Часть 2. Распределённые системы
Распределённая система это такая штука, в которой отказ компьютера, о существовании которого вы даже не знаете, может привести ваш собственный компьютер в недоступное состояние.
- Лесли Лампорт
Без распределённых систем мы не были бы способны делать телефонные звонки, переводить деньги или обмениваться сведениями на больших расстояниях. Мы ежедневно пользуемся распределёнными системами. Порой даже не имея представления о них: любое приложение клиент/ сервер является распределённой системой.
Для многих современных систем вертикальное масштабирование (масштабирование за счёт запуска того же самого программного обеспечения на большей, более быстрой машине с большим числом ЦПУ, ОЗУ или быстрых дисков) не жизнеспособно. Большие машины более дороги, их сложнее менять, а многие требуют особого сопровождения. Некой альтернативой является горизонтальное масштабирование: запуск программного обеспечения на множестве машин, соединённых через их сетевую среду и работающих как единая логическая сущность.
Распределённые системы могут различаться как в размерах, начиная с нескольких штук до сотен машин, так и по характеристикам их участников, от малых наладонных или сенсорных устройств до высокопроизводительных компьютеров.
Те времена, когда системы баз данных в основном запускались на отдельном узле давно ушли, и большинство современных баз данных имеют множество соединённых в кластер узлов для роста ёмкости хранения, улучшения производительности и расширения доступности.
Даже хотя некоторые из основных теоретических прорывов в распределённых вычислениях и не новы, большинство их практических приложений проявились относительно недавно.В наши дни мы наблюдаем растущий интерес к данному предмету, выполняется больше исследований и новых разработок.
В распределённой системе у нас имеются участники (порой носящими название процессов, узлов или реплик). Каждый участник обладает своим собственным состоянием. Участники взаимодействуют обменом сообщений, применяя соединения между ними.
Процессы могут получать доступ ко времени при помощи часов, которые могут быть логическими или физическими. Логические часы реализуются при помощи некого вида монотонно растущих счётчиков. Физические часы, также носящие название ходиков (wall clock) ограничены представлением времени физического мира и доступ к ним осуществляется через средства локального процесса; например, через некую операционную систему.
Важно обсуждать распределённые системы без упоминания присущих им внутренним сложностям, вызываемых тем фактом, что их части расположены по отдельности друг от друга. Удалённые процессы взаимодействуют через соединения, которые могут быть медленными или ненадёжными, что делает знание о точном состоянии удалённого процесса более сложным.
Большинство исследований на полях распределённых систем связано с тем фактом, что ничто полностью не надёжно: каналы взаимодействия могут иметь задержки, выполняться повторно, либо выдавать отказы в доставке сообщений; процессы способны делать паузу, останавливаться, испытывать крушение, выходить из под контроля или внезапно переставать отвечать.
Существует множество тем общих с областями одновременного и распределённого программирования, так как ЦПУ являются крошечными распределёнными системами со связями, процессорами и протоколами взаимодействия. Вы обнаружите множество параллелей с одновременным программированием в разделе Модели согласованности. Однако большинство примитивов не могут применяться напрямую по причине стоимости взаимодействия между удалёнными частями и ненадёжностью соединений и процессов.
Для преодоления трудностей распределённой среды нам требуется применять особый класс алгоритмов, распределённых алгоритмов, которые обладают представлениями о локальном и удалённом состоянии, а также исполняются и работают вне зависимости от ненадёжности сетевых сред и отказов компонентов. Мы описываем алгоритмы в терминах состояния или шага (либо фазы) с переходами между ними. Всякий исполняющий локально шаги алгоритма процесс, а также сочетание локальных исполнений и взаимодействия процессов составляют некий распределённый алгоритм.
Распределённые алгоритмы описывают имеющееся локальное поведение и взаимодействие множества независимых узлов. Узлы взаимодействуют друг с другом отправкой сообщений. Алгоритмы определяют роли участников, обмен сообщениями, состояния, переходы, шаги исполнения, свойства самой доставляемой среды, предположения о временах, модели отказов, а также прочие характеристики, описывающие процессы и их взаимодействия.
Распределённые алгоритмы обслуживают множество различных целей:
- Координация
Некий процесс, который наблюдает за происходящими действиями и поведением обособленных исполнителей.
- Кооперация
Множество участников полагаются друг на друга для завершения своих задач.
- Рассеяние
Процессы кооперируют в быстром и надёжном распространении необходимых сведений для всех заинтересованных сторон.
- Консенсус
достижение согласия между множеством процессов.
В этой книге мы обсуждаем алгоритмы в самом контексте их применения и предпочитаем некий практический подход над чисто академическими материалами. Прежде всего, мы рассматриваем все необходимые абстракции, сам процесс и имеющиеся соединения между ними, а также развитие в построении более сложных шаблонов взаимодействия. Мы начинаем с UDP, при котором отправитель не имеет никаких гарантий в том, достигнет или нет его сообщение своего получателя; и наконец, достижения консенсуса, при котором множество процессов согласны с неким значением.
Глава 8. Введение и обзор
Содержание
Что делает распределённые системы внутренне отличающимися от систем с единственным узлом? Давайте рассмотрим некий простой пример и попытаемся увидеть. В некой программе единственного узла мы определяем переменные и сам процесс исполнения (некий набор шагов).
Допустим, мы можем задать некую переменную и выполнить с ней простые арифметические операции:
int i = 1;
i += 2;
i *= 2;
У нас имеется единственная история исполнения: мы определили некую переменную, увеличили её на два, затем умножили её
на два и получили соответствующий результат: 6. Давайте допустим, что
вместо наличия одного потока исполнения этих операций, у нас имеются два потока, которые должны иметь доступ на чтение
и запись к переменной x.
Как только двум потокам исполнения дозволено выполнять доступ к имеющейся переменной, точный выход имеющегося одновременного пошагового исполенения непредсказуем, пока эти шаги не синхронизованны между данными потоками. Вместо единственного возможного вывода мы приходим к четырём, что отображает Рисунок 8-1 (Перекрытие, при котором наш умножитель выполняет считывпие перед сумматором, опущено для краткости, так как оно приводит к тому же результату что и a)).
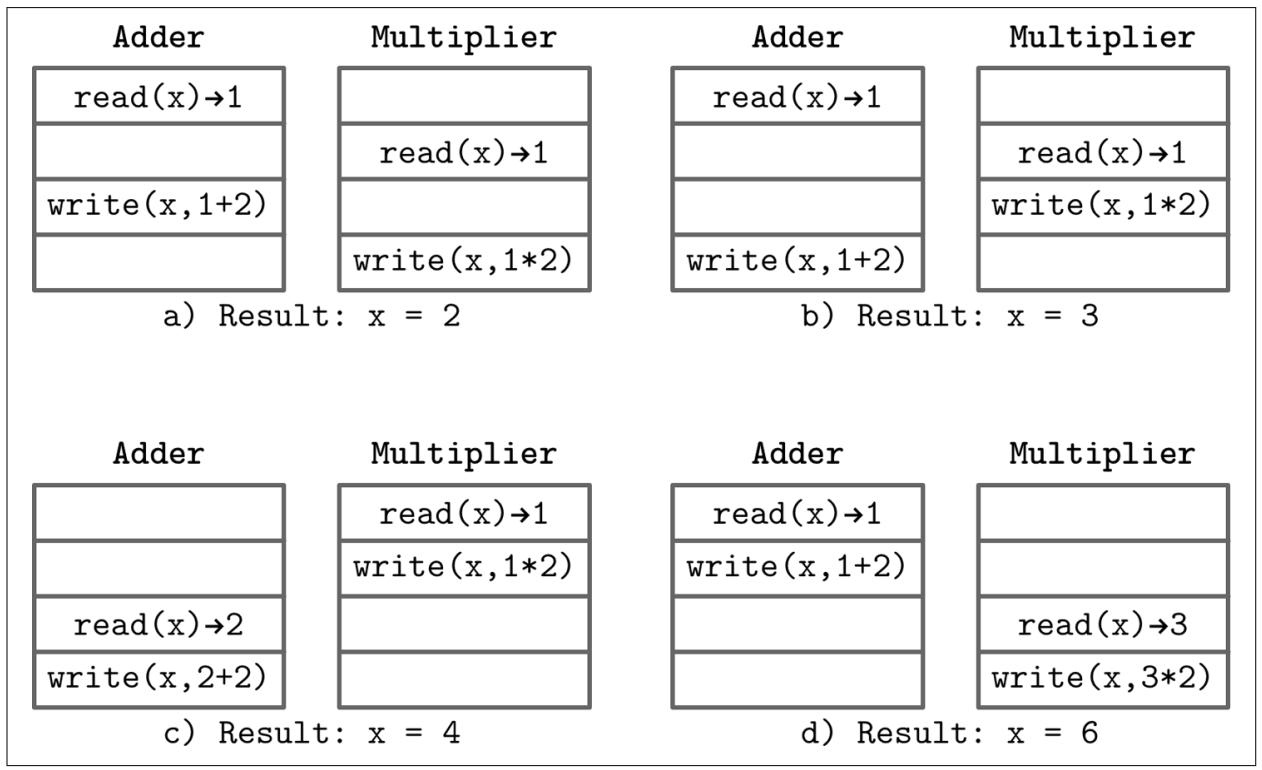
-
x = 2, если оба потока считали некое начальное значение, сумматор записал своё значение, но его переписал результат умножения. -
x = 3, если оба потока считали некое начальное значение, умножитель записал своё значение, но его переписал результат сложения. -
x = 4, если умножитель может считать имеющееся начальное значение и выполнить свою операцию, причём прежде чем начнёт сумматор. -
x = 6, если сумматор может считать имеющееся начальное значение и выполнить свою операцию, причём прежде чем начнёт умножитель.
Даже до того как мы пересечём границу отдельного узла, мы сталкиваемся с первой проблемой в распределённых системах: одновременностью. Всякая одновременно выполняемая программа обладает свойствами распределённой системы. Потоки выполняют доступ к разделяемому состоянию, выполняют некую операцию локально и распространяют свой результат обратно в совместно используемые переменные.
Для точного определения историй и снижения числа возможных выдач, нам требуются непротиворечивые модели. Согласованные (непротиворечивые) модели описывают одновременные исполнения и устанавливают некий порядок, в котором могут исполняться и становиться видимыми для всех участников операции. Применяя различные непротиворечивые модели, мы можем ограничивать или ослаблять общее число состояний, в котором способна пребывать наша система.
Существует множество перекрытий в терминологии и исследованиях в имеющихся областях распределённых систем и одновременных вычислений, но также имеются и некие отличия. В некой одновременной системе мы можем обладать разделяемой памятью, которую могут использовать процессоры для обмена своими сведениями. В некой распределённой системе каждый процессор обладает своим собственным состоянием, а участники взаимодействуют обменом сообщений.
![[Замечание]](/common/images/admon/note.png) | Одновременное и параллельное |
|---|---|
|
Мы часто взаимозаменяемо применяем вычислительные термины одновременно и параллельно, однако эти понятия обладают небольшим семантическим отличием. Когда две последовательности шагов выполняются одновременно, обе они пребывают в своём развитии, но только одна из них выполняется в некий момент времени. Когда две последовательности выполняются параллельно, их шаги выполняются совместно. Одновременные операции перекрываются по времени, в то время как параллельные операции исполняются на множестве процессоров [WEIKUM01]. Джо Армстронг, создательязыка программирвоания Эрланг, даёт некий пример: одновременное исполнение это как наличие двух очередей к одной кофе- машине, в то время как параллельное исполнение подобно двум очередям к двум кофе- машинам. Несмотря на это, огромное большинство источников применяют термин одновременности для описания отдельных параллельно исполняющихся потоков, а сам термин параллельности применяется редко. |
Мы можем попытаться ввести некое понятие разделяемой памяти в распределённой системе, например, для отдельного источника сведений, такого как база данных. Даже если мы решим основные проблемы с одновременным доступом к ним, мы всё ещё не сможем гарантировать что все процессы синхронны.
Для доступа к этой базе данных, процессам придётся следовать через установленную среду взаимодействия отправкой и получением сообщений для запросов или изменения имеющегося состояния. Тем не менее, что произойдёт если если один из процессов не поличит некого отклика от этой базы данных за продолжительное время? Чтобы ответить на этот вопрос, мы должны вначале определить что в точности означает продолжительно. Для этого наша система должна описываться в терминах синхронности: будет ли наше взаимодействие полностью асинхронным, или же будут некие предположнения относительно времени. Такие предположения о времени позволяют нам вводить операции таймаутов и повторов.
Мы не знаем, не может ли база данных по причине своей перегруженности, недоступности или медленности, или же по причине сетевых проблем на пути к ней. Это описывает некая природа крушения: процессы могут испытывать крушение путём отказа в дальнейшем участии в шагах алгоритма, иметь временный отказ, или пропустить некоторые из своих сообщений. Нам необходимо определить какую- то модель отказа и описать способы, коими способны происходить отказы прежде чем мы решим как их трактовать.
Некое свойство, которое описывет надёжность системы и то, способна или нет она продолжать правильно работать в присутствии отказов носит название отказоустойчивости (fault tolerance). Отказы неизбежны, поэтому нам необходимо строить системы с надёжными компонентами и исключать некую единую точку отказа в том виде, как уже упоминавшаяся ранее база данных с единственным узлом, может стать самым первым шагом в этом направлении. Мы можем делать это вводя некую избыточность и добавляя какую- то резервную копию базы данных. Однако теперь мы сталкиваемся с другой проблемой: как нам сохранять множество копий разделяемого состояния в процессе синхронизации?
До сих пор попытки введения некого разделяемого состояния для нашей простой системы оставляли нам больше вопросов чем ответов. Теперь мы знаем, что разделяемое состояние это не так просто как всего лишь ввести некую базу данных и получить некий более гранулированный подход, а также описыватьвзаимодействие в терминах независимых процессов и передачи сообщений между ними.
В некой идеальной ситуации при общении через сеть двух компьютеров всё работает просто идеально: некий процесс открывает соединение, отправляет необходимые данные, получает отклики и все счастливы. Предположение что операции всегда успешны и ничто не может пойти плохо опасно, так как когда что- то ломается и наше предположение становится ошибочным, система ведёт себя спосбами, которые трудно или невозможно предсказать.
В большинстве случаев предположение что сетевая среда надёжна имеет
под собой основание. Она обязана быть надёжной по крайней мере до определённой степени чтобы быть полезной.
Все мы пребывали в ситуации, когда мы пытаемся установить некое соединение со своим удалёным сервером и получаем
вместо этого сообщение Network is Unreachable. Однако даже когда имеется
возможность установления соединения, некое успешное начальное соединение со
свои сервером не гарантирует что это соединение стабильно и что это соединение не прервётся в любой момент времени.
Наше сообшение может достичь удалённой части, однако его отклик может быть утрачен, или же данное соединение было
прервано до того как доставлен такой отклик.
Сетевые коммутаторы ломаются, кабели отсоединяются, а нстройки сетевой среды могут измениться в любой момент времени. Нам следует строить свою систему с деликатной обработкой всех этих ситуаций.
Некое соединение может быть стабильным, но мы не можем ожидать что удалённые вызовы будут столь же быстрыми, что и локальные. Нам следует сделать некие допущения относительно возможных задержек и никогда не предполагать что латентность нулевая. Чтобы наше сообщение достигло некого удалённого сервера, ему придётся пройти несколько программных уровней, а также физическую среду, например, оптическое волокно или кабель. Все эти операции не являются мгновенными.
Мишель Льюис в своей книге Flash Boys (Simon and Schuster) повествуют историю о компании, которая потратила миллионы долларов на снижение задержки в несколько миллисекунд чтобы быть способными к более быстрому доступу к рынку чем их конкуренты. Это прекрасный пример применения задержки в качестве конкурентного преимущества, однако стоит отметить, что согласно некоторым исследованиям, таким как [BARTLETT16], сама возможность скупки и продажи устаревающих котировок (возможности получения прибыли от способности обладания ценами и исполнения заказов быстрее своих конкурентов) не даёт возможностям трейдерам эксплуатировать рынки.
Изучая свои упражнения, мы добавили повторы, восстановление соединений и удалили предположения относительно немедленного исполнения, но этого всё равно ещё недостаточно. При росте общего числа, скоростей и размеров обмена сообщениями, либо добавления новых процессов к уже имеющейся сетевой среде, нам не следует считать что полоса пропускания бесконечна.
|
| Замечание |
|---|---|
|
В 1994 Питер Дютч опубликовал ныне знаменитый перечень утверждений, озаглавленный как "Обманки распределённых вычислений", описывающий те стороны распределённых вычислений, которые н просто наблюдать. Дополнительно к предположениям о надёжности, задержках и полосе пропускания сетевой среды он описал и некие прочие проблемы. Например, сетевая безопасность, собственно возможность сопернчающих сторон, намеренные и неумышленные изменения топологии, которые способны нарушать наши предположения относительно наличия и места особенных ресурсов, стоимости транспортировки в терминах как ресурсов, так и вермени, и, наконец, само существование единственной авторизации, обладающей сведениями относительно всей сетевой среды и управления ею. |
Список обманок распределённых вычислений Дютча достаточно исчерпывающ, однако он сосредоточен на том, что может пойти не так при отправке сообщения от одного процесса другому через имеющееся соединение. Эти соображения справедливы и описывают большинство распространённых и относящихся к ниженему уровню сложностей, но к сожалению, существует множество прочих соображений, которые нам следует делать относительно распределённых систем при их проектировании и реализации, которые способны вызывать проблемы при работе с системами.
Прежде чем некий удалённый процесс получит возможность отправлять некий отклик на только что полученное им сообщение, ему требуется осуществить некие действия локально, поэтому мы не можем предполагать, что обработка мгновенна. Не достаточно учитывать сетевую задержку, так как выполняемые удалёнными процессами операции также не мгновенные.
Более того, нет никаких гарантий того,что обработка будет запущена сразу по доставке своего сообщения. Это сообщение может лежать в очереди ожиданий своего удалённого сервера и может понадобиться некое ожидание пока не будут обработаны все те сообщения, которые возникли раньше.
Узлы могут располагаться ближе или дальше друг от друга, иметь различные ЦПУ, объёмы ОЗУ, отличающиеся диски или же запускать различные версии и конфигурации программного обеспечения. Мы не можем ожидать от них обработки запросов с одной и той же скоростью. Когда нам приходится дожидаться пока отдельные удалённые серверы работают параллельно над откликом всей нашей задачи, само исполнение в целом настолько же медленно, насколько не быстр наш удалённый сервер.
В противоположность широко распространённому мнению, ёмкость очереди не является безграничной и нагромождение дополнительных запросов вовсе не делает систему лучше. Противодействие является той стратегией, которая позволяет нам совладать с с производителями, публикующими сообщения со скоростью, быстрее скорости, с которой потребители способны их обрабатывать замедляя таких поставщиков. Противодействие это одно из недооценённых и слабо применяемых понятий в распределённых системах, часто выстраиваемых по возникновению события, вместо того чтобы выступать в качестве составной части архитектуры всей системы.
Даже хотя увеличение занчения ёмкости очереди и может звучать как неплохая мысль, а также способна помогать в конвейеризации, распараллеливании и эффективном планировании запросов, с самими запросами ничего не происходит пока они сидят в своей очереди и ждут своего запуска. Увеличение размера очереди может оказывать отрицательное воздействие на задержку, так как её изменение не оказывает никакого влияния на саму скорость обработки.
В целом, локально обрабатываемые очереди используются для достижения следующих целей:
- Разъединение
Приём и обработка разделены по времени и происходят независимо.
- Конвейеризация
Запросы на различных стадиях обрабатываются как независимые части общей системы. Та подсистема, которая отвечает за приём сообщений не должна блокироваться пока не будет полностью обработано предыдущее сообщение.
- Поглощение кратковременных всплесков
Нагрузка системы имеет тенденцию к изменениям, однако времена между появлениями запросов скрыты от тех компонентов,которые отвечают за обработку запросов. Общая задержка системы растёт по причине времени, проводимого в очереди, но обычно это всё равно лучше чем отвечать отказом и повторять сам запрос.
Размер очереди зависит от особенностей рабочей нагрузки и приложения. Для относительно стабильных рабочих потоков мы можем устанавливать размер очередей измеряя время обработки задач и усредня то время, которое каждая задача проводит в своей очереди прежде чем она будет обработана, и при этом пребывать в уверенности, что задержка остаётся в допустимых границах при росте пропускной способности. В этом случае размеры очереди относительно малы. Для непредвиденных рабочих потоков, когда идёт лавинообразный рост задач, размеры очереди должны быть также установлены в размер, соответствующий всплесками и высокой нагрузке.
Имеющийся удалённый сервер может работать над запросами быстро, но это не означает, что мы всегда получаем от него положительный отклик. Он может отвечать и отказом: он не способен выполнить запись,искомое значени отсутствует или же он может столкнуться с некой ошибкой. Суммируя, даже наиболее предпочтительный сценарий всё ещё требует некого внимания с нашей стороны.
Время призрачно. Обеденное время вдвойне.
- Форд Префект, Руководство Хитчхикера по Галактике
Допущение о том, что часы в удалённых машинах идут синхронно, также опасно. В сочетании с латентность нулевая и обработка мгновенная это приводит к иным групповым отличительным особенностям, в особенности, при обработке данных временных последовательностей и данных в реальном времени. Например, при сборе и агрегировании сведений от участников с различным восприятием времени, вам следует понимать временное соотношение между ними нормализовать времена надлежащим образом вместо того чтобы просто полагаться на имеющиеся временные отметки источника. Пока вы не применяете высокоточные источники времени, вам не следует полагаться на временные отметки для синхронизации или упорядочивания. Конечно, это не означает что мы не можем вовсе полагаться на время: в конечном итоге любая система синхронизации для таймаутов пользуется локальными часами.
Существенно всегда исчислять возможные временные отличия между имеющимися процессами и то время, которое необходимо для доставки и обработки самих сообщений. Например, Spanner (см. раздел Распределённые транзакции при помощи Spanner) применяет специальный API времени, который возвращает некую временную отметку и несомненные границы для выставления строгогопорядка транзакции. Некоторые алгоритмы выявления отказов полагаются на разделяемое представлени времени и гарантии того, что расхождение часов всегда в допустимых для верности границах [GUPTA01].
Помимо того факта, что синхронизация часов в распределённых системах всегда сложна, значение текущего времени постоянно изменяется: вы можете запросить текущую временную отметку POSIX у своей операционной системы и запросить другую текущую временную отметку после выполнения нескольких шагов, причём эти две будут отличаться. Это достаточно очевидное наблюдение, но осознание обоих источников времени и какой в точности момент зацепляет данная временная отметка критически важно.
Также помогает понимание того, что ваш источник часов монолитен (т.е. что он никогда не движется в обратном направлении) и то, насколько способны расходиться ваши запланированные по времени операции, связанные со временем.
Большинство из наших предыдущих предположений попадают в категорию почти всегда не верные, но также ещё имеются и те, которые лучше описывать как не всегда правильные: когда проще предпринять мысленную отметку и упростить свою модель представляя её особый путь, игнорируя некие хитроумные граничные случаи.
Распределённые алгоритмы не всегда гарнтируют толчное соответсивие состояния. Некоторые подходы обладают обладают утрачиваемыми ограничениями и допускают расхождение между репликами, полагаясь на разрешение конфликтов (некую возможность выявления и разрешения расхождения состояний внутри данной системы) и восстановления данных в реальном времени (приведение реплик обратно в синхронное состояние в процессе считываний при ситуациях, когда они отвечают с различными результатами). Дополнительные сведения об этом понятии вы можете найти в Главе 12. Предположение что данное состояние полностью согласовано по всем узлам может приводить к едва уловимым ошибкам.
В конечном итоге согласованная система распределённой базы данных может обладать соответствующей логикой для обработки расхождений реплик путём запроса кворума узлов в процессе чтений, однако в предположении,что сама схема базы данных и её представление в данном кластере строго согласованы. Пока мы не усилим согласованность этих сведений, когда мы полагаемся на такое предположение, это может приводить к суровым последствиям.
Например, в Apache Cassandra имелась некая ошибка, вызываемая тем, что изменения схемы распротсранялись в серверы в различное время. Когда вы пытаетесь выполнять чтение из этой базы данных во время распространения данной схемы, имелась вероятность разрушения, так как один сервер кодировал результаты в предположении одной схемы, а другой декодировал их применяя иную схему.
Другим образцом является некая ошибка, вызываемая расхождением представления имеющегося кольца: огда один из узлов предполагает что другой узел содержат данные для некого ключа, но этот другой узел имеет несколько иное представление о своём кластере, считывание и запись данных могут иметь результатом потерю записей данных или получения пустого отклика, в то время как записи данных на самом деле счастливо присутствуют на этом другом узле.
Будет лучше задуматься о возможных проблемах заранее, даже если полное решение затратно в реализации. Понимая и обрабатывая такие случаи, вы можете вставлять меры безопасности или изменять сам проект таким образом, чтобы превращать своё решение в более естественное.
Сокрытие сложности позади некого API может быть опасным. Например, когда у вас имеется некий итератор по всему локальному набору данных, вы обоснованно можете предсказывать что происходит за сценой, даже когда вы не знакомы с его механизмом хранения. Понимание установленного процесса итераций по имеющемуся удалённо набору данных это совершенно иная задача: вам необходимо понимать непротиворечивость и семантику доставки, согласование данных, подкачку страниц, слияния, последствия одновременного доступа и много прочих моментов.
Простое сокрытие их обоих за одним и тем же интерфейсом, хотя и полезно, может сбивать с толку. Для отладки, настройки и наглядности могут потребоваться дополнительные параметры API. Нам всегда следует держать в уме что локальное и удалённое исполнение это не одно и то же [WALDO96].
Наиболее важной видимй проблемой для сокрытия удалённых вызовов являются задержки: удалённые вызовы во много раз более дороги нежели локальные, поскольку они содержат транспортировку в обе стороны, сериализацию/ распаковку, а также множество иных шагов. Чередование локальных и блокирование удалённых вызовов могут приводить к деградации производительности и непреднамеренным сторонним эффектам [VINOSKI08].
Это отлично начинать работать в некой системе в пердположении что все узлы подняты и работают нормально, однако представление о том, что это имеет место всегда чревато опасностями. В длительно работающих системах узлы могут отключаться на обслуживание (которое обычно происходит через деликатное отключение) или же испытывать крушение по различным причинам: проблемы с программным обеспеченеим, уничтожения нехваткой памяти [KERRISK10], ошибки времени исполнения, проблемы с оборудованием и т.п. Процессы реально падают, и лучшее что вы можете предпринять, это подготовиться к таким отказам для их обработки.
Когда определённый удалённый серерв не отвечает, нам не всегда известна точная причина этого. Это может быть вызвано крушением, неким сетевым отказом, самим удалённым процессом или соединение с ним стало слишком медленным. Некоторые распределённые алгоритмы применяют протоколы сердцебиения или выявления отказов для формирования предположений относительно того какие из участников работают и достижимы.
Когда два или более серверов не способны взаимодействовать друг с другом, мы называем такое положение дел сетевым разделением. В "Перспективах теоремы CAP" [GILBERT12], Сет Гилберт и Нэнси Линч провели различие между случаем когда два участника не могут взаимодействовать друг с другом и когда различные группы участников изолированы друг от друга, не способны обмениваться сообщениями и следовать своему алгоритму.
Общая ненадёжность сетевой среды (потеря пакетов, повторные передачи, трудно предсказуемые задержки) являются досадными но терпимыми, в то время как сетевые разделы могут вызывать намного больше проблем, поскольку независимые группы могут продолжать своё выполнение и производить вступающие в конфликт результаты. Сетевые соединения к тому же способны отказывать ассиметрично: сообщения могут всё ещё доставляться от одного процесса к другому, но не наоборот.
Для построения некой устойчивой к наличию отказов одного или множества процессов системы, нам придётся рассматривать варианты частичных отказов [TANENBAUM06] и того как эта система может продолжать работу даже несмотря на то что её часть недоступна или функционирует неверно.
Отказы сложно выявлять и они не всегда видятся одними и теми же из различных частей одной системы. При проектировании некой системы с высокой доступностью, всегда следует задумываться о граничных случаях: что если мы реплицируем свои данные и не получаем подтверждения? Требуется ли нам повторять? Стоит ли эти данные всё ещё рассматривать как доступные для чтения в тех узлах, которые отправили подтверждения?
Закон Мёрфи (являющийся неким афоризмом, который можно суммировать следующим образом: "Нечто, что может пойти не так, пойдёт не так", которое получило популярность и часто используется как устойчивое выражение в народной культуре) говорит нам что такие отказы происходят на самом деле. Фольклор программистов добавляет, что тот отказ, который произойдёт, случится в наихудшем варианте, поэтому наше задание как инженеров распределённых систем состоит в гарантированном снижении общего числа ситуаций, при которых дела идут плохо и подготовиться к отказам в том случае, который содержит разрушения, способные провоцироваться ими.
Не возможно предотвращать все отказы, но мы всё ещё способны строить эластичную систему, которая правильно работает при их наличии. Наилучшим способом подготовки к отказам является их проверка. Почти невозможно представить себе все возможные ситуации отказов и предсказать устанавливаемое поведение множества процессов. Настройка проверки снаряжения, которое создаёт разделы, эмуляция битовой деградации [GRAY05], увеличение задержек, расхождение часов и увеличение относительных скоростей обработки это лучший способ их прохода. Установки распределённых систем реальной практики могут быть достаточно состязательными, недружественными и "креативными" (однако черезчур неприятельским способом), поэтому следует предпринять все свои усилия по проверке настолько большого числа ситуаций, насколько это возможно.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
На протяжении последних лет мы наблюдаем ряд проектов с открытым исходным кодом, которые способствуют воссозданию различных ситуаций отказов. Toxiproxy способен помочь с имитацией сетевых проблем: пределом величины полосы пропускания, вводо задержек, таймаутами и прочим. Chaos Monkey предпринимает более радикальный подход и выставляет инженеров для воспроизводства отказов отключая произвольным образом службы. CharybdeFS помогает эмулировать ошибки и отказы файловой системы и оборудования. Вы можете применять эти инструменты для проверки своего программного обеспечения и обеспечения того что оно ведёт себя должным образом при наличии подобных отказов. CrashMonkey, некая равнодушная к файловой системе инфраструктура записи- воспроизводства- и- проверки, помогает проверять согласованность данных и метаданных для постоянно хранимых файлов. |
При работе с расперделёнными системами, нам приходится серьёзно относиться к отказоустойчивости, эластичности, возможным сценариям отказов и граничным ситуациям. Аналогично "у семи нянек дитя без глазу", мы можем сказать, что достаточно большой кластер в конечном итоге столкнётся со всеми возможными проблемами. В то же самое время, задавшись достаточными проверками, мы будем способны в результате найти все имеющиеся проблемы.
Мы не можем всегда полностью изолировать отказы: некий процесс, опрокидывающийся под высокой нагрузкой увеличивает общую загруженность оставшегося кластера, что делает ещё более вероятным отказ и прочих узлов. Каскадные отказы могут распротсраняться из одной части системы в другую, увеличивая область действия этой проблемы.
Порой каскадные отказы способны даже вызываться исколючительно благими намерениями. К примеру, некий узел пребывал какое- то время в отключке и не получал самые последние обновлеия. После того как он вернулся обратно в рабочее состояние, предупредительные одноранговые собратья желают помочь ему нагнать самые последние происшествия и стартуют потоки с данными, которые он пропустил, переполняя сетевые ресурсы или вызывая падение этого узла вскорости после его запуска.
|
| Совет |
|---|---|
|
Для защиты некой системы от распространения отказов и деликатного обращения со сценариями отказов могут применяться прерыватели (circuit breakers). В энергоснабжении автоматические выключатели защищают дорогостоящие и трудные для замены части от перегрузок или короткого замыкания, прерывая электрический ток. В разработке программного обеспечения прерыватели отслеживают отказы и делают доступными механизмы запасного варианта, которые способны защитить даную систему, удерживая её от соответствующего обслуживания отказа и предоставляя некоторое время на востановление, при этом деликатно обрабатывая отказавшие вызовы. |
В случае отказа установленного с неким сервером соединения или когда этот сервер не отвечает, данный клиент начинает некий цикл повторного подключения. К этому моменту, некий перегруженный сервер уже испытывает трудные времена, навёрстывая новые запросы на подключения, а клиентская сторона в повторных попытках стеснённого цикла не способствует улучшению этой ситуации. Во избежание этого мы можем применять некую стратегию отката (backoff). Вместо немедленного повтора клиенты выжидают некоторое время. Откат способен помочь нам избегать рост проблем планированием повторов и увеличением временного окна между последовательными запросами.
Откат применяется для увеличения промежутков времени между запросами от отдельного клиента. Тем не менее, использование различными клиентами одной и той же стратегии отката также способно производить солидную нагрузку. Чтобы воспрепятствовать различным клиентам всем одновременно повторять попытку после соответствующего промежутка отката, мы можем вводить некое дрожжание (jitter). Дрожжание добавляет небольшие произвольные промежутки времени в откат и снижают значение вероятности просыпания клиентов в одно и то же время для повторных попыток.
Аппаратные отказы, деградация битов и программные ошибки могут в результате приводить к разрушениям, которые способны распространяться стандартными механизмами доставки. Например, разрушенные записи данных могут реплицироваться в прочие узлы когда они не выявлены. Без присутсвия механизма удостоверения система способна распространять разрушенные данные в прочие узлы, потенциально выполняя переписывание неразрушенные записи данных. Во избежание этого нам следует применять контрольные суммы и удостоверение на предмет наличия целостности любого обмениваемого между нашими узлами содержимого.
Перегруженность и горячие точки можно избегать планируя и координируя исполнение. Вместо того чтобы позволять одноранговым собратьям независимо выполнять шаги операций, мы можем применять координацию, которая готовит некий план исполнения на соновании доступных ресурсов и предсказывает загруженность на основании последних доступных ей данных исполнения.
В итоге, нам всегда следует рассматривать случаи, при которых отказы в одной части системы могут вызывать проблемы ещё где бы то ни было. Нам требуется снабжать свою систему механизмами прерывания, откатов, удостоверения и координации. Обработка небольших изолированных проблем всегда более проста нежели попытка восстановления после большого выхода из строя.
Мы только что затратили целый раздел на обсуждение проблем и потенциальных сценариев отказов в распределённых системах, однако мы должны расмматривать это как некое предостережение, а не как нечто для того чтобы запугать нас.
Понимание того что может пойти не так и аккуратные проектирование и проверка наших систем делает их более надёжными и эластичными. Наличие сведений об этих проблемах способно помочь вам в выявлении и поиске потенциальных источников проблем в процессе разработки, а также при их отладке в практическом применении.
При обсуждении языков программирования мы применяем общую терминологию и определяем свои программы в терминах функций, операторов, классов, переменных и указателей.
Наличие общего словаря помогает нам избегать изобретения новых слов всякий раз когда мы описываем нечто. Чем более точны и менее двусмысленны наши определения, тем проще нашим слушетелям понимать нас.
Прежде чем мы перейдём к алгоритмам, мы вначале рассмотрим словарь распределённых систем: определения, с которыми вы часто сталкиваетесь в разговорах, книгах и статьях.
Сетевые среды не надёжны: сообщения могут теряться, задерживаться и повторяться. Теперь, имея это на уме, мы попытаемся построить отдельные протоколы взаимодействия. Мы начнём с наименее надёжных и устойчивых, указывая те состояния, в которых они способны пребывать и выводя необходимые возможные добавления для этих протоколов, которые способны предоставлять лучшие гарантии.
Справедливо утрачиваемые соединения
Мы можем начать с двух процессов, подключённых неким соединением (link). Процессы могут отправлять сообщения друг другу, как это отображено на Рисунке 8-2. Все среды взаимодействия не идеальны и сообщения могут теряться или задерживться.

Давайте рассмотрим какие гарантии мы можем получать. После отправки нашего сообщения M,
с точки зрения отправителя могут присутствовать следующие состояния:
-
Ещё пока не доставлено процессу
B(но будет лоставлено в некий момент времени) -
Безвозвратно утрачено в процессе транспортировки
-
Успешно доставлено удалённому процессу
Отметим, что наш отправитель не имеет никакой возможности определить что его сообщение уже доставлено. В терминологии распределённых систем такой вид соединений носит название справедливо утрачиваемых (fair- loss). Основные свойства этого вида соединений таковы:
- Справедливая утрата
Если и отправитель и получатель верны, и этот отправитель сохраняет повторную передачу определённого сообщения неограниченно много раз, оно в конечном итоге будет доставлено (более точное определение состоит в том, что если верный процесс A отправляет сообщение верному процессу B неограниченно часто, оно будет доставлено неограниченно часто [CACHIN11]).
- Имеющее предел дублирование
Отправленные сообщения не будут доставляться неограниченно много раз.
- Никакого создания
Никакое соединение не может появиться с сообщениями; иными словами, оно не способно доставить никогда не отправленное сообщение.
Некое справедливо утрачиваемое соединение является полезной абстракцией и неким первичным строительным блоком для протоколов взаимодействия со строгими гарантиями. Мы можем предположить, что такое соединение не теряет сообщения между взаимодействующими частями систематически и не создаёт никаких новых сообщений. Но, в то же самое время мы не можем целиком полагаться на это. Это может напоминать вам протокол UDP (User Datagram Protocol), который позволяет нам отправлять сообщения от одного процесса к другому, однако не имеет сематики достоверной доставки на уровне самого протокола.
Подтверждения сообщений
Для улучшения положения дел и получения большей ясности в терминах состояния сообщения, мы можем ввести подтверждения (acknowledgments): некий способ, которым получатель уведомляет отправителя что он получил данное сообщение. Для этого нам требуется применять двунаправленные каналы взаимодействия и добавить некое средство, позволяющее нам вносить ясность между имеющимися сообщениями; например, последовательные номера, которые уникальным образом монотонно увеличивают идентификаторы сообщения.
|
| Замечание |
|---|---|
|
Достаточно иметь некий уникальный идентификатор для каждого сообщения. Последовательные номера это просто определённый вариант некого уникального идентификатора, при котором мы достигаем уникальности, вытаскивая идентификатоы из некого счётчика. При использовании алгоритмов хэширования для уникальной идентификации сообщений мы должны учитывать возможные противоречия и иметь уверенность того, что мы всё ещё в состоянии устранять неоднозначность сообщений. |
Теперь процесс A может отправить некое сообщение
M(n), где n это монотонно растущий
счётчик сообщений. Как только B получает данное сообщение, он отправляет
подтверждение ACK(n) обратно к A.
Рисунок 8-3 отображает данную форму взаимодействия.

Такое подтверждение, также как и само первоначальное сообщение, способно быть утраченным на своём пути. Общее
число состояний данного сообщения может слегка измениться. Пока A не
получит некого подтверждения, это сообщение всё ещё пребывет в одном из трёх упомянутых ранее состояний, однако
как только A получает соответствующее подтверждение, он может быть
уверен что это сообщение доставлено B.
Повторная передача сообщений
Добавления подтверждений всё ещё недостаточно для того чтобы называть данный протокол надёжным: некое отправленное сообщение всё равно может быть утрачено, либо сам удалённый процесс может отказать до отправки его подтверждения. Для решения этой проблемы и предоставления гарантий доставки мы можем вместо этого попробовать повторную передачу. Повторные передачи являются неким способом для отправителя повторить потенциально отказавшую операцию. Мы говорим потенциально отказавшую по той причине, что отправитель на самом деле не знает был отказ или нет, так как тот тип соединения, который мы обсуждаем, не использует подтверждения.
После того как процесс A отправил сообщение
M, он ожидает пока не включится таймаут T
и пытается отправить то же самое сообщение снова. В предположении что данное соединение между процессами всё ещё
остаётся невредимым, сетевые разделы между этими процессами не являются безграничными и не
все пакеты теряются, мы можем постулировать, что с точки зрения отправителя,
это сообщение либо ещё пока не доставлено процессу
B, либо оно успешно доставлено процессу
B. Так как A пытается отправить это
сообщение, мы можем сказать, что это не может стать невосполнимой утратой
в процессе транспортировки.
В терминологии распределённых систем, такая абстракция носит название настойчивого соединения (stubborn link). Оно именуется настойчивым, поскольку сам отправитель продолжает повторную отправку данного сообщения снова и снова до бесконечности, однако, поскольку этот вид абстракции будет в высшей степени непрактичным, нам требуется сочетать переповторы с подтверждениями.
Проблемы с повторной передачей сообщений
Всякий раз когда мы отправляем очередное сообщение, пока мы не получим подтверждения от соответствующего удалённого процесса, была ли доставка выполнена, будет ли она выполнена в скорости, было ли сообщение утрачено или же её удалённый процесс потерпел крушение до его получения - все эти состояния возможны. Мы можем повторить эту операцию и отправить данное сообщение снова, но это может иметь результатом дублирование сообщения. Дублирование сообщения безопасно лишь когда та операция, которую мы намерены выполнять идемпотентна.
Некая операция идемпотентна, когда она может быть выполнена множество раз, давая один и тот же результат без производства дополнительных сторонних эффектов. Например, останов сервера может быть идемпотентной операцией, самый первый вызов инициирует останов, а все последующие вызовы не производят никаких дополнительных эффектов.
Если все операции были идемпотентны, мы можем меньше задумываться о семантике доставки, больше полагаясь на повторы для отказоустойчивости и строить систему неким целиком активным способом: включением некого действия в качестве отклика на какие- то сигналы без непреднамеренных сторонних эффектов. Тем не менее, операции не обязательно идемпотентны и лишь предполагают что они могут приводить к сторонним эффектам для всего кластера. Например, пополнение кредитной карты потребителя не идемпотентно и её пополнение множество раз определённо не желательно.
Идемпотентность в частности важна при наличии частичных отказов и сетевых разделов, так как мы не всегда способны обнаружить в точности состояние удалённой операции - была ли она успешно, получила ли отказ или будет вскорости выполнена - и нам просто приходится больше ждать. Поскольку обеспечение того что все выполняемые операции являются идемпотентными является не реальным требованием, нам необходимо предоставлять гарантии, эквивалентные идемпотентности без изменения всей лежащей в основе семантике действий. Для достижения этого мы пользуемся дедупликацией и избегаем обрабатывать сообщения более одного раза.
Порядок сообщений
Ненадёжные сети являют нам две задачи: сообщения могут приходить не в установленном порядке и, по причине повторов, некоторые сообщения могут возникать более одного раза. Мы уже ввели последовательные номера и мы можем пользоваться этими идентификаторами сообщений на принимающей стороне для проверки порядка первый- пришедший- обрабатывается- первым (FIFO - first-in, first-out). Поскольку каждое сообщение обладает неким последовательным номером, наш получатель способен отслеживать:
-
nпоследовательный, определяющий значение наивысшего последовательного номера, вплоть до которого мы наблюдали все сообщения. Сообщения вплоть до этого номера могут быть помещены обратно в установленном порядке. -
nобработанный, определяющий значение наивысшего последовательного номера, вплоть до которого сообщения были помещены обратно в их первоначальном порядке и обработаны. Это число может применяться для дедупликации.
Когда получаемое нами сообщение имеет не идущий следом последовательный номер, наш получатель помещает его в
свой буфер упорядочения. Например, он получает сообщение с последовательным номером 5
после получения сообщения с номером 3 и мы знаем что 4
пока пропущено, поэтому нам отложить 5 в сторону пока не придёт
4 и мы сможем реконструировать первичный порядок сообщений. Поскольку мы
выполняем построение поверх соединения со справедливой утратой, мы полагаем, что сообщения между
nпоследовательный
и nмакс_увиденный в конечном итоге будут доставлены.
Наш получатель может безопасно все получаемые им сообщения с последовательными номерами до
nпоследовательный, так как они уже гарантировано доставлены.
Дедупликация работает над проверкой того, что сообщение с последовательным номером n
уже было обработано (прошло вниз по стеку своего получателя) и отвергает
уже обработанные сообщения.
В терминологии распределённых систем этот тип подключения носит название совершенного соединения (perfect link), которое предоставляет следующие гарантии [CACHIN11]:
- Надёжная доставка
Всякое единожды отправленное сообщение правильным процессом
Aверному процессуBбудет в конечном итоге доставлено.
- Отсутствие дублирования
Никакое сообщение не доставляется более одного раза.
- Никакого создания
Подобно всем прочим типам соединений, оно способно доставлять только те сообщения, которые на самом деле были отправлены.
Это может напоминать вам протокол TCP (см., однако надёжная доставка в TCP гарантирована только в рамках некого отдельного сеанса). Конечно, данная модель всего лишь упрощённое предсталение, которое мы применяем лишь целях иллюстрации. TCP обладает намного более сложно устроенной моделью для ведения дел с подтверждениями, которая группирует подтверждения и снижает имеющиеся накладные расходы уровня протокола. Кроме того, TCP обладает выборочными подтверждениями, управлением потоком, контролем заторов, выявлением ошибок и многими прочими свойствами, которые выходят за рамки нашего обсуждения.
В точности одна доставка
В распределённых системах имеются всего лишь две проблемы: 2. В точности одна доставка 1. Гарантированный порядок сообщений 2. В точности одна доставка
- Матиас Вираис
Существовало множество обсуждений на предмет того, возможна или нет в точности одна доставка. Здесь имеет значение семантика и точность формулировок. Поскольку может иметься некий отказ соединения, препятствующий доставке сообщения с самой первой попытки, большинство систем реального мира используют по крайней мере одну доставку, что обеспечивает повторы отправителя пока он не получит некое подтверждение,в противном случае данное сообщение не рассматривается как полученное. Другая семантика доставки состоит в не более одного раза: наш отправитель посылает своё сообщение и не дожидается никаких подтверждений о доставке.
Имеющийся протокол TCP работает над разбиением сообщений на пакеты, передачу их одного за другим и сшивание их обратно воедино на своей стороне приёма. TCP может повторять некоторые из отправленных пакетов и может происходить более одной попытки передачи. Поскольку TCP помечает все пакеты последовательными номерами, даже несмотря на то, что некоторые пакеты могут передаваться более одного раза, он способен выполнять дедупликацию пакетов и гарантировать, что его получатель увидит данное сообщение и обработает его только один раз. В TCP такая гарантия доступна лишь для отдельного сеанса: когда данное сообщение получило подтверждение и обработано, однако его отправитель не получил соответствующее уведомление о получении до того как данный сеанс был прерван, его приложение не осведомлено о такой доставке и, в зависимости от его логики, может попробовать отправит данное сообщение ещё раз.
Это означает, что здесь нас интересует именно в точности одна обработка, так как дублированные доставки (или передачи пакетов) не имеют сторонних эффектов и всего лишь выступают в качестве неких артефактов наилучших усилий данного соединения. Например, когда узел базы данных только получил необходимую запись, но не сохранил его, доставка произошла, однако он не будет никакого его применения пока данная запись не будет повторена (иными словами, пока она не будет и доставлена, и обработана).
Для поддержки гарантии только одного раза, узлы обязаны обладать общим знанием [HALPERN90]: все знают некий факт и каждый знает что все кроме него также знают об этом факте. Упрощённо говоря, узлы должны прийти к согласию относительно состояния данной записи: оба узла согласны с тем, что она либо была, либо нет сохранена. Как вы обнаружите позднее в данной главе, это теоретически невозможно, однако на практике мы всё же пользуемся такой нотацией ослабляя требования координации.
Любые недопонимания относительно того, возможна или нет в точности одна доставка скорее всего появляются из подхода к этой задаче со стороны различных протоколов и уровней абстракции, а также самого определения "доставки". Совершенно невозможно построить надёжное соединение без того чтобы не передавать какое- то сообщение более одного раза, но мы способны создать иллюзию в точности одной доставки с точки зрения отправителя обработкой сообщения лишь один раз и игнорируя дублирования.
Теперь, когда мы установили основные средства для надёжного взаимодействия, мы можем двинуться далее и рассмотреть способы достижения единообразия и согласия между процессами в определённой распределённой системе.
Одной из наиболее рельефных описаний согласия в распределённых системах является мысленный эксперимент, широко известный как проблемы двух генералов.
Этот мысленный эксперимент демонстрирует что невозможно достичь какого бы то ни было согласия между частями для асинхронного взаимодействия при наличии отказов в соединении. Даже несмотря на то, что TCP представляет свойства некого совершенного соединения, важно помнить, что совершенные соединения, несмотря на своё наименование, не гарантируют совершенную доставку. Они также не обеспечивают участникам возможности присутствия на протяжении всего времени и этот термин относится лишь к транспорту.
Представми себе две армии, ведомые двумя генералами, готовящимися к атаке на укреплённое поселение. Эти армии расположены с двух стороно от данного поселения и способны достичь учпеха в своей осаде только когда они атакуют одновременно.
Их генералы могут взаимодействовать, отправляя посыльных и уже разработали некий план атаеи. Единственный момент, который им осталось согласовать это приводить или нет даннй план в исполнение. Вариантами этой задачи являются случаи, когда у одного из этих генералов более высокий ранг, но ему требуется быть уверенным, что данная атака скоординирована; или же что этим генералам требуется согласовать её точное время. Такие детали не меняют основного определения задачи: генералам требуется достичь согласия.
Генералам этих армий требуется лишь иметь договорённость по тому факту, что они оба произведут данную атаку.
В противном случае эта атака не будет успешной. Генерал A отправляет некое
сообщение MSG(N), утверждающее намерение выполнить данную атаку в какое- то
определённое время, если другая сторона также согласна на это.
После того как A отправляетданное послание, он не знает, было ли его донесение
доставлено или нет: посыльный мог быть перехвачен, или не выполнил доставку этого донесения. Когда генерал
B получает данное донесение, он должен отправить уведомление о его
получении ACK(MSG(N)).
Рисунок 8-4
отображает что некое сообщение было отправлено одним из путей и другой стороной была подтверждена его доставка.
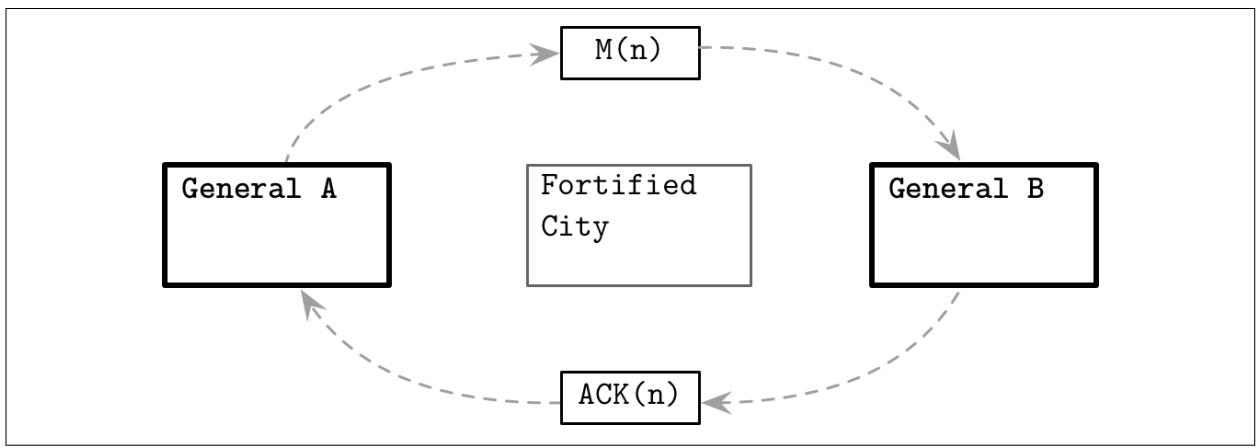
Посыльный, доставляющий подтверждение получения донесения также мог быть захвачен или не выполнил его доставку.
У B нет никакого способа узнать что его посыльный успешно доставил его
подтверждение.
Чтобы иметь уверенность в этом, B приходится дожидаться
ACK(ACK(MSG(N))), подтверждающего состояния второго порядка о том, что
A плучил подтверждение подтверждения.
Не имеет значения сколько дальнейших подтверждений эти генералы отправят друг другу, они всегда будут на одно
ACK позади осознания того факта, что они способны уверенно провести атаку.
Эти генералы обречены на чудо, что их несущее это последнее подиверждение послание достигло своего получателя.
Обратите внимание, что мы не делали никаких предположений о времени: взаимодействие между генералами полностью асинхронное. Нет никакого верхнего временного ограничения на то, как долго эти генералы могут отвечать.
В статье Фишера, Линча и Патерсона, её авторы описали некую задачу, широко известную как Проблема невозможности FLP [FISCHER85] (по заглавным буквам фамилий авторов), в которой они обсудили некий вид согласия, в котором процессы стартовали с неким начальным значением и пытаются договориться о неком новом значении. После выполнения этого алгоритма, данное новое значение должно быть одним и тем же для всех продолжающих работу процессов.
Достигнуть некого соласия по определённому значению очень просто когда сетевая среда полностью надёжна; но в действительности, системы склонны ко многим различного рода отказам, таким как потеря сообщений, дублирование, разбиение сетей на разделы, а также медленные или испытывающие крушения процессы.
Некий протокол согласования описывает какую- то систему, которая обладая множеством запущенных процессов при их первоначальном состоянии приводит все эти процессы в соответствующее урегулированное состояние. Чтобы некий протокол согласования был верным, он должен сохранять три свойства:
- Согласие
Принимаемое данным протоколом решение должно быть единодушным: все процессы выбирают какое- то значение и оно должно быть одинаковым для всех процессов. В противном случае мы не достигли согласия.
- Обоснованность
Даное согласуемое значение должно быть предложено одним из участников, что означает что данная система должна не просто "прийти" к этому значению. Это также подразумевает нетривиальность данного значения: процессы не всегда должны принимать решение о неком предварительно определённом значении.
- Прекращение
Некой согласование завершено только когда нет никакого процесса, который не достиг состояния данного решения.
[FISCHER85] предполагает, что обработка полностью асинхронная: ет никакого совместного представления о временах между этими процессами. Алгоритмы в такой системе не могут основываться на таймаутах, и нет никакого способа для процессов определять претерпели ли прочие процессы крушение или просто очень медленно работают. Данная статья показыает, что при заданных предположениях, не существует никакого протокола, который был бы способен обеспечить согласование в ограниченный срок. Никакой полностью асинхронный алгоритм не может быть толерантным к падениям без предупреждений даже некого отдельного удалённого процесса.
Мы не рассматриваем какую- то верхнюю гранцу для завершения шагов этого алгоритма таким процессом, отказы процессов не могут быть надёжно выявляться и нет никакого детерминированного алгоритма достижения согласия.
Тем не менее, невозможность FLP не означает что нам придётся упаковать свои шмотки и идти домой, так как достижение согласия невозможно. Она лишь означает, что мы не можем всегда достигать согласия в асинхронных системах в ограниченное время. На практике системы демонстрируют по крайней мере какую- то степень синхронности, а получаемое решение данной задачи требует дополнительно уточнённой модели.
Вследствии невозможности FLP мы можем заключить, что предположение о значении времени это одна из критически важных характеристик для рассматриваемых распределённых систем. В некой асинхронной системе нам не известны относительные скорости процессов и мы не способны обеспечивать доставку сообщений в ограниченный промежуток времени или неким определённым порядком. Сам процесс может потребовать неограниченно долгого ответа, а отказы процессов не всегда могут надёжно выявляться.
Основная критика асинхронных систем состоит в том, что эти требования не реалистичны: процессы не могут обладать произвольно различными скоростями оброботки, а соединения не требуют неограниченно длительного промежутка времени для доставки сообщений. Когда мы полагаемся на время, мы одновременно и упрощаем рассуждения, и способствуем предоставлению верхнего ограничения гарантий по времени.
Не всегда возможно разрешить задачу согласования в некой асинхронной модели [FISCHER85]. Более того, не всегда достижимо проектирование некого действенного синхронного алгоритма и более вероятно быть зависимым от времени [ARJOMANDI83].
Такие предположения могут быть ослабляющими и подобная система может рассматриваться как способной быть синхронной. Для этого мы вводим понятие соотнесения по времени. Намного проще рассуждать о системе в рамках синхронной модели. Это предполагает, что процессы развиваются с сопоставимыми скоростями, что задержки передачи имеют границы, а доставка сообщения не может продолжаться произвольно долго.
Некая синхронная система также может представляться в терминах синхронизуемых локальных для процесса часов: существует некая верхняя граница разницы во времени между конкретными двумя локальными для процесса источниками времени [CACHIN11]..
Проектирование систем в рамках некой синхронной модели позволяет нам применять таймауты. Мы способны строить более сложные абстракции, такие как выбор лидера, консенсус, выявление отказов, и много чего ещё поверх них. Это делает рекомендуемые сценарии более надёжными, однако приводят к отказам в случае несоблюдения предположений о времени. Нпример, в алгоритме согласования Raft мы можем в итоге получить множество процессов, полагающих что они являются лидерами, что разрешается принудительным процессом торможения для принятия иного процесса в качестве лидера. Алгоритмы выявления сбоев (см. Главу 9) могут ошибочно идентифицировать некий процесс как отказавший и наоборот. При проектировании своих систем нам необходимо проверять что мы рассмотрели такие возможности.
Свойства как синхронных, так и асинхронных моделей могут сочетаться и мы можем представлять себе системы как частично синхронные. Некая частично синхронная система представляет какие- то из свойств синхронных систем, однако значения границ времени доставки сообщений, расхождений по времени и относительных скоростей обработки могут не быть абсолютно точными и сохраняться лишь в большинстве случаев [DWORK88].
Синхронность это некое существенное свойство рассматриваемой распределённой системы: оно оказывает воздействие на производительность, масштабируемость и общую разрешимость, а также обладает множеством факторов, которые требуются для корректной работы наших систем. Некоторые из обсуждаемых нами в данной книге алгоритмов работают в предположениях синхронных систем.
Мы продолжаем упоминать отказы, однако до сих пор это было достаточно обширное и общее соображение, которое могло охватывать множество значений. Аналогично тому как мы можем делать различные предположения о временных соотнесениях, мы способны предполагать наличие различных типов отказов. Некая модель отказов в точности описываете как могут разрушаться процессы в распределённых системах и разрабатываемые в рамках этих предположениях алгоритмы. К примеру, мы можем допустить, что некий процесс может испытать крушение и никогда не восстанавливаться, или же что ожидается его восстановление по прошествию некого промежутка времени. или же что он может отказать выйдя из под контроля и предоставив неверные значения.
В распределённых системах процессы полагаются один на другой для выполнения некого алгоритма, а потому отказы способны приводить к неверной работе во всей системе.
Мы обсудим множество представленных в распределённых системах моделей отказов, таких как крушения, пропуски и произвольные отказы.
Обычно мы предполагаем что наш процесс должен выполнить корректно все шаги некого алгоритма. Самый простой способ крушения процесса состоит в остановке своего исполнения для всех последующих требуемых для алгоритма шагов и не отправлять никакие сообщения прочим процессам. Иными словами, данный процесс потерпел крушение. В большинстве случаев мы предполагаем некую абстракцию останова крушением, которая предписывает, что после крушения данного процесса он остаётся в таком состоянии.
такая модель не предполагает что имеется возможность восстановления данного процесса и препятствует восстановлению или пытается предотвратить его. Она лишь предполагает, что данный алгоритм не полагается на восстановление для того чтобы исправиться или воспрять. Ничто не препятствует восстановлению процессов, догонять необходимое состояние системы у принимать участие в следующем экземпляре данного алгоритма.
Отказавшие процессы не способны продолжать своё участие в данном текущем раунде переговоров,в процессе которого они испытали отказ. Назначение данному восстановленному процессу некого нового, иного логического элемента не делает эту модель эквивалентной восстановлению после крушения (обсуждаемой следом), так как большинство алгоритмов применяют предварительно заданный список процессов и чётко определяют семантику отказов в терминах того, какому числу отказов они могут быть равнодушны [CACHIN11].
Восстановление после отказа (Crush- recovery) это иная абстракция процесса, при которой данный процесс остановил выполнение тех шагов, которые требуются его алгоритмом, но восстановился в некий более поздний момент и пытается выполнять последующие шаги. Такая возможность восстановления требует введения в рассматриваемую систему некого надёжного состояния и протокола восстановления [SKEEN83]. Допускающим восстановление после крушения алгоритмам необходимо учитывать все возможные состояния восстановления, так как их процесс восстановления может попытаться продолжить выполнение с самого последнего известного ему шага.
Имеющим целью эксплуатацию восстановления алгоритмам приходится учитывать как состояние так и идентичность. Восстановление после отказа в таком случае может также представляться как некий особый случай отказа пропуска, ибо с точки зрения иного процесса нет никакой разницы между тем процессом, который был недосягаем и который испытал крушение и восстановился.
Другой моделью отказа является отказ пропуска (omission fault). Данная модель предполагает, что наш алгоритм опустил некоторые шаги своего алгоритма, или был не в состоянии выполнить их, либо это исполнение не видно прочими участниками, или же он не способен отправлять или принимать сообщения прочих участников. Отказ пропуска захватывает разбиение на сетевые разделы между имеющимися процессами, вызываемые отказами сетевых соединений, сбоями коммутаторов или сетевыми переполнениями. Разбиения на сетевые разделы может представляться как пропуски сообщений между индивидуальными процессами или группами процессов. Некое крушение может имитироваться полным пропуском всех сообщений к процессу или от него.
Когда определённый процесс работает медленнее чем все прочие участники и отправляет отклики намного позже чем они ожидаются, для всей оставшейся части системы это может выглядеть как будто о нём забыли. Вместо полной остановки, некий медленный узел пытается отправлять свои результаты вне рамок синхронизации с прочими узлами.
Отказы пропуска случаются когда тот алгоритм, который,как предполагалось, исполнил конкретные шаги, либо пропустил их, либо сами результаты их исполнения не видны. Например, это может происходить когда соответствующее сообщение утрачено по пути к своему получателю, или отправитель потерпел неудачу с его отправкой и снова продолжает свою работу как если бы оно было успешно доставлено, даже несмотря на то что оно было безвозвратно потеряно. Отказы пропуска также могут вызываться непродолжительными разрывами соединения, сетевыми перегрузками, полными очередями и тому подобному.
Самым сложным классом для овладения ими отказов выступают произвольные или Византийские отказы: некий процесс продолжает выполнять шаги своего алгоритма, но неким образом, который вступает в противоречие с этим алгоритмом (к примеру, когда некий процесс в алгоритме консенсуса принимает решение о значении, о котором прочие участники даже и не предполагали).
Такие отказы могут происходить по причине ошибок программного обеспечения, либо в результате исполнения процессами различных версий этого алгоритма и в этом случае ошибки проще в обнаружении и понимании. Это может быть намного сложнее когда у нас нет полного контроля над всеми процессами, а один из процессов намеренно вводит в заблуждение прочие процессы.
Возможно вы слышали о Византийской отказоустойчивости в аэрокосмической индустрии: системы самолётов и космических кораблей не получают ответы от своих составных компонентов с непосредственными значениями и проводят перекрёстную проверку их результатов.
Мы можем маскировать отказы формируя группы процессов и вводя в свои алгоритмы избыточность: даже когда один из процессов отказывает, его пользователь не замечет такого отказа [CHRISTIAN91].
Могут иметься некие связанные с отказами штрафы в производительности: обычное исполнение полагается на отклики процессов, а системе приходится откатывать обратно к замедлению в пути исполнения для обработки и исправления ошибок. Многие отказы могут быть предотвращены на уровне программного обеспечения просмотром кода, расширенным тестированием, гарантированной доставкой сообщений через введение таймаутов и переповторов и пребывания в полной уверенности относительно правильного локального выполнения.
Большинство из тех алгоритмов, которые мы собираемся рассмотреть здесь предполагают соответствующую модель восстановления после крушения и обрабатывают отказы за счёт введения избыточности. Такие предположения помогают в создании алгоритмов, которые лучше выполняются и более просты в понимании и реализации.
В данной главе мы обсудили часть терминологии распределённых систем и ввели некие базовые понятия. Мы поговорили о внутренне присущих трудностях и сложностях, вызываемых ненадёжностью самих системных компонентов: соединения могут отказывать в доставке сообщений, процессы могут претерпевать крушения, или сетевые среды могут делиться на части.
Этой терминологии нам должно хватить для продолжения нашего обсуждения. Оставшаяся часть книги посвящена тем решениям, которые обычно применяются в распределённых системах: мы опять задумаемся о том что может пойти не так и увидим какие варианты нам доступны.
|
| Последующее чтение |
|---|---|
|
Если вы желаете узнать больше относительно упоминавшихся в этой главе понятий, вы можете ссылаться на следующие источники:
|