Глава 2. Как сочетаются друг с другом компоненты QRadar
Содержание
После изучения различных компонентов QRadar давайте теперь разберёмся с тем как они сочетаются друг с другом. Существуют различные способы проектирования реализации QRadar и они находятся в полной зависимости от той области операций безопасности, которые мы намерены предпринимать. Они зависят от значения числа конечных точек, приложений, пользователей и серверов, которые мы желаем привнести под такой радар.
Таким образом, в данной главе мы исследуем два различных вида развёртываний, а также почему и когда они применяются. Мы будем обсуждать два следующих вида реализации QRadar:
-
Комплексное (all- in- one) развёртывание
-
Распределённое развёртывание
Также мы обсудим те условия, при которых в данные реализации добавляются различные компоненты.
При данном виде развёртывания вся обработка всех данных выполняется только самой Консолью. Итак, при данном типе реализации не будет никаких процессоров данных (отличных от имеющейся Консоли), а также в этом развёртывании даже не будет никаких отдельных Процессоров событий и Процессоров Потоков. Как нам известно, процессоры отвечают за обработку и хранение данных. При Комплексном развёртывании (all- in- one deployment), основная цель состоит в том, чтобы сама Консоль была бы тем компонентом, в котором бы мы обладали хранимыми данными или же имели бы подключённым к этой консоли некий Узел данных.
Для этого вида реализации могут добавляться Сборщики событий и потоков. Кроме того, может быть добавлен QNI, который будет накапливать потоки и отправлять для обработки данные в имеющуюся Консоль.
Приводимые далее схемы это некоторые образцы комплексных реализаций.
В своём следующем примере мы наблюдаем Консоль QRadar, которая накапливает данные из различных Источников журналов и Источников потоков. Также через веб браузер у нас имеется доступ к интерфейсу пользователя (UI) QRadar. Администраторы и аналитики имеют возможность регистрироваться через графический интерфейс пользователя QRadar для настройки накопления данных, отслеживания событий и работы с сигнализацией безопасности, также именуемой как проступки (offenses).
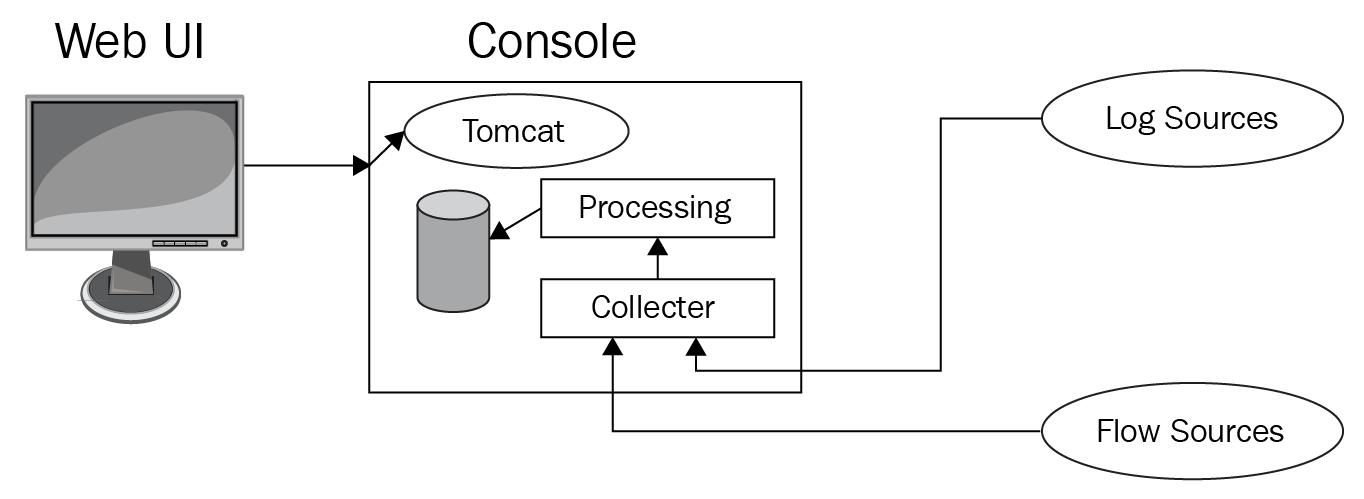
На приводимой далее схеме мы видим Консоль QRadar со Сборщиком событий и Сборщиком потоков. Здесь, вместо того чтобы собирать сведения непосредственно в самой Консоли, данные накапливают Сборщик событий и Сборщик потоков.
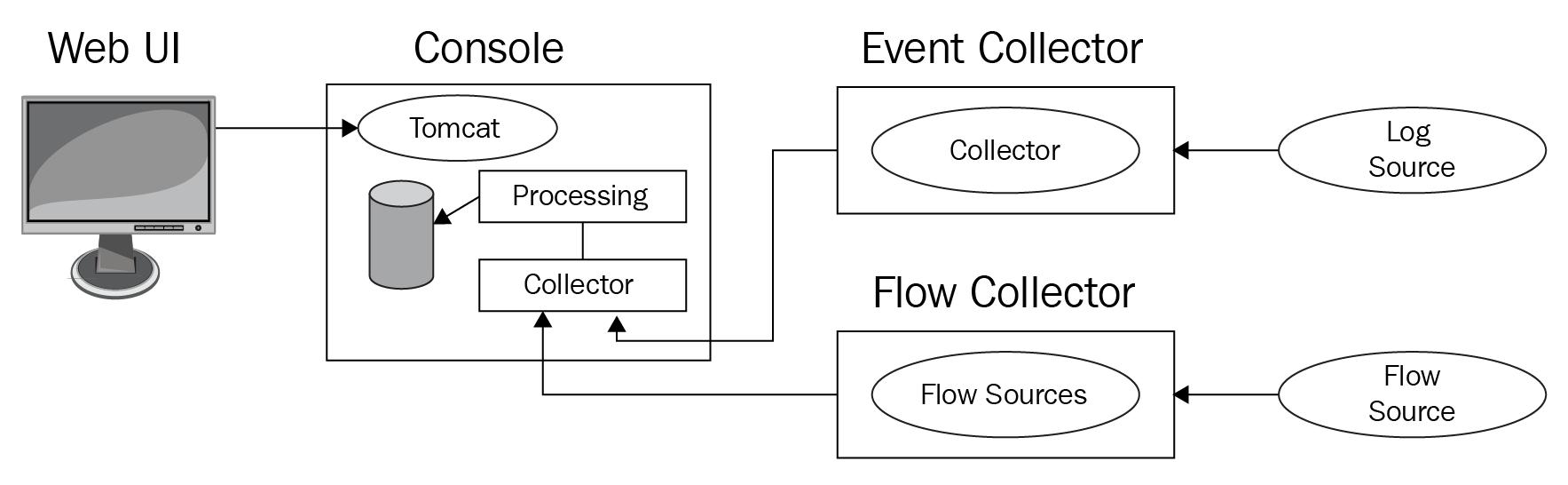
В своём следующем примере мы замечаем, что помимо Источников журналов и Источников потоков у нас имеется другой компонент, с названием Хоста прикладных приложений (App Host). Как обсуждалось в Главе 1, Хост прикладных приложений не хранит никакие данные событий или потоков. Тем самым, даже после добавления такого Хоста прикладных приложений, этот тип реализации всё ещё будет носить название комплексной (all- in- one).
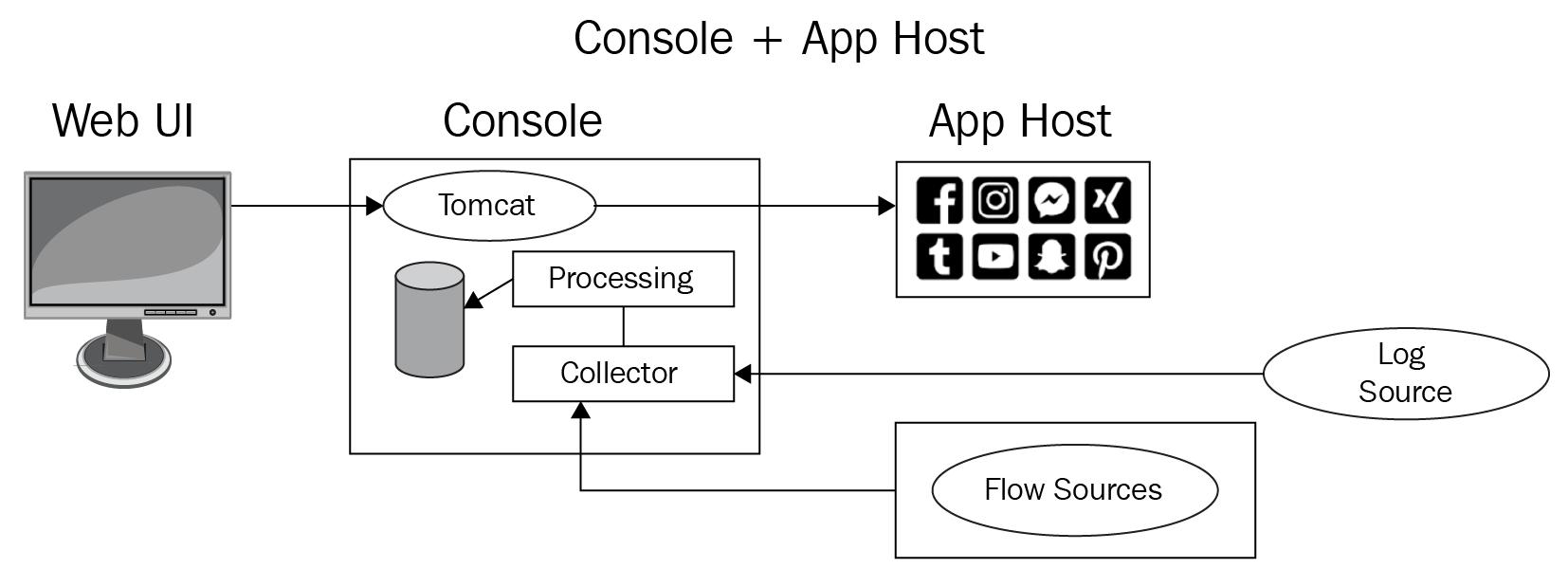
Хост прикладных приложений требуется когда рассматривается в качестве устанавливаемых ряд прикладных приложений. Такие прикладные приложения как UBA (User Behavior Analytics) и Watson Advisor являются приложениями с применяющими Машинное обучение (ML) и модели Искусственного интеллекта (ИИ) интенсивными вычислениями. Это требует существенно больше вычислений ЦПУ и памяти, что могло бы гигантским образом загрузить саму Консоль, которая и так выполняет уже настолько большой объем работ.
Прикладные приложения ничто иное как образы Docker, запускающиеся в качестве контейнеров в развёртывании QRadar. QRadar предоставляет этим прикладным приложениям некую инфраструктуру для их работы независимо друг от друга.
Подробнее мы обсудим прикладные приложения в идущей далее Главе 8.
При комплексной реализации самой Консолью выполняется тяжёлое поднятие работы в плане обработки данных и хранения. Когда мы добавляем процессоры, мы добавляем дополнительную мощность и больше хранилищ. Это помогает нашей Консоли высвободить ресурсы для прочих важных задач.
В гигантских реализациях пользователей при ежедневной обработке терабайт данных применение комплексного решения будет недостаточным. Для установления соотнесения данных и их хранения нам требуется больше процессоров. Всякий процессор поставляется с индивидуальной ёмкостью хранения. Например, для одного из крупнейших решений QRadar, которое ежедневно обрабатывает около 2ТБ сведений у нас имеется 3 Процессора событий. Эти Процессоры событий пребывают в состоянии высокой доступности, что подразумевает, что для каждого первичного Процессора событий у нас имеется вторичный Процессор событий. Каждый из этих трёх процессором совместно пользуется нагрузкой корреляции событий входящих событий для этого конкретного процессора. Итак, в среднем, усреднённый размер событий может составлять около 500 байт, что переводится в приблизительно 2ТБ, делимых на 500байт/событие = 4 000 000 событий в день. Кроме того, 4 000 000 событий в день равно 46 296 EPS (events per second, событий в секунду).
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Здесь мы обсуждаем Процессоры событий, но те же самые вычисления и соображения работают также и для Процессоров потоков. |
Обработка около 45 000EPS для Консоли было бы неподъёмной тяжестью. Представляется разумным добавление большего числа процессоров для совместного применения корреляции и хранения имеющейся нагрузки. Для разделения значения в 45k EPS нам бы рекомендовалось, чтобы в зависимости от спецификации оборудования соответствующего процессора, добавить от 2 до 3 процессоров. Если мы выбрали 3 процессора, каждый из них способен тогда обрабатывать 15k EPS.
|
| Замечание |
|---|---|
|
Соответствующая спецификация оборудования определяет величину объёма EPS лицензии, которая применяется к данному процессору. |
Таким образом, распределённая реализация, это когда в неё добавлены процессоры. В корпоративных решениях крупного масштаба реализуемые развёртывания обычно распределённые. К примеру, Процессоры событий и потоков порой разнесены географически. Консоль может располагаться в Северной Америке, в то время как Процессоры событий могут пребывать в Австралии, Индии, на Среднем востоке и в Европе.
Следующая схема показывает образец сценария с распределённым решением:
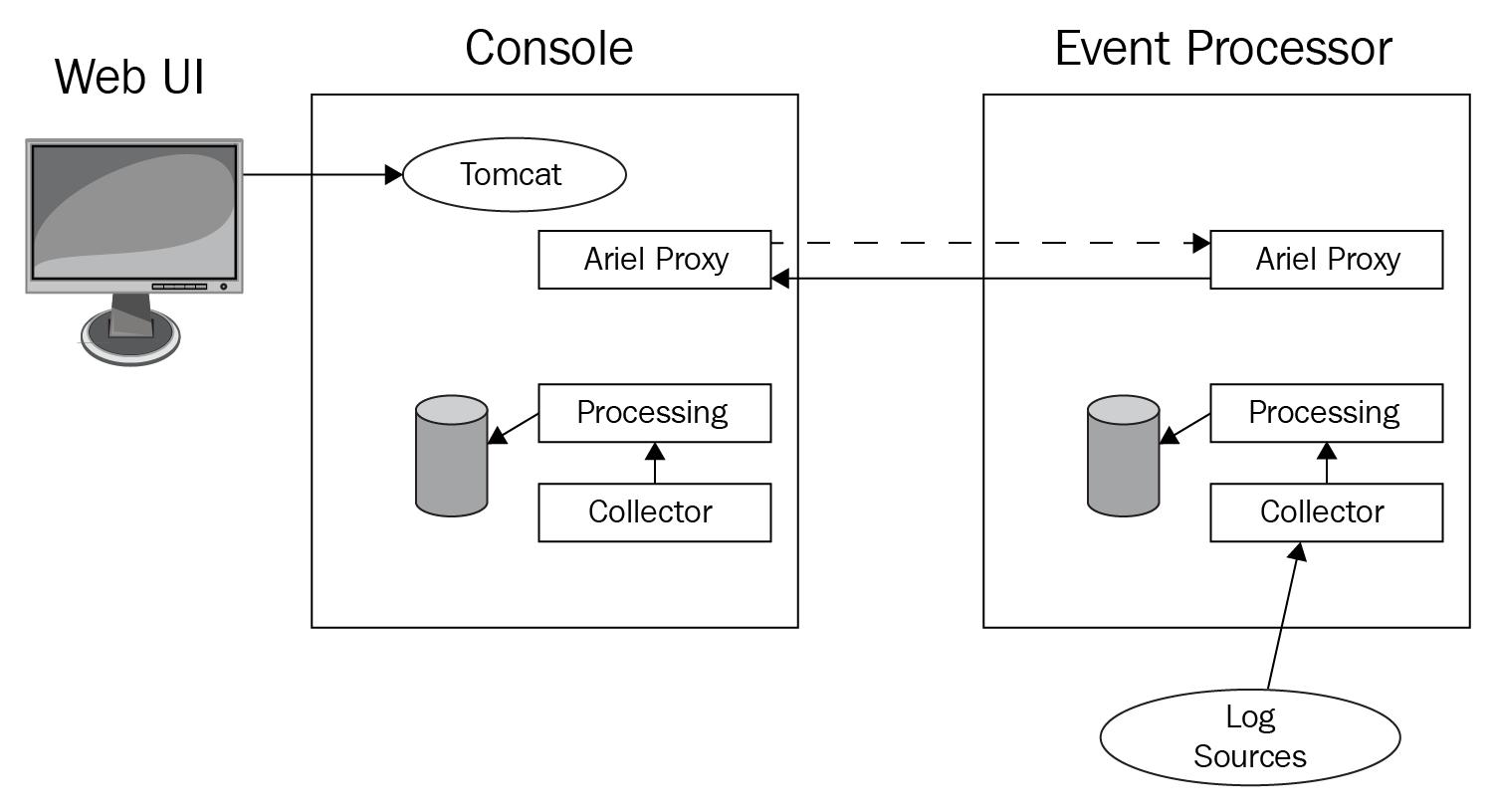
В нашей предыдущей схеме в общее решение добавлен Процессор событий. Сбор событий и их обработка выполняются этим Процессором событий. Когда из интерфейса пользователя QRadar осуществляется досмотр, а именно, из нашей Консоли служба Tomcat отправляет соответствующий запрос в службу посредника Ariel, которая, в свою очередь, отправляет этот запрос во все управляемые хосты (параллельно), которые обладают запущенными службами Запросов Ariel. В подобной ситуации, в соответствующем управляемом хосте у нас имеется некий Процессор событий, в который отправляется такой запрос. Сервер Запросов Ariel накапливает регистрации из своей локальной базы данных (в данном случае из базы данных Ariel Процессора событий) и отправляет получаемые в результате данные обратно в свою Консоль, в которой отображаются эти результаты досмотра.
Аналогичным образом в общее решение может добавляться Процессор потока.
Теперь давайте разберёмся с некоторыми интригами географически распределённых решений.
Давайте отступим на шаг назад чтобы поглубже в данные событий. На данный момент мы понимаем, что собираем сведения из различных Источников журналов и что эти данные можно найти и отобразить в закладке QRadar Log Activity. Если мы дважды щёлкнем по любому из событий, мы можем обнаружить подробности события:

В своём предыдущем примере мы наблюдаем событие с названием Infected file detected (обнаружен заражённый файл). Из закладки Log Activity вы можете выполнить фильтрацию значения числа столбцов, которое вы бы желали видеть. По умолчанию, для некого события, у нас имеются Event Name, Log Source (с которым ассоциировано данное событие), Event Count (это связано с соединением событий, которое мы рассмотрим в последующих главах), Time (этого события), Low Level Category (его же), Source IP и Source Port.
Одним из самых важных обсуждаемых нами факторов выступает значение времени. По умолчанию в Log Activity отражено время начала:
-
Start Time это значение времени, когда данное событие попало в Конвейер (pipeline) Событий QRadar, это то показание времени, когда событие получено службой
ecs-ec-ingress. -
Storage Time это значение времени, когда процесс
ecs-epсохранил данное событие в своей базе данных Ariel. -
Log Source Time то значение времени, когда данное событие создано в Журнале источника.
Теперь давайте в этом образце взглянем на подробности времени события:
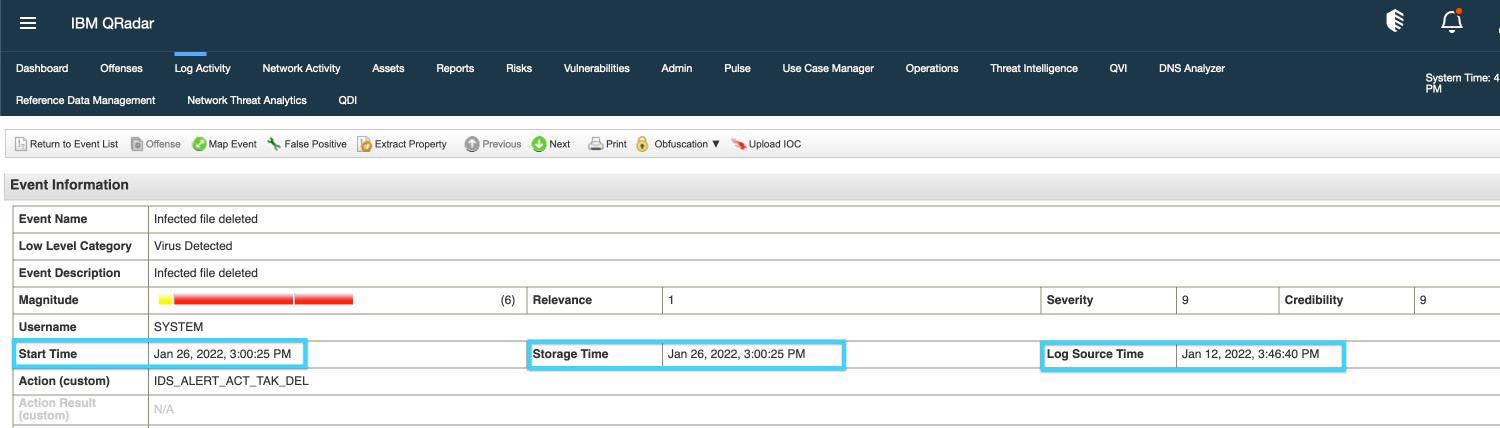
Из предыдущего снимка экрана мы видим, что Log Source Time и Start Time разные. Это означает, что данное событие было создано по пути до отправки в QRadar для своего синтаксического разбора и обработки. Для этого могут иметься различные причины. Она из причин может заключаться в том, что тот протокол, который применяется для выбороки регистраций имеет проблемы. Например, когда вы выполняете выборку регистраций при помощи протокола JDBC Java Database Connectivity, имеются файлы маркеров, которые определяют какие сведения подлежат выемке. Если такой файл маркера испорчен, потребуется его сброс. После сброса протокол JDBC начнёт свою работу. Однако это создаст разницу во временах Log Source Time и Start Time. Главное что мы можем уяснить из данного примера, так это то, что Log Source Time может отличаться от Start Time.
QRadar способен преобразовывать значение времени из своей полезной нагрузки в ту временную зону, в которой выполняется обработка. Что касается нашего примера, Консоль QRadar находится в зоне времени Индии, а происходящие события накапливаются во временной зоне Японии. Когда Сборщик событий в Японии отправляет свои события на хранение в Консоль, значение времени Журнала источника будет преобразовано во временную зону Индии. Когда данное событие это часть некого проступка (предупреждения) в QRadar, тогда очень полезно если все события в единой временной зоне для понимания хронологии этих событий.
Другой стороной при проектировании распределённых реализаций является значение объёма накапливаемых и обрабатываемых данных событий и данных потока. Консоль обладает ограничениями на основе EPS и FPM (flows per minute, потоков в минуту), которые она способна обрабатывать.
Существуют ограничения на значения EPS и FPM, которые может обрабатывать определённая Консоль. Когда некой организации требуется накапливать и обрабатывать данные с более чем 30k EPS, нам требуется добавить новый Процессор событий. Аналогично, для потока данных с величиной более 1.2M FPM, мы будем в свою реализацию добавлять новый Процессор потоков.
Ещё один вопрос, на который стоит обратить внимание, это значение периода хранения, установленное для данных событий и потоков. Величина срока хранения настраивается в соответствии с потребностями ведения дел или, при их наличии, некими правилами, подлежащими выполнению. Скажем, для определённого состояния требуется, чтобы такие финансовые учреждения как банки, хранили события и потоки по крайней мере за 2 года. В данной ситуации, даже если значения EPS находятся в рамках возможности своей Консоли в отношении обработки, в самой консоли имеются ограничения по пространству. И для такого ограничения в пространстве крайне важно обладать Процессорами событий и потоков (по мере их необходимости).
В своей предыдущей главе мы обнаружили, что в QRadar имеются и прочие компоненты. Давайте разберёмся как они подгоняются друг к другу.
Процессор Криминалистики инцидентов QRadar (QRIF) добавляется к Консоли QRadar аналогично прочим управляемым хостам. К такому процессору QRIF присоединяется устройство перехвата пакетов. Оно помогает данному процессору импортировать все необходимые сведения перехвата пакетов из устройства PCAP (packet capture).
Обычно когда мы исследуем некий проступок (offense), мы бы хотели посмотреть что случилось, что существенно при расследовании происшествий. К примеру, некий проступок включён для сотрудника с именем Bob. Когда мы щёлкнем правой кнопкой по Bob и кликните по Forensic recovery (восстановлению расследования), ваш процессор QRIF соберёт все относящиеся к Bob сведения, такие как отправленные Бобом сообщения электронной почты, его скачивания, сеансы чат, историю просмотров в браузере и тому подобное.
Наш процессор QRIF запрашивает накопленные данные на основании установленного фильтра из устройства PCAP и воссоздаёт обмен в его первозданном виде. Таким образом, будут восстановлены отправленные Бобом вложения в электронную почту.

Реализация QRadar также способна обладать множеством процессоров QRIF и некоторым числом подключённых к ним PCAP. Такие устройства PCAP перехватывают весь сетевой обмен с абонентских (TAP) портов соответствующего коммутатора, маршрутизатора и тому подобных устройств.
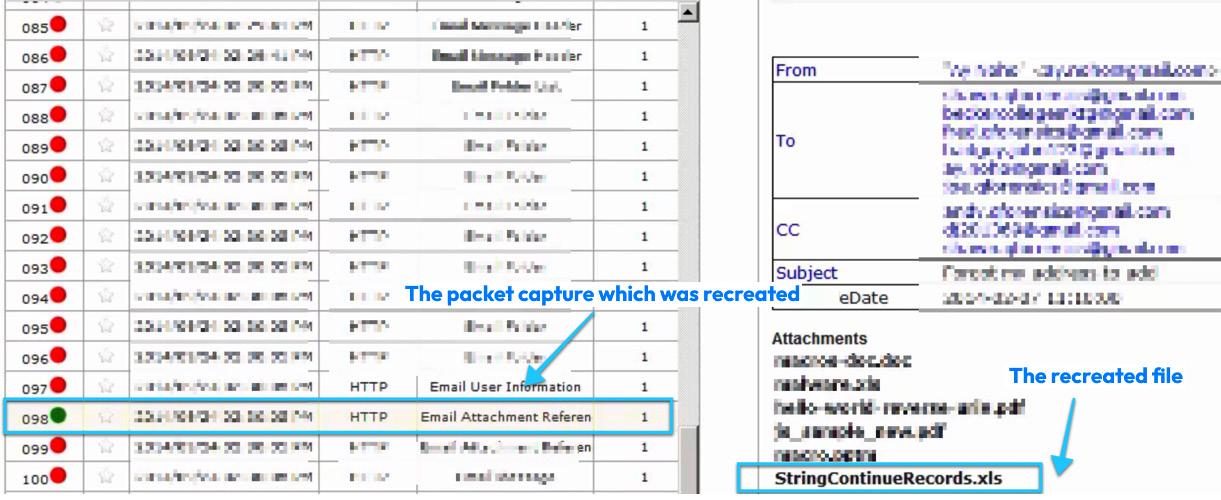
Наш предыдущий рисунок это снимок экрана закладки Forensic из интерфейса пользователя QRadar. Здесь у нас имеется восстановление из PCAP (с номером 98). Из данного PCAP может быть осуществлена выборка всех вложений электронной почты. Мы можем видеть восстановленным файл XLS, а также можно просматривать его подробности. Это помогает нам в криминалистических расследованиях для произошедшего инцидента.
Как и для прочих управляемых хостов, может добавляться множество процессоров QRIF. Причём к каждому из управляемых хостов может добавляться множество PCAP.
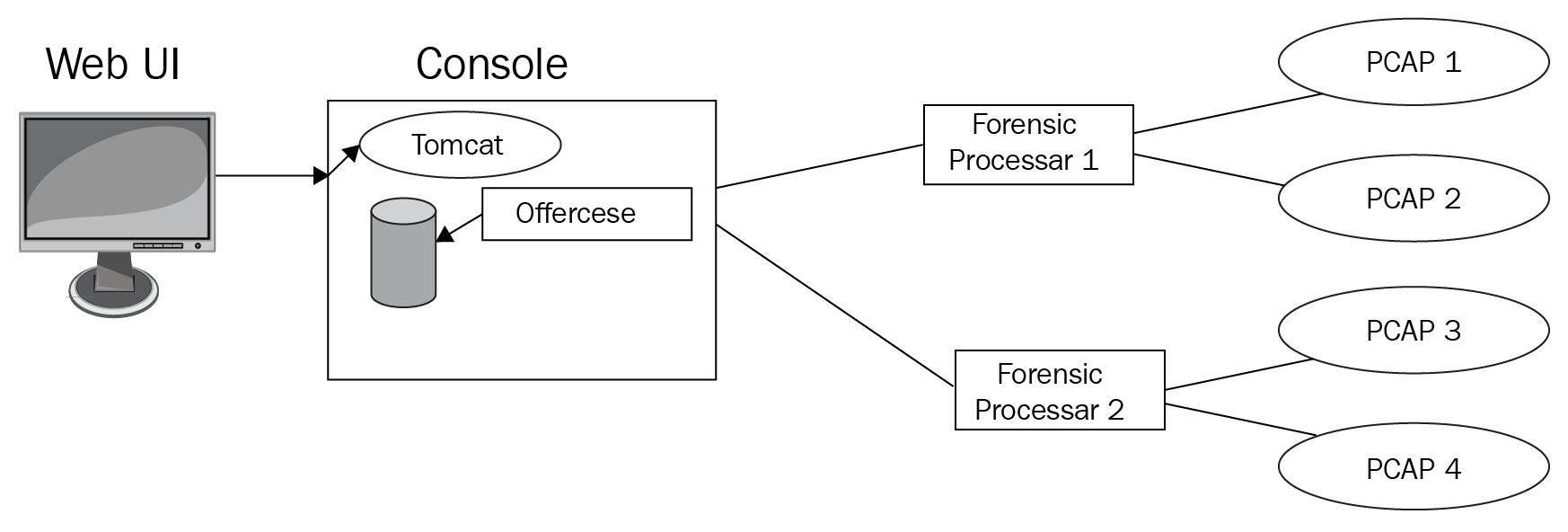
Наша предыдущая схема отображает в реализации множество процессоров QRIF.
|
| Замечание |
|---|---|
|
В реализации QRadar значения версии Консоли QRADAR и всех управляемых хостов одинаковые. Например, когда у Консоли QRadar версия 7.5, все управляемые хосты обязаны иметь также версию 7.5. PCAP QRADAR не является управляемым хостом и имеющаяся Консоль QRadar не управляет им. Следовательно, версии Консоли QRadar и PCAP могут отличаться. |
В данном разделе мы рассмотрели как в реализацию QRadar помещается QRIF и подробно обсудили как он работает. В своём следующем разделе мы рассмотрим как в реализации QRadar размещается QRM.
Диспетчер рисков QRadar (QRM, QRadar Risk Manager) это ещё один управляемый хост, который можно добавляь в реализацию QRadar. В каждой реализации может присутствовать только один QRM. QRM пользуется сведениями топологии сетевой сред, например, резервными копиями конфигураций сетевых устройств, а также сведениями об уязвимостях из событий чтобы разбиваться с имеющимися рисками и выстраивать их приоритеты.
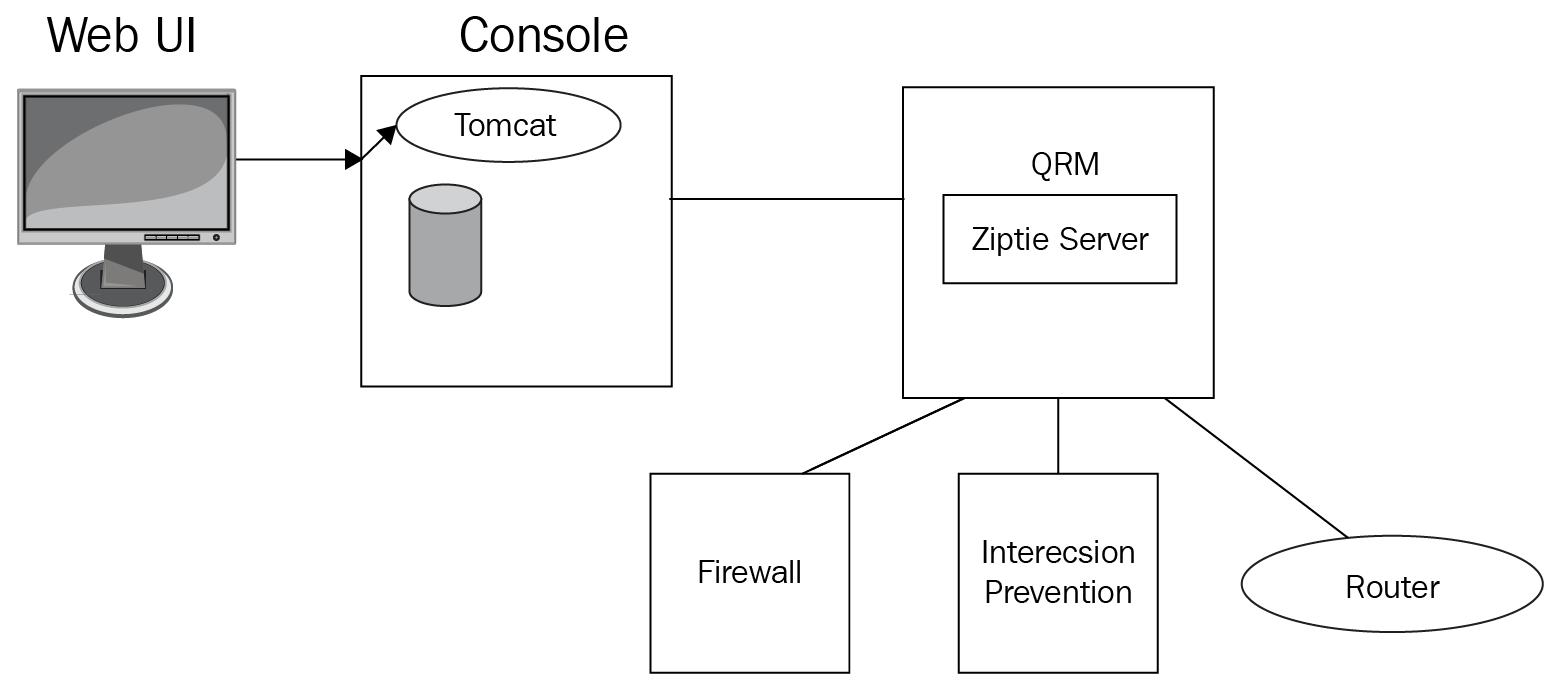
На Рисунке 2.10 мы наблюдаем что QRM подключается к таким сетевым устройствам как межсетевые экраны, системы предотвращения проникновений и маршрутизаторы. QRM обладает большим числом функциональных возможностей, которые способны облегчать жизнь администраторов QRadar. Он предоставляет функциональную возможность "discovery" (выявления). Администратору потребуется предоставить значение диапазона адресов IP. Затем QRM приступит к сканированию и выявит все имеющиеся в этой подсети сетевые устройства. Можно предоставлять несколько диапазонов IP адресов, что сделает возможным выявления различных сетевых устройств.
|
| Замечание |
|---|---|
|
QRM работает на 3 Уровне модели OSI (Open Systems Interconnection). |
Будучи выявленными, подробности конфигурации от сетевых устройств могут импортироваться при помощи резервного копирования по расписанию. Такие подробности конфигураций сетевых устройств снабжают QRM необходимыми сведениями для создания схемы топологи сетевой среды.
QRM обладает различными переходниками, которые способны импортировать установленные конфигурации сетевых устройств. Например, переходник для межсетевого экрана F5 будет отличаться от переходника для маршрутизатора Cisco. QRM способен поддерживать большое число сетевых устройств при помощи их соответствующих переходников (адаптеров).
Для сбора всех резервных копий конфигураций и нормализации их данных для применения в QRadar используется сервер Ziptie. На основании собранных сетевых конфигураций могут сопоставляться политики различных устройств. Когда имеются пропущенные политики, в виде проступков (offenses) могут отправляться сигналы оповещения.
Одной из самых замечательных функциональных возможностей QRM является имитация атаки на сетевые ресурсы. Получаемые в результате имитации атаки сведения могут применяться для того чтобы разобраться с тем, какие ресурсы находятся в зоне риска и как это исправить. Другим видом возможной имитации является изменение сетевых политик в имеющихся сетевых устройствах с последующей имитацией атак.
Некоторые организации обладают особыми требованиями соответствия, такими как HIPAA (Health Insurance Portability and Accountability Act, Федерального закона США "О перемещаемости и подотчётности страхования здоровья") и GDPR (General Data Protection Regulation, Всеобщего положения защиты данных). QRM способен также оказывать содействие в автоматизации проверок соответствия.
QRM это управляемый хост, а как и все прочие управляемые хосты, обладает той же самой версией что и Консоль QRadar.
В данной главе мы обсудили как комплексное развёртывание отличается от распределённой реализации. Также мы взглянули на современные вызовы безопасности в отношении интеграции воедино множества источников событий, потоков и активов чтобы разобраться с состоянием безопасности вашей организации. Применяя все эти рассмотренные нами компоненты QRadar мы можем выстроить подходящую нашим потребностям безопасности среду QRadar. Мы подробно обсудили различные составляющие QRadar по всей длине со схемами чтобы понять как они интегрируются друг с другом. Надеемся, что после ознакомления с нашей предыдущей главой у вас сложилось более чёткое представление о том как может выглядеть общее строение QRadar.
В своей следующей главе мы поглубже окунёмся в различные виды развёртываний QRadar. Кроме того, мы обсудим как масштабировать QRadar и выполнять её обновления. Это обсуждение также содержит использование в QRadar лицензий.