Часть 1. Механизмы хранения
Самое первейшее задание любой системы управления базой данных состоит в надёжном хранении данных и создания их доступности для пользователей. Мы используем базы данных как некий первичный источник данных, помогающий нам совместно применять их различными частями наших приложений. Вместо того чтобы искать некий способ хранения сведений и их выборки, а также изобретения нового пути организации данных при каждом создании какого- то нового прикладного приложения, мы пользуемся базами данных. Тем самым мы можем сосредоточиться на логике приложения вместо инфраструктуры.
Так как сам термин DBMS (database management system, систем управления базами данных - СУБД) достаточно объёмист, на протяжении этой книги мы будем применять более компактные термины системы базы данных и базы данных для ссылки на то же самое понятие.
Базы данных являются модульными системами и они состоят из многих частей: транспортный уровень принимает запросы, процессор запросов определяет наиболее действенный способ исполнения запросов, механизм исполнения заботится о самих действиях, а механизм хранения отвечает за хранение (см. Архитектура DBMS).
Такой механизм хранения (storage engine, или механизм базы данных) является неким программным компонентом системы управления базой данных, ответственным за хранение, выборку и управление данными в памяти {=оперативной памяти} и на диске, спроектированным для захвата некой постоянной, долговременной памяти каждого из узлов [REED78]. В то время как базы данных способны отвечать на сложные запросы, механизмы хранения рассматривают данные более гранулировано и предлагают некий простой API манипулирования данными, позволяя пользователям создавать, обновлять, удалять и выбирать записи. Одним из способов взглянуть на это состоит в том, что системы управления базой данных являются приложениями, которые строятся поверх механизмов хранения, предлагая некие схему, язык запросов, индексацию, транзакции и множество прочих полезных функциональных возможностей.
Для гибкости и ключи и значения могут быть произвольными последовательностями байт без какой бы то ни было
установленной формы. Их семантики сортировки и представления определяются подсистемами верхнего уровня. Например,
вы можете в качестве ключа в одной из таблиц можете применять int32
(32- битное целое), и ascii (строку ASCII) для другой; с точки зрения нашего
механизма хранения оба ключа это всего лишь упорядоченные записи.
Такие механизмы хранения, как BerkeleyDB, LevelDB и их потомки RocksDB, LMDB, а также их последователи libmdbx, Sophia, HaloDB и многие прочие, все они были разработаны независимо от своих систем управления базами данных, в которые они теперь встроены. Применение подключаемых механизмов хранения позволило разработчикам баз данных раскручивать системы баз данных применяя имеющиеся механизмы хранения и сосредоточиться на прочих подсистемах. {Прим. пер.: есть и обратные примеры использования механизмов хранения без систем управления базами данных, см. использование RocksDB в BlueStore Ceph.}
В то же самое время, чёткое разделение между компонентами системы базы данных открывает для нас некую возможность переключения между различными механизмами, потенциально лучше подходящими для различных вариантов использования. Например, MySQL, популярная система управления базой данных имеет несколько механизмов хранения, включающих InnoDB, MyISAM и RocksDB (в соответствующем дистрибутиве MyRocks). MongoDB позволяет переключаться между механизмами хранения WiredTiger, In-Memory и (теперь считающимся устаревшим) MMAPv1.
Сопоставление баз данных
Ваш выбор системы управления базой данных может иметь долговременные последствия. Если существует шанс, что какая- то база данных не хорошо подходит по причинам проблем с производительностью, спорной согласованности или вызовами в работе, лучше обнаружить это на более раннем цикле разработки, ибо может оказаться нетривиальной миграция на другую систему. В некоторых случаях могут потребоваться существенные изменения в самом прикладном коде.
Всякая система базы данных имеет сильные и слабые стороны. Для снижения риска затратной миграции вы можете потратить некое время прежде чем вы решите что некая конкретная база данных для построения заслуживает доверия к своим возможностям отвечать потребностям вашего приложения.
Попытка сравнивать базы данных на основе их компонентов (например, какой механизм хранения они используют, как разделяются, реплицируются и распространяются и т.п. данные), их ранжирования (произвольного значения популярности, присваиваемого консалтинговыми агентствами, такими как ThoughtWorks, либо такими вебсайтами как DB-Engines или Database of Databases), либо языка реализации (C++, Java или Go и тому подобных), могут влечь за собой неверные или преждевременные выводы. Эти методы могут применяться только для некого сравнения на самом верхнем уровне и способны выступать лишь грубой прикидкой в выборе между HBase и SQLite, а потому даже поверхностное понимание того как работает каждая база данных и что у неё внутри может помочь вам приземлиться с более весомым заключением.
Всякое сравнение следует начинать с чёткого определения искомой цели, так как даже небольшие отклонения способны полностью лишить силы всех ваших изысканий. Когда вы ищете базу данных которая была бы хороша для имеющихся у вас рабочих нагрузок (или которые вы планируете получить), наилучшая вещь, которую вы можете предпринять, это эмулировать такие рабочие нагрузки для разных систем баз данных, выполнить замеры производительности тех параметров, которые важны вам и далее сопоставлять результаты. Некоторые проблемы, в особенности когда дело касается производительности и масштабирования, начинают проявляться только через некоторое время или по мере роста ёмкости. Для выявления потенциальных проблем лучше иметь долгоиграющими тестами в некой среде, которые имитируют промышленную установку из реального мира настолько точно, насколько это возможно.
Имитация рабочих нагрузок из реальной практики не только помогает вам понимать как выполняет работу эта база данных, но также способствует вашему изучению того как оперировать, отлаживать и выявляет насколько дружелюбно и полезно ей сообщество. Выбор базы данных это всегда некое сочетание таких факторов, а производительность зачастую перестаёт быть наиболее важной стороной дела: обычно намного лучше применять некую базу данных, которая медленнее сохраняет свои данные, чем в одночасье быстро потерять их.
Для сравнения баз данных полезно понимать вариант использования более подробно и определять значения текущих и ожидаемых переменных, таких как:
-
Схема и размеры записей
-
Число клиентов
-
Типы запросов и шаблонов доступа
-
Частоты запросов чтения и записи
-
Ожидаемые изменения каждой из этих переменных
Знание этих переменных позволит вас ответить на следующие вопросы:
-
Поддерживает ли эта база данных все необходимые запросы?
-
Способна ли рассматриваемая база данных обрабатывать то количество данных, которое мы планируем хранить?
-
Какое число операций чтения и записи способен обрабатывать некий отдельный узел?
-
Сколько узлов должна иметь данная система?
-
Как мы расширяем этот кластер в предположении его роста?
-
В чём состоит процесс сопровождения?
Обладая ответами на эти вопросы, вы можете сконструировать некий кластер для проверки и провести имитацию ваших рабочих нагрузок. Большинство баз данных уже обладают инструментами стресс- тестирования, которые можно применять для реконструкции определённых вариантов применения. Когда для выработки случайным образом рабочих нагрузок в экосистеме рассматриваемой базы данных нет стандартного инструментария стресс- тестирования, вы можете попробовать имеющиеся инструменты общего назначения или реализовать его с нуля.
Если эти тесты показывают положительные результаты, вам может оказаться полезным познакомиться с кодом этой базы данных. Рассматривая такой код часто полезно вначале понять основные части этой базы данных, как отыскать необходимый код для различных компонентов, а затем уже путешествовать по нему. Обладание даже грубым представлением о коде рассматриваемой базы данных поможет вам лучше разбираться в производимых ею записях журнала, её параметрах настройки и поможет вам находить проблемы в том приложении, которое её применяет и даже в самом коде базы данных.
Было бы идеальным, если бы мы могли использовать базы данных как чёрные ящики и никогда не заглядывать вовнутрь них, но практика показывает, что рано или поздно некая ошибка, простой, регрессия производительности или какая- то иная проблема всплывает наружу и лучше быть готовым к этому. Когда вы знаете и понимаете внутреннее устройство базы данных, вы можете снизить риски для дела и улучшит шансы на быстрое восстановление.
Одним из популярных инструментов для эталонного тестирования, оценки производительности и сопоставления является Yahoo! Cloud Serving Benchmark (YCSB). YCSB предлагает некую инфраструктуру и общий набор рабочих нагрузок, который можно применять для различных хранилищ данных. Как и всякая прочая вещь общего применения, этот инструмент следует использовать с предосторожностями, так как просто прийти к неверному заключению. Для осуществления справедливого сравнения и принятия выверенного решения, необходимо затратить значительное время на понимание условий реального мира, в которых вашей базе данных придётся работать и подгонять эталонное тестирование надлежащим образом.
![[Замечание]](/common/images/admon/note.png) | Эталонное тестирование TPC-C |
|---|---|
|
Transaction Processing Performance Council (TPC, Совет по производительности обработки транзакций) имеет некий набор эталонного тестирования, который производители баз данных применяют для сравнения предлагаемой производительности своих продуктов. TPC-C является неким интерактивным эталонным тестом обработки транзакций (OLTP), некую смесь транзакций только на чтение и обновлений, которая имитирует распространённые рабочие нагрузки приложений.. Этот эталонный тест касается производительности и правильности выполнения одновременных транзакций. Основным показателем производительности выступает пропускная способность: общее число транзакций, которое тестируемая база данных способна выполнять за минуту. Выполняемые транзакции требуют сохранения свойств ACID и соответствия набору свойств, задаваемых этим тестом. Данный эталонный тест не сосредоточен на каком бы то ни было определённом сегменте бизнеса, а вместо этого представляет некий абстрактный набор действий, важных для большинства приложений, которым подходят базы данных OLTP. Он содержит определённые таблицы и записи, такие как хранилища данных, рынки (описи), потребителей и заказы, определения табличных схем, подробности транзакций, которые могут выполняться для таких таблиц, значения минимального числа строк для таблиц и ограничения на долговечность данных. |
Не важно, что эталонное тестирование может применяться только для сопоставления баз данных. Эталонные тесты могут оказываться полезными для определения подробностей тестов показателей SLA (service-level agreement, соглашений об уровне обслуживания - обязательстве поставщика услуг относительно качества предоставляемых им услуг. Помимо прочего, SLA может содержать сведения о задержках, пропускной способности, вариабельности, а также о числе отказов), понимании требований к системе, планирования ёмкости и прочего. Чем большими знаниями вы обладаете о базе данных до её применения, тем больше времени вы сохраните при её работе в промышленной реализации.
Выбор базы данных является долговременным решением и будет лучше отслеживать вновь появляющиеся версии, в точности понимать что изменилось и зачем, а также иметь некую стратегию обновлений. Новые выпуски обычно содержат улучшения и исправления ошибок, а также проблем безопасности, но способны вводить новые ошибки, регрессию производительности или неожиданное поведение, поэтому проверка новых версий до их раскрутки также критически важна. Проверка того, как разработчики базы данных обрабатывали обновления ранее, может дать вам хорошее представление о том, чего ожидать в дальнейшем. Плавные обновления более раннего периода не гарантируют что последующие будут также гладкими, но сложности с обновлениями в прошлом могут указывать на то, что последующие будут непростыми.
Осознание компромиссов
В качестве пользователя вы можете наблюдать как ведут себя базы данных в различных условиях, однако при работе с базами данных нам приходится непосредственно делать выбор между такими воздействиями на поведение.
Разработка механизма хранения определённо намного сложнее чем простая реализация структура данных некого участника: имеется слишком много деталей и граничных условий, которые трудно осознавать прямо на старте. Нам требуется проектировать саму физическую структуру данных и организовывать указатели, принимать решения по формату сериализации, понимать как собирать мусор, как механизм хранения укладывается в имеющуюся семантику самой системы базы данных в целом, определять как заставить его работать в некой среде одновременной обработки, а в конечном счёте гарантировать что мы не утратим никакие данные ни при каких обстоятельствах.
Но нам не просто приходится принимать решение на основании этого большого числа моментов, большинство этих решений также влекут за собой компромиссы. Например, когда мы сохраняем записи в том порядке, в котором они вставляются в нашу базу данных, мы можем запоминать их быстрее, однако если мы выполняем их выборку во внутреннем лексикографическом порядке, нам придётся выполнить их повторную сортировку перед возвращением клиенту. Как вы увидите на протяжении этой книги, существует множество различных подходов к проектированию механизма хранения, причём всякая реализация имеет свои собственные достижения и оборотные стороны.
При рассмотрении различных механизмов хранения, мы обсуждаем их преимущества и недостатки. Если бы для каждого рассматриваемого способа использования имелся бы абсолютно оптимальный механизм хранения, все бы просто применяли именно его. Но так как его не существует, нам необходимо делать мудрый выбор на основании имеющихся рабочих нагрузок и вариантов применения, которые мы пытаемся обслуживать.
Существует множество механизмов хранения, использующих все виды структур данных, реализуемых на различных языках программирования, причём в диапазоне от низкого уровня, например, C, до верхнего уровня, например, Java. Все механизмы хранения сталкиваются с одними и теми же вызовами и ограничениями. Чтобы провести параллель с городским планированием, можно строить для определённой группы населения и выбирать застройку вверх и застройку вширь. В обоих случаях в этот город поместится одно и то же число жителей, но эти подходы приведут к радикально отличающимся стилям жизни. при строительстве города ввысь, жители обитают в апартаментах, а плотность населения скорее всего приведёт к большему трафику на меньшей площади; в более обширном городе люди скорее всего будут жить в домах, но ежедневные поездки на работу потребуют преодоления больших расстояний.
Аналогично, принимаемые разработчиками механизма хранения решения проектирования сделают их более пригодными для различных вещей: некоторые оптимальны для низких задержек чтения или записи, некоторые пытаются максимизировать плотность (объём хранимых в узле данных), а иные сосредоточены на упрощении работы.
В приводимых Выводах глав вы сможете найти законченные алгоритмы, которые можно применять для конкретной реализации и прочие дополнительные справочные сведения. Прочтение этой книги должно снабдить вас всем необходимым для производительной работы с такими источниками и предоставит вам солидное понимание имеющихся альтернатив к описываемым здесь понятиям.
Глава 1. Введение и обзор
Содержание
Системы управления базами данных могут обслуживать различные цели: некоторые применяются в первую очередь для временных горячих данных, некоторые служат как долговременные холодные хранилища, какие- то допускают сложные аналитические запросы, а какие- то допускают лишь доступ к значениям по ключу, иные оптимизированы под хранение данных временных последовательностей, а есть также эффективные хранилища больших двоичных объектов (blobs). Для осознания различий и проведения разграничений, мы начнём с некой короткой классификации и обзора, так как это поможет нам понять саму сферу для последующего обсуждения.
Терминология порой может быть двусмысленной и тяжёлой для понимания без полного контекста. Например, различия между столбцами и хранилищами широких столбцов, которые не имеют практически ничего общего, или же то как кластеризованные и неклатерезованные индексы связаны с организованными по индексу таблицами. Данная глава имеет целью устранить неоднозначность таких терминологий и найти им точные определения.
Мы начнём с некого обзора архитектур систем управления базами данных (см. Архитектура DBMS) и обсудим компоненты системы и их зоны ответственности. После этого мы обсудим имеющиеся отличия между системами управления базами данных в терминах среды хранения (см. Сопоставление DBMS в памяти и основанных на дисках), а также схему (см. Сопоставление DBMS ориентированных на столбцы и на строки).
Эти две группы не представят полной систематики систем управления базами данных и имеется множество прочих способов их классификации. К примеру, некоторые источники группируют DBMS на три основные категории:
- Базы данных OLTP (Online transaction processing, ориентированных на обработку транзакций в реальном времени)
Они обрабатывают большое число запросов и транзакций со стороны пользователя. Запросы часто определены заранее и имеют короткое время жизни.
- Базы данных OLAP (Online analytical processing, оперативной аналитики)
Эти обрабатывают сложные конгломераты. Базы данных OLAP часто применяются для аналитики и организации информационных хранилищ (data warehousing), причём способны обрабатывать сложные, долгоживущие не регламентированные запросы (ad hoc queries).
- HTAP (Hybrid transactional and analytical processing, гибридная обработка транзакций и аналитики)
Такие базы данных сочетают свойства и OLTP, и OLAP хранилищ.
Существует много прочих терминов и классификаций: хранилища ключ- значение, реляционные базы данных, ориентированные на документы хранилища, а также графовые базы данных. Эти понятия не определяются здесь, так как предполагается, что читатель имеет на верхнем уровне знание и понимание об их функциональных возможностях. Поскольку обсуждаемые нами здесь понятия имеют широкую область применения и применяются в какой- то степени в большинстве из упомянутых типов хранилищ, для последующего обсуждения нет никакой необходимости и важности в полной систематизации.
Так как I Часть данной книги сосредоточена на самих хранилищах и структурах индексации, нам требуется понимать подходы к организации данных на самом верхнем уровне, а также имеющуюся взаимосвязь между самими данными и индексными файлами (см. Файлы данных и индексные файлы.)
Наконец, в разделе Буферизация, неизменность и упорядоченность мы обсудим три технологии, широко используемые для разработки действенных структур хранения и то, как применение этих технических приёмов оказывают своё влияние на проектирование и реализацию.
Не существует никакой общей кальки для разработки систем управления базами данных. Все базы данных строятся совершенно по- разному, а границы компонентов это нечто что трудно увидеть и определить. Даже когда эти границы обозначены на бумаге (то есть в проектной документации), в коде выглядящие независимыми компоненты могут быть связанными по причине оптимизации производительности, обработке пограничных случаев или архитектурных решений.
Описывающие архитектуру систем управления базами данных (например, [HELLERSTEIN07], [WEIKUM01], [ELMASRI11] и [MOLINA08]) определяют компоненты и взаимосвязи между ними по- разному. Та архитектура, которая представлена на Рисунке 1-1, демонстрирует некоторые общие темы этих представителей.
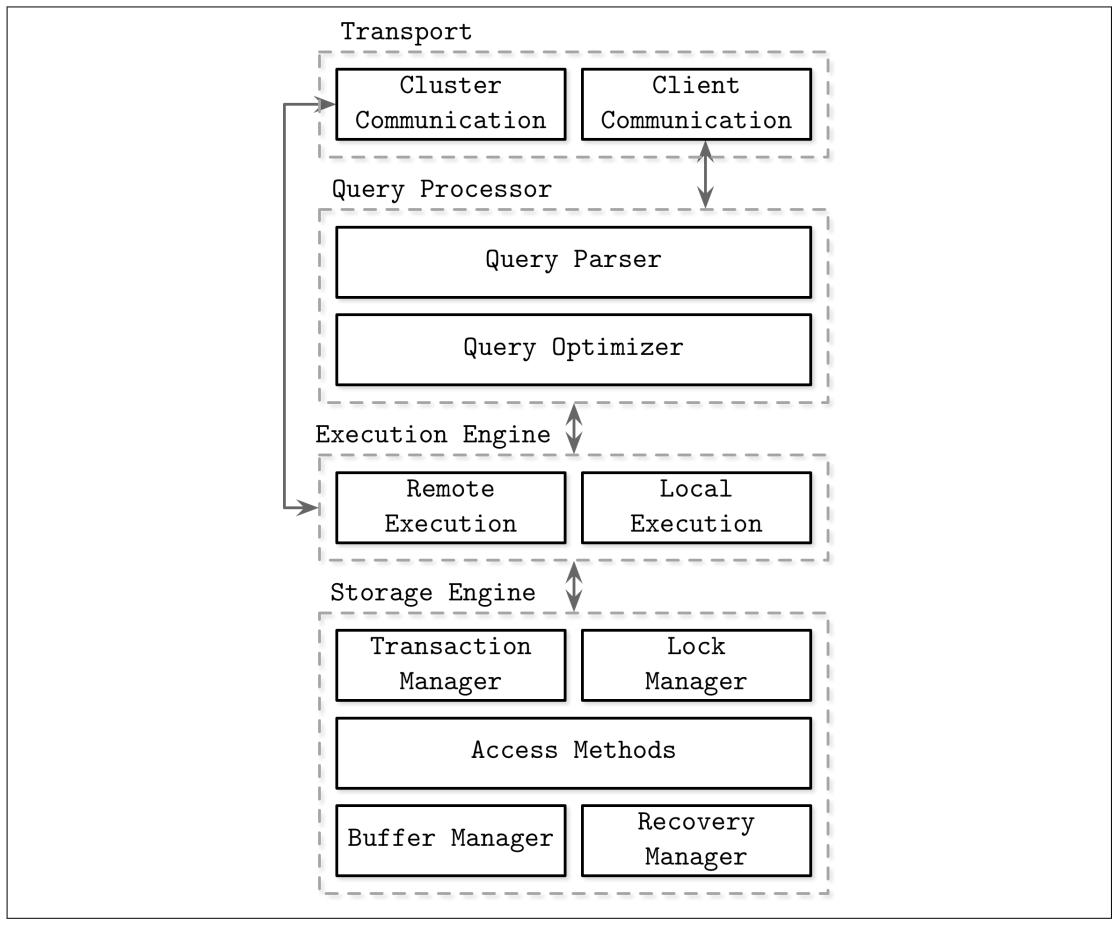
Системы управления базами данных применяют модель клиент/ сервер, в которой экземпляры системы базы данных (узлы) берут на себя роль серверов, а экземпляры приложения выполняют роль клиентов.
Требования клиентов появляются через имеющуюся транспортную подсистему. Требования поступают в виде запросов (queries), наиболее часто выражаемых на неком языке запросов. Имеющаяся транспортная система также отвечает за взаимодействие с прочими узлами в установленном кластере базы данных.
После получения, эта транспортная система вручает полученный запрос в руки процессора запросов, который осуществляет синтаксический разбор, интерпретацию и его удостоверение. Позднее управление доступом проверяет выполнение, так как запросы могут быть обработаны только после их интерпретации.
Разобранный запрос передаётся в имеющийся оптимизатор запроса, который исключает невозможные и избыточные части полученного запроса, а затем пытается найти наиболее действенный способ его исполнения на основе внутренних статистических данных (кардинальных значений индексов, приблизительный размер разбиения и т.п.) а также размещения данных (какие узлы в имеющемся кластере содержат необходимые данные и оценку стоимостей в связи с их пересылкой). Такой оптимизатор обрабатывает как необходимые для разрешения запроса реляционные операции, обычно представляемые неким деревом зависимостей, а также оптимизации, такие как упорядочение индексов, оценку кардинальных значений и выбор метода доступа.
Такой запрос обычно представляется в виде некого плана выполнения (или плана запроса): последовательности операций, которые предстоит осуществить для того чтобы его результаты рассматривались как выполненные. Так как один и тот же запрос может быть удовлетворён различными планами выполнения, которые могут разниться в эффективности, данный оптимизатор закрепляет наилучший доступный план.
Такой план выполнения обрабатывается механизмом исполнения, который собирает получаемые результаты исполнения локальных и удалённых операций. Удалённое исполнение может содержать запись и считывание данных в- и мз- прочих узлов в общем кластере, а также репликации.
Локальные запросы (поступающие обычно от клиентов или из прочих узлов) исполняются механизмом хранения. Такой механизм хранения обладает рядом компонентов с выделенными зонами ответственности:
- Диспетчер транзакций
Данный диспетчер управляет транзакциями и гарантирует что они не могут покидать эту базу данных в логически не согласованном состоянии.
- Диспетчер блокировки
Этот диспетчер блокирует в своей базе данных объекты для выполнения транзакций, гарантируя что одновременные действия не разрушат физическую целостность данных.
- Методы доступа (структуры хранения)
Они управляют доступом и организацией данных на диске. Методы доступа включают в себя файлы кучи и такие структуры хранения, как B- деревья (см.Вездесущие B- деревья) или Деревья LSM.
- Диспетчер буфера
Данный диспетчер кэширует данные страниц в памяти (см.Управление буфером).
- Диспетчер восстановления
Этот диспетчер сопровождает имеющийся журнал действий и восстанавливает необходимое состояние системы в случае отказа (см.Восстановление)
Диспетчеры транзакций и блокировки совместно отвечают за контроль одновременности (см.Управление одновременностью): они гарантируют логическую и физическую целостность данных и в то же самое время обеспечивают одновременность исполнения операций настолько эффективно, насколько это возможно.
Системы баз данных хранят данные в оперативной памяти {Прим. пер.: далее просто в памяти} и на диске. системы управления базами данных в памяти (In-memory, порой именуемые как DBMS основной памяти), хранят данные преимущественно в памяти и применяют диск для восстановления и ведения журналов. Основанные на дисках DBMS удерживают основные свои данные на диске и используют память для кэширования содержимого диска или в качестве некого временного хранилища. Оба типа систем используют в определённой степени свой диск, однако базы данных основной памяти хранят своё содержимое по большей части исключительно в оперативной памяти (RAM).
доступ к памяти был и остаётся более быстрым на несколько порядков чем доступ к диску (да, вы можете найти визуализацию сравнения латентности диска и памяти, а также множество прочих числовых значений, относящихся к этому вопросу по годам), поэтому имеется потребность в применении памяти в качестве первичного хранилища, причём по мере снижения цен на память это становится экономически всё более целесообразным. Однако, цены на оперативную память всё ещё остаются высокими по сравнению с устройствами постоянного хранения, такими как SSD и HDD.
Системы баз данных основной памяти отличаются от их основанных на дисках конкурентов не только в отношении первичного носителя хранения, но также и в отношении используемых ими структур данных, организации и технологий оптимизации.
Использующие память как первичное хранилище данных базы данных делают это в основном по причине производительности, относительно меньших стоимости доступа и гранулированности доступа. Программирование для основной памяти также намного проще чем его выполнение для дисков. Операционные системы абстрагируют управление памятью и позволяют нам мыслить в терминах выделения и освобождения фрагментов памяти произвольного размера. На дисках же, нам приходится вручную управлять ссылками на данные, форматами сериализации, освобождением памяти и фрагментацией.
Основными ограничивающими факторами общего роста баз данных в памяти являются непостоянство оперативной памяти (иными словами, отсутствие живучести) и стоимости. Так как содержимое оперативной памяти не является постоянным, ошибки программного обеспечения, крушения, отказы оборудования и отключения электропитания могут в результате приводить к утрате данных. Существуют способы гарантии живучести, такие как непрерывное электроснабжение и снабжаемая батареями оперативным память, но это требует дополнительных аппаратных ресурсов и опыта работы. На практике, все приходят к выводу, что диски проще в сопровождении и имеют существенно более низкую стоимость.
Такое положение дел имеет вероятность измениться, поскольку растёт доступность и популярность технологии NVM (Non-Volatile Memory, энергонезависимой памяти) [ARULRAJ17]. Хранилища NVM снижают или даже полностью исключают (в зависимости от степени точности технологии) ассиметричность между задержками в чтении и записи, дополнительно улучшают производительнсть чтения и записи и делают возможным доступ с побайтовой адресацией.
Системы баз данных в памяти для предоставления живучести и предотвращения утраты изменяемых данных поддерживают резервное копирование на диск. Некоторые базы данных хранят данные исключительно в памяти без гарантии живучестви, однако мы не обсуждаем их в рамках данной книги.
Прежде чем соответствующую операцию можно рассматривать как завершённую, её результаты обязаны быть записанными в некий последовательный файл журнала. Более подробно мы рассмотрим журналы с упреждающей записью в разделе Восстановление. Во избежание повторного воспроизведения всего содержимого журнала в процессе запуска или после крушения, хранилища в памяти поддерживают некую копию резервирования (backup copy). Такая копия резервирования сопровождается как некая структура данных, хранимая на диске и вносимые в эту структуры изменения зачастую асинхронны (отсоединены от запросов клиентов), а также для снижения общего числа операций ввода/ вывода применяются пакетно. В процессе восстановления, содержимое базы данных может восстанавливаться из такой резервной копии и журналов.
Записи журналов обычно применяются к резервной копии в пакетном режиме. После обработки такого пакета записей журнала, резервная копия хранит некий моментальный снимок (snapshot) базы данных на определённый момент времени, а содержимое журнала вплоть до этого момента времени может быть отвергнуто. Такой процесс имеет название создания контрольных точек (checkpointing). Он снижает время восстановления за счёт удержания располагающейся на диске базы данных по большей части в актуальном состоянии с записями журнала без блокирования запросов клиентов в ожидании обновления своей резервной копии.
|
| Замечание |
|---|---|
|
Будет несправедливо говорить, что база данных в памяти эквивалентна дисковой базе данных с гигантским кэшем страниц (см. раздел Управление буфером). Даже хотя страницы и кэшируются в памяти, их формат сериализации и схемы данных вносят дополнительные накладные расходы и не позволяют той же самой степени оптимизации, которой способны достигать хранилища в памяти. |
Дисковые базы данных используют особые структуры хранения, которые оптимизированы для доступа к диску. При работе с памятью, по указателям можно проходить достаточно быстро и доступ к памяти с произвольной адресацией значительно быстрее произвольного дискового доступа {Прим. пер.: справедливости ради, следует сказать что протоколы NVMe существенно снизили это отличие}. Структуры дискового хранения зачастую имеют вид широких и коротких деревьев (см. раздел Деревья для основанных на дисках хранилищах), в то время как основанные на памяти реализации вольны делать выбор из большего пула структур данных и осуществлять оптимизацию, которая в противном случае была бы невозможна или сложна для реализации на дисках [MOLINA92]. Аналогично, обработка данных переменной длины на дисках требует особого внимания, в то время как в памяти это зачастую просто вопрос обращения к значению по ссылке.
Для некоторых вариантов использования имеет смысл предположить что весь набор данных мы намерены уместить в памяти. Некоторые наборы данных ограничены своими представлениями в реальном мире, например, записи обучающихся для школ, записи потребителей для компаний, или описи для некого интернет- магазина. Каждая запись потребляет не более нескольких кБ, а их число ограничено.
Большинство систем баз данных хранят некий набор записей данных, состоящих из столбцов и строк в таблицах. Поля являются неким пересечением столбцов и строк: отдельное значение некого типа. Относящиеся к одному и тому же столбцу поля, обычно, обладают одним и тем же типом данных. Например, когда мы определяем какую- то таблицу, содержащую записи пользователей, все имена имели бы один и тот же тип и относились бы к одному и тому же столбцу. Некое собрание значений, которое относились бы логически к одной и той же записи (как правило, идентифицируемое соответствующим ключом) составляет некую строку.
Один из способов классификации баз данных состоит в том как такая база данных хранится на диске: строками или столбцами. Таблицы могут разбиваться на разделы либо горизонтально (сохраняя совместно значения, относящиеся к одной и той же строке), либо вертикально (совместно храня значения, относящиеся к одному и тому же столбцу). Рисунок 1-2 выделяет это отличие (a) показывает значения, разбиваемые на разделы столбцами, а (b) отражает значения, делящиеся на разделы по строкам.
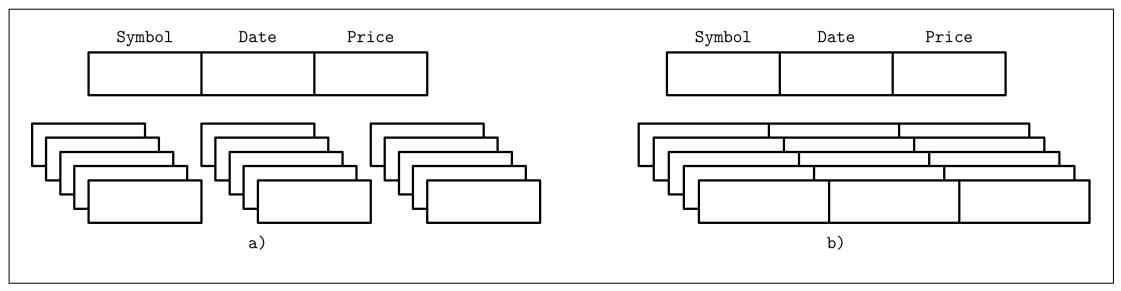
Примеров систем управления базами данных, ориентированных на хранение строк предостаточно: MySQL, PostgreSQL и большая часть всех традиционных реляционных баз данных. Двумя пионерами ориентированных на столбцы хранилищ являются MonetDB и C-Store (C-Store это предшественник Vertica, имеющий открытый исходный код).
Ориентированные на строки системы управления базами данных хранят данные в записях или в строках. Их схема достаточна близка табличному представлению данных, при котором каждая строка имеет тот же самый набор полей. например, некая ориентированная на строки база данных способна эффективно хранить записи пользователей, удерживая в себе имена, даты рождения и телефонные номера:
| ID | Name | Birth Date | Phone Number |
| 10 | John | 01 Aug 1981 | +1 111 222 333 |
| 20 | Sam | 14 Sep 1988 | +1 555 888 999 |
| 30 | Keith | 07 Jan 1984 | +1 333 444 555 |
Этот подход хорошо работает в случаях, при которых несколько полей постулируют необходимую запись (имя, дату рождения и телефонный номер) уникально идентифицируемую значением своего ключа (в данном примере некого монотонно увеличивающегося приращением числа). Все поля представляющие запись некого отдельного пользователя часто представляются совместно. При создании записей (например, когда определённый пользователь заполняет какую- то регистрационную форму), мы также записываем их совместно. В то же самое время, каждое поле может изменяться по отдельности.
Так как ориентированные на строки хранилища наиболее полезны в тех ситуациях, когда нам приходится выполнять доступ к данным по строкам, совместное хранение всей строки улучшает пространственную локальность [DENNING68] (пространственная локальность является одним из основных Принципов локальности, утверждающим что при обращении к некому местоположению в памяти, в ближайшем будущем будет выполнен доступ к расположенной рядом памяти).
Так как доступ к данным в постоянном носителе, таком как диск, обычно выполняется поблочно (иными словами, блок это некий минимальный элемент дискового доступа), отдельный блок будет содержать сведения для всех столбцов. Это великолепно для ситуаций когда мы бы желали получить доступ к некой записи пользователя целиком, но делает более затратным доступ к индивидуальным полям множества пользователей (например, для запросов, выполняющих выборку только телефонных номеров), так как данные прочих полей также будут разбиты по страницам.
Ориентированные на столбцы системы управления базами данных разбивают данные на разделы вертикально (т.е. по столбцам) вместо их хранения в строках. В этом случае значения для одного и того же столбца хранится непрерывной последовательностью на диске (в противоположность непрерывной строке из предыдущего примера). Например, когда мы храним историю рыночных биржевых цен, котировки цен хранятся вместе. Хранение значений для различных столбцов в отдельных файлах или сегментах файлов делает возможными эффективные запросы по столбцам, так как они могут считываться за один проход вместо употребления строк целиком и отбрасывания данных, которых нет в запросе.
Ориентированные на столбцы хранилища хорошо подходят для аналитических рабочих нагрузок, вычисляющих агрегатные значения, например, поиска тенденций, вычисления средних значений и т.п. Обработка сложных агрегатных значений может применяться в ситуациях, когда логические записи имеют множество полей, но некоторые из них (как в случае с ценами котировок) имеют разную значимость и часто употребляются совместно.
С логической точки зрения, те данные, которые представляют цены рыночных котировок всё ещё могут представляться в виде таблицы:
| ID | Symbol | Date | Price |
| 1 | DOW | 08 Aug 2018 | 24,314.65 |
| 2 | DOW | 09 Aug 2018 | 24,136.16 |
| 3 | S&P | 08 Aug 2018 | 2,414.45 |
| 4 | S&P | 09 Aug 2018 | 2,232.32 |
Однако физическая схема базы данных на основе столбцов выглядит совершенно иначе. Значения, относящиеся к одной и той же строке внизу хранятся близко друг к другу:
Symbol: 1:DOW; 2:DOW; 3:S&P; 4:S&P
Date: 1:08 Aug 2018; 2:09 Aug 2018; 3:08 Aug 2018; 4:09 Aug 2018
Price: 1:24,314.65; 2:24,136.16; 3:2,414.45; 4:2,232.32
Для реконструкции кортежей данных, что может быть полезно для соединений, фильтрации и агрегации множества строк, нам потребуется сберегать некие метаданные на уровне определённого столбца для идентификации какой именно точке из другого столбца они соответствуют. Когда вы делаете это в явном виде, каждое значение будет иметь некий ключ для удержания, что увеличивает дублирование и приводит росту объёма хранимых данных. Некторые хранилища столбцов применяют неявные идентификаторы (виртуальные ID) вместо использования конкретного значения позиции (иными словами, его смещение) для указания обратного соответствия для связанных с ним значений [ABADI13].
На протяжении последних нескольких лет, вероятно по причине роста спроса на выполнение сложных аналитических запросов по всё растущим наборам данных, мы наблюдаем множество новых ориентированных на столбцы форматов файлов, таких как Apache Parquet, Apache ORC, RCFile, а также ориентированные на столбцы хранилища, например, Apache Kudu, ClickHouse и многие иные [ROY12].
Будет недостаточным просто сказать что различия между строковыми и столбцовыми хранилищами сводятся только к самому способу хранения их данных. Выбор схемы самих данных это только один из шагов в последовательности возможных оптимизаций, которые имеют своей целью столбцовые хранилища.
Считывание множества значений для одного и того же столбца за один проход значительно улучшает действенность применения кэширования и вычислений. В современных ЦПУ для обработки множества точек данных могут использоваться векторные инструкции в отдельной операции ЦПУ [DECANDIA07]. (Векторные инструкции, такие как Single Instruction Multiple Data (SIMD), описываются как некий класс инструкций ЦПУ, которые выполняют одно и то же действие для множества пунктов данных.)
Совместное хранение данных, имеющих один и тот же тип данных (то есть числа с прочими числами, строки и другие строки) предлагает лучшее соотношение сжатия. Мы можем использовать различные алгоритмы компрессии в зависимости от конкретного типа данных и указывать наиболее действенный метод сжатия для каждого конкретного случая.
Для принятия решения относительно того применять ли ориентированное на столбцы или на строки хранилище вам требуется понимать свои шаблоны доступа. Когда считываемые данные потребляются записями (то есть требуется большинство или все столбцы) и рабочие нагрузки в основном состоят из запросов указания и сканирования диапазонов, скорее всего именно ориентированный на строки подход даст наилучшие результаты. Когда сканирование охватывает множество строк или вычисляются агрегатные значения по некому подмножеству столбцов, стоит рассмотреть некий ориентированный на столбцы подход.
Ориентированные на столбцы базы данных не стоит путать с хранилищами широких столбцов, например BigTable или HBase, где данные представляются в виде некой многомерной карты, а колонки группируются на семейства столбцов (обычно хранящих данные одного и того же типа), а внутри каждого семейства столбцов данные хранятся строками. Такая схема наилучшая для хранения данных, выбираемых по ключу или некой последовательности ключей.
Неким каноническим примером из основополагающей статьи Bigtable [CHANG06] является Webtable. Webtable хранит моментальные снимки содержимого веб страниц, их атрибуты и имеющиеся между ними связи для определённой временной отметки. Страницы идентифицируются значениями приводимых в обратном порядке URL, а все атрибуты (например, content и anchors представляют связи между страницами) идентифицируются значениями временных отметок в которые были взяты эти моментальные снимки. Для простоты это можно представить как некое встраиваемое соответствие, как это показано на Рисунке 1-3.

Данные хранятся в неком многомерном сортированном соответствии с иерархической индексацией: мы можем определять
местоположение данных в соответствии с некой определённой веб страницей по её реверсивному URL и её содержимое или
ссылки по значению временной метки. Каждая строка индексируется собственным ключом
строки. Соответствующие колонки группируются совместно в семейства
столбцов - в данном примере это contents и
anchor - которые хранятся на диске по отдельности. Каждая колонка внутри
семейства столбцов идентифицируется ключом колонки, который в сочетании с
названием семейства столбцов и некого квалификатора (в данном примере html,
cnnsi.com, my.look.ca). Семейства
столбцов хранят множество данных по временной метке. Такая схема делает для нас возможным быстрое определение
местоположения записей верхнего уровня (в данном случае веб страниц) и их параметров (версий содержимого и ссылок
на прочие соответствующие страницы).
Хотя полезно понимать такое концептуальное представление хранилищ широких столбцов, их физическая схема совершенно иная. Схематическое представление имеющейся схемы данных в семействах столбцов показано на Рисунке 1-4: семейства столбцов хранятся раздельно, однако в каждом семействе столбцов все данные относящиеся к одному и тому же ключу сведения хранятся совместно.

Самая первая цель системы базы данных состоит в хранении данных и создании возможности быстрого доступа к ним. Но как эти данные организованы? Зачем вам требуется система управления базой данных и почему бы просто не пользоваться пачкой файлов? Как организация файлов улучшает эффективность?
Системы баз данных используют файлы для хранения самих данных , однако вместо того чтобы полагаться на иерархии файловой системы каталогов и файлы для расположения записей, они составляют файлы применяя особые форматы реализации. Основными причинами для применения специальной организации файлов вместо плоских файлов таковы:
- Эффективность хранения
Файлы организованы неим обарзом, чтобы минимизировать накладные расходы хранения, исчисляемые на запись хранимых данных.
- Эффективность доступа
Записи могут быть расположены за самое минимальное количество шагов.
- Эффективность обновлений
- Обновления записи выполняются каким- то методом, который минимизирует общее число изменений на диске.
Системы баз данных хранят записи данных, состоящие из множества полей, причём в таблицах, при этом каждая таблица обычно представляется отдельным файлом. Каждая запись в такой таблице может быть найдена при помощи ключа поиска. Для определения местоположения некой записи системы баз данных используют индексы: вспомогательные структуры данных, которые позволяют им определять местоположение записей данных без сканирования таблиц целиком при каждом доступе. Индексы строятся на основании подмножеств идентифицирующих эту запись полей.
Система базы данных обычно разделяет файлы данных и индексные файлы: файлы данных хранят данные записей, в то время как индексные файлы хранят записи метаданных и используют их для определения местоположения записей в файлах данных. Индексные файлы обычно меньше своих файлов данных. Файлы разбиваются на разделы страницами, которые обычно имеют размер одного или нескольких дисковых блоков. Страницы могут быть организованы как последовательности страниц или как перекидные страницы (см. раздел Перекидные страницы).
Теперь записи (вставляемые) и обновления уже имеющихся записей представлены парами ключ/ значение. Большинство современных систем хранения не удаляют данные на страницах непосредственно. Вместо этого они применяют маркеры удаления (также имеющие название надгробий - tombstones), которые содержат метаданные удаления, такие как некий ключ и метку времени (timestamp). Занимаемое такой записью пространство экранируется их обновлениями или маркерами удаления и возвращаются в процессе сборки мусора, которая считывает данную страницу, записывает здравствующие (то есть не экранированные) записи в их новое место и отбрасывают те, которые экранированы.
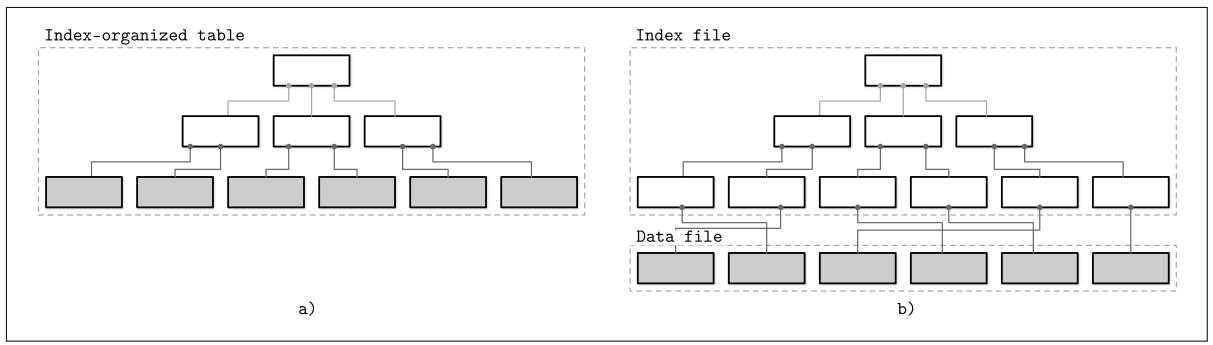
Некий индекс является структурой, которая организует записи данных на диске таким образом, чтобы способствовать эффективности операций выборки. Индексные файлы организованы как специализированные структуры, которые устанавливают соответствие ключей местоположениям в файлах данных, в которых хранятся подобные записи, идентифицируемые этими ключами (в случае файлов кучи) или первичными ключами (в ситуации организованных индексом таблиц).
Некий индекс в первичном файле (данных) имеет название первичного индекса. Однако в большинстве случаев мы можем также предположить что такой первичный индекс строится поверх некого первичного ключа или набора ключей, указанных в качестве первичных. Все прочие индексы имеют название вторичных.
Вторичные индексы могут указывать непосредственно на определённые записи данных, либо просто хранить их первичный ключ. Некий указатель на запись данных способен содержать некое смещение относительно какого- то файла кучи или некой таблицы, упорядоченной индексом. Множество вторичных индексов может указывать на одну и ту же запись, что делает возможным отдельной записи данных идентифицироваться различными полями и располагаться в различных индексах. В то время как файлы первичного индекса содержат некую уникальную запись для каждого ключа поиска, вторичные индексы могут содержать несколько записей для одного и того же ключа поиска [MOLINA08].
Когда порядок записей данных соответствует порядку значений ключа поиска, такой индекс именуется кластеризованным (что также имеет синоним кластеризации). Записи данных в случае кластеризации обычно хранятся в одном и том же файле, или в неком файле кластеризации, в котором сохраняется порядок ключей. Когда имеющиеся данные хранятся в неком обособленном файле, а порядок в нём не соответствует порядку ключей, такой индекс имеет название некластеризованного (порой именуемого как не имеющего кластеризации).
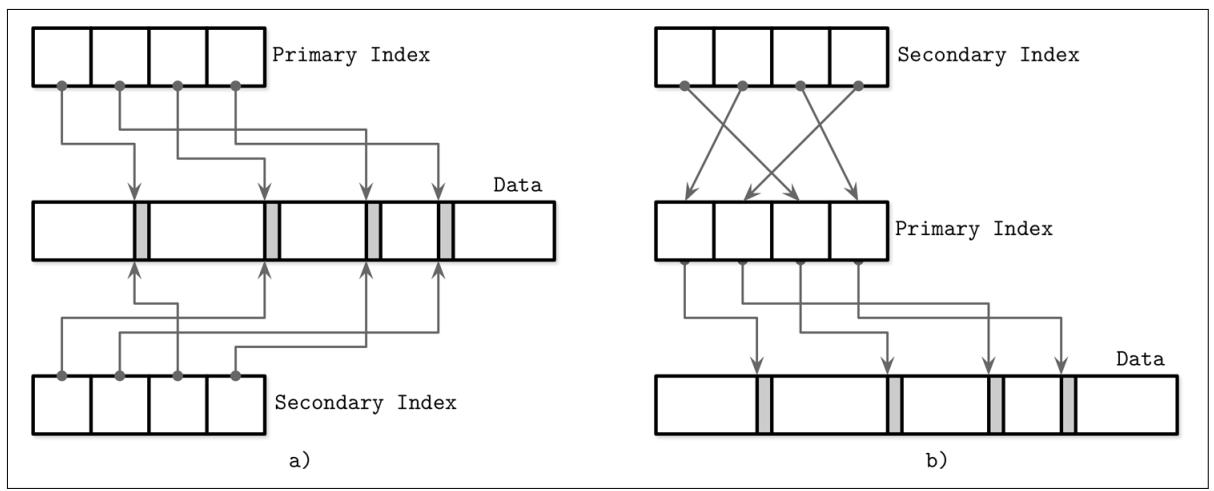
Рисунок 1-5 показывает разницу между двумя подходами:
-
Два индекса ссылаются на записи данных непосредственно из файлов вторичных индексов.
-
Некий вторичный индекс проходит через косвенный уровень какого- то первичного индекса для определения местоположения искомых записей данных.
Рисунок 1-5
Хранение записей данных в неком индексном файле в сопоставлении с хранением смещений в самом файле данных (сегменты индексов показаны белым, удерживающие данные сегменты записей данных показаны серыми)
|
| Замечание |
|---|---|
|
Таблицы с индексной организацией сохраняют информацию в соответствии с порядком индекса и кластеризованы по умолчанию. Первичные индексы чаще всего кластеризованы. Вторичные индексы не кластеризованы по определению, ибо они применяются для удобства доступа по ключам, отличающихся от первичных. Кластеризованные индексы могут быть как имеющими индексную организацию, так и иметь раздельные файлы индексов и данных. |
Многие системы баз данных имеют встроенные первичные ключи в явном виде, некое множество столбцов, которые уникально идентифицируют такую запись базы данных. В том случае, когда такой первичный ключ не определён, сам механизм хранения может создать некий не явный первичный ключ (к примеру, MySQL и InnoDB добавляют некий новый столбец с автоматическим инкрементальным приращением и автоматически заполняют его значение).
Данная терминология используется в различных видах систем баз данных: реляционных систем (таких как MySQL и PostgreSQL), основанных на Dynamo хранилищ NoSQL (например, Apache Cassandra и Riak), а также в хранилищах документах (подобных MongoDB). Иогут иметься некие особенные для проекта названия, но наиболее часто имеется чистое соответствие данной терминологии.
Существуют варианты в сообществе баз данных, при которых на записи данных требуются непосредственные ссылки (через смещение в файле) или через значение индекса первичного ключа. (первоначальный пост, который вызвал данное обсуждение, был спорным и односторонним, однако вы можете воспользоваться материалами соответствующей презентации, сопоставляющей индексы и форматы хранения MySQL и PostgreSQL, которые также ссылаются на первоисточник.)
Оба подхода имеют свои за- и против- и лучше обсуждаются в конкретной сфере полной реализации. При прямой ссылке на данные мы имеем возможность снижения общего числа дисковых поисков, но должны оплачивать стоимость обновления указателей при каждом обновлении такой записи или перемещения в процессе некого сопровождения. Применение косвенного вида первичного индекса позволяет нам снизить стоимость обновления указателей, но имеет более высокую стоимость считывания пути.
Обновление всего лишь пары индексов способно работать когда наша рабочая нагрузка в основном состоит из считываний, однако этот подход не работает достойным образом при интенсивных рабочих нагрузках записи для большого числа индексов. Для снижения стоимости обновлений индексов, вместо полезной нагрузки смещений некоторые реализации пользуются первичными ключами для косвенной адресации. Например, MySQL, InnoDB при выполнении некого запроса применяют некий первичный индекс и осуществляют два поиска: один по значению своего вторичного индекса и один в первичном индексе [TARIQ11]. Это добавляет некие накладные расходы поиска по первичному ключу вместо непосредственному следованию по смещению из значения вторичного индекса.
Рисунок 1-6 показывает чем отличаются два этих подхода:
-
Два индекса ссылаются на записи данных напрямую из файлов вторичных индексов.
-
Вторичный индекс следует через соответствующий косвенный уровень первичного индекса для определения местоположения самих записей данных.
Рисунок 1-6
Непосредственное отражение кортежа данных (a) в сопоставлении с с косвенным использованием первичного индекса (b)
Также можно пользоваться гибридным подходом и хранить сразу и смещения в файлах данных, и первичные ключи. Вначале вы проверяете является ли значение смещения данных всё ещё допустимым, и если оно изменилось, вы платите дополнительную стоимость за следование по первичному ключу, обновляя данный файл индекса после того как обнаружите новое смещение.
Механизм хранения основывается на некой структуре данных. Однако эти структуры не описывают имеющуюся семантику кэширования, восстановления способности к транзакциям и прочим моментам, которые такие механизмы хранения добавляют поверх неё.
В своих последующих главах мы приступим к такому обсуждению с B- деревьев (см. Вездесущие B- деревья) и попытаемся понять почему имеется так много вариантов B- деревьев и почему выходят в свет новые структуры хранения баз данных.
Структуры хранения обладают тремя общими переменными: они пользуются буферизацией (либо избегают её использование), применяют неизменные (или изменяемые) файлы, а также хранят значения упорядоченными (или не прибегая к упорядочиванию). Большинство различий и оптимизаций в обсуждаемых этой книгой структурах хранения связаны с одним из этих трёх понятий.
- Буферизация
Она определяет будет или нет конкретная структура хранения выбирать сбор определённого объёма данных в памяти перед их помещением на диск. Конечно, всякой дисковой структуре приходится применять буферизацию в определённой степени, так как наименьшим элементом данных для обмена с диском является некий блок, и всегда желательно записывать заполненные блоки. Здесь мы говорим об избежании буферизации, которой порой придерживаются разработчики механизма хранения. Одной из самых первых обсуждаемых в данной книги оптимизаций выступает добавление буферов памяти в узлы B- дерева для амортизации стоимостей ввода/ вывода (см. Ленивые B- деревья). Однако не единственный способ, которым мы можем использовать буферизацию. Например, двухкомпонентные LSM деревья (см. Двухкомпонентные LSM деревья), вопреки своему сходству с B- деревьями, пользуются буферизацией совершенно иным образом и сочетают буферизацию с неизменностью.
- Изменяемость (или неизменность)
Это определяет будет или нет данная структура хранения считывать части в данном файле, обновлять их и записывать результаты обновления в том же самом местоположении этого файла. Неизменные структуры являются дописываемыми исключительно в конец: после своей записи единожды, содержимое файла не изменяется. Вместо этого изменения добавляются в самый конец файла. Существуют и иные способы реализации неизменности. Один из них это копирование- записью (copy-on-write, см. Копирование записью), при котором значение изменяемой страницы, содержащее изменяемую версию рассматриваемой записи, записывается в новое место данного файла вместо его первоначального расположения. Часто само обсуждение относительно LSM и B- деревьев рисуется как сопоставление неизменности с обновлением хранилища на месте, однако существуют структуры (например, Bw- деревья), которые инспирированы B- деревьями, но при этом неизменны.
- Упорядочение
Определяет будут или нет записи данных храниться в порядке своего ключа в имеющихся на диске страницах. Иными словами, те ключи, которые сортируются близко, сохраняются в непрерывных сегментах диска. Упорядочение часто определяет будет или нет возможным действенно сканировать определённый диапазон записей, а не просто определять местоположение определённых записей данных. Хранение данных неупорядоченным образом (чаще всего в порядке вставки) открывает некие оптимизации времени записи. Например, Bitcask (см. Bitcask) и WiscKey (см. WiscKey) хранят записи данных непосредственно в файлах с исключительным добавлением в конец.
Конечно же, краткое обсуждение этих трёх понятий не достаточно чтобы показать их мощность, и мы продолжим обсуждать их на протяжении всей остающейся книги.
В этой главе мы обсудили собственно архитектуру системы управления базой данных и охватили её первичные составляющие.
Для того чтобы выделить саму важность структур на диске и их отличия от используемых в памяти, мы рассмотрели хранилища в памяти и на диске. Мы пришли к заключению, что основанные на дисках структуры важны для обоих типов хранилищ, но используются для разных целей.
Для понимания того как шаблоны доступа влияют на проектирование систем баз данных, мы обсудили системы управления базами данных, ориентированными на столбцы и строки, а также те первичные стороны, которые противопоставляют их друг другу. В качестве начала беседы относительно того как хранятся сами данные, мы рассмотрели файлы данных и индексов.
Наконец, мы ввели три центральных понятия: буферизацию, неизменность и упорядочение. Мы будем пользоваться ими на протяжении данной книги для высвечивания свойств конкретных использующих их механизмов хранения.
|
| Последующее чтение |
|---|---|
|
Если вы желаете узнать больше относительно упоминавшихся в этой главе понятий, вы можете ссылаться на следующие источники:
|