Глава 3. BlueStore
Содержание
В этой главе мы изучим BlueStore, совершенно новое хранилище объектов в Ceph, разработанное для замены имеющегося файлового хранилища. Оно увеличивает производительность и расширяет набор свойств, разработанных с целью позволить Ceph продолжить рост и предоставлять некую надёжную высокопроизводительную систему хранения на будущее. Начиная с выпуска Luminous BlueStore теперь является рекомендуемой и хранилищем объектов по умолчанию, которая применяется при создании новых OSD. Эта глава рассмотрит как работает BlueStore и почему оно лучше нежели Filestore подходит для требований Ceph. Затем следуя пошаговыми инструкциями вы получите руководство того как обновить некий кластер Ceph на BlueStore.
Мы изучим следующие темы:
-
Что такое BlueStore?
-
Имеющиеся ограничения при файловом хранении
-
Какие проблемы преодолевает BlueStore
-
Все компоненты BlueStore и как они работают
-
Введение в
ceph-volume -
Как развёртывать OSD BlueStore
-
Подходы к обновлению кластеров в реальном масштабе времени с файлового хранения на BlueStore
BlueStore является неким хранилищем объектов Ceph, которое в первую очередь разработано для решения имеющихся ограничений файлового хранения, которые, вплоть до редакции Luminous являлось хранилищем объектов по умолчанию. Изначально некое новое хранилищем объектов с названием Новое хранилище (NewStore) было разработано для замены файлового хранения. NewStore было некоторой комбинацией RockDB, некоторого хранилища ключ- значение для запоминания метаданных и какой- то стандартной файловой системы POSIX (portable operating system interface) для самих реальных объектов. Однако, быстро стало очевидным, что применением файловой системы POSIX приводит к высоким накладным расходам, что было одной их ключевых причин для попытки уйти прочь от файлового хранения в его первом месте.
Таким образом, родилось BlueStore; применение сырых блочных устройств в комбинации с RockDB дало решение ряда проблем, угнетавших NewStore. Само название BlueStore было неким отображением такого объединения применения слов Block и NewStore:
Block+NewStore=BlewStore=BlueStore
BlueStore разработано для удаления штрафов двойной записи, вызываемых файловым хранением и для увеличения производительности, которые можно достигать на том же самом оборудовании. Помимо этого, благодаря новой возможности иметь больший контроля над тем путём, которым объекты сохраняются на диск, могут быть реализованы дополнительные свойства, такие как контрольные суммы и сжатие.
Предыдущее хранилище объектов Ceph имеет целый ряд пределов, которые начали ограничивать требующееся масштабирование с которым способно работать Ceph и те свойства, которые оно может предоставлять. Далее приводятся некоторые из основных причин зачем требуется BlueStore.
Некий объект в Ceph, совместно со своими данными, также располагает связанными с ними определёнными метаданными, причём решающее значение имеет тот факт, что и сами данные, и метаданные обновляются автоматически. Если либо такие метаданные, либо данные обновляются одно без другого, существует риск непротиворечивости модели Ceph в целом. Чтобы гарантировать, что такие обновления произошли автоматически, они должны обслуживаться в некоторой единой транзакции.
Ограничения файлового хранения
Файловое хранилище первоначально проектировалось как некое хранилище объектов чтобы позволить разработчикам протестировать Ceph на их локальных машинах. Благодаря его стабильности оно быстро стало стандартным хранилищем объектов и обнаружило себя применяемым в промышленных кластерах по всему миру.
Первоначально идея относительно файлового хранилища предполагала, что приходящая на вооружение btrfs (B-tree file system), которая предлагает поддержку транзакций, позволит Ceph выгрузить требования атомарности в btrfs. Транзакции позволили бы некоторому приложению отправлять какую- то последовательность запросов в btrfs и всего лишь получать один раз подтверждение, когда всё будет зафиксировано для стабильного хранения. Без поддержки транзакций, в случае если на полпути какой бы то ни было операции записи Ceph возникает любое прерывание, либо сами данные или метаданные могут быть утрачены, либо одно из них потеряет синхронность с другим.
К сожалению, зависимость от btrfs для решения этих проблем оказалась ложной надеждой, к тому же, был обнаружен ряд ограничений. Btrfs все ещё можно применять для файлового хранения, но имеется целый ряд известных проблем, которые могут повлиять на стабильность Ceph.
В конце концов, всё вернулось к тому, что XFS была наилучшим выбором для использования в качестве хранения файлов, однако XFS имела самое главное ограничение, что она не поддерживала транзакций, а это означало тот факт, что для Ceph не имелось возможности гарантии атомарности её операций записи. Единственным решением этого состояло в применении журнала с упреждающей записью. Все записи, включая данные и метаданные должны были вначале быть записанными в некий журнал, располагающийся на некотором сыром блочном устройстве. Когда данная файловая система содержит содержит подтверждение того, что все данные и метаданные были успешно сброшены на диск, такие записи журнала могут быть освобождены. Благоприятным побочным эффектом этого является то, что при использовании SSD для хранения журнала шпиндельного диска, он действует как кеш обратной записи, что уменьшает латентность записи до скоростей самого SSD. Однако, если такой журнал файлового хранилища располагается на том же самом устройстве хранения, что и сам раздел данных, тогда пропускная способность, по крайней мере, делится пополам.
В случае OSD шпиндельного диска этого может приводить к очень плохой производительности, так как имеющиеся дисковые головки непрерывно перемещаются между двумя областями дисков, причём даже при последовательных операциях. Хотя файловое хранилище на основе SSD OSD не страдает примерно такими же штрафами в отношении производительности, их пропускная способность по- прежнему в действительности сокращается вдвое за счёт удвоения подлежащих записи данных. В любом случае, такая потеря производительности крайне нежелательна, а в случае флеш- устройств также влечёт вдвое более быстрый износ самого устройства, что требует более дорогостоящих устройств с увеличенным числом циклов перезаписи. Приводимая ниже схема отображает как Файловое хранилище и его журнал взаимодействуют с неким блочным устройством, причём вы можете увидеть, что вся обработка данных должна проходить сквозь имеющийся журнал Файлового хранилища и его журнал файловой системы.
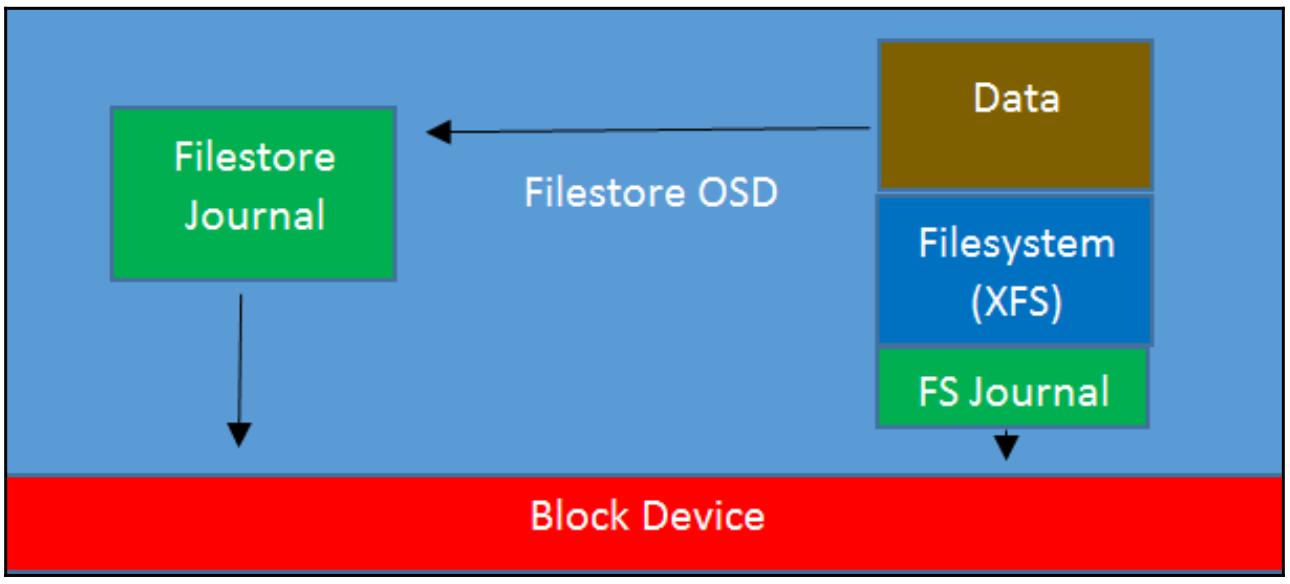
Дополнительные проблемы с файловым хранилищем состояли в попытке разработчиков контролировать все действия лежащей в его основе файловой системы POSIX для того, чтобы она выполняла работу и вела себя так, как это требуется Ceph. На протяжении многих лет разработчики файловой системы выполняли большой объём работы в попытках сделать файловые системы интеллектуальными и предсказывать как некое приложение может представлять свой ввод/ вывод. В случае с Ceph, целый ряд таких оптимизаций переплетаются с тем, как она пытается инструктировать поведение имеющейся файловой системы, что требует дополнительной работы и усложняет весь процесс.
Метаданные объекта хранятся в виде комбинации атрибутов файловой системы с названием XATTR (Extended Attributes, Расширенных атрибутов) и в некотором хранилище ключ- значение LevelDB, которое также располагается на самом диске OSD. LevelDB была выбрана в момент создания файлового хранилища вместо RockDB, так как RockDB не была доступна, а LevelDB удовлетворяла целому ряду требований Ceph.
Ceph разрабатывалось для масштабирования до петабайт данных и хранения миллиардов объектов. Однако, из- за ограничений вокруг общего числа файлов, которые вы можете объективно сохранять в некотором каталоге, вводились дальнейшие обходные ухищрения чтобы помочь с такими ограничениями. Объекты хранятся в некоторой иерархии хэшированных имён каталогов; когда общее число файлов в одной из таких папок достигает установленного предела, такой каталог расщепляется на некий последующий уровень и все объекты перемещаются.
Тем не менее, имеется некий компромисс для улучшения общей скорости нумерации объектов, так как при возникновении расщепления такого каталога это влияет на производительность, поскольку все объекты перемещаются в надлежащие каталоги. На дисках большего размера такое увеличивающееся число каталогов приводит к дополнительной нагрузке на имеющийся кэш VFS и может повлечь дополнительные штрафы производительности для объектов с не частым использованием.
Как данная книга рассмотрит в соответствующей главе настройки производительности, основное узкое место
производительности в файловом хранилище состоит в том, когда XFS начинает поиск
inode и записей каталога, а они
в настоящий момент не кэшированы в оперативной памяти. В случаях, когда имеется некое большое число объектов,
хранимое в расчёте на один OSD, в настоящее время нет реального решения для данной проблемы и достаточно
распространённым является наблюдение, что определённый кластер Ceph постепенно начинает замедляться по мере
своего заполнения.
Уход прочь от хранения объектов в некоторой файловой системе POSIX в действительности единственный способ для решения большей части этих проблем.
BlueStore было разработано для решения этих ограничений. Начиная с разработки NewStore, было очевидно, что попытка использования какой либо файловой системы POSIX в качестве лежащей в основополагающем уровне хранилища при любом подходе повлекло бы целый ряд задач, которые также присутствовали бы и в файловом хранилище. Чтобы Ceph было способным получать некий гарантированный уровень производительности, который ожидается от лежащего в основе хранилища, ему также требуется иметь прямой доступ на уровне блоков к самим устройствам хранения без дополнительных накладных расходов некоторой обособленной файловой системы Linux. Сохраняя метаданные в RocksDB, а все реальные данные объекта напрямую в блочных устройствах, Ceph может намного усилить контроль над лежащим в его основе хранилищем и в то же самое время также и предоставить лучшую производительность.
Следующая схема показывает как BlueStore взаимодействует с неким блочным устройством. В отличие от файлового хранилища, данные напрямую записываются в имеющееся блочное устройство, а операции с метаданными обрабатываются RocksDB.
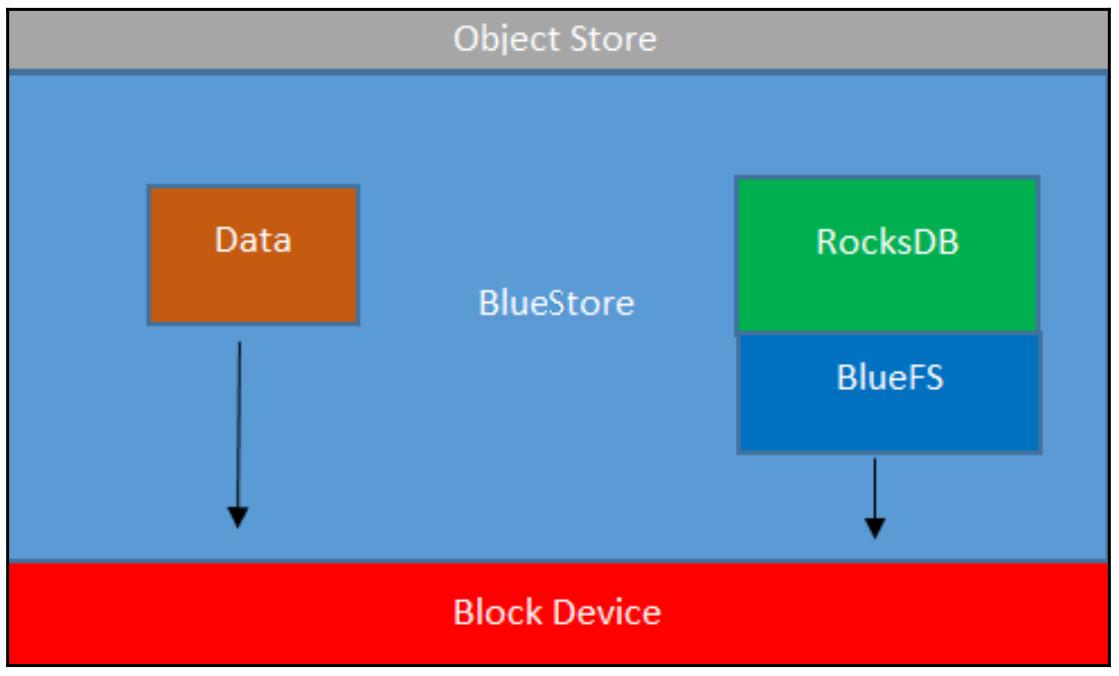
Данное блочное устройство делится между хранилищем данных RocksDB и реальными данными пользователя, сохраняемыми в Ceph. Каждый объект сохраняется как некое число blob, выделяемых из данного блочного устройства. RocksDB содержит метаданные для каждого объекта и отслеживает информацию использования и выделения для самих blob данных.
RocksDB является некоторым высокопроизводительным хранилищем ключ- значение, которое первоначально ответвилось от LevelDB, однако после доработки Facebook прошёл к предложению значительных улучшений производительности приспособленных к многопроцессорным серверам с низколатентными устройствами хранения. Оно также получило большое число улучшенных свойств, некоторые из которых используются в BlueStore.
RocksDB применяется для хранения метаданных самих хранимых объектов, которые изначально обрабатывались в виде комбинации LevelDB и XATTR в файловом хранилище.
Некоторой ключевой особенностью RocksDB является тот способ, коим данные записываются на самих уровнях базы данных. Она обязана своими свойствами её происхождением в LevelDB. Новые данные записываются в некую таблицу на основе памяти с неким не обязательным журналом транзакций в постоянном хранилище, WAL (write-ahead log, журнале упреждающей записи); по мере заполнения такой таблицы на основе памяти, данные перемещаются вниз на следующий уровень имеющейся базы данных процессом с названием уплотнение (compaction). Когда и этот уровень заполняется, данные вновь мигрируют вниз и так далее. Все эти уровни хранятся в том, что RocksDB именует файлами SST. В Ceph каждый из этих уровней настраивается с тем чтобы он ы 10 раз превышал размер предыдущего уровня, что привносит в игру некие интересные вопросы когда вы пытаетесь хранить всю свою RockDB на SSD в некоторой гибридной схеме HDD- SSD.
Все новые данные записываются в имеющуюся таблицу на основе памяти и WAL, причём таблица на основе памяти именуется нулевым уровнем. BlueStore настраивает нулевой уровень на 256 МБ. Значение размера множителя между уровнями по умолчанию равно десяти, а это означает, что уровень 1 также равен 256 МБ, уровень 2 2.56 ГБ, уровень 3 25.6 ГБ, а уровень 4 256 ГБ. Для большинства вариантов применения Ceph среднее значение общего размера метаданных на OSD должно находиться в пределах 20- 30 ГБ, причём весь набор горячих данных обычно меньше этого значения. Хотелось бы надеяться, что уровни 0, 1 и 2 будут содержать большую часть горячих данных для записи, а потому размер раздела SSD не менее 3 ГБ мог бы означать, что эти уровни хранятся в SSD. Производительность записи должна быть хорошей, поскольку все метаданные для записи будут попадать на имеющийся SSD; однако при чтении метаданных - скажем, в процессе запросов клиента на чтение - имеется вероятность что такие метаданные могут располагаться на уровне 3 или 4 и тем самым потребуют чтения со шпиндельного диска, что окажет отрицательное воздействие на латентность и увеличит нагрузку на диск.
Таким образом, очевидным решением было бы каким- то образом рассчитать насколько велики по вашему мнению метаданные BlueStore для вашего набора данных и увеличить размер имеющегося хранилища RocksDB чтобы обеспечить его хранение целиком на SSD. В достижении этого имеются две сложности.
Во- первых, очень сложно выполнить предварительный расчёт того размера ваших метаданных, исходя из величины размера имеющихся в действительности данных. В зависимости от самой модели клиента - RBD, CephFS, или RGW - будут сохраняться различные объёмы метаданных. Кроме того, такие вещи как моментальные снимки и будете ли вы применять пулы с репликациями или с удаляющим кодированием, также приводит к расхождению в размерах метаданных.
Следующей проблемой при правильном определении размеров вашего фдеш- устройства это обеспечение того что помещаются все имеющиеся метаданные. Как мы уже упоминали ранее, RocksDB уплотняет данные вниз посредством различных уровней своей базы данных. Когда RocksDB создаёт соответствующие файлы для RocksDB, она будет помещать некий определённый уровень на ваше флеш- устройство если этот уровень целиком помещается на нём. Следовательно имеются минимальные размеры требующиеся для локализации каждого из уровней на фдеш- устройстве. Например, чтобы гарантировать что соответствующая часть DB уровня 2 2.56 ГБ поместится на флеш- устройстве, вам понадобится иметь по крайней мере 4-5 ГБ раздел SSD. Это происходит по той причине, что необходимо поместить все верхние уровни, и уровень 0, и уровень 1, и уровень 2, а также небольшой объём для накладных расходов. Для помещения целиком уровня 3 вам потребуется по крайней мере 30 ГБ; любое пространство меньшего размера и дополнительное пространство поверх уровня 2 не будут использоваться. Для обеспечения размещения уровня 4 вам скорее всего потребуется флеш пространство свыше 300 ГБ.
Сохранение имеющегося WAL в некотором более быстром устройстве хранения - что может помочь в снижении латентности работы RocksDB - рекомендуется если вы применяете флеш хранилище для своих реальных данных и вам требуется дальнейшее увеличение производительности. Если вы применяете шпиндельные диски, перемещение WAL на некое выделенное устройство скорее всего покажет минимальное улучшение. Существует целый ряд возможных настроек схем хранения, при которых WAL, DB и данные могут помещаться на различные устройства хранения. Приведём здесь три примера таких настроек:
-
WAL, DB и данные - все находятся на шпиндельных дисках
-
WAL и DB на SSD, а данные на шпиндельных дисках
-
WAL на NVMe, DB на SSD, а данные на шпиндельных дисках
Другим удобным свойством BlueStore является то, что оно включило сжатие данных на уровне подобъектов, blobs внутри BlueStore. Это означает, что все записанные в Ceph данные, вне зависимости от модели доступа клиента, могут получать преимущества данной функциональности. Сжатие включается на основе каждого пула, но по умолчанию отключено.
Помимо самой возможности включения сжатия для каждого пула, имеется также ряд дополнительных вариантов для упроавления поведением такого сжатия, что отображено в приводимом далее списке:
-
compression_algorithm: Управляет тем какая библиотека сжатия используется для компрессии данных. Значением по умолчанию являетсяsnappy, написанная в Google библиотека сжатия. Хотя её соотношение сжатия и не самое лучшее, она обладает очень высокой производительностью и если у вас нет особых требований к ёмкости, вам скорее всего стоит остановиться наsnappy. Другими вариантами являютсяzlibиzstd. -
compression_mode: Управляет значением состояния обработки сжатия на основе применения к каждому пулу. Может быть установлено в одно из значенийnone,passive,aggressiveилиforce. Значение установкиpassiveвключает применение сжатие, но осуществляет компрессию объектов только помеченных для сжатия с верхних уровней. Значение настройкиaggressiveбудет выполнять попытку сжатия и сжимать все объекты, только если не указано в явном виде не делать этого. Значение установкиforceвсегда будет выполнять попытку и сжимать данные. -
compress_required_ratio: По умолчанию это значение установлено на величину 87.5%. Некий сжимаемый объект должен подвергнуться компрессии по крайней мере ниже данного значения как рассматриваемый заслуживающим сжатия; в противном случае данный объект будет сохраняться в формате без сжатия.
Хотя сжатие и требует дополнительного ЦПУ, snappy является очень эффективным, а сама
распределённая природа Ceph хорошо подходит для этой задачи, так как обязанности по сжатию распределяются по большому количеству
процессоров по всему кластеру. В сопоставлении с этим, наследуемый массив хранения должен был применять больше своего дорогостоящего
ограниченного ресурса сдвоенного контроллера ЦПУ.
Неким дополнительным преимуществом сжатия помимо снижения потребляемого пространства также является производительность ввода/ вывода при чтении или записи больших блоков данных. Поскольку эти данные подлежат сжатию, сами устройства дисков или флеш- памяти будут иметь меньше данных для чтения или записи, что подразумевает более быстрое время отклика. Кроме того, флеш- устройства вероятно будут наблюдать меньший износ записью, в силу того что снижается общий объём записываемых данных.
Для увеличения защищённости данных BlueStore вычисляет и сохраняет значения контрольных сумм записываемых данных. При каждом запросе на чтение BlueStore считывает значение контрольной суммы и сравнивает с самими считанными с устройства данными. Если обнаруживается несовпадение, BlueStore выдаёт отчёт об ошибке чтения и восстанавливает разрушение. Затем Ceph выполняет попытку чтения с другого OSD , поддерживающего данный объект. Хотя современное оборудование имеет собственные искушённые контрольные суммы и выявления ошибок, введение дополнительного уровня в BlueStore прокладывает длинный путь к устранению риска скрытого повреждения данных. По умолчанию BlueStore создаёт контрольные суммы при помощи crc32, который с очень высокой вероятностью отлавливает любые скрытые повреждения данных; тем не менее, доступны и дополнительные алгоритмы, если это необходимо.
В отличии от файлового хранения, при котором для кэширования страниц в данном узле OSD применяется вся доступная оперативная память, в BlueStore оперативную память необходимо выделять для OSD статическим образом при запуске. Для OSD шпиндельных дисков этим объёмом является 1 ГБ; SSD на основе флеш- памяти имеют выделенными под них 3 ГБ. Эта оперативная память применяется для некоторого некоторого числа различных кэшей внутренним образом: кэш RockDB, кэш метаданных BlueStore и кэш самих данных BlueStore. Самые первые два отвечают за гарантию равномерной работы внутренних механизмов BlueStore при поиске существенных метаданных; установленные по умолчанию значения были выставлены для предложения хорошей производительности, а их дальнейшее увеличение демонстрирует убывающую прибыль. Финальный кэш данных BlueStore фактически будет кэшировать хранящиеся в кластере Ceph пользовательские данные. По умолчанию он установлен относительно низким по сравнению с тем, что могли бы хранить в кэше страниц некоторые хранилища файлов OSD; это предотвращает высокое потребление памяти в BlueStore по умолчанию.
Если ваши узлы OSD имеют достаточно свободной памяти после того как все ваши OSD запущены и сохраняют данные, тогда возможно увеличить значение памяти, выделяемое каждому OSD и принять решение как расщеплять её между различными кэшами.
Последние версии Ceph содержат в BlueStore некую функциональность, которая автоматически настраивает выделение памяти между имеющимися в BlueStore различными кэшами. По умолчанию определённому OSD ставится цель потреблять около 4 ГБ памяти, и выполняя на постоянной основе анализ имеющегося использования памяти выравнивать выделение для каждого из кэшей. Самое основное улучшение такой автоматической подстройки привносит то, что различные рабочие нагрузки используют различные кэши BlueStore по- разному и попытка предварительно выделить память со статическими переменными является чрезвычайно сложной задачей. Помимо потенциальной настройки самого порогового значения, остающаяся часть автоматической подстройки в основном выполняется самостоятельно и скрыта от администратора Ceph.
В случае отключения автоматической подстройки BlueStore откатится обратно к своему поведению выделения кэшей вручную.
Последующий раздел подробно поясняет различные кэши BlueStore, которые можно настраивать в ручном режиме. В данном
режиме имеются две основные настройки, которые управляют тем объёмом памяти, который выделяется каждому OSD,
bluestore_cache_size_hdd и bluestore_cache_size_ssd.
Как и указывает их название, вы можете вы можете каждым из них управлять значением выделяемой памяти либо для HDD, либо
под SSD. Однако мы можем не просто выделять общий объём памяти для некого OSD; также существует ряд дополнительных настроек
для контроля самим расщеплением имеющихся трёх кэшей, что показано в следующем перечне:
-
Значение настройки
bluestore_cache_kv_ratio, по умолчанию назначенное на 0.5, выделит 50% от всей выделяемой памяти под кэш RockDB. Этот кэш применяется внутренним механизмом RockDB и напрямую не управляется из Ceph. В настоящее время считается, что это обеспечивает наилучшую отдачу в отношении производительности при принятии решения о том куда выделять память. -
Величина установки
bluestore_cache_meta_ratio, по умолчанию назначенное на 0.5, выделит 50% от всей выделяемой памяти под кэширование метаданных BlueStore. Обратите внимание, что в зависимости от объёма доступной памяти и значенияbluestore_cache_kv_minв конечном итоге для кэширования метаданных может быть выделено менее 50%. Кэш метаданных BlueStore содержит необработанные метаданные до их сохранения в RocksDB. -
Значение настройки
bluestore_cache_kv_min settingпо умолчанию устанавливается в 512 МБ, гарантируя что по крайней мере 512 МБ памяти используется под объём кэширования RockDB. Всё что превосходит это значение будет совместно разделяться в пропорции 50:50 с объёмом кэширования метаданных BlueStore.
Наконец, вся остающаяся после предыдущих двух соотношений память будет применяться под кэширование реальных данных.
По умолчанию из- за kv и meta_ratios
это будет 0%. Большинство клиентов Ceph будут иметь свои собственный локальный кэш чтения, который, как мы надеемся, будет
хранить чрезвычайно горячие данные кэшированными; однако в случае применения клиентов, которые не имеют своего собственного
локального кэширования, возможно, стоит выяснить приносит ли пользу регулирование коэффициентов кэширования под использование
неболього объёма кэша для использования данными.
По умолчанию автоматические регулировки BlueStore предоставляют наилучший баланс использования памяти и предоставляют наилучшую производительность и не рекомендуется изменять их вручную.
В отличии от файлового хранилища, в котором каждая запись целиком сохраняется и в сам журнал, и, в конечном итоге, на диск, в BlueStore вся часть данных данной записи в большинстве случаев записывается напрямую в имеющееся блочное устройство. Это удаляет необходимость штрафов дублирования, а на чистых шпиндельных дисках впечатляюще увеличивает производительность. Однако, как уже упоминалось ранее, такая двойная запись имела обратное воздействие уменьшения латентности записи в случае, когда шпиндельные диски комбинируются с журналами SSD. BlueStore также может применять устройства дискового хранения на основе флеш- памяти для снижения латентности путём отложенных (deferred) записей, вначале записывая данные в имеющиеся WAL RocksDB, а затем позже сбрасывая эти записи на диск. В отличие от файлового хранилища в имеющийся WAL записываются не все записи, параметры настройки определяют установленный размера отсечения ввода/ вывода до которого запись откладывается. Здесь продемонстрирован соответствующий параметр настройки:
bluestore_prefer_deferred_size
Он управляет тем размером ввода/ вывода, который будет записан вначале в WAL. Для шпинделных дисков это по умолчанию 32кБ, в то время как для SSD по умолчанию нет отложенных записей. Если латентность записи важна и ваши SSD достаточно быстрые, тогда увеличив это значение вы можете увеличить тот размер ввода/ вывода, который вы желаете придерживать в WAL.
Хотя основным побудителем BlueStore был отказ от лежащей в основе файловой системы, BlueStore всё же нуждается в некотором методе сохранения RockDB и самих данных в имеющийся в OSD диск. Именно с этой целью была разработана BlueFS, которая является чрезвычайно усечённой файловой системой, предоставляющей всего лишь определённый минимальный набор свойств для имеющегося тонкого набора операций, передаваемых Ceph. Она также удаляет накладные расходы являющиеся результатом необходимости двойной журнальной записи, которые присутствовали бы при использовании некой стандартной POSIX файловой системы.
В отличии от файлового хранения вы не можете просто просматривать структуру данной папки и вручную отслеживать все
имеющиеся объекты, поскольку BlueFS не является естественной файловой системой Linux; тем не менее, имеется возможность
смонтировать некую файловую систему при помощи ceph-objectstore-tool для включения
её зондирования или чтобы позволить вручную исправлять ошибки. Мы рассмотрим это дополнительно в соответствующем разделе
восстановления после сбоев.
Хотя он и не является в точности частью BlueStore, инструмент ceph-volume
был выпущен в то же самое время что и BlueStore и является рекомендуемым инструментом для предоставления OSD BlueStore.
Именно он является непосредственной заменой для имеющегося инструмента ceph-disk,
который имеет целый ряд проблем относительно условий состязательности и той предсказуемости OSD, которые подлежат
правильному перечислению и запуску. Инструмент ceph-disk применяет
udev для указания монтируемых и активируемых OSD. В настоящее время инструмент
ceph-disk признан устаревшим и все новые OSD следует создавать при помощи
ceph-volume.
Хотя ceph-volume может функционировать и в режиме simple,
рекомендуемым подходом является применение его режима lvm. Ккак и подразумевает его
название, он предполагает использование диспетчера логических томов Linux для сохранения информации относительно самих OSD
и для управления блочными устройствами. Кроме того, dm-cache, являющийся частью
lvm, может применяться для предоставления кэширования на блочном уровне лежащим ниже
OSD.
Данный инструмент ceph-volume также имеет некий пакетный режим, который служит цели
интеллектуального предоставления OSD с заданным списком блочных устройств. Следует позаботиться о том чтобы применить
режим --report чтобы быть уверенным что его предполагаемое действие соответствует
вашим ожиданиям. В противном случае рекомендуется создать разделы вручную, а затем и OSD.
Для создания некоторого OSD BlueStore при помощи ceph-volume, вы запускаете
приведённую ниже команду, описывая необходимые устройства для данных и хранилища RocksDB. Как уже упоминалось ранее,
если пожелаете, вы можете разделить части DB и WAL RocksDB:
ceph-volume create --bluestore /dev/sda --block.wal /dev/sdb --block.db /dev/sdc (--dmcrypt)
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Указанный в скобках вариант служит шифрованию. Рекомендуется шифровать все новые OSD, только если у вас нет особых требований не предпринимать этого. При современных ЦПУ шифрование создаёт чрезвычайно низкие накладные расходы и делает намного более простыми обычно забываемые мероприятия по безопасности при замене дисков. С недавним введением различных новых законов о защите данных, таких как GDPR в Европе, настоятельно рекомендуется шифровать данные в состоянии покоя. |
Предыдущие код предполагает, что вашим диском данных является /dev/sda.
Для данного примера, допустим, что вы применяете некий шпиндельный диск, а также у вас есть некое более быстрое устройство,
например SSD, /dev/sdb и очень быстрое устройство NVMe
/dev/sdс. Инструмент Ceph-volume
создаст два раздела на имеющемся диске данных: один для хранения реальных объектов Ceph и другой маленький раздел
XFS для хранения подробностей о самом OSD. Она также затем поместит некую ссылку на ваш SSD для сохранения на нём RocksDB и
ссылку на ваше устройство NVMe для хранения создаваемого WAL. Вы можете создать множество OSD, совместно использующие одни и
те же SSD для DB и WAL разделяя эти устройства на разделы, либо воспользовавшись
lvm для нарезки на нём логических томов.
Однако, как мы уже обсуждали в Главе 2, Развёртывание Ceph, применение соответствующего инструмента развёртывания для вашего кластера помогает уменьшению времени развёртывания и обеспечивает согласованность по всему кластеру. Хотя имеющиеся модули Ansible Ceph также поддерживают развёртывание OSD BlueStore, на момент публикации данной книги (февраль 2019), они не поддерживают сейчас раздельное развёртывание разделов DB и WAL на неком отдельном диске.
Теперь, когда вы понимаете как создавать OSD BlueStore, следующей подлежащей обсуждению темой является обновление некого уже существующего кластера.
Скорее всего некоторые из читающих данную книгу имеют существующие рабочие кластеры Ceph, которые применяют файловое хранилище. Этим читателям может быть интересно узнать стоит ли им выполнять обновление до BlueStore, и если да, то какой из методов будет для этого наилучшим.
Следует понять, что хотя filestore всё ещё поддерживается, он пребывает в самом конце своего жизненного цикла и не планируются никакие его дальнейшие разработки, за исключением исправления неких критически важных ошибок. Поэтому настоятельно рекомендуется чтобы вы спланировали обновление своего кластера до BlueStore чтобы воспользоваться всеми текущими и грядущими усовершенствованиями и продолжить исполненние поддерживаемого выпуска Ceph. Сам путь поддержки для файлового хранения не был заявлен в последующих выпусках, но было бы разумно поставить целью запустить OSD BlueStore к выпуску Ceph после Nautilus.
Не существует специального пути по обновлению некого OSD до BlueStore; этот процесс заключается в простом уничтожении имеющегося OSD, его повторном создании в качестве BlueStore с последующим дозволением Ceph восстановить его данные в таком вновь созданном OSD. Скорее всего из- за различных требований к размеру между журналами файлового хранения и RocksDB BlueStore, изменение размеров разделов потребует одновременного уничтожения нескольких OSD. Поэтому вероятно стоит подумать о том, следует ли перестраивать на этом этапе операционную систему.
Для данного процесса обновления существует два основных подхода, которые в основном определяются склонностью самого оператора Ceph к риску и доступности запасной ёмкости перечисляемых далее:
-
Обновление деградацией: При обновлении деградацией конкретный текущий OSD уничтожается без перераспределения его содержимого по всем остающимся OSD. Как только данный OSD возвращается обратно в рабочее состояние в качестве OSD BlueStore, именно тогда выполняется перестроение утраченных копий данных. Пока данный кластер не вернётся в полностью жизнеспособное состояние, некая часть ваших данных в этом кластере Ceph будет пребывать в состоянии даградировавших и, хотя всё ещё имеется множество копий, будет иметься высокая вероятность риска что такой кластер испытает отказ некого вида. Времена восстановления будут зависеть от общего числа подлежащих восстановлению OSD и самому размеру данных, хранящихся на каждом OSD. Поскольку очень вероятно что несколько OSD будут обновляться одновременно, ожидаемое значение времени восстановления будет выше нежели это было бы для какого- то отдельного OSD. Пожалуйста, обратите также внимание на то, что при установках по умолчанию со значениями
size=3иmin_size=2, в случае отказа некого дополнительного диска, некоторые PG будут иметь лишь одну копию и теперь, когда это будет ниже значенияmin_size, для этих PG будет подвешен весь ввод/ вывод до тех пор пока запущенное восстановление не воссоздаст некую вторую копию. Основным преимуществом обновления деградацией является то, что вам всего лишь приходится подождать от самого кластера повторной балансировки во время восстановления и вам не требуется дополнительное пространство, что может быть единственным вариантом для кластеров, которые более или менее заполнены. -
Обновление out-and-in:: Если вы желаете обезопасить себя от любой возможности утраты данных или невозможности иметь достаточного пространства для перераспределения текущего содержимого обновляемых среди имеющегося кластера OSD, тогда именно обновление out-and-in (вывода- и- включения) является рекомендуемым подходом. Сделав определённый OSD подлежащим обновлению в качестве out, Ceph выполнит повторную балансировку его PG по всем прочим OSD. По завершению этого процесса, данный OSD может быть остановлен и уничтожен без какого либо воздействия на надёжность и доступность. После того как на нём повторно будет представлен OSD, но уже BlueStore, его PG наполнятся обратно и на протяжении всего периода времени не будет иметься никакого понижения числа копий данных.
Code.
Любой из методов приведёт к той же самой конфигурации и, в конечном итоге, сводится к личным предпочтениям. Если в вашем кластере большое число OSD, то может потребоваться некая форма автоматизации чтобы уменьшить нагрузку на оператора; однако, если вы пожелаете автоматизировать весь процесс, следует позаботиться относительно самого этапа уничтожения имеющегося файлового хранилища OSD, так как всего одна ошибка может более чем предназначенные для того OSD. В качестве полумеры можно создать некий небольшой сценарий, который автоматизирует этапы затирания, разбиения и создания. Он затем может исполняться вручную на каждом OSD.
В качестве основы демонстрации BlueStore мы воспользуемся ceph-volume для
обновления без потерь данных вручную в реальном времени некого OSD кластера с файлового хранения на BlueStore. Если вы
пожелаете попробовать данную процедуру на деле, вам следует отработать раздел
Ansible из
Главы 2, Развёртывание Ceph в контейнерах
для развёртывания некого кластера с OSD файлового хранения и затем пройти все последующие инструкции для его обновления.
Эти OSD будут обновлены в соответствии с методом деградации, при котором OSD удаляются вместе с имеющимися в них данными.
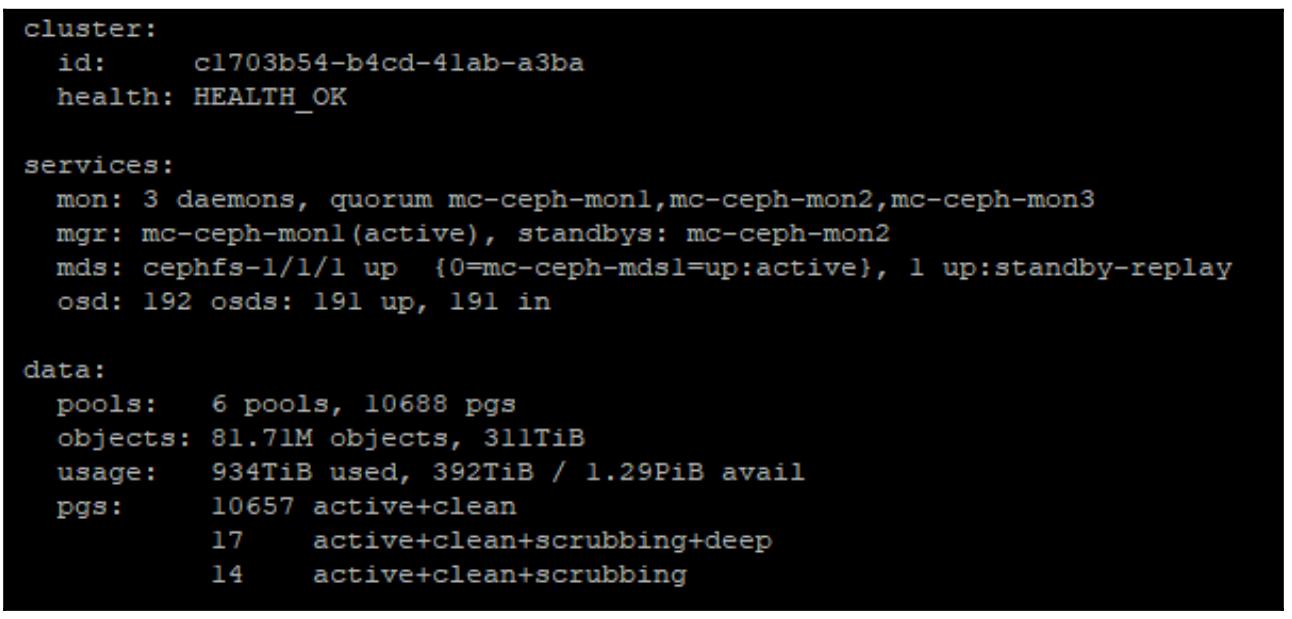
Убедитесь что ваш кластер Ceph пребывает в полностью жизнеспособном состоянии выполнив проверку с помощью команды
ceph -s, как это показано в приводимом ниже коде. Мы будем обновлять OSD сначала
удаляя его из своего кластера и затем позволяя Ceph восстанавливать все данные в его новый OSD BlueStore, поэтому нам
потребуется уверенность в том, что Ceph имеет достаточное число допустимых копий ваших данных прежде чем мы начнём.
Воспользовавшись преимуществами возможности Ceph такого сопровождения в горячем режиме вы можете повторить эту процедуру
для всех имеющихся в вашем кластере OSD без простоя:
Теперь вам требуется остановить все требующиеся OSD от их исполнения, размонтировать их диски и затем почистить их проходя следующие этапы:
-
Для останова соответствующих служб OSD воспользуйтесь такой командой:
sudo systemctl stop ceph-osd@*Ваша предыдущая команда выдаст следующий вывод:
Мы сможем убедиться что эти OSD были остановлены и что Ceph всё ещё исполняется воспользовавшись командой
ceph -sснова, как это показано на снимке экрана внизу:
-
Теперь размонтируйте свой раздел XFS; все ошибки можно игнорировать:
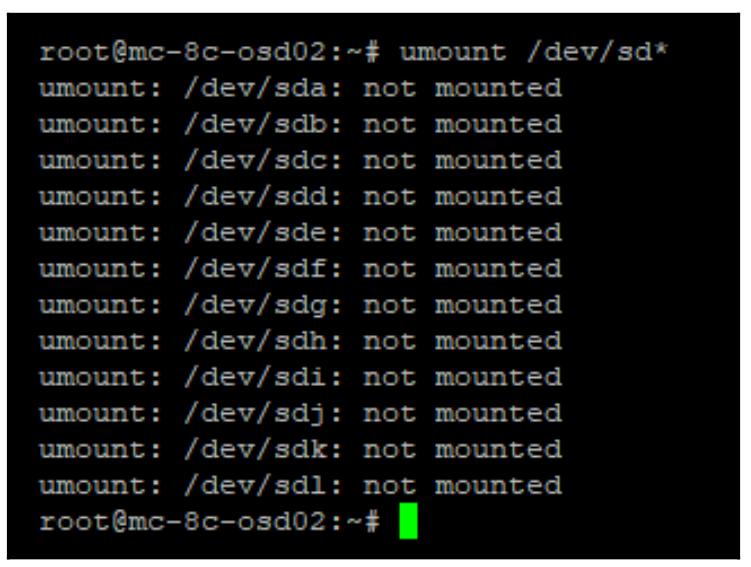
sudo umount /dev/sd*
-
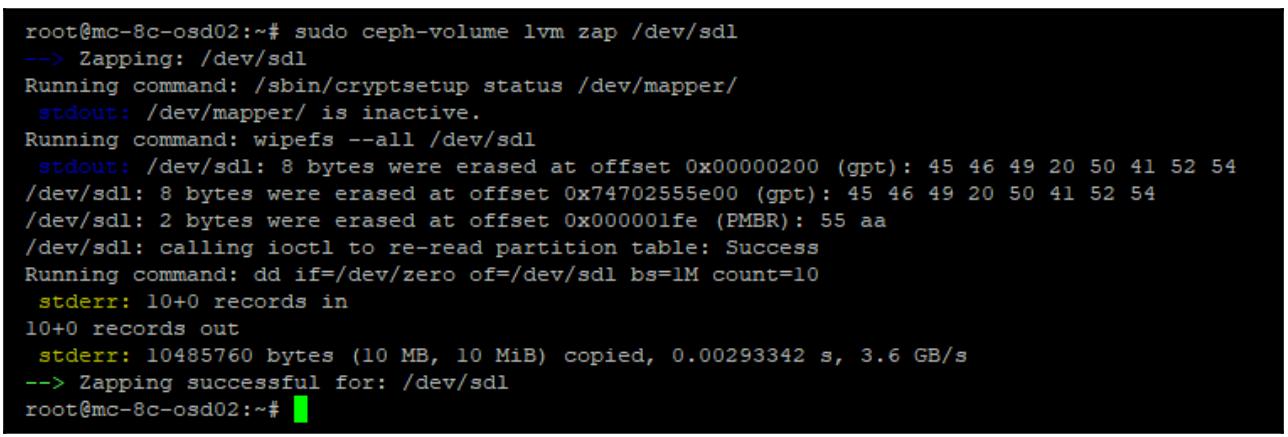
Удаление монтирования данной файловой системы будет означать что все диски теперь больше не блокируются и вы можете вычистить эти диски при помощи такого кода:
sudo ceph-volume lvm zap /dev/sd<x>
-
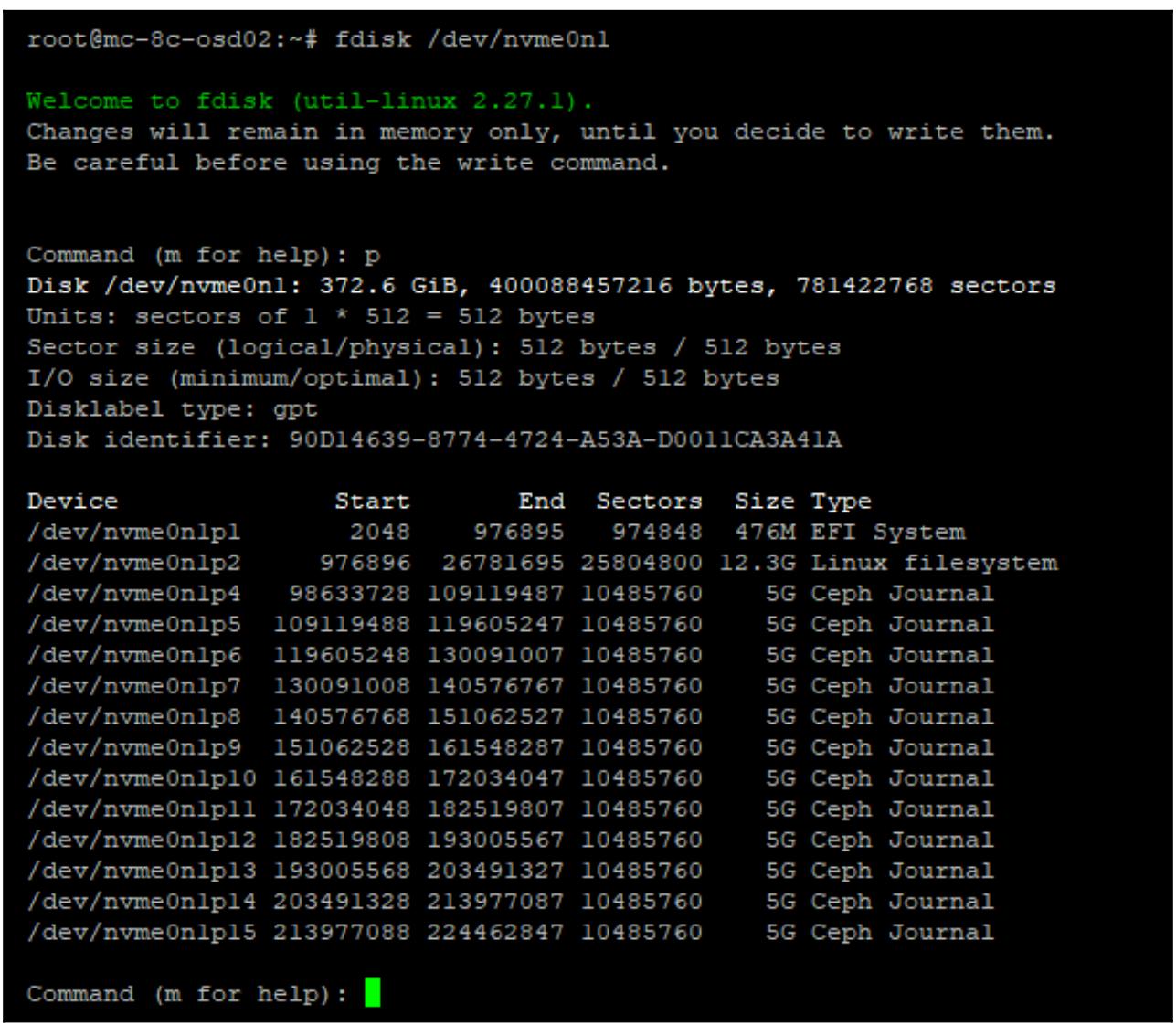
Теперь вы можете также отредактировать саму таблицу разделов в имеющемся флеш устройстве для удаления журналов его файлового хранилища и повторно создать их в качестве RocksDB BluStore подходящего размера при помощи следующего кода. В данном примере нашим флеш устройством является некий NVMe:
sudo fdisk /dev/sd<x>
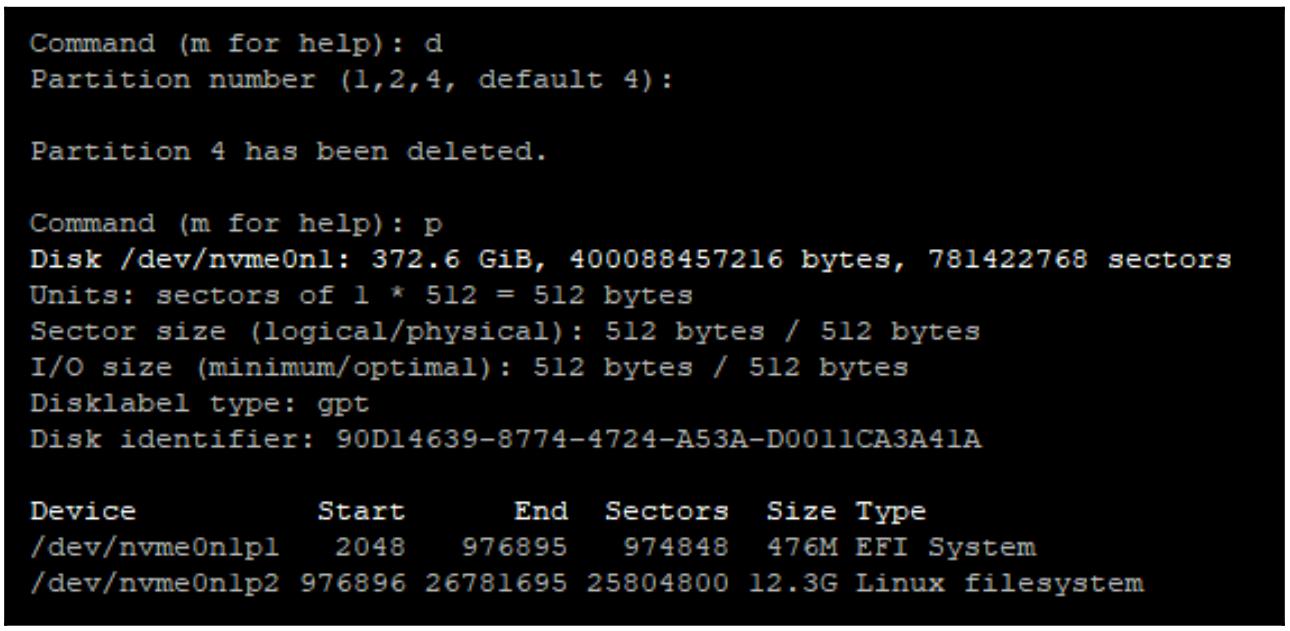
Отсоедините все разделы журнала Ceph воспользовавшись соответствующей командой
dследующим образом:
Теперь создайте все требуемые новые разделы для BlueStore как это показано на следующем снимке экрана:
Добавьте по одному разделу для каждого OSD, котрые вы намерены создать. После завершения ваша таблица разделов должна выглядеть как- то аналогично такому:
Воспользуйтесь командой
wчтобы записать эту новую таблицу разделов на диск, как это показано на снимке экрана ниже. После выполнения вы получите сообщение что ваша новая таблица разделов в настоящее время применяется и поэтому нам придётся запуститьsudo partprobeчтобы загрузить эту таблицу в своё ядро:
-
Вернитесь обратно в один из своих мониторов. Для начала убедитесь что все OSD которые мы собирались удалять удалены и уничтожьте сами OSD воспользовавшись следующими командами
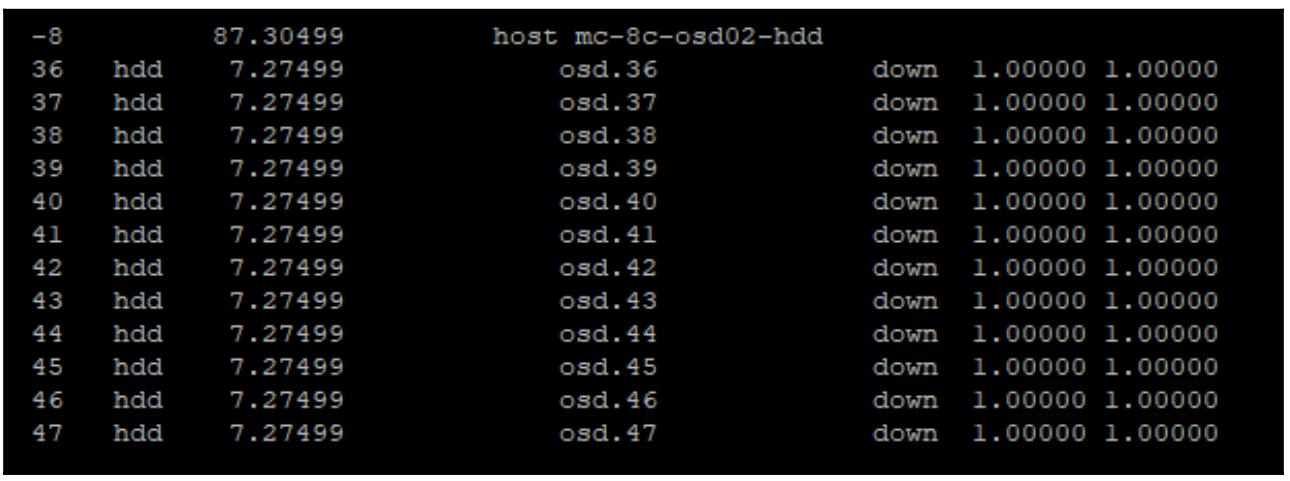
purge:sudo ceph osd treeПредыдущая команда выдаст следующий вывод:
Теперь удалите записи соответствующих логических OSD из своего кластера Ceph - в данном примере OSD 36:
sudo ceph osd purge x --yes-i-really-mean-it
-
Проверьте состояние своего кластера Ceph с помощью команды
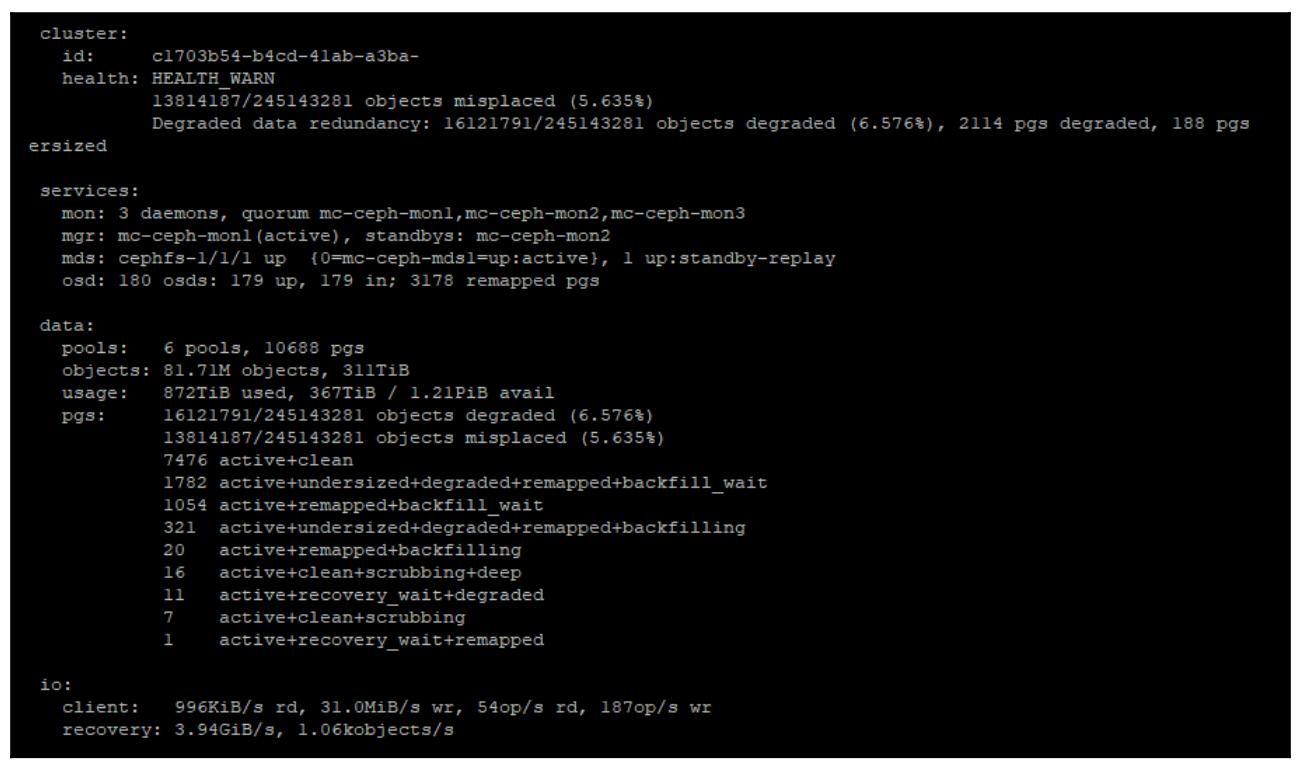
ceph -s. Теперь вы должны увидеть что необходимые OSD были удалены, что отображено на следующем снимке экрана:
Отметим, что общее число OSD упало, а это произошло потому что данные OSD були удалены из общей карты CRUSH, Ceph теперь запустил попытку и восстанавливает все утраченные данные на остающиеся OSD. Может быть неплохой идеей не позволить Ceph оставаться в таком состоянии слишком долго чтобы избежать не требующихся перемещений данных.
-
Теперь вызовите команду
ceph-volumeчтобы создать необходимый OSDbluestoreпри помощи приводимого далее кода. В данном примере мы будем хранить свою DB на отдельном флеш устройстве, поэтому нам потребуется определить этот вариант. Кроме того, следуя рекомендациям данной книги этот OSD будет зашифрованным:sudo ceph-volume lvm create --bluestore --data /dev/sd<x> --block.db /dev/sda<ssd> --dmcryptНаша предыдущая команда выдаст большой вывод, но в случае успеха мы получим в конце следующее:
-
Снова проверьте состояние Ceph при помощи
ceph -sчтобы убедиться что ваши новые OSD были добавлены и что Ceph восстанавливает на них данные, ккак это показано на следующем снимке экрана:

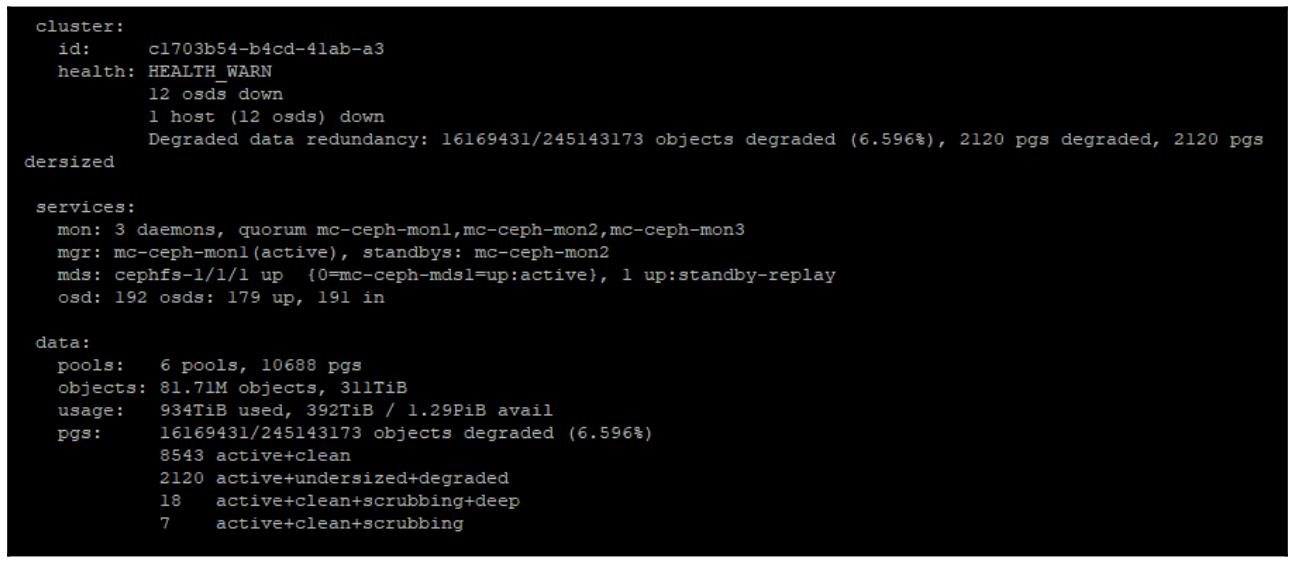




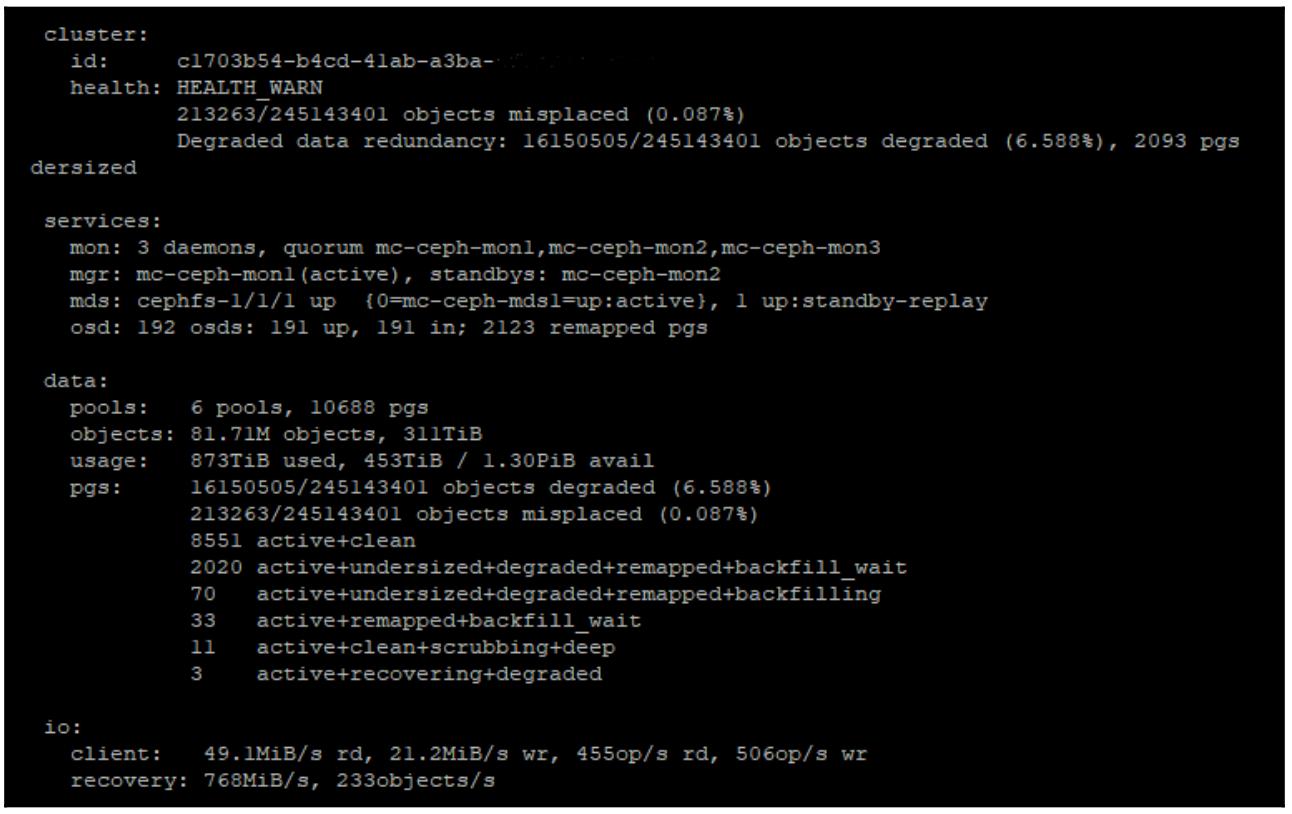
Обратите внимание, что общее число неуместных объектов теперь почти равно нулю, благодаря нашим новым OSD, которые были помещены в то же самое место в имеющейся карте CRUSH прежде чем они были обновлены. Для Ceph теперь требуется только восстановить все данные, не перераспределяя саму схему данных.
Если требуется дальнейшее обновление узлов, дождитесь завершения процесса заполнения и того пока состояние всего Ceph
вернётся в HEALTH_OK. Затем вся работа может быть проделана на следующем узле.
Как вы можете увидеть, вся процедура целиком очень проста и идентична тем шагам, которые требуются для замены отказавшего диска.
В этой главе мы изучили новое хранилище объектов в Ceph под названием BlueStore. Надеемся, вы получили лучшее понимание того зачем оно понадобилось и основные ограничения в архитектуре с файловым хранением. Вы также должны получить некое базовое представление во внутреннем устройстве работы BlueStore и получить уверенность в том как обновлять свои OSD под BlueStore.
В нашей следующей главе мы рассмотрим как хранилище Ceph может экспортироваться через широко применяемые протоколы хранения для включения хранилища Ceph в его употребление не- Linux клиентами.
-
Какое хранилище объектов по умолчанию применяется при создании OSD в Luminous и более новых выпусках?
-
Какая база данных применяется внутри BlueStore?
-
Как называется процесс перемещения данных между уровнями данных в части самой базы данных BlueStore?
-
Как иенуется то метод, когда небольшие записи могут временно записываться в некий SSD вместо HDD?
-
Как вы можете смонтировать BlueFS и просматривать её в виде некой стандартной файловой системы Linux?
-
Какой алгоритм сжатия по умолчанию используется в BlueStore?
-
На какой множитель увеличивается значение размера базы данных BlueStore при продвижении вверх на следующий уровень?