Глава 6. Лексический и синтаксический разбор при помощи синтаксических деревьев
Содержание
В нашей предыдущей главе вы исследовали как считывается текст Python из различных источников. Затем его требуется преобразовать в некую структуру, которую способен применять компилятор.
Этот этап носит название синтаксического разбора (parsing):
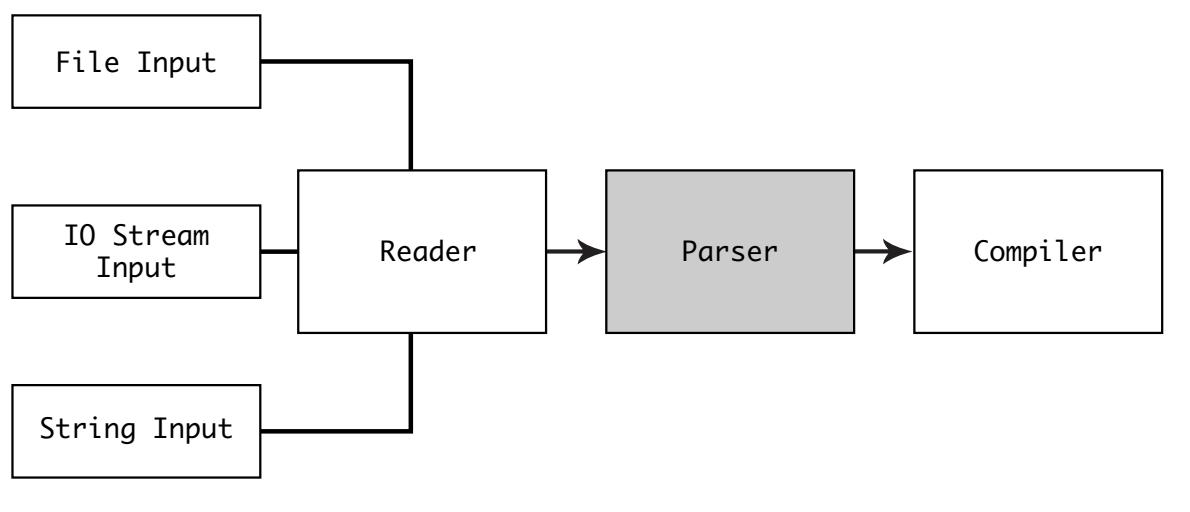
В данной главе вы исследуете как для вашего текста выполняется синтаксический разбор на логические структуры, которые могут компилироваться.
Для синтаксического анализа в CPython имеются две структуры, а именно, concrete syntax tree (CST, дерево реального синтаксиса) и abstract syntax tree (AST, абстрактное синтаксическое дерево)

Процесс синтаксического разбора обладает двумя частями:
-
Создание дерева реального синтаксиса при помощи синтаксического анализатора лексем (parser-tokenizer) или лексического анализатора (lexer)
-
Создание абстрактного синтаксического дерева из реального синтаксического дерева с применением синтаксического разбора (parser)
Эти два этапа являются общей парадигмой, применяемой во многих языках программирования.
Дерево реального синтаксиса (CST, concrete syntax tree), порой именуемое parse tree (деревом синтаксического анализа) является некой упорядоченной, направленной структурой, которая представляет код в контекстно- независимой (контекстно- свободной) грамматике.
CST создаётся из tokenizer (механизма определения лексем - токенов, символов) и parser (синтаксического анализатора). Генератор синтаксического анализатора вы изучили в Главе 4, Язык и грамматика Python. Выводом генератора синтаксического анализа является таблица синтаксического анализа DFA (deterministic finite automaton, конечно- детерменированного автомата), описывающего все возможные состояния контекстно- независимой грамматики.
![[Совет]](/common/images/admon/tip.png) | Смотри также |
|---|---|
|
Первоначальный автор Python, Гвидо ван Россум, разработал некую контекстную грамматику для применения в CPython 3.9, в качестве альтернативы LL(1), грамматике, применявшейся в предварительных версиях CPython. Эта новая грамматика носит название PEG (parser expression grammar, грамматика выражений синтаксического анализа). Такой синтаксический анализатор PEG стал доступным в Python 3.9. В Python 3.10 старая грамматика LL(1) будет удалена окончательно. |
В Главе 4, Язык и грамматика Python вы изучили некоторые типы выражений, например,
if_stmt и with_stmt. Наше реальное синтаксическое дерево (CST)
представляет подобные if_stmt символы, как ветвление с лексемами и терминальными символами в качестве
листовых узлов.
К примеру, наше арифместическое выражение a + 1 превращается в такое реальное синтаксическое дерево
(CST):
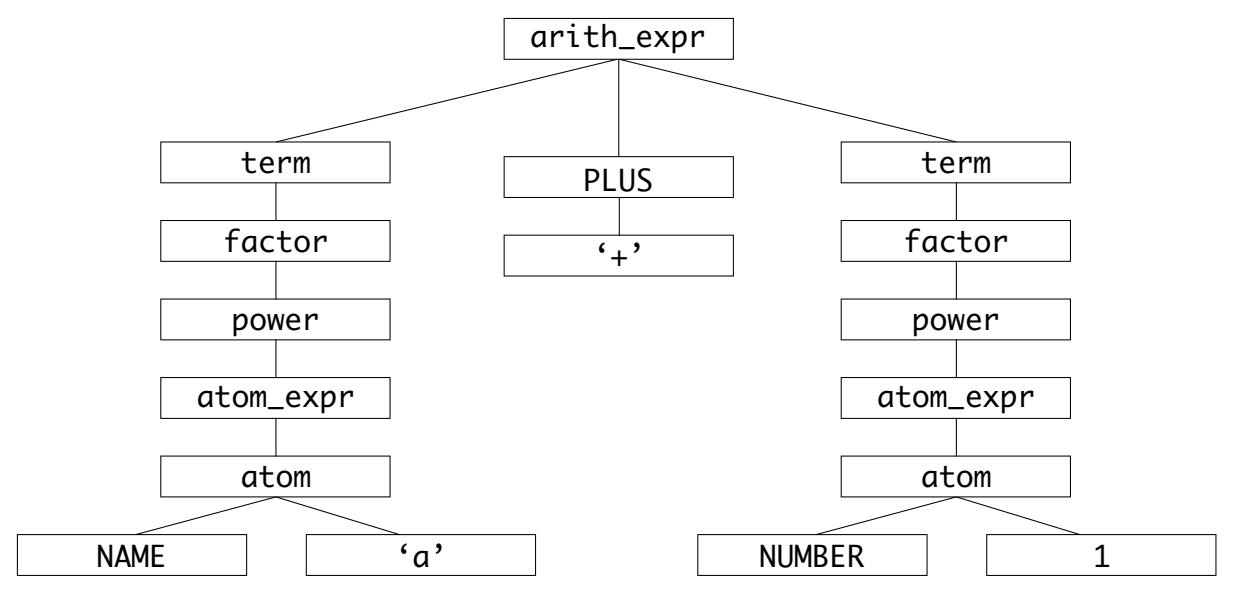
Некое арифметическое выражение представляется здесь с тремя основными ветвями: левой ветвью, ветвью оператора и правой ветвью.
Наш синтаксический анализатор проходит в итерациях по лексемам из некого потока на входе и устанавливает их соответствие относительно всех возможных состояний и лексем в своей грамматике для построеня реального синтаксического дерева (CST).
Все отражённые в нашем показаном выше реальном синтаксическом дереве символы определены в
Grammar/Grammar:
arith_expr: term (('+'|'-') term)*
term: factor (('*'|'@'|'/'|'%'|'//') factor)*
factor: ('+'|'-'|'~') factor | power
power: atom_expr ['**' factor]
atom_expr: [AWAIT] atom trailer*
atom: ('(' [yield_expr|testlist_comp] ')' |
'[' [testlist_comp] ']' |
'{' [dictorsetmaker] '}' |
NAME | NUMBER | STRING+ | '...' | 'None' | 'True' | 'False')
Все лексемы определены в Grammar/Tokens:
ENDMARKER
NAME
NUMBER
STRING
NEWLINE
INDENT
DEDENT
LPAR '('
RPAR ')'
LSQB '['
RSQB ']'
COLON ':'
COMMA ','
SEMI ';'
PLUS '+'
MINUS '-'
STAR '*'
...
Токен NAME представляет собой название некой переменной, функции, класса или модуля. Синтаксис
Python не позволяет чтобы NAME был одним из зарезервированных ключевых слов, как это имеется в случае
await и async или численного либо иного иного литерального
типа.
Например, если вы попытаетесь определить некую функцию с названием 1, тогда Python возбудит
некую SyntaxError:
>>> def 1():
File "<stdin>", line 1
def 1():
^
SyntaxError: invalid syntax
Токен NAME это определённый тип лексемы для представления одного из множества численных выражений
Python. Python обладает особой грамматикой для чисел, включающей следующее:Code
-
Восьмеричные значения, такие как
0o20 -
Шестнадцателичные значения, такие как
0x10 -
Двоичные значения, такие как
0b10000 -
Комплексные числа, такие как
10j -
Числа с плавающей запятой, такие как
1.01 -
С подчёркиванием в качестве разделителя, такие как
1_000_000
Вы можете увидеть скомпилированные символы и лексемы при помощи модулей symbol и
token в Python:
$ ./python
>>> import symbol
>>> dir(symbol)
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__',
'__name__', '__package__', '__spec__', '_main', '_name', '_value',
'and_expr', 'and_test', 'annassign', 'arglist', 'argument',
'arith_expr', 'assert_stmt', 'async_funcdef', 'async_stmt',
'atom', 'atom_expr',
...
>>> import token
>>> dir(token)
['AMPER', 'AMPEREQUAL', 'AT', 'ATEQUAL', 'CIRCUMFLEX',
'CIRCUMFLEXEQUAL', 'COLON', 'COMMA', 'COMMENT', 'DEDENT', 'DOT',
'DOUBLESLASH', 'DOUBLESLASHEQUAL', 'DOUBLESTAR', 'DOUBLESTAREQUAL',
...
Языки программирования обладают различными реализациями лексических анализаторов. Некоторые используют генераторы лексического анализа в качестве дополнения к генератору синтаксического анализа.
CPython обладает модулем синтаксического анализа и разбиения на лексемы (parser-tokenizer), написанном на C.
Вот связанные с модулем синтаксического анализа и разбиения на лексемы:
| Файл | Назначение |
|---|---|
|
Исполняет синтаксический анализ и компиляцию из входных данных |
|
Реализация синтаксического анализа и разбиения на лексемы |
|
Реализация разбиения на лексемы |
|
Файл заголовков для реализация разбиения на лексемы, который описывает такие модели данных как состояние лексемы |
|
Определение типов лексем, вырабатываемое
|
|
Взаимодействие и макросы узла дерева синтаксического анализа для разбиения на лексемы |
Точка входа для синтаксического анализа и разбиения на лексемы, PyParser_ASTFromFileObject(), получает дескриптор файла, флаги компиляции и некий экземпляр PyArena,
после чего преобразует соответствующий файловый объект в модуль.
Имеются два этапа:
-
Преобразование в реальное синтаксическое дерево (CRT) при помощи PyParser_ParseFileObject().
-
Преобразование в абстрактное синтаксическое дерево (AST) или модуль посредством функции AST PyAST_FromNodeObject().
Функция PyParser_ParseFileObject() обладает двумя важными задачами:
-
Создание экземпляра состояния разбиения на лексемы,
tok_state, при помощи PyTokenizer_FromFile() -
Преобразование лексем в реальное синтаксическое дерево (CST, список узлов) посредством parsetok()
Имеющийся синтаксический анализатор и механизм разбиения на лексемы получает текстовые входные данные и выполняет разбиение на лексемы, а также синтаксический анализ в цикле до тех пор, пока пока его курсор не достигнет самого конца этого текста (или не произойдёт синтаксическая ошибка).
Перед исполнением сам синтаксический анализатор и механизм разбиения на лексемы устанавливает tok_state,
временную структуру данных для хранения всех состояний, вырабатываемых разбиением на лексемы. Конкретное состояние разбиения на лексемы
содержит такие сведения, как текущие положения курсора и строки.
Для получения следующей лексемы синтаксический анализатор - механизм разбиения на лексемы вызывает tok_get().
Синтаксический анализатор - механизм разбиения на лексемы передаёт значение идентификатора результирующей лексемы в свой синтаксический
анализатор, который использует конечно- детерминированный автомат (DFA) генератора синтаксического анализа для создания некого узла в
соответствующем дереве реального синтаксиса.
tok_get() является одной из наиболее сложных функцмй во всём базовом коде CPython. Она обладает более чем 640 строками и содержит десятки наследований с конечными вариантами, новыми функциональными возможностями языка, а также синтаксисисом.
Сам процесс вызова разбиения на лексемы и синтаксического анализа в цикле можно проиллюстрировать следующим образом:
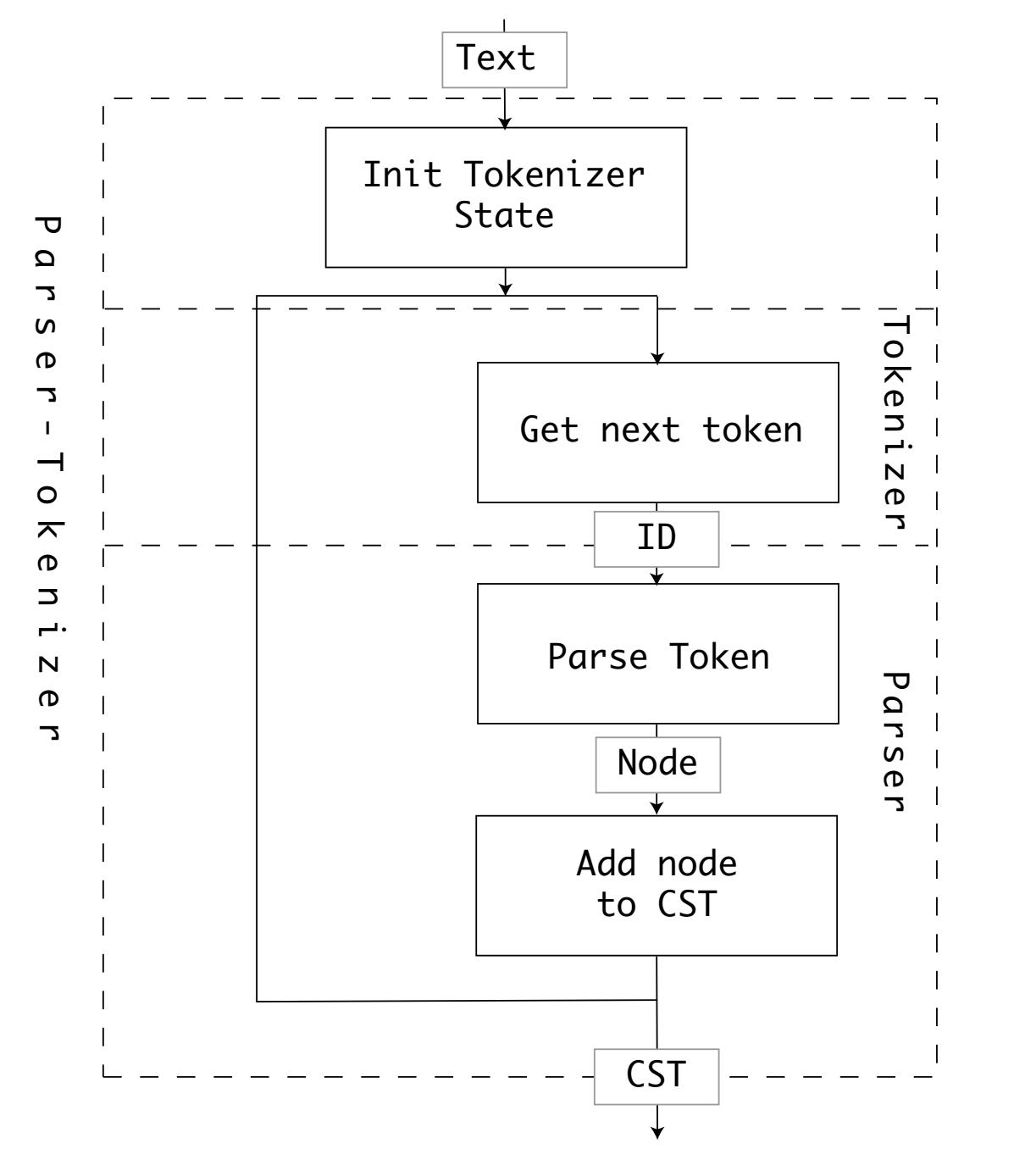
Возвращаемый PyParser_ParseFileObject() корневой node дерева реального синтаксиса (CST) является
существенным для следующего этапа, преобразования CST в дерево абстрактного синтаксиса (AST).
Значение типа узла определяется в Include/node.h:
typedef struct _node {
short n_type;
char *n_str;
int n_lineno;
int n_col_offset;
int n_nchildren;
struct _node *n_child;
int n_end_lineno;
int n_end_col_offset;
} node;
Поскольку дерево реального синтаксиса (CST) является деревом синтаксиса, идентификаторами лексем и символами, его компилятору было бы трудно принимать быстрые решения на основе Python.
Прежде чем выполнить безусловный переход в соответствующее дерево абстрактного синтаксиса (AST), существует способ получения вывода с
этой стадии синтаксического анализа. CPython обладает стандартным библиотечным модулем, parser,
который выставляет необходимые функции C с неким API Python.
Его вывод будет в численном виде, с применением номеров лексем и символов , выработанных на этапе
make regen-grammar и хранимых в
Include/token.h:
>>> from pprint import pprint
>>> import parser
>>> st = parser.expr('a + 1')
>>> pprint(parser.st2list(st))
[258,
[332,
[306,
[310,
[311,
[312,
[313,
[316,
[317,
[318,
[319,
[320,
[321, [322, [323, [324, [325, [1, 'a']]]]]],
[14, '+'],
[321, [322, [323, [324, [325, [2, '1']]]]]]]]]]]]]]]]],
[4, ''],
[0, '']]
Чтобы быстрее с этим разобраться, вы можете взять все эти числа из своих модулей symbol и
token, поместить их в некий словарь и рекурсивно заменять эти значения в своём выводе
parser.st2list() значениями имён соответствующих лексем,
cpython-book-samples/21/lex.py:
import symbol
import token
import parser
def lex(expression):
symbols = {v: k for k, v in symbol.__dict__.items()
if isinstance(v, int)}
tokens = {v: k for k, v in token.__dict__.items()
if isinstance(v, int)}
lexicon = {**symbols, **tokens}
st = parser.expr(expression)
st_list = parser.st2list(st)
def replace(l: list):
r = []
for i in l:
if isinstance(i, list):
r.append(replace(i))
else:
if i in lexicon:
r.append(lexicon[i])
else:
r.append(i)
return r
return replace(st_list)
Чтобы представить как это выглядит в дереве синтаксического анализа, вы можете выполнить lex() с
простым выражением, скажем, a + 1:
>>> from pprint import pprint
>>> pprint(lex('a + 1'))
['eval_input',
['testlist',
['test',
['or_test',
['and_test',
['not_test',
['comparison',
['expr',
['xor_expr',
['and_expr',
['shift_expr',
['arith_expr',
['term',
['factor', ['power', ['atom_expr', ['atom',
['NAME', 'a']]]]]],
['PLUS', '+'],
['term',
['factor',
['power', ['atom_expr', ['atom', ['NUMBER',
'1']]]]]]]]]]]]]]]]],
['NEWLINE', ''],
['ENDMARKER', '']]
В данном выводе вы можете наблюдать имеющиеся символы в нижнем регистре, например, 'arith_expr', а
значения лексем в верхнем регистре, такие как 'NUMBER'.
Следующий этап в интерпретаторе CPython состоит в преобразовании выработанное синтаксическим анализатором реальное дерево синтаксиса (CST) в нечто более логичное, что можно исполнить.
Деревья реального синтаксиса через-чур буквальное представление текста из файла кода. На данном этапе это может быть множество языков программирования. Основная грамматическая структура Python прошла интерпретацию, однако вы не могли применять CST для определения функций, областей действий, циклов или каких- либо основных функциональных возможностей языка программирования Python.
Прежде чем компилировать код, реальное дерево синтаксиса (CST) надлежит преобразовать в структуру более высокого уровня, которая представляет реальные конструкции Python. Такая структура является представлением CST, носящим название абстрактного синтаксического дерева (AST, abstract syntax tree).
В качестве примера рассмотрим бинарную операцию в AST с названием BinOp и определяемую как некий тип
операции. Она обладает тремя компонентами:
-
left: Левая часть данной операции -
op: сам оператор, например,+,-или* -
right: правая часть операции
Соответствующее дерево абстрактного синтаксиса (AST) a + 1 может быть представлено так:
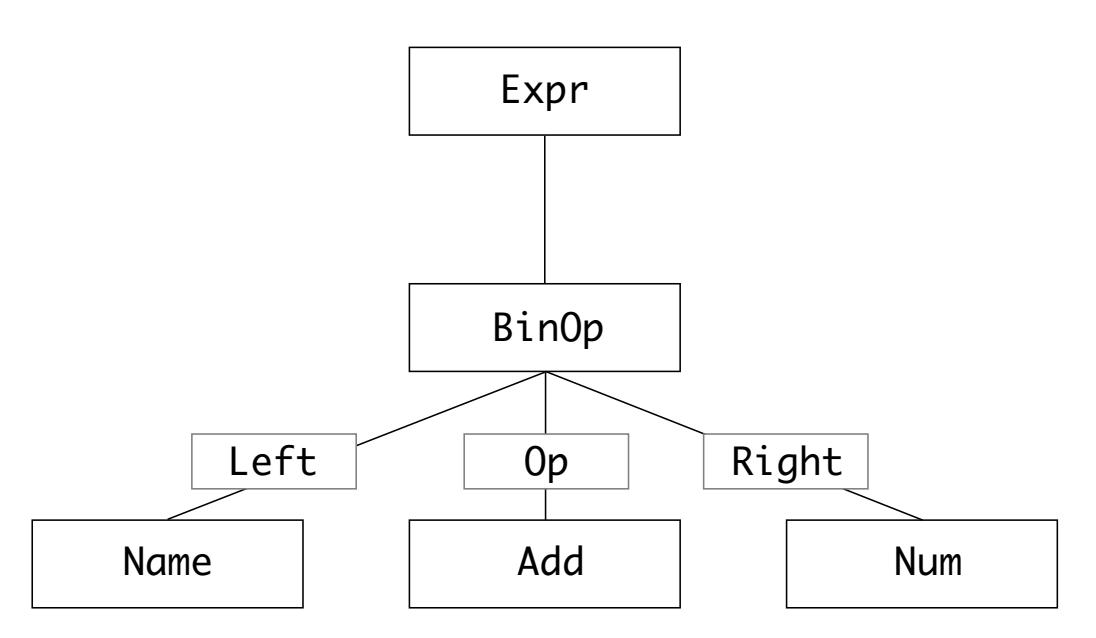
Деревья абстрактного синтаксиса производятся синтаксическим анализатором CPython, но вы также можете генерировать их из кода Python при
помощи модуля ast из стандартной библиотеки.
Прежде чем окунуться в собственно реализацию AST, было бы полезным разобраться с тем, как AST выглядит в качестве базового фрагмента кода Python.
Ниже приводятся исходные файлы, связанные с деревьями абстрактного синтаксиса:
| Файл | Назначение |
|---|---|
|
Определение типов AST, вырабатываемое
|
|
Список типов и свойств узлов в специфичным для этой области языке, ASDL 5 |
|
Реализация AST |
Instaviz это пакет Python, написанный для его применения в этой книге. Он отображает AST и скомпилированный код в неком веб- интерфейсе.
Для установки Instaviz, выполните её из pip для пакета instaviz:
$ pip install instaviz
Затем откройте REPL, запустив python в своей командной строке без аргументов.
Наша функция instaviz.show() получает отдельный аргумент с типом code
object. Вы рассмотрите объект кода в нашей следующей главе. Для данного примера определим некую функцию и воспользуемся названием этой
функции в качестве значения своего аргумента:
$ python
>>> import instaviz
>>> def example():
a = 1
b = a + 1
return b
>>> instaviz.show(example)
Вы обнаружите в своей командной строке что был запущен веб сервер с портом 8080. Если вы используете
этот порт, вы можете изменить его, вызвав instaviz.show (например,
port=9090) или с иным номером порта.
В своём браузере вы сможете увидеть подробный разбор по частям своей функции:
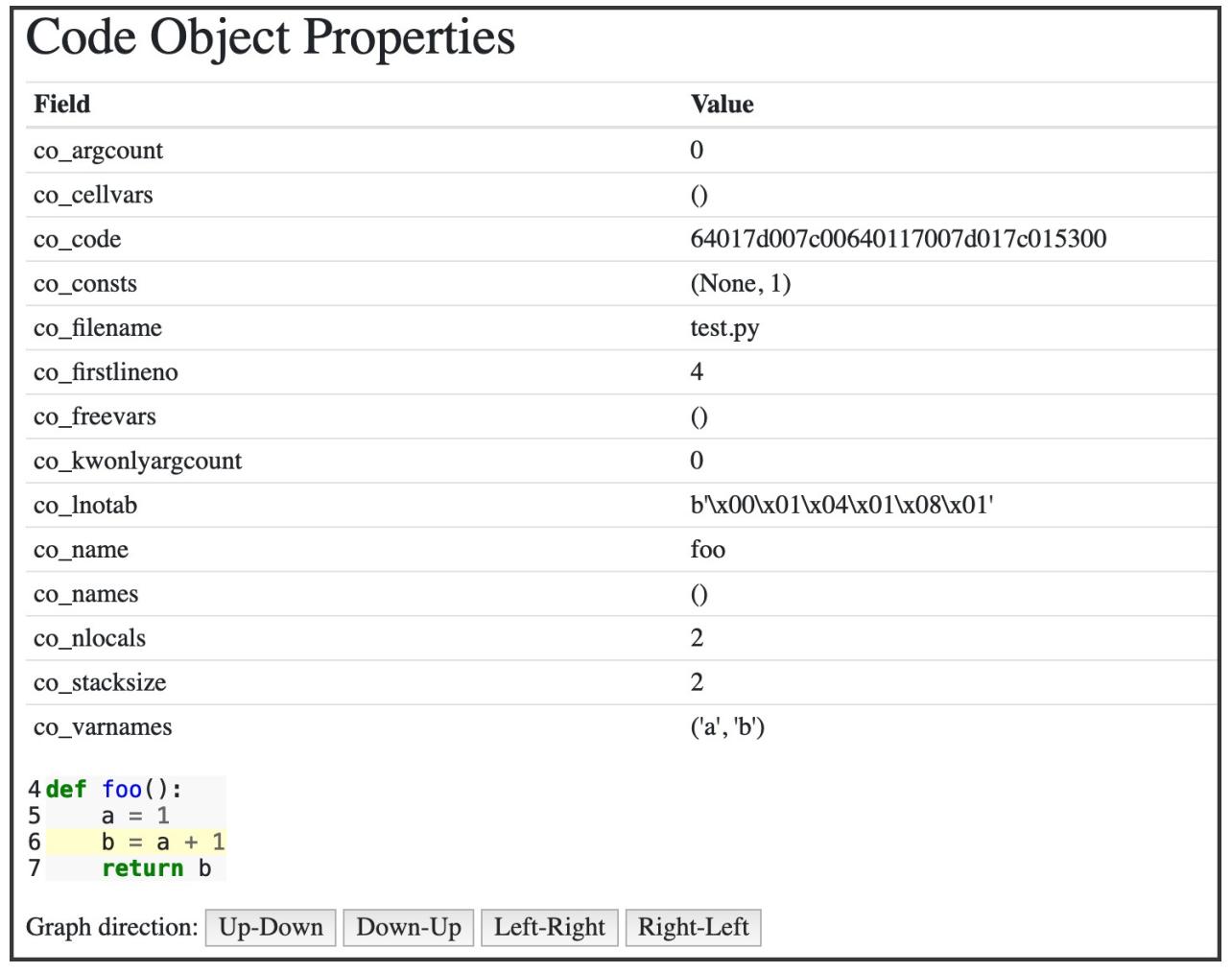
График внизу слева это та функция, которую вы определили в своём REPL, представленное в качестве дерева абстрактного синтаксиса. Каждый узел в
этом дереве представлен неким типом AST. Их все можно найти в модуле ast и унаследовать из
_ast.AST.
Некоторые из узлов обладают свойствами, которые связывают их с дочерними узлами, в отличии от дерева реального синтаксиса (CST), которое обладало общим свойством дочернего узла.
Например, если вы кликните по своему узлу Assign в центре, тогда он будет связан со строкой
b = a + 1:
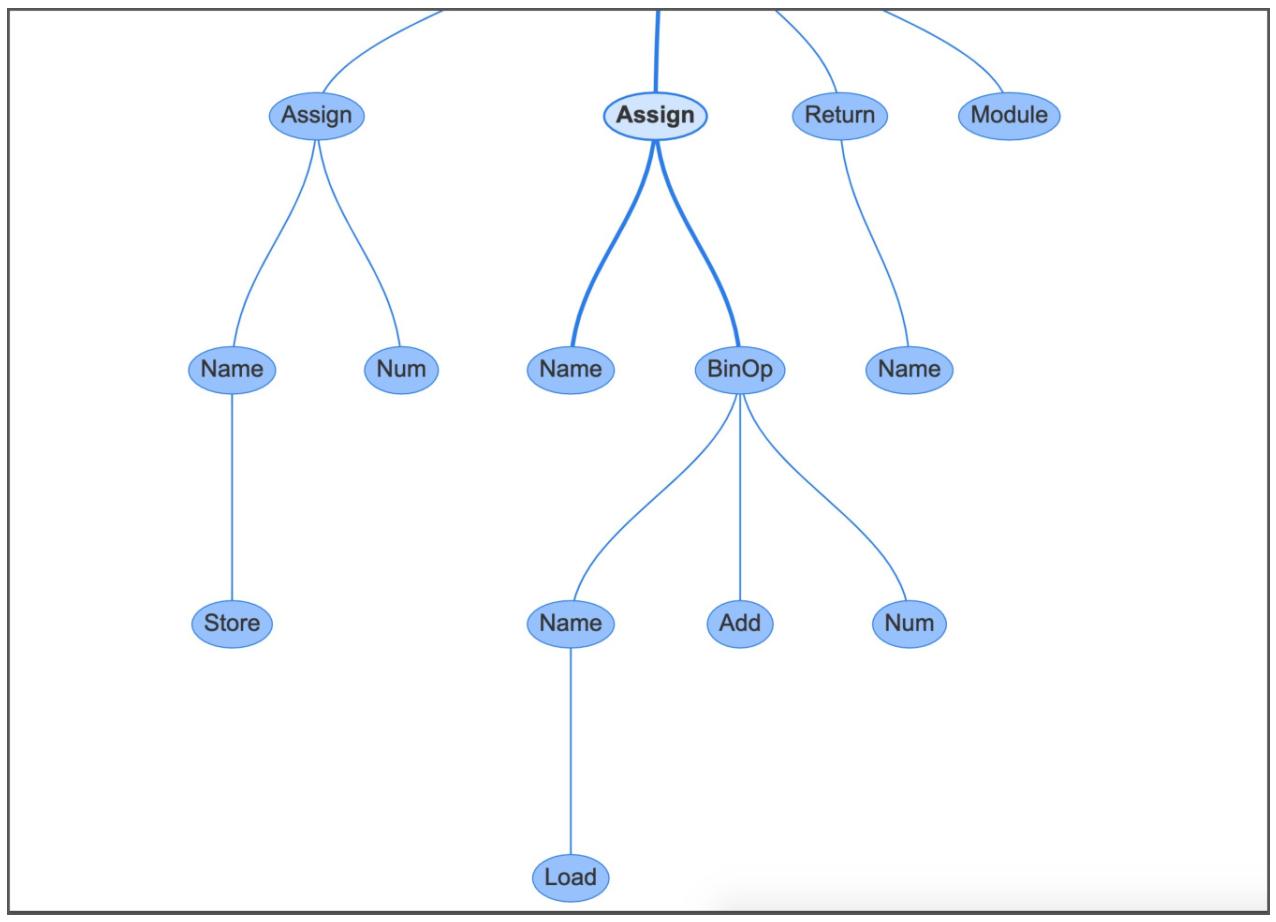
Этот узел Assign обладает двумя свойствами:
-
targetsэто список подлежащих назначению имён. Это именно список, так как вы можете выполнять назначение множеству переменных при помощи единственного выражения, применяя распаковку. -
valueэто подлежащее назначению значение, которое в данном случае является операторомBinOp, а именноa + 1.
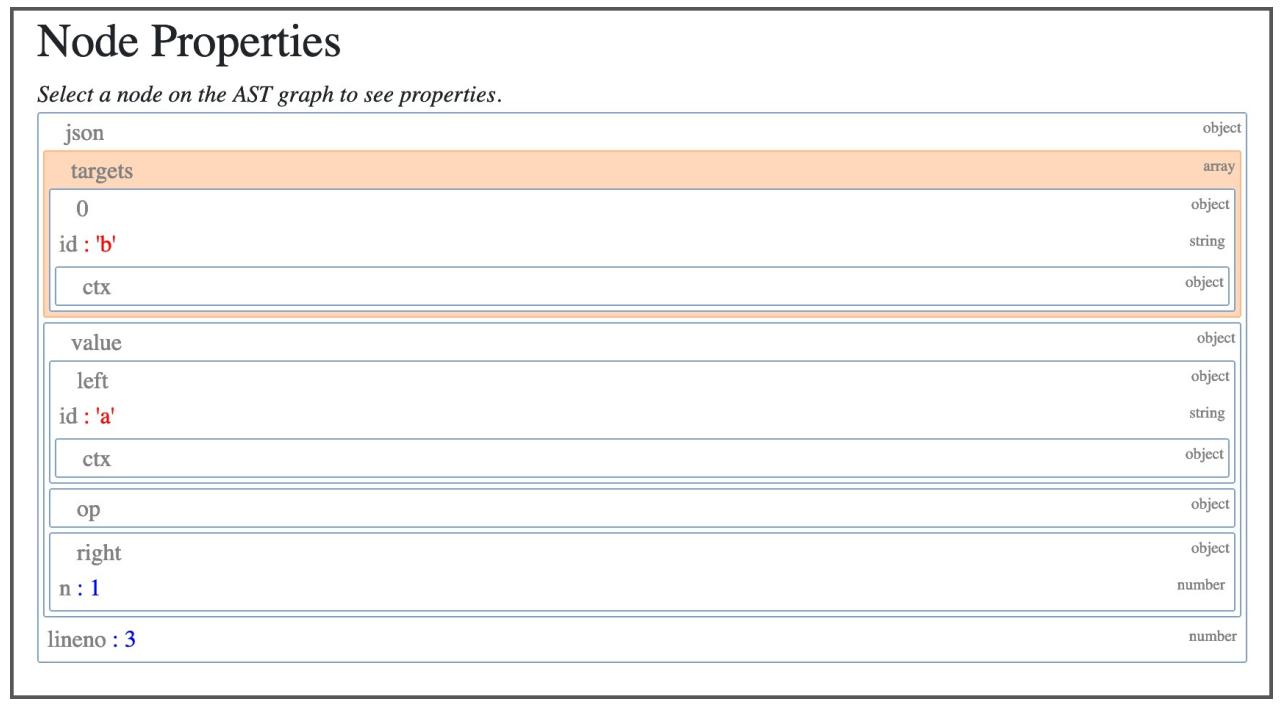
Когда вы кликните по оператору BinOp, будут отражены относящиеся к нему свойства:
-
leftнаходящийся слева от этого оператора узел -
opсобственно оператор, в нашем случае узел является операторомAdd(+) для сложения. -
rightнаходящийся справа от этого оператора узел
Компиляция AST в C является непростой задачей. Соответствующий модуль
Python ast.c имеет более 5 000 строк кода.
Существует несколько точек входа, формирующих общедоступную часть API дерева абстрактного синтаксиса (AST). Этот API AST получает некий узел дерева (реального синтаксиса, CST), название файла, значения флагов компиляции и область хранения в памяти.
Получаемым в результате типом является mod_ty, представляющий модуль Python, определяемый в
Include Python-ast.h.
mod_ty является структурой контейнера для одного из четырёх типов в Python:
-
Module -
Interactive -
Expression -
FunctionType
Все эти типы перечислены в Parser/Python.asdl. Вы обнаружите
значение типов модулей, типов операторов (предложений), типов выражений, операций (операторов) и понимание того, что все они определены в
этом файле.
Значения названий типов в Parser/Python.asdl соотносятся с теми
классами, которые выработаны деревом абстрактного типа (AST) и с теми же самыми классами, получившими свои названия в модуле
ast стандартной библиотеки:
-- ASDL's 4 builtin types are:
-- identifier, int, string, constant
module Python
{
mod = Module(stmt* body, type_ignore *type_ignores)
| Interactive(stmt* body)
| Expression(expr body)
| FunctionType(expr* argtypes, expr returns)
Модуль ast импортирует Include Python-ast.h,
файл, автономно создаваемый из Parser/Python.asdl при повторной генерации
грамматики. Все параметры и названия в Include Python-ast.h напрямую
коррелируют с теми, что определены в Parser/Python.asdl.
Тип mod_ty вырабатывается в Include Python-ast.h
из определения Module в
Parser/Python.asdl:
enum _mod_kind {Module_kind=1, Interactive_kind=2, Expression_kind=3,
FunctionType_kind=4};
struct _mod {
enum _mod_kind kind;
union {
struct {
asdl_seq *body;
asdl_seq *type_ignores;
} Module;
struct {
asdl_seq *body;
} Interactive;
struct {
expr_ty body;
} Expression;
struct {
asdl_seq *argtypes;
expr_ty returns;
} FunctionType;
} v;
};
Соответствующие файл заголовка и структур C применяются для того, чтобы программа
Python/ast.c могла быстро выработать необходимые структуры с
указателями на относящиеся к делу данные.
Сама точка входа AST, PyAST_FromNodeObject(), по существу, некий оператор switch по результатам от
TYPE(n). TYPE() это макро, применяемое AST для определения
значения типа узлов в дереве реального синтаксиса. Результатом этого TYPE() будет либо тип некого
символа, либо лексемы.
При запуске в корневом узле он может быть только одним из типов модуля, определённого как Module,
Interactive, Expression или
FunctionType:
-
Для
file_inputзначением типа должен бытьModule. -
Для
eval_input, такого как из REPL, значением типа должен бытьExpression
Для каждого типа оператора в Python/ast.c существует соответственная
функция C ast_for_xxx, которая будет смотреть за узлами реального синтаксического дерева для завершения
свойств такого оператора.
Одним из простейших примеров является оператор возведения в степень, например, 2 ** 4, или 2 в 4 степени.
ast_for_power() возвратит некую
BinOp с оператором Pow (возведение в степень), причём с левой
стороны как e (2), а с правой стороны как f (4), строка 2717
Python/ast.c :
static expr_ty
ast_for_power(struct compiling *c, const node *n)
{
/* power: atom trailer* ('**' factor)*
*/
expr_ty e;
REQ(n, power);
e = ast_for_atom_expr(c, CHILD(n, 0));
if (!e)
return NULL;
if (NCH(n) == 1)
return e;
if (TYPE(CHILD(n, NCH(n) - 1)) == factor) {
expr_ty f = ast_for_expr(c, CHILD(n, NCH(n) - 1));
if (!f)
return NULL;
e = BinOp(e, Pow, f, LINENO(n), n->n_col_offset,
n->n_end_lineno, n->n_end_col_offset, c->c_arena);
}
return e;
}
Вы можете увидеть результаты этого, отправив короткую функцию в модуль instaviz:
>>> def foo():
2**4
>>> import instaviz
>>> instaviz.show(foo)
Вы также можете увидеть соответствующие свойства в своём интерфейсе пользователя:

Итак, суммируя, всякий тип оператора и выражения обладают соответствующей функцией ast_for_*()
для их создания. Их аргументы определены в Parser/Python.asdl и
выставляются через модуль ast в стандартной библиотеке.
Если некое выражение или оператор (предложение) обладают потомками, тогда они вызывают соответствующую дочернюю функцию
ast_for_*() при обходе вглубь.
Ниже приводятся некоторые ключевые для данной главы термины:
-
Abstract syntax tree (AST, дерево абстрактного синтаксиса): Некое контекстное дерево представления грамматики и синтаксиса Python
-
Concrete syntax tree (CST, дерево реального синтаксиса): Дерево представления лексем и символов без контекста
-
Parse tree (Дерево синтаксического анализа): Другой термин обозначения дерева реального синтаксиса
-
Token: Лексема, некий тип символа, например,
+ -
Tokenization (разбор лексем): Процесс преобразования текста в лексемы
-
Parsing (синтаксический разбор): Процесс преобразования текста в CST или AST
Для сведение всего воедино, вы можете добавить некий фрагмент синтаксиса в язык Python и повторно скомпилировать CPython чтобы разобраться с этим.
Некое выражение сравнения сопоставляет два или более значений:
>>> a = 1
>>> b = 2
>>> a == b
False
Применяемые в выражениях сравнения операторы носят название операторов сравненияю Вот некоторые из тех, с которыми вы знакомы:
-
Меньше чем:
< -
Больше чем:
> -
Равенство:
== -
Не равенство:
!=
|
| Смотри также |
|---|---|
|
Для Python 2.1 в PEP 207 в его модели данных были предложены богатые сравнения. Этот PEP содержал контекст, историю и выравнивание для индивидуальных типов Python для реализации методов сравнения. |
Теперь давайте добавим другой оператор сравнения с названием почти равны, который
будет представляться как ~=. Он будет обладать следующим поведением:
-
Если вы сравниваете число с плавающей запятой и целое, тогда он выполнит приведение числа с плавающей запятой к целому и проведёт сравнение с целым для получения результата.
-
Когда вы сопоставляете два целых, будут применяться обычные операторы равенства.
В REPL этот новый оператор должен возвращать следующее:
>>> 1 ~= 1
True
>>> 1 ~= 1.0
True
>>> 1 ~= 1.01
True
>>> 1 ~= 1.9
False
Для добавления нового оператора вам вначале следует обновить свою грамматику CPython. В
Grammar/python.gram операторы сравнения определяются как
символ comp_op:
comparison[expr_ty]:
| a=bitwise_or b=compare_op_bitwise_or_pair+ ...
| bitwise_or
compare_op_bitwise_or_pair[CmpopExprPair*]:
| eq_bitwise_or
| noteq_bitwise_or
| lte_bitwise_or
| lt_bitwise_or
| gte_bitwise_or
| gt_bitwise_or
| notin_bitwise_or
| in_bitwise_or
| isnot_bitwise_or
| is_bitwise_or
eq_bitwise_or[CmpopExprPair*]: '==' a=bitwise_or ...
noteq_bitwise_or[CmpopExprPair*]:
| (tok='!=' {_PyPegen_check_barry_as_flufl(p) ? NULL : tok}) ...
lte_bitwise_or[CmpopExprPair*]: '<=' a=bitwise_or ...
lt_bitwise_or[CmpopExprPair*]: '<' a=bitwise_or ...
gte_bitwise_or[CmpopExprPair*]: '>=' a=bitwise_or ...
gt_bitwise_or[CmpopExprPair*]: '>' a=bitwise_or ...
notin_bitwise_or[CmpopExprPair*]: 'not' 'in' a=bitwise_or ...
in_bitwise_or[CmpopExprPair*]: 'in' a=bitwise_or ...
isnot_bitwise_or[CmpopExprPair*]: 'is' 'not' a=bitwise_or ...
is_bitwise_or[CmpopExprPair*]: 'is' a=bitwise_or ...
Изменим выражение compare_op_bitwise_or_pair чтобы разрешить новую пару
ale_bitwise_or:
compare_op_bitwise_or_pair[CmpopExprPair*]:
| eq_bitwise_or
...
| ale_bitwise_or
Определим новое выражение ale_bitwise_or под уже имеющимся выражением
is_bitwise_or:
...
is_bitwise_or[CmpopExprPair*]: 'is' a=bitwise_or ...
ale_bitwise_or[CmpopExprPair*]: '~=' a=bitwise_or
{ _PyPegen_cmpop_expr_pair(p, AlE, a) }
Этот новый тип определяет именованное выражение, ale_bitwise_or, которое содержит терминальный символ
'~='.
Этот вызов функции _PyPegen_cmpop_expr_pair(p, AlE, a) является выражением для получения из дерева
абстрактного синтаксиса (AST) узла cmpop. Его типом является
AlE для Almost
Equal.
Затем добавьте в Grammar/Tokens лексему:
ATEQUAL '@='
RARROW '->'
ELLIPSIS '...'
COLONEQUAL ':='
# Add this line
ALMOSTEQUAL '~='
Для обновления имеющейся грамматики и лексем в C вам требуется повторно сгенерировать соответствующие заголовки.
В macOS или Linux воспользуйтесь следующей командой:
$ make regen-token regen-pegen
В Windows, находясь в каталоге PCBuild воспользуйтесь такой командой:
> build.bat --regen
Эти шаги автоматически обновят ваш механизм разбора лексем. Например, откройте исходный код Parser/token.c
и вы обнаружите как изменился выбор (case) в функции PyToken_TwoChars():
case '~':
switch (c2) {
case '=': return ALMOSTEQUAL;
}
break;
}
Когда вы повторно скомпилируете CPython на этом этапе и откроете REPL, тогда вы обнаружите, что ваш механизм распознования лексем успешно распознает эту лексему, однако дерево абстрактного синтаксиса не знает как его обрабатывать:
$ ./python
>>> 1 ~= 2
SystemError: invalid comp_op: ~=
Эта исключительная ситуация возбуждена ast_for_comp_op() внутри Python/ast.c потому как она
не распознала ALMOSTEQUAL как допустимый оператор для предложения сравнения.
Compare это тип выражения, определённый в Parser/Python.asdl.
Он обладает свойствами для своего левого выражения; список операторов с названием ops, а также
список выражений для сравнения с названием comparators:
Compare(expr left, cmpop* ops, expr* comparators)
Внутри определения Compare имеется справка для перечисления
cmpop:
cmpop = Eq | NotEq | Lt | LtE | Gt | GtE | Is | IsNot | In | NotIn
Это перечень возможных листьевых узлов AST, которые способны действовать как операторы сравнения. Мы пропустили свою и нужно её
добавить. Обновите этот список вариантов, чтобы он включал и новую, AlE:
cmpop = Eq | NotEq | Lt | LtE | Gt | GtE | Is | IsNot | In | NotIn | AlE
Затем снова повторно сгенерируйте дерево абстрактного синтаксиса чтобы обновить файлы заголовков AST:
$ make regen-ast
Это обновит перечисление нашего оператора сравнения (_cmpop) внутри
Include/Python-ast.h, чтобы он включал и возможность
AlE:
typedef enum _cmpop { Eq=1, NotEq=2, Lt=3, LtE=4, Gt=5, GtE=6, Is=7,
IsNot=8, In=9, NotIn=10, AlE=11 } cmpop_ty;
Наше дерево абстрактного синтаксиса не знает что лексема ALMOSTEQUAL эквивалентна оператору
сравнения AlE. Поэтому нам необходимо обновить свой код C для AST.
Переместитесь к ast_for_comp_op() из
Python/ast.c. Отыщите предложение переключателя для лексем этого
оператора. Это вернёт вам одно из перечисляемых значений _cmpop.
Добавьте две строки чтобы отлавливать лексему ALMOSTEQUAL и возвращать оператор сравнения
AlE, строка 1222 в Python/ast.c:
static cmpop_ty
ast_for_comp_op(struct compiling *c, const node *n)
{
/* comp_op: '≪'|'>'|'=='|'>='|'≪='|'!='|'in'|'not' 'in'|'is'
|'is' 'not'
*/
REQ(n, comp_op);
if (NCH(n) == 1) {
n = CHILD(n, 0);
switch (TYPE(n)) {
case LESS:
return Lt;
case GREATER:
return Gt;
case ALMOSTEQUAL: // Add this line to catch the token
return AlE; // And this one to return the AST node
На этом этапе наши механизм разбора лексем и его дерево абстрактного синтаксиса способны выполнять синтаксический анализ данного кода,
однако наш компилятор не может знать как обрабатывать такой оператор. Чтобы проверить представительство нашего AST воспользуйтесь
ast.parse() и изучите первый оператор в полученном выражении:
>>> import ast
>>> m = ast.parse('1 ~= 2')
>>> m.body[0].value.ops[0]
<_ast.AlE object at 0x10a8d7ee0>
Это некий экземпляр нашего типа оператора AlE, а потому наше дерево абстрактного синтаксиса
правильно провело синтаксический разбор кода.
В своей следующей главе вы изучите как работает компилятор CPython и повторно посетите наш оператор почти- равно для окончательной сборки его поведения.
Многосторонность и выполнение API нижнего уровня CPythonпревращает его в идеального претендента на встроенный механизм сценариев. Вы обнаружите, что CPython применяется во множестве приложений пользовательского интерфейса, например, в проектировании игр, 3D графике, и автоматизации систем.
Его процесс интерпретации гибкий и действенный. Теперь, когда вы понимаете то, как он работает, вы готовы разобраться с компилятором.