Глава 11. Объекты и типы
Содержание
CPython поставляется с неким набором базовых типов, таких как строки, списки, котрежи, словари и объекты. Все эти типы встроенные. Вам нет нужды импортировать какие бы то ни было библиотеки, причём даже из его стандартной библиотеки.
Например, чтобы создать некий новый список, вы просто вызываете list():
lst = list()
Или же вы можете воспользоваться квадратными скобками:
lst = []
Строки можно конкретизировать из литеральных строк, применяя либо двойные, либо одинарные кавычки. В Главе 4, Язык и грамматика Python , вы изучили имеющиеся определения грамматики,которые заставляют имеющийся компилятор воспринимать двойные кавычки в качестве строкового литерала.
Все типы в Python наследуются из object, некого встроенного базового типа. Даже строки, кортежи и списки
наследуются из object.
В Objects/object.c вся базовая реализация самого типа
object написана на чистом коде C. Существует несколько конкретных реализаций базовой логики, таких как
поверхностные сопоставления.
Вы можете представлять себе объект Python как состоящий из двух вещей:
-
Модели данных ядра с указателями на скомпилированные функции
-
Некий словарь со всеми индивидуальными атрибутами и методами
Большинство составляющей базового API объекта объявляется в Objects/object.c,
например, реализация встроенной функции repr() , PyObject_Repr. Вы также обнаружите PyObject_Hash() и прочие API.
Все эти функции функции могут перекрываться в неком персональном объекте через реализацию dunder methods в неком объекте Python:
class MyObject(object):
def __init__(self, id, name):
self.id = id
self.name = name
def __repr__(self):
return "<{0} id={1}>".format(self.name, self.id)
Все вместе эти встроенные функции носят название модели данных Python. Не все методы в неком объекте Python являются частью этой модели данных, что позволяет объектам Python содержать класс или экземпляр атрибутов, а также методы.
![[Совет]](/common/images/admon/tip.png) | Смотри также |
|---|---|
|
Одним из наилучших ресурсов для модели данных Pyton выступает Fluent Python, 2nd Edition, by Luciano Ramalho. |
На протяжении этой главы всякий поясняемый тип будет содержать некий пример. В таком примере вы будете реализовывать оператор почти эквивалентности. который вы собирали в более ранних главах.
Если вы ещё не осилили те подобные замены, которые подробно изложены в главах по грамматике и компилятору CPython, тогда несомненно вернитесь обратно и сделайте это, прежде чем продолжить. Это необходимо для реализации всех приводимых ниже примеров.
Модель данных ядра определена в PyTypeObject, а основные функции определяются в
Objects/typeobject.c.
Каждый из исходных файлов обладает соответствующим заголовком в Include. Например,
Objects/rangeobject.c имеет файл заголовка
Include/rangeobject.h.
Вот список исходных файлов и соответствующие им типы:
| Исходный файл | Тип |
|---|---|
|
Встроенные методы и базовый объект |
|
Тип |
|
Тип |
|
Тип |
|
Тип |
|
Абстракция типа |
|
Встроенный тип объекта |
|
Тип комплексного числа |
|
Тип итератора |
|
Тип |
|
Численный тип |
|
Тип базовой памяти |
|
Тип метода класса |
|
Тип модуль |
|
Тип пространства имён |
|
Тип упорядоченного словаря |
|
Тип генертора диапазона |
|
Тип |
|
Тип ссылки на долю |
|
Тип |
|
Тип |
|
Тип |
|
Тип |
|
Тип |
В этой главе мы изучим некоторые из этих типов.
Поскольку C не является объектно- ориентированным языком в отличии от Python, объекты в C не наследуются один из другого. PyObject выступает изначальным
сегментом данных для каждого объекта Python, а PyObject * представляет ссылку на него.
При определении типов Python собственно typedef применяет один из следующих макросов:
-
PyObject_HEAD (PyObject)для простого типа -
PyObject_VAR_HEAD (PyVarObject)для типа контейнера
Самый простой тип PyObject обладает следующими полями:
| Поле | Тип | Назначение |
|---|---|---|
|
|
Счётчик ссылок на экземпляр |
|
|
Тип объекта |
Например, cellobject определяет одно дополнительное поле, ob_ref
и эти базовые поля:
typedef struct {
PyObject_HEAD
PyObject *ob_ref; /* Content of the cell or NULL when empty */
} PyCellObject;
Тип переменной, PyVarObject, расширяет этот тип PyObject и
также обладает следующими полями:
| Поле | Тип | Назначение |
|---|---|---|
|
|
Базовый тип |
|
|
Число содержащихся в нём элементов |
Например, тип int, PyLongObject, обладает следующим описанием:
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
}; /* PyLongObject */
В Python объекты обладают свойством ob_type. Вы можете получить значение этого свойства при помощи
встроенной функции type():
>>> t = type("hello")
>>> t
<class 'str'>
Результатом type() выступает некий экземпляр PyTypeObject
>>> type(t)
<class 'type'>
Объекты типа используются для определения самой реализации абстракции базовых классов.
Например, объекты всегда реализуют метод __repr__():
>>> class example:
... x = 1
>>> i = example()
>>> repr(i)
'<__main__.example object at 0x10b418100>'
Реализация __repr__() всегда пребывает по тому же самому адресу в самом типе определения всякого
объекта. Эта позиция именуется слотом типа.
Все слоты типов определены в Include/cpython/object.h.
Каждый слот типа обладает неким названием свойства и функцией подписи. Функция __repr__(), например,
носит название tp_repr и обладает подписью reprfunc:
struct PyTypeObject
---
typedef struct _typeobject {
...
reprfunc tp_repr;
...
} PyTypeObject;
Такая подпись reprfunc определена в
Include/cpython/object.h как обладающая единственным аргументом
PyObject* (self):
typedef PyObject *(*reprfunc)(PyObject *);
В качестве примера, cellobject реализует слот tp_repr при
помощи функции cell_repr:
PyTypeObject PyCell_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"cell",
sizeof(PyCellObject),
0,
(destructor)cell_dealloc, /* tp_dealloc */
0, /* tp_vectorcall_offset */
0, /* tp_getattr */
0, /* tp_setattr */
0, /* tp_as_async */
(reprfunc)cell_repr, /* tp_repr */
...
};
Помимо базовых слотов типов PyTypeObject, обозначаемых префиксом
tp_, имеются прочие типы определений слотов:
| Тип слота | Префикс |
|---|---|
|
|
|
|
|
|
|
|
|
|
Все слоты типов обладают заданным уникальным номером, определяемым в
Include/typeslots.h. При ссылке на слот типа некого объекта, или же при
его выборке, вы обязаны пользоваться этими константами.
К примеру, tp_repr обладает положением константы 66, эта
константа Py_tp_repr всегда ставит в соответствие положение данного слота типа. Эти константы полезны при
проверке того, что некий объект реализует определённую функцию слота типа.
Внутри модулей расширения C и в самом коде CPython вы часто будете работать с типом PyObject*.
Например, если вы запускаете x[n] в неком объекте с индексацией, таком как список или строка, тогда
это вызовет PyObject_GetItem(),
который просмотрит соответствующий объект x чтобы определить как его индексировать, строка 146
Objects/abstract.c:
PyObject *
PyObject_GetItem(PyObject *o, PyObject *key)
{
PyMappingMethods *m;
PySequenceMethods *ms;
...
PyObject_GetItem() обслуживает как типы сопоставления, такие как словари, так и типы последовательностей, такие как списки и кортежи.
Когда соответствующий экземпляр, o, обладает методами последовательности, тогда
o->ob_type->tp_as_sequence будет вычисляться истинным. К тому же, если этот экземпляр обладает
определённой функцией слота sq_item, тогда предполагается, что он обладает верно реализованным протоколом
своей последовательности.
Само значение key вычисляется для проверки что это целое и данный элемент запрашивается из соответствующего
объекта последовательности при помощи
PyObject_GetItem():
ms = o->ob_type->tp_as_sequence;
if (ms && ms->sq_item) {
if (PyIndex_Check(key)) {
Py_ssize_t key_value;
key_value = PyNumber_AsSsize_t(key, PyExc_IndexError);
if (key_value == -1 && PyErr_Occurred())
return NULL;
return PySequence_GetItem(o, key_value);
}
else {
return type_error("sequence index must "
"be integer, not '%.200s'", key);
}
}
Python поддерживает определение новых типов при помощи ключевого слова class. Определяемые
пользователем типы создаются type_new() из модуля объекта самого типа.
Определяемые пользователем типы будут обладать словарём свойств, доступным через __dict__(), причём
реализуемый по умолчанию __getattr__() выполняет поиск в этом словаре свойств. Методы класса, свойства
класса и свойства экземпляра, все они располагаются в этом словаре.
PyObject_GenericGetDict()
реализует собственно логику извлечения такого экземпляра словаря для заданного объекта.
PyObject_GetAttr() реализует
устанавливаемую по умолчанию реализацию __getattr__(), а
PyObject_SetAttr() реализует
__setattr__().
|
| Смотри также |
|---|---|
|
Существует множество индивидуальных типов и они были в значительной степени документированы. Можно написать целую книгу по метаклассам, но в данной книге вы придерживаетесь лишь собственно реализации.. Если вы желаете подробнее изучить метапрограммирование, отсылаем вас к книге Real Python Python Metaclasses. |
Тип bool это самая простая реализация из всех встроенных типов. Он наследуется из
long и обладает предопределёнными константами Py_True и Py_False.
Эти константы являются неизменными экземплярами, создаваемые самой конкретизацией
интерпретатора Python.
Внутри Objects/boolobject.c вы можете обнаружить вспомогательную
функцию создания некого экземпляра bool из числа, строка 28
Objects/boolobject.c:
PyObject *PyBool_FromLong(long ok)
{
PyObject *result;
if (ok)
result = Py_True;
else
result = Py_False;
Py_INCREF(result);
return result;
}
Эта функция применяет соответствующее вычисление C численного типа для назначения Py_True и
Py_False результата и увеличения на единицу соответствующих счётчиков ссылок.
Реализуются численные функции для and, xor и
or, однако, сложение, вычитание и деление разыменовываются из базового типа
long, поскольку нет смысла с делении двух Булевых значений.
Реализация and для значения bool вначале проверяет что
a и b являются Булевыми. Если это не так, они приводятся к целым
и соответствующая операция and выполняется с двумя числами, строка 61
Objects/boolobject.c:
static PyObject *
bool_and(PyObject *a, PyObject *b)
{
if (!PyBool_Check(a) || !PyBool_Check(b))
return PyLong_Type.tp_as_number->nb_and(a, b);
return PyBool_FromLong((a == Py_True) & (b == Py_True));
}
Тип long слегка сложнее чем bool. При переходе с Python 2
на Python 3, CPython отбросил поддержку для типа int и вместо него применяет тип
long как самый первичный тип целого.
Тип Python long достаточно специфичен в отношении того, что он способен хранить числа переменной
длины. Значение максимальной длины устанавливается в самом компилируемом исполняемом файле.
Структура данных long Python составляется из заголовка переменной
PyObject и списка цифр. Этот список цифр, ob_digit, изначально
устанавливается на наличие одной цифры, однако при инициализации он расширяется на большую длину, строка 85
Include/longintrepr.h:
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
Например, число 1 имело бы ob_digit [1], а число
24601 обладало бы ob_digit [2, 4, 6, 0, 1].
Для нового long память выделяется посредством _PyLong_New().
Эта функция получает фиксированные длины и проверяет что они меньше чем MAX_LONG_DIGITS. Затем
она перераспределяет необходимую память для ob_digit чтобы соответствовать необходимой длине.
Для преобразования типа long C в тип long Python, этот
long C конвертируется в список цифр, выделяется память под соответствующий
long Python и затем устанавливаются все цифры.
Для чисел с единственной цифрой, наш объект long инициализируется с
ob_digit уже имеющей длину 1, затем его значение устанавливается
без выделения дополнительной памяти, строка 297 Objects/longobject.c:
PyObject *
PyLong_FromLong(long ival)
{
PyLongObject *v;
unsigned long abs_ival;
unsigned long t; /* unsigned so >> doesn't propagate sign bit */
int ndigits = 0;
int sign;
CHECK_SMALL_INT(ival);
...
/* Fast path for single-digit ints */
if (!(abs_ival >> PyLong_SHIFT)) {
v = _PyLong_New(1);
if (v) {
Py_SIZE(v) = sign;
v->ob_digit[0] = Py_SAFE_DOWNCAST(
abs_ival, unsigned long, digit);
}
return (PyObject*)v;
}
...
/* Larger numbers: loop to determine number of digits */
t = abs_ival;
while (t) {
++ndigits;
t >>= PyLong_SHIFT;
}
v = _PyLong_New(ndigits);
if (v != NULL) {
digit *p = v->ob_digit;
Py_SIZE(v) = ndigits*sign;
t = abs_ival;
while (t) {
*p++ = Py_SAFE_DOWNCAST(
t & PyLong_MASK, unsigned long, digit);
t >>= PyLong_SHIFT;
}
}
return (PyObject *)v;
}
Для преобразования чисел двойной точности с плавающей запятой в long Python,
PyLong_FromDouble() выполняет для
вас необходимую математику.
Остаток реализации функций в Objects/longobject.c
обладают утилитами, такими как преобразование строки Unicode в число при помощи
PyLong_FromUnicodeObject().
Всё богатство сравнений слота типов для long установлено в
long_richcompare(). Эта функция
обёртывает long_compare():
static PyObject *
long_richcompare(PyObject *self, PyObject *other, int op)
{
Py_ssize_t result;
CHECK_BINOP(self, other);
if (self == other)
result = 0;
else
result = long_compare((PyLongObject*)self, (PyLongObject*)other);
Py_RETURN_RICHCOMPARE(result, 0, op);
}
long_compare() вначале проверяет значение длины (число цифр) двух переменных
a и b. Если длины равны, тогда она проходит в цикле по
всем цифрам на предмет равны ли они друг другу.
long_compare() возвращает одно из трёх типов значений:
-
Когда
a < b, она возвращает отрицательное число. -
Когда
a == b, она возвращает ноль. -
Когда
a > b, она возвращает положительное число.
Например, когда вы вычисляете 1 == 5, result равен
-4. Для 5 == 1 получается
4.
Вы можете реализовать следующий блок кода прежде чем макро Py_RETURN_RICHCOMPARE возвратит
True при результате абсолютного значения <=1. Применяется
соответствующий макро Py_ABS(), который возвращает абсолютное значение целого со знаком:
if (op == Py_AlE) {
if (Py_ABS(result) <= 1)
Py_RETURN_TRUE;
else
Py_RETURN_FALSE;
}
Py_RETURN_RICHCOMPARE(result, 0, op);
После повторной компиляции Python, вы должны обнаружить воздействие этого изменения:
>>> 2 == 1
False
>>> 2 ~= 1
True
>>> 2 ~= 10
False
Строки Python Unicode сложны. Кросс-платформенные типы Unicode сложны на любой платформе.
Основной причиной такой сложности является количество предлагаемых кодировок и различные конфигурации по умолчанию на тех платформах, которые поддерживает Python.
Строковый тип Python 2 хранился в C с применением типа char. Однобайтовый тип
char в достаточной степени хранит всякий из символов ASCII (American Standard Code for Information
Interchange) и применялся в программировании компьютеров с 1970-х.
ASCII не поддерживает тысячи языков и наборов символов, которые применяются по всему миру. Кроме того, существуют расширенные наборы символьных глифов, таких как эмодзи, которые она не способна поддерживать.
Для решения этих проблем была введена консорциумом Unicode в 1991 году стандартная система кодирования и базы данных символов, носящая название стандарта Unicode. Современный стандарт Unicode содержит символы для всех языков с написанием, а также расширенные глифы и символы.
База данных символов Unicode (UCD, Unicode Character Database ) содержит 143 859 именованных символов в версии 13.0, по сравнению с всего лишь 128 в ASCII. Стандарт Unicode определяет эти символы в некой таблице символов с названием UCS (Universal Character Set, универсальный набор символов). Каждый символ обладает уникальным идентификатором, носящим название точки кодирования (code point).
Существует множество различных кодировок, которые пользуются стандартом Unicode и преобразовывают точки кодирования в двоичные значения.
Строки Unicode Python поддерживают три длины кодировок:
-
1- байтовую (8- бит)
-
2- байтовую (16- бит)
-
4- байтовую (32- бита)
Эти кодировки переменной длины внутри имеющейся реализации обладают следующими отражениями:
-
1- байтовый
Py_UCS1, хранимый как 8- битовый типintбез знакаuint8_t -
2- байтовый
Py_UCS2, хранимый как 16- битовый типintбез знакаuint16_t -
4- байтовый
Py_UCS4, хранимый как 32- битовый типintбез знакаuint32_t
Вот те исходные файлы, которые относятся к строкам:
| Файл | Назначение |
|---|---|
|
Определение объекта строки Unicode |
|
Определение объекта строки Unicode |
|
Реализация объекта строки Unicode |
|
Пакет |
|
Модуль кодеков |
|
Модуль расширений C кодеков, реализация специфичных для ОС кодировок |
|
Реализации кодеков для диапазона альтернативных кодировок |
CPython не содержит копию собственно UCD (базы данных символов Unicode), также ему не приходится обновлять всякий раз сценарии и символы, добавляемые в сам стандарт Unicode.
Строки Unicode в CPython заботятся лишь о кодировании. Сами операционные системы обрабатывают основную задачу представления позиций кода в своём правильном сценарии.
Сам стандарт Unicode содержит UCD и регулярно обновляет её новыми сценариями, эмодзи и символами. Операционные системы берут эти обновления Unicode и обновляют своё программное обеспечение через исправления. Такие исправления содержат новые позиции кода UCD и поддерживают различные кодировки Unicode. Сама UCD расщепляется на разделы с названием кодовых блоков.
Таблицы кода Unicode публикуются на вебсайте Unicode.
Другим моментом поддержки Unicode выступает веб браузер. Веб браузеры декодируют двоичные данные HTML в соответствии с преобразованием кодировки заголовка HTTP. Когда вы работаете с CPython в качестве веб сервера, тогда ваше кодирование Unicode обязано соответствовать заголовкам HTTP, подлежащим отправке вашим пользователям.
Существуют две распространённые кодировки:
-
UTF-8 это 8- битная кодировка символов, которая поддерживает все возможные символы в имеющейся UCD с позициями кода от 1 до 4 байт
-
UTF-16 это 16- битная кодировка символов, аналогичная UTF-8, но не совместимая с 7- или 8- битными кодировками, такими как ASCII.
UTF-8 это наиболее распространённая кодировка Unicode.
Во всех кодировках Unicode, кодовые позиции могут представляться при помощи шестнадцатеричных условных обозначений. Вот несколько примеров:
-
U+00F7для символа деления ('÷') -
U+0107для Латинской строчной c с острым ударением (с акутом,'ć')
В Python, кодовые позиции Unicode могут кодироваться непосредственно в самом коде при помощи символа экранирования
\u и соответствующего шестнадцатеричного значения его позиции кодирования:
>>> print("\u0107")
ć
CPython не пытается дополнять такие данные, поэтому если вы попробуете \u10, тогда он выдаст вам
следующую исключительную ситуацию:
>>> print("\u107")
File "<stdin>", line 1
SyntaxError: (unicode error) 'unicodeescape' codec can't decode
bytes in position 0-4: truncated \uXXXX escape
И XML, и HTML поддерживают позиции кодирования Unicode со специальным символом экранирования &#val;,
где val это десятичное значение позиции кодирования. Когда вам требуется преобразовывать позиции кодирования
Unicode в XML или HTML, тогда вы можете применять обработчик xmlcharrefreplace из метода
.encode():
>>> "\u0107".encode('ascii', 'xmlcharrefreplace')
b'ć'
Его вывод будет содержать позицию кодирования, экранированную HTML или XML. Все современные браузеры будут декодировать эти экранированные последовательности в правильные символы.
Когда вы работаете с кодированным ASCII текстом, тогда важно понимать основное отличие между UTF-8 и UTF-16. UTF-8 обладает большим преимуществом совместимости с кодированным ASCII текстом. Преобразование ASCII является кодированием 7- бит.
Самые первые 128 позиций кодирования стандарта Unicode представляют собой имеющиеся в стандарте ASCII 128 символы. Например, Латинская буква
"a" это 97- й символ в ASCII и 97- й символ в Unicode. Десятичные 97 эквивалентны 61
в шестнадцатеричной системе счисления, следовательно позицией кода Unicode для "a" выступает
U+0061.
В своём REPL вы можете создавать значение двоичного кода для буквы "a":
>>> letter_a = b'a'
>>> letter_a.decode('utf8')
'a'
Её можно правильно декодировать в UTF-8.
UTF-16 работает с кодовыми позициями от 2 до 4 байт. Соответствующее однобайтовое представление буквы "a"
не будет декодировано:
>>> letter_a.decode('utf16')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-16-le' codec can't decode
byte 0x61 in position 0: truncated data
На это важно обращать внимание при выборе механизма кодирования. UTF-8 является более безопасным вариантом, когда вам требуется импортировать кодированные ASCII данные.
Когда вы обрабатываете входную строку Unicode с неизвестной кодировкой при помощи исходного кода CPython, тогда будет применяться тип C
wchar_t.
wchar_t это стандарт C для строк с широкими символами и его достаточно для хранения в памяти строк
Unicode. После PEP 393 именно тип
wchar_t был выбран в качестве формата хранения Unicode. Сам объект строки Unicode предоставляет
PyUnicode_FromWideChar(), функцию утилиты, которая будет преобразовывать константу
wchar_t в объект строки.
Например, pymain_run_command(),
применяемая python -c, преобразует значение аргумента -c в
строку Unicode, строка 226 Modules/main.c:
static int
pymain_run_command(wchar_t *command, PyCompilerFlags *cf)
{
PyObject *unicode, *bytes;
int ret;
unicode = PyUnicode_FromWideChar(command, -1);
При декодирования неких входных данных, таких как файл, CPython определяет значение порядка байт из маркера порядка байт (BOM, byte order mark). BOM это особые символы, которые появляются в самом начале потока байт Unicode. Они сообщают получателю в каком именно порядке сохранены их данные.
Различные вычислительные системы могут выполнять кодирование с различными порядками байт. Если вы воспользуетесь неверным порядком байт, даже при верном кодировании, тогда ваши данные будут искажёнными. Обратный (big-endian, "тупоголовый") порядок размещает наиболее значимый байт первым. Прямой (little-endian, "остроконечный") порядок помещает первым наименее значимый байт.
Спецификация UTF-8 поддерживает BOM, однако он не оказывает воздействия. UTF-8 BOM может появляться в самом начале последовательности
кодированных данных, в представлении b'\xef\xbb\xbf' и будет указывать CPython что его поток данных, скорее
всего, UTF-8. UTF-16 и UTF-32 поддерживают прямой и обратный BOM.
Значение по умолчанию порядка байт в CPython устанавливается глобальным значением sys.byteorder:
>>> import sys; print(sys.byteorder)
little
Пакет encodings из Lib/encodings
поставляется с более чем сотней встроенных поддерживаемых кодировок для CPython. Всякий раз когда вызывается метод
.encode() или .decode() из строки или байтовой строки, соответствующая
кодировка отыскивается в этом пакете.
Каждая кодировка определяется как некий отдельный модуль. Например, ISO2022_JP это широко применяемая
кодировка для Японских систем электронной почты и она определяется в
Lib/encodings/iso2022_jp.py.
Все модули кодировок будут определять функцию getregentry() и регистрировать следующие характеристики:
-
Её уникальное название
-
Её функции кодирования и декодирования из модуля кодека
-
Её классы приращения на единицу кодера и декодера
-
Её классы считывания из потока и записи в поток
Многие модули кодирования совместно используют одни и те же кодеки либо из модуля
codecs, либо из модуля _mulitbytecodec. Неоторые модули
кодировок применяют отдельный модуль кодека на C из Modules/cjkcodecs.
Например, модуль кодирования ISO2022_JP импортирует некий модуль расширения C,
_codecs_iso2022.c, из
Modules/cjkcodecs/_codecs_iso2022.c:
import _codecs_iso2022, codecs
import _multibytecodec as mbc
codec = _codecs_iso2022.getcodec('iso2022_jp')
class Codec(codecs.Codec):
encode = codec.encode
decode = codec.decode
class IncrementalEncoder(mbc.MultibyteIncrementalEncoder,
codecs.IncrementalEncoder):
codec = codec
class IncrementalDecoder(mbc.MultibyteIncrementalDecoder,
codecs.IncrementalDecoder):
codec = codec
Пакет encodings также обладает модулем
Lib/encodings/aliases.py, который содержит некий словарь
aliases. Этот словарь применяется для установки соответствия в реестре альтернативными названиями. К
примеру, utf8, utf-8 и
u8 вся являются псевдонимами кодировки utf_8.
Модуль codecs обрабатывает необходимую трансляцию данных со специфической кодировкой. Соответствующие
функции кодирования и декодирования определённой кодировки могут достигаться при помощи getencoder() и
getdecoder(), соответственно:
>>> iso2022_jp_encoder = codecs.getencoder('iso2022_jp')
>>> iso2022_jp_encoder('\u3072\u3068') # hi-to
(b'\x1b$B$R$H\x1b(B', 2)
Соответствующая функция кодирования вернёт двоичный результат и значение числа байт в выводе в качестве кортежа.
codecs также реализует встроенную функцию open() для
открытия обработчиков файла из своей операционной системы.
Реализация объекта Unicode (Objects/unicodeobject.c) содержит
следующие модули кодировок:
| Кодек | Кодировщик |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Все методы декодирования будут обладать аналогичными названиями, но с заменой Decode на
Encode.
Реализация прочих методов кодирования располагается внутри Modules/_codecs
чтобы не загромождать реализацию основного объекта строк Unicode. Кодеки unicode_escape и
raw_unicode_escape являются внутренними для CPython.
CPython поставляется с неким числом внутренних кодировок. Они уникальны для CPython и полезны для некоторых функций его стандартной библиотеки, а также при работе с производимым исходным кодом.
Для любого входного и выходного текста могут использоваться такие кодировки текста:
| Кодек | Назначение |
|---|---|
|
Реализует RFC 3490 |
|
Кодирует в соответствии с кодовой страницей ANSI (только Windows) |
|
Преобразовывает в строки для сырых литералов в исходном коде Python |
|
Преобразовывает в строчные литералы для исходного кода Python |
|
Пробует установленную по умолчанию в системе кодировку |
|
Преобразовывает в литералы Unicode для исходного кода Python |
|
Возвращает внутреннее представление CPython |
Также имеются некоторые кодировки только в двоичном виде, которые требуются для применения с
codecs.encode() и codecs.decode() для входных байтовых
строк, например таких:
>>> codecs.encode(b'hello world', 'base64')
b'aGVsbG8gd29ybGQ=\n'
Вот перечень таких кодировок только в двоичном представлении:
| Кодек | Псевдонимы | Назначение |
|---|---|---|
|
|
Преобразовывает в MIME base64 |
|
|
Сжимает строку при помощи bz2 |
|
|
Преобразовывает в шестнадцатеричное представление с двумя цифрами на байт |
|
|
Преобразовывает в операнды в MIME в кавычках для вывода на печать |
|
|
Возвращает кодирование шифром Цезаря (сдвиг на 13 позиций) |
|
|
Преобразовывает с применением uuencode |
|
|
Сжимает при помощи gzip |
Наш слот типа tp_richcompare выделен для
PyUnicode_RichCompare() в PyUnicode_Type. Эта функция
выполняет сравнение строк и может быть приспособлена для применения нашего оператора ~=. Это поведение
вы реализуете в нечувствительном к регистру сравнению двух строк.
Прежде всего, добавим некое предложение варианта для проверки того когда левая и правая строки эквивалентны в двоичном виде, строка 11361
Objects/unicodeobject.c:
PyObject *
PyUnicode_RichCompare(PyObject *left, PyObject *right, int op)
{
...
if (left == right) {
switch (op) {
case Py_EQ:
case Py_LE:
>>> case Py_AlE:
case Py_GE:
/* a string is equal to itself */
Py_RETURN_TRUE;
Затем добавим новый блок else if для обработки своего оператора
Py_AlE. Это осуществят такие наши действия:
-
Преобразовать левую строку в некую новую строку в верхнем регистре
-
Преобразовать правую строку в некую новую строку в верхнем регистре
-
Сравнить эти две строки
-
Разыменовать эти обе временные строки с тем чтобы вернуть память
-
Вернуть полученный результат
Ваш код должен выглядеть как- то так:
else if (op == Py_EQ || op == Py_NE) {
...
}
/* Add these lines */
else if (op == Py_AlE){
PyObject* upper_left = case_operation(left, do_upper);
PyObject* upper_right = case_operation(right, do_upper);
result = unicode_compare_eq(upper_left, upper_right);
Py_DECREF(upper_left);
Py_DECREF(upper_right);
return PyBool_FromLong(result);
}
После выполнения вами повторной компиляции, ваше не чувствительное к регистру сопоставление строк должно в вашем REPL выдавать такие результаты:
>>> "hello" ~= "HEllO"
True
>>> "hello?" ~= "hello"
False
Словари являются быстрым и гибким типом соответствия. Они применяются разработчиками для хранения данных и установления их соответствия, также как и объектов, в равной степени, с целью запоминания свойств и методов.
Словари Python также применяются для локальных и глобальных переменных, для аргументов ключевых слов и во многих прочих ситуациях. Словари Python компактны, что означает, что сами таблицы хэширования хранят лишь значения соответствия.
Сам алгоритм хэширования, который выступает частью всех неизменных встроенных типов является быстрым. Именно это придаёт словарям Python их скорость.
Все неизменные встроенные типы предоставляют некую функцию хэширования. Она определена в слоте типа tp_hash,
или, для настраиваемых (индивидуальных) типов при помощи магического метода __hash__(). Хэш- значения
имеют тот же размер что и указатель (64 бита для 64- битных систем, 32 бита для 32- битных систем), однако они не представляют своими величинами
значения адреса в памяти.
Получаемый в результате хэш для любого объекта Python не должен изменяться в процессе его времени жизни. Хэши для двух неизменных экземпляров с идентичными значениями обязаны быть равными:
>>> "hello".__hash__() == ("hel" + "lo").__hash__()
True
Не должно существовать никаких коллизий хэширования. Два объекта с различными значениями обязаны производить различные хэш- значения.
Некоторые хэш- значения просты, например, longs Python:
>>> (401).__hash__()
401
Для длинных значений хэширование long выдаётся более сложным:
>>> (401123124389798989898).__hash__()
2212283795829936375
Многие встроенные типы пользуются модулем Python/pyhash.c , который
предоставляет следующие вспомогательные функции хэширования:
-
Байты:
_Py_HashBytes(const void*, Py_ssize_t) -
Числа двойной точности:
_Py_HashDouble(double) -
Указатели:
_Py_HashPointer(void*)
Строки Unicode, к примеру, применяют для хэширования байтовых данных своих строк _Py_HashBytes():
>>> ("hello").__hash__()
4894421526362833592
Настраиваемые классы могут определять функцию хэширования через реализацию __hash__(). Вместо
реализации некого индивидуального хэширования, настраиваемые классы обязаны применять некое
уникальное свойство. Убедитесь что оно неизменно при выполнении доступного только
для чтения свойства, затем хэшируйте его воспользовавшись встроенной hash():
class User:
def __init__(self, id: int, name: str, address: str):
self._id = id
def __hash__(self):
return hash(self._id)
@property
def id(self):
return self._id
Экземпляры этого класса теперь можно хэшировать:
>>> bob = User(123884, "Bob Smith", "Townsville, QLD")
>>> hash(bob)
123884
Этот экземпляр теперь можно применять в качестве некого ключа словаря:
>>> sally = User(123823, "Sally Smith", "Cairns, QLD")
>>> near_reef = {bob: False, sally: True}
>>> near_reef[bob]
False
Множества снизят дублирование хэш- значений этого экземпляра:
>>> {bob, bob}
{<__main__.User object at 0x10df244b0>}
Вот те исходные файлы, которые относятся к словарям:
| Файл | Назначение |
|---|---|
|
Определение API объекта словаря |
|
Определение типов объекта словаря |
|
Реализация объекта словаря |
|
Определение записи ключа и объектов ключа |
|
Внутренний алгоритм хэширования |
Некий объект словаря, PyDictObject составляется из таких элементов:
-
Свойств словаря объекта, содержащих его размер, тег версии и сами ключи и значения
-
Объект таблицы ключей словаря,
PyDictKeysObject, содержащий сами ключи и хэш- значения всех записей
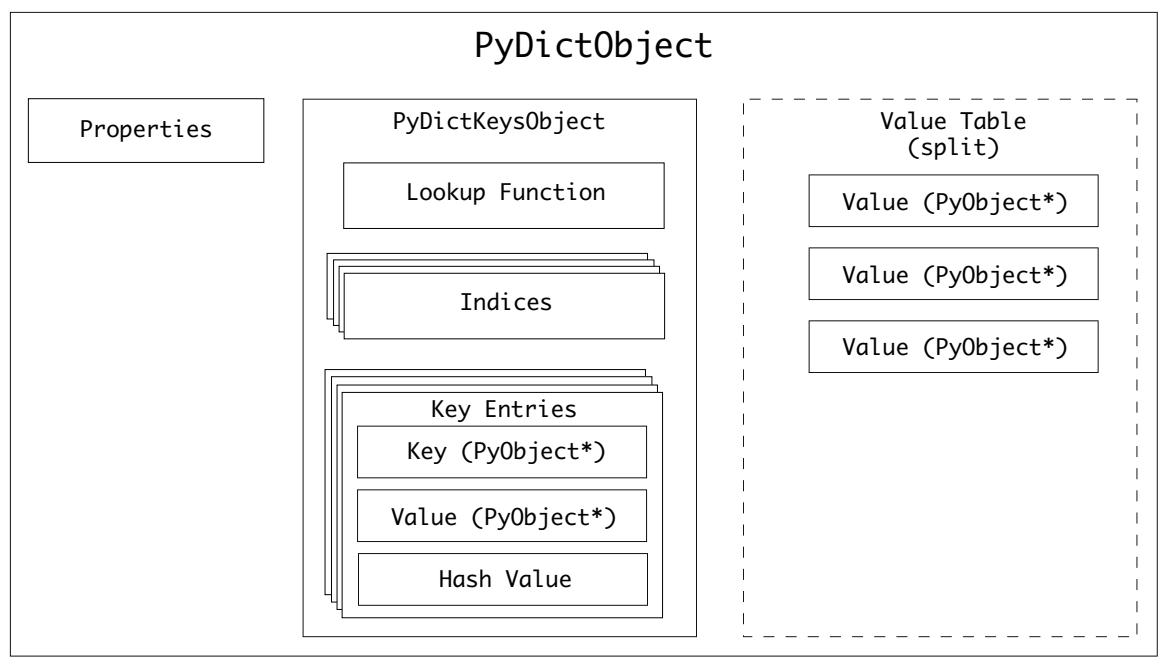
Наш PyDictObject обладает следующими свойствами:
| Поле | Тип | Назначение |
|---|---|---|
|
|
Объект таблицы ключей словаря |
|
|
Число содержащихся в этом словаре |
|
|
Не обязательный массив значений (см. Замечание) |
|
|
Номер версии этого словаря |
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Словари способны обладать одним из двух состояний: расщеплённом или комбинированном. Когда словари комбинированы, соответствующие указатели на значении этого словаря хранятся в объектах их ключей. Когда словарь расщеплён, его значения хранятся в неком отдельном свойстве, |
Наша таблица ключей словаря PyDictKeysObject обладает следующими свойствами:
| Поле | Тип | Назначение |
|---|---|---|
|
|
Размещение массива записей ключей словаря |
|
|
Таблица хэш- значений и соответствий для |
|
|
Функция обнаружения (см. следующий раздел) |
|
|
Значения числа используемых записей в общей таблице записей |
|
|
Счётчик ссылок |
|
|
Значения размера самой таблицы хэширования |
|
|
Общее число используемых записей в общей таблице записей, при изменении размера словаря
|
Запись ключа словаря PyDictKeyEntry обладает следующими свойствами:
| Поле | Тип | Назначение |
|---|---|---|
|
|
Кэшированный хэш код |
|
|
Указатель на сам объект ключа |
|
|
Указатель на значение объекта |
Для заданного объекта ключа имеется некая общая функция поиска: lookdict().
Поиск по словарю обязан удовлетворять трём моментам:
-
Значение адреса памяти этого ключа имеется в общей таблице ключей.
-
Хэш- значение его объекта имеется в общей таблице ключей.
-
Сам ключ не имеется в его словаре.
|
| Смотри также |
|---|---|
|
Сама функция обнаружения основывается на знаменитой книге Дональда Кнута The Art of Computer Programming Смотрите Главу 6, раздел 4 по хэшиованию. |
Вот сама последовательность поиска:
-
Получить хэш значение для
ob. -
Отыскать это хэш значение
obв общем словаре ключей и получить его значение индекса,ix. -
Если
ixпустой, тогда вернутьDKIX_EMPTY(не найден). -
Получить запись ключа,
ep, для определённого значения индекса. -
Когда значения ключей совпадают по причине самого объекта, тогда
obэто тот же самый указатель в этом значении ключа. Вернуть полученный результат. -
Если эти хэш значения ключа совпадают по причине самого объекта,
ob, разрешить то же самое значение хэша какep->me_mash, затем вернуть полученный результат.
|
| Замечание |
|---|---|
|
Атрибут Документация GCC, “Common Function Attributes”. Это особенность компиляторов GCC, однако при компиляции с помощью Проводимой профилем оптимизации, эта функция, скорее всего, будет автоматически оптимизирована компилятором. |
Теперь, когда вы рассмотрели реализацию встроенных типов, вы готовы изучать всё остальное.
При изучении классов Python важно помнить, что имеются встроенные типы, написанные на C и классы, наследуемые из этих типов, написанные на Python или C.
Некоторые библиотеки обладают типами, написанными на C вместо наследования из имеющихся встроенных типов. Одним из примеров выступает NumPy, библиотека для числовых массивов. Её тип nparray написан на C и обладает высокими эффективностью и производительностью.
В своей следующей главе вы изучите те классы и функции, которые определены в имеющейся стандартной библиотеке.