Глава 10. Параллельность и одновременность
Содержание
- Глава 10. Параллельность и одновременность
- Модели параллельности и одновременности
- Структура процесса
- Многопроцессный параллелизм
- Ветвление процесса в POSIX
- Многопроцессность в Windows
- Пакет
multiprocessing - Относящиеся к делу файлы
- Порождение и ветвление процессов
- Создание дочернего процесса
- Конвейеризация данных дочернему процессу
- Исполнение дочернего процесса
- Обмен данными при помощи очередей и конвейеров
- Разделяемые состояния между процессами
- Аннотация мультипроцессности
- Многопоточность
- Асинхронное программирование
- Генераторы
- Сопрограммы
- Асинхронные генераторы
- Подчинённые интерпретаторы
- Выводы
Самые первые компьютеры проектировались для выполнения одной вещи за раз. Бо́льшая часть их работы состояла в области вычислительной математики. Время шло, и компьютерам потребовалось обрабатывать входные данные из разнообразных источников, некоторые из которых настолько далеки, как расстояния галактик.
Последствие этого состоит в том, что компьютерные приложения теперь тратят большую часть времени впустую на ожидание для отклика, будь он из шины, входных данных, расположения в памяти, вычислениях, неком API или в удалённом ресурсе.
Другим движением вперёд в вычислениях был уход от однопользовательского терминала к многозадачным операционным системам. Приложениям требуется исполняться в фоновом режиме для ожидания откликов из сетевой среды и обработки входных данных, таких как перемещения курсора мыши.
Многозадачность была хорошо востребована до наступления современных многоядерных ЦПУ, поэтому операционная система долгое время была способна разделять совместные ресурсы между множеством процессов.
В ядре любой операционной системы заложена регистрация запущенных процессов. Всякий процесс обладает неким владельцем, а также он способен потреблять ресурсы, такие как оперативная память и ЦПУ. В нашей последней главе вы изучили выделение памяти.
Для некого ЦПУ соответствующий процесс запрашивает время ЦПУ в виде подлежащих исполнению операций. Он делает это распределяя время ЦПУ и планируя процессы по приоритетам:
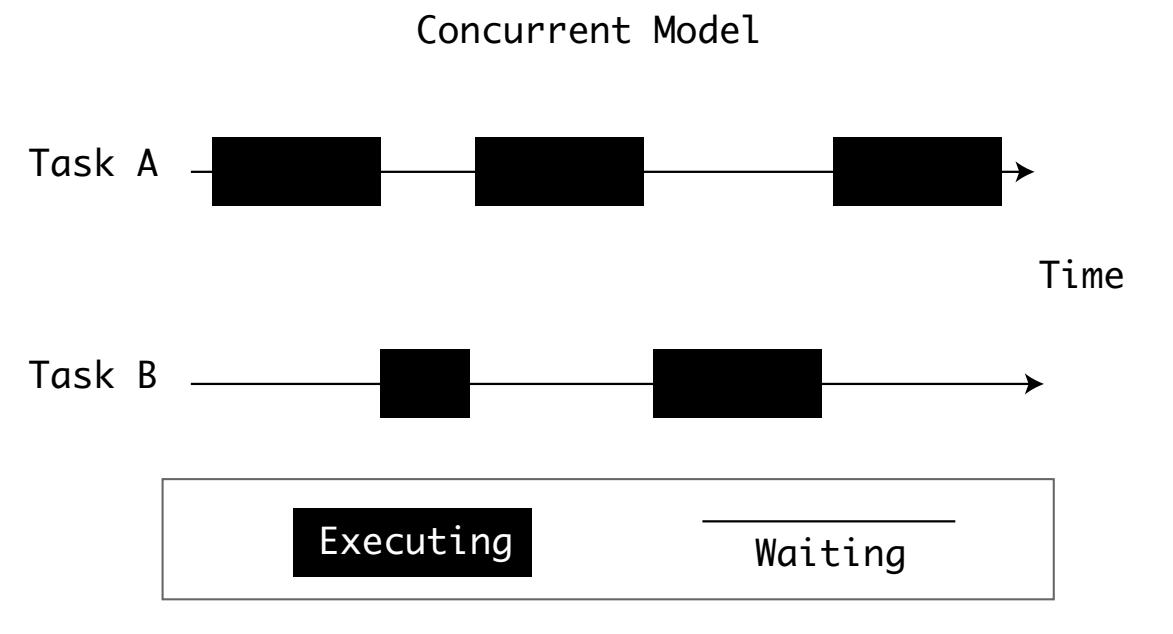
Некому отдельному процессу может потребоваться выполнять более одной вещи за раз. Например, когда вы пользуетесь текстовым процессором, он проверяет правильность написание в то время как вы выполняете набор. Современные приложения осуществляют это выполняя множество потоков одновременно и обрабатывая их собственные ресурсы.
Одновременность (concurrency) это исключительное решение для ведения дел с многозадачностью, однако ЦПУ обладают своими собственными пределами. Некоторые высокопроизводительные компьютеры для растягивания задач применяют развёртывание либо множества ЦПУ, либо множества ядер. Операционные системы предоставляют некий способ планирования процессов по множеству ЦПУ:
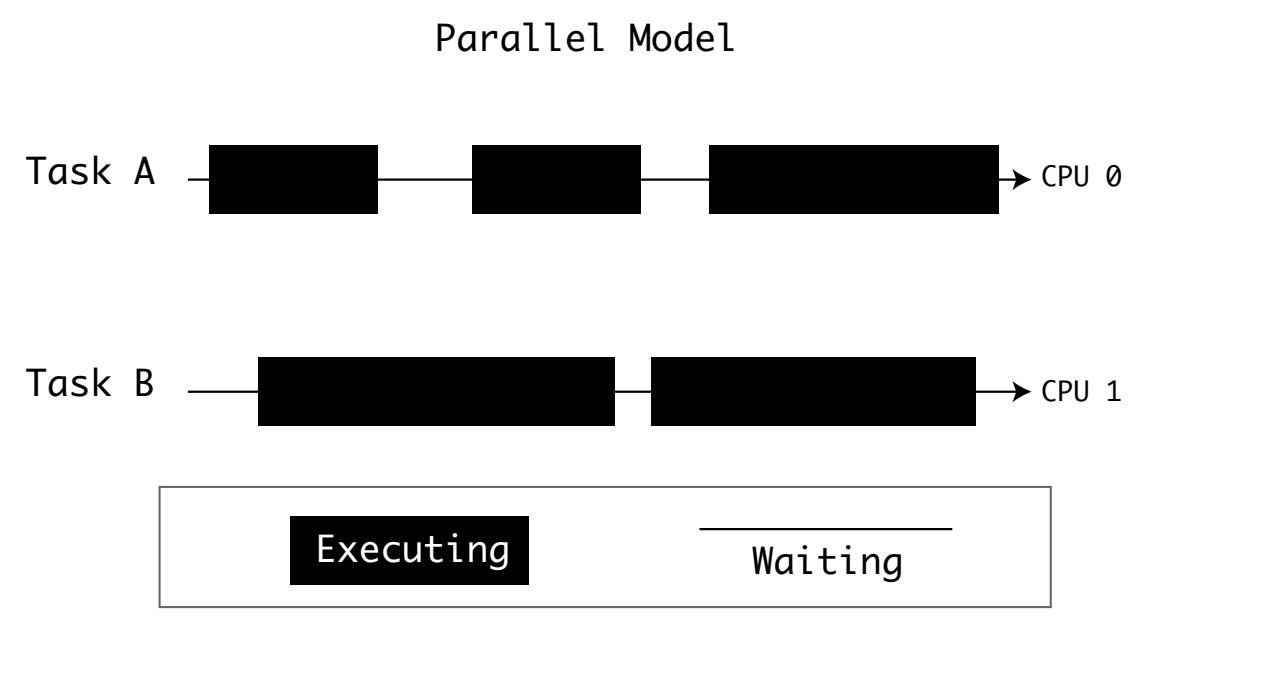
Суммируя, компьютеры для обработки проблемы многозадачности применяют параллельность и одновременность:
-
Чтобы обладать параллельностью, вам требуется множество вычислиьельных элементов. Вычислительные элементы могут быть центральными процессорами ил ядрами.
-
Для получения одновременности, вам нужен некий способ планирования задач с тем, чтобы простой одной не блокировал имеющиеся ресурсы.
Многие части архитектуры CPhyton абстрагируют сложность операционных систем чтобы предоставить разработчикам простой API. Подход CPhyton к параллельности и одновременности не является исключением.
CPython предлагает большое число подходов к параллельности и одновременности. Ваш выбор зависит от нескольких факторов. Между моделями, в которые вовлечён CPython также имеются перекрытия.
Вы можете обнаружить, что определённой задачи существует множество реализаций одновременности из которых предстоит выбор, причём каждая из них обладает своими за и против.
Существует четыре модели, которыми снабжается CPython:
| Подход | Модуль | Одновременность | Параллельность |
|---|---|---|---|
Обработка в потоках |
|
Да |
Нет |
Множество процессов |
|
Да |
Да |
Асинхронная обработка |
|
Да |
Нет |
Подчинённые интерпретаторы |
|
Да |
Да |
Одна из основных задач операционной системы, такой как Windows, macOS или Linux является контроль над исполняемыми процессами. Эти процессы могут быть приложениями с пользовательским интерфейсом, такие как браузер или IDE. Это также могут быть фоновые процессы, такие как сетевые службы или службы операционной системы.
Для управления этими процессами соответствующая операционная система предоставляет некий API для старта нового процесса. Когда процесс создан, он регистрируется этой операционной системой с тем, чтобы она знала какие процессы выполняются. Процессам придаётся некий уникальный идентификатор (PID). В зависимости от самой операционной системы они могут обладать некоторыми прочими свойствами.
Процессы POSIX обладают минимальным набором свойств, регистрируемых в их операционной системе:
-
Управляющий терминал
-
Текущий рабочий каталог
-
Эффективный групповой идентификатор и эффективный идентификатор пользователя
-
Дескрипторы файлов и маска режима создания файла
-
Групповой идентификатор процесса и идентификатор процесса
-
Идентификатор реальной группы и идентификатор реального пользователя
-
Корневой каталог
Вы можете видеть эти атрибуты для запущенных процессов в macOS или Linux, выполняя команду ps.
![[Совет]](/common/images/admon/tip.png) | Смотри также |
|---|---|
|
Стандарт IEEE POSIX (1003.1-2017) определяет собственно взаимодействие и стандартное поведение для процессов и потоков. |
Windows обладает аналогичным перечнем свойств, однако устанавливает свой собственный стандарт. Файловые полномочия, структуры каталогов и реестр процессов Windows сильно отличается от POSIX.
Представленные Win32_Process процессы Windows могут запрашиваться в WMI, Windows Management Instrumentation (инструментарии управления Windows) времени выполнения, или при помощи Диспетчера задач (Task Manager).
После того как процесс стартовал в некой операционной системе, придаются:
-
Стек памяти для вызова подпрограмм
-
Куча (см. раздел Динамическое выделение памяти в C)
-
Доступ к файлам, блокировкам и сокетам в его операционной системе
Сам ЦПУ вашего компьютера также удерживает некоторые дополнительные сведения при выполнении такого процесса, например:
-
Некий регистр, содержащий текущую подлежащую исполнению инструкцию или иные прочие данные, необходимые данному процессу для данной инструкции
-
Указатель инструкций или счётчике программы, указывающий какая инструкция в данной последовательности программы подлежит исполнению
Процесс CPython содержит в себе скомпилированный интерпретатор CPython и скомпилированные модули. Эти модули загружаются во время выполнения и преобразуются в инструкции циклом вычислений CPython:
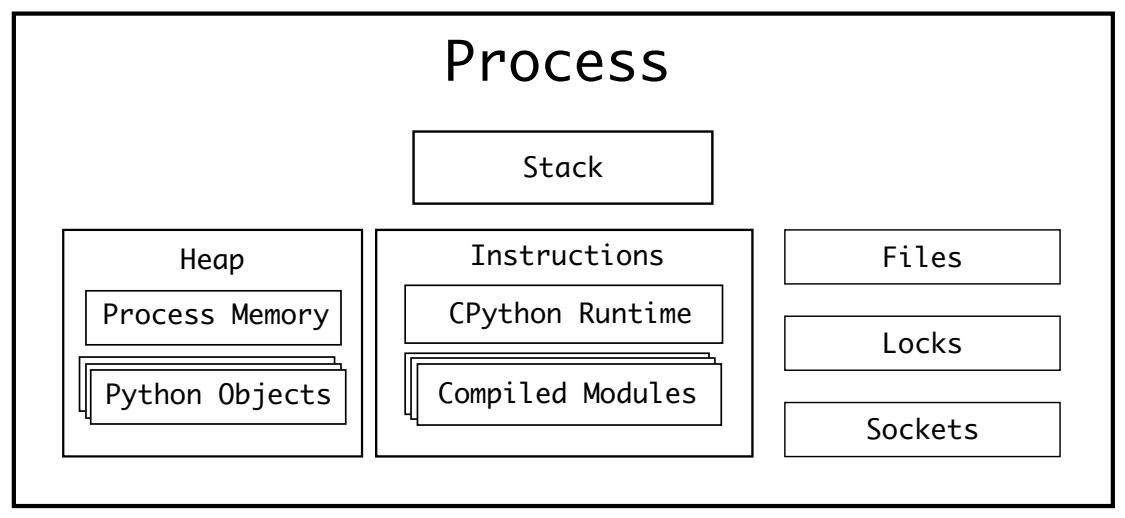
Указанные регистр программы и счётчик программы указывают на единственную инструкцию в этом процессе. Это означает, что за один раз может исполняться лишь одна инструкция. Для CPython это означает, что в некий заданный момент времени может исполняться лишь одна инструкция байтового кода Python.
Существует два основных подхода для допуска параллельного выполнения инструкций в неком процессе:
-
Ответсвить (fork) другой процесс
-
Породить (spawn) некий поток
Тепеь, когда вы прикинули что составляет некий процесс, вы можете изучить ветвление и порождение дочернего процесса.
Системы POSIX предоставляют некий API для того чтобы всякий процесс мог ответвлять (fork) дочерний процесс. Ветвление процесса это API вызова нижнего уровня к операционной системе, который может делаться любым исполняемым процессом.
Когда такой вызов сделан, сама операционная система клонирует все имеющиеся атрибуты исполняемого в данный момент процесса и создаст новый процесс. Такая операция клонирования включает кучу, регистр и положение счётчика родительского процесса. В момент ветвления такой дочерний процесс способен считывать любые переменные из своего родительского процесса.
В качестве некого образца воспользуемся примером приложения преобразования градусов по Фаренгейту в градусы по Цельсию., применявшееся в
самом начале раздела Динамическое выделение памяти в C. Вы можете приспособить его для
порождения некого дочернего процесса под каждое значение градуса по Фаренгейту вместо вместо вычисления их в последовательности при помощи
fork(). Каждый дочерний процесс продолжит работу с этого момента,
cpython-book-samples/33/thread_celsius.c:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
static const double five_ninths = 5.0/9.0;
double celsius(double fahrenheit){
return (fahrenheit - 32) * five_ninths;
}
int main(int argc, char** argv) {
if (argc != 2)
return -1;
int number = atoi(argv[1]);
for (int i = 1 ; i <= number ; i++ ) {
double f_value = 100 + (i*10);
pid_t child = fork();
if (child == 0) { // Is child process
double c_value = celsius(f_value);
printf("%f F is %f C (pid %d)\n", f_value, c_value, getpid());
exit(0);
}
}
printf("Spawned %d processes from %d\n", number, getpid());
return 0;
}
Исполнение этой программы из командной строки предоставит вывод подобный следующему:
$ ./thread_celsius 4
110.000000 F is 43.333333 C (pid 57179)
120.000000 F is 48.888889 C (pid 57180)
Spawned 4 processes from 57178
130.000000 F is 54.444444 C (pid 57181)
140.000000 F is 60.000000 C (pid 57182)
Наш родительский процесс (57718) порождает четыре процесса. Для каждого дочернего процесса наша программа продолжается со строки
child = fork(), где результирующим значением для child выступает
0. Она затем выполняет свои вычисления, выводит на печать полученное значение и выходит из
своего процесса. Наконец, их родительский процесс выводит сколько процессов он породил и свой собственный PID.
Время, которое потребовалось для выполнения третьего и четвёртого процессов было длиннее чем потребовалось для завершения их родительскому процессу. Именно по этой причине родительский процесс вывел на печать окончательный результат до того как третий и четвёртый процессы вывели на печать свои собственные.
Родительский процесс может выйти со своим собственным кодом выхода до дочернего процесса. Дочерние процессы добавляются в некую группу процессов самой операционной системой, что облегчает контроль над взаимосвязанными процессами:
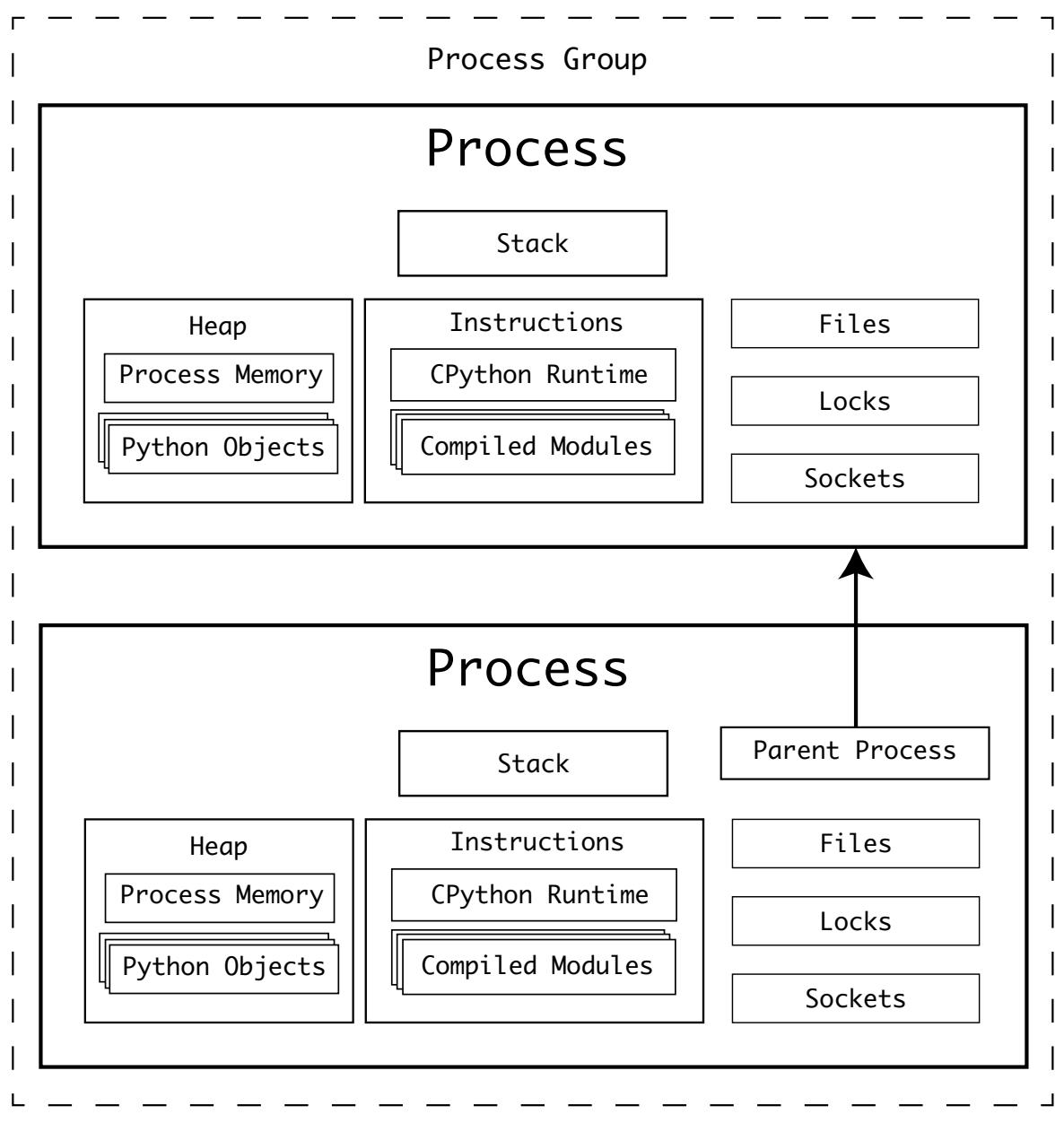
Самым крупным негативным последствием такого подхода к параллельности является то, что дочерний процесс является точной копией своего родительского процесса.
В случае с CPython это означает, что вам придётся иметь запущенными два интерпретатора CPython, причём обоим придётся загружать соответствующие модули и все библиотеки. Это создаёт значительные накладные расходы. Применение множества процессов становится существенным, когда накладные расходы ветвления процесса перевешиваются размером подлежащих исполнению задач.
Другим главным недостатком ветвления процессов является то, что они имеют раздельные, изолированные от своего родительского процесса кучи. Это означает, что такой дочерний процесс не способен выполнять запись пространство памяти своего родительского процесса.
Когда такой дочерний процесс создаётся, куча его предка становится доступной этому дочернему процессу. Для отправки сведений обратно своему предку должна применяться некая форма межпроцессного взаимодействия (IPC, interprocess communication).
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Модуль |
До сих пор вы знакомились с моделью POSIX. Windows не предоставляет эквивалента fork() и Python
обязан (настолько хорошо, насколько это возможно), обладать одним и тем же API для Linux, macOS и
Windows.
Чтобы преодолеть это, для порождения другого процесса python.exe с аргументом командной строки
-c используется API
CreateProcessW(). Этот этап носит название порождения (spawn) процесса
и он также возможен в POSIX. На протяжении данной главы вы найдёте ссылку на это.
CPython предоставляет некий API поверх работы с ветвлением процессов в операционной системе, которое делает простым создания параллельности со множеством процессов в Python.
Этот API доступен из пакета multiprocessing, который предоставляет расширенные возможности для сбора
в пулы процессов, очередей, ветвлений, создания куч разделяемой памяти, соединения процессов между собой и многое иное.
Вот те исходные файлы, которые относятся к многопроцессности:
| Файл | Назначение |
|---|---|
|
Исходный код Python для пакета |
|
Модуль расширения C обёртывающий системный вызов |
|
Модуль расширения C обёртывающий API ядра Windows |
|
Модуль расширения C используемый пакетом |
|
Интерфейс Python для библиотеки времени исполнения Microsoft Visual C |
Пакет multiprocessing предлагает три метода для запуска новых параллельных процессов:
-
Ветвление интерпретатора (только для POSIX)
-
Порождение нового процесса интерпретатора (POSIX и Windows)
-
Запуск некого сервера ветвлений, в котором создаётся новый процесс, который затем ответвляет любое число процессов (только POSIX)
|
| Замечание |
|---|---|
|
Для Windows и macOS, установленным по умолчанию методом является порождение. В Linux по умолчанию установлено ветвление. Вы можете
перекрывать установленный по умолчанию метод при помощи |
API Python для запуска нового процесса, принимает вызываемую, target, и кортеж аргументов,
args.
Воспользуемся этим примером порождения нового процесса для преобразования градусов Фаренгейта в градусы Цельсия,
cpython-book-samples/33/spawn_process_celsius.py:
import multiprocessing as mp
import os
def to_celsius(f):
c = (f - 32) * (5/9)
pid = os.getpid()
print(f"{f}F is {c}C (pid {pid})")
if __name__ == '__main__':
mp.set_start_method('spawn')
p = mp.Process(target=to_celsius, args=(110,))
p.start()
Хотя вы можете запустить единственный процесс, API multiprocessing предполагает что вы желаете запустить
множество. Существуют удобные методы порождения множества процессов и и наполнения их данными. Одним их таких методов является класс
Pool.
Наш предыдущий пример может быть расширен для вычисления диапазона значений в отдельных интерпретаторах Python,
cpython-book-samples/33/pool_process_celsius.py:
import multiprocessing as mp
import os
def to_celsius(f):
c = (f - 32) * (5/9)
pid = os.getpid()
print(f"{f}F is {c}C (pid {pid})")
if __name__ == '__main__':
mp.set_start_method('spawn')
with mp.Pool(4) as pool:
pool.map(to_celsius, range(110, 150, 10))
Обратите внимание, что наш вывод показывает тот же самый PID. По той причине что процесс интерпретатора CPython обладает значительными
накладными расходами, Pool будет рассматривать всякий процесс в пуле неким
исполнителем (worker). Если исполнитель выполнен, он будет применяться повторно.
Вы можете изменить это установив следующую замену эту строку:
with mp.Pool(4) as pool:
Изменяя её следующим кодом:
with mp.Pool(4, maxtasksperchild=1) as pool:
Теперь наш пример многозадачности будет выводить на печать нечто аналогичное такому:
$ python pool_process_celsius.py
110F is 43.333333333333336C (pid 5654)
120F is 48.88888888888889C (pid 5653)
130F is 54.44444444444445C (pid 5652)
140F is 60.0C (pid 5655)
Данный вывод отображает значения идентификаторов процессов вновь порождённых процессов и вычисленных значений.
Оба этих сценария создадут новый процесс интерпретатора Python и передадут ему данные при помощи pickle.
|
| Совет |
|---|---|
|
Этот модуль |
Для систем POSIX создание соответствующего подчинённого процесса модуля multiprocessing является
эквивалентом данной команды, где <i> это описатель файлового дескриптора, а
<j> это описатель дескриптора конвейера:
$ python -c 'from multiprocessing.spawn import spawn_main; \
spawn_main(tracker_fd=<i>, pipe_handle=<j>)' --multiprocessing-fork
Для систем Windows вместо файлового дескриптороа отслеживания применяется значение родительского PID, как в той команде, где
<k> это значение родительского PID, а <j> это
значение описания дескриптора конвейера:
> python.exe -c 'from multiprocessing.spawn import spawn_main; \
spawn_main(parent_pid=<k>, pipe_handle=<j>)' --multiprocessing-fork
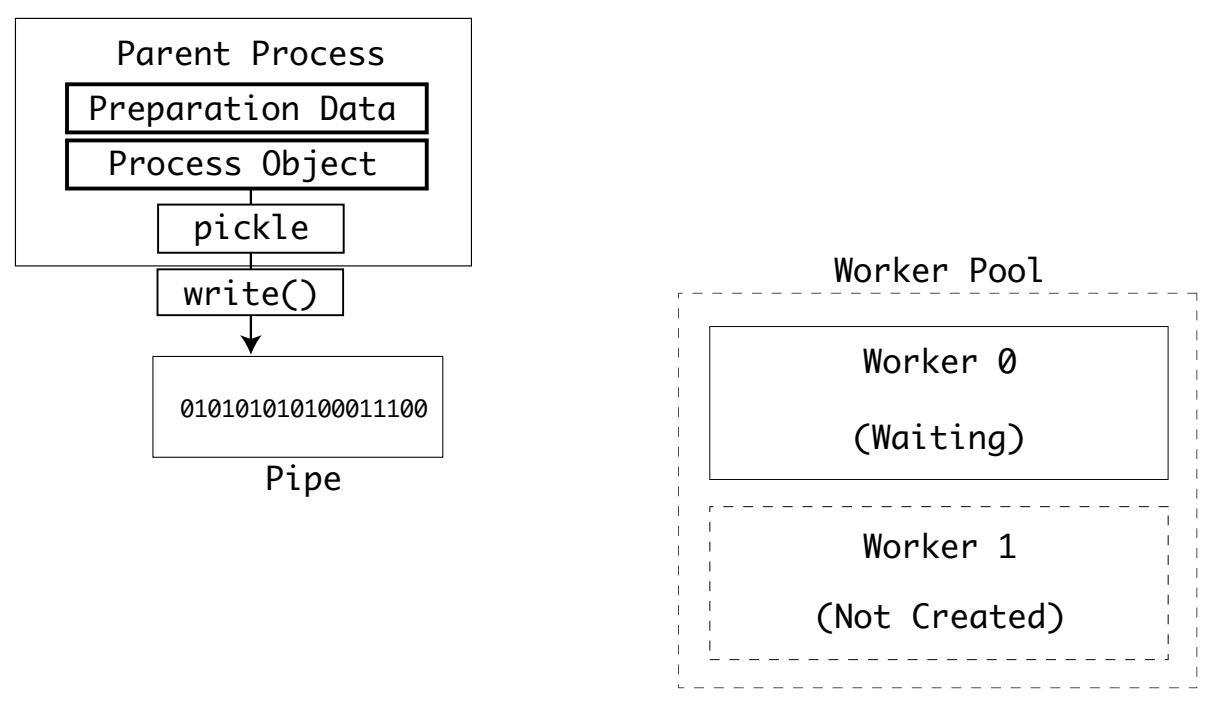
Когда этот новый дочерний процесс был установлен экземпляром в своей операционной системы, он будет дожидаться инициализации данных от своего родительского процесса.
Этот родительский процесс записывает в файловый поток конвейера два объекта. Такой файловый поток конвейера является особым потоком ввода/ вывода, применяемый для пересылки данных между процессами в командной строке.
Самый первый записанный родительским процессом объект это объект данных подготовки. Этот объект является
словарём, содержащим некие сведения относительно своего родителя, такие как значение каталога исполнения, метод запуска, все специальные
аргументы командной строки, а также sys.path.
Вы можете посмотреть некий пример того что выработано запуском
multiprocessing.spawn.get_preparation_data(name):
>>> import multiprocessing.spawn
>>> import pprint
>>> pprint.pprint(multiprocessing.spawn.get_preparation_data("example"))
{'authkey': b'\x90\xaa_\x22[\x18\ri\xbcag]\x93\xfe\xf5\xe5@[wJ\x99p#\x00'
b'\xce\xd4)1j.\xc3c',
'dir': '/Users/anthonyshaw',
'log_to_stderr': False,
'name': 'example',
'orig_dir': '/Users/anthonyshaw',
'start_method': 'spawn',
'sys_argv': [''],
'sys_path': [
'/Users/anthonyshaw',
]}
Вторым записываемым объектом выступает экземпляр дочернего класса BaseProcess. В зависимости от
того как была вызвана многопроцессность и в какой операционной системе это применялось, один из дочерних классов
BaseProcess будет соответствующим упорядоченным экземпляром.
Оба объекта данных подготовки и объект процесса упорядочены при помощи модуля pickle и записаны в
поток конвейера своего родительского процесса:
|
| Замечание |
|---|---|
|
Реализация порождения дочернего процесса и упорядочение процесса POSIX расположены в
Аналогичная реализация Windows находится в
|
Точка входа дочернего процесса, multiprocessing.spawn.spawn_main(), получает значене аргумента
pipe_handle, а также либо parent_pid для Windows, либо
tracked_fd для POSIX:
def spawn_main(pipe_handle, parent_pid=None, tracker_fd=None):
'''
Run code specified by data received over pipe
'''
assert is_forking(sys.argv), "Not forking"
Для Windows соответствующая функция вызовет API OpenProcess значения родительского PID. Это используется для создания файлового дескриптора,
fd, конвейера своего родительского процесса:
if sys.platform == 'win32':
import msvcrt
import _winapi
if parent_pid is not None:
source_process = _winapi.OpenProcess(
_winapi.SYNCHRONIZE | _winapi.PROCESS_DUP_HANDLE,
False, parent_pid)
else:
source_process = None
new_handle = reduction.duplicate(pipe_handle,
source_process=source_process)
fd = msvcrt.open_osfhandle(new_handle, os.O_RDONLY)
parent_sentinel = source_process
Для POSIX файловым дескриптором, fd, становится pipe_handle и
он дублируется чтобы стать значением parent_sentinel:
else:
from . import resource_tracker
resource_tracker._resource_tracker._fd = tracker_fd
fd = pipe_handle
parent_sentinel = os.dup(pipe_handle)
Затем вызывается _main() со значением файлового дескриптора родительского конвейера,
fd, а также сигнальной меткой родительского процесса, parent_sentinel.
Возвращаемое значение _main() становится кодом выхода для данного процесса и его интерпретатор
прекращается:
exitcode = _main(fd, parent_sentinel)
sys.exit(exitcode)
_main() вызывается с fd и
parent_sentinel для проверки того что из родительского процесса был выполнен выход в процессе
исполненния его потомка.
_main() преобразует упорядоченные двоичные данные байтового потока
fd в параллельные . Помните, это файловый дескриптор соответствующего конвейера. Этот процесс применяет
ту же самую библиотеку pickle, которой пользуется его родительский процесс:
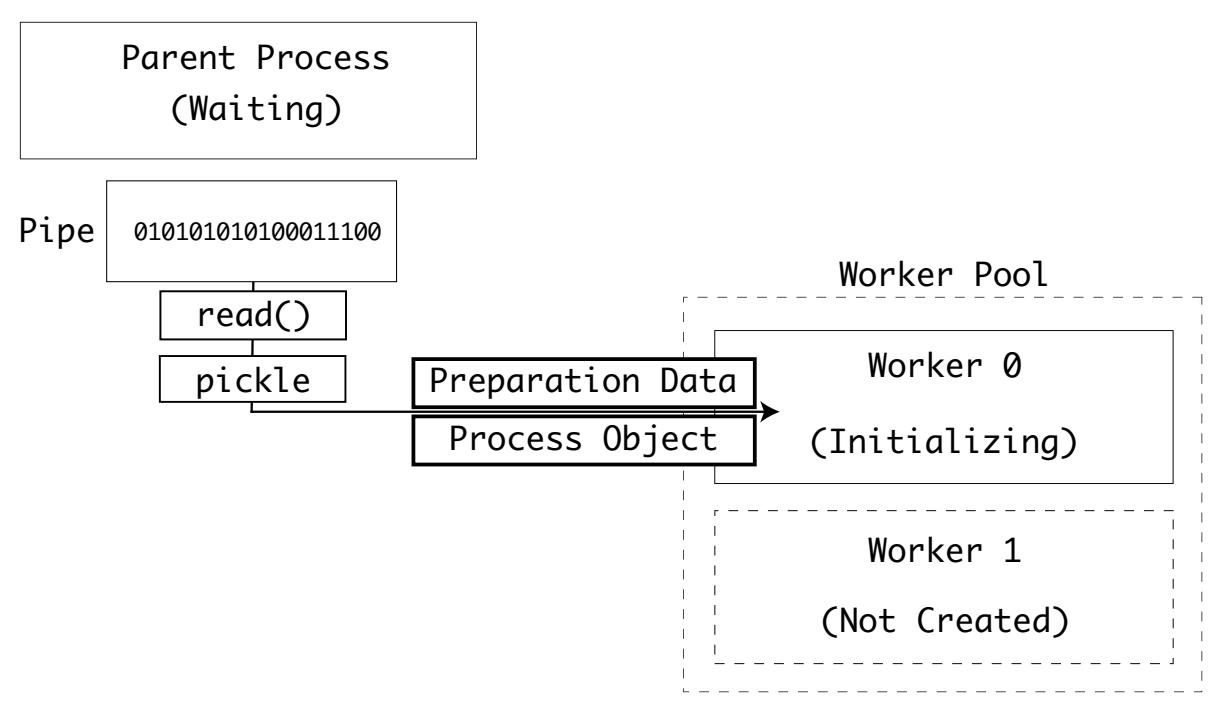
Самым первым значением является dict, содержащий соответствующие данные подгоовки. Вторым значением
выступает некий экземпляр SpawnProcess, который затем применяется как некий экземпляр для
_bootstrap() при:
def _main(fd, parent_sentinel):
with os.fdopen(fd, 'rb', closefd=True) as from_parent:
process.current_process()._inheriting = True
try:
preparation_data = reduction.pickle.load(from_parent)
prepare(preparation_data)
self = reduction.pickle.load(from_parent)
finally:
del process.current_process()._inheriting
return self._bootstrap(parent_sentinel)
_bootstrap() обрабатывает конкретизацию экземпляра BaseProcess
из превращённых в параллельные из последовательных данных, а затем вызывается целевая функция с соответствующими аргументами и аргументами
ключевых слов. Эта завершающая задача выполняется BaseProcess.run():
def run(self):
'''
Method to be run in subprocess; can be overridden in subclass
'''
if self._target:
self._target(*self._args, **self._kwargs)
Код выхода, self._bootstrap() устанавливается как код выхода и этот дочерний процесс
прекращается.
Такой процесс позволяет своему родительскому процессу упорядочить сам модуль и его исполняемую функцию. Это также позволяет его дочернему процессу разобрать обратно этот экземпляр, исполнение этой функции с аргументами и возврат.
Это не позволяет обмениваться данными после запуска соответствующего дочернего процесса. Такая задача выполняется с применением
расширений Queue и Pipe объектов.
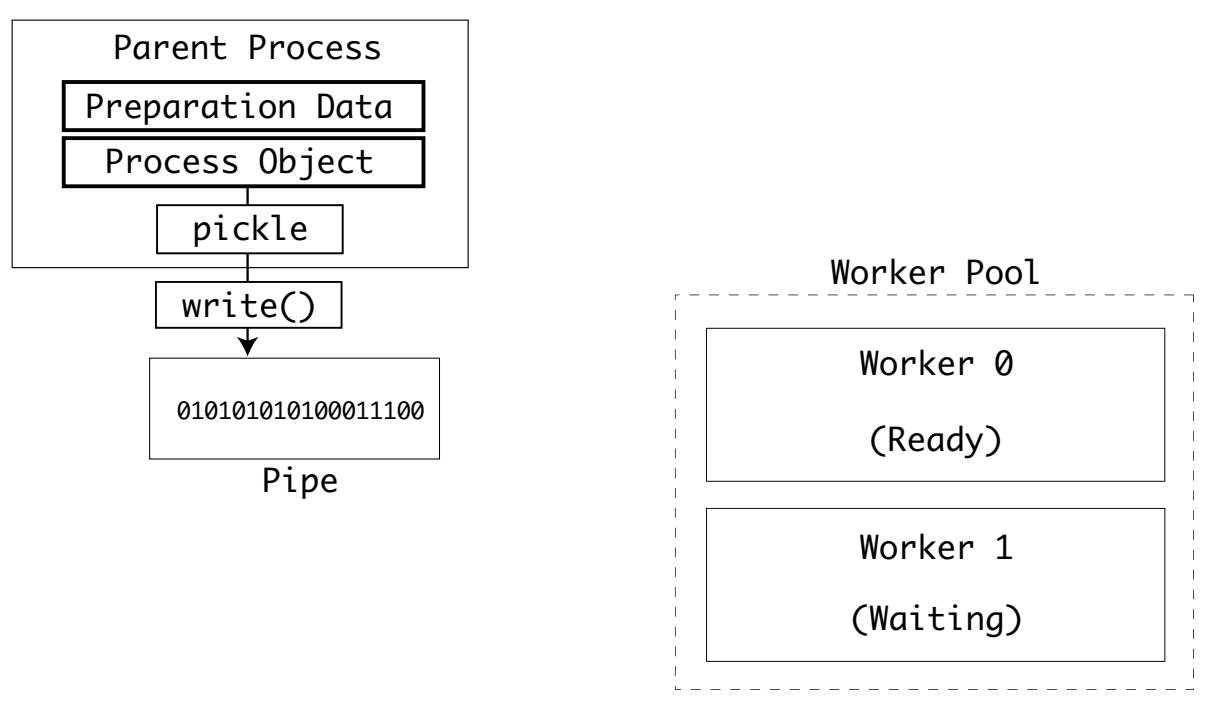
Когда процессы подлежат созданию в пуле, тогда самый первый процесс будет готов и будет пребывать состоянии ожидания. Его родительский процесс повторяет этот процесс и отправляет необходимые данные своему следующему исполнителю:
Следующий исполнитель получает свои данные и инициализирует своё состояние и запускает свою целевую функцию:
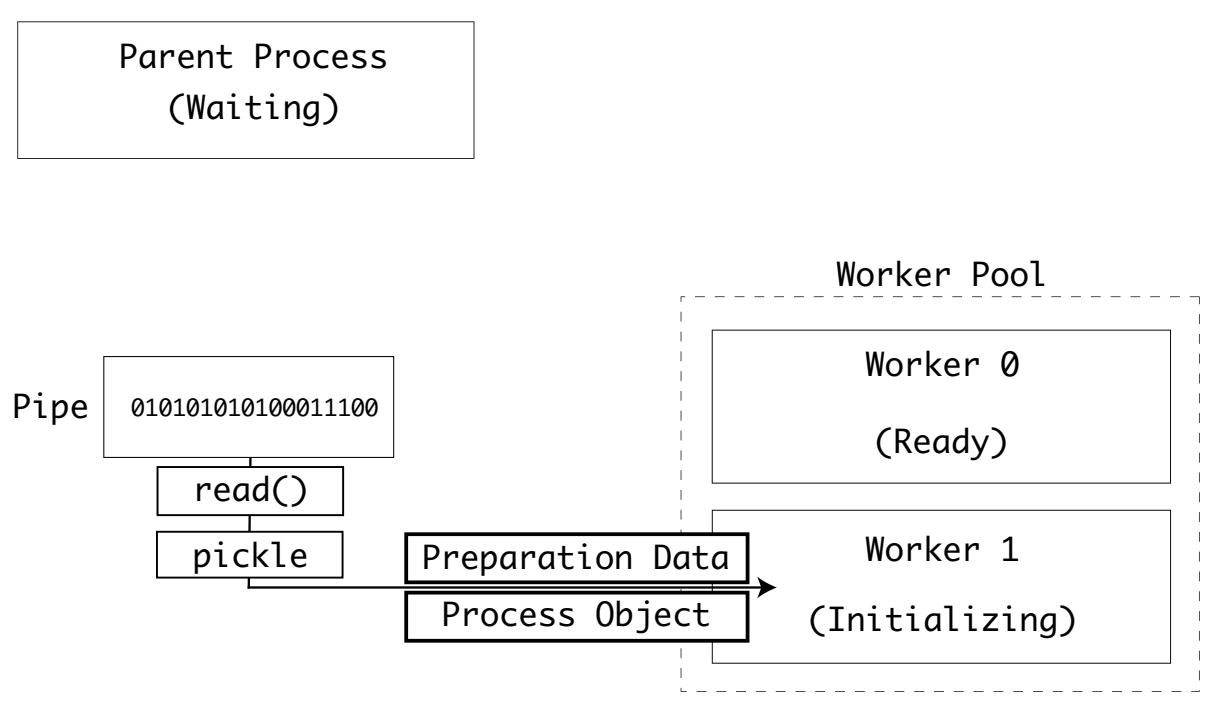
Для совместного использования данных вне инициализации следует применять очереди и конвейеры.
В нашем предыдущем раздели вы видели как порождаются дочерние процессы и затем применяются конвейеры в качестве упорядоченных потоков для сообщения своему дочернему процессу какую функцию вызывать с аргументами.
Существуют два типа взаимодействия между процессами, в зависимости от природы своих задач: очередей и конвейеров. Прежде чем изучить каждое из них, вы быстро взглянете на то как операционные системы защищают доступ к ресурсам при помощи переменных, носящих название семафоров.
Семафоры
Многие механизмы при работе со множеством процессов применяют семафоры в качестве некого способа сигнализации о том что данный ресурс заблокирован, пребывает в состоянии ожидания или не применяется. Для блокирования ресурсов, подобных файлам, сокетов и прочего операционные системы пользуются в качестве простого типа бинарные семафоры.
Когда один процесс выполняет запись в некий файл или сетевой сокет, тогда вы не желаете чтобы другой процесс внезапно начал запись в тот же файл. Такие данные немедленно были бы разрушены.
Вместо этого операционные системы помещают на ресурс некое блокирование при помощи светофоров. Процессы Могут также сигнализировать что они ожидают высвобождения такой блокировки с тем, чтобы когда оно произойдёт, они получат сообщение о том, что они готовы и процессы могут приступать к их использованию.
В нашем реальном мире семафоры это метод сигналов, которые применяют флаги для передачи сообщений. Поэтому вы можете представлять сигналы семафора для состояний ожидания, блокировки и отсутствия использования ресурса подобным образом:
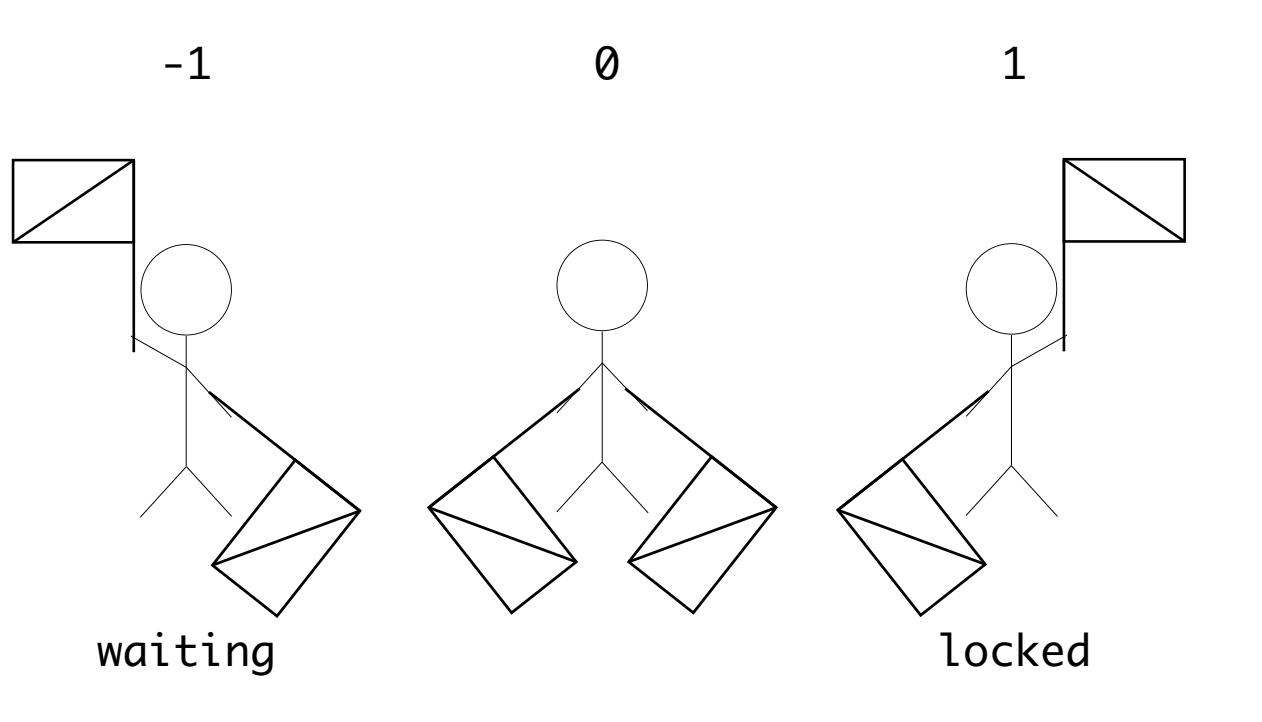
В операционных системах API семафора отличаются, поэтому имеется некий класс абстракции,
multiprocessing.synchronize.Semaphore
Для многопроцессности применяются семафоры потому, что они поддерживают безопасность как потоков, так и процессов. Сама операционная система обрабатывает взаимные блокировки чтения или записи для одного и того же семафора.
Реализация такий функций API семафоров располагается в модуле расширения C
Modules/_multiprocessing/semaphore.c. Этот модуль расширения предлагаеи
метод сигналов для создания, блокирования и высвобождения семафоров с прочими операциями.
Соответствующий вызов к самой операционной системе выполняется последовательностью макросов, которые компилируются в различных реализациях в зависимости от своей операционной системы платформы.
Для Windows этот макрос пользуется API функциями <winbase.h> для семафоров:
#define SEM_CREATE(name, val, max) CreateSemaphore(NULL, val, max, NULL)
#define SEM_CLOSE(sem) (CloseHandle(sem) ? 0 : -1)
#define SEM_GETVALUE(sem, pval) _GetSemaphoreValue(sem, pval)
#define SEM_UNLINK(name) 0
Для POSIX соответствующий макрос применяет API <semaphore.h>:
#define SEM_CREATE(name, val, max) sem_open(name, O_CREAT | O_EXCL, 0600,...
#define SEM_CLOSE(sem) sem_close(sem)
#define SEM_GETVALUE(sem, pval) sem_getvalue(sem, pval)
#define SEM_UNLINK(name) sem_unlink(name)
Очереди
Очереди это великолепный способ отправки небольших данных от или к множеству процессов.
Вы можете приспособить наш более ранний пример со множеством процессов для применения экземпляра multiprocessing
Manager() и создания двух очередей:
-
inputsдля удержания входных значений градусов по Фаренгейту -
outputsдля удержания получаемых в результате значений градусов по Цельсию
Измените значение размера пула на 2, чтобы у вас было два исполнителя,
cpython-book-samples/33/pool_queue_celsius.py:
import multiprocessing as mp
def to_celsius(input: mp.Queue, output: mp.Queue):
f = input.get()
# Time-consuming task ...
c = (f - 32) * (5/9)
output.put(c)
if __name__ == '__main__':
mp.set_start_method('spawn')
pool_manager = mp.Manager()
with mp.Pool(2) as pool:
inputs = pool_manager.Queue()
outputs = pool_manager.Queue()
input_values = list(range(110, 150, 10))
for i in input_values:
inputs.put(i)
pool.apply(to_celsius, (inputs, outputs))
for f in input_values:
print(outputs.get(block=False))
Это выводит на печать список кортежей своей очереди outputs:
$ python pool_queue_celsius.py
43.333333333333336
48.88888888888889
54.44444444444445
60.0
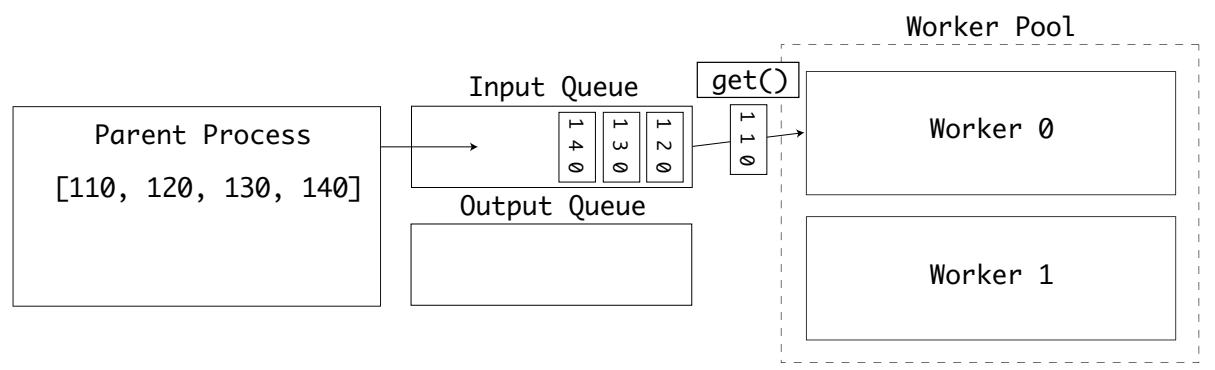
Наш родительский процесс вначале помещает свои входные значения в очередь inputs. Самый первый
исполнитель затем получает из этой очереди некий элемент. Всякий раз, когда некий элемент берётся из этой очереди при помощи
.get(), в объекте этой очереди применяется блокирующий семафор:
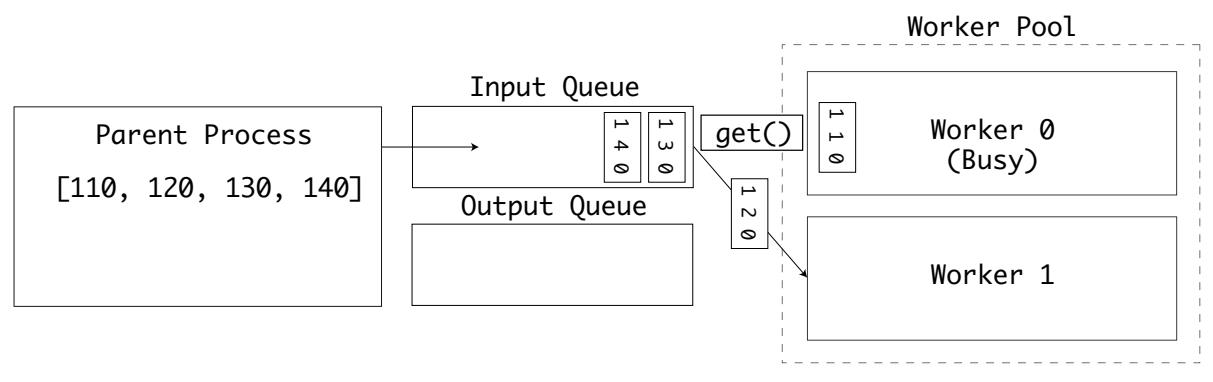
Пока этот исолнитель занят, затем второй исполнитель берёт из этой очереди другое значение:
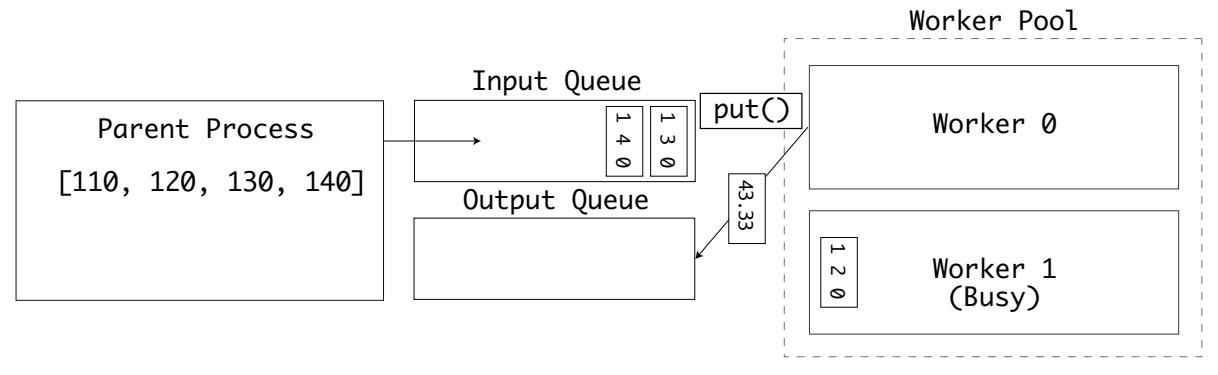
Первый исполнитель завершил свои вычисления и помещает полученные результаты в очередь outputs:
Две очереди применяются для разделения входных и выходных значений. В конечном счёте, обрабатываются все данные на входе и очередь
outputs заполнена. Полученные значения затем выводятся на печать своим родительским процессом:
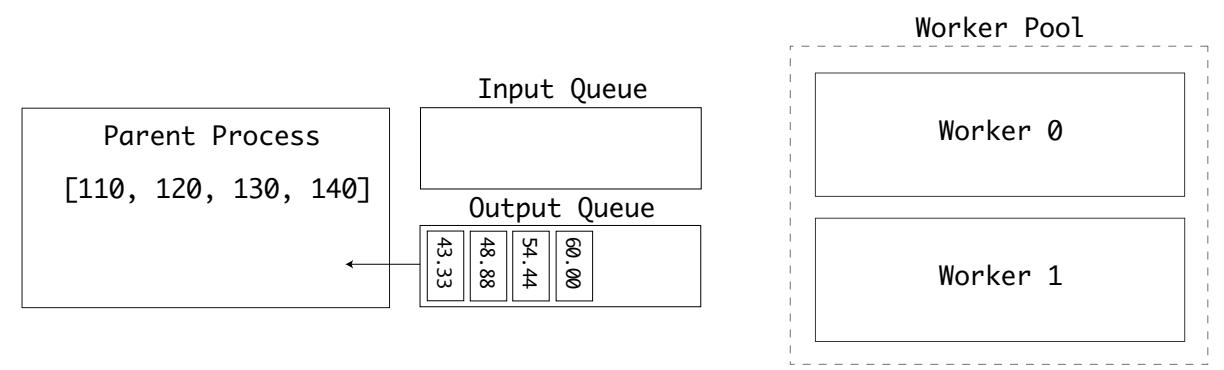
Этот пример показывает как некий пул исполнителей может получать очередь небольших, дискретных значений и обрабатывать их параллельно для отправки обратно полученных результатов в свой процесс хоста.
На практике, преобразование градусов по Цельсию из градусов по Фаренгейту это маленькое, тривиальное вычисление, не подходящее для параллельного выполнения. Когда процесс исполнителя выполнялся бы для иного, интенсивно использующего ЦПУ вычисления, это привело бы к значительному увеличению производительности в компьютере со множеством ЦПУ или ядер.
Для поточных данных вместо дискретных очередей вы можете пользоваться вместо этого конвейерами.
Конвейеры
Внутри пакета multiprocessing имеется тип Pipe. Установленный
конвейер возвращает два соединения, родителя и потомка. Оба способны отправлять и получать данные:
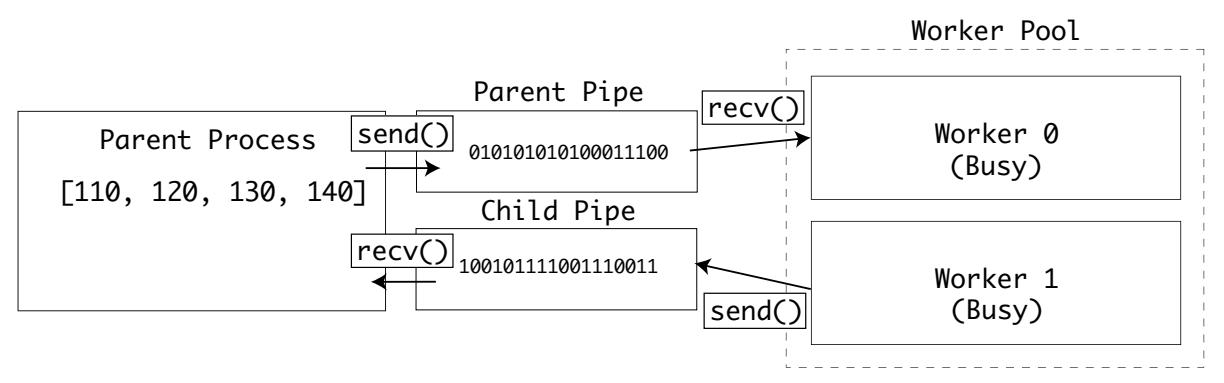
В примере очереди, в саму очередь неявным образом помещалась некая блокировка при отправке или получении данных. Конвейеры не обладают таким поведением, поэтому вам надлежит быть аккуратными в том, чтобы два процесса не пытались выполнять запись в одном и том же конвейере в одно и то же время.
Чтобы приспособить наш последний пример на работу с конвейером, потребуется заменить pool.apply() на
pool.apply_async(). Это изменяет наше выполнение следующего процесса в некую операцию без блокирования,
cpython-book-samples/33/pool_pipe_celsius.py:
import multiprocessing as mp
def to_celsius(child_pipe: mp.Pipe):
f = child_pipe.recv()
# time-consuming task ...
c = (f - 32) * (5/9)
child_pipe.send(c)
if __name__ == '__main__':
mp.set_start_method('spawn')
pool_manager = mp.Manager()
with mp.Pool(2) as pool:
parent_pipe, child_pipe = mp.Pipe()
results = []
for input in range(110, 150, 10):
parent_pipe.send(input)
results.append(pool.apply_async(to_celsius, args=(child_pipe,)))
print("Got {0:}".format(parent_pipe.recv()))
parent_pipe.close()
child_pipe.close()
Существует некий риск, что два или более процессов попытаются выполнить чтение из своего родительского конвейера одновременно в следующей строке:
f = child_pipe.recv()
Имеется также риск, что два или более процесса попробуют одновременно выполнить запись в свой дочерний конвейер:
child_pipe.send(c)
Если это произойдёт, данные будут разрушены либо в операции получения, либо в операции отправки:
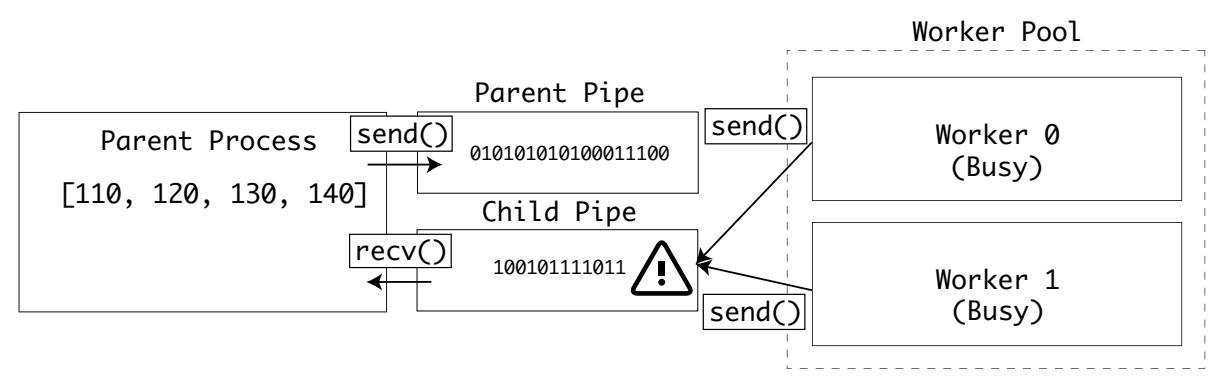
Чтобы избежать этого, вы можете реализовать блокировку семафором операционной системы. Тогда все дочерние процессы будут проверять наличие блокирования перед чтением или записью в один и тот же конвейер.
Требуются две блокировки, одна на стороне получения родительского конвейера и другая на конце отправки дочернего конвейера,
cpython-book-samples/33/pool_pipe_locks_celsius.py:
import multiprocessing as mp
def to_celsius(child_pipe: mp.Pipe, child_lock: mp.Lock):
child_lock.acquire(blocking=False)
try:
f = child_pipe.recv()
finally:
child_lock.release()
# time-consuming task ... release lock before processing
c = (f - 32) * (5/9)
# reacquire lock when done
child_lock.acquire(blocking=False)
try:
child_pipe.send(c)
finally:
child_lock.release()
if __name__ == '__main__':
mp.set_start_method('spawn')
pool_manager = mp.Manager()
with mp.Pool(2) as pool:
parent_pipe, child_pipe = mp.Pipe()
child_lock = pool_manager.Lock()
results = []
for i in range(110, 150, 10):
parent_pipe.send(i)
results.append(pool.apply_async(
to_celsius, args=(child_pipe, child_lock)))
print(parent_pipe.recv())
parent_pipe.close()
child_pipe.close()
Теперь соответствующий процесс исполнителя будет ожидать получения блокировки перед отправкой данных и снова дожидаться овладения другой блокировкой на отправку данных:
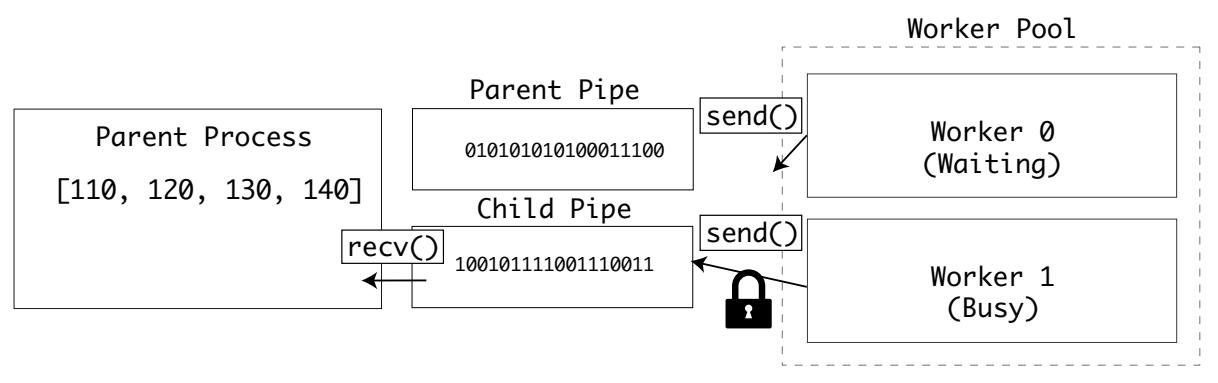
Этот пример подходит для тех ситуаций, когда проходящие по конвейеру данные велики, поскольку вероятность коллизий тут выше.
До сих пор вы наблюдали как данные совместно используются процессами потомков и родителей.
Могут существовать ситуации, при которых вы пожелаете разделять данные между дочерними процессами. В таком случае пакет
multiprocessing предоставляет два решения:
Пример приложения
В качестве демонстрационного примера на протяжении остающейся части этой главы, вы будете перестраивать некий сканер портов TCP для различных технологий одновременности и параллельности.
Поверх сетевой среды некий хост способен контактировать в портах, которые нумеруются с 1 до 65535. Распространённые службы обладают стандартными портами. Например, HTTP применяет порт 80, а HTTPS работает в 443. Сканеры портов TCP это распространённый инструмент тестирования для проверки того, что пакеты способны отправляться в некой сетевой среде.
Данный пример кода пользуется интерфейсом Queue, реализацию очереди в безопасном потоке, аналогичную той,
что мы применяли в примерах со множеством процессов. Наш код также пользуется пакетом socket для
пробы соединения к удалённому порту с коротким таймаутом в одну секунду.
check_port() обнаружит отклик от своего host по заданному
port при его возникновении. Если это происходит, тогда
check_port() добавит этот номер порта в очередь results.
При выполнении данного сценария check_port() вызывается последовательно для портов с номерами от 80
до 100. После его выполнения извлекается очередь results и полученные результаты выводятся на печать в
командной строке. С тем чтобы вы могли сопоставлять отличия, здесь будет в самом конце выводиться на печать время исполнения,
cpython-book-samples/33/portscanner.py:
from queue import Queue
import socket
import time
timeout = 1.0
def check_port(host: str, port: int, results: Queue):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(timeout)
result = sock.connect_ex((host, port))
if result == 0:
results.put(port)
sock.close()
if __name__ == '__main__':
start = time.time()
host = "localhost" # Replace with a host you own
results = Queue()
for port in range(80, 100):
check_port(host, port, results)
while not results.empty():
print("Port {0} is open".format(results.get()))
print("Completed scan in {0} seconds".format(time.time() - start))
Наше выполнение выведет на печать полученные открытые порты и значение времени, которое ушло на это:
$ python portscanner.py
Port 80 is open
Completed scan in 19.623435020446777 seconds
Вы можете перестроить этот пример на использование множества процессов. Переставьте свой интерфейс Queue
для multiprocessing.Queue и отсканируйте все порты вместе применяя исполнитель pool,
cpython-book-samples/33/portscanner_mp_queue.py:
import multiprocessing as mp
import time
import socket
timeout = 1
def check_port(host: str, port: int, results: mp.Queue):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(timeout)
result = sock.connect_ex((host, port))
if result == 0:
results.put(port)
sock.close()
if __name__ == '__main__':
start = time.time()
processes = []
scan_range = range(80, 100)
host = "localhost" # Replace with a host you own
mp.set_start_method('spawn')
pool_manager = mp.Manager()
with mp.Pool(len(scan_range)) as pool:
outputs = pool_manager.Queue()
for port in scan_range:
processes.append(pool.apply_async(check_port,
(host, port, outputs)))
for process in processes:
process.get()
while not outputs.empty():
print("Port {0} is open".format(outputs.get()))
print("Completed scan in {0} seconds".format(time.time() - start))
Как вы могли ожидать, это приложение намного быстрее, потому как оно тестирует все порты параллельно:
$ python portscanner_mp_queue.py
Port 80 is open
Completed scan in 1.556523084640503 seconds
Работа со множеством процессов предлагает некий масштабируемый параллельный API для Python. Данные могут совместно применяться процессами, а интенсивно использующие ЦПУ исполнители могут разбиваться на параллельные задачи для получения преимуществ компьютеров со множеством ядер или множеством ЦПУ.
Обработка множеством процессов не подходящее решение когда ваша подлежащая выполнению задача ограничена вводом/ выводом больше чем интенсивным использованием ЦПУ. Например, когда вы расширяете на четыре исполнительных процесса чтения и запись в одни и те же файлы, затем один выполнял бы всю имеющуюся работу, а оставшиеся три ожидали бы высвобождения имеющегося блокирования.
Работа со множеством процессов также не подходит для варианта с задачами с коротким временем жизни по причине накладных расходов времени и обработки, требующихся для запуска нового интерпретатора Python.
В обоих подобных ситуациях вы можете обнаружить более удобными наши следующие подходы.
CPython предоставляет для создания, порождения и управления потоков из Python API как верхнего уровня, так и нижнего уровня.
Чтобы разобраться с потоками Python, вам вначале следует понять как работают потоки операционной системы. В CPython имеются две реализации потоков:
-
pthreads: потоки POSIX для Linux и macOS -
nt threads: потоки NT для Windows
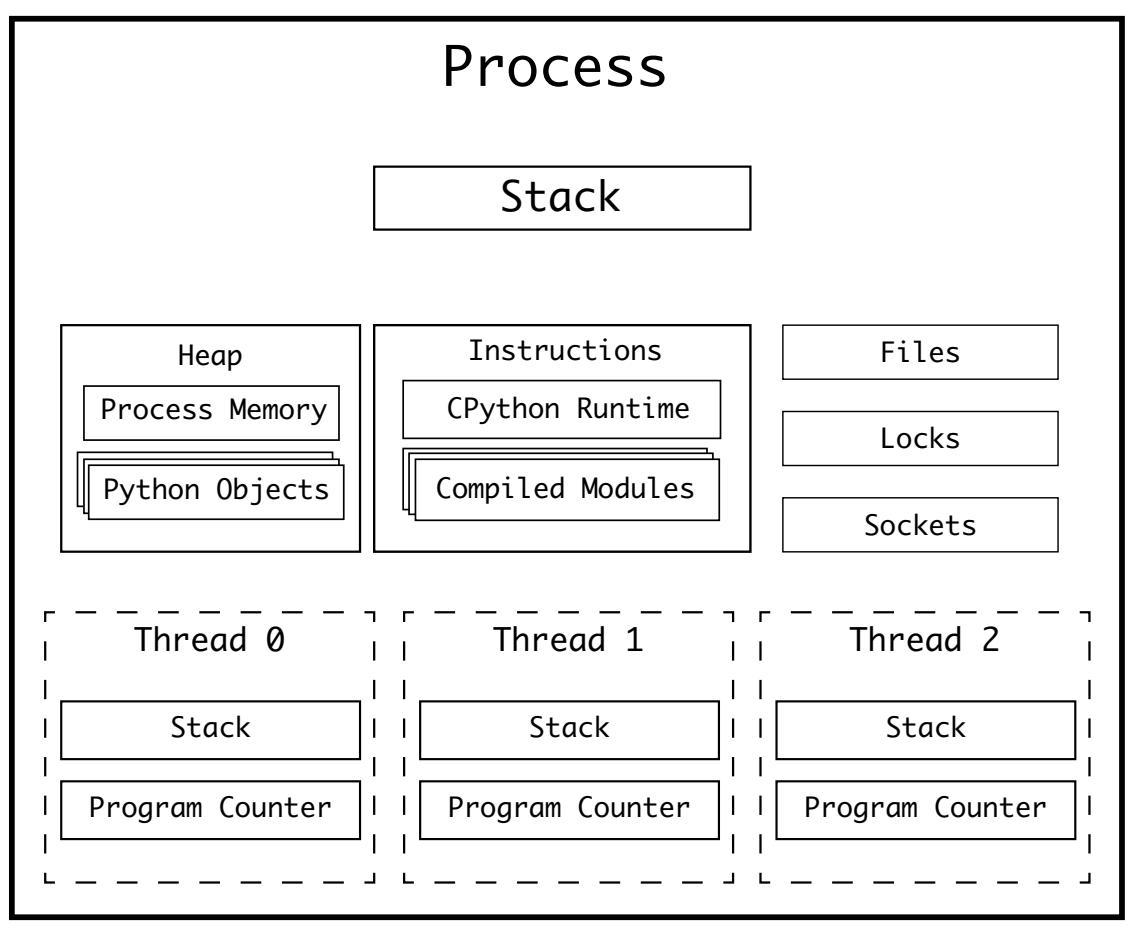
В нашем разделе Структура процесса вы видели, что процесс обладает следующими функциональными возможностями:
-
Стеком подпрограмм
-
Кучей памяти
-
Доступом к файлам, блокировкам и сокетам своей операционной системы
Самым большим ограничением на масштабирование отдельного процесса является то, что его операционная система будет иметь для такого исполнения единственный программный счётчик.
Чтобы обойти это, современные операционные системы позволяют процессам сигнализировать своей операционной системе ветвить их исполнение по множеству потоков.
Каждый поток будет обладать своим собственным счётчиком программы, но применять те же самые ресурсы, что и его процесс хоста. Каждый поток также обладает своим собственным стеком вызовов, поэтому он способен исполнять различные функции.
Поскольку множество потоков способны выполнять чтение и запись в одном и том же пространстве памяти, могут возникать столкновения. Основным решением этого выступает безопасность потоков, которая вовлекает обеспечение уверенности что пространство памяти блокируется единственным потоком перед доступом к нему.
Некий отдельный процесс с тремя потоками будет обладать такой структурой:
|
| Смотри также |
|---|---|
|
В качестве вводного руководства в API потоков Python обратитесь к книге Real Python Intro to Python Threading. |
Если вы знакомы с потоками NT или потоками POSIX в C, либо вы пользовались другим языком программирования верхнего уровня, тогда вы могли бы ожидать параллельности от множества потоков.
В CPython имеющиеся потоки основываются на API C, но являются потоками Python. Это означает,что всякий поток требует исполнения байтового кода Python через его цикл вычислений.
Имеющийся цикл вычислений Python не предоставляет безопасность потокам. Существует множество частей состояния интерпретатора, например, сборщик мусора, которые используются совместно и глобально. Чтобы обойти это, разработчики CPython реализовали некую мега- блокировку с названием GIL (global interpreter lock, глобальную блокировку интерпретатора). Прежде чем какой бы то ни было код выполняется в своём цикле вычисления кадра, имеющийся GIL блокируется его потоком. По окончанию выполнения конкретного кода операции, эта GIL высвобождается.
Хотя это и предоставляет глобальную сохранность потока для каждой операции в Python, такой подход обладает главным недостатком. Все операции, которые занимают продолжительное время исполнения, будут оставлять остальные потоки ждущими высвобождения GIL перед своим исполнением. Это означает, что в любой заданный момент времени только один поток способен исполнять некую операцию байтового кода.
Для овладения GIL выполняется вызов к take_gil(). Чтобы освободить её, вызывается drop_gil(). Овладение GIL выполняется внутри самого кадра ядра цикла вычисления,
_PyEval_EvalFrameDefault().
Чтобы прекратить исполнение отдельным кадром от непрерывного удерживания имеющейся GIL, состояние цикла вычислений хранит некий флаг,
gil_drop_request. После выполнения в неком кадре каждой операции байтового кода, проверяется этот флаг и
GIL временно высвобождается перед повторным овладением ею:
if (_Py_atomic_load_relaxed(&ceval->gil_drop_request)) {
/* Give another thread a chance */
if (_PyThreadState_Swap(&runtime->gilstate, NULL) != tstate) {
Py_FatalError("ceval: tstate mix-up");
}
drop_gil(ceval, tstate);
/* Other threads may run now */
take_gil(ceval, tstate);
/* Check if we should make a quick exit. */
exit_thread_if_finalizing(tstate);
if (_PyThreadState_Swap(&runtime->gilstate, tstate) != NULL) {
Py_FatalError("ceval: orphan tstate");
}
}
...
Несмотря на те ограничения, которые налагает GIL на параллельное исполнение, она превращает многопоточность в Python в очень безопасное и идеальное для одновременного выполнения задач, связанных с вводом/ выводом.
Вот те исходные файлы, которые относятся к потокам:
| Файл | Назначение |
|---|---|
|
API и определение PyThread |
|
API построения потоков и модуль стандартной библиотеки верхнего уровня |
|
API построения потоков и модуль стандартной библиотеки нижнего уровня |
|
Расширение C для модуля |
|
API построения модулей Windows |
|
API построения модулей POSIX |
|
Реализация блокировки GIL |
Чтобы продемонстрировать получаемый выигрыш производительности от обладания многопоточным кодом (несмотря на имеющуюся GIL), вы можете реализовать простое сканирование портов в Python.
Вы начнёте с клонирования нашего предыдущего сценария, но с заменой его логики на порождение некого потока для каждого порта с применением
threading.Thread(). Это аналогично предыдущему API multiprocessing,
где получались вызываемая, target, и кортеж, args.
Запускайте потоки внутри соответствующего цикла, однако не дожидайтесь их завершения. Вместо этого, добавляйте в конец некого списка,
threads, соответствующий экземпляр потока:
for port in range(80, 100):
t = Thread(target=check_port, args=(host, port, results))
t.start()
threads.append(t)
После того как все потоки были созданы, выполнит итеративно проход по списку threads и вызывайте
.join() чтобы дожидаться из выполнения:
for t in threads:
t.join()
Затем исчерпайте полностью все элементы из своей очереди results и выведите их на печать на экране:
while not results.empty():
print("Port {0} is open".format(results.get()))
Вот весь сценарий целиком, cpython-book-samples/33/portscanner_threads.py:
from threading import Thread
from queue import Queue
import socket
import time
timeout = 1.0
def check_port(host: str, port: int, results: Queue):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(timeout)
result = sock.connect_ex((host, port))
if result == 0:
results.put(port)
sock.close()
def main():
start = time.time()
host = "localhost" # Replace with a host you own
threads = []
results = Queue()
for port in range(80, 100):
t = Thread(target=check_port, args=(host, port, results))
t.start()
threads.append(t)
for t in threads:
t.join()
while not results.empty():
print("Port {0} is open".format(results.get()))
print("Completed scan in {0} seconds".format(time.time() - start))
if __name__ == '__main__':
main()
Когда вы вызовете этот сценарий с построением потоков из своей командной строки, он исполнится быстрее более чем в десять раз чем пример с единственным потоком:
$ python portscanner_threads.py
Port 80 is open
Completed scan in 1.0101029872894287 seconds
Он также исполняется на от 50 до 60 процентов быстрее чем пример со множеством процессов. Помните, что подход со множеством процессов обладает накладными расходами для запуска своих новых процессов. Потоки также обладают накладными расходами, однако они намного меньше.
Вы можете удивиться, Раз GIL означает что лишь одна операция способна выполняться за раз, тогда почему это может быть быстрее?
Вот предложение, которое отнимает 1 - 1000мс:
result = sock.connect_ex((host, port))
В модуле расширения C, Modules/socketmodule.c, эта функция
реализует такое соединение, строка 3245 Modules/socketmodule.c:
static int
internal_connect(PySocketSockObject *s, struct sockaddr *addr, int addrlen,
int raise)
{
int res, err, wait_connect;
Py_BEGIN_ALLOW_THREADS
res = connect(s-gt;sock_fd, addr, addrlen);
Py_END_ALLOW_THREADS
Системный вызов connect() окружают макросы Py_BEGIN_ALLOW_THREADS
и Py_END_ALLOW_THREADS. Эти макросы определены следующим образом в
Include/ceval.h:
#define Py_BEGIN_ALLOW_THREADS { \
PyThreadState *_save; \
_save = PyEval_SaveThread();
#define Py_BLOCK_THREADS PyEval_RestoreThread(_save);
#define Py_UNBLOCK_THREADS _save = PyEval_SaveThread();
#define Py_END_ALLOW_THREADS PyEval_RestoreThread(_save); \
}
Итак, при обращении к Py_BEGIN_ALLOW_THREADS, он вызывает
PyEval_SaveThread().
Эта функция изменяет состояние текущего потока на NULL и
отбрасывает (drops) GIL, строка 444
Python/ceval.c:
PyThreadState *
PyEval_SaveThread(void)
{
PyThreadState *tstate = PyThreadState_Swap(NULL);
if (tstate == NULL)
Py_FatalError("PyEval_SaveThread: NULL tstate");
assert(gil_created());
drop_gil(tstate);
return tstate;
}
Поскольку GIL отброшен, может продолжаться любой прочий выполняющийся поток. Этот поток будет покоиться и дожидаться системного вызова без блокирования своего цикла выполнения.
После успешного завершения connect() или выхода по таймауту, макро
Py_END_ALLOW_THREADS исполняет PyEval_RestoreThread() с изначальным состоянием потока. Значение состояния потока восстанавливается и повторно берётся GIL. Вызов
take_gil() это блокирующий вызов, дожидающийся семафора, строка 458
Python/ceval.c:
void
PyEval_RestoreThread(PyThreadState *tstate)
{
if (tstate == NULL)
Py_FatalError("PyEval_RestoreThread: NULL tstate");
assert(gil_created());
int err = errno;
take_gil(tstate);
/* _Py_Finalizing is protected by the GIL */
if (_Py_IsFinalizing() && !_Py_CURRENTLY_FINALIZING(tstate)) {
drop_gil(tstate);
PyThread_exit_thread();
Py_UNREACHABLE();
}
errno = err;
PyThreadState_Swap(tstate);
}
Это не просто системный вызов, обёрнутый не блокирующей GIL парой Py_BEGIN_ALLOW_THREADS и
Py_END_ALLOW_THREADS. Существует более трёх сотен его применений в стандартной библиотеке, включающих:
-
Выполнение запросв HTTP
-
Взаимодействие с локальным оборудованием
-
Шифрование данных
-
Чтение и запись файлов
CPython предоставляет свою собственную реализацию управления потоком. Поскольку потоками требуется исполнять байтовый код Python в своём цикле вычислений, запуск некого потока в CPython это не простое порождение некого потока операционной системы.
Потоки Python носят название PyThread. Вы кратко рассматривали их в
Главе 8, Цикл расчёта.
Потоки Python исполняют код объектов и порождаются своим интерпретатором.
Чтобы напомнить:
-
CPython обладает единственной средой времени исполнения, которая обладает своим собственным состоянием времени исполнения.
-
CPython способен обладать одним или множеством интерпертаторов.
-
Интерпретатор обладает состоянием с названием состояние интерпетатора.
Некий интерпретатор возьмёт объект кода и преобразует его в последовательность объектов кадров.
-
Некий интерпретатор обладает по крайней мере одним потоком и каждый поток обладает состоянием потока.
-
Объекты кадров исполняются в стеке, носящем название стека кадров.
-
CPython ссылается на переменные из стека значений.
-
Значение состояния интерпретатора содержит связанный список своих потоков.
Среда времени исполнения с единственным потоком, единственным интерпретатором будет обладать следующими состояниями:
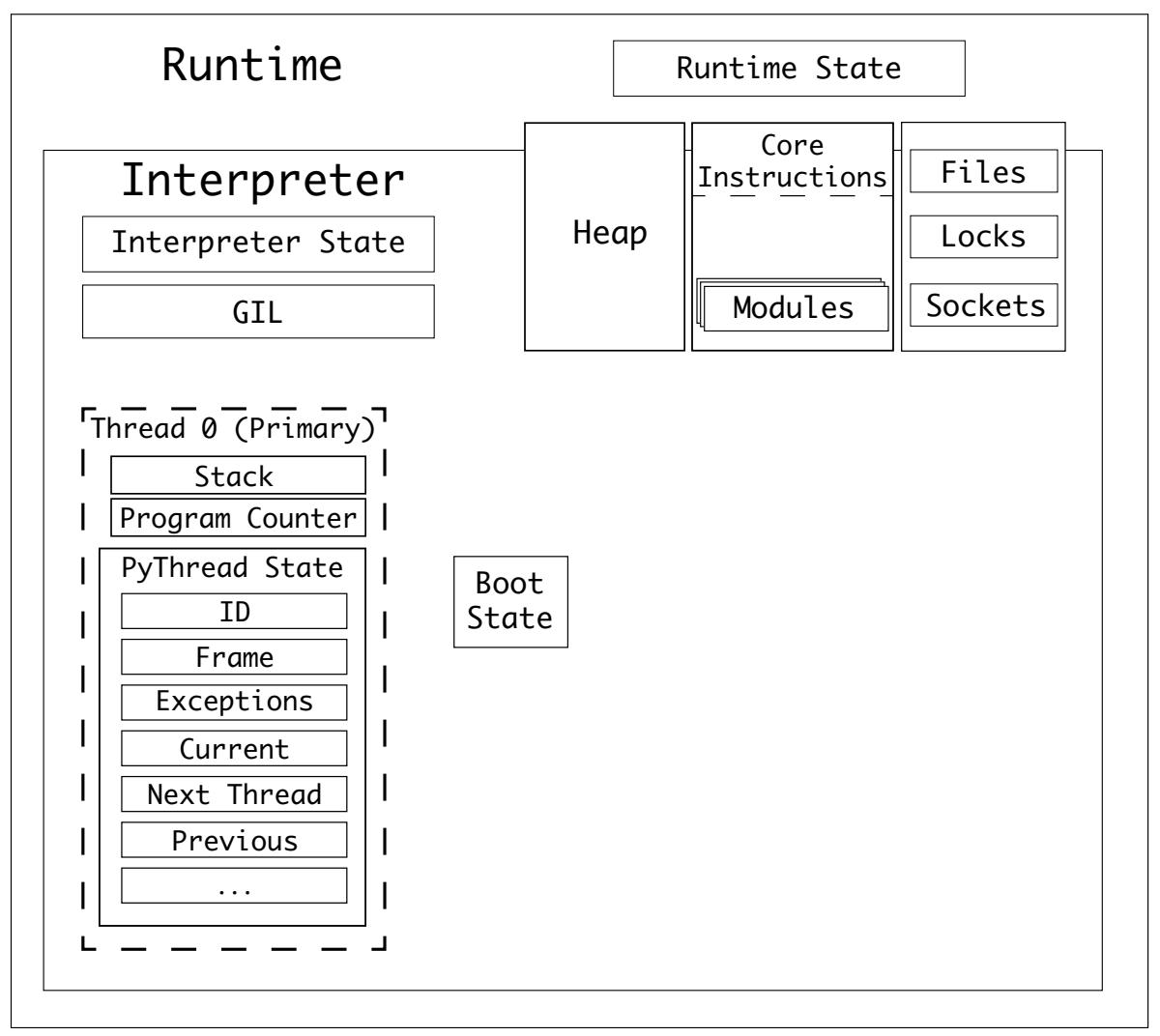
Тип состояния соответствующего потока, PyThreadState, обладает более чем тридцатью свойствами, включая:
-
Уникальный идентификатор
-
Связный список с прочими состояниями потоков
-
Значение состояния породившего его интерпретатора
-
Значение исполняемого в данный момент кадра
-
Значение текущей глубины рекурсии
-
Не обязательные функции отслеживания
-
Обрабатываемая в данный момент исключительная ситуация
-
Все обрабатываемые в данный момент асинхронные исключительные ситуации
-
Стек возбуждённых исключительных ситуаций
-
Счётчик GIL
-
Счётчики асинхронного генератора
Как и подготовительные данные обработки множества процессов, потоки обладают неким состоянием запуска. Тем не менее, потоки совместно используют одно и то же пространство памяти, поэтому нет необходимости упорядочения данных и отправки их через некий файловый поток.
Потоки конкретизируются при помощи своего типа threading.Thread . Это модуль верхнего уровня, который
абстрагирует тип PyThread. Экземпляры PyThread управляются
модулем расширения C _thread.
Этот модуль _thread обладает точкой входа для запуска нового потока, thread_PyThread_start_new_thread().
start_new_thread() это метод в экземпляре с типом Thread.
Новые потоки конкретизируются в такой последовательности:
-
Создаётся
bootstate, связывается со своейtarget, причём с аргументамиargsиkwargs. -
Значение
bootstateпривязывается к состоянию его интерпретатора. -
Создаётся новое
PyThreadState, которое привязывается к своему текущему интерпретатору. -
Включается его GIL, если она ещё не разрешена, при помощи вызова к PyEval_InitThreads().
-
Полученный новый поток запускается в зависимой от своей операционной системы реализации
PyThread_start_new_thread.
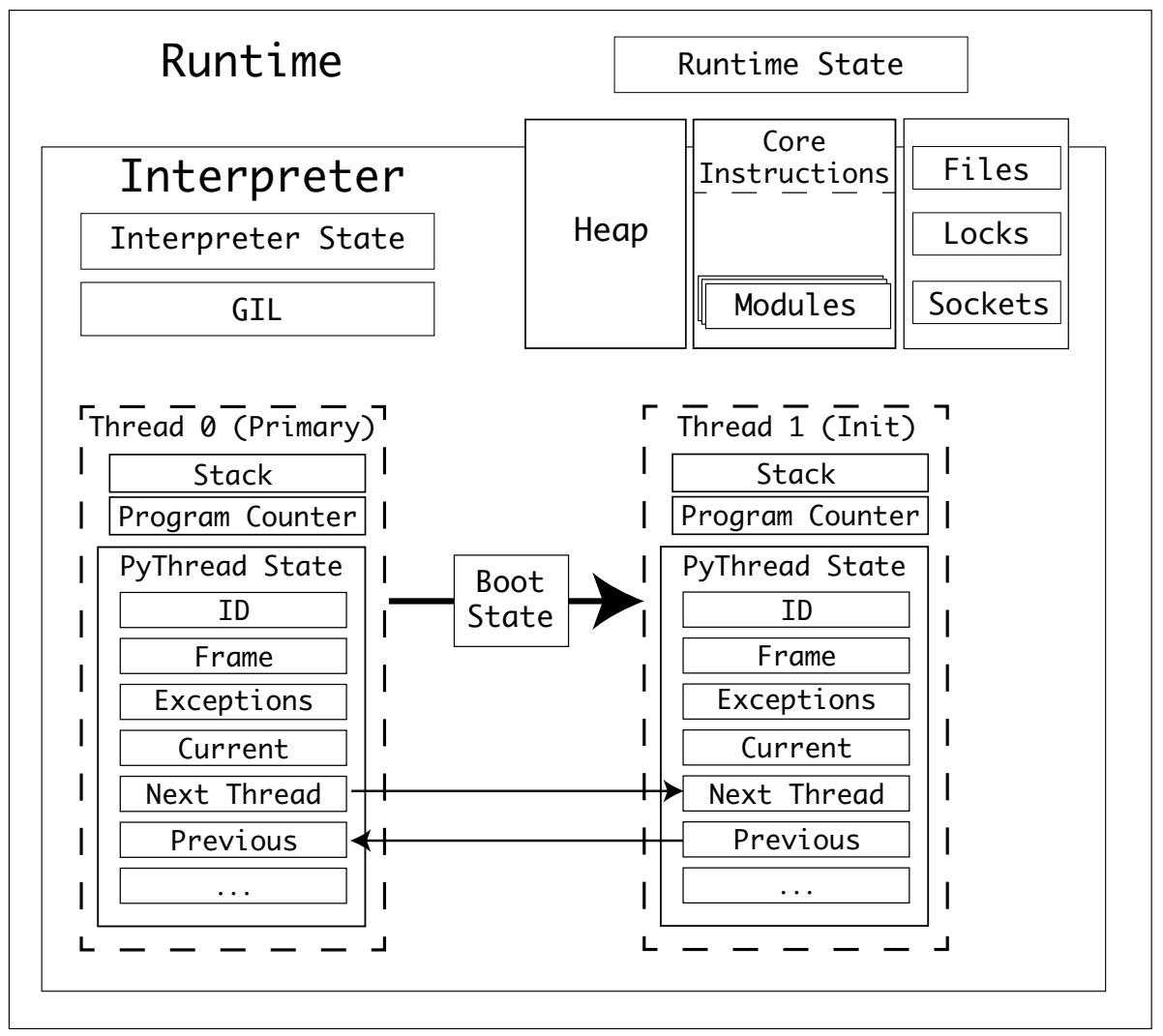
Значение bootstate потока обладает следующими свойствами:
| Поле | Тип | Назначение |
|---|---|---|
|
|
Ссылка на управляющий этим потоком интерпретатор |
|
|
Ссылка на свой |
|
|
Аргументы для вызова с ними |
|
|
Аргументы ключевых слов для вызова с ними |
|
|
Состояние потока для этого нового потока |
Для bootstate соответствующего потока имеются две реализации
PyThread:
-
Потоки POSIX для Linux и macOS
-
Потоки NT для Windows
Обе эти реализации создают необходимый поток операционной системы, устанавливают его атрибуты и затем выполняют соответствующий обратный вызов t_bootstrap() изнутри вновь созданного потока.
Эта функция вызывается с единственным аргументом, boot_raw, назначаемом
bootstate, построенном в thread_PyThread_start_new_thread().
Эта функция t_bootstrap()
выступает интерфейсом между потоком нижнего уровня и средой времени исполнения Python. Такой начальный самораскрутчик проинициализирует свой
поток, а затем исполнит вызываемый target при помощи
PyObject_Call().
После исполнения свей вызываемой цели соответствующий поток выполняет выход:

Потоки POSIX, носящие название pthreads, обладают реализацией в
Python/thread_pthread.h. Эта реализация абстрагирует API C
<pthread.h> при помощи некоторых дополнительных мер безопасности и оптимизаций.
Потоки способны обладать неким настраиваемым размером стека. Python обладает своей собственной конструкцией кадра стека, который вы
изучили в Главе 8, Цикл расчёта. Когда существует некая проблема, вызываемая каким- то
рекурсивным циклом, а сам исполняемый кадр достигает значения предела глубины, тогда Python возбуждает RecursionError,
которую вы способны обрабатывать при помощи блока try...except в коде Python.
Поскольку pthreads обладают своим собственным размером стека, значение максимальной глубины размеров
стека Python и pthread могут вступать в конфликт. Когда значение размера стека потока меньше чем
величина максимальной глубины кадра в Python, тогда весь процесс Python целиком может испытать крушение перед возбуждением некой
RecursionError.
Во время исполнения значение максимальной глубины в Python можно настраивать при помощи sys.setrecursionlimit(). Во избежание крушений реализация pthread CPython устанавливает
величину размера стеа в значение pythread_stacksize состояния своего интерпретатора.
Большинство современных совместимых с POSIX операционных систем поддерживают системное планирование pthreads.
Если PTHREAD_SYSTEM_SCHED_SUPPORTED определяется в pyconfig.h,
тогда значение pthread устанавливается в PTHREAD_SCOPE_SYSTEM, что
означает, что значение приоритета этого потока в планировщике операционной системы принимается на основе сопоставления с прочими потоками в этой
системе, а не только с потоками внутри самого процесса Python.
После того как были настроены свойства потоков, при помощи API pthread_create() создаётся необходимый
поток. Это запускает функцию самораскрутки изнутри такого нового потока.
Позднее, соответствующий обработчик потока, pthread_t, выполняет выравнивание на
unsigned long возвращается чтобы превратиться в надлежащий идентификатор потока.
Потоки Windows реализуются в Python/thread_nt.h, следуя аналогичным,
но более простым шаблоном.
Значение размера стека своего нового потока настраивается на значение интерпретатора pythread_stacksize
(когда оно установлено). Этот поток затем создаётся при помощи API Windows _beginthreadex() с применением его функции самораскрутки в качестве обратного вызова. Наконец, возвращается значение
идентификатора потока.
Это не является исчерпывающим руководством по потокам Pytho. Реализация потока Python обширна и предлагает множество механизмов для совместного использования данных между потоками, блокировок объектов и ресурсов.
Потоки это великолепный, действенный способ улучшения времени выполнения вашего приложения Python когда вы ограничены операциями ввода/ вывода. В этом разделе вы рассмотрели чем является GIL, зачем она существует и какие части общей стандартной библиотеки могут выводиться из- под её ограничений.
Python предлагает множество способов одновременного программирования без применения потоков и множества процессов. Эти функциональные возможности добавлялись, расширялись и часто заменялись лучшими альтернативами.
Для нашей текущей версии в этой книге, 3.9, считается устаревшим декоратор @coroutine.
Всё ещё доступны следующие системы:
-
Создание фьючерсов из ключевых слов
async -
Запуск сопрограмм при помощи ключевых слов
yield from
Генераторы Python это возвращающие предложение yield функции и способные постоянно вызываться для
выработки последующих значений.
Генераторы зачастую применяются как более действенный в отношении памяти способ зацикливания по значениям в большом блоке данных, таком как
некий файл, база данных или при работе с сетевой средой. Объекты генератора возвращаются на месте
значения при использовании yield вместо
return. Такой объект генератора создаётся из предложения yield и
возвращается вызывавшей его стороне.
Эта простая функция генератора даст в результате буквы с a по z,
cpython-book-samples/33/letter_generator.py:
def letters():
i = 97 # Letter 'a' in ASCII
end = 97 + 26 # Letter 'z' in ASCII
while i < end:
yield chr(i)
i += 1
Если вы вызовете letters(), тогда она не возвратит вам некое значение. Вместо этого она будет
возвращать некий объект генератора:
>>> from letter_generator import letters
>>> letters()
<generator object letters at 0x1004d39b0>
В имеющийся синтаксис предложения for встроена возможность перебирать объект генератора пока он
не прекратит выдавать значения:
>>> for letter in letters():
... print(letter)
a
b
c
d
...
Эта реализация использует протокол самого итератора. Объекты, обладающие методом __next__() могут
применяться в циклах for и while, либо при помощи
встроенного next().
Все типы контейнеров (такие как списки, наборы и кортежи) в Python реализуют этот протокол итератора. Генераторы уникальны, поскольку
сама реализация его метода __next__() повторно вызывает эту функцию генератора из её последнего
состояния.
Генераторы не исполняются в своём фоновом режиме - они приостанавливаются. Когда вы запрашиваете другое значение, они восстанавливают
исполнение. Внутри структуры самого объекта генератора имеется соответствующий объект кадра в том виде, каким он был в самом последнем
предложении yield.
Объекты генератора создаются шаблонным макро, _PyGenObject_HEAD(prefix).
Этот макро применяется со следующими типами префиксов:
-
Объекты генератора:
PyGenObject(gi_) -
Объекты сопрограммы:
PyCoroObject(cr_) -
Объекты асинхронного генератора:
PyAsyncGenObject(ag_)
Позднее в этой главе вы рассмотрите объекты сопрограмм и асинхронного генератора.
Сам тип PyGenObject обладает такими базовыми свойствами:
| Поле | Тип | Назначение |
|---|---|---|
|
|
Скомпилированная функция, которую выдаёт этот генератор |
|
|
Сведения исключительной ситуации если вызов этого генератора возбуждает исключительную ситуацию |
|
|
Текущий объект кадра для данного генератора |
|
|
Название этого генератора |
|
|
Полностью определённое имя этого генератора |
|
|
Устанавливается в |
|
|
Список слабых ссылок на объекты внутри функции этого генератора |
Поверх этих базовых свойств, PyCoroObject обладает таким свойством:
| Поле | Тип | Назначение |
|---|---|---|
|
|
Кортеж, содержащий свой исходный кадр и вызывающую сторону |
Поверх имеющихся базовых свойств, PyAsyncGenObject обладает такими свойствами:
| Поле | Тип | Назначение |
|---|---|---|
|
|
Флаг маркировки того, что этот генератор закрыт |
|
|
Ссылка на финализирующий метод |
|
|
Флаг маркировки того, что соответствующие специальные точки входа проинициализированы |
|
|
Флаг маркировки того, что этот генератор исполняется |
Вот те исходные файлы, которые относятся к генераторам:
| Файл | Назначение |
|---|---|
|
API генератора и определение |
|
Реализация объекта генератора |
Когда компилируется функция, содержащая предложение yield, результирующий объект кода обладает неким
дополнительным флагом, CO_GENERATOR.
В разделе Построение объектов кадров Главы 8, Цикл расчёта вы изучали как компилированный объект кода преобразуется в объект кадра при его исполнении. В этом процессе имеется специальный вариант для генераторов, сопрограмм и асинхронных генераторов.
_PyEval_EvalCode() проверяет
соответствующий объект кода на флаги CO_GENERATOR, CO_COROUTINE и
CO_ASYNC_GENERATOR. Когда он обнаруживает один из этих флагов, тогда вместо вычисления этого объекта
кода в реальном времени, его функция создаёт некий кадр и возвращает его в объект генератора, сопрограммы или асинхронного генератора применяя,
соответственно, PyGen_NewWithQualName(),
PyCoro_New() или
PyAsyncGen_New():
PyObject *
_PyEval_EvalCode(PyObject *_co, PyObject *globals, PyObject *locals, ...
...
/* Handle generator/coroutine/asynchronous generator */
if (co->co_flags & (CO_GENERATOR | CO_COROUTINE | CO_ASYNC_GENERATOR)) {
PyObject *gen;
PyObject *coro_wrapper = tstate->coroutine_wrapper;
int is_coro = co->co_flags & CO_COROUTINE;
...
/* Create a new generator that owns the ready-to-run frame
* and return that as the value. */
if (is_coro) {
>>> gen = PyCoro_New(f, name, qualname);
} else if (co->co_flags & CO_ASYNC_GENERATOR) {
>>> gen = PyAsyncGen_New(f, name, qualname);
} else {
>>> gen = PyGen_NewWithQualName(f, name, qualname);
}
...
return gen;
}
...
Имеющаяся фабрика генератора, PyGen_NewWithQualName(), получает соответствующий кадр и выполняет некие шаги по заполнению полей объекта этого генератора:
-
Устанавливает свойство
gi_codeв значение скомпилированного объекта кода -
Устанавливает этот генератор как не исполняющийся (
gi_running = 0) -
Устанавливает списки исключительных ситуаций и слабых ссылок в
NULL
Вы можете рассмотреть этот скомпилированный объект кода gi_code для своей функции генератора
импортировав модуль dis и дизассемблировав полученный внутри байтовый код:
>>> from letter_generator import letters
>>> gen = letters()
>>> import dis
>>> dis.disco(gen.gi_code)
2 0 LOAD_CONST 1 (97)
2 STORE_FAST 0 (i)
...
В Главе 8, Цикл расчёта вы изучили Тип объекта кадра. Объекты кадра содержат локальные и глобальные элементы, самые последние исполненные инструкции и подлежащий выполнению код.
Встроенное поведение и состояние объектов кадра делает возможным для генераторов приостанавливаться и возобновляться по запросу.
Всякий раз когда в неком объекте генератора вызывается __next__(), с этим экземпляром генератора
вызывается gen_iternext(),
который немедленно вызывает gen_send_ex() внутри Objects/genobject.c.
gen_send_ex() это функция, которая преобразует объект генератора в выдаваемый следующим результат. Вы обнаружите много аналогичного с тем способом, которым конструируются кадры из объекта кода, поскольку эти функции обладают схожими задачами.
gen_send_ex() совместно применяется с генераторами, сопрограммами и асинхронными генераторами и обладает следующими этапами:
-
Выполняется выборка текущего состояния потока.
-
Выполняется выборка необходимого объекта кадра из данного объекта генератора.
-
Если этот генератор выполняется при вызове
__next__(), тогда возбуждаетсяValueError. -
Когда этот кадр внутри самого генератора расположен в верху стека:
-
Если это сопрограмма и эта сопрограмма уже не помечена как закрытая, тогда возбуждается
RuntimeError. -
Если это некий асинхронный генератор, возбуждается
StopAsyncIteration. -
Если это стандартный генератор, возбуждается
StopIteration.
-
-
Когда самая последняя инструкция в этом кадре (
f->f_lasti) всё ещё-1по причине того что она только что была запущена, и если это сопрограмма или асинхронный генератор, тогда любое значение, за исключениемNoneне может быть передано в качестве некого аргумента и возбуждается некая исключительная ситуация. -
В противном случае это самый первый случай её вызова и аргументы доступны. Значение этого аргумента выдаётся в стек значений этого кадра.
-
Поле
f_backданного кадра это вызывающая сторона, которой возвращаются отправленные значения, поэтому оно устанавливается в значение текущего кадра в этом потоке. Это означает, что такое возвращаемое отправляется вызываемой стороне, не самому создателю этого генератора. -
Данный генератор помечается как исполняемый.
-
Самая последняя исключительная ситуация из имеющихся сведений исключительных ситуаций генератора копируется из самой последней исключительной ситуации состояния его потока.
-
Сведения об исключительной ситуации состояния этого потока устанавливаются в адрес сведений исключительной ситуации данного генератора. Это означает, что если вызывающая сторона входит в некую точку прерывания в пределах исполнения некого генератора, тогда отслеживание стека проходит через данный генератор и проблемный код очищается.
-
Сам код внутри этого генератора выполняется внутри основного цикла выполнения
Python/ceval.cи возвращается полученное значение. -
Сведения о последней исключительной ситуации состояния потока сбрасываются в значение до вызова этого кадра.
-
Данный генератор помечается как не выполняющийся.
-
Затем следующие варианты ставят в соответствие возвращаемое значение и все исключительные ситуации перемещаются вызовом в сам генератор. Помните, что генераторы должны возбуждать по своему исчерпанию
StopIteration, либо вручную, любо не выдавая некое значение:-
Если из этого кадра не возвращается никакое значение, тогда для генераторов возбуждается
StopIterationиStopAsyncIterationвозбуждается для асинхронных генераторов. -
Если
StopIterationбыло возбуждено в явном виде, но это сопрограмма или асинхронный генератор, тогда возбуждаетсяRuntimeError, поскольку это недопустимо. -
Если было возбуждено
StopAsyncIterationи это некий асинхронный генератор, тогда возбуждаетсяRuntimeError, поскольку это недопустимо.
-
-
В конце концов полученный результат возвращается обратно вызывающей стороне
__next__().
Собрав всё это воедино, вы можете увидеть что выражение генератора это мощный синтаксис, в котором единственное ключевое слово,
yield, включает целый поток создания уникального объекта, копирование некого скомпилированного объекта
кода в качестве свойства, установки кадра и сохранения списка переменных в его локальной области действия.
Генераторы обладают основным ограничением: они способны выдавать значения только своей непосредственно вызывающей стороне.
Для обхода этого ограничения в Python был добавлен некий дополнительный синтаксис, предложение yield from.
Применяя такой синтаксис вы можете повторно собирать генераторы в функции утилит и затем yield from
их.
Например, ваш генератор букв можно повторно собрать в некую функцию утилиты, в которой значением начальной буквы выступает некий аргумент.
Применяя yield from вы можете выбирать какой объект генератора возвращать,
cpython-book-samples/33/letter_coroutines.py:
def gen_letters(start, x):
i = start
end = start + x
while i < end:
yield chr(i)
i += 1
def letters(upper):
if upper:
yield from gen_letters(65, 26) # A--Z
else:
yield from gen_letters(97, 26) # a--z
for letter in letters(False):
# Lowercase a--z
print(letter)
for letter in letters(True):
# Uppercase A--Z
print(letter)
Генераторы также отлично походят для отложенных последовательностей, в которых они могут вызываться множество раз.
Опираясь на такое поведение генераторов как их способность приостанавливать и возобновлять исполнение, во множестве API Python вновь и вновь появлялось понятие сопрограммы.
Генераторы являются ограниченной формой сопрограммы, потому как вы можете отправлять данные им при помощи метода
.send(). Имеется возможность отправки сообщений в двух направлениях между вызывающей стороной и её
целью. Сопрограммы также запоминают вызывающую сторону в своём атрибуте cr_origin.
Сопрограммы изначально были доступны через некий декоратор, но с тех пор это было признано устаревшим в пользу "естественных"
сопрограмм, применяющих ключевые слова async и await.
Чтобы пометить, что некая функция возвращает какую- то сопрограмму, вы обязаны предварить эту функцию ключевым словом
async. Такое ключевое слово async в явном виде указывает на то,
что в отличие от генераторов, данная функция возвращает некую сопрограмму вместо какого- то значения.
Для создания сопрограммы, вы определяете некую функцию ключевым словом async def. В данном примере
вы добавляете таймер при помощи функции asyncio.sleep() и возвращаете некую строку после пробуждения:
>>> import asyncio
>>> async def sleepy_alarm(time):
... await asyncio.sleep(time)
... return "wake up!"
>>> alarm = sleepy_alarm(10)
>>> alarm
<coroutine object sleepy_alarm at 0x1041de340>
Когда вы вызовете эту функцию, она возвратит некий объект сопрограммы.
Существует множество способов исполнения сопрограммы. Самый простой состоит в применении asyncio.run(coro).
Исполнив asyncio.run() со своим объектом сопрограммы, далее, после 10 секунд, вы услышите
будильник:
>>> asyncio.run(alarm)
'wake up'
Основное преимущество сопрограмм состоит в том, что можете исполнять их одновременно. По той причине, что сам объект сопрограммы это некая переменная, которую вы способны передавать в некую функцию, эти объекты можно связывать воедино и в цепочки, либо создавать некую последовательность.
К примеру, если вы желаете получить десять предупреждений с различными интервалами, а запустить их одновременно, тогда могли бы преобразовать эти объекты сопрограмм в задачи.
API задачи применяется для планирования и исполнения множества сопрограмм одновременно. Перед планированием задач надлежит запустить некий цикл событий. Основным заданием этого цикла событий является планирование одновременных задач и соединение событий, таких как окончание (completion), отмена (cancellation) и исключительные ситуации (exceptions), с обратными вызовами.
Когда вы вызываете asyncio.run() (из
Lib/asyncio/runners.py), эта функция выполняет для вас такие задачи:
-
Запускает новый цикл событий.
-
Обёртывает соответствующий объект сопрограммы в некую задачу.
-
Устанавливает некий обратный вызов по окончанию этой задачи.
-
Выполняет цикл по всем задачам пока они не завершатся.
-
Возвращает полученный результат.
Вот тот исходный файл, который относится к сопрограммам:
| Файл | Назначение |
|---|---|
|
Реализация стандартной библиотеки Python для asyncio |
Циклы событий выступают тем клеем, который совместно удерживает асинхронный код. Написанные на чистом Python, циклы событий это содержащие задачи объекты.
Все имеющиеся в этом цикле задачи могут обладать обратными вызовами. Данный цикл будет запускать такие обратные вызовы в случае окончаний или отказов задачи:
loop = asyncio.new_event_loop()
Внутри некого цикла имеется последовательность задач, представленных типом asyncio.Task. Задачи
планируются в неком цикле, а затем, когда этот цикл запущен, он обходит циклом все эти задачи до тех пор, пока они не окончатся.
Вы можете преобразовать отдельный таймер в некий цикл задач,
cpython-book-samples/33/sleepy_alarm.py:
import asyncio
async def sleepy_alarm(person, time):
await asyncio.sleep(time)
print(f"{person} -- wake up!")
async def wake_up_gang():
tasks = [
asyncio.create_task(sleepy_alarm("Bob", 3), name="wake up Bob"),
asyncio.create_task(sleepy_alarm("Yudi", 4), name="wake up Yudi"),
asyncio.create_task(sleepy_alarm("Doris", 2), name="wake up Doris"),
asyncio.create_task(sleepy_alarm("Kim", 5), name="wake up Kim")
]
await asyncio.gather(*tasks)
asyncio.run(wake_up_gang())
Это выдаст на печать следующий вывод:
Doris -- wake up!
Bob -- wake up!
Yudi -- wake up!
Kim -- wake up!
Запущенный цикл событий исполняется по всем своим сопрограммам наблюдая их окончание. Аналогично тому как ключевое слово
yield способно возвращать множество значений из одного и того же кадра, ключевое слово
await может возвращать множество состояний.
Этот цикл событий будет выполнять имеющиеся объекты сопрограмм sleepy_alarm() снова и снова до
тех пор, пока их await asyncio.sleep() не выдаст выполненный результат и не будет способен выполниться
print().
Для этой работы вам надлежит воспользоваться asyncio.sleep() вместо блокирующего (и не осведомлённого
об асинхронности) time.sleep().
Вы можете преобразовать пример сканирования портов со множеством процессов в asyncio следующими
шагами:
-
Заменить
check_port()на применение соединения с сокетом изasyncio.open_connection(), что создаст некий фьючерс вместо какого- то немедленного подключения. -
Воспользоваться этим фьючерсом подключения к сокету по событию таймера при помощи
asyncio.open_connection(). -
В случае успеха добавить полученный порт в общий список результатов.
-
Добавить новую функцию,
scan(), чтобы создавать сопрограммыcheck_port()для каждого порта и добавлять их в списокtasks. -
Слить все полученные
tasksв некую новую сопрограмму при помощиasyncio.gather(). -
Запустить своё сканирование при помощи
asyncio.run().
Вот этот код, cpython-book-samples/33/portscanner_async.py:
import time
import asyncio
timeout = 1.0
async def check_port(host: str, port: int, results: list):
try:
future = asyncio.open_connection(host=host, port=port)
r, w = await asyncio.wait_for(future, timeout=timeout)
results.append(port)
w.close()
except OSError: # pass on port closure
pass
except asyncio.TimeoutError:
pass # Port is closed, skip and continue
async def scan(start, end, host):
tasks = []
results = []
for port in range(start, end):
tasks.append(check_port(host, port, results))
await asyncio.gather(*tasks)
return results
if __name__ == '__main__':
start = time.time()
host = "localhost" # Pick a host you own
results = asyncio.run(scan(80, 100, host))
for result in results:
print("Port {0} is open".format(result))
print("Completed scan in {0} seconds".format(time.time() - start))
Данное сканирование оканчивается чуть больше чем за секунду:
$ python portscanner_async.py
Port 80 is open
Completed scan in 1.0058400630950928 seconds
Те понятия, которые вы изучали до сих пор, генераторы и сопрограммы, могут быть скомбинированы в асинхронные генераторы.
Когда некая функция объявляется с ключевым словом async и содержит предложение
yield, тогда она при вызове преобразуется в объект асинхронного генератора.
Как и генераторы, асинхронные генераторы должны исполнятся чем- то, что понимает протоколы. На месте
__next__(), асинхронные генераторы обладают методом __anext__().
Обычный цикл for не понимает асинхронный генератор, поэтому вместо него пользуйтесь предложением
async for.
Вы можете переделать check_port() в некий асинхронный генератор, который выдаёт значение следующего
открытого порта пока он не столкнётся с самым последним портом или не обнаружит предписанное число открытых портов:
async def check_ports(host: str, start: int, end: int, max=10):
found = 0
for port in range(start, end):
try:
future = asyncio.open_connection(host=host, port=port)
r, w = await asyncio.wait_for(future, timeout=timeout)
yield port
found += 1
w.close()
if found >= max:
return
except asyncio.TimeoutError:
pass # Closed
Для выполнения этого воспользуйтесь предложением async for:
async def scan(start, end, host):
results = []
async for port in check_ports(host, start, end, max=1):
results.append(port)
return results
Весь пример полностью вы можете найти в
cpython-book-samples/33/portscanner_async_generators.py.
На данный момент вы рассмотрели:
-
Параллельное исполнение с применением множества процессов
-
Одновременное выполнение при помощи потоков и асинхронности
Негативной стороной взаимодействия множества процессов выступает то, что применяемые межпроцессным взаимодействием конвейеры и очереди медленнее совместно используемой памяти, а также значительны накладные расходы на запуск нового процесса.
Потоки и асинхронное взаимодействие обладают малыми накладными расходами, но не предлагают реального параллельного исполнения по причине гарантий безопасности потока в своей GIL.
Четвёртым вариантом является subinterpreters, который обладает меньшими накладными расходами, нежели
multiprocessing и делает возможным некий GIL для каждого подчинённого интерпретатора. В конце концов, это
глобальная блокировка интерпретатора.
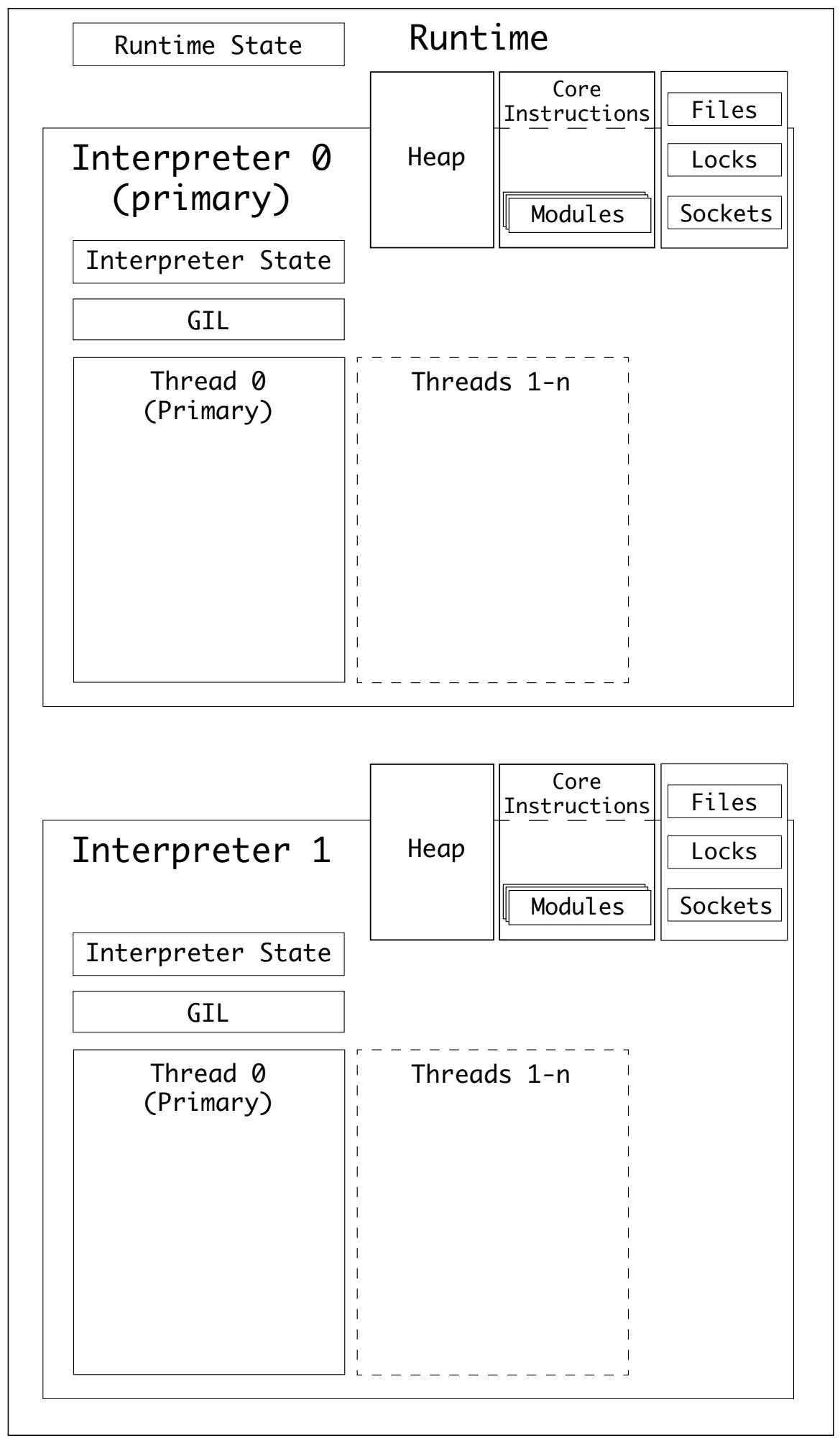
Внутри среды времени исполнения CPython всегда имеется один интерпретатор. Этот интерпретатор удерживает значение состояние интерпретатора, а также внутри интерпретатора у вас есть возможность обладать одним или более потоками Python. Такой интерпретатор выступает надлежащим контейнером для своего цикла вычислений. Он также управляет своей собственной памятью, счётчиком ссылок и сборкой мусора.
CPython обладает API C нижнего уровня для создания интерпретаторов, например, Py_NewInterpreter():
|
| Замечание |
|---|---|
|
Модуль |
По той причине, что значение состояния интерпретатора содержит распределитель памяти арены - коллекцию всех указателей на объекты Python (как локальных, так и глобальных) - подчинённые интерпретаторы не могут получать доступ к имеющимся глобальным переменным прочих интерпретаторов.
Аналогично работе со множеством процессов, для совместного использования объектов между интерпретаторами вам надлежит упорядочивать их
или применять ctypes и пользоваться некой формой IPC (сетевая среда, диск, либо совместная память).
Вот те исходные файлы, которые относятся к подчинённым интерпретаторам:
| Файл | Назначение |
|---|---|
|
Реализация C модуля |
|
Реализация C API управления самим интерпретатором |
В финальном примере приложения, наш код реального подключения должен заключаться в некой строке. В 3.9, подчинённый интерпретатор может исполнять лишь строку кода.
Для запуска каждого подчинённого интерпретатора, запускается некий список потоков с обратным вызовом к функции,
run().
Эта функция будет:
-
Создавать канал взаимодействия
-
Запускать новый интерпретатор
-
Отправлять в подчинённый интерпретатор необходимый для исполнения код
-
Получать данные через установленный канал взаимодействия
-
В случае успешного подключения к порту, добавлять его в очередь с безопасным потоком,
cpython-book-samples/33/portscanner_subinterpreters.py:
import time
import _xxsubinterpreters as subinterpreters
from threading import Thread
import textwrap as tw
from queue import Queue
timeout = 1 # In seconds
def run(host: str, port: int, results: Queue):
# Create a communication channel
channel_id = subinterpreters.channel_create()
interpid = subinterpreters.create()
subinterpreters.run_string(
interpid,
tw.dedent(
"""
import socket; import _xxsubinterpreters as subinterpreters
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(timeout)
result = sock.connect_ex((host, port))
subinterpreters.channel_send(channel_id, result)
sock.close()
"""),
shared=dict(
channel_id=channel_id,
host=host,
port=port,
timeout=timeout
))
output = subinterpreters.channel_recv(channel_id)
subinterpreters.channel_release(channel_id)
if output == 0:
results.put(port)
if __name__ == '__main__':
start = time.time()
host = "127.0.0.1" # Pick a host you own
threads = []
results = Queue()
for port in range(80, 100):
t = Thread(target=run, args=(host, port, results))
t.start()
threads.append(t)
for t in threads:
t.join()
while not results.empty():
print("Port {0} is open".format(results.get()))
print("Completed scan in {0} seconds".format(time.time() - start))
По причине снижения накладных расходов по сравнению с работой со множеством процессов, этот пример должен исполняться на от 30 до 40 процентов быстрее и с меньшими ресурсами памяти:
$ python portscanner_subinterpreters.py
Port 80 is open
Completed scan in 1.3474230766296387 seconds
Поздравляем с освоением самой большой главы в этой книге! Вы прошли большой путь. Давайте вспомним некоторые понятия и способы их применения.
Для действительного параллельного выполнения вам необходимо множество ЦПУ и
ядер. Вам также требуется применять либо пакет multiprocessing, либо пакет
subinterpreters с тем, чтобы интерпретатор Python был способен исполняться параллельно.
Помните, что время запуска значительно, а потому всякий интерпретатор обладает большими накладными расходами памяти. Когда та задача, которую вы желаете исполнить, имеет короткое время жизни, пользуйтесь пулом исполнителей и очередью задач.
Если у вас имеется большое число задач, ограниченных вводом/ выводом и вы желаете исполнять их
одновременно, тогда вам следует применять работу со множеством потоков или сопрограммы
из пакета asyncio.
Все эти четыре подхода требуют некого понимания того как безопасно и действенно обмениваться данными между процессами и потоками. Наилучший способ закрепления изученного вами материала состоит в просмотре написанного вами приложения и поиске того, как оно может быть воспроизведено с целью применения этих технологий.