Глава 12. Анти- энтропия и рассеивание
Содержание
Большинство обсуждавшихся нами до сих пор шаблонов взаимодействия были либо одноранговыми, либо один- ко- многим (координатор и реплики). Для надёжного распространения записей данных по всей системе нам требуется чтобы сам распространяющий узел был доступным и способным достигать прочих узлов, причём даже когда пропускная способность ограничивается одной единственной машиной.
Быстрое и надёжное распространение может быть менее применимым для записей данных и более важным для необходимых метаданных по всему кластеру, например сведения об участниках (присоединяющиеся и покидающие его узлы), состояния узлов, отказы, изменения схемы и т.п. Содержащие эти сведения сообщения как правило не часты и малы, но должны распространяться настолько быстро и надёжно, насколько это возможно.
Такие обновления обычно могут распространяться во все узлы данного кластера с применением одного из имеющихся трёх подходов групп широкого общения [DEMERS87]. Схематические описания этих шаблонов взаимодействия отображены на Рисунке 12-1:
-
Широковещательное оповещение от одного процесса всех прочих.
-
Периодический одноранговый информационный обмен. Одноранговые партнёры соединяются парами и обмениваются сообщениями.
-
Кооперативное широкое вещание, при котором получатели сообщений становятся широковещателями и помогают распылять необходимые сведения быстрее и более надёжно.
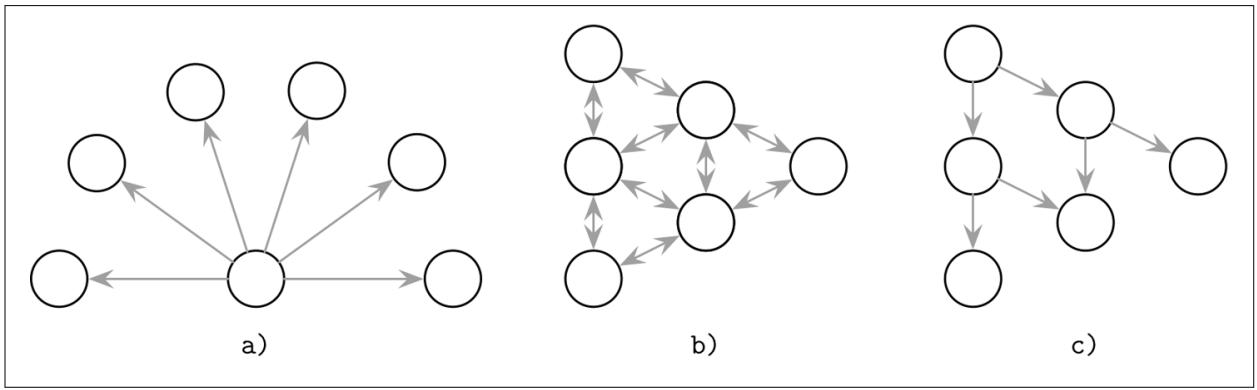
Широковещательная отправка сообщений всем прочим процессам наиболее прямолинейный подход, который хорошо работает когда число узлов в кластере невелико, однако в больших кластерах он становится затратным по причине большого числа узлов и ненадёжным из- за чрезвычайной зависимости от некого единственного процесса. Индивидуальные процессы могут не всегда знать о существовании всех прочих процессов в данной сетевой среде. Более того, должно существовать некое перекрытие по времени на протяжении которого и сам ведущий широковещание процесс и каждый из его получателей войдут в контакт, что в некоторых ситуациях может оказываться трудно достижимым.
Для ослабления этих ограничений мы можем предположить, что некоторые обновления могут получать отказ в распространении. Наш координатор сделает всё от него зависящее и доставит все сообщения всем доступным участникам, а затем механизмы анти- энтропии вернут узлы обратно в синхронное состояние в случае наличия некоторых отказов. Тем самым, ответственность за доставку сообщений разделяется между всеми узлами в данной системе и расщепляется на два этапа: первичную доставку и периодическую синхронизацию.
Энтропия это некое свойство, которое представляет измерение для беспорядка в определённой сисеме. В некой распределённой системе энтропия представляет какую- то степень состояния расхождения между имеющимися узлами. Так как это свойство является нежелательным, а его величину следует сводить к минимуму, существует множество технологий для того чтобы иметь дело с энтропией.
Анти- энтропия обычно применяется для приведение соответствующего узла обратно в актуальное состояние в случае отказа первичного механизма доставки. Данная система способна продолжать свою работу корректно даже когда их координатор отказал в некий момент, так как прочие узлы продолжат распространение необходимых сведений. Иными словами, анти- энтропия используется для снижения величины расхождения временных границ в системах с согласованностью в конечном счёте.
Для сохранения узлов в синхронном состоянии анти- энтропия включает фоновый процесс или процесс переднего плана, который сопоставляет и согласовывает пропущенные или конфликтующие записи. Фоновые процессы анти- энтропии применяют вспомогательные структуры, такие как деревья Меркель и обновляют журналы для выявления расхождений. Процессы анти- энтропии переднего плана цепляют прицепом запросы чтения или записи: намекающие передачи, считывание восстановлений и тому подобное.
Когда в некой системе с репликациями расходятся реплики, для восстановления согласованности и приведения их обратно в синхронное состояние, нам приходится находить и чинить пропущенные записи сравнивая состояния реплик попарно. Для больших наборов данных это может быть очень дорогостоящие: нам приходится считывать весь набор данных целиком в обоих узлах и уведомлять реплики относительно наиболее последних изменений состояний, которые ещё не были распространены. Для снижения этой стоимости мы можем рассмотреть пути, которыми реплики могут становиться устаревшими и шаблоны доступа к данным.
Проще всего выявлять расхождение реплик в процессе их чтения, так как в этот момент мы можем осуществлять контакт с репликами, требовать запрос состояния от каждой из них и рассматривать их отклики на предмет соответствия. Обратите внимание, что в этом случае вы запрашиваете некий хранимый в каждой из реплик набор данных целиком и мы ограничиваем свою цель лишь теми данными, которые были запрошены самим клиентом.
Наш координатор выполняет некое распределённое чтение, оптимистично предполагая что реплики находятся в синхронном состоянии и имеют доступной одни и те же сведения. Если реплики присылают различные отклики, наш координатор отсылает пропущенные обновления тем репликам, которые их пропустили.
Данный механизм носит название восстановления чтением. Он часто применяется для выявления и искоренения несогласованностей. В процессе восстановления чтением имеющийся узел координатора выполняет запросы к репликам, дожидается отклика от них и сравнивает их. В том случае, когда некоторые реплики пропустили самые последние обновления и их отклики различаются, наш координатор выявляет несогласованности и отправляет обновления обратно в эти реплики [DECANDIA07].
Некоторые базы данных в стиле Dynamo решили отменить требование контактов со всеми репликами и используют место этого настраиваемые уровни согласованности. Для возврата согласованных результатов нам нет нужды в установке контакта со всеми имеющимися репликами и их восстановлением, а лишь с тем числом узлов, которое удовлетворяет заданному уровню согласованности. Когда мы выполняем чтения или записи кворума, мы всё ещё получаем согласованные результаты, однако некоторые из имеющихся реплик всё ещё могут не содержать все записи.
Восстановление чтением может быть реализовано как блокируемая или как асинхронная операция. В процессе блокируемого восстановления чтением наш первоначальный клиент обязан дожидаться пока имеющийся координатор не "восстановит" соответствующие реплики. Асинхронное восстанавливающее чтение просто определяет расписание некой задачи, которая может быть исполнена после возврата результатов своему пользователю.
Блокирующее восстановление чтением обеспечивает монотонность чтения (см. раздел Модели сеанса) для чтений кворума: как только данный клиент считает некое особое значение, последующие чтения возвращают то значение,которое не старше уже увиденного, так как состояния реплики восстановлены. Если мы не пользуемся для чтения кворумами, мы теряем такие гарантии монотонности, так как данные могут быть не доставлены своему целевому узлу к моменту последующего чтения. В то же самое время, блокирующие восстановления чтением приносят в жертву доступность по причине того что восстановления обязаны выдавать подтверждения от своих целевых реплик, а само чтение не может быть возвращено пока они не ответят.
Для выявления того какие именно записи различаются в откликах реплик, некоторые базы данных (например, Apache Cassandra) пользуются особыми итераторами со слиянием ожидающих, которые реконструируют различия между такими сливаемыми результатами и индивидуальными входными данными. Их данные на выходе затем используются имеющимся координатором для уведомления соответствующих реплик относительно пропущенных данных.
Восстановление чтением предполагает, что реплики в целом синхронны и не ожидают от каждого запроса снова впадать в некое блокирующее восстановление. Благодаря имеющейся монотонности чтения блокирующего восстановления мы также можем ожидать что последовательные запросы возвращают те же самые согласованные результаты до тех пор, пока не происходило никаких операций записи, которые были завершены в этом промежутке времени.
Вместо того чтобы вызывать для каждого узла полное чтение, наш координатор имеет возможность вызывать лишь один полный запрос чтения и отправлять в прочие реплики лишь запросы свёрток (diggest). Некий запрос свёртки считывает только данные локальной реплики и, вместо того чтобы возвращать весь снимок запрошенных данных, он вычисляет некий хэш для своего отклика. Теперь наш координатор способен вычислить хэш своего полного чтения и сравнить его со свёрткой от прочих узлов. Когда все свёртки пребывают в соответствии, это может расцениваться как то что эти реплики синхронны.
В случае несоответствия свёрток, наш координатор не знает какая из реплик ушла вперёд, а какая отстаёт. Для приведения отставания реплик обратно в синхронное состояние со всеми прочими узлами, этому координатору придётся вызывать полные чтения всех реплик, которые ответили различными свёртками, сопоставить их отклики, согласовать имеющиеся данные и отправить обновления запаздывающим репликам.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Свёртки обычно вычисляются при помощи не криптографических хэш функций, например, MD5, так как их требуется вычислять быстро чтобы делать "счастливый путь" производительным. Хэширующие функции могут испытывать противоречия, однако их вероятность ничтожно мала для большинства систем реального мира. Так как базы данных обычно применяют больше чем только механизм анти- энтропии, мы можем ожидать, что даже в случае маловероятного события противоречия с хэшем, данные будут согласованы различными подсистемами. |
Другой подход анти- энтропии с названием наводящей передачи (hinted handoff) [DECANDIA07], это некий механизм восстановления стороны записи. Когда некий целевой узел отказывает в подтверждении записи, имеющийся координатор записи, или одна из реплик сохраняют особую запись с названием наводка (hint), которая выдаётся ответом соответствующему целевому узлу как только он вернётся обратно.
В Apache Cassandra до тех пор пока не используется уровень согласованности ANY
[ELLIS11], наводящие записи не учитываются счётчиками в
сторону значения множителя репликаций (см. раздел Настраиваемая
согласованность), так как сами данные в установленном журнале наводок не доступны для чтений и используются только
в помощь отлавливанию запаздывающих участников.
Некоторые базы данных, например, Riak, совместно с наводящими передачами применяют сырые кворумы (sloppy quorums). При сырых кворумах, в случае отказов реплик операции записи могут пользоваться дополнительными жизнеспособными узлами из своего перечня узлов и этим узлам не приходится выступать в качестве целевых реплик для данных исполняемых операций.
Например, допустим, у нас имеется кластер из пяти узлов с узлами {A, B, C, D, E},
где {A, B, C} являются репликами для соответствующей исполняемой операции записи, а
узел B упал. A, выступая в роли координатора
для данного запроса указывает на узел D для удовлетворения сырому кворуму и поддерживает
желательные гарантии доступности и долговечности. Теперь данные реплицированы в {A, D, C}.
Тем не менее, эта запись в D будет обладать некой наводкой в своих метаданных, так
как эта запись первоначально предназначалась для B. Как только
B восстановится, D попытается пробросить эту
наводку обратно в него. Как только эта наводка воспроизводится в B, она может быть
безопасно удалена без снижения общего числа реплик[DECANDIA07].
При аналогичных обстоятельствах, если узлы {B, C} на короткий промежуток времени
отделяются от остального кластера возникающим делением сетевой среды на разделы, а сырой кворум записи был выполнен для
{A, D, E}, некоторое чтение в {B, C}, немедленно
следующее за данной записью не будет наблюдать данного самого последнего чтения
[DOWNEY12]. Иными словами, сырые кворумы улучшают доступность
за счёт согласованности.
Поскольку восстановление чтением способно исправлять несогласованности лишь в запрашиваемых в настоящий момент данных, для тех данных, которые не участвуют активно в запросах, нам требуется применять иные механизмы.
Как мы уже обсуждали, обнаружение в точности какие именно строки расходятся в репликах требует попарного обмена и сопоставления соответствующих записей данных. Это в высшей степени не практично и затратно. Для снижения стоимости восстановления согласия многие базы данных применяют деревья Меркель [MERKLE87].
Деревья Меркель составляют компактное хэшированное представление всех локальных данных, выстраивая дерево из хэшей. Самый нижний уровень этого дерева хэшей строится путём сканирования некой содержащей записи данных таблицы целиком и вычисляет хэши диапазонов записей. Более высокие уровни дерева содержат хэши соответствующих значений хэширования нижнего уровня, выстраивая некое иерархическое представление, которое позволяет нам быстро определять несогласованности сопоставляя значения хэшей, следуя рекурсивно по данному дереву хэшей, суживая диапазоны несогласованностей. Это можно выполнять обменом и сопоставлением поддеревьев по уровням, или выполняя обмен и сопоставление деревьев целиком.
Рисунок 12-2 представляет некую композицию дерева Меркель. Его самый нижний уровень состоит из значений хэширований диапазонов записей данных. Хэши для каждого более высокого уровня вычисляются по хэш- значениям лежащего в основе уровня хэшей, представляя данный процесс рекурсивно до самого корня дерева.
Рисунок 12-2
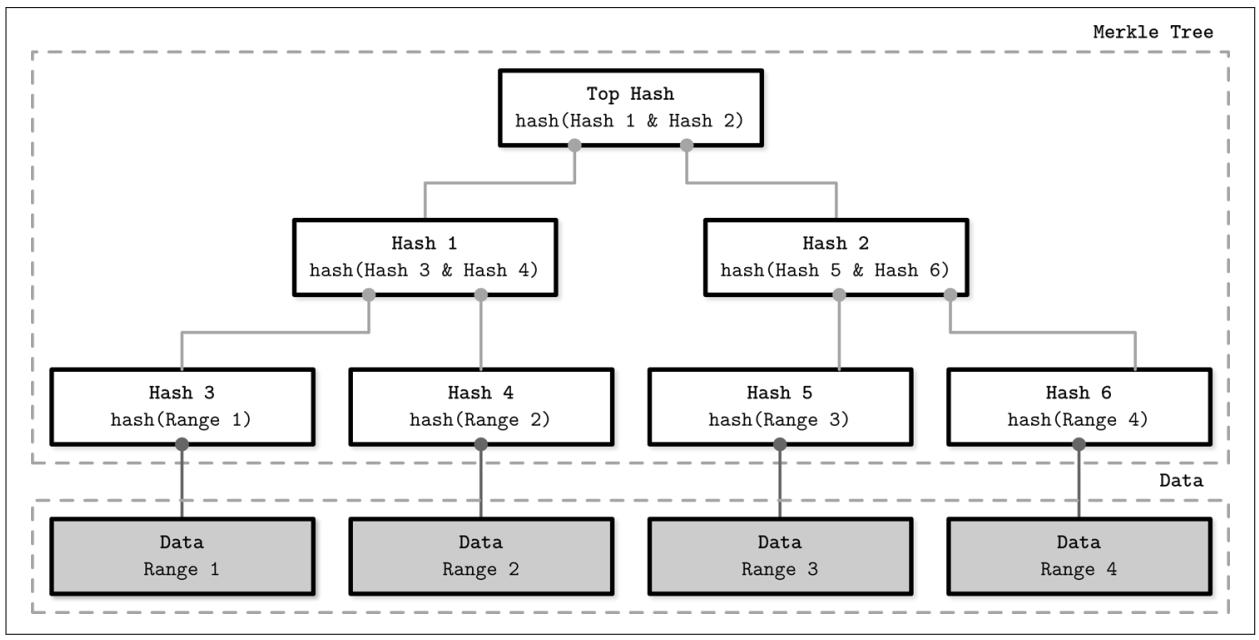
Дерево Меркль. Сеые блоки представляют диапазоны записи данных. Белые блоки представляют иерархию некого дерева хэшей.
Для определения того существует или нет некая несогласованность между двумя репликами, нам лишь требуется сравнить значения хэшей уровня корня в их деревьях Меркель. Попарным сравнением от корня вниз имеется возможность локализовать диапазоны, содержащие различия между своими узлами и выполнить восстановление содержащихся в них данных.
Так как деревья Меркель вычисляются рекурсивно снизу вверх, некое изменение в данных включает повторное вычисление всего своего поддерева. Также существует некий компромисс значения размера дерева (соответственно размеров обмена данными) и его точности (насколько мелко и точно данные поделены на диапазоны).
Самые последние исследования данного предмета ввели векторы побитной маски версии [GONÇALVES15], которые могут применяться для разрешения конфликтов на основании новизны: каждый узел отслеживает одноранговый журнал операций которые происходили локально или были реплицированы. В процессе анти- энтропии журналы сопоставляются и пропущенные сведения реплицируются в необходимый целевой узел.
Каждая координируемая неким узлом запись представляется некой точкой
(i, n): неким событием последовательности с номером
i локального узла, координируемой соответствующим узлом
n. Данная последовательность с номером
i начинается с 1 и последовательно
увеличивается при каждом выполнении этим узлом операции записи.
Для отслеживания состояний реплик мы пользуемся локальными для узла логическими часами. Каждые часы выдают некий набор точек, представляющих записи этого узла, наблюдавшиеся непосредственно (координировавшихся самим этим узлом) или транзитивно (координируемых и реплицируемых другими узлами).
Для логических часов самго узла события координируются самим узлом и не будут иметь зазоров. Когда некоторые записи не реплицировались с прочих узлов, наши часы будут содержать пробелы. Для обратного восстановления синхронности двух узлов они могут обмениваться логическими часами, выявляя промежутки, представленные такими пропущенными точками, а затем реплицируя связанные с ними записи данных. Для этого нам требуется реконструировать сами записи данных, на которые ссылается каждая точка. Эти сведения хранятся в неком контейнере причинных точек (DCC, dotted causal container), который устанавливает соответствие точек причинным сведениям для данного ключа. Таким образом перехватываются разрешения конфликтов, имеющие причинную связь между соответствующими записями.
Рисунок 12-3
(адаптировано из [GONÇALVES15])
отображает некий пример представления значения состояния трёх узлов в определённой системе,
P1, P2 и
P3 с точки зрения P2,
отслеживающей какие значения она наблюдает. Всякий раз, когда P2
делает некую запись или реплицирует значение, она обновляет эту таблицу.
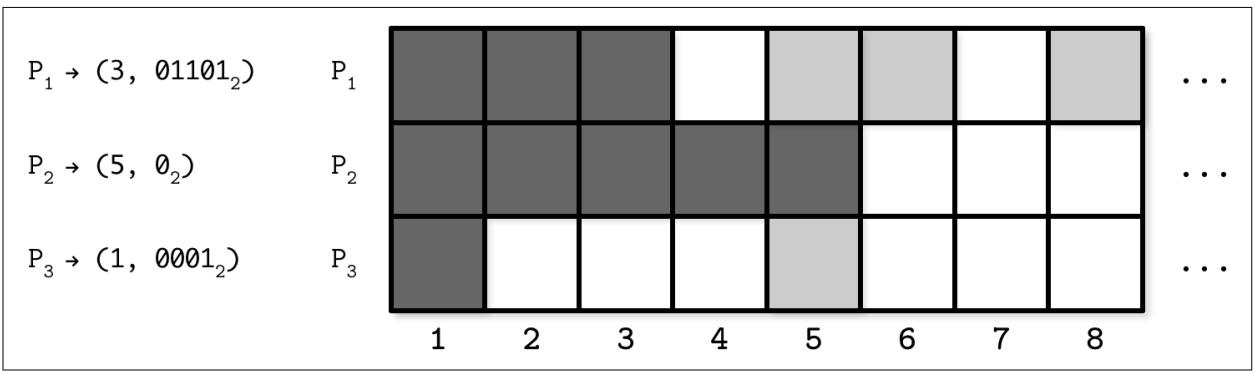
В процессе репликации P2 создаёт некое компактное представление
этого состояния и создаёт какое- то соответствие от значения идентификатора узла к паре последних значений, в отношении
которых он наблюдал последовательные записи, а также какую- то побитовую маску, в которой прочие наблюдавшиеся
записи кодируются 1. (3, 011012)
здесь означает, что узел P2 наблюдал последовательные обновления
для третьего значения во второй, третьей и пятой позициях относительно 3 (то
есть наблюдались значения с последовательными номерами 5,
6 и 8).
В процессе обмена с прочими узлами он получит пропущенные обновления для для прочих видимых ему узлов. После
того как все узлы в данной системе будут видны с последовательными значениями для данного индекса
i, данный вектор может быть отсечён от этого индекса.
Неким преимуществом данного подхода является то, что он перехватывает причинные взаимоотношения между подлежащими записи значениями и позволяет узлам точно выявлять сами моменты пропуска данных во всех прочих узлах. Возможным недостатком этого является то, что когда узел остановлен достаточно продолжительное время, одноранговые узлы не способны усекать свой журнал, так как данные всё ещё подлежат репликации в отстающие узлы как только они вернутся в строй.
Массы всегда выступают питательной средой для физических эпидемий.
- Карл Юнг
Для вовлечения в процесс прочих процессов и распространять обновления со всем богатством широкого вещания и надёжностью анти- энтропии мы можем применять протоколы gossip (болтовни).
Протоколы gossip это вероятностные процедуры взаимодействия, основывающиеся на том как распространяются слухи в человеческом сообществе или как заболевания распространяются в соответствующей популяции. Слухи и эпидемии представляют достаточно наглядные способы описания того как работают эти протоколы: слухи распространяются пока их сообщество заинтересовано в том чтобы их слышать; заболевания распространяются до тех пор, пока в популяции имеются восприимчивые к ним участники.
Основным предметом протоколов gossip является применение корпоративного распространения для рассеивания сведений от одного процесса во все прочие в этом кластере. Так же как некий вирус распространяется по людскому сообществу, передаваясь от одного индивидуума к другому, потенциально возрастая на каждом шагу, сведения передаются по всей системе, имея результатом всё большее вовлечение процессов.
Некий процесс, хранящий какую- то запись, которая должна быть распространена имеет название инфицированного. Все прочие процессы, которые пока ещё не получили этого обновления далее являются восприимчивыми. Инфекционные процессы, которые не желают дальше распространять данное новое состояние после какого- то периода активного рассеивания именуются снятыми (removed) [DEMERS87]. Все процессы начинают с состояния восприимчивых. Всякий раз когда возникает некое обновление для какой- то записи данных, получивший их процесс переходит в состояние инфицированного и запускает рассеивание данного обновления на прочие случайные соседние процессы, инфицируя их. Как только инфицированные процессы достигли определения того что данное обновление было распространено, они переходят в состояние снятого.
Чтобы избегать координации в явном виде и поддержки некого глобального списка получателей, а также требования какого- то отдельного координатора широковещательных сообщений для всех прочих получателей в данной системе, данный класс алгоритмов моделей завершённости применяет собственную функцию утраты интереса. Значение эффективности протокола затем определяется по тому насколько быстро он способен инфицировать настолько много узлов, насколько это возможно, в то же время сводя к минимальному значению накладные расходы, вызываемые избыточными сообщениями.
Gossip может применяться для асинхронной доставки сообщений в разнородных системах без централизации, в которых узлы могут не иметь долговременного членства или обладать некой организационной топологией. Так как протоколы gossip обычно не требуют координации в явном виде, они могут оказываться полезными в системах с гибким участием (когда узлы часто присоединяются и открепляются) или в смешанных сетевых средах.
Протоколы Gossip очень устойчивы и помогают достигать высокой надёжности в присутствии отказов, присущих распределённым системам. Поскольку сообщения пересылаются неким случайным образом, они могут доставляться даже в случае выхода из строя некоторых соединений между ними, просто по другому пути. Можно сказать, что такая система приспосабливается к отказам.
Процессы периодически выбирают случайным образом f одноранговых собратьев
(где Code это настраиваемый параметр, носящий название веера
- fanout) и обмениваются с ними "горячими" сведениями. Всякий раз когда данный процесс узнаёт о новом
фрагменте сведений от своих однаранговых партнёров, он попытается передать их далее. Поскольку одноранговые
пратнёры выбираются случайным образом, всегда будет иметься некое перекрытие и сообщения будут доставляться с повторами
и могут продолжать циркуляцию какое- то время. Избыточность сообщений это некое
измерение, которое перехватывает число перекрытий, происходящих при повторных доставках. Избыточность является неким
необходимым свойством, и оно критически важно для того как работает gossip.
Общая продолжительность, требуемая для данной системы для достижения сходимости носит название латентности. Существует небольшая разница между достижением сходимости (остановки данного процесса gossip) и доставкой данного сообщения всем одноранговым партнёрам, так как может иметься короткий промежуток времени когда оповещения получены уже всеми участниками одноранговой сети, а gossip ещё продолжается. Веерность и латентность зависят от имеющегося размера системы: в некой крупной системе нам либо приходится увеличивать значение веерности для удержания стабильного значения латентности, либо допускать большую латентность.
Со временем, когда узлы обнаружат что они снова и снова получают одни и те же сведения, данное сообщение начинает утрачивать важность и узлам в конечном счёте придётся прекращать его передачу. Утрата заинтересованности может рассчитываться либо вероятность (значение вероятности распространения останова рассчитывается для каждого процесса на каждом шаге), либо с использованием некого порогового значения (ведётся подсчёт получаемых дубликатов и это распространение останавливается после достижения ими слишком высокого значения). Оба подхода должны исходить из учёта значения размера кластера и веерности. Подсчёт дублирований для измерения расходимости может улучшать латентность и снижать избыточность [DEMERS87].
В терминах согласованности, протоколы gossip предлагают согласованность сходимости [DECANDIA07]: узлы обладают более высокой вероятностью обладать тем же самым представлением событий, которые произошли дальше в прошлом.
Даже несмотря на то что протоколы gossip важны и полезны, обычно они применяются для узкого круга проблем. Подходы
без эпидемий способны распространять соответствующее сообщение с несомненной вероятностью, меньшей избыточностью и
в целом более оптимальным образом [BIRMAN07].
Алгоритмы gossip часто заслуживают похвалы за свою масштабируемость и тот факт, что и имеется возможность
распространения сообщения за log N раундов (где N
это значение размера кластера) [KREMARREC07], однако
важно иметь в виду и сохранность значения числа избыточных сообщений, вырабатываемых
в процессе раундов gossip. Для достижения надёжности протоколы на основе gossip производят
некоторые доставки дублирующих сообщений.
Выбор узлов случайным образом значительно улучшает устойчивость: если существует некое разбиение сетевой среды на разделы, сообщения в конечном счёте будут доставлены когда имеются связи которые не напрямую соединяют два узла. Очевидным недостатком этого подхода является то, что он не оптимален с точки зрения обмена сообщениями: для обеспечения устойчивости нам приходится поддерживать избыточные подключения в своей одноранговой сети и отправлять избыточные сообщения.
Золотой серединой между этими двумя подходами является построение некой временной фиксированной топологии в системе gossip. Это может достигаться созданием некой перекрывающейся сетевой среды (overlay network) из одноранговых узлов: узлы могут делать выборку своих партнёров и подбирать наилучшие точки контактов на основании близости (обычно измеряемой латентностью).
Узлы в определённой системе способны организовывать форму связующих деревьев (spanning trees): ненаправленного графа без зацикливаний с отличающимися гранями, охватывающими всю сетевую среду. Обладая таким графом, сообщения способны распространяться за фиксированное число шагов.
Рисунок 12-4 показывает некий образец связующего дерева (этот пример применяется исключительно для целей иллюстрации: узлы в сетевой среде обычно не выравнены сеткой):
-
Мы достигаем полной согласованности между всеми точками без применения всех имеющихся граней.
-
Мы можем терять связность для определённого дерева целиком в случае разрыва всего одной связи.
Рисунок 12-4
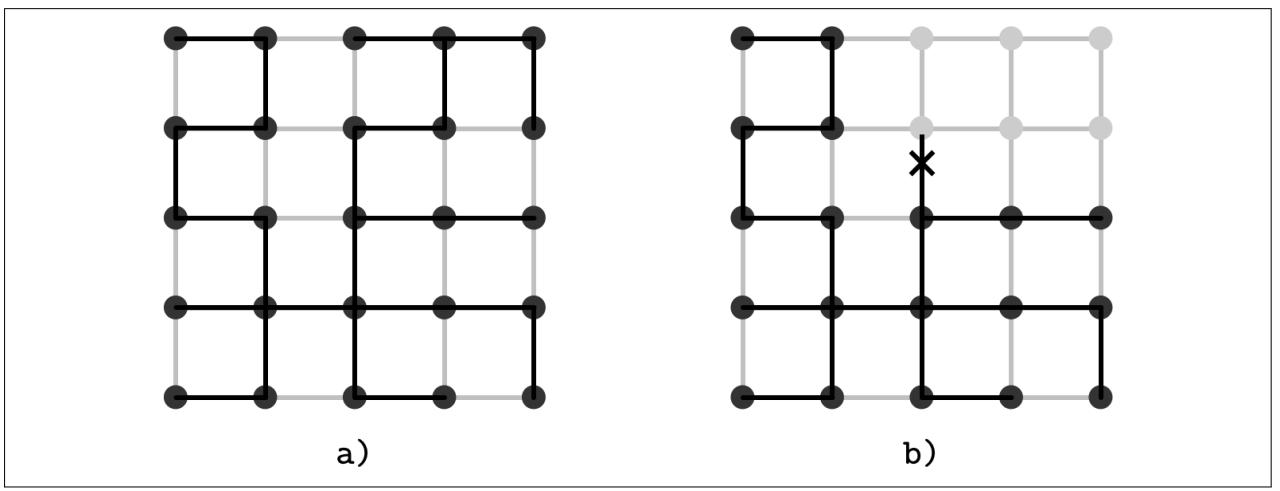
Связующее дерево. Тёмные точки представляют узлы. Тёмные линии представляют сетевую сеть перекрытия. Серые линии представляют прочие доступные имеющиеся соединения между узлами.
одним из потенциальных недостатков этого подхода является то, что он способен приводить к формированию взаимосвязанных "островов" одноранговых узлов, обладающих сильными предпочтениями в отношении друг друга.
Чтобы сохранять общее число сообщений низким, и при этом допускать быстрое восстановление в случае утраты связности, мы можем смешивать оба подхода - фиксированной топологии и основанного на дереве широковещания - когда наша система пребывает в стабильном состоянии и отступать обратно к gossip для отказоустойчивости и восстановления системы.
Деревья со множественной адресацией Push/ lazy-push (Plumtrees, сливовые деревья) [LEITAO07] представляют некий компромисс между эпидемическими примитивами и примитивами широкого вещания на основании деревьев. Сливовые деревья работают через создание некого связующего дерева перекрывающихся узлов для активного распространения сообщений и с наименьшими накладными расходами. При нормальных условиях узлы отправляют полные сообщения всего лишь небольшому подмножеству одноранговых узлов предоставляя через одноранговую сеть службу выборки.
Каждый узел отправляет полное сообщение этому небольшому подмножеству узлов, а для всех остальных имеющихся узлов он лениво отправляет лишь значение идентификатора сообщения. Когда соответствующий узел получает сообщение со значением идентификатора некого сообщения, которое он никогда не видел, он может запросить у своих однорагоговых собратьев познакомит его с ним. Такой этап ленивой активной доставки (lazy- push) обеспечивает высокую надёжность и предоставляет некий способ быстрого лечения имеющегося дерева широкого вещания. В случае отказов протокол отступает к соответствующему подходу gossip через этапы ленивой активной доставки широковещательно распространяя соответствующее сообщение и восстанавливая необходимое перекрытие.
По причине самой природы распределённых систем, всякий узел и каждое соединение между узлами способны испытывать отказ в любой момент времени, делая невозможным обход по своему дереву когда этот сегмент становится недоступным. Ленивая сетевая среда gossip способствует уведомлению одноранговых партнёров относительно видимых сообщения для построения и восстановления своего дерева.
Рисунок 12-5 демонстрирует иллюстрацию такой двойственной связи: узлы соединены неким действенным связующим деревом (сплошные линии) и соответствующей ленивой сетью gossip (пунктирные линии). Эта иллюстрация не демонстрирует какие- то особые сетевые топологии, а всего лишь соединения между узлами.
Рисунок 12-5
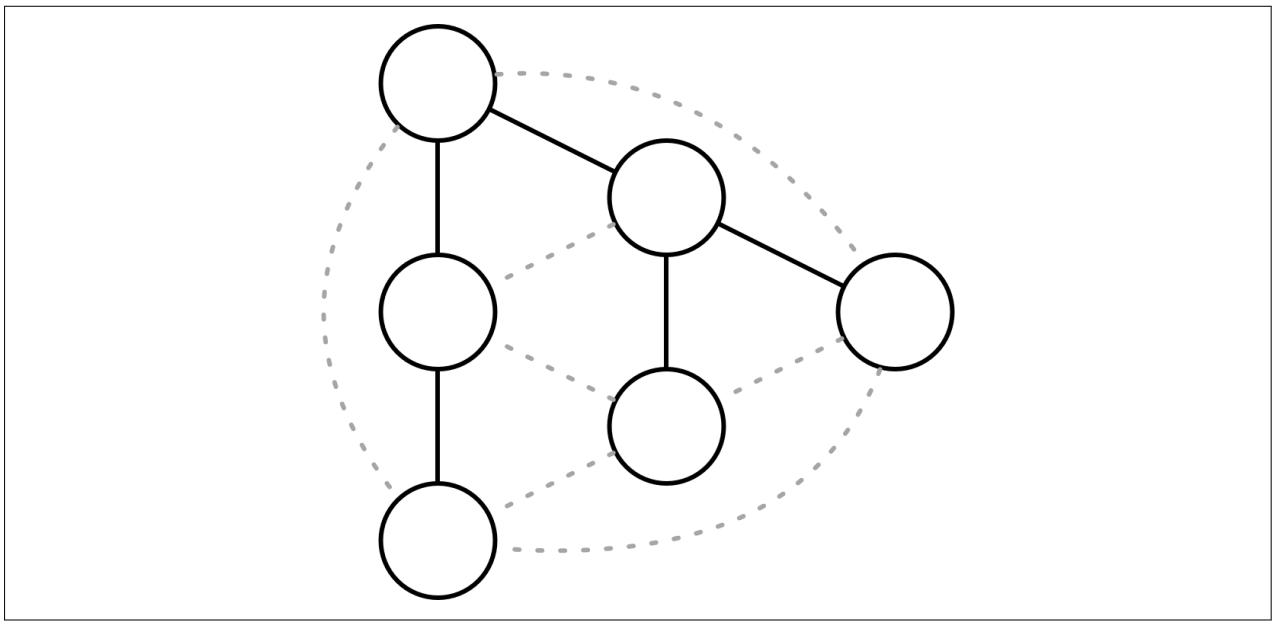
Ленивые и энергичные сетевые среды. Сплошные линии представляют широковещательное дерево. Пунктирные линии обозначают ленивые gossip.
Одним из основных преимуществ использования данного механизма ленивой активной доставки для построения и реконструкции является то, что в сетевой среде с постоянной нагрузкой будет иметься тенденция к выработке некого дерева, которое к тому же минимизирует задержки сообщений, поскольку в имеющееся дерево широкого вещания добавляются отвечающие первыми узлы.
Широковещательные сообщения всем известным одноранговым собратьям и сопровождение полного представления всего кластера может становиться затратным и непрактичным, в особенности когда имеющееся перемешивание (churn, мера общего числа присоединяющихся к системе и покидающих её узлов) достаточно высокое. Во избежание этого протоколы gossip зачастую применяют некую службу выборки одноранговых партнёров (peer sampling service). Эта служба сопровождает частичное представление всего кластера, которое периодически освежается при помощи gossip. Частичные представления перекрываются, так как в протоколах gossip желательна некая степень избыточности, однако слишком большая избыточность означает, что мы выполняем дополнительную работу.
Например, протокол HyParView (Hybrid Partial View, Гибридного частичного представления) [LEITAO07] поддерживает небольшое активное представление и большое пассивное представление своего кластера. Узлы из активного представления создают некое перекрытие и могут использоваться для рассеивания. Пассивное представление применяется для поддержки списка узлов, которые могут применяться для замены отказавших из имеющегося активного представления.
Периодически узлы выполняют операцию перетасовки, в процессе которой они обмениваются своими активными и пассивными представлениями. На протяжении такого обмена узлы добавляют участников как из пассивного, так и из активного представлений от своих одноранговых партнёров в свои пассивные представления, отключая самые старые значения для ограничения размера списка.
Активное представление обновляется на основании значения состояния изменений узлов в данном представлении и
запросов от своих одноранговых собратьев. Когда процесс
P1 подозревает что P2,
один из одноранговых собратьев в его активном представлении, отказал, P1
удаляет P2 из своего активного представления и пытается установить
соединение с заменяющим его процессом P3 из пассивного представления.
Если соединение неудачно, P3 удаляется из пассивного представления
P1.
В зависимости от общего числа процессов в активном представлении P1,
P3 может выбирать отклонение такого соединения когда его активное
представление уже полное. Когда представление P1 пустое,
P3 обязан заменить одного из
своих текущих одноранговых партнёров в своём активном представлении на P1.
Это способствует самостоятельной раскрутке или восстановлению узлов чтобы быстрее превращаться в действенных участников
данного кластера за счёт стоимости неких циклических соединений.
Данный подход способствует снижению общего числа сообщений в данной системе, применяя для рассеивания лишь узлы активного представления, в то же время поддерживая высокую надёжность применением пассивного представления в качестве некого механизма восстановления. Одним из измерений производительности и качества является то, насколько быстро служба выборки одноранговых партнёров сводит стабильное перекрытие в случаях реорганизации топологии [JELASITY04]. Результаты HyParView здесь достаточно высокие, благодаря тому как поддерживаются представления и так как он даёт преимущество раскручивающимся процессам.
HyParView и Plumtree (Сливовое дерево) применяют подход гибридного gossip: применяя небольшое подмножество одноранговых собратьев для широковещательных сообщений и отступая обратно к более широкой одноранговой сети в случае отказов и появления сетевых разделов. Обе системы не полагаются на некое глобальное представление, включающее в себя всех имеющихся одноранговых партнёров, что может быть полезным не только по причине большого числа узлов в данной системе (что не является таковым в большинстве случаев, но также по причине стоимостей, связанных с сопровождением актуального списка участников в каждом из узлов. Частичные представления позволяют узлам активно взаимодействовать только с небольшим подмножеством соседних узлов.
Согласуемые в конечном счёте системы допускают расхождение состояния реплик. Настраиваемая согласованность позволяет нам обменивать согласованность на доступность и наоборот. Расхождение реплик может разрешаться с помощью одного из механизмов анти- энтропии:
- Наводящая передача
Временно сохраняет записи в соседних узлах в случае когда его целевой узел остановлен и воспроизводит её для данной цели когда она возвращается в строй.
- Восстановление чтением
Согласовывает запрашиваемые диапазоны данных в процессе своего чтения сравнивая отклики, выявляя пропущенные записи и отправляя их запаздывающим репликам.
- Деревья Меркель
Выявляет диапазоны подлежащих восстановлению данных сопоставляя иерархические деревья значений хэшец и обмениваясь ими.
- Побитные векторы соответствия версии
Выявляют пропущенные записи, поддерживая компактные записи, содержащие сведения относительно наиболее последних записей.
Такие подходы анти- энтропии оптимизируют один из трёх существенных параметров: сферу снижения, новизну и завершённость. Мы способны снизить сферу анти- энтропии только выполняя синхронизацию данных, которые активно запрашивались (восстановление чтением) или индивидуальных пропущенных записей (наводящая передача). Когда мы предполагаем что большинство отказов временное, а участники восстанавливаются после них настолько быстро, насколько это возможно, мы можем сохранять сам журнал наиболее последних событий расхождения и в точности знать что синхронизировать в случае отказа (побитные векторы соответствия версии). Когда нам требуется сопоставлять все наборы данных целиком во множестве узлов попарно, а также действенно определять место отличий между ними, мы можем хэшировать все данные и сопоставлять значения хэшей (деревья Меркель).
Для надёжного распространения сведений в крупномасштабной системе могут применяться протоколы gossip. Гибридные протоколы gossip снижают общее число обмена сообщениями и в то же время оставаться стойкими к разделам сетевой среды, когда это возможно.
Многие современные системы применяют gossip для выявления отказов и сведений об участниках [DECANDIA07]. HyParView применяется в Partisan, высоко- производительной, обладающей большой масштабируемостью распределённой вычислительной инфраструктуре. Plumtree применялись в ядре Riak для сведений обо всём кластере.
|
| Последующее чтение |
|---|---|
|
Если вы желаете узнать больше относительно упоминавшихся в этой главе понятий, вы можете ссылаться на следующие источники:
|