Глава 4. Архитектура и тенденции HPC
Содержание
В данной главе описываются аппаратные возможности, доступные для обработки данных в среде высокопроизводительных вычислений. В ней представлен обзор последних тенденций состоянии архитектуры высокопроизводительных вычислений относительно сетевой среды, хранения и вычислений. Также рассматривается некий обзор программного интерфейса, который делает возможным для разработчиков применять такие ресурсы высокопроизводительных вычислений.
Наиболее современные HPC кластеры следуют простой архитектуре, которая иллюстрируется на Рисунке 4.1. Все машины серверов, более общо именуемые "узлами" что играет иную роль, взаимосвязаны высокоскоростным сетевым интерконнектом. Полные архитектура и развёртывание всех индивидуальных узлов HPC составляются тремя относящимися к оборудованию сторонами: вычислениями, сетевой средой и хранением. Обладая этим в своей основе, всякий HPC кластер покрывается четырьмя основными компонентами: вычислительными узлами, узлами хранения, узлами ввода/ вывода и высокоскоростной сетевой средой.
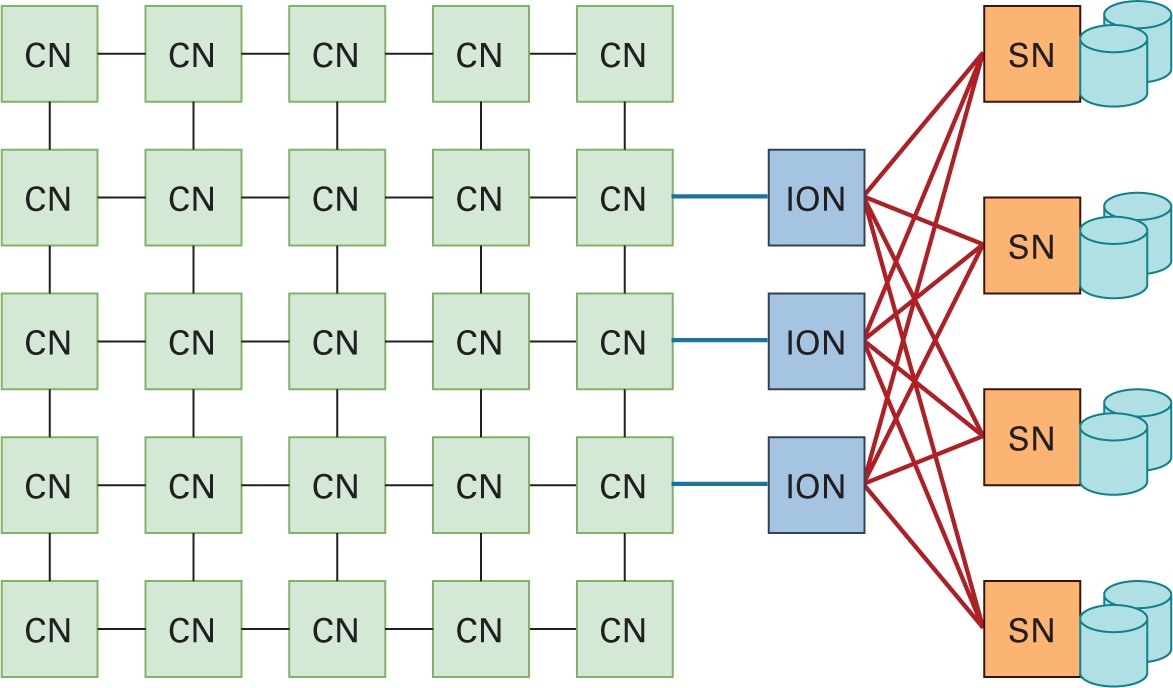
Вычислительный узел: CN (compute node) сопоставим с отдельно стоящей машиной сервера и обслуживает некий набор вычислительных элементов, в которых обрабатываются данные. Эти узлы снабжаются памятью (обычно неким набором оперативной памяти), которая доступна всем ЦПУ. В наши дни CN содержат многоядерные ЦПУ с поддержкой набора инструкций AVX2/ AVX-512 (то есть 512-битными Advanced Vector Extensions для инструкций single instruction multiple data [SIMD] в архитектуре x86), с поддержкой разгружающих ускорителей, таких как GPU NVIDIA с поддержкой CUDA (NVIDIA, 2021m) и GPU AMD (AMD, 2021a).
Каждый из таких узлов также снабжён локальным хранилищем узла, включая (1) хранилище NVM с широкой полосой пропускания, например, NVMe-SSDs (NVMe, NVM Express, 2021), а также (2) развивающейся PMEM с близкими к оперативной памяти задержками, например, 3DXPoint (Handy, 2015).
Узел хранения: Уровень SN (storage node) или связной архитектуры SAN составляют большую глобальную и совместно используемую параллельную файловую систему (PFS, parallel file system PFS), такую как Lustre (Braam and Zahir, 2002). Он внутренне состоит из одного или более узлов сервера метаданных, в которых хранятся метаданные пространства имён для всех SN и ряда узлов OSS, в которых хранятся фактические данные. CN (клиенты PFS) получают доступ к данным на этом уровне совместно используемого хранилища через его единое пространство имён.
Узлы ввода/ вывода: Узлы I/O (ION) это специализированные узлы, которые выступают мостом общего внутреннего интерконнекта всех вычислительных систем и связную архитектуру SAN своей PFS. В ION устанавливаются быстрые массивы на основе NVM, выстраиваемые при помощи PCIe-/ NVMe- SSD и они работают в прозрачном режиме для доступа к данным через свои SN. В некоторых системах этот уровень к тому же содержит уровень ускоряющего буфера (burst buffer).
Высокопроизводительная сетевая среда: Высокоскоростные сетевые интерконнекты позволяют применять современные протоколы взаимодействия с низкой латентностью, такие как InfiniBand (IBTA, 2021a), RoCE (Infiniband Trade Association, 2010), iWARP (Internet Wide Area RDMA Protocol) (Dalessandro et al., 2005), Amazon Elastic Fabric Adapter (EFA) (Amazon, 2021d) и тому подобные. Эти интерконнекты соединяют возможности хранения и вычислений индивидуальных узлов, что иллюстрируется Рисунком 4.1.
В промышленных системах HPC необходимые CN могут выделяться динамически для развёртывания вычислительных приложений с интенсивным доступом к данным короткого и длительного исполнения через планировщик заданий или систему пакетных заданий, например, Slurm (SchedMD, 2020b). Для получения высокой производительности от передовых технологий сетевой среды, хранилищ и вычислений в прошлом и в настоящее время в сообществе высокопроизводительных вычислений предлагались обширная поддержка встроенных библиотек и API. В последующих разделах мы обсудим каждую из этих трёх сторон архитектуры высокопроизводительных вычислений, а также представим подробный обзор доступных естественных библиотек.
Поскольку приложения наших дней и их рабочие наборы данных растут как в сложности, так и в размере, современные ЦПУ разрабатываются в главенствующем направлении включения оптимизированной под рабочую нагрузку функциональности, более быстрого перемещения данных и более действенного хранения данных. Обычная система HPC составляется из CN, которые применяют одну или более из следующих четырёх типов вычислительных технологий для ускорения приложений с интенсивной обработкой данных: (1) много ядерные ЦПУ, (2) GPU, (3) FPGA (field programmable gate arrays - программируемая вентильная матрица) и (4) ASIC (application-specific integrated circuits - специализированные интегральные схемы).
Ядра ЦПУ (CPU, центральный процессор) формируют собственно сердце всякого кластера HPC. Многоядерные ЦПУ наших дней снабжены десятками ядер и часто идут ноздря в ноздрю с такими ускорителями как GPU.
Тенденции аппаратных средств
В настоящее время имеется четыре доминирующих игрока в существующих кластерах HPC и центрах обработки данных(ЦОД), которые делают возможными быстрые и эффективные архитектуры ЦПУ.
Intel Xeon: Intel это наиболее преобладающий игрок со своим семейством Xeon (Intel, 2021g). Intel Skylake (Doweck et al., 2017) поддерживает многопроцессорность с общим числом процессоров до восьми, вплоть до двадцати восьми ядер на разъём (сокет) и содержит в себе x86 расширения AVX-512. {Прим. пер.: неточность: процессоры 2 поколения Intel® Xeon® Scalable помимо разъёма FCLGA4189 обладают и разъёмом FCBGA5903, в котором они поддерживают до 32-56 ядер на разъём при конфигурации с двумя разъёмами, Q2'19, а процессоры 3 поколения Intel® Xeon® Scalable (Q2'21), 10nm помимо 28 ядер в одном разъёме FCLGA4189 поддерживают 32/36/38/40 ядер.} Они поддерживают векторные инструкции SSE (Streaming SIMD Extension; 128-bit), AVX2 (256-bit) и AVX-512 (512-bit). Intel Cascade Lake (Arafa et al., 2019) пакуют сорок восемь ядер, встроенных в пару двадцати четырёх ядерных микросхем (два разъёма), соединяемых с применением Intel Ultra Path Interconnect. Они представили дюжину каналов памяти Double Data Rate 4 (DDR4) для поддержки DIMM (dual in-line memory module - модуль оперативной памяти с двухсторонним расположением микросхем) Intel Optane PMEM в иерархической конфигурации хранилища. Текущие версии Cascade Lake применяют PCIe 3.0, но в планах PCIe 4.0 {Прим. пер.: в процессорах 3 поколения Intel® Xeon® Scalable на рынке с апреля 2021}. Cascade Lake также представляет расширения для своего модуля векторной обработки AVX-512, которые ускоряют вычисления глубокого обучения. Эти инструкции векторной нейронной сети AVX-512 (VNNI), также именуемые DL Boost, расширены для поддержки формата AI с плавающей запятой. Последняя микроархитектура Intel Cooper Lake представила масштабируемые процессоры Intel Xeon третьего поколения (14-нм микроархитектура) в качестве преемника Cascade Lake, выпущенного в июне 2020 года (Intel, 2019d). Cooper Lake поддерживает до пятидесяти шести ядер, Intel Optane PMEM, память DDR4-3200 и более высокую производительность при выполнении рабочих нагрузок глубокого обучения. Утверждается, что Cooper Lake является первым процессором x86 со встроенным ускорением обучения глубокому обучению благодаря недавно представленной поддержке bfloat16. Ожидается, что последующие процессоры 10 нм++ Sapphire Rapids Xeon (Intel, 2020c) будут включать оперативную память DDR5 следующего поколения с поддержкой стандарта PCI-e 5.0 (insideHPC, 2021) и Compute Express Link со скоростью до 32,0 ГТ/с (гигапередач в секунду). для предоставления решений ввода-вывода с малой задержкой и высокой пропускной способностью, каждое из которых имеет пятьдесят шесть ядер и, возможно, до семидесяти двух ядер на узел (Morgan, 2019).
IBM Power: семейство ЦПУ IBM Power усилено архитектурой набора инструкций Power (ISA, instruction-set architecture), разработанных фондом OpenPOWER, поддерживаемым IBM. Сами ЦПУ POWER9 (Sadasivam et al., 2017) это многоконвейерные (superscalar), многопоточные симметричные мультипроцессоры на основе Power ISA. Они обеспечивают от сорока до сорока четырёх ядер с поддержкой до 2ТБ оперативной памяти. Они также предоставляют современную технологию подсистемы ввода/ вывода, включающую NVIDIA NVLink, PCIe Gen-4, and OpenCAPI (Coherent Accelerator Processor Interface). Грядущие процессоры POWER10 будут производиться с применением 7-нм технологического процесса и поддерживать большое число важных усовершенствований своего предшественника POWER9, включая большее количество ядер, улучшенную архитектуру, большее число контроллеров памяти и более совершенную поддержку подсистем ввода- вывода для OpenCAPI 4.0 и NVLink3 (IBM, 2020). {Прим. пер.: на рынке с 2021 года, выпускается Samsung, подробнее: Wikipedia, IBM.}
AMD Epyc: AMD EPYC (Lepak et al., 2017) это семейство x86 64- битных процессоров, разрабатываемых AMD. Этот процессор основывается на микроархитектуре Zen и производится 14-нм процессом. Процессоры Epyc настоящего времени снабжаются корпоративными серверными микропроцессорами с двумя разъёмами до 32 ядер {Прим. пер.: сведения о первом поколении Epyc 7001, Zen1, Naples, 2017.} Наряду с этим были представлены процессоры следующего поколения с 7-нм {TSMC} процессорной микроархитектурой Zen2 (Singh et al., 2020) под кодовым названием "EPYC Rome" {7002}. Они упаковывают до 64 ядер на разъём, с общим числом ядер в системе 128 (256 потоков) и восемью каналами памяти. Самые последние серверные микросхемы AMD, EPYC Milan {7003}, основаны на архитектуре Zen3 (AMD, 2021e) и содержат до 64 ядер с поддержкой 8- канальной памяти DDR4 SDRAM и 128 линий PCIe 4.0. {Прим. пер.: на рынке с 15 марта 2021 года, кодовое название "EPYC Milan" 7003; 21 марта 2022 вышли в свет ЦПУ EPYC Milan-X, 7003X, применяющие технологию 3D V-Cache для увеличения максимума кэша L3 на разъём с 256МБ до 768МБ, подробнее: Wikipedia. Технически говоря, все процессоры Epyc представляют собой микросборку кристаллов: до 8 7-нм вычислительных и одного чипа ввода вывода на 14-нм техпроцессе под одной крышкой в одном разъёме для процессоров 2 и 3 поколений при том, что в процессорах Milan-X третьего поколения применяются усовершенствованные сквозные кремниевые переходы для установки дополнительного кристалла поверх каждого из 8 вычислительных чипов, добавляя 64МБ кэш- памяти L3 для каждого чипа. 8 ноября 2021 года AMD обнародовала последующее поколение микросхем Epyс с новым разъёмом LGA-6096 SP5 (разъём всех предыдущих поколений LGA-4094 SP3). Под кодовым названием Genoa первые процессоры Epyc на базе Zen4 будут строиться на 5-нм техпроцессе TSMC и поддерживать до 96 ядер и 192 потока на разъём, а также 12 каналов DDR5, 128 линий PCIe 5.0 и Compute Express Link 1.1 (2022, Genoa-X 2023 ). AMD также поделилась информацией о родственном Genoa процессоре под кодовым названием Bergamo (2023). Bergamo будет основан на модифицированной микроархитектуре Zen 4 с названием Zen 4c, предназначенной для обеспечения гораздо большего количества ядер и эффективности за счёт более низкой производительности одного ядра, ориентированной на облачных поставщиков услуг и рабочие нагрузки по сравнению с традиционными рабочими нагрузками высокопроизводительных вычислений. Bergamo будет совместим с Socket SP5 и будет поддерживать до 128 ядер и 256 потоков на разъём. Для китайского рынка серверов совместным предприятием AMD и Китая создан вариант системы Hygon Dhyana, почти полностью повторяющий AMD Epyc. Для его поддержки кодом ядра имеется менее 200 строк нового кода ядра. По имеющимся сведениям, некоторые инструкции с плавающей запятой работают хуже, а вместо AES шифрования криптография заменена китайским вариантом.}
ARM: Несмотря на достижение огромного прогресса в улучшении возможностей ЦПУ жизненно важным также становится снижение эксплутационных расходов и воздействия на окружающую среду за счёт использования "зелёных" архитектур. Одной из таких энергоэффективных архитектур, оказывающих в наши дни большое влияние, особенно для обработки больших объёмов данных и научных вычислений, выступают процессоры Fujitsu A64FX (Fujitsu, 2021) с 64-разрядной архитектурой ARM (ARM, 2021b). Процессор A64FX состоит из сорока восьми ядер, применяющих 512- разрядное масштабируемое векторное расширение ARMv8.2-A и четырёх неоднородных узлов доступа к памяти (двенадцать ядер на узел). Каждый ЦПУ оснащён 32ГБ памяти с высокой пропускной способностью (HBM, high-bandwidth memory), обеспечивающей пропускную способность обмена с памятью 1ТБ/с, соединяемых через интерконнект Tofu. Процессоры A64FX способны выполнять три Тера операций с плавающей запятой в секунду (TFLOPS) при пиковой пропускной способности и при этом обладать в десять раз большей энергоэффективностью чем процессор x86. Он применяется для снабжения вычислительной мощностью кластера Fugaku (Monroe, 2020), который занял первое место в списке Top500 и десятое место в списке Green500 по состоянию на ноябрь 2020 (TOP500.org, 2020). В том же направлении ARM также работает над высокопроизводительными процессорами, известными как Neoverse V1 (ARM, 2021a), для приложений машинного обучения и искусственного интеллекта. {Прим. пер.: Процессор A64FX заменил собой выпускавшийся ранее с чередованием поколений под HPC / серверы баз данных (Oracle) компанией Fujitsu процессоры SPARC64 V. Его аналог, например, Kunpeng 920-6426, на фабриках TSMC с 7-нм техпроцессом на базе микроархитектуры TaiSHan v110 также выпускает компания Huawei.}
Оптимизированные под ЦПУ библиотеки
ЦПУ с поддержкой векторов или SIMD способен одновременно выполнять операцию над несколькими операндами данных при помощи одной инструкции. Одна из таких технологий, носящих название AVX, доступна в процессорах Intel или совместимых процессорах прочих производителей, поддерживающих SIMD. Длина таких векторов разнится от 128 до 512 бит.
В частности, при помощи 512- битных расширений AVX для x86 ISA у нас имеется возможность работы со всей строкой кэша в
единственной инструкции. Образец из Листинга 4.1 помогает проиллюстрировать простую программу добавления двух массивов
(векторов) с применением векторных инструкций AVX-512 посредством Intel Intrinsics (Intel, 2021e). Инструкции
_mm_512_* позволяют выполнять операцию сложения одновременно над шестнадцатью 32-
битными числами с плавающей запятой.
Листинг 4.1. Образец AVX-512 продукта DOT
float dot512 (float *xl, float *x2, size_t len) {
assert(len % 16 == 0);
__m512 sum = _mm512_setzero_ps ()
if (len > 15) {
size_t limit = len — 15;
for ( size_t i = 0; i < limit ; i += 16) {
__m512 vl = _mm512_loadu_ps(xl + i);
__m512 v2 = _mm512_loadu_ps (x2 + i);
sum = _mm512_add_ps (sum, _mm512_mul_ps (v1 , v2 ));
}
}
float buffer [16];
_mm512_storeu_ps( buffer , sum);
return buffer[0] + buffer[1] + buffer[2] + buffer[3] +
buffer[4] + buffer[5] + buffer[6] + buffer[7] +
buffer[8] + buffer[9] + buffer[10] + buffer[11] +
buffer[12] + buffer[13] + buffer[14] + buffer[15];
}
Некоторые библиотеки и инструменты применяют такие возможности SIMD ЦПУ для различных операций. Примечательные примеры включают следующее:
Intel ISA-L: Эта библиотека представляет инструменты для максимального увеличения пропускной способности, безопасности и отказоустойчивости хранилища, а также для минимизации применяемого дискового пространства. Она представляет набор оптимизированных функций для избыточного массива независимых дисков, удаляющего кодирования (erasure code), циклического избыточного кодирования, криптографического хэширования, шифрования и сжатия. Эти функции применяют встроенные функции SIMD ЦПУ через Intel SSE, AVX2 и AVX-512 для повышения производительности таких вычислений.
Intel MKL: MKL это сокращение от math kernel library - математической библиотеки ядра (Intel, 2021f). Она представляет набор оптимизированных математических процедур для научных, инженерных и финансовых приложений. В частности, oneDNN (Intel, 2021h) (ранее носившая название Intel MKL DNN) предоставляет набор математических программ для распространённых компонентом Глубинных нейронных сетей (DNN, deep neural network). MKL-DNN применяется Caffe (Intel, 2019b), OpenVINO (OpenVINO, 2021), TensorFlow (Ould-Ahmed-Vall et al., 2017), PyTorch (Greeneitch et al., 2019) и прочими популярными платформами программного обеспечения (ПО). Такие функциональные возможности содержать матричное умножение, пакетное нормирование, нормализацию, а также свёртку. Данная библиотека оптимизирована под развёртывание моделей на ЦПУ Intel Например, она содержит поддержку AVX-512 VNNI в процессорах Cascade Lake .
Директивы SIMD OpenMP: Возможности SIMD также применяются в библиотеках параллельного
программирования, таких как OpenMP (Dagum and Menon, 1998), которые спроектированы под применение симметричной многопроцессорной
модели (SMP). Подлежащая одновременному исполнению часть кода помечается специальной директивой (omp
pragma). Когда исполнение достигает параллельной секции, эта директива вызывает формирование подчинённых потоков
и каждый из них выполняет параллельную секцию кода независимо. После завершения потока он присоединяется к своему хозяину и продолжает
выполнять код, следующий за этой параллельной секцией.
OpenMP обеспечивает интеграцию SIMD через директиву omp simd (OpenMP, 2018), которая
сообщает своему компилятору что ему надлежит рассматривать векторное представление такого параллельного цикла. Директивы SIMD
OpenMP превращают OpenMP в более доступный благодаря ясному синтаксису и переносимости вне пределов MMX (Matrix Math Extensions)
и встроенных средств AVX. Лстинг 4.2 демонстрирует как можно упрощать пример скалярного произведения из Листинга 4.1 за
счёт простоты применения таких библиотек как OpenMP.
Листинг 4.2. Образец OpenMP продукта DOT
float dot_openmp_simd(float *xl, float *x2, size_t len) {
float sum = 0;
#pragma omp simd reduction (+:sum)
for (int i=0; i<len; ++i) {
sum += xl[i] * x2 [i] ;
}
return sum;
}
В наши дни графические процессоры (GPU) общего назначения стали наилучшим выбором аппаратных средств для ускорения вычислительных рабочих нагрузок в современных кластерах высокопроизводительных вычислений. В отличие от ЦПУ, которые оптимизированы под низкие значения задержек, графические процессоры предоставляют ориентированную на пропускную способность архитектуру, которая обеспечивает примерно в три раза больше одновременных потоков по сравнению с многоядерными ЦПУ. Одно устройство GPU состоит из множества кластеров процессоров, содержащих большое число SM (streaming multiprocessors, потоковых мультипроцессоров). Каждый SM содержит слой кэша L1 со связанными с ним ядрами. Как правило, один SM пользуется выделенным кэшем L1 и общим кэшем L2 перед выборкой данных из глобальной, подобной оперативной, памяти.
Тенденции аппаратных средств
Наряду с многоядерными ЦПУ, два ведущих производителя работают над внедрением архитектур графических процессоров, обеспечивающих высокую производительность для систем Глубинного обучения, HPC и облачных ЦОД.
GPU NVIDIA: Архитектура NVIDIA Volta (NVIDIA, 2017) и флагманский высокопроизводительный графический процессор Tesla М100 содержит 21.1 миллиардов транзисторов и почти 100 миллиардов соединений, что обеспечивает на 33% большую ёмкость по сравнению со своим предшественником, GPU Pascal (NVIDIA, 2021k). GPU Volta усиленные тензорными ядрами направлено разработаны для Глубинного обучения, обеспечивая до двенадцати кратного превосходства в отношении наивысшего пикового показателя TFLOPS для обучения и шести кратного для наивысшего пикового значения TFLOPS логического вывода, а тщательно построенная подсистема памяти HBM2 ёмкостью 16ГБ обеспечивает пиковую пропускную способность памяти 900ГБ/с. Ускоритель NVIDIA Tesla V100 построен на базе графического процессора Quadro GV100 GPU (NVIDIA, 2021l). В мае 2020 года NVIDIA выпустила ускоритель A100 на базе архитектуры Ampere (NVIDIA, 2021g). GPU A100 поддерживает производительность 19.5 TFLOPS при 32- разрядных операциях с плавающей запятой, 6912 ядер CUDA и 40 ГБ памяти GPU с полосой пропускания обмена в памяти 1.6ТБ/с. Эти передовые процессоры можно сочетать при помощи технологии интерконнекта NVLink NVIDIA (Foley and Danskin, 2017) для масштабирования памяти и производительности, создания массивного вычислительного решения в одной рабочей станции/ сервере. {Прим. пер.: 22 марта 2022 года NVIDIA анонсировала GPU H100 (кодовое название Hooper), подробнее: NVIDIA и Wikipedia}
На основе новейших графических процессоров NVIDIA была представлена специально создаваемая оптимизированная под Глубинное обучения система с полностью интегрированным аппаратным и программным обеспечением, которое можно быстро и легко развёртывать, с названием NVIDIA DGX (NVIDIA, 2021j). NVIDIA DGX (NVIDIA, 2021h), была первой такой представленной системой, построенной на Pascal и последующих версиях графических процессоров Volta. Следующее поколение системы NVIDIA DGX-2 (NVIDIA, 2021i) объединяет шестнадцать взаимосвязанных графических процессоров, обеспечивающих как скорость, так и масштабируемость. Платформа DGX-2, основанная на программном обеспечении NVIDIA DGX и масштабируемой архитектуре NVIDIA NVSwitch, платформа DGX-2 обещает в десять раз более высокую производительность Глубинного обучения для решения современных сложных задач искусственного интеллекта. Графические процессоры A100 также были развёрнуты в сервере DGX третьего поколения, включая восемь графических процессоров A100. Рабочая станция DGX A100 обладает 15 ТБ хранилища PCIe Gen-4 NVMe, двумя шестидесяти четырёх ядерными ЦПУ AMD Rome 7742, 1ТБ основной памяти и интерконнектом Mellanox High Dynamic Range (HDR) (200Гбит/с). {Прим. пер.: Анонсированный в марте 2022 года сервер 4 поколения DGX H100 строится на базе 8 Hopper ускорителей H100, что в общей сложности составляет 32 PFLOPS вычислений ИИ FP8 и 640ГБ памяти HBM3, что является обновлением по сравнению с HBM2 памятью DGX A100. Такое обновление к тому же увеличивает полосу пропускания VRAM (видео памяти) до 3ТБ/с. DGX H100 увеличивает стоечный размер до 8U чтобы приспособиться к TDP 700W для каждой из карт H100 SXM. DGX H100 также обладает двумя твердотельными накопителями ёмкостью 1.97ТБ для хранения операционной системы и 30.72ТБ твердотельного хранилища для данных приложений. Ещё одним заметным дополнением выступает наличие двух DPU Nvidia Bluefield 3 и обновление до 400Гбит/с Infiniband через сетевые карты Mellanox ConnectX-7, удваивающие полосу пропускания DGX A100. В DGX H100 применяются новые карты Cedar Fever, каждая с четырьмя контроллерами ConnectX-7 400 ГБ/с и по две карты на систему. Это даёт DGX H100 пропускную способность связной архитектуры 3,2 Тбит/с в сети Infiniband. DGX H100 имеет два не обладающими в настоящее время спецификацией Scalable ЦПУ Xeon 4-го поколения (под кодовым названием Sapphire Rapids) и 2 Терабайтами системной памяти.}
GPU AMD: В выпущенных в 2018 году GPU AMD Radeon Instinct (MI60 and MI50) (AMD, 2021b), представлены конструкции на основе архитектуры AMD Vega. Эти графические процессоры оптимизированы для операций Глубинного обучения, быстрых операций двойной точности и 16- 32ГБ сверхбыстрой памяти HBM2, обеспечивающей скорости обмена с памятью 1 ТБ/с. Данные карты также поддерживают PCIe Gen.4 и прямые соединения GPU- GPU с применением AMD Infinity Fabric, которая используется их ядрами ЦПУ Ryzen и EPYC обещая обеспечивать максимально полосу пропускания до 200 ГБ/с между четырьмя графическими процессорами (что примерно в три раза быстрее PCIe Gen.4). Недавно AMD выпустила графический процессор MI100 {Arcturus XL}, построенный на базе 7-нм+ {TSMC} процессоров и оснащённый 32ГБ памяти HBM2 {Прим. пер.: 4096-бит, с полосой пропускания до 1228.8 ГБ/с}, около 800 ядер {Прим. пер.: 120 CU} с вычислительной производительностью 100 TOPs (Тера операций в секунду) INT8 (целочисленного типа данных с 8 байтами) (AMD, 2021c). {Прим. пер.: 8 ноября 2021 AMD представила AMD Instinct MI250 (Aldebaran) и AMD Instinct MI250X (Aldebaran XT) (208 и 220 CU, соответственно, с памятью 128ГБ HBM2e на 8192- битной шине c с полосой пропускания до 3276.8 ГБ/с, TDP 500Вт), а 22 марта 2022 упрощённую версию AMD Instinct MI210 (Aldebaran) (120 CU с памятью 64ГБ/ шиной 4096- бит, TDP 300Вт) - все по технологии 6-нм (TSMC), подробнее...}
GPU Intel: Графические процессоры Ponte Vecchio (Intel, 2019c) это первые графические процессоры Intel, основанные на 7-нм микроархитектуре Xe-HPC. Эти графические процессоры, которые обычно применяются совместно с процессором Intel Xeon Scalable Sapphire Rapids следующего поколения, например, в грядущем суперкомпьютерном кластере Aurora (Argonne National Lab, 2021), должны обеспечивать производительность более 1 экзаFLOPS 64- битных операций с плавающей точкой. {Прим. пер.: планируемое завершение- конец 2022}. Каждый GPU содержит более 100 миллиардов транзисторов на сорока семи вычислительных плитках, что позволяет применять в одном корпусе два кристалла графического процессора и восемь модулей памяти HBM2 (по четыре на каждый GPU). {Прим. пер.: собирается из вычислительных плиток TSMC N5, Intel7 (10нм) и TSMC N7. 31 мая 2022 года Intel официально объявила о преемнике Ponte Vecchio, графическом процессоре под кодовым названием Rialto Bridge, подробнее...}
Программный интерфейс для GPU
Применяемые для программирования графических процессоров программные библиотеки традиционно расширялись за счёт библиотек конкретных поставщиков (например, библиотеки NVIDIA CUDA (NVIDIA, 2021a)). С другой стороны, недавнее появление спроса на вычисления с ускорением на GPU привело к появлению универсальных платформ, таких как ROCm (AMD, 2021d).
CUDA: NVIDIA создала архитектуру параллельных вычислений и платформу для своих графических процессоров под названием CUDA (NVIDIA, 2021a), которая позволяет разработчикам приложений выражать в коде простые операции обработки. В приложениях с ускорением на графическом процессоре последовательная часть рабочей нагрузки выполняется на ЦПУ, в то время как часть приложения с интенсивными вычислениями выполняется на тысячах ядер (core) графического процессора одновременно. Выгружаемые из ЦПУ в GPU вычислительные задачи, носят название ядерное приложение (kernel) GPU. CUDA позволяет разрабатывать приложения во множестве популярных языков программирования, включая C, C++, Fortran, Python и другие, а также выражать одновременность при помощи простых расширений API.
В Листинге 4.3 представлен образец программы CUDA для сложения двух векторов, а также различных этапов вычислений GPU.
Прежде всего со стороны ЦПУ вызывается cudaMemcpy для передачи массива или векторных
данных со своего хоста в устройство GPU. Затем активируется соответствующее подлежащее исполнению ядерное приложение CUDA.
Когда это ядерное приложение запущено, определяется количество потоков на блок (blockDim)
и число блоков на сетку (gridDim) (общее число потоков =
[blockDim * gridDim]). Каждый поток графического процессора производит оценку одной
копии ядерного приложения и вычисляет один или несколько векторных индексов для одновременного сложения множества элементов
массива. После завершения ядерного приложения GPU и синхронизации со ЦПУ своего хоста данные копируются обратно с устройства
GPU в ЦПУ его хоста.
Листинг 4.3. Векторная сумма с применением CUDA
#define SIZE 65536
#define NUMBER OF BLOCKS 1
#define THREADS PER BLOCK 65536
__global__ void vecsum_kernel(const float *v1, const float *v2,
float *out , size_t num) {
/* compute current thread id */
int idx = blockldx.x * blockDim.x + threadIdx .x;
/* each thread iterates one or more vector element */
while( idx < num_elements ) {
out [idx] = vl[idx] + v2[idx];
idx += gridDim.x * blockDim.x;
}
}
void vecsum_offload(float *v1, float *v2, float *out) {
/* GPU allocated memory */
float *dev_inl, dev_in2, dev_out;
cudaMalloc(&dev_inl, SIZE);
cudaMalloc(&dev_in2, SIZE);
cudaMalloc(&dev_out , SIZE);
/* copy data to GPU */
cudaMemcpy(dev_inl, vl, SIZE, cudaMemcpyHostToDevice);
cudaMemcpy(dev_in2, v2, SIZE, cudaMemcpyHostToDevice);
/* kernel launch on GPU */
sum_vectors_gpu<<<NUMBER OF BLOCKS, THREADS_PER BLOCK>>>
(dev_inl, dev_in2, dev_out, SIZE);
/* retrieve results from GPU */
cudaMemcpy(vout, dev_out, SIZE, cudaMemcpyDeviceToHost);
}
ROCm: это платформа класса HPC для вычислений на базе GPU, которые не зависят от языка программирования. Она создаёт прочную основу для современных вычислений, бесшовно интегрируя ЦПУ и GPU для решения рабочих нагрузок с интенсивными вычислениями. Это программное обеспечение обеспечивает высокопроизводительную работу графических процессоров AMD для ориентированных на вычисления задач в операционной системе Linux. ROCm обеспечивает непосредственную поддержку OpenCL, Python и ряда вариантов C++. Инструментарий Heterogeneous-Compute Interface for Portability из ROCmпредлагает независимый от производителя диалект C++, который готов к компиляции для GPU AMD или NVIDIA.
Альтернативой ЦПУ и GPU являются специализированные аппаратные средства FPGA (ПЛИС), которые служат в качестве перенастраиваемых интегральных схем. FPGA делают возможной аппаратную реализацию алгоритмов на уровне схем. Такой подход предлагает исключительную производительность при очень низком энергопотреблении, но при этом также обеспечивая большую гибкость, позволяя своему разработчику изменять лежащее в основе оборудование для наилучшей поддержки изменения программного обеспечения (ПО). В настоящее время, они в первую очередь применяются в умозаключениях Машинного обучения, видео- алгоритмах и в тысячах специализированных приложений малого масштаба. Основными современными разработчиками FPGA включают в себя Intel и Xilinx. Хотя они и обещают производительность, для них требуются дополнительные навыки программирования под применение подобного специализированного оборудования FPGA. Некоторые примечательные образцы включают в свой состав следующее:
Intel FPGA
FPGA Stratix 10 SX предоставляют собой высокопроизводительные программируемые карты ускорения FPGA на базе PCIe для центров обработки данных (ЦОД) и сред высокопроизводительных вычислений. Эти устройства с высокой пропускной способностью применяют так называемый "стек ускорения" для ЦПУ Xeon с FPGA и предоставляют разработчикам приложений надёжную платформу для развёртывания ускоряемых на основе FPGA рабочих нагрузок. {Прим. пер.: подробнее...}
AMD Xilinx Virtex и Versal
Virtex это флагманское семейство продуктов FPGA, разработанное Xilinx (2021) (27 октября 2020 года было заключено соглашение о слиянии компаний AMD и Xilinx). К К FPGA Virtex UltraScale можно подключить до 120 приёмопередатчиков, обеспечивающих скорость обмена данными до 30.5 Гбит/с в сочетании с огромными возможностями встроенной и внешней памяти. В качестве преемников своих FPGA Xilinx также представила Versal Adaptive Compute Acceleration Platform (ACAP) (Gupta, 2020). Она предоставляет элементы векторной и скалярной обработке, тесно связанные с программируемой логикой следующего поколения ПЛИС (FPGA). Они взаимодействуют между собой через высокоскоростную сетую среду в микросхеме. {Прим. пер.: подробнее...}
Альтернативой ЦПУ, GPU и FPGA выступает проектирование специально разрабатываемых ASIC, предназначенных для чрезвычайно быстрого выполнения фиксированных операций, поскольку вся имеющаяся логика микросхемы может быть выделена под некий набор ограниченных функций.
Google TPU
TPU это специально разработанный под Google ASIC. Они применяются для ускорения рабочих нагрузок Машинного обучения. В частности, они ускоряют выполнение вычислений линейной алгебры, которые широко применяются в подобных приложениях Машинного обучения. TPU минимизируют время достижения точности при обучении больших и сложных моделей нейронных сетей. {Прим. пер.: Google Tensor Processing Units, подробнее...}
Intel Nervana и Habana
Процессоры Intel Nervana Neural Network (Intel, 2021d), созданные исключительно для молниеносного обучения моделей Глубинного обучения, содержат большой объем памяти HBM и локальное статическое запоминающее устройство (SRAM) гораздо ближе к тому месту, где происходят вычисления. Это означает, что в кристалле может быть сохранено в кристалле, для экономии значительной энергии под повышение производительности. Процессор нейронной сети Intel Nervana оснащён высокоскоростными внутренними и внешними соединениями, позволяющими соединять несколько процессоров, для работы в качестве единой действенной микросхемы и масштабирования под поддержу более крупных моделей для более Глубинного обучения. На смену процессорам Nervana придёт учебный процессор Intel Habana Gaudi AI Training Processor (Habana, 2019 г.), специально разработанный для обучения моделей Глубинного обучения. Он применяет восемь ядер Tensor Processor Core 2.0, встроенное SRAM и четыре устройства HBM2, которые обеспечивают ёмкость 32ГБ и пропускную способность 1ТБ/с. Он также изначально включает 10 портов Ethernet 100 Гбит/с версией RoCE2. Точно так же, процессор искусственного интеллекта Habana Goya (карта HL-1000 PCIe) (Habana, 2019) обеспечивает пропускную способность около 15 000 изображений в секунду для рабочей нагрузки ResNet-50 (50-слойная остаточная нейронная сеть) с задержкой около 1 мс. {Прим. пер.: подробнее..., Habana.}
Cerebras WSE
Специалисты по таким технологиям как Cerebras (2021a), представили микросхемы для искусственного интеллекта (ИИ), обеспечивающие высокую производительность для приложений Машинного и Глубинного обучения. Масштабируемый механизм Cerebras Wafer Scalable Engine (WSE-2) (Cerebras, 2021b) представляет собой кремниевую пластину, состоящую из 2.6 трлн. транзисторов и 850 000 полностью программируемых ядер, оптимизированных под ИИ для обеспечения наилучшей в мире плотности вычислений ИИ. Перемещение данных между ядрами и памятью происходит полностью в кристалле, что гарантирует высокую полосу пропускания и минимальную латентность связи. В отличие от традиционных вычислительных устройств, которые работают с очень маленькой кэш- памятью, WSE-2 на основе технологии 7-нм пользуется 40ГБ распределённой по всей микросхеме статической памятью (SRAM) для обеспечения быстрых и ориентированных на память вычислений. Прогнозируется, что его производительность будет в несколько тысяч раз выше чем у новейших графических процессоров при в тысячу раз большей ёмкости устройства. Система Cerebras CS-2 построена для ускорения приложений ИИ с применением микросхем WSE-2 {Прим. пер.: 7-нм, TSMC, 2021}. Она интегрируется с платформами Машинного обучения с открытым исходным кодом, например, TensorFlow и PyTorch. {Прим. пер.: подробнее..., Cerebras.}
SambaNova
Специалисты по технологиям, подобным SambaNova (2021b), предоставляют ориентированные на ИИ/ Машинное обучение вычислительные решения посредством своих RDU (Reconfigurable DataFlow Unit - модулей повторно настраиваемого потока данных) SambaNova. RDU (Emani et al., 2021) это процессор нового поколения, обеспечивающий собственную обработку потоков данных и программируемое ускорение. Он применяет мозаичную архитектуру, состоящую из массива повторно настраиваемых блоков обработки и памяти. Они связаны между собой высокоскоростной трёхмерной коммутационной матрицей в кристалле. Такая повторно настраиваемая архитектура позволяет действенно программировать большое количество шаблонов параллельных данных как комбинацию вычислений, памяти и коммуникационных сетевых сред. Система SambaNova Systems DataScale оснащена очень большой памятью с применением множества RDU в своей стойке. Благодаря такой архитектуре и специальному стеку программного обеспечения они могут помогать в ускорении обучению моделей Машинного обучения, которые иначе не поместились бы в памяти графического процессора. Предполагается, что для дальнейшего масштабирования будет применяться память DDR5 следующего поколения (SambaNova, 2021a).{Прим. пер.: подробнее..., SambaNova.}
Graphcore
Такие полупроводниковые технологии как Graphcore (2021) разработали и выпустили специализированные процессоры ИИ. Их ASIC, носящие название IPU (intelligence processor units - интеллектуальных процессорных блоков), представляют собой массивны параллельные процессоры, предназначенные для хранения полной модели Машинного обучения и проведения внутри своего процессора вычислений с её помощью. Новейшие IPU второго поколения, носящие название IPU Colossus Mk2 GC200, разработаны на основании 7-нм микросхемы с 59.4 миллиардами транзисторов, 1472 вычислительными ядрами и 900МБ встроенной памяти (Toon, 2020). Такие процессоры GC200 применялись для создания IPU-Machine M2000 (четыре GC200 на машину) и обеспечивают 1 ПетаFLOP вычислений ИИ, поддерживаемых обменной памятью до 450ГБ и связной архитектурой IPU со скоростью 2,8 Тбит/с для связи с низкой задержкой, причём в одном лезвии 1U (1,75 дюйма) для удовлетворения потребностей в производительности большинства рабочих нагрузок ИИ (Moor Insights and Strategy, 2020). {Прим. пер.: подробнее..., Graphcore.}
Emu
Традиционные системы ЦПУ - GPU, как правило, обладают узким местом по причине перемещения данных из памяти в память, что может отрицательно сказываться на приложениях крупного масштаба для работы с Большими данными. Для облегчения этого, подобно Cerebras WSE, Emu (Dysart et al., 2016) предлагает новую архитектуру, которая вводит "обработку- в- оперативной памяти" и объединяет память и логику в единой микросхеме. Необходимые вычисления перемещаются туда, где располагается память при помощи новой концепции "мигрирующих потоков" (migratory threads). Такая система составляется из некого набора узлов, соединяемых системным интерконнектом на основе RapidIO, причём каждый подразделяется на "нодлеты". Каждый нодлет вносит свою память в глобальное адресное пространство для развёртывания системы с разделяемой памятью на основе модели разбитого на разделы глобального адресного пространства (PGAS, Partitioned global address space) (Padua, 2011). Это делает возможным доступ с высокой детализацией без необходимости кэширования или шин. Благодаря такому модульному подходу приложения работы с Большими данными способны достигать высокой производительности, поскольку отсутствует необходимость перемещения наборов данных на протяжении их рабочих процессов.
Приложения для работы с Большими данными включают разнообразный набор рабочих нагрузок с интенсивным применением данных. Например, в то время как автономная аналитика данных содержит в себе пакетные задания с крупными наборами данных, новые приложения Глубинного обучения работают с большим числом небольших файлов. Что ещё более важно, они оба требуют хранения и доступа к таким крупным наборам данных. Тем самым, для высокопроизводительного анализа данных, жизненно важно обеспечивающее высокоскоростной одновременный доступ к данным хранилище с высокой производительностью.
С появлением экономичных накопителей на сонове флэш- памяти, таких как PCIe-SSD и NVMe-SSD (NVMe, NVM Express, 2021 г.), современные и нарождающиеся узлы HPC оснащаются быстрыми локальными хранилищами на основе SSD. Новые технологии, такие как PCM (phase-change memory - память с фазовым переходом) (Wong et al., 2010) и 3D XPoint (Micron, 2019), которые предоставляют байтовую адресацию и близкую к оперативной памяти (DRAM) латентность, также широко изучаются в качестве хранилищ следующего поколения для наведения моста в зазоре между оперативной памятью и основанными на блочном доступе NVMe-SSD, что иллюстрируется на Рисунке 4.2.
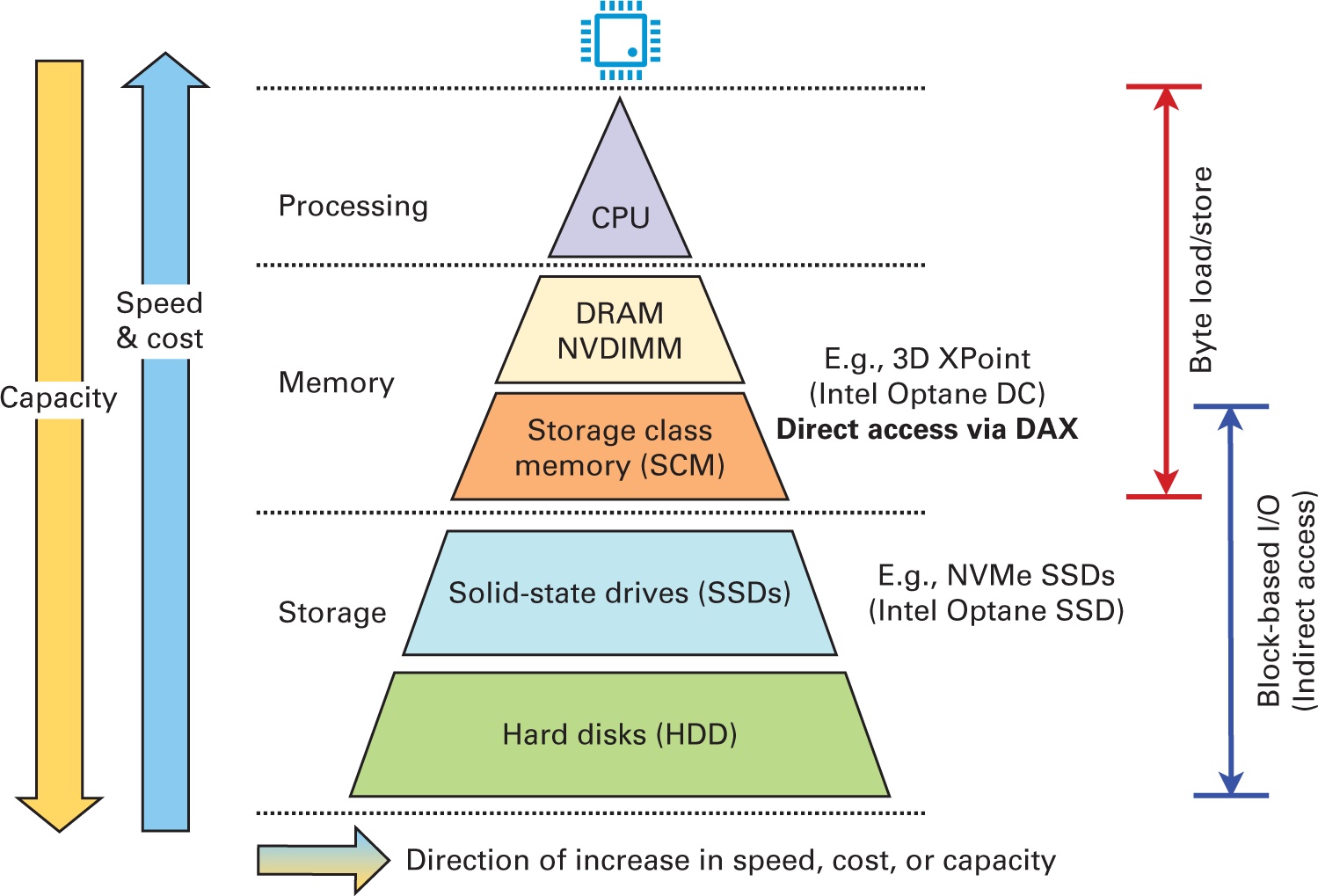
SSD на основе PCIe
Твердотельные накопители (SSD) на сонове PCIe представляют собой новый класс SSD, который может подключаться в ЦПУ через шину PCIe. PCIe-SSD заменяют твердотельные накопители SAT по причине более быстрых латентности и полосы пропускания структуры PCIe. Такие твердотельные накопители в своей основе обладают новыми технологиями хранения, например NAND (NOT AND logic gate - логического элемента НЕ-И) или памяти 3D XPoint (Intel, 2015b). Как правило, большинство твердотельных накопителей обладает множеством каналов, которые способны работать одновременно. Даже внутри канала для достижения высокой степени одновременности можно пользоваться конвейерной обработкой и чередованием в виде одновременности на уровне грани-, микросхемы- и кристалла-. Таким образом, PCIe-SSD обеспечивают возможность высокопроизводительного ввода/ вывода. Необходимые команды ввода/ вывода располагаются в памяти хоста или в памяти контроллера внутри самого своего SSD. Обмен данными обрабатывается запросами DMA (direct memory access - прямого доступа к памяти) поверх связной архитектуры PCIe. После последнего выпуска PCIe 6.0 (PCI-SIG, 2019) появился новый класс SSD, которые способны удовлетворять высоким требованиям к вводу/ выводу современных приложений для центров обработки данных (ЦОД).
NVMe
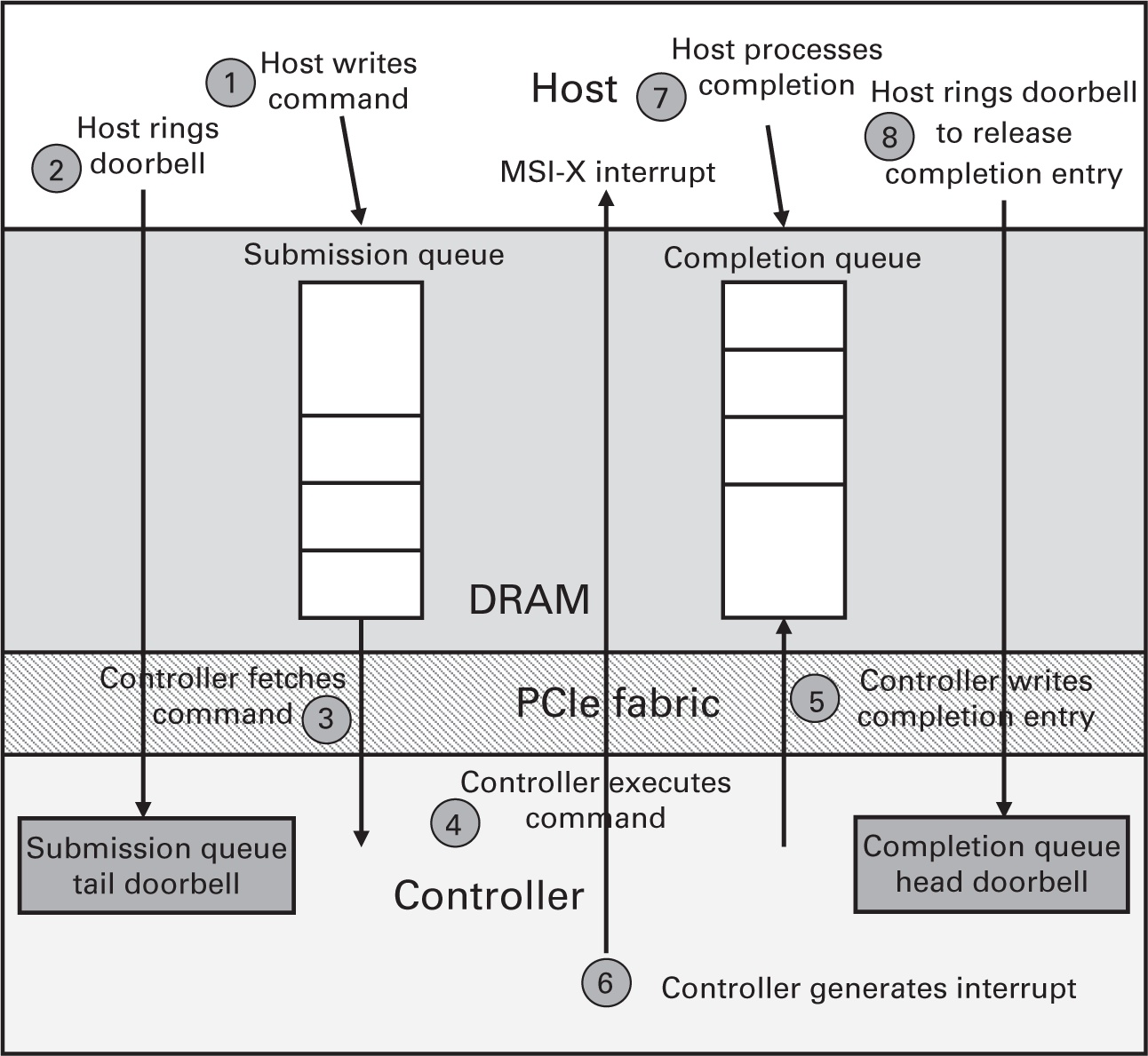
NVMe (NVMe, NVM Express, 2021) это стандарт взаимодействия с твердотельными накопителями на основе PCIe. NVMe заменяет устаревший и не масштабируемый стандарт Advanced Host Controller Interface (AHCI) standard (Intel, 2021b), который выступает технологическим стандартом для определения необходимых операций SATA контроллеров хоста. NVMe был создан с нуля для обработки малой латентности и высокой пропускной способности. В отличие от протокола AHCI, NVMe позволяет создавать большое число аппаратных очередей ввода/ вывода для отправки и выполнения запросов. Может иметься до 64k очередей, причём каждая очередь способна обладать до 64k ожидающих запросов. Это значительно улучшает возможности одновременного ввода/ вывода, учитывая гигантское число каналов флэш- памяти в современных твердотельных накопителях. Н Рисунке 3.4 представлен обзор конвейера обработки запросов NVMe Сначала хост записывает необходимую команду в свою очередь отправки на основе оперативной памяти и делает вызов в дверной звонок своего контроллера для сообщения о необходимости обработки команды. Его контроллер при помощи считывания DMA выполняет выборку этой команды и исполняет её. После выполнения, этот контроллер вырабатывает запись о завершении и помещает её в очередь завершения (CQ, completion queue), применяя DMA запись. Далее он вырабатывает MSI-X (enhanced message signaled interrupt - расширенного прерывания, доставляемого сообщением) для уведомления хоста о завершении запроса. Такой конвейер обеспечивает некую гибкость. Например, соответствующие представление и CQ могут помещаться в память контроллера, вместо памяти хоста. Кроме того, хост способен сам опрашивать CQ для проверки выполнения запроса, с целью снижения задержки. Самая последняя версия спецификации NVMe (версия 1.4) (NVMe, NVM Express, 2021), выпущенная в 2019 году, превратилась в стандарт, который теперь включён в твердотельные накопители, применяемые в современных ЦОД и кластерах высокопроизводительных вычислений. {Прим. пер.: в оригинале ошибочно указано значение стандарта 4.1 вместо 1.4. В настоящее время опубликована спецификация 2.0.}
Устройства NVMe революционным образом изменяют ПО промежуточного уровня для Больших данных через RDMA доступ, то есть, NVMe over Fabrics (NVMe-oF) (NVMe Express, 2016), а также протоколы удалённой сохраняемой памяти (Talpey, 2016, 2019; Li et al., 2020). В Главе 9 будет обсуждаться ускорение обработки Больших данных и управления ПО промежуточного уровня при помощи таких технологий на основании NVMe.
Память долговременного хранения
PMEM это новая аппаратная технология, сочетающая производительность оперативной памяти (DRAM) с энергонезависимостью SSD. По сути, она служит в качестве памяти долговременного хранения приложениям, требующим высокой производительности и долговечности. Самое большое преимущество, скорее всего, выступает адресация на уровне байт, подобно оперативной памяти, которая позволяет применять стандартные инструкции для загрузки и сохранения при доступе к данным. Такие новые технологии памяти, как PCM (Lee et al., 2010, 2009), ReRAM (Akinaga and Shima, 2010), оперативной памяти вращающего момента с передачей спина (spin-transfer torque, Tulapurkar et al., 2005) и Мемристор, (Strukov et al., 2008), все он рассматриваются как претенденты для реализации PMEM. Такие функциональные возможности кардинальным образом меняют принципы проектирования многих систем постоянного хранения, как это представлено в (Facebook, 2018, Kim et al., 2016, Wu and Reddy, Huang et al., 2014, Islamic, 2016b, Engel and Mertens, 2005, Ли, 2015 г.).
Память долговременного хранения (PMEM) может размещаться на шине памяти совместно с оперативной памятью (DRAM) в качестве энергонезависимых модулей с двусторонним расположением (DRAM, dual in-line memory modules). Ей энергонезависимость гарантирует, что данные остаются неизменными сразу после записи. Тем самым, ожидается, что латентность PMEM на запись будет хуже чем у оперативной памяти, например, ожидается, что PCM будет обладать задержкой в два- пять раз более медленной чем у оперативной памяти (Lee et al.). Аналогично, новая память Intel Optane DC (Izraelevitz et al., 2019), согласно оценкам, предоставляет пиковые значения полосы пропускания на считывание и запись в 33.2 ГБ/с и 8.9 ГБ/с, соответственно, причём задержки на запись медленнее чем у оперативной памяти и составляют около 346 нс. Продолжают появляться новые достижения, например, на недавнем мероприятии Memory and Storage 2020 event (Intel, 2020b) анонсирована Intel Optane Memory H20. {Прим. пер.: выпуск прекращён в январе 2021 года, сосредоточившись на производстве памяти на основе 3D NAND, (в том числ гибридной 3D XPoint и QLC 3D NAND).} Эти технологии памяти долговременного хранения настоящего времени и будущего к тому же предоставляют протоколы удалённого хранения и доступа PMEM (доступ к данным через RDMA, Talpey, 2016, 2019).
Модель программирования памяти постоянного хранения (Rudoff, 2013) позволяет получать доступ к PMEM (или NVRAM) как отображаемым в оперативной памяти файлам через функциональную возможность непосредственного доступа, Direct Access (DAX) (Rudoff, 2017). Это позволяет приложениям осуществлять загрузку/ сохранение непосредственно в PMEM. Поскольку данная модель не пользуется кэшированием страниц, самим операционной системе или приложению пользователя необходимо только сбрасывать соответствующие строки кэша ЦПУ для внесения соответствующих изменений данных в область постоянного хранения. Надёжная запись PMEM содержит два следующих шага:
1. Этап наполнения (flush): На протяжении данной фазы все связанные с рассматриваемыми
данными строки кэша подлежат постоянному хранению и записываются в PMEM. Для архитектуры x86 это может быть задействовано при
помощи инструкций clflush, clflushopt
и clwb.
2. Этап слива (drain): На этой фазе активируется барьер постоянного хранения для
обеспечения глобальной видимости наполненных данных. Для систем x86 в качестве такого барьера могут применяться такие инструкции
как sfence.
Буферизация ускорения и параллельная файловая система
В системах HPC текущего поколения CN обычно обладают локальным хранилищем ограниченной ёмкости по причине традиционной модели архитектуры Beowulf (Sterling et al. 2003). Как показано в Разделе 1 этой главы, SN образуют выделенный и совместно применяемый кластер хранения, в котором размещается высокопроизводительная параллельная файловая система (PFS, например, Lustre (Braam and Zahir, 2002), GPFS (IBM, 2021)), к которой и подключён CN через высокопроизводительные интерконнекты, такие как Infiniband. Приложения HPC для хранения данных крупного масштаба и доступа к ним полагаются на подобные Lustre PFS. Однако, по причине растущих требований к обработке приложений Больших данных в системах HPC традиционный уровень PFS запросто превращается в узкое место производительности имеющегося конвейера ввода/ вывода приложений Больших данных. Таким образом, современные кластеры высокопроизводительных вычислений обратились к аппаратным или программным технологиям буферирования взрывного ускорения. Основной целью взрывного буферирования выступает поглощение создаваемых приложениями работы с Большими данными штабелей данных, которые обычно производятся намного быстрее чем способна предоставлять PFS. Система буферизации взрыва (burst) обычно развёртывается в качестве промежуточного уровня высокопроизводительного хранения. В настоящее время разработали и продолжают выпускать системы буферизации взрыва ряд производителей, например, Infinite Memory Engine (IME) DDN и DataWarp Cray.
DDN IME: IME это решение DDN (2021), которое пользуется естественной платформой хранения только во флэш- носителях для этапа ввода/ вывода, а также кэширования необходимых файлов и включения масштабирования PFS. INE DDN вводит новый уровень поверх установленной PFS, который улучшает значение производительности сетевой среды и хранения посредством приспособления ввода/ вывода и слияния в единое целое приложений с интенсивным вводам/ выводом. Для возникающих приложений Машинного обучения и Глубинного обучения IME DDN способно действенно удовлетворять различным требованиям ввода/ вывода в неоднородных средах на основе ЦПУ и GPU.
Cray DataWarp: Cray DataWarp (Henseler et al., 2016) это технология ускорения ввода/ вывода, которая, подобно IME DDN, поддерживает необходимые шаблоны взрывного ввода/ вывода, типичные для приложений высокопроизводительных вычислений с интенсивным применением данных. Она направлена на разработку устройств хранения на базе флэш- памяти, которое можно применять в качестве глобального хранения кэша. По сути, блейд- модули DataWarp представляют собой вычислительные серверы Cray XC40, оснащаемые локальными твердотельными дисками и подключаемые через высокоскоростной интерконнект Cray Aries HPC. Каждый тип серии XC пользуется интерконнектом Aries.
Для доступа к каждому из разнообразных обсуждавшимися нами устройств хранения доступны различные программные интерфейсы. В данном разделе мы обсудим несколько из них.
Intel SPDK: Intel Storage Performance Development KIt (SPDK) (Intel, 2017) это библиотека хранения пространства пользователя, разработанная под современные приложения, которым требуется высокопроизводительный доступ к данным. Все необходимые драйверы помещаются в пространство пользователя, а вместо прерывания применяется опрос (polling), что гарантирует высокопроизводительный доступ к данным. Помимо наследуемых протоколов хранения (таких как POSIX, iSCSI и тому подобных) SPDK предлагает поддержку для стандарта NVMe, включая NVMeoF/NVMf. SPDK непосредственно применяет набор команд NVMe для взаимодействия с PCIe-SSD, полностью обходя стек программирования операционной системы. Для обработки запросов NVMe с применением NVMe пользователь обязан создать пару очередей (QP, queue pair), которая по своей сути представляет собой набор очередей для представления и финализации. Для каждой очереди QP способны обрабатываться целиком одновременно. Синхронизация внутри QP оставляется на усмотрение пользователя. В целом, для каждого потока (thread) ввода/ вывода рекомендуется создавать обособленную пару очередей, что делает максимально возможным применение одновременного ввода/ вывода и устраняет необходимость синхронизации. Операции ввода/ вывода обрабатываются асинхронно. Приложениям необходимо в явном виде обрабатывать финализацию, запрашивая у среды SPDK времени исполнения опрос соответствующих CQ (completed queue, финализированных очередей). {Прим. пер.: подробнее об организации опроса в нашем переводе Глава 63 API Epoll, Интерфейс программирования Linux Майкл Керриск (с) 2010, No Starch Press, Inc.} Архитектура SPDK решает большинство проблем с производительностью, которые досаждают драйверу NVMe, как это было представлено Yang et al. (2017).
В листинге 4.4 показан образец применения SPDK для записи блока данных в устройство NVMe. Это слепок с более подробного примера
"hello world", представленного в репозитории примеров SPDK (spdk.io). При инициализации и настройке подключения к
устройству NVMe (обозначается как init_spdk() [дополнительные сведения см. в spdk.io])
выделяется QP ввода/ вывода. Когда буфер данных ввода/ вывода для записи в файл готов, для запуска функции записи вместе с
функцией обратного вызова rw_complete(), применяется
spdk_nvme_ns_cmd_write(), которая вызывается по завершении записи. Завершение записи
можно отслеживать при помощи spdk_nvme_qpair_process_completions().
Листинг 4.4. Образец записи SPDK
struct workreq_t {
struct ns_entry *entry;
char *buf;
atomic_flag is_cmpl;
};
static void rw_complete(void *arg,
const struct spdk_nvme_cp1 *cmpl)
{
struct workreq_t *wr = arg;
wr—>is_cmpl = spdk_nvme_cpl_is_error (cmpl) ? —1 : 1;
}
void write_example_spdk (...) {
/* init NVMe device */
init_spdk (..);
struct workreq_t wr;
wr.entry —>qpair =
spdk_nvme_ctrlr_alloc_io_qpair (wr.entry —>ctrlr, 0);
wr.is_cmpl = 0;
wr. buf = rte_zmalloc(NULL, 0x1000, 0x1000);
sprintf, (wr.buf, "Hello Big Data!");
rc = spdk_nvme_ns_cmd_write( entry —>ns,
wr.entry —>qpair, wr.buf, 0, /* LBA start */,
1 /* num. of LBAs */, rw_complete, &wr, 0);
/* wait till write completes */
while (!wr.is_cmpl) {
spdk_nvme_qpair_process_completions (wr.entry —>qpair , 0);
}
spdk_free (wr.buf);
spdk_nvme_ctrlr_free_io_qpair(wr.entry —>qpair);
/* detach an free 1VVMe device */
cleanup (...);
}
Intel PMDK: Intel Persistent Memory Development Kit (PMDK) (Intel, 2019e) это сборник библиотек и инструментов для сохранения данных в PMEM и их сопровождения. Эти библиотеки собираются на функциональной возможности DAX, которая позволяет приложениям выполнять прямой доступ к PMEM в виде файлов соответствия памяти.
Библиотека libpmem предоставляет поддержку нижнего уровня памяти долговременного
хранения. В частности, она предоставляет сопровождение изменений наполнения (flushing) для своего устройства PMEM. В Листинге
4.5 иллюстрируется образец с этой libpmem для доступа к памяти долговременного
хранения. Как показывает данный пример, взаимодействие с располагающимися в PMEM данными через DAX аналогичны выполнению
операций в памяти. Они могут записываться для постоянного хранения в своё устройство PEM для долговременного хранения с
применением функций libpmem PMDK, таких как
pmem_memcpy_persist(). К тому же, данные могут изменяться в своих буферах кэширования и
наполняться для долговременного хранения только с применением таких функций как
pmem_persist().
Листинг 4.5. Образец сохранения памяти долговременного хранения PMDK
char *pmemaddr;
size_t len;
int is_pmem;
/* create a pmem file and memory map it */
if ((pmemaddr = pmem_map_file("/pmem—fs/myfile",
4096, PMEM_FlLE_CREATE,
0666, &len , &is_pmem)) == NULL I is_pmem == 0) {
exit(1); /* error; exit with failure */
}
/* store a string and flush to the persistent memory */
pmem_memcpy_persist(pmemaddr, "Hello ! PMEM", len);
/* delete the mappings */
pmem_unmap (pmemaddr, len);
По причине того, что непосредственный доступ к носителю хранения вводит новые задачи программирования, PMDK к тому же,
предлагает приложения с различными интерфейсами, включая libpmemobj для хранения
объектов на уровне транзакций, librpmem для удалённого доступа к PMEM с применением
сетевых карт (NIC) с возможностями RDMA, libpmempool для автономного управления
пулом и тому подобные.
На протяжении последнего десятилетия в области высокопроизводительных вычислений (HPC) произошёл переход к общедоступным кластерам, соединяемых современными высокопроизводительными интерконнектами, такими как InfiniBand (32 Гбит/с, 56 Гбит/с, 100 Гбит/с или 200 Гбит/с {Прим. пер.: а также 400 Гбит/с и выше}), Ethernet (10 Гбит/с, 25 Гбит/с, (32 Гбит/с, 56 Гбит/с, 40 Гбит/с, 50 Гбит/с, 100 Гбит/с или 200 Гбит/с {Прим. пер.: и Терабит Ethernet - 400 Гбит/с }), iWARP (10 Гбит/с, 25 Гбит/с, 40 Гбит/с, 50 Гбит/с или 100 Гбит/с), RoCE (10 Гбит/с, 25 Гбит/с, 40 Гбит/с, 50 Гбит/с, 100 Гбит/с или 200 Гбит/с) и Omni-Path (100 Гбит/с) {Прим. пер.: в июле 2019 года Intel объявила об отказе от продолжения работ над серией OPA 200, однако в сентябре 2020 анонсировала продление сетевой продукции Omni-Path в новом венчурном предприятии с Cornelis Networks}, {Прим. пер.: также стоит отметить применяемый в HPC интерфейс RapidIO (9.85 Гбит/с на дорожку (lane) - 10.3125 ГБод/с, до 25 ГБод/с) и отечественную Ангара, НИЦЭВТ}. На рис. 4.4 показаны различные широко применяемые высокоскоростные интерконнекты и протоколы. Кроме того, во многих высокопроизводительных вычислительных системах применяются такие частные сетевые среды как Cray Aries, Amazon EFA и NVIDIA NVlink. Cray работает над архитектурой Slingshot следующего поколения. В этом разделе мы даём краткий обзор этих сетевых технологий и их особенностей.
Рисунок 4.4
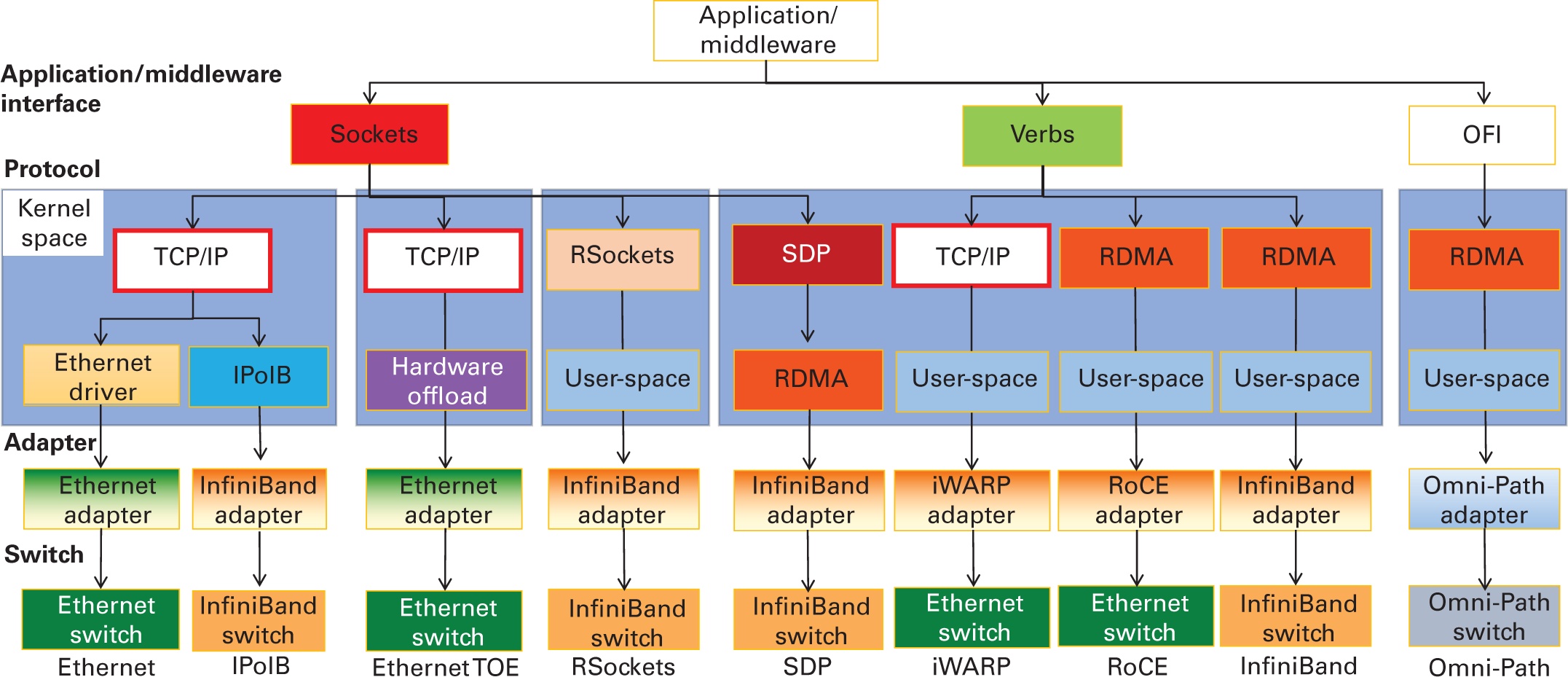
Обзор высокопроизводительных сетевых интерконнектов и протоколов. OFI (OpenFabrics Interfaces).
Современные сетевые интерконнекты характеризуются более высокими полосами пропускания, низкой латентностью и пониженной загрузкой ЦПУ. Н арене общедоступного оборудования эти технологии включают InfiniBand, высокоскоростной Ethernet и Intel Omni-Path. На арене частных решений, они содержат Cray Aries, Cray Slingshot и так далее.
Высокоскоростной Ethernet (1 Gb/s, 10 Gb/s, 25 Gb/s, 40 Gb/s, 50 Gb/s, 100 Gb/s): Традиционно для соединения серверов в центах обработки данных (ЦОД) применялся интерконнект Ethernet 1 Гбит/с (1-GigE). Благодаря улучшениям производительности последних лет в ЦПУ и вводе/ выводе, сетевая среда 1-GigE всё чаще превращается в узкое место в производительности приложений и рабочих нагрузок. В последнее время архитектуры ЦОД обновляются д сочетания соединения 10-GigE и более высокоскоростных подключений. Низкая задержка (латентность) имеет решающее значение для многих приложений высокопроизводительных вычислений, в том числе для сред финансовой торговли, а 10-GigE обеспечивает существенное улучшение латентности по всей сетевой среде. В то время как 10-GigE всё ещё прокладывает себе путь в ЦОД, спрос на более высокую полосу пропускания и скорость обмена данными уступает место 25 GigE, 40 GigE, 50 GigE или 100 GigE. Несколько лет назад был представлен стандарт 25 GigE, обеспечивающий в 2.5 раза более высокую производительность по сравнению с 10 GigE, что превращает его в экономически более выгодное обновление до инфраструктуры 10 GigE. Многие из таких высокоскоростных инфраструктур Ethernet применяют версии TCP/IP с аппаратным ускорением. Они носят название механизма разгрузки TCP (TOE, Transmission Control Protocol offload engines), которые применяют аппаратное обеспечение своей NIC для разгрузки протокола TCP. Преимущества TOE состоят в том, что они поддерживают полную семантику потокового обмена сокетов и действенно реализуют её в аппаратных средствах для уменьшения задержки и повышения полосы пропускания.
InfiniBand: InfiniBand (IBTA, 2021a) это стандартная в отрасли связная архитектура коммуникации, которая разрабатывается для соединения узлов в кластерах высокопроизводительных вычислений. Доступные в виде устройств PCIe с невысокой стоимостью, эти интерконнекты предоставляют не только высокую полосу пропускания (до 200 Гбит/с (Mellanox, 2018) {Прим. пер.: и выше}) и низкую латентность ( < 1мкс), {Прим. пер.: и ниже}, но также способствуют масштабируемости за счёт минимального вмешательства ЦПУ и сокращения копирования памяти для интенсивных сетевых операций. Дополнительно к этому, они предоставляют расширенные функциональные возможности, такие как RDMA, которые позволяют разрабатывать новые протоколы и библиотеки взаимодействия. Такая функциональная возможность позволяет программному обеспечению (ПО) считывать содержимое памяти иного процесса в другом узле или сервере (в удалённом процессе) без участия ПО на удалённой стороне. Это всё чаще применяется для разработки масштабируемых механизмов взаимодействия для HPC вычислений и ПО промежуточного уровня Больших данных с интенсивной работой с данными. Она всё чаще применяется для разработки масштабируемых механизмов взаимодействия в топовых системах суперкомпьютеров и ЦОД. Опубликованный в ноябре 2020 года список TOP500 показывает, что более 31% всех систем Top500 (TOP500.org) пользуются InfiniBand {Прим. пер.: 46% всех систем Top500 июня 2022}. Современные архитектуры с RDMA для ПО промежуточного уровня Больших данных обсуждаются в Главе 7.
Intel Omni-Path: Intel Omni-Path (Birrittella et al., 2015) это часть среды систем Intel Scalable, которые проектировались для снятия блокировки возникающих рабочих нагрузок HPC до десятков тысяч узлов. Выступая преемницей True Scale Fabric, такая оптимизированная под HPC связная архитектура построена на основании усовершенствованного интернет- протокола (IP) и технологии Intel с большим числом функциональных возможностей: адаптивной и дисперсионной маршрутизации, оптимизации потока обмена, защиты целостности пакетов и динамического масштабирования дорожек (lane) для обеспечения отказоустойчивости приложений времени исполнения. За последнее десятилетие Omni-Path была развёрнута в ряде топовых суперкомпьютеров. Опубликованный в ноябре 2020 года список TOP500 (TOP500.org) показывает, что 9.4% систем применяют Omni-Path {Прим. пер.: 8.2% всех систем Top500 июня 2022}. В 2019 году Intel остановила свой план по Omni-Path второго поколения. Однако в конце 2020 года было объявлено о новом дочернем предприятии Intel (Cornelis Networks (Cornelis, 2020)) для продолжения проектирования и разработки высокопроизводительного сетевого продукта следующего поколения в качестве преемника продукта Omni-Path.
Aries: Интерконнекты Cray Aries (Alverson, 2012), представленные как часть её системы Cray XC в сочетании с сетевой средой Dragonfly были разработаны для обеспечения действенной в отношении стоимости, масштабируемой глобальной полосы пропускания. Такие частные интерконнекты применяются рядом ведущих суперкомпьютерных кластеров, в том числе Piz Daint (CSCS, 2021) в Swiss National Supercomputing Centre и National Energy Research Scientific Computing Center (NERSC) Cori (NERSC, 2021a) в Berkeley lab.
Slingshot: Cray Slingshot совместим с Ethernet, способен подключаться к сторонним хранилищам данных и может выполнять всё чтобы системы имели возможность работать на скоростях на скоростях экза- масштабов. Обладая шестьюдесятью четырьмя коммутаторами со способностью пропускания 25.6 ТБ/с на коммутатор, по оценкам, он поддерживает до четверти миллиона оконечных точек при всего трёх скачках (hops) с применением всего одного оптического кабеля. Он предназначен для развёртывания предэкза- масштабной системы машин NERSC-9 "Perlmutter" (NERSC, 2021b) следующего поколения и машин экза- масштаба Argonne Aurora (Argonne National Lab, 2021), Oak Ridge National Laboratory Frontier (Oak Ridge National Laboratory (ORNL), 2021a), а также Lawrence Livermore National Library El Capitan (Lawrence Livermore National Laboratory, 2020). {Прим. пер.: лидер Top500 июня 2022, 1.102 ЭкзаФЛОПС, пользующийся 8 730 112 ядер, на основе новой архитектуры HPE Cray EX, сочетающей 3 поколение оптимизированные под HPC ЦПУ AMD EPYC™ и под ИИ ускорители AMD Instinct™ 250X, а также интерконнект Slingshot-11.}
NVLink: NVLink (Foley and Danskin, 2017) это высокоскоростной интерконнект непосредственно GPU с GPU. Для конфигураций с большим числом GPU он решает задачи интерконнекта предоставляя большие полосы пропускной способности, дополнительные связи и улучшая масштабируемость. Единственный GPU NVIDIA Tesla V100 способен поддерживать до шести подключений NVLink с общей полосой пропускания 300 ГБ/с, что позволяет получать десятикратное преимущество в полосе пропускания по сравнению с PCIe Gen-3. Такие серверы, как NVIDIA DGX-1 и DGX-2, предназначены для применения этой технологии под масштабирование распределённых вычислительных задач. {Прим. пер.: Hopper обладает 18 соединениями NVLink 4.0, допускающими общую полосу пропускания 900 ГБ/с.}
SR-IOV: Виртуализация ввода/ вывода с единым корнем (single root I/O virtualization) это спецификация, которая позволяет устройству PCIe отображаться как несколько обособленных физических устройств PCIe {Прим. пер.: подробнее в нашем переводе Технология PCI Express 3.0, Майк Джексон, Рави Бадрак, (с) 2012 MindShare, Inc.}. Спецификация SR-IOV это расширение спецификации PCIe (PCI-SIG, 2021). Она обеспечивает высокоскоростное взаимодействие, позволяя сетевому обмену обходить уровень программного коммутатора стека виртуализации Hyper-V. Она применяется в таких облачных решениях как Chameleon (Chameleon, 2021) и в экземплярах HPC Microsoft Azure (Microsoft, 2021a) для обеспечения практически натуральной сетевой производительности в средах виртуализации. {Прим. пер.: примером применения также является AMD MxGPU.}
Amazon Elastic Fabric Adapter: Amazon EFA (Raja, 2019) это сетевой интерфейс следующего поколения, предназначенный для предоставления расширенных сетевых возможностей экземплярам облачного решения Amazon’s EC2 с поддержкой сетевых скоростей до 100 Гбит/с при помощи настраиваемого интерфейса в среде виртуализации.
InfiniBand (IBTA, 2021a) это стандарт отрасли структуры коммуникации, который разрабатывался для взаимодействия CN и ION в кластерах HPC. В данном разделе мы предоставим краткий обзор его функциональных возможностей.
Модель взаимодействия и передача данных: Программное обеспечение (ПО) верхнего уровня пользуется интерфейсом с названием API Глаголов (Verbs) для доступа к предоставляемым адаптерами каналов хоста (HCA, Host Channel Adapter) и прочим сетевым оборудованием (например, коммутаторами) функциональными возможностями, включая установление соединения и взаимодействие в InfiniBand. Это проиллюстрировано на Рисунке 4.4.
InfiniBand следует модели на основе QP (queue pair, пар очередей). Процесс обладает возможностью постановки в очередь набора инструкций, которые выполняет имеющееся оборудование. Такое средств носит название рабочей очереди (WQ, work queue). WQ всегда создаются парами, некой QP, причём одна для операций отправки, а вторая для операций получения. Как правило, WQ отправки содержат инструкции, которые вызывают передачу данных из памяти одного процесса в память другого процесса, а WQ получения содержит инструкции о том, куда помещать получаемые данные. О завершении записей рабочей очереди (WQE, work queue entries) сообщается через CQ. применяемая для взаимодействия через Infiniband память должна регистрироваться в сетевом адаптере Infiniband. Регистрация выполняется с применением вызова Глаголов Infiniband, которые закрепляют соответствующие страницы в памяти и возвращают локальные (lkey) и удалённые (rkey) ключи регистрации.
Infiniband предлагает различные режимы обмена: Reliable Connection (RC, надёжного соединения), Reliable Datagram (надёжных дейтаграмм), Unreliable Connection (ненадёжных соединений) и Unreliable Datagram (UD, ненадёжных дейтаграмм), Extended Reliable Connected (расширенных надёжных соединений), Dynamic Connected (динамических соединений) и прочих. RC это ориентированная на соединение служба и для каждого взаимодействующего однорангового узла требуется обособленная QP. Она обеспечивает возможности RDMA, атомарные операции и надёжность службы. Одна QP UD способна связываться с любым количеством прочих QP UD. Однако UD не предлагает RDMA, надёжность и упорядочение сообщений. Более того, сообщения, размер которых превышает размер MTU (Maximum Transmission Unit, в современном оборудовании Mellanox 8кБ {Прим. пер.: в некоторых современных моделях 4кБ.}), должны быть разбиты на сегменты и отправлены фрагментами размером в MTU.
Семантики взаимодействия и образец API Глаголов: InfiniBand поддерживает два типа семантик взаимодействия в обмене RC: семантики канала и памяти.
При семантиках канала и в обмен данными между ними должны быть вовлечены и отправитель, и получатель. Отправитель обязан внести (post) запись рабочего запроса (WSE, work request entry) на отправку, которая соответствует внесённому его получателем рабочему запросу на получение. Значения буфера и lkey указываются в самом запросе. Рабочий запрос на получение должен вноситься до того как отправитель инициирует обмен данными. Значение размера буфера приёма должно быть равным или больше чем размер буфера отправки. Это позволяет осуществлять передачу без копирования, но требует строгой синхронизации между этими двумя процессами. Библиотеки более высокого уровня избегают такой синхронизации, предварительно внося запросы на получение с промежуточными буферами. Соответствующие данные копируются в фактический буфер приёма после того как целевой запрос вносит соответствующий запрос на получение. Это позволяет отправителю продолжить работу сразу после внесения им запроса. Существует компромисс между затратами на синхронизацию и дополнительными копиями. Мы проиллюстрируем применение таких двусторонних семантик SEND с применением API Глаголов InfiniBand на простом образце в Листингах 4.6 и 4.7.
Что касается образцов в Листингах 4.6 и 4.7, два равноправных узла регистрируют буферы отправки/ получения (применяя API
ibv_reg _mr()) и выполняют друг с другом обмен сведениями о своих QP, пользуясь
внеполосным механизмом (например, TCP/IP). При получении запроса на соединение, соответствующий целевой процесс, как это
показано в Листинге 4.7, предварительно вносит запрос на получение перед обменом информацией его QP с хостом. После
соединения, процесс хоста, как показано в Листинге 4.6, вносит двустороннее сообщение SEND применяя
ibv_poll_cq(). На целевой стороне соответствующий одноранговый узел опрашивает свою CQ,
ожидая необходимого сообщения от своего однорангового партнёра.
Листинг 4.6. Образец Глаголов send/receive InfiniBand (хост)
/* init IB device */
ibv_qp *qp;
ibv_cq *cq;
ibv_wc wc;
init_ib(qp, cq, ...);
char *buffer = malloc(1024);
struct ibv_mr *mr;
struct ibv_sge sge;
struct ibv_send_wr wr, *bad_wr;
uint32_t peer_key;
uint64_t peer_addr;
int flag;
mr = ibv_reg_mr(pd, buffer, SIZE,
IBV_ACCESS_LOCAL_WRITE);
/* exchange qp with target peer */
strcpy(buffer, "Big Data");
memset(&wr, 0, sizeof(wr));
sge.addr = (uint64_t)buffer;
sge.length = SIZE;
sge.lkey = mr—>lkey;
wr. sg_list = &sge;
wr.num_sge = 1;
wr.opcode = IBV_WR_SEND;
wr.send_flags = IBV_SEND_SIGNALED;
/* post a send
* poll for completion */
ibv_post_send(qp, &wr, &bad_wr);
while (!ibv_poll_cq(cq,1, &wc));
if (wc. status != 0)
perror ("send failure");
/* free and detach IB device */
cleanup (..);
Листинг 4.7. Образец Глаголов send/receive InfiniBand (цель)
/* init IB device */
ibv_qp *qp;
ibv_cq *cq;
ibv_wc wc;
init_ib(qp, cq, ...);
int flag;
char *buffer = malloc(1024);
struct ibv_mr *mr;
uint32_t my_key;
uint64_t my_addr;
struct ibv_mr *mr;
struct ibv_sge sge;
struct ibv_send_wr wr, *bad_wr;
flag = IBV_ACCESS_LOCAL_WRITE;
mr = ibv_reg_mr(pd, buffer,
SIZE, flag);
key = mr—>rkey;
addr = (uint64_t)mr—>addr;
/* exchange qp with host peer*/
sge addr = (uint64_t)buffer;
sge.length = SIZE;
sge.lkey = mr—>lkey;
flag = IBV_SEND_SIGNALED;
wr.sg_list = &sge;
wr.num_sge = 1;
wr.send_flags = flag;
/* pre—post a receive request*/
ibv_post_recv (qp,&wr,&bad_wr);
/* poll for completion */
while (!ibv_poll_cq(cq,1,&wc));
if (wc.status != 0)
perror("receive failure");
При семантике памяти, вместо операций отправки/ получения применяются операции RDMA. Эти операции RDMA являются односторонними и не требуют на целевой стороне вовлечения программного обеспечения. Соответствующий удалённый хост не должен выдавать рабочий запрос на обмен данными. Выставляемый запрос на отправку содержит значения адреса и lkey буфера источника, а также rkey своего буфера получателя. В InfiniBand поддерживаются как Write RDMA (запись в местоположения удалённой памяти), так и Read RDMA (считывание из местоположения удалённой памяти). Мы иллюстрируем применение RDMA с Глаголами InfiniBand при помощи простых образцов в Листингах 4.8 и 4.9.
В указанном выше примере наши два одноранговых узла сначала регистрируют блоки памяти, обмениваются дескрипторами
памяти и вносят (post) операции чтения/ записи. Регистрация осуществляется при помощи вызова
ibv_reg_mr(), который закрепляет указанный блок памяти на месте и возвращает структуру
ibv_mr, содержащую уникальный uint32_t key, тем
самым обеспечивая удалённый доступ к зарегистрированной памяти. Этот ключ вместе с адресом блока обменивается между
одноранговыми партнёрами через какой- то внеполосный механизм. Затем сам хост пользуется значениями удалённого ключа и адреса
для подготовки рабочего запроса на запись RDMA, который он выставляет в ibv_post_send().
Листинг 4.8. Образец Глаголов write RDMA (хост)
char *buffer = malloc(1024);
struct ibv_mr *mr;
struct ibv_sge sge;
struct ibv_send_wr wr, *bad_wr;
uint32_t peer_key;
uint64_t peer_addr ;
mr = ibv_reg_mr(pd, buffer, SIZE,
IBV ACCESS_LOCAL_WRITE);
/* get peer_key and peer_addr from target */
strcpy(buffer ,"Big Data!");
memset(&wr, 0, sizeof(wr));
sge.addr = (uint64_t)buffer;
sge.length = SIZE;
sge.lkey = mr—>lkey;
wr.sg_list = &sge;
wr.num_sge = 1;
wr.opcode = IBV_WR_RDMA_WRITE;
wr.wr.rdma.remote_addr = peer_addr;
wr.wr.rdma.rkey = peer_key;
/* post RDMA write */
ibv_post_send(qp, &wr, &bad_wr);
/* poll for completion */
while(!ibv_poll_cq(cq,1,&wc));
if (wc.status != 0)
perror("write failure");
Листинг 4.9. Образец Глаголов write RDMA (цель)
char *buffer = malloc(1024);
struct ibv_mr *mr;
uint32_t my_key;
uint64_t my_addr;
int flag;
flag = IBV_ACCESS_REMOTE_WRITE;
mr = ibv_reg_mr(pd, buffer,
SIZE, flag);
key = mr—>rkey;
addr = (uint64_t)mr—>addr;
/* exchange qp, key and addr with peer 2 */
/* server bypass;
* no polling or waits */
/* ... */
/* ... */
/* ... */
/* ... */
/* ... */
/* free to process
* other operations */
/* ... */
/* ... */
/* ... */
/* ... */
Соответствующий целевой одноранговый узел участвует только в настройке соединения через QP и в обмене адресами памяти, в отличие от семантики канала. Таким образом, говорят, что этот одноранговый хост выполняет удалённый обход ЦПУ или об односторонней связи. Поскольку сетевая карта с поддержкой RDMA напрямую записывает данные в соответствующие буферы памяти пользователя и не осуществляет никаких копий данных в явном виде в буферы взаимодействия, такой процесс носит название "нулевого копирования" (zero- copy).
InfiniBand это один из наиболее широко применяемых интерконнектов в TOP500 суперкомпьютеров (TOP500.org). Большинство приложений для высокопроизводительных вычислений и программного обеспечения (ПО) промежуточного уровня (например, библиотека MVAPICH2 MPI (Network Based Computing (NOWLAB), 2021b)), пользуются преимуществами InfiniBand либо через собственные интерфейсы InfiniBand, либо через собственные интерфейсы Глаголов (Verbs), RoCE или iWARP. С другой стороны, промежуточное ПО для Больших данных (такое как Hadoop и Spark) традиционно работало в кластерах с интерконнектом 10/40/100 GigE. Хотя применение возможностей RDMA лежащих в основе высокопроизводительных сетевых интерконнектов и является идеальным, это может потребовать потенциального изменения архитектуры. Таким образом, чтобы преодолеть разрыв между высокопроизводительными вычислениями и Большими данными, были введены два альтернативных подхода к применению собственных API интерфейсов Verbs: (1) совместимые с TCP/IP сетевые протоколы поверх InfiniBand (например, IP-over-InfiniBand) и (2) RDMA - возможность связи по высокоскоростным сетевым средам Ethernet (например, TCP/IP TOE). В этом разделе мы подробно остановимся на некоторых из таких современных сетевых протоколов.
Уровень IP Infiniband: InfiniBand, помимо прочего, предоставляет драйвер для реализации уровня IP. Это выставляет данное устройство Infiniband просто как ещё один доступный из данной системы сетевой интерфейс с IP адресом. Обычно такие устройства Infiniband представляются как ib0, ib1 и так далее. Эти интерфейсы представлены на Рисунке 4.4 (вторая колонка слева, с названием IPoIB). Этот уровень обычно носит название "IP-over-IB" или "IPoIB" для краткости. Для IPoIB существует два режима. Одним из них является режим дейтаграмм, реализуемый поверх UD, а другой это режим соединения, реализуемый поверх RC. Такой режим соединения предлагает лучшую производительность, поскольку он пользуется надёжностью своего оборудования.
Протокол непосредственных сокетов Infiniband: Sockets Direct Protocol (SDP) (Goldenberg et al., 2005) это транспортный протокол потока байт, который в точности имитирует семантику потока TCP сокета. Это спецификация стандарта отрасли, в которой применяются расширенные возможности сетевых стеков для достижения высокой производительности без необходимости внесения изменения в существующие приложения на основе сокетов. Данный интерфейс представлен на Рисунке 4.4 (пятая колонка слева, носящая название SDP). SDP представляет собой уровень поверх модели обмена сообщениями InfiniBand. Преобразование протокола потока байтов в лежащую в его основе ориентированную на сообщения семантику было разработано для обмена данными приложения одним из двух методов: через промежуточные частные буферы (пользуясь копированием буфера) или непосредственно между буферами приложения (нулевое копирование) с применением RDMA. Как правило, имеется пороговое значение размера сообщения, при превышении которого применяется нулевое копирование, что обеспечивает обмен данными в обход операционной системы. SDP также может использоваться в буферизованном режиме.
Rsockets: RSockets это протокол поверх RDMA, который поддерживает API уровня сокетов для приложений. Данный интерфейс представлен на Рисунке 4.4 (четвёртый столбец слева с названием RSockets). Интерфейсы API RSockets предназначены для соответствия поведению соответствующих вызовов сокетов. RSockets содержится в виде библиотеки оболочки в имеющемся стеке ПО OpenFabrics Enterprise Distribution InfiniBand с близкой к оптимальной скоростью в сетевых средах InfiniBand. Необходимый метод библиотеки оболочки, в принципе, можно применять в любой системе с динамической компоновкой (linking). Достигаемое за счёт горизонтального масштабирования повышение производительности для увеличения одновременности с применением RSockets поверх InfiniBand значительно выше того, что может достигаться при использовании обычных сетевых сред Ethernet.
Протокол Internet Wide Area RDMA: Для улучшения полосы пропускания в центрах обработки данных (ЦОД), широко применяющих 10/40 GigE, в качестве стандарта был принят 10 GigE.Для поддержки возрастающих скоростей сетевого оборудования невозможно было лишь традиционный интерфейс сокетов и появлялась необходимость снижения числа копий в памяти при обмене сообщениями. В связи с этим был представлен стандарт iWARP (RDMA Consortium, 2016). iWARP очень похож на применяемый InfiniBand слой Глаголов (Verbs) за исключением того, что iWARP нуждается в диспетчере соединений. Этот интерфейс представлен на Рисунке 4.4 (четвёртая колонка справа, с названием iWARP). Сетевой стек OpenFabrics (OpenFabrics Alliance, 2021 г.) предоставляет унифицированный интерфейс как для iWARP, так и для InfiniBand.
RDMA поверх конвергентного Ethernet: InfiniBand начала проникать в коммерческую сферу благодаря недавнему схождению (конвергенции) вокруг RoCE (IBTA, 2021b). Данный интерфейс представлен на Рисунке 4.4 (третий столбец справа с названием RoCE). Имеются две версии RoCE: RoCE v1 и RoCE v2. RoCE v1 представляет собой протокол канального уровня (link layer) Ethernet, а следовательно позволяет осуществлять связь между любыми двумя хостами в одной и той же широковещательной области (домене) Ethernet. RoCE v2 это протокол уровня Интернета, что означает, что пакеты RoCE v2 способны выполнять маршрутизацию. Благодаря своим современным функциональным возможностям RoCE v2 набирает обороты в последние годы.
Численные примеры производительности RDMA: Как мы только что обсуждали, сети с поддержкой RDMA способны обеспечивать очень хорошую производительность конечным приложениям. На Рисунках 4.5 и 4.6 показаны примеры значений производительности RDMA в последние годы. Эти значения взяты из библиотеки MPI MVAPICH2. На Рисунках 4.5a и 4.5b показаны значения односторонней задержки при обмене небольшими и большими сообщениями в сетевых средах InfiniBand и Omni-Path разных поколений. Как мы видим, для передачи небольших сообщений коммуникационная библиотека MVAPICH2 на основе RDMA способна обеспечить между двумя узлами задержку около 1 мкс. На Рисунках 4.6a и 4.6b показаны однонаправленные и двунаправленные полосы пропускания для обмена сообщений различного размера по разным поколениям сетей InfiniBand и Omni-Path. Как мы видим, для обмена большими сообщений коммуникационная библиотека MVAPICH2 на основе RDMA способна достичь почти пикового значения пропускной способности.
Рисунок 4.5
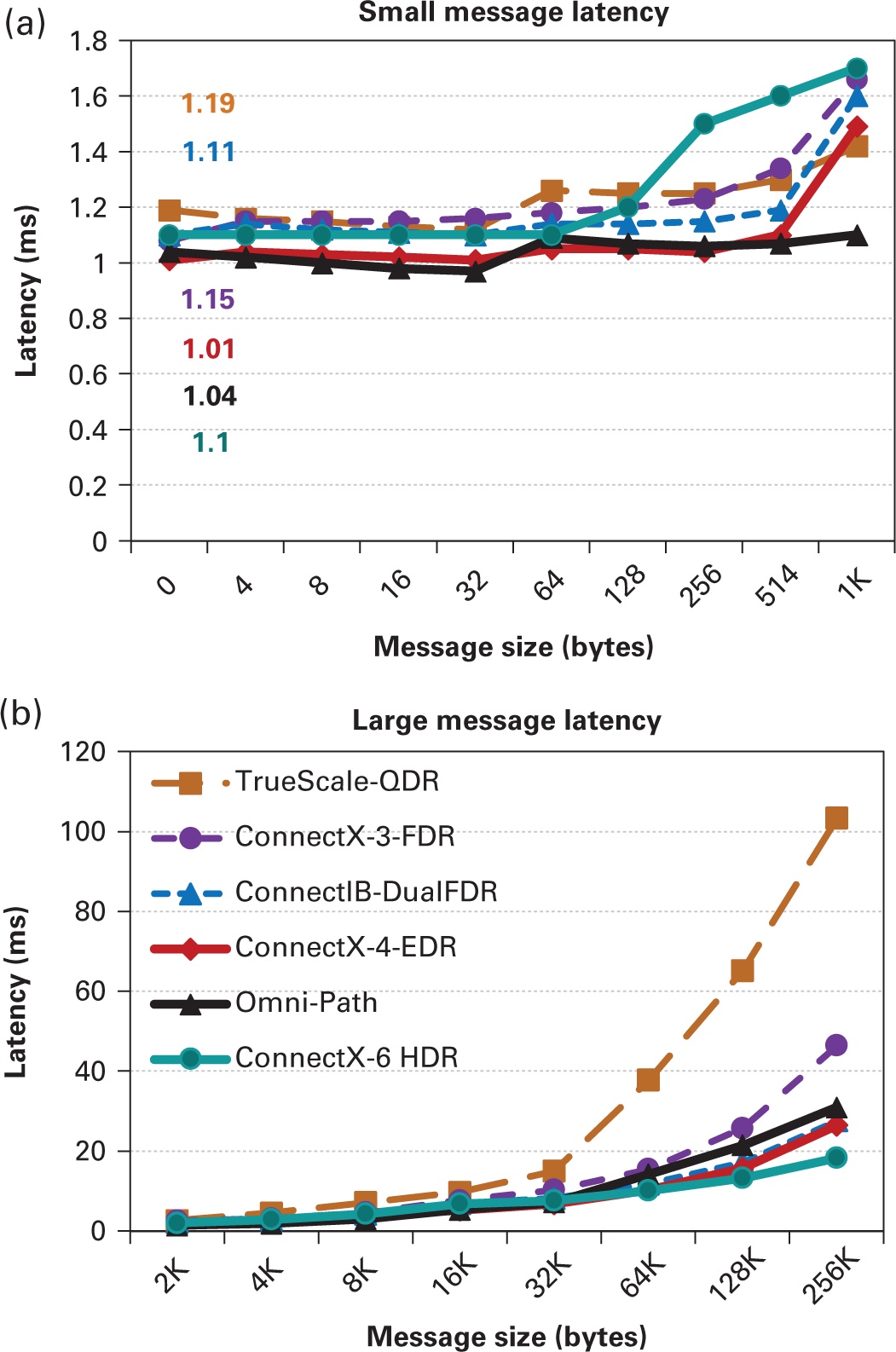
Односторонняя задержка: сетевые среды MPI over RDMA с применением MVAPICH2. (a) Задержка небольшого сообщения. (b) Задержка большого сообщения.
Рисунок 4.6
Пропускная способность: сетевые среды MPI over RDMA с применением MVAPICH2. (a) Однонаправленная пропускная способность. (b) Пропускная способность в двух направлениях.
И устройства RDMA, и устройства NVMe/PMEM разработаны для работы поверх шины PCIe. Таким образом, к устройствам хранения NVM имеется возможность получения удалённого доступа с применением любой технологии RDMA, включая InfiniBand, RoCE и iWARP. RDMA поверх твердотельных накопителей NVMe и устройств PMEM противопоставлены на Рисунке 4.7.
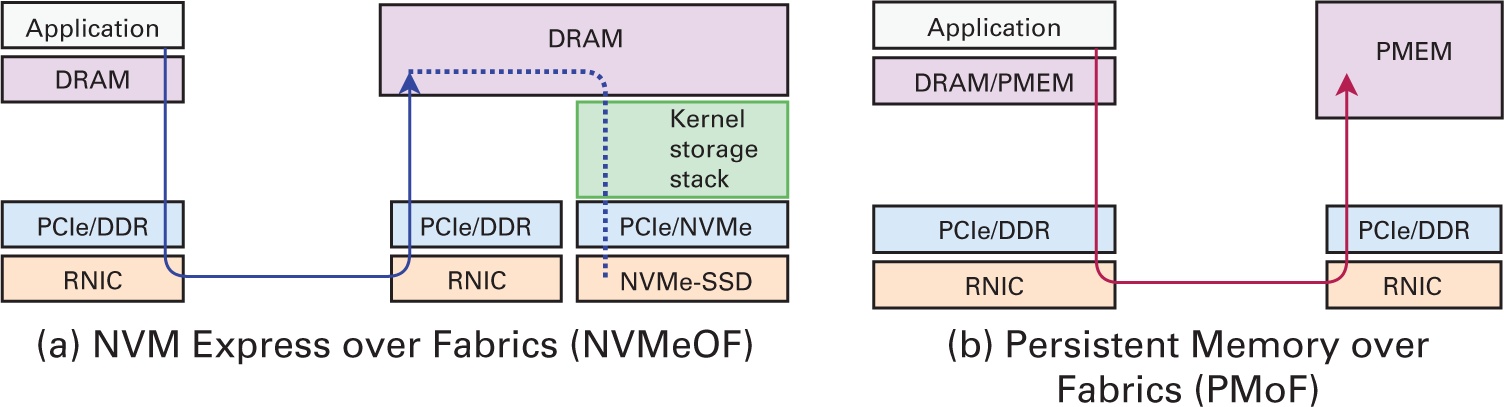
NVM Express over Fabrics: NVMeoF определяет общую архитектуру, которая поддерживает некий диапазон связных архитектур хранения для протокола блочного хранения между узлами хранения или ввода/ вывода в этой сетевой связной архитектуре. Такой протокол может применяться для обмена командами хранения NVMe между клиентскими узлами хранения поверх сетевых сред InfiniBand или Ethernet с применением технологии RDMAк целевым узлам, как это отражено на Рисунке 4.7a. Он разработан как приложение с небольшим весом, которое работает поверх стандартного интерфейса RDMA, как это осуществляет API Глаголов (Verbs). Этот протокол NVMeoF имеет целью стандартизацию протокола кабеля и драйверов для действенного доступа через сетевые среды с поддержкой RDMA при минимальной обработке, необходимой имеющимся целевым узлам.
Память долговременного хранения поверх связных архитектур: Для Persistent Memory over Fabrics (PMoF), устройства PMEM способны подключаться к имеющимся шинам памяти, как это отражено на Рисунке 4.7b. Благодаря такой архитектуре у нас имеется возможность получения доступа к удалённой памяти долговременного хранения (PMEM) непосредственно через RDMA C. Zhang et al. (2015). Read RDMA с целевого устройства памяти долговременного хранения способно предоставлять аналогичную оперативной памяти (DMAM) производительность, причём с такими аппаратными оптимизациями как Intel Data Direct I/O (Intel, 2012). Тем не менее, Write на основе RDMA в память долговременного хранения способна гарантировать лишь доставку на удалённую сторону; для обеспечения долговечности (операции фиксации) необходимы дополнительные шаги.
В настоящее время существует два обсуждаемых в этом сообществе механизма (см. Douglas [2015] и Talpey [2015]):
Долговечность на уровне устройства: Были предложены (Talpey and Pinkerton, 2016)
новые команды с аппаратной поддержкой (на уровне HCA - host channel adapter), такие как
RDMA Commit (Talpey, 2015), причём с односторонней
семантикой, аналогичной Read RDMA, для поддержки расширенного удалённого непосредственного сохранения данных (Talpey and
Pinkerton, 2016). Расширение PCI для поддержки RDMA Commit способно позволить сетевому
адаптеру обеспечивать надёжное хранение памяти долговременного хранения при минимальном или нулевом участии ядер целевого ЦПУ для
очистки своего кэша. В настоящее время для разрешения такой односторонней операции удалённого сброса изучается
RDMA Read. RDMA Read способен инициировать
целевой адаптер канала хоста (HCA) для принудительного сброса данных на устройство памяти долговременного хранения (PMEM) через
PCI (Douglas, 2015). Однако, в настоящее время этот метод требует применения записей без выделения (nonallocating writes),
которые обходят кэш ЦПУ при любой локальной или удалённой записи.
Долговечность сервера общего назначения: Выделенный процесс целевого узла может получать
уведомление в явном виде от выполняющего запись RDMA в память долговременного хранения (PMEM) хоста чтобы (1) сбросить связанные
с указанными данными строки кэша (cflush) и активировать барьер постоянного хранения
(sfence), а также (2) отправить уведомительное сообщение о завершении сохранения
(фиксации).
В данной главе представлен обзор возможностей современных аппаратных средств, которые применяются для разработки кластеров высокопроизводительных вычислений. Эти возможности охватывают новейшие технологии вычислений, хранения и сетевых сред. Чтобы разобраться как эти технологии делают возможными в своём сочетании высокопроизводительные вычисления, рассмотрим систему Summit, занявшую второе место в рейтинге Top500 (TOP500.org) (на основе рейтинга за ноябрь 2020 года). Кластер Summit (Oak Ridge National Laboratory, 2021b) в Национальной лаборатории Ок-Риджа состоит из 4356 узлов, каждый из которых оснащён двумя ЦПУ IBM Power9, шестью графическими процессорами NVIDIA V100 и NVLink для высокоскоростной связи ЦПУ-ЦПУ и ЦПУ-GPU. Он содержит более половины терабайта оперативной памяти и большой взрывной буфер на основе DDN IME для действенных операций ввода-вывода, подключаемый через двухканальное соединение Mellanox EDR (100 Гбит/с) InfiniBand. Он обеспечивает производительность 148.6 петаFLOPS для научных эталонных тестов HPC.
В то время как рабочие нагрузки научных вычислений продемонстрировали высокую степень масштабируемости приложений с применением новейших технологий высокопроизводительных данных, приложениям Больших данных ещё только предстоит полностью воспользоваться этими технологиями. Это открывает множество возможностей для разработки программного обеспечения (ПО) промежуточного уровня настоящего и грядущего времени для Больших данных, которое исследует действенные способы объединения Больших данных и технологий HPC для высокопроизводительного анализа данных. Дополнительное обсуждение ускоренного проектирования ПО промежуточного уровня Больших данных с применением технологий HPC представлено в Главах 7-9.