Глава 14. Консенсус
Содержание
Мы обсудили достаточно много понятий распределённых систем, начиная с основ, таких как ссылки и процессы, проблемы с распределёнными вычислениями; затем прошлись по моделям отказов, их выявлением и выборам лидера; обсудили модели согласованности; и в конце концов мы готовы собрать это всё воедино для вершины исследования распределённых систем: распределённого консенсуса.
Алгоритмы консенсуса в распределённых системах делают возможным для множества процессов достигать согласия по некому значению. Невозможность FLP показывает что невозможно обеспечить согласие в некой целиком асинхронной системе за ограниченное время. Даже когда доставка сообщения гарантирована, одному процессу невозможно узнать испытал ли другой крушение, либо то что он медленно работает.
В Главе 9 мы обсуждали что существует компромисс между точностью выявления отказов и тем насколько быстро такой отказ может быть определён. Алгоритмы консенсуса полагаютс на модель асинхронности и гарантию безопасности, в то время как некий определитель внешних отказов может предоставлять сведения относительно прочих процессов, гарантируя жизнеспособности [CHANDRA96]. Так как выявление отказов не всегда целиком точны, будут иметься ситуации при которых алгоритмы консенсуса ожидают выявления некого отказа процесса, либо когда данный алгоритм перезапускается потому как некоторые процессы неверно подозреваются в отказе.
Процессы должны прийти к согласию по некому представляемому одним из участников значению, даже когда некоторые из них испытали крушение. Некий процесс называется Корректным, когда он не испытал крушения и продолжает исполнение шагов алгоритма. Консенсус чрезвычайно полезен для помещения событий в неком определённом порядке и обеспечивает согласованность между имеющимися участниками. Применяя консенсус мы можем обладать некой системой, в которой процессы перемещаются от одного к следующему без утраты уверенности относительно того, какие значения наблюдаются их клиентами.
С теоретической точки зрения, алгоритмы консенсуса обладают тремя свойствами:
- Согласованность
Значение данного решения одно и то же для всех Корректных процессов.
- Обоснованность
Принятое значение было предложено одним из имеющихся процессов.
- Завершаемость
Все Корректные процессы в конечном итоге достигают определённого решения.
Всякое из этих свойств чрезвычайно важно. Само согласие встроено в человеческое понимание консенсуса. Такое словарное определение консенсуса имеет в себе слово "единодушие". Это означает что в соответствии с таким согласием никакому процессу не дозволяется иметь мнение, отличное от выдаваемого на выходе. Представляйте себе его как некое согласие встретить в некий определённый момент и в определённом месте своих приятелей: все вы хотите встретиться, согласовывается лишь сама специфика данного события.
Обоснованность существенна, так как без ней консенсус может быть тривиальным. Алгоритмы консенсуса требуют всем процессам прийти к согласию по некому значению. Когда процессы используют какое- то заранее определённое, произвольное установленное по умолчанию значение в качестве выводимого решения независимо от предлагаемых значений, они достигнут единогласия, но вывод такого алгоритма не будет правомерным и не будет полезно в реальности.
Без завершаемости наш алгоритм будет продолжаться неограниченно долго без достижения какого бы то ни было согласия или будет дожидаться неопределённо долго возврата обратно крушения процесса, что ни в одном из случаев не слишком полезно. Процессы в конце концов обязаны достигать согласия и, чтобы некий алгоритм согласия был практичным, это должно происходить достаточно быстро.
Некое широковещание это абстракция взаимодействия, часто применяемая в распределённых системах. Алгоритмы широковещания используются для рассеивания сведений по некому набору процессов. Существует много алгоритмов широковещания, делающих различные предположения и предоставляющих различные гарантии. Широковещание является неким важным примитивом и применяется во множестве мест, включая и алгоритмы консенсуса. Мы уже обсуждали одну из форм широковещания - рассеяние gossip (см. раздел Рассеивание Gossip).
Средства широковещания часто используются для репликации базы данных когда некий отдельный узел координатора должен распространять необходимые данные всем прочим участникам. Однако, превращение этого процесса в надёжное не тривиальное средство: когда такой координатор испытывает крушение после распространения данного сообщения в некоторые узлы, но не к части прочих, это оставляет данную систему в каком- то несогласованном состоянии: часть из имеющихся узлов уже видит некое новое сообщение, а прочие нет.
Самый простой и наиболее прямолинейный способ для широковещательного распространения сообщений состоит в широкое вещание с максимальными усилиями [CACHIN11]. В этом случае, сам отправитель отвечает за обеспечение доставки событий всем имеющимся целям. В случае его отказа все прочие участники не пытаются повторно широковещательно распространять это сообщение и в случае крушения координатора, этот вид широковещания тихо откажет.
Для надёжности широкого вещания необходимо обеспечивать кто все Корректные процессы получили одни и те же сообщения, даже если сам отправитель испытывает крушение в процессе передачи.
Для реализации некой наивной версии некого надёжного широковещания, мы можем пользоваться неким определителем отказов
и какой- то механизм отхода. Наиболее прямолинейный механизм отхода состоит в разрешении каждому принимающему
данное сообщение процессу переправления его всем прочим процессам, о которых он осведомлён. Когда соответствующий
процесс источника отказывает, прочие процессы выявляют это падение и продолжают широковещательно распространять это
сообщение, действенно заполняя данную сетевую среду
N2 сообщениями (как это показано на
Рисунке 14-1).
Даже если такой отправитель претерпел крушение, сообщения всё ещё подбираются и доставляются всей оставшейся системой,
улучшая её надёжность и позволяя всем получателям видеть те же самые сообщения
[CACHIN11].
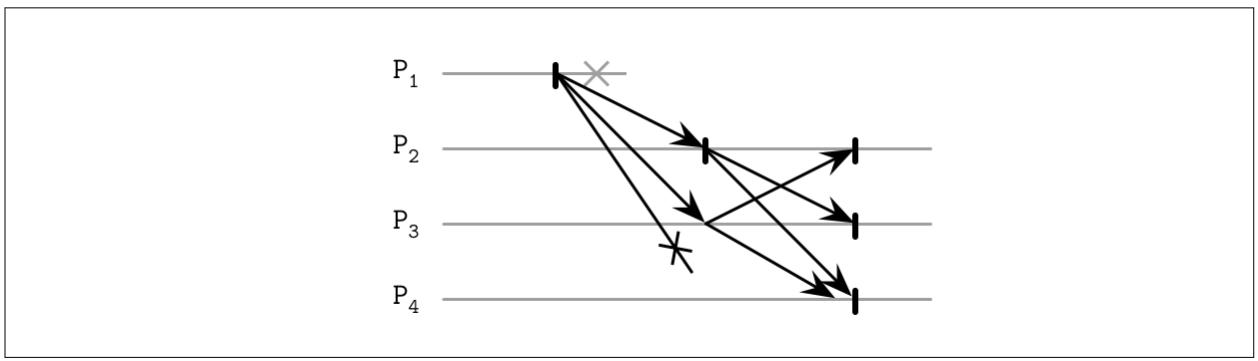
Одной из обратных сторон данного подхода является тот факт, что он применяет
N2 сообщений, где N это
общее число остающихся получателей (так как каждый процесс широковещания исключает сам
первоначальный процесс и его самого). В идеале мы бы желали снизить общее число сообщений, необходимых для
надёжного широковещания.
Даже несмотря на то, что наш только что описанный заполняющий алгоритм может гарантировать доставку, он не обеспечивает доставку в каком бы то ни было определённом порядке. Сообщения достигают в конце концов своего получателя, причём в некий неизвестный момент времени. Когда нам необходимо доставлять сообщения по порядку, нам приходится применять атомарное широковещание (также носящего название тотально упорядоченной групповой передачи), которая гарантирует и надёжную доставку и тотальное упорядочение.
В то время как надёжное широковещание гарантирует что процессы согласовывают необходимый набор доставки сообщений, некое атомарное широковещание также обеспечивает что они согласовывают одну и ту же последовательность сообщений (т.е. что порядок доставки сообщений одинаков для всех целей).
В сумме некое атомарное широковещание обязано гарантировать два существенных свойства:
- Атомарность
Процессы должны достичь согласия по установленному множеству полученных сообщений. Либо все всем неотказавшим процессам доставлено данное сообщение, либо ни одному из них.
- Упорядоченность
Всем не отказавшим процессам сообщения доставляются в одном и том же порядке.
Сообщения в данном случае доставляются атомарно: каждое сообщение либо доставляется всем процессам, либо ни одному из них, причём когда такое сообщение доставлено, все прочие сообщения все прочие сообщения упорядочиваются до или после этого сообщения.
Одна из инфраструктур для применяемого для широковещания группового взаимодействия носит название виртуальной синхронизация. Некое атомарное широковещание способствует доставки тотально упорядоченных сообщений статическим группам процессов,а виртуальная синхронизация доставляет тотально упорядоченные сообщения динамической одноранговой группе.
Виртуальная синхронизация организует процессы по группам. Пока такая группа существует, сообщения доставляются всем её членам в одном и том же порядке. В таком случае сам порядок не предписывается этой моделью, и некоторые модели способны принимать это в качестве своего преимущества для извлечения производительности пока такой предоставляемый ими порядок согласован по всем участникам [BIRMAN10].
Процессы обладают одним и тем же представлением данной группы и сообщения ассоциируются с такой группой идентично: процессы могут видеть все идентичные сообщения только пока они относятся к одной и той же группе.
Как только один из участников присоединяется к группе или покидает её, либо отказывает и принуждается к выходу из ней, представление этой группы изменяется. Это происходит через анонсирование такого изменения группы всем её участникам. Всякое сообщение ассоциировано с той группой, из которой оно произошло.
Виртуальная синхронизация различает получение сообщения (когда некий участник группы получает сообщение) и его доставку (которая происходит после того как все участники этой группы получили данное сообщение). Когда сообщение отправлено в одном представлении, оно может быть доставлено только в том же самом представлении, что можно определить сопоставлением текущей группы с той группой, с которой ассоциировано данное сообщение. Полученные сообщения остаются ожидающими в своей очереди пока данный процесс не получит уведомления об его успешной доставке.
так как всякое сообщение соотнесено к некой определённой группе, до тех пор, пока все процессы в этой группе не получат его прежде чем её представление изменится, никакой из участников группы не способен рассматривать данное сообщение доставленным. Это подразумевает, что все сообщения отправляются и доставляются между изменениями своего представления, что снабжает нас обеспечением атомарной доставки. В данном случае групповые представления служат неким барьером, который широковещательные сообщения не могут пересекать.
Некоторые алгоритмы тотального широковещания упорядочивают сообщения при помощи отдельного процессора (упорядочивающего - sequencer) который и отвечает за его определение. Такие алгоритмы могут быть проще в реализации, однако полагаются на определение отказов соответствующего лидера для живучести. применение упорядочивающего процесса может улучшать производительность, так как нам не требуется устанавливать консенсус между процессами для каждого из сообщений и мы можем применять вместо этого представление локальное для процесса упорядочения. Такой подход может всё ещё масштабироваться путём разбиения соответствующих запросов на разделы.
Несмотря на свою техническую обоснованность, виртуальная синхронизация не получила широкого распространения и не является средством общего применения в коммерческих системах конечных пользователей [BIRMAN06].
Одной из самых популярных и широко известных реализаций обсуждаемого атомарного широковещания является ZAB, применяемый Apache Zookeeper [HUNT10] [JUNQUEIRA11], иерархическое распределённое хранилище ключ- значение, в котором оно используется для обеспечения необходимого тотального порядка событий и атомарной доставки, требующейся для сопровождения согласованности между установленными состояниями реплик.
Процессы в ZAB могут принимать одну из двух ролей: Лидер и Последователь. Лидер это временная роль. Она движет данным процессом через выполнение этапов алгоритма, широковещательно распространяет сообщения Последователям и устанавливает необхдимый порядок событий. Для сохранения новых записей и выполнения считываний, которые наблюдают самые последние значения, клиенты соединяются с одним их имеющихся узлов в общем кластере. Когда данный узел оказывается лидером, именно он и будет обрабатывать данный запрос. В противном случае он передаёт этот запрос своему лидеру.
Для гарантии уникальности Лидера, временная линия этого протокола расщепляется на эпохи, идентифицируемые неким монотонно- и инкрементально- возрастающим числом. В процессе каждой эпохи может иметься лишь один лидер. Соответствующий процесс начинает с отыскания Предполагаемого лидера при помощи механизма выборов до тех пор пока он не выберет некий процесс, который поднят с высокой вероятностью. Поскольку безопасность обеспечивается всеми последующими этапами алгоритма, определение Предполагаемого лидера - это скорее оптимизация производительности. Предполагаемый лидер также может образовываться как следствие отказа предыдущего Лидера.
Как только установлен некий предполагаемый лидер, он выполняет некий протокол в три фазы:
- Обнаружение
Данный Предполагаемый лидер изучает значение самой последней эпохи, известной прочим процессам и предлагает некую новую эпоху, которая превышает текущую эпоху всех Последователей. Последователи отвечают на предложение эпохи значением идентификатора самой последней транзакции, видимой из своей предыдущей эпохи. После этого шага никакой процесс не буде принимать широковещательные предложения для более ранних эпох.
- Синхронизация
Эта фаза применяется для восстановления отказа своего предыдущего Лидера и вводит отстающих последователей в курс дела. Предполагаемый лидер отправляет некое сообщение своим Последователям, заявляя о себе как о лидере данной новой эпохи и собирает их подтверждения. Как только получены подтверждения, устанавливается данный лидер. После данного этапа Последователи не будут принимать попыток от прочих процессов стать лидером данной эпохи. В процессе синхронизации устанавливаемый новый лидер обеспечивает чтобы Последователи обладали той же самой историей и доставляет фиксированные предложения от установленных лидеров более ранних эпох. Эти предложения доставляются до того как доставлено какое бы то ни было предложение от данной новой эпохи.
- Широкое вещание
Как только все Последователи вернулись в синхронное состояние, запускаются активные сообщения. На протяжении этого этапа установленный лидер получает сообщения клиентов, устанавливает их порядок и выполняет их широковещание всем имеющимся Последователям: он отправляет некое новое предложение, дожидается кворума Последователей ответами подтверждений и, наконец, фиксирует его. Данный процесс аналогичен двухфазной фиксации без прерываний: голоса являются всего лишь подтверждениями и клиент не может голосовать против некого допустимого предложения лидера. Тем не менее, предложения от лидеров из неверных эпох не должны подтверждаться. Данная фаза широковещания продолжается вплоть до крушения её Лидера, разбиение на разделы Последователей или ожидания наступления крушения по причине задержки соответствующего предложения.
Рисунок 14-2 отображает все три фазы данного алгоритма ZAB и обмен сообщений на каждом из этапов.

Безопасность данного протокола обеспечивается когда Последователи гарантированно принимают предложения от своего Лидера для данной установленной эпохи. Два процесса могут попытаться быть выбранными, но лишь один из них может победить и установить себя в качестве Лидера эпохи. Это также предполагает что процессы выполняют предписанные этапы в духе доброй воли и следуют установленному протоколу.
Как Лидер, так и Последователи полагаются на сердцебиения для определения жизнеспособности соответствующего удалённого процесса. Когда установленный Лидер не получает сердцебиений от необходимого кворума Последователей, он уходит с поста Лидера и перезапускает весь процесс выборов. Аналогично, когда один из его Последователей определяет крушение своего Лидера, он запускает процесс новых выборов.
Сообщения тотально упорядочены и установленный Лидер не предпринимает попыток отправить своё следующее сообщение пока не было подтверждено предыдущее сообщение. Даже когда некоторые сообщения получаются Последователями более одного раза, их повторное приложение не производит дополнительных сторонних эффектов при следовании порядку доставки. ZAB способен обрабатывать множество нерешённых одновременных изменений состояний клиентов, так как некий уникальный лидер будет получать запросы на запись, устанавливать необходимый порядок событий и широковещательно распространять эти изменения.
Всеобщая упорядоченность сообщений также позволяет ZAB улучшать производительность восстановления. На протяжении своего этапа синхронизации,Последователи отвечают значениями наивысших фиксированных предложений. Их Лидер просто может выбрать для восстановления узел с наивысшим предложением и он может оказаться единственным узлом, с которого требуется копировать сообщения.
Одним из преимуществ ZAB является его эффективность: его процесс широковещания требует лишь двух раундов сообщений, а отказы Лидера могут восстанавливаться путём потокового обмена всеми пропущенными сообщениями от единственного актуального процесса. Присутствие долгоживущего лидера может иметь положительное воздействие на производительность: нам не требуются дополнительные раунды консенсуса для установления некой истории событий, поскольку установленный лидер способен упорядочивать их на основании своего собственного локального представления.
некое атомарное широкое вещание это задача, эквивалентная согласию в какой- то асинхронной системе с отказами крушения [CHANDRA96], так как участникам приходится договариваться о необходимом порядке сообщений и они обязаны иметь возможность его изучения. Между атомарным широковещанием и алгоритмами согласования вы обнаружите множество сходного как в мотивации, так и в реализации.
Вероятно наиболее широко известным алгоритмам консенсуса является Paxos. Он впервые был предложен Лесли Дампортом в его статье "The Part-Time Parliament" [LAMPORT98]. В этой статье консенсус описывается в выражениях терминологии, вдохновлённой законодательным и избирательным процессом на Эгейском острове Паксос. В 2001 этот автор выпустил следующую статью, озаглавленную "Paxos Made Simple" [LAMPORT01], которая вводила более простую терминологию, которая теперь и применяется для объяснения данного алгоритма.
Участники Paxos способны выполнять одну из трёх ролей: Заявителей, Получателей или Обучаемых.
- Заявители
Получают от клиентов значения, создают предложения по принятию этих значений и пытаются собрать голоса от Получателей.
- Получатели
Голосуют за принятие или отклонение предложенного Заявителем значения. Для отказоустойчивости данный алгоритм требует наличия множества Получателей, однако для его жизнеспособности с целью принятия выставленного предложения требуется лишь кворум (большинство) голосов Получателей.
- Обучаемые
Играют роль реплик, храня все выводимые сведения по принятым предложениям.
Всякий участник способен выполнять любую роль, причём большинство реализаций совмещают их: некий отдельный процесс может одновременно выступать в роли Заявителем, Получателя и Обучаемого.
Всякое предложение состоит из некого значения, предлагаемого соответствующим
клиентом, а также монотонно возрастающим номером предложения. Этот номер затем используется для обеспечения общего порядка
исполняемых операций и устанавливает взаимосвязи происхождения -до/ -после между ними. Номера предложений также часто
реализуются при помощи неких пар (id, timestamp), где также сопоставляется и
идентификатор узла, который может применяться в качестве разрывающих связей (break ties) для временных отметок.
Сам алгоритм Paxos может быть в целом разделён на два этапа: фазу голосования (или предложения) и репликацию. На протяжении этапа голосования, Вносящие предложение состязаются за установление своего лидерства. В процессе репликации, установленный Вносящий предложение распространяет соответствующее значение Получателям.
Вносящий предложение является некой точкой инициализации контакта с клиентом. Он получает некое значение, по которому следует принять решение, и пытается собрать голоса от своего кворума Получателей. Когда это выполнено, Получатели распространяют соответствующие сведения относительно данного согласованного значения Обучаемым, закрепляя (ратифицируя) полученный результат. Обучаемые увеличивают значение множителя репликаций данного значения, по которому было достигнуто согласие.
Только один Вносящий предложение способен собирать значение большинства голосов. При некоторых обстоятельствах голоса могут делиться поровну между имеющими Вносящими предложение и ни один из них не будет иметь возможности собирать большинство на протяжении данного раунда, принуждая его к повторному запуску. Мы обсуждали этот и прочие сценарии в разделе Сценарии отказов.
На протяжении этапа предложения установленный Вносящий предложение отправляет
некое сообщение Prepare(n) (где n это
номер предложения) некому большинству Получателей и предпринимает попытку сбора их голосов.
Когда некий Получатель принимает этот подготовительный запрос, он обязан ответить, сохраняя следующие инварианты [LAMPORT01]:
-
Если этот Получатель ещё не ответил на некий подготовительный запрос с каким- то более высоким последовательным номером, он обещает, что не будет принимать никакие предложения с меньшим последовательным номером.
-
Если этот Получатель ранее уже принял - получил сообщение
Accept!(m,vaccepted)- любое иное предложение, он отвечает сообщениемPromise(m,vaccepted), уведомляя своего Вносящего предложение чтоон уже принял определённое предложение с порядковым номеромm. -
Если этот Получатель уже откликнулся на некий подготовительный запрос с более высоким последовательным номером, он уведомляет своего Заявителя о присутствии предложения с более высоким номером.
-
Получатель способен отвечать более чем на один подготовительный запрос, по мере того как самый последний из них имеет более высокий последовательный номер.
На протяжении соответствующего этапа репликации, после сбора голосов большинства, установленный Заявитель может
запустить необходимую репликацию, в которой он фиксирует значение предложения отправляя
Получателям некое сообщение Accept!(n, v) со значением
v и номером предложения n.
vэто то значение, которое связано с имеющим наивысший номер из всех принятых
им от Получателей откликов предложением или любое его собственное значение когда их отклики не содержат старых
принятых предложений.
Соответствующий Получатель принимает это предложение с номером
n, если только на протяжении этапа предложения он уже не ответил
Prepare(m), где m больше чем
n. Когда Получатель отвергает данное предложение, он уведомляет об этом своего
Заявителя, отправляя самое большое последовательное число, которое он наблюдал в своём запросе
содействуя своему Заявителю поймать его
[LAMPORT01].
Вы можете рассмотреть обобщённое отображение некого раунда Paxos на Рисунке 14-3.
После достижения консенсуса по обсуждаемому значению (иначе говоря, оно было принято по крайней мере одним Получателем), последующим Заявителям приходится принимать решение о том же самом значении для обеспечения необходимого согласия. Именно поэтому Получатели отвечают самым последним принятым ими значением. Когда ни один из Получателей не видел какого- то предыдущего значения, имеющийся Заявитель волен выбрать своё собственное значение.
Обучаемый обязан отыскать то значение, по которому было принято решение, с которым он может ознакомиться после получения уведомлений от большинства Получателей. Чтобы позволить имеющемуся Обучаемому узнать о новом установленном значении настолько быстро, насколько это возможно, Получатели могут уведомлять их о таком значении как только они его приняли. Если имеются более одного Обучаемых, каждому Получателю придётся уведомлять всех Обучаемых. Один или более обучаемых могут быть Выдающимися (distinguished), и в этом случае он будет уведомлять и прочих Обучаемых относительно принимаемых значений.
Итак, основная цель самого первого этапа алгоритма состоит в установлении некого лидера для данного раунда и понимания каое значение подлежит принятию, что делает возможным такому лидеру продолжить вторым этапом: широковещательным распространением этого значения. На практике, мы бы желали снизить общее число этапов в данном алгоритме, потому мы позволяем своему Заявителю предлагать более одного значения. Мы обсудим это более подробно в разделе Multi-Paxos.
Кворумы применяются для обретения уверенности в том, что несмотря на способность некоторых из имеющихся участников к отказу, мы всё ещё способны продолжать пока мы можем собирать голоса от прочих находящихся в работе. Некий кворум это значение минимального числа голосов, необходимого для осуществления данного действия. Это число обычно составляет некое большинство участников. Самая главная стоящая за кворумом мысль состоит в том, что даже когда участники отказывают или возникает разбиение на сетевые разделы, существует по крайней мере один участник, выступающий неким арбитром, обеспечивающим корректность протокола.
После того как достаточное число участников приняло данное предложение, протокол гарантирует принятие данного значения, так как любые два большинства обладают по крайней мере одним общим участником.
Paxos обеспечивает безопасность при наличии любого числа отказов. Не существует конфигураций, которые способны производить некорректные или не состоятельные состояния, так как это противоречило бы самому понятию консенсуса.
Жизнеспособность гарантируется при наличии f отказавших процессов. Для этого
данный протокол требует в общей сложности 2f + 1 процессов с тем, чтобы когда
произойдёт f отказов, всё ещё будет иметься
f + 1 процессов, способных продолжать работу. Применяя кворумы, вместо того чтобы
требовать присутствия всех процессов, Paxos (и прочие алгоритмы консенсуса) обеспечивают результаты даже в сучае
возникновения f отказов. В разделе
Гибкий Paxos
мы обсудим кворумы слегка в иной терминологии и опишем как строит протоколы, требующие лишь пересечения кворумов
между этапами алгоритма.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Важно помнить, что кворумы описывают лишь определённые блочные свойства данной системы. Для обеспечения безопасности, на каждом этапе нам приходится дожидаться откликов по крайней мере от кворума узлов. Мы можем отправлять предложения и принимать команды для большего числа узлов; для продолжения нам просто не требуется дожидаться их откликов. Мы можем отправить сообщения большему числу узлов (некоторые системы применяют спекулятивное исполнение: вызывают избыточное число запросов, что способствует достижению требуемого числа откликов в случае отказов узлов), однако для обеспечения жизнеспособности, мы можем продолжать как только мы обнаружили необходимый кворум. |
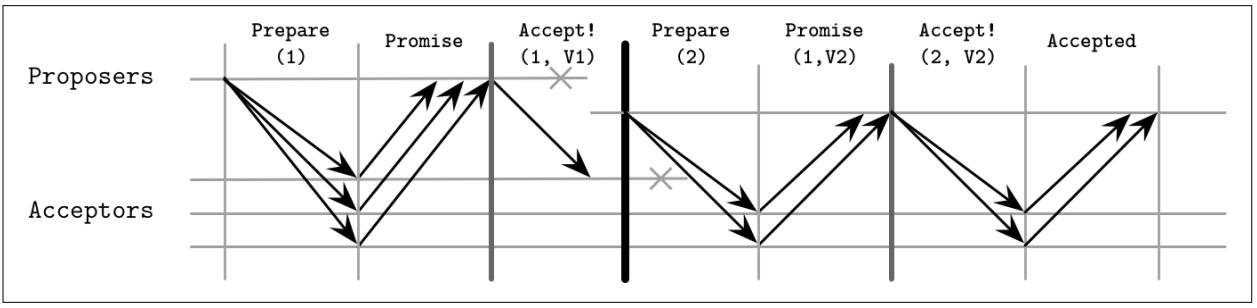
Обсуждение распределённых систем становится особенно занимательным при рассмотрении отказов. Один из возможных сценариев отказа, демонстрирующих отказоустойчивость, состоит в том, когда на втором этапе отказывает Заявитель, причём до того как он получил возможность широковещательно распространять необходимое значение всем имеющимся Получателям (некая подобная ситуация может произойти если данный Заявитель в рабочем состоянии, но медленный или не способен взаимодействовать с некоторыми Получателями). В этом случае избираемый новый Заявитель может подхватить и зафиксировать данное значение, распространяя его прочим участникам.
Рисунок 14-4 отображает такую ситуацию:
-
Заявитель
P1проходит этап выборов с неким предложением номер1, однако отказывает после отправки соответствующего значенияV1всего лишь одному получателюA1. -
Другой Заявитель
P2запускает новый раунд с более высоким номером предложения2, собирает некий кворум из откликов Получателей (в данном случаеA1иA2) и продолжает фиксацию своего старого значенияV1, предложенногоP1.
Рисунок 14-4
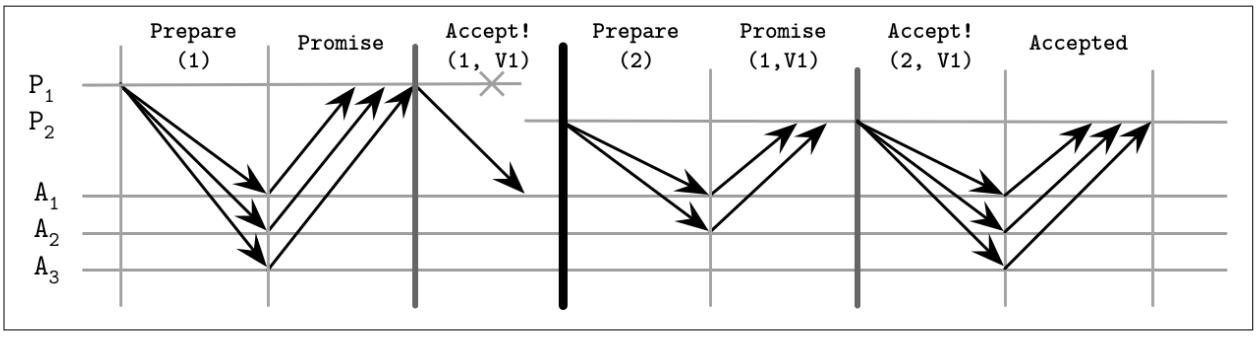
Сценарий отказа Paxos: Вносящий предложение отказывает полагаясь на своё старое значение
Так как значение состояния данного алгоритма реплицируется множеству узлов, отказ Заявителя не
приводит в результате к отказу в достижении консенсуса. Если установленный Заявитель отказывает даже
после приёма устанавливаемого значения единственным Получателем A1,
его предложение может быть подхвачено следующим установленным Заявителем.
Это также может подразумевать, что всё это может происходить и без того чтобы об этом узнал сам
первоначальный Заявитель.
В неком приложении клиент/ сервер, в котором определённый клиент соединяется лишь с первоначальным Заявителем, это может повлечь за собой ситуации, при которых данный клиент не знает об окончательном результате исполнения данного раунда Paxos (к примеру, такое положение вещей описывается в https://databass.dev/links/68).
Тем не менее, также возможны и иные сценарии, как это отображено на Рисунке 14-5. Например:
-
P1отказывает в точности так же как и в предыдущем примере, после отправки своего значенияV1лишь кA1. -
Наш следующий Заявитель,
P2запускает некий новый раунд с более высоким номером предложения2и собирает некий кворум откликов Получателей, однако на этот раз первыми откликаютсяA2иA3. После сбора кворума,P2фиксирует своё собственное значение,несмотря на тот факт, что теоретически присутствует некое иное фиксируемое значение вA1.
Рисунок 14-5
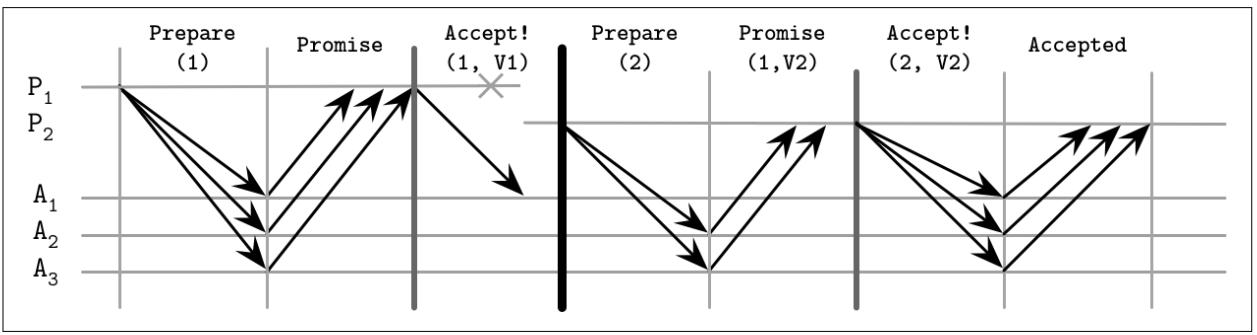
Сценарий отказа Paxos: Вносящий предложение отказывает полагаясь на своё новое значение
В данных обстоятельствах имеется ещё одна возможность, отображаемая на Рисунке 14-6:
-
Заявитель
P1отказывает лишь после единственного ПолучателяA1, принявшего выставленное значениеV1.A1вскорости после приёма данного предложения отказывает, причём до того как он смог оповестить своего следующего Заявителя о своём значении. -
Заявитель
P2, который запустил необходимый новый раунд после отказаP1не перекрывался сA1и продолжает вместо этого фиксацией своего значения. -
Всякий Заявитель, который вступает после такого раунда и который будет перекрываться с
A1, будет игнорировать значениеA1и выбирать вместо него более позднее принимаемое предложение.
Рисунок 14-6
Сценарий отказа Paxos: Вносящий предложение отказывает вслед за отказом своего Получателя
Иной сценарий отказа происходит когда два или более Заявителя стартуют состязание, причём каждый пытается пройти через свой этап предложения, но не способны собрать большинство, так как их побеждает соперник.
Хотя Получатели и обещают не принимать никакие предложения с более низкими номерами, они всё ещё отвечают множеству подготовительных запросов до тех пор, пока не появится самый последний с неким более высоким последовательным номером. Когда некий Заявитель пытается фиксировать данное значение, он может обнаружить что Получатели уже ответили на некий подготовительный запрос с более высоким последовательным номером. Это может повлечь к тому, что множество процессов постоянно повтряют свою попытку и препятствуют друг другу в последующем развитии. Такая проблема обычно разрешается через вовлечение некого случайного отката, который в конечном счёте позволит одному из имеющихся Заявителей продолжать, вто время как другой засыпает.
Алгоритм Paxos может не обращать внимания на отказы Получателя, но только когда всё ещё имеется достаточно рабочих Получателей для формирования большинства.
До сиз пор мы обсуждали классический алгоритм Paxos, в котором мы придерживаемся некого произвольного Заявителя и
пытаемся запустить некий раунд Paxos. Одной из основных проблем данного подхода состоит в том, что для всякого раунда
происходящего в данной системе репликации необходим некий раунд предложения. Лишь после того как соответствующий
Заявитель установлен для данного раунда, что происходит после отклика большинства Получателей неким
Promise на соответствующий Prepare,
он способен запустить данную репликацию. Чтобы избежать соответствующего этапа предложения и позволить установленному
Заявителю повторно применять его общепризнанное положение, мы можем применять Множественный Paxos (Multi-Paxos), который
вводит некое понятие Лидера: некого Высокопоставленного
Заявителя (distinguished proposer) [LAMPORT01].
Именно это является критическим добавлением, которое значительно улучшает действенность алгоритма.
Обладая установленным Лидером, мы способны пропускать сообтветствующий этап предложения и продолжать непосредственно репликацией: распространять какое- то значение и собирать подтверждения Получателей.
В своём классическом алгоритме Paxos, читателей можно реализовывавть запуском раунда Paxos, который собирал бы все значения от незавершённых раундов, когда таковые имеются. Это необходимо выполнять, так как нет гарантий что самый последний известный Заявитель содержит все самые последние сведения, так как мог иметься иной Заявитель, который обладает изменённым состоянием и при этом установленный Заявитель не знает об этом.
Аналогичная ситуация может происходить и в Множественном Paxos: мы пытаемся выполнить некое чтение из известного Лидера после того как уже избран другой Лидер, возвращая устаревшие сведения, что входит в противоречие с необходимостью для консенсуса обеспечения линеаризуемости. Во избежание этого и дабы гарантировать что никакой иной процесс не способен успешно представить значения, некоторые реализации Множественного Paxos применяют аренду (leases). Установленный Лидер периодически взаимодействует с имеющимися участниками, уведомляя их что он всё ещё работает, действенно продлевая свою аренду. Участники должны откликаться и позволять этому Лидеру продолжать свои операции, обещая что они не будут принимать предложения от прочих лидеров на данный период аренды [CHANDRA07].
Аренда не обеспечивает корректности, а всего лишь выступает оптимизацией производительности, которая делает возможным считывания с установленного активного Лидера без сбора кворума. Для обеспечения безопасности аренда полагается на значения ограничения по часам синхронности между имеющимися участниками. Если их часы расходятся слишком сильно и установленный Лидер полагает, что он всё ещё имеет полномочия, в то время как прочие частники полагают что его аренда истекла, линеаризуемость невозможно гарантировать.
Множественный Paxos иногда описывается как некий реплицируемый журнал операций, применённых к какой- то структуре. Данный алгоритм не обращает внимания на установленную для данной структуры семантику и сосредоточен лишь на согласованном реплицировании значений, которые будут добавляться в конец его журнала. Для сохранения значения состояния в случае крушений процессов, участники сохраняют некий долговечный журнал получаемых сообщений.
Для предотвращения роста журнала до неопределённо большого размера, к его содержимому следует применять обсуждавшуюся ранее структуру. После того как данный журнал синхронизирует содержимое со своей первичной структурой, создаётся некий моментальный снимок, а сам журнал может быть усечён. Журнал и состояние моментальных снимков обязаны быть взаимно согласованными, причём изменения моментального снимка должны применяться атомарно с усечением откидываемого сегмента журнала [CHANDRA07].
Мы можем представлять себе отдельное постановление Paxos как некий однократно- записываемый регистр: у нас есть некий разъём, в который мы имеем возможность помещать некое значение и как только мы записали туда своё значение, невозможны никакие последующие изменения. На протяжении самого первого этапа предложения состязаются за обладание данным регистром,а на втором этапе один из них записывает своё значение. В то же самое время, Множественный Paxos может представляться нам как некий дописываемый исключительно в конец журнал, состоящий из некой последовательности таких значений: за раз мы можем записывать единственное значение, все значения строго упорядочены и мы не имеем возможности изменять уже записанные значения [RYSTSOV16]. Имеются примеры алгоритмов консенсуса, которые предлагают наборы регистров считывания- изменения- записи и используют разделение состояния вместо того чтобы реплицировать конечные автоматы, например, Active Disk Paxos [CHOCKLER15] и CASPaxos [RYSTSOV18].
Мы можем снизить общее число проходов туда и обратно на один по сравнению со своим классическим алгоритмом
Paxos, позволив любому Заявителю взаимодействовать с Получателями напрямую вместо
того чтобы полагаться на установленного Лидера. Для этого нам требуется увеличить размер своего кворума до
2f + 1 (где f это общее число процессов,
для которых допустим отказ), в сравнении с f + 1 для классического Paxos, а
общее число Получателей до 3f + 1
[JUNQUEIRA07].
Такая организация носит название Быстрого Paxos
[LAMPORT06].
Наш алгоритм классического Paxos обладает неким условием, когда на протяжении выполняемого этапа репликации установленный Заявитель может выцеплять любое значение, которое он собирал на своём этапе предложения. Быстрый Paxos обладает двумя типами раундов: классическим, при котором данный алгоритм продолжается тем же самым способом , что и в своей классической версии и быстрым, когда он разрешает Получателям принимать прочие значения.
При определении данного алгоритма мы будем именовать своего Заявителя, который должен собрать достаточное число откликов на этапе предложения Координатором и зарезервировать термин Заявителя для всех прочих Заявителей. некоторые описания Быстрого Paxos сообщают, что клиенты могут вступать в контакт с Получателями напрямую [ZHAO15].
В неком быстром раунде, когда установленному Координатору дозволено выцеплять своё собственное значение на протяжении
выполняемого этапа репликации, он имеет возможность этого вместо вызова для Получателей какого- то специального сообщения
Any. Получателям в таком случае позволяется воспринимать значение
любого Заявителя как если бы это был классический раунд и они получили некое
сообщение с данным значением от своего Координатора. Иначе говоря, Получатели независимо принимают решение по получаемым
ими от различных Заявителей значениям.
Рисунок 14-7 отображает некий образец классического и быстрого раундов в Быстром Paxos. Исходя из этого рисунка может показаться, что отображённый быстрый раунд имеет больше шагов исполнения, но имейте в виду, что в классическом раунде для представления своего значения установленному Заявителю необходимо пройти через своего Координатора для получения фиксации своего значения.
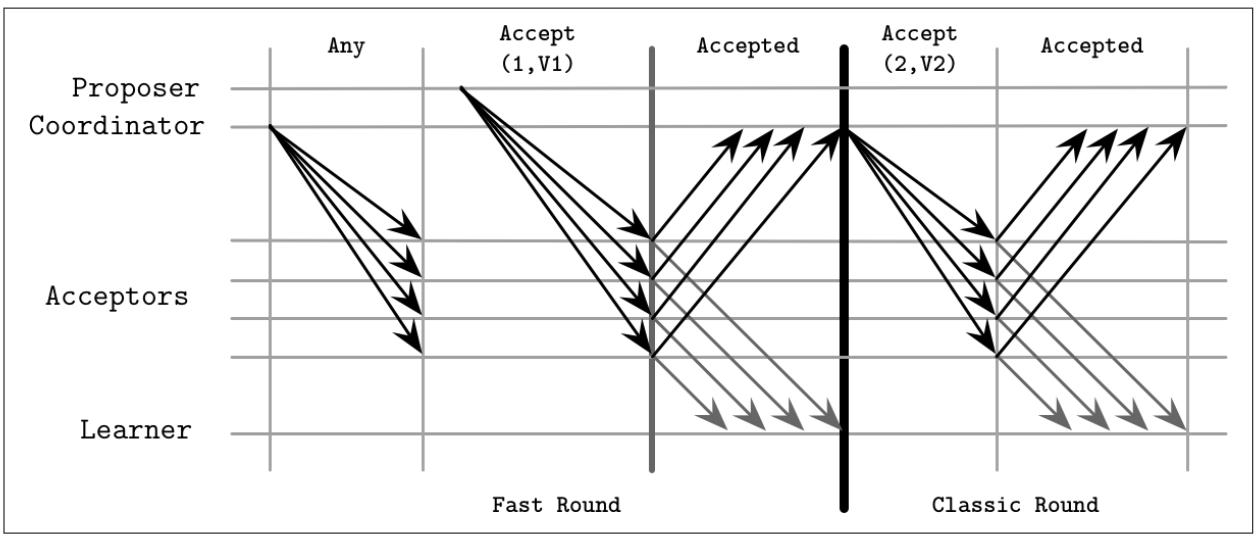
Такой алгоритм предрасположен к столкновениям, которые происходят когда два или более Заявителей пытаются воспользоваться соответствующим быстрым этапом и снизить общее число проходов туда и обратно, а Получатели принимают различные значения. Установленному Координатору приходится вмешиваться и запускать восстановление через инициацию нового раунда.
Это означает, что Получатели, после приёма значений от различных Заявителей, могут принимать решение в пользу конфликтных
значений. Когда установленный Координатор выявляет некий конфликт (коллизию значений), ему необходимо повторно инициировать
некий этап Propose, чтобы позволить Получателям сойтись к какому- то единому
значению.
Одним из недостатков Быстрого Paxos является растущее число проходов в оба конца и задержек запросов при столкновениях при большой скорости запросов. [JUNQUEIRA07] показал, что по причине растущего числа реплик и, в конечном счёте, обмениваемых между участниками сообщений, несмотря на снижение числа этапов, Быстрый Paxos может обладать большими задержками нежели его классический конкурент.
Применяя Высокопоставленного Заявителя в качестве некого Лидера делает систему склонной к отказам: как только такой лидер падает, данной системе приходится выбирать нового до того как она будет способна продолжать последующие шаги. Другая проблема состоит в том, что обладание Лидером может помещать в него непропорциональной нагрузки, ослабляя производительность системы.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Один из способов помещения всей нагрузки системы целиком на установленного Лидера является разбиение на разделы. Многие системы расщепляют весь диапазон возможных значений на меньшие сегменты и допуская для части этой системы выступать ответственной за определённый диапазон и не беспокоиться о прочих частях. Это способствует доступности (изолированием отказов в неком отдельном разделе и предотвращением распространения в прочие части данной системы), производительности (поскольку обслуживающие различные значения сегменты не перекрываются) и масштабированию (ибо мы способны масштабировать данную систему увеличивая общее число разделов). Важно иметь в виду, что производительность некой операции на множестве разделов требует некой атомарной фиксации. |
Вместо применения Лидера и предлагаемых номеров для последовательных команд мы можем пользоваться Лидером для конкретной фиксации этой определённой команды и установления порядка просмотра и установки зависимостей. Такой подход обычно именуется Уравнивающим Paxos (Egalitarian Paxos) или EPaxos [MORARU11]. Основная мысль допуска независимой фиксации не конфликтующих записей в имеющемся реплицируемом конечном автомате впервые была предложена в [LAMPORT05] и носила название Обобщённого Paxos. EPaxos это первая реализация Обобщённого Paxos.
EPaxos делает попытку предложить как преимущества классического алгоритма Paxos, так и Множественного Paxos. Классический Paxos предлагает высокую доступность, так как Лидер устанавливается в каждом раунде, но имеет более высокую сложность сообщений. Множественный Paxos предлагает высокую пропускную способность и требует меньшего числа сообщений, но Лидер способен превращаться в узкое место.
EPaxos запускается фазой Предварительного приёма, в процессе которого некий процесс превращается в Лидера для данной определённой цели. Каждое предложение содержит:
- Зависимости
Все команды, которые потенциально взаимодействуют с текущим предложением, но для них нет необходимости быть уже фиксированными.
- Последовательный номер
Он разбивает циклы между зависимостями. Устанавливает его в значение большее любого последовательного номера известных зависимостей.
После сбора этих сведений, он направляет сообщение Pre-Accept
быстрому кворуму реплик. Быстрый кворум это
⌈3f/4⌉ реплик, где
f это значение числа возможных отказов.
Реплики проверяют свои журналы локальных команд, обновляют зависимости предложения на основании их представления конфликтующих предложений и отправляют такие сведения обратно своему Лидеру. Когда этот Лидер получает отклики от быстрого кворума реплик, а их перечень зависимостей находится в согласии со всеми прочими и самого лидера, он может фиксировать эту команду.
Когда установленный Лидер не получает достаточного числа откликов или если его получаемый от своих реплик список
команд отличен и содержит пересекающиеся команды, он обновляет свои зависимости неким новым перечнем зависимостей
и последовательным номером. Этот новый список зависимостей основывается на отклика предыдущих реплик и сочетает
все собранные зависимости. Установленный новый последовательный номер обязан
быть больше чем самый наивысший наблюдавшийся в репликах последовательный номер. После этого, данный Лидер отправляет
свою новую, изменённую команду в ⌊f/2⌋ + 1 реплик. После осуществления
этого, данный Лидер может окончательно зафиксировать данное предложение.
На самом деле у нас имеются два сценария:
- Быстрый путь
Когда зависимости находятся в соответствии и установленный Лидер способен безопасно продолжать этап фиксации только с репликами быстрого кворума.
- Медленный путь
Когда существуют разногласия между имеющимися репликами и их перечни команд следует обновить прежде чем установленный Лидер будет иметь возможность продолжать фиксацию.
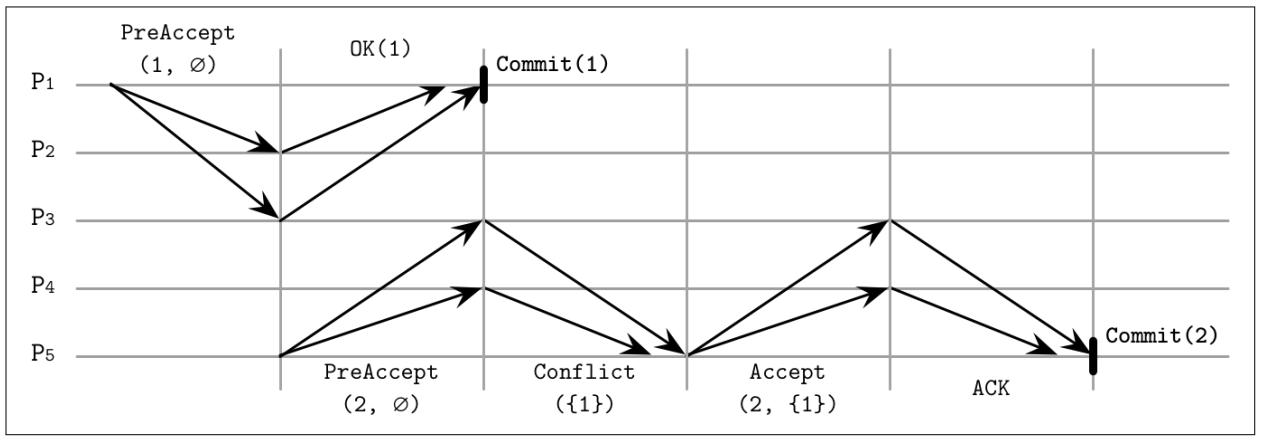
Рисунок 14-8 отображает эти сценарии -
P1 инициирует запуск быстрого пути, а P5
инициирует запуск медленного пути:
-
P1запускается с предложением номер1и без зависимостей и отправляет сообщение.PreAccept(1, ∅). Поскольку журналы командP2иP3пусты,P1может продолжать выполнение фиксации. -
P5создаёт некое предложение с последовательным номером2. Так как его журнал команд на данный момент пуст, он также объявляет отсутствие зависимостей о отправляет сообщениеPreAccept(2, ∅).P4не осведомлён об имеющемся фиксированном предложении1, однакоP3уведомляетP5относительно данного конфликта и отправляет свой журнал команд:{1}. -
P5обновляет свой список локальных зависимостей и отправляет сообщение чтобы убедиться что реплики имеют те же самые зависимости:Accept(2,{1}). Как только соответствующие реплики откликаются, он может фиксировать данное значение.
Две команды, A и B, пересекаются
только если имеет значение их порядок; иначе говоря, когда исполнение A перед
B и выполнение B до
A приводит к различным результатам.
Фиксация выполняется откликом клиенту и асинхронным уведомлением реплик сообщением
Commit. Команды выполняются после
их фиксации.
Так как зависимости собираются в процессе этапа Предварительного приёма, на момент исполнения запросов необходимый порядок команд уже установлен и никакая команда не может внезапно появиться каким- то образом промеж них: она лишь может добавляться в конец после команды, обладающей самым большим последовательным номером.
Для выполнения команды реплики строят некий граф зависимостей и исполняют все команды в порядке, обратном зависимостям. Говоря иначе, прежде чем какая- то команда может быть выполнена, необходимо выполнить все её зависимости (и, затем и все их зависимости). Так как только пересекающиеся команды обязаны зависеть друг от друга, подобная ситуация должна быть достаточно редкой для большей части рабочих нагрузок [MORARU13].
Аналогично Paxos, EPaxos применяет номера предложений, что предотвращает распространение устаревших сообщений. Последовательный номер составляется из некой эпохи (идентификатора конфигурации данного текущего кластера, который изменяется когда узлы покидают этот кластер или присоединяются к нему), монотонно последовательно увеличивающегося счётчика локального узла и некого идентификатора реплики. Когда какая- то реплика получает предложение с последовательным номером ниже уже наблюдавшегося ею, она отвечает отрицательным подтверждением на данное предложение и отправляет в отклике свой наивысший последовательный номер, а также известный ей обновлённый перечень команд.
Некий кворум обычно определяется как большинство процессов. По определению, у нас имеется какое- то пересечение между двумя кворумами, в независимости от того как мы прихватывали узлы: всегда имеется по крайней мере один узел, который способен разорвать связь.
Нам требуется ответить на два важных вопроса:
-
Есть ли необходимость взаимодействовать с большинством серверов на каждом этапе исполнения?
-
Все ли кворумы имеют пересечения? Иначе говоря, должны ли иметь общие узлы используемый нами кворум для выбора Высокопоставленного Заявителя (первый этап), применяемый нами для определения значения кворум (второй этап) и каждый экземпляр исполнения (например, когда одновременно выполняются несколько экземпляров второго этапа)?
Так как мы всё ещё обсуждаем консенсус, мы не можем изменять никакие определения безопасности: наш алгоритм обязан обеспечивать установленные соглашения.
Во Множественном Paxos собственно фаза выбора Лидера не является частой и нашему Высокопоставленному Лидеру
позволено фиксировать различные значения без возврата к соответствующему этапу выборов, потенциально оставаясь
установленным Лидером длительное время. В разделе
Настраиваемая согласованность
мы обсудили формулу, способствующую нам в поиске конфигурации в которой мы обладаем пересечениями между своими
наборами узлов. Одним из примеров было простое ожидание того что один узел подтвердит соответствующую запись (и
позволит имеющимся запросам во всех остальных узлах завершаться асинхронно) и чтение со всех
доступных узлов. Иными словами, пока мы имеем R + W > N, существует
по крайней мере один общий узел между наборами чтения и записи.
Можем ли мы воспользоваться этой же логикой для консенсуса? Оказывается, да, причём в Paxos нам всего лишь требуется чтобы группа узлов из нашего первого этапа (которая выбирает Лидера) перекрывалась с группой второго этапа (участвующей в принятии предложений).
Говоря другими словами, некий кворум не обязательно должен определяться как некое большинство, а всего лишь как
какая- то не пустая группа узлов. Если мы определим общее число участников как N,
N, общее число узлов, требуемых для успешности этапа предложения как
Q1, а общее число узлов для успешности этапа приёма как
Q2, нам всего лишь требуется чтобы
Q1 + .
Так как наш второй этап как правило более распространён чем первый, Q2 > NQ2
может содержать лишь N/2 Получателей, в то время как
Q1 настраивается на соответствующее большее значение
(Q1 = N - Q2 + 1).
Эта находка является важным наблюдением, критически важным для понимания консенсуса. Тот алгоритм, который мы применяем
в данном подходе носит название Гибкого Paxos
[HOWARD16].
Например, когда у нас имеется пять Получателей, до тех пор пока нам требуется для победы в соответствующем раунде выборов собирать голоса от четырёх из них, мы можем позволить установленному Лидеру на соответствующем этапе репликации дожидаться откликов от двух из них. Более того, поскольку существует некое перекрытие между любыми состоящими из двух Получателей подмножествами в нашем кворуме выбора этого Лидера, мы имеем возможность представлять предложения по не пересекающимя наборам Получателей. Интуитивно ясно, что это работает, так как всякий раз, когда новый Лидер избирается без ведома текущего, всегда найдётся по крайней мере один Получатель, которому известно о существовании установленного нового Лидера.
Гибкий Paxos делает возможным компромисс с доступностью в пользу задержек: мы снижаем общее число узлов, участвующих
во втором этапе, но нам приходится собирать больше голосов, что требует большего числа участников доступными на этапе
выборов своего Лидера. Хорошая новость состоит в том, что данная конфигурация может продолжать соответствующий
этап репликации и быть безразличной вплоть до отказа N - Q2 + 1
узлов, пока установленный Лидер стабилен и не требуется новый раунд выборов.
Другим вариантом Paxos, использующим ту же идею пересечения кворумов является Вертикальный Paxos. Вертикальный Paxos делает различия между кворумами чтения и записи. Эти кворумы обязаны пересекаться. Некий Лидер должен собирать кворум меньшего размера чтений для одного или более предложений с меньшими номерами и кворум большего размера записи для своего собственного предложения [LAMPORT09]. [LAMPSON01] также проводит различие между кворумами выдачи и решения, что транслируется в этапы подготовки и принятия и снабжает нас определением кворума, аналогичным Гибкому Paxos.
Paxos порой может оказываться слегка сложным при обсуждении: множество ролей, этапов и сложность отслеживания всех возможных вариантов. Однако мы можем представлять себе его и в более простых выражениях. Вместо того чтобы разделять роли между участниками и получать раунды принятия решений, мы можем пользоваться простым набором понятий и правил для достижения обеспечения единственного решения Paxos. Мы обсудим этот подход лишь вкратце, поскольку это относительно новая разработка [HOWARD19] - его важно знать, однако мы ещё не видели его реализаций и практических применений.
У нас имеется некий клиент и набор серверов. Каждый сервер обладает множеством регистров. некий регистр имеет идентифицирующий его индекс, запись в него может производиться только один раз и он может находиться в трёх состояниях: незаписанном, содержащем некое значение и содержащим nil (особое пустое значение).
Регистры с одним и тем же значением, расположенные в различных серверах образуют некий
набор регистров. Всякий набор регистров может обладать одним или более
кворумами. В зависимости от значения состояния регистров в нём, кворум может быть в одном из состояний
без решения (undecided, Any
и Maybe v), либо с решением
(None и Decided v):
AnyВ зависимости от последующих операций, этот набор кворума может принять решение с любым значением.
Maybe vКогда этот кворум принимает решение, его решением может быть только
v.NoneЭтот кворум не способен принимать решение по конкретному значению.
Decided vДанный кворум принял решение со значением
v.
Соответствующий клиент обменивается сообщениями с имеющимися серверами и поддерживает таблицу состояний, в которой он отслеживает значения и регистры, а также может делать вывод в отношении принятого этими кворумами решения.
Для сопровождения корректности, нам приходится ограничивать то как клиенты способны взаимодействовать с серверами и какие значения они способны записывать, а какие нет. С точки зрения чтения значений, соответствующий клиент может вывести выбранное значение только когда он должен прочитать его из своего кворума серверов в том же самом наборе регистров.
Правила записи слегка сложнее, так как для обеспечения безопасности алгоритма нам необходимо сохранять ряд инвариантов.
Прежде всего, нам требуется быть уверенными что наш клиент не просто предлагает новые значения: ему разрешается записывать
в регистр некое определённое значение только когда он получил его в качестве входных данных или считал его из некого
регистра. Клиенты не способны записывать значения, которые допускают различные кворумы в одном и том же регистре для
принятия решения по различным значениям. И, наконец, клиенты не могут записывать значения, которые отменяют предыдущие
решения, принятые в более ранних наборах регистров (принятые в наборе регистров вплоть до r - 1
решения обязаны быть None, Maybe v или
Decided v.)
Обобщённый алгоритм Paxos
Совмещая эти три правила воедино, мы можем реализовать некий обобщённый алгоритм Paxos, который достигает согласия
относительно некого отдельного значения при помощи регистров с единственной записью
[HOWARD19].
Допустим, у нас имеются три сервера [S0, S1, S2], регистры
[R0, R1, …] и клиенты
[C0, C1, …], причём эти клиенты способны записывать лишь в соответствующие
назначенные подмножества регистров. Для всех регистров мы применяем кворумы простого большинства
({S0, S1}, {S0, S2}, {S1, S2}).
Сам процесс принятия решения в данном случае состоит из двух фаз. Самый первый этап обеспечивает, что он безопасен для записи некого значения в необходимый регистр, а второй записывает это значение в соответствующий регистр:
- В процессе фазы 1
Наш клиент проверяет что тот регистр, в который он намерен выполнить запись не записан через отправку команды
P1A(register)в его сервер. Когда этот регистр не записан, все регистры вплоть доregister - 1установлены в значениеnil, что препятствует клиентам запись в предыдущие регистры. Соответствующий сервер откликается неким набором регистров, записанных до сих пор. Если клиент получает отклики от большинства серверов, он выбирает либо соответствующее значение из полученного регистра с наибольшим индексом, либо своё собственное значение в случае когда нет представленного значения. В противном случае он перезапускает этот первый этап.- В процессе фазы 2
Наш клиент уведомляет все серверы относительно того значения, которое он выбрал на протяжении своего первого этапа, отправляя им
P2A(register, value). Если большинство серверов откликаются на это сообщение, он может выдать своё выбранное значение. В противном случае он вновь начинает с фазы 1.
Рисунок 14-9 отображает обобщённый Paxos
(адаптировано из [HOWARD19]). Клиент
C0 предпринимает попытку фиксации значения V.
В процессе своего первого этапа его таблица состояний пуста, а серверы S0 и
S1 откликаются с пустыми значениями набора регистров, что указывает на то,
что до сих пор не записан ни один из регистров. На протяжении второго этапа он может представить своё значение
V, так как никакое иное значение не было записано.
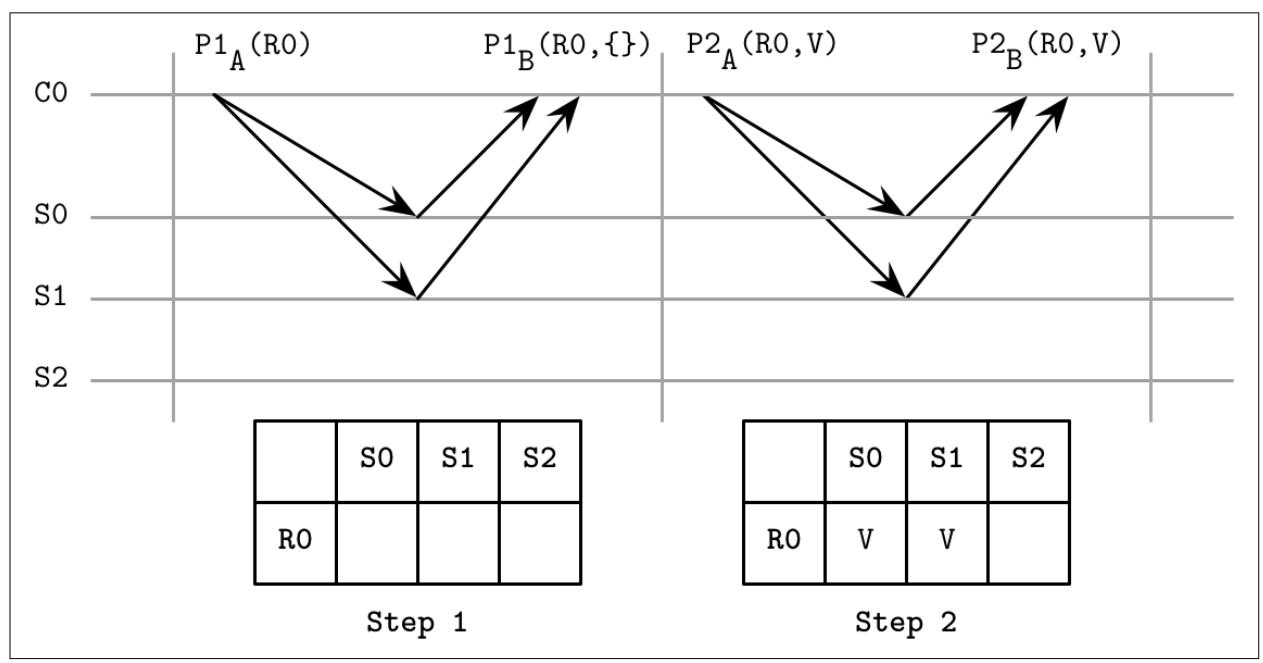
В этот момент, какой- то иной клиент может сделать серверам запрос поиска значения текущего состояния. Кворум
{S0, S1} достиг состояния Decided A, а
кворумы {S0, S2} и {S1, S2} достигли
значения состояния Maybe V для R0, а
потому C1 выбирает значение V.
В этот момент никакой из клиентов не способен принять решения отличного от V.
Данный подход позволяет понять семантику Paxos. Вместо того чтобы представлять себе значение состояния с точки зрения взаимодействия удалённых акторов (то есть Заявителей, обнаруживающих может или нет некий Получатель быть уже принявшим некое иное предложение), мы можем представлять себе его в терминах самого последнего известного состояния, что превращает наш процесс принятия решения в простой и удаляет возможные неопределённости. Также может быть более простой реализация неизменного состояния и передачи сообщений.
Мы также можем провести параллели с оригинальным Paxos. Например, в неком сценарии, в котором наш клиент определяет
что один из имеющихся предыдущих наборов регистров обладает соответствующим решением
Maybe V, он выбирает V и пробует
зафиксировать его снова, что схоже с тем, как некий Заявитель в Paxos может предлагать своё значение после произошедшего
отказа имевшегося ранее Заявителя, и который мог зафиксировать это значение по крайней мере у одного Получателя. Точно так же,
когда конфликты в Лидерах Paxos разрешаются перезапуском данного голосования с большим номером предложения, в нашем обобщённом
алгоритме все незаписанные регистры с низшими рангами установлены в значение
nil.
Paxos был основным алгоритмом консенсуса на протяжении более десяти лет, однако в сообществе распределённых систем он был известен как трудный для обсуждения. В 2013 появился некий новый алгоритм с названием Raft (Плот). Разработавшие его исследователи хотели создать некий алгоритм, который просто понять и реализовать. Впервые он был представлен в статье с названием "В поисках понятного алгоритма консенсуса" [ONGARO14].
В распределённых системах итак имеется достаточно сложностей, а потому наличие более простых алгоритмоы весьма желательно. Наряду со статьёй авторы выпустили некую справочную реализацию с названием LogCabin для устранения возможных неоднозначностей и чтобы помочь последующим разработчикам получить лучшее понимание.
Локально участники хранят журнал, содержащий последовательность команд, выполняемых соответствующим конечным автоматом. Поскольку получаемые процессами входные данные идентичны, а журналы содержат одинаковые команды в одном и том же порядке, применение этих команд к соответствующему конечному автомату обеспечивает одинаковый вывод. Raft упрощает получение консенсуса, создавая понятие Лидирующего первокласного гражданина. Лидер применяется для координации манипуляций и репликаций конечного автомата. Имеется множество сходств между Raft и алгоритмами атомарного широковещания, а также Множественного Paxos: некий обособленный Лидер всплывает из репликаций, принимает атомарные решения и устанавливает порядок сообщений.
Каждый участник Raft может выполнять одну из трёх ролей:
- Кандидат
Лидерство является временным условием и любой участник способен взять на себя эту роль. Чтобы стать Лидером, этому узлу вначале придётся перейти в состояние некого кандидата и попытаться набрать большинство голосов. Когда и не побеждает и не проигрывает на выборах (полученные голоса распределяются между множеством кандидатов и ни один из них не имеет большинства голосов), выдвигается новый срок и выборы запускаются повторно.
- Лидер
Некий текущий, временный Лидер кластера, который обрабатывает запросы клиента и взаимодействует с неким реплицируемым конечным автоматом. Этот лидер выбирается на период, именуемый сроком (term). Всякий срок идентифицируется монотонно приращиваемым числом и может продолжаться некий произвольный период времени. Новый Лидер выбирается в случае крушения текущего, когда он перестаёт отвечать, либо в других процессах имеется ожидание того что он должен отказать, что может происходить по причине разбиения сетевой среды на разделы или задержек сообщений.
- Последователь
Некий пассивный участник, который сохраняет регистрационные записи и откликается на запросы от установленного Лидера и Кандидатов. Последователь в Raft это некая роль аналогичная Получателю и Обучаемому из Paxos. Все процессы начинают с Последователей (Follower).
Чтобы гарантировать глобальное частичное упорядочение без того чтобы полагаться на синхронизацию часов, время подразделяется на сроки (также называемые эпохами), на протяжении которых установленный Лидер является уникальным и стабильным. Сроки монотонно нумеруются и все команды уникально идентифицируются сроком и соответствующим номером сообщения внутри этого срока [HOWARD14].
Может так получиться, что различные участники не пришли к согласию какой из сроков является текущим, поскольку они могли обнаружить соответствующий новый срок в разное время или могли пропустить выборы Лидера для одного из множества сроков. Так как всякое сообщение содержит некий идентификатор срока, когда один из участников обнаруживает что его срок не актуален, он обновляет свой срок на имеющий более высокий номер [ONGARO14]. Это означает, что могут иметься на лету несколько сроков в любой определённый момент времени, однако в случае некого конфликта побеждает тот, у которого более высокий номер. Некий узел обновляет свой срок только когда он запускает новый процесс выборов или обнаруживает что его срок не актуален.
При запуске, или когда Последователь не получает сообщения от своего Лидера и полагает что он потерпел крушение, он запускает процесс выборов необходимого Лидера. Некий участник пробует стать Лидером переходя в состояние Кандидата и собирая голоса от большинства узлов.
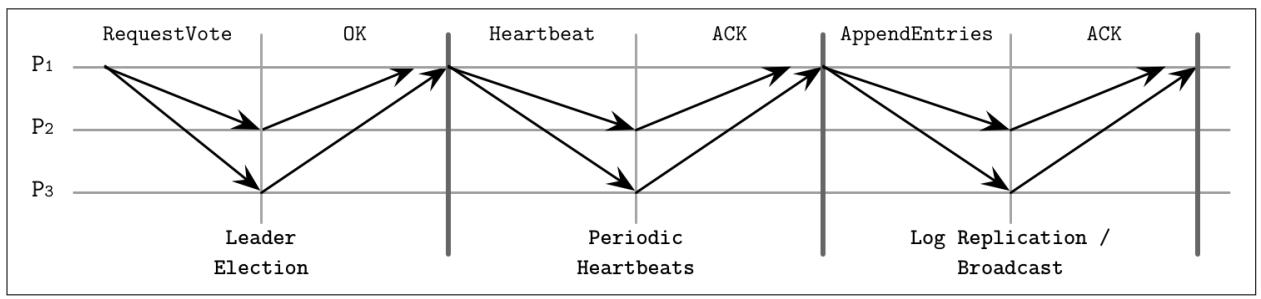
Рисунок 14-10 показывает диаграмму последовательности, представляющую все основные компоненты обсуждаемого алгоритма Raft:
- Выбор Лидера
Кандидат
P1отправляет сообщениеRequestVoteвсем прочим процессам. Это сообщение содержит значение срока кандидата, самый последний известный ему срок и значение идентификатора самой последней наблюдавшейся им регистрационной записи. После сбора большинства голосов этот Кандидат успешно избирается в качестве Лидера на даннй срок. Все процессы отдают свой голос не более чем за одного кандидата.- Периодические сердцебиения
Данный протокол пользуется механизмом сердцебиений для обеспечения необходимой жизнеспособности участников. Сам Лидер периодически отправляет сердцебиения всем Последователям для сопровождения своего срока. Когда Последователь не получает новых сердцебиений на протяжении некого периода, носящего название таймаута выборов, он предполагает что его Лидер отказал и запускает новые выборы.
- Репликация журнала/ широковещание
Установленный Лидер может неоднократно добавлять новые значения в конец своего реплицируемого журнала отправляя сообщения
AppendEntries. Это сообщение содержит значение срока Лидера, индекс и срок той регистрационной записи, которая непосредственно предшествовала той, которую он отправляет в настоящий момент, а также одну или более записей для сохранения.
Некий Лидер может быть выбран только из тех узлов, которые хранят все фиксированные записи: если в процессе данных выборов сведения соответствующего Последователя более актуальны (иначе говоря, имеют более высокий идентификатор срока или более длинную последовательность зарегистрированных записей, когда сроки равны) чем у рассматриваемого Кандидата, его голос отрицательный.
Чтобы победить на выборах, некий Кандидат должен собрать большинство голосов. Записи всегда реплицируются по порядку, поэтому чтобы понять является или нет один из участников актуальным, всегда достаточно сравнивать идентификаторы с самыми последними записями.
Будучи избранным, этот Лидер обязан принимать запросы клиентов (которые также могут передаваться ему с прочих узлов) и реплицировать их своим Последователям. Это осуществляется добавлением в конец его журнала соответствующей записи и её параллельной отправки всем Последователям.
Когда Последователи получают некое сообщение AppendEntries, они добавляют все
записи из этого сообщения в конец своего локального журнала, давая своему Лидеру знать что они приняли их на постоянное
хранение. Как только достаточное число реплик отправило свои подтверждения, данная запись рассматривается фиксированной
и соответствующим образом помечается в журнале установленного Лидера.
Так как Лидером может становиться лишь самый актуальный Кандидат, Последователям никогда не приходится приводить своего Лидера в актуального и регистрационный записи перетекают только от Лидера к Последователю, а не наоборот.
Рисунок 14-11 показывает данный процесс:
-
В конец журнала установленного Лидера добавляется новая команда
x = 8. -
Прежде чем это значение может быть фиксировано, его следует реплицировать в большинство участников.
-
Как только установленный Лидер покончит с репликациями, он фиксирует это значение локально.
-
Решение о данной фиксации реплицируется всем Последователям.
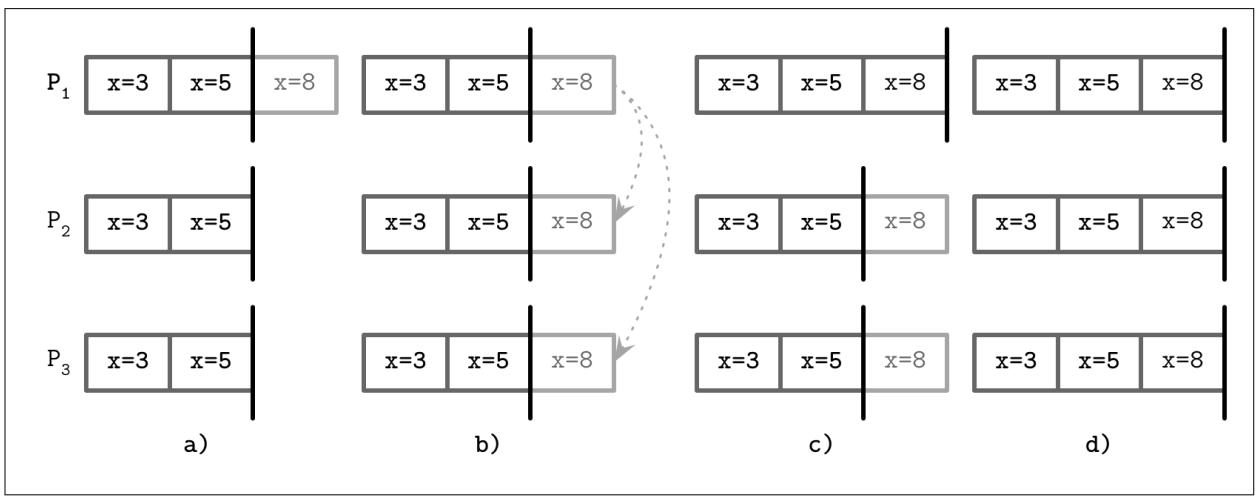
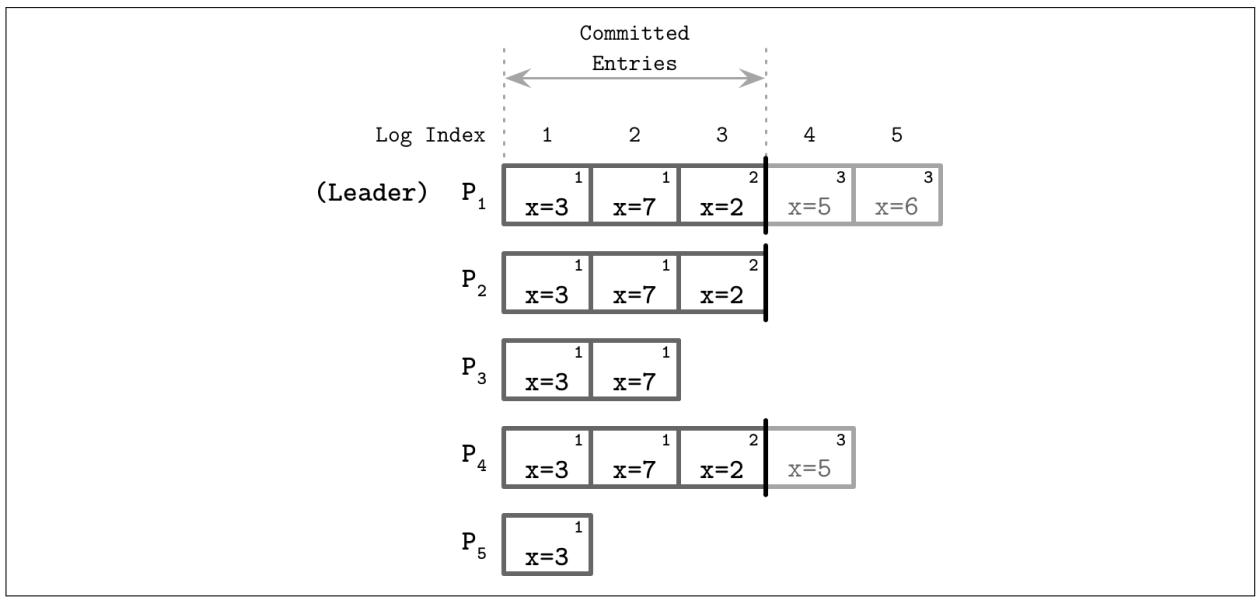
Рисунок 14-12 показывает некий образец раунда консенсуса,
в котором P1 выступает имеющим наиболее последнее представление
событий Лидером. Этот Лидер продолжает реплицирование всех записей своим Последователям и фиксирует их после сбора
подтверждений. Фиксация некой записи также фиксирует все предшествующие ей записи в соответствующем журнале. Только
установленный Лидер способен принимать решение по вопросу будет или нет фиксирована данная запись. Все регистрируемые
записи помечаются идентификатором срока (числом в правом верхнем углу каждого блока регистрационной записи) и неким
индексом регистрации, указывающим его положение в данном журнале. Фиксированные записи гарантированно реплицируются в
установленный кворум участников и безопасно применяются к установленному конечному автомату именно в том порядке, в
котором они возникают в соответствующем журнале.
Когда множество Последователей принимают решение выступить Кандидатами и никакой из Кандидатов не набирает большинства голосов, такая ситуация носит название разделения голосов (split vote). Для снижения значения вероятности множества последовательных выборов, заканчивающихся разделением голосов, Raft применяет выставляемые случайным образом флажки часов. Один из имеющихся Кандидатов может запустить свои следующие выборы раньше и набрать достаточное число голосов, в то время как прочие проспят и предоставят дорогу ему. Такой подход ускоряет подобные выборы без необходимости дополнительно координации между кандидатами.
Последователи могут останавливаться или замедляться с откликом, и установленному Лидеру придётся предпринять всё от него зависящее чтобы обеспечить доставку сообщения. Он может попробовать отправку сообщения снова когда не получает некого подтверждения за ожидаемый по времени срок . В качестве оптимизации производительности, он может отправлять параллельно множество сообщений.
Так как реплицируемые установленным Лидером сообщения идентифицируются уникально, повторная доставка сообщений гарантированно не нарушает порядок соответствующего журнала. Последователи выполняют дедупликацию сообщений пользуясь их последовательными идентификаторами и обеспечивая отсутствие сторонних эффектов со стороны дублированных доставок.
Последовательные идентификаторы также применяются для обеспечения необходимого упорядочения в журнале. Некий Последователь отвергает запись с более высоким номером когда значение идентификатора и срока той отправленной установленным Лидером записи, которая непосредственно ей предшествовала, не соответствует значению наивысшей записи в его собственных записях. Когда записи в двух журналах различных реплик обладают одним и тем же сроком и одним и тем же индексом, они хранят те же самые команды и все те же самые предшествующие им записи.
Raft гарантирует, что никогда не будет отображаться никакое не зафиксированное сообщение в качестве фиксированного, но, по причине замедления сетевой среды или репликации, уже зафиксированные сообщения могут всё ещё рассматриваться как пребывающие в процессе выполнения, что является достаточно безопасным качеством, причём его можно обойти, повторяя команду клиента до её окончательной фиксации [HOWARD14].
Для выявления отказов установленный Лидер обязан отправлять своим Последователям сердцебиения. Таким образом установленный Лидер поддерживает свой срок. Когда один из узлов замечает что его текущий Лидер остановился, он пытается инициировать новые выборы. Вновь установленному Лидеру приходится восстанавливать значение состояния своего кластера до самой последней известной актуальной записи журнала. Это осуществляется через поиск общей земли (common ground, самой наивысшей записи, по которой имеют согласие и этот Лидер и Последователь) и ориентирует Последователей отвергать все (не зафиксированные) записи, добавляемые в конец с этого момента. Затем он отправляет самые последние записи из своего журнала, перезаписывая историю своих Последователей. Собственные записи журнала установленного Лидера никогда не удаляются и не перезаписываются: он имеет возможность только добавлять записи в конец своего журнала.
Итого наш алгоритм Raft предоставляет следующие гарантии:
-
За раз для заданного срока может выбираться лишь один Лидер; никакие два Лидера не могут быть активными на протяжении одного и того же срока.
-
Установленный лидер не имеет возможности удалять содержимое в своём журнале или изменять его порядок; он способен только добавлять в его конец новые записи.
-
Фиксированные записи регистрации гарантированно присутствуют в журналах для последующих Лидеров и не могут отыгрываться обратно, так как до того как данная запись зафиксирована, известно что она реплицирована установленным Лидером.
-
Все сообщения уникально идентифицируются идентификаторами сообщения и срока; ни текущие, ни последующие Лидеры не могут повторно применять один и тот же идентификатор для иной записи.
С момента своего появления Raft превратился в очень популярный и в настоящее время применяется во множестве баз данных и прочих распределённых систем, включая CockroachDB, Etcd и Consul. Это можно связать с его простотой, но также может означать и то, что Raft оправдывает ожидания стать надёжным алгоритмом консенсуса.
Все обсуждавшиеся нами до сих пор алгоритмы консенсуса предполагали отказы не- Византийскими (см. раздел Произвольные отказы). Иначе говоря, узлы исполняют свои алгоритмы "добропорядочно" и не пытаются применять их в своих целях или выдумывать свои результаты.
Как мы обнаружим, это предположение позволяет достигать согласия с меньшим числом участников и за меньшее число проходов туда и обратно для некой фиксации. Тем не менее, распределённые системы порой реализуются в потенциально соперничающих средах, когда имеющиеся узлы не контролируются одним и тем же логическим элементом и нам требуются алгоритмы, которые способны обеспечить правильную работу системы даже когда некоторые узлы ведут себя состязательно или даже злонамеренно. Помимо дурных намерений, Византийские отказы могут также вызываться ошибками, неверной настройкой, проблемами с оборудованием или разрушением данных.
Большинство алгоритмов Византийского консенсуса требует N2 сообщений
для выполнения некого этапа алгоритма, где N это размер необходимого кворума,
так как каждому узлу в этом кворуме требуется взаимодействовать друг с другом. Это необходимо для перекрёстного
подтверждения на каждом этапе от прочих узлов, так как узлы не могут полагаться друг на друга или на установленного
Лидера и им приходится проверять поведение прочих узлов сопоставляя возвращаемые результаты с получаемым большинством
откликов.
Мы обсудим здесь только один алгоритм Византийского консенсуса, Практическую Задачу Византийских генералов (pBFT, Practical Byzantine Fault Tolerance). [CASTRO99]. pBFT предполагает независимость отказов узлов (т.е. отказы не скоординированы, но вся система целиком не может быть захвачена одномоментно или, по крайней мере, одним и тем же применяемым методом). Такая система делает слабые предположения о синхронизации, например, что вы можете ожидать в качестве обычного поведения сетевой среды: сбои могут появляться, но они не являются неопределённо долгими и в конечном счёте восстанавливаются.
Все взаимодействия между имеющимися узлами шифруются, что препятствует подделке сообщений и сетевым атакам. Репликам известны прочие общедоступные ключи для проверки идентичности и расшифровки сообщений. Отказавшие узлы способны сливать сведения изнутри общей системы, так как даже несмотря на использование шифрации, всем узлам требуется интерпретировать содержимое сообщений для реакции на них. Это не подрывает сам алгоритм, ибо он служит иной цели.
Для того чтобы pBFT обеспечивал как безопасность, так и живучесть, отказавшими может быть не более
(n - 1)/3 реплик (где n это
общее число участников). Для того чтобы система переносила f
скомпрометированных узлов, ей требуется иметь по крайней мере n = 3f + 1 узлов.
Это именно так, ибо большинству узлов необходимо прийти к согласию по данному значению: может оказать
f реплик и может иметься f реплик,
которые не отвечают, но могут не являться отказавшими (например, по причине сетевого разделения, отказа питания или
сопроводительных работ). Данный алгоритм должен быть способным собирать достаточное число откликов от не отказавших,
но всё ещё численно превосходящих отказавшие.
Свойства консенсуса pBFT аналогичны свойствам прочих алгоритмов консенсуса: все не отказавшие реплики обязаны согласовывать как сам набор полученных значений, так и их порядок, причём несмотря на возможные отказы.
Для различения конфигураций кластера pBFT применяет представления (view).
В каждом представлении одна из реплик выступает первичной, а все остальные
рассматриваются как резервные копии. Все узлы последовательно нумеруются и
значением индекса первичного узла выступает v mod N, где
v это значение идентификатора представления, а
N это общее число узлов в данной текущей конфигурации. Данное представление
может измениться в случаях падения своего первичного. Клиенты выполняют свои операции для установленного
первичного. Этот первичный осуществляет широковещание соответствующих запросов резервным копиям, которые исполняют
такие запросы и отправляют некий отклик обратно своему клиенту. Соответствующий клиент дожидается отклика от
f + 1 реплик с одним и тем же результатом
для успеха каждой операции.
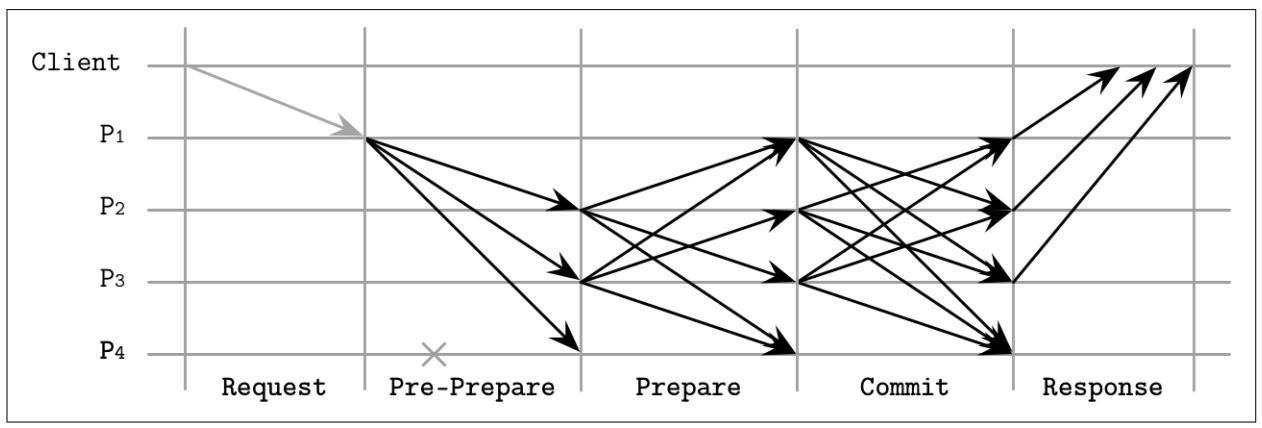
После того как первичный узел получает некий запрос клиента, протокол исполнения следует трём фазам:
- Предварительная подготовка
Установленный первичный узел широковещательно отправляет сообщения, содержащие некий идентификатор представления, уникального и монотонно растущего, некую полезную нагрузку (запрос клиента) и свёртку (digest) полезной нагрузки. Свёртка вычисляется при помощи сильной устойчивой к конфликтам функции хэширования и подписываются этим отправителем. Соответствующая резервная копия принимает данное сообщение когда его представление совпадает с представлением первичного и сам запрос клиента не был испорчен: вычисленная свёртка полезной нагрузки совпадает с полученной.
- Подготовка
Если резервная копия получила сообщение предварительной подготовки, оно вступает на этап подготовки и запускает широковещательные сообщения
Prepare, содержащие идентификатор представления, идентификатор сообщения и свёртку полезной нагрузки, но без самой полезной нагрузки, во все прочие реплики (включая и саму первичную). Реплики могут выходить из этого состояния Подготовки только когда получили2fPrepareот различных резервных копий, которые совпадают с сообщением, полученным на этапе Предварительной подготовки: они обязаны иметь то же самое представление, тот же самый идентификатор и ту же самую свёртку.- Фиксация
После этого соответствующая резервная копия перемещается на этап Фиксации, на котором она широковещательно распространяет сообщения
Commitвсем прочим репликам и дожидается сбора2f + 1совпадающих сообщенийCommit(возможно, включающих и её собственное) от прочих участников.
Некая свёртка в данном случае применяется для снижения размера отправляемого на этапе подготовки сообщения, так как нет необходимости повторной широковещательной отправки полезной нагрузки целиком для её проверки, поскольку именно свёртка обслуживает резюме полезной нагрузки. Криптографические функции хэширования устойчивы к конфликтам: сложно произвести два значения, которые обладают одной и той же свёрткой, не говоря уж о двух сообщениях с совпадающими свёртками, которые имеют значение в контексте данной системы. Кроме того, свёртки подписываются для уверенности того, что эта свёртка сама по себе пришла от доверенного источника.
Значение числа 2f является важным, так как этому алгоритму требуется убедиться
что клиенту запроса откликнулось по крайней мере f + 1 реплик.
Рисунок 14-13 показывает схему последовательности раунда
алгоритма pBFT для обычного случая: рассматриваемый клиент отправляет запрос в P1
а узлы перемещаются по этапам собирая достаточное число совпадающих откликов от ведущих
себя как положено одноранговых партнёров. P4 может
оказаться отказавшим или может откликаться несовпадающими сообщениями, поэтому его отклики не будут приниматься в
расчёт.
На протяжении необходимых этапов подготовки и фиксации узлы взаимодействуют посредством отправки сообщений друг другу и ожидания сообщений от соответствующего числа прочих узлов чтобы проверить их совпадение и убедиться что неверные сообщения не распространяются широковещательно. Одноранговые партнёры взаимно проверяют все сообщения с тем чтобы только не отказавшие узлы имели возможность фиксации сообщений. Когда невозможно собрать достаточное число совпадающих сообщений, этот узле не способен перейти на следующий этап.
После того как реплики собрали достаточное число фиксированных сообщений, они уведомляют своего клиента, завершая этот
раунд. Их клиент не может быть уверен относительно полностью корректного исполнения пока он не получит
f + 1 совпадающих откликов.
Изменения представления происходят когда реплики замечают, что их первичная является не активной и они полагают что
оно могла отказать. Обнаружившие отказ первичной реплики узлы перестают откликаться на последующие сообщения (кроме
контрольной точки и тех что связаны с изменением представления), широковещательно транслируют уведомление об изменении
представления и дожидаются подтверждений. Когда устанавливаемая новым представлением первичная реплика получает
2f событий изменения представления, она инициирует новое представление.
Для снижения общего числа сообщений в данном протоколе клиент может собирать 2f + 1
совпадающих откликов от узлов, которые в предварительном порядке выполняют
какой- то запрос (т.е. после того как они собрали достаточное число совпадающих сообщений
Prepared). Когда клиент не способен собрать достаточного числа совпадающих
предварительных откликов, он повторяет попытку и дожидается f + 1
откликов без предварительного порядка, как это описывалось ранее.
Требующие только чтения операции в pBFT могут выполняться только проходом в одну сторону. Соответствующий клиент
отправляет некий запрос во все реплики. Реплики выполняют этот запрос в своих состояниях предварительного порядка, затем
фиксируются все получаемые на выходе состояния и отправляется отклик клиенту. После сбора 2f + 1
откликов с одним и тем же значением от различных реплик данная операция завершается.
Реплики сохраняют принимаемые сообщения в неком стабильном журнале. Все сообщения должны сохраняться пока они не
выполнятся по крайней мере f + 1 узлами. Данный журнал может применяться для
ускорения прочих реплик в случае разбиения сети на разделы, однако восстановленным репликам требуется некое средство
проверки того что полученное ими состояние правильное, так как в противном случае восстановление может применяться как
некое направление атаки.
Чтобы продемонстрировать верность данного состояния узел вычисляет свёртку значения состояния сообщений вплоть до данного последовательного номера. Узлы могут сопоставлять свёртки, проверять целостность состояния и убедиться в том, что принятые ими на протяжении добавления восстановления сообщения дошли до верного окончательного состояния. Этот процесс также слишком затратен для его выполнения во всех запросах.
После каждых N запросов, где N это
настраиваемая постоянная, установленная первичная реплика выполняет стабильную
контрольную точку, в которой она широковещательно отправляет все последовательные номера самых последних
запросов, исполнение которых отражается в данном состоянии и значение свёртки данного состояния. Затем она дожидается
2f + 1 отклик в ответ. Эти ответы служат доказательством для данной контрольной
точки и гарантией того, что реплики могут быть безопасно отбрасывать для данного порядкового номера состояние для
всех сообщений предварительной подготовки, подготовки, фиксации и контрольной точки.
Отказоустойчивость к Византийским отказам (Byzantine fault tolerance, BFT, Задача Византийских генералов) существенна для понимания и применения систем хранения в потенциально состязательных сетевых средах. В большинстве случаев для этого достаточно для аутентификации и шифрования межузлового взаимодействия, однако когда нет доверительных отношений между установленными частями общей системы, необходимо пользоваться аналогичными pBFT алгоритмами.
Поскольку устойчивые к Византийским отказам алгоритмы выставляют значительные накладные расходы на количество сообщений при обмене, важно понимать их варианты использования. Прочие протоколы, такие как [BAUDET19] и [BUCHMAN18] пытаются оптимизировать алгоритм pBFT для систем с большим числом участников.
Алгоритмы консенсуса являются одним из самых интересных, но в то же самое время самым сложным предметом в распределённых системах. На протяжении последних лет появились новые алгоритмы и множество реализаций имеющихся алгоритмов, что доказывает растущую важность и популярность данного предмета.
В этой главе мы обсудили классический алгоритм Paxos и ряд вариантов Paxos, каждый из которых улучшает его различные свойства:
- Multi-Paxos
Позволяет Заявителю удерживать свою роль и реплицировать множество значения вместо только одного.
- Быстрый Paxos
Делает возможным снижение числа сообщений применяя быстрые раунды когда Получатели могут продолжать обмен сообщениями с Заявителем, отличающимся от установленного им Лидера.
- ЕPaxos
Устанавливает порядок событий, разрешая зависимости между представляемыми сообщениями.
- Гибкий Paxos
Ослабляет требования кворума и запрашивает лишь пересечения кворума своего первого этапа (голосования) с кворумом для своего второго этапа (репликации).
Raft упрощает выражения в которых описвается консенсус и создаёт руководство высококлассного гражданина в своём алгоритме. Raft разделяет репликацию журнала, выбор Лидера и безопасность.
Для обеспечения безопасного консенсуса в состязательных средах следует пользоваться устойчивыми к Византийским отказам алгоритмами; например, pBFT. В pBFT участники перекрёстно проверяют прочие отклики и продолжают исполнение только когда существует достаточное число узлов, которые подчинены предварительно описанным правилам алгоритма.
|
| Последующее чтение |
|---|---|
|
Если вы желаете узнать больше относительно упоминавшихся в этой главе понятий, вы можете ссылаться на следующие источники:
|
Производительность и масштабируемость являются важными качествами любой системы баз данных. Механизм хранения и локальный для узла путь чтения- записи способны оказывать большее воздействие на производительность рассматриваемой системы: насколько быстро она способна обрабатывать запросы локально. В то же самое время, некая ответственная за взаимодействие в общем кластере система часто обладает большим воздействием на величину масштабирования рассматриваемой системы баз данных? максимальный размер кластера и ёмкость. Тем не менее, определённый механизм хранения может применяться только в ограниченном числе вариантов применения когда он не масштабируем, а его производительность деградирует по мере роста набора данных. Вместе с тем, размещение поверх самого быстрого механизма хранения некого медленного протокола фиксации не даст хороших результатов.
Распределённые, применяемые по всему кластеру и локальные для узла процессы взаимосвязаны и их следует рассматривать как целое. при проектировании некой системы баз данных вы обязаны принимать во внимание то, как различные подсистемы подходят друг к другу и работают сообща.
Часть II начинается с обсуждения того чем распределённые системы отличаются от приложений для одного узла и какие трудности можно ожидать в подобных средах.
Мы обсудим все основные строительные блоки базовай распределённой системы, различные согласованные моделей, а также различные важные классы распределённых алгоритмов, причём некоторые из них могут применяться для реализации таких непротиворечивых моделей:
- Выявление отказов
Точно и действенно определяет отказы удалённых процессов.
- Выбор лидера
Быстро и надёжно выбирает единственный процесс для временного обслуживания в роли координатора.
- Рассеяние
Надёжно распространяет сведения при помощи однорангового взаимодействия.
- Анти- энтропия
Выявляет и восстанавливает состояние расхождения между имеющимися узлами.
- Распределённые транзакции
Атомарно выполняет последовательности операций для множества разделов.
- Консенсус
Достигает некого согласия между удалёнными участниками, оставаясь безразличным к отказу процессов.
Данные алгоритмы используются во многих системах баз данных, очередях сообщений, планировщиках и прочем важном инфраструктурном программном обеспечении. Применяя полученные в этой книге знания, вы будете способны лучше осознавать как оно работает, что, в свою очередь, поспособствует принятию лучших решений относительно того какое именно программное обеспечение применять и как выявлять потенциальные проблемы.
|
| Последующее чтение |
|---|---|
|
В самом конце каждой главы вы можете найти относящиеся к представленным в этой главе материалам. Здесь вы можете найти книги, к которым вы можете обращаться для последующего обучения, охватывающие как упомянутые в нашей книге понятия, так и прочие концепции. Этот перечень не подразумевает завершённость, однако эти источники содержат многие важные и полезные сведения, существенные для энтузиастов систем баз данных, часть из которых охвачена и в этой книге:
|