Глава 6. Работа в кластере Ceph и управление им
В данной главе мы обсудим следующие рецепты:
-
Понимание управления службами Ceph
-
Координация файла настроек кластера
-
Выполнение Ceph с применением SYSVINIT
-
Выполнение Ceph как службы
-
Сопоставление расширения и увеличения в масштабе
-
Увеличение в масштабе вашего кластера Ceph
-
Уменьшение в масштабе вашего кластера Ceph
-
Замена отказавшего диска в вашем кластере Ceph
-
Обновление вашего кластера Ceph
-
Сопровождение вашего кластера Ceph
Содержание
- 6. Работа в кластере Ceph и управление им
- Введение
- Понимание управления службами Ceph
- Координация файла настроек кластера
- Выполнение Ceph с применением SYSVINIT
- Выполнение Ceph как службы
- Сопоставление расширения и увеличения в масштабе
- Увеличение в масштабе вашего кластера Ceph
- Уменьшение в масштабе вашего кластера Ceph
- Замена отказавшего диска в вашем кластере Ceph
- Обновление вашего кластера Ceph
- Сопровождение вашего кластера Ceph
На текущий момент, как я надеюсь, вы хорошо осведомлены о развёртывании кластера Ceph, его подготовке к работе, а также о мониторинге. В данной главе мы обсудим стандартные темы, такие как управление службами Ceph. Мы также обсудим расширенные темы, такие как масштабирование вашего кластера добавлением узлов OSD и MON и, наконец, обновление кластера Ceph с последующим небольшим обсуждением операций сопровождения.
Все компоненты Ceph, будь то MON, OSD, MDS или RGW выступают в роли служб поверх лежащей в основе операционной системы. Как администратору
хранения Ceph, вам необходимо знать о ваших службах Ceph и том, как их обрабатывать. В дистрибутивах на основе Red Hat, демоны Ceph могут
управляться различными способами: как традиционным SYSVINIT, так и
в качестве службы. {Прим. пер.: подробнее см.
Глава 6. Как запускается пользовательское
пространство в нашем переводе книги Брайана Варда "Как работает Linux".} Всякий раз, когда вы
start,
restart и
stop демоны Ceph (или весь кластер целиком), вы обязаны предписывать
по крайней мере один параметр и одну команду. Вы можете также определить тип демона или экземпляра демона. Общий синтаксис для этого
следующий:
{ceph service command} [options] [command] [daemons]
Параметры Ceph включают в себя:
-
--verbosили-v: Применяется для регистрации с подробностями -
--valgrind: (Используется исключительно для Dev и QA.) Применяется для отладки valgrind -
--allhostsили-a: Действие выполняется на всех узлах, которые приведены вceph.conf, вслучае их отсутствия наlocalhost. -
--confили-c: Применяется, причём в качестве замены, как файл настроек. -
--restart: Автоматически перезапускать, в случае падения его ядра. -
--norestart: Эта команда сообщает об отсутствии необходимости перезапуска в случае падения его ядра.
Команды Ceph включают в свой состав:
-
status: Отобразить состояние демона -
start: Запустить демон -
stop: Остановить демон. -
restart: Остановить и после этого запустить демон. -
forcestop: Принудительно остановить демон; аналогичноkill-9. -
killall: Уничтожить все демоны определённого типа. -
cleanlogs: Очистить ваш каталог журналов. -
cleanalllogs: Очистить всё в вашем каталог журналов.
Демоны Ceph состоят из:
-
mon -
osd -
msd
Кода вы управляете большим кластером, будет хорошей практикой сохранять в вашем файле настроек кластера
(/etc/ceph/ceph.conf) все изменения информации об узлах мониторов кластера, OSD, MDS и RGW.
При наличии таких записей на своём месте вы сможете управлять всеми вашими службами кластера с одного узла.
Чтобы лучше понять сказанное, мы обновим файл настроек Ceph на ceph-node1 и добавим подробности
обо всех узлах мониторов, OSD и MDS.
Добавление узлов монитора в ваш файл настроек Ceph
Поскольку у нас есть три узла монитора, добавим подробности о них в ваш файл /etc/ceph/ceph.conf
на ceph-node1.
[mon] mon data = /var/lib/ceph/mon/Scluster-$id [mon.ceph-node1] host = ceph-node1 mon addr = ceph-node1:6789 [mon.ceph-node2] host = ceph-node2 mon addr = ceph-node2:6789 [mon.ceph-node3] host = ceph-node3 mon addr = ceph-node3:6789
Добавление узлов MDS в ваш файл настроек Ceph
Как и в случае для монитора добавим узел MDS в ваш файл /etc/ceph/ceph.conf
на ceph-node1.
[mds] [mon.ceph-node2] host = ceph-node2
Добавление узлов монитора в ваш файл настроек Ceph
Теперь давайте добавим подробности об узлах OSD в ваш файл /etc/ceph/ceph.conf
на ceph-node1.
[osd] osd data = /var/lib/ceph/osd/Scluster-$id osd juurnal = /var/lib/ceph/osd/Scluster-$id/journal [osd.0] host = ceph-node1 [osd.1] host = ceph-node1 [osd.2] host = ceph-node1 [osd.3] host = ceph-node2 [osd.4] host = ceph-node2 [osd.5] host = ceph-node2 [osd.6] host = ceph-node3 [osd.7] host = ceph-node3 [osd.8] host = ceph-node3
SYSVINIT всё ещё является традиционно рекомендуемым методом
управления демонами Ceph в системах на основе Red Hat, а также для некоторых более старых дистрибутивов на основе Debian/ Ubuntu.
{Прим. пер.: подробнее проблемы запуска служб см. в Глава 6. Как запускается пользовательское
пространство в нашем переводе книги Брайана Варда "Как работает Linux".} Общий синтаксис дл управления демонами
Ceph с использованием SYSVINIT такой:
/etc/init.d/ceph [options] [command] [daemons].
Чтобы запустить и остановить все демоны Ceph выполните следующий набор команд.
Давайте рассмотрим как запустить и остановить все демоны Ceph:
-
Для запуска вашего кластера Ceph выполните команду
start. Эта команда запустит все службы которые вы развернули для всех хостов приведённых в вашем файлеceph.conf.# /etc/init.d/ceph -a start
-
Для останова вашего кластера Ceph выполните команду
stop. Эта команда остановит все службы Ceph развёрнутые вами на всех хостах приведённых в вашем файлеceph.conf. Параметр-aслужит для выполнения на всех узлах:# /etc/init.d/ceph -a stop
![[Предостережение]](/common/images/admon/warning.png)
Предостережение Если вы применяете параметр
-aдля управления службами, убедитесь что ваш файлceph.confимеет определёнными в наличии все ваши хосты Ceph и что текущий узел имеетsshсоединение со всеми прочими узлами. Если параметр-aне применяется, то ваша команда выполняется только на локальном хосте.
Чтобы запустить и остановить все демоны Ceph по их типу выполните следующий набор команд.
Давайте рассмотрим как запустить и остановить все демоны Ceph определённого типа:
Запуск демонов определённого типа
-
Для запуска демонов монитора на локальном хосте выполните Ceph с командой
startи последующим типом демона:# /etc/init.d/ceph start mon
-
Для запуска демонов монитора на всех ваших хостах выполните ту же команду с параметром
-a:# /etc/init.d/ceph -a start mon
-
Аналогично вы можете запускать демоны других типов, то есть
osd,mdsиceph-radosgw:# /etc/init.d/ceph -a start osd # /etc/init.d/ceph start mds # /etc/init.d/ceph start ceph-radosgw
Останов демонов определённого типа
-
Чтобы остановить демоны монитора на локальном хосте выполните Ceph с командой
stopи последующим типом демона:# /etc/init.d/ceph stop mon
-
Для останова демонов монитора на всех ваших хостах выполните ту же команду с параметром
-a:# /etc/init.d/ceph -a stop mon
-
Аналогично вы можете останавливать демоны других типов, то есть
osd,mdsиceph-radosgw:# /etc/init.d/ceph -a stop osd # /etc/init.d/ceph stop mds # /etc/init.d/ceph stop ceph-radosgw
Чтобы запустить и остановить определённый демон Ceph выполните следующий набор команд.
Давайте рассмотрим как запускать и останавливать определённые демоны.
Запуск определённого демона
Для запуска определённого демона на локальном хосте выполните Ceph с командой start и
последующим {тип_демона}.{экземпляр}, например:
-
Для запуска демона
mon.0:# /etc/init.d/ceph start mon.ceph-node1
-
Аналогично вы можете запускать прочие демоны и их экземпляры:
# /etc/init.d/ceph start osd.1 # /etc/init.d/ceph -a start mon.ceph-node2 # /etc/init.d/ceph start ceph-radosgw.gateway1
Останов определённого демона
Для останова определённого демона на локальном хосте выполните Ceph с командой stop и
последующим {тип_демона}.{экземпляр}, например:
-
Для запуска демона
mon.0:# /etc/init.d/ceph stop mon.ceph-node1
-
Аналогично вы можете запускать прочие демоны и их экземпляры:
# /etc/init.d/ceph stop osd.1 # /etc/init.d/ceph -a stop mon.ceph-node2 # /etc/init.d/ceph stop ceph-radosgw.gateway1
В предыдущем рецепте мы изучили управление службой Ceph с применением SYSVINIT;
в данном рецепте мы получим понимание об управлении Ceph в качестве служб, то есть при помощи команды Linux
service. Начиная с выпуска Ceph Argonaut мы можем управлять демонами Ceph при помощи
команды Linux service, имеющей следующий синтаксис:
ervice ceph [options] [command] [daemons]
Чтобы запустить и остановить все демоны Ceph выполните следующий набор команд.
Давайте рассмотрим как запустить и остановить все демоны Ceph:
-
Для запуска вашего кластера Ceph выполните команду
start. Эта команда запустит все службы которые вы развернули для всех хостов приведённых в вашем файлеceph.conf. Раз вы запускаете Ceph с параметром-a, Ceph должен начать работать:# service ceph -a start
-
Для останова вашего кластера Ceph выполните команду
stop. Эта команда остановит все службы Ceph развёрнутые вами на всех хостах приведённых в вашем файлеceph.conf. Раз вы останавливаете Ceph с параметром-a, Ceph должен выключиться:# service ceph -a stop
Чтобы запустить и остановить все демоны Ceph по их типу выполните следующий набор команд.
Давайте рассмотрим как запустить и остановить все демоны определённого типа:
Запуск демонов определённого типа
-
Для запуска демонов монитора на локальном хосте выполните службу Ceph с командой
startи последующим типом демона:# service ceph start mon
-
Для запуска демонов монитора на всех ваших хостах выполните ту же команду с параметром
-a:# service ceph -a start mon
-
Аналогично вы можете запускать демоны других типов, то есть
osd,mdsиceph-radosgw:# service ceph start osd # service ceph start mds # service ceph start ceph-radosgw
Останов демонов определённого
-
Для останова демонов монитора на локальном хосте выполните
service cephс командойstopи последующим типом демона:# service ceph stop mon
-
Для останова демонов монитора на всех ваших хостах выполните ту же команду с параметром
-a:# service ceph -a stop mon
-
Аналогично вы можете останавливать демоны других типов, то есть
osd,mdsиceph-radosgw:# service ceph stop -a osd # service ceph stop mds # service ceph stop ceph-radosgw
Чтобы запустить и остановить определённый демон Ceph выполните следующий набор команд.
Давайте рассмотрим как запускать и останавливать определённые демоны.
Запуск определённого демона
Для запуска определённого демона на локальном хосте выполните службу Ceph с командой start и
последующим {тип_демона}.{экземпляр}, например:
-
Для запуска демона
mon.0:# service ceph start mon.ceph-node1
-
Аналогично вы можете запускать прочие демоны и их экземпляры:
# service ceph start osd.1 # service ceph -a start mds.ceph-node2 # service ceph start ceph-radosgw.gateway1
Останов определённого демона
Для останова определённого демона на локальном хосте выполните службу Ceph с командой stop и
последующим {тип_демона}.{экземпляр}, например:
-
Для запуска демона
mon.0:# service ceph start mon.ceph-node1
-
Аналогично вы можете запускать прочие демоны и их экземпляры:
# service ceph stop osd.1 # service ceph -a stop mds.ceph-node2 # service ceph stop ceph-radosgw.gateway1
Когда вы выстраиваете инфраструктуру хранения, масштабируемость является одним из наиболее важных аспектов проекта. Решения хранения, которые вы выбрали для своей инфраструктуры должны иметь возможность достаточного масштабирования для размещения ваших грядущих потребностей в данных. Обычно системы хранения начинают с малой или средней ёмкости и мало по малу они вырастают в большие решения хранения.
Традиционные системы хранения базировались на архитектуре расширения (scale-up) и были ограничены ёмкостью хранения. Если вы расширяете эти системы хранения сверх некоего предела, вам могут потребоваться компромиссы между производительностью, надёжностью и доступностью. Методология расширения для хранилища включает добавление дисковых ресурсов в существующие системы контроллеров, которые становятся узким местом для производительности, ёмкости и управляемости по достижению определённого уровня.
С другой стороны, архитектура увеличения в масштабе (scale-out) сосредотачивается на добавлении целиком нового устройства, содержащего диски, ЦПУ, оперативную память и прочие ресурсы в ваш существующий кластер хранения. При таком типе архитектуры вы не столкнётесь с вызовами, которые мы наблюдаем при архитектуре расширения; более того,в качестве преимущества мы получаем линейное улучшение производительности. Следующая схема поясняет архитектуру систем хранения с расширением и увеличением в масштабе:
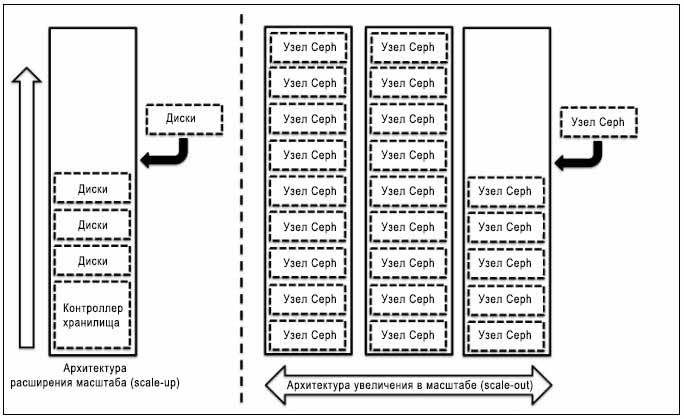
Ceph является бесшовной масштабируемой системой хранения основанной на архитектуре увеличения в масштабе, при которой вы можете добавлять вычислительный узел с кучей дисков в существующий кластер Ceph и расширять вашу систему до большей ёмкости {Прим. пер.: при одновременном линейном росте как производительности, так и стоимости}.
С самых своих корней Ceph разрабатывался для роста от нескольких узлов до нескольких сотен и при этом предполагалось его масштабирование на лету без какого быто ни было времени простоя. В этом рецепте мы погрузимся глубже в функциональность Ceph увеличения в масштабе путём добавления узлов MON, OSD,MDS и RGW.
Добавление узла OSD в кластер Ceph является процессом реального времени. Для его демонстрации нам потребуется новая виртуальная
машина с именем ceph-node4, имеющую три диска,которые будут работать как OSD. Этот новый узел
затем будет добавлен в ваш существующий кластер Ceph.
Выполняйте следующие команды на узле ceph-node1, если не предписано иное:
-
Создайте новый узел,
ceph-node4, с тремя дисками (OSD). Вы можете последовать процессу создания новой виртуальной машины с дисками и настройки ОС, приведённом в рецепте Настройка виртуальной инфраструктуры в Главе 1. Введение и за его пределами, и убедитесь, чтоceph-node1имеет SSH доступ кceph-node4.Перед добавлением нового узла в кластер Ceph давайте проверим текущее дерево OSD. Как показано на следующем снимке экрана, кластер имеет три узла с общим числом OSD в количестве девяти:
# ceph osd tree [root@ceph-node1 ~]# ceph osd tree # id weight type name up/down reweight -1 0.08998 root default -3 0.03 host ceph-node2 3 0.009995 osd.3 up 1 4 0.009995 osd.4 up 1 5 0.009995 osd.5 up 1 -4 0.03 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 -2 0.02998 host ceph-node1 0 0.009995 osd.0 up 1 1 0.009995 osd.1 up 1 2 0.009995 osd.2 up 1 [root@ceph-node1 ~]#
-
Убедитесь, что новые узлы имеют установленные пакеты Ceph. Рекомендуемой практикой является сохранение на всех узлах кластера одной и той же версии Ceph. С узла
ceph-node1установите пакеты Ceph наceph-node4:# ceph-deploy install ceph-node4 --release giant
-
Выведите перечень дисков для
ceph-node4:# ceph-deploy disk list ceph-node4
-
Давайте добавим диски с
ceph-node4в имеющийся у нас кластер Ceph:# ceph-deploy disk zap ceph-node4:sdb ceph-node4:sdc cephnode4:sdd # ceph-deploy osd create ceph-node4:sdb ceph-node4:sdc cephnode4:sdd
-
После того как вы добавили новые OSD в свой кластер Ceph, вы заметите, что кластер Ceph приступил к ребалансировке существующих данных на новые OSD. Вы можете наблюдать за ребалансировкой с применением следующей команды; через некоторое время вы отметите, что ваш кластер стабилизировался:
watch ceph -s
-
Наконец, когда добавление дисков
ceph-node4завершено, вы отметите новую ёмкость хранения вашего кластера:# rados df
-
Проверьте своё дерево OSD; это даст вам лучшее понимание вашего кластера. Вы должны заметить свои новые OSD на
ceph-node4, которые только что были добавлены:# ceph osd tree [root@ceph-node1 ~]# ceph osd tree # id weight type name up/down reweight -1 0.12 root default -3 0.03 host ceph-node2 3 0.009995 osd.3 up 1 4 0.009995 osd.4 up 1 5 0.009995 osd.5 up 1 -4 0.03 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 -2 0.02998 host ceph-node1 0 0.009995 osd.0 up 1 1 0.009995 osd.1 up 1 2 0.009995 osd.2 up 1 -5 0.02998 host ceph-node4 0 0.009995 osd.9 up 1 1 0.009995 osd.10 up 1 2 0.009995 osd.11 up 1 [root@ceph-node1 ~]#
Эта команда выводит некоторую полезную информацию, такую как вес OSD, какой узел Ceph размещает какие OSD, состояние
UP/DOWN OSD, а также состояние IN/OUT ваших
OSD, представляемое 1 или 0.
Прямо сейчас мы изучили как добавлять новый узел в существующий кластер Ceph. Теперь пришло хорошее время для понимания того, что
поскольку число OSD возрастает, выбор правильного значения для групп размещения (PG) становится более важным, поскольку оно имеет
значительное влияние на поведение вашего кластера. Увеличение числа PG на большом кластере может быть затратной операцией.
Я рекомендую вам взглянуть на
http://docs.ceph.com/docs/master/rados/operations/placement-groups/#choosing-the-number-of-placement-groups для
получения некоей новой информации по PG
(Placement Groups).
В окружении, в котором вы развернули большой кластер Ceph, вы можете захотеть увеличить число своих мониторов. Как и в случае с
OSD, добавление новых мониторов в ваш кластер Ceph является процессом реального масштаба времени. В данном рецепте мы настроим
ceph-node4 в качестве узла монитора.
Поскольку мы имеем тестовый кластер Ceph, мы добавим ceph-node4 в качестве четвёртого
узла монитора, однако в промышленной сборке вам всегда следует иметь нечётное число узлов монитора в вашем кластере Ceph; это улучшает
устойчивость к сбоям.
-
Чтобы настроить
ceph-node4в качестве узла монитора, выполните следующую команду сceph-node1:# ceph-deploy mon create ceph-node4
-
Когда
ceph-node4настроен в качестве узла монитора, проверьте состояние вашего Ceph для просмотра состояния кластера. Заметьте, пожалуйста, чтоceph-node4является вашим новым узлом монитора:[root@ceph-node1 ceph]# ceph -s cluster 9609b429-eee2-4e23-af31-28a24fcf5cbc health HEALTH_OK monmap e6: 4 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0,ceph-node4=192.168.1.104:6789/0}, election epoch 958, quoru m 0,1,2,3 ceph-node1,ceph-node2,ceph-node3,ceph-node4 mdsmap e217: 1/1/1 up {0=ceph-node2=up:active} osdmap e3951: 12 osds: 12 up, 12 in pgmap v32414: 1628 pgs, 45 pools, 2422 MB data, 3742 objects 7920 MB used, 172 GB / 179 GB avail 1628 active+clean [root@ceph-node1 ceph]# -
Проверьте состояние монитора Ceph и отметьте
ceph-node4в качестве нового узла монитора.[root@ceph-node1 ceph]# ceph mon stat e6: 4 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0,ceph-node4 =192.168.1.104:6789/0}, election epoch 958, quorum 0,1,2,3 ceph-node1,ceph-node2,ceph-node3,ceph-node4 [root@ceph-node1 ceph]#
В случае применения в качестве хранилища объектов, вам потребуется развёртывание компонентов RGW Ceph, а для достижения высоких доступности и производительности вашей службы хранения объектов вам необходимо развернуть более одного экземпляра RGW Ceph. Служба хранения объектов Ceph может быть легко масштабируема с одного на несколько узлов RGW. Следующая схема показывает, как множество экземпляров RGW может быть развёрнуто и масштабировано для предоставления высокой доступности службы хранения объектов:
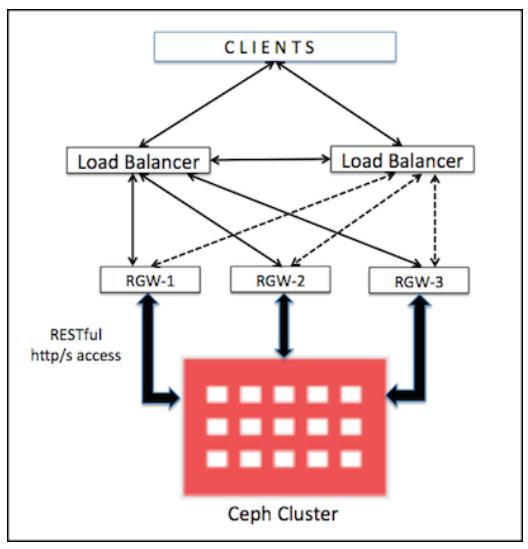
Масштабирование RGW аналогично добавлению дополнительных узлов RGW; для справки обращайтесь, пожалуйста, к рецепту Стандартные наладка, установка и настройка шлюза RADOS в Главе 3. Работа с хранилищем объектов Ceph для добавления дополнительных узлов RGW в вашу среду Ceph.
Одной из наиболее важных функциональностей системы хранения является её гибкость. Хорошее решение хранения должно быть достаточно гибким для поддержки его расширения и уменьшения без причинения каких бы то ни было простоев ваших служб. Традиционные системы хранения имеют ограниченную гибкость; расширение и уменьшение такой системы являются трудной работой. Иногда вы ощущаете блокированность в ёмкости хранения и не можете выполнить изменения в соответствии с вашими потребностями.
Ceph является абсолютно гибкой системой которая поддерживает изменения на лету в ёмкости хранения, причём безотносительно в сторону
расширения или уменьшения. В последнем рецепте мы изучили как легко увеличивать в масштабе (scale-out) кластер Ceph. В данном рецепте
мы уменьшим в масштабе кластер Ceph без какого бы то ни было воздействия на его доступность, просто удалив
ceph-node4 из вашего кластера Ceph.
Перед выполнением уменьшения размера кластера, уменьшением его масштаба или удалением узла OSD, убедитесь, что вашему кластеру хватит пространства для размещения всех данных, присутствующих на узле, который вы планируете отселить. Ваш кластер не должен быть в своём полном заполнении, которое является его процентным значением занятости дискового пространства в OSD. Поэтому установившейся практикой является отказ от удаления OSD или узла OSD без рассмотрения его воздействия на коэффициент заполнения.
Выполняйте следующие команды на узле ceph-node1, если не предписано иное:
-
Поскольку нам нужно уменьшить масштаб нашего кластера, мы удалим
ceph-node4и все связанные с ним OSD из нашего кластера. OSD Ceph должны быть установлены на удаление чтобы Ceph смог выполнить восстановление данных. На любом из узлов Ceph выведите OSD из вашего кластера:# ceph osd out osd.9 # ceph osd out osd.10 # ceph osd out osd.11 [root@ceph-node1 ~]# ceph osd out osd.9 marked out osd.9. [root@ceph-node1 ~]# ceph osd out osd.10 marked out osd.10. [root@ceph-node1 ~]# ceph osd out osd.11 marked out osd.11. [root@ceph-node1 ~]#
-
Как только вы пометите OSD на вывод из кластера, Ceph начнёт ребалансировку вашего кластера путём миграции своих групп размещения (PG) с этого OSD, который выводится из кластера, на другие OSD внутри вашего кластера. Состояние вашего кластера на какое- то время станет опасным (unhealthy), но он будет по прежнему в состоянии обслуживать данные клиентов. В зависимости от числа удаляемых OSD может существовать провал в производительности кластера до полного завершения восстановления. Как только кластер снова станет жизнеспособным (healthy), онбуде работать как прежде.
# ceph -s [root@ceph-node1 ~]# ceph -s cluster 9609b429-eee2-4e23-af31-28a24fcf5cbc health HEALTH_WARN 65 pgs degraded; 8 pgs recovering; 22 pgs stuck unclean; recovery 1594/11226 objects degraded (14.199%) monmap e6: 4 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2-192.168.1.102:6789/0,ceph-node3-192.168.1.103:6789/0,ceph-node4-192.168.1.104:6789/0}, election epoch 978, quorum 0,1,2,3 ceph-node1,ceph-node2,ceph-node3,ceph-node4 mdsmap e222: 1/1/1 up {0=ceph-node2=up:active} osdmap e4081: 12 osds: 12 up, 9 in pgmap v32727: 1628 pgs, 45 pools, 2422 MB data, 3742 objects 8065 MB used, 127 GB / 134 GB avail 1594/11226 objects degraded (14.199%) 1563 active+clean 57 active+degraded 8 active+recovering+degraded recovery io 27934 kB/s, 2 keys/s, 35 objects/s client io 297 kB/s wr, 0 op/s [root@ceph-node1 ~]#Здесь мы можем увидеть, что кластер находится в режиме восстановления, нов то же время он продолжает обслуживать данные клиентов. Вы можете наблюдать за процессом восстановления, воспользовавшись:
# ceph -w [root@ceph-node1 ~]# ceph -w cluster 9609b429-eee2-4e23-af31-28a24fcf5cbc health HEALTH_OK monmap e6: 4 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0,ceph-node4=192.168.1.104:6789/0}, election epoch 978, quorum 0,1,2,3 ceph-node1,ceph-node2,ceph-node3,ceph-node4 mdsmap e222: 1/1/1 up {0=ceph-node2=up:active} osdmap e4081: 12 osds: 12 up, 9 in pgmap v32734: 1628 pgs, 45 pools, 2422 MB data, 3742 objects 8514 MB used, 126 GB / 134 GB avail 1628 active+clean 2015-07-26 23:01:05.012972 mon.0 [INF] pgmap v32734: 1628 pgs: 1628 active+clean; 2422 MB data, 8514 MB used, 126 GB / 134 GB avail; 38045 kB/s, 35 objects/s recovering 2015-07-26 23:01:54.896226 mon.0 [INF] pgmap v32735: 1628 pgs: 1628 active+clean; 2422 MB d ata, 8514 MB used, 126 GB / 134 GB avail -
Поскольку мы пометили
osd.9,osd.10иosd.11на выведение из нашего кластера, они не принимают участия в сохранении данных, однако их службы всё ещё работают {Прим. пер.: и могут обслуживать чтение!}. Давайте остановим эти OSD:# ssh ceph-node4 service ceph stop osd [root@ceph-node1 ~]# ssh ceph-node4 service ceph stop osd === osd.11 === Stopping Ceph osd.11 on ceph-node4...kill 4721...kill 4721...done === osd.10 === Stopping Ceph osd.10 on ceph-node4...kill 2341...kill 2341...done === osd.9 === Stopping Ceph osd.9 on ceph-node4...kill 4319...kill 4319...done [root@ceph-node1 ~]#
Когда OSD отключатся, проверьте ваше дерево OSD; вы будете наблюдать, что OSD выключены
DOWNи выведены (OUT):# Ceph osd tree [root@ceph-node1 ~]# ceph osd tree # id weight type name up/down reweight -1 0.12 root default -3 0.03 host ceph-node2 3 0.009995 osd.3 up 1 4 0.009995 osd.4 up 1 5 0.009995 osd.5 up 1 -4 0.03 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 -2 0.02998 host ceph-node1 0 0.009995 osd.0 up 1 1 0.009995 osd.1 up 1 2 0.009995 osd.2 up 1 -5 0.02998 host ceph-node4 9 0.009995 osd.9 down 0 10 0.009995 osd.10 down 0 11 0.009995 osd.11 down 0 [root@ceph-node1 ~]#
-
Теперь, когда эти OSD больше не являются частью вашего кластера Ceph, давайте удалим их из карты CRUSH:
# ceph osd crush remove osd.9 # ceph osd crush remove osd.10 # ceph osd crush remove osd.11 [root@ceph-node1 ~]# ceph osd crush remove osd.9 removed item id 9 name 'osd.9' from crush map [root@ceph-node1 ~]# ceph osd crush remove osd.10 removed item id 10 name 'osd.10' from crush map [root@ceph-node1 ~]# ceph osd crush remove osd.11 removed item id 11 name 'osd.11' from crush map [root@ceph-node1 ~]#
-
Как только эти OSD удалены из вашей карты CRUSH, кластер CEPH становится жизнеспособным (health). Вам следует также просмотреть карту ваших OSD; так как мы не удалили эти OSD, мы вё ещё видим 12 OSD, причём 9
UPи 9IN. -
Удалим ключи аутентификации этих OSD:
# ceph auth del osd.9 # ceph auth del osd.10 # ceph auth del osd.11 [root@ceph-node1 ~]# ceph auth del osd.9 updated [root@ceph-node1 ~]# ceph auth del osd.10 updated [root@ceph-node1 ~]# ceph auth del osd.11 updated [root@ceph-node1 ~]#
-
Наконец, удалим эти OSD и проверим состояние вашего кластера; вы должны наблюдать 9 OSD, причём 9
UPи 9IN, а жизнесопсобность (helth) кластера должна бытьOK.# ceph osd rm osd.9 # ceph osd rm osd.10 # ceph osd rm osd.11 [root@ceph-node1 ~]# ceph osd rm osd.9 removed osd.9 [root@ceph-node1 ~]# ceph osd rm osd.10 removed osd.10 [root@ceph-node1 ~]# ceph osd rm osd.11 removed osd.11 [root@ceph-node1 ~]#
-
Чтобы оставить ваш кластер очищнным, выполните некую работу по домоводству; поскольку мы удалили все эти OSD из нашей карты CRUSH,
ceph-node4больше не содержит никаких элементов. Удалитеceph-node4из карты CRUSH; это удалит все следы данного узла из кластера Ceph: :# ceph osd crush remove ceph-node4 # ceph -s [root@ceph-node1 ~]# ceph -s cluster 9609b429-eee2-4e23-af31-28a24fcf5cbc health HEALTH_OK monmap e6: 4 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0,ceph-node4=192.168.1.104:6789/01, election epoch 980, quorum 0,1,2,3 ceph-node1,ceph-node2,ceph-node3,ceph-node4 mdsmap e222: 1/1/1 up {0=ceph-node2=up:active} osdmap e4095: 9 osds: 9 up, 9 in pgmap v32801: 1628 pgs, 45 pools, 2422 MB data, 3742 objects 8185 MB used, 126 GB / 134 GB avail 1628 active+clean [root@ceph-node1 ~]#
Удаление монитора Ceph обычно не часто востребованная задача. Когда вы удаляете мониторы из некого кластера, имейте в виду, что
мониторы Ceph используют алгоритм PAXOS для
установления консенсуса о вашей главной карте кластера. Вы должны иметь достаточное число мониторов для установления некоего кворума
для согласия по ваше карте кластера. В данном рецепте мы изучим как удалить монитор
ceph-node4 из вашего кластера Ceph.
-
Проверьте состояние монитора:
# ceph mon stat [root@ceph-node1 ~]# ceph mon stat e6: 4 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0,ceph-node4=192.168.1.104:6789/0}, election epoch 996, quorum 0,1,2,3 ceph-node1,ceph-node2,ceph-node3,ceph-node4 [root@ceph-node1 ~]# -
Чтобы удалить монитор
ceph-node4, выполните следующую команду с узлаceph-node4:# ceph-deploy mon destroy ceph-node4 [root@ceph-node1 ceph]# ceph-deploy mon destroy ceph-node4 [ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf [ceph_deploy.cli][INFO ] Invoked (1.5.25): /bin/ceph-deploy mon destroy ceph-node4 [ceph_deploy.mon][DEBUG ] Removing mon from ceph-node4 [ceph-node4][DEBUG ] connected to host: ceph-node4 [ceph-node4][DEBUG ] detect platform information from remote host [ceph-node4][DEBUG ] detect machine type [ceph-node4][DEBUG ] get remote short hostname [ceph-node4][INFO ] Running command: ceph --cluster=ceph -n mon. -k /var/lib/ceph/mon/ceph-ceph-node4/keyring mon remove ceph-node4 [ceph-node4][WARNIN] removed mon.ceph-node4 at 192.168.1.104:6789/0, there are now 3 monitors [ceph-node4][INFO ] polling the daemon to verify it stopped [ceph-node4][INFO ] Running command: service ceph status mon.ceph-node4 [ceph-node4][INFO ] Running command: mkdir -p /var/lib/ceph/mon-removed [ceph-node4][DEBUG ] move old monitor data [root@ceph-node1 ceph]#
-
Выполните проверку чтобы увидеть что ваши мониторы покинули кворум:
# ceph quorum_status --format json-pretty [root@ceph-node1 ceph]# ceph quorum_status --format json-pretty { "election_epoch": 998, "quorum": [ 0, 1, 2], "quorum_names": [ "ceph-node1", "ceph-node2", "ceph-node3"], "quorum_leader_name": "ceph-node1", "monmap": -{ "epoch": 7, "fsid": "9609b429-eee2-4e23-af31-28a24fcf5cbc", "modified": "2015-07-27 21:22:38.523853", "created": "0.000000", "mons": [ { "rank": 0, "name": "ceph-node1", "addr": "192.168.1.101:6789\/0"}, { "rank": 1, "name": "ceph-node2", "addr": "192.168.1.102:6789\/0"}, { "rank": 2, "name": "ceph-node3", "addr": "192.168.1.103:6789\/0"}]}} [root@ceph-node1 ceph]# -
Наконец, проверьте состояние мониторов; ваш кластер должен иметь три монитора:
# ceph mon stat [root@ceph-node1 ceph]# ceph mon stat e7: 3 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0}, election epoch 998, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3 [root@ceph-node1 ceph]#
Кластер Ceph может быть собран из общего числа физических дисков от 10 до нескольких тысяч, которые предоставляют ёмкость хранения вашему кластеру. По мере роста числа физических дисков в вашем кластере Ceph, частота отказов дисков также возрастает. Следовательно, замена отказавшего дискового устройства может стать повторяемой задачей для администратора хранилища Ceph. В данном рецепте мы изучим процесс замены диска для кластера Ceph.
-
Давайте проверим жизнеспособность(health) кластера; так как этот кластер не имеет никаких состояний отказавших дисков, оно будет
HEALTH_OK:# ceph status [root@ceph-node1 ceph]# ceph -s cluster 9609b429-eee2-4e23-af31-28a24fcf5cbc health HEALTH_OK monmap e7: 3 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0}, election epoch 998, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3 mdsmap e232: 1/1/1 up {0=ceph-node2=up:active} osdmap e4118: 9 osds: 9 up, 9 in pgmap v33667: 1628 pgs, 45 pools, 2422 MB data, 3742 objects 7718 MB used, 127 GB / 134 GB avail 1628 active+clean [root@ceph-node1 ceph]# -
Так как мы демонстрируем этот пример на виртуальных машинах, нам необходимо принудительно выполнить отказ диска переведя
ceph-node1в отключённое (DOWN) состояние, отключив диск и включив эту виртуальную машину опять. Выполните следующие команды на машине вашего хоста:storageattach ceph-node1 --storagectl "SATA" --port 1 --device 0 --type hdd --medium none # VBoxManage startvm ceph-node1
Следующий экранный снимок будет вашим выводом:
teeri:ceph-cookbook ksingh$ vBoxManage controlvm ceph-node1 poweroff 0%...10%...20%...30%...40%...50%...60%...70%...80%...90%...100% teeri:ceph-cookbook ksingh$ teeri:ceph-cookbook ksingh$ vBoxManage storageattach ceph-node1 --storagectl "SATA" --port 1 --device 0 --type hdd --medium none teeri:ceph-cookbook ksingh$ vBoxManage startvm ceph-node1 waiting for vm "ceph-node1" to power on... VM "ceph-node1" has been successfully started. teeri:ceph-cookbook ksingh$
-
Теперь
ceph-node1содержит отказавший диск,osd.0, который должен быть заменён:# ceph osd tree [root@ceph-node1 ~]# ceph osd tree # id weight type name up/down reweight -1 0.08998 root default -3 0.03 host ceph-node2 3 0.009995 osd.3 up 1 4 0.009995 osd.4 up 1 5 0.009995 osd.5 up 1 -4 0.03 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 -2 0.02998 host ceph-node1 0 0.009995 osd.0 down 1 1 0.009995 osd.1 up 1 2 0.009995 osd.2 up 1 [root@ceph-node1 ~]#
Вы также отметите, что
osd.0, находится вDOWN, однако, он всё ещё помечен какIN, кластер Ceph не переключит восстановление данных для этого диска. По умолчанию, кластер Ceph будет ждать 300 секунд перед тем как пометит выключенный диск какOUT, а после этого переключится на восстановление данных. Причина для данного таймаута заключается в попытке избежать не нужного перемещения данных обусловленных краткосрочными перерывами, например, перезагрузкой сервера. Можно увеличить или даже уменьшить этот таймаут при такой необходимости. -
Вы должны подождать 300 секунд для переключения на восстановление данных или иначе вы можете вручную пометить этот диск как
OUT:# ceph osd out osd.0
-
Как только OSD помечен как
OUT, ваш кластер Ceph инициирует операцию восстановления для групп размещения (PG), которые размещались на вашем отказавшем диске. Вы можете наблюдать за процессом восстановления с применением следующей команды:# ceph status
-
Теперь давайте удалим этот отказавший диск OSD из вашей карты CRUSH:
# ceph osd crush rm osd.0
-
Удаляем ключи аутентификации вашей Ceph для этого OSD:
# ceph auth del osd.0
-
Наконец, удаляем этот OSD из вашего кластера Ceph:
# ceph osd rm osd.0 [root@ceph-node1 ~]# ceph osd crush rm osd.0 removed item id 0 name 'osd.0' from crush map [root@ceph-node1 ~]# [root@ceph-node1 ~]# ceph auth del osd.0 updated [root@ceph-node1 ~]# ceph osd rm osd.0 removed osd.0 [root@ceph-node1 ~]#
-
Так как один из ваших OSD недоступен, жизнеспособность (heath) кластера не будет
OKи ваш кластер будет выполнять восстановление. Не стоит беспокоиться об этом; это нормальное действие Ceph. Когда операция восстановления завершится, ваш кластер получит опятьHEALTH_OK:# ceph -s # ceph osd stat [root@ceph-node1 ~]# ceph -s cluster 9609b429-eee2-4e23-af31-28a24fcf5cbc health HEALTH_OK monmap e7: 3 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0}, election epoch 1028, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3 mdsmap e246: 1/1/1 up {0=ceph-node2=up:active} osdmap e4164: 8 osds: 8 up, 8 in pgmap v33855: 1628 pgs, 45 pools, 2422 MB data, 3742 objects 7918 MB used, 112 GB / 119 GB avail 1628 active+clean [root@ceph-node1 ~]# [root@ceph-node1 ~]# ceph osd stat osdmap e4164: 8 osds: 8 up, 8 in [root@ceph-node1 ~]# -
На данный момент вам следует физически заменить отказавший диск новым устройством на вашем узле Ceph. В наши дни почти все сервера и операционные системы поддерживают горячую замену, поэтому вам не требуется никакое время простоя для замены диска.
-
Поскольку мы симулировали это на виртуальной машине, нам необходимо выключить нашу ВМ, добавить новый диск и перезапустить эту ВМ. Когда новый диск вставлен, сделайте замечание о его идентификаторе устройства OC:
# VBoxManage controlvm ceph-node1 poweroff # VBoxManage storageattach ceph-node1 --storagectl "SATA" --port 1 --device 0 --type hdd --medium ceph-node1_disk2.vdi # VBoxManage startvm ceph-node1
-
Теперь, после того когда был добавлен новый диск, ввашу систему, давайте отобразим список ваших дисков:
# ceph-deploy disk list ceph-node1
-
Перед добавлением этого диска в ваш кластер Ceph выполним
disk zap:# ceph-deploy disk zap ceph-node1:sdb
-
Наконец, создадим OSD на этот диск и Ceph добавит его как
osd.0:# ceph-deploy --overwrite-conf osd create ceph-node1:sdb
-
Когда этот OSD добавлен в ваш кластер Ceph, Ceph выполнит операцию наполнения и запустит перемещение PG со вторичных OSD на этот новый OSD. Операция восстановления потребует некоторого времени, однако по её завершению ваш кластер Ceph будет снова
HEALTHY_OK:# ceph -s # ceph osd stat [root@ceph-node1 ceph]# ceph -s cluster 9609b429-eee2-4e23-af31-28a24fcf5cbc health HEALTH_OK monmap e7: 3 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0}, election epoch 1032, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3 mdsmap e248: 1/1/1 up {0-ceph-node2=up:active} osdmap e4191: 9 osds: 9 up, 9 in pgmap v33983: 1628 pgs, 45 pools, 2422 MB data, 3742 objects 8160 MB used, 126 GB / 134 GB avail 1628 active+clean [root@ceph-node1 ceph]# [root@ceph-node1 ceph]# ceph osd stat osdmap e4191: 9 osds: 9 up, 9 in [root@ceph-node1 ceph]#
Одной из целого ряда причин для величия Ceph состоит в том, что почти все действия в кластере Ceph могут выполняться в реальном времени, во включённом состоянии, что означает, что ваш кластер Ceph находится в промышленной эксплуатации и вы можете выполнять свои административные задачи на этом кластере без простоя. Одна из таких операций состоит в обновлении версии вашего кластера Ceph.
Так как впервой главе мы воспользовались редакцией Giant для Ceph, что было сделано намеренно, тогда теперь мы можем продемонстрировать обновление версии кластера Ceph с Giant на Hammer. В качестве установившейся практики вам следует придерживаться рекомендуемой последовательности обновления для Ceph, которая состоит в следующем порядке:
-
Инструментарий ceph-deploy
-
Демоны монитора Ceph
-
Демоны OSD Ceph
-
Выполнение Ceph как службы
-
Серверы метаданных Ceph
-
Шлюзы объектов Ceph
В качестве общего правила, рекомендуется чтобы вы обновляли все свои демоны определённого типа (например, все демоны
ceph-mon, все демоны ceph-osd и так далее),
чтобы гарантировать, что у них увсех одна и та же редакция.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Когда вы обновите демон Ceph, вы уже не сможете понизить его назад. Каждая редакция Ceph может иметь дополнительные шаги; очень сильно рекомендуется изучать справочную информацию разделов специфических для различных редакций http://docs.ceph.com/docs/master/release-notes/ для идентификации специфичных для редакции процедур при обновлении вашего кластера Ceph. |
В этом рецепте мы обновим наш кластер Ceph, который работает в редакции Giant (0.84.2) на самую последнюю стабильную редакцию Hammer.
-
Перед запуском процесса обновления давайте проверим нашу текущую версию
ceph-deploy, монитора Ceph, OSD, MDS и демонаceph-rgw:# ceph-deploy --version # for i in 1 2 3 ; do ssh ceph-node$i service ceph status; done | grep -i running [root@ceph-node1 ~]# ceph-deploy --version 1.5.25 [root@ceph-node1 ~]# [root@ceph-node1 ~]# for i in 1 2 3 ; do ssh ceph-nodeSi service ceph status; done I grep -i running mon.ceph-node1: running {"version":"0.87 2"} osd.0: running {"version":"0.87.2"} osd.1: running {"version":"0.87.2"} osd.2: running {"version":"0.87.2"} mon.ceph-node1: running {"version":"0.87.2"} osd.0: running {"version":"0.87.2"} osd.1: running {"version":"0.87.2"} osd.2: running {"version":"0.87.2"} mon.ceph-node2: running {"version":"0.87 2"} osd.3: running {"version":"0.87.2"} osd.4: running {"version":"0.87.2"} osd.5: running {"version":"0.87.2"} mds.ceph-node2: running {"version":"0.87.2"} mon.ceph-node3: running {"version":"0.87.2"} osd.6: runwing {"version":"0.87.2"} osd.7: running {"version":"0.87.2"} osd.8: running {"version":"0.87.2"} [root@ceph-node1 ~]# -
Обновите
ceph-deployна его самую последнюю версию:# yum update -y ceph-deploy # ceph-deploy --version
-
Обновите репозитории
yumсвоего Ceph на целевую редакцию Hammer. Обновитеbaseurlв/etc/yum.repos.d/ceph.repoна Hammer, как показано далее:[root@ceph-node1 ~]# cat /etc/yum.repos.d/ceph.repo [Ceph] name=Ceph packages for $basearch baseurl=http://ceph.com/rpm-hammer/e17/$basearch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plainj=keys/release.asc priority=1 [Ceph-noarch] name=ceph noarch packages baseurl=http://ceph.com/rpm-hammer/e17/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plainj=keys/release.asc priority=1 [ceph-source] name=ceph source packages baseurl=http://ceph.com/rpm-hammer/e17/SRPmS enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plainj=keys/release.asc priority=1 [root@ceph-node1 ~]#
-
Скопируйте репозитории
yumвашего Ceph на остальные узлы Ceph:# scp /etc/yum.repos.d/ceph.repo ceph-node2:/etc/yum.repos.d/ceph.repo # scp /etc/yum.repos.d/ceph.repo ceph-node3:/etc/yum.repos.d/ceph.repo [root@ceph-node1 ~]# scp /etc/yum.repos.d/ceph.repo ceph-node2:/etc/yum.repos.d/ceph.repo ceph.repo 100% 611 0.6KB/s 00:00 [root@ceph-node1 ~]# scp /etc/yum.repos.d/ceph.repo ceph-node3:/etc/yum.repos.d/ceph.repo ceph.repo 100% 611 0.6KB/s 00:00 [root@ceph-node1 ~]#
Так как наша сборка тестового кластера имеет демоны MON, OSD и MDS работающие на одной и той же машине, обновление исполняемых файлов вашего программного обеспечения Ceph на редакцию Hammer будет иметь результатом обновление демонов MON, OSD и MDS в один шаг. В противном случае вы можете столкнуться с проблемами.
Замечание В промышленной среде вам следует придерживаться последовательности обновления Ceph, как это предписывалось в начале главы, во избежание проблем. {Прим. пер.: подробнее см. раздел Модернизация вашего кластера Ceph в нашем переводе первой книги Карана Сингха Изучаем Ceph.}
Обновите Ceph с Giant (0.87.2) на стабильную редакцию Hammer (0.94.2):
# ceph-deploy install --release hammer ceph-node1 ceph-node2 ceph-node3
Перезапустите ваши демоны монитора Ceph на своих узлах монитора Ceph один за другим так, чтобы этот монитор не терял кворум:
# service ceph restart mon
Давайте проверим жизнеспособность(health) кластера; так как этот кластер не имеет никаких состояний отказавших дисков, оно будет
HEALTH_OK:# ceph status
Перезапустите демоны OSD Ceph на всех узлах OSD Ceph один за другим:
# service ceph restart osd
Перезапустите демон MDS Ceph на узле MDS Ceph:
# service ceph restart mds
Наконец, когда все службы были успешно перезапущены, проверьте вашу версию Ceph:
# ceph -v # for i in 1 2 3 ; do ssh ceph-node$i service ceph status; done | grep -i running [root@ceph-node1 ~]# for i in 1 2 3 ; do ssh ceph-node$i service ceph status; done 1 grep -i running mon.ceph-node1: running {"version":"0.94.2"} osd.0: running {"version":"0.94.2"} osd.1: running {"version":"0.94.2"} osd.2: running {"version":"0.94.2"} mon.ceph-node1: running {"version":"0.94.2"} osd.0: running {"version":"0.94.2"} osd.1: running {"version":"0.94.2"} osd.2: running {"version":"0.94.2"} mon.ceph-node2: running {"version":"0.94.2"} osd.3: running {"version":"0.94.2"} osd.4: running {"version":"0.94.2"} osd.5: running {"version":"0.94.2"} mds.ceph-node2: running {"version":"0.94.2"} mon.ceph-node3: running {"version":"0.94.2"} osd.6: running {"version":"0.94.2"} osd.7: running {"version":"0.94.2"} osd.8: running {"version":"0.94.2"} [root@ceph-node1 ~]#
Для вас, как для администратора хранилища Ceph, сопровождение вашего кластера Ceph будет одним из самых высоких приоритетов. Ceph является распределённой системой, которая разработана для роста от десятков OSD до нескольких тысяч. Одна из ключевых вещей требующая сопровождения кластера Ceph состоит в управлении его OSD. В данном рецепте мы обсудим под команды для OSD и групп размещения (PG), которые помогут вам при сопровождении кластера и обнаружении ошибок.
Чтобы лучше понять необходимость этих команд, давайте предположим сценарий, в котором вы хотите добавить новый узел в свой промышленный кластер Ceph. Один из вариантов состоит в простом добавлении нового узла с некоторым числом дисков в ваш кластер Ceph, и кластер приступит к заполнению и перетасовке данных на ваш новый узел. Это прекрасно для тестового кластера.
Однако, ситуация становится очень критичной когда она происходит на сборке, находящейся в промышленной эксплуатации, где вам следует
применять некоторые из под команд/ флагов ceph osd, которые приводятся ниже, перед добавлением
новогоузла в ваш кластер, например, noin, nobackfill и
тому подобных. Это делается для того, чтобы ваш кластер не приступал к процессу заполнения немедленно после установки нового узла. Далее
вы можете изменить установку этих флагов в промежуток не пиковых часов, и кластер выполнит в это время перебалансировку:
-
Применение этих флагов так же просто как установка и сброс. Например, чтобы установить флаг, примените следующую командную строку:
# ceph osd set <flag_name> # ceph osd set noout # ceph osd set nodown # ceph osd set norecover
-
Теперь, чтобыс бросить тот же флаг, примените следующие командные строки:
# ceph osd unset <flag_name> # ceph osd unset noout # ceph osd unset nodown # ceph osd unset norecover
Здесь мы изучим чем эти флаги являются и зачем они применяются.
-
noout: Это принуждает ваш кластер Ceph не помечать любой OSD как покинувший (out) кластер, безотносительно к его состоянию. Это гарантирует, что все такие OSD останутся внутри вашего кластера. -
nodown: Это принуждает ваш кластер Ceph не помечать любой OSD как отключённый (down), безотносительно к его состоянию. Это гарантирует, что все такие OSD останутсяUPи никто из них не перейдёт вDOWN. -
noup: Это принуждает ваш кластер Ceph не помечать любой OSD как включённый (UP). Следовательно, любой OSD, который помеченDOWNсможет перейти в состояниеUPтолько после переустановки этого флага. Это также применимо к новым OSD, которые присоединились к вашему кластеру. -
noin: Это принуждает ваш кластер Ceph не разрешать никаким новым OSD присоединяться к вашему кластеру. Это чрезвычайно полезно, когда вы добавляете множество OSD за один раз и не хотите чтобы они присоединялись к вашему кластеру автоматически. -
norecover: Это принуждает ваш кластер Ceph не выполнять восстановление кластера. -
nobackfill: Это принуждает ваш кластер Ceph не выполнять наполнение. Это чрезвычайно полезно, когда вы добавляете множество OSD за один раз и не хотите чтобы Ceph выполнял автоматическое размещение данных на этот узел. -
norebalance: Это принуждает ваш кластер Ceph не выполнять ребалансировку кластера. -
noscrub: Это принуждает ваш кластер Ceph не выполнять чистку OSD. -
nodeep-scrub: Это принуждает ваш кластер Ceph не выполнять глубокую чистку OSD. -
notieragent: Это запрещает ваш агент многоуровневого кэширования.
Дополнительно к этим флагам вы также можете использовать следующие команды для восстановления OSD и PG:
-
ceph osd repair: Это выполнит восстановление на предписанном OSD. -
ceph pg repair: Это выполнит восстановление на предписанной PG. Применяйте эту команду с предосторожностью; в зависимости от состояния вашего кластера эта команда способна воздействовать на данный пользователя, если применяется не должным образом. -
ceph pg scrub: Это выполнит очистку предписанной PG. -
ceph deep-scrub: Это выполнит глубокую очистку предписанной PG.
Ceph CLI обладает чрезвачайной мощностью для сквозного управления кластером. Вы можете получить дополнительную информацию здесь: http://ceph.com/docs/master/man/8/ceph/.