Глава 13. Распределённые транзакции
Содержание
- Глава 13. Распределённые транзакции
Для сопровождения порядка в некой распределённой системе нам приходится обеспечивать по крайней мере некую согласованность. В разделе Модели согласованности мы обсуждали модели согласованности единственного объекта единственной операции, которая помогла нам порассуждать относительно таких индивидуальных операций. Однако в базах данных нам часто требуется исполнять множество операций атомарно.
Атомарные операции объяснялись в терминах переходов состояний: до того как стартовала некая транзакция наша база
данных пребывала в состоянии A; к моменту её завершения это состояние перешло из
A в B. В терминах операции это просто понять,
так как транзакции не имеют никакого предварительно определённого прикреплённого состояния. Вместо этого они применяют
операции к записям данных, запускаясь в некоторый момент времени. Это предоставляет
нам некую гибкость в терминах составления расписания и исполнения: транзакции могут менять порядок и даже выполняться
повторно.
Основная сосредоточенность обработки транзакций состоит в определении допустимых историй, ля моделирования и представления возможных сценариев перекрытия исполнения. История в данном случае представляет некий граф зависимостей: какие из транзакций были выполнены прежде чем исполняется текущая транзакция. Об истории мы говорим как о подлежащей сериализуемости, когда она эквивалентна (то есть имеет тот же самый граф зависимости) некоторой истории, которая выполняет эти транзакции последовательно. Вы можете вернуться к понятиям историй, их эквивалентности, сериализуемости и прочим концепциям в разделе Возможность преобразования в последовательную форму. В целом, данная глава дублирует для распределённых систем Главу 5, в которой мы обсуждали обработку транзакций локально в узле.
Транзакции единственного раздела вовлекают пессимистические (основанные на блокировке или отслеживании) или оптимистические (попытка и валидация) схемы контроля одновременностью, которые обсуждались в Главе 5, однако ни один из этих подходов не решает основную проблему транзакций со множеством разделов, которые требуют координации между различными серверами, распределённые фиксации и протоколы отката.
Говоря в общем, когда вы переводите деньги с одного счёта на другой, вы бы желали одновременно кредитовать свой первый счёт и дебетовать свой второй. Однако если мы разобъём эту транзакцию на индивидуальные шаги, дебетование и кредитование не выглядят атомарными даже в первой площадке: нам требуется считать значение старого баланса, добавить или вычесть требуемое значение и сохранить этот результат. Каждый из этих подэтапов вовлекает различные операции: данный узел получает некий запрос, выполняет его синтаксический разбор, определяет местоположение данных на диске, выполняет запись и, наконец, получает её подтверждение. Даже это представление достаточно высокого уровня: для выполнения простой записи нам придётся выполнить сотни небольших шажков.
Это означает, что нам придётся вначале исполнить эту транзакцию и лишь затем сделать её результаты видимыми. Но для начала давайте определим что такое транзакция. Некая транзакция это набор операций, некого атомарного элемента исполнения. Атомарность транзакции подразумевает, что все её результаты становятся видимыми, либо ни один из них таковым не становится. Например, когда мы изменяем определённые строки, или даже таблицы в некой отдельной транзакции, будут применены либо все эти изменения, либо ни одно из них.
Для обеспечения атомарности транзакции должны быть восстанавливаемыми, иначе говоря, если транзакция не может быть выполнена, она прерывается или приостанавливается, а её результаты полностью откатываются обратно. Некая незавершённая, частично выполненная транзакция может оставить свою базу данных в неком несогласованном состоянии. Суммируя, в случае не успешности выполнения транзакции, значение состояния базы данных должно быть возвращено в предыдущее состояние, как будто даже никогда и не существовало никакой попытки этой транзакции по её первому месту.
Другой важной стороной являются сетевые разделы и отказы узлов: узлы в такой системе отказывают и восстанавливаются независимо, однако их состояния должны оставаться согласованными. Это означает, что такое требование атомарности сохраняется не только для своих локальных операций, но и для исполняемых в прочих узлах операций: изменения должны распространяться на долговременной основе во все те узлы, которые вовлечены в данную транзакцию, либо ни в один из них [LAMPSON79].
Чтобы заставить множество операций представляться как атомарные, в особенности когда часть из них являются удалёнными, нам требуется применять некий класс алгоритмов, носящих название фиксируемых атомарно. Атомарная фиксация не допускает рассогласования между своими участниками: некая транзакция не будет зафиксирована когда хотя бы один из участников возражает против неё. В то же самое время это означает, что отказавшие процессы должны достичь того же самого согласия, что и остальные из этой когорты компаньонов. Другим важным заключением из этого факта является то, что алгоритмы атомарной фиксации не работают в присутствии Византийских отказов: когда данный процесс лжёт относительно своего состояния или решений по произвольным значениям, так как это вступает в противоречие с единодушием [HADZILACOS05].
Та основная задача, которую пытается решать атомарность состоит в достижения согласия по тому стоит или нет выполнять предложенную транзакцию. Компаньоны не могут выбираться, подвергаться воздействию или изменять саму предполагаемую транзакцию либо предлагать какую- то альтернативу: они лишь могут либо за, либо против того желают ли они её исполнить [ROBINSON08].
Алгоритмы атомарной фиксации не устанавливают строгих требований на саму семантику или операции подготовки, фиксации или отката транзакции. Разрабатывающие базу данных должны принимать решение по:
-
Тому когда эти данные рассматриваются готовыми к фиксации и остаётся лишь переключить ссылку чтобы сделать эти изменения общедоступными.
-
Как выполнять данную фиксацию саму по себе чтобы сделать результаты данной транзакции видимыми в самый кратчайший по возможности временной промежуток.
-
Как откатить обратно все сделанные этой транзакцией изменения если данный алгоритм принял решение не выполнять фиксацию.
Мы уже обсуждали в Главе 5 эти процессы для реализаций локального узла.
Многие распределённые системы применяют алгоритмы атомарной фиксации - например, MySQL (для распределённых транзакций) и Kafka (для производителей и потребителей итераций) [MEHTA17].
В базах данных распределённые транзакции исполняются своими компонентами, обычно носящими название диспетчеров транзакций. Диспетчер транзакций это некоторая подсистема, которая отвечает за планирование, координацию, выполнение и отслеживание транзакций. В некоторой распределённой среде такой диспетчер транзакций отвечает за обеспечение гарантии видимости локального узла находятся в согласии с той видимостью, которая предписывается распределёнными атомарными операциями. Иначе говоря, транзакции фиксируются во всех разделах, для всех реплик.
Мы обсудим два алгоритма атомарной фиксации: двухфазную фиксацию, которая решает задачу фиксации, но не допустима при отказах самого координирующего процесса; а также трёхфазную фиксацию [SKEEN83], которая решает проблему неблокируемой атомарной фиксации (отличная статья отмечает что в "предположении высоконадёжной сетевой среды", иными словами, в некой сетевой среде, предотвращающей разбиение на разделы [ALHOUMAILY10]; следствия данного предположения были обсуждены в разделе этой статьи по описанию алгоритма), и позволяет участникам выполнение даже в случае отказа координатора [BABAOGLU93].
Давайте начнём с наиболее прямолинейного протокола для распределённой фиксации, который допускает атомарные обновления множества разделов. (Для дополнительных сведений по разделам вы можете обратиться к секции Разбиение баз данных на разделы)/ Двухфазная фиксация (2PC, Two-phase commit) обычно обсуждается в контексте транзакций базы данных. 2PC выполняется в две фазы. В прроцессе своей первой фазы распространяется определённое значение и собираются голоса. В процессе второй фазы просто перекидывают свой переключатель, делая полученные в первой фазе результаты видимыми.
2PC предполагает наличие некого лидера (или координатора), который удерживает значение состояния, собирает голоса и выступает первичной точкой ссылки для раунда принятия согласия. Остальные узлы именуются когортой (Пособниками). Пособники, в данном случае, это обычно разделы, которые работают с разъединёнными наборами данных для которых и выполняются транзакции. Имеющийся координатор и все Пособники ведут журналы локальных операций для каждого исполняемого шага. Участники голосуют принимать или отклонять некоторое значение, собираемые установленным координатором. Наиболее часто это значение некоторый идентификатор данной подлежащей исполнению транзакции, однако 2PC может использоваться и в иных контекстах.
Установленный координатор может быть неким узлом, который принимает какой- то запрос на исполнение определённой транзакции или он может указываться случайным образом, при помощи алгоритма выбора лидера, назначаться вручную или даже фиксироваться на всё время жизни данной системы. Сам протокол не помещает ограничения на роль своего координатора и данная роль может передаваться другому участнику для надёжности или производительности.
Как и предполагает её название, двухфазная фиксация осуществляется за два шага:
- Подготовка
Установленный координатор оповещает Пособников (когорту) относительно данной новой транзакции, отправляя сообщение
Propose. Пособники принимают решение будут или нет они фиксировать ту часть данной транзакции, которая применяется к ним. Если Пособники считают что они могут её фиксировать, они оповещают своего координатора о своём положительном голосе. В противном случае они отвечают координатору просьбой прервать данную транзакцию. Все принятые Пособниками решения сохраняются в журнале этого координатора, а каждый Пособник хранит некую копию своего решения локально.
- Фиксация/ прерывание
Операции внутри некой транзакции могут изменять состояние в различных разделах (каждое представляется неким Пособником). Если хотя бы один из Пособников голосует за прерывание данной транзакции, их координатор отправляет им всем сообщение
Abort. Только когда все Пособники дали положительные голоса, их координатор рассылает им завершающее сообщениеCommit.
Этот процесс показан на Рисунке 13-1.
Рисунок 13-1
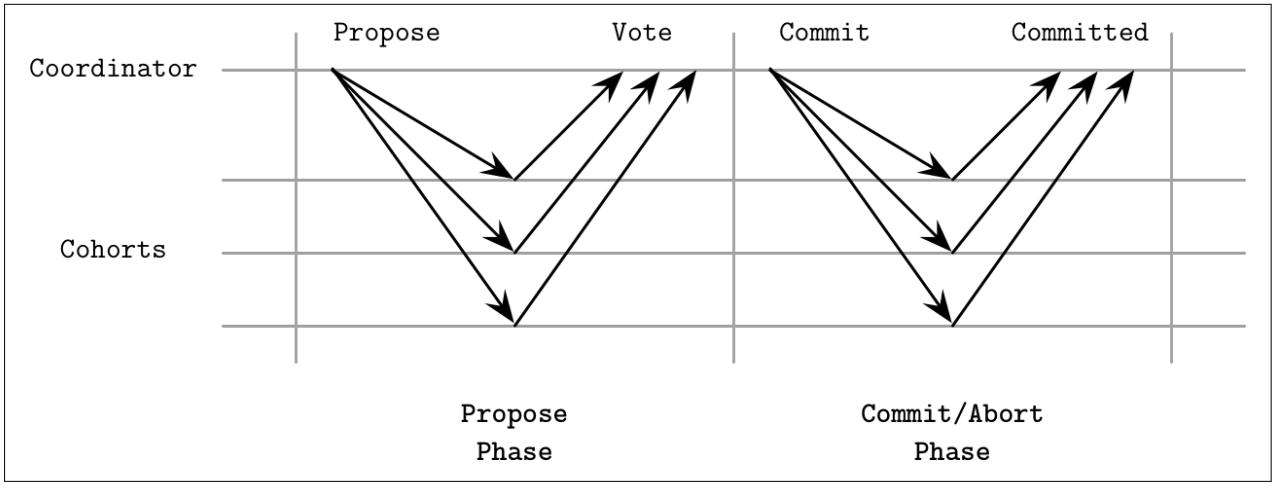
Протокол двухфазной фиксации. В процессе самой первой фазы коллеги оповещаются относительно данной новой транзакции. На протяжении второй фазы эта транзакция либо фиксируется, либо прерывается.
На протяжении фазы подготовки установленный координатор распространяет предлагаемое значение и собирает голоса от участников относительно того будет или нет данное предлагаемое значение фиксировано. Пособники могут, например, выбирать отклонение предложения когда иная конфликтующая транзакция уже фиксировала некое иное значение.
После того как установленный координатор собрал все голоса, он может принять решение о
фиксации этой транзакции или прервать
её. Когда все Пособники проголосовали положительно, он принимает решение о фиксации и уведомляет их отправкой
сообщения Commit. В противном случае этот координатор отправляет всем Пособникам
сообщение Abort и данная транзакция откатывает обратно. Иными словами, когда
данное предложение отклоняет один узел, прерывается весь раунд.
На протяжении каждого шага установленный координатор и Пособники должны записывать все результаты каждой операции в постоянное хранилище чтобы иметь возможность реконструировать своё состояние и восстановиться в случае локальных отказов и быть способной передавать и воспроизводить результаты для прочих участников.
В контексте систем баз данных всякий раунд 2PC обычно отвечает за некую отдельную транзакцию. На протяжении своей фазы подготовки содержимое транзакции (операции, идентификаторы и прочие метаданные) передаются от установленного координатора имеющимся Пособникам. Сама транзакция выполняется Пособниками локально и остаётся в состоянии частичной фиксации (иногда именуемой предварительной фиксацией), приводя их в готовность для установленного координатора финализировать исполнение в процессе следующей фазы либо фиксируя, либо прерывая её. К моменту фиксации данной транзакции, её содержимое уже сохранено на постоянной основе во всех прочих узлах [BERNSTEIN09].
Давайте рассмотрим различные сценарии отказов. Например, как отображено на Рисунке 13-2, когда один из Пособников отказывает на фазе предложения, установленный координатор не способен продолжать некую фиксацию, так как ему необходимы все голоса положительными. Когда один из Пособников недоступен, наш координатор прервёт данную транзакцию. Это требование имеет негативное воздействие на доступность: отказ отдельного узла может препятсвовать прохождению транзакции. Некоторые системы, например Spanner (см. раздел Распределённые транзакции при помощи Spanner), выполняет 2PC для групп Paxos вместо того чтобы делать это для индивидуальных узлов для улучшения доступности протокола.
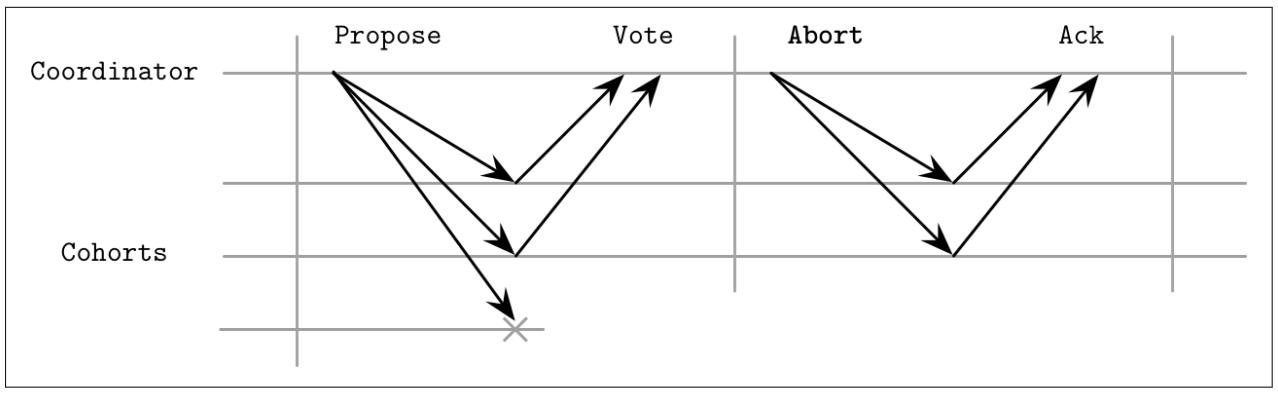
Основная стоящая за 2PC идея состоит в обещании от Пособников, что раз уж они откликнулись положительно на данное предложение, они не отзовут обратно своё решение, а потому лишь координатор способен прервать данную транзакцию.
Когда один из Пособников отказывает после принятия данного предложения, ему придётся изучать реальный ход голосования прежде чем он сможет обслужить значения правильно, так как координатор мог прервать данную фиксацию по причине соответствующих решений прочих Пособников. После восстановления узла Пособника, ему придётся поторопиться для окончательного решения координатора. Обычно это выполнятся сохранением на постоянной основе соответствующего журнала решений на стороне установленного координатора и реплицированием значений решений своим отказавшим участникам. До тех пор такой Пособник не способен обслуживать запросы по причине своего несогласованного состояния.
Поскольку этот протокол обладает множеством пятен в которых процессы дожидаются прочих участников (пока установленный координатор собирает голоса, или когда Пособники ожидают соответствующей фазы фиксации/ прерывания), отказы соединений способны приводить к потере сообщений и такое ожидание будет происходить неопределённо долго. Когда установленный координатор не получает отклика от соответствующей реплики в процессе фазы предложения, он может включить некий таймаут и прервать данную транзакцию.
Когда один из Пособников не получает команды фиксации или прерывания от своего координатора на протяжении установленной второй фазы, как это показывается на Рисунке 13-3, он обязан попытаться определить какое именно решение было сделано его координатором. Его координатор мог принять решение по данному значению, но не имел возможности выполнить взаимодействие со своей определённой репликой. В подобных случаях, сведения о принятом решении могут реплицироваться из соответствующих журналов транзакций одноранговых партнёров или из имеющейся резервной копии координатора. Реплицируемые решения по фиксации безопасны, ибо они всегда единодушны: вся точка целиком в 2PC либо фиксирована либо прервана на всех площадках, а фиксация на одном из Пособников подразумевает что все прочие Пособники также должны иметь фиксацию.
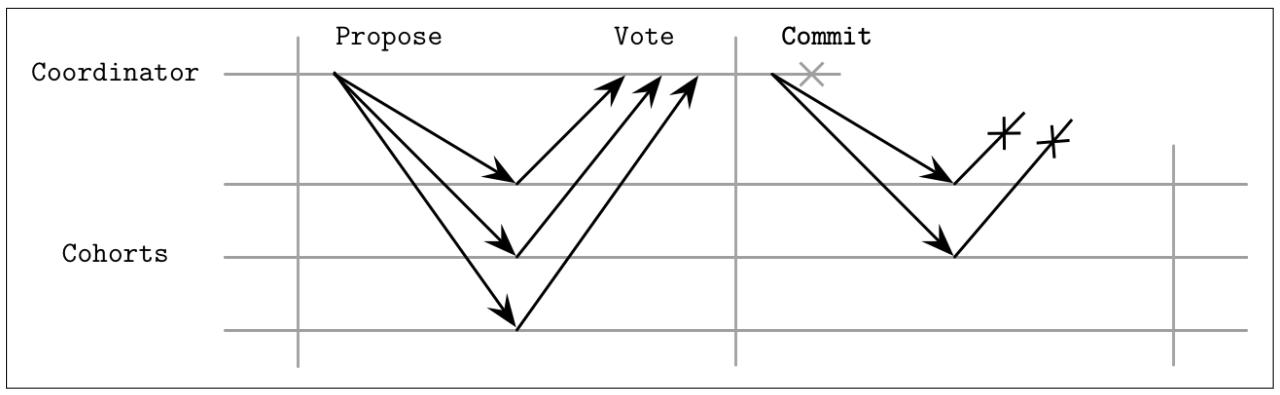
На протяжении своей первой фазы установленный координатор собирает голоса и, впоследствии, обещания от Пособников, что они дождутся его команды фиксации или прерывания в явном виде. Если установленный координатор падает после сбора голосов, но до широковещательного оповещения о результатах голосования, его Пособники приходят в конце концов в некое состояние неопределённости. Это отражено на Рисунке 13-4. Пособники не знают что в точности решил их координатор и были или нет ккие- то участники (потенциально также недоступные) уведомлены о результатах данной транзакции [BERNSTEIN87].
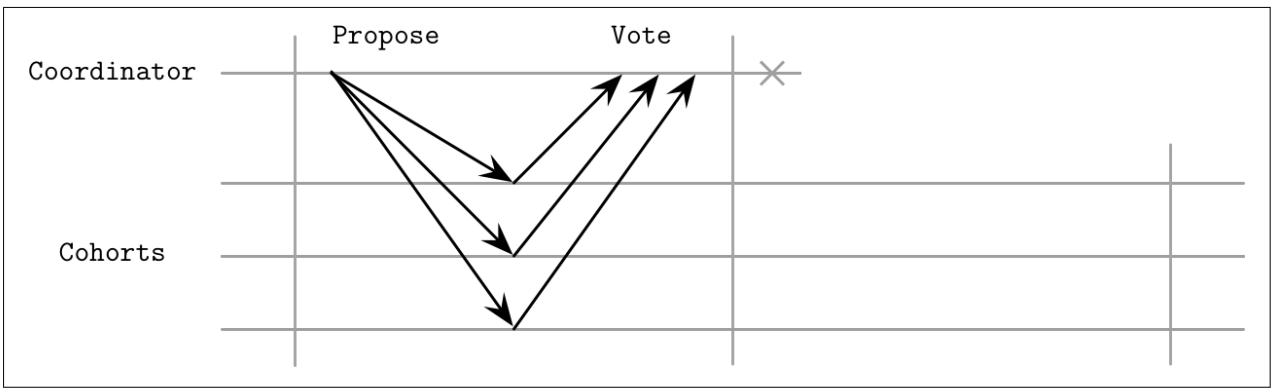
Неспособность установленного координатора продолжать фиксацию или прерывание оставляет данный кластер в неком неопределённом состоянии. Это означает, что Пособники не будут иметь возможности изучить окончательное решение в случае непрерывного отказа своего координатора. По причине данного свойства мы говорим, что 2PC является блокирующим алгоритмом атомарной фиксации.Если установленный координатор никогда не восстановится, его заместителю придётся собирать голоса для данной транзакции заново и продолжить принятие окончательного решения.
Многие базы данных применяют 2PC: MySQL, PostgreSQL, MongoDB (однако документация сообщает, что относительно v3.6, 2PC предоставляет лишь подобную транзакции семантику) и прочие. Двухфазная фиксация часто используется для реализации распределённых транзакций по причине своей простоты (о ней просто рассуждать, реализовывать и отлаживать) и низким накладным расходам (сложность сообщения и общее число проходов туда- обратно на низком уровне). Важно реализовывать надлежащим образом механизмы восстановления и иметь резервные копии узлов координаторов для снижения только что описанных шансов на отказ.
Для того чтобы сделать некий протокол атомарной фиксации надёжным в отношении отказов координаторов и избегать неопределённых состояний, протокол трёхфазной фиксации (3PC, three-phase commit) добавляет некий дополнительный шаг и таймауты с обеих сторон, которые способны позволить Пособникам продолжать либо фиксацией либо прерыванием в случае отказа координатора, в зависимости от значения состояния системы. 3PC предполагает некую синхронную модель и что отказы взаимодействия невозможны [BABAOGLU93].
3PC добавляет некую фазу подготовки перед шагом фиксации/ прерывания, которая взаимодействует с состояниями Пособников, собранными установленным координатором на протяжении фазы предложения, позволяя данному протоколу выполнять передачу даже при отказе координатора. Все прочие свойства 3PC и требование обладания координатором для соответсвующего раунда аналогичны его двухфазному собрату. Другим полезным добавлением в 3PC являются таймауты на стороне Пособников. В зависимости от того на каком шагу выполняется в настоящий момент данный процесс, по таймауту форсируется либо решение о фиксации, либо о прерывании.
Как отображено на Рисунке 13-5, раунд трёхфазной фиксации состоит из трёх этапов:
- Предложение
Установленный координатор отправляет некое предлагаемое значение и собирает имеющиеся голоса.
- Подготовка
Установленный координатор уведомляет Пособников относительно полученных результатов голосования. Если все голоса прошли и все Пособники приняли решение о фиксации, наш координатор отправляет сообщение
Prepare, выдавая им инструкцию о подготовке к фиксации. В противном случае отправляется сообщениеAbortи данный раунд завершается.- Фиксация
Пособники уведомляются своим координатором о фиксации данной транзакции.
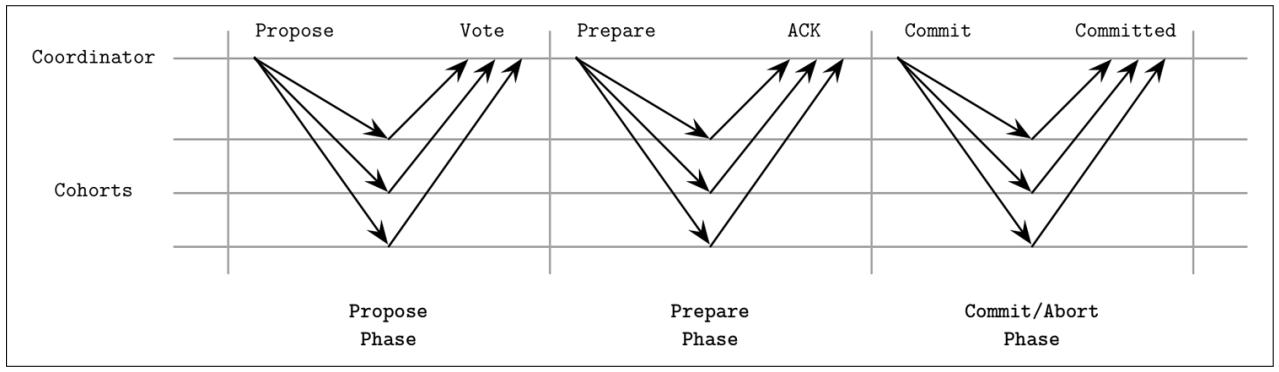
На протяжении шага подготовки, аналогично 2PC, установленный координатор распространяет своё предлагаемое значение и собирает голоса от Пособников, как это показано на Рисунке 13-5. Если наш координатор испытывает на данной фазе крушение и все операции выходят по таймауту, или если один из имеющихся Пособников голосует отрицательно, данная транзакция будет прервана.
После сборки всех голосов установленный координатор принимает решение. Когда этот координатор решает продолжать данную
транзакцию, он вызывает команду Prepare. Может так случиться, что этому
координатору не удастся распространить подготовленное сообщение всем Пособникам или он испытает отказы в приёме их
подтверждений. В таком случае Пособники способны прервать данную транзакцию по истечению таймаута, так как данный алгоритм
не переместил все слоты в состояние подготовленных.
Как только все Пособники успешно перейдут в состояние подготовленных, а их координатор получит их подтверждения о подготовленности, данная транзакция будет фиксирована даже если какая- то из сторон откажет. Это может быть сделано так как все участники на своих этапах обладают одним и тем же представлением о значении состояния.
В процессе фиксации, установленный координатор делится полученными результатами фазы подготовки со всеми имеющимися участниками, сбрасывая их счётчики таймаутов и действенно завершаю данную транзакцию.
Все переходы состояний координируются и Пособники не способны переходить в следующую фазу до тех пор, пока все не выполнят предыдущую: установленный координатор обязан дожидаться продолжения репликаций. Пособники могут со временем прерывать свою транзакцию когда им не услышан их координатор до окончания таймаута, если они не прошли фазу подготовки.
Как мы уже обсуждали ранее, 2PC не способен восстанавливать отказы координатора и Пособники могут застрять в состоянии неопределённости до тех пор пока в строй не вернётся их координатор. 3PC избегает блокирования процессов в подобном случае и позволяет Пособникам продолжать с неким детерминированным решением.
Наихудшим из сценариев для 3PC является некое разбиение на сетевые разделы, отображаемое на Рисунке 13-6. Некоторые узлы успешно перешли в состояние подготовленных и теперь способны продолжать фиксацию по завершению таймаута. Часть же не может взаимодействовать со своим координатором и они будут прерваны после своего таймаута. В результате это приводит к расщеплению сознания: некоторые узлы продолжат фиксацией, а какие- то будут прерваны, причём всё в соответствии с установленным протоколом, оставляя участников в неком несогласованном и противоречивом состоянии.
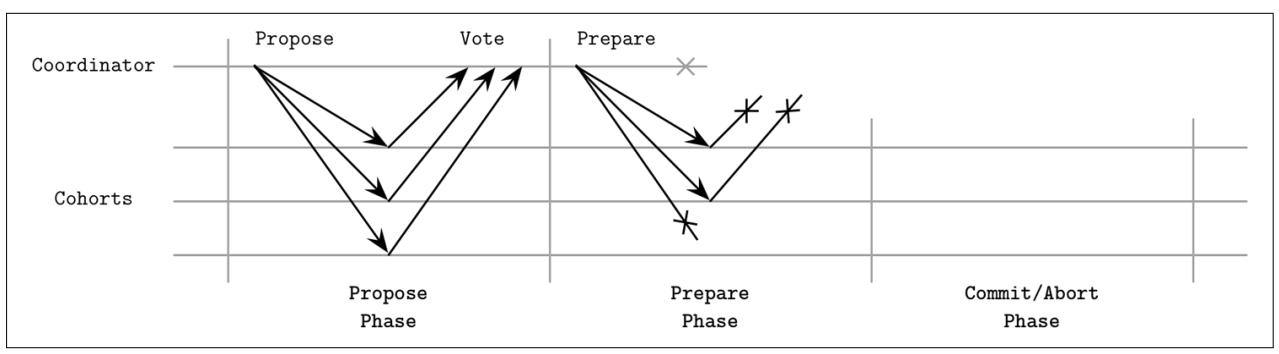
Хотя в теории 3PC и решает, до некоторой степени, основную проблему с блокированием 2PC, она обладает большими накладными расходами сообщений, вводит потенциальные противоречия и не работает должным образом при наличии разбиения на сетевые разделы. Именно это может служить самой основной причиной почему 3PC широко не применяется на практике.
Мы уже касались темы стоимости синхронизации и различные способы её решения. Однако существуют и прочие пути снижения разногласий и общего объёма времени на протяжении которого транзакции удерживают блокировки. Один из способов для такой работы состоит в том, чтобы позволять репликам согласовывать необходимый порядок исполнения и границы транзакции до овладения блокировками и продолжения выполнения. Когда мы можем достигать этого, отказы узлов не вызовут прерываний транзакции, так как узлы могут восстанавливать состояние от прочих участников параллельно исполняющих ту же самую транзакцию.
Традиционные системы баз данных исполняют транзакции применяя двухфазную блокировку или оптимистический контроль одновременности и не имеют никакого детерминированного порядка транзакции. Это означает, что узлам приходится координировать для сохранения необходимого порядка. Детерминированный порядок транзакции удаляет накладные расходы координации на протяжении фазы выполнения и, поскольку все реплики получили те же самые исходные данные, они также производят эквивалентные вывода. Этот подход общеизвестен как Calvin, быстры протокол транзакции [THOMSON12]. Одним из бросающихся в глаза примеров реализации распределённых транзакций при помощи Calvin является FaunaDB.
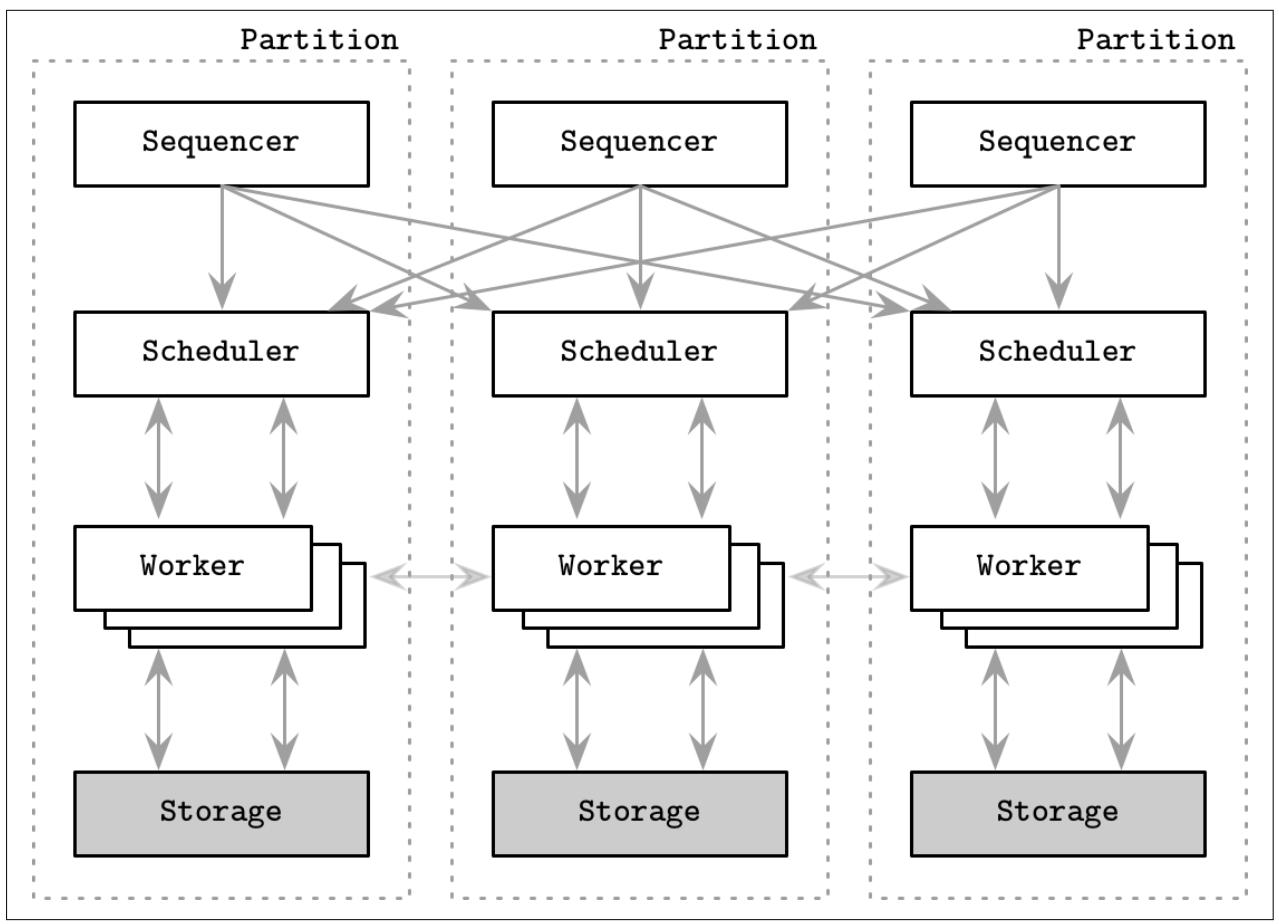
Для достижения детерминированного порядка, Calvin пользуется некой программой упорядочения (sequencer): входной точкой для всех транзакций. Данная программа упорядочения определяет необходимый порядок в котором исполняются транзакции и устанавливает некую глобальную последовательность входных данных транзакции. Для минимизации содержимого и решений в пакете, имеющаяся временная линия разбивается на эпохи. Программа упорядочения собирает транзакции и группирует их в короткие временные окна (первоначальная статья упоминает пакеты в 10- миллисекунд), которые также превращаются в элементы репликации, а потому транзакциям не приходится взаимодействовать по отдельности.
После того как некий пакет транзакции успешно реплицирован, программа упорядочения переправляет его в планировщик, который дирижирует исполнением транзакции. Такой планировщик применяет детерминированный протокол планирования, который выполняет части транзакции параллельно, в то же самое время сохраняя тот порядок последовательного исполнения, который определён программой упорядочения. Так как применение транзакции к некому определённому состоянию обеспечивает производство лишь определённых данной транзакцией изменений, а порядок транзакции предварительно определён, репликам не приходится выполнять дальнейшее взаимодействие со своей программой упорядочения.
Всякая транзакция в Calvin обладает неким набором чтений (её зависимостями, которые являются коллекцией записей данных из текущего состояния базы данных, требуемых для её же исполнения) и набором записи (результатами исполнения этой транзакции; иными словами, её стороннего воздействия). Calvin не поддерживает естественным путём транзакции, которые полагаются на дополнительные чтения, которые определяли бы наборы чтения и записи.
Поток исполнителя (worker) управляемый планировщиком, выполняет свои действия за четыре шага:
-
Анализирует имеющиеся наборы чтения и записи, определяет записи данных набора чтения, локальные для узла, и создаёт список активных участников (т.е. тех, которые содержат необходимые элементы набора записи и будут осуществлять изменение имеющихся данных).
-
Он собирает все локальные данные, необходимые для выполнения данной транзакции, иначе говоря, те записи набора чтения, которым посчастливилось присутствовать на стороне данного узла. Все собранные записи данных передаются соответствующим активным участникам.
-
Если данный поток исполнителя осуществляется в неком узле активного участника, он получает записи данных, передаваемые от прочих участников в качестве некого дубликата выполненных на протяжении шага 2 операций.
-
Наконец, он исполняет некий пакет транзакций, сохраняя результаты в локальном хранилище. Он не должен переправлять результаты выполнения прочим узлам, поскольку они получили те же самые входные данные для транзакций и выполнения и самостоятельно сохраняют результаты локально.
Обычная реализация Calvin объединяет в одном месте подсистемы программы упорядочения, планировщика, исполнителя и хранения как это отображает Рисунок 13-7. Чтобы убедиться что программа упорядочения в точности достигла согласия какие транзакции выполнять в текущих эпохе/ пакете, Calvin пользуется алгоритмом консенсуса Paxos (см. раздел Paxos) или асинхронные репликации, в которых лидером выступает некое выделенное обслуживание реплики. Хотя применение некого лидера способно улучшать латентность, это происходит за счёт более высокой стоимости восстановления, поскольку узлам приходится для выполнения по порядку повторно воспроизводить значение состояния своего отказавшего лидера.
Calvin часто противопоставляется другому подходу для управления распределёнными транзакциями с названием Spanner [CORBETT12]. Его реализации (или производные) включают некоторые базы данных с открытым исходным кодом, с наиболее известными CockroachDB и YugaByte DB. В то время как Calvin устанавливает глобальный порядок выполнения транзакции достигая согласия относительно последовательности. Spanner использует двухфазную фиксацию поверх групп согласия для раздела (иными словами для Фрагмента, Осколка, Черепка - shard). Spanner имеет достаточно сложную настройку и мы рассмотрим в рамках данной книги лишь подробности верхнего уровня.
Для достижения согласованности и фиксации порядка транзакции Spanner пользуется TrueTime высокоточным API часов- ходиков, которые также выставляют некое ограничение неопределённости, позволяя локальным операциям вводить искусственные замедления чтобы дождаться пересечения границу неопределённости.
Spanner предлагает три основных типа операций: транзакции чтение- запись, транзакции только чтения и чтения моментального снимка. Транзакции чтения- записи требуют блокировок, пессимистического контроля одновременности и наличия соответствующей лидирующей реплики. Транзакции исключительного чтения свободны от блокировки и могут исполняться для любой реплики. Некий лидер требуется только для чтения самой последней временной отметки, которая получает самое последнее фиксированное значение соответствующей группы Paxos. Считывания в такую определённую временную метку согласованно, поскольку значения снабжены версиями и содержимое моментального снимка не может изменяться при записи. Всякая запись данных имеет назначенную ей временную метку (tinestamp), которая содержит значение времени фиксации соответствующей транзакции. Это также подразумевает, что может храниться множество версий с временными отметками определённой записи.
Рисунок 13-8 отображает архитектуру Spanner. Всякий Спансервер (реплика, некий обслуживающий данные клиента экземпляр) содержит различные Плитки (tablets), причём к ним присоединены машины состояний Paxos (см. раздел Paxos). Реплики группируются в наборы реплик, носящие название групп Paxos, некого элемента помещения и репликации данных. Всякая группа Paxos обладает долгоживущим лидером (см. раздел Multi-Paxos). Лидеры взаимодействуют друг с другом в процессе транзакций со множеством Фрагментов (multishard).
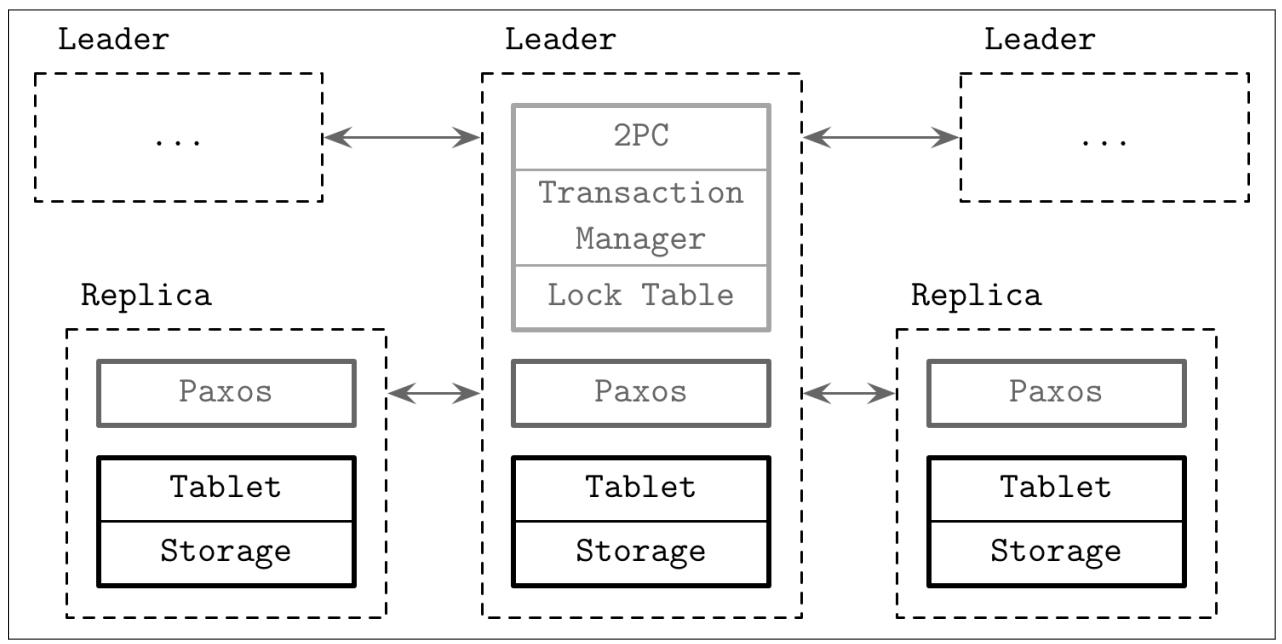
Всякая запись обязана проходить через лидера группы Paxos, в то время как считывания могут обслуживаться напрямую из Плиток в актуальных репликах. Соответствующий лидер удерживает некую таблицу блокировок, которая применяется для реализации контроля одновременности с использованием механизма двухфазной блокировки (см. раздел Управление одновременностью на основе блокировок) и некого диспетчера транзакции, который отвечает за распределённые транзакции множества Фрагментов. Требующие синхронизации операции (такие как записи и чтения в рамках некой транзакции) должны овладевать соответствующими блокировками из установленной таблицы блокировок, в то время как прочие операции (считывания моментальных снимков) могут получать доступ к данным напрямую.
Для транзакция со множеством Фрагментов лидеры групп должны выполнять координацию и осуществлять двухфазные фиксации для обеспечения согласованности, а также применять двухфазные блокировки для гарантии изолированности. Так как соответствующий алгоритм 2PC требует присутствия всех участников для некой успешной фиксации, он травмирует доступность. Spanner разрешает это применяя группы Paxos вместо индивидуальных участников в качестве Пособников. Это означает, что 2PC способен продолжать действия даже когда некоторые его участники в данной группе остановлены. Внутри соответствующей группы Paxos 2PC контактирует только с тем узлом, который служит лидером.
Группы Paxos используются для согласованной репликации состояний диспетчера транзакций по множеству узлов. Сам лидер
Paxos вначале овладевает блокировками записи и выбирает временную отметку записи, которая гарантирует что она будет иметь
значение больше чем любая предыдущая временная отметка транзакции и записывает через Paxos некую запись 2PC
prepare. Установленный координатор транзакции собирает временные отметки и
вырабатывает некую временную отметку фиксации, которая обладает значением больше всех имеющихся временных отметок
подготовки и регистрирует в журнале запись commit через Paxos. Затем он дожидается
пока не произойдёт фиксация после значения выбранной для ней временной отметки,
так как ему требуется обеспечить что клиент будет наблюдать результаты, чьи временные отметки относятся к прошлому. После
этого он отправляет данную временную отметку своему клиенту и лидерам, которые регистрируют в журнале соответствующую
запись commit с этим новым значением временной отметки в своих локальных группах
Paxos и теперь вольны высвобождать соответствующие блокировки.
Транзакциям с единственным Фрагментом не приходится консультироваться со своим диспетчером транзакций (и, позднее, не приходится выполнять некую двухфазную фиксацию по платформам), так как для обеспечения порядка транзакции и согласованности внутри соответствующего Фрагмента достаточно консультаций внутри группы Paxos и таблицы блокировок.
Транзакции чтения- записи Spanner предлагают некое упорядочение, носящее наименование внешней
согласованности: временные метки транзакции отражают порядок упорядочения, причём даже в случае распределённых
транзакций. Внешняя согласованность обладает свойствами реального времени, эквивалентными линеаризации: когда транзакция
T1 фиксируется до запуска T2,
временная отметка T1 имеет значение меньше чем временная отметка для
T2.
Чтобы суммировать, Spanner применят Paxos для согласованной репликации журнала транзакции, двухфазную фиксацию для транзакция по Фрагментам и TrueTime для детерминированного упорядочения транзакций. Это означает, что транзакции со множеством разделов обладают большей стоимостью по причине некого дополнительного раунда двухфазной фиксации, в сравнении с Calvin [ABADI17]. Важно понимать оба подхода, так как они позволяет нам выполнять транзакции в разбитых на части распределённых хранилищах данных.
При обсуждении Spanner и Calvin мы достаточно интенсивно пользовались термином разбиения на разделы. Давайте теперь обсудим его более подробно. Так как хранение всех записей базы данных в неком отдельном узле для большинства современных приложений достаточно нереально, многие базы данных применяют разбиение на разделы: некое логическое деление данных на управляемые сегменты меньшего размера.
Наиболее прямолинейным способом разбиения данных является расщепление на диапазоны и разрешение управления лишь определёнными диапазонами (разделами) лишь наборам реплик (replica sets). При выполнении запросов, клиенты (или координаторы запроса) должны осуществлять маршрутизацию запросов на основании соответствующего ключа маршрутизации к верному набору реплик как для чтений, так и для записей. Такая схема разбиения обычно носит наименования фрагментации (sharding): каждый набор реплик выступает как некий отдельный источник для какого- то подмножества данных.
Для более действенного применения разделов, для них следует устанавливать размеры, принимая во внимание имеющуюся
нагрузку и распределений значений. Это означает, что диапазоны с частым доступом, интенсивными чтением/ записью
могут расщепляться на разделы с меньшим размером для разделения по ним имеющейся нагрузки. В то же самое время, когда
некоторые диапазоны более плотны чем иные, хорошей мыслью может быть также расщепление их на меньшие разделы. Например,
когда мы цепляемся за диапазоны zip code в качестве ключа маршрутизации,
поскольку население определённой страны неравномерно разделено, некоторые диапазоны индекса могут иметь выделенными им
больше сведений (т.е. людей и заказов).
При добавлении или удалении в соответствующем кластере узлов наша база данных должна перестраивать разбиение на разделы для соблюдения баланса данных. Для обеспечения согласованных перемещений нам требуется передислоцировать соответствующие данные до того как мы обновим метаданные своего кластера и запустим запросы маршрутизации к своим новым целям. Некоторые базы данных осуществляют автоматическую фрагментацию и передислоцируют необходимые данные при помощи алгоритмов размещения, которые определяют оптимальные разбиения. Такие алгоритмы пользуются сведениями о нагрузках чтения, записи и объёмах данных в каждом из Фрагментов.
Для поиска некого целевого узла по соответствующему ключу маршрутизации некоторые системы баз данных вычисляют какой- то хэш данного ключа и применяют некий вид соответствия по значению данного хэш- значения соответствующему идентификатору узла. Одним из преимуществ использования хэширующих функций для определения размещения реплики является то, что он способствует снижению горячих пятен диапазонов, так как хэш значения не сортируются также как и их первоначальные значения. В то время как два лексикографически близких ключа маршрутизации помещались бы в одно и то же самое множество реплик, при применении хэш- значений мы будем помещать их в разные разделы.
Наиболее прямолинейный способ установления соответствия хэш- значений идентификаторам узлов состоит в получении
остатка от деления соответствующего значения хэша на размер данного кластера (по модулю - modulo). Когда у нас имеется
в нашей системе N узлов, значение идентификатора целевого узла закрепляется
вычислением hash(v) modulo N. Самой основной проблемой при таком подходе
является то, что по мере добавления или удаления узлов и изменении размера кластера с
N на N', многие возвращаемые
hash(v) modulo N' значения будут отличаться от своих первоначальных. Это
означает, что придётся перемещать большую часть данных.
Для ослабления указанной проблемы некоторые базы данных, например, Apache Cassandra и Riak (помимо прочих), применяют иную схему разбиения на разделы с названием согласованного хэширования (consistent hashing). Как уже упоминалось ранее, значения ключей маршрутизации хэшируются. Возвращаемые соответствующей хэш- функцией значения ставятся в соответствие в неком кольце, с тем, чтобы после самого большего возможного значения они возвращались к своему наименьшему. Всякий узел получает своё собственное место в данном кольце и становится ответственным за соответствующий диапазон значений между своим предшественником и его собственным местом.
Применение согласованного хэширования способствует снижению общего числа передислокаций, необходимых для
поддержания баланса: некое изменение в данном кольце воздействует лишь на имеющихся непосредственных
соседей данного покинувшего или присоединившегося узла, а не на весь кластер целиком. Значение слова
согласованный в этом определении подразумевает, что при изменении размера
соответствующей таблицы хэширования, когда у нас имеется K возможных ключей
хэша и n узлов, в среднем нам придётся передислоцировать только
K/n ключей. Иначе говоря, выдача некой согласованной хэш- функции изменяется
минимально по мере изменения диапазона функции [KARGER97].
Возвращаясь обратно к предмету распределённых транзакций, может оказаться сложным рассуждение относительно уровней изоляции по причине допуска аномалий чтения и записи. Когда соответствующим приложением не требуется сериализуемость, один из способов избежания аномалий записи описывается в SQL-92 и он состоит в применении некой модели транзакции с названием изоляции моментального снимка (SI, snapshot isolation).
Изоляция моментального снимка обеспечивает то, что все выполняемые в рамках данной транзакции чтения делаются согласованно в каком- то моментальном снимке базы данных. Такой моментальный снимок содержит все значения, которые были фиксированы до того, как данная транзакция запустила свою временную метку. Если имеется некий конфликт запись- запись (то есть когда две одновременно выполняющиеся транзакции пытаются осуществить некую запись в ту же самую ячейку), фиксируется лишь одна из них. На такое свойство обычно ссылаются как на выигрывает первый фиксирующий.
Изоляция моментального снимка предотвращает скошенное чтение
(read skew), некую аномалию, допускаемую на уровне фиксации- чтения. Например, предполагается, что сумма
x и y должна составлять
100. Транзакция T1
выполняет операцию read(x) и считывает значение
70. T2 обновляет два значения,
write(x, 50) и write(у, 50), а также
выполняет фиксацию. Если T1 попытается выполнить
read(y) и продолжит выполнение транзакции на основании значения
y(50), заново фиксированного T2,
это повлечёт к некому рассогласованию. То значение x, которое
T1 считала перед
фиксацией T2 и данное новое значение
y не согласованы друг с другом. Так как изоляция моментальным снимком относит
значения лишь к определённому моменту времени, видимого для транзакций, такое новое значение
y, 50 не будет видно для
T1
[BERENSON95].
Изоляция моментальным снимком обладает рядом удобных свойств:
-
Она допускает только повторяемые считывания фиксированных данных.
-
Значения согласованы, так как они считываются из соответствующего моментального снимка с некой определённой временной меткой.
-
Конфликтующие записи прерываются и выполняется их повторная попытка для предотвращения несогласованностей.
Несмотря на это, истории под изолированными моментальными снимками не сериализуемы. Поскольку прерываются лишь конфликтующие записи в одни и те же ячейки, мы всё равно способны получить скошенную запись (см. раздел Аномалии чтения и записи). Скошенные записи происходят когда две транзакции изменяют отсоединённые наборы значений, причём каждая сохраняет инварианты этих данных для записываемых ею данных. Обеим транзакциям дозволена фиксация, однако некое сочетание выполняемых этими транзакциями записей может нарушать эти инварианты.
Изоляция моментальных снимков предоставляет семантики, которые могут быть полезны для многих приложений и иметь большое преимущество эффективных чтений, так как не приходится захватывать никакие блокировки так какие могут быть изменены данные моментального снимка.
Percolator это библиотека, которая реализует API транзакций поверх распределённой базы данных Bigtable (см. раздел Хранилища с широкими столбцами). Это прекрасный пример построения API транзакций поверх имеющейся системы. Percolator сохраняет записи данных, фиксирует положение точки данных (метаданные сохранения) и выполняет блокировки в различных столбцах. Во избежание условий состязательности и для надёжности блокирования таблиц в неком отдельном вызове RPC он использует условную изменчивость API Bigtable, которая позволяет ему выполнять операции чтения- изменения- записи единственным удалённым вызовом.
Каждая транзакция обязана консультироваться с предсказателем временной метки (timestamp oracle, некий источник монотонно возрастающих по всему кластеру временных штампов) дважды: для временной метки запуска транзакции и в процессе фиксации. Записи буферируются и фиксируются при помощи управляемой клиентом двухфазной фиксации (см. раздел Двухфазная фиксация).
Рисунок 13-9 отображает как содержимое определённой таблицы изменяется на протяжении исполнения необходимых шагов транзакции:
-
Начальное состояние. После выполнения предыдущей транзакции,
TS1это самый последний временной штамп для обеих учётных записей. Никакая блокировка не удерживается. -
Самая первая фаза носит название предварительной записи. Данная транзакция пробует захватить блокировки для всех записываемых на протяжении этой транзакции ячеек. Одна из этих блокировок помечается как первичная и используется для восстановления клиента. Эта транзакция проверяет все возможные конфликты: когда любая иная транзакция уже записала любые данные с более поздней временной отметкой или существует не высвобожденная блокировка для любой временной отметки. Если выявлен какой- то конфликт, эта транзакция прерывается.
-
Когда все блокировки были успешно захвачены и сама возможность конфликта разрулена, эта транзакция может продолжаться. На протяжении второй фазы данный клиент высвобождает свои блокировки с некой сохранённой записи, обновляет метаданные сохранения со значением временной отметки самой последней точки данных.
Рисунок 13-9
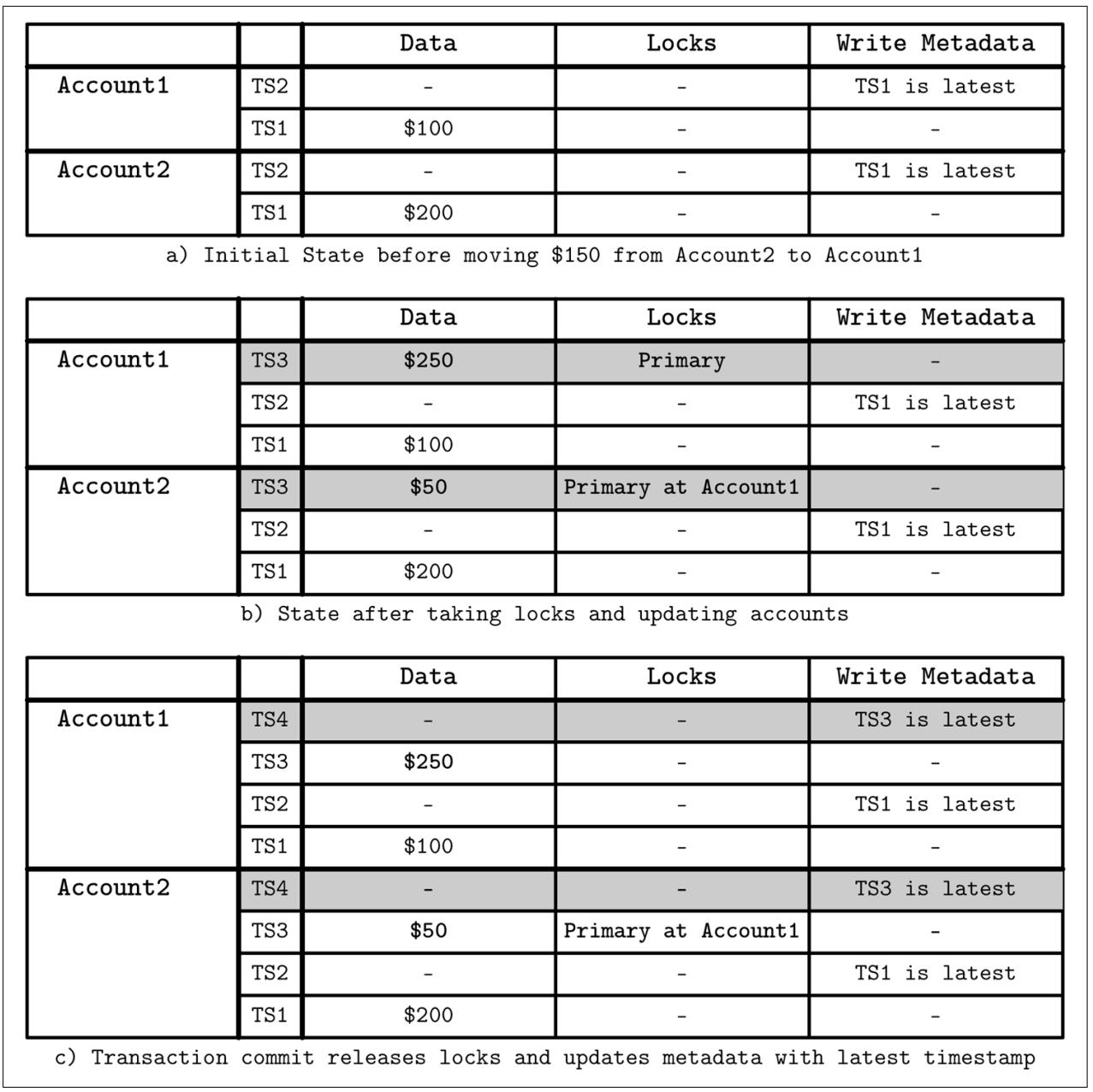
Шаги исполнения транзакции Percolator. Транзакция кредитует $150 с Account2 и дебетует Account1
Так как данный клиент может получить отказ при попытке фиксации своей транзакции, нам требуется убедиться что частичные транзакции финализированы или откачены обратно. Когда более поздняя транзакция сталкивается с неким незавершённым состоянием, ей необходимо попытаться освободить свою первичную блокировку и зафиксировать эту транзакцию. Если такая первичная блокировка уже высвобождена, содержимое транзакции необходимо фиксировать. Лишь одна транзакция способна удерживать блокировку в некий момент времени и все состояния транзакций являются атомарными, поэтому не возможны ситуации, при которых две транзакции пытаются выполнять операции с данным содержимым.
Изоляция моментального снимка является важной и полезной абстракцией, обычно применяемой при обработке транзакций. Так как она упрощает семантики, предотвращает ряд аномалий и открывает некую возможность для улучшения одновременности и производительности, многие системы MVCC предлагают данный уровень изоляции.
Одним из образцов баз данных, основанных на данной модели Percolator является TiDB (Ti это сокращение от Titatium). TiDB строго согласованна, обладает высокой доступностью и является горизонтально масштабируемой базой данных с открытым исходным кодом, причём совместимой с MySQL.
Ещё одним обсуждающим затраты на сериализуемость и попытку снижения общего числа координаций и при этом всё ещё предоставляющим обеспечение строгой согласованности примером является уклонение от координации [BAILIS14b]. Можно избегать координации и при этом сохранять ограничения целостности данных, когда операции инвариантно совпадают. Инвариантное совпадение (I- совпадающие, Invariant Confluence) определяется как некое свойство, которое обеспечивает что два допустимых инвариантами, но расходящихся состояния базы данных могут быть слиты в единое допустимое, конечное состояние. Инварианты в данном случае сохраняют согласованность в терминах ACID.
Поскольку два допустимых состояния могут быть слиты в отдельное допустимое состояние, I- совпадающие операции могут выполняться без дополнительной координации, что значительно улучшает характеристики производительности и потенциал масштабирования.
Для сохранения этого инварианта, дополнительно к определению некой операции, которая переносит нашу базу данных в её новое состояние, нам приходится определять функцию Слияния, которая принимает два состояния. Эта функция применяется в случае независимо обновляемых состояний и привнесения расходящихся состояний обратно в сходящиеся.
Транзакции выполняются для имеющихся локальных версий базы данных (моментальных снимков). Когда некой транзакции для выполнения требуется какое- то состояние из прочих разделов, такое состояние делается для неё доступным локально. Когда некая транзакция фиксируется, выполненные в данном локальном моментальном снимке и полученные в результате изменения мигрируют и сливаются с имеющимися моментальными снимками во всех прочих узлах. Некая модель системы, которая позволяет уклоняться от координации обязана обеспечивать такие свойства:
- Глобальная допустимость
Необходимые инварианты всегда удовлетворяются, причём как для сливаемых, так и для расходящихся фиксированных состояний базы данных, а транзакции не могут следовать недопустимым состояниям.
- Доступность
Если все удерживаемые состояния достижимы всеми клиентами, данная транзакция обязана достигать решения фиксации, либо прерываться, когда её фиксация приводила бы к нарушению одного из инвариантов данной транзакции.
- Сходимость
Узлы могут поддерживать свои локальные состояния независимо, но в отсутствии последующих транзакций и неопределённых сетевых разделов, они должны обладать способностью достигать того же самого состояния.
- Свобода координации
Выполнение локальной транзакции не зависит от тех операций с имеющимися локальными состояниями, которые выполняются от имени прочих узлов.
Одним из примечательных образцов реализации уклонения от координации являются транзакции RAMP (Read-Atomic Multi Partition, Атомарное чтение из множества разделов) [BAILIS14c]. RAMP пользуется контролем одновременности множества версий и метаданными текущих выполняемых на- лету операций для извлечения любых пропущенных состояний из прочих узлов, делая возможным одновременное выполнение операций чтение и записи. Например, могут выявляться читатели, перекрывающиеся с неким писателем, изменяющим ту же самую запись и, когда это необходимо, выполнять восстановление за счёт извлечения необходимых сведений из метаданных выполняемой на- лету записи в неком дополнительном раунде взаимодействия.
Использование подходов на основе блокировок в распределённой среде может быть не самой лучшей идеей, а вместо этого RAMP предоставляет два свойства:
- Независимость синхронизации
Транзакции одного из клиентов не будут выполнять останов, прерывание или принуждения к ожиданию транзакций прочих клиентов.
- Независимость разделов
Клиенты не должны контактировать с разделами, значения которых не вовлечены в их транзакции.
RAMP вводит уровень изоляции атомарного чтения: транзакции не способны видеть никакие изменения состояния в процессе из выполняемых в реальном времени, незафиксированных и прерванных транзакций. Согласно данному определению, данный уровень изоляции атомарного чтения также предотвращает частичные чтения: когда некая транзакция наблюдает лишь какое- то подмножество из исполнения какой- либо иной транзакции.
RAMP предлагает атомарную видимость записи без необходимости взаимного исключения, которое для иных решений, например, для распределённых блокировок,часто следуют в паре. Это означает, что транзакции могут выполняться без опрокидывания ими друг друга.
RAMP распространяет метаданные транзакции, которые позволяют выявлять одновременные происходящие на- лету записи. Применяя такие метаданные, транзакции способны определять подобное наличие более новых версий записи, отыскивать и извлекать самые последние и работать с ними. Для уклонения от координации, все локальные решения фиксации должны также быть допустимыми глобально. В RAMP это решается требованием того, что на тот момент времени, когда запись становится видимой в одном разделе, записи той же самой транзакции во всех прочих вовлечённых разделах также видны для читателей в этих разделах.
Чтобы позволить продолжение исполнения читателям и писателям без блокирования прочих одновременных с ними читателей и писателей, при поддержке уровня изоляции данного атомарного чтения как локально, так и для всей системы (во всех прочих разделах, изменяемых данной фиксацией транзакции), записи в RAMP устанавливаются и делаются видимыми при помощи двухфазной фиксации:
- Подготовка
Самый первый этап готовит и помещает записи в их соответствующие целевые разделы не делая их видимыми.
- Фиксация/ прекращение
Данный второй этап публикует необходимые изменения состояния, выполненные данной операцией записи текущей фиксируемой транзакции, делая их доступными атомарно во всех разделах, либо откатывая обратно эти изменения.
RAMP делает возможным присутствие в любой определённый момент времени множества версий одной и той же записи: самого последнего значения, находящихся в исполнении на- лету не зафиксированных изменений, а также утративших силу версий, перезаписанных более поздними транзакциями. Устаревшие версии должны удерживаться вокруг только для находящихся в процессе запросов чтения. Как только все одновременные считывания завершены, утратившие силу значения могут быть отвергнуты.
Превращение распределённых транзакций в производительные и масштабируемые затруднено по причине тех накладных расходов на координацию, которые связаны с предотвращением, выявлением и избежанием конфликтов одновременных операций. Чем крупнее ваша система, или чем больше транзакций она пытается обслуживать, тем большим накладным нагрузкам она подвержена. Описанные в данном разделе подходы пытаются снизить общее количество координаций применяя инварианты для выявления того можно ли уклониться от координации и платя лишь полную стоимость когда это абсолютно необходимо.
В этой главе мы обсудили различные пути реализации распределённых транзакций. Прежде всего мы обсудили два алгоритма атомарных фиксаций: двух- и трёх- этапные фиксации. Самым большим преимуществом этих алгоритмов является то, что они просты для понимания и реализации, однако имеют некоторые недостатки. В 2PC, некому координатору (или по крайней мере его представителя) обязан быть в рабочем состоянии на протяжении всего процесса фиксации, что значительно снижает доступность. 3PC в некоторых случаях снимает это требование, но в случае появления сетевых разделов склонен к расщеплению сознания.
Распределённые транзакции в современных системах баз данных часто реализуются при помощи алгоритмов консенсуса, которые мы намерены обсудить в своей следующей главе. Например, и Calvin и Spanner, обсуждавшиеся в данной главе, применяют Paxos.
Алгоритмы консенсуса более сложны чем алгоритмы атомарной фиксации, однако обладают намного лучшими свойствами отказоустойчивости, отделяют решения от их инициаторов и позволяют участникам принимать решение по некому значению, вместо того чтобы принимать или нет определённое значение [GRAY04].
![[Замечание]](/common/images/admon/note.png) | Последующее чтение |
|---|---|
|
Если вы желаете узнать больше относительно упоминавшихся в этой главе понятий, вы можете ссылаться на следующие источники:
|