Глава 15. Эталонное тестирование, профилирование и трассировка
Содержание
- Глава 15. Эталонное тестирование, профилирование и трассировка
При внесении изменений в CPython вам требуется удостовериться что ваши изменения не имеют значительного пагубного воздействия на производительность. Вы даже можете пожелать вносить изменения в CPython, которые улучшают производительность.
Существуют решения профилирования, которые вы рассмотрите в этой главе:
-
Применение модуля
timeitдля проверки проверки предложения Python тысячи раз для исчисления средней скорости исполнения -
Выполнения
pyperformance, комплекта эталонного тестирования Python для сопоставления множества версий Python -
Использование
cProfileдля анализа времени исполнения кадров -
Профилирование исполнения CPython зондированием
Основной выбор решения зависит от типа задачи:
-
Эталонное тестирование воспроизведёт среднее или медианное значение времени исполнения фрагмента фиксированного кода с тем, чтобы вы могли сопоставлять множество сред исполнения Python.
-
Профилирование снабжает грфом вызовов с временами выполнения с тем, чтобы вы были способны разобраться какие функции наиболее медленные.
Профилирование доступно на уровне C или Python. Если вы профилируете некую функцию, модуль ил сценарий, написанные на Python, тогда вы пожелаете применять профилировку Python. Если вы профилируете модуль расширения C или изменяете соответствующий код C в CPython, тогда вам требуется применять профилировку C или сочетание профилировки C и Python.
Вот суммирование некоторых доступных инструментов:
| Инструмент | Категория | Уровень | Поддерживаемая ОС |
|---|---|---|---|
|
Эталонное тестирование |
Python |
Все |
|
Эталонное тестирование |
Python |
Все |
|
Профилирование |
Python |
Все |
|
Трассировка/ профилирование |
C |
Linux, macOS |
![[Замечание]](/common/images/admon/note.png) | Важно |
|---|---|
|
Прежде чем вы запустите некое эталонное тестирование, будет лучше закрыть все ваши приложения в компьютере чтобы ваш ЦПУ был выделен для такого эталонного тестирования. |
Комплект эталонного тестирования Python является всесторонним тестом среды времени исполнения CPython со множеством итераций. Если вы желаете
выполнить быстрое, простое сопоставление определённого фрагмента кода, воспользуйтесь вместо этого модулем
timeit.
Чтобы исполнить timeit для короткого сценария, запустите CPython с модулем
-m timeit и сценарий в кавычках:
$ ./python -m timeit -c "x=1; x+=1; x**x"
1000000 loops, best of 5: 258 nsec per loop
Для меньшего числа циклов воспользуйтесь флагом -n:
$ ./python -m timeit -n 1000 "x=1; x+=1; x**x"
1000 loops, best of 5: 227 nsec per loop
В этой книге вы внесли изменения поддержки оператора почти равенства в свой тип float.
Попробуйте проверить его чтобы увидеть значение текущей производительности сравнения двух плавающих значений:
$ ./python -m timeit -n 1000 "x=1.0001; y=1.0000; x~=y"
1000 loops, best of 5: 177 nsec per loop
Реализация этого сравнения находится в float_richcompare(), внутри Objects/floatobject.c,
строка 358:
static PyObject*
float_richcompare(PyObject *v, PyObject *w, int op)
{
...
case Py_AlE: {
double diff = fabs(i - j);
double rel_tol = 1e-9;
double abs_tol = 0.1;
r = (((diff <= fabs(rel_tol * j)) ||
(diff <= fabs(rel_tol * i))) ||
(diff <= abs_tol));
}
break;
}
Обратите внимание на то, что значения rel_tol и abs_tol
являются константами, но не были помечены таковыми. Изменим это следующим образом:
const double rel_tol = 1e-9;
const double abs_tol = 0.1;
Теперь скомпилируем CPython снова и повторим свой тест:
$ ./python -m timeit -n 1000 "x=1.0001; y=1.0000; x~=y"
1000 loops, best of 5: 172 nsec per loop
Вы можете отметить незначительное (от 1 до 5 процентов) улучшение в производительности. Поэкспериментируйте с различными реализациями сравнения чтобы увидеть сможете ли вы улучшать её дальше.
Комплекта эталонного тестирования Python (Python Benchmark Suite) это инструмент для применения в том случае, когда вы желаете сопоставлять общую производительность Python. Комплект эталонного тестирования Python это коллекция приложений Python, разработанная для тестирования множества сторон среды времени исполнения Python под нагрузкой.
Этот комплект эталонного тестирования выполняет тестирование чистого Python, поэтому он может применяться для многих сред исполнения, например, PyPy и Jython. Он также совместим с Python 2.7 вплоть до самых последних версий.
Любые фиксации для основной ветви в github.com/python/cpython будут проверены при помощи инструмента эталонного тестирования и полученные результаты будут разгружены в Python Speed Center:
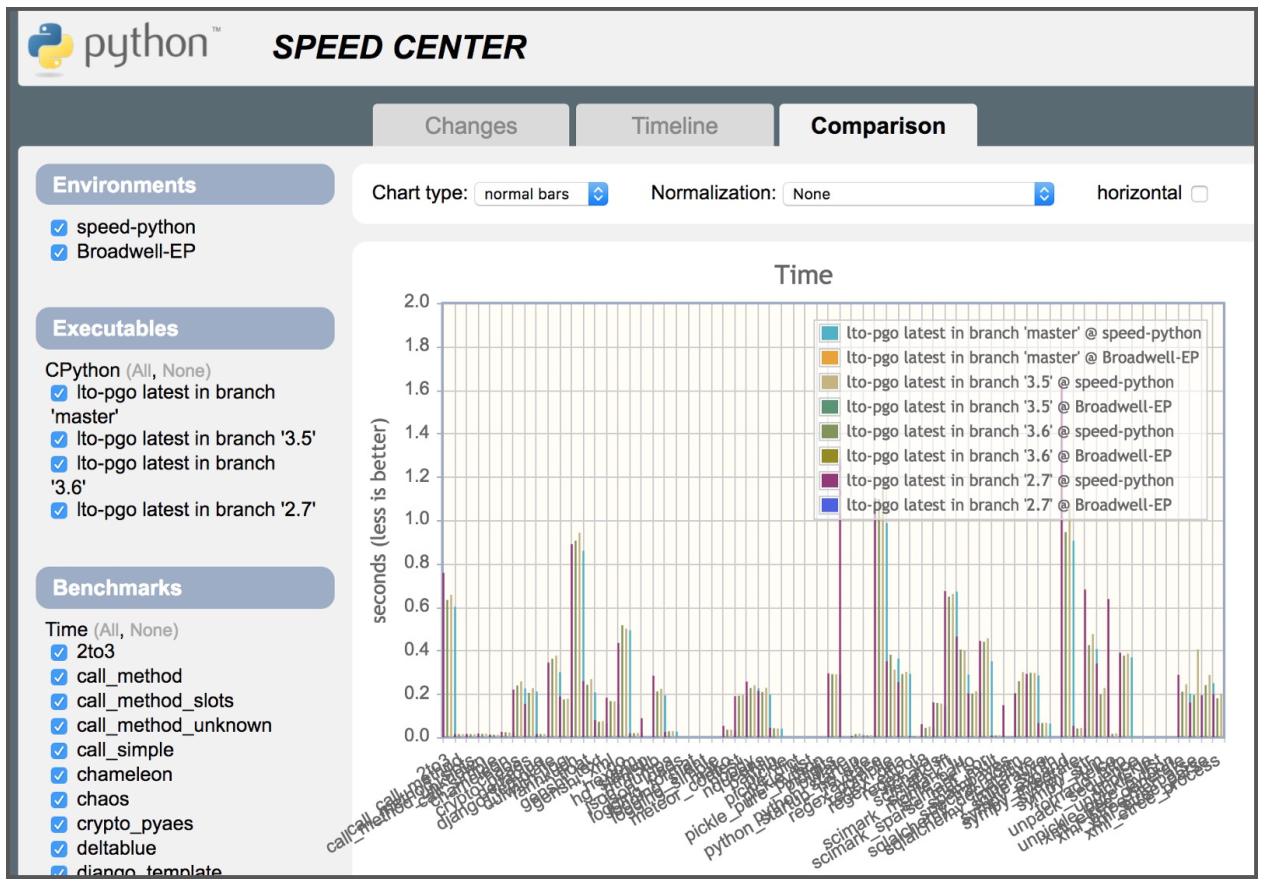
Вы можете сравнивать фиксации, ветви и теги шаг за шагом применяя этот Центр скорости. Все эталонные тесты применяют как руководимую профилем оптимизацию, так и обычные сборки с фиксированной аппаратной конфигурацией для производства стабильного сопоставления.
Вы можете установить Комплект эталонного тестирования Python из PyPI при помощи среды времени исполнения Python (отличающейся от той, в которой вы проводите тестирование) в некой виртуальной среде:
(venv) $ pip install pyperformance
Затем вам следует создать некий файл настроек и каталог выходных данных для своего тестируемого профиля. Рекомендуется чтобы вы создавали этот каталог вне вашего рабочего каталога Git. Это также поможет вам проверять большое число версий.
В своём файле настроек, например, ~/benchmarks/benchmark.cfg добавьте такие строки,
cpython-book-samples/62/benchmark.cfg:
[config]
# Path to output json files
json_dir = ~/benchmarks/json
# If True, then compile CPython in Debug mode (LTO and PGO disabled),
# run benchmarks with --debug-single-sample, and disable upload.
#
# Use this option to quickly test a configuration.
debug = False
[scm]
# Directory of CPython source code (Git repository)
repo_dir = ~/cpython
# Update the Git repository (git fetch)?
update = False
# Name of the Git remote, used to create revision of
# the Git branch.
git_remote = remotes/origin
[compile]
# Create files in bench_dir:
bench_dir = ~/benchmarks/tmp
# Link-time optimization (LTO)?
lto = True
# Profile-guided optimization (PGO)?
pgo = True
# The space-separated list of libraries that are package only
pkg_only =
# Install Python? If False, then run Python from the build directory
install = True
[run_benchmark]
# Run "sudo python3 -m pyperf system tune" before running benchmarks?
system_tune = True
# --benchmarks option for 'pyperformance run'
benchmarks =
# --affinity option for 'pyperf system tune' and 'pyperformance run'
affinity =
# Upload generated JSON file?
upload = False
# Configuration to upload results to a Codespeed website
[upload]
url =
environment =
executable =
project =
[compile_all]
# List of CPython Git branches
branches = default 3.6 3.5 2.7
# List of revisions to benchmark by compile_all
[compile_all_revisions]
# List of 'sha1=' (default branch: 'master') or 'sha1=branch'
# used by the "pyperformance compile_all" command
После настройки своего файла конфигурации вы можете запустить это эталонное тестирование при помощи такой команды:
$ pyperformance compile -U ~/benchmarks/benchmark.cfg HEAD
Она скомпилирует CPython в предписанном вами каталоге repo_dir и создаст вывод JSON со сведениями
эталонного тестирования в том каталоге, который определён в вашем файле настроек.
Если вы хотите сопоставлять результаты JSON, имейте ввиду, что Комплект эталонного тестирования Python не поставляет какого бы то ни было графического решения. Вместо этого вы можете воспользоваться следующим сценарием изнутри виртуальной среды.
Прежде всего, установите зависимости:
$ pip install seaborn pandas pyperformance
Затем создайте сценарий profile.py,
cpython-book-samples/62/profile.py:
import argparse
from pathlib import Path
from perf._bench import BenchmarkSuite
import seaborn as sns
import pandas as pd
sns.set(style="whitegrid")
parser = argparse.ArgumentParser()
parser.add_argument("files", metavar="N", type=str, nargs="+",
help="files to compare")
args = parser.parse_args()
benchmark_names = []
records = []
first = True
for f in args.files:
benchmark_suite = BenchmarkSuite.load(f)
if first:
# Initialize the dictionary keys to the benchmark names
benchmark_names = benchmark_suite.get_benchmark_names()
first = False
bench_name = Path(benchmark_suite.filename).name
for name in benchmark_names:
try:
benchmark = benchmark_suite.get_benchmark(name)
if benchmark is not None:
records.append({
"test": name,
"runtime": bench_name.replace(".json", ""),
"stdev": benchmark.stdev(),
"mean": benchmark.mean(),
"median": benchmark.median()
})
except KeyError:
# Bonus benchmark! Ignore.
pass
df = pd.DataFrame(records)
for test in benchmark_names:
g = sns.factorplot(
x="runtime",
y="mean",
data=df[df["test"] == test],
palette="YlGnBu_d",
size=12,
aspect=1,
kind="bar")
g.despine(left=True)
g.savefig("png/{}-result.png".format(test))
После этого, для создания графика, исполните этот сценарий из своего интерпретатора с созданными вами файлами JSON:
$ python profile.py ~/benchmarks/json/HEAD.json ...
Это воспроизведёт последовательность графиков в соответствующем подкаталоге png/ для каждого
из произведённых эталонных тестов.
Стандартная библиотека поставляется с двумя профилировщиками для кода Python:
-
profile: профилировщик чистого Python -
cProfile: более быстрый профилировщик, написанный на C
В большинстве ситуаций лучшим модулем для применения является cProfile.
Вы можете применять cProfile для анализа запущенного приложения и собирать детерминированные
профили в вычисленных кадрах. Вы можете отображать итоги из cProfile в своей командной строке или же
сохранять их в файл .pstat для анализа неким внешним инструментом.
В Главе 10, Параллельность и одновременность вы написали сканер портов н Python.
Попробуйте спрофилировать это приложение в cProfile.
Для запуска модуля cProfile, запустите в своей командной строке Python
с аргументом -m cProfile. Вторым аргументом является тот сценарий, который надлежит исполнять:
$ python -m cProfile portscanner_threads.py
Port 80 is open
Completed scan in 19.8901150226593 seconds
6833 function calls (6787 primitive calls) in 19.971 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
2 0.000 0.000 0.000 0.000 ...
Получаемый вывод выдаст на печать таблицу со следующими колонками:
| Столбец | Назначение |
|---|---|
|
Число вызовов |
|
Общее время, затраченное в этой фунции (минус подфункции) |
|
Показатель |
|
Общее время, затраченное в этой функции (включая подфункции) |
|
Показатель |
|
Данные каждой из функций |
Вы можете добавить аргумент -s и название колонки по которой производить сортировку получаемого вывода:
$ python -m cProfile -s tottime portscanner_threads.py
Эта команда отсортирует получаемый вывод по значению общего времени, потраченного на каждую из функций.
Вы можете снова запустить свой модуль cProfile с аргументом -o
для определения некого пути вывода файла:
$ python -m cProfile -o out.pstat portscanner_threads.py
Это создаст файл, out.pstat, который вы сможете загрузить для анализа при помощи класса Stats или некого внешнего инструмента.
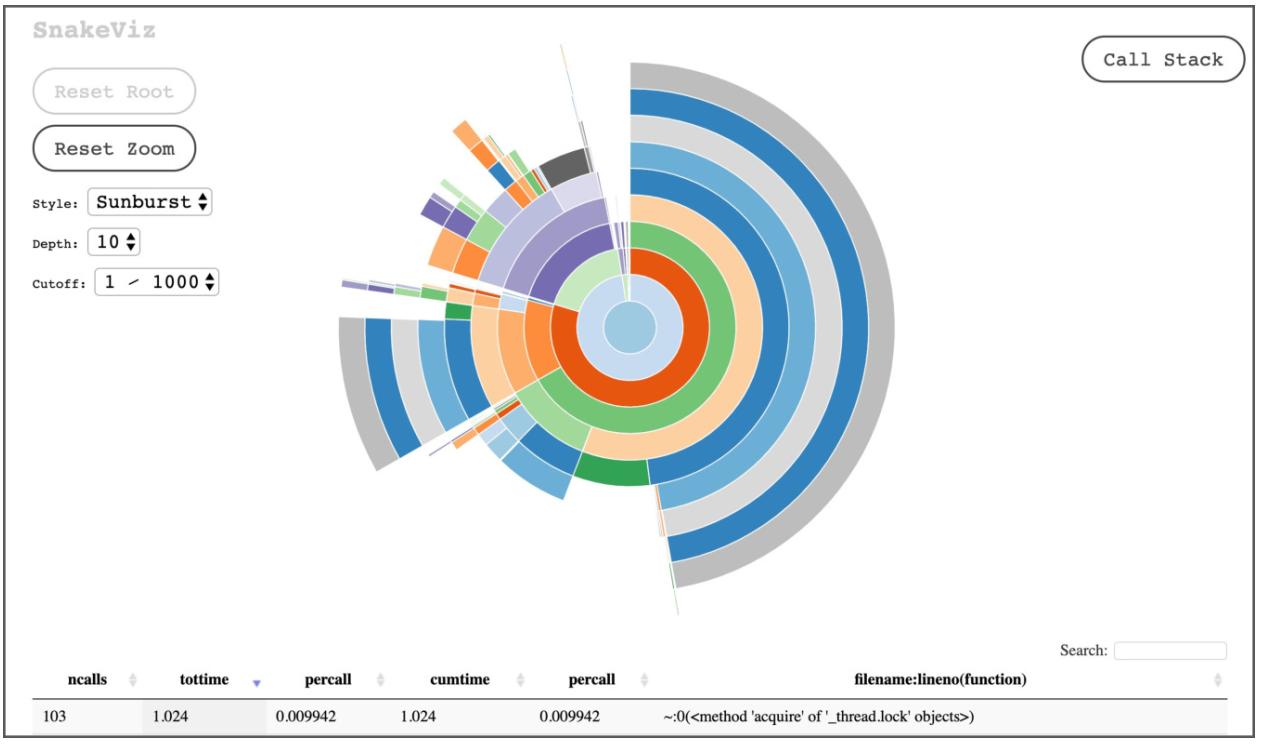
Визуализация при помощи SnakeViz
SnakeViz это свободно распространяемый пакет Python для визуализации данных профиля внутри некого веб браузера.
Для установки SnakeViz воспользуйтесь pip:
$ python -m pip install snakeviz
Затем в своей командной строке запустите snakeviz с путём для созданного вами файла статистических
данных:
$ python -m snakeviz out.pstat
Это откроет ваш браузер и позволит вам изучать и анализировать полученные данные:
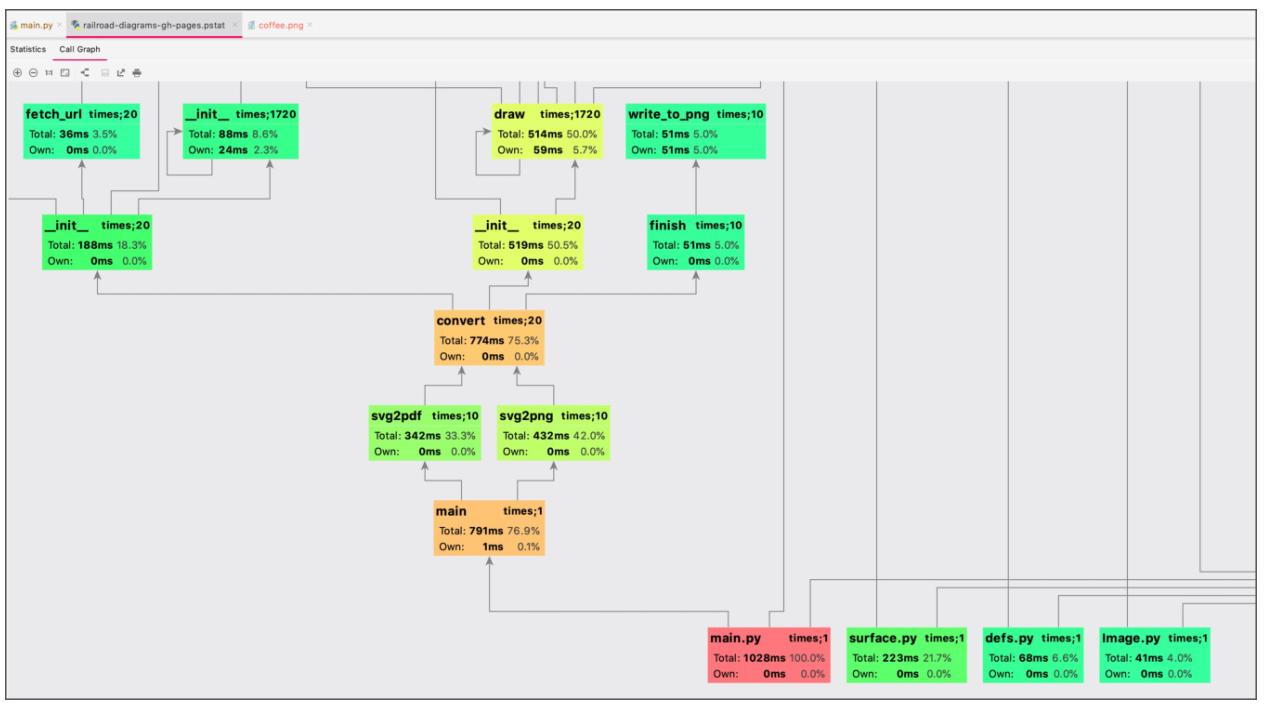
Визуализация при помощи PyCharm
PyCharm обладает встроенным инструментарием для запуска cProfile и визуализации получаемых
результатов. Для его исполнения вам требуется иметь настроенной цель Python.
Для запуска этого профилировщика выберите свою запускаемую цель, затем выберите в своём верхнем меню
Run/Profle (target). Это запустит на исполнение цель с
cProfile и откроет окно визуализации с табличными данными и граф вызовов:
Сам исходный код CPython обладает некоторыми маркерами для инструмента отслеживания DTrace. DTrace исполняет скомпилированный двоичный файл C/C++, а затем отлавливает и обрабатывает события внутри применяемых им зондов (probes).
Чтобы DTrace предоставлял существенные сведения, само компилируемое приложение обязано обладать маркерами, скомпилированными в это приложение. Это события, возбуждаемые на протяжении времени выполнения. Такие маркеры могут подключать произвольные данные в помощь отслеживанию.
Например, функция вычисления кадра в Python/ceval.c содержит
вызов dtrace_function_entry():
if (PyDTrace_FUNCTION_ENTRY_ENABLED())
dtrace_function_entry(f);
Это возбуждает в DTrace некий маркер с названием function__entry при каждом входе в некую
функцию.
CPython обладает встроенными маркерами для:
-
Исполняемой строки
-
Входа в функцию и возврата из неё (исполнения кадра)
-
Запуска и завершения сборки мусора
-
Запуска и завершения импорта модуля
-
События особых точек входа аудита из
sys.audit()
Каждый из этих маркеров обладает аргументами для дополнительных сведений. Например, маркер
function__entry обладает аргументами для:
-
Названия файла
-
Имени функции
-
Номера строки
Все статические аргументы маркера определены в официальной документации.
DTrace способен исполнять некий файл сценария, написанного на D для исполнения индивидуального кода при включении зондов. Вы также можете отфильтровывать зонда на основании их атрибутов.
Вот относящиеся к DTrace исходные файлы:
| Файл | Назначение |
|---|---|
|
Определение API для маркеров DTrace |
|
Метаданные для поставщика Python, используемого DTrace |
|
Автоматически вырабатываемые заголовки для обрабатываемых зондов |
DTrace поставляется предварительно установленным в macOS и может быть установлен в Linux одним из инструментов, поставляемых пакетом.
Вот команда для основанных на YUM {DNF} систем:
$ yum install systemtap-sdt-devel
А это команда для базирующихся на APT систем:
$ apt-get install systemtap-sdt-dev
Поддержка DTrace может быть скомпилированной в CPython. Вы можете сделать это при помощи соответствующего сценария
./configuration.
Запустите снова ./configure с теми же самыми параметрами, которые вы применяли в
Главе 3, Компиляция CPython и добавьте флаг
--with-dtrace. По завершению этого исполните
make clean && make для повторной сборки своего исполняемого файла.
Убедитесь что ваш инструмент конфигурирования создал соответствующий заголовок зонда:
$ ls Include/pydtrace_probes.h
Include/pydtrace_probes.h
![[Совет]](/common/images/admon/tip.png) | Важно |
|---|---|
|
Более новые версии macOS обладают защитой уровня ядра с названием SIP (System Integrity Protection), которая взаимодействует с DTrace. Примеры из этой главы пользуются установленными зондами CPython. Если вы желаете включить зонды |
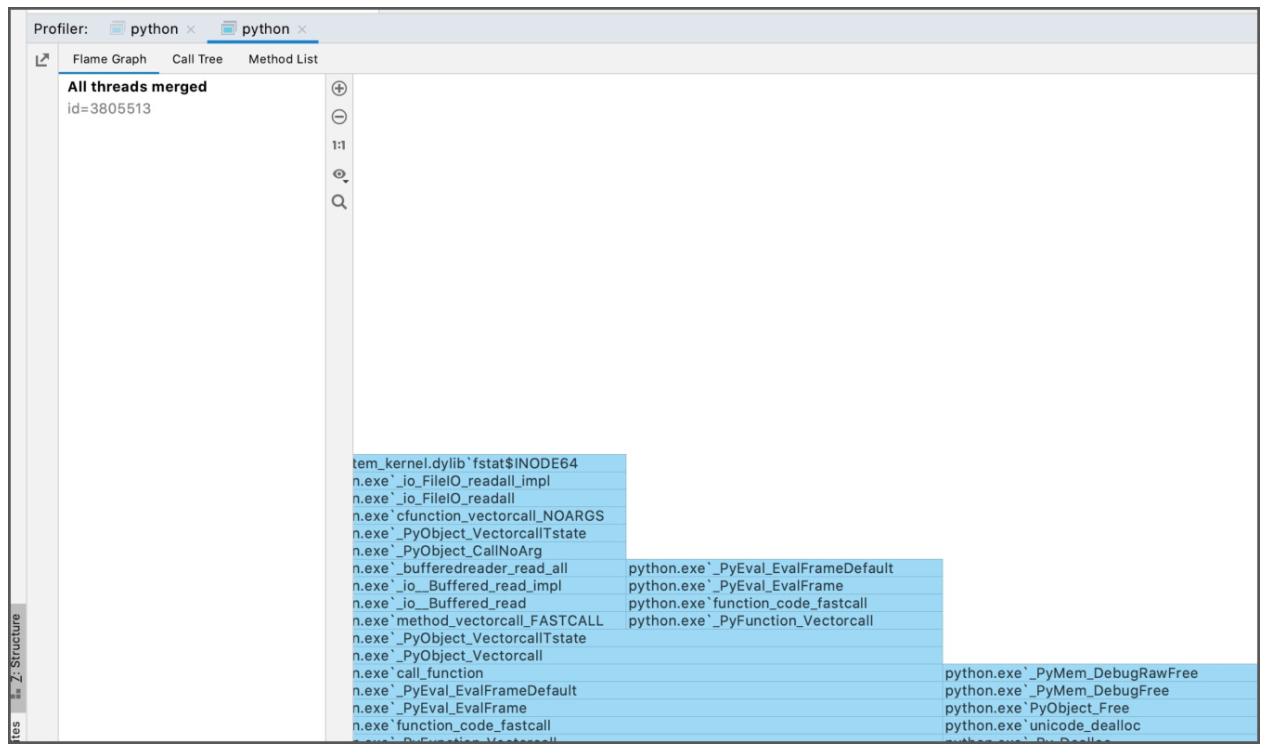
IDE CLion поставляется оснащённым поддержкой DTrace. Для запуска отслеживания пройдите в
Run/Attach Profler to Process и выберите
запуск процесса Python.
Окно профилирования выдаст вам приглашение для запуска и останова своего сеанса трассировки. По завершению отслеживания он снабдит вас графом кадров, отображающим стеки выполнения и времена вызовов, дерево вызовов и список методов:
В этом примере вы протестируете многопоточный сканер портов, созданный вами в Главе 10, Параллельность и одновременность.
Создайте сценарий профиля profile_compare.d. Для снижения уровня шума от запуска самого интерпетатора,
этот профилировщик запустится после входа в portscanner_threads.py:main(),
cpython-book-samples/62/profile_compare.d:
#pragma D option quiet
self int indent;
python$target:::function-entry
/basename(copyinstr(arg0)) == "portscanner_threads.py"
&& copyinstr(arg1) == "main"/
{
self->trace = 1;
self->last = timestamp;
}
python$target:::function-entry
/self->trace/
{
this->delta = (timestamp - self->last) / 1000;
printf("%d\t%*s:", this->delta, 15, probename);
printf("%*s", self->indent, "");
printf("%s:%s:%d\n", basename(copyinstr(arg0)), copyinstr(arg1), arg2);
self->indent++;
self->last = timestamp;
}
python$target:::function-return
/self->trace/
{
this->delta = (timestamp - self->last) / 1000;
self->indent--;
printf("%d\t%*s:", this->delta, 15, probename);
printf("%*s", self->indent, "");
printf("%s:%s:%d\n", basename(copyinstr(arg0)), copyinstr(arg1), arg2);
self->last = timestamp;
}
python$target:::function-return
/basename(copyinstr(arg0)) == "portscanner_threads.py"
&& copyinstr(arg1) == "main"/
{
self->trace = 0;
}
Этот сценарий выводит на печать некую строку при каждом исполнении некой функции и значение временной дельты между тем когда эта функция стартовала и выполнила выход.
Вам следует выполнять его с аргументом сценария -s profile_compare и аргументом команды
-c './python portscanner_threads.py':
$ sudo dtrace -s profile_compare.d -c './python portscanner_threads.py'
0 function-entry:portscanner_threads.py:main:16
28 function-entry: queue.py:__init__:33
18 function-entry: queue.py:_init:205
29 function-return: queue.py:_init:206
46 function-entry: threading.py:__init__:223
33 function-return: threading.py:__init__:245
27 function-entry: threading.py:__init__:223
26 function-return: threading.py:__init__:245
26 function-entry: threading.py:__init__:223
25 function-return: threading.py:__init__:245
|
| Важно |
|---|---|
|
Более ранние версии DTrace могут не обладать параметром |
В получаемом выводе, самый первый столбец это значение временной дельты в микросекундах с самого последнего события, за которым следуют название этого события, имя файла и номер строки. При вложении вызовов функций, значение имени файла будет прирастать отступами справа.
В этой главе вы изучили эталонное тестирование, профилирование и отслеживание с применением множества инструментов, разработанных для CPython. При помощи правильного инструментария вы можете обнаруживать узкие места, сопоставлять производительность множества сборок и выявлять возможности улучшения.