Глава 10. Анализ файловых систем и блочного уровня
Содержание
Доступ на считывание и запись к устройствам хранения обычно происходит после передачи через несколько промежуточных слоёв, таких как файловые системы и соответствующий блочный уровень. Также имеется кэш страниц, в котором консервируются запрошенные данные прежде чем они медленно фиксируются в лежащем в основе хранилище. До сих пор мы пытались разобраться с различными сторонами, которые способны оказывать воздействие на производительность диска и изучали важные метрики, относящиеся к физическим диском, однако Шерлок Холмс сказал бы "Совершенно здравый анализ, но я надеялся, что вы копнёте глубже."
У приложений тенденция взаимодействовать со своей файловой системой вместо её физического хранилища. Задачей именно файловой системы состоит трансляция запроса приложения и его отправка вниз к более нижним слоям для последующей обработки. Каждый запрос пройдёт последующую обработку на блочном уровне и в конечном счёте будет спланирован для своего устройства хранения. Всякий этап в этой иерархии добавляет свои собственные накладные расходы обработки. Таким образом, для выполнения анализа производительности чрезвычайно важно изучать имеющиеся файловую систему и блочный уровень.
В этой главе мы сосредоточимся на тех методиках, которые применимы при изучении файловой системы и блочного уровня. На данном этапе я бы предпочёл рассматривать первые шесть глав, как способствующие нам в построении приличного понимания этих уровней (я определённо надеюсь на это). Знакомство с соответствующими методологиями анализа не должно представлять проблем.
Вот сумма того что мы будем рассматривать:
-
Исследование файловой системы и блочного уровня
-
Различные типы ввода/ вывода файловой системы
-
Что вызывает латентность файловой системы?
-
Выявление своих целевых уровней
-
Поиск верного инструментария
Данная глава сосредоточится на инструменте производительности Linux BCC
(BPF Compiler Collection). Обладание базовыми навыками системного администрирования окажется
полезным, псокольку эти инструменты имеют дело с мониторингом и анализом на системном уровне. Знакомство с процессами, применением системных ресурсов и
метриками производительности окажет содействие вам в интерпретации получаемых от инструментов BCC результатов. Для запуска этих инструментов лучше будет
обладать необходимыми полномочиями (root или sudo).
Имеющие отношение к данной главе пакеты операционной системы могут быть установлены так:
-
Для Ubuntu/Debian:
-
sudo apt install strace -
sudo apt install bpfcc-tools
-
-
Для систем на основе Fedora/CentOS/Red Hat {/Rocky Linux}:
-
sudo yum install strace -
sudo yum install bcc-tools
-
Принимая во внимание что система хранения намного медленнее прочих компонентов системы, не является удивительным то, что зачастую проблемы производительности связаны с вводам/ выводом. Тем не менее, простое отнесение проблем производительности к относящимся ко вводу/ выводу вопросам является чрезмерным упрощением.
Файловые системы выступают первым местом контакта приложения и рассматриваются как бутерброд между приложением и физическим хранилищем. Традиционно именно физическое хранилище было в центре внимания при выполнении любого анализа производительности. Большинство инструментов сосредоточено на на загруженности, пропускной способности и латентности самих физических устройств, в то же время оставляя в стороне прочие стороны запроса на ввод/ вывод. Тщательное исследование хранилища, как правило, начинается и завершается физическими дисками, оставляя за скобками анализ файловых систем.
Аналогично, вс1 происходящее на блочном уровне также имеет тенденцию засыпать под радаром когда речь заходит об анализе производительности. Те инструменты, которые мы обсуждали в Главе 9, обычно предоставляют усреднённые по определённому интервалу значения, что часто вводит в заблуждение. Например, предположим, что приложение производит за интервал в 10 секунд следующее число запросов на ввод/ вывод:
| Секунда | Число запросов | Секунда | Число запросов |
|---|---|---|---|
1 |
10 |
6 |
20 |
2 |
15 |
7 |
5 |
3 |
500 |
8 |
15 |
4 |
20 |
9 |
8 |
5 |
5 |
10 |
2 |
Если я собираю статистические данные каждые 10 секунд, то средним числом запросов на ввод/ вывод будет 60 - то есть общее число запросов делится на длину интервала. Такое среднее значение может рассматриваться нормальным, но оно совершенно игнорирует имеющийся всплеск запросов на ввод/ вывод, активируемых около отметки в 3 секунды. Те инструменты, которые снабжают нас статистическими данными дискового уровня не дают никакого представления на основе операций ввода/ вывода.
Традиционный подход всегда состоял в сборе сведений с нижнего уровня файловой системы, то есть с её физических дисков. Однако это многогранная задача, в которую вовлекаются следующие слои:
-
Системные и библиотечные вызовы: Для запроса ресурсов из пространства ядра приложения применяют взаимодействие с общими системными вызовами. Когда некое приложение вызывает какую- то функцию, которая предоставляется её ядром, тогда время её исполнения проводится внутри пространства ядра. Такие функции носят название системных вызовов (system calls). В свою очередь, библиотечные вызовы выполняются в пространстве пользователя. Когда некое приложение желает воспользоваться определяемой в какой- то библиотеке функцией, она отправляет запрос, который носит название библиотечного вызова (library call). Для точной оценки производительности существенно измерять продолжительность времени, затрачиваемое как в пространстве ядра, так и в пространстве пользователя. Отслеживая эти вызовы, становится возможным получать значимое представление о том как ведёт себя приложение и выявлять потенциальные проблемы, например, конкуренцию за ресурсы или блокировки, которые способны заклинивать процесс.
-
VFS: Как мы уже поясняли на протяжении всей книги, VFS выступает в качестве интерфейса между своим пользователем и лежащей в основе файловой системой. Она отцепляет само приложение от операций с файлами для конкретной файловой системы, скрывая подробности реализации позади общих системных вызовов. VFS к тому же для ускорения дискового доступа включает в себя кэширование страниц, индексный дескриптор (inode) и кэш dentry. Анализ VFS может оказываться полезным для общей характеристики рабочей нагрузки, выявления закономерностей работы приложения с течением времени и точного определения того, как приложение использует различные типы доступного кэша.
-
Файловые системы: Для организации данных на диске каждая файловая система применяет свой подход. Как мы уже поясняли в Главе 9, важно характеризовать тип той рабочей нагрузки, которым будет управлять файловая система - например, шаблоны доступа приложения, синхронные или асинхронные операции, соотношение числа запросов на считывание и запись, соотношение попадания в кэш и промахов, а также размер запросов на ввод/ вывод. Внутри себя файловые системы осуществляют такие действия как упреждающее считывание, предварительная выборка, блокировки, а также ведение журналов, которые способны оказывать воздействие на общую производительность ввода/ вывода тем или иным способом.
-
Блочный уровень: Когда некий запрос на ввод/ вывод поступает на блочный уровень, он может ставиться в соответствие другому устройству, например LVM, программно определяемому RAID (Redundant Array of Independent Disks ) или устройству со множеством путей. Поверх таких логических устройств принято иметь создаваемую файловую систему. В подобных случаях при наличии какого бы то ни было ввода/ вывода файловой системы соответствующие задачи для этих методик требуют ресурсов, которые способны выступать источником содержимого ввода/ вывода, скажем, RAID с чередованием или устройств ввода/ вывода со множеством путей.
-
Диспетчер: Выбор дискового планировщика также способен оказывать воздействие на значение производительности ввода/ вывода приложения. Диспетчер имеет возможность применения таких методик, как слияние или сортировка, которые способны вносить изменения в конечный порядок, в котором запросы поступают на диск. Как уже пояснялось в Главе 6, ядро Linux предлагает различные предпочтения планировщиков диска. Некоторые диспетчеры ввода/ вывода подходят только для высокопроизводительных устройств хранения, в то время как прочие хорошо работают с более медленными устройствами. Поскольку все среды различны, перед принятием решении о подходящем планировщике диска требуется учитывать множество факторов.
-
Физическое хранилище: Именно физический уровень обычно выступает пунктом притяжения внимания в любом сценарии устранения неисправностей. Мы уже обсуждали в Главе 9 часть, касающуюся анализа различных метрик физических дисков.
Хотя здесь это и не рассматривается, важно понимать, что можно обойти файловую систему и выполнить запись данных непосредственно в физическое хранилище. Это носит название сырого доступа (raw access), а устройство, к которому выполняется доступ при помощи подобных методов именуется сырым устройством (raw device). Некоторые приложения, например, базы данных, обладают возможностью записи в сырые устройства. Основная причина такого подхода состоит в том, что любой уровень абстракции, такой как файловая система или диспетчер томов добавляют накладные расходы обработки. Файловые системы пользуются кэшем буфера для кэширования операций считывания или записи, откладывая их исполнение на диске на более поздний срок. При отсутствии файловой системы такие крупные приложения как базы данных способны обходить кэш файловой системы, что делает для них возможным управлять своим собственным кэшем. Подобный подход предоставляет более детальный контроль ввода/ вывода устройств и способен помогать в тестировании исходной скорости устройств хранения данных, ибо позволяет избегать любых дополнительных затрат на обработку.
Рисунок 10.1 выделяет основные факторы, которые способны оказывать воздействие на значение производительности ввода/ вывода приложения:
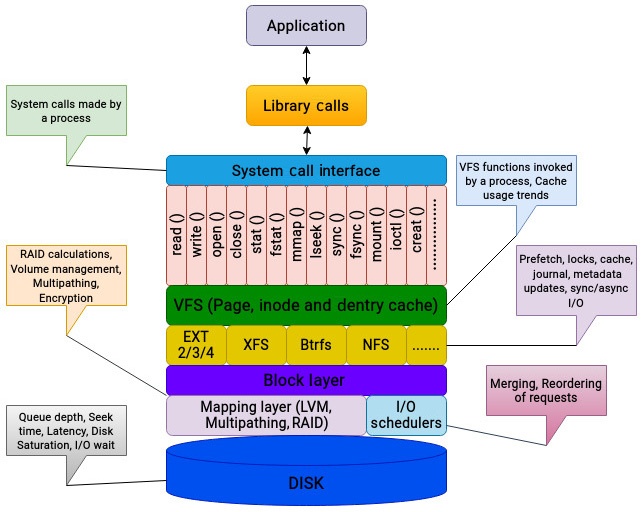
Суммируя, различные уровни общего стека ввода/ вывода способны оказывать воздействие на производительность ввода/ вывода приложения различными способами. Таким образом, при устранении неисправностей любой из проблем производительности самым первым шагом является разбиение на меньшие фрагменты; упрощая эту задачу удаляя максимально возможное число слоёв.
Существует слишком большое число типов запросов на ввод/ вывод, которые могут активироваться файловой системой. Для краткости и ясности мы будем рассматривать какой- то запрос на ввод/ вывод, активируемый процессом в качестве логического ввода/ вывода, в то время как реальную операцию, которая выполнялась с его диском будет носить название физического ввода/ вывода. Как вы уже догадались, они оба не эквивалентны. логический ввод/ вывод ссылается на процесс считывания или записи данных на логическом уровне, подразумевая что это уровень соответствующей файловой системы или приложения. И наоборот, физический ввод/ вывод вовлекает в себя передачу данных между устройством хранения и оперативной памятью. Именно он происходит на той стадии, когда данные перемещаются на уровне оборудования и управляются аппаратным устройством, таким как контроллер диска.
Дисковый ввод/ вывод может раздуваться или спускаться. Один логический запрос на ввод/ вывод может приводить ко множеству физических операций с диском. И наоборот, логический запрос процесса может вовсе не требовать физического ввода/ вывода с диска.
Чтобы подробнее разобраться с этим понятием, давайте рассмотрим некоторые факторы, которые превращают эти два типа запросов в несоразмерные:
-
Кэширование: Ядро Linux интенсивно пользуется доступной оперативной памятью для кэширования данных. Когда данные загружаются с диска, они удерживаются в кэше с тем, чтобы последующие доступы к тем же самым данным могли бы запросто обслуживаться. Если запрос на считывание приложением обслуживается из кэша, он не будем иметь результатом физической операции.
-
Обратная запись: Поскольку записи кэшируются по умолчанию, это также вносит свой вклад в различия между общим числом физических и логических операций. Механизм кэширования с обратной записью откладывает и соединяет операции перед окончательным сбросом их на диски.
-
Предварительная выборка: Большинство файловых систем обладают механизмом предварительной выборки, посредством которой они способны предварительно выбирать последовательные идущие следом блоки в кэш, в то время как некий блок считывается с диска. Файловая система предвидит что эти данные потребуются приложению и считывает их в оперативную память прежде чем приложение и в самом деле запросит их. Такие операции предварительной выборки превращают последовательное считывание в очень быстрое. Когда такие данные уже были предварительно выбраны в её кэш, файловая система может избегать последующих путешествий к физическому хранилищу, тем самым снижая общее число физических операций.
-
Ведение журнала: В зависимости от применяемой в конкретной файловой системе методике ведения журнала общее число операций записи может удваиваться. Сначала они будут записаны в журнал файловой системы, а затем сбрасываются на диск.
-
Метаданные: При каждом осуществлении доступа к файлу или при его изменении, самой файловой системе требуется обновлять её временные отметки. Аналогично, когда записываются какие бы то ни было новые данные, файловой системе требуется обновлять свои внутренние метаданные, например, значение числа используемых и свободных блоков. Все такие изменения требуют выполнения на диске физических операций.
-
RAID: Это часто можно упускать из виду, однако тип настроек RAID в лежащем в основе хранилище может оказывать громадное влияние на потребности в дополнительных записях. Например, такие операции как распределение данных по нескольким дискам, запись избыточных сведений (корректирующих сумм), создание зеркальных копий а также перестройка данных, все они требуют дополнительных записей.
-
Диспетчеризация: Планировщики ввода/ вывода как правило пользуются таким методиками как слияние и повторное упорядочение для минимизации позиционирований на диске и улучшения дисковой производительности. Следовательно, множество запросов могут консолидироваться в единый запрос на уровне планирования.
-
Уменьшение данных: Когда осуществляются какие- то сжатия или дедупликация, общий объём запросов на осуществление на дисках физического ввода/ вывода будет меньше чем в инициируемых приложением логических запросах.
Как мы это уже обсуждали в Главе 9, латентность это отдельная наиболее важная метрика при любом измерении производительности и при анализе. С точки зрения файловой системы, латентность измеряется как величина времени начиная с которого был инициирован логический запрос вплоть до момента его завершения на физическом диске.
Возникающая по причине наличия узких мест в физическом хранилище задержка выступает одним из факторов, увеличивающих общее время отклика файловой системы. Однако, чтобы не повторять наше обсуждение из предыдущего раздела, поскольку файловые системы не просто передают запрос на ввод/ вывод физическому диску, задержка может возникать в силу более чем одного из способов, например так:
-
Конкуренция за ресурс: Когда множество процессов одновременно производят запись в один и тот же файл, это может оказывать воздействие на производительность файловой системы. Блокировка файла способна быть существенной проблемой производительности для больших приложений, например, для баз данных. Основная цель блокировки состоит в последовательном доступе к файлам. Для блокирования файловые системы Linux пользуются общими методами VFS.
-
Промахи кэша: Основная цель кэширования данных в оперативной памяти заключается в том чтобы избегать частых походов на диски. Когда некое приложение настроено на то чтобы избегать применение имеющегося кэша страниц, оно также способно испытывать задержки.
-
Размер блока: Большинство систем хранения спроектировано под работу с конкретным размером блока, например, 8к, 32к или 64к. Когда активируемые запросы имеют большие размеры, им сначала потребуется разбиение до подходящих размеров, что вовлекает в себя дополнительную обработку.
-
Обновления метаданных: Обновления метаданных файловой системы способны выступать основным источником латентности. Обновление метаданных файловой системы вовлекает в себя выполнение ряда дисковых операций, в том числе позиционирование в надлежащем месте на диске, записи обновлённых сведений, а затем синхронизации дискового кэша с данными на диске. В зависимости от величины размера и положения подлежащих обновлению метаданных эта последовательность может отнимать значительное количество времени, в особенности когда файловая система интенсивно используется и диски заняты прочими операциями. В результате это может приводить к отставанию запросов и общему замедлению производительности файловой системы.
-
Разбиение логического ввода/ вывода: Как уже пояснялось ранее в предыдущем разделе, логическая операция на ввод/ вывод может потребовать разбиения на множество физических операций ввода/ вывода. Это способно увеличивать латентность файловой системы, ибо всякая операция физического ввода/ вывода требует дополнительного времени доступа к диску, что в результате приводит к дополнительным накладным расходам обработки.
-
Выравнивание данных: Разделы файловой системы обязаны быть аккуратно выравненными в соответствии с геометрией физического диска. Неверное выравнивание будет вызывать снижение производительности, в особенности в отношении томов RAID.
Учитывая гигантское число факторов, способных оказывать воздействие на значение производительности ввода/ вывода приложения, не вызовет удивления то, что большинство людей неохотно изучают эту дорогу и в основном сосредотачиваются на статистических данных уровня диска, которые гораздо проще понимать. До сих пор мы рассматривали лишь общие проблемы, которые способны оказывать воздействие на жизнь некого запроса на ввод/ вывод. Устранение неисправностей это сложный навык мастерства и может оказываться сложным принимать решение о достойной отправной точке для начала. Общую путаницу усугубляет туча инструментов, которыми можно пользоваться для анализа производительности. Несмотря на то, что здесь мы сосредоточены лишь на хранении данных, невозможно охватить длинный перечень инструментов, которые в той или иной степени способны оказывать нам содействие в достижение поставленной цели.
Приводимая ниже таблица суммирует различные целевые уровни для анализа производительности и имеющиеся за и против для каждого из подходов:
| Уровень | За | Против |
|---|---|---|
Приложение |
Регистрации приложений, специальные инструменты или методики отладки должны определять сферу действия проблемы, что может способствовать последующим шагам. |
Методики отладки не распространены и отличаются для каждого приложения. |
Интерфейс системных вызовов |
Простота трассировки вызовов, производимых процессом. |
Сложности с фильтрацией, поскольку для одной и той же функции имеется множество системных вызовов. |
VFS |
Общие вызовы применяются для всех файловых систем. |
Существует потребность изоляции самой файловой системы в вопросе, поскольку трассировка может содержать данные для всех файловых систем, включая файловые системы pseudo. |
Файловые системы |
Файловые системы это самый первый пункт контакта для приложения, что превращает их в идеальных кандидатов для анализа. |
Имеется слишком мало доступных механизмов трассировки файловых систем. |
Блочный уровень |
Имеется в доступности большое число механизмов трассировки, которые могут применяться для идентификации того как обрабатываются запросы. |
Некоторые компоненты, например диспетчеры, не предлагают множества настроек. |
Диск |
Его проще анализировать, так как это не требует глубокого понимания более верхних уровней. |
Это не рисует ясную картину поведения приложения. |
Общее мнение (а в нём определённо присутствуют некоторые преимущества) состоит в том, что исследование всех уровней является слишком трудоёмким! Корпорации, у которых имеются специалисты по анализу производительности берут за привычку проверять все подробности и выявлять потенциально узкие места системы. Однако в последнее время более распространённым подходом стало увеличение вычислительной мощности, в особенности для облачных рабочих нагрузок. Новой нормой становится добавление большего количества аппаратных ресурсов в приложение по мере того, как оно превращается в более ресурсоёмкое. Зачастую устранение неполадок производительности игнорируется в пользу переноса приложений на более совершенные платформы.
Попытка глубоко разобраться в поведении приложения может оказаться обескураживающей задачей. В этом отношении имеющиеся уровни абстракции в общем стеке ввода/ вывода не облегчают наше задание. Чтобы проанализировать каждый из уровней в общей иерархии ввода/ вывода, вам требуется хорошо разбираться во всех понятиях, применяемых на каждом из уровней. Задание превращается в ещё более сложное когда в эту настройку вы включаете и само приложение. Хотя имеющиеся в Linux механизмы трассировки и способны оказать вам содействие в понимании вырабатываемых приложением шаблонов, нет возможности для каждого из них обладать одинаковым представлением о подробностях проектирования и реализации данного приложения.
Когда вы запускаете критически важное приложение, например, базу данных OLTP (Online Transaction Processing, обработки транзакций в реальном масштабе времени), которая ежедневно обрабатывает миллионы транзакций, может быть полезным знать где впустую тратятся циклы ЦПУ. Например, с некой транзакцией имеется несколько соглашений о предоставлении уровня обслуживания и она обязана завершаться в течении нескольких секунд. Когда требуется завершить одну транзакцию в течении 10 секунд, а на обработку файловой системы и дисковый ввод/ вывод тратится только одна секунда, очевидно, что ваше хранилище не выступает узким местом, поскольку на общий стек ввода/ вывода тратится лишь 10% от общего времени. Если же приложение было заблокировано на уровне своей файловой системы на протяжении пяти секунд, совершенно ясно, что необходима некая настройка.
Давайте взглянем на различные имеющиеся у нас варианты анализа общего стека ввода/ вывода. Обратите внимание на тот факт, что это ни коим образом далеко не полный перечень инструментов. BCC сам по себе содержит избыток подобных инструментов. Представляемые ниже инструменты были отобраны исключительно на основе личных предпочтений.
Утилита strace это один из наиболее известных инструментов Linux, который отображает сведения
относительно выполняемых процессом системных вызовов. Команда strace помогает выявлять те функции ядра, с которыми программа
проводит своё время. Например, наша следующая команда представляет итоговый отчёт и показывает частоту и проводимое за каждым из системных вызовов время.
Переключатель -c отображает значение счётчика. Здесь myapp это просто пример
программы пространства пользователя:
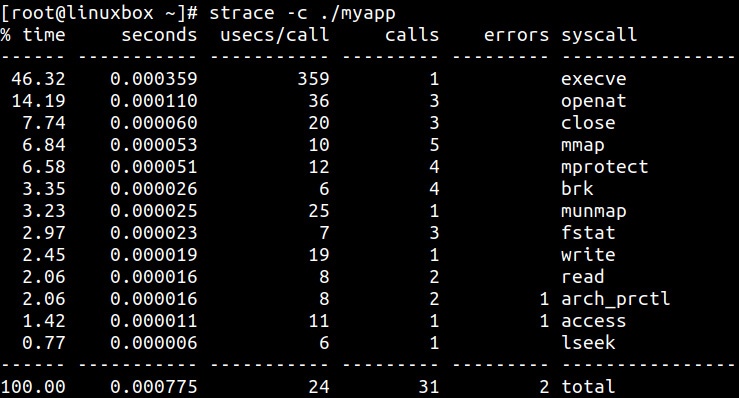
Эта команда способна подтверждать полезные для точного выявления некоторые типы узких мест производительности процесса. Для фильтрации вывода и отображения
лишь конкретного системного вызова применяется флаг -e:
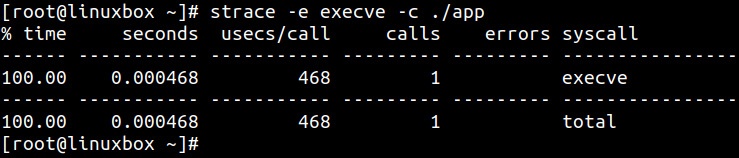
Давайте предпримем ещё шаг вперёд и посмотрим сможем ли мы что вывести из фактических получаемых от трассировки сведений. Также вы можете распечатать все
временные отметки и затраченное на каждый системный вызов время. При помощи флага -o все выводимые данные трассировки
можно сохранять в файл:
strace -T -ttt -o output.txt ./myapp
Сосредоточимся лишь на том подмножестве, которое соответствует порции ввода/ вывода приложения, обратите внимание на значение числа после знака равенства в самой первой системной записи. Мы можем видеть, что вызов записи имел возможность буферировать все данные в одном вызове функции записи. Наше приложение записало 319 488 байт за 156 микросекунд:

Команда strace также способна подключаться к уже исполняемому процессу. Вывод
strace достаточно внушительный и прежде чем вы к чему- то придёте, вам придётся кропотливо просматривать большой
объём сведений. Именно по этой причиной неплохой мыслью будет знать о наиболее часто вырабатываемых приложениями системных вызовах. Для анализа ввода/
вывода сосредоточьтесь на таких системных вызовах как open, read и
write. Это может способствовать в понимании шаблона ввода/ вывода некого приложения с точки зрения перспектив вашего
приложения. Хотя strace и не сообщает вам что именно операционная система делает с запросами на ввод/ вывод впоследствии,
она и в самом деле сообщает вам что производит ваше приложение.
Суммируя, для быстрого анализа выполните следующее:
-
Сгенерируйте итог системных вызовов, производимых исследуемым приложением.
-
Проверьте время выполнения каждого системного вызова.
-
Изолируйте те вызовы, о которых вы желаете получить сведения. Для анализа ввода/ вывода сосредоточьтесь на вызовах считывания и записи.
Для получения общих сведений относительно рабочей нагрузки в самом начале ваших изысканий может оказаться полезным анализ VFS. Также будет правильно
выявить насколько действенно приложение пользуется различными типами кэширования VFS. Программа BCC содержит такие инструменты как
vfsstat и vfscount, которые оказывают содействие в понимании таких событий в VFS.
Инструментарий vfsstat показывает статистические итоги для некоторых распространённых вызовов VFS, таких как
read, write, open,
create и fsync:
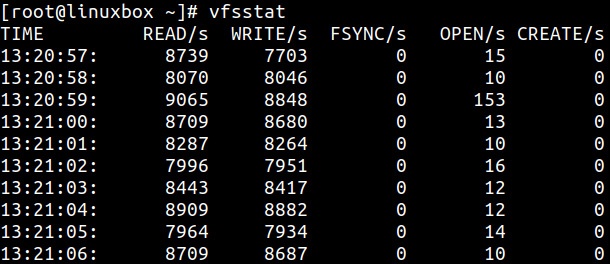
Дополнительно к вызовам read, write сохраняйте обзор столбца
open. Он показывает значение числа открываемых в секунду файлов. Внезапный рост общего числа открытых файлов способен
сильно увеличивать величину запросов на ввод/ вывод, в особенности для операций с метаданными.
Запуск этих инструментов поодиночке может не давать вам слишком глубокого представления. Хорошо применять их в сочетании с некими инструментами анализа
диска, например, iostat. Это позволит вам сопоставлять вам запросы логического ввода/ вывода с запросами физического
ввода/ вывода.
Одним из ограничений vfsstat является то, что она не разделяет активность ввода/ вывода на уровне файловой системы.
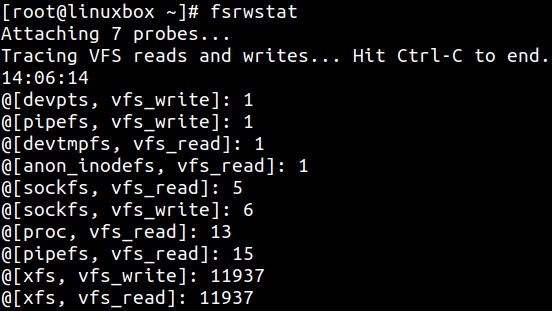
Другая программа, fsrwstat, отслеживает указанные функции считывания и записи и разбивает их далее по различным
доступным файловым системам. Приводимый ниже рисунок показывает такую разбивку общего числа вызовов считывания и записи по различным файловым системам:
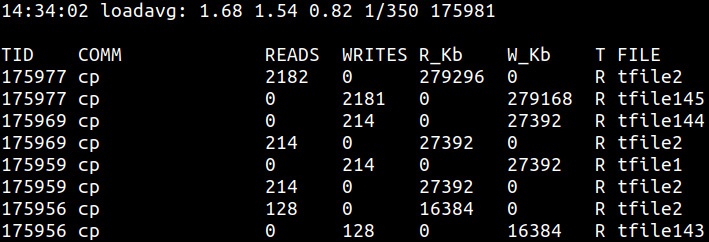
Продолжая с выводом vfsstat, когда вы замечаете открытым большое число файлов, не примените воспользоваться
filetop. Она покажет вам файлы с наиболее частым доступом в вашей системе и отобразит их активность на считывание и
запись:
Отправляемые в VFS запросы представляют собой логические запросы на ввод/ вывод. При анализе VFS придерживайтесь следующего:
-
Попробуйте составить общую картину рабочей нагрузки в системе
-
Проверьте частоту наиболее распространённых вызовов VFS
-
Сопоставьте полученную картину с запросами на физическом уровне
Для ускорения доступа к часто применяемым объектом VFS содержит множество кэшей. Поведением по умолчанию Linux является завершать все операции записи в кэше и сбрасывать записанные данные на диск позднее. Аналогично, ядро пытается обслуживать операции считывания из кэша и показывать статистические данные попаданий и промахов в кэш.
Для показа статистических сведений соотношений попаданий и промахов в кэш можно применять инструмент cachestat:
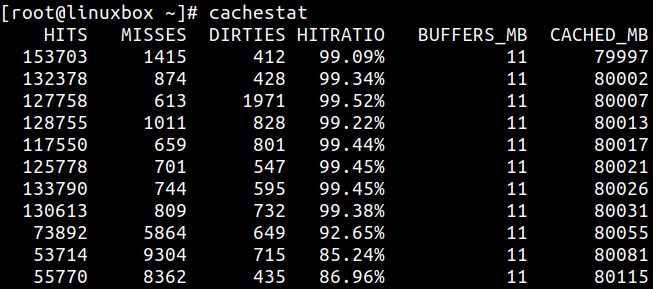
На предыдущем рисунке мы можем наблюдать исключительно высокое соотношение попадания в кэш, причём порой даже близкое к 100%. Это указывает на то, что наше ядро способно удовлетворять запросы на ввод/ вывод приложения из своей оперативной памяти. Чем выше процентное значение попаданий в кэш, тем лучшую производительность получает приложение.
Аналогично, инструмент cachetop предоставляет статистические данные попаданий и промахов в кэше по процессам. Его
вывод отображается неким интерактивным интерфейсом подобно команде top:
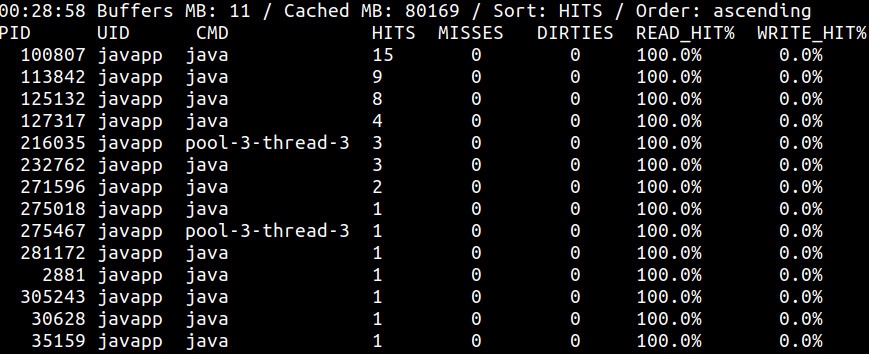
При применении этих инструментов для анализа использования кэша придерживайтесь следующего:
-
Взгляните на соотношение попаданий и промахов в кэше чтобы понимать какое процентное соотношение запросов подлежит обслуживанию из оперативной памяти
-
Когда значение соотношения низкое, может потребоваться настройка приложения или операционной системы
Хотя имеется не большое число способных отслеживать операции уровня файловой системы приложений, BCC предлагает несколько исключительных сценариев для
обзора файловых систем. Два сценария, ext4slower и xfsslower, применяются для
анализа медленных операций в наиболее часто используемых файловых системах, Ext4 и XFS.
Получаемый обоими инструментами, ext4slower и xfsslower, вывод идентичен.
По умолчанию, оба инструмента печатают операции, которые тратят на завершение более 10мс, но вы имеете возможность изменить это, передавая значение продолжительности
в качестве параметра. Оба инструмента способны подключаться к конкретному процессу:
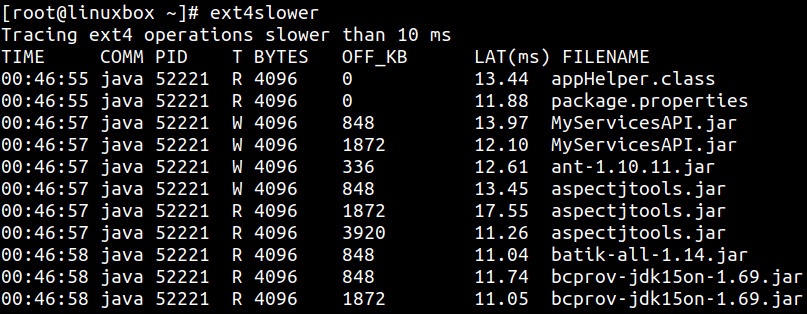
Столбец T показывает тип операции, коими могут быть R для считывания, W для записи или O для открытия. Столбец BYTES показывает размер производимого ввода/ вывода в байтах, в то время как столбец OFF_KB отражает значение смещения в файле для ввода/ вывода в кБ. Наиболее важным столбцом является LAT(ms), который показывает значение продолжительности запроса на ввод/ вывод, измеряемый с того момента как он был активирован в VFS для соответствующей файловой системы до того как он завершён. Это достаточно точное измерение продолжительности значения латентности, испытываемое приложением при выполнении ввода/ вывода в файловой системе.
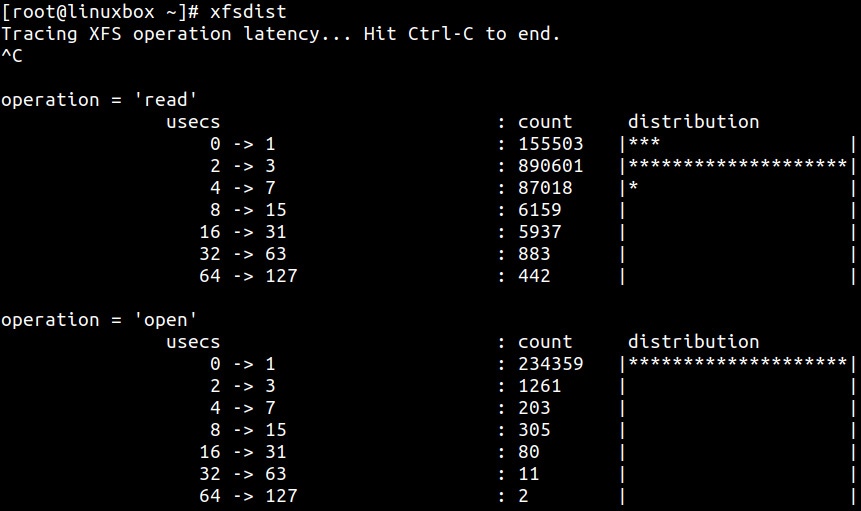
Пара других включённых в этот набор инструментов это xfsdist и ext4dist. Оба
инструмента показывают одни и те же сведения, просто для разных файловых систем - XFS и Ext4, соответственно. Данный инструменты суммируют величину времени,
затрачиваемого на выполнение распространённых операций файловых систем и предоставляет разбивку распределений испытываемых латентностей гистограммами. Оба
приложения можно присоединять к конкретному приложению:
При использовании специфичных для файловой системы инструментов, помните о следующем:
-
Инструменты
ext4dist/ xfsdistмогут помочь при установлении базового уровня - то есть является ли рабочая нагрузка ориентированной на считывание или на запись. -
Сценарии
ext4slower/ xfsslowerчрезвычайно действенны при определении реального значения латентности, испытываемой процессом при выполнении ввода/ вывода файловой системы. При их выполнении для определения объёма испытываемых приложением задержек проверяйте значение столбца латентности.
Как мы уже наблюдали в Главе 9, стандартные инструменты анализа диска, такие как
iostat, предоставляют сведения, имеющие отношение к числу считываемых или записываемых в секунду байт, занятости
диска, а также очередей, связанных с конкретными устройствами. Эти метрики усредняются по некоторому периоду времени и не дают представления на основе
отдельных операций ввода/ вывода. Выделение сведений из того что именно происходит на конкретном интервале времени невозможно.
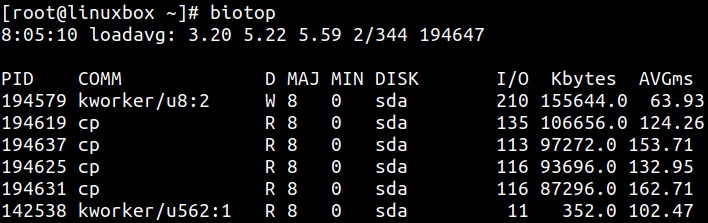
Аналогично VFS и файловым системам, BCC также содержит ряд инструментов, которые способствуют анализу событий, происходящих на блочном уровне. Одним
из таких инструментов является biotop, который аналогичен команде top для
дисков. По умолчанию, инструментарий biotop проводит трассировку всех операций ввода/ вывода в определённом блочном
устройстве и отображает итог всякой активности процесса в секунду. Этот итог сохраняется на основе топовых потребителей диска в терминах пропускной способности,
измеряемой в кБ. В итоговом представлении отображаются значения идентификатора и имени процесса, представляя значение времени когда изначально была создана
операция на ввод/ вывод, что помогает выявлению отклика процесса:
Другим инструментом BCC анализа блочного уровня выступает biolatency. Как и предполагает его название,
biolatency отслеживает ввод/ вывод блочных устройств и печатает гистограмму, которая показывает распределение латентностей
ввода/ вывода:
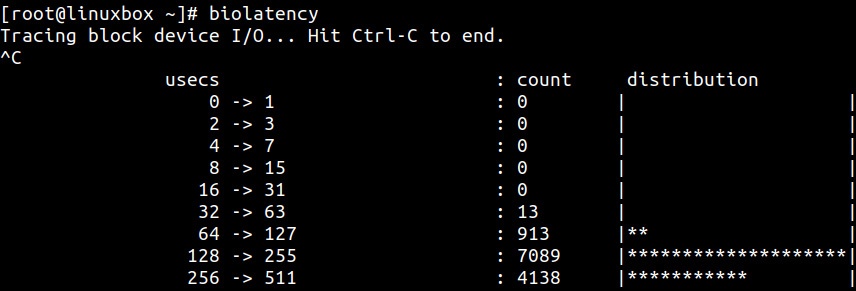
Как очевидно из предыдущего вывода, основная часть запросов на ввод/ вывод требует для своего завершения 128- 255 микросекунд. В зависимости от характера рабочих нагрузок эти показатели могут быть намного выше.
Инструмент biosnoop из BCC отслеживает ввод/ вывод блочного устройства и печатает его подробности, включая тот процесс,
который инициировал данный запрос:
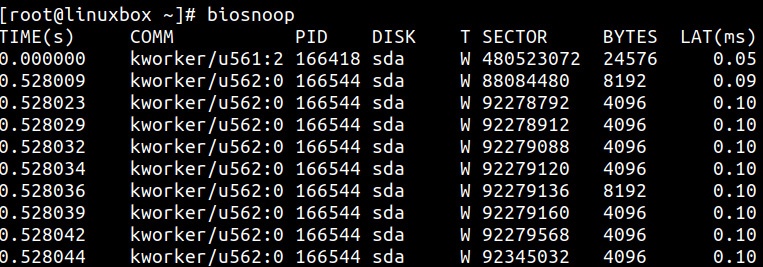
Получаемый biosnoop вывод содержит значения латентностей от времени активации запроса в своём устройстве до его
завершения. Вывод biosnoop можно применять для выявления отклика процесса на чрезмерную запись на диск.
Одним из последних инструментов, который я бы хотел упомянуть, это bitesize, который применяется для описания
характеристик размеров ввода/ вывода блочного устройства:
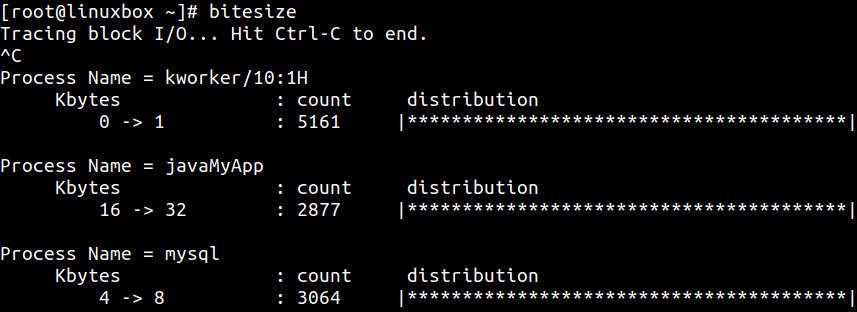
Как показано в предыдущем выводе, наш процесс javaMyApp (простое приложение на основе Java) производит запросы в пределах 16-32кБ, в то время как mysql пользуется диапазоном в 4-8кБ.
При анализе блочного уровня не забывайте о следующем:
-
Для получения представления о дисковой активности в вашей системе с топовой стороны пользуйтесь
biotop. -
Для отслеживания размеров ввода/ вывода приложений применяйте
bitesize. Когда рабочая нагрузка приложения последовательная, тогда использование больших размеров блоков в результате способно приводить к лучшей производительности. -
Для наблюдения за латентностями блочных устройств воспользуйтесь
biolatency. Он снабдит вас итогом значений временных диапазонов для блочных запросов на ввод/ вывод. Когда вы наблюдаете более высокие значения, требуется более глубокое погружение. -
Для дальнейших проверок применяйте
biosnoop. Чтобы найти значение времени, затрачиваемое между созданием подлежащего активации к некому устройству запроса на ввод/ вывод, воспользуйтесь флагом-Qдляbiosnoop.
Приводимая ниже таблица суммирует те инструменты, которые могут применяться для анализа событий на различных уровнях:
| Уровень | Инструмент анализа |
|---|---|
Приложение |
Специфичные для этого приложения инструменты |
Интерфейс системных вызовов |
|
VFS |
|
Кэш |
|
Файловые системы |
|
Блочный уровень |
|
Диск |
|
Обратите внимание на то, что данная таблица не ограничивает все имеющиеся инструменты. Один только набор инструментария BCC содержит ряд прочих инструментов, которые можно применять для анализа производительности. Кроме того, существует множество параметров, которые можно передавать каждому из инструментов для получения более значимого результата. Принимая во внимание множество задействованных в общей иерархии слоёв, диагностика проблем производительности ввода/ вывода является комплексной задачей и, как и в ситуации с любым иным сценарием устранения неполадок, для этого потребуется вовлечение целого ряда команд.
В данной главе мы возобновили свой анализ производительности и распространили его на более верхние слои общего стека ввода/ вывода. В большинстве ситуаций анализ более верхних уровней пропускается и основное внимание уделяется исключительно физическому уровню. Однако для чувствительных ко времени приложений нам требуется расширять свой подход и искать потенциальный источник задержек во времени отклика приложений.
Вы начали эту главу с пояснения различных источников задержек, которые можно наблюдать в приложении при считывании или записи в файловой системе. Операции файловой системы проистекают из инициируемых приложением запросов на ввод/ вывод. Дополнительно к запросам на ввод/ вывод приложения файловая система способна тратить время на такие задачи, как осуществление обновлений метаданных, ведение журналов, или сброс имеющихся в кэше данных на диски. Всё это имеет результатом дополнительные операции ввода/ вывода. Обсуждавшиеся нами в Главе 9 инструменты были сосредоточены вокруг дисков и не предлагали большой визуализации в происходящие в VFS и на блочном уровне события. BCC предлагает богатый набор сценариев, способных отслеживать события в своём ядре и снабжать нас внутренним представлением для индивидуальных запросов на ввод/ вывод.
В своей следующей главе мы предпримем дальнейший анализ и изучим различные трюки настроек, которые способны применяться на различных уровнях в общей иерархии ввода/ вывода, при этом улучшая производительность.