Глава 9. Управление памятью
Содержание
- Глава 9. Управление памятью
- Выделение памяти в C
- Проектирование системы управления памятью Python
- Распределитель памяти CPython
- Области распределителя памяти объекта и PyMem
- Область распределителя сырой памяти
- Персональные распределители доменов
- Персональные уборщики выделенной памяти
- Арена памяти PyArena
- Подсчёт ссылок
- Сборка мусора
- Выводы
Двумя наиболее важными частями вашего компьютера выступают его оперативная память и ЦПУ. Ни одна из них не может работать без другой. Они должны использоваться должным образом и они должны быть действенными.
При проектировании языка программирования авторам приходится принимать решение о том как пользователь обязан управлять памятью компьютера. Существует множество вариантов, в зависимости от того насколько простым требуется интерфейс для авторов, желают ли они чтобы язык был переносимым между платформами, а также оценивают ли они производительность выше стабильности.
Авторы Python предприняли эти решения для вас, а также оставили для вас некоторые дополнительные возможности чтобы вы могли принимать свои решения.
В этой главе вы исследуете то как C управляет памятью, поскольку CPython написан на C. Вы взглянете на две критически важных стороны управления памятью в Python:
-
Подсчёт ссылок
-
Сборка мусора
К концу этой главы вы получите понимание того, как CPython выделяет память в своей операционной системе, как выделяется и освобождается память объектов и как CPython управляет утечками памяти.
{Прим. пер.: сборка мусора и подсчёт ссылок предоставляют элегантное, но весьма затратное решение (как в отношении ресурсов, так и в отношении времени исполнения), существует подход к ускорению кода без применения сборки мусора в программах на Rust, которые способны интегрироваться с кодом Python, что описывается в нашем переводе Ускоряем ваш Python при помощи Rust Максвелл Флиттон, Packt, 2022.}
В C переменные, прежде чем они смогут применяться, должны обладать своей памятью, выделенной из операционной системы. В C существует три механизма выделения памяти:
-
Статическое выделение памяти: Требования к памяти вычисляются во время калькуляции и выделяются самим исполняемым кодом после его запуска.
-
Автоматическое выделение памяти: Требования к памяти для некой сферы действий выделяются в рамках стека вызова при входе кадра и высвобождаются когда этот кадр завершается.
-
Динамическое выделение памяти: Память может быть запрошена и выделяется динамически во время выполнения через вызовы API выделения памяти.
Типы в C обладают фиксированным размером. Сам компилятор вычисляет требования к памяти для всех статических и глобальных переменных и затем вычисляет эти требования в приложении:
static int number = 0;
Вы можете увидеть размер типа в C, воспользовавшись sizeof(). В моей системе, 64-х битной macOS с
исполняемым GCC, int это 4 байта. Базовые типы в C могут обладать
различными размерами в зависимости от архитектуры.
Массивы определены статически. Рассмотрим такой массив из 10 целых:
static int numbers[10] = {0,1,2,3,4,5,6,7,8,9};
Компилятор C преобразует это предложение в выделение sizeof(int) * 10 байт памяти.
Компилятор C для выделения памяти пользуется системными вызовами. Эти системные вызовы зависят от операционной системы и являются функциями нижнего уровня. для своего ядра в отношении выделения памяти из имеющихся страниц системной памяти.
Аналогично статическому выделению памяти, автоматическое выделение памяти вычисляет требования к выделению памяти во время компиляции.
Данный пример демонстрирует преобразование 100 градусов по Фаренгейту в градусы по Цельсию,
cpython-book-samples/32/automatic.c:
#include <stdio.h>
static const double five_ninths = 5.0/9.0;
double celsius(double fahrenheit) {
double c = (fahrenheit - 32) * five_ninths;
return c;
}
int main() {
double f = 100;
printf("%f F is %f C\n", f, celsius(f));
return 0;
}
Данный пример применяет как статическое, так и автоматическое выделение памяти:
-
Значение
constfive_ninthsвыделяется статически так как обладает ключевыс словомstatic. -
Значение переменной
cвнутриcelsius()выделяется автоматически при вызовеcelsius()и высвобождается по завершениюcelsius(). -
Значение переменной
fвнутриmain()выделяется автоматически при вызовеmain()и освобождается по завершениюmain(). -
Значение результата
celsius(f)подразумевает автоматическое выделение. -
Все автоматические требования памяти со стороны
main()освобождаются когда эта функция выполнена.
Во многих случаях бывает недостаточно ни статического, ни автоматического выделения памяти. Например, некая программа может оказаться не способной вычислить требования к памяти в момент компиляции, потому как она определяется входными данными пользователя.
В таких случаях память выделяется динамически. Динамическое выделение памяти работает через вызовы API выделения памяти C. Операционные системы резервируют некий раздел системной памяти для обработки динамического выделения памяти. Этот раздел памяти носит название кучи (heap).
В своём следующем примере вы динамически выделяете память некому массиву значений градусов по Фаренгейту и по Цельсию. Это приложение
вычисляет величины значений градусов по Цельсию соотносясь с специфичными для пользователя числами значений градусов по Фаренгейту,
cpython-book-samples/32/dynamic.c:
#include <stdio.h>
#include <stdlib.h>
static const double five_ninths = 5.0/9.0;
double celsius(double fahrenheit) {
double c = (fahrenheit - 32) * five_ninths;
return c;
}
int main(int argc, char** argv) {
if (argc != 2)
return -1;
int number = atoi(argv[1]);
double* c_values = (double*)calloc(number, sizeof(double));
double* f_values = (double*)calloc(number, sizeof(double));
for (int i = 0 ; i < number ; i++ ){
f_values[i] = (i + 10) * 10.0 ;
c_values[i] = celsius((double)f_values[i]);
}
for (int i = 0 ; i < number ; i++ ){
printf("%f F is %f C\n", f_values[i], c_values[i]);
}
free(c_values);
free(f_values);
return 0;
}
Если вы выполните эту программу со значением аргумента 4, тогда она выведет на печать следующие
результаты:
100.000000 F is 37.777778 C
110.000000 F is 43.333334 C
120.000000 F is 48.888888 C
130.000000 F is 54.444444 C
Этот пример использует динамическое выделение памяти для выделения некого блока памяти из имеющейся кучи, которые затем возвращаются после того как становятся не нужными. Если какая- то динамическая память не возвращена, это вызовет утечку памяти (memory leak).
Будучи построенным поверх C, CPython обязан применять ограничения статического, динамического и автоматического выделения памяти. Некоторые стороны проектирования языка программирования Python превращают эти ограничения в ещё более вызывающие:
-
Python является языком программирования с динамической типизацией. Значение размера переменных не может быть вычислено во время компиляции.
-
Большинство типов ядра Python обладают динамическими размерами. Тип
listможет иметь любой размер,dictможет обладать любым числом ключей, и дажеintявляется динамическим. Сам пользователь никогда не должен определять значение размера этих типов. -
Имена в Python могут повторно применяться для значений различных типов:
>>> a_value = 1 >>> a_value = "Now I'm a string" >>> a_value = ["Now" , "I'm", "a", "list"]
Для преодоления этих ограничений CPython в значительной степени полагается на динамическое распределение памяти, но добавляет рельсы безопасности для автоматизации высвобождения памяти с помощью алгоритмов сборки мусора и подсчёта ссылок.
Вместо того чтобы разработчику Python приходилось выделять память, память объекта Python выделяется автоматически, отдельным, унифицированным API. Такая архитектура требует, чтобы стандартная библиотека CPython и его модули ядра (написанные на C), все они целиком, применяли этот API.
CPython поступает с тремя областями динамического выделения памяти:
-
Сырая область применяется для выделения из системной кучи и большой, не относящейся к объектам памяти.
-
Область объектов используется для выделения всех связанных с объектами Phyton памяти.
-
Область PyMem, то же самое что
PYMEM_DOMAIN_OBJ. Она присутствует для целей наследования API.
Каждый домен реализует один и тот же интерфейс функций:
-
_Alloc(size_t size)выделяет память размеромsizeбайт и возвращает указатель. -
_Calloc(size_t nelem, size_t elsize)выделяетnelemэлементов, причём каждый с размеромelsizeи возвращает указатель. -
_Realloc(void *ptr, size_t new_size)изменяет выделение памяти до размераnew_size. -
_Free(void *ptr)высвобождает память с указателемptrобратно в кучу.
Перечисление PyMemAllocatorDomain представляет эти три области в CPython как
PYMEM_DOMAIN_RAW, PYMEM_DOMAIN_OBJ и
PYMEM_DOMAIN_MEM.
CPython использует два распределителя памяти:
-
malloc: распределитель самой операционной системы для области сырой (raw) памяти. -
pymalloc: распределитель памяти CPython для доменов PyMem и памяти объектов.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Распределитель CPython, |
Когда вы компилируете CPython с отладкой (применяя --with-pydebug в macOS или Linux, либо цель
Debug в Windows), тогда всякая функция выделения памяти пройдёт в реализацию Debug. Например, при
включённой отладке, ваше выделение взывает вместо _PyMem_Alloc()
_PyMem_DebugAlloc().
Распределитель памяти CPython расположен поверх системного распределителя памяти и обладает своим алгоритмом для выделения. Этот алгоритм аналогичен системному выделению памяти, за исключением того, что он индивидуализирован под CPython:
-
Большинство запросов на выделение памяти обладает малым размером и обладают фиксированным размером, ибо
PyObjectэто 16 байт,PyASCIIObjectэто 42 байта,PyCompactUnicodeObjectзанимает 72 байта, аPyLongObjectсоставляет 32 байта. -
Распределитель памяти
pymallocвыделяет блоки памяти только по 256 кБ, нечто большего размера отправляется в системный распределитель памяти. -
Распределитель памяти
pymallocпользуется GIL вместо системной проверки безопасности потоков.
Чтобы помочь прояснить это положение вещей, вы можете представить себе в качестве аналогии спортивный стадион, домашний для футбольного клуба CPython. В помощь управления толпой, ФК CPython реализует некое системное разбиение своего стадиона на секторы с A по E, причём с сидениями по рядам с 1 по 40:
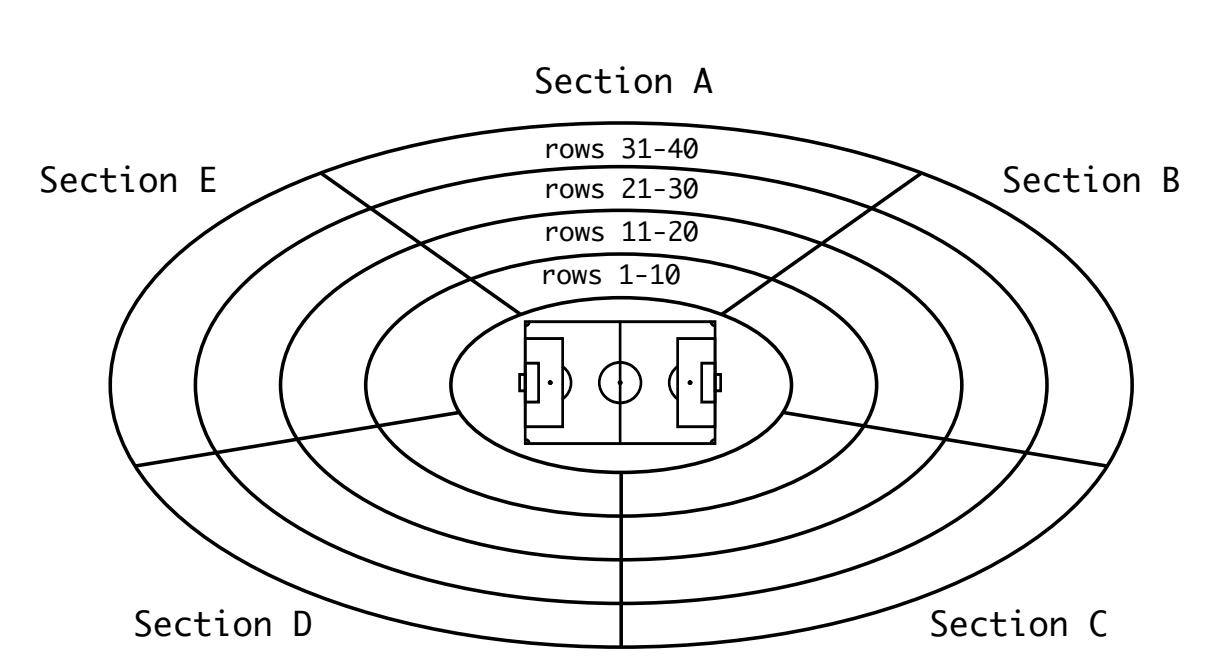
По фронту стадиона, ряды с 1 по 10 представляют собой просторные премиальные сидения с 80 местами в каждом ряду. Позади, ряды с 31 по 40 являются экономичными сидениями со 150 мест в каждом ряду.
Алгоритм выделения памяти Python обладает аналогичными характеристиками:
-
В точности как стадион обладает сидениями, алгоритм pymalloc обладает блоками памяти.
-
Так же как сидения могут быть премиальными, обычными или экономичными, блоки памяти обладают фиксированным размером. Вы не можете принести свой шезлонг!
-
Ровно так же, как сидения одного размера помещены в ряды, блоки одного и того же размера помещаются в пулы.
Некий центральный реестр отслеживает запись, в которой находятся блоки и значение числа доступных в пуле блоков, точно так же, как стадион распределяет места. Когда некий ряд на стадионе заполняется, используется следующий ряд. После заполнения пула блоков применяется следующий пул. Пулы группируются по аренам. аналогично тому как стадион группирует свои ряды в сектора.
Для такой стратегии имеется ряд преимуществ:
-
Такой алгоритм более производителен для основных вариантов применения в CPython: небольшие объекты с коротким периодом жизни.
-
Этот алгоритм применяет GIL вместо системного выявления блокировок потоков.
-
Данный алгоритм использует установку соответствия в памяти (
mmap()) вместо выделения памяти в куче.
Вот те исходные файлы, которые относятся к распределению памяти:
| Файл | Назначение |
|---|---|
|
API выделения памяти PyMem |
|
API настроек выделения памяти PyMem |
|
Структура данных сборщика мусора и внутренние API |
|
Реализация выделения памяти области и реализация |
Ниже приводятся некоторые важные термины, с которыми вы встретитесь в этой главе:
-
Запрашиваемая память соответствует размеру некого блока.
-
Все блоки одного и того же размера помещаются в один и тот же пул памяти.
-
Пулы группируются по аренам.
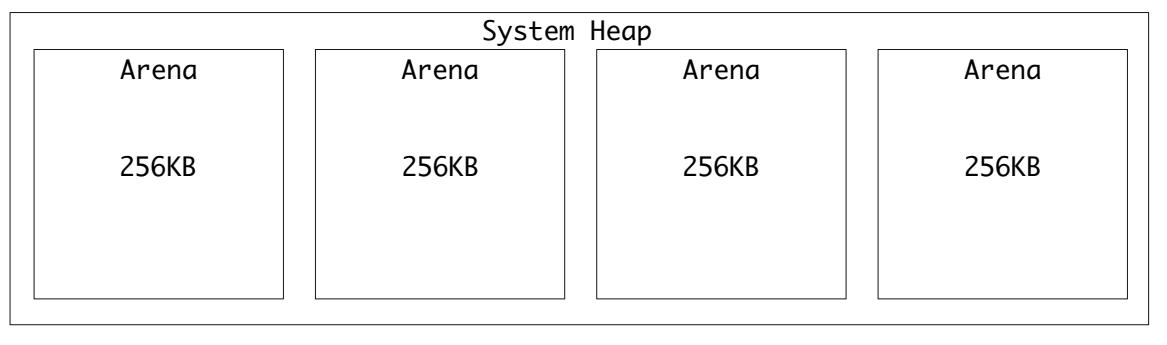
Самой крупной группой памяти выступает арена. CPython создаёт арены по 256 кБ для выравнивая на границы системных страниц памяти. Границы системных страниц это непрерывные участки памяти фиксированной длины.
Даже для современной высокоскоростной памяти непрерывная память будет загружаться быстрее фрагментированной. Обладание непрерывной памятью является преимуществом.
Арены выделяются из системной кучи и при помощи mmap() в поддерживающих анонимное отображение памяти системах. Установка соответствия в памяти помогает снижать в аренах фрагментацию памяти.
Вот некое визуальное представление для четырёх арен внутри кучи системной памяти:
Арены обладают структурой данных arenaobject:
| Поле | Тип | Назначение |
|---|---|---|
|
|
Адрес памяти арены |
|
|
Указатель на следующий подлежащий отрезанию для выделения памяти пул |
|
|
Значение числа пулов в этой арене (свободные пулы плюс никогда не выделяемые пулы) |
|
|
Общее количество пулов в арене, вне зависимости от того доступны они или нет |
|
|
Односвязный список доступных пулов |
|
|
Следующая арена (см. замечание) |
|
|
Предыдущая арена (см. замечание) |
|
| Замечание |
|---|---|
|
Арены связываются между собой в двусвязный список внутри структуры данных арены при помощи указателей
Если данная арена не выделена, используется следующий участник
Когда данная арена взаимодействует с некой выделенной ареной по крайней мере одним доступным пулом, для использования в двусвязном
списке |
Внутри некой арены для блоков размером до 512 байт создаются пулы. Для 32- битных систем значением шага является 8 байт, поэтому имеется 64 класса:
| Запрос в байтах | Размер выделяемого блока | Индекс размера класса |
|---|---|---|
1-8 |
8 |
0 |
9-16 |
16 |
1 |
17-24 |
24 |
2 |
25-32 |
32 |
3 |
... |
... |
... |
497-504 |
504 |
62 |
505-512 |
512 |
64 |
В 64- битных системах шаг составляет 16 байт, поэтому имеется 32 класса:
| Запрос в байтах | Размер выделяемого блока | Индекс размера класса |
|---|---|---|
1-16 |
16 |
0 |
17-32 |
32 |
1 |
33-48 |
48 |
2 |
49-64 |
64 |
3 |
... |
... |
... |
480-496 |
496 |
30 |
497-512 |
512 |
31 |
Все пулы имеют 4096 байт (4кБ), поэтому в арене всегда имеется 64 пула:
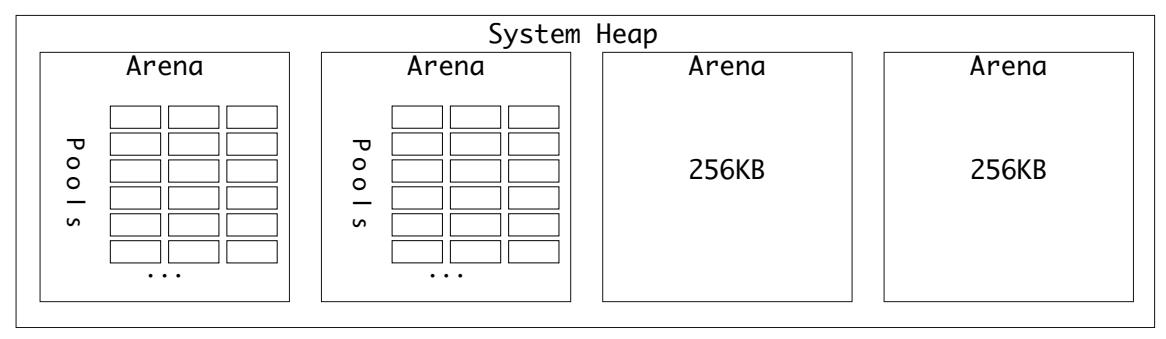
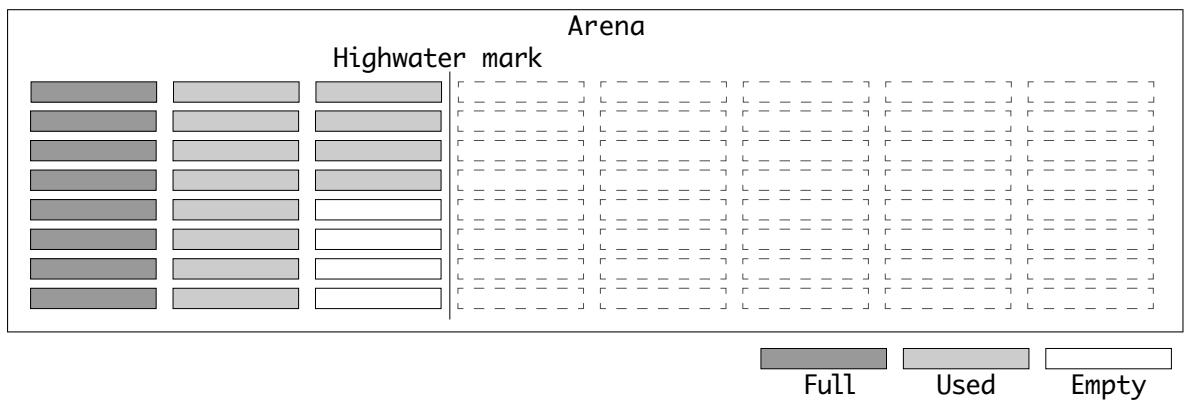
Пулы выделяются по запросу. Когда нет доступных пулов для запрашиваемого индекса размера класса, предоставляется некий новый. Арены обладают верхней отметкой уровня для индексации того сколько пулов было предоставлено.
Пулы обладают тремя возможными состояниями:
-
Заполненный (Full): В этом пуле выделены все блоки.
-
Используемый (Used): Этот пул выделен и некоторые блоки были установлены, но он всё ещё обладает пространством.
-
Пустой (Empty): Этот пул выделен, но никакие блоки не были установлены.
В некой арене отметка верхнего уровня вмещает пулы, которые по крайней мере выделены.
Пулы обладают структурой данных poolp, которая является статическим выделением в памяти структуры
pool_header. Тип pool_header обладает следующими свойствами:
| Поле | Тип | Назначение |
|---|---|---|
|
|
Число выделенных в настоящее время блоков в пуле |
|
|
Указатель на заголовок свободного списка этого пула |
|
|
Указатель на следующий пул этого класса размера |
|
|
Указатель на предыдущий пул этого класса размера |
|
|
Односвязный список доступных пулов |
|
|
Индекс размера класса данного пула |
|
|
Число байт неиспользуемых блоков |
|
|
Максимальное число, которым может быть |
Каждый пул определённого класса размера будет удерживать двусвязный список на следующий и предыдущий пулы этого класса. Когда происходит задача, достаточно просто выполнять переходы между пулами одного и того же класса размера внутри некой арены следуя по этому списку.
Реестр всех пулов внутри некой арены носит название таблицы пулов. Таблица пулов представляет собой двусвязный циклический список с заголовком частично используемых пулов.
Такая таблица пулов сегментирована по индексу класса размера, i. Для индекса
i, usedpools[i + i] указывает на заголовок списка всех частично
используемых пулов, которые обладают значением индекса размера для данного класса размера.
Таблицы пулов обладают некоторыми существенными характеристиками:
-
Когда пул становится заполненным, ссылка на него изымается из перечня
usedpools[]. -
Если в заполненном пуле освобождается некий блок, тогда этот пул помещается обратно в состояние используемого. Вновь высвобожденный пул привязывается в начало списка
usedpools[]с тем, чтобы следующее выделение памяти для его класса размера использовало бы этот освобождённый блок. -
При переходе в состояние пустого, пул отсоединяется из своего списка
usedpools[]и присоединяется к передней части односвязного спискаfreepoolsв его арене.
Внутри пулов память выделяется блоками. Блоки обладают следующими характеристиками:
-
Внутри пула могут выделяться и освобождаться блоки класса фиксированного размера.
-
Доступные блоки внутри некого пула перечислены в односвязном списке
freeblock. -
Когда блок освобождается, он вставляется спереди списка
freeblock. -
При инициализации некого пула внутри списка
freeblockсвязаны только самые первые два блока. -
До тех пор пока пул пребывает в состоянии используемого, будут иметься доступными блоки для их выделения.
Вот как выглядит частично распределённый пул в комбинации используемых, освобождённых и доступных блоков:
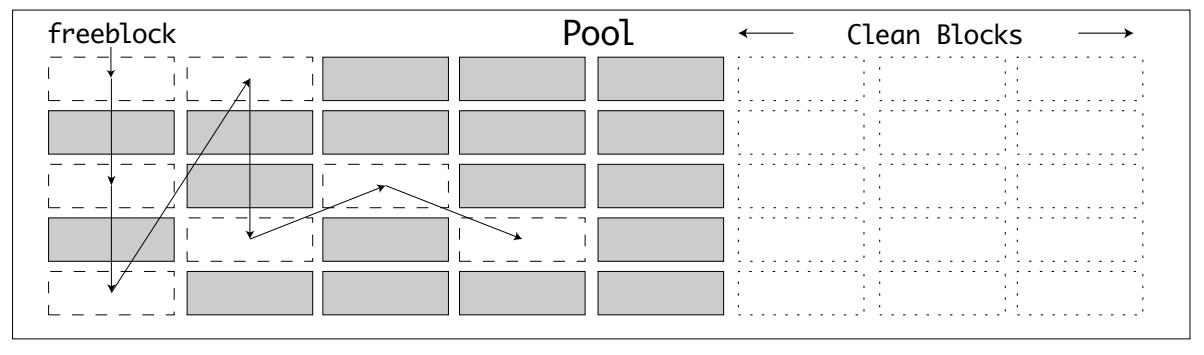
Когда блок памяти запрашивается в области памяти, которая применяет pymalloc, вызывается
pymalloc_alloc(). Эта функция
хорошее место для вставки точки прерывания и шаг по вашему коду чтобы проверить ваши знания блоков, пулов и арен, строка 1590
/Objects/obmalloc.c:
static inline void*
pymalloc_alloc(void *ctx, size_t nbytes)
{
...
Запрос nbytes = 30 не равен ни нулю, не больше значения
SMALL_REQUEST_THRESHOLD в 512 байт:
SMALL_REQUEST_THRESHOLD of 512:
if (UNLIKELY(nbytes == 0)) {
return NULL;
}
if (UNLIKELY(nbytes > SMALL_REQUEST_THRESHOLD)) {
return NULL;
}
Для 64- битной системы значение индекса класса размера вычисляется как 1. Это коррелирует со вторым
индексом класса размера (17 - 32 байт).
Целевой пул затем это usedpools[1 + 1] (usedpools[2]):
uint size = (uint)(nbytes - 1) >> ALIGNMENT_SHIFT;
poolp pool = usedpools[size + size];
block *bp;
Затем выполняется проверка, чтобы что имеется доступным ('used') некий пул для этого индекса
класса размера. Когда список freeblock пребывает в конце своего пула, тогда всё в этом пуле ещё имеются
доступными чистые блоки.
Вызывается pymalloc_pool_extend() для расширения списка
freeblock:
if (LIKELY(pool != pool->nextpool)) {
/*
* There is a used pool for this size class.
* Pick up the head block of its free list.
*/
++pool->ref.count;
bp = pool->freeblock;
assert(bp != NULL);
if (UNLIKELY((pool->freeblock = *(block **)bp) == NULL)) {
// Reached the end of the free list. Try to extend it.
pymalloc_pool_extend(pool, size);
}
}
Когда нет доступных пулов, создаётся новый пул и возвращается его первый блок. allocate_from_new_pool()
автоматически добавляет такой новый пул в список usedpools:
else {
/* There isn't a pool of the right size class immediately
* available. Use a free pool.
*/
bp = allocate_from_new_pool(size);
}
return (void *)bp;
}
Наконец, возвращается значение адреса нового блока.
Модуль sys содержит некую внутреннюю функцию, _debugmallocstats(),
для получения значения числа используемых блоков для каждого значения пула класса размера. Он также выводит на печать значение числа выделенных и
возвращённых арен совместно со значением числа используемых блоков.
Вы можете воспользоваться этой функцией для просмотра использования памяти времени выполнения:
$ ./python -c "import sys; sys._debugmallocstats()"
Small block threshold = 512, in 32 size classes.
class size num pools blocks in use avail blocks
----- ---- --------- ------------- ------------
0 16 1 181 72
1 32 6 675 81
2 48 18 1441 71
...
2 free 18-sized PyTupleObjects * 168 bytes each = 336
3 free 19-sized PyTupleObjects * 176 bytes each = 528
Этот вывод отображает значения таблицы индексов классов размера, имеющиеся выделения памяти и некоторые дополнительные статистические сведения.
Распределитель памяти объектов CPython это первая из трёх областей, которые вы изучите. Основная цель распределителя памяти объектов состоит в выделении памяти, связанной с объектами Python, например, новые заголовки объектов и данные объектов, такие как ключи и значения словарей или списки элементов.
Этот распределитель памяти также применяется самими компилятором, деревом абстрактного синтаксиса (AST), синтаксическим анализатором,
а также циклом вычислений. Исключительным образцом выделения в использование памяти объектам является конструктор типа
PyLongObject (int), PyLong_New():
-
Когда строится новый
int, память выделяется под конструкцию создания переменной в динамической памяти (allocator, распределитель) необходимого объекта. -
Запрашиваемая величина размера это значение размера структуры
PyLongObjectплюс то количество памяти, которое требуется для хранения цифр.
Python long не является эквивалентом типу long в C. Он выступает неким
списком цифр. Число 12378562834 в Python будет представлено как
список цифр [1,2,3,7,8,5,6,2,8,3,4]. Именно с такой структурой Python способен работать с гигантскими
числами, не заботясь об ограничениях 32- или 64- битных целых.
Давайте взглянем на построитель PyLong, чтобы увидеть образец выделения памяти объекту:
PyLongObject *
_PyLong_New(Py_ssize_t size)
{
PyLongObject *result;
...
if (size > (Py_ssize_t)MAX_LONG_DIGITS) {
PyErr_SetString(PyExc_OverflowError,
"too many digits in integer");
return NULL;
}
result = PyObject_MALLOC(offsetof(PyLongObject, ob_digit) +
size*sizeof(digit));
if (!result) {
PyErr_NoMemory();
return NULL;
}
return (PyLongObject*)PyObject_INIT_VAR(result, &PyLong_Type, size);
}
Если вы вызовете _PyLong_New(2), он высчитает значение size_t
подобным образом:
| Значение | Байты |
|---|---|
sizeof(digit) |
4 |
размер |
2 |
смещение заголовка |
26 |
Итого |
32 |
Вызов PyObject_MALLOC() должен бы быть выполнен со значением
size_t равным 32.
В моей системе значение максимального числа цифр в long, MAX_LONG_DIGITS, равно
2305843009213693945 (очень, очень большое число). Если вы исполните
_PyLong_New(2305843009213693945), то это вызвало бы
PyObject_MALLOC() для 9223372036854775804, или
8,589,934,592 гигабайт (больше чем я имею в доступности оперативной памяти).
Модуль tracemalloc из стандартной библиотеки можно применять для отладки выделения памяти через
распределитель памяти объектам. Он предоставляет сведения где размещён некий объект и значение числа выделенных блоков памяти. В качестве
отладочного средства tracemalloc может помогать вам вычислять значение объёма потребляемой памяти
запуская ваш код и выявляя утечки памяти.
Чтобы включить отслеживание памяти вы можете запустить Python с -X tracemalloc=1, где
1 это значение числа глубины кадров, которое вы желаете отслеживать. В качестве альтернативы вы можете
воспользоваться переменной среды PYTHONTRACEMALLOC=1. Вы можете предписать сколько кадров в глубину
отслеживать, заменив 1 любым целым.
Вы можете воспользоваться take_snapshot() для создания экземпляра моментального снимка, а затем
сопоставлять множество моментальных снимков при помощи compare_to(). Создадим некий файл примера
tracedemo.py чтобы увидеть это в действии,
cpython-book-samples/32/tracedemo.py:
import tracemalloc
tracemalloc.start()
def to_celsius(fahrenheit, /, options=None):
return (fahrenheit-32)*5/9
values = range(0, 100, 10) # values 0, 10, 20, ... 90
for v in values:
c = to_celsius(v)
after = tracemalloc.take_snapshot()
tracemalloc.stop()
after = after.filter_traces([tracemalloc.Filter(True, '**/tracedemo.py')])
stats = after.statistics('lineno')
for stat in stats:
print(stat)
Его исполнение выводит на печать построчный список используемой памяти с наивысших к наинисшим значениям:
$ ./python -X tracemalloc=2 tracedemo.py
/Users/.../tracedemo.py:5: size=712 B, count=2, average=356 B
/Users/.../tracedemo.py:13: size=512 B, count=1, average=512 B
/Users/.../tracedemo.py:11: size=480 B, count=1, average=480 B
/Users/.../tracedemo.py:8: size=112 B, count=2, average=56 B
/Users/.../tracedemo.py:6: size=24 B, count=1, average=24 B
Строкой с наивысшим потреблением памяти была return (fahrenheit-32)*5/9, которая и выполняла
реальные вычисления.
Область выделения сырой памяти используется либо напрямую, либо когда две прочих области вызываются с запросом памяти, превышающим
512кБ. Он получает величину запрашиваемого размера, в байтах, и вызывает malloc(size). Когда значением
аргумента является 0, тогда некоторые системы вернут для malloc(0)
NULL, что будет воспринято как некая ошибка. Некоторые платформы вернут какой- то указатель без стоящей за ним памяти, что вызвало бы
прерывание pymalloc.
Для решения этой проблемы _PyMem_RawMalloc() добавляет некий дополнительный байт перед вызовом
malloc().
|
| Замечание |
|---|---|
|
По умолчанию, распределители памяти области PyMem применяют выделение памяти объектам. |
CPython также позволяет вам перекрывать реализацию имеющегося распределителя памяти для любой из трёх областей. Если в вашей системной среде требуются сшитые на заказ проверки памяти или алгоритмы для распределения памяти, тогда вы способны подключить новый набор функций распределения памяти к своей среде исполнения.
PyMemAllocatorEx это typedef struct с участниками для
всех методов, которые вам потребуется реализовать для перекрытия имеющегося распределителя памяти:
typedef struct {
/* User context passed as the first argument to the four functions */
void *ctx;
/* Allocate a memory block */
void* (*malloc) (void *ctx, size_t size);
/* Allocate a memory block initialized by zeros */
void* (*calloc) (void *ctx, size_t nelem, size_t elsize);
/* Allocate or resize a memory block */
void* (*realloc) (void *ctx, void *ptr, size_t new_size);
/* Release a memory block */
void (*free) (void *ctx, void *ptr);
} PyMemAllocatorEx;
Для получения имеющейся реализации доступен метод API PyMem_GetAllocator():
PyMemAllocatorEx * existing_obj;
PyMem_GetAllocator(PYMEM_DOMAIN_OBJ, existing_obj);
![[Предостережение]](/common/images/admon/warning.png) | Важно |
|---|---|
|
Существуют некоторые важные тесты архитектуры для индивидуальных распределителей памяти:
|
Если вы реализовали необходимые функции My_Malloc(), My_Calloc(),
My_Realloc() и My_Free(), при помощи подписей
PyMemAllocatorEx, тогда вы можете перекрыть имеющийся распределитель для каждой из областей, например,
для PYMEM_DOMAIN_OBJ:
PyMemAllocatorEx my_allocators =
{NULL, My_Malloc, My_Calloc, My_Realloc, My_Free};
PyMem_SetAllocator(PYMEM_DOMAIN_OBJ, &my_allocators);
Уборщики выделенной памяти (Memory allocation sanitizers) это дополнительные алгоритмы, помещаемые между имеющимися системными вызовами для выделения памяти и собственно функциями ядра для распределения памяти в вашей системе. Они применяются для сред, которые требуют особых ограничений стабильности или очень высокой безопасности или же для отладки ошибок выделения памяти.
CPython может быть скомпилирован с применением различных уборщиков памяти. Они являются частью библиотек компилятора, а не чем- то разработанным под CPython. Обычно они значительно замедляют CPython и не могут комбинироваться. В основном они предназначены для применения в сценариях отладки или в системах, в которых критически важным является предотвращение порчи памяти.
AddressSanitizer это быстрый определитель ошибок в памяти. Он способен выявлять большое число относящихся к памяти ошибок времени исполнения:
-
Выход за границы кучи, стека и глобальных элементов
-
Подлежащая использованию память после её высвобождения
-
Двойное освобождение и неверное высвобождение
Вы можете включить AddressSanitizer выполнив следующее:
$ ./configure --with-address-sanitizer ...
|
| Важно |
|---|---|
|
AddressSanitizer способен замедлять приложения вплоть до двух раз и потреблять в три раза больше памяти. |
AddressSanitizer поддерживается в следующих операционных системах:
-
Linux
-
macOS
-
NetBSD
-
FreeBSD
Для получения дополнительных сведений обратитесь к официальной документации
MemorySanitizer это определитель не инициализированных чтений. Если происходит обращение по адресу к некому адресному пространству до его инициализации (выделения), тогда такой процесс будет остановлен до того как может быть считана запрашиваемая память.
Вы можете включить MemorySanitizerвыполнив следующее:
$ ./configure --with-memory-sanitizer ...
|
| Важно |
|---|---|
|
MemorySanitizer способен замедлять приложения вплоть до двух раз и потреблять в два раза больше памяти. |
MemorySanitizer поддерживается в следующих операционных системах:
-
Linux
-
NetBSD
-
FreeBSD
Для получения дополнительных сведений обратитесь к официальной документации
UndefinedBehaviorSanitizer (UBSan) это средство быстрого выявления не предопределённого поведения. В процессе выполнения он способен выявлять различные виды не заданного поведения:
-
Неправильно выровненный или нулевой указатель
-
переполнение целого со знаком
-
Преобразование в, из или между типами с плавающей запятой
Вы можете включить UndefinedBehaviorSanitizer выполнив следующее:
$ ./configure --with-undefined-behavior-sanitizer ...
UndefinedBehaviorSanitizer поддерживается в следующих операционных системах:
-
Linux
-
macOS
-
NetBSD
-
FreeBSD
Для получения дополнительных сведений обратитесь к официальной документации
UBSan обладает множеством конфигураций. При помощи --with-undefined-behavior-sanitizer будет установлен
профиль undefined. Для применения иного профиля, например, nullability,
запустите ./configure с индивидуальным CFLAGS:
$ ./configure CFLAGS="-fsanitize=nullability" \
LDFLAGS="-fsanitize=nullability"
После того как вы повторно скомпилируете CPython? эта конфигурация воспроизведёт исполняемый файл CPython с применением UndefinedBehaviorSanitizer.
На протяжении этой книги вы будете наблюдать ссылки на объект PyArena. PyArena это обособленное выделение API, применяемое для самого компилятора,
вычисления кадра, и прочих частей ваше системы не исполняемых из выделения API объекта Python.
PyArena также обладает своим собственным списком выделенных объектов внутри данной структуры арены.
Выделяемая PyArena память не является целью сборщика мусора.
Когда память выделяется в экземпляре PyArena, будет перехвачено запущенного общего числа выделенных
блоков, после чего вызывается PyMem_Alloc. Запросы на выделение памяти к
PyArena применяют распределитель памяти объектов для блоков с размером меньшим или равным 512кБ и
распределитель сырой памяти для блоков большего размера.
Вот связанные с PyArena файлы:
| Файл | Назначение |
|---|---|
|
API PyArena и определения типа |
|
Реализация PyArena |
Как вы до сих пор наблюдали в этой главе, CPython собирается в системе динамического распределения памяти C. Требования к памяти определяются во время
исполнения и память выделяется вашей системе при помощи API PyMem.
Для разработчиков Python эта система была абстрагирована и упрощена. Разработчикам не приходится сильно беспокоиться относительно выделения и освобождения памяти.
Для упрощения управления памятью Python приспособил две стратегии по управлению распределением под объекты памяти:
-
Подсчёт ссылок
-
Сборка мусора
Далее мы рассмотрим их более подробно.
Для создания некой переменной в Python вам необходимо назначить некое значение уникально именованной переменной:
my_variable = ["a", "b", "c"]
При присвоении некого значения какой-то переменной в Python, её название проверяется внутри локальной и глобальной сфер действия на предмет того не существует ли уже такое.
В нашем примере выше my_variable ещё пока нет ни в каких словарях
locals() или globals(). Создаётся новый объект
list и указатель на него сохраняется в словаре locals().
Теперь имеется одна ссылка на my_variable.
Список объектов памяти не должен освобождаться пока имеются допустимые ссылки на него. Если эта память была освобождена, тогда данный
указатель на my_variable указывал бы на недопустимое пространство памяти и CPython испытал бы
крушение.
На протяжении кода C CPython вы будете наблюдать вызовы Py_INCREF() и Py_DECREF(). Эти макросы в первую очередь выступают API для инкрементального увеличения и уменьшения ссылок на объекты Python. Всякий раз когда нечто полагается на некое значение, значение счётчика ссылок увеличивается на 1. Когда эта зависимость больше не имеет места, значение этого счётчика уменьшается на 1.
Когда значение счётчика достигает нуля, это предполагает, что данная память больше не требуется и она автоматически освобождается.
Всякий экземпляр PyObject обладает свойством ob_refcnt. Это
свойство выступает счётчиком значения числа ссылок на данный объект.
Ссылки на некий объект прирастают на единицу во многих случаях. В базовом коде CPython имеется более 3000 вызовов
Py_INCREF(). Наиболее распространены вызовы огда его объект:
-
Назначается некой переменной с названием
-
Служит ссылкой в качестве аргумента функции или метода
-
Возвращается или выдаётся из функции
Сама стоящая за макро Py_INCREF логика обладает лишь одним шагом. Она увеличивает величину
значения ob_refcnt на единицу:
static inline void _Py_INCREF(PyObject *op)
{
_Py_INC_REFTOTAL;
op->ob_refcnt++;
}
Когда CPython компилируется в режиме отладки, тогда
_Py_INC_REFTOTAL будет увеличивать на единицу счётчик глобальных ссылок,
_Py_RefTotal.
|
| Замечание |
|---|---|
|
Вы можете наблюдать глобальный счётчик ссылок добавляя флаг Самое первое число в квадратных скобках это значение числа ссылок сделанное на протяжении данного процесса, а второе значение число выделенных блоков. |
ССылки на некий объект уменьшаются на единицу когда переменная выходит из сферы действий в которой она была определена. Сфера действий в Python может ссылаться на функцию или метод, область обзора или лямбду. Это некоторые из наиболее буквальных областей видимости, но имеется также большое число неявно подразумеваемых сфер действия, таких как передача переменных вызову функции.
Py_DECREF() более сложный чем Py_INCREF(), потому как он
также управляет логикой ссылки по достижению 0, которая требует освобождения памяти данного
объекта:
static inline void _Py_DECREF(
#ifdef Py_REF_DEBUG
const char *filename, int lineno,
#endif
PyObject *op)
{
_Py_DEC_REFTOTAL;
if (--op->ob_refcnt != 0) {
#ifdef Py_REF_DEBUG
if (op->ob_refcnt < 0) {
_Py_NegativeRefcount(filename, lineno, op);
}
#endif
}
else {
_Py_Dealloc(op);
}
}
Внутри Py_DECREF(), когда значение счётчика его ссылки
(ob_refcnt) становится равным 0, вызывается деструктор
_Py_Dealloc(op) и вся выделенная память освобождается.
Как и в случае Py_INCREF(), имеются некоторые дополнительные функции когда CPython скомпилирован
в режиме отладки.
Для некого инкрементального увеличения должна иметься аналогичная операция уменьшение. Если ссылка на объект становится отрицательным числом, тогда это указывает на некую несбалансирвоанность в коде на C. Некая попытка уменьшения ссылки на единицу для объекта, не обладающего ссылкой породит такое сообщение об ошибке:
<file>:<line>: _Py_NegativeRefcount: Assertion failed:
object has negative ref count
Enable tracemalloc to get the memory block allocation traceback
object address : 0x109eaac50
object refcount : -1
object type : 0x109cadf60
object type name: <type>
object repr : <refcnt -1 at 0x109eaac50>
При внесении изменений в поведение некой операции, языка программирования Python или его компилятора, следует аккуратно рассматривать воздействие ссылок на объекты.
Большая часть подсчёта числа ссылок Python происходит внутри операций байтового кода в
Python/ceval.c.
Подсчитаем число ссылок на переменную у в этом примере:
y = "hello"
def greet(message=y):
print(message.capitalize() + " " + y)
messages = [y]
greet(*messages)
На первый взгляд имеется четыре ссылки на у:
-
В качестве переменной в самой верхней области действия
-
В качестве значения по умолчанию для аргумента ключевого слова
message -
Внутри
greet() -
Как элемент внутри списка
message
Выполните этот код со следующей дополнительной вставкой:
import sys
print(sys.getrefcount(y))
В действительности имеется в общей сложности шесть ссылок на у.
Вместо того чтобы пребывать внутри некой центральной функции, которая должна принимать во внимание все эти варианты и многое иное, логика для увеличения и уменьшения ссылок на единицу расщепляется на небольшие части.
Операции байтового кода обязаны обладать детерменированным воздействием на счётчик ссылок для тех объектов, которые он получает в качестве аргументов.
Например, в соответствующем кадре цикла вычислений, операция LOAD_FAST загружает свой объект с
заданным названием и помещает его в вершину своего стека значений. Поскольку это название переменной, которое представлено в
oparg было разрешено при помощи GETLOCAL(), значение счётчика
ссылок было увеличено на единицу:
...
case TARGET(LOAD_FAST): {
PyObject *value = GETLOCAL(oparg);
if (value == NULL) {
format_exc_check_arg(tstate, PyExc_UnboundLocalError,
UNBOUNDLOCAL_ERROR_MSG,
PyTuple_GetItem(co->co_varnames, oparg));
goto error;
}
Py_INCREF(value);
PUSH(value);
FAST_DISPATCH();
}
Операция LOAD_FAST компилируется в большом числе узлов дерева абстрактного синтаксиса (AST), которые
обладают операциями.
Например, допустим, вы выполняете назначение двум переменным, a и
b, затем создаёте третью, c, на основе произведения
a и b:
a = 10
b = 20
c = a * b
В нашей третьей операции, c = a * b, выражение с правой стороны,
a * b, будет ассемблировано в три операции:
-
LOAD_FAST, разрешение значения переменнойaи её помещение в стек значений, с последующим увеличением значения числа ссылок наaна единицу -
LOAD_FAST, разрешение значения переменнойbи её помещение в стек значений, с последующим увеличением значения числа ссылок наbна единицу -
BINARY_MULTIPLY, умножение значений переменных слева и справа и помещение их результата в стек значений
Оператор бинарного умножения, BINARY_MULTIPLY, знает, что ссылки на левую и правую переменную в его
операции были загружены в первую и вторую позицию в стеке значений. Он также подразумевает, что сама операция
LOAD_FAST прирастила на единицу их счётчики ссылок.
В реализации этой операции BINARY_MULTIPLY значения этих ссылок для обоих, и
a (левого), и b (правого) уменьшаются на единицу после
вычисления соответствующего результата:
case TARGET(BINARY_MULTIPLY): {
PyObject *right = POP();
PyObject *left = TOP();
PyObject *res = PyNumber_Multiply(left, right);
Py_DECREF(left);
Py_DECREF(right);
SET_TOP(res);
if (res == NULL)
goto error;
DISPATCH();
}
Получаемое в результате число, res, будет иметь счётчик ссылок равным
1 прежде чем оно будет установлено в вершине стека значений.
Счётчик ссылок CPython обладает преимущества в своей простоте, скорости и действенности. Самым большим недостатком такого счётчика ссылок выступает потребность в ведении его учёта, а также тщательного баланса, принимая воздействие каждой операции.
Как вы только что видели, некая операция байтового кода увеличивает значения счётчика на единицу и это предполагает, что эквивалентная операция уменьшит его на единицу надлежащим образом. Что произойдёт в случае непредвиденной ошибки? Все ли возможные сценарии были проверены?
Всё что обсуждалось до сих пор относится к сфере исполнения CPython, Разработчик Python практически не способен контролировать это поведение.
Существует ещё один существенный недостаток в подходе с подсчётом ссылок: циклические ссылки.
Воспользуемся таким примером на Python:
x = []
x.append(x)
del x
Значения счётчика ссылок для x всё ещё 1, поскольку он
ссылается сам на себя.
В угоду этой сложности и для устранения таких типов утечек памяти CPython обладает вторым механизмом управления памяти, носящим название Сборки мусора (garbage collection).
Как часто вы занимаетесь уборкой мусора? Каждую неделю или раз в две недели?
Когда вы покончили с чем- то, вы избавляетесь от него и выбрасываете в мусорную корзину. Однако мусор не исчезнет сразу. Вам требуется дождаться мусоровоза чтобы сдать мусор.
CPython пользуется тем же самым принципом для алгоритма сборки мусора. Сборщик мусора CPython работает над возвратом которая была задействована более не существующими объектами. По умолчанию он включён и работает в фоновом режиме.
Поскольку алгоритм сборки мусора намного сложнее подсчёта ссылок, он не происходит всё время. Когда он в деле, он будет потреблять большой объём ресурсов ЦПУ. Сборка мусора работает периодически после некоторого набора операций.
Вот связанные со сборкой мусора файлы:
| Файл | Назначение |
|---|---|
|
Реализация модуля и алгоритмя сборки мусора |
|
Реализация PyArenaСтруктура данных и внутреннее API сборки мусора |
Как вы установили в нашей предыдущей главе,каждый объект Python удерживает в памяти некий счётчик числа ссылок на него. Как только этот счётчик достигает нуля, этот объект прекращает существование и его память освобождается.
Многие из контейнерных типов Python, такие как списки, кортежи, словари и наборы, в результате могут приводить к циклическим ссылкам. Собственно счётчик ссылок не является достаточным механизмом того, чтобы обеспечивать тот факт, что этот объект не надо больше освобождать.
Хотя и следует избегать создания циклических ссылок в контейнерах, внутри стандартной библиотеки и ядра интерпретатора имеется множество примеров
таковых. Вот ещё один распространённый пример в котором тип контейнера (class) может ссылаться сам на себя,
cpython-book-samples/32/user.py:
__all__ = ["User"]
class User(BaseUser):
name: 'str' = ""
login: 'str' = ""
def __init__(self, name, login):
self.name = name
self.login = login
super(User).__init__()
def __repr__(self):
return ""
class BaseUser:
def __repr__(self):
# This creates a cyclical reference
return User.__repr__(self)
В данном примере экземпляр User ссылается на тип BaseUser,
который обратно ссылается на этот экземпляр User. Основная цель сборки мусора состоит в поиске
недостижимых объектов и их пометке как мусора.
Некоторые алгоритмы сборки мусора, такие как пометить и вымести (mark and sweep)
или остановиться и скопировать (stop and copy), стартуют в самом корне и
изучают все достижимые объекты. Это сложно выполнять в CPython, ибо модули расширения C могут определять
и сохранять свои собственные объекты. У вас нет возможности запросто определять все объекты просто просматривая их в
locals() и globals().
Для процессов с длительным временем работы и большими задачами обработки данных истощение памяти может вызывать значительные проблемы.
Вместо этого сборщик мусора CPython отыскивает критически важные ссылки в определённых типах контейнеров.
Сборщик мусора ищет типы, обладающие в своём определении типа установленным флагом Py_TPFLAGS_HAVE_GC.
Вы рассмотрите определения типов в Главе 11, Объекты и типы.
Вот те типы, которые помечаются для сборки мусора:
-
Объекты класса, метода и функции
-
Объекты ячейки
-
Массивы байтов, строки байтов и Unicode
-
Словари
-
Применяемые в атрибутах объекты дескриптора
-
Перечисляемые объекты
-
Исключительные ситуации
-
Объекты кадров
-
Списки, кортежи, именованные кортежи и наборы
-
Объекты памяти
-
Модули и пространства имён
-
Объекты типов и слабых ссылок
-
Итераторы и генераторы
-
Буферы маринования
Интересуетесь что пропущено? Не помечены для сборки мусора числа с плавающей запятой, целые, Булевы, и
NoneType.
Индивидуальные типы, написанные при помощи модулей расширения C могут помечаться как требующие сборки мусора при помощи API C сборщика мусора.
Сборщик мусора будет отслеживать определённые типы на предмет изменения их свойств для выявления того какие из них не достижимы.
Некоторые экземпляры контейнеров не являются предметом изменения, потому как они непреложные, поэтому данный API предоставляет механизм для избавления от отслеживания (untracking). Чем меньше имеется объектов для отслеживания сборщиком мусора, тем быстрее и действеннее оказывается сборщик мусора.
Исключительным примером не отслеживаемых объектов являются кортежи. Кортежи неизменны. После их создания вы не можете их изменять. Тем не менее, кортежи могут содержать изменяемые типы, такие как списки и словари.
Такая архитектура в Python создаёт множество побочных эффектов, одним из которых является алгоритм сборки мусора. После создания кортежа, пока он не станет пустым, он помечается как отслеживаемый.
При работе сборщика мусора просматривается содержимое всякого кортежа на предмет того содержит ли он исключительно неизменные (не отслеживаемые) экземпляры. Этот шаг выполняется в PyTuple_MaybeUntrack(). Когда котреж определяется как состоящий лишь из неизменных типов, таких как Булевы или целые, он удалит себя из отслеживания сборщиком мусора посредством вызова _PyObject_GC_UNTRACK().
После своего создания словари пустые и не отслеживаемые. После того как в словарь добавляется некий элемент, когда это подлежащий отслеживанию объект, тогда этот словарь запрашивает у сборщика мусора своего отслеживания.
Вы можете определять подлежит ли какой нибудь объект отслеживанию через вызов gc.is_tracked(obj).
Далее мы изучим сам алгоритм сборки мусора. Команда разработки ядра CPyhon написала подробное руководство, которым вы можете пользоваться как справочником для получения дополнительных сведений.
Инициализация
Для запуска и останова сборщика мусора его точка входа PyGC_Collect() следует процессом из пяти шагов:
-
Получить из своего интерпретатора состояние сборщика мусора,
Code. -
Убедиться что сборщик мусора включён.
-
Убедиться в том что сборщик мусора уже исполняется.
-
Запустить функцию сборки, collect(), с продвижением по обратным вызовам.
-
Пометить сборщик мусора как выполненный.
Когда сборщик мусора был исполнен и завершён, вы можете определить методы обратных вызовов при помощи списка
gc.callbacks. Обратные вызовы обязаны обладать подписью соответствующего метода
f(stage: str, info: dict):
Python 3.9 (tags/v3.9:9cf67522, Oct 5 2020, 10:00:00)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import gc
>>> def gc_callback(phase, info):
... print(f"GC phase:{phase} with info:{info}")
...
>>> gc.callbacks.append(gc_callback)
>>> x = []
>>> x.append(x)
>>> del x
>>> gc.collect()
GC phase:start with info:{'generation': 2,'collected': 0,'uncollectable': 0}
GC phase:stop with info:{'generation': 2,'collected': 1,'uncollectable': 0}
1
Стадия уборки
В главной функции сборки мусора, collect() имеет целью три поколения в CPython. Прежде чем вы ознакомитесь с поколениями, вначале важно понять сам алгоритм сборки.
Для всякой уборки сборщик мусора применяет двусвязный список с типом PyGC_HEAD. С тем, чтобы
сборщику мусора не приходилось выполнять поиск во всех типах контейнеров, те, которые выступают в качестве цели для сборщика мусора
обладают неким дополнительным заголовком, который связывает их в двусвязный список.
Когда создаётся один из таких типов контейнеров, он сам добавляет себя в этот список, а когда он уничтожается, он сам удаляет себя.
Вы можете рассмотреть некий образец в типе cellobject.c, строка 7
Objects/cellobject.c:
PyObject *
PyCell_New(PyObject *obj)
{
PyCellObject *op;
op = (PyCellObject *)PyObject_GC_New(PyCellObject, &PyCell_Type);
if (op == NULL)
return NULL;
op->ob_ref = obj;
Py_XINCREF(obj);
>> _PyObject_GC_TRACK(op);
return (PyObject *)op;
}
Поскольку ячейки изменяемые, этот объект помечается как отслеживаемый через вызов _PyObject_GC_TRACK().
Когда объекты ячеек удаляются, вызывается cell_dealloc(), эта функция предпринимает три шага:
-
Её деструктор сообщает сборщику мусора об останове отслеживания данного экземпляра через вызов _PyObject_GC_TRACK(). Поскольку он подлежит уничтожению, его содержимое нет нужды проверять на изменения в последующих уборках.
-
Py_XDECREFэто стандартный вызов во всяком деструкторе для уменьшения на единицу счётчика его ссылок. Значение счётчика ссылок инициализируется со значением1, поэтому он обсчитывает эту операцию. -
PyObject_GC_Del() удаляет данный объект из связного списка сборки мусора через вызов gc_list_remove(), а затем освобождает память при помощи PyObject_FREE().
Вот исходный код cell_dealloc(),
строка 79 /Objects/cellobject.c:
static void
cell_dealloc(PyCellObject *op)
{
_PyObject_GC_UNTRACK(op);
Py_XDECREF(op->ob_ref);
PyObject_GC_Del(op);
}
Когда запускается уборка, она сливает более молодые поколения в текущее поколение. Например, если вы убираете своё второе поколение, тогда
когда оно запускает уборку, оно будет слито с объектами первого поколения в соответствующий список сборщика мусора при помощи
gc_list_merge().
Сборщик мусора затем выявит недостижимые объекты в своём young (выступающем текущей целью) поколении.
Сама логика для выявления недостижимых объектов располагается в deduce_unreachable(). Она следует такими
этапами:
-
Для каждого объекта в соответствующем поколении копируется значение счётчика
ob->ob_refcntвob->gc_ref. -
Для каждого объекта вычитаются внутренние (циклические) ссылки из
gc_refsдля определения того сколько объектов может быть убрано сборщиком мусора. Еслиgc_refsзавершается0, этот объект недостижим. -
Создаётся список недостижимых объектов и добавляются все объекты, которые соответствуют указанному на этапе 2 критерию.
Не существует единственного метода для выявления циклических ссылок. Каждый тип должен определять индивидуальную функцию с подписью
traverseproc в слоте tp_traverse. Для осуществления
указанного выше этапа 2,
deduce_unreachable()
вызывает функцию обхода для каждого объекта внутри
subtract_refs().
Эта функция обхода должна выполнять обратный вызов
visit_decref()
для каждого содержащего ею элемента, строка 462 /Modules/gcmodule.c:
static void
subtract_refs(PyGC_Head *containers)
{
traverseproc traverse;
PyGC_Head *gc = GC_NEXT(containers);
for (; gc != containers; gc = GC_NEXT(gc)) {
PyObject *op = FROM_GC(gc);
traverse = Py_TYPE(op)->tp_traverse;
(void) traverse(FROM_GC(gc),
(visitproc)visit_decref,
op);
}
}
Такие функции обхода удерживаются внутри исходного кода каждого объекта в Objects.
Например, функция обхода tuple,
tupletraverse(),
для всех своих элементов вызывает
visit_decref().
Аналог в типе словаря будет вызывать
visit_decref() для
всех своих ключей и значений.
Всякий объект, который не завершён, подлежит перемещению в список unreachable, выпускаемый для
следующего поколения.
Высвобождение объектов
После того как выявлены недостижимые объекты, могут быть (аккуратно) высвобождены следуя приводимым ниже шагам. Конкретный подход зависит от того, будет ли рассматриваемый тип реализовывать старый или новый слот доведения до конца.
-
Когда объект обладает завершителем в наследуемом слоте
tp_del, тогда он не способен безопасно удаляться и помечается как не подлежащий уборке. Они добавляются в списокgc.garbageс тем, чтобы их разработчик уничтожал их вручную. -
Когда некий объект имеет завершитель в слоте
tp_finalize, тогда он помечается как завершённый во избежание повторного вызова. -
Если некий объект на этапе 2 был воскрешён повторной инициализацией, тогда сборщик мусора повторно выполняет свой цикл уборки.
-
Для всех объектов вызывается слот
tp_clear. Этот слот изменяет значение счётчика ссылок,ob_refcnt, в0, включая освобождение памяти.
Сборка мусора по поколениям
Сборка мусора по поколениям это техника, основанная на том, наблюдении, что большинство объектов (80 процентов и более) уничтожаются сразу после их создания.
Сборка мусора CPython использует три поколения, которые обладают пороговыми значениями для включения их уборки. Самое юное поколение
(0) обладает самым высоким пороговым значением во избежание слишком частого запуска цикла уборки.
Если некий объект пережил уборку мусора, тогда он отправляется во второе поколение, а затем в третье.
В функции уборки целью выступает отдельное поколение и она сливает более юные поколения в себя перед исполнением. По этой причине, когда вы запускаете collect() для поколения 1, затем она будет прибирать и поколение 0. Аналогично, запуск collect() на поколении 2 будет убираться и в поколениях 0 и 1.
Когда создаются экземпляры объекта, счётчики поколения увеличиваются на единицу. Когда этот счётчик достигает порогового значения, collect() запускается автоматически.
Применение API сборки мусора из Python
Стандартная библиотека CPython поставляется с модулем Python gc для взаимодействия с конкретной
ареной и сборщиком мусора. Вот как пользоваться модулем gc в режиме отладки:
>>> import gc
>>> gc.set_debug(gc.DEBUG_STATS)
Это будет выдавать на печать статистические значения при каждом запуске сборщика мусора:
gc: collecting generation 2...
gc: objects in each generation: 3 0 4477
gc: objects in permanent generation: 0
gc: done, 0 unreachable, 0 uncollectable, 0.0008s elapsed
Вы применяете gc.DEBUG_COLLECTABLE для изучения когда элементы собраны под мусор. Когда вы
сочетаете это с флагом отладки gc.DEBUG_SAVEALL, это переместит элементы в перечень
gc.garbage, после того как они будут прибраны:
>>> import gc
>>> gc.set_debug(gc.DEBUG_COLLECTABLE | gc.DEBUG_SAVEALL)
>>> z = [0, 1, 2, 3]
>>> z.append(z)
>>> del z
>>> gc.collect()
gc: collectable <list 0x10d594a00>
>>> gc.garbage
[[0, 1, 2, 3, [...]]]
Вы можете получить величину порогового значения, после которого запускается сборщик мусора, вызвав
get_threshold():
>>> gc.get_threshold()
(700, 10, 10)
Вы также можете получить значение текущего счётчика порогового значения:
>>> gc.get_count()
(688, 1, 1)
Наконец, вы можете запускать для некого поколения алгоритм сборки мусора вручную и затем возвращать собранное итоговое значение:
>>> gc.collect(0)
24
Если вы не предписываете поколение, тогда по умолчанию им будет 2, что сольёт вместе также и
поколения 0 и 1.
В этой главе вы рассмотрели как CPython выделяет память, управляет ею и освобождает её. Эти операции происходят тысячи раз на протяжении жизненного цикла даже самого простого сценария Python. Надёжность и масштабируемость системы управления памятью CPython это именно то, что делает возможным его масштабирование со сценария из двух строк до всего того, что исполняет самые популярные в мире вебсайты.
Системы выделения памяти объектам и сырой памяти, которые были показаны в этой главе, превратятся в полезные если вы разрабатываете
модули расширения C. Модули расширения C требуют некого интимного знакомства с системой управления памятью CPython. Даже единственный
пропущенный Py_INCREF() способен вызывать утечки памяти или крушение системы.
При работе с чистым кодом Python, знакомство со сборкой мусора полезно при разработке кода с долгим временем жизни. Например, когда вы разрабатываете отдельную функцию, которая исполняется часами, днями и даже ещё дольше, тогда такая функция должна аккуратно управлять своей памятью в рамках ограничений той системы, в которой она выполняется.
Теперь вы можете применять некоторые изученные в данной главе технические приёмы для управления и регулировок поколениями сборки мусора для лучшей оптимизации своего кода и его отпечатка в памяти.
{Прим. пер.: сборка мусора и подсчёт ссылок предоставляют элегантное, но весьма затратное решение (как в отношении ресурсов, так и в отношении времени исполнения), существует подход к ускорению кода без применения сборки мусора в программах на Rust, которые способны интегрироваться с кодом Python, что описывается в нашем переводе Ускоряем ваш Python при помощи Rust Максвелл Флиттон, Packt, 2022.}