Глава 1. Введение и за его пределами
В данной главе мы охватим следующие рецепты:
-
Ceph - начало новой эры
-
RAID - конец эпохи
-
Ceph - обзор архитектуры
-
Планирование развёртывания Ceph
-
Настройка виртуальной инфраструктуры
-
Установка и настройка Ceph
-
Увеличение Ceph в размерах
-
Практическое применение кластера Ceph
Содержание
В настоящее время Ceph является самой востребованной технологией Систем хранения управляемых программным обеспечением (SDS, Software Defined Storage), которая встряхнула всю индустрию хранения данных. Это проект с открытым исходным кодом, которые предоставляет унифицированное решение определяемое программным обеспечением (ПО) для хранения Блоков, Файлов и Объектов. Основная идея состоит в предоставлении распределённой системы хранения, которая является массивно масштабируемой и высокопроизводительной при отсутствии единой точки отказа. С самого начала она разрабатывалась для высокой масштабируемости (до уровня Экзабайт и выше) и при этом способная работать на общедоступном рыночном оборудовании.
Ceph получает всё большую поддержку продвижения в отрасли систем хранения благодаря присущей ей открытости, масштабируемости и надёжности. Именно эра облачных вычислений и инфраструктур определяемых программным обеспечением является тем, где нам требуется поддержка хранения, которая полностью определяется ПО и, что ещё более важно, готова к облачным технологиям. Ceph вписывается здесь просто великолепно, вне зависимости от того, работаете ли вы в общедоступных, частных или гибридных облачных решениях.
Современные системы программного обеспечения очень интеллектуальны и делают возможным использование общедоступных аппаратных средств для работы в инфраструктурах гигантских масштабов. Ceph является одним из них; она интеллектуально использует обычное оборудование для производства устойчивых и высоконадёжных систем хранения уровня крупного предприятия
Ceph был выращен и вскормлен на философии архитектуры, которая содержит в себе следующее:
-
Все компоненты должны масштабироваться линейно
-
Не должно существовать единой точки отказа
-
Решение должно быть основано на программном обеспечении, причем с открытым исходным кодом, а также быть адаптивным
-
Программное обеспечение Ceph должно работать на легко доступном общеупотребимом оборудовании
-
Все компоненты должны быть самоуправляемыми и самовосстанавливающимися по мере возможности
В основании Ceph лежат объекты, которые являются строительными блоками, а хранилища объектов подобные Ceph являются предложением для текущих и последующих потребностей неструктурированного хранения данных. Хранилища объектов имеют преимущества над традиционными решениями хранения; мы можем получить независимость от платформы и аппаратных средств при их использовании. Ceph тщательно обращается с объектами и реплицирует их по всему кластеру для достижения надёжности; в Ceph объекты не связаны физическим путём, делая независимым местоположение объекта. Подобная гибкость делает возмоожным линейное масштабирование Ceph для масштабов уровней от Петабайт до Экзабайт.
Ceph предоставляет организациям великолепные производительность, мощность и гибкость. Она помогает организациям освободиться от затратных проприетарных бункеров хранения. Несомненно, Ceph является решением хранения уровня корпорации, которое работает на общедоступных аппаратных средствах; она является системой хранения с богатым набором функциональности при низкой стоимости. Универсальная система хранения Ceph предоставляет возможности хранения Блоков, Файлов и Объектов под одним колпаком, предоставляя пользователям выбирать метод применения хранимого по своему усмотрению.
Ceph разрабатывается и совершенствуется очень быстрыми темпами. 3 июля 2012 Sage анонсировала первый выпуск LTS Ceph с кодовым именем Argonaut. С этого момента мы уже увидели появление семи новых выпусков. Выпуски Ceph категоризируются как LTS (Long Term Support в терминах долговременной поддержки) и выпусков разработок, а каждая альтернативная редакция является выпуском LTS. За дополнительной информацией, пожалуйста, обращайтесь к https://Ceph.com/category/releases/.
| Название редакции Ceph | Версия редакции Ceph | Дата выпуска |
|---|---|---|
|
V0.48 (LTS) |
3 июля 2012 |
|
V0.56 (LTS) |
1 января 2013 |
|
V0.61 |
7 мая 2013 |
|
V0.67 (LTS) |
14 августа 2013 |
|
V0.72 |
9 ноября 2013 |
|
V0.80 (LTS) |
7 мая 2014 |
|
V0.87.1 |
26 февраля 2015 |
|
V0.94 (LTS) |
7 апреля 2015 |
|
V9.0.0 |
5 мая 2015 |
V10.0.0 |
ноябрь 2015 |
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Существует такой факт: имена редакций следуют в алфавитном порядке; следующая будет начинаться с "K". |
![[Замечание]](/common/images/admon/note.png)
На протяжении последних нескольких лет требования к хранению данных растут взрывообразно. Исследование показывает, что данные в больших организациях ежегодно растут со скоростью от 40 до 60 процентов, а многие компании ежегодно удваивают отпечатки своих данных. Аналитики IDC оценивают, что по всему миру в 2000 году существовало 54.4 Экзабайт общих данных. В 2007 они выросли до 295 Экзабайт, а к 2020 по всему миру ожидается рост до 44 Зеттабайт. Такой рост данных не способен управляться традиционными системами хранения; нам требуются системы подобные Ceph, которые являются распределёнными, масштабируемыми и, что наиболее важно, экономически жизнеспособными. Ceph разрабатывалась намеренно для соответствия сегодняшнему дню, а также потребностям хранилищ данных будущего.
SDS (Software Defined Storage) это то, что необходимо для уменьшения TCO вашей инфраструктуры хранения. Помимо уменьшения стоимости хранения, SDS может предоставить гибкость, масштабируемость и надёжность. Ceph является полноценным SDS решением; она работает на общедоступном оборудовании без привязок к определённому производителю с низкой стоимостью на ГБ. В отличие от традиционных систем хранения, в которых оборудование заранее обручено с ПО, в SDS вы вольны в выборе доступного на рынке оборудования любых производителей и свободны в проектировании гетерогенных аппаратных решений для ваших собственных нужд. Программно определяемое хранилище Ceph поверх таких аппаратных средств предоставляет всю необходимую вам интеллектуальность и позаботится обо всём, предоставляя всю функциональность корпоративной системы хранения прямо на уровне программного обеспечения.
Одним из недостатков облачной инфраструктуры является система хранения. Каждой облачной инфраструктуре требуется система хранения, которая является надёжной, недорогой и масштабируемой при более тесной интеграции в сравнении с прочими компонентами облака. На рынке присутствует большое число традиционных решений для хранения, которые утверждают, что готовы к применению в облаке, однако сегодня нам нужна не просто готовность к применению в облачных решениях, но и многое поверх неё. Нам нужна система хранения данных, которая должна быть полностью интегрированной с облачными системами и может обеспечивать более низкую совокупную стоимость владения без какого- либо ущерба для надёжности и масштабируемости. Облачные системы определяются программно и строятся поверх общедоступных аппаратных средств; аналогично, ей требуется система хранения, которая будет следовать той же методологии, то есть, программно определяемое решение поверх общедоступного оборудования, и Ceph является лучшим выбором доступным для облачных вариантов решений.
Ceph стремительно развивается и преодолевает разрыв реальной основы хранения в облачных решениях. Он захватывает центральное место во всех основных облачных платформах с открытым исходным кодом, а именно, OpenStack, CloudStack и OpenNebula {Прим. пер.: а также Proxmox VE и т.п. }. Кроме того, Ceph успешен в создании партнёрских отношений с поставщиками облачных решений, например, с Red Hat, Canonical, Mirantis, SUSE и многими другими. Эти компании уделяют много времени Ceph и включают его в качестве официальной основы хранения для своих дистрибутивов облачных решений OpenStack, тем самым делая Ceph красной горячей технологией в пространстве хранения облачных решений.
OpenStack является одним из лучших примеров ПО с открытым исходным кодом наделяющих мощностью общедоступные и частные облачные решения. Оно зарекомендовало себя как сквозное облачное решение с открытым исходным кодом. OpenStack является набором программных средств таких как cinder, glance и swift, которые предоставляют возможности хранения для OpenStack. Этим компоненты OpenStack требуется надёжное, масштабируемое и всё-в-одном основное хранилище, подобное Ceph. По этой причине OpenStack и Ceph сообщества уже долгие годы проводят совместные работы для разработки полностью совместимой основы хранения Ceph для OpenStack.
Основанная на Ceph облачная инфраструктура обеспечивает поставщикам услуг столь необходимую гибкость для создания решений хранилища- как- службы (Storage-as-a-Service) и инфраструктуры- как- службы (Infrastructure-as-a-Service ), которые они не могут получить у прочих традиционных решений хранения, поскольку они не разработаны для полного соответствия требованиям облачных решений. Применяя Ceph, поставщики служб могут предлагать своим потребителям экономичное, надёжное облачное хранение.
В последнее время определение единого хранилища претерпело изменения. Несколько лет назад термин "унифицированное хранение" относился к предоставлению хранения файлов и блоков в единой системе. Сегодня благодаря последним технологическим достижениям, таким как облачные вычисления, большие данные, а также интернету вещей, развился новый вид хранения, а именно, хранение объектов. Таким образом, все системы хранения, которые не поддерживают хранение объектов, уже не являются унифицированными решениями хранения. Истинное унифицированное хранилище подобно Ceph; оно поддерживает хранение блоков, файлов и объектов в единой системе.
В Ceph термин "единообразное хранение" является более значимым, чем то, что по их утверждениям предоставляют существующие производители систем хранения. Ceph был разработан с нуля для готовности к будущему и он построен таким образм, что он способен обрабатывать гигантские объёмы данных. Когда мы называем Ceph "готовым к будущему", мы имеем в виду его сосредоточенность на своих способностях хранения объектов, которые наилучшим образом подходят для сегодняшнего сочетания неструктурированных данных вместо блоков или файлов. В Ceph всё полагается на интеллектуальные объекты, будь то хранение блоков или хранение файлов. Вместо того, чтобы управлять блоками и файлами на нижнем уровне, Ceph управляет объектами и поддерживает хранение на- основе- блоков- и- файлов поверх них. Объекты предоставляют предоставляют невообразимое масштабирование при увеличении производительности за счёт устранения обработки метаданных. Для динамического вычисления того, где следует хранить объект и откуда его получать, Ceph применяет алгоритм.
Обычная архитектура хранения системы SAN или NAS является весьма ограниченной. В основном они следуют традиции контроллера высокой доступности, т.е. если один контроллер хранения отказывает, они обслуживают данные вторым контроллером. Но что, если второй контроллер отказал в то же время, или даже хуже, если отказывает вся полка? В большинстве случаев вы в конечном счёте теряете свои данные. Такой вид архитектуры, который не может выдерживать множественные отказы, несомненно не то, что мы хотим видеть сегодня. Другим недостатком традиционных систем хранения является их механизм хранения данных и доступа к ним. Он поддерживает централизованное таблицу поиска для отслеживания метаданных, что означает, что при каждой отправке запроса пользователя на операцию чтения или записи эта система хранения вначале выполняет поиск в гигантской таблице метаданных, а уже после получения действительного местоположения данных выполняет операцию клиента. Для систем хранения небольшого размера вы можете не заметить скачков производительности, однако задумайтесь о больших кластерах хранения - вы, несомненно, будете зажаты рамками производительности при подобном подходе. Это было бы также ограничением вашей масштабируемости.
Ceph не следует подобной традиции архитектуры хранения; на самом деле, архитектура была разработана заново. Вместо того чтобы хранить метаданные и оперировать ими, Ceph вводит новый подход: алгоритм CRUSH. CRUSH является сокращением от Controlled Replication Under Scalable Hashing, Управляемых масштабируемым хешированием репликаций. Вместо выполнения поиска в таблице метаданных для каждого клиентского запроса, алгоритм CRUSH по требованию вычисляет где должны быть записаны данные или откуда их прочитать. За счёт вычисления метаданных отпадает необходимость управления централизованной таблицей метаданных. Современные компьютеры имеют впечатляющую производительность и могут очень быстро выполнять CRUSH просмотр; более того, эта вычислительная нагрузка, которая обычно незначительна, может быть распределена по узлам кластера, применяя мощность распределённого хранения. В дополнение к этому CRUSH имеет уникальное свойство, а именно осведомлённость об инфраструктуре. Он понимает взаимосвязь между различными компонентами вашей инфраструктуры и сохраняет ваши данные в уникальной зоне отказа, такой как диск, узел, стойка, ряд и помещение центра данных, помимо всего прочего. CRUSH хранит все копии ваших данных таким образом, что они будут доступными даже если несколько компонентов в зоне отказа выйдут из строя. Это обусловлено в CRUSH тем, что Ceph может обрабатывать несколько отказов компонентов, тем самым предоставляя надёжность и долговечность.
Алгоритм CRUSH делает Ceph самоуправляемой и самовосстанавливающейся. В случае поломки компонента в зоне отказа, CRUSH понимает какой компонент вышел из строя и определяет воздействие на кластер. Без какого- либо административного вмешательства CRUSH самостоятельно управляет и самостоятельно вносит коррективы, выполняя операцию восстановления для потерянных при отказе данных. CRUSH восстанавливает данные из реплицированных копий, которые поддерживает кластер. Если вы настроили карту CRUSH надлежащим образом, он гарантирует что по крайней мере одна копия ваших данных всегда будет доступна. Применяя CRUSH мы можем разрабатывать надёжную инфраструктуру без единых точек отказа. Это делает Ceph высоко масштабируемой и надёжной системой хранения, которая готова к будущему.
RAID технология была основным строительным блоком для систем хранения данных в течение многих лет. Она доказала свою эффективность практически для всех типов данных, которые были сгенерированы на протяжении последних трёх десятилетий. Но все эпохи должны подходить к какому- то концу, и в этот раза настала очередь RAID. Эти системы начали демонстрировать ограничения и не способны обеспечить грядущие потребности в хранении. На протяжении нескольких последних лет облачные инфраструктуры получили мощный импульс и вводят новые требования для хранения и сложные испытания традиционных систем RAID. В данном разделе мы раскроем накладываемые RAID системами ограничения.
Основную головную боль в технологии RAID предоставляет её слишком продолжительный процесс перестроения. Производители дисков упаковывают в один диск очень большую ёмкость хранения. В настоящее время они производят дисковые устройства сверхвысокой ёмкости по отношению к его стоимости. Больше мы не говорим о дисках 450ГБ, 600ГБ или даже 1ТБ, поскольку на сегодняшний день доступны диски большей ёмкости. Более новые спецификации дисков уровня предприятия доходят до дисковых устройств в 4ТБ, 6ТБ и даже 10ТБ, причём ёмкость растёт год за годом.
Задумайтесь о системе хранения предприятия на базе RAID которая выполнена на большом количестве дисковых устройств с 4 или 6ТБ. К несчастью, когда такие диски отказывают, контроллеру RAID потребуется несколько часов , порой и дней для восстановления отдельного отказавшего диска. В то же время, если в той же RAID группе откажет другой диск, то ситуация станет непредсказуемой. Восстановление множества больших дисковых устройств при помощи RAID является обременительным процессом.
RAID система требует несколько дисков в качестве дисков горячей замены. Это всего навсего диски, которые будут использованы только в случае отказа диска, иначе они никогда не будут применяться для хранения данных. Это добавляет дополнительную стоимость в систему и увеличивает стоимость совокупного владения. Более того, если при вашей работе не хватает запасных дисков, а диск сразу выходит из строя в группе RAID, то вам придётся столкнуться с серъёзной проблемой.
Для RAID необходим набор идентичных дисковых устройств в отдельной группе RAID; вы можете столкнуться со штрафами если вы измените размер диска, скорость вращения шпинделя или тип диска. Это может негативно повлиять на ёмкость и производительность вашей системы хранения. Это делает RAID весьма разборчивым в оборудовании.
Кроме того, системы уровня предприятия на основе RAID часто требуют дорогостоящих аппаратных компонентов, таких как контроллеры RAID, что значительно повышает стоимость системы. Такие контроллеры RAID становятся единой точкой отказа если у вас нет их достаточного количества.
RAID может попасть в тупик, когда он не может увеличить размер своей группы RAID, а это означает отсутствие поддержки масштабирования. После достижения подобной точки вы не способны наращивать вашу систему на базе RAID даже если у вас есть средства. Некоторые системы позволяют добавлять дисковые полки, но до очень ограниченных ёмкостей; однако, такие новые дисковые полки поставляют дополнительную нагрузку существующим контроллерам хранения. Таким образом, вы можете получить некую ёмкость, но за счёт компромисса с производительностью.
RAID может быть настроен с большим разнообразием типов; наиболее общими типами являются RAID5 и RAID6, которые выдерживают отказ одного и двух дисков соответственно. RAID не может гарантировать надёжность данных после отказа двух дисков. Это одна из основных помех в RAID системах.
Более того, во время операции перестроения RAID, запросы клиентов скорее всего будут страдать от нехватки пропускной способности вплоть до завершения перестроения. Другой ограничивающий фактор RAID состоит в том, что он защищает только от отказов дисков; он не может защищать от отказов сетевой среды, серверного оборудования, ОС, источников питания или прочих бедствий в центре обработки данных.
После обсуждения недостатков RAID мы можем заключить, что нам требуется система, которая может преодолевать все эти недостатки производительно и экономически выгодно. Система хранения Ceph является одним из наилучших решений доступных сегодня в отношении таких проблем. Давайте рассмотрим как.
Для надёжности Ceph применяет метод репликации данных, что означает, что он не применяет RAID, тем самым обходя все проблемы, которые могут быть найдены в системах уровня предприятия на основе RAID. Ceph является хранилищем, определяемым ПО, следовательно нам не требуется специализированное оборудование для репликации данных; более того, уровень репликации глубоко настраивается при помощи команд, что означает, что администратор хранилища Ceph может управлять множителем репликации от минимума в одну и максимум до более высоких значений, что полностью определяется лежащей в основе инфраструктурой.
При отказе одного или большего числа дисков, репликации Ceph являются лучшим процессом чем RAID. В случае отказа дискового устройства, все располагавшиеся на этом диске данные в этот момент времени начинают восстанавливаться с его одноранговых дисков. Поскольку Ceph является распределённой системой, все копии данных разбросаны по всему кластеру дисков в форме объектов так, что никакие две копии объектов не должны располагаться на одном и том же диске и должны размещаться в различных зонах отказа, определяемых картой CRUSH. Хорошая часть дисков всего кластера принимает участие в восстановлении данных. Это делает операцию восстановления впечатляюще быстрой при меньших проблемах с производительностью. В дополнение к этому операция восстановления не требует никаких дополнительных дисков для замены; данные просто реплицируются на другие имеющиеся в вашем кластере Ceph диски. Ceph применяет механизм весов для своих дисков, таким образом различные размеры дисков не являются проблемой.
Дополнительно к методу репликаций Ceph также предоставляет другие современные способы надёжности данных: применение технологии кодирования удаления. Пулы с кодированием удаления требуют меньше пространства хранения по сравнению с реплицируемыми пулами. При кодировании уделения данные восстанавливаются или регенерируются алгоритмически путём вычисления кода удаления. Вы можете применять обе технологии доступности данных, то есть и репликацию, и кодирование удаления в одном и том же кластере Ceph, однако в различных пулах данных. Мы изучим дополнительные сведения о технологии кодирования удаления в последующих главах.
Архитектура Ceph очень проста и мы будем изучать её при помощи следующей схемы:
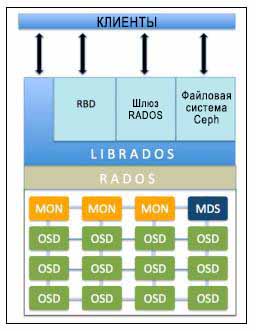
-
Мониторы Ceph (MON): Мониторы Ceph отслеживают состояние всего кластера поддерживая карту состояния вашего кластера. Они обслуживают информацию об отдельном соответствии для всех компонент, что включает карту OSD, карту MON и карту PG (обсуждаются в последующих главах), а также карту CRUSH. Все узлы кластера предоставляют отчёт узлам Монитора и предоставляют для совместного использования информацию обо всех изменениях своего состояния. Монитор не сохраняет фактические данные; это работа OSD.
-
Мониторы Ceph (MON): Не должно существовать единой точки отказа
-
Устройства хранения объектов Ceph (OSD, Object Storage Device): Поскольку ваши приложения выдают операции записи, данные сохраняются в вашем OSD в форме объектов. Это единственный компонент кластера Ceph в котором сохраняются фактические данные пользователей и эти же данные выдаются когда клиент выдаёт операцию чтения. Обычно один демон OSD привязывается к одному физическому диску в вашем кластере. Тем самым, обычно, общее число физических дисков в вашем кластере то же самое, что и число демонов OSD, работающих ниже для сохранения данных пользователя на всех физических дисках.
-
Сервер метаданных Ceph (MDS, Metadata Server): MDS поддерживает отслеживание иерархии файлов и хранит метаданные исключительно для вашей файловой системы CephFS. Блочные устройства Ceph и шлюзы RADOS не требуют метаданных, следовательно они не нуждаются в демоне Ceph MDS. MDS не предоставляет данные клиенту напрямую, тем самым удаляя единую точку отказа из вашей системы.
-
RADOS (Reliable Autonomic Distributed Object Store, Безотказное автономное распределенное хранилище объектов): Является фундаментом вашего кластера хранения Ceph. Всё в Ceph сохраняется в виде объектов, а хранилище объектов RADOS отвечает за сохранение этих объектов вне зависимости от их типов данных. Уровень RADOS гарантирует что данные всегда остаются согласованными. Для этого они выполняют репликацию данных, определение отказов и восстановление,а также миграцию данных и ребалансировку по узлам кластера.
-
librados: Библиотека librados является удобным путём получения доступа к RADOS с поддержкой языков программирования PHP, Ruby, Java, Python, C и C++. Она предоставляет естественный интерфейс для вашего кластера хранения Ceph (RADOS), а также основу для прочих служб, таких как RBD, RGW и CephFS, которые строятся поверх librados. Librados также поддерживает прямой доступ к RADOS из приложений без накладных расходов на HTTP.
-
Блочные устройства RADOS (RBD, RADOS Block Devices): RBD, которые также называются блочными устройствами Ceph, предоставляют постоянное блочное хранение, которое является динамично выделяемыми (thin provisioning) {Прим. пер.: http://en.wikipedia.org/wiki/Thin_provisioning, http://habrahabr.ru/post/170389/}, изменяемыми в размере и хранят данные с чередованием по множеству OSD. Служба RBD строится в виде естественного интерфейса поверх librados.
-
Интерфейс шлюза RADOS (RGW, RADOS Gateway interface): RGW предоставляет службу хранения объектов. Он применяет librgw (библиотеку шлюза RADOS) и librados, позволяя приложениям устанавливать соединения с хранилищем объектов Ceph. RGW обеспечивает RESTful API интерфейсами, которые совместимы с Amazon S3 и OpenStack Swift.
-
CephFS: Файловая система CephFS предоставляет POSIX- совместимую файловую систему, которая использует кластер хранения Ceph для хранения пользовательских данных в файловой системе. Как и RBD, и RGW, служба CephFS также реализует естественный интерфейс с librados.
Кластер хранеия Ceph создаётся поверх общедоступных аппаратных средств. Такое общедоступное оборудование включает сервера промышленного стандарта загружаемые физическими дисковыми устройствами которые предоставляют ёмкость хранения и некоторую стандартную сетевую инфраструктуру. Такие сервера выполняют стандартные дистрибутивы Linux и программное обеспечение Ceph поверх них. Следующая схема поможет вам понять базовый вид кластера Ceph:
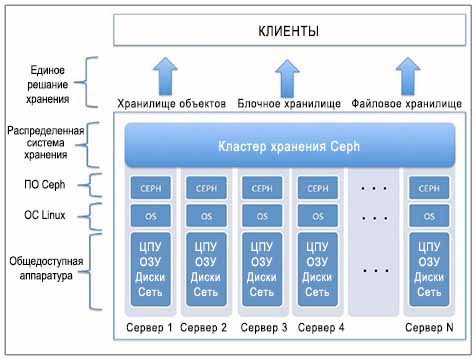
Как уже объяснялось ранее, Ceph не имеет очень специфических требований к аппаратным средствам. Для целей тестирования и изучения мы можем развернуть кластер Ceph поверх виртуальных машин. В данном разделе и в последующих главах этой книги мы будем работать с кластером Ceph который строится поверх виртуальных машин. Для тестирования Ceph очень удобно применять среду виртуальных машин, поскольку это достаточно просто установить и они могут быть удалены и воссозданы в любое время. Следует знать, что виртуальная инфраструктура для кластера Ceph не должна применяться для промышленных сред, иначе в этом случае вы можете столкнуться с серъёзными проблемами.
Для установки виртуальной инфраструктуры вам понадобится ПО с открытым исходным кодом подобное Oracle VirtualBox и Vagrant для автоматизации создания для вас виртуальных машин. Проверьте что у вас имеется следующее установленное и корректно работающее программное обеспечение на вашей хост-машине. Процесс установки программного обеспечения выходит за рамки данной книги; вы можете следовать их соответствующим документациям для корректной установки и последующей работы. {Прим. пер.: в предыдущей своей книге, Изучаем Ceph автор даёт некие инструкции, можно попытаться следовать им с учётом того факта, что за прошедший с того времени срок более года произошли серъёзные изменения. Мы постараемся в ближайшее время подготовить свои инструкции по реализации данного стенда в среде Proxmox VE, обращайтесь за консультациями!}
Для начала вам потребуется следующее программное обеспечение:
-
Oracle VirtualBox: Это программный пакет виртуализации с открытым исходным кодом для размещения машин на базе x86 и AMD64/Intel64. Он поддерживает размещение операционных систем Microsoft Windows, Linux и Apple MAC OSX. Убедитесь что он установлен и работает соответствующим образом. Дополнительную информацию вы можете найти на https://www.virtualbox.org. После установки VirtualBox выполните следующую команду для проверки установки:
# VBoxManage --version HOST:~ksingh$ HOST:~ksingh$ VBoxManage --version 4/3/22r98236 HOST:~ksingh$
-
Vagrant: Это программное обеспечение предназначено для создания виртуальных сред разработки. Оно работает в качестве обертки вокруг виртуального программного обеспечения подобного VirtualBox, VMware, KVM и тому подобного. Оно поддерживает размещение операционных систем Microsoft Windows, Linux и Apple Mac OSX. Убедитесь, что оно установлен и работает правильно. Более подробную информацию можно найти на сайте https://www.vagrantup.com/. После того как вы установили Vagrant, выполните следующую команду чтобы гарантировать установку:
# vagrant --version HOST:~ ksingh$ HOST:~ ksingh$ vagrant --version Vagrant 1.7.2 HOST:~ ksingh$
-
Git: Это распределённая система управления редакций, а также наиболее популярная и широко применяемая система управления версиями для разработчиков программного обеспечения. Она поддерживает операционные системы Microsoft Windows, Linux и Apple MAC OSX. Убедитесь, что она установлена и работает правильно. Дополнительную информацию можете получить по адресу http://git-scm.com/. {Прим. пер.: см. Основы Git.} Когда вы установите
Git, выполните следующую команду для гарантированности установки:
# git --version HOST:~ ksingh$ HOST:~ ksingh$ git --version git version 1.9.3 (Apple Git-50) HOST:~ ksingh$
После установки указанного программного обеспечения мы продолжим создание виртуальных машин:
-
Git клонирует репозиторий
ceph-cookbook, для вашей машины хоста VirtualBox:# git clone https://github.com/ksingh7/ceph-cookbook.git HOST:~ ksingh$ HOST:~ ksingh$ git clone https://github.com/ksingh7/ceph-cookbook.git Cloning into 'ceph-cookbook' remote: Counting objects: 18, done. remote: Compressing objects: 100% (11/11), done. remote: Total 18 (delta 5), reused 14 (delta 1), pack-reused 0 unpacking objects : 100% (18/18), done. Checking connectivity... done. HOST:~ ksingh$
-
В клонированном каталоге вы найдёте
Vagrantfile, который является нашим файлом настроек Vagrant который в основном отдаёт распоряжения VirtualBox запускать ВМ, которые требуются нам на различных этапах данной книги. Vagrant автоматизирует создание ваших ВМ, а также их установку и настройку для вас; это делает настройку начальной среды достаточно простой.:$ cd ceph-cookbook ; ls -l
-
Далее мы запустим три ВМ при помощи Vagrant; они потребуются в данной главе:
$ vagrant up ceph-node1 ceph-node2 ceph-node3 HOST:ceph-cookbook ksingh$ HOST:ceph-cookbook ksingh$ vagrant up ceph-node1 ceph-node2 ceph-node3 Bringing machine 'ceph-node1' up with 'virtualbox' provider... Bringing machine 'ceph-node2' up with 'virtualbox' provider... Bringing machine 'ceph-node3' up with 'virtualbox' provider... ===>ceph-node1 Box 'centos7-standard' could not be found. Attempting to find and install... ceph-node1 Box Provider: virtualbox ceph-node1 Box Version: >= 0
-
Проверьте состояние виртуальных машин:
$ vagrant status ceph-node1 ceph-node2 ceph-node3 HOST:ceph-cookbook ksingh$ vagrant status ceph-node1 ceph-node2 ceph-node3 Current machine states: ceph-node1 running (virtualbox) ceph-node2 running (virtualbox) ceph-node3 running (virtualbox) This environment represents multiple VMs. The VMs are all listed above with their current state. For more information about a specific VM, run `vagrant status NAME`. HOST:ceph-cookbook ksingh$
-
По умолчанию Vagrant установит имена хоста в виде
ceph-node<node_number>, IP адрес подсети в192.168.1.X, а также создаст дополнительные диски, которые будут использованы в качестве OSD кластером Ceph. Зарегистрируйте каждую из этих машин одну за другой и проверьте правильно ли установлены Vagrant-ом имя хоста, сетевая среда и дополнительные диски:$ vagrant ssh ceph-node1 $ ip addr show $ sudo fdisk -l $ exit
-
Vagrant настроен для обновления файла
hostsна ваших ВМ. Для удобства измените файл/etc/hostsна вашей машине хоста следующим содержимым.192.168.1.101 ceph-node1 192.168.1.102 ceph-node2 192.168.1.103 ceph-node3 HOST:ceph-cookbook ksingh$ HOST:ceph-cookbook ksingh$ cat /etc/hosts | grep -i ceph-node 192.168.1.101 ceph-node1 192.168.1.102 ceph-node2 192.168.1.103 ceph-node3 HOST:ceph-cookbook ksingh$
-
Сгенерируйте ключи SSH для
ceph-node1эти ключи наceph-node2иceph-node3. Пароль для пользователяrootна этих ВМ установлен вvagrant. Введите паролль пользователяrootпосле получения запроса от командыssh-copy-id, затем продолжите со следующими установками:$ vagrant ssh ceph-node1 $ sudo su - # ssh-keygen # ssh-copy-id root@ceph-node2 # ssh-copy-id root@ceph-node3 [root@ceph-nodel ~]# ssh-copy-id root@ceph-node2 The authenticity of host 'ceph-node2 (192.168.1.102)' can't be established. ECDSA key fingerprint is af:2a:a5:74:a7:0b:f5:5b:ef:c5:4b:2a:fe:ld:30:8e. Are you sure you want to continue connecting (yes/no)? yes /bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@ceph-node2's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh iroot@ceph-node21" and check to make sure that only the key(s) you wanted were added. [root@ceph-nodel ~]#
-
Когда SSH ключи скопированы на
ceph-node2иceph-node3, пользовательrootнаceph-node1может выполнять регистрацию ВМ через ssh без ввода пароля:# ssh ceph-node2 hostname # ssh ceph-node3 hostname [root@ceph-nodel ~]# ssh ceph-node2 hostname ceph-node2 [root@ceph-nodel ~]# [root@ceph-nodel ~]# ssh ceph-node3 hostname ceph-node3 [root@ceph-nodel ~]#
-
Сделайте доступными порты, которые требуются для Ceph MON, OSD и MDS в работающем в системе межсетевом экране. Выполните на всех ВМ следующие команды:
# firewall-cmd --zone=public --add-port=6789/tcp --permanent # firewall-cmd --zone=public --add-port=6800-7100/tcp --permanent # firewall-cmd --reload # firewall-cmd --zone=public --list-all [root@ceph-nodel ~]# firewall-cmd --zone=public --add-port=6789/tcp --permanent success [root@ceph-nodel ~]# firewall-cmd --zone=public --add-port=6800-7100/tcp --permanent success [root@ceph-nodel ~]# firewall-cmd --reload success [root@ceph-nodel ~]# [root@ceph-nodel ~]# firewall-cmd --zone=public --list-all public (default, active) interfaces: enp0s3 enp0s8 sources: services: dhcpv6-client ssh ports: 6789/tcp 6800-7100/tcp masquerade: no forward-ports: icmp-blocks: rich rules: [root@ceph-nodel —]#
-
Запретите SELINUX на всех ваших ВМ:
# setenforce 0 # sed –i s'/SELINUX.*=.*enforcing/SELINUX=disabled'/g /etc/selinux/config [root@ceph-nodel ~]# setenforce 0 [root@ceph-nodel ~]# sed –i s'/SELINUX.*=.*enforcing/SELINUX=disabled'/g /etc/selinux/config [root@ceph-nodel ~]# cat /etc/selinux/config | grep =disabled SELINUX=disabled [root@ceph-nodel ~]#
-
Установите и настройте
ntpна всех ВМ:# yum install ntp ntpdate -y # ntpdate pool.ntp.org # systemctl restart ntpdate.service # systemctl restart ntpd.service # systemctl enable ntpd.service # systemctl enable ntpdate.service
-
Добавьте на все узлы репозитории для Ceph версии Giant и обновите yum:
# rpm -Uhv http://ceph.com/rpm-giant/el7/noarch/ceph-release-1-0.el7.noarch.rpm # yum update -y [root@ceph-nodel ~]# rpm -Uhv http://ceph.com/rpm-giant/el7/noarch/ceph-release-1-0.el7.noarch.rpm Retrieving http://ceph.com/rpm-giant/el7/noarch/ceph-release-1-0.el7.noarch.rpm warning: /var/tmp/rpm-tmp.y9SGTx: Header V4 RSA/SHA1 Signature, key ID 17ed316d: NOKEY Preparing... ################################# [100%] updating / installing... 1:ceph-release-1-0.el7 ################################# [100%] [root@ceph-nodel ~]#
Чтобы развернуть наш первый кластер Ceph мы воспользуемся инструментарием ceph-deploy для
установки и настройки Ceph на всех трёх виртуальных машинах. Инструментарий ceph-deploy является
частью программно определяемого хранилища Ceph, которое применяется для более простого развёртывания и управления вашим кластером
хранения Ceph. В предыдущем разделе мы создали три виртуальные машины с CentOS7, которые имеют связь с интернетом через NAT, а также
с частной сетевой средой только внутри хоста.
Мы настроим эти машины в качестве кластера хранения Ceph, как это отображено на следующей схеме:
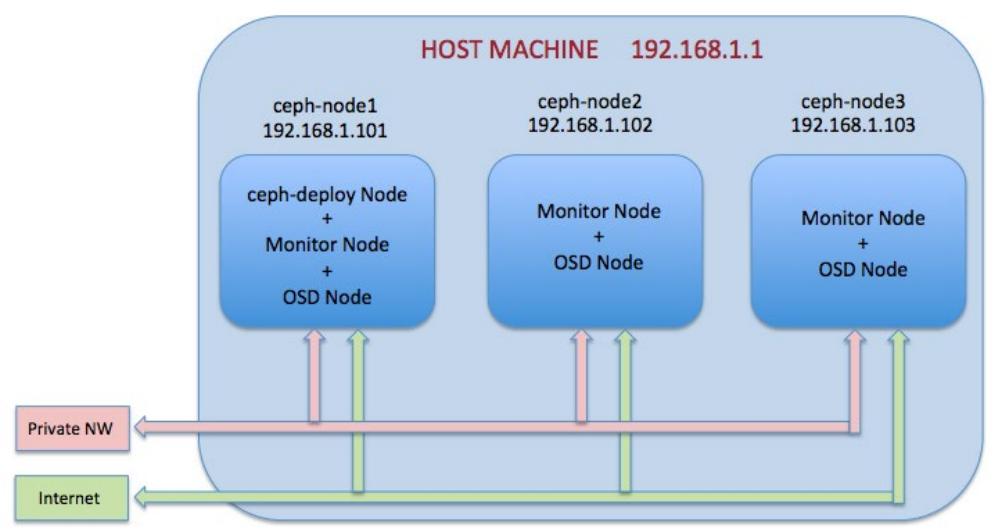
Для начала мы установим Ceph и настроим ceph-node1 в качестве монитора Ceph и
узла OSD Ceph. Последующие рецепты введут ceph-node2 и
ceph-node3.
-
Установите
ceph-deployнаceph-node1:# yum install ceph-deploy -y
-
Далее мы создадим кластер Ceph используя
ceph-deployвыполнив следующие команды наceph-node1:# mkdir /etc/ceph ; cd /etc/ceph # ceph-deploy new ceph-node1
Подкоманда
newвceph-deployразвернёт новый кластер применяяcephв качестве имени кластера, что является значением по умолчанию; она создаст настройку кластера и файлы ключей. Просмотрите настоящее состояние рабочего каталога; вы найдёте свои файлыceph.confиceph.mon.keyring:[root@ceph-nodel ceph]# ceph-deploy new ceph-nodel [ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf [ceph_deploy.cli][INFO ] Invoked (1.5.22): /usr/bin/ceph-deploy new ceph-nodel [ceph_deploy.new][DEBUG ] creating new cluster named ceph [ceph_deploy.new][INFO ] making sure passwordless SSH succeeds [ceph-node1][DEBUG ] connected to host: ceph-nodel [ceph-nodel][DEBUG ] detect platform information from remote host [ceph-node1][DEBUG ] detect machine type [ceph-node1][DEBUG ] find the location of an executable [ceph-nodel][INFO ] Running command: /usr/sbin/ip link show [ceph-node1][INFO ] Running command: /usr/sbin/ip addr show [ceph-nodel][DEBUG ] IP addresses found: ['192.168.1.101', '10.0.2.15'] [ceph_deploy.new][DEBUG ] Resolving host ceph-nodel [ceph_deploy.new][DEBUG ] Monitor ceph-nodel at 192.168.1.101 [ceph_deploy.new][DEBUG ] Monitor initial members are ['ceph-nodel'] [ceph_deploy.new][DEBUG ] Monitor addrs are ['192.168.1.101'] [ceph_deploy.new][DEBUG ] creating a random mon key... [ceph_deploy.new][DEBUG ] writing monitor keyring to ceph.mon.keyring... [ceph_deploy.new][DEBUG ] writing initial config to ceph.conf... [root@ceph-nodel ceph]#
-
Чтобы установить программное обеспечение Ceph в двоичном виде на все машины с применением
ceph-deploy, выполните следующую команду на узлеceph-node1:# ceph-deploy install ceph-node1 ceph-node2 ceph-node3
Инструментарий
ceph-deployвыполнит первую установку всех зависимостей следуя двоичным файлам Ceph Giant. Когда команда успешно завершится, проверьте версию Ceph и его состояние на всех ваших узлах, как показано далее:# ceph -v
-
Создайте первый ваш монитор Ceph на
ceph-node1:# ceph-deploy mon create-initial
Когда создание монитора успешно завершится, проверьте ваше состояние кластера. Ваш кластер на текущий момент не должен быть готов:
# ceph -s [root@ceph-nodel ceph]# ceph -s cluster 975efaaa-387e-4528-9285-3fcc664c117e health HEALTH_ERR 64 pgs stuck inactive; 64 pgs stuck unclean; no osds monmap el: 1 mons at {ceph-nodel=192.168.1.101:6789/0}, election epoch 2, quorum 0 ceph-nodel osdmap el: 0 osds: 0 up, 0 in pgmap v2: 64 pgs, 1 pools, 0 bytes data, 0 objects 0 kB used, 0 kB / 0 kB avail 64 creating [root@ceph-nodel ceph]# -
Создайте OSD на
ceph-node1:-
Выведите список доступных на
ceph-node1дисков:# ceph-deploy disk list ceph-node1
Аккуратно выберите диски из вывода (отличные от разделов OS) на которых мы должны создать OSD Ceph. В нашем случае диски имеют имена
sdb,sdcиsdd. -
Подкоманда
disk zapразрушит существующую таблицу разделов и содержимое диска. Перед выполнением этой команды убедитесь что вы используете верные имена дисковых устройств:# ceph-deploy disk zap ceph-node1:sdb ceph-node1:sdc cephnode1:sdd
-
Подкоманда
osd createвыполнит начальную подготовку диска, т.е. очистит диск с файловой системой, которой по умолчанию является xfs, а затем активирует первый раздел в качестве раздела данных а второй в качестве журнала:# ceph-deploy osd create ceph-node1:sdb ceph-node1:sdc ceph-node1:sdd
-
Проверьте состояние Ceph и отметьте число OSD. На данном этапе ваш кластер должен быть в рабочем состоянии; нам нужно добавить несколько дополнительных узлов в кластер Ceph так чтобы вы могли реплицировать объекты три раза (по умолчанию) в кластере и достичь рабочеспособного состояния. Вы найдёте дополнительную информацию об этом в следующем рецепте:
# ceph -s [root@ceph-nodel ceph]# ceph -s cluster aade8340-a44b-45f5-9679-39442daeal8d health HEALTH_WARN 64 pgs incomplete; 64 pgs stuck inactive; 64 pgs stuck unclean monmap el: 1 mons at {ceph-nodel=192.168.1.101:6789/0}, election epoch 2, quorum 0 ceph-nodel osdmap ell: 3 osds: 3 up, 3 in pgmap v17: 64 pgs, 1 pools, 0 bytes data, 0 objects 67344 kB used, 10152 MB / 10217 MB avail 64 incomplete [root@ceph-nodel ceph]#
-
На данный момент у нас есть работающий кластер Ceph с одним MON и тремя OSD настроенными в ceph-node1.
Теперь мы масштабируем наш кластер добавляя ceph-node2 и
ceph-node1 как узлы MON и OSD.
Кластеру Ceph для работы необходим по крайней мере один монитор. Для достижения высокой доступности кластер хранения Ceph
полагается на нечётное число мониторов, причём более одного, например, 3 или 5 для оформления кворума. Он применяет алгоритм
Paxos для получения большинства кворума.
Поскольку у нас уже есть один монитор, работающий на ceph-node1,
давайте создадим два дополнительных монитора для нашего кластера Ceph;
-
Добавьте в файл
/etc/ceph/ceph.confвceph-node1:public network = 192.168.1.0/24
-
Примените
ceph-deployнаceph-node1для создания монитора наceph-node2:# ceph-deploy mon create ceph-node2
-
Повторите этот шаг создания монитора на
ceph-node3:# ceph-deploy mon create ceph-node3
-
Проверьте состояние вашего кластера Ceph; он должен отображать три монитора в разделе MON:
# ceph -s # ceph mon stat [root@ceph-nodel ceph]# ceph -s cluster aade8340-a44b-45f5-9679-39442daeal8d health HEALTH_WARN 64 pgs incomplete; 64 pgs stuck inactive; 64 pgs stuck unclean monmap e3: 3 mons at {ceph-nodel=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0, ceph-node3=192.168.1.103:6789/0}, election epoch 10, quorum 0,1,2 ceph-nodel,ceph-node2,ceph-node3 osdmap e11: 3 osds: 3 up, 3 in pgmap v21: 64 pgs, 1 pools, 0 bytes data, 0 objects 100792 kB used, 15228 MB / 15326 MB avail 64 incomplete [root@ceph-nodel ceph]# [root@ceph-nodel ceph]# [root@ceph-nodel ceph]# ceph mon stat e3: 3 mons at {ceph-nodel=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=1 92.168.1.103:6789/0}, election epoch 10, quorum 0,1,2 ceph-nodel,ceph-node2,ceph-node3 [root@ceph-nodel ceph]#Вы заметите, что ваш кластер Ceph в настоящий момент показывает
HEALTH_WARN; это происходит по той причине, что мы не настроили никаких OSD за пределамиceph-node1. По умолчанию данные в кластере Ceph реплицируются три раза, причём, к тому же, на трёх различных OSD размещающихся на трёх различных узлах. Теперь мы настроим OSD наceph-node2иceph-node3: -
Примените
ceph-deployнаceph-node1для выполненияdisk list,disk zap, а также создания OSD наceph-node2иceph-node3:# ceph-deploy disk list ceph-node2 ceph-node3 # ceph-deploy disk zap ceph-node2:sdb ceph-node2:sdc cephnode2:sdd # ceph-deploy disk zap ceph-node3:sdb ceph-node3:sdc cephnode3:sdd # ceph-deploy osd create ceph-node2:sdb ceph-node2:sdc cephnode2:sdd # ceph-deploy osd create ceph-node3:sdb ceph-node3:sdc cephnode3:sdd
-
Поскольку мы добавили дополнительные OSD, нам следует настроить значения
pg_numиpgp_numдля того, чтобы пулrbdдостиг статусаHEALTH_OKв нашем кластере Ceph:# ceph osd pool set rbd pg_num 256 # ceph osd pool set rbd pgp_num 256
Совет Начиная с редакции Ceph Hammer,
rbdявляется единственным создаваемым по умолчанию пулом. Предшествующие Hammer редакции создавали три различных пула:data,metadataиrbd. -
Проверьте состояние вашего кластера Ceph; на данном этапе ваш кластер должен быть работоспособным:
[root@ceph-nodel ceph]# ceph -s cluster aade8340-a44b-45f5-9679-39442daea18d health HEALTH_OK monmap e3: 3 mons at {ceph-nodel.192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0}, election epoch 10, quorum 0,1,2 ceph-nodel,ceph-node2,c eph-node3 osdmap e64: 9 osds: 9 up, 9 in pgmap v189: 256 pgs, 1 pools, 0 bytes data, 0 objects 317 MB used, 45663 MB / 45980 MB avail 256 active+clean [root@ceph-nodel ceph]#
Теперь, когда у нас есть работающий кластер Ceph, мы будем выполнять некоторую связанную с жизнью практику для получения навыков работы с Ceph, применяя некоторые основные команды.
-
Проверьте состояние своей установки Ceph:
# ceph -s or # ceph status
-
Проверьте работосопсобность кластера:
# ceph -w
-
Проверьте состояние кворума монитора Ceph:
# ceph mon dump
-
Проверьте состояние применения кластера:
# ceph df
-
Проконтролируйте статистику ваших мониторов, OSD и групп размещения Ceph:
# ceph mon stat # ceph osd stat # ceph pg stat
-
Выведите перечень групп размещения:
# ceph pg dump
-
Выведите список ваших пулов Ceph:
# ceph osd lspools
-
Попробуйте просмотреть карту CRUSH OSD:
# ceph osd tree
-
Выведите перечень ключей аутентификации вашего кластера:
# ceph osd tree
Это некоторые основные команды, которые мы изучили в данном разделе. В последующих главах мы изучим расширенные команды для управления кластером Ceph.