Глава 14. Расширенное управление хранилищем при помощи Stratis и VDO
В этой главе мы ознакомимся со Основы StratisStratis и Virtual Data Optimizer (VDO, Оптимизатором виртуальных данных).
Stratis это инструмент управления хранилищем для упрощения исполнения наиболее обычных ежедневных задач. Он пользуется лежащими в его основе технологиями, объяснёнными в наших предыдущих главах, таких как LVM, схемы разбиения на разделы и файловые системы.
VDO это уровень хранения, который содержит некоторый драйвер, сидящий между нашим приложением и собственно устройством хранения для предоставления дедупликации и сжатия хранимых данных, а также инструменты для управления этой функциональностью. Это позволяет нам, например, максимизировать общую способность нашей системы в хранении экземпляров виртуальных машин (ВМ), которые будут потреблять дисковое пространство только на основе того, что делает их уникальными, при этом храня всего лишь один раз те данные, которые являются для них общими.
Мы также можем применять VDO для хранения различных вариантов своих резервных копий, зная что использование диска всё ещё будет оптимальным.
К концу этой главы вы узнаете как работает VDO и что требуется для настройки его под нашу систему.
Мы изучим как подготавливать, настраивать т применять наши системы в следующих разделах:
-
Основы Stratis
-
Установка и включение Stratis
-
Управление пулами хранения и файловыми системами при помощи Stratis
-
Подготовка системы к применению VDO
-
Создание тома VDO
-
Назначение тома VDO LVM
-
Тестирование VDO и просмотр статистических данных
Давайте окунёмся в подготовку своих систем к применению VDO.
Можно продолжать практиковать применение ВМ созданной в самом начале этой книги в Главе 1, Установка RHEL8. Все дополнительные необходимые для этой главы пакеты будут указаны и из можно выгрузить с https://github.com/PacktPublishing/Red-Hat-Enterprise-Linux-8-Administration.
Для раздела Основы Stratis нам потребуются те же самые два диска, которые мы добавляли в Главе 13, Гибкое управление хранилищем при помощи LVM, после того как с них были очищены все компоненты соответствующей LVM.
В качестве новой функциональной возможности для управления хранилищем, Stratis был включён в RHEL 8 в виде технологического предварительного представления (начиная с версии 8.3 RHEL). Stratis был создан для управления локальным хранилищем посредством комбинации с некой системной службой, stratisd с добрыми старыми знакомыми инструментами из LVM (объяснёнными в Главе 13, Гибкое управление хранилищем при помощи LVM), а также нашей файловой системой XFS (объяснённой в Главе 12, Управление локальным хранилищем м файловыми системами), что делает его весьма солидным и надёжным.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Все создаваемые Stratis файловые системы/ пулы должны управляться именно им, а не инструментами LVM/XFS. Точно так же, уже созданные тома LVM не должны управляться при помощи Stratis. |
Stratis комбинирует локальные диски в пулы, а затем распространяет это хранилище в файловые системы, как это отображено на следующей схеме:
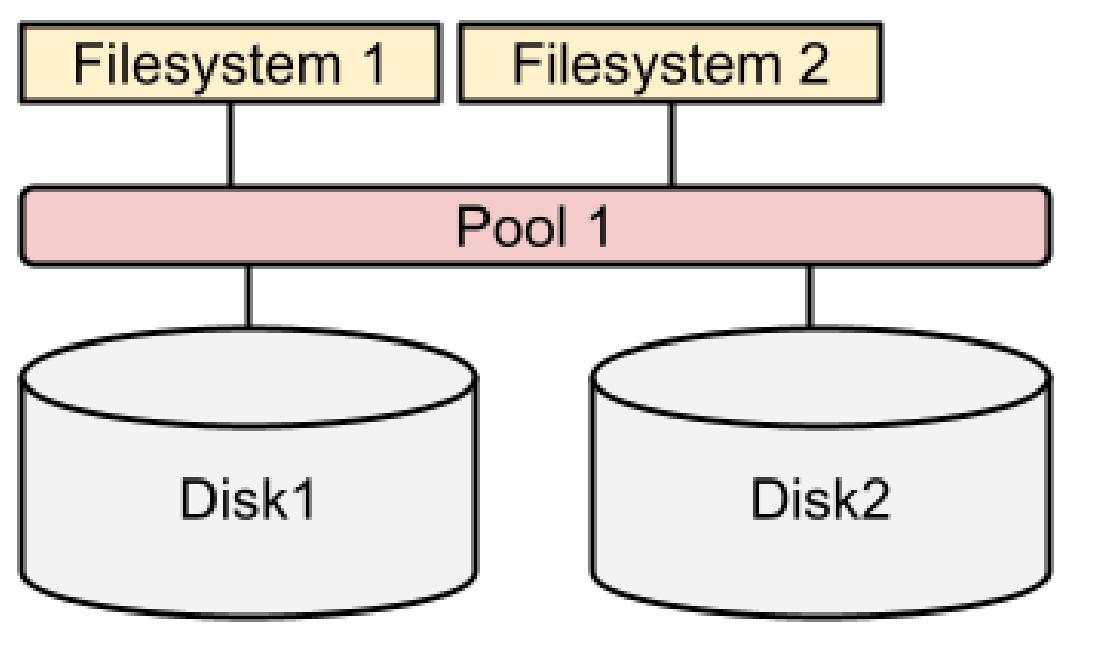
Как можно видеть, по сравнению с LVN, Stratis предоставляет намного более простой и лёгкий для понимания интерфейс для управления хранилищем. В наших последующих разделах мы установим и включим Stratis, а затем воспользуемся теми же самыми дисками, которые мы создали в Главе 13, Гибкое управление хранилищем при помощи LVM для создания некого пула и пары файловых систем.
Чтобы иметь возможность работать со Stratis мы приступим к его установке. Вот те два пакета, которые требуются для работы с ним:
-
stratis-cli: Инструментарий командной строки для выполнения задач управления хранилищем -
stratisd: Системная служба (также именуемая демоном) которая получает команды и осуществляет задачи нижнего уровня
Для его установки мы воспользуемся командой dnf:
[root@rhel8 ~]# dnf install stratis-cli stratisd
Updating Subscription Management repositories.
Red Hat Enterprise Linux 8 for x86_64 - BaseOS (RPMs) 17 MB/s | 32 MB 00:01
Red Hat Enterprise Linux 8 for x86_64 - AppStream (RPMs) 12 MB/s | 30 MB 00:02
Dependencies resolved.
====================================================================================================
Package Arch Version Repository Size
====================================================================================================
Installing:
stratis-cli noarch 2.3.0-3.el8 rhel-8-for-x86_64-appstream-rpms 79 k
stratisd x86_64 2.3.0-2.el8 rhel-8-for-x86_64-appstream-rpms 2.1 M
[omitted]
Complete!
Теперь мы запускаем службу stratisd при помощи systemctl:
[root@rhel8 ~]# systemctl start stratisd
[root@rhel8 ~]# systemctl status stratisd
● stratisd.service - Stratis daemon
Loaded: loaded (/usr/lib/systemd/system/stratisd.service; enabled; vendor preset: enabled)
Active: active (running) since Sat 2021-05-22 17:31:35 CEST; 53s ago
Docs: man:stratisd(8)
Main PID: 17797 (stratisd)
Tasks: 1 (limit: 8177)
Memory: 1.2M
CGroup: /system.slice/stratisd.service
└─17797 /usr/libexec/stratisd --log-level debug
[omitted]
Сейчас нам следует включить её для старта при запуске:
[root@rhel8 ~]# systemctl enable stratisd
[root@rhel8 ~]# systemctl status stratisd
● stratisd.service - Stratis daemon
Loaded: loaded (/usr/lib/systemd/system/stratisd.service; enabled; vendor preset: enabled)
[omitted]
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Мы можем выполнить обе эти задачи одной командой, которая будет такой:
|
Давайте проверим при помощи stratis-cli что этот демон (также носящий название системной службы)
запущен:
[root@rhel8 ~]# stratis daemon version
2.3.0
Он у нас уже имеется, а потому настало время приступит к работе с дисками. Давайте перейдём к следующему подразделу.
Чтобы обладать доступным для Stratis хранилищем, мы воспользуемся дисками /dev/vdb и
/dev/vdc. Нам требуется быть уверенными что они не обладают в себе никакими логическими томами или
разделами.
[root@rhel8 ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
root rhel -wi-ao---- <8,00g
swap rhel -wi-ao---- 1,00g
[root@rhel8 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
rhel 1 2 0 wz--n- <9,00g 0
[root@rhel8 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/vda2 rhel lvm2 a-- <9,00g 0
У нас всё хорошо: все созданные LVM объекты пребывают на диске /dev/vda. Давайте проверим два других
диска, /dev/vdb и /dev/vdc:
[root@rhel8 ~]# parted /dev/vdb print
Model: Virtio Block Device (virtblk)
Disk /dev/vdb: 1074MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
[root@rhel8 ~]# parted /dev/vdc print
Error: /dev/vdc: unrecognised disk label
Model: Virtio Block Device (virtblk)
Disk /dev/vdc: 1074MB
Sector size (logical/physical): 512B/512B
Partition Table: unknown
Disk Flags:
Диск /dev/vdc не обладает никакими метками таблиц разделов. У нас хорошо и здесь. Тем не менее,
диск /dev/vdb обладает таблицей разделов. Давайте удалим её:
[root@rhel8 ~]# dd if=/dev/zero of=/dev/vdb count=2048 bs=1024
2048+0 records in
2048+0 records out
2097152 bytes (2,1 MB, 2,0 MiB) copied, 0,0853277 s, 24,6 MB/s
|
| Совет |
|---|---|
|
Наша команда |
Теперь мы уже готовы создать самый первый пул при помощи команды stratis:
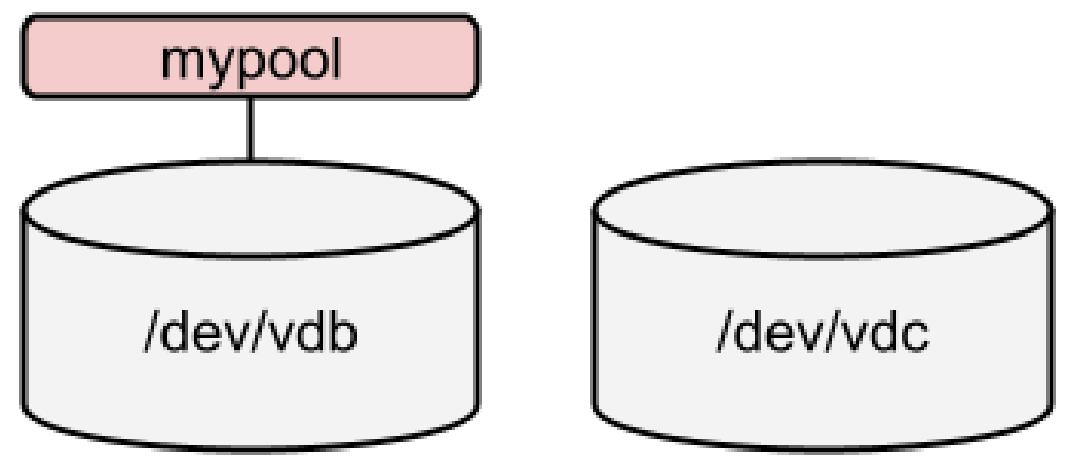
[root@rhel8 ~]# stratis pool create mypool /dev/vdb
[root@rhel8 ~]# stratis pool list
Name Total Physical Properties
mypool 1 GiB / 37.63 MiB / 986.37 MiB ~Ca,~Cr
В настоящее время мы обладаем созданным пулом, что показано на следующей схеме:
У нас имеется созданный пул; теперь мы создаём поверх него файловую систему:
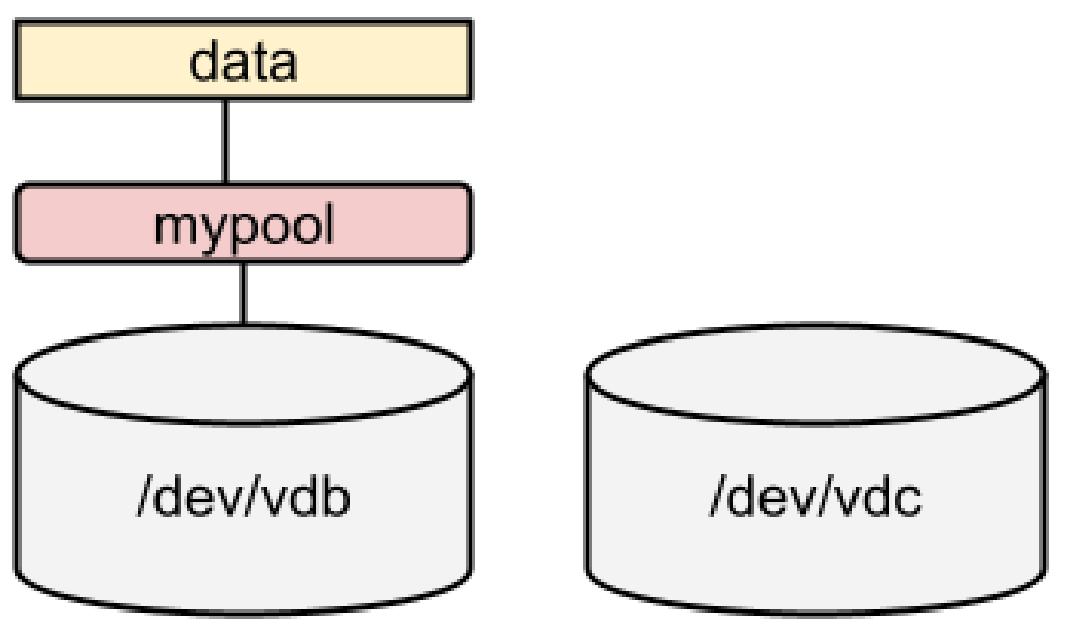
[root@rhel8 ~]# stratis filesystem create mypool data
[root@rhel8 ~]# stratis filesystem list
Pool Name Name Used Created Device UUID
mypool data 546 MiB May 23 2021 19:16 /dev/stratis/mypool/data b073b6f1d56843b888cb83f6a7d80a43
Вот состояние нашего хранилища:
Давайте подготовимся к монтированию файловой системы. Нам требуется добавить в /etc/fstab следующую
строку:
dev/stratis/mypool/data /srv/stratis-data xfs defaults,x-systemd.requires=stratisd.service 0 0
|
| Замечание |
|---|---|
|
Чтобы файловая система Stratis корректно монтировалась в процессе запуска, нам надлежит добавить параметр
|
Теперь мы можем монтировать его:
[root@rhel8 ~]# mkdir /srv/stratis-data
[root@rhel8 ~]# mount /srv/stratis-data/
Давайте теерь расширим этот пул:
[root@rhel8 ~]# stratis blockdev list mypool
Pool Name Device Node Physical Size Tier
mypool /dev/vdb 1 GiB Data
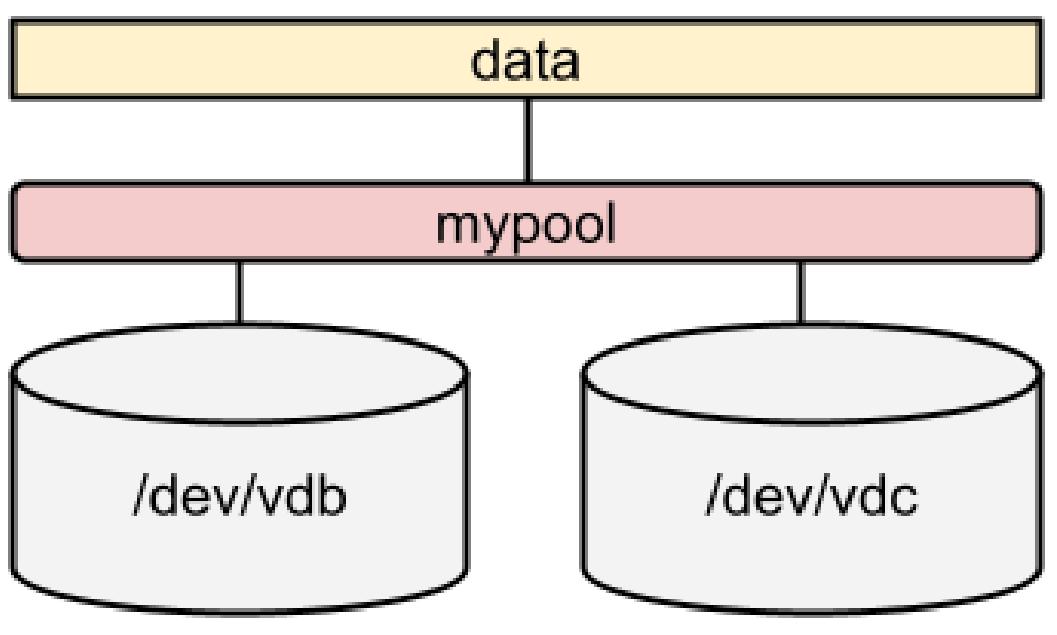
[root@rhel8 ~]# stratis pool add-data mypool /dev/vdc
[root@rhel8 ~]# stratis blockdev list mypool
Pool Name Device Node Physical Size Tier
mypool /dev/vdb 1 GiB Data
mypool /dev/vdc 1 GiB Data
Поскольку лежащий в основе уровень применяет динамично развёртываемые пулы (thin-pooling), нам нет нужды расширять имеющуюся файловую систему. Вот наше хранилище:
Настало время воспользоваться командой stratis snapshot для создания моментального снимка. Давайте
создадим некие данные, а затем выполним их моментальный снимок:
[root@rhel8 ~]# stratis filesystem
Pool Name Name Used Created Device UUID
mypool data 546 MiB May 23 2021 19:54 /dev/stratis/mypool/data 08af5d5782c54087a1fd4e9531ce4943
[root@rhel8 ~]# dd if=/dev/urandom of=/srv/stratis-data/file bs=1M count=512
512+0 records in
512+0 records out
536870912 bytes (537 MB, 512 MiB) copied, 2,33188 s, 230 MB/s
[root@rhel8 ~]# stratis filesystem
Pool Name Name Used Created Device UUID
mypool data 966 MiB May 23 2021 19:54 /dev/stratis/mypool/data 08af5d5782c54087a1fd4e9531ce4943
[root@rhel8 ~]# stratis filesystem snapshot mypool data data-snapshot1
[root@rhel8 ~]# stratis filesystem
Pool Name Name Used Created Device UUID
mypool data 1.03 GiB May 23 2021 19:54 /dev/stratis/mypool/data 08af5d5782c54087a1fd4e9531ce4943
mypool data-snapshot1 1.03 GiB May 23 2021 19:56 /dev/stratis/mypool/data-snapshot1 a2ae4aab56c64f728b59d710b82fb682
|
| Совет |
|---|---|
|
Чтобы увидеть внутренние составляющие Stratis вы можете выполнять команду |
Со всем этим, мы получили некий обзор Stratis чтобы осветить основы управления им. Помните, что Stratis пребывает в состоянии предварительного просмотра и им не следует пользоваться в промышленных системах.
Давайте теперь двинемся далее к прочим расширенным параметрам в управлении хранилищем просмотром дедупликации данных при помощи VDO.
Как уже упоминалось ранее, VDO это драйвер, а именно, драйвер отображения устройств Linux, который применяет два модуля:
-
kvdo: он выполняет сжатие данных -
uds: этот отвечает за дедупликацию
Обычные устройства хранения, такие как локальные диски, RAID (Redundant Array of Inexpensive Disks, Массив экономичных дисков с избыточностью), и тому подобное, выступают окончательной базой, в которой хранятся данные; располагающийся поверх VDO снижает загруженность диска за счёт следующего:
-
Удаления заполненных нулями блоков, сохраняя их в метаданных
-
Дедупликация: дублируемые блоки данных помечаются ссылками в соответствующих метаданных, но хранятся лишь один раз.
-
Сжатие при помощи блоков данных по 4кБ с алгоритмом сжатия без потерь (LZ4)
Эти методы в прошлом применялись в прочих решениях, например, в виртуальных машинах с динамическим выделением пространства, что только сохраняло отличие между виртуальными машинами, но VDO осуществляет это прозрачно.
Аналогично динамическому предоставлению, VDO может означать более быструю пропускную способность, поскольку данные могут кэшироваться системными контроллерами и отдельными службами и даже виртуальными машинами, которые могут применять эти данные без необходимости дополнительных чтений дисков для доступа к ним.
Давайте установим все необходимые пакеты в нашей системе чтобы создавать тома VDO установив пакеты vdo и
kmod-kvdo:
dnf install vdo kmod-kvdo
Теперь, обладая этими двумя установленными пакетами, мы готовы создать свой первый том в нашем следующем разделе.
Для создания устройства VDO мы воспользуемся тем устройством петли обратной связи, которое мы создали в Главе 12, Управление локальным хранилищем м файловыми системами, поэтому давайте сначала проверим смонтирован ли он или нет выполнив это:
mount|grep loop
Если нет никакого вывода, мы выполнили настройку для создания своего тома vdo поверх него следующим
образом:
vdo create -n myvdo --device /dev/loop0 –force
Получаемый вывод отображается на следующем снимке экрана:
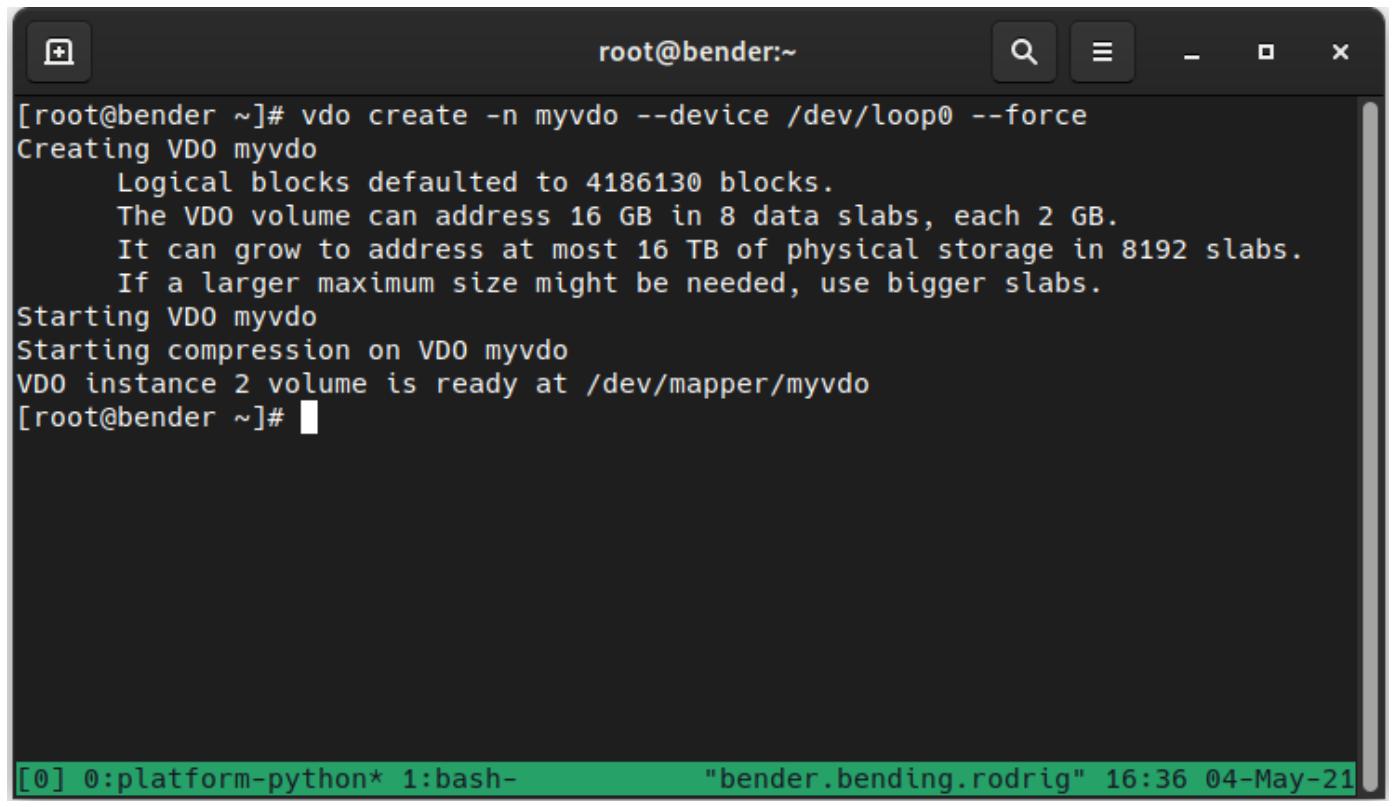
После того как том был создан, мы можем выполнить vdo status для получения подробных сведений о созданных томах,
что можно наблюдать на приводимом ниже снимке экрана:
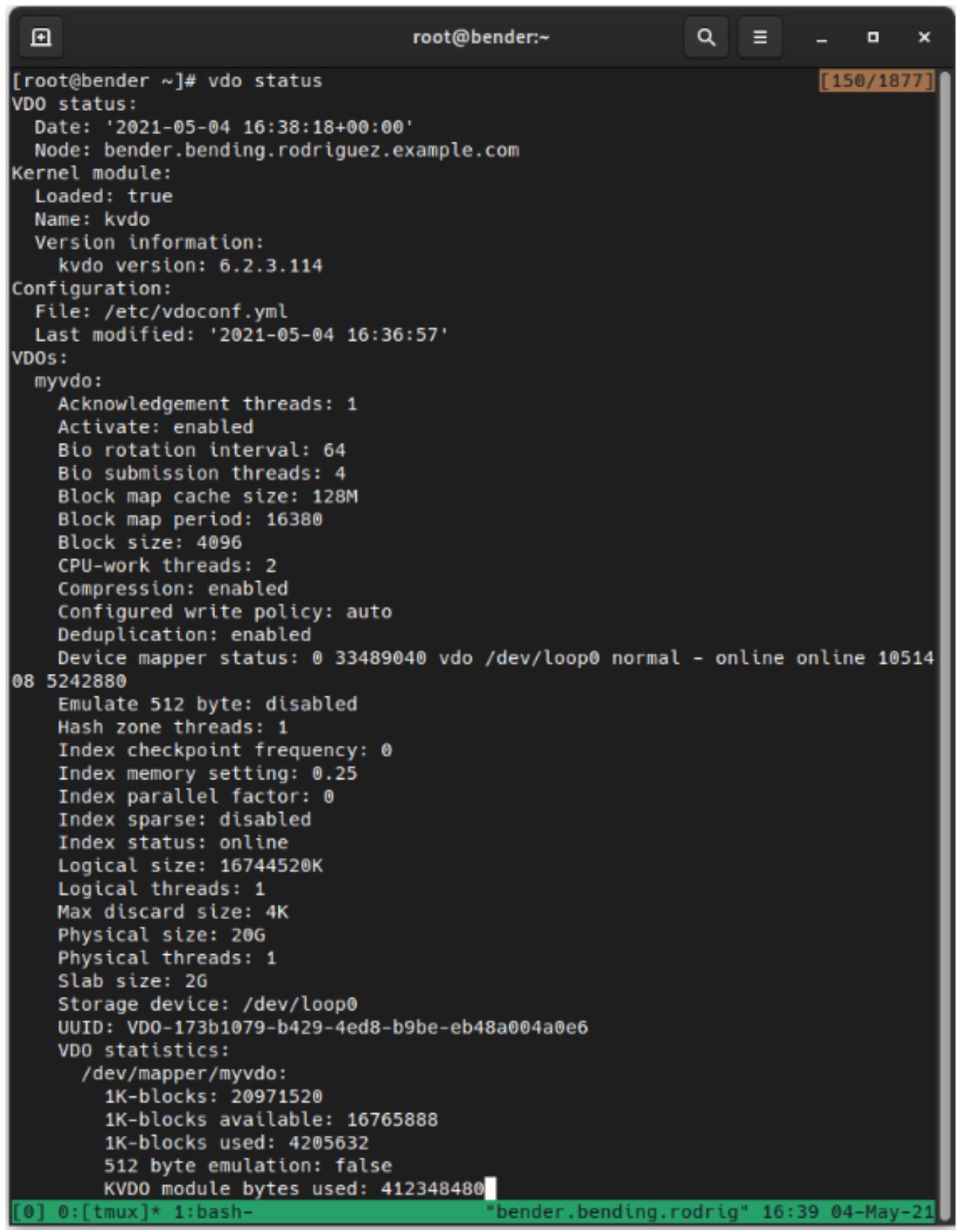
Как мы можем видеть, имеются сведения относительно версии kvdo, используемом файле конфигурации и наших
томах (размер, состояние сжатия и тому подобное).
Этот новый том теперь можно видеть через /dev/mapper/myvdo (то имя, которое мы назначили в
–n)
и он уже используется.
Также мы можем выполнить vdo status|egrep -i "compression|dedupli" и получить вывод, который
выглядит следующим образом:
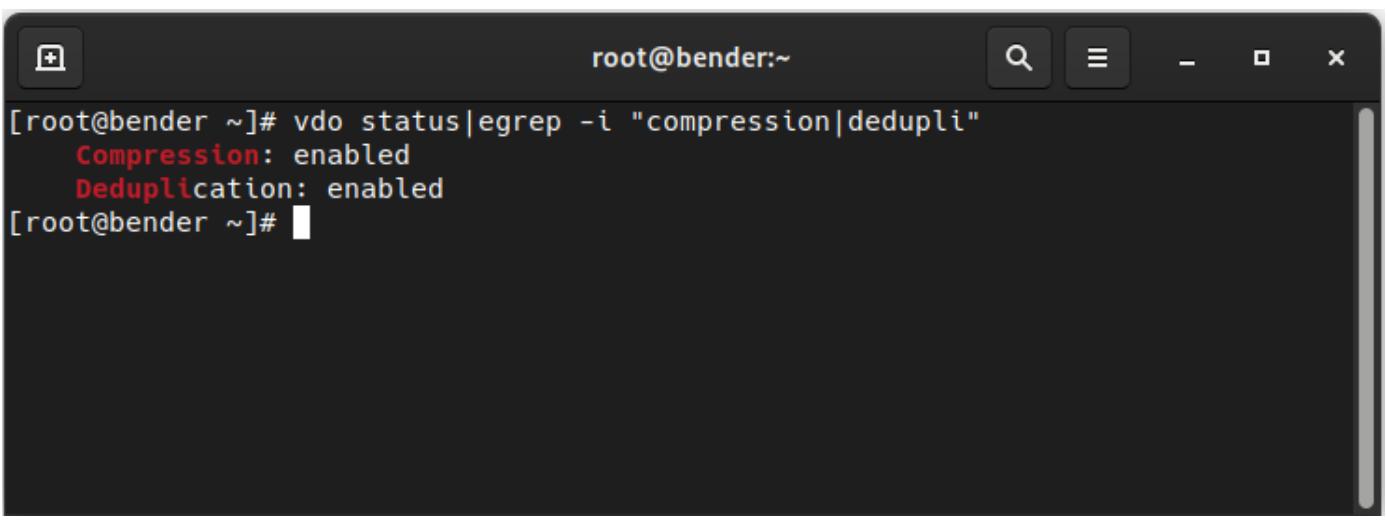
Это означает, что в нашем томе назначены и сжатие и дедупликация, а потому мы готовы к проверке этой функциональности добавляя их к некому тому LVM в своём следующем разделе.
В своём предыдущем разделе мы создали некий том VDO, который теперь превратится в наш PV (physical volume, физический том) когда будет создана некая группа тома LVM и какие- то логические тома поверх неё.
Давайте создадим этот PV выполнив такую последовательность команд:
-
pvcreate /dev/mapper/myvdo -
vgcreate myvdo /dev/mapper/myvdo -
lvcreate -L 15G –n myvol myvdo
К этому моменту наш /dev/myvdo/myvol готов к форматированию. Давайте воспользуемся файловой системой XFS:
mkfs.xfs /dev/myvdo/myvol
После того как необходимая файловая система была создана, давайте поместим в неё некие данные, смонтировав её следующим образом:
mount /dev/myvdo/myvol /mnt
Теперь давайте проверим этот том VDO в нашем следующем разделе.
Для проверки дедупликации и сжатия мы будем проверять большой файл, например, образ гостевой KVM RHEL 8, доступны в https://access.redhat.com/downloads/content/479/ver=/rhel---8/8.3/x86_64/product-software.
После его выгрузки сохраните его как rhel-8.3-x86_64-kvm.qcow2 и скопируйте его четыре раза в нашем
томе VDO:
cp rhel-8.3-x86_64-kvm.qcow2 /mnt/vm1.qcow2
cp rhel-8.3-x86_64-kvm.qcow2 /mnt/vm2.qcow2
cp rhel-8.3-x86_64-kvm.qcow2 /mnt/vm3.qcow2
cp rhel-8.3-x86_64-kvm.qcow2 /mnt/vm4.qcow2
Это будет типичный вариант для хранящего ВМ сервера, который запускает один и то же образ базового диска, но увидим ли мы какие- то улучшения?
Давайте для проверки своих данных исполним vdostats --human-readable. Обратите внимание, что наш
выгруженный образ имеет размер 1.4ГБ, о чём сообщает ls –si. Вот вывод, получаемый от
vdostats --human-readable:
Device Size Used Available Use% Space saving%
/dev/mapper/myvdo 20.0G 5.2G 14.8G 25% 75%
Наш изначальный том (файл петли обратной связи) имел размер 20 ГБ, поэтому именно этот размер мы и можем наблюдать, однако созданный нами том LVM имел размер 15ГБ, что мы оцениваем по полученному выводу и мы видим, что потребляется только примерно 1.2ГБ, даже хотя мы и получили четыре файла по 1.4ГБ каждый.
Процентное значение также совершенно очевидно. Мы сохранили 75% своего пространства (три файла из четырёх являются точными копиями). Если мы выполним некую дополнительную копию, мы обнаружим, что процентное соотношение превратится в 80% (1 из 5 копий).
Давайте проверим другой подход, создав пустой файл (заполненный нулями):
[root@bender mnt]# dd if=/dev/zero of=emptyfile bs=16777216 count=1024
dd: error writing 'emptyfile': No space left on device
559+0 records in
558+0 records out
9361883136 bytes (9.4 GB, 8.7 GiB) copied, 97.0276 s, 96.5 MB/s
Как мы можем видеть, мы способны записать 9.4ГБ до того как диск полностью заполнится, однако давайте проверим статистические данные своего
vdo снова при помощи vdostats --human-readable, как это видно из
приводимого ниже снимка экрана:
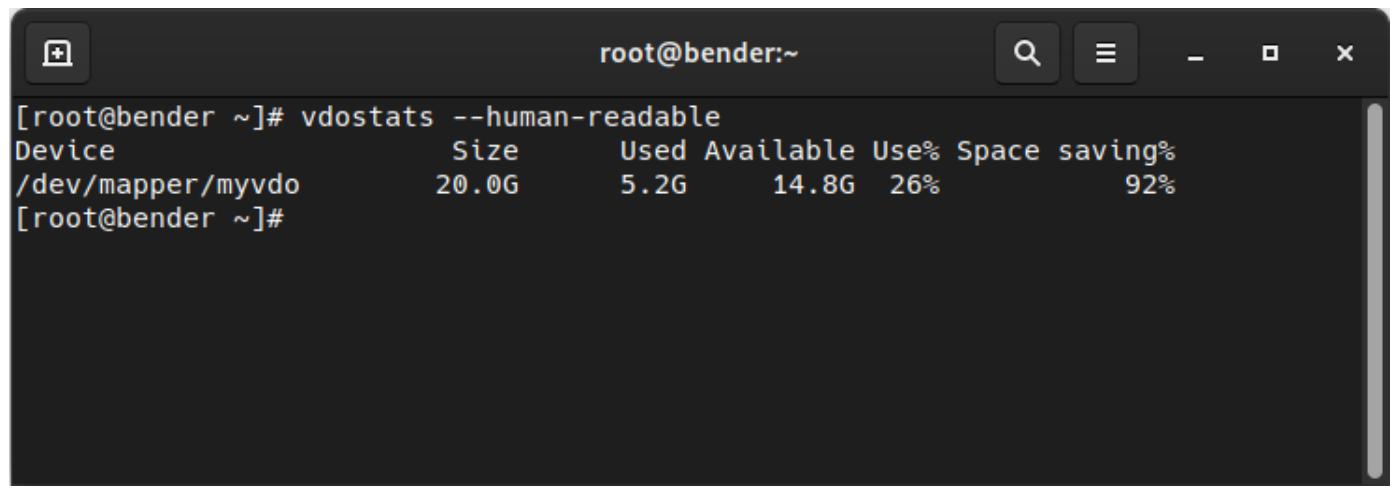
Как мы можем наблюдать, у нас всё ещё имеется доступными 14.8ГБ и мы увеличили сбережение дискового пространства с 80% до 92%, потому как этот большой файл пустой.
Постойте, если мы применяем дедупликацию и сжатие, как мы заполнили том если его 92% было сохранено?
Поскольку мы не указали значение логического размера своего тома VDO, по умолчанию он устанавливает соотношение 1 : 1 с лежащим в его основе устройством. Именно таков самый безопасный подход, но мы не применяем действительных преимуществ сжатия и дедупликации, выходящих за рамки производительности.
Для максимального применения оптимизации мы можем создать логический диск большего размера поверх имеющегося у нас тома. Например, когда мы уверены, что на протяжении длительного периода времени мы достаточно уверены, что оптимизация диска может оказываться аналогичной, мы можем увеличить значение логического размера при помощи такой команды:
vdo growLogical --name=myvdo --vdoLogicalSize=30G
Конечно же, это не увеличит значение доступного размера, поскольку мы определили PV с группой томов и логическим томом сверху. Поэтому нам также потребуется расширить его выполнив такие команды:
-
pvresize /dev/mapper/myvdo -
lvresize –L +14G /dev/myvdo/myvol -
xfs_growfs /mnt
Применив это, мы расширили свой физический том, увеличили значение своего логического тома и расширили свою файловую систему, а потому это пространство теперь доступно к применению.
Когда мы теперь исполним df|grep vdo, мы обнаружим нечто подобное следующему:

Начиная с этого момента нам следует быть очень аккуратными, поскольку наша реальная загруженность дискового пространства может быть не настолько оптимальной в отношении возможности сжатия, как это происходило до сих пор, что в результате может приводить к ошибкам при записях. Далее следует выполнять мониторинг доступного дискового пространства, а также состояния VDO чтобы быть уверенным что мы не пытаемся воспользоваться большим чем доступно пространством, например, когда сохраняемые файлы не могут сжиматься или дедуплицироваться в том же самом соотношении.
|
| Замечание |
|---|---|
|
Заманчиво создать действительно большой том из нашего на самом деле большого логического тома или из реального пространства физического диска, однако нам следует планировать наперёд и задумываться об избежании проблем в будущем, например, о вероятности того, что степень сжатия не будет столь же высокой, что и наш оптимизм. Адекватное профилирование подлежащих сохранению реальных данных и значения типичных соотношений сжатия могут снабжать лучшим представлением о том, какой именно безопасный подход применять при том, что мы продолжаем действенно наблюдать за развитием загруженности дисков, причём как для своего логического тома, так и для его физического собрата. |
Давным- давно, когда дисковое пространство было и в самом деле дорогим (а размеры жёстких дисков составляли не более 80МБ), было очень популярным применение инструментов, которые позволяли увеличивать дисковое пространство применяя прозрачный уровень сжатия, который выполнял некие оценки и выдавал отчёт о большем пространстве; однако на самом деле, мы знаем, что такое содержимое как изображения и фильмы не сжимаются настолько же хорошо как прочие форматы документов, такие как текстовые файлы. Некоторые форматы документов, например, применяемые LibreOfce, это уже сжатые файлы, поэтому не достигаются никакие дополнительные преимущества.
Однако это меняется когда мы обсуждаем виртуальные машины, когда собственно основа каждой из них более или менее эквивалентна (на основании политик и стандартов компании) и развёртывается через клонирование образов диска и последующего выполнения небольших персонализаций, однако по- существу, совместно используя бо́льшую часть содержимого диска.
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
В целом, имейте в виду, что оптимизация в действительности подразумевает компромисс. В случае подстройки профилей вы регулируете пропускную способность с учётом задержки, и в нашем случае вы платите ресурсами ЦПУ и оперативной памяти за доступность дисков. Единственный способ узнать стоит ли что- то предпринимать, это реализовать это и посмотреть как оно работает, взглянуть на полученные преимущества и затем продолжать со временем отслеживать производительность. |
В этой главе мы изучили VDO и Stratis. Мы взглянули на простейшие способы управления хранилищем, как прозрачно сберегать дисковое пространство и как увеличивать некую пропускную способность в общем процессе.
При помощи Stratis мы создали пул из двух дисков и назначили его точке монтирования. Это заняло несколько больше шагов, чем когда мы предпринимали это с LVM, однако с другой стороны у нас меньше контроля над тем что мы делаем. В любом случае, мы ознакомились с тем, как применять эту технолгию в состоянии предварительного просмотра в RHEL 8.
При помощи VDO мы пользуемся тем томом, который мы создали для определения некого физического тома LVM и, поверх него, группы тома и логического тома, которые мы отформатировали при помощи знаний, полученных в предыдущих главах для хранения несколько раз образа диска ВМ, чтобы имитировать ситуацию, при которой несколько виртуальных машин начинают с одной и той же базы.
Также мы изучили как проверять значение оптимизаций VDO и величину сохраняемого диска.
Теперь мы готовы к использованию Stratis вместо LVM для группирования и распространения хранилища (хотя и не в промышленных масштабах). Также мы реализовали VDO для своих серверов чтобы начать оптимизировать применение дисков.
В своей следующей главе мы ознакомимся с процессом запуска.