Раздел 3. Администрирование ресурсами - хранилище, процесс запуска, регулировки и контейнеры
Управление ресурсами машин, исполняющих RHEL является основополагающим с точки зрения производительности, действенности среды ИТ. Понимание хранилища, регулировок производительности (включая необходимые конфигурации, превращаемые в неизменные в процессе запуска), а затем применение контейнеров для изоляции процессов и более эффективного выделения ресурсов это области, в которых системный администратор с уверенностью будет работать каждый день.
В этот раздел включены такие главы:
Глава 12. Управление локальным хранилищем и файловыми системами
В своих предыдущих главах мы изучили безопасность и системное администрирование. В этой главе мы сосредоточимся на администрировании ресурсов, а именно администрировании хранилища.
Администрирование хранилища это важная часть удержания системы в рабочем состоянии: журналы системы способы съедать всё доступное пространство, новые приложения могут потребовать установки дополнительного хранилища для них (даже на обособленных дисках для улучшения производительности), а такие проблемы могут потребовать наших действий для их разрешения.
В этой главе мы изучим такие вопросы:
-
Разбиение дисков на разделы: диски с Master Boot Record (MBR, Главной загрузочной записью) и Globally Unique Identifer (GUID) Partition Table (GPT, Таблицей разделов с Глобально идентифицированным идентификатором)
-
Форматирование и монтирование файловых систем
-
Настройка монтирований по умолчанию и параметров в
fstab -
Применение сетевых файловых систем при помощи Network File System (NFS)
Это снабдит нас базовыми знаниями, которые позволят нам развить наши навыки администрирования хранилища чтобы наши системы продолжали работать.
Итак, засучим рукава!
Вы можете продолжать практиковаться при помощи той Виртуальной машины (ВМ), которую мы создали в самом начале книги в Главе 1, Установка RHEL8. Все прочие пакеты, необходимые для данной галвы, будут указываться по ходу текста. Вам также потребуются разбитые на разделы диски (диски MBR и GPT)
Раздел это логическое подразделение устройства хранения и оно применяется для логического разделения доступного хранилища на меньшие части.
Теперь, давайте перейдём к изучению происхождения хранилища, чтобы лучше разобраться с ним.
Хранилище также относится к некой систем, способной применять его, поэтому давайте немного поясним саму историю Персональных компьютеров (ПК), того программного обеспечения, которое позволяло ему запускаться - Basic Input/Output System (BIOS, Базовой системы ввода/ вывода) и того как это воздействует на администрирование хранилища.
Это может показаться слегка странным, но изначально хранилище требовалось лишь для небольшого количества килобайт (кБ), а для первых жёстких дисков в ПК хранилище составляло всего несколько Мегабайт (МБ).
ПК также обладали одной функциональностью и ограничением: ПК были совместимыми, что означало, что последующие подели были совместимыми с первоначальной архитектурой ПК International Business Machines (IBM).
Традиционное разбиение диска на разделы использовало пространство в самом начале дисков после соответствующей MBR, что делало возможным четыре регистрации разделов (начало, конец, размер, тип раздела, флаг активности), что носило название первичных (primary) разделов.
Когда такой ПК загружается, BIOS проверит имеющуюся таблицу разделов этого диска, исполняя небольшую программу в своей MBR, а затем он загружает свою область запуска из имеющегося активного раздела и исполняет её для получения запуска необходимой операционной системы.
Такие IBM PC содержали Disk Operating System (DOS) и совместимые ОС (MS-DOS, DR-DOS, FreeDOS и прочие) и также применяли файловую систему с названием File Allocation Table (FAT). Такая FAT содержала некоторые структуры, основывающиеся на её развитии, обозначенных как значение размера адресации кластера (а также некоторые прочие функции).
Обладая пределом в значении числа кластеров, обладание дисками бо́льшего размера означало обладание бо́льшими блоками, поэтому когда файл применял всего лишь ограниченный объём пространства, остающееся не могло применяться прочими файлами. Тем самым, стало более или менее обычным разбивать большие дисковые устройства на логические разделы меньшего масштаба с тем, чтобы маленькие файлы не съедали всё доступное пространство по причине ограничений.
Представляйте себе это как некое расписание с максимальным числом записей, похожее на быстрый набор в вашем телефоне: когда у вас имеется лишь девять позиций для быстрого набора, такой короткий номер, как вызов голосовой почты всё равно будет считаться сохраняющим столько же цифр, сколько и в большом международном телефонном номере, поскольку они оба применяют один и тот же слот.
Некоторые из подобных ограничений в последующих версиях размера FAT были снижены, что параллельно увеличило максимально поддерживаемые размеры диска.
Естественно, другие операционные системы вводили свои собственные файловые системы, но применяли ту же самую схему разбиения на разделы.
Позднее был создан иной тип разбиения на разделы: extended partition (расширенное разбиение на разделы), которое применялось в одном из четырёх доступных слотов первичных разделов и теперь допускало определение внутри него дополнительных разделов, что позволило нам создавать логические диски для выделения по мере необходимости.
Кроме того, обладание несколькими первичными разделами также позволяет установку в одном и том же компьютере различных операционных систем с их собственным выделенным пространством, которое полностью независимо от прочих операционных систем.
Итак... разбиение на разделы позволяет компьютерам обладать различными операционными системами, лучше использовать доступное хранилище или даже логически сортировать имеющиеся данные оставляя их в различных областях, например, удерживать пространство операционной системы отдельно от данных пользователя с тем, чтобы заполнение пользователем всего доступного пространства не оказывало воздействия на работу его компьютера.
Как мы уже сказали, многие из этих архитектур поставлялись с наличием ограничения совместимости с первоначальным IBM, поэтому, когда новые компьютеры применяют Extensible Firmware Interface (EFI, Расширенный интерфейс встроенного программного обеспечения), появившегося для обхода имеющихся ограничений традиционного BIOS, появился новый формат таблиц разделов с названием GPT.
Применяющие GPT системы могут пользоваться 32- битной и 64- битной поддержкой вместо 16- битной поддержки, применяемой в BIOS (наследуемой из совместимости с IBM PC), поэтому для наших дисков может применяться бо́льшая адресация, а также дополнительные функциональные возможности, такие как загрузка расширенных контроллеров. {Прим. пер.: подробнее в нашем переводе Практика загрузки. Изучение процесса загрузки Linux, Windows и Unix Йогеша Бабара.}
Теперь, давайте в своём следующем разделе изучим разбиение диска на разделы.
Как уже упоминалось, применение дисковых разделов позволяет нам более эффективно использовать то пространство, которое доступно в наших компьютерах и серверах.
Давайте окунёмся глубже в разбиение диск на разделы прежде всего выявляя тот диск, с которым предстоит работать.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Раз мы ознакомились с тем что вызывает разделение дисков на разделы и ограничениям этого, нам надлежит следовать той или иной схемой, основанной на спецификации нашей системы, но имейте в виду, что EFI требует GPT, а BIOS нуждается в MBR, поэтому система, поддерживающая UEFI, но обладающая разбиением дисков на разделы при помощи MBR будет загружать саму систему в совместимом с BIOS режимом. {Прим. пер.: подробнее в нашем переводе Практика загрузки. Изучение процесса загрузки Linux, Windows и Unix Йогеша Бабара.} |
Linux применяет различную нотацию для дисков на основании того способа, которым они подключаются к своей системе, поэтому - например - вы можете
видеть диски как hda или sda, или
mmbclk0 в зависимости от применяемого подключения. Традиционно диски, подключаемые при помощи интерфейса
Integrated Drive Electronics
(IDE) при их применении имели названия hda,
hdb и так далее, в то время как диски, использующие Small
Computer System Interface (SCSI) при своём использовании обладают
именами sda, sdb и тому подобное.
Мы можем перечислять такие доступные устройства при помощи fdisk –l или
lsblk –fp, как это можно наблюдать на нашем следующем снимке экрана:
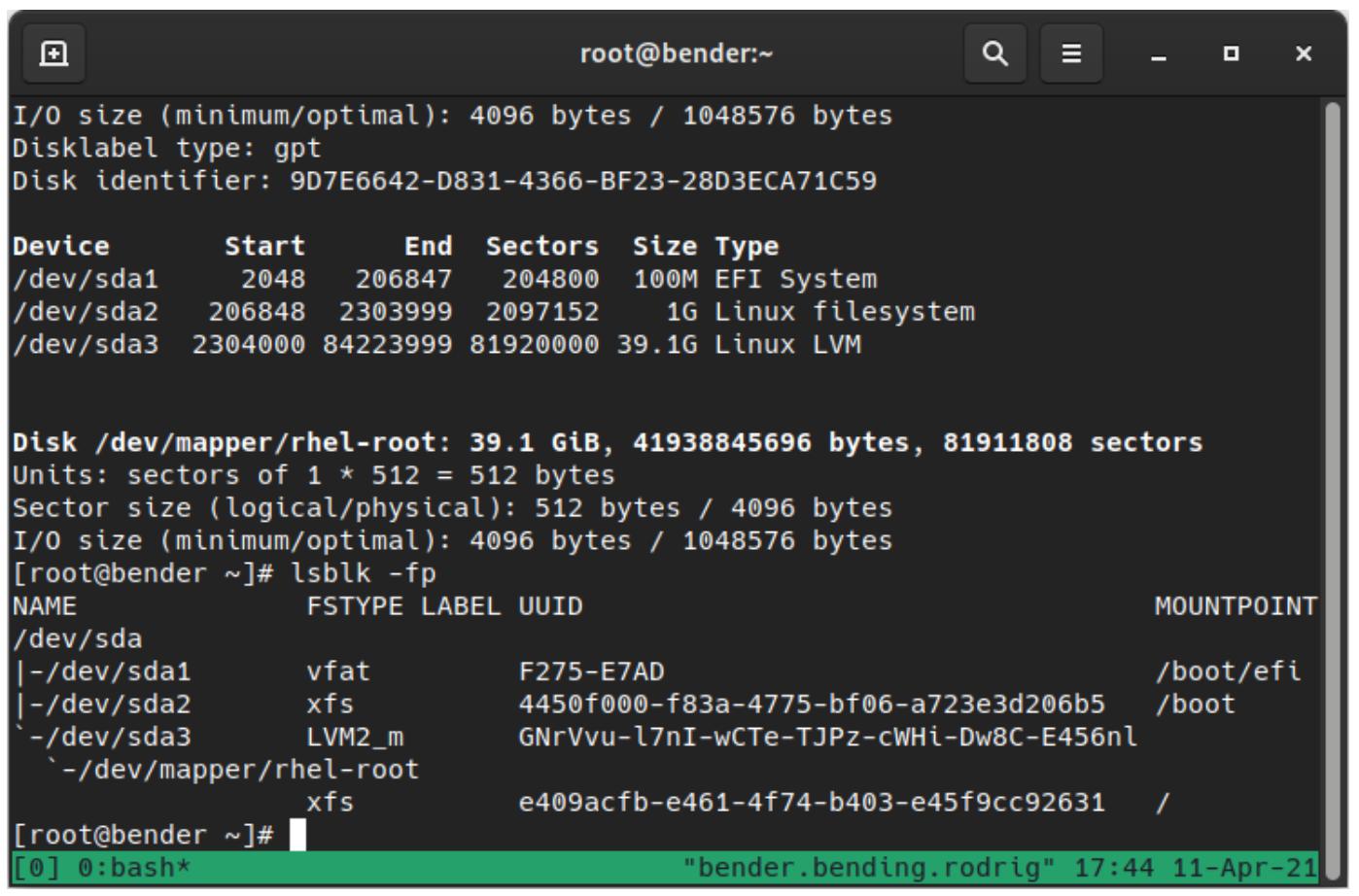
Как мы можем видеть, наш диск с названием /dev/sda имеет три раздела: sda1,
sda2 и sda3, причём sda3
выступает группой тома LVM, который обладает томом с названием
/dev/mapper/rhel-root.
Для демонстрации разбиения диска на разделы неким безопасным способом и для упрощения читателям применения ВМ для тестирования мы создадим
для проверок поддельный virtual hard drive
(VHD). При выполнении этого мы воспользуемся утилитой
truncate, которая поставляется с пакетом coreutil и утилитой
losetup, предоставляемой при помощи пакета util-linux.
Для создания некого VHD мы воспользуемся приводимой ниже последовательностью команд в том виде как они появляются на Рисунке 12-2:
-
truncate –s 20G myharddrive.hddЗамечание Данная команда создаёт файл с размером 20 гигабайт (ГБ), однако это будет пустой файл, что означает что этот файл в действительности не будет использовать 20 ГБ нашего диска, просто показывая этот размер. Пока мы не пользуемся им, он не будет потреблять дополнительное дисковое пространство (он носит название sparse file, разряженного файла).
-
losetup –f, которая обнаружит наше следующее доступное устройство -
losetup /dev/loop0 myharddrive.hdd, что установит соответствиеloop0с созданным файлом. -
lsblk –fpдля проверки только что зацикленного диска -
fdisk –l /dev/loop0для перечисления доступного пространства в нашем недавно созданном диске
Приводимый ниже снимок экрана отображает вывод нашей предыдущей последовательности команд:
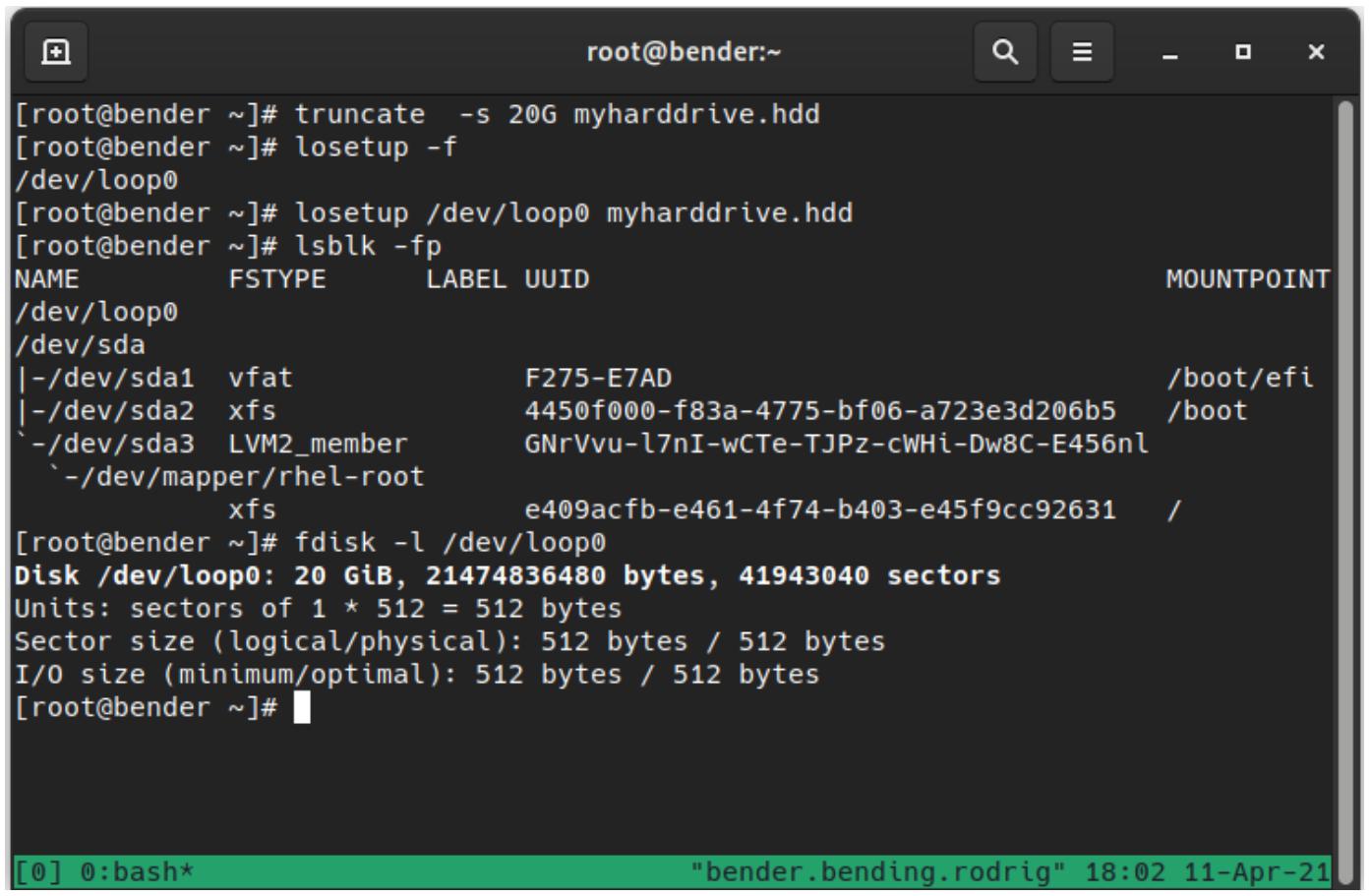
Команда losetup –f обнаруживает следующее доступное устройство обратной петли, которым является
устройство для зацикливания обратно доступа к лежащему в основе файлу. Это часто применяется, например, для локального монтирования файлов
ISO.
При помощи третьей команды применяем своё изначально доступное устройство обратной петли для настройки некого зацикленного соединения
между устройством устройствва loop0 и тем файлом, который мы создали в своей самой первой команде.
Как вы можете видеть, в наших оставшихся командах это устройство теперь появляется при исполнении тех же команд, которые мы исполняли в Рисунке 12-1, показывая что у нас имеется диск с доступными 20ГБ.
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
Операции по созданию разделов на дисках могут представлять опасность и способны превратить систему в негодную и потребовать
восстановления или повторной установки. Чтобы уменьшить такую возможность, в примерах данной главы будет применяться созданный
поддельный диск |
Давайте приступим к созданию разделов выполняя fdisk /dev/loop0 в нашем вновь созданном устройстве, как
это показано на нашем следующем снимке экрана:
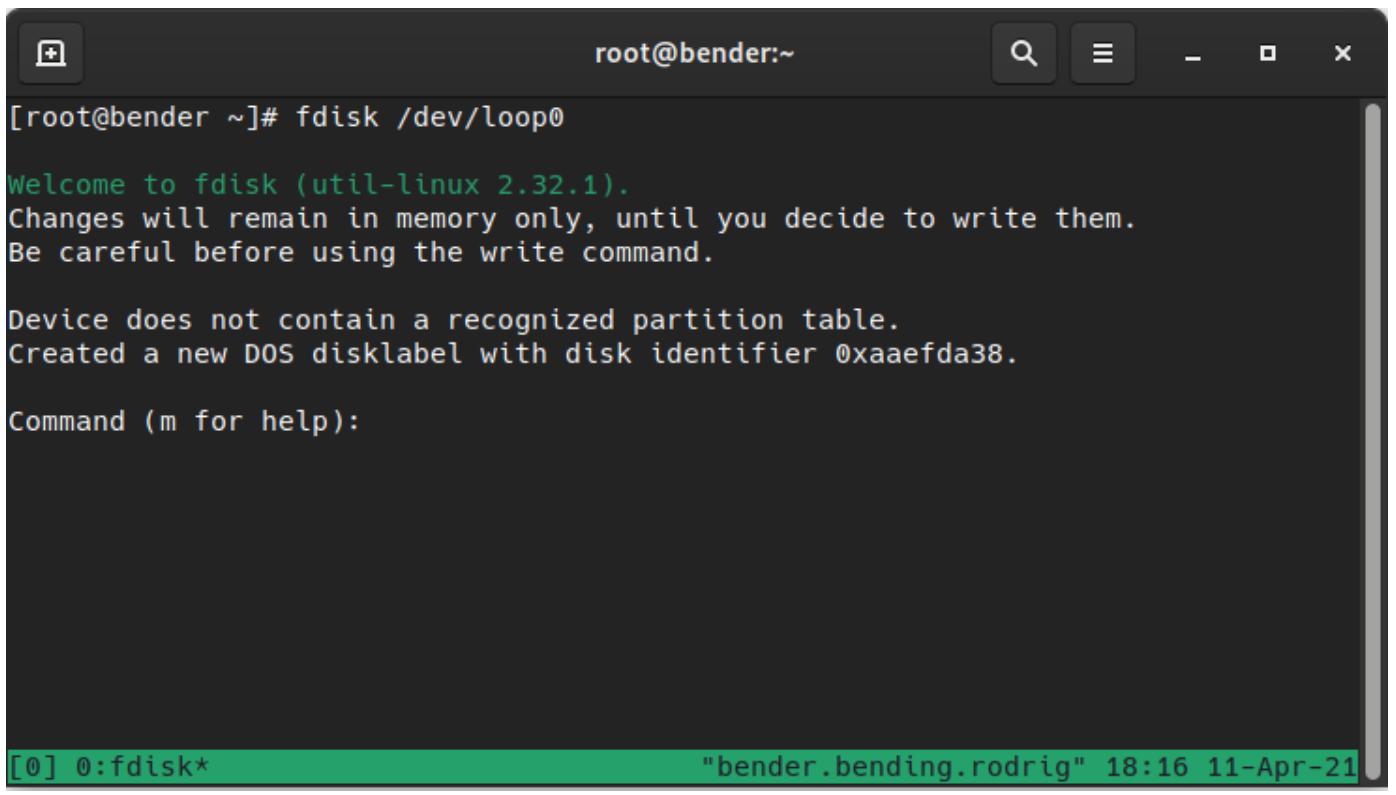
Как мы можем видеть на Рисунке 12-3, этот диск не содержит распознаваемой таблицы разделов, поэтому новая метка раздела диска DOS создаётся, однако эти изменения остаются лишь в памяти до обратной записи на диск.
Внутри соответствующей команды fdisk мы можем применять различные параметры для создания раздела. Самый
первый, о котором нам следует знать, это m, который указан на
Рисунке 12-3, который показывает справку функциональности и доступные команды.
Самым первым моментом, который следует учитывать это наши предыдущие соображения относительно UEFI, BIOS и тому подобного. По умолчанию,
fdisk создаёт некий раздел DOS, однако, как мы можем видеть внутри приводимого руководства (manual,
m), мы имеем возможность создания раздела GPT выполняя внутри fdisk
команду g.
Ещё одна важная команда, которую стоит помнить, это p, которая выводит на печать текущую схему диска и
разделы, как это показано на нашем следующем снимке экрана:
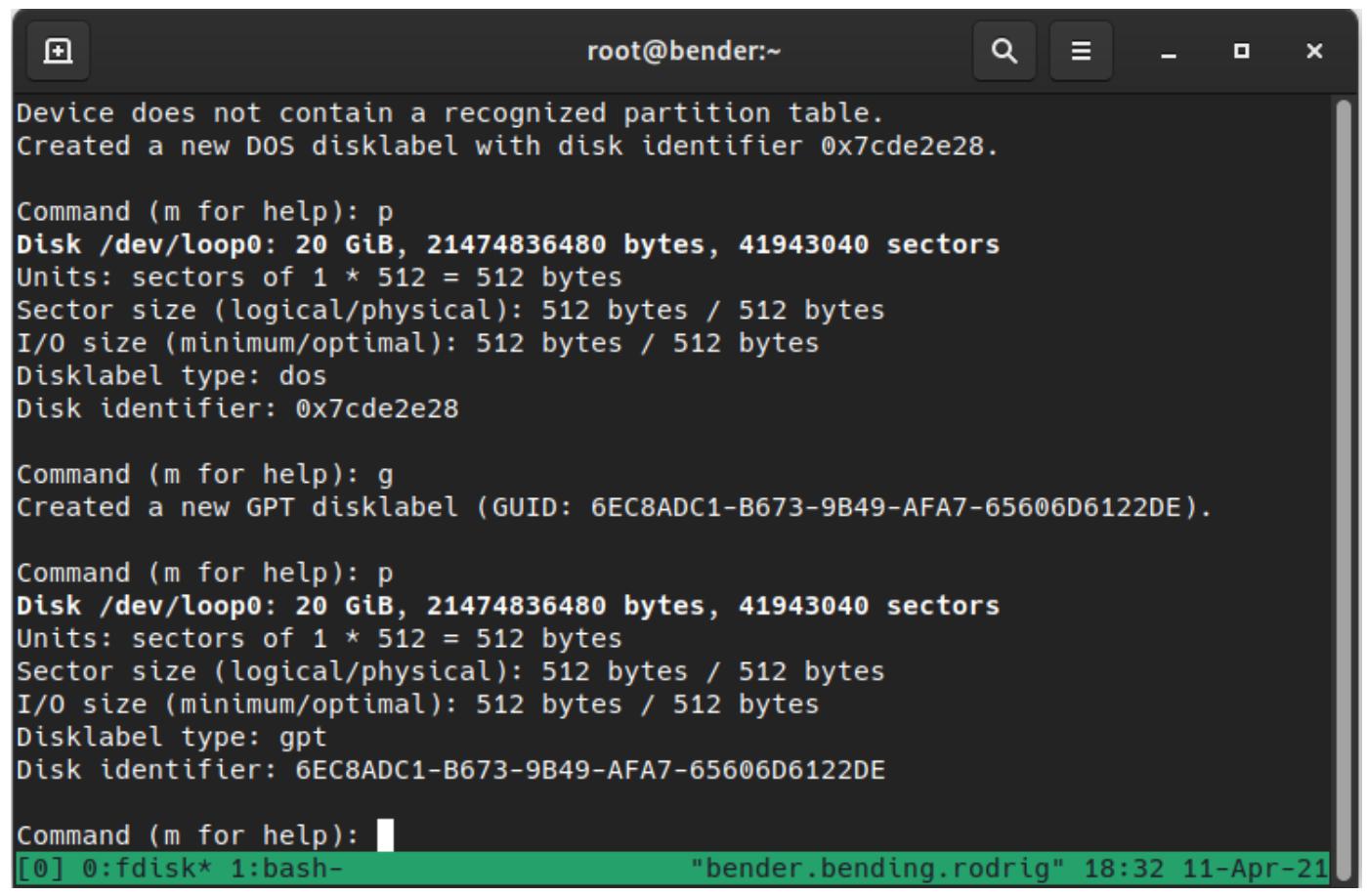
Как мы можем наблюдать, нашим изначальным типом disklabel был dos,
а теперь он gpt, совместимый с EFI/ UEFI.
Давайте рассмотрим некоторые основные команды, которые мы можем применять, вот они:
-
n: создаёт некий новый (new) раздел -
d: удаляет (delete) раздел -
m: отображает страницу руководства (manual, подсказку) -
p: выводит (print) текущую схему -
x: входит в расширенный режим (extra функциональность, предназначающаяся экспертам) -
q: выход (quit) без сохранения -
w: запись (write) изменений на диск с последующим выходом -
g: создание новой метки диска GPT -
o: создание метки диска DOS -
a: в режиме DOS устанавливает флаг запуска (Active) в одном из имеющихся первичных разделов
Какой была бы необходимая последовательность для создания новой обычной схемы разделов диска с неким разделом запуска для собственно операционной системы и другого для данных пользователя по пол диска на каждую?
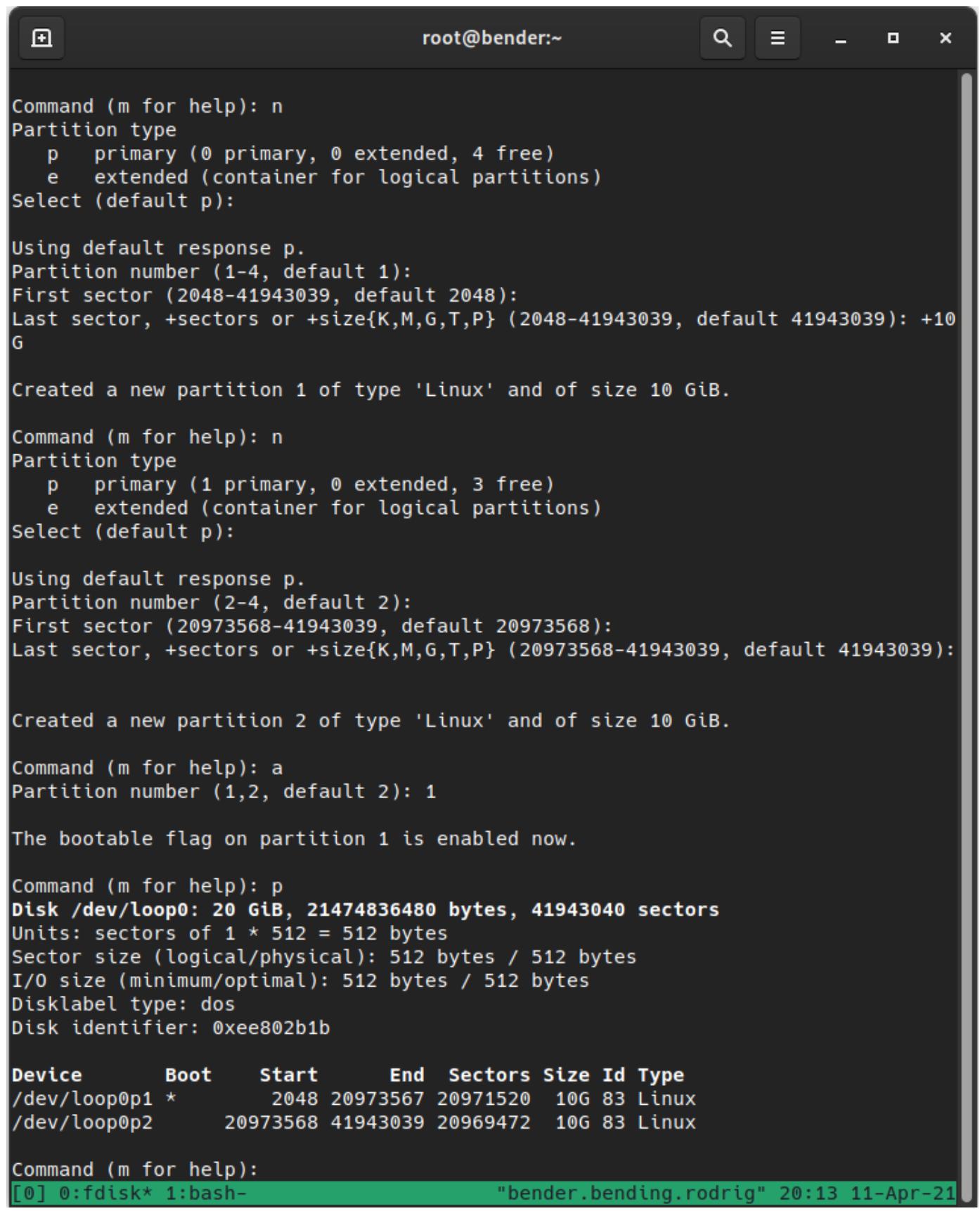
Вот эта последовательность команд (также отображаемая на Рисунке 12-5):
-
oс последующим нажатием наEnterдля создания новой метки диска DOS -
nс нажатием наEnterдля создания нового раздела -
Нажатие на
Enterчтобы принять тип первичного раздела -
Нажатие на
Enterдля подтверждения применения первого раздела (1) -
Нажатие на
Enterдля принятия начального сектора -
+10Gс последующимEnterдля указания 10ГБ в размере от первого сектора -
nи нажатиеEnterдля создания второго нового раздела -
Нажатие
Enterдля принятия его в качестве типа первичного раздела -
Нажатие
Enterдля принятия значения номера раздела (2) -
Нажатие на
Enterдля принятия самого первого сектора, который предлагается по умолчанию fdisk -
Нажатие на
Enterдля принятия самого последнего сектора, который предлагается по умолчанию fdisk -
aиEnterдля пометки раздела загружаемым -
1иEnterдля пометки нашего первого раздела
Как вы можете видеть, большинство параметров применяются по умолчанию; единственное изменение состояли в определении размера раздела в
+10G, что означает, что он должен составлять 10ГБ (весь диск это 20ГБ) и затем приступить ко второму
разделу при помощи команды n, причём теперь без определения значения размера, поскольку мы желаем
воспользоваться всем остающимся. Самый последний шаг состоит в пометке нашего первого раздела как активного для запуска.
Естественно, вы помните что мы сказали ранее: пока мы не выполним свою команду w, эти изменения
не записываются на диск и мы можем воспользоваться p для их просмотра как это отображено в нашем
следующем снимке экрана:
Чтобы завершить этот раздел, давайте запишем все изменения на диск при помощи команды w и
давайте перейдём в своём следующем разделе к обсуждению файловых систем. Перед этим давайте исполним
partprobe /dev/loop0 чтобы выполнить обновление своего ядра в его внутреннем представлении имеющихся
дисков и обнаружить эти два новых раздела. Без этого могут быть не созданы специальные файлы /dev/loop0p1
и /dev/loop0p2, а следовательно они будут не доступны.
Обратите внимание на то, что некоторые изменения разделов не будут обновлены даже после выполнения partprobe
и могут потребовать перезагрузки данной системы. Это, например, происходит на дисках с задействованными разделами, такими как тот, который
содержит корневую файловую систему нашего компьютера.
В своём предыдущем разделе мы изучили как логически делить свой диск, однако этот диск всё ещё не применим для хранения данных. Чтобы разрешить выполнять это, в качестве первого шага превращения его в доступный для нашей системы, нам требуется определить в нём файловую систему.
Файловая система это некая логическая структура, которая определяет ка хранятся и предоставляются файлы, папки и прочее, причём на основе каждого типа, с различным набором характеристик.
Общее число и типы поддерживаемых файловых систем зависят от значения версии операционной системы, поскольку в процессе развития могли добавляться, удаляться и тому подобное, новые файловые системы.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Помните, что Red Hat Enterprise Linux (RHEL) сосредоточена на стабильности, поэтому существует строгий контроль относительно добавляемых функциональных особенностей или снятия их для новых выпусков, однако не в рамках данного выпуска. Дополнительно об этом вы можете прочесть в https://access.redhat.com/articles/rhel8-abi-compatibility. |
В RHEL 8 файловой системой по умолчанию выступает eXtended File System (XFS), однако вы можете ознакомиться со списком файловых систем в документации RHEL, находящейся в https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/system_design_guide/overview-of-available-file-systems_system-design-guide, и, естественно, может применяться Fourth Extended Filesystem (EXT4).
Вариант выбора конкретной файловой системы зависит от ряда факторов, таких как, намерение применения, тип файлов, которые мы намерены применять, и тому подобное, поскольку различные файловые системы могут обладать последствиями для производительности.
Например, и EXT4, и XFS являются журналируемыми файловыми системами, которые предоставляют дополнительную защиту от отказов питания, однако значение максимума файловой системы отличается в плане прочих сторон, таких как вероятность фрагментации и тому подобное.
Перед выбором файловой системы неплохо получить некие соображения относительно основного вида подлежащих развёртыванию файлов и шаблона их применения, ибо неправильный выбор может оказать воздействие на производительность системы.
Как мы определили в нашем VHD из своего предыдущего раздела, мы можем попробовать создать обе файловые системы, и XFS, и EXT4. И снова, будьте предельно внимательны при выполнении действий, поскольку создание файловой системы это разрушающая операция, которая записывает обратно на свой диск новые структуры и при работе в качестве пользователя root данной системы, что является необходимым, неверный выбор способен за секунды разрушить все доступные данные, имевшиеся в нашей системе.
|
| Предостережение |
|---|---|
|
Не забудьте проверить справочную страницу (man page) на предмет подлежащих выполнению команд чтобы ознакомиться с различными рекомендациями и параметрами, доступными для каждой из них. |
Давайте далее воспользуемся двумя созданными нами разделами для проверки двух файловых систем, XFS и EXT4, применяя команды
mkfs.xfs и mkfs.ext4 для каждого из имеющихся устройств,
соответственно, следующим образом:
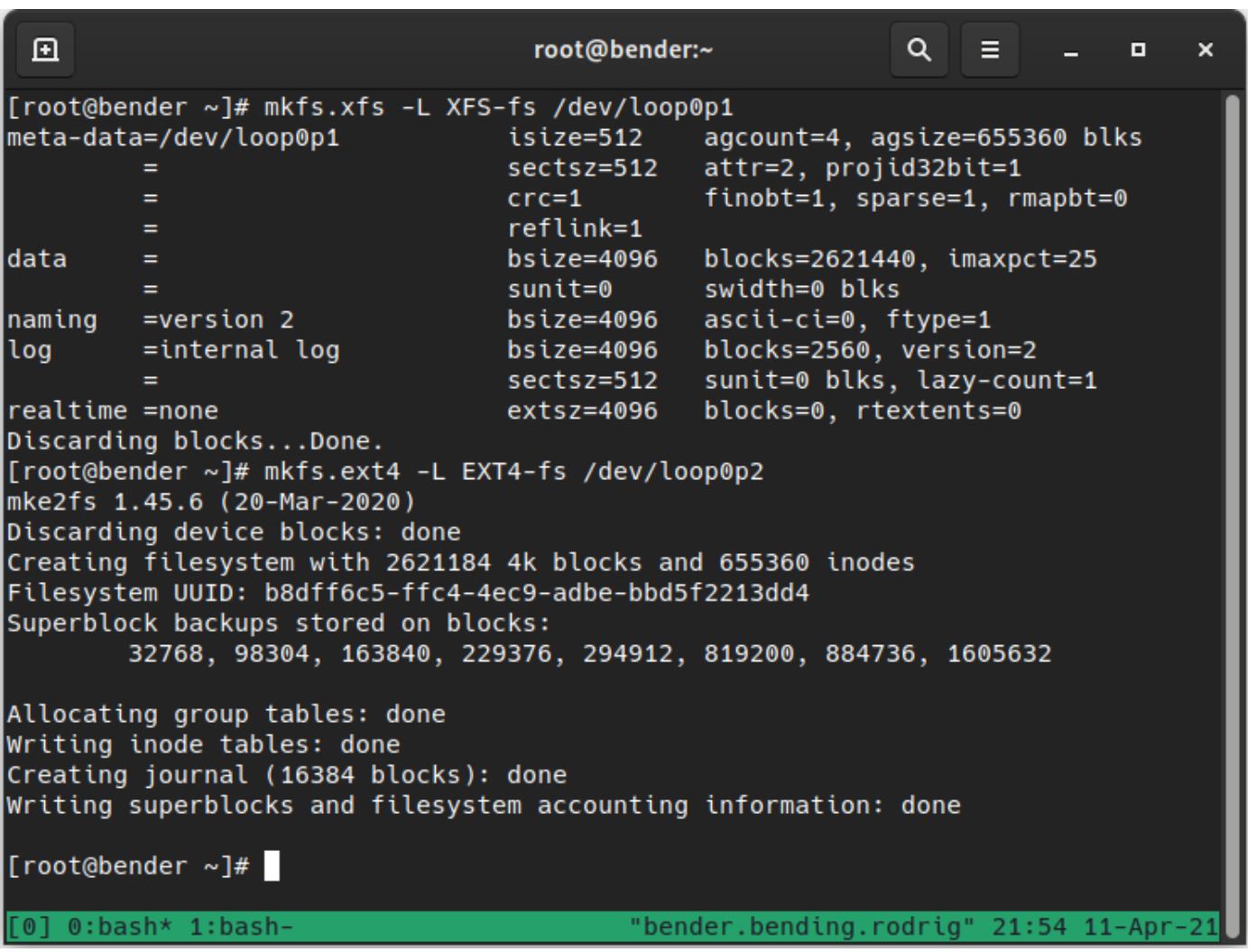
Обратите внимание, что мы определили значение различных разделов зацикленного устройства и мы также определили по одному параметру
-L для каждой команды. Мы рассмотрим это позже.
Теперь, когда файловая система была создана, мы можем выполнить lsblk -fp для проверки этого и мы
можем видеть оба устройства, теперь указывающих эти файловые системы применяемыми , а также значения LABEL
и UUID (те самые, которые отображаются при создании данной системы при помощи
mkfs), как мы это можем наблюдать на приводимом ниже снимке экрана:
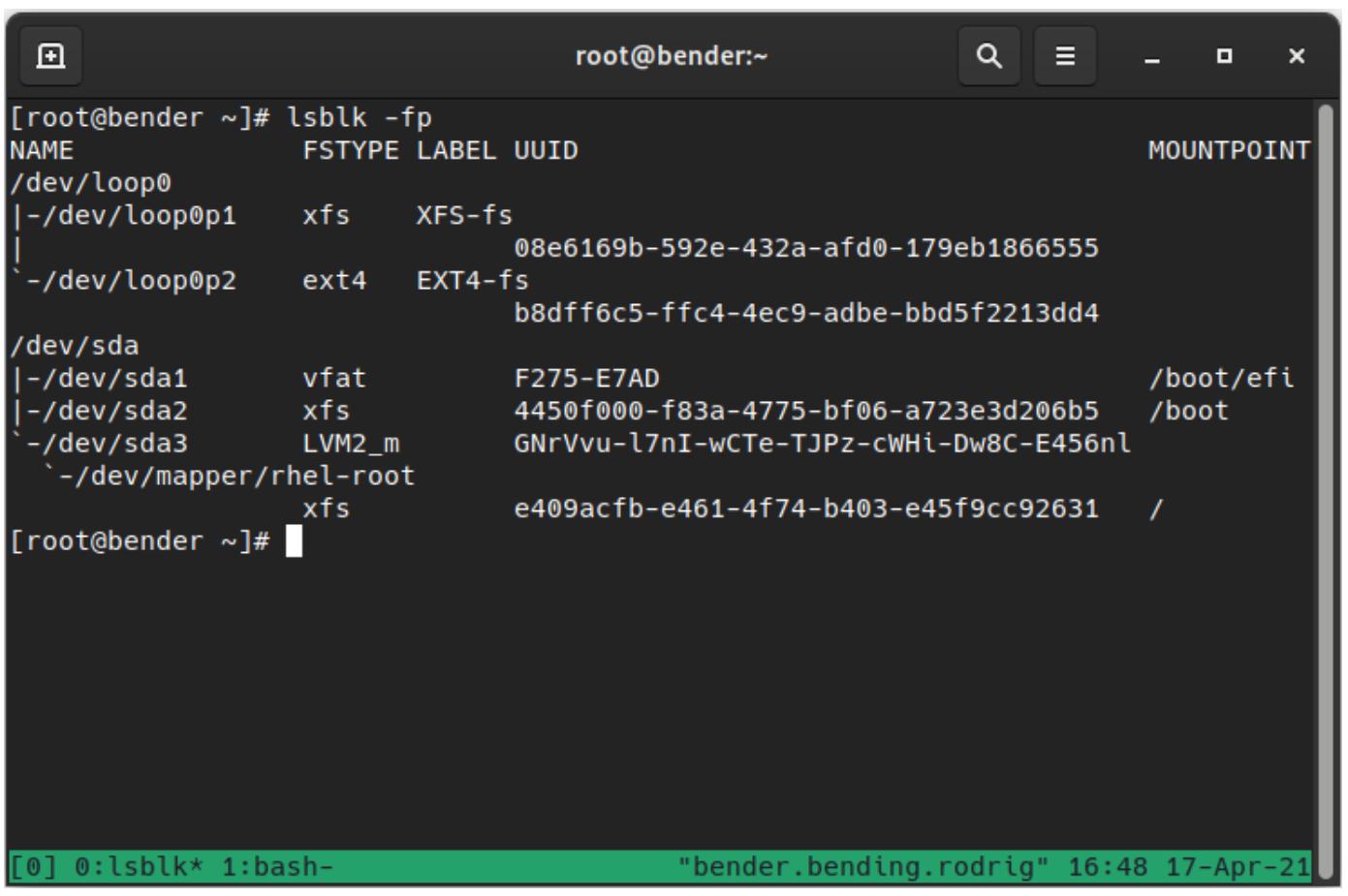
В нашем предыдущем выводе важно уделить внимание значениям LABEL и UUID
(как вы помните, эти значения определяются в нашей команде mkfs при помощи параметра
-L), поскольку позднее в этой главе мы будем пользоваться ими.
Теперь, после того как необходимые файловые системы были созданы, чтобы воспользоваться ими, нам требуется смонтировать их, что означает сделать эти файловые системы доступными в неком пути нашей системы с тем, чтобы всякий раз, когда мы выполняем сохранение внутри данного пути, мы бы применяли это устройство.
Монтирование файловой системы может выполняться различными способами, однако самый простой состоит в автоматическом определении и простом определении
определённого устройства для монтирования и значения локального пути для его монтирования, однако более сложные варианты, которые допускают для определения
некоторые параметры, можно обнаружить при проверке справочной страницы man mount.
Для монтирования наших двух созданных файловых систем мы создадим две папки и затем продолжим монтирование каждого из устройств путём выполнения приводимых далее команд:
-
cd -
mkdir first second -
mount /dev/loop0p1 first/ -
mount /dev/loop0p2 second/
К этому моменту наши две файловые системы будут доступны в нашей домашней папке (пользователя root) в подкаталогах с названиями
first и second.
Наше ядро автоматически обнаружит каждую из файловых систем, применяемых для каждого из устройств и загрузит их через соответствующий контроллер
и это сработает, однако порой мы можем пожелать определять конкретные параметры - например, принудительный тип своей файловой системы, который
применялся в прошлом, когда ext2 и ext3 были распространёнными
файловыми системами для разрешения или запрета журналирования или, например, для отключения встроенных функциональных возможностей, таких как
обновления значения времени доступа к файлу или каталогу для снижения ввода/ вывода своего диска и увеличения производительности.
Все указанные в нашей командной строке или монтируемых файловых системах параметры станут недоступными после перезапуска нашей системы, поскольку они изменяются лишь во время исполнения. Давайте перейдём к своему следующему разделу и узнаем как определять параметры по умолчанию и монтирования конкретной файловой системы при запуске.
В своём предыдущем разделе мы ввели вас в курс дел того как могут монтироваться диски и разделы с тем, чтобы наши службы и пользователи могли пользоваться ими. В этом разделе мы изучим как заставлять эти файловые системы быть доступными на постоянной основе.
Имеющийся файл /etc/fstab содержит определения соответствующих файловых систем для нашей системы и, естественно,
он обладает посвящённым ему руководством, с которым можно ознакомиться при помощи man fstab, содержащим
полезные сведения относительно имеющихся форматов, полей, порядка и того подобного, что следует принимать во внимание, поскольку данный файл критически
важен для гладкой работы нашей системы.
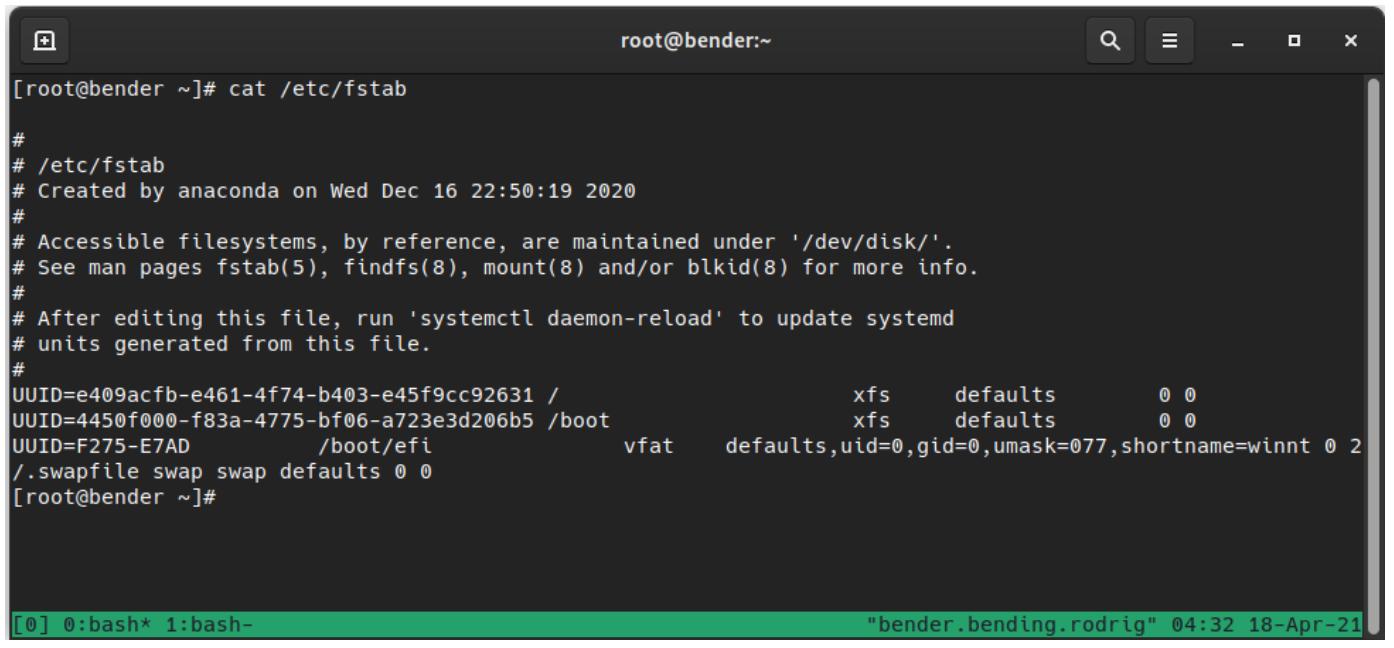
Основной формат файла определяется несколькими полями, разделёнными табуляциями или пробелами , причём начинающиеся с
# строки рассматриваются в качестве комментариев.
Например, мы воспользуемся этой строкой чтобы рассмотреть определение каждого поля:
LABEL=/ / xfs defaults 0 0
Самое первое поле выступает определением данного устройства, которым может быть особое блочное устройство, удалённая файловая система или, - как
мы можем наблюдать - некий переключатель, осуществляемый LABEL, UUID или,
для GPT систем, также
PARTUUID либо PARTLABEL. Соответствующая страница
man предоставляет дополнительные сведения для mount,
blkid и lsblk относительно идентификаторов устройств.
Значение второго поля это положение точки монтирования для данной файловой системы, которое является тем местом, в котором доступно содержимое данной
файловой системы на основании иерархии каталога нашей системы. Некоторые специальные устройства/ разделы, например, области подкачки (swap) обладают
этим полем, определяемым как none, поскольку на самом деле его содержимое не делается доступным через имеющуюся
файловую систему.
Третье поле это значение типа файловой системы в качестве поддерживаемого командой mount или,
для разделов подкачки, swap.
Значение четвёртого поля это параметры монтирования, как они поддерживаются командами mount или
swapon (для получения дополнительных сведений ознакомьтесь с их страницами
man), будучи установленным defaults это является псевдонимом для наиболее
распространённых параметров (чтение/ запись, разрешать устройства, разрешать исполнение, автоматическое монтирование при запуске, асинхронный доступ и тому
подобное). Другим распространённым параметром может быть noauto, который определяет данную файловую систему, но не
выполняет монтирование при запуске (часто применяется для удаляемых устройств), user, который позволяет
пользователям монтировать и демонтировать его и _netdev, который определяет удалённые пути, требующие поднятой
сетевой среды перед попыткой этого монтирования.
Значение пятого поля применяется dump для определения того каккие файловые системы надлежит применять - его значение
по умолчанию установлено в 0.
Значение шестого поля применяется fsck для определения значения порядка для файловых систем, подлежащих
проверке при запуске. Имеющаяся корневая файловая система обязана обладать значением 1, а прочие должны
иметь значение 2 (значением по умолчанию выступает 0, без
fsck). Проверки выполняются одновременно для ускорения общего процесса запуска. Обратите внимание, что для обладающих
журналом файловых систем, такая файловая система сама по себе способна осуществлять быструю проверку вместо выполнения полной проверки.
На приводимом ниже снимке экрана давайте рассмотрим как это выглядит в нашей системе при помощи вывода
cat /etc/fstab:
Почему мы пользуемся UUID или LABEL вместо устройств, скажем,
/dev/sda1?
Упорядочение дисков может изменяться при запуске системы, поскольку некоторые ядра могут вводить различия для имеющихся устройств в том как осуществляется к ним доступ и тому подобное, что приводит к изменениям в нумерации имеющихся устройств; причём это происходит не только для удаляемых устройств, подобных устройствам Universal Serial Bus (USB), но также и для внутренних устройств, таких как сетевые интерфейсы или жёсткие диски.
Когда вместо определения соответствующих устройств мы пользуемся UUID или
LABEL, даже в случае изменения порядка устройств, наша система всё ещё будет способна находить верное
устройство для применения и запускаться с него. Это было в особенности важно, когда в системах применялись диски
IDE и Serial Advanced Technology
Attachment (SATA), а также
SCSI, или даже в наши дни, когда могут в отличном от ожидаемого порядка подключаться
устройства internet SCSI
(iSCSI), что в результате приводит к изменению названий устройств и отказом при
достижении их.
Не забывайте пользоваться командами blkid или lsblk –fp для проверки
значений меток соответствующих файловых систем и universally unique identifers
(UUID), которые могут применяться при ссылках на них.
|
| Предостережение |
|---|---|
|
При внесении изменений в файл |
Давайте ознакомимся в нашем следующем разделе с монтированием удалённой NFS.
Монтирование удалённой NFS не сильно отличается от монтирования локальных устройств, однако вместо определения локального устройства как мы
это делали в своём предыдущем разделе для своего файла /dev/loop0p1, мы предоставляем в качестве устройства
server:export.
Знакомясь со страницами руководства через man mount, мы можем обнаружить некий диапазон доступных параметров
и они показывают нам различные имеющиеся варианты и те способы, которыми выглядят эти устройства.
Когда мы собираемся применять монтирование NFS, нашему администратору потребуется воспользоваться его хостом и значением экспортируемого названия для монтирования такого устройства - например, на основании следующих сведений относительно значения экспорта NFS:
-
Server:
server.example.com -
Export:
/isos -
Mount point:
/mnt/nfs
При помощи предыдущих сведений несложно сконструировать необходимую команду mount, которая выглядит
следующим образом:
mount –t nfs sever.example.com:/isos /mnt/nfs
Если мы проанализируем свою предыдущую команду, оно определит значение типа подлежащей монтированию файловой системы как
nfs, предоставляемой именем хоста server.example.com и
при помощи экспорта NFS /isos, а также сделает её доступной локально в папке
/mnt/nfs.
Когда мы желаем определить эту файловую систему доступной при запуске, нам надлежит добавить в /etc/fstab
некую запись, но... как нам следует указывать её?
На основании настроек, приведённых на протяжении этой главы, необходимая конструкция записи выглядела бы как- то так:
server.example.com:/isos /mnt/nfs nfs defaults,_netdev 0 0
Наша предыдущая строка кода содержит необходимые параметры, которые мы указывали в своей командной строке, однако также она добавляет что имеется некий ресурс, который требует сетевого доступа перед попыткой его монтирования, поскольку требуется доступной сетевая среда чтобы достигать сервера NFS, что аналогично тому, что нам потребуется другое хранилище на основе сетевого доступа, такое как монтирования Samba, iSCSI и тому подобного.
|
| Предостережение |
|---|---|
|
Возвращаясь к идее сохранения нашей системы способной к загрузке после внесения изменения в конфигурационный файл
|
В этой главе мы изучили как диск логически разделяется для оптимального применения хранилища и как позднее создать на таком подразделении диска некую файловую систему с тем, чтобы ей можно было бы применять для реального хранения данных.
После того как была создана реальная файловая система была создана, мы изучили как превратить её в доступную в нашей системе и как гарантировать что
она доступна после следующего перезапуска нашей системы через внесение изменений в файл конфигурации /etc/fstab.
Наконец, мы также изучили применение удалённой файловой системы на основе данных NFS, которые были нам предоставлены и как добавить это в наш файл
fstab чтобы сделать это неизменным.
В своей следующей главе мы изучим как превратить наше хранилище в ещё более полезное при помощи Logical Volume Management (LVM), что усиливает имеющееся определение различных логических элементов, у которых можно изменять размер, сочетать для предоставления избыточности и тому подобного.