этой главе команды и примеры безразличны к дистрибутиву и могут запускаться в любой операционной системе Linux, например, в
Debian, Ubuntu, Red Hat, Fedora и так далее. Существует ряд ссылок на исходный код ядра. Если вы желаете выгрузить исходный код ядра, вы можете
выполнить это с https://www.kernel.org. Все фрагменты справочного кода из этой книги
происходит из ядра 5.19.9.
Как мы уже говорили ранее, одно из основных преимуществ применения Linux состоит в широком диапазоне поддерживаемых файловых систем. Его ядро содержит поддержку сразу после установки для некоторых из них, например, XFS, Btrfs и файловых систем extended версий 2, 3 и 4. Они рассматриваются в качестве естественных файловых систем, поскольку разработаны с учётом принципов и философии Linux. С другой стороны отсека выступают такие файловые системы как NTFS и FAT. Они рассматриваются как пришлые файловые системы . Это обусловлено тем, что хотя ядро Linux и способно понимать такие файловые системы, их поддержка обычно требует дополнительных настроек, поскольку они не встают в одну линию с соглашениями, стоящими на вооружении натуральных файловых систем. Мы продолжим сосредотачиваться на естественных файловых системах и пояснять основные относящиеся к ним ключевые понятия.
Хотя всякая файловая система заявляет претензию быть лучше, быстрее и более надёжной и безопасной, нежели все прочие, важно отметить, что никакая файловая система не может наилучшим образом подходить подо все виды приложений. Каждая файловая система поступает со своими достоинствами и ограничениями. С точки зрения функциональности файловые системы могут быть классифицированы следующим образом:
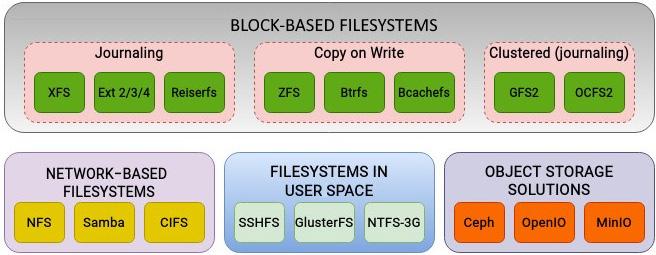
Рисунок 3.1 предоставляет беглый взгляд на некоторые поддерживаемые файловые система, а также их соответствующие категории. Принимая во внимание изобилие поддерживаемых Linux файловых систем, обзор их всех приведёт к нехватке места (игра слов файловой системы). Хотя подробности реализации и отличаются, как правило, файловые системы пользуются для своих внутренних операций некими общими методами. Часть основных понятий, таких как ведение журнала, больше распространены среди файловых систем. Аналогично, ряд файловых систем применяют популярную технику CoW (записи копированием), благодаря которой у них отсутствует потребность ведения журнала.
Давайте поясним понятие журналирования в файловых системах.
Для организации данных на своём физическом диске файловая система пользуется сложными структурами. В случае крушения или внезапного отказа системы, файловая система не способна аккуратно завершить свои операции, что способно разрушать её организационные структуры. После того как такая файловая система включается в следующий раз, пользователю требуется выполнить некого вида проверку согласованности и целостности для этой файловой системы для выявления подобных разрушенных структур и их восстановления.
Когда в Главе 2 мы давали пояснения структур данных VFS, мы обсуждали, что одним из фундаментальных принципов, которому следуют в Linux, является отделение метаданных от реальных данных. Все метаданные некого файла определены в некой независимой структуре, именуемой inode (индексным дескриптором). Также мы наблюдали как некий каталог рассматривается в качестве особого файла и он содержит соответствие названий файлов их номерам индексных дескрипторов. Имея это в виду, допустим, мы создаём простой файл и добавляем в него некий текст. Чтобы осуществить это, ядру потребуется выполнить следующие действия:
-
Создать и инициализировать для данного файла новый индексный дескриптор. Внутри файловой системы индексный дескриптор обязан быть уникальным.
-
Обновить временную отметку для того каталога, в котором создаётся данный файл.
-
Обновить значение индексного дескриптора для данного каталога. Это необходимо по причине того, что обновляется значение соответствия имён файлов к индексному дескриптору.
Даже для столь простой операции как создание простого текстового файла, ядру потребуется выполнить ряд операций ввода/ вывода для обновления большого числа структур. Предположим, что в процессе выполнения одной из подобных операций имеет место отказ питания, по причине которого данная система внезапно останавливается. Все те операции, которые требуются для создания нового файла не будут успешно завершены, что представит данную файловую систему структурно незавершённой. Если индексный дескриптор для данного файла был инициализирован и не связан с тем каталогом, который содержит данный файл, такой индексный дескриптор будет рассматриваться как сиротский (висячий, orphaned). После того как эта система вернётся в рабочее состояние, в её файловой системе будет выполнена проверка согласованности, которая удалит такие индексные дескрипторы, которые не связаны ни с каким каталогом. После своего крушения, файловая система сама по себе может оставаться неповреждённой, однако конкретные файлы могут испытать воздействие. В наихудшей ситуации подобная файловая система может также превратиться в повреждённую на постоянной основе.
Для улучшения надёжности файловой системы в случае выхода из строя и крушений системы, в валовых системах была введена функциональная возможность ведения журнала (журналирования). Самой первой поддерживающей подобную функциональную возможность файловой системой была JFS IBM, также носящей название Journaled Filesystem. На протяжении последних лет ведение журнала превратилось в существенную составную часть архитектуры файловых систем.
Понятие журналирования файловой системы восходит своими корнями к архитектуре систем баз данных. В большинстве баз данных ведение журнала обеспечивает согласованность и целостность данных в случае отказа транзакции по причине внешних событий, например, аппаратных сбоев. Журнал базы данных отслеживает не зафиксированные изменения записывая подобные операции в некий журнал. Журналирование файловой системы следует тем же путём.
Все подлежащие осуществлению изменения соответствующей файловой системы вначале записываются последовательным образом в журнал. Эти изменения или модификации носят название транзакций. После того как транзакция записана в журнал, она далее записывается в надлежащее место на своём диске. В случае крушения системы, сама файловая система воспроизводит свой журнал с целью проверки наличия не завершённых транзакций. Когда все транзакции были записаны по своим местам на диске, они удаляются из этого журнала.
В зависимости от подхода к ведению журнала, первыми в журнал записываются либо метаданные, либо реальные данные (или совместно). После того как данные записаны в свою файловую систему, данная транзакция удаляется из ведущегося журнала:
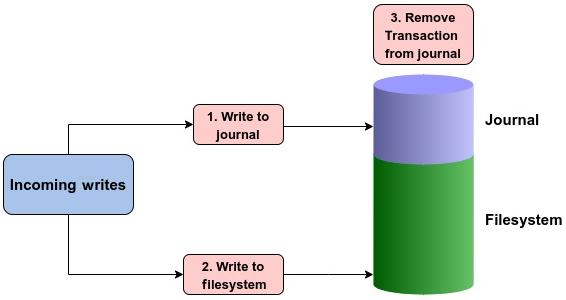
Важно сделать замечание, что по умолчанию журнал файловой системы также хранится в той же самой файловой системе, хотя и в обособленном разделе. Некоторые файловые системы к тому же хранят такой журнал на отдельном диске. Обычно размер подобного журнала всего лишь несколько мегабайт.
Весь смысл ведения журнала состоит в том, чтобы сделать файловую систему более надёжной и сохранять её структуру в случае системных сбоев и отказов оборудования. При применении файловой системы с журналом данные сначала записываются в журнал, а затем в указанное место на диске. Нетрудно заметить что для достижения пункта назначения мы добавляем дополнительный переход, ибо нам требуется дважды записывать одни и те же данные. Неужели это не приведёт к неприятным последствиям и снижению производительности файловой системы?
Это один из тех вопросов, ответ на который кажется очевидным, но это не так. Применение журналирования не обязательно приводит к снижению производительности. В действительности, в большинстве ситуаций всё ровно с точностью до наоборот. Могут иметься рабочие нагрузки, при которых разница для обоих случаев незначительна, но в большинстве ситуаций, в особенности при рабочих нагрузках с интенсивным применением метаданных, ведение журнала файловой системы в действительности ускоряет производительность. Величина степени роста производительности может варьироваться.
Рассмотрим файловую систему без ведения журнала. При каждом изменении файла естественный ход действий состоит в выполнении соответствующих модификаций на диске. Для операций с интенсивными метаданными это может оказывать отрицательное воздействие на производительность. Например, изменения в содержимом файла также требуют обновления надлежащих временных отметок этого файла. Это означает, что при каждом внесении изменений в такой файл его файловая система обязана проследовать с обновлениями не только реальных данных файла, но также и с обновлениями метаданных. При включённом ведении журнала по мере записи на диск требуется меньше поисков на физическом диске, причём только при фиксации изменений транзакции в журнале или при переполнении журнала. Другим преимуществом выступает последовательная запись в журнал. При использовании журнала случайные операции записи преобразуются в последовательные записи.
В большинстве ситуаций в качестве результата прекращения операций с метаданными происходит улучшение производительности. Когда требуется быстрое обновление метаданных, например, при рекурсивном выполнении операций над каталогом и его содержимым, применение ведения журнала может повысить производительность за счёт сокращения частых обращений к дискам и выполнения нескольких обновлений в рамках атомарной операции.
Естественно, в этом к тому же важную роль играет и то как файловая система реализует ведение журнала. Файловые системы предлагают различные подходы к журналированию. К примеру, некоторые файловые системы записывают в журнал лишь метаданные файла, тогда как прочие записывают в журнал как метаданные, так и фактические данные. Ряд файловых систем также в своём подходе предлагают гибкость и позволяют конечным пользователям выбирать режим ведения журнала.
Подводя итог, можно сказать, что ведение журнала выступает важной составляющей современных файловых систем, поскольку оно обеспечивает сохранность структурной целостности файловой системы даже в случае системного сбоя.
CoW это механизм управления ресурсом, который применяется в ядре Linux. Данное
понятие чаще всего ассоциируется с системным вызовом fork (). Системный вызов
fork () создаёт новый процесс дублируя свой вызывающий процесс. Когда при помощи
fork () создаётся некий новый процесс, страницы памяти разделяются между родительским и дочерним процессами.
По мере совместного использования данных страниц они не могут изменяться. Когда либо родительский, либо дочерний процесс пытаются внести
модификации в страницу, само ядро дублирует такую страницу и помечает её как доступную для записи.
Большинство существующих уже длительное время файловых систем применяют очень традиционный подход когда речь заходит о принципах проектирования. За последние несколько лет двумя основными изменениями в файловой системе extended стали применение ведения журналов и экстентов. Хотя и были предприняты усилия по масштабированию имеющихся файловых систем на современное применение, некоторые столь важные области как выявление ошибок, моментальные снимки и дедупликация остались без внимания. Современных корпоративным средам хранения данных необходимы такие функциональные возможности.
Использующие подход CoW для записи данных файловые системы существенно отличаются от прочих файловых систем. При перезаписи данных в файловой системе Ext4 или XFS новые данные записываются поверх существующих. Это означает, что исходные данные будут уничтожены. Применяющие подход CoW файловые системы копируют необходимые старые данные в некое иное место на диске. В этом новом месте записываются новые входные данные. Отсюда и фраза Copy on Write (Запись копированием, Копирование при записи). Раз старые данные или их моментальный снимок всё ещё присутствуют, использование пространства файловой системы будет намного большим, нежели ожидал обнаружить пользователь. Это зачастую сбивает с толку новых пользователей и чтобы привыкнуть к этому может потребоваться некоторое время. По этому поводу у некоторых пользователей существует достаточно забавное мнение: CoW слопала мои данные. Как показано на Рисунке 3.3, пользующийся CoW подход записывает входные данные в новый блок:
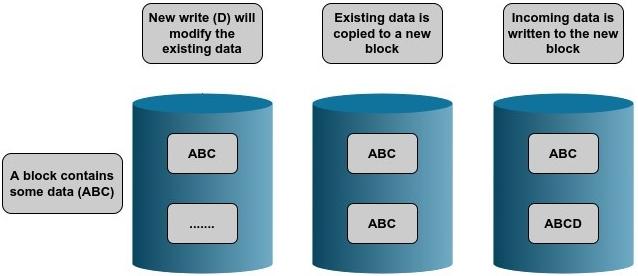
В качестве аналогии, в общих чертах, мы можем соотносить это с понятием путешествия во времени. Когда некто путешествует во времени и вносит в прошлое изменения, создаётся параллельная временная шкала. При этом создаётся отдельная копия отличающейся от оригинальной временной шкалы. Подобным образом работают файловые системы CoW. Когда для некого файла запрашивается какая- то модификация, вместо непосредственного изменения исходных данных создаётся отдельная копия этих данных. При этом исходные данные остаются нетронутыми, а изменённая версия хранится отдельно.
Поскольку при этом сохраняются исходные данные, это открывает некоторые заманчивые возможности. Благодаря данному подходу упрощается восстановление файловой системы в случае сбоя. Предыдущее состояние данных хранится в ином месте на диске. Следовательно, в случае сбоя, файловая система способно запросто вернуться в прежнее состояние. Это превращает в устаревшее ведение какого бы то ни было журнала. К тому же, это делает возможным реализовывать моментальные снимки на уровне такой файловой системы. В новое место копируются лишь подвергшиеся изменению блоки данных. Когда файловую систему необходимо восстановить применяя конкретный моментальный снимок, необходимые данные элементарно восстанавливаются.
Таблица 3.1 выделяет некоторые основные отличия между файловыми системами с ведением журнала и на основе CoW. Будьте добры обращать внимание на то, что собственно реализация и доступность некоторых из этих функциональных возможностей может отличаться в зависимости от типа файловой системы:
| Журналирование | CoW | |
|---|---|---|
|
Перед своим применением в реальной файловой системе изменения записываются в журнал |
Для выполнения модификации создаётся отдельная копия данных |
|
Изначальные данные перекрываются |
Оригинальные данные остаются нетронутыми |
|
Согласованность данных обеспечивается записью изменений метаданных и их воспроизведением в случае необходимости |
Согласованность гарантируется тем, что изначальные данные никогда не изменяются |
|
Минимальные накладные расходы, зависящие от типа ведения журнала |
Некоторые преимущества в производительности за счёт более быстрых записей |
|
Размер журнала, как правило, составляет мегабайты, а потому не требуется никакое дополнительное пространство |
Требуется больше пространства по причине обособленных копий данных |
|
Быстрое время восстановления, ибо журнал может воспроизводится мгновенно |
Более медленное восстановление, так как данные требуют перестроения при помощи последних копий |
|
Нет никакой встроенной поддержки таких возможностей как сжатие или дедупликация |
Встроенное сопровождение для сжатия и дедупликации |
Применяющие для организации данных подход CoW файловые системы включают в свой состав ZFS (Zettabyte Filesystem), Btrfs (B-Tree Filesystem) и Bcachefs. ZFS изначально применялась в Solaris и быстро стала популярной по причине своих мощных функциональных возможностей. Хотя по причине проблем с лицензированием она и не включена в ядро, она была портирована в Linux благодаря проекту ZFS on Linux. Файловая система Bcachefs была разработана из кода кэширования блоков ядра и быстро обретает популярность. Она может стать частью ядра последующих выпусков. Btrfs, также любовно именуемая ButterFS, целиком вдохновлена ZFS. К сожалению, по причине ряда ошибок в ранних выпусках её адаптация замедлилась в сообществе Linux. Тем не менее, она пребывает в активной разработке и уже более десяти лет выступает частью ядра Linux.
Несмотря на ряд проблем, Btrfs является самой современной присутствующей в ядре файловой системой благодаря своему богатому набору функциональных возможностей. Как уже упоминалось ранее, Btrfs черпает своё вдохновение от ZFS и пытается предложить практически идентичные функции. Как и ZFS, Btrfs это не просто дисковая файловая система, она к тому же предлагает функциональные возможности диспетчера логических томов и программного обеспечения RAID (Redundant Array of Independent Disks). Некоторые из её функциональных возможностей включают в себя моментальные снимки, контрольные суммы, шифрование, дедупликацию и сжатие, которые, как правило, не доступны в обычных блочных файловых системах. Все эти характеристики существенно упрощают управление хранилищем.
Подводя итог, можно сказать, что подход CoW к таким файловым системам как ZFS и Btrfs гарантирует, что существующие данные никогда не подвергнутся перезаписи. Тем самым, даже в случае внезапного сбоя системы имеющиеся данные не будут пребывать в противоречивом состоянии.
Файловая система extended, сокращаемая до Ext, слыла надёжным помощником ядра Linux с момента его создания и почти столь же стара как и само ядро Linux. Впервые она была представлена в ядре 0.96c. За прошедшие годы расширенная (Extended) файловая система претерпела серьёзные изменения, которые привели к появлению нескольких версий этой файловой системы. Эти версии кратко поясняются следующим образом:
-
Первая файловая система Extended: Самой первой файловой системой для запуска в Linux была Minix и она поддерживала максимальный размер файловой системы в 64 МБ. Файловая система Extended была разработана для преодоления недостатков Minix и обычно рассматривалась расширением файловой системы Minix. Эта расширенная файловая система поддерживала максимальный размер файловой системы в 2 ГБ. К тому же это была первая файловая система, применявшая VFS. Самая первая файловая система Ext для каждого файла допускала лишь одну временную метку по сравнению с тремя применяемыми в наши дни метками.
-
Вторая файловая система Extended: Почти через год после выпуска первой расширенной файловой системы вышла её вторая версия - Ext2. Файловая система Ext2 устранила ограничения своей предшественницы, такие как размеры разделов, фрагментация, длина имени файла, метки времени и максимальный размер файла. Она также представила ряд новых функциональных возможностей, включая понятие блоков файловой системы. Архитектура Ext2 была вдохновлена Berkeley Fast File System BSD. Файловая система Ext2 поддерживала намного большие размеры файловой системы, вплоть до нескольких терабайт.
-
Третья файловая система Extended: Файловая система Ext2 получила широкое распространение, однако фрагментация и повреждение файловой системы в случае сбоя оставались сложной проблемой. С учётом этого была разработана третья расширенная файловая система Ext3. Самой важной введённой этим выпуском функциональной возможностью было введение журнала. Благодаря ведению журнала файловая система Ext3 отслеживала изменения без их фиксации. Это снизило риск утраты данных в случае системного сбоя по причине выхода из строя аппаратных средств или пропадания питания.
-
Четвёртая файловая система Extended: В настоящее время самой последней версией семейства расширенных файловых систем выступает Ext4. Файловая система Ext4 предлагает ряд улучшений по сравнению с Ext2 и Ext3 с точки зрения производительности, фрагментации и масштабируемости, при этом сохраняя обратную совместимость с Ext2 и Ext3. Что касается дистрибутивов Linux, вероятно, Ext4 является наиболее часто развёртываемой файловой системой.
Мы намерены в основном сосредоточиться на архитектуре и структуре наиболее последней версии расширенной файловой системы, Ext4.
На самом нижнем уровне адресация жёсткого диска производится в единицах секторов. Секторы это физической свойство дискового устройства и обычно они составляют 512 байт. Хотя, в наши дни нет ничего необычного в том, чтобы обнаружить устройства, применяющие размер сектора в 4 кБ. Величина размера сектора это нечто, что мы не способны изменять, поскольку он определяется производителем диска. Поскольку сектор это наименьший адресуемый элемент на диске, любая выполняемая на физическом диске операция всегда будет больше или равна размеру сектора.
Файловая система создаётся поверх физического диска и не выполняет адресацию к такому диску в терминах секторов. Все файловые системы (а семейство расширенных файловых систем не являются исключением) осуществляют адресацию в терминах блоков. Блок это группа физических секторов, и именно он выступает фундаментальным элементом файловой системы. Файловая система Ext4 осуществляет все операции в терминах блоков. В системах x86, по умолчанию, размер файлового блока устанавливается в 4 кБ. Хотя он всегда может быть установлен в меньшее или большее значение, размер блока всегда должен удовлетворять двум следующим ограничениям:
-
Размер блока должен быть степенью двух, помноженной на величину размера сектора.
-
Значение размера блока всегда должно быть меньше или равно величине размера страницы памяти.
Значение максимального размера блока файловой системы это величина размера страницы соответствующей архитектуры. В большинстве систем на основе
x86 значение размера страницы ядра по умолчанию равняется 4 кБ. Таким образом, размер блока файловой системы не может превосходить 4 кБ. Значение
размера страницы кэша VFS также исчисляется 4кБ. Установленное ограничение на величину размера блока быть меньше чем или равняться значению размера
страницы ядра не ограничивается только расширенной файловой системой. Значение размера страницы определяется при компиляции ядра и для систем x86_64
составляет 4 кБ. Как будет показано далее, программа mkfs для Ext4 в случае, когда указан размер блока более
определённого значения размера страницы, возбудит предупреждение. Даже когда файловая система создана с размером блока большим значения размера
страницы, она не сможет быть смонтированной:
[root@linuxbox ~]# getconf PAGE_SIZE
4096
[root@linuxbox ~]# mkfs.ext4 /dev/sdb -b 8192
Warning: blocksize 8192 not usable on most systems.
mke2fs 1.44.6 (5-Mar-2019)
mkfs.ext4: 8192-byte blocks too big for system (max 4096)
Proceed anyway? (y,N) y
Warning: 8192-byte blocks too big for system (max 4096), forced to continue
[....]
[root@linuxbox ~]# mount /dev/sdb /mnt
mount: /mnt: wrong fs type, bad option, bad superblock on /dev/sdb, missing codepage or helper program, or other error.
[root@linuxbox ~]#
[root@linuxbox ~]# dmesg |grep bad
[ 5436.033828] EXT4-fs (sdb): bad block size 8192
[ 5512.534352] EXT4-fs (sdb): bad block size 8192
[root@linuxbox ~]#
После того как файловая система была создана, значение размера блока не может быть изменено. По умолчанию, файловая система Ext4 делит доступное
хранилище на логические блоки в 4 кБ. Выбор размера блока имеет существенное влияние на эффективность пространства и производительность своей
файловой системы. Значение размера блока выделяет минимум пространства на диске файла, причём даже если его реальный размер менее этого размера
блока. Давайте предположим что наша файловая система использует размер блока в 4 кБ и мы сохраняем в ней простой текстовый файл в 10 байт. Это файл
в 10 байт, при его сохранении на физическом диске, использует 4 кБ пространства. Блок способен содержать отдельный файл. Это означает, что для файла
в 10 байт в блоке бесполезно тратится остальное пространство (4 кБ - 10 байт). Как показано далее, простой текстовый файл, содержащий строку
"hello" будет занимать полный блок файловой системы:
robocop@linuxbox:~$ echo "hello" > file.txt
robocop@linuxbox:~$ stat file.txt
File: file.txt
Size: 6 Blocks: 8 IO Block: 4096 regular file
Device: 803h/2051d Inode: 2622288 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ robocop) Gid: ( 1000/ robocop)
Access: 2022-11-10 12:55:55.406596713 +0500
Modify: 2022-11-10 13:01:12.962761327 +0500
Change: 2022-11-10 13:01:12.962761327 +0500
Birth: -
robocop@linuxbox:~$
Команда stat предоставляет нам число блоков 8, что слегка вводит
в заблуждение, поскольку в действительности это число секторов. Это связано с тем, что всякий вызов stat
предполагает, что на каждый блок выделяется 512 байт дискового пространства. В данном случае количество блоков указывает на то, что на диске
выделено 4096 байт (8 х 512). Размер нашего файла составляет лишь
6 байт, однако он занимает блок целиком. Как показано ниже, когда мы добавляем в текст этого файла другую
строку, значение размера файла увеличится с 6 до 19 байт, тем не менее
число применяемых секторов и блоков останется тем же самым:
robocop@linuxbox:~$ echo "another line" >> file.txt
robocop@linuxbox:~$ stat file.txt
File: file.txt
Size: 19 Blocks: 8 IO Block: 4096 regular file
Device: 803h/2051d Inode: 2622288 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ robocop) Gid: ( 1000/ robocop)
Access: 2022-11-10 12:55:55.406596713 +0500
Modify: 2022-11-10 13:01:59.772249416 +0500
Change: 2022-11-10 13:01:59.772249416 +0500
Birth: -
robocop@linuxbox:~$
Принимая во внимание что маленький текстовый файл занимает блок целиком, нетрудно обнаружить влияние размера блока файловой системы. Присутствие большого числа файлов с маленьким размером в файловой системе с большим размером блока способно приводить к трате впустую дискового пространства, а в файловой системе могут быстро исчерпаться блоки. Для более чёткого понимания давайте посмотрим на визуальное представление.
Предположим, у нас имеются четыре следующих файла разного размера:
-
Файл A -> 5кБ
-
Файл B -> 1кБ
-
Файл C -> 7кБ
-
Файл D -> 2кБ
Следуя подходом, при котором для отдельного файла выделяется весь блок целиком (4кБ), такие файлы будут храниться на диске так:

Как понятно из Рисунка 3.4, мы впустую тратим 3кБ пространства в блоках 2 и 3, а также 1кБ и 2кБ в блоках 5 и 6 соответственно. Совершенно очевидно, что слишком большое число мелких файлов грабят блоки!
Давайте испытаем альтернативный подход и попробуем хранить эти файлы в более сжатом формате во избежании траты впустую пространства:

Нетрудно заметить, что такой второй подход более компактный и эффективный. Теперь мы способны хранить те же самые четыре файла всего лишь в четырёх блоках по сравнению с шестью при первом подходе. У нас даже есть возможность сберечь ещё 1кБ пространства файловой системы. Очевидно, что выделение блока файловой системы целиком для отдельного файла выглядит недейственным методом управления пространства, однако на практике это необходимое зло.
На первый взгляд наш второй подход кажется намного лучшим, но неужто вам незаметен недостаток? Следующая данных подходом файловая система будет обладать серьёзными упущениями. Если бы файловые системы были разработаны под размещение нескольких файлов в одном блоке, им бы пришлось изобретать механизм, отслеживающий границы отдельных файлов в одном блоке. Это значительно увеличивает сложность архитектуры. Кроме того, это приведёт к массовой фрагментации,что ухудшит производительность файловой системы. Когда размер файла увеличивается, входящие данные придётся изменять в отдельном блоке. Файлы будут храниться в блоках случайным образом и последовательный доступ будет отсутствовать. Всё это приведёт к снижению производительности файловой системы и сведёт на нет все преимущества, получаемые от подобного подхода со сжатием. Таким образом, каждый файл занимает блок целиком, даже если его размер меньше размера блока файловой системы. {Прим. пер.: для файловых систем с CoW, тем не менее, перечисленные здесь недостатки удаётся до некоторой степени смягчать, см. например ZFS.}
В Ext4 индивидуальные блоки выравниваются в другой элемент с названием групп блоков. Группа блоков это коллекция непрерывных блоков. Когда речь заходит о собственно организации групп блоков, существует два варианта. Для самой первой группы блоков её первые 1024 байта не используются. Они зарезервированы для установки секторов запуска. Вот схема такой самой первой группы блоков:

Когда файловая система создаётся с размером блока в 1кБ, её суперблок будет храниться в следующем блоке. Для всех прочих групп блоков схема превращается в следующую:

Давайте обсудим составные части группы блоков Ext4.
Суперблок
Как уже пояснялось в Главе 2, суперблок
это одна из важнейших структур в VFS. Она обязательна для файловой системы с целью организации структуры суперблока, которая содержит все метаданные
файловой системы. Суперблок Ext4 определён в fs/ext4/ext4.h и, как показано далее, он содержит десятки полей,
определяющих различные атрибуты своей файловой системы:
struct ext4_super_block {
__le32 s_inodes_count; /* Inodes count */
__le32 s_blocks_count_lo; /* Blocks count */
__le32 s_r_blocks_count_lo; /* Reserved blocks count */
__le32 s_free_blocks_count_lo; /* Free blocks count */
__le32 s_free_inodes_count; /* Free inodes count */
__le32 s_first_data_block; /* First Data Block */
__le32 s_log_block_size; /* Block size */
__le32 s_log_cluster_size; /* Allocation cluster size */
/*20*/ __le32 s_blocks_per_group; /* # Blocks per group */
__le32 s_clusters_per_group; /* # Clusters per group */
__le32 s_inodes_per_group; /* # Inodes per group */
__le32 s_mtime; /* Mount time */
/*30*/ __le32 s_wtime; /* Write time */
__le16 s_mnt_count; /* Mount count */
[……]
Значение типа данных __le32 указывает что наше представление реализовано в прямом порядке байт (little-endian).
Как видно из данного определения в исходном коде ядра, приводимый суперблок Ext4 определяет некоторое число свойств для характеристик своей файловой
системы. Они содержат такие сведения, как общее число блоков и групп блоков в данной файловой системе, общее число задействованных и не используемых
блоков, значение размера блока, общее число применяемых и не задействованных индексных дескрипторов, состояние данной файловой системы и много чего
иного. Все содержащиеся в суперблоке сведения имеют первостепенное значение, поскольку это самое первое, что считывается при монтировании файловой
системы. Учитывая его критическую важность, в разных местах хранятся несколько копий суперблока.
С большинством полей из суперблока не сложно разобраться. Поясним здесь некоторые представляющие интерес поля:
-
Block size calculation: Значение размера блока файловой системы Ext4 вычисляется при помощи 32- битного значения. Вот как вычисляется величина размера блока:
Ext4 block size = 2 ^ (10 + s_log_block_size)Минимальным значение размера блока файловой системы Ext4 может быть 1кБ, когда
s_log_block_sizeравно нулю. Файловая система Ext4 поддерживает максимальный размер блока в 64кБ. -
Block clusters: Даже хотя в последние несколько лет значение ёмкости дисковых устройств растёт по экспоненте, наша файловая система Ext4 работает с блоками в несколько килобайт. Чем больше размер диска, тем больше число блоков и их накладные расходы. В качестве обходного пути разработчики Ext4 добавили в Ext4 функциональную возможность кластеров блоков. Вместо выделения отдельных блоков по 4кБ, файловая система имеет возможность выделять блоки бо́льшими группами применяя понятие групп блоков. Сама файловая система Ext4 сопровождает необходимое соответствие мкжду такими блоками бо́льшего размера и блоками в 4кБ. Твкая функциональная возможность имеет название bigalloc. Значение размера кластера блоков может определяться в момент создания файловой системы и сохраняется в
s_log_cluster_size. -
Filesystem state and checks: Проверка согласованности файловой системы может включаться в трёх ситуациях. Значение поля
s_mnt_countуказывает величину числа раз, которое данная файловая система монтировалась с момента последней проверки согласованности. Величина поляs_max_mnt_countвыставляет жёсткий предел в числе монтирований, свыше которого обязательна проверка согласованность. Значение состояния файловой системы сохраняется вs_state. Оно может быть одним из следующих:-
cleanly unmounted(аккуратно демонтирована) -
errors detected(выявлены ошибки) -
orphans being recovered(подлежащая восстановлению подвисшая)
Если значение состояния в
s_stateне чистое (clean), соответствующая проверка вырабатывается автоматически. Значение даты последней проверки на согласованность хранится вs_lastcheck. Если значение времени из поляs_checkinterval, прошедшее с момента последней проверки прошло, в данной файловой системе принудительно выполняется проверка на согласованность. -
-
Magic signatures: Различные файловые системы пользуются понятием магических чисел, которые появляются по определённым смещениям. Разнообразные инструменты пользуются таким числом для идентификации типа конкретной файловой системы. Такое магическое число содержится в поле
s_magicсуперблока. Для Ext4 его значение равняется0xEF53. Значения полейs_rev_levelиs_minor_rev_levelиспользуются для отличий между версиями файловой системы. -
Block reservation: Это значения идентификаторов пользователя и группы по умолчанию для резервирования блоков. По умолчанию оно установлено в
0(пользователь root). Файловая система Ext4 резервирует 5% блоков файловой системы под суперпользователя или пользователя root. Это осуществляется с той целью, чтобы процессы пользователя root продолжали выполняться, причём даже когда процессы не root не способны выполнять запись в данную файловую систему. -
First inode number: Это значение самого первого индексного дескриптора, который может применяться для обычных файлов и каталогов. Данное значение обычно равно
11, причём в файловой системе Ext4 оно относится к каталогуlost+found. -
Filesystem UUID: Это значение из 128- бит, которое применяется в качестве уникального идентификатора тома для файловой системы Ext4. В системах, в которых часто добавляются или удаляются устройства, значения имён устройств (таких как
sdaиsdb) могут часто меняться, в результате приводя к путанице и некорректным точкам монтирования. Значение UUID это уникальный идентификатор для файловой системы и может применяться в/etc/fstabдля монтирования файловых систем. -
Compatible features: Оба этих значения являются 32- битными. Поле
s_feature_compatсодержит 32- битную маску бит совместимых функциональных возможностей. Конкретная файловая система вольна поддерживать те функциональные возможности, которые определены в данном поле. С другой стороны, если любые из определённых вs_feature_incompatфункциональных возможностей не распознаются данным ядром, операция монтирования такой файловой системы будет неудачной.
Блок данных и карта бит индексного дескриптора
Файловая система Ext4 пользуется незначительным объёмом пространства для организации неких внутренних структур. Бо́льшая часть пространства в файловой системе применяется для хранения данных пользователя. Файловая система Ext4 хранит данные пользователя в блоках данных. Как мы уже изучали в Главе 2, значения метаданных каждого файла хранятся в обособленной структуре, имеющей название индексного дескриптора (inode). Такие индексные дескрипторы также хранятся на диске, хотя и в зарезервированном пространстве. Индексные дескрипторы уникальны в файловой системе. Всякая файловая система пользуется некой методикой для отслеживания выделения и доступности индексных дескрипторов. Аналогично, должен существовать метод, посредством которого может отслеживаться значение числа выделенных и свободных блоков.
В качестве структуры для выделения Ext4 пользуется маской бит. Маска бит это некая последовательность бит. Отдельные маски бит применяются для
отслеживания числа индексных дескрипторов и блоков данных. Величина маски бит блоков данных отслеживает применение блоков данных внутри своей
группы блоков. Аналогично, маска бит индексных дескрипторов отслеживает записи в своей таблице индексных дескрипторов. Значение бита
0 указывает что данный блок или индексный дескриптор доступны для применения. Значение
1 указывает на то, что данный блок или индексный дескриптор заняты.
Размер масок битов и для индексных дескрипторов, и для блоков данных составляют один блок для каждого. Поскольку байт состоит из 8 бит, это означает,
что для размера блока по умолчанию в 4кБ величина маски бит блока способна представлять максимально 8 x 4кБ = 32 768 блоков для группы. Это можно
проверить в выводе mkfs или при помощи программы tune2fs.
Таблицы индексных дескрипторов
Дополнительно к маскам бит индексных дескрипторов, группа блоков также содержит некую таблицу индексных дескрипторов. Такая таблица индексных
дескрипторов распространяется на серии последовательных блоков. Само определение индексного дескриптора Ext4 представлено в файле
fs/ext4/ext4.h:
struct ext4_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size_lo; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Inode Change time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks_lo; /* Blocks count */
__le32 i_flags; /* File flags */
[…………..]
Индексный дескриптор Ext4 обладает размером в 256 байт. Вот некоторые поля, представляющие особый интерес:
-
Ownership: Поля
i_uidиi_gidслужат в качестве идентификаторов соответствующих пользователя и группы. -
Timestamps: Значения временных меток для конкретного файла сохраняются в
i_atime,i_ctimeиi_mtime. Они, соответственно, описывают значение времени последнего доступа, времени изменения индексного дескриптора и данных времени внесения изменений. Значение времени удаления хранится вi_dtime. Эти четыре поля являются 32- битными целыми со знаком, которые представляют секунды, прошедшие с времени эпохи Unix, 1 января, 1970, 00:00:00 UTC. Для вычисления времени с точностью менее секунд применяются поляi_atime_extra,i_mtime_extraиi_ctime_extra. -
Hard links: в противоположность мягким (программным, soft) ссылкам, жёсткие ссылки указывают на некий файл по его номеру индексного дескриптора. Значение счётчика жёстких ссылок на некий файл определяется в поле
i_links_count. Это 16- битное значение, что подразумевает, что Ext4 допускает для некого файла максимально 65k жёстких ссылок. -
Data block pointers: Дополнительно к некоторым общим метаданным, индексный дескриптор такж содержит сведения относительно местоположений блоков данных на диске. Эти сведения хранятся в
i_block, которое представляет собой массив длиной вEXT4_N_BLOCKS. ЗначениеEXT4_N_BLOCKSравно15. Как уже обсуждалось в Главе 2, структура индексного дескриптора для адресации блоков пользуется указателями. Первые 12 указателей ссылаются непосредственно на адреса блоков и именуются direct pointers (непосредственными, прямыми указателями). Следующие три указателя являются косвенными указателями. Indirect pointers (косвенный указатель) ссылается на блок указателей. Соответственные 13й, 14й и 15й указатели предоставляют одинарный- , двойной- и тройной- уровни косвенной адресации.
Дескрипторы групп
Дескрипторы групп хранятся сразу после своего суперблока в соответствующей схеме файловой системы. Всякий блок групп обладает связанным с ним
дескриптором групп, а потому имеется столько же дескрипторов групп, сколько и групп блоков. Важно осознавать, что такие дескрипторы групп блоков
описывают содержимое каждой группы блоков в своей файловой системе. Это означает, что они содержат сведения обо всех локальных, а также обо всех прочих
группах блоков в своей файловой системе. Структура дескриптора группы определена в fs/ext4/ext4.h:
struct ext4_group_desc
{
__le32 bg_block_bitmap_lo; /* Blocks bitmap block */
__le32 bg_inode_bitmap_lo; /* Inodes bitmap block */
__le32 bg_inode_table_lo; /* Inodes table block */
__le16 bg_free_blocks_count_lo;/* Free blocks count */
__le16 bg_free_inodes_count_lo;/* Free inodes count */
__le16 bg_used_dirs_count_lo; /* Directories count */
__le16 bg_flags; /* EXT4_BG_flags (INODE_UNINIT, etc) */
[…………]
Ниже приводятся некоторые наиболее важные поля:
-
Bitmap location: Дескрипторы групп содержат сведения относительно расположения на диске карт битов группы, битовых соответствий индексных дескрипторов и собственно таблицы индексных дескрипторов. Эти сведения хранятся в следующих полях в виде младших и старших битов. Последние значимые биты хранятся в
bg_block_bitmap_lo,bg_inode_bitmap_loиbg_inode_table_lo, в то время как старшие биты запоминаются вbg_block_bitmap_hi,bg_inode_bitmap_lhiиbg_inode_table_hi. -
Block and inode usage: Дескрипторы групп также содержат информацию относительно числа свободных блоков, индексных дескрипторов и каталогов. Они также хранятся в виде младших и старших бит. Применяемыми для содержания этих сведений полями выступают
bg_free_blocks_count_lo,bg_free_blocks_count_hi,bg_free_inodes_count_lo,bg_free_inodes_count_hi,bg_used_dirs_count_loиbg_used_dirs_count_hi.
Раз всякий дескриптор группы блоков содержит сведения относительно как локальных так и не локальных групп блоков, там содержатся дескрипторы для всех дескрипторов групп своей файловой системы. По этой причине, из каждой отдельной группы блоков могут быть определены следующие сведения:
-
Значение числа свободных блоков и индексных дескрипторов
-
Местоположение таблицы индексных дескрипторов в их файловой системе
-
Местоположение карт битов блоков и индексных дескрипторов
Зарезервированные блоки GDT
Одной из наиболее полезны функциональных возможностей файловой системы Ext4 выступает расширение "на лету". Значение размера файловой системы Ext4 может увеличиваться на лету без каких бы то ни было поломок. Во время создания файловой системы запасаются резервные блоки GDT (group descriptor table, таблицы групповых дескрипторов). Это имеет целью облегчение процесса расширения файловой системы. Увеличение размера файловой системы предполагает добавление физического дискового пространства и создание блоков файловой системы во вновь добавляемом дисковом пространстве. Это также означает, что для размещения вновь добавляемого пространства понадобится больше групп блоков и дескрипторов групп. Данные резервные блоки GDT применяются в случае когда файловая система Ext4 подлежит расширению.
Режимы ведения журнала
Как и большинство файловых систем, Ext4 также реализует понятие ведение журнала для предотвращения разрушения данных и их несогласованности в случае
системных сбоев. Определяемый по умолчанию размер журнала, как правило, это всего несколько мегабайт. Ведение журнала в Ext4 пользуется общим
уровнем журналирования в ядре, имеющим название journaling block device
(блочного устройства ведения журнала JBD или
JBD2). Если вы когда либо проверяли те процессы, которые потребляют более всего (top)
операций ввода/ вывода в занятой системе Linux, вероятно, вы наблюдали в этом перечне процесс jbd2 это поток
ядра, который отвечает за обновление журнала Ext4.
Ext4 предлагает большую гибкость ведения журналов. Файловая система Ext4 поддерживает три режима ведения журналов. В зависимости от имеющихся требований, при необходимости, можно изменять режим ведения журнала. По умолчанию, ведение журнала включается во время создания файловой системы. При желании, позднее его можно отключить. Ниже приводятся различные режимы ведения журнала:
-
Ordered: При упорядоченном режиме журналированию подлежат только метаданные. Реальные данные записываются на диск напрямую. Порядок операций строго соблюдается. Сначала метаданные записываются в журнал, далее на диск записываются собственно данные; и, наконец, на диск записываются метаданные. В случае сбоя структуры файловой системы остаются в сохранности. Однако записываемые во время сбоя данные могут быть утрачены.
-
Writeback: Режим обратной записи также вносит в журнал только метаданные. Единственное отличие в том, что реальные данные и метаданные могут записываться в любом порядке. Это слегка более рискованный подход нежели упорядоченный режим, однако он предлагает намного лучшую производительность.
-
Journal: В режиме журналирования и данные, и метаданные сначала записываются в свой журнал перед их фиксацией на диск. Это предлагает наивысший метод безопасности и согласованности, однако может неблагоприятно воздействовать на производительность, поскольку все операции записи должны выполняться дважды.
Режимом ведения журнала по умолчанию является ordered. Если вы желаете изменить значение режима
ведения журнала, вам необходимо демонтировать его файловую систему и добавить необходимый режим в соответствующую запись
fstab. Например, для изменения режима журналирования на writeback,
для соответствующей записи файловой системы в файле /etc/fstab добавьте
data=writeback. Выполнив это, вы можете проверить режим ведения журнала следующим образом:
[root@linuxbox ~]# mount |grep sdc
/dev/sdc on /mnt type ext4 (rw,relatime,data=writeback)
[root@linuxbox ~]#
Вы также можете отобразить сведения относительно применяемого ведения журнала при помощи команды logdump
из debugfs. Например, вы можете проверить журналирование для sdc
следующим образом:
[root@linuxbox ~]# debugfs -R 'logdump -S' /dev/sdc
debugfs 1.44.6 (5-Mar-2019)
Journal features: journal_64bit journal_checksum_v3
Journal size: 32M
Journal length: 8192
Journal sequence: 0x00000005
Journal start: 1
Journal checksum type: crc32c
Journal checksum: 0xb78622f2
Journal starts at block 1, transaction 5
Found expected sequence 5, type 1 (descriptor block) at block 1
Found expected sequence 5, type 2 (commit block) at block 13
Found expected sequence 6, type 1 (descriptor block) at block 14
[…............]
Экстенты файловой системы
Для обращения к файлам большого размера мы рассматривали применение косвенных указателей. Благодаря применению косвенных указателей индексный дескриптор способен отслеживать включающие в себя содержимое больших файлов блоки данных. Для файлов бо́льшего размера данный подход слегка утрачивает действенность. Чем больше блоков занимает файл, тем больше указателей требуется чтобы отслеживать каждый блок. Это создаёт сложную схему установления сопоставлений и увеличивает размер применяемых для каждого файла метаданных. В результате некоторые из операций с файлами большого размера выполняются достаточно медленно.
Для решения данной проблемы Ext4 пользуется экстентами и снижает объём метаданных, требующихся для отслеживания блоков данных. Некий extent это указатель плюс длина блоков - в основном, связки непрерывных физических блоков. При применении экстентов нам требуется знать значение адресов только первого и последнего блоков данного непрерывного диапазона. Например, допустим, мы пользуемся размером экстента в 4МБ. Для хранения файла в 100МБ мы можем выделить 25 непрерывных блоков. Поскольку эти блоки непрерывные, нам потребуется значения адресов первых и последних блоков. В предположении что размер блока 4кБ, при использовании указателей для хранения файла в 100МБ нам бы потребовалось создавать косвенное соответствие 25 600 блоков.
Политики выделения блоков
Когда речь заходит о производительности файловой системы, фрагментация превращается в тихого убийцу. Для улучшения общей производительности и снижения фрагментации файловая система Ext4 пользуется рядом технологий. Политики выделения блоков в Ext4 гарантируют что взаимосвязанные сведения присутствуют внутри одной и той же группы блоков файловой системы.
Когда требуется создать и сохранить новый файл, файловой системе потребуется выполнить инициализацию индексного дескриптора для такого файла. Затем Ext4 выберет для данного файла подходящую группу блоков. Имеющаяся архитектура Ext4 гарантирует что максимальные усилия будут предприняты для осуществления следующего:
-
Выделение необходимого индексного дескриптора в той группе блоков, которая содержит родительский каталог данного файла
-
Выделение требуемой файлу группы блоков, которая содержит индексный дескриптор данного файла
После того как файл сохранён на диск, через какое- то время его пользователь пожелает добавить в этот файл новые данные. Ext4 приступит к поиску свободных блоков, причём начиная с тех блоков, которые были выделены для этого файла наиболее последними.
При записи данных в файловой системе Ext3 за раз система выделения блоков размещала только единственный блок в 4кБ. В предположении что размер блока 4кБ, для одного файла в 100МБ, эту систему размещения блоков потребовалось бы вызывать 25 600 раз. Аналогично, когда файл расширяется, и выделяются новые блоки из соответствующей группы блоков, они могут поступать случайным образом. Такое выделение случайным образом в результате может приводить к интенсивным позиционированиям на диске. Такой подход плохо масштабируется и вызывает фрагментацию и проблемы с производительностью. Файловая система Ext4 предлагает в этом значительное улучшение путём применения системы выделения множественных блоков. При создании нового файла система многоблочного размещения Ext4 за единственный вызов выделяет большое число блоков. Это снижает общие накладные расходы и увеличивает производительность. Когда файл пользуется такими блоками, его данные записываются в едином экстенте большого числа блоков. Когда этот файл не пользуется такими дополнительно выделенными блоками, они освобождаются.
Файловая система Ext4 пользуется отложенным выделением и не выделяет необходимые блоки немедленно в процессе операции записи. Это осуществимо по причине интенсивного применения ядром своего страничного кэша. Все операции изначально выполняются в страничном кэше своего ядра, а затем, через какой- то промежуток времени, сбрасываются на диск. Применяя отложенное выделение, все блоки выделяются только когда данные реально подлежат записи на диск. Это чрезвычайно полезно, ибо такая файловая система для хранения подобного файла может затем выделять непрерывные экстенты.
Ext4 пытается удерживать необходимые блоки данных файла в той же самой группе блоков, в которой пребывает его индексный дескриптор. Аналогично, все индексные дескрипторы в неком каталоге помещаются в ту же самую группу блоков, что и сам каталог.
Изучение результата операции mkfs
Давайте подведём черту под нашим обсуждением Ext4 и посмотрим что происходит когда мы создаём при помощи mkfs
файловую систему Ext4. Следующая команда была выполнена на диске всего с 1 ГБ:
[root@linuxbox ~]# mkfs.ext4 -v /dev/sdb
mke2fs 1.44.6 (5-Mar-2019)
fs_types for mke2fs.conf resolution: 'ext4'
Discarding device blocks: done
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
65536 inodes, 262144 blocks
13107 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=268435456
8 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Filesystem UUID: ebcfa024-f87b-4c52-b3e1-25f1d4d31fec
Superblock backups stored on blocks:
32768, 98304, 163840, 229376
Allocating group tables: done
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
Давайте ознакомимся с получаемым выводом.
Как сообщает вам страница man mkfs для .ext4, функциональная
возможность избавления от блоков устройств особенно полезна для твердотельных устройств. По умолчанию, команда
mkfs будет активировать команду TRIM для информирования лежащего
в основе устройства по поводу удаления не используемых блоков.
Наша файловая система состоит из 262 144 блоков по 4кБ каждый. Общее число индексных дескрипторов в этой файловой системе 65 536. Для
монтирования в fstab может применяться UUID.
Значения ширины шага и полосы применяются когда базовое хранилище представляет собой том RAID.
Для своего суперпользователя, по умолчанию, файловая система Ext4 зарезервирует 5% пространства.
Мы видим, что наша файловая система поделила свои 262 144 блоков на 8 групп блоков. В каждой из групп присутствует по 32 768 блоков. Во всех блоках имеется по 8 192 индексных дескрипторов. Это согласуется с упомянутым ранее общим числом индексных дескрипторов, то есть 8 x 8 192 = 65 536.
Необходимые копии структуры своего суперблока хранятся во множестве блоков. Эта файловая система всегда будет монтироваться при помощи своего первичного суперблока. Но если по какой- либо причине этот первичный суперблок будет разрушен, наша файловая система имеет возможность монтирования с применением резервной копии, сохранённой в иных местоположениях. Журнал данной файловой системы занимает 8 192 блока, что даёт нам размер журнала в 8 192 x 4кБ = 32МБ.
Файловая система extended один из старейших проектов специфичного для Linux программного обеспечения. С годами он прошёл ряд расширений в плане надёжности, масштабируемости и производительности. Большинство из связанных с Ext4 понятий, тких как ведение журнала, применение экстентов, а также отложенного выделения, применяются и в XFS, хотя для реализации этих технологий XFS пользуется иными методиками. Как и все файловые системы на основе блоков, Ext4 делит всё доступное дисковое пространство на блоки фиксированного размера. Будучи естественной по своей природе файловой системой, она интенсивно пользуется определяемыми в VFS структурами и реализует их как для своей собственной архитектуры. Благодаря своей доказанной репутации стабильности, это наиболее часто применяемая файловая система в дистрибутивах Linux.
Эволюция вычислительных сетей и сетевых протоколов сделала возможным удалённое совместное применение файлов. Это породило понятие распределённых вычислений и архитектур клиент- сервер, которые носят название распределённых файловых систем. Основная мысль состояла в хранении данных в централизованном местоположении в одном или более серверов. Имеется большое число клиентов, которые запрашивают доступ к этим данным через разнообразные программы и протоколы. Они включают в себя такие протоколы как FTP (File Transfer Protocol) и SFTP (Secure File Transfer Protocol). Применение подобных программ делает возможным обмен данными между двумя машинами.
По сравнению с любой обычной файловой системой, применяющая распределённый подход файловая система потребует для своего функционирования некие
дополнительные элементы. Мы уже видели, что процессы пользуются уровнем общих системных вызовов для активации запросов на считывание и запись.
В случае обычных файловых систем, и сам процесс (который активирует данный запрос) и его хранилище (которое обслуживает такой запрос) выступают
частями единой системы. В распределённых системах
может присутствовать всецело предназначенное для этого приложение клиент- сервер, которое применяется для доступа к своей файловой системе. В ответ
на общий системный вызов, подобный read (), сторона клиента отправит некое сообщение своему серверу запрашивая
доступ на считывание конкретного ресурса.
Одной из старейших следующих такому подходу файловых систем выступает Network Filesystem, сокращённо именуемая как NFS. Протокол NFS был создан в 1984 году Sun Microsystems. NFS это распределённая файловая система, которая делает возможным доступ к хранимым в удалённом месторасположении файлам. Наиболее последним применяемым протоколом является NFS версии 4. Так как взаимодействие между клиентом и сервером осуществляется плверх сетевой среды, все запросы всех клиентов будут передаваться по всем уровням в модели OSI (Open Systems Interconnection).
С точки зрения построения, NFS обладает тремя основными компонентами:
-
RPC (Remote Procedure Calls): Чтобы сделать возможными отправку и получение сообщений друг другу, ядро предлагает различные механизмы IPC (inter-process communication, взаимодействия между процессами). В качестве метода взаимодействия между некими клиентом NFS и сервером, NFS пользуется RPC (удалёнными вызовами процедур). RPC это некое расширение механизма IPC. Как и предполагает его название, при RPC вызываемая своим клиентом процедура не требует своего пребывания в том же самом адресном пространстве, что и сам клиент. Она может пребывать в неком удалённом адресном пространстве {Прим. пер.: при использовании RDMA это утверждение может не соблюдаться: адресное пространство также может разделяться между клиентом и сервером}. Данная служба RPC реализуется на уровне сеанса.
-
XDR (External Data Representation): NFS пользуется XDR (внешним представлением данных) в качестве стандарта для кодирования двоичных данных на уровне представления модели OSI. Применение XDR гарантирует что все держатели стека пользуются при взаимодействии одним и тем же языком. Такое применение стандартного метода для передачи данных необходимо, поскольку представление данных может отличаться для двух систем. Например, имеется возможность того, что участник NFS способен обладать архитектурными отличиями и обладать различными порядками следования байт в машинных словах. Для представления данных XDR пользуется каноническим методом. Когда клиенту NFS необходимо выполнить запись данных в неком сервере NFS, он преобразует своё логическое представление относящихся к делу сведений в эквивалентное кодирование XDR. Аналогично, когда кодированные XDR данные получаются соответствующим сервером, они будут декодированы и преобразованы обратно в своё логическое представление.
-
NFS procedures: Все операции NFS функционируют на уровне приложений модели OSI. Все определяемые на данном уровне процедуры устанавливают различные задачи, которые могут осуществляться над располагающимися в сервере NFS файлами. Такие процедуры включают в свой состав операции с файлами, операции с каталогами и операции файловой системы.
Рисунок 3.8 отображает тот маршрут, который предпринимает запрос на ввод/ вывод при использовании NFS:
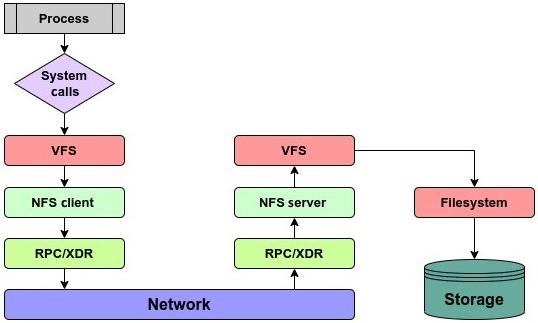
В версии 2 NFS в качестве лежащего в основе протокола пользовалась UDP и, как результат, NFS v2 и v3 не обладали состоянием. Преимуществом такого подхода была слегка большая производительность по причине меньших накладных расходов при применении UDP. Начиная с NFS v4 протокол по умолчанию был изменён на TCP. Монтирование совместных ресурсов с применением TCP это более надёжный вариант. NFS версии 4 обладает состоянием, что подразумевает, что и клиент и сервер поддерживают сведения относительно открытых файлов и блокировок файлов. В случае крушения сервера и сторона его клиента и сервер работают над восстановлением предшествующего крушению состояния. NFS версии 4 к тому же представила формат составного (compound) запроса. Применяя формат составного запроса, Клиент NFS способен сочетать в едином запросе несколько операций. Соответствующая составная процедура действует в качестве обёртки для соединения одной или более операций в единый запрос RPC.
Как и всякая обычная файловая система, NFS также нуждается в монтировании для установления логического соединения между своими клиентом и
сервером. Данная операция монтирования слегка отличается от операции в локальной файловой системе. При монтировании файловой системы NFS нам нет
нужды в создании файловой системы, ибо необходимая файловая система уже существует на своей удалённой стороне. Соответствующая команда
mount будет содержать значение названия подлежащего монтированию удалённого каталога. В терминах NFS
это носит название экспорта. Соответствующий сервер NFS отслеживает список
файловых систем, которые могут быть экспортированы, а также перечень хостов, которым допустимо выполнять доступ к таким экспортам.
Для уникальной идентификации некого файла сервер NFS применяет специальную структуру. Данная структура носит название описателя файла (дескриптора файла - file handle). Такой описатель пользуется неким номером индексного дескриптора, идентификатором файловой системы и номером поколения. При данном процессе идентификации критически важную роль играет значение номера поколения. Допустим, имевший номер 100 индексного дескриптора файл A был удалён своим пользователем. Некий новый файл, скажем, B, был создан и ему был присвоен недавно высвобожденный номер индексного дескриптора, 100. При попытке доступа к файлу при помощи его описателя файла это может вызвать путаницу, поскольку теперь, использующим данный, ранее применявшийся файлом A, номер индексного дескриптора файлом выступает B. По этой причине соответствующая структура описателя файла также применяет номер поколения. Данный номер поколения увеличивается на единицу при каждом повторном применении своим сервером некого индексного дескриптора.
Сетевые файловые системы также носят название хранилища с пятью уровнями. Раз так, выполняемые в NFS операции ввода/ вывода именуются пятиуровневыми операциями ввода/ вывода. В отличии от блочных файловых систем, ввод/ вывод с пятью уровнями при запросе операции не определяет значение адреса блока файла. Отслеживание точного местоположения конкретного файла на диске это задание для самого сервера NFS. После получения соответствующего запроса от своего клиента NFS, сам сервер NFS выполнит преобразование его в запрос блочного уровня и осуществит запрошенную операцию. На практике это приводит к дополнительным накладным расходам и выступает одной из главных причин того, что производительность NFS бледнеет по сравнению с обычной блочной файловой системой. В случае блочных файловых систем и устройств приложения обладают собственной свободой для решения каким образом будут выполняться доступ или изменения блоков файловой системы. Для NFS такое управление структурами файловой системы целиком в ответственности соответствующего сервера NFS.
Мы можем наблюдать основные отличия между NFS и блочной файловой системой:
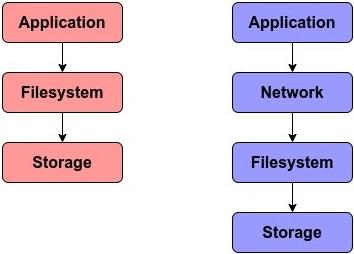
Суммируя, NFS это один из наиболее популярных протоколов для удалённого совместного использования файлов. По своей природе он распределённый и следует архитектуре клиент- сервер. Соответствующий запрос клиента NFS завершает свой путь в своём сервере NFS после прохождения по всему стеку сетевой среды. Для стандартизации данных между своими клиентом и сервером NFS применяет XDR для кодирования данных на собственном уровне представления согласно модели OSI. Хотя она и отстаёт в производительности при сопоставлении с обычным блочным хранилищем, она всё ещё применяется большинством корпоративных инфраструктур, причём в основном для целей резервного копирования и архивов.
Мы уже обсуждали как ядро делит свою систему на две порции: пространство пользователя и пространство ядра. Все необходимые привилегированные ресурсы располагаются в пространстве ядра. Собственно код ядра, в том числе и файловых систем, также присутствует в обособленной области пространства ядра. Обычные программы пространства пользователя не имеют возможности получать к нему доступ. Имеющееся отличие между пространством пользователя и программами пространства ядра ограничивает возможности любого обычного процесса в изменении кода ядра.
Хотя данный подход и существенный для архитектуры ядра, на практике он создаёт ряд проблем в процессе разработки. Рассмотрим конкретный пример любой файловой системы. Поскольку весь код файловой системы присутствует в пространстве своего ядра, в случае ошибки в коде такой файловой системы чрезвычайно трудно осуществлять её устранение или отладку по причине подобного разделения. Все операции в этой файловой системе также надлежит осуществлять от имени пользователя root.
Для решения некоторых из подобных ограничений была спроектирована инфраструктура FUSE (filesystem in user space, файловой системы в пространстве пользователя). Посредством применения взаимодействия с FUSE файловые системы могут создаваться без возни с необходимым кодом ядра. Раз так, сам код для таких файловых систем присутствует только в пространстве пользователя. Как реальные данные, так и метаданные такой файловой системы управляются процессами пространства пользователя. Это чрезвычайно гибко, ибо допускает монтирование подобных файловых систем не имеющими привилегий пользователям. Важно отметить, что файловые системы на основе FUSE могут составляться в стек, что означает, что они могут разрабатываться поверх существующих файловых систем, таких как Ext4 и XFS. Одним из наиболее широко применяемых решений FUSE, использующего данный подход, выступает GlusterFS. GlusterFS работает в качестве файловой системы пространства пользователя и может строиться стеком поверх любой имеющейся блочной файловой системы, такой как Ext4 или XFS.
Предоставляемые FUSE функциональные возможности достигаются за счёт применения модуля ядра (fuse.ko) и
демона пространства пользователя, пользующегося библиотекой libfuse. Сам модуль ядра FUSE отвечает за регистрацию
данной файловой системы при помощи VFS. Взаимодействие между соответствующим демоном пространства пользователя и его ядром достигается при помощи
некого символьного устройства, /dev/fuse. Данное устройство играет роль моста между соответствующим демоном
пространства пользователя и своим модулем ядра. Такой демон пространства пользователя будет для данного устройства выполнять запросы считывания и
записи:
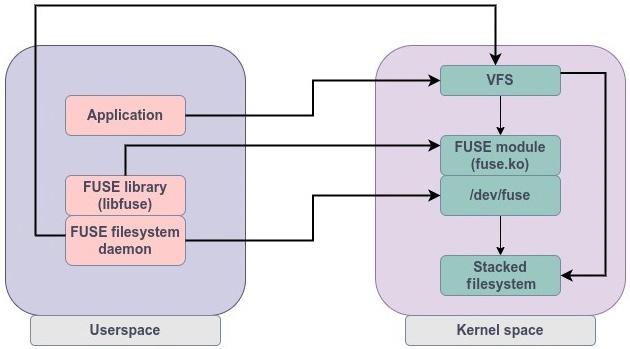
Когда некий процесс пространства пользователя выполняет любую операцию в файловой системе FUSE, соответствующий системный запрос отправляется в
имеющийся уровень VFS. Выполнив проверку того, что он относится к файловой системе на основе FUSE, VFS перенаправит такой запрос в модуль ядра FUSE.
Надлежащий драйвер FUSE создаст структуру запроса и поместит её в очередь FUSE в /dev/fuse. Необходимое
взаимодействие между модулем ядра и библиотекой libfuse достигается при помощи особого файлового дескриптора.
Надлежащий демон пространства пользователя откроет устройство /dev/fuse для обработки получаемого результата.
Когда файловая система FUSE строится стеком поверх некой существующей файловой системы, тогда этот запрос снова переправляется в пространство ядра
с тем, чтобы он был передан лежащей в основе файловой системе.
Файловые системы FUSE не столь надёжны как обычные файловые системы, однако они предлагают великолепную сделку с гибкостью. Они просты в развёртывании и могут монтироваться пользователями без привилегий. Поскольку весь код такой файловой системы находится в пространстве пользователя, в нём проще устранять неполадки и в него легче вносить изменения. Даже при наличии некой ошибки в таком коде это не окажет воздействия на функциональные возможности самого ядра.
Заполучив описание работы VFS в первых двух главах, данная глава знакомит вас с основами общих файловых систем и их понятиями. Ядро Linux способно поддерживать порядка 50 файловых систем и охватить каждую из них - непосильная задача. Мы по- прежнему уделяли особое внимание натуральным файловым системам Linux, ибо само ядро способно поддерживать их сразу после установки. Мы пояснили некоторые функции, общие для групп файловых систем, таких как пользующихся механизмами ведения журнала, CoW, а также для FUSE. Основное внимание данной главы было сосредоточено на работе и внутреннем устройстве файловой системы extended. Эта расширенная файловая система присутствует начиная с версии ядра 0.96 и является наиболее широко представленной в вычислительных платформах файловой системой. Мы также пролили некий свет на архитектуру сетевых файловых систем и пояснили имеющиеся отличия между файловым и блочным хранилищем. По окончанию мы обсудили FUSE, которая предлагает взаимодействие для программ пространства пользователя по экспорту файловой системы в ядро Linux.
Данной главой мы теперь завершили исследование уровней VFS и файловой системы в ядре. Это подводит итог Части 1 данной книги. Мне бы хотелось полагать, что это оказалось достойным вариантом обучения и, я надеюсь, что оно и останется таковым. Вторая часть книги, начиная с Главы 4, сосредоточится на блочном уровне в самом ядре, который обеспечивает восходящее взаимодействие со всеми файловыми системами.