Глава 9. Выявление отказов
Содержание
Когда в лесу падает дерево и никто вокруг не слышит этого, издаёт ли оно звук?
- Неизвестный автор
Чтобы система надлежащим образом реагировала на отказы, отказы должны выявляться своевременно. С отказавшим процессом можно связываться даже если он не способен отвечать, что увеличивает задержки и снижает общую доступность системы.
Выявление отказов в асинхронных распределённых системах (то есть без выполнения каких бы то ни было предположений о соотнесении по времени) чрезвычайно сложно, поскольку невозможно сказать столкнулся ли определённый процесс с крушением, либо он медленно работает и требует неограниченно длинного времени на отклик. Мы уже обсудили эту задачу в разделе Невозможность FLP.
Такие термины как умер, отказал и претерпел крушение обычно применяются для описания некого процесса, который прекратил выполнение своих шагов надлежащим образом. Такие термины как неотвечающий, сбойный и замедлившийся применяются для описания сомнительных (suspected) процессов, которые на самом деле могут быть умершими.
Отказы могут происходить на уровне установленного соединения (сообщения между процессами теряются или работают медленно), или на уровне самого процесса (сам процесс претерпел крушение или он работает медленно), а медленность может не всегда отличаться от отказа. Это означает, что всегда существует некий компромисс между ошибочным подозрением работающего процесса умершим (производящим ошибочные заключения - false- positives), и отсрочкой не отвечающего процесса умершим, что даёт ему преимущество сомнения и ожидания от него в конечном итоге отклика (производя ошибочно отрицательные заключения - false- negatives).
Определитель отказов это некая локальная подсистема, отвечающая за выявление отказавших или недостижимых процессов для их исключения из общего алгоритма чтобы гарантировать жизнеспособность при сохранении безопасности.
Жизнеспособность и безопасность являются свойствами, которые описывают некую способность алгоритма разрешать конкретную проблему и скорректировать свой вывод. Более формально, жизнеспособность это свойство, которое обеспечивает что некое определённое намеченное событие обязано произойти. Например, когда один из процессов отказал, определитель отказа обязан выявить такой отказ. Безопасность гарантирует что нежелательные события не случатся. Например, когда определитель отказов пометил некий процесс как умерший, этот процесс, фактически, должени быть умершим [LAMPORT77] [RAYNAL99] [FREILING11].
С практической точки зрения, исключение отказавших процессов помогает избегать ненужной работы и предотвращать распространение ошибок и каскадирование отказов, при снижении доступности в случае, когда мы исключаем потенциально живой процесс.
Алгоритмы выявления отказов должны демонстрировать существенные свойства. Прежде всего, каждый неотказавший участник должен в конечном итоге заметить такой имеющийся отказавший процесс и этот алгоритм должен быть способен развиваться и в конце концов достичь своего конечного результата. Это свойство носит название завершённости.
Мы можем судить о качестве алгоритма по его действенности: насколько быстро определитель отказов способен выявлять отказы. Другим способом делать это является рассмотрение точности такого алгоритма: более эффективный алгоритм может быть менее точным, а более точный алгоритм обычно менее действенный. Практически невозможно построить некий определитель отказов, который и точен, и эффективен. В то же самое время, определителям отказов допускается производить ошибочные заключения (т.е. неверно рассматривать рабочие процессы как отказавшие и наоборот) [CHANDRA96].
Определители отказов являются насущным предварительным требованием и интегральной составной частью многих алгоритмов консенсуса и атомарного широковещания, которые мы будем далее обсуждать в этой книге.
Многие распределённые системы реализуют определители отказов применяя сердцебиения (heartbeats). Такой подход достаточно популярен, так как он прост и строго полон. Обсуждаемые нами здесь алгоритмы предполагают отсутствие Византийских отказов: процессы не пытаются преднамеренно лгать о своём состоянии или состояниях своих соседей.
Мы можем запрашивать значение состояния удалённых процессов включая один из двух периодических процессов:
-
Мы можем включать некий ping. который отправляет сообщения удалённым процессам, проверяя что они ещё работают, ожидая некий отклик через определённый временной период.
-
Мы можем включить некое сердцебиение, когда определённый процесс активно уведомляет своих одноранговых собратьев что он всё ещё запущен, отправляя им сообщения.
В качестве некого примера мы здесь воспользуемся ping, но та же самая задача может быть решена и при помощи сердцебиений, производя аналогичные результаты.
Каждый процесс поддерживает некий перечень прочих процессов (рабочих, умерших и подозреваемых в этом) и обновляет его
последним по времени откликом для каждого процесса. Когда некий процесс перестаёт откликаться на некий ping продолжительное
время, он помечается как подозрительный (suspected)
Рисунок 9-1 отображает обычное функционирование системы:
процесс P1 запрашивает значение состояния соседнего узла
P2, который отвечает неким подтверждающим откликом.

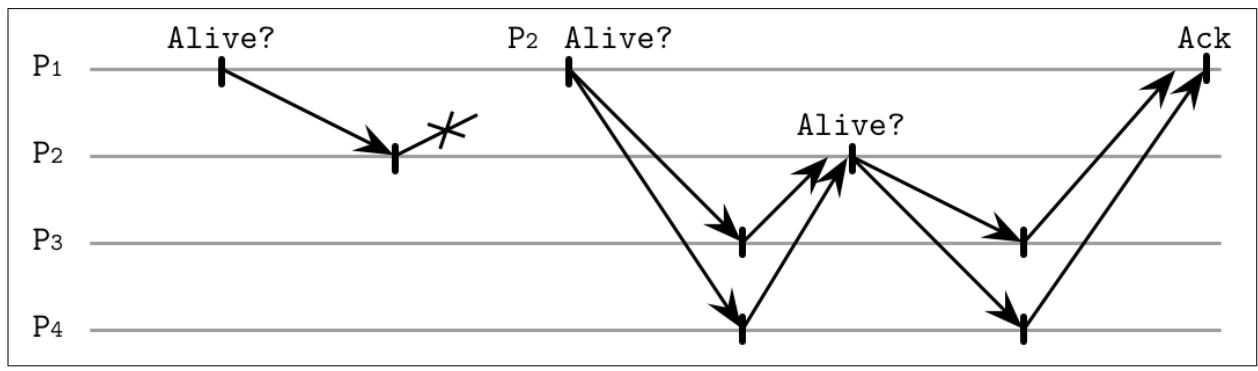
В противоположность этому, Рисунок 9-2 показывает как задерживаются подтверждающие сообщения, что в результате может приводить к пометке соответствующего активного процесса как упавшего.
Рисунок 9-2

Ping для выявления отказов: отклики задерживаются, приходя после отправки следующего сообщения
Многие алгоритмы выявления отказов основываются на сердцебиениях и таймаутах. К примеру, Akka, популярная инфраструктура построения распределённых систем, имеет некую реализацию выявления отказов срока окончания, которая использует сердцебиения и отчёты об отказах некого процесса когда тот отказал в регистрации за фиксированный промежуток времени.
Такой подход обладает рядом потенциальных недостатков: его точность полагается на тщательный выбор частоты ping и времени отклика, к тому же он не отражает видимость процесса с точки зрения прочих процессов. (см. раздел Независимые сигналы сердцебиения)
Некоторые алгоритмы при выявлении отказов избегают полагаться на таймауты. Например, Heartbeat, алгоритм выявления отказов без таймаутов [AGUILERA97], является неким алгоритмом, который лишь подсчитывает число сердцебиений и позволяет соответствующим приложениям выявлять процесс отказов на основании значений данных в соответствующих векторах счётчиков сердцебиений. Поскольку данный алгоритм свободен от таймаутов, он работает в предположениях асинхронных систем.
Этот алгоритм предполагает, что любые два правильных процесса соединены друг с другом неким справедливым путём, который содержит лишь справедливые соединения (т.е. когда сообщение отправляется через это соединение бесконечно часто, оно также и принимается бесконечно часто), а также что каждый процесс осведомлён о существовании всех прочих процессов в его сетевой среде.
Все процессы поддерживают перечень соседей и связанные с ними счётчики. Процессы начинают отправлять своим соседям сердцебиения. Всякое сердцебиение содержит некий путь, который пришлось пройти данному сердцебиению. Само первоначальное сообщение содержит значение своего первичного отправителя в этом пути и некий уникальный идентификатор, который может применяться во избежание широковещательной отправки того же самого сообщения множество раз.
Когда соответствующий процесс получает некое сообщение сердцебиения, он увеличивает значение счётчика для всех тех участников, которые присутствуют в этом пути и отправляет это сердцебиение одному из тех, который не присутствует там, добавляя себя в данный путь. процесс останавливает распространение сообщений, как только видно, что все известные процессы уже получили его (иначе говоря, идентификаторы процессов присутствуют в этом пути).
Так как сообщения распространяются по различным процессам, а пути сердцебиения содержат агрегированные сведения, получаемые от имеющихся соседей, мы можем (правильно) помечать некие не достигнутые процессы как работающие даже когда непосредственное соединение между этими двумя процессами отказывает.
Счётчики сердцебиений представляют некое глобальное и нормализованное представление всей системы. Это представление схватывает то как сердцебиения распространяются друг относительно друга, позволяя нам сравнивать процессы. Однако, одним из недостатков данного подхода является то, что интерпретация счётчиков сердцебиений может быть достаточно замысловатой: нам требуется указывать некое пороговое значение, которое может давать желаемые результаты. Пока мы не сможем сделать этого, наш алгоритм будет ошибочно помечать активные процессы как подозрительные.
Некий альтернативный, применяемый SWIM (Scalable Weakly Consistent Infection-style Process Group Membership Protocol, Масштабируемым слабо согласованным протоколом участия в группах процессов в стиле инфекции) [GUPTA01] служит для использования независимых сердцебиений (outsourced heartbeats) для улучшения надёжности используемых сведений относительно жизнеспособности соответствующего процесса с точки зрения его соседей. Такой подход не требует от процессов осведомлённости обо всех прочих процессах в его сетевой среде, а лишь о неком подмножестве соединённых однораногвых партнёров.
Как показано на Рисунке 9-3, процесс
P1 отправляет какое- то сообщение ping процессу
P2. P1 не
отвечает на это сообщение, поэтому P1 продолжает выбирать множество
случайных участников (P3 и P4).
Эти произвольные участники пытаются отправлять сообщения сердцебиений к P2
и, если он отвечает, преправлять подтверждения обратно к P1.
Это позволяет вести учёт как прямой так и косвенной досягаемости. Например, когда у нас имеются процессы
P1, P2 и
P3, мы можем проверять состояние
P3 с точки зрения как P1,
так и P2.
Независимые сердцебиения делают возможным надёжное выявление распределённой возможности ответов для принятия решения по определённой группе участников. Такой подход не требует широковещательных сообщений для пространных групп одноранговых участников. Так как независимые запросы могут включаться параллельно, этот подход способен быстро собирать дополнительные сведения относительно подозрительных процессов и позволяет нам принимать более точные решения.
Вместо того чтобы рассматривать отказ узла как некую двоичную задачу, при которой процесс способен быть только в двух состояниях: рабочем или отключённом, определитель отказов начисления фи (phi-accrual, φ-accrual) [HAYASHIBARA04] обладает непрерывной шкалой, перехватывая значение вероятности крушения соответствующего отслеживаемого процесса. Он работает сопровождая некое смещающееся окно, собирая времена появления наиболее последних сердцебиений от имеющихся одноранговых процессов. Эт сведения используются для оценки возникновения следующего сердцебиения, сравнивает это приближение со значением реального времени его появления и вычисляя значение подозреваемого уровня φ: насколько определённое значение определителя отказов близко к факту отказа на основании текущих условий сетево среды.
Этот алгоритм работает над сбором и выборкой времён возникновения, создания некого представления, которое может применяться для производства надёжных заключений относительно здоровья узла. Он применяет такие выборки для вычисления текущего значения φ: когда это значение достигает некого порогового, данный узел помечается как отключённый. Такой выявитель отказов динамично адаптируется к изменениям условий сетевой среды выравнивая ту шкалу, по которой определённый узел может помечаться как подозрительный.
С точки зрения архитектуры, выявитель отказов начисления фи может представляться как сочетание трёх подсистем:
- Отслеживание
Сбор сведений о жизнеспособности через ping, сердцебиения или выборочные запрос- отклик.
- Интерпретация
Принятие решения о том следует или нет помечать определённый процесс как подозрительный.
- Действие
При каждой пометке соответствующего процесса как подозрительного выполняется некий обратный вызов.
Обозначенный процесс отслеживания собирает и сохраняет выборки данных (которые, как предполагается, следуют нормальному распределению) в некотором окне фиксированного размера времён возникновения сердцебиений. Более новые появляющиеся добавляются в это окно, а более старые отметки сведений о сердцебиениях отвергаются.
Оценка параметров распределения из окна выборки производится определением среднего значения в рамках элементов
времени t после самого последнего. Отталкиваясь от этих сведений мы вычисляем
φ, который описывает с какой вероятностью мы должны принимать верное решение о жизнеспособности процесса. Иначе говоря,
насколько вероятно совершить ошибку и получить некое сердцебиение, которое будет противоречить вычисленным
предположениям.
Этот подход был выработан исследователями из Japan Advanced Institute of Science and Technology и теперь применяется во многих распределённых системах; например, в Cassandra и Akka (помимо уже упомянутого выявителя отказов срока окончания).
Другой подход, который избегает полагаться на представление некого отдельного узла на принятие решения это служба выявления отказов в стиле болтовни [VANRENESSE98], которая применяет болтовню (gossip, см. раздел Рассеивание Gossip) для сбора и распространения состояний соседних процессов.
Все участники поддерживают некий список прочих участников, их счётчики сердцебиений, а также временные отметки, определяющие когда произошло в последний раз приращение данного сердцебиения. Периодически каждый участник увеличивает свой счётчик сердцебиенией и распространяет свой список случайному соседу. По получению данного сообщения такой соседний узел сливает полученный список со своим собственным, обновляя счётчики сердцебиений для прочих соседей.
Узлы также периодически проверяют свой список состояний и счётчики сердцебиений. Когда некий узел не обновлял свой счётчик достаточно долго, он рассматривается как отказавший. Данный промежуток таймаута должен выбираться аккуратно для минимизации вероятности ложных включений. Насколько часто участники должны взаимодействовать друг с другом (иначе говоря, полоса пропускания наихудшего случая) ограничивается сверху, причём это значение может расти почти линейно с общим числом процессов в данной системе.
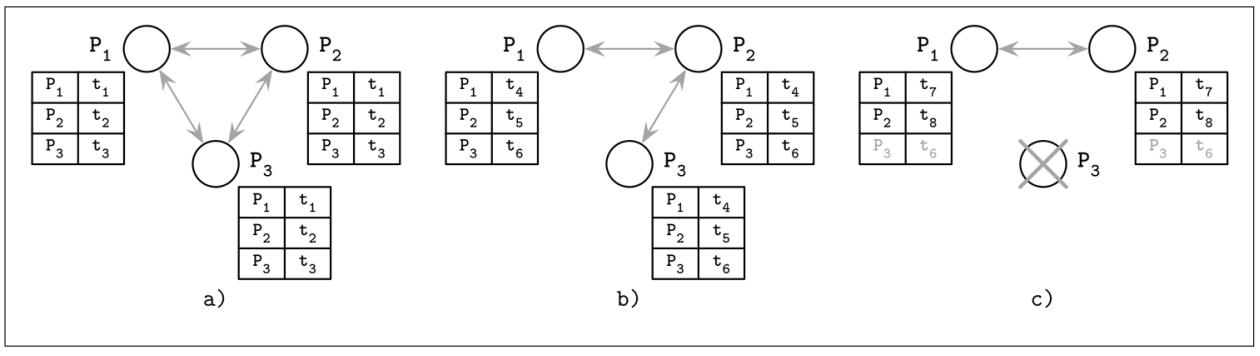
Рисунок 9-4 отображает три взаимодействующих процесса, разделяющих свои счётчики сердцебиений:
-
Все три могут взаимодействовать и обновлять свои временные отметки.
-
P3не способен взаимодействовать сP1, однако его временная отметкаt6всё ещё способна распространяться черезP2. -
P3испытывает крушение. Так как он более не отправляет обновления, он выявляется прочими процессами как отказавший.
Таким образом мы способны выявлять претерпевшие крушение узлы, а также те узлы, которые недостижимы со стороны прочих участников кластера. Это решение надёжное, так как такое представление кластера агрегируется от множества узлов. Когда имеется отказ в соединении между двумя хостами, сердцебиения всё ещё способны распространяться через прочие процессы. Применение gossip для распространения состояний системы увеличивает общее число сообщений в данной системе, однако позволяет сведениям распространяться более надёжно.
Так как распространение сведений об отказах не всегда возможно, а к тому же их распространение для всех участников может быть затратным, один из подходов с названием FUSE (failure notification service, служба уведомления об отказах) [DUNAGAN04], сосредоточена на надёжном и не затратном распространении сведений об отказах, которое работает даже в случае разбиения сетевой среды на разделы.
Для выявления отказавшего процесса данный подход выстраивает все процессы по группам. Когда одна из групп становится недоступной, все участники выявляют такой отказ. Иначе говоря, при каждом выявлении отказа отдельного процесса он преобразуется в некий групповой отказ и так и распространяется. Это позволяет выявлять отказы, при наличии любого шаблона отсоединённых разделов и отказы узла.
Процессы в определённой группе периодически отправляют сообщения ping прочим участникам, запрашивая являются ли они ещё пока рабочими. Если один из участников не способен ответить на данное сообщение по причине своего крушения, присутствия в сетевом разделе или отказа соединения, тот участник, который инициировал этот ping, в свою очередь, прекратит сам отвечать на сообщения ping.
Рисунок 9-5 отображает четыре взаимодействующих процесса:
-
Начальное состояние: все процессы в работе и способны взаимодействовать.
-
P2испытывает крушение и перестаёт отвечать на сообщения ping. -
P4выявляет отказP2и совсем прекращает отвечать на сообщения ping. -
В конце концов
P1иP3замечают что иP2, иP4не отвечают и отказ процессов распространяется на всю данную группу целиком.

Все отказы распространяются по всей системе от самого источника отказа на всех прочих участников. Участники постепенно прекращают откликаться на ping, преобразуя отказ из отказа отдельного узла на отказ группы.
В данном случае мы пользуемся отсутствием взаимодействия как средством распространения. Неким преимуществом данного подхода является то, что все участники гарантированно уясняют наличие группового отказа и адекватно реагируют на это. Одним из его недостатков является то, что отказ соединения отдельного процесса с прочими может быть преобразован также и в групповой отказ, но это же можно рассматривать и как некое преимущество в зависимости от варианта использования. Приложения могут применять свои собственные определения распространения отказов для учёта такого развития событий.
Выявление отказов является существенной частью любой распределённой системы. Как показывает результат невозможности FLP, никакой протокол не способен обеспечивать консенсус в некой асинхронной системе. Определители отказов помогают пополнять данную модель, позволяя нам решать некую задачу консенсуса при помощи компромисса между точностью и завершённостью. Одной из важнейших находок в этой области, доказывающей полезность определителей отказов, было описание в [CHANDRA96], которое показало, что решение консенсуса возможно даже при некотором определителе отказов, который делает бесконечное число ошибок.
Мы рассмотрели несколько алгоритмов выявления отказов, причём каждый из них предпринимал отличительный подход: некоторые сосредотачивались на выявлении отказов при непосредственном взаимодействии, какие- то пользовались широковещанием или gossip для распространения имеющихся сведений вокруг, а некоторые применяли вариант использования неподвижности (иначе говоря, отсутствия взаимодействия) как некого средства распространения. Теперь мы знаем, что мы способны применять сердцебиения или ping, аппаратные сроки окончания или непрерывные шкалы. Всякий из этих подходов обладает своими собственными сильными сторонами: простотой, правильностью или точностью.
![[Замечание]](/common/images/admon/note.png) | Последующее чтение |
|---|---|
|
Если вы желаете узнать больше относительно упоминавшихся в этой главе понятий, вы можете ссылаться на следующие источники:
|