Часть IV: Спускаемся на Физический уровень
Данная часть сосредоточится на различных критериях, которые можно применять для оценки и калибровки производительности хранилища. Мы представим различные метрики определения производительности и обсудим различные инструменты и методики, которые могут применяться при исследовании производительности на каждом из уровней стека хранения. Также мы предоставим некие рекомендации, которые поспособствуют улучшению производительности.
Эта часть содержит следующие главы:
Глава 9. Анализ производительности физического хранилища
Содержание
"Когда вы устраняете невозможное, все, что остаётся, каким бы невероятным оно бы ни было, должно быть правдой." - сэр Артур Конан Дойль
Теперь, когда мы покончили с разбором в тонкостях системы хранения данных Linux, мы можем применить это понимание на практике. Мне всегда нравится сравнивать стек хранения с моделью OSI в сетях, где каждый уровень обладает посвящённой ему функцией и для взаимодействия пользуется иными данными. На протяжении первых восьми глав мы углубили своё понимание многоуровневой иерархии стека хранения и его концептуальной модели. Если вы всё ещё следите за развитием событий, вы получили некоторое представление о том, как даже самые простые запросы от приложений обязаны проходить множество уровней прежде чем будут обработаны лежащими в основе дисками.
Будучи славной командой, а это так, когда мы работаем с кем- то, мы можем проявлять излишнюю осторожность и, как правило, получать удовольствие от придирок. Это приводит нас к нашему следующему этапу своего путешествия - как мы оцениваем и замеряем производительность своего хранилища?Всегда будет присутствовать зазор между нашими ресурсами вычислений и хранения, ибо диск на порядки медленнее процессора и оперативной памяти. Это превращает анализ производительности в очень обширную и сложную область. Как вы определяете насколько велико слишком много и насколько мало слишком медленно? Некий набор значений может оказываться исключительным для некой среды, и в то же время вызывать беспокойство в ином месте. В зависимости от рабочих нагрузок эти переменные разные в каждом из окружений.
В Linux имеется в доступности великое множество инструментов и механизмов отслеживания, которые могут способствовать в выявлении потенциально узких мест общей производительности системы. Мы намерены в особенности сосредоточиться на подсистеме хранения и воспользоваться таким инструментарием чтобы лучше осознать что происходит за сценой. Некоторые из таких инструментов доступны по умолчанию в большинстве дистрибутивов Linux, что служит хорошей отправной точкой.
Вот некая сумма того, что мы охватим в этой главе:
-
Как исчислять производительность?
-
Разбираемся в топологии хранения
-
Анализируем физическое хранилище
-
Применяем инструменты анализа операций ввода/ вывода
Эта глава потребует больше работы руками и начальных навыков в обращении с командной строкой Linux. Большинство читателей уже наслышаны о части обсуждаемых
в данной главе инструментов и методик. Будет полезным обладать некими навыками системного администрирования, ибо этот инструментарий имеет дело с ресурсами
мониторинга и анализа. Для запуска этих инструментов будет лучше обладать необходимыми полномочиями (root или sudo). В зависимости от избранного вами дистрибутива
Linux вам потребуется установить надлежащие пакеты. Чтобы установить в Debian/Ubuntu iostat и
iotop воспользуйтесь следующим:
apt install sysstat iotop
Для установки iostat и iotop в Fedora/ Red Hat /{Rocky Linux} применяется такое:
yum install sysstat iotop
Чтобы установить Performance Co-Pilot для справки вы можете пользоваться инструкциями из их официальной документации.
Применение всех этих команд одинаковое во всех дистрибутивах.
Существуют различные объективы, при помощи которых мы способны выполнять оценку производительности системы. Распространённым подходом является сравнивать производительность системы со скоростью процессора. Если вернуться назад к более простым временам когда в порядке вещей были однопроцессорные системы и сравнить их с современными многосокетными системами со множеством ядер, мы обнаружим, что, проще говоря, значение производительности процессора увеличилась эпически. Когда мы сопоставляем коэффициент роста производительности процессора с аналогом для диска, процессор побеждает безусловно.
Величина времени отклика для устройств хранения, как правило, измеряется в миллисекундах. Для процессоров и оперативной памяти это значение измеряется наносекундами. В результате это приводит к несоответствию между требованиями приложения и тем, что в действительности способно предоставлять лежащее в основе хранилище. Таким образом отпадает тот аргумент равенства производительности системы производительности процессора. Точно в той же степени, что прочность цепи определяется её самым слабым звеном, общая производительность системы также зависит от её самого слабого компонента.
Большинство инструментов и утилит, как правило, сосредоточены исключительно на производительности диска и не дают представления о производительности его более верхних уровней. Как мы обнаружили в ходе своего путешествия, когда приложение отправляет запрос ввода/ вывода в устройство, за кулисами имеется великое множество деталей. Имея это в виду, мы разделим свой анализ производительности на такие две части:
-
анализ физического хранилища
-
анализ более верхних уровней в общем стеке ввода/ вывода, таких как файловые системы и блочный уровень
В обоих случаях мы намерены пояснить относящиеся к делу метрики и то как они способны оказывать воздействие на производительность. Анализ файловых систем и блочного уровня будет рассмотрен в Главе 10. Также мы рассмотрим как мы способны проверять эти показатели доступными в дистрибутивах Linux инструментами.
Большинство сред хранения обычно содержат смесь следующих типов хранилищ:
-
DAS (Direct Attached Storage DAS Непосредственно подключаемое хранилище): Это наиболее распространённый тип хранения и он напрямую подключается к системе. Поскольку среды ЦОД (центров обработки данных) обязаны обладать неким уровнем избыточности в каждом из слоёв, непосредственно подключаемое хранилище в корпоративных серверах составляются несколькими дисками, которые затем группируются к конфигурацию RAID для улучшения производительности и защиты данных.
-
Сеть хранения Fibre Channel: Это протокол хранения блочного уровня, который применяет технологию Fibre Channelи делает возможным для серверов доступ к устройствам хранения. Он предлагает чрезвычайно высокую производительность и низкие времена отклика по сравнению с традиционными DAS и используется для работы критически важных приложений. Он к тому же намного более затратен по сравнению с прочими вариантами, поскольку требует специального оборудования, такого как адаптеры Fibre Channel, коммутаторы Fibre Channel и массивы хранения.
-
iSCSI SAN: Это также протокол блочного уровня, который способен пользоваться уже имеющейся сетевой инфраструктурой и позволяет хостам осуществлять доступ к устройствам хранения. Для транспортировки пакетов SCSI между источником и целью блочного хранилища сети хранения iSCSI применяют сетевую среду TCP. Поскольку он не пользуется специально выделенной сетевой средой подобно FC SAN, он обладает более низкой производительностью нежели FC SAN. Тем не менее, реализовать iSCSI SAN намного проще и несоизмеримо менее затратно, поскольку он не требует специальных адаптеров или коммутаторов. {Прим. пер.: Последнее верно лишь до определённой степени, так как самое экономичное сетевое оборудование является плохим средством организации сети хранения.}
-
NAS (Network-Attached Storage, Подключаемое к сети хранилище): NAS это протокол хранения файлового уровня. Как и SAN iSCSI, массивы NAS также полагаются на уже имеющуюся сетевую инфраструктуру и не требует никакого дополнительного оборудования. Тем не менее, поскольку доступ к хранилищу выполняется через механизмы файлового уровня, его производительность не самая лучшая его сторона. Тем не менее, массивы NAS наименее затратны из всего перечисленного и обычно применяются для долгосрочного хранения резервных копий.
На Рисунке 9.1 показано упрощённое сопоставление этих технологий. Чтобы сосредоточиться исключительно на вовлекаемые в доступ каждого из типов различия, дополнительные подробности более верхних уровней опущены:
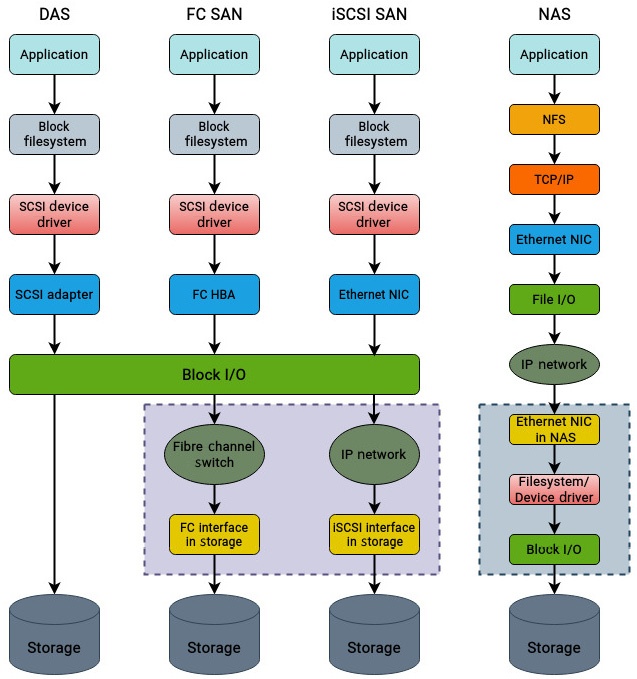
В своё обсуждение мы не намерены включать коммутаторы FC или какие бы то ни было массивы SAN. Тем не менее, имейте в виду, что при доступе к различным типам технологий хранения в этот процесс вовлечено множество компонентов. Каждый уровень требует тщательного изучения, а потому при диагностике сред хранения всегда следует иметь в виду карту топологии.
Производительность определяет насколько хорошо дисковые устройства функционируют при доступе к ним, выборке или сохранении данных. Для содействия определению производительности дисковых подсистем имеется всего несколько средств измерения. Для тех, кто уже сталкивался с производителями хранилищ при оценке приобретения высокопроизводительных массивов хранения, IOPS будет очень знакомым термином. Производителям часто нравится применять это сокращение и ссылаться на IOPS системы хранения данных в качестве одного из основных преимуществ при продаже.
IOPS (Input Output Operations per Second, число операций ввода/ вывода в секунду) вполне может оказаться совершенно бесполезным показателем, только если он не сочетается с прочими возможностями системы хранения, такими как время отклика, соотношение скоростей чтения и записи, пропускной способностью и размером блока. Показатель IOPS, как правило, относят к идиллическим числам и он редко даёт некое представление о возможностях системы, если только не идёт в паре с прочими показателями. Когда вы приобретаете автомобиль, вам требуется знать о таких сложных подробностях как его ускорение, экономичности по топливу и насколько хорошо он вписывается в повороты. Вы редко задумываетесь о его максимальной скорости. Точно также вам требуется знать о всех деталях своей системы хранения.
Оставляя свой фокус на физическом диске, в первую очередь мы определяем метрики производительности на основе времени, поскольку именно они поясняют как и где тратится время. Всякий раз когда при анализе производительности вы слышите слово латентность или задержка, обычно это указывает на потерянное время. Это именно то время, которое можно было бы потратить на работу с чем- то, но вместо этого оно было затрачено на ожидание того, что это нечто произойдёт.
Давайте сначала разберёмся с пониманием зависящих от времени измерений, которые потребуются нам рассматривать при анализе физических дисков. Как только мы получим некое представление о понятиях, для поиска потенциально узких мест мы будем применять специальные инструменты. На нашем следующем рисунке представлены наиболее распространённые временные показатели для оценки производительности диска:
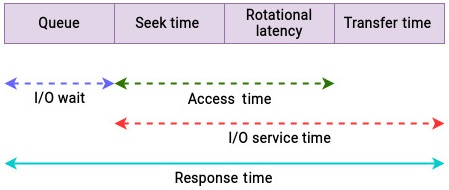
Здесь важно отметить, что вышеупомянутые показатели не принимают в расчёт затрачиваемые на прохождение иерархии ввода/ вывода ядра время, например, файловой системы, блочного уровня и диспетчеризации. Мы собираемся рассмотреть их отдельно. А сейчас мы намерены сосредоточиться на физическом уровне.
Поясним здесь применённые на Рисунке 9.2 термины:
-
I/O wait (ожидание ввода/ вывода): Некий запрос на ввод/ вывод может дожидаться своего в некой очереди, либо активно обслуживаться. Перед распределением на обслуживание запрос на ввод/ вывод вставляется в очередь на диске. Величина продолжительности времени, затрачиваемого на ожидании в очереди и определяется как ожидание ввода/ вывода.
-
I/O service time: (время обслуживания ввода/ вывода): Значение времени обслуживания ввода/ вывода это то время, на протяжении которого дисковый контроллер активно обслуживает данный запрос на ввод/ вывод. Иными словами, это время, которое запрос на ввод/ вывод не тратит на ожидание в очереди. Время обслуживания содержит следующее:
-
Время позиционирования на диске это то время, которое требуется для перемещения головки чтения/ записи в радиальном направлении к предписанному треку.
-
После того как головка чтения/ записи помещена в требуемом треке, поверхность пластины вращается до местоположения в точности того сектора (до того места, в котором надлежит считывать или записывать данные) и выравнять на него головку чтения/ записи. Значение затрачиваемого на это время носит название латентности вращения.
-
После того как головка чтения/ записи позиционирована над требуемым сектором, осуществляется реальная операция ввода/ вывода. Они исчисляется временем обмена. Время обмена это затрачиваемое на передачу к/ от диска из/ в сторону системы хоста время.
-
-
Response time (время отклика): Величина времени отклика или латентность это сумма времён обслуживания и ожидания и может рассматриваться в качестве полного цикла запроса на ввод/ вывод. Оно выражается в миллисекундах и наиболее весомый термин при работе с устройствами хранения, поскольку обозначает всё время от выпуска запроса на ввод/ вывод до его реального завершения, как это поясняет Рисунок 9.3:
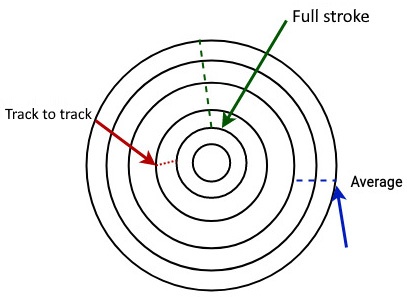
Как показано на Рисунке 9.4, производители хранилища обычно упоминают следующие определения времён позиционирования:
-
Full stroke (Полный цикл): Представляет собой время, затрачиваемое головкой чтения/ записи на перемещение с самой внутренней дорожки на самую внешнюю.
-
Average (Среднее): Это среднее значение времени, необходимое для перемещения головки чтения/ записи с одного случайного трека на другой.
-
Track to track (От дорожки к дорожке): Это требующееся для перемещения головки чтения/ записи между соседними треками.
Вот как отображаются на Рисунке 9.4 понятия времён позиционирования:
Величина скорости обмена может быть и далее разбита на внутреннюю и внешнюю скорости обмена:
-
Скорость внутреннего обмена: Это та скорость, с которой данные переносятся с пластины диска во внутренний кэш или буфер.
-
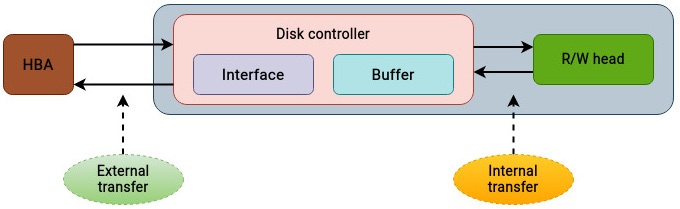
Скорость внешнего обмена: После того как произведена выборка необходимых данных в имеющийся буфер, они далее передаются в адаптер шины хоста (hba) через поддерживаемый диском интерфейс или протокол. Как это выделено на Рисунке 9.5, значение скорости, с которой данные передаются из буфера в адаптер шины хоста определяет величину скорости внешнего обмена:
Как мы уже поясняли в Главе 8, в отличии от механических дисков, SSD не применяют механических компонентов. тем самым, такие понятия как латентность вращения и время позиционирования к ним не применимы. Значение времени отклика содержит в себе все относящиеся ко времени стороны и именно этот термин наиболее часто используется при проверке относящихся к производительности задач.
Шаблоны доступа на ввод/ вывод в большей мере относятся к механическим дискам. Производимый приложением шаблон ввода/ вывода может представлять собой сочетание последовательных и произвольных операций:
-
Последовательный ввод/ вывод: К операциям последовательного ввода/ вывода относятся операции, которые считывают или записывают данные в последовательных или непрерывных местах на диске. Для механических дисков это в результате придаёт основной скачок производительности, поскольку требует от головки чтения/ записи крайне малого перемещения. Они снижают время позиционирования.
-
Произвольный ввод/ вывод: Запросы произвольного ввода/ вывода осуществляются из не являющихся непрерывными положений на диске и,как вы можете предугадать, в результате мы имеем большие значения времён позиционирования, что привносит отрицательное воздействие в производительность диска.
И снова, операции произвольного ввода/ вывода оказывают воздействие на шпиндельные диски и не влияют на SSD. Хотя, поскольку считывание расположенных рядом байт на диске требует от своего контроллера намного меньших усилий, последовательные операции на SSD быстрее произвольных. Тем не менее, эта разница намного ниже, нежели у шпиндельных устройств.
IOPS в отдельности не рисуют полную картину производительности диска и в них всегда необходимо добавлять гранулу соли. Важно принимать во внимание размер
запросов на ввод/ вывод и величину соотношения операций считывания и записи. К примеру, сложные системы хранения разрабатываются под конкретные соотношения
чтения/ записи и размеры ввода/ вывода, скажем считывание/ запись 70/ 30 или размеры блоков
32кБ.
Различные приложения обладают разными требованиями и ожиданиями от лежащих в основе дисков. Важно обладать грубой оценкой процентного соотношения подлежащих
выполнению в устройстве хранения операций ввода/ вывода. К примеру, приложения обработки транзакций в реальном времени обычно составлены соотношением
чтения/ записи равным 70/ 30. С другой стороны, приложения регистрации могут быть заняты записью и могут требовать
меньшего считывания.
Размер запросов на ввод/ вывод также может варьироваться в зависимости от типа приложений. При некоторых обстоятельствах может оказываться гораздо более действенным подход к передаче больших блоков. Необходимое для обработки такого запроса время продолжительнее чем у запроса меньшего размера. С другой стороны, рассмотрение того же объёма данных, комбинируемого временами обработки и отклика множества меньших запросов может оказаться продолжительнее чем у отдельного запроса большего размера.
Современные диски поставляются с дисковым кэшем или с буфером на борту. Такой дисковый буфер это встроенная в дисковом устройстве память, которая действует в качестве буфера между HBA (host bus adapter, адаптером шины хоста) и дисковой пластиной или феш- памятью, которые используются для хранения.
Приводимая ниже таблица отражает эффект кэширования для различных шаблонов ввода/ вывода:
| Тип ввода/ вывода | Считывание | Запись |
|---|---|---|
Произвольный |
Трудно кэшировать и выполнять предварительную выборку, ибо шаблон невозможно предугадать. |
Кэширование крайне действенно, поскольку произвольная запись требует большого времени позиционирования. |
Последовательный |
Кэширование чрезвычайно эффективно, так как для данных предварительная выборка простая. |
Кэширование действенно и может быстро сбрасываться, ибо данные подлежат записи в последовательных местах. |
Применение кэша ускоряет процесс запоминания и доступа к данным с жёсткого диска. Корпоративные массивы обычно обладают гигантским объёмом доступного для этого кэша.
Помимо латентности, IOPS и пропускная способность определяют основополагающие характеристики физического хранилища:
-
IOPS: Представляет значение скорости, с которой могут происходить операции ввода/ вывода в пределах определённого периода времени. Замер IOPS снабдит нас значением числа операций в секунду, которое доставляет в настоящее время система хранения.
-
Пропускная способность: Обозначает тот объём данных, который передаётся от или к дисковому устройству - иначе говоря, тот кусок пиццы, который вы можете откусить за раз. Также это именуется полосой пропускания. Поскольку пропускная способность измеряется как реальная передача данных, она выражается в МБ или в ГБ в секунду.
Вот пара вещей, которые важно помнить:
-
Показатель IOPS всегда стоит соотносить с латентностью, соотношениями считывания/ записи и размерами запроса на ввод/ вывод. При независимом применении он не имеет большого значения.
-
При обработке больших объёмов данных более значимой чем IOPS может оказываться полоса пропускания.
Величина глубины очереди диктует общее число запросов на ввод/ вывод, которые могут обрабатываться за раз одновременно. В целом, это значение не будет требовать изменений. Для среды SAN крупного масштаба, в которой хосты соединены с массивами хранения при помощи HBA FC, оно становится значимой величиной. В такой ситуации существуют отдельные значения глубин очередей для дисков, HBA, и портов массива хранения.
Когда значение числа активируемых запросов на ввод/ вывод превосходит поддерживаемую глубину очереди, никакие новые запросы не будут способны занимать устройство хранения. Вместо этого хосту будет возвращаться сообщение "очередь заполнена". Когда в очереди нет места, хосту приходится повторно отправлять получивший отказ запрос на ввод/ вывод. Значение глубины очереди может оказывать воздействие как на механические диски, так и на твердотельные. Механические устройства и SSD, которые применяют интерфейсы SATA и SAS поддерживают только единственную очередь с 32 и 256 командами. И наоборот, устройства NVMe обладают 64к очередями по 64к команд на очередь.
В большинстве ситуаций настройки по умолчанию для глубины очереди могут быть достаточными. Всякий компонент в среде хранения обладает некими настройками глубины очереди. Например, контроллер RAID также обладает своей собственной глубиной очереди, которая может быть длиннее чем общее сочетание глубин очередей индивидуальных дисков.
Имеется некоторое число понятий, которые определяют какая часть диска реально задействована. Они описываются следующим образом:
-
Utilization (Загруженность): Загруженность диска это достаточно распространённая метрика, которую вы можете наблюдать в отчётах различных инструментов. Загруженность означает, что данный диск для некого определённого интервала активно применяется. Это значение представляется в виде процентного соотношения времени. Например, загруженность 70% указывает, что если ядро просматривало диск 100 раз, в 70 случаях он был занят выполнением какого- то запроса на ввод/ вывод. Аналогично, загруженный на 100% диск означает, что он непрерывно обслуживает запросы ввода/ вывода. И снова, полностью загруженный диск может быть, а может и нет узким местом. Это значение следует коррелировать с некоторыми прочими метриками, например, связанной с этим латентностью и глубиной очереди. Может так случиться, что хотя запросы на ввод/ вывод непрерывно активируются, они достаточно малы и последовательны; следовательно, этот диск способен обслуживать их своевременно. Аналогично, массивы RAID обладают способностью параллельной обработки запросов, а раз так, 100% загруженность может не быть проблемой.
-
Utilization (Насыщение): Насыщение означает, что активируемое для диска количество запросов может превышать значение, которое на самом деле может быть доставлено. Это подразумевает, что мы пытаемся превзойти его ёмкость скорости. Когда происходит насыщение, приложениям приходится выполнять ожидание прежде чем иметь возможность считывания или записи на этот диск. Насыщение в результате приведёт к росту числа откликов и воздействию на общую производительности системы.
Вполне объяснимо что ожидание ввода/ вывода зачастую является наиболее не верно понимаемым показателем при проверке проблем производительности. Хотя в его названии и присутствует ввод/ вывод, время ожидания ввода/ вывода на самом деле является показателем ЦПУ, но он не указывает на проблемы с производительностью ЦПУ. Всё ясно?
Время ожидания ввода/ вывода это процентное соотношение времени которое ЦПУ простаивал, причём на протяжении него система обладала отложенными запросами на ввод/ вывод. Что это превращает в трудное для понимания, так это то, что можно обладать рабочеспособной системой с высоким процентным соотношением ожидания на ввод/ вывод, а также можно иметь медленно работающую системы ввода/ вывода без низкого процентного соотношения ожидания ввода/ вывода. Высокое соотношение ожидания ввода/ вывода означает, что ЦПУ простаивает в ожидании завершения запросов к диску. Давайте поясним это на ряде примеров:
-
Например, если процесс отправил какое- то число запросов на ввод/ вывод, а лежащий в их основе диск не способен немедленно удовлетворить такой запрос, о таком ЦПУ говорят как о пребывающем в состоянии ожидания, ибо он дожидается завершения своего запроса. Следовательно, такое ожидание указывает, что циклы ЦПУ тратятся впустую и лежащий в основе диск может быть медленным для откликов на запросы ввода/ вывода.
-
Далее имеется и обратная сторона. Допустим, процесс A чрезвычайно интенсивен в отношении ЦПУ и постоянно удерживает ЦПУ занятым. Другой исполняемый в этой системе процесс, процесс B обладает интенсивным вводам/ выводом и занимает весь диск. Даже когда диск медленный для отклика на запросы процесса B и превращается в источник узкого места для своей системы, при данных обстоятельствах величина ожидания ввода/ вывода буде очень низкой. Почему? Потому как ЦПУ не простаивает, раз он упакован обслуживанием процесса A. Таким образом, хотя ожидание ввода/ вывода и низкое, в хранилище потенциально может иметься узкое место.
Высокие значения ожидания ввода/ вывода могут вызываться любым сочетанием следующих факторов:
-
Узкими местами в физических хранилищах
-
Большой очередью запросов на ввод/ вывод
-
Близкие к насыщению или полностью насыщенные диски
-
Процессы в состоянии непрерывного ожидания, носящего название состояния
D(это достаточно распространённое явление, когда доступ к хранилищу осуществляется через NFS - network file system, сетевую файловую систему) -
Медленная сетевая скорость в случае NFS
-
Высокая активность подкачки страниц
Я полагаю, мы рассмотрели достаточно много вещей, на которые стоит обратить внимание при анализе устройств хранения. И снова, когда ваша среда хранения содержит все компоненты среды SAN, то вам надлежит обратить внимание на несколько дополнительных моментов, таких как коммутаторы FC (fibre channel) и любые потенциально узкие места в массиве хранения. Для устранения неисправностей FC вам требуется получить азы представления о протоколе FC.
Давайте рассмотрим как мы можем выявлять эти красные флаги при помощи доступных инструментов.
Теперь мы получили базовое представление о том что мы ищем при выявлении проблем с лежащим в основе хранилищем. В большинстве ситуаций такое проблемное поведение впервые шлёт сообщения на уровне приложения и перед фактическим выявлением проблемы проверяется множество уровней. Проблемная ситуация может быть по своей природе перемежающейся, что ещё больше может затруднять ей выявление. К счастью, в наборе инструментов Linux имеется множество утилит, которые можно применять для определения подобного проблемного поведения. Мы рассмотрим их одну за другой и выделим те важные моменты, на которые стоит обращать внимание при устранении неполадок в производительности.
top это одна из наиболее часто применяемых команд при устранении неполадок производительности. Что превращает её в столь
действенную, так это то, что она способна быстро снабжать вас текущим состоянием системы и, возможно, давать подсказку о потенциальной проблеме. Хотя большинство
людей пользуются ею для анализа ЦПУ и оперативной памяти, имеется одно конкретное поле, которое способно указывать на проблему с лежащим в основе хранилищем.
Как показано в следующем выводе, команда top способна быстро снабдить вас итоговым просмотром текущего состояния
системы:
top - 19:11:56 up 96 days, 12:38, 0 users, load average: 9.44, 6.71, 3.75
Tasks: 498 total, 14 running, 484 sleeping, 0 stopped, 0 zombie
%Cpu(s): 20.6%us, 7.9%sy, 0.0%ni, 13.4%id, 57.1%wa, 0.1%hi, 0.9%si, 0.0%st
KiB Mem : 19791910+total, 10557456 free, 80016952 used, 10734470+buff/cache
KiB Swap: 8388604 total, 5058092 free, 3330512 used. 11555254+avail Mem
Как мы уже обсуждали ранее, высокий показатель ожидания ввода/ вывода указывает на узкое место на уровне хранилища. Значение поля
wa это величина среднего ожидания и указывает ту часть времени, которую ЦПУ вынужден пребывать в ожидании по причине
диска. Высокое среднее значение ожидания подразумевает, что такой диск не отвечает вовремя. Хотя это здесь и не обсуждается, средние величины загрузки способны
также увеличиваться по причине более высоких средних величин ожиданий. Это связано с тем, что средние значения загрузки содержат активность ожидания
диска.
Утилита top обладает рядом параметров, способных давать представление о загруженности ЦПУ и оперативной памяти, но
мы не будем заострять на них своё внимание. Поскольку нашей основной задачей здесь является хранилище, нам надлежит следит за высокими значениями столбца
wa и средних величин загруженности.
Команда iotop это подобная top утилита для отслеживания связанной с диском
активности. По умолчанию, команда top сортирует вывод на основе применения ЦПУ. Аналогично, команда
iotop сортирует процессы по количеству считываний и записей данных для каждого процесса. Она отражает столбцы, которые
выделяют топовых потребителей полосы пропускания диска вашей системы. Кроме того, она также отражает значение пропорций времени, которое потоки/ процессы занимали
в подкачке в ожидании операций ввода/ вывода. Для каждого процесса указывается значение приоритета ввода/ вывода как в терминах класса, так и в плане уровня.
Лучше запускать iotop с флагом -o, поскольку это отобразит процессы, которые
производят запись на диск в данный момент:
Total DISK READ : 231.10 K/s | Total DISK WRITE : 556.40 K/s
Actual DISK READ: 233.13 K/s | Actual DISK WRITE: 593.72 K/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
23744 be/2 root 0.00 B/s 519.08 K/s 0.00 % 3.03 % mysql
10395 be/4 root 231.10 K/s 37.32 K/s 0.00 % 1.58 % java
На что обратить внимание: Команда iotop показывает тот
объём данных, который подлежит считыванию или записи на соответствующий диск процессом. Проверьте поддерживаемые скорости считывания и записи диска и сравните
их с пропускной способностью топовых процессов. Это также может помочь выявить необычную активность приложений на диске и определить, может ли какой-либо процесс
считывать или записывать не нормальный объём данных на лежащие в основе диски.
Порой команда iotop может выражать недовольство тем, что в ядре не включён учёт задержек. Это можно исправить
следующим образом:
sysctl kernel.task_delayacct = 1
Команда iostat это наиболее популярный инструмент анализа диска, поскольку она отображает широкое разнообразие
сведений, способных оказать содействие в анализе проблем с производительностью. Большинство метрик, которые мы поясняли ранее, такие как насыщение диска,
его загруженность и ожидание ввода/ вывода можно анализировать посредством iostat.
Самая первая строка вывода iostat это статистические данные диска, просуммированные начиная с самого последнего запуска,
которые показывают средние значения для всего времени пока система была поднята. Последующие строки отображаются в виде секундных статистических данных,
вычисленных при помощи заданных в её командной строке интервалов, что отображено на следующем снимке экрана:

Вот на что стоит обратить внимание:
-
Самая первая строка,
avg-cpu, отображает процентное соотношение использования ЦПУ, которое происходило при выполнении каждого состояния. -
Значения чисел
r/sиw/sдаёт разбивку величин числа активируемых в данном устройстве запросов на считывание и запись в секунду. -
Величина
avgqu-szпредставляет счётчик операций, которые либо пребывали в состоянии стоящих в очереди, либо активно обслуживаемых. Значениеawaitсоответствует средней продолжительности между помещением запроса в очереди и его исполнением. Столбцыr_awaitиw_awaitпоказывают среднее время ожидания для операций считывания и записи. Когда вы наблюдаете здесь стабильно высокие значения, возможно, данное устройство близко к насыщению. -
Величина столбца
%utilпоказывает то количесество времени, на протяжении которого данный диск был занят обслуживанием пор крайней мере одного запроса на ввод/ вывод. Это значение загруженности может вводить в заблуждение когда лежащее в основе хранилище это том на основе RAID.
Общее предположение состоит в том, что по мере приближения загруженности устройства к 100% оно превращается в более насыщенное. Это справедливо когда речь идёт о представленном единственным диском устройстве хранения. Однако массивы SAN или тома RAID состоят из множества дисков и способны обслуживать одновременно большое число запросов. Ядро не обладает непосредственным представлением о том как обустроено данное устройство ввода/ вывода, что в ряде обстоятельств превращает данный показатель в сомнительный.
PCP (Performance Co-Pilot) это
инфраструктура и инструментарий с открытым исходным кодом, которая разработана для отслеживания, анализа и отклика на различные стороны данных производительности
системы в реальном масштабе времени и в прошлом. PCP к тому же содержит ряд утилит для анализа производительности системы. Те инструменты, что представлены в
PCP, очень похожи на включаемые в пакет sysstat. Инструменты PCP также содержат графическое приложение для создания
графиков из производимых замеров и обладают возможностью сохранения исторически накапливаемых данных для просмотра в дальнейшем. Вот пара инструментов,
способных содействовать анализу хранилища:
-
pcp atop: Предоставляет сведения аналогично командамiotopиatop. Эта команда перечисляет процессы, которые выполняют ввод/ вывод совместно с используемыми ими полосами пропускания. Как иiotopсtop,pcp atopэто годный инструмент для быстрого захвата происходящих в системе изменений. -
pcp iostat: Командаpcp iostatвыдаёт отчёт статистических сведений о ввода/ выводе диска в реальном времени во многом подобно командеiostat, которую мы уже видели ранее. Как показано на рисунке 9.7, значения столбцов в её выводе аналогичны столбцам изiostat:
При устранении неисправностей производительности диска или связанных с ресурсами проблемах, значимые сведения способна предоставлять
vmstat, так как она способна выявлять заторы дискового ввода/ вывода неумеренное разбиение на страницы или чрезмерную
активность подкачки страниц.
Название команды vmstat происходит от "virtual memory statistics" и является естественной утилитой,
включаемой практически во все дистрибутивы Linux. Как показано на Рисунке 9.8, она выдаёт отчёты сведений об активности процессов, оперативной памяти, страниц,
дисков и процессора:

На что обратить внимание: столбец b в выводе
показывает номер заблокированного процесса при ожидании некого ресурса, например дискового ввода/ вывода. Вот дополнительные сведения, наиболее полезные при
устранении неисправностей ввода/ вывода:
-
si: Данное поле представляет тот объём памяти, причём в килобайтах, который подкачивается из пространства подкачки страниц на диске в оперативную память системы за секунду. Более высокое значение поляsiуказывает на рост активности подкачки страниц, что предполагает что данная система часто выполняет выборку данных из пространства подкачки. -
so: Данное поле представляет значение объёма памяти, в килобайтах, которое выгружается из оперативной памяти системы в пространство подкачки на диске за секунду. Более высокие значения в полеsoуказывают на рост активности подкачки, что может происходить когда система находится под давлением по памяти и нуждается в освобождении физической памяти. -
bi: Данное поле определяет ссылки на скорость обмена данными с диска в оперативную память. Более высокое значение в полеbiуказывает на рост активности считывания с диска. -
bo: Отражает активность вывода или тот объём данных, которые записываются из системной памяти на диск. Более высокие значения в полеboпредполагают рост активности записи, указывая на то, что запись из памяти на диск производится часто. -
wa: Это поле представляет процентное соотношение времени, которое простаивает ЦПУ когад его система ожидает завершения операций ввода/ вывода. Более высокие показатели в данном полеwaпредполагают, что данная система переживает узкие места или задержки ввода/ вывода, причём её ЦПУ часто ожидает завершения операций ввода/ вывода.
PSI (Pressure Stall Index) это относительно новый инструментарий в Linux и он предлагает новый способ получения метрик для оперативной памяти, ЦПУ и дискового ввода/ вывода. Когда присутствует конкуренция за ЦПУ, оперативную память или устройства ввода/ вывода могут происходить всплески, в результате приводящие к росту времени ожидания для рабочих нагрузок. Имеющиеся функциональные возможности PSI выявляют это и выдают на печать суммарное представление этих сведений в реальном масштабе времени.
Доступ ко всем значениям PSI осуществляется через файловую систему pseudo
/proc. Сырые глобальные значения PSI появляются в каталоге /proc/pressure в файлах
с названиями cpu, io и memory. Давайте
взглянем на файл io:
[root@linuxbox ~]# cat /proc/pressure/io
some avg10=51.30 avg60=41.28 avg300=23.33 total=84845633
full avg10=48.28 avg60=39.22 avg300=22.78 total=75033948
На что обратить внимание: Значения полей avg представляют
процентное соотношение времён за последние 10, 60 и 300 секунд, соответственно, которые процессы были истощены дисковым
вводом/ выводом. Те строки, в префиксе которых имеется some представляется значение порции времени, на протяжении
которого одна или более задач были задержаны по причине недостаточности ресурсов. Строка с префиксом full представляется
процентным соотношением времени, в течении которого все задачи были задержаны по причине конкуренции за ресурсы, причём указывая величину степени непродуктивного
времени. Это слегка похоже на средние нагрузки в top. Вывод здесь отображает высокие значения для средних по
интервалам в 10-, 60- и 300- секунд, что
указывает на то что процессы заглохли.
Суммируя, Linux предлагает изобилие утилит для анализа значения производительности вашей системы. Обсуждённые нами здесь инструменты применяются не только для анализа хранилищ, но также и для установления общего портрета системы, причём включая его подсистемы процессора и памяти. Каждый из инструментов представляет широкий диапазон параметров, которые можно применять когда мы желаем анализировать определённую сторону. Мы выставили на обзор основные индикаторы при использовании каждого из инструментов, однако поскольку всякая среда составлена различными переменными, не существует фиксированного подхода устранения неисправностей.
Устранение неисправностей производительности это сложный вопрос, так как на их диагностику и анализ может тратиться много времени. Из трёх основных компонентов среды - хранилища, вычислителя и памяти - хранилище самое медленное. Всегда будет наблюдаться несоответствие в их производительности, а любое снижение производительности диска может повлиять на общую работу системы.
Помня об этой цели, мы разделили это главу на два раздела. В своём первом разделе мы пояснили наиболее важные показатели, с которыми вам следует ознакомиться перед устранением каких бы то ни было неполадок. Мы обсудили связанные со временем показатели, относящиеся к устройствам хранения, среднему значению времени ожидания ЦПУ, насыщению диска и его занятости, а также различные схемы доступа при считывании с физического диска или записи на него.
В своей второй части мы наблюдали различные способы, коими мы имеем возможность анализировать метрики, выделенные в первом разделе. Существует большое
число доступных в Linux механизмов, способных оказывать содействие в идентификации потенциальных узких мест общей производительности системы. Для анализа
производительности диска мы воспользовались такими инструментами как top, PSI,
iostat, iotop и vmstat.
В своей следующей главе мы продолжим свой анализ стека хранения и сосредоточимся на более верхних слоях, таких как блочный уровень и файловые системы. Для этой цели мы воспользуемся различными доступными в Linux механизмами трассировки.