Глава 11. Репликация и согласованность
Содержание
- Глава 11. Репликация и согласованность
Прежде чем мы двинемся в обсуждении консенсуса и алгоритмов атомарной фиксации, давайте соберём воедино последние фрагменты для их глубинного осознания: модели согласованности. Модели согласованности важны, так как они поясняют семантику видимости и поведение самой системы при наличии множества копий данных.
отказоустойчивость это некое свойство системы, которая может продолжать правильную работу при наличии отказов своих компонентов. Превращение системы в отказоустойчивую не простая задача, к тому же может быть сложным добавление отказоустойчивости в уже имеющуюся систему. Первичная цель состоит в исключении из такой системы единой точки отказа и обеспечения избыточности критически важных компонентов. Как правило, избыточность полностью прозрачна для самого пользователя.
Система способна продолжать правильную работу сохраняя множество копий данных с тем, чтобы при отказе одной из машин прочие смогли обслуживать отработку после отказа. В системах, для которых справедлив единственный источник (например, базы данных с первичными данными/ репликой), восстановление после отказа может выполняться в явном виде, продвижением некой реплики на роль нового хозяина. Прочие системы не требуют перестроения системы в явном виде и обеспечивают согласованность сбором откликов от множества участников в процессе запросов на чтение и запись.
Репликация данных это некий способ введения избыточности сопровождением множества копий данных в такой системе. Тем не менее, поскольку атомарное обновление множества копий данных это задача, эквивалентная консенсусу [MILOSEVIC11], может быть достаточно дорогостоящим выполнять это действие для каждой операции в базе данных. Мы можем изучить некие более действенные в отношении стоимости и более гибкие способы выполнения согласованным поиска данных с точки зрения своего пользователя, в то же время допуская до некой степени расхождение между участниками.
Репликации особенно важны в реализациях со множеством центров обработки данных. Географические репликации в этом случае служат множеству целей: они увеличивают доступность и возможность устоять при отказах в одном или более центрах обработки данных предоставляя избыточность. Они также помогают снижению величины задержек помещая копии данных физически ближе к своим клиентам.
При изменении записей данных, их копии должны изменяться соответствующим образом. Когда мы обсуждаем репликации, в основном мы заботимся о трёх событиях: записи, обновлении реплики и чтении. Эти операции включают некую последовательность инициируемых их клиентом событий. В некоторых случаях обновления реплик могут происходить после завершения записей с точки зрения их клиента, однако это всё равно не изменяет того факта, что этот клиент должен иметь возможность отслеживать операции в определённом порядке.
Мы уже обсуждали обманчивость распределённых систем и указывали на многие моменты, которые могут пойти не так. В реальном мире узлы не всегда являются работающими или способными взаимодействовать друг с другом. Тем не менее, перемежающиеся отказы не должны воздействовать на доступность: с точки зрения конечного пользователя, данная система в целом должна продолжать работать как будто ничего не произошло.
Доступность системы чрезвычайно важное свойство: при разработке программного обеспечения мы всегда стремимся достичь высокой доступности и пытаемся сводить к минимуму время простоя. Команды программистов бравируют своими измерениями времени работы без остановов. Мы столь сильно заботимся о доступности по ряду причин: программное обеспечение стало неотъемлемой частью сообщества и многие важные моменты не могут происходить без него: банковские транзакции, взаимодействие, путешествия и тому подобное.
Для компаний отсутствие доступности может означать утрату потребителей или средств: вы не можете выполнять продажи в интернет магазине когда он остановлен, или перечислять средства, когда не отвечает вебсайт банка.
Чтобы превратить систему в высокодоступную, нам требуется спроектировать её неким образом, чтобы позволить обработку отказов или недоступности одного или более участников деликатным образом. Для этого нам требуется вводить избыточность и репликации. Тем не менее, как только мы добавляем избыточность, мы сталкиваемся с задачей поддержки синхронности нескольких копий данных и должны реализовывать механизмы восстановления.
Доступность это свойство, означающее возможность системы успешно обслуживать отклики для каждого запроса. Само теоретическое определение доступности подразумевает в конечном счёте отклик, однако, в реальных системах, естественно, мы бы желали избегать обслуживания, которое требует неограниченно длительного отклика.
В идеале, мы бы желали согласованности для каждой операции. Согласованность в данном случае определяется как атомарная или линеаризуемая согласованность (см. раздел Линеаризация). История линеаризации может быть выражена как последовательность моментальных операций, сохраняющих первоначальный порядок операции. Линеаризация упрощает рассуждения относительно возможных состояний системы и заставляет некую распределённую систему проявляться как если бы она исполнялась на отдельной машине.
Мы бы желали достичь и согласованности и доступности, и в тоже время допускать разбиение сетевой среды на разделы. Сетевая среда может расщепляться на различные части когда процессы не имеют возможности взаимодействия друг с другом: некоторые отправляемые между разбитыми на разделы узлами сообщения не достигают своих получателей.
Доступность требует от любого не отказавшего узла доставки результатов, в то время как согласованность требует линеаризуемости результатов. Гипотеза CAP, сформулированная Эриком Брюером, обсуждает компромиссы между допустимостью Согласованности, Доступности и Разделов (Consistency, Availability и Partition) [BREWER00].
Требования доступности невозможно удовлетворить в некой асинхронной системе и мы не можем реализовать некую систему, которая одновременно обеспечивает и доступность и согласованность при наличии сетевых разделов [GILBERT02]. Мы можем строить системы, которые обеспечивают строгую согласованность в тоже время предоставляя наилучшие усилия в отношении доступности или гарантировать доступность при предоставлении наилучших усилий для согласованности [GILBERT12]. Наилучшие усилия в данном случае подразумевают, что когда всё работает, данная система не будет целенаправленно нарушать какие бы то ни было гарантии, но эти гарантии допускается ослаблять и нарушать в случае разбиения на сетевые разделы.
Иными словами, CAP описывает совокупность тесно связанных между собой событий потенциальных выборов, когда при различных сторонах имеющегося спектра у нас имеется система, которая:
- Допускает согласованность и разделы
Системы CP предпочитают отказывать запросам для обслуживания потенциально несогласованных данных.
- Допускает доступность и разделы
Системы AP утрачивают требование согласованности и позволяют обслуживать потенциально несогласованные значения в процессе запроса.
Неким примером системы CP является реализация какого- то алгоритма консенсуса, требующего для своего развития большинства узлов: всегда согласованное, но может быть недоступным в случае некого разбиения сетевой среды на разделы. В качестве примера системы AP, база данных всегда принимает записи и обслуживает чтения до тех пор, пока работает даже отдельная реплика, что может приводить утрате данных или обслуживанию несогласованных результатов.
Предположение PACELEC [ABADI12], некое расширение гипотезы CAP, постулирует, что при наличии сетевых разделов существует некий выбор между согласованностью и доступностью (PAC). Иначе (E - Else), даже когда эта система работает нормально, нам всё ещё придётся выбирать между задержкой и согласованностью.
Важно отметить, что CAP обсуждает разбиение сети на разделы вместо крушения узлов или прочих типов отказов (таких, как крушение- восстановление). Некий узел, будучи отделённым от остального кластера, способен обслуживать запросы несогласованно, однако претерпевший крушение узел не будет откликаться вовсе. С другой стороны, это подразумевает, что нет необходимости заставлять все узлы отключаться чтобы сталкиваться с проблемой согласованности. А ещё с другой стороны, это не является вариантом для реальной практики: существует множество различных сценариев отказов (некоторые из которых могут имитироваться разбиением сетевой среды на разделы).
CAP подразумевает, что мы можем сталкиваться с задачами согласованности даже когда все узлы работают, но между ними имеются проблемы согласованности , так как мы ожидаем от каждого не отказавшего узла корректных откликов вне зависимости от того сколько узлов отказало.
Гипотеза CAP иногда иллюстрируется неким треугольником, как если бы могли повернуть ручку и получить в той или иной степени все три параметра. Однако когда мы поворачиваем ручку и меняем согласованность на доступность, допустимость разделов является неким свойством, которое мы в здравом уме можем настраивать в угоду чего то иного [HALE10].
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Согласованность в CAP определяется несколько иначе чем в ACID (см. Главу 5). Согласованность ACID описывает согласованность транзакции: транзакция переводит свою базу данных из одного согласованного состояния в другое, поддерживая все имеющиеся инварианты базы данных (такие как однозначность ограничений и ссылочную целостность). В CAP она означает что операции являются атомарность (операции завершаются успешно или отказывают целиком) и согласованы (операции никогда не оставляют данные в несогласованном состоянии). |
Доступность в CAP также отличается от обсуждавшейся ранее высокой доступности [KLEPPMANN15]. Определений CAP не накладывает никаких ограничений на задержку выполнения. Кроме того, доступность в базе данных, в противоположность CAP, не требует от каждого не отказавшего узла откликаться на каждый запрос.
Гипотеза CAP используется для объяснения распределённых систем, причин сценариев отказов и оценивает возможные ситуации, однако важно помнить, что нет чёткой линии раздела между отказом от согласованности и обслуживанием непредсказуемых результатов.
Базы данных, заявляющие о присутствии на стороне доступности, при верном использовании, всё ещё способны обслуживать согласованные результаты из реплик, при том что имеется достаточное число реплик в рабочем состоянии. Естественно, существуют и более сложные сценарии отказов, а гипотеза CAP это всего лишь отлитое в граните правило и нет необходимости утверждать что оно истина в последней инстанции (кворумы считываются и записываются в контексте состоятельных в итоге историй, что более детально обсуждается в разделе Окончательная согласованность).
Гипотеза CAP обсуждает согласованность и доступность лишь в их самых строгих формах: линеаризуемочти и способности данной системы в конечном итоге откликаться на все запросы.
Это принуждает нас осуществлять сложный компромисс между этими двумя свойствами. Однако некоторые приложения способны извлекать преимущества из слегка ослабляемых предположений и мы можем задуматься об этих свойствах в их слегка более ослабленном виде.
Вместо того, чтобы быть либо согласованной, либо доступной, системы могут предоставлять ослабленные гарантии. Мы можем определить два настраиваемых измерения: Сбор (harvest) и Выход (yeld) для выбора между тем как всё- таки составлять верное поведение [FOX99].
- Сбор
Определяет насколько завершён запрос: когда наш запрос возвращает 100 строк, но может осуществить выборку лишь 99 из- за недоступности части узлов, это всё же будет лучше чем провалить запрос целиком и не вернуть ничего.
- Выход
Определяет общее число полностью успешно выполненных запросов в сравнении с общим числом предпринятых попыток. Извлечение дохода (yield) отличается от периода работоспособного состояния (uptime), поскольку, к примеру, занятой узел не простаивает, однако всё ещё способен отказывать части запросов.
Это смещает собственно сосредоточенность нашего компромисса с его абсолютного значения в сторону относительных терминов. Мы можем сместить сбор всего что есть в сторону выхода (результата, дохода) и допускать чтобы некоторые запросы возвращали неполные данные. Одним из способов увеличения доходности является возврат результатов только из доступных разделов (см. раздел Разбиение баз данных на разделы). Например, когда некое подмножество узлов, хранящих записи о каких- то пользователях полегло, мы всё ещё способны продолжать обслуживать запросы прочих пользователей. В качестве альтернативы мы можем требовать для критически важных данных приложения возвращать их исключительно целиком, но при этом допускать некие отклонения для прочих запросов.
Определение, измерение и выполнение сознательного выбора между сбором того что есть и доходностью помогает нам строить системы, которые более эластичны в отношении отказов.
Для некого клиента наша хранящая его данные распределённая система действует так, как если бы она обладала неким совместным хранилищем, аналогичным системе из одного узла. Взаимодействие между узлами и обмен сообщениями абстрагируются прочь и происходят за сценой. Это создаёт некую иллюзию совместно используемой памяти.
Некий отдельный элемент хранения, доступный для операций чтения или записи, обычно имеет название регистра. Мы можем представлять совместно используемую память в некой распределённой системе как какой- то массив регистров в распределённой базе данных.
Мы определяем каждую операцию её событиями вызова и завершения. Мы определяем операцию как отказавшую если вызвавший её процесс завершается крушением до его завершения. Если и события вызова, и завершения для одной операции происходят до осуществления другой операции, мы говорим, что данная операция предшествует этой другой и эти две операции являются последовательными. В противном случае мы говорим что они одновременные.
На Рисунке 11-1 вы можете видеть процессы
P1 и P2, выполняющие
различные операции:
-
Та операция, которая выполняется
P2, запускается после уже завершённой операции, выполняемойP1и эти две операции являются последовательными. -
Существует некое перекрытие между этими двумя операциями, поэтому эти две операции одновременные.
-
Та операция, которая исполняется
P2, запускается после и завершается после операции, исполняемойP1Эти операции также одновременны.

Множество читателей и писателей могут осуществлять доступ к определённому регистру одновременно. Операции чтения и записи с регистрами не являются прямыми и требуют какого- то времени. Одновременные выполняемые различными процессами операции чтения/ записи не последовательные (serial) в зависимости от того как регистры вели себя при перекрытии операций, они могут по разному упорядочиваться и способны производить различные результаты. В зависимости от того как вели себя регистры от одновременных операций, мы различаем три типа регистров:
- Безопасные
Считывание в безопасные регистры может возвращать произвольные значения внутри данного диапазона этих регистров в процессе одновременных записей (что не звучит очень практичным, но может описывать саму семантику некой асинхронной системы, которая не фиксирует этот порядок). Безопасные регистры с двоичными значениями могут возникать в качестве мерцающих (то есть возвращаемые результаты перемежаются между этими двумя значениями) на протяжении считываний, одновременных с записями.
- Обычные
Для обычных регистров у нас имеются слегка более сильные гарантии: операция чтения может возвращать только то значение, которое записано наиболее последним завершённой записью или значением, которое сохранено той операцией записи, которая перекрывается данным текущим считыванием. В этом случае данная система обладает неким пониманием о порядке, но результаты записи не видны всем читателям одновременно (например, это может происходить в некой реплицируемой базе данных, когда сам хозяин принимает записи и реплицирует их обслуживающим чтения исполнителям).
- Атомарные
Атомарные регистры гарантируют линериаизуемость: все операции записи имеют некий отдельный момент до того как каждая операция чтения вернёт какое- то старое значение и после чего каждая операция чтения возвращает некое новое. Атомарность это некое фундаментальное свойство, которое упрощает обсуждение относительно самого состояния системы.
Когда мы наблюдаем некую последовательность событий, у нас имеется некое понимание отнрсительно её порядка исполнения. Тем не менее, в распределённой системе это не всегда просто, ибо трудно знать когда точно нечто произойдёт и незамедлительно получать эти сведения во всём кластере. Каждый из участников может обладать своим собственным представлением об определённом состоянии, поэтому нам приходится отслеживать каждую операцию и определять её в терминах событий вызова и завершения и описывать границы данной операции.
Давайте определим некую систему, в которой процессы способны выполнять операции
read(register) и write(register, value)
с совместно используемыми регистрами. Каждый процесс выполняет свои собственные последовательно действие (то есть всякая
вызванная операция должна завершиться прежде чем он сможет запустить следующую). Такое сочетание последовательного исполнения
процессов формирует некую глобальную историю при которой некоторые операции могут выполняться одновременно.
Проще всего представлять себе согласованные модели в терминах операций чтения и записи и способов, коими они могут перекрываться: операции чтения не обладают сторонними эффектами, а операции записи изменяют состояние своего регистра. Это помогает рассуждениям относительно того, когда в точности данные становятся доступными к чтению после своей записи. Например, расмоторим историю, при которой два процесса одновременно выполняют следующие события:
Process 1: Process 2:
write(x, 1) read(x)
read(x)
Когда мы просматриваем эти события, не совсем ясно что мы получаем на выходе операций
read(x) в обоих случаях. У нас имеются различные возможные истории:
-
Запись завершена до обоих считываний.
-
Запись и два чтения могут перемежаться и запись может быть выполнена между двумя считываниями.
-
Оба считывания выполнены до завершения записи.
Не существует простого ответа на то, что произойдёт если у нас просто имеется одна копия данных. В системе с репликациями у нас имеется больше сочетаний возможных состояний и это может становиться ещё более сложным когда у нас имеется множество процессов считывающих и записывающих данные.
Когда все эти операции выполняются определённым единственным процессом, мы смогли бы задать строгий порядок событий, однако то сложнее сделать в случае со множеством процессов. Мы можем сгруппировать все потенциальные сложности в две группы:
-
Операции могут перекрываться.
-
Эффекты от имеющихся не перекрывающихся вызовов могут быть невидимыми немедленно.
Для рассуждений относительно порядка операций и обладания недвусмысленными описаниями возможных результатов нам придётся определить модели согласованности. Мы обсуждаем одновременность в распределённых системах в терминах разделяемой памяти и одновременных систем, так как всё ещё применимо большинство определяющих согласованность формулировок и правил. Даже несмотря на то, что большая часть терминологии между одновременными и распределёнными системами перекрываются, мы не можем напрямую пользоваться большинством имеющихся одновременных алгоритмов по причинам различий в шаблонах взаимодействия, производительности и надёжности.
Поскольку операциям над совместно используемыми регистрами дозволено перекрываться, нам следует определить чёткую семантику: что происходит когда множество клиентов считывают и изменяют различные копии данных одновременно или на протяжении короткого периода времени. Не существует никакого единственно верного ответа на этот вопрос, ибо подобные семантики могут отличаться в зависимости от своих приложений, но они хорошо изучены в контексте моделей согласованности.
Модели согласованности предоставляют различные семантики и гарантии. Вы можете представлять себе модель согласованности в качестве некого контракта между его участниками: что должна делать каждая реплика для удовлетворения имеющимся требованиям семантики и что пользователь может ожидать при вызове операций чтения и записи.
Модели согласованности описывают какие ожидания могут иметь клиенты в терминах возможно возвращаемых значений, несмотря на наличие множества копий данных и одновременного доступа к ним. В данном разделе мы обсуждаем модели согласованности отдельной операции.
Каждая модель описывает насколько отличается поведение определённой системы от того поведения, которое мы могли бы ожидать или обнаруживать в природе. Это помогает нам проводить различие между "все возможные истории" перекрывающихся операций и "истории, допустимы моделью X", что значительно упрощает рассждения относительно видимости изменения состояний.
Мы можем представлять себе согласованность с точки зрения состояния, описывая допустимые инварианты состояния и установление разрешённых взаимодействий между копиями размещаемых в различных репликах копиях данных. В качестве альтернативы мы можем рассматривать согласованность операции, которая производится неким сторонним представлением для данного хранилища данных, описывать операции и накладывать ограничения на тот порядок, в котором они происходят [TANENBAUM06] [AGUILERA16].
Без неких глобальных часов трудно представлять распределённые операции в точном и детерминированном порядке. Это подобно Специальной Теории Относительности для данных: всякий участник имеет свою собственную точку зрения на состояние и время.
Теоретически, мы имеем возможность овладевать некой глобальной блокировкой системы всякий раз, когда мы желаем изменять состояние такой системы, но это крайне непрактично. Вместо этого мы применяем некий набор правил, определений и ограничений, которые ограничивают общее число возможных историй и выходов.
Модели согласованности добавляют другое измерение в то, что обсуждалось в разделе Печально известная CAP. Теперь нам приходится жонглировать не только согласованностью и доступностью, но также рассматривать согласованность в терминах стоимости синхронизации [ATTIYA94]. Стоимость синхронизации может содержать задержки, вспомогательные затрачиваемые на дополнительно выполняемые операции циклы ЦПУ, применяемый для сохранения восстанавливаемых сведений дисковый ввод/ вывод, время ожидания, сетевой ввод/ вывод и всё прочее, что может предупреждаться избежанием синхронизации.
Прежде всего мы сосредоточимся на видимости и распространении результатов операции. Вернувшись обратно к своему примеру с одновременными чтениями и записями, мы получим возможность ограничения общего числа возможных историй либо позиционированием зависимых записей одной всед за другой, либо определением некого момента, в который распространяются вновь полученное значение.
Мы обсудим модели согласованности в терминах процессов (клиентов), вызывающих
операции read и write для определённого
состояния базы данных. Поскольку мы обсуждаем согласованность в контексте реплицируемых данных, мы предполагаем что наша
база данных способна обладать множеством реплик.
Строгая согласованность эквивалентна полной прозрачности репликаций:
любая запись всякого процесса немедленно доступна для соответствующих последующих чтений любым процессом. Она вовлекает
в себя понятие глобальных часов и, если в момент времени t1
произошла write(x, 1) , любое read(x)
вернёт вновь записанное значение 1 в любой
момент времени t2 > t1.
К сожалению, это всего лишь теоретическая модель, и она не возможна в реализации, ибо законы физики и сами способы работы распределённых систем накладывают ограничение на то, насколько быстро могут происходить вещи [SINHA97].
Линеаризуемость это самый сильный одиночный объект для модели согласованности с отдельной операцией. При данной модели эффекты записи становятся видимыми для всех читателей в точности один раз в некий момент времени между его началом и окончанием, и никакой клиент не способен наблюдать состояние перехода или сторонние эффекты частичной (то есть незавершённой, всё ещё пребывающей на лету) или невыполненной (то есть прерванной до завершения) операций записи [LEE15].
Одновременные операции представляются как одна из возможных последовательных историй при которой удерживаются свойства видимости. При линеаризуемости существует некий недетерминизм, ибо могут иметься более одного способа упорядочения [HERLIHY90].
Когда две операции перекрываются, они способны оказывать воздействие друг на друга. Все завершающиеся по выполнению операции записи операции чтения способны наблюдать полученные в результате такой операции эффекты. Как только некая отдельная операция чтения возвращает определённое значение, все происходящие после неё считывания возвращают по крайней мере результаты, полученные не ранее этого [BAILIS14a].
В терминах того порядка, в котором происходят в некой глобальной истории одновременные события имеется до определённой степени гибкость, однако они не могут переупорядочиваться произвольным образом. Результаты операций не должны вступать в действие до запуска этой операции, ибо это потребовало бы некого оракула, способного предсказывать будущее операций. В то же самое время, результаты должны вступать в действие ли её завершения, так как в противном случае мы были бы не способны определять момент линеаризации.
Линеаризуемость признаётся как порядком последовательных операций локального процесса, так и установленным порядком запущенных параллельно операций относительно прочих процессов и определяет всеобщий порядок происходящих событий.
Этот порядок обязан быть согласованным, что означает, что каждое считывание разделяемого значения должно возвращать самое последнее предшествующее такому чтению записанное в эту совместно используемую переменную значение или же то значение записи, которое перехлёстывается с данным чтением. Линеаризуемый доступ на запись к некой разделяемой переменной также подразумевает взаимное исключение: среди двух одновременных записей только одна может пройти первой.
Даже несмотря на то, что операции одновременны и обладают неким перекрытием, сами действия, благодаря которым они становятся видимыми до некой степени заставляют их казаться последовательными. Никакая операция не происходит мгновенно, однако всё ещё проявляется как атомарная.
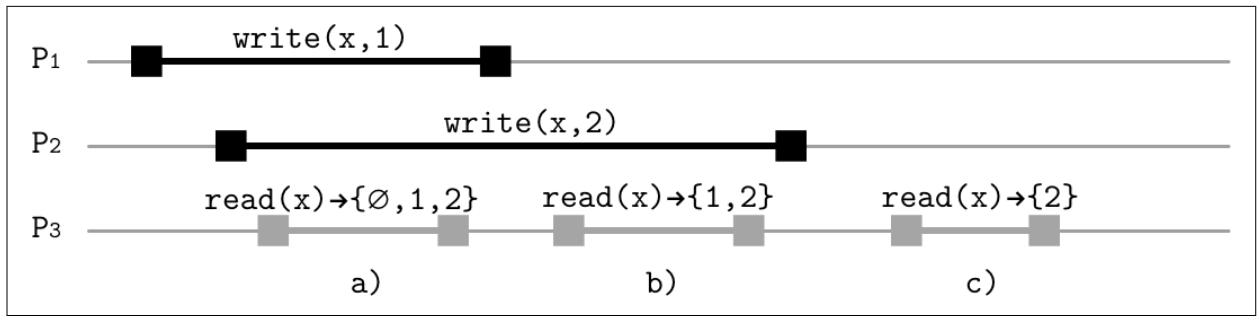
Давайте рассмотрим следующую историю:
Process 1: Process 2: Process 3:
write(x, 1) write(x, 2) read(x)
read(x)
read(x)
На Рисунке 11-2 у нас имеются три процесса, два из
которых выполняют операции записи в регистр х, который обладает начальным
значением ∅. Операции чтения способны наблюдать эти записи следующими
способами:
-
Самая первая операция чтения может вернуть значения
1,2и∅(первоначальное значение, состояние до обеих записей) так как обе записи всё ещё в процессе полёта. Самое первое считывание может получить порядок до обеих записей, между первой и второй записями и после обеих записей. -
Наше второе чтение может вернуть только
1и2, так как самая первая запись уже выполнена, а вторая ещё пока не завершилась. -
Третье считывание способно вернуть лишь
2, так как вторая запись по порядку идёт после первой.
Момент линеаризации
Одним из наиболее важных штрихов линеаризуемости является её видимость: после того как операция завершена, все имеют возможность видеть её и данная система "не способна вернуться назад во времени", вернув всё обратно или сделав её невидимой для ряда участников. Иными словами, линеаризация запрещает считывание просроченного и требует момнотонного чтения.
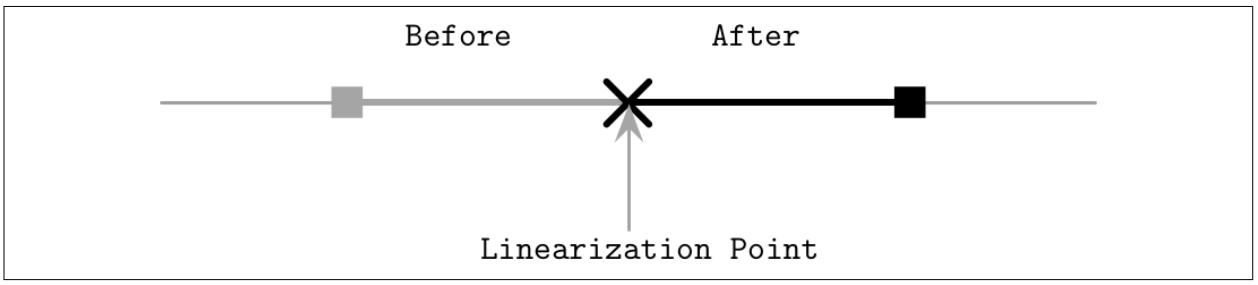
Данная модель согласованности лучше всего поясняется в терминах атомарности (то есть непрерывности, неделимости) операций. Операции не обязаны быть моментальными (ещё и потому что таковых не бывает), однако их эффект должен становиться видимым в некий момент времени, производя иллюзию, что она была моментальной. Эта точка носит название момента линеаризации.
Сразу после такого момента линеаризации (иными словами, когда это значение становится видимым для прочих процессов) все процессы обязаны видеть либо само значение данной операции, либо какое- то более позднее значение, если некая дополнительная операция записи была по порядку после неё. Некое видимое значение должно оставаться стабильным до тех пор пока соответствующее следующее не станет видимым после него и значение данного регистра не должно изменяться между этими двумя последними состояниями.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Большинство языков программирования в наши дни предлагает некие атомарные примитивы, которые допускают
атомарные операции |
Рассматриваемый момент линеаризации служит неким отсечением, после которого становятся видимыми эффекты от операции. Мы можем реализовать его при помощи блокировки для предохранения некой критической секции, атомарности чтения/ записи или примитивов считай- измени- запиши.
Рисунок 11-3 показывает, что линеаризация предполагает жёсткие
границы и наличие часов в реальном времени с тем, чтобы эффекты операции становились
видимыми между t1, когда была
вызвана данная операция и t2, когда этот процесс получил отклик.

Рисунок 11-4 иллюстрирует, что момент линеаризации рассекает историю на до и после. До данного момента линеаризации видно старое значение, после него видимым является новое значение.
Стоимость линеаризации
В наши дни многие системы избегают реализации линеаризации. Даже ЦПУ не предлагает по умолчанию линеаризуемости при доступе к основной памяти. Это происходит по причине того, что инструкции синхронизации затратны, медленны и вовлекают в себя обмен между ЦПУ узлов с признанием несостоятельности кэширования. Тем не менее, существует возможность линеаризуемости при помощи примитивов нижнего уровня [MCKENNEY05a] [MCKENNEY05b].
При одновременном программировании для введения линеаризуемости мы можем пользоваться операциями сравнения- и-
перестановки (compare-and-swap). Многие алгоритмы занимаются подготовкой с последующим
CAS для замены местами указателей и их публикацией.
Например, мы можем реализовать некую очередь одновременности созданием связанного списка узлов, который затем атомарно добавляется
в конец имеющегося хвоста самого списка [KHANCHANDANI18].
В распределённых системах линеаризуемость требует координации и упорядочения. Это можно реализовывать при помощи консенсуса: клиенты взаимодействуют с неким обладающим репликациями хранилищем при помощи сообщений, а имеющийся модуль консенсуса отвечает за обеспечение согласованности и идентичности применяемых операций по всему кластеру. Всякая операция записи будет проявляться как моментальная, причём в точности один раз в некий момент времени между событиями вызова и завершения [HOWARD14].
Что занимательно, линеаризуемость в её традиционном понимании относится к некому локальному свойству и подразумевает составление из независимо реализуемых и удостоверяемых элементов [HERLIHY90]. Иначе говоря, некая система, в которой все элементы линеаризованы, также линеаризуема. Это очень полезное свойство, но нам следует помнить, что его сфера ограничена единственным объектом и, даже если операции с двумя независимыми объектами и линеаризуемы, операции в которые вовлечены оба объекта должны полагаться на дополнительные средства синхронизации.
|
| Инфраструктура с повторным использованием для линеаризуемости |
|---|---|
|
Инфраструктура с повторным использованием для линеаризуемости (RIFL, Reusable Infrastructure for Linearizability) это некий механизм для реализации линеаризуемости вызовов удалённой обработки (RPC, remote procedure calls) [LEE15]. В RIFL сообщения уникально идентифицируются значением идентификатора клиента и монотонно возрастающим последовательным номером.. Для назначения идентификатора клиента RIFL применяет найм (leases), вызывая общую для всей системы службу: уникальные идентификаторы применяются для установления уникальности и разрыва связей последовательной нумерации. Когда определённый отказавший клиент пытается выполнить некую операцию при помощи найма с истекшим сроком, эта операция не будет фиксирована: этому клиенту придётся выполнить новый найм и повторить действие. Если определённый сервер испытывает крушение до того как он смог выдать уведомление о записи, его клиент может
попытаться повторить эту операцию не зная о том, что она уже была применена. Мы даже можем завершить ситуацией, при
которой клиент Выполненные объекты хранятся в неком надёжном хранилище, причём совместно с реальными записями данных. Тем не менее, их время жизни различно: такой выполненный объект должен существовать до тех пор, пока сам выполнивший вызов клиент не пообещает больше не повторять эту операцию, или пока сам сервер не обнаружит некий сбой клиента, и в этом случае все выполненные объекты могут быть безопасно удалены. Клиенты обязаны периодически обновлять свои наймы чтобы cообщать о своём присутствии. Когда такой клиент отказывает в обновлении своего найма, он помечается как претерпевший крушение и все связанные с его наймом данные собираются в мусор. Наймы обладают ограничением по времени жизни чтобы гарантировать что относящиеся к претерпевшим отказ клиентам операции не могут оставаться навсегда в имеющемся журнале. Когда отказавший клиент пытается продолжать операцию с истекшим наймом, его результаты не будут зафиксированы и этому клиенту придётся начинать с чистого листа. Основным преимуществом RIFL является то, что обеспечивая гарантию того, что данный RPC не может быть выполнен более одного раза, некая операция может быть превращена в линеаризуемую обеспечивая атомарную видимость ей результатов, причём основная часть подробностей реализации не зависит от лежащей в основе системы хранения. |
Достижение линеаризуемости может быть чересчур затратным, но имеется возможность ослабления этой модели, все ещё обеспечивая достаточно строгую согласованность. Последовательная согласованность предоставляет возможность упорядочивать операции как если бы они исполнялись некоторым последовательным образом, в то же время требуя от операций каждого индивидуального процесса в том же самом порядке, в котором они выполняются данным процессом.
Процессы могут наблюдать исполняемые прочими участниками операции в соответствующем согласованном порядке их собственной истории, однако это представление может произвольно устаревать с глобальной точки зрения [KINGSBURY18a]. Порядок исполнения между процессами не определён, так как нет никакого совместного представления времени.
Последовательная согласованность вначале была введена в контексте одновременности, описываясь как некий способ корректного выполнения программ множеством процессоров. Самое первоначальное описание требовало упорядочения в очередь (FIFO, в порядке возникновения) запросов к памяти в одной и той же самой ячейке, не выставляя глобального порядка для перекрывающихся записей в независимые ячейки памяти и допуская считывания выборок необходимых ячеек памяти, или самых последних значений из самой очереди, когда эта очередь не пуста [LAMPORT79]. Этот пример помогает понимать семантику последовательной согласованности. Операции могут упорядочиваться различными способами (в зависимости от самого порядка возникновения, или даже произвольно в случае одновременно появляющихся двух записей), однако все процессы наблюдают эти операции в одном и том же порядке.
Каждый процесс может выпускать запросы на чтение и запись неким порядком, определяемым его собственной программой, что достаточно понятно. Все не одновременные, программы с единственным потоком исполняют их пошагово таким же образом: одну за другой. Все распространяемые одним и тем же процессом операции записи возникают в том порядке, в котором они поставляются этим процессом. Поставляемые различными процессами операции могут упорядочиваться произвольно, однако этот порядок будет согласованным с точки зрения их читателей.
|
| Замечание |
|---|---|
|
Последовательная согласованность часто путается с линеаризуемостью, так как оба понятия имеют аналогичную семантику. Последовательная согласованность, как и линеаризуемость, требует глобальной упорядоченности операций, однако линеаризуемочть требует согласованности как для локального порядка в каждом из процессов, так и глобального порядка. Иначе говоря, линеаризуемость ожидает некого порядка операций в реальном масштабе времени. При последовательной согласованности упорядочение необходимо только для записей от того же самого источника [VIOTTI16]. Другим важным отличием является композиция: мы можем сочетать линеаризуемые истории и всё ещё ожидать что результат будет линеаризуемым,в то время как расписания последовательной согласуемости не сочетаются в композиции [ATTIYA94]. |
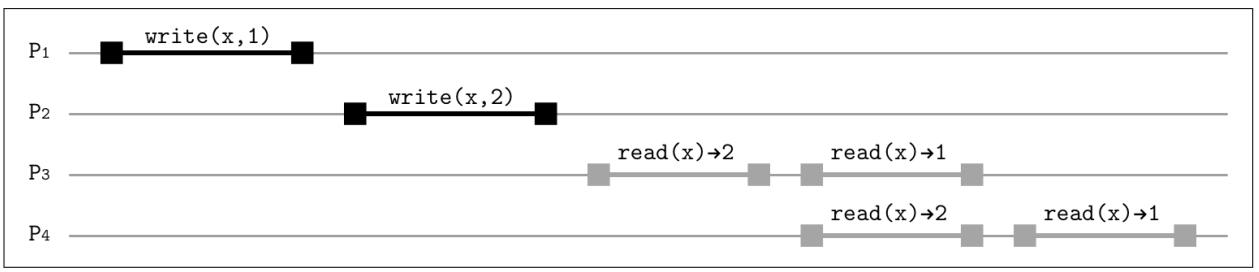
Рисунок 11-5 показывает как
write(x,1) и write(x,2) могут становиться
видимыми для P3 и P4.
Даже хотя в терминах ходиков (wall-clock) 1 была записана
до 2, он может идти по порядку после
2. В то же самое время, поскольку P3
уже считал значение 1, P4
всё ещё может продолжать чтение 2. Однако, оба
допустимы порядка, 1 → 2 и 2 → 1, так как они
согласованны для различных читателей. Что здесь важно, так это то, что и P3,
и P4 наблюдают значения в том же самом порядке:
сначала 2, затем 1
[TANENBAUM14].
Считывания устаревших сведений можно пояснить, например, расхождением реплик: даже хотя записи распространяются в различные реплики в одном и том же порядке, они могут появляться в различное время.
Основным отличием от линеаризуемости является отсутствие глобальных принудительных ограничений по времени. При линеаризуемости
некая операция вступает в действие внутри временных границ ходиков. Ко времени завершения операции записи
W1 её результаты уже должны быть применены, и каждый читатель должен
видеть то значение, которое по крайней мере не позднее записанного
W1. Аналогично, после возврата операции считывания
R1, всякая происходящая после неё операция должна возвращать увиденное
R1 значение, или более позднее (что, естественно, должно следовать одному
и тому же правилу).
Последовательная согласованность ослабляет это требование: результаты операции могут становиться видимыми после такого завершения, до тех пор пока этот порядок находится в согласии с точкой зрения его персонального процесса. Записи из одного и того же источника не могут &quuot;перепрыгивать&quuot; друг через друга: установленного в их программе порядка, относительно их собственного процесса исполнения, который должен сохраняться. Другим ограничением является то, что тот порядок, в котором операции должны появляться должны быть согласованными для всех читателей.
Аналогично линеаризуемости, современные ЦПУ не обеспечивают последовательной согласованности по умолчанию, так как сам процессор способен переупорядочивать инструкции, нам следует применять барьеры памяти (также носящие название ограждений - fences) чтобы обеспечивать последовательность видимости записей одновременно исполняемых потоков по порядку [DREPPER07] [GEORGOPOULOS16].
Видите ли, существует лишь одна постоянная, одна универсальная, и именно выступающая единственной истиной: причинность. Действие. Реакция. Причина и следствие.
- МеровингенМатрица. Перезагрузка.
Даже хотя зачастую и нет необходимости иметь некий глобальный порядок действий, может требоваться установление порядка между некоторыми операциями. В рамках модели причинной согласованности, все процессы обязаны наблюдать причинно связанные операции в одном и том же порядке. Одновременные записи без причинной взаимосвязи могут рассматриваться в различном порядке отличающимися процессорами.
Прежде всего, давайте рассмотрим зачем нам требуется причинность и как должны
распространяться записи без причинной взаимосвязи. На Рисунке 11-6
выполняющие записи процессы P1 и P2
не связаны в причинном порядке. Получаемые в результате этих операций результаты
могут распространяться читателям в различное время и в не установленном порядке. Процесс P3
видит значение 1 до того как он заметит значение 2, в то
время как процесс P4 сначала видит 2, а уж
затем 1.
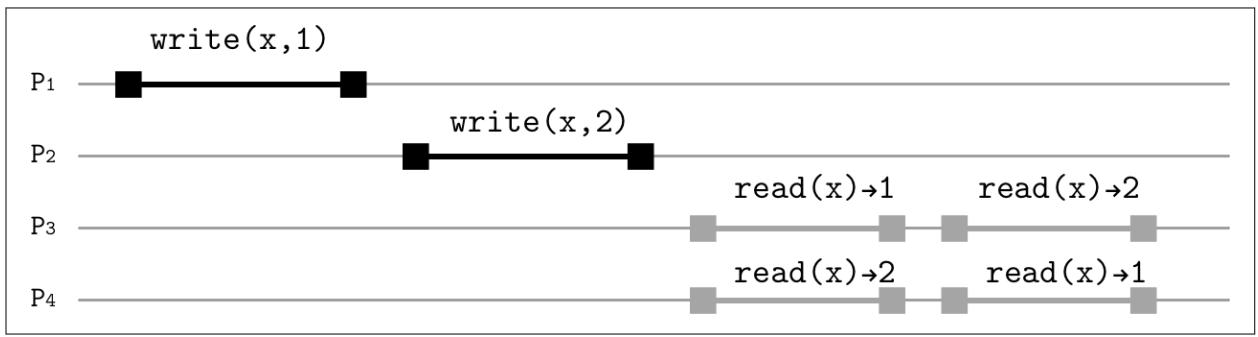
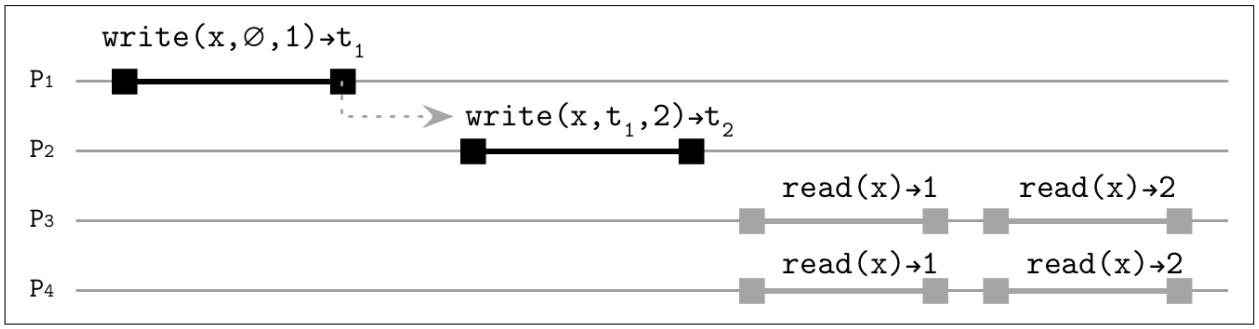
Рисунок 11-7 показывает некий образец причинно связанных
записей. Дополнительно к записанным значениям, нам теперь требуется определить значение логических часов, которое
установило бы причинный порядок между операциями. P1 стартует с операции
write(x,∅,1)→t1, которая начинается со своего начального значения
∅, P2 исполняет другую
операцию, write(x, t1, 2) и определяет, что она логически следует
за t1, требующей распространения
операции только в том порядке, который установлен их логическими часами.

Это устанавливает некий причинный порядок между данными операциями. Даже когда самая последняя запись распространяется быстрее чем предшествующая, она не станет видимой пока не появятся все её зависимости, а сам порядок событий восстанавливается по значением их временных отметок. Иначе говоря, взаимосвязь произошло- до устанавливается логически, без применения физических часов, причём все процессы согласны с этим порядком.
Рисунок 11-8 отображает процессы
P1 и P2, делающие
причинно связанные записи, которые распространяются в P3 и
P4 в их логическом порядке, это предоствращает нас от той ситуации, которая
отображена на Рисунке 11-6; вы можете сопоставить истории
P3 и P4 на обоих
рисунках.
Вы можете представить себе это в терминах некого взаимодействия в интернет- форуме: вы что-то постите онлайн, кто- то видит ваш пост и откликается на него, а третья персона наблюдает эти отклики и продолжает поток обсуждения. Для потоков обсуждения могут иметься расхождения: вы может выбрать отклик в одном из обсуждений в соответствующем потоке и продолжать отслеживать цепь событий, но некоторые потоки будут иметь в целом лишь несколько сообщений, а потому может не иметься отдельной истории для всех этих сообщений.
В некой системе с причинной зависимостью мы получаем гарантии сеанса для определённого приложения, обеспечивая соответствующее представление самой базы данных с её собственными действиями, причём даже когда она исполняет запросы на чтение и запись для различных, потенциально не согласованных серверов [TERRY94]. Такими гарантиями выступают: монотонные чтения, монотонные записи, считывание- ваших- записей, записей- вслед за- чтениями. Вы можете найти дополнительные сведения по этим моделям сеансов в разделе Модели сеанса.
Причинная согласованность может быть реализована при помощи локальных часов [LAMPORT78] и отправлять метаданные контекста с каждым сообщением, суммируя какие операции предшествовали этой текущей. При получении обновления от соответствующего сервера, оно содержит самую последнюю версию своего контекста. Всякая операция может быть продолжена только когда все предшествующие ей операции уже были применены. Те сообщения, для которых не совпадают контексты, буферизируются на самом сервере, ибо их слишком рано доставлять.
Те два заметных и часто цитируемых проекта, которые реализованы при помощи причинной согласованности являются COPS (Clusters of Order-Preserving Servers, Кластеры серверов сохранения заказов) [LLOYD11] и Eiger [LLOYD13]. Оба проекта реализуют причинность через некую библиотеку (реализуемую как некий сервер интерфейса, к которому подключены пользователи) и отслеживают зависимости для обеспечения согласованности. COPS отслеживает зависимости версиями ключей, в то время как Eiger устанавливает вместо этого порядок операций (операции в Eiger могут зависеть от исполняемых в прочих узлах операций; например, в случае транзакций со множеством разделов). Оба проекта не содержат выходящих из строя операций, как это в конечном счёте могут осуществлять согласованные хранилища. Вместо этого они выявляют и обрабатывают конфликты: в COPS это выполняется проверкой порядка значений ключей и использованием особенных для приложения функций, а Eiger реализует правило выигрывает- последний- записывающий.
Векторные часы
Установление причинно- следственной связи помогает данной системе восстанавливать последовательность событий даже
когда сообщения доставляется не по порядку, заполнять промежутки между получаемыми сообщениями и избегать публикации
операций, когда некоторые сообщения всё ещё отсутствуют. Например, если каждое из определяющих свои зависимости сообщений
{M1(∅, t1), M2(M1, t2), M3(M2, t3)} являются причинно связанными и
распространялись без соблюдения порядка, сам процесс буферирует их до тех пор, пока он способен собирать все зависимости
операций и восстанавливать ил причинный порядок [KINGSBURY18b].
Многие базы данных, например, Dynamo [DECANDIA07] и Riak
[SHEEHY10a] используют вектор
часов [LAMPORT78]
[MATTERN88]
для установления порядка причинности.
Ветор часов это некая структура для установки частичной упорядоченности между имеющимися событиями, выявления и разрешения расхождений между представленными цепочками событий. При помощи вектора часов мы можем имитировать общее время, глобальное состояние и представлять асинхронные события именно асинхронными. Процессы поддерживают векторы логических часов, причём с единственными часами для каждого процесса. Каждые часы запускаются в неком первоначальном значении и инкрементально растут при возникновении каждого нового события (к примеру, при появлении некой записи). При получении векторов часов от прочих процессов, процесс обновляет свой локальный вектор до величин значений наивысших часов каждого из процессов из полученных векторов (то есть при каждом просмотре самые наивысшие значения часов, наблюдавшиеся передающим узлом).
Чтобы применять векторы часов для разрешения конфликтов, при каждой записи в базу данных мы вначале проверяем что данное значение для подлежащего записи ключа уже имеется локально. Когда такое предыдущее значение уже имеется, мы добавляем в конец некую новую версию для своего вектора версий и устанавливаем соответствующую причинную взаимосвязь между этими двумя записями. В противном случае мы запускаем некую новую цепь событий и инициализируем соответствующее значение единственной версией.
Мы уже обсуждали согласованность в терминах доступа к регистрам совместно используемой памяти и упорядочения операций ходиками, а также впервые упомянули потенциально возможное расхождение реплик при обсуждении последовательной согласованности. Поскольку необходимо упорядочивать только операции записи в одну и ту же область памяти, мы не можем в конечном результате оказаться в ситуации, при которой мы будем иметь конфликт когда значения независимы [LAMPORT79].
Так как мы находимся в поиске модели согласованности, которая допускала бы повышение и доступности, и производительности,
нам придётся позволять расхождение реплик не только за счёт обслуживания устаревших операций считывания, но и путём принятия
потенциально вступающих в конфликт записей, а потому данной системе позволяется создание двух независимых цепочек событий.
Рисунок 11-9 отображает такое расхождение: с точки зрения одной из
реплик, мы видим историю как 1, 5, 7, 8 , в то время как другая сообщает
1, 5, 3. Riak позволяет пользователям наблюдать и разрешать расходящиеся истории
[DAILY13].

|
| Замечание |
|---|---|
|
Для реализации причинной согласованности нам приходится сохранять историю причин, добавлять сборку мусора и запрашивать своего пользователя на примирение расходящихся историй в случае их конфликта. Векторные часы способны сообщать нам о происхождении такого конфликта, но не предлагают в точности как его разрешать, так как семантика разрешения зачастую является особенной для приложения. По этой причине некоторые в конечном счёте согласованные базы данных, например, Apache Cassandra, не упорядочивают операции по причинам и применяют вместо этого для разрешения конфликта правило выигрывает- последний- записывающий [ELLIS13]. |
Представление согласованности в терминах распространения значения полезно для разработчиков базы данных, так как способствует пониманию и наложению необходимых инвариантов данных, однако некоторые моменты проще понимать и пояснять с точки зрения самого клиента. Вместо того чтобы рассматривать нашу распределённую систему с точки зрения множества клиентов, мы можем делать это с позиции одного клиента.
Модели сеанса [VIOTTI16] (также носящие название клиент- центрических моделей согласованности [TANENBAUM06]) способствуют рассуждениям относительно значения состояния распределённой системы с точки зрения самого клиента: как каждый клиент наблюдает значение состояния данной системы при вызове операций чтения и записи.
Если прочие обсуждавшиеся нами до сих пор модели согласованности были сосредоточены на объяснении порядка операций при наличии одновременных клиентов, клиент- центрическая согласованность сосредоточена на том как отдельный клиент взаимодействует с этой системой. Мы всё ещё предполагаем, что все операции клиента последовательные: ему требуется завершить одну операцию прежде чем он сможет начать исполнение следующей. Если данный клиент претерпевает крушение или теряет соединение со своим сервером до завершения его операции, мы не делаем никаких предположений относительно значения состояния незавершённой операции.
В распределённой системе клиенты часто имеют возможность соединяться с любой доступной репликой и, если получаемые результаты последней записи для одной реплики не распространяются на другую, такой клиент может быть не способным наблюдать изменение сделанного им значения состояния.
Одним из разумных ожиданий является то, что всякая вызванная клиентом запись видна ему. Именно это предположение скрывается
за моделью согласованности чтения- собственных- записей, которая постулирует, что
каждая операция считывания, следующая за соответствующей записью в той же самой или иной реплике обязана наблюдать своё
изменённое значение. Например, read(x), которое выполнялось немедленно после
write(x,V) вернёт установленное значение V.
Модель монотонных чтений ограничивает значение видимости значения и состояния тем,
что если определённое read(x) наблюдало величину значения V,
все последующие чтения должны наблюдать значение по крайней мере настолько же позднее как V
или некоторые более поздние значения.
Модель монотонных записей предполагает, что возникающие от одного и того же клиента
значения появляются в том порядке, в котором этот клиент их исполняет. Если, согласно установленному порядку сеанса данного
клиента, write(x,V2) была выполнена после
write(x,V1), их эффект должен быть виден в том же самом порядке (то есть
вначале V1, затем V2) для
всех прочих пользователей. Без данного предположения старые данные способны
"воскресать", приводя в результате к утрате данных.
Записи- следую- за- чтениями (иногда именуемая причинностью сеанса) обеспечивает
что записи идут по порядку за записями, которые наблюдались в предыдущих операциях чтения. Например, когда
write(x,V2) идёт по порядку после read(x),
которое вернуло V1, write(x,V2) будет идти
по порядку после write(x,V1).
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
Модели сеансов не делают предположений относительно операций, выполняемых
различными процессами (клиентами) или из различных логических сеансов
[TANENBAUM14]. Эти модели описывают порядок с точки зрения
одного отдельного процесса. Тем не менее, те же самые гарантии должны сохраняться для
каждого процесса в этой системе. Иными словами, когда
|
Сочетание монотонных чтений, монотонных записей и считывания- собственных- записей даёт согласованность PRAM (Pipelined RAM) [LIPTON88] [BRZEZINSKI03], также именуемую как согласованность FIFO. PRAM обеспечивает, что появившиеся из одного из процессов операции записи будут распространяться в том порядке, в котором они исполнялись этим процессом. В отличии от последовательной согласованности, записи различных процессов могут наблюдаться в различном порядке.
Данные свойства, описываемые моделями клиент- центрической согласованности, желательны, и в большинстве случаев применяются разработчиками распределённых систем для утверждения своих систем и упрощения их применения.
Синхронизация затратна как в отношении программирования множества процессоров, так и в распределённых системах. Как мы уже обсуждали в Моделях согласованности, мы можем ослаблять гарантии согласованности и применять модели, которые допускают некое расхождение между узлами. К примеру, последовательная согласованность допускает распространение чтений с различной скоростью.
При согласованности в конечном счёте обновления распространяются по рассматриваемой системе асинхронно. Формально, она постулирует, что при отсутствии каких бы то ни было дополнительных обновлений, выполняемых для определённого элемента данных, в конечном счёте все доступы возвратят самое последнее записанное значение [VOGELS09]. В случае некоторого конфликта, данное понятие самого последнего может измениться, поскольку сами значения от разошедшихся реплик примиряются при помощи некой стратегии разрешения конфликтов, например, выигрывает- последняя- запись или применяющая Векторные часы.
В конечном счёте это занимательное понятие для описания распространения значения, так как оно не определяет никаких жёстких временных рамок в которые это должно произойти. Когда служба доставки не производит ничего иного кроме гарантий "в конечном счёте", это не звучит как нечто, на что можно полагаться.
Тем не менее, на практике это хорошо работает и многие базы данных в наши дни описываются как имеющие согласованность в конечном счёте.
Системы с согласованностью в конечном счёте иногда описываются в терминах CAP: вы можете менять доступность на согласованность и наоборот (см.раздел Печально известная CAP). С точки зрения стороны сервера, согласуемые в конечном счёте системы обычно реализуют настраиваемую согласованность, при которой данные реплицируются, считываются и записываются применяя три изменчивости:
- Множитель репликации
N Число узлов, которое будет хранить некую копию данных.
- Согласованность записи
W Число узлов, которое должно выдать подтверждение записи для её успешности.
- Согласованность чтения
R Число узлов, которое должно отвечать на операцию чтения для её успешности.
Выбирая уровни согласованности, при которых (R + W > N), данная система
способна обеспечивать возврат наиболее последних записанных значений, поскольку всегда имеется некое перекрытие между
наборами чтений и записи. Например, когда N = 3, W = 2
и R = 2, данная система будет безразлична к отказу всего одного узла. Два узла
из трёх обязаны выдавать подтверждение соответствующей записи. В идеальном сценарии данная система также асинхронно реплицирует
эту запись в свой третий узел. Когда третий узел отключён, механизмы анти- энтропии (см. Главу 12) в конечном счёте распространят её.
В процессе соответствующего чтения две реплики из трёх должны быть доступными для обслуживания нам соответствующего запроса чтобы соответствовать результатам согласованности. Любые сочетания узлов предоставят нам по крайней мере один узел, который будет обладать наиболее современной записью для заданного ключа.
|
| Совет |
|---|---|
|
При выполнении некой записи соответствующий координатор обязан поставлять её в |
Системы с интенсивной записью могут порой указывать W = 1 и
R = N, что делает возможными записи при получении подтверждения для их успешности
лишь от одного узла, однако это потребовало бы от всех реплик (даже потенциально
отказавших) доступности на чтение. То же самое справедливо и при комбинации W = N,
R = 1: самое последнее значение может быть считано с любого узла, до тех пор
пока записи успешны только после их применения ко всем репликам.
Увеличение уровней согласованностей чтения или записи увеличивает задержки и повышает требования доступности для узлов в процессе запросов. Их снижение улучшает доступность системы при принесении в жертву согласованности.
|
| Кворумы |
|---|---|
|
Некий состоящий из При выполнении операций чтения и записи с применением кворума система не может быть безразлична к отказу большинства узлов. Например, когда в сумме имеются три реплики, а две из них упали, операции чтения и записи не способны достичь значения числа узлов, требуемого для согласованности чтения и записи, ибо лишь один узел из трёх способен отвечать на соответствующие запросы.. Чтения и записи с применением кворума не гарантируют монотонности в случае незавершённых записей. Когда некоторые операции записи отказали после записи некого значения в одну реплику из трёх, в зависимости от конкретных пребывающих в контакте реплик, некое чтение с кворумом способно вернуть либо результат незавершённой операции, либо старое значение. Так как при контактах с одними и теми же репликами нет необходимости в последовательных чтениях одного значения, возвращаемые ими значения могут меняться. Для достижения монотонности чтения (за счёт доступности) нам приходится применять блокирование чтения- восстановления (см. раздел Восстановление чтения). |
Применение кворума для согласованного чтения способствует улучшению доступности: даже кгда некоторые из узлов отключены, система базы данных ещё способна принимать чтения и обслуживать записи. Требования наличия большинства обеспечивает что благодаря наличию некого перекрытия по крайней мере одним узлом для большинства в любом случае, всякое чтение корумом будет наблюдать наиболее последнюю выполненную кворумом запись. Тем не менее, использование реплик и требований большинства увеличивает стоимости хранения: нам приходится хранит во всех репликах копию своих данных. Когда наш множитель реплик составляет значение пять, нам приходится хранить пять реплик.
Мы можем улучшить стоимость хранения при помощи понятия, носящего название свидетельской реплики (witness replicas).. Вместо того чтобы хранить копию соответствующей записи в каждой реплике, мы можем расщеплять реплики на подмножества копий и свидетельств. Реплики копий по- прежнему содержат как и ранее записи данных. При обычных операциях реплики свидетельства единственно хранят те записи, которые указывают факт того, что данная операция записи произошла. Тем не менее, может произойти некая ситуация, при которой общее число копий реплик слишком низко. Например, когда у нас имеются три копии реплик и два свидетельства, а две копии реплик падают, мы приходим к кворуму из одной реплики и двух свидетельств реплик.
При возникновении таймаутов записи или отказа реплики копии, реплики свидетельства могут обновляться до временного хранения соответствующей записи на месте отказавшей или завершённой тайм- аутом реплики копии. Как только первоначальная реплика копии будет восстановлена, обновлённые реплики могут вернуться к своим предыдущим состояниям или же восстановленные реплики могут стать свидетельскими.
Давайте рассмотрим некую систему с репликациями в трёх узлах, два из которых хранят копии данных, а третья обслуживается в качестве
свидетельской: [1c, 2c, 3w]. Мы предпринимаем попытку выполнения записи, однако
2c временно недоступна и мы не можем завершить операцию. В этом случае мы временно
сохраняем необходимую запись в своей свидетельской реплике 3w. Когда в конце концов
2c: вернётся обратно в сторй, механизмы восстановления приведут её в современное состояние
и удалят избыточную копию у свидетельской.
При неком ином сценарии мы можем попытаться выполнить некое чтение, а запись имеется в 1c
и 3w, но не в 2c. Так как для построения кворума достаточно
любых двух реплик, когда имеются подмножества узлов из двух реплик, будь то копии двух реплик [1c, 2c]
или одна реплика копии и одно свидетельство, [1c, 3w] или
[2c, 3w], мы способны гарантированно обслуживать согласованный результаты. При чтении
из [1c, 2c] мы выбираем самую последнюю запись из 1c
и можем реплицировать её в 2c, так как в ней значение пропущено. В случае когда доступна
лишь [2c, 3w], самая последняя запись будет выбрана из
3w. Для восстановления первоначальной конфигурации и приведения
2c в актуальное состояние, необходимая запись может быть реплицирована в неё и
удалена из свидетельской.
В более общем случае, когда мы обладаем n репликами копий и
m репликами свидетельств, мы можем предоставить те же самые гарантии что и
n + m копий, когда мы следуем двум правилам:
-
Операции чтения и записи выполняются с применением большинства (т.е.,
N/2 + 1участниками) -
По крайней мере одна из имеющихся реплик в этом кворуме обязательно является копией
Это работает по той причине, что данные гарантированно имеются либо в некой реплики копии, либо в реплике свидетельства. Реплики копий приводятся в актуальное состояние имеющимся механизмом восстановления в случае какого- то отказа, а реплика свидетельства хранит необходимые данные в этом промежутке времени.
Применение свидетельских реплик помогает снижению стоимости хранения в то же время сохраняя инварианты согласованности. Существуют различные реализации данного подхода; например, Spanner [CORBETT12] и Apache Cassandra.
Мы обсудили некоторые модели строгой согласованности, такие как линеаризуемость и сериализация, а также сформировали слабую согласованность: согласованность в конечном счёте. Возможная золотая середина находится промеж них, предлагая некоторые преимущества обеих моделей и это строгая согласованность в конечном счёте. Для данной модели обновления в серверы допускаются поздними и с нарушением порядка, однако когда все обновления в конечном итоге распространены в целевые узлы, между ними могут быть разрешены конфликты и они могут быть слиты для производства одного и того же допустимого состояния [GOMES17].
При некоторых обстоятельствах мы можем ослаблять свои требования согласованности, допуская операциям сохранять дополнительное состояние, которое позволяет согласовывать расходящиеся состояния (иными словами, сливать) после выполнения. Одним из наиболее выдающихся образцов такого подхода является реализация CRDTs (Conflict-Free Replicated Data Types, Освобождённые от конфликтов реплицируемые типы данных, [SHAPIRO11a]), например, в REDIS [BIYIKOGLU13].
CRDTs это специализированные структуры данных, которые предотвращают само наличие конфликтов и позволяют операциям с этими типами данных применяться в любом порядке без изменения результата. Данное свойство может быть чрезвычайно полезным в распределённых системах. Например, в системе со множеством узлов, которая применяет свободные от конфликтов реплицируемые счётчики, мы можем увеличивать приращениями значения в каждом из узлов независимо, причём даже когда они не способны взаимодействовать друг с другом по причине наличия сетевых разделов. Как только взаимодействие восстановится, результаты от всех узлов могут быть согласованы и не буде утеряна ни одна из операций, применённых в процессе такого разбиения на разделы.
Это делает полезным CRDTs для согласуемых в конечном счёте систем, так как состоянием реплик в таких системах допустимо временно расходиться. Реплики могут исполнять операции локально, причём без предварительной синхронизации с прочими узлами, а операции в конечном счёте распространяются во все прочие реплики, и при этом потенциально не в установленном порядке. CRDTs позволяет нам восстанавливать полное состояние системы из локальных индивидуальных состояний или последовательностей операций.
Самым простым примером CRDTs являются основанные на операциях CmRDTs (Commutative Replicated Data Types, Коммутативные реплицируемые типы данных). Для работы с CmRDTs нам необходимо позволить операциям быть:
- Свободными от сторонних эффектов
Их приложение не изменяет состояние системы.
- Коммутативными
Порядок аргументов не имеет значения:
x • y = y • x. Иначе говоря, нет разницы сливается лихcy, либоyсливается сх.
- Причинная упорядоченность
Успешность их доставки зависит от предварительных условий, которые обеспечивают что данная система достигла того состояния, к которому может применяться эта операция.
Например, мы можем реализовать исключительно растущий счётчик. Каждый сервер может
хранить некий вектор состояния, соответствующего последним известным обновлениям счётчика от прочих участников, инициализированный
нулями. Каждому серверу дозволено обновлять только своё собственное значение в этом векторе. При распространении обновлений,
функция merge(state1, state2) сольёт значения состояний от двух серверов.
Например, у нас имеются три сервера с инициализированными начальными векторами состояний:
Node 1: Node 2: Node 3:
[0, 0, 0] [0, 0, 0] [0, 0, 0]
Когда мы обновляем счётчики в первом и третьем узлах, их состояния изменяются следующим образом:
Node 1: Node 2: Node 3:
[1, 0, 0] [0, 0, 0] [0, 0, 1]
При распространении обновлений мы применяем функцию слияния для сочетания результатов, указывая максимальные значения для каждого из слотов:
ode 1 (Node 3 state vector propagated):
merge([1, 0, 0], [0, 0, 1]) = [1, 0, 1]
Node 2 (Node 1 state vector propagated):
merge([0, 0, 0], [1, 0, 0]) = [1, 0, 0]
Node 2 (Node 3 state vector propagated):
merge([1, 0, 0], [0, 0, 1]) = [1, 0, 1]
Node 3 (Node 1 state vector propagated):
merge([0, 0, 1], [1, 0, 0]) = [1, 0, 1]
Для определения значения текущего состояния вектора вычисляется сумма значений во всех слотах:
sum([1, 0, 1]) = 2. Данная функция слияния коммутативна. Поскольку
серверам дозволено обновлять лишь свои собственные значения, а эти значения независимы, не требуется никакой
дополнительной координации.
Существует возможность создания Позитивно- негативного счётчика (PN- Counter,
Positive-Negative-Counter), который поддерживает как приращения так и вычитания применяя полезные нагрузки, состоящие
из двух векторов: P, который применяется для приращений, и
N, в котором хранятся вычитания. В некой большой системе во избежание распространения
гигантских векторов мы може пользоваться super-peers (суперодноранговостью).
Суперодноранговость распространяет состояния счётчиков и помогает избегать постоянного однорангового дребезга
[SHAPIRO11b].
Для сохранения и репликации значений мы можем применять регистры. Самой простой версией такого регистра является регистр выигрывает- последний- записавший (LWW регистр, last-write-wins), который хранит некую уникальную, глобально упорядоченную временную отметку, прикрепляемую к каждому значению для разрешения конфликтов. В случае конфликта записи мы сохраняем лишь одно значение с самой большой временной отметкой. Когда мы не можем допускать отбрасывания значений, мы можем применять особую для приложения логику слияния и пользоваться регистром со множественным значением, который хранит все значения, которые были записаны и позволяет самому приложению указывать верное.
Другим примером CRDTs выступает неупорядоченное только- растущее множество (G-Set, grow-only set). Каждый узел поддерживает своё собственное локальное состояние и может добавлять в его конец элементы. Добавление элементов производит некое допустимое множество. Слияние двух множеств также коммуникативная операция. Аналогично счётчикам, мы можем пользоваться двумя множествами для поддержки как добавлений, так и удалений. В этом случае мы можем сохранять некий инвариант: только содержащиеся во множестве добавлений могут добавляться в имеющееся множество удалений. Для восстановления текущего состояния этих множеств, все содержащиеся в множестве удалений вычитаются из множества добавлений [SHAPIRO11b].
Неким примером бесконфликтного типа, который сочетает более сложные структуры является бесконфликтный тип реплицируемых JSON данных, допускающий такие изменения, как вставки, удаления и назначения в глубоко встраиваемые документы JSON с типами списком и соответствий. Этот алгоритм выполняет операции слияния на стороне клиента и не требует распространения операций неким особенным образом[KLEPPMANN14].
Существует достаточно много возможностей, которые предоставляют нам CRDTs м мы можем наблюдать всё больше хранилищ данных, которые используют это понятие для предоставления SEC (Strong Eventual Consistency, Строгой согласованности в конечном счёте). Это мощное понятие которое можно добавлять в наш арсенал инструментов для построения отказоустойчивых распределённых систем.
Отказоустойчивые системы применяют репликацию для улучшения доступности: даже когда некоторые процессы отказывают или не отвечают, наша система в целом может продолжать работу правильно. тем не менее, удержание можества копий в синхронном состоянии требует дополнительной координации.
Мы обсудили некоторые модели согласованности с единственной операцией в порядке от тех, которые дают больше гарантий к тем, у которых их меньше (Эти краткие определения даны исключительно для повтора, читателю рекомендуется обратиться к полным определениям для осознания контекста):
- Линеаризуемость
Операции проявляются как применяемые мгновенно, а также поддерживается порядок операций в реальном времени.
- Последовательная согласованность
Эффекта от операций распространяются в неком общем порядке, причём этот порядок соответствует тому порядку, коим они выполнялись своими индивидуальными процессами.
- Причинная согласованность
Эффекты от имеющих причинную взаимосвязь операций видятся в одном и том же порядке всеми процессами.
- Согласованность PRAM/FIFO
Эффекты от операций становятся видимыми в том же самом порядке, как они исполняются отдельными процессами. Записи от отдельных процессов могут наблюдаться в различном порядке.
После этого мы обсудили модели множества сеансов:
- Считывание- собственных- записей
Операции чтения отражают свои предыдущие записи. Записи распространяются в данной системе и становятся доступными для последующих чтений того же самого клиента.
- Монотонные чтения
Любое чтение, наблюдавшее некое значение не способно наблюдать значение, которое старше уже наблюдавшегося.
- Монотонные записи
Поступающие от одного и того же клиента записи распространяются прочим клиентам в том порядке, в каком они сделаны этим клиентом.
- Записи- следуют за- считываниями
Операции записи упорядочиваются после записей, которые вступили в действие после их наблюдения в предыдущих считываниях того же самого клиента.
Знание и понимание этих концепций может помочь вам в осознании тех гарантий, которые лежат в основе систем и применять их для разработки приложений. Модели согласованности описывают правила, которым должны следовать операции над данными, однако их сфера действия ограничена особенностями системы. Составление систем в стек с более слабыми гарантиями поверх тех, у которых обязательства сильнее или игнорирование подразумеваемого согласованностью лежащих в основе систем может повлечь невосстановимую несогласованность и утрату данных.
Мы также обсудили понятия согласованности в конечном счёте и настраиваемой. основанные на кворуме системы пользуются большинством для обслуживания согласованности данных. Для снижения стоимости хранения могут применяться свидетельские реплики.
|
| Последующее чтение |
|---|---|
|
Если вы желаете узнать больше относительно упоминавшихся в этой главе понятий, вы можете ссылаться на следующие источники:
|