Глава 5. Обработка и восстановление транзакции
Содержание
- Глава 5. Обработка и восстановление транзакции
- Управление буфером
- Восстановление
- Управление одновременностью
- Выводы
В этой книге мы придерживаемся восходящего подхода снизу вверх к понятиям систем баз данных: вначале мы изучили структуры хранения. Теперь мы готовы перейти к компонентам более верхнего уровня, отвечающим за управление буферизацией, управление блокировкой и восстановлением, которые выступаю предпосылками для понимания транзакций базы данных.
Некая транзакция является неделимым элементом работы системы управления базой данных, которая позволяет вам представлять множество операций как единый этап. Выполняемые транзакциями операции включают считывание и сохранение записей базы данных. Некая транзакция базы данных обязана сохранять атомарность (atomicity), связность (consistency), изоляцию (isolation) и долговечность (durability). Эти свойства обычно носят название ACID [HAERDER83]:
- Атомарность
Этапы транзакции невидимы, что означает, что либо все связанные с этой транзакцией этапы успешно выполнены, либо не сделан ни один из них. Иными словами, транзакции не должны применяться частично. Каждая транзакция может быть либо зафиксирована (commit, внести все изменения операций записи выполняемых в процессе видимости этой транзакции), либо прерваться (abort, откатить обратно все эффекты, которые ещё пока не стали видными). Фиксация (commit) является финальным действием. После прерывания данная транзакция может быть попробована вновь.
- Связность
Связность выступает гарантией, специфичной для приложения; некая транзакция должна приводить свою базу данных лишь из одного допустимого состояния в другое допустимое состояние, сопровождая все инварианты базы данных (например, ограничения, ссылочную целостность и прочее). Связность наиболее слабо определяемое свойство, возможно, по той причине, что это единственное свойство, которое контролируется самим пользователем, а не самой базой даных.
- Изоляция
Множество одновременно выполняемых транзакция обязано иметь возможность исполнения без взаимодействия, как если бы никакие иные транзакции больше не выполнялись в то же самое время.
Изоляция определяет когда вносимые в состояние этой базы данных изменения иогут стать видимыми и какие изменения могут становиться видимыми для имеющихся одновременными транзакций. Многие базы данных используют уровни изоляции, которые слабее чем приведённое определение изоляции по причинам производительности. В зависимости от тех методов и подходов, которые применяются для управления одновременностью, изменения могут быть видимыми или не видимыми прочим одновременным транзакциям (см. раздел Уровни изоляции).
- Долговечность
Как только некая транзакция фиксирована, все изменения состояния базы данных должны стать постоянными на диске и способными выживать при отключении электропитания, отказах системы и крушениях.
Реализация транзакций в некой системе баз данных, дополнительно к некой структуре хранения, которая организует и хранит данные на диске, требует для совместной работы определённых компонентов. В неком узле локально, имеющийся диспетчер транзакции координирует, составляет расписание и отслеживает транзакции и их индивидуальные этапы.
Определённый диспетчер блокировок предохраняет доступ к этим ресурсам и предотвращает одновременный доступ, который нарушил бы целостность данных. Всякий раз когда запрашивается некая блокировка, такой диспетчер блокировок проверяет не имеет ли он уже удержаний со стороны прочих транзакций в разделяемом или исключительном режиме и предоставляет доступ к ним если значение запрашиваемого уровня не входит ни в какие противоречия. Поскольку исключительные блокировки могут захватываться не более чем одной транзакцией в некий определённый момент времени, прочим запрашивающим их транзакциям приходится ждать высвобождения блокировок, либо прерываться и повторяться позднее. Как только данная блокировка высвобождается или всякий раз когда данная транзакция прерывается, данный диспетчер блокировок уведомляет одну из отложенных транзакций, позволяя ей получить необходимую блокировку и продолжить.
Установленный кэш страниц служит неким посредником между постоянным хранилищем (диском) и всем остальным механизмом хранилища. Он устанавливает изменения состояний в основной памяти и служит кэшем для всех страниц, которые ещё не были синхронизированы с постоянным хранилищем. Все изменения в состоянии некой базы данных изначально применяются в таких кэшированных страницах.
Имеющийся диспетчер журнала удерживает историю операций (записи журнала), применяемые к кэшированным страницам, но ещё пока не синхронизированы с постоянным хранилищем чтобы обеспечить что они не будут утрачены в случае крушения. Иными словами, этот журнал используется для повторного применения этих операций и воссоздания состояния кэша в процессе запуска. Записи журнала могут также применяться для повторных изменений в определённых прерванных транзакциях.
Распределённые (множества разделов) транзакции требуют дополнительной координации и удалённого исполнения. Мы обсудим протоколы распределённых транзакций в Главе 13.
Большинство баз данных строится с применением двухуровневой иерархии памяти:более медленного постоянного хранилища (диск) и более быстрой основной памяти (ОЗУ). Для снижения общего числа доступов к постоянному хранилищу страницы кэшируются в оперативной памяти. Когда необходимая страница запрашивается снова на уровне хранения, возвращается её кэшированная копия.
Доступные в памяти кэшированные страницы могут применяться повторно в том предположении, что никакие процессы больше не изменили её данные на диске. Этот подход иногда именуется как виртуальный диск [BAYER72]. Доступы по чтению виртуального диска к физическому хранилищу выполнятся только когда нет уже доступными этих страниц в оперативной памяти. Более распространённым названием для этого понятия являются кэширование страниц или буферный пул. Такой кэш страниц отвечает за кэширование чтений страниц с диска в оперативную память. В случае крушения некой базы данных или неверного её останова, кэшированное содержимое теряется.
Поскольку основной цели данной структуры отвечает термин кэширование страниц, данная книга по умолчанию применяет именно его. Термин буферный пул звучит так, как будто его первичной целью является держать в неком пуле и повторно применять некие пустые буферы, причём без совместного использования их содержимого, что может быть полезной частью кэширования страниц или даже отдельным компонентом, но не отражает в точности всей цели полностью.
Основная проблема кэширования страниц не ограничивается сферой баз данных. Операционные системы также имеют понятие кэширования страниц. Операционные системы применяют не востребованные сегменты памяти для прозрачного кэширования содержимого диска с целью улучшения производительности системных вызовов ввода/ вывода.
При загрузке некэшированных страниц с диска они именуются подгружаемыми (paged in). После того как в кэшированную страницу вносятся какие- бы то ни было изменения, она именуется испорченной (dirty), пока эти изменения не сброшены (flushed) обратно на диск.
Так как та область в памяти, где удерживаются кэшированные страницы, как правило, меньше всего набора данных, в конечном счёте этот кэш страниц заполняется и, чтобы подгрузить какую- то новую страницу, одна из уже кэшированных страниц подлежит вытеснению (evicted).
На Рисунке 5-1 вы можете видеть взаимоотношения между логическим представлением страниц B- дерева, их кэшированной версиями и самими страницами на диске. Имеющийся кэш страниц загружает страницы в свободные разъёмы не по порядку, поэтому нет прямого соответствия между тем как страницы упорядочены на диски и в оперативной памяти.
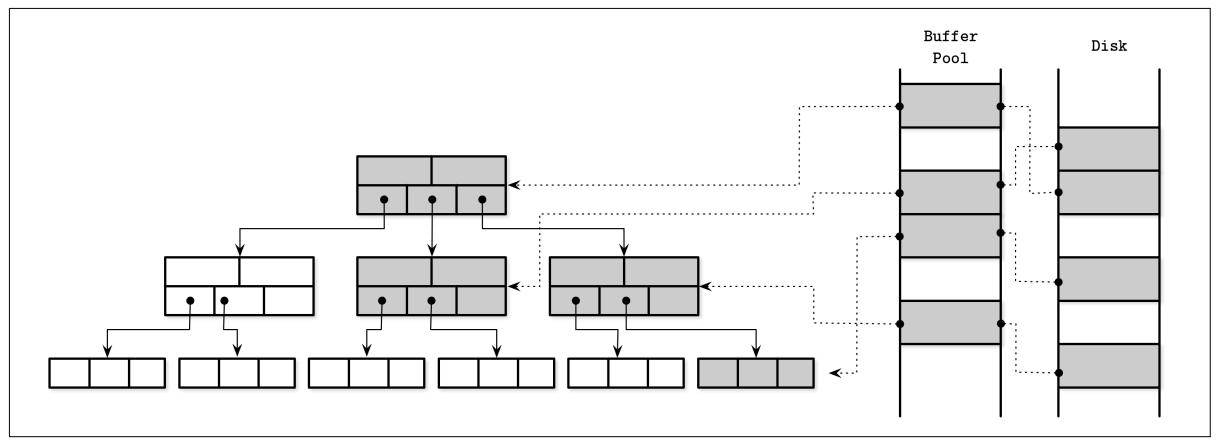
Самые первичные функции кэшированных страниц можно суммировать следующим образом:
-
Они удерживают кэшированные страницы в оперативной памяти.
-
Они делают возможной буферизацию изменений дисковых страниц совместно с выполнением таковых для их кэшированных версий.
-
Когда некая запрашиваемая страница отсутствует в оперативной памяти и достаточно пространства для её размещения, она подгружается своим кэшем страниц и возвращается её кэшированная версия.
-
Если запрошена уже кэшированная версия, возвращается её версия из кэша.
-
В случае когда для такой новой страницы недостаточно пространства, вытесняются и их содержимое сбрасывается на диск.
![[Замечание]](/common/images/admon/note.png) | Обход кэширования страниц ядром |
|---|---|
|
Многие системы баз данных открывают файлы при помощи флага O_DIRECT. Данный флаг делает возможным системным вызовам ввода/ вывода обходить кэш страниц ядра, получая прямой доступ к диску и пользоваться специфичным для базы данных управлением буферизации. Порой это осуждается парнями, ответственными за операционную систему. Линус Торвальдс критиковал применение
Мы можем получать некий контроль над тем как само ядро вытесняет страницы из своего кэша применяя fadvise, однако это позволяет нам лишь запрашивать своё ядро учитывать наше мнение, но не гарантирует что именно так это и произойдёт. Во избежание системных вызовов при выполнении ввода/ вывода мы можем применять составление карты оперативной памяти, но тогда мы утрачиваем контроль над кэшированием. |
Все выполняемые в буферах изменения остаются в оперативной памяти пока они в конечном счёте на записываются обратно на диск. Так как никакому иному процессу не позволено вносить изменения в лежащий в основе файл, такая синхронизация является однонаправленным процессом: из памяти на диск и не наоборот. Имеющийся кэш страниц позволяет своей базе данных иметь дополнительный контроль над управлением памятью и дисковым доступом. Вы можете представлять себе это как некий специфичный для приложения эквивалент кэширования страниц ядром: он осуществляет прямой доступ к необходимому блочному устройству, подразумевая подобную функциональность и обслуживая аналогичную цель. Это создаёт абстракцию дискового доступа и отвязывает операции логической записи от физических.
Кэширование страниц позволяет частично удерживать имеющееся дерево в оперативной памяти без внесения дополнительных изменений в сам алгоритм и материализовать объекты в оперативной памяти. Всё что нам требуется делать, это подменять дисковый доступ своими вызовами к имеющемуся кэшу страниц.
При выполнения доступа механизмом хранения (иными словами, при запросах) к определённой странице, мы вначале проверяем не кэшировано ли уже её содержимое и в этом случае возвращается содержимое кэша данной страницы. Если же содержимое такой страницы ещё не кэшировано, сам кэш транслирует полученный логический адрес страницы или номер страницы в её физический адрес, загружает её содержимое в оперативную память и возвращает её кэшированную версию в своё механизм хранения. После возврата, такой буфер с кэшированными страницами именуется как снабжённый ссылкой (referenced), а его механизм хранения обязан возвращать его обратно в такой кэш страниц или разименовывать (удалять ссылки) его по завершению. Данный кэш страниц может получить инструкции по избежанию вытеснения страниц закрепляя (pinning) их.
В случае изменения страниц (например, когда к ней в конец добавляется некий элемент), она помечается как испорченная. Установленный на определённой странице флаг испорченности (dirty) указывает что её содержимое не синхронизировано с диском и для обеспечения долговечности подлежит сбросу.
Удержание кэшей наполненными это хорошо: мы можем обслуживать больше чтений без проходов к постоянному хранилищу и больше записей в те же самые страницы могут быть буферированы совместно. Однако, имеющийся кэш страниц обладает ограниченной ёмкостью и, рано или поздно, для обслуживания нового содержимого старые страницы подлежат вытеснению. Когда содержимое синхронно со своим диском (то есть уже сброшено или никогда не подвергалось изменениям) и данная страница не закреплена и не снабжена ссылкой, она может быть прямо вытеснена. Испорченные страницы необходимо сбрасывать перед их вытеснением. Снабжённые ссылкой страницы нельзя вытеснять пока ими пользуется некий иной поток.
Так как включение некого сброса при каждом вытеснении может негативно сказываться на производительности, некоторые базы данных применяют обособленный фоновый процесс, который в цикле обходит испорченные страницы, которые скорее всего будут вытеснены, обновляя их дисковую версии. Например, PostgreSQL обладает неким фоновым сбросом записи для выполнения именно этого.
Другим важным свойством для отслеживания на глазу является долговечность: если происходит крушение базы данных, все не сброшенный данные будут утрачены. Чтобы убедиться что все изменения стали постоянными, сбросы координируются имеющимся процессом контрольных точек. Такой процесс контрольных точек управляет журналом упреждающей записи (WAL, write-ahead log) и кэшем страниц и обеспечивает гарантию того что они работают в строгом соответствии. Из WAL могут отвергаться только записи журнала, связанные с теми применёнными кэшированными страницами, которые были сброшены на диск. Испорченные страницы не могут вытесняться пока не завершится данный процесс.
Это означает, что всегда существует некий компромисс между некоторыми обстоятельствами:
-
Откладывание сброса для снижения общего числа доступа к диску
-
Упреждающий сброс страниц для того чтобы допускать быстрое вытеснение
-
Непкая действенная пометка страниц для вытеснения и сброса
-
Удержание размера кэша в рамках его границ в оперативной памяти
-
Избежание утраты данных по причине того что они не стали постоянными в своём первичном хранилище
Мы изучим определённых техник, которые способствуют нам в улучшении первых трёх свойств при удержании в заданных рамках остающиеся два.
Необходимость выполнения дисковых вводов/ выводов для каждого чтения или записи непрактична: последовательные считывания могут требовать одну и ту же страницу, точно та же как последовательные записи могут менять одну и ту же самую страницу. Так как B- деревья становятся "более узкими" по мере подъёма вверх, узлы более верхнего уровня (те, которые ближе к самому корню) попадаются для большинства операций чтения. Расщепления и слияния также в конечном счёте распространяются до таких узлов верхнего уровня. Это означает, что всегда имеется по крайней мере часть дерева, которая может получать значительные преимущества от её кэширования.
Мы можем "блокировать" страницы, которые обладают высокой вероятностью быть задействованной в ближайшее время. Блокированные страницы в имеющемся кэше носят название закреплённых (pinning). Закреплённые страницы остаются в памяти более длительное время, что способствует снижению общего числа доступов к диску и улучшению производительности [GRAEFE11].
Поскольку всякий более нижний уровень узлов B- дерева имеет экспоненциально больше узлов чем более верхний уровень,
а узлы более верхнего уровня представляют лишь малую часть всего дерева, эта часть дерева способна располагаться в оперативной
памяти постоянно, а прочие части могут подкачиваться по запросу. Это означает, что для выполнения некого запроса нам не
приходится выполнять h обращений к диску (как это обсуждалось в разделе
Сложность поиска в В- деревьях,
h это высота данного дерева), а лишь попадать на диск только для самых нижних
уровней, для которых страницы не кэшированы.
Выполняемые в дереве действия могут иметь результатом структурные изменения, которые противоречат друг другу - например, множество операций удаления вызывают слияния, за которыми следуют записи, приводящие к расщеплениям и наоборот. Точно так же происходит и для структурных изменений, распространяющихся из различных поддеревьев (происходящие близко по времени друг к дргу структурные изменения в различных частях рассматриваемого дерева распространяются вверх). Эти операции могут буферироваться совместно посредством применения изменений лишь в оперативной памяти, что может снижать общее число записей на диск гасить стоимость такой операции, так как вместо множества записей может быть выполнена лишь одна.
|
| Предварительная выборка и немедленное вытеснение |
|---|---|
|
Кэширование страниц к тому же позволяет механизму хранения обладать тонкой грануляцией контроля над упреждающей выборкой и вытеснением. Например, при обходе терминальных узлов для возникающих случайным образом операций поиска, могут предварительно загружаться последующие листья. Аналогично, когда некий процесс сопровождения загружает определённую страницу, она может быть вытеснена непосредственно сразу после завершения данного процесса, так как маловероятно то она будет полезной для уже находящихся в полёте запросов. Некоторые базы данных, к примеру, PostgreSQL, применяют некий циклический буфер (иными словами, политику FIFO замещения страниц) для крупных последовательных сканирований. |
По достижению ёмкости кэша для загрузки новых страниц следует вытеснять старые. Однако, если мы не вытесняем те страницы, к которым наименее вероятен вскорости опять доступ, мы можем прийти к ситуации, при которой мы загружаем их последовательно несколько раз вместо того чтобы удерживать их в оперативной памяти всё это время. Для оптимизации этого нам требуется определить некий способ оценки правдоподобности последовательного доступа странице.
Для этого мы можем сказать что страницы должны вытесняться согласно установленной политики вытеснения (также иногда носящей название политики страничного обмена - page-replacement). Она предпринимает попытку поиска страниц, к которым снова вскорости доступ будет менее вероятно. Когда такая страница вытесняется из имеющегося кэша, на её место может быть загружена необходимая новая страница.
Чтобы реализация кэширования страниц была производительной, необходим некий действенный алгоритм обмена страницами. Некая идеальная стратегия обмена страниц потребует какого- то кристаллического шара, который бы предсказывал тот порядок, коим предполагается выполнение доступа и вытеснения страниц, которых не будут касаться наиболее длительное время. Так как запросы не обязаны следовать никакому заданному шаблону или распределению, точное предсказание поведения может быть сложным, но применение верной стратегии страничного обмена может способствовать снижению общего числа вытеснений.
Кажется логичным, что мы можем снизить общее число вытеснение просто применяя больший кэш. Тем не менее, это не так. Один из примеров, демонстрирующих эту дилемму носит название Аномалии Bélády [BEDALY69]. Он показывает, что увеличение общего числа страниц способно увеличивать общее число вытеснений когда применяемый алгоритм страничного обмена не оптимален. При запросе траниц сразу по вытеснению споследующей загрузкой вновь траницы начинают конкурировать за пространство в своём кэше. По этой причине нам следует с умом рассматривать применяемый нами алгоритм с тем, чтобы он бы улучшал текущую ситуацию, не превращая её в худшую.
FIFO и LRU
Наиболее наивной стратегией страничного обмена выступает пришедший первым, уходит первым (FIFO).
FIFO поддерживает некую очередь идентификаторов страниц в порядке их вставки, добавляя новые страницы в хвост своей очереди.
Всякий раз, когда имеющийся кэш страниц заполнен, он берёт элемент с головы своей очереди чтобы найти ту страницу, которая была
подкачена в самый давний момент времени. Так как он ни принимает во внимание последующие обращения к страницам, а лишь
учитывает события появления страниц, это оказывается непрактичным для большинства систем реального мира. Например, сам корень
и страницы наиболее верхнего уровня подкачиваются первыми и, согласно данному алгоритму, выступают первыми претендентами на
вытеснение, даже хотя из самой структуры дерева совершенно ясно, что такие страницы скорее всего будут подкачены вскорости
вновь, если не немедленно.
Естественным расширением алгоритма FIFO выступает дольше всех не использованная (LRU, least-recently used) [TANENBAUM14]. Он также поддерживает некую очередь кандидатов на вытеснение в порядке вставки, но позволяет вам помещать некую страницу обратно в самый хвост своей очереди при повторном доступе, как если бы это было самым первым обращением к данной странице. Однако, обновление ссылок и повторное подключение узлов при каждом обращении может становиться затратным при некой среде с одновременной обработкой.
Существуют и прочие основанные на LRU стратегии вытеснения из кэша. Например, 2Q (LRU с двумя очередями - Queue) поддерживает
две очереди и помещает страницы в свою первую очередь в процессе первоначального доступа и перемещает её во вторую
горячую очередь при последующих обращениях, позволяя вам отличать последние и
имеющие частые обращения страницы [JONSON94]. LRU-K идентифицирует
страницы с частыми ссылками отслеживая самые последние k обращений и применяя
эти сведения для оценки времени доступа на основе страниц [ONEIL93].
CLOCK
при некоторых обстоятельствах эффективность может оказываться важнее чем частота. Часто в качестве компактных, дружественных к кэшированию и альтернативы с одновременным доступом для LRU часто используются вариации алгоритма CLOCK [DECANDIA07]. Например, Linux применяет некий вариант алгоритма CLOCK.
Очистка CLOCK удерживает ссылки на страницы и связанные с ними биты доступа в неком циклическом буфере. Некоторые
варианты применяют счётчики вместо битов для
учёта частот. Всякий раз при обращении к соответствующей странице её бит устанавливается в 1.
Этот алгоритм работает посредством обхода циклического буфера, проверяя биты доступа:
-
Когда бит доступа равен
1и страница разыменована, его значение устанавливается равным0и проверяется следующая страница. -
Когда значение бита доступа уже равно
0, данная страница становится неким претендентом и заносится в расписание на вытеснение. -
Если данная страница в данный момент снабжена ссылкой, её бит доступа остаётся без изменений. Предполагается, что значение бита некой страницы с обращением к ней не может быть равным
0, а потому она не может быть вытеснена. Это превращает снабжённые ссылками страницы в наименее вероятные для обмена.
Рисунок 5-2
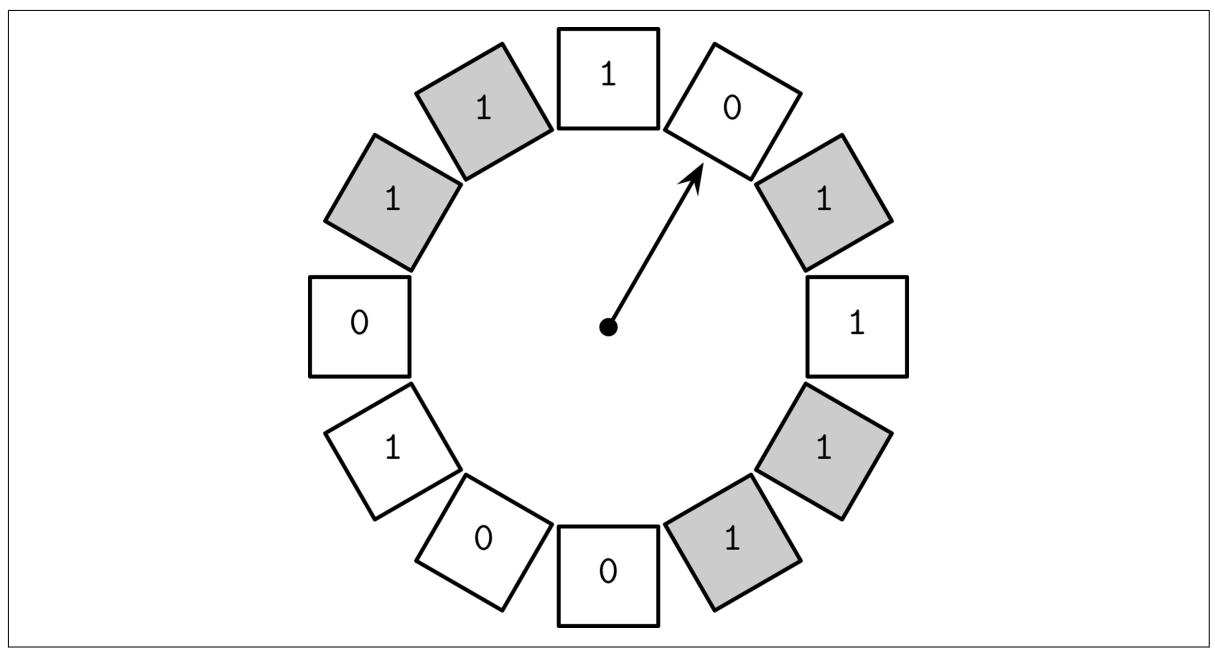
Пример очистки CLOCK. Счётчики для для снабжённых ссылкой страниц показаны серыми. Счётчики для разыменованых страниц показаны белыми. Часовая стрелка указывает на тот элемент, который будут помечаться следующим.
Неким преимуществом применения циклического буфера является то, что и сама стрелка указателя часов, и содержимое способны изменяться операциями сравни- и- поменяй и не требуют дополнительных механизмов блокировки. Этот алгоритм прост в его осознании и реализации часто используется как в руководствах [TANENBAUM14], так и в реальных системах.
Для систем баз данных LRU не всегда наилучшая стратегия замещения. Порой может быть более практичным рассматривать в качестве фактора предсказания частоту применения вместо новизны. И, в конце концов, для сильно загруженных баз данных новизна может не выступать хорошим индикатором, так как она лишь представляет тот порядок, в котором производились обращения к элементам.
LFU
Для улучшения данного положения вещей мы можем начать отслеживать события ссылок на страницы вместо событий подкачки . Одним из позволяющих нам выполнять такое отслеживание подходов выступают наименее часто применяемые (LFU? least-frequently used) страницы.
TinyLFU, политика вытеснения страниц на основе частот [EINZIGER17], в точности это и делает: вместо вытеснения страниц на основании новизны подкачки, он упорядочивает страницы при помощи частоты использования. Он реализуется в популярной библиотеке Java с названием Caffeine.
Для поддержки компактной истории обращений к кэшу TinyLFU применяет гистограмму частот [CORMODE11], так как хранение всей истории целиком может быть запретно расточительным для практических целей.
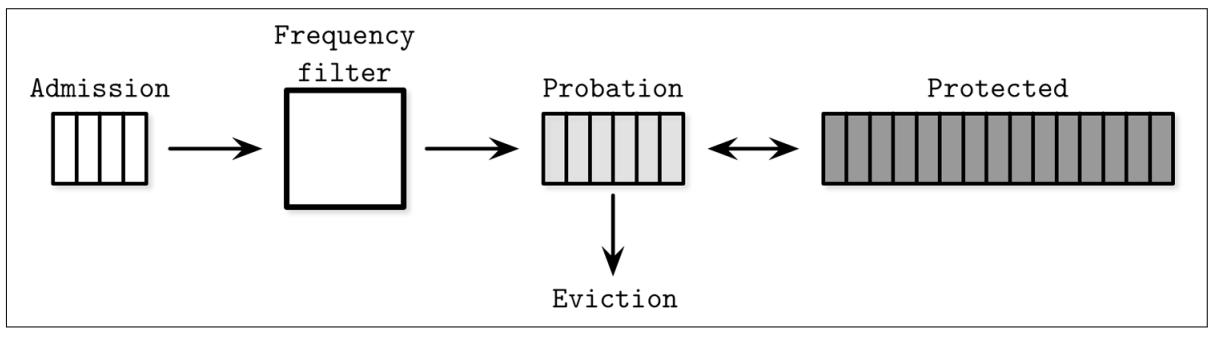
Элементы могут пребывать в одной из трёх очередей:
-
Приёма (Admission), поддерживающей вновь добавляемые элементы, реализуемую с применением политики LRU.
-
Испытания (Probation), удерживающей элементы, скорее всего подлежащие вытеснению.
-
Защищённую (Protected), хранящую элементы, которые должны оставаться в данной очереди более продолжительное время.
Вместо того чтобы всякий раз выбирать какой именно элемент вытеснять, данный подход выбирает какому из них предложить сохранность. В очередь испытания могут быть перемещены лишь те элементы, которые за счёт их продвижения обладают большей частотой, нежели подлежащие вытеснению. При последовательных обращениях элементы могут перемещаться из очереди испытаний в защищённую очередь. Если защищённая очередь заполнена, один из элементов в ней может быть помещён обратно в очередь испытаний. Элементы с более высокой частотой обращений обладают более высокими шансами на удержание, а с менее частым доступом скорее всего будут вытеснены.
Рисунок 5-3 отображает логические связи между очередями приёма, испытания и защищённой, установленным фильтром частот и вытеснением.
Имеется множество прочих алгоритмов, которые могут применяться для оптимального вытеснения из кэша. Сделанный выбор стратегии страничного обмена имеет значительное воздействие на латентность и общее число выполняемых операций ввода/ вывода и подлежит рассмотрению.
Системы баз данных строятся поверх различных аппаратных средств и уровней программного обеспечения, которые могут обладать своими собственными проблемами со стабильностью и надёжностью. Системы баз данных сами по себе, а также лежащие в основе программное обеспечение и компоненты оборудования, могут подвергаться отказам. Реализующим базу данных приходится рассматривать такие сценарии отказов и гарантировать что все данные, которые получили "обещание" быть записанными, на самом деле записаны.
Журнал упреждающей записи (WAL, write-ahead log, для краткости, также носящий название журнала фиксаций - commit log) является расположенной на диске вспомогательной структурой с записью только в конец, применяемой для восстановления после крушений и транзакций. Сами кэшированные страницы делают возможной буферизацию изменений содержимого страниц в оперативной памяти. Пока всё содержимое кэша не сброшено на диск, только расположенная на диске копия хранит всю историю действий в своём WAL. Многие базы данных применяют журналы упреждающей записи с исключительным добавлением в конец; например, PostgreSQL и MySQL.
Основные функциональные возможности журнала упреждающей записи можно суммировать следующим образом:
-
Делать возможной собственно буферизацию обновлений кэшированных страниц в расположенных на диске страницах обеспечивая долговременные семантики в более общем контексте системы базы данных.
-
Удерживать на диске все операции до тех пор пока копии подвергшихся воздействию этих операций страниц н будут синхронизованы с диском. Все операции изменения состояния самой базы данных должны регистрироваться на диске до изменения самого содержимого, связанного с этими страницами.
-
Делать возможным восстановление изменений в оперативной памяти из имеющегося журнала операций в случае некого крушения.
Дополнительно к этим функциональным возможностям, журналы упреждающей записи играют некую важную роль в обработке транзакций. трудно переоценить имеющиеся возможности такого WAL, ибо он гарантирует что данные превращает данные в постоянно хранимые и они доступны в случае некого крушения, поскольку данные без фиксации повторно воспроизводятся из такого журнала и полностью восстанавливают состояние базы данных до крушения. В данном разделе мы часто будем упоминать ARIES (Algorithm for Recovery and Isolation Exploiting Semantics, Алгоритм семантик эксплуатации восстановления и изоляции), некий современный алгоритм восстановления, который широко применяется и цитируется [MOHAN92].
|
| Сопоставление PostgreSQL и fsync() |
|---|---|
|
PostgreSQL использует контрольные точки для гарантии того что файлы индексов и данных были обновлены всеми сведениями вплоть
до определённой записи в его файле журнала. Этим процессом контрольной точки периодически осуществляется за раз сброс всех
испорченных (изменённых) страниц. Синхронизация содержимого испорченных страниц с диском выполняется путём вызова ядра
В Linux и некоторых прочих операционных системах Так как механизм контрольных точек не отслеживает все открытые в данный момент времени файлы, может так произойти, что он пропустит уведомление об ошибке. Поскольку флаги dirty были очищены, этот механизм предположит, что данные успешно оказались на диске, в то время как на самом деле они могли быть не записаны. Некое сочетание такого поведения способно стать источником утраты данных или разрушения базы данных при наличии потенциальных отказов в восстановлении. Такое поведение может быть сложно выявить, а некоторые из состояний, к которым оно может приводить, могут быть невосстановимыми. Порой даже включение такого поведения может быть нетривиальным. При работе с механизмами восстановления нам всегда следует предпринимать дополнительную заботу и продумать проверку всех возможных сценариев отказа. |
Журнал упреждающей записи допускает запись только в конец, а записанное в нём содержимое неизменно, поэтому все записи в этот журнал являются последовательными. Поскольку сам WAL неизменяемая структура данных с записью в конец, читатели способны безопасно выполнять доступ к его содержиому вплоть до порога самой последней записи, в то время как записывающая сторона продолжает добавлять данные в конец хвоста этого журнала.
Сам WAL состоит из регистрационных записей. Каждая запись обладает неким уникальным, монотонно увеличивающимся номером регистрационной последовательности (LSN, log sequence number). Обычно LSN представляется неким внутренним счётчиком или временной отметкой. Так как регистрационные записи не обязательно занимают блок диска целиком, их содержимое кэшируется в имеющемся буфере журнала и сбрасываются на диск некой принудительной (force) операцией. Такие операции принуждения происходят по мере заполнения имеющихся буферов журнала и могут запрашиваться имеющимся диспетчером транзакций или кэшем страниц. Все регистрационные записи обязаны быть сброшены на диск в порядке LSN.
Помимо записей индивидуальных операций, данный WAL хранит записи, указывающие завершение транзакций. Некая транзакция не может рассматриваться как фиксированная пока данный журнал не будет принуждён к фиксации его записей соответствующих LSN.
Для гарантии того что данная система может продолжать правильную работу после крушения в процессе отката или восстановления, некоторые системы применяют регистрационный записи компенсации (CLR, compensation log records) на протяжении возврата и сохраняют их в своём журнале.
Сам WAL обычно сцеплен с некой первичной структурой хранения особым интерфейсом, который позволяет отсекать (trimming) его всякий раз по достижению некой контрольной точки. Ведение журнала является одним из наиболее критически важной стороной корректности го базы данных, которую порой замысловато сделать верной: даже лёгкие несоответствия между отсечениями журнала и гарантией того, что все его данные выполнены в его первичной структуре хранения, могут вызвать утрату данных.
Контрольные точки являются неким способом для журнала чтобы узнавать что регистрационные записи до какой- то определённой отметки целиком сохранены и более не требуются, что значительно снижает общий объём работы, требуемый в процессе запуска этой базы данных. Некий процесс, который принуждает к сбросу на диск все испорченные страницы обычно носит название синхронизации контрольной точки, ибо он полностью синхронизует свою первичную структуру хранения.
Сброс всего содержимого на диск достаточно непрактичен и потребует паузы для всех выполняемых действий пока не выполнится
данная контрольная точка, по этой причине многие системы баз данных реализуют нечёткие
контрольные точки (fuzzy checkpoints). В этом случае указатель last_checkpoint,
хранимый в заголовке этого журнала, начинается с особой регистрационной записи begin_checkpoint и
заканчивается регистрационной записью end_checkpoint, содержащими сведения относительно
определённых испорченных страниц и самого содержимого некой таблицы транзакции. До тех пор, пока все имеющиеся страницы,
определённые такой записью не сброшены, данная контрольная точка рассматривается как незавершённая.
Страницы сбрасываются асинхронно и, когда он выполнен, запись last_checkpoint
обновляется соответствующим LSN соответствующей записи begin_checkpoint и, в случае
краха, процесс восстановления запустится отсюда [MOHAN92].
Некоторые сисемы баз данных, например, System R [CHAMBERLIN81]? применяют теневые страницы: некую технологий копирования- записью (copy- on- write), гарантирующую долговечность данных и атомарность транзакции. Новое содержимое помещается в соответствующую новую неопубликованную теневую страницу и делается видимой переворачиванием некого указателя, со старой страницы на новую, которая хранит обновлённое содержимое.
Всякое изменение состояния может быть представлено образом-до и образом-после или соответствующими операциями выполнения повторно (redo), либо демонтажа (undo). применение некой операции повторного выполнения к образу-до производит некий образ-после. Аналогично, операция демонтажа для некого образа-после производит образ-до.
Мы можем использовать какой- то физический журнал (который хранит в себе полное состояние страницы или все изменения байт), либо некий логический журнал (который хранит операции, которые надлежит выполнить для текущего состояния) для перемещения записей или страниц из одного состояния в другое, причём как обратно, так и вперёд по времени. Важно отслеживать значение точного состояния всех страниц, к кторым могут быть применены такие физические и логические регистрационные записи.
Физическое ведение журнала записывающее образы до- и после- требует регистрации целиком страниц, на которые оказывает
воздействие данная операция. Некий применяющий к данной странице операции логический журнал должен определять, например,
"insert a data record X for key Y", а для соответствующей операции демонтажа,
к примеру, "remove the value associated with Y".
На практике многие системы баз данных используют некую комбинацию двух таких подходов, применяя логическую регистрацию для выполнения какого- то демонтажа (для одновременности и производительности) и физическую регистрацию для повторного выполнения (для улучшения времени восстановления) [MOHAN92].
Для определения того когда сделанные в памяти изменения должны быть сброшены на диск, системы управления базами данных определяют политики воровства, без- воровства и принуждения/ без- принуждения. Эти политики в основном применяются к имеющемуся кэшу страниц, но их лучше обсуждать в контексте восстановления, так как они обладают значительным воздействием на то, какие подходы восстановления могут применяться в сочетании с ними.
Некий метод восстановления, который позволяет сбрасывать какую- то изменённую определённой транзакцией страницу даже до фиксации этой транзакции имеет название политики воровства (steal). Политика без воровства не допускает никакого сброса содержимого на диск никакой незафиксированной транзакции. Воровство некой испорченной страницы здесь означает сброс её содержимого из оперативной памяти на диск и загрузке на её место другой страницы с диска.
Поитика принуждения требует сброса на диск всех изменённых определённой транзакцией страниц до фиксации этой транзакции. С дргой стороны, политика без принуждения допускает фиксацию некой транзакции даже когда некоторые изсенённые в процессе такой транзакции страницы ещё не были сброшены на диск. Принудить некую испорченную страницу здесь означает сбросить её на диск до осуществления фиксации.
Политики воровства и принуждения важны для понимания, так как они подразумеваются для демонтажа и поторного выполнения транзакции. Демонтаж (undo) откатывает обратно обновления и принуждает страницы зафиксировать транзакции, в то время как повторное выполнение (redo) применяет изменения, выполненные транзакциями на диске.
Применение политик без воровства делает возможным реализовать восстановление применяя только записи повторного выполнения: старую копию, содержащуюся в соответствующей странице на диске и изменения, хранимые в имеющемся журнале [WEIKUM01]. Применяя политику без воровства мы потенциально можем буферировать некоторые обновления на страницы, задерживая их. Так как содержимое страницы должно на это время кэшироваться в памяти, может потребоваться больший кэш страниц.
При применении политики принуждения, восстановление после сбоя не требует никакой дополнительной работы по восстановлению полученных результатов фиксированных транзакций, поскольку изменённые такими транзакциями страницы уже сброшены. основным недостатком применения данного подхода является то, что такие транзакции требуют более длительной фиксации по причине всех необходимых операций ввода/ вывода.
Говоря в более общем смысле, пока данная транзакция не зафиксирована, нам требуется достаточно сведений для демонтажа её результатов. Когда сброшены все затронутые данной транзакцией страницы, нам требуется отслеживать сведения демонтажа в своём журнале до тех пор, пока её фиксации способны откатить обратно. В противном случае нам придётся отслеживать в своём журнале записи повторного выполнения до их фиксаций. В обоих случаях транзакции не могут фиксироваться пока либо записи демонтажа, либо записи повторного выполнения не будут записаны в соответствующем журнале.
ARIES это некий алгоритм воровства/ без принуждения. Он применяет физическое повторное выполнение для улучшения производительности в процессе восстановления (так как изменения могут быть установлены быстрее) и логический демонтаж для улучшения одновременности в процессе обычных действий (поскольку операции логического демонтажа могут независимо применяться к страницам). Он пользуется записями WAL для реализации повторяемой истории в процессе восстановления для полного перестроения самого состояния базы данных до демонтажа не фиксированных транзакций и создаёт компенсационные регистрационные записи в процессе демонтажа [MOHAN92].
При перезапуске соответствующей системы базы данных после крушения восстановление проходит за три фазы:
-
Фаза анализа выявляет испорченные страницы в имеющемся кэше страниц и транзакции, которые находились в исполнении на момент крушения. Сведения об испорченных страницах применяются для выявления самой начальной точки для фазы повторного выполнения. Некий перечень находящихся в работе транзакций используется в процессе фазы демонтажа для отката обратно незавершённых транзакций.
-
Фаза повторного выполнения (redo) повторяет всю историю вверх до самого момента крушения и восстанавливает свою базу данных в её предыдущее состояние. Эта фаза выполняется для незавершённых транзакций, а также для тех, которые фиксированы, но чьё содержимое не было сброшено на устройство постоянного хранения.
-
Фаза демонтажа (undo) откатывает обратно все незавершённые транзакции и восстанавливает свою азу данных до последнего согласованного состояния. Все действия откатываются обратно в реверсивном хронологическом порядке. В случае крушения этой базы данных снова в процессе восстановления, операции демонтажа транзакции зарегистрированы также во избежание их повторения снова.
Для идентификации регистрационных записей ARIES пользуется LSN, отслеживая изменённые выполнением транзакций страницы в соответствующей таблице испорченных страниц и применяя физическое повторное выполнение, логический демонтаж и нечёткие контрольные точки. Даже несмотря на то, что описывающая такую систему статья была выпущена в 1992, большинство понятий, подходов и образцов всё ещё значимы и сегодня в обработке транзакций и восстановлении.
Когда мы обсуждали архитектуру системы управления базой данных в Архитектура DBMS мы упоминали, что наши диспетчер транзакций и диспетчер блокировок работают совместно над обработкой контроля одновременности. Управление одновременностью это набор технологий для обработки взаимодействия между одновременно исполняемыми транзакциями. Эти технологии могут быть грубо разбиты на следующие категории:
- Оптимистичный контроль одновременностью (OCC, Optimistic concurrency control)
Позволяет транзакциям выполнять одновременные операции чтения и записи и определять будет или нет получаемый в результате комбинации этого исполнения результат поддаваться упорядочению в последовательную форму (сериализации). Иными словами, транзакции не блокируют друг друга, сопровождают истории своих действий и проверяют эти истории на возможные конфликты перед фиксацией. Когда некий результат конфликтует, одна из конфликтующих транзакций прерывается.
- Контроль одновременности множества версий (MVCC, Multiversion concurrency control)
Гарантии согласованности представления в некоторый момент времени в прошлом определяются значением временной отметки посредством допуска множества версий с данной записью. MVCC может реализовываться при помощи технологий утверждений, делая возможным выигрыш лишь одного из имеющихся обновлений и фиксации транзакций, а также при помощи технологий без блокирования, таких как упорядочение временных отметок или основанных на блокировании, например, двухфазной блокировки.
- Пессимистичный (также именуемый как консервативный) контроль одновременности (PCC)
Имеются консервативные метода как на основе блокировок, так и без блокирования, которые отличаются тем как они выполняют управление и предоставляют доступ к совместным ресурсам. Подходы на основе блокировок требуют от транзакций поддержки блокировок записей базы данных для предотвращения модификации блокированных записей прочими транзакциями и доступа к таким подвергшимся изменениям записям до тех пор пока блокирующие транзакции не высвободят их. Подходы без блокировок поддерживают списки действий чтения и записи и ограничивают исполнение на основании расписания незавершённых транзакций. Пессимистичные расписания могут приводить в результате к некой взаимной блокировке при которой множество транзакций ожидают друг друга с тем, что их оппонент высвободит блокировку для продолжения работы.
В данной главе мы сосредоточимся на технологиях контроля одновременности в локальном узле. В Главе 13 вы сможете найти сведения относительно распределённых транзакций и прочих подходов, таких как детерминированный контроль одновременности (см. раздел Распределённые транзакции с применением Calvin).
Прежде чем мы продолжим дальнейшее обсуждение контроля одновременности, нам требуется определить некий набор задач, которые мы попытаемся решить и обсудить то, как перекрываются операции транзакции и последствия имеет такое перекрытие.
Транзакции составляются из операций чтения и записи, выполняемых для определённого состояния базы данных и бизнес логики (преобразований, применяемых к самому считанному содержимому). Некое расписание является списком операций, требуемых для выполнения набора транзакций с точки зрения самой системы базы данных (то есть, только тех, которые взаимодействуют с состоянием этой базы данных, например, операций чтения, записи, фиксации и прерывания), так как все прочие операции предполагаются не имеющими побочных эффектов (иными словами, не воздействующими на значение состояния базы данных) [MOLINA08].
Некое расписание выполнено если имеет выполненными все операции для каждой исполняемой в нём транзакции. Правильные расписания являются эквивалентами для имеищегося изначально перечня операций, однако их части могут выполняться параллельно или переупорядочиваться с целями оптимизации, пока они не нарушают свойств ACID и собственно правильности получаемых результатов индивидуальных транзакций [WEIKUM01].
О расписании говорят как о последовательном (serial), когда транзакции в нём выполняются полностью независимо и пез перекрытий: все предыдущие транзакции полностью выполнены до того как начнётся следующая. О последовательном выполнении рассуждать просто, в отличии от всех возможных чередований между несколькими транзакциями из множества шагов. Однако постоянное выполнение транзакций одной за другой значительно бы ограничивало пропускную способность системы и травмировало бы производительность.
Нам требуется отыскать некий способ одновременного выполнения операций транзакций при поддержании правильности и простоты
некого последовательного расписания. Мы можем достигать этого сериализуемыми
(преобразуемыми в последовательную форму) расписаниями. расписание преобразуется в последовательную форму когда оно
эквивалентно некому полностью последовательному расписанию для того же самого набора
транзакций. Иными словами, оно производит тот же самый результат, как если бы выполнялся некий набор транзакций одна за
другой в неком порядке.
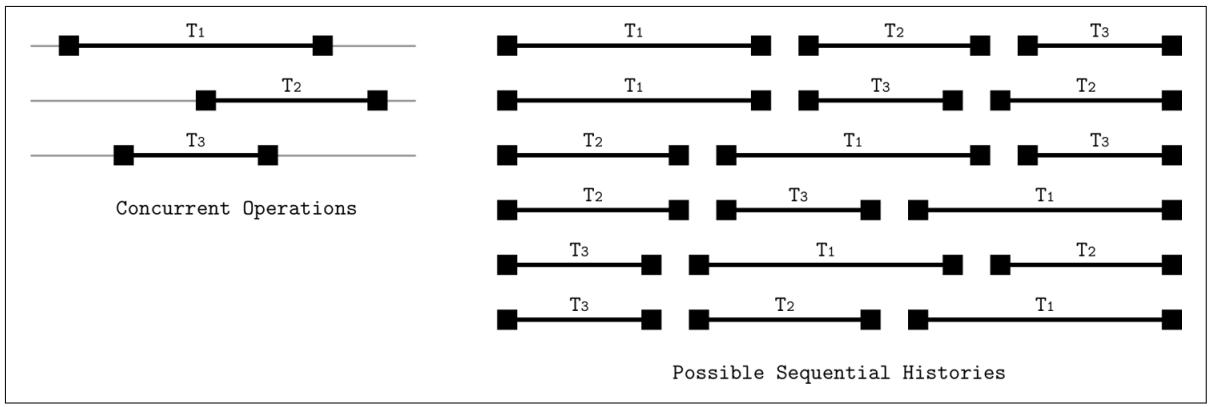
Рисунок 5-4
отображает три одновременные транзакции, а также возможные истории выполнения (3! = 6
возможностей, в любом возможном порядке).
Системы баз данных с транзакциями допускают различные уровни изоляции транзакций. Некий уровень изоляции предписывает как и где части данной транзакции могут и должны становиться видимыми для прочих транзакций. Иначе говоря, уровни изоляции описывают ту степень, до которой транзакции изолированы от прочих одновременно выполняемых транзакций и какие аномалии могут встречаться в процессы выполнения.
Достижение изоляции имеет свою цену: для того чтобы избежать распространения за границы транзакции незавершённых или временных записей, нам требуется дополнительная координация и синхронизация, которые отрицательно сказываются на производительности.
Собственно стандартный SQL [MELTON06] выделяет и описывает аномалии чтения, которые могут происходить в процессе выполнения одновременных транзакций: испорченные, неповторяемые и фантомные чтения.
Некое испорченное чтение (dirty) это ситуация, при которой транзакция способна
считать незафиксированные изменения другой транзакции. К примеру, транзакция T1
обновляет некую запись пользователя новым значением в поле адреса, а транзакция
T2 считывает и изменяет адрес до фиксации
T1. Транзакция T1
прерывается о откатывает обратно результаты своего выполнения. Тем не менее, T1
уже имела возможность считать это значение, поэтому она получила доступ к значению, которое никогда не было фиксировано.
Некое неповторяемое чтение (иногда носящее название
нечёткого - fuzzy - чтения) это ситуация, при которой транзакция запрашивает
ту же самую строку дважды и получает различные результаты. Например, это может
происходить когда транзакция T1 считывает некую строку, затем транзакция
T2 изменяет её и фиксирует это
изменение. Если T1 запросит ту же самую строку снова до завершения своего
выполнения, полученный результат будет отличаться от предыдущего.
Когда в процессе определённой транзакции мы применяем диапазон считываний (т.е. считываем не отдельную запись данных, а некий диапазон записей), мы можем наблюдать некие фантомные записи. Фантомное чтение происходит когда транзакция запрашивает тот же самый набор строк дважды и получает различные результаты. Это аналогично неповторяемому чтению, но происходит для диапазона запросов.
Такще существуют аномалии записи с аналогичной семантикой: утерянное обновление, испорченная запись и перекос записи.
Утерянное обновление происходит когда обе транзакции
T1 и T2 пытаются обновить
имеющееся значение V. T1 и
T2 считывают установленное значение V.
T1 обновляет V и выполняет фиксацию,
а T2 обновляет V после этого
и также делает фиксацию. Так как эти транзакции не осведомлены о наличии друг друга, когда им обеим разрешена фиксация,
результаты T1 будут переписаны результатами
T2 и будет утрачено обновление
T1.
Испорченная запись это некая ситуация, при которой одна транзакция получает некое незафиксированное значение (т.е. испорченное чтение), изменяет и сохраняет его. Иными словами, когда результаты транзакции основаны на значении, которое никогда не было фиксировано.
Перекос записи (write skew) происходит когда каждая транзакция по отдельности соблюдает
необходимые инварианты, но их комбинация не удовлетворяет этим инвариантам. К примеру, транзакции
T1 и T2 изменяют значения
для двух счетов, A1 и A2.
A1 стартует со 100$, а
A2 начинается со 150$. Величина значения
счёта может быть отрицательной до тех пор, пока сумма двух счетов не отрицательна:
A1 + A2 >= 0. Каждая из
T1 и T2 пытается удержать
200$ с A1 и A2,
соответственно. Поскольку на момент времени старта этих транзакций
A1 + A2 = 250,
250$ доступна в качестве итого. Обе транзакции предполагают что они сохраняют
инварианты и им допустимы фиксации. После соответствующей фиксации A1
имеет -100$, а A2 обладает
-50$. Что, совершенно ясно, нарушает основное требование удержания суммы счетов
положительной [FEKETE04].
Самый нижний (говоря иначе, самый слабый) уровень изоляции это чтение нефиксированного. На этом уровне изоляции, имеющаяся система транзакций допускает одной транзакции наблюдать нефиксированные изменения других одновременных с нею транзакций. Другими словами, разрешены испорченные чтения.
Мы можем избегать некоторые имеющиеся аномалии. Например, мы можем быть уверенными, что любые выполненные для конкретной транзакции чтения способны считывать лишь уже фиксированные изменения. Однако, это не обеспечит того, что когда данная транзакция попытается считать ту же самую запись данных снова на некой более поздней стадии, она увидит те же самые данные. Если между двумя считываниями имелось фиксированное изменение, два запроса в одной и той же транзакции дадут различные результаты. Иначе говоря, испорченные чтения не разрешены, но фантомные и неповторяемые чтения имеют место. Такой уровень изоляции носит название чтения фиксированного. Если мы ещё и запретим неповторимые чтения, мы получим уровень изоляции повторяемого чтения.
Самым сильным уровнем изоляции является преобразуемый в последовательную форму (сериализуемый). Как мы уже обсуждали в разделе Возможность преобразования в последовательную форму, он гарантирует что результаты транзакций будут отображаться в некотором порядке, как если бы они выполнялись последовательно (т.е. без перекрытия по времени). Запрет одновременного исполнения имел бы реально имеющееся отрицательное воздействие на производительность такой базы данных Транзакции можно переупорядочить когда соблюдаются их внутренние инварианты и могут выполняться одновременно, но их отображения будут появляться неким последовательным образом.
Таблица 5-5 отображает уровни изоляции и допускаемые ими аномалии.
| Испорченные Dirty |
Неповторяемые Non- repeatable |
Фантомные Phantom |
|
|---|---|---|---|
Чтение не фиксированных |
Допускает |
Допускает |
Допускает |
Чтение фиксированных |
- |
Допускает |
Допускает |
Повторяемое чтение |
- |
- |
Допускает |
Сериализуемые |
- |
- |
- |
Не имеющие зависимостей транзакции могут выполняться в любом порядке так как их результаты полностью независимы. В отличии от линеаризуемости (которую мы обсудим в её контексте в распределённых системах; см. раздел Линеаризация), возможность преобразования в последовательность (сериализуемость) это свойство множества операций выполняться в произвольном порядке. Она не подразумевает и не пытается навязывать какой бы то ни было определённый порядок выполнения транзакций. Изоляция в терминах ACID означает сериализуемость [BAILIS14a]. К сожалению, реализация возможности преобразования в последовательность требует координации. Говоря иначе, выполняемые одновременно транзакции должны координироваться для сохранения инвариантов и накладывая некий последовательный порядок на конфликтующие выполнения [BAILIS14b].
Некоторые базы данных пользуются изоляцией моментальных снимков. При изоляции снимков транзакция может рассматриваться как изменения состояния, выполняемое всеми транзакциями, которые фиксируются по значению времени их запуска. Каждая транзакция получает некий моментальный снимок данных и выполняет для него запросы. Такая транзакция фиксируется только если изменённые её значения не изменились в процессе её выполнения. В противном случае она прерывается и откатывается обратно.
Если две транзакции пытаются изменить одно и то же значение, фиксация допускается только для одной из них. Это
предотвращает аномалию потери обновлений. Например, транзакции
T1 и T2, обе,
пытаются изменить V. Они считывают текущее значение V
из того моментального снимка, который содержит изменения всех транзакций, фиксированных до их зпуска. Всякий раз, когда
транзакция пытается выполнить фиксацию первой, она это сделает, а другая будет вынуждена прерваться. Такие отказавшие
транзакции будут повторяться вместо переписывания имеющегося значения.
При изоляции моментального снимка может происходить аномалия Перекоса записи (write skew). так как если две транзакции выполняют чтение локального состояния, изменяют независимые записи и сохраняют локальные инварианты, им обеим дозволяется фиксация [FEKETE04]. более подробно Мы обсудим изоляцию моментальных снимков в их контексте распределённых транзакций в разделе Распределённые транзакции посредством Percolator.
Оптимистический контроль одновременности предполагает что транзакции конфликтуют достаточно редко и, вместо использования блокировок и блокирующего исполнения транзакций, мы можем удостоверять транзакции на предмет предотвращения конфликтов чтения/ записи с одновременно выполняемыми транзакциями и обеспечивать возможность преобразования в последовательность до фиксации их результатов. Обычно исполнение транзакции расщепляется на три фазы [WEIKUM01]
- Фаза чтения
Сама транзакция выполняет свои шаги в своём собственном частном контексте без осуществления каких бы то ни было изменений, видимых остальным транзакциям. После этого шага все зависимости транзакции (набор чтения) известны, также как и сторона производимых этой транзакцией эффектов (набор записи).
- Фаза проверки
Наборы чтения и записи одновременных транзакций проверяются на наличие возможных конфликтов между их операциями, которые могут нарушать возможность преобразования в последовательность. Если некие считанные этой транзакцией данные теперь не актуальны, или будут переписаны некоторые из значений, записываемых транзакциями, которые фиксировались в процессе её фазы чтения, её частный контекст очищается и такая фаза чтения перезапускается. Иначе говоря, фаза проверки определяет будут или нет фиксации этой транзакции сохранять свойства ACID.
- Фаза записи
Если фаза проверки не выявила никаких конфликтов, данная транзакция может фиксировать свой набор записи из собственного частного контекста в соответствующем состоянии базы данных.
Подтверждение может быть осуществлено проверкой наличия конфликтов с самими транзакциями, которые уже были фиксированы (обратная ориентация), либо с теми транзакциями, которые в настоящий момент пребывают в фазе проверки (прямая ориентация). Фазы проверки и записи различных транзакций должны выполняться атомарно. Никаким транзакциям не допускается фиксация пока некие иные транзакции подвержены подтверждению. Поскольку фазы проверки и записи обычно короче чем первичная фаза чтения, это допустимый компромисс.
Контроль одновременности с обратной ориентацией гарантирует что для любой пары транзакций
T1 и T2
сохраняются следующие свойства:
-
Когда
T1зафиксирована до начала фазы чтенияT2, тогда и дляT2допустима фиксация. -
Если
T1была фиксирована до соответствующей фазы записиT2и сам набор записиT1не пересекается с набором чтенияT2. Иными словами,T1не должна записывать никакие значения, которые должна видетьT2. -
Фаза чтения
T1завершилась до соответствующей фазы чтенияT2и имеющийся набор записиT2не пересекается с имеющимся набором записиT1. Другими словами, транзакции работали на независимых наборах записей данных, а потому им обеим позволена фиксация.
Такой подход является действенным когда обычно ожидается успешность подтверждение проверки и транзакциям не придётся выполняться повторно, так как повторы оказывают существенное отрицательное воздействие на производительность. Естественно, оптимистическая одновременность всё ещё обладает неким критическим разделом, в который транзакции могут входить по одной за раз. Другой подход, который делает возможным не исключительное обладание некими операциями состоит в применении блокировок читателей (чтобы допускать для читателей совместный доступ) и обновляемые блокировки (для разрешения соглашений совместным блокировкам эксклюзивности, когда она требуется).
Контроль одновременности множества версий (MVCC) является неким способом достижения согласованности транзакций в системах управления базами данных за счёт допуска множества версий записи и применения монотонно увеличивающихся идентификаторов или временных отметок транзакций. Это позволяет чтениям и записям происходить при минимальной координации на уровне своего хранилища, так как чтения могут продолжать доступ к более старым значениям пока не фиксированы новые.
MVCC различает версии с фиксацией и без фиксации, которые относятся к значениям версий фиксированных и не фиксированных транзакций. Самая последняя фиксированная версия определённого значения предполагается текущей. Обычно, основная цель имеющегося диспетчера транзакций в этом случае заключается в обладании самым последним по времени не фиксированным значением.
В зависимости от реализованного рассматриваемой системой базы данных значения уровня изоляции, операциям чтения может разрешаться или нет доступ к значениям без фиксации [WEIKUM01]. Одновременность со множеством версий может реализовываться при помощи технологий блокировок, расписаний и разрешения конфликтов (например, двухфазного блокирования), либо упорядочения временных отметок. Одним из главных вариантов применения MVCC состоит в реализации изоляции моментальных снимков [HELLERSTEIN07].
Схемы пессимистического контроля за одновременностью более консервативны нежели оптимистические. Эти схемы определяют конфликты транзакций в процессе их выполнения и блокируют или прерывают их выполнение.
Одной из простейших пессимистических схем контроля одновременности (без блокировки) является
упорядочение временных отметок, при которой все транзакции обладают штампами
времени. Будет или нет операциям транзакции позволено исполнение определяется тем была или нет уже фиксирована какая- то
транзакция с более ранней временной отметкой. Для реализации этого имеющийся
диспетчер транзакций должен сопровождать для значений величины max_read_timestamp
и max_write_timestamp, описывая выполняемые одновременными транзакциями операции
чтения и записи.
Операции чтения, которые пытаются считать некое значение с какой- то временной
отметкой, ниже чем max_write_timestamp, вызовут прерывание относящихся к ним
транзакций, так как уже имеется некое более новое значение и разрешение этой операции привело бы к нарушению
установленного порядка транзакции.
Аналогично, операции записи с временной отметкой ниже нежели
max_read_timestamp конфликтовали бы с более поздними чтениями. Однако, операции
записи с меньшими временными отметками по отношению к
max_write_timestamp допустимы, так как мы можем безопасно игнорировать устаревшие
записанные значения. Такое предположение обычно носит название Правила записи Томаса
[THOMAS79]. сразу по окончанию осуществления операций чтения или
записи, обновляется соответствующее максимальное значение временной метки. Прерванные транзакции запускаются повторно с
неким новым временным штампом, так как в противном случае они гаратнированно были бы
снова прерваны
[RAMAKRISHNAN03].
Схемы с контролем одновременности на основе блокировок являются неким видом пессимистичного управления одновременностью, который пользуется блокировками в явном виде для своих объектов базы данных вместо того чтобы разрешать расписания, как протоколы подобные временным меткам делают упорядочение. Некими обратными сторонами блокировок выступают проблемы состязательности и масштабирования [REN16].
Одной из наиболее распространённых технологий на основе блокировок является двух- фазная блокировка (2PL, two-phase locking), которая разделяет управление блокировкой на две фазы:
-
Фазу роста (также носящую название фазы расширения, в процессе которой запрашиваются все необходимые для определённой транзакции блокировки и никакие блокировки не высвобождаются.
-
Фаза сжатия, на протяжении которой все полученные на фазе роста блокировки высвобождаются.
Некое правило, которое вытекает из этих двух определений, состоит в том, что некая транзакция не может запросить никакие блокировки как только она высвободит по крайней мере обну из них. Важно отметить, что 2PL не запрещает транзакциям выполнение шагов во время одного из этих этапов; однако, некоторые варианты 2PL (такие как консервативный 2PL) накладывают и это ограничение.
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
Несмотря на схожесть в названиях, двух- фазная блокировка это понятие, которое совершенно отлично от двух- фазной фиксации (см. раздел Двухфазная фиксация). Двухфазная фиксация это протокол, применяемый для распределённых по множеству разделов транзакций, в то время как двух- фазная блокировка это механизм управления одновременностью, зачастую используемый для реализации возможности преобразования в последовательную форму. |
Взаимные блокировки
В протоколах блокирования транзакции пытаются заполучить блокировки над необходимыми объектами своей базы данных и, когда блокировка не может быть немедленно предоставлена, транзакции придётся дожидаться пока эта блокировка не высвободится. Может сложиться ситуация, при которой две транзакции в попытке достичь необходимых им для продолжения исполнения блокировок в конечном итоге окажутся дожидающимися друг друга на высвобождение прочих удерживаемых ими блокировок. Такая ситуация носит название взаимной блокировки (deadlock).
Рисунок 5-6
отображает некий пример взаимной блокировки: T1 удерживает блокировку
L1 и ожидает высвобождения блокировки
L2, в то время как T2
удерживает блокировку L2 и ожидает высвобождения
L1..
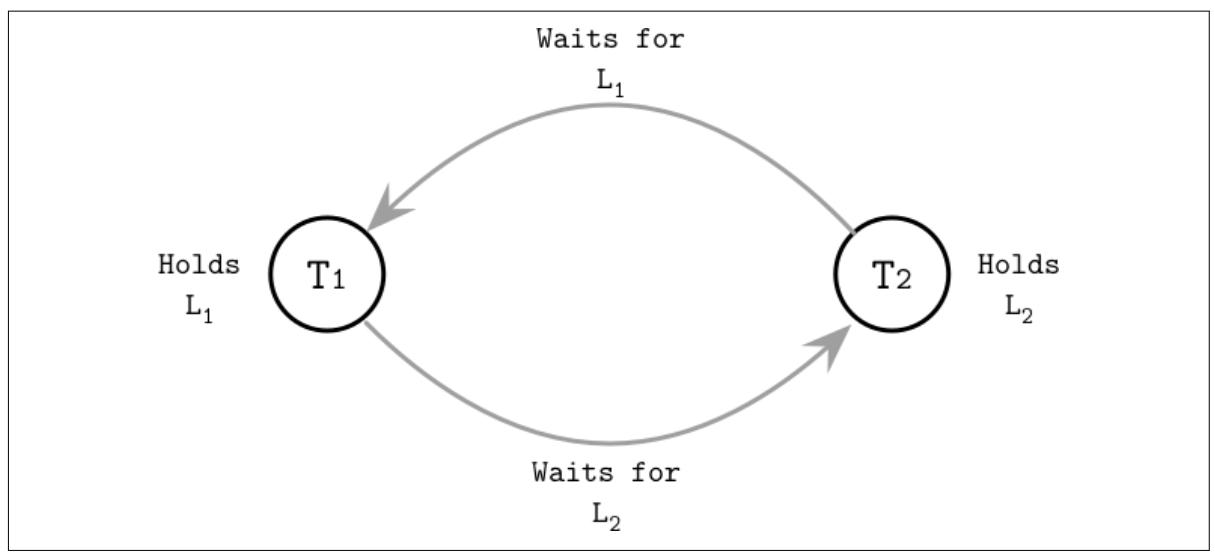
Простейшим способом обработки взаимной блокировки является введение таймаутов и прерывание длительно выполняющихся транзакций в предположении что они могут быть взаимно блокированными. Иная стратегия, консервативное 2PL, требует получение всех необходимых блокировок до того как они могут быть выполнить какие бы то ни было свои действия и прерывания когда они не способны их получить. Однако, такие подходы значительно ограничивают одновременность систем и системы баз данных в основном пользуются диспетчером транзакций для выявления или избежания (иными словами, предотвращения) взаимного блокирования.
Выявление взаимных блокировок обычно выполняется при помощи графа ожиданий, который отслеживает взаимоотношения между находящимися в полёте транзакциями и устанавливает между ними взаимоотношения ожидания.
Циклы в данном графе указывают наличие некой взаимной блокировки: транзакция T1
дожидается T2, которая в свою очередь ожидает
T1. Выявление взаимных блокировок может выполняться
периодически (один раз в заданном временном интервале) или
непрерывно (при каждом обновлении графа ожиданий)
[WEIKUM01]. Одна из транзакций (как правило, та, которая пытается
заполучить свою блокировку наиболее последней) прерывается.
Во избежание взаимных блокировок и ограничения запросов на блокирование, для случаев, при которых в результате не будет взаимного блокирования, имеющийся диспетчер транзакций может применять временные метки для определения их приоритета. Более нижняя временная метка подразумевает более высокий приоритет, и наоборот.
Если транзакция T1 пытается заполучить блокировку, в настоящее время
удерживаемую T2 и T1
обладает более высоким приоритетом (она началась раньше T2), для избежания
взаимного блокирования мы можем воспользоваться одним из следующих ограничений:
- Дожидаться смерти
T1получает разрешение выполнить блокировку и ждать эту блокировку. В противном случаеT1прерывается и перезапускается. Иначе говоря, некая транзакция может быть блокирована лишь транзакцией с более поздней временной меткой.
- Ожидание ранения
T2прерывается и перезапускается (T1ранитT2). В противном случае (когдаT2была запущена доT1), разрешается ожидание дляT1. Иными словами, некая транзакция может быть блокирована только транзакцией с меньшим временным штампом.
Обработка транзакций требует для обработки взаимных блокировок некого расписания. В то же самое время, защёлки (см. раздел Защёлки) полагаются на самого программиста, который обеспечит невозможность возникновения взаимного блокирования и не полагаются на механизмы избежания взаимных блокировок.
Блокировки
Когда две транзакции запрашиваются одновременно, причём для изменения перекрывающихся разделов данных, ни одна из них не должна видеть частичные результаты другой, а следовательно сохраняя логическую согласованность. Аналогично, два потока одной и той же транзакции обязаны наблюдать одно и то же содержимое базы данных и обладать доступом к данным друг друга.
При обработке транзакций имеется отличие между тем механизмом, который ограждает имеющуюся логическую и физическую целостность. Те два понятия, которые отвечают за логической и физической целостностью это, соответственно, блокировки (locks) и защёлки (latches). Эти названия являются несколько неудачными, так как то что носит название защёлки здесь обычно относится к некоторой блокировке в системе программирования, однако мы проясним это отличие и его последствия в данном разделе.
Блокировки используются для изоляции и расписания перекрывающихся транзакций, а также для управления содержимым базы данных, но не самой внутренней структуры хранения, и к тому же запрашиваемых по значению ключа. Блокировки могут ограждать либо некий определённый ключ (вне зависимости от его наличия или отсутствия) или некого диапазона ключей. Блокировки в основном хранятся и управляются за пределами самой реализации дерева и представляют понятие верхнего уровня, управляемого диспетчером блокировок базы данных.
Блокировки обладают большим весом нежели защёлки и удерживаются на протяжении всей транзакции.
Защёлки
С другой стороны, защёлки ограждают имеющееся физическое представление: содержимого терминальной страницы, изменяемого в процессе операции вставки, обновления и удаления. Изменяемое в процессе операций содержимое не терминальной страницы и некая структура дерева имеют результатом расщепления и слияния, которые распространяются от незаполненных и переполненных листьев. Защёлки ограждают имеющееся физическое представление дерева (содержимое страницы и саму структуру дерева) в процессе таких операций и достигается на уровне самой страницы. Любая страница может быть защёлкнута чтобы допускать одновременный доступ к ней. Технологии управления одновременностью без блокировок всё ещё обязаны пользоваться защёлками.
Поскольку некое отдельное изменение на имеющемся терминальном уровне может распространяться на более высокие уровни данного B- дерева, защёлкам может потребоваться их получения на множестве уровней. Выполняемые запросы не должны иметь возможности наблюдать страницы в неком несогласованном виде, например при незавершённой записи или частичном расщеплении узла, в процессе чего данные могут быть представлены и в узле источника, и в целевом узле, либо еще не быть распространёнными к их предкам.
Те же самые правила применяются к обновлениям указателей родителей или братьев. Общее правило заключается в том, чтобы удерживать защёлки наименее продолжительное время - а именно, когда данная страница считывается или обновляется - для увеличения одновременности.
Взаимодействия между одновременными операциями грубо можно сгруппировать в три категории:
-
Одновременные чтения, когда несколько потоков пытаются получить доступ к одной и той же странице без её изменения.
-
Одновременные обновления, при которых несколько потоков пытаются выполнить изменения в одной и той же странице.
-
Чтение при записи, когда один из имеющихся потоков пытается изменять содержимое определённой страницы, а все прочие пытаются выполнять доступ к той же самой странице по чтению.
Эти сценарии также применимы для доступа, который перекрывается сопровождением базы данных (таком как фоновые процессы, описанные в разделе Уборка и сопровождение)
Блокировка читатели- писатель
Самая простая реализация будет гарантировать исключительный доступ на чтение/ запись для запрашивающего потока. Однако, в большинстве случаев нам не требуется изолировать друг от друга все имеющиеся процессы. Например, чтения могут получать доступ к страницам одновременно не вызывая никаких проблем, поэтому нам требуется лишь быть уверенными что не перекрывается множество одновременных писателей, и что читатели не перекрываются с писателями. Для достижения этого уровня гранулярности мы можем воспользоваться болкировкой читатели- писатель, или блокировкой RW.
Некая блокировка RW делает возможным одновременный доступ множества читателей и лишь писатели (которых обычно меньше) должны получать исключительный доступ к своему объекту. Таблица 5-7 отображает таблицу совместимости блокировок читатели- писатель: только читатели способны совместно разделять обладание блокировкой, в то время как все прочие сочетания читателей и писателей обязаны получать исключительное обладание.
| Читатель | Писатель | |
|---|---|---|
Читатель |
Разделяют |
Исключительно |
Писатель |
Исключительно |
Исключительно |
На Рисунке 5-8 a) у нас имеется множество читателей с доступом
к определённому объекту, в то время как писатель в ожидает своей очереди, так как он не может изменять данную страницу пока
читатели обладают к ней доступом. На Рисунке 5-8 b)
writer 1 удерживает исключительную блокировку к своему объекту, в то время как другой
писатель и три читателя вынуждены ожидать.

Так как два пытающихся получить доступ к одной и той же странице перекрывающихся чтения не требуют иной синхронизации кроме как предотвращения от выборки с диска имеющимся кэшем страниц дважды, чтения способны безопасно выполняться одновременно в совместном режиме. Как только в игру вступают писатели, нам требуется изолировать их от обоих одновременных чтений и от прочих записей.
|
| Технологии длительного ожидания и очередей |
|---|---|
|
Для управления совместным доступом к страницам мы можем применять либо алгоритмы блокирования, которые перекраивают расписание потоков и пробуждают их как только они способны продолжать, либо применять алгоритмы длительного ожидания. Алгоритмы длительного ожидания позволяют потокам ожидать продолжительное время вместо возврата управления назад планировщику. Очереди обычно реализуются при помощи инструкций сравнения- и- перестановки, применяемых для выполнения действий, гарантированно атомарно блокирующих получение и обновление очереди. Когда данная очередь пуста, запрашивающий поток получает доступ немедленно. В противном случае этот поток сам ставится в конец для ожидания своей очереди и крутится в значении переменной, которая может обновиться лишь потоком, который предшествует ему в данной очереди. Это помогает снизить объём обмена ЦПУ для получения и высвобождения блокировки [MELLORCRUMMEY91]. |
Сцепляющая защёлка
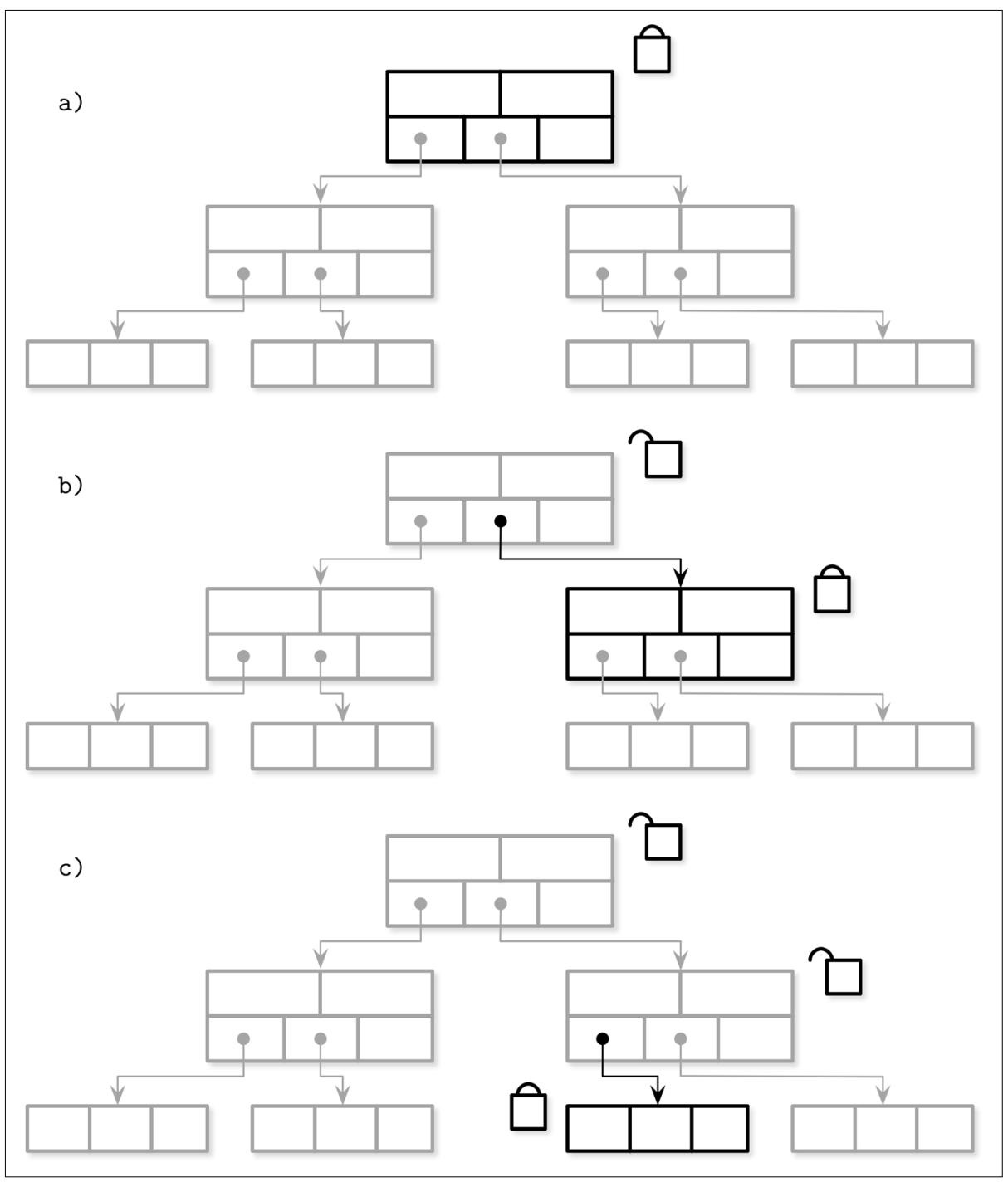
Самый простой подход для получения защёлки состоит в захвате по пути от корня к своему целевому листу всех присутствующих защёлок. Это создаёт некое узкое место в одновременности и в большинстве случаев его можно избежать. значение времени, на протяжении которого некая защёлка удерживается, должно быть минимизировано. Одной из таких возможных в достижении оптимизаций носит название сцепляющей защёлки (latch crabbing, или соединительной защёлки) [RAMAKRISHNAN03].
Сцепляющая защёлка это достаточно простой метод, который позволяет удерживать защёлки меньше времени и высвобождать их как только выполняемая в них операция больше их не требует. В самом пути чтения, как только найден необходимый дочерний узел и защёлка получена, защёлка её родительского узла может быть высвобождена.
В процессе вставки, такая родительская защёлка может быть высвобождена если данная операция гарантирует не получать в результате структурные изменения, которые могут распространиться до неё. иначе говоря, эта родительская защёлка может быть высвобождена когда её дочерний узел не полон.
Аналогично, в процессе удалений, когда соответствующий дочерний узел содержит достаточно элементов и сама операция не вызовет слияния узлов одного уровня, имеющаяся у его предка защёлка может быть высвобождена.
Рисунок 5-9 показывает проход от корня к листу в процессе вставки:
-
Защёлка записи запрашивается на уровне корня.
-
Определяется узел следующего уровня и запрашивается его защёлка записи. Этот узел проверяется на потенциальные структурные изменения. Поскольку данный узел не заполнен, его родительская защёлка может быть вызвобождена.
-
Данная операция спускается вниз к своему следующему уровню. Запрашивается защёлка записи, имеющийся лист назначения проверяется на потенциальные структурные изменения и её родительская защёлка высвобождается.
Этот подход является оптимистическим: большинство операций вставки и удаления не вызывают структурных изменений, которые распространяются по множеству уровней вверх. Большая часть операций требует лишь присутствия защёлки на самом целевом узле, а то число случаев, которое затрагивает защёлки предков относительно не велико.
Когда такая дочерняя страница ещё не загружена в установленный кэш страниц, мы можем либо защёлкнуть загружаемую далее страницу, либо высвободить некую родительскую защёлку и перезапустить необходимый проход от- корня- к- листу после загрузки этой страницы для снижения разногласий. Перезапуск обхода от- корня- к- листьям звучит затратным, но в действительности нам придётся выполнять его достаточно редко и можно применять механизм выявления того будут ли какие бы то ни было структурные изменения на верхних уровнях начиная с самого момента обхода [GRAEFE10].
|
| Обновление защёлки и охота за указателем |
|---|---|
|
Вместо запроса защёлок в процессе обхода в неком исключительном режиме прямо по пути, можно запрашивать обновление защёлок. Такой подход вовлекает получение совместных защёлок в искомом пути и их обновления на исключительное блокирование, когда оно требуется.. Первый запрос на исключительное блокирование операций записи происходит лишь на уровне самого листа. Когда такой лист должен быть расщеплён или слит, сам алгоритм проходит вверх по своему дереву для обновления некой совместной защёлки, которой располагает его предок, приобретая исключительное обладание защёлками для участвующей части этого дерева (т.е. узлов, которые также в результате данной операции будут расщепляться или сливаться). Поскольку множество потоков может попытаться получить исключительные защёлки на одном из имеющихся верхних уровней, одной из них придётся ждать или выполнить перезапуск. Вы можете заметить, что все сами описанные до сих пор механизмы приобретали некую защёлку в узле имеющегося корня. Все запросы обязаны проходить через узел своего корня, так как вначале должны заполниться все его потомки. Это означает, что сам узел корня может всегда защёлкиваться оптимистично необходимая стоимость некого повтора (погоня за указателем) платится редко. |
Деревья Blink
Деревья Blink строятся поверх B*- деревьев (см. раздел Повторная балансировка) и добавляют верхние ключи, (см. раздел Верхние ключи узла), а также указатели ссылок одного уровня [LEHMAN81]. Некий верхний ключ указывает на значение самого верхнего возможного ключа в поддереве. Все узлы за исключением корневого в неком Blink- дереве обладают двумя указателями: неким указателем потомка, исходящим от его родителя и некий братский указатель от имеющегося слева узла, расположенного на том же самом уровне.
Blink допускают некое состояние с названием половинного расщепления (half-split),при котором данный узел уже обладает ссылкой братского указателя, но не дочерней ссылкой своего предка. Половинное расщепление идентифицируется значением верхнего ключа. Когда значение искомого ключа превосходит значение верхнего ключа в данном узле (что нарушает значение инварианта верхнего ключа), наш алгоритм поиска заключает, что данная структуры одновременно изменяется и для продолжения поиска следует по имеющейся братской ссылке.
Значение указателя должно быстро добавляться к его предку, обеспечивая наилучшую производительность, однако сам процесс поиска не должен прерываться или перезапускаться, так как в этом дереве доступны все элементы. Основное преимущество при этом состоит в том, что нам не приходится удерживать блокировку своего предка при сходе к необходимому дочернему уровню, причём даже когда этот потомок намерен расщепляться: мы можем делать новый узел видимым через его братскую ссылку и лениво обновлять указатель его предка не жертвуя правильностью [GRAEFE10].
Хотя это слегка и менее действенно чем прямое нисхождение от имеющегося предка и требует доступа к некой дополнительной странице, это в результате приводит к верному спуску от- корня- к- листу при упрощении одновременного доступа. Поскольку расщепления относительно редкая операция и B- деревья не часто сжимаются, этот вариант исключительный и его стоимость незначительна. Такой подход обладает достаточным числом преимуществ: он снижает конкуренцию, предотвращая удержание блокировки предка в процессе расщеплений и снижает общее число блокировок, удерживаемых в процессе изменения структуры дерева неким постоянным числом. Что ещё более важно, это делает возможным одновременное чтение структурных изменений дерева и предотвращает взаимные блокировки, которые в противном случае приходили бы в результате одновременных изменений, восходящих к соответствующим родительским узлам.
В этой главе мы обсудили те компоненты механизма хранения, которые ответственны за обработку транзакций и восстановление. При реализации обработки транзакций нам были представлены две задачи:
-
Для улучшения эффективности нам необходимо допускать одновременное выполнение транзакций.
-
Для сохранения правильности нам требуется гарантировать что одновременно выполняющиеся транзакции сохраняют свойства ACID.
Одновременное выполнение транзакций может вызывать различные виды аномалий чтения и записи. Присутствие или отсутствие таких аномалий определяется и ограничивается реализацией различных уровней изоляции. Подходы к контролю одновременности определяют как планируются и выполняются транзакции.
Кэширование страниц отвечает за снижение общего числа доступов к диску: оно кэширует страницы в оперативной памяти и позволяет выполнение из них операций чтения и записи. Когда этот кэш достигает своей ёмкости, страницы вытесняются и сбрасываются обратно на диск. Чтобы быть уверенным что не сброшенные изменения не утратятся в случае крушений узла, а также для поддержки отката транзакции, мы пользуемся журналами упреждающей записи. Имеющиеся кэш страниц и журналы упреждающей записи координируются при помощи политик принуждения и воровства, обеспечивая эффективное исполнение всех транзакций и обратного отката без ущерба для долговечности.
|
| Последующее чтение |
|---|---|
|
Если вы желаете узнать больше относительно упоминавшихся в этой главе понятий, вы можете ссылаться на следующие источники:
|