Глава 3. Архитектура и компоненты Ceph
В данной главе мы охватим:
-
Архитектуру системы хранения Ceph
-
Ceph RADOS
-
Устройство хранения объектов Ceph (OSD)
-
Мониторы Ceph (MON)
-
librados
-
Блочное хранилище Ceph
-
Шлюз объектов Ceph
-
Ceph MDS и CephFS
Содержание
Кластер хранения данных состоит из нескольких различных демонов программного обеспечения. Каждый из этих демонов заботится об уникальной функциональности Ceph и добавляет ценность для своих соответствующих компонент. Каждый из этих демонов отделен от других. Это одна из причин, которая позволяет удерживать стоимость кластера Ceph ниже при сопоставлении с корпоративными, фирменными системами хранения, представляющими собой черный ящик.
Следующая диаграмма кратко выделяет функции каждого компонента Ceph:
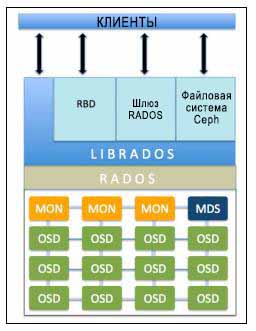
Безотказное автономное распределённое хранилище объектов (RADOS,
Reliable Autonomic Distributed Object Store) является основой хранения данных кластера Ceph.
Все в Ceph хранится в виде объектов, а хранилище объектов RADOS отвечает за хранение этих объектов,
независимо от их типа данных. Слой RADOS гарантирует, что данные всегда остаётся в согласованном состоянии
и надежны. Для согласованности данных он выполняет репликацию данных, обнаружение отказов и восстановление
данных, а также миграцию данных и изменение баланса в узлах кластера.
Как только ваше приложение выполняет операцию записи на ваш кластер Ceph, данные сохраняются в виде объектов в
устройстве хранения объектов Ceph (OSD, Object Storage Device).
Это единственная составляющая кластера Ceph в которой хранятся фактические данные пользователя, и эти же данные
получаются клиентом, когда он выполняет операцию чтения. Как правило, один OSD демон связан с одним физическим
диском вашего кластера. Следовательно, обычно, общее число физических дисков в вашем кластере Ceph совпадает с
количеством демонов OSD, которые выполняют работу по хранению пользовательских данных в тесном взаимодействии
со своим физическим диском.
Мониторы Ceph(MON, Ceph monitor)
отслеживает состояние всего кластера путем хранения карты состояния кластера, которая включает в себя
карты OSD, MON, PG и CRUSH. Все узлы кластера сообщают узлам монитора и делают общедоступной информацию обо
всех изменениях в своих состояниях. Монитор поддерживает отдельную карту информации для каждого компонента.
Монитор не хранит фактические данные; это является работой OSD.
Библиотека librados является удобным способом
получения доступа к RADOS с поддержкой языков программирования PHP, Ruby, Java, Python, C и C++. Она предоставляет
собственный интерфейс для кластера хранения данных Ceph, RADOS, и является основанием для других служб, таких
как RBD, RGW а также интерфейса POSIX для CephFS. librados API поддерживает прямой доступ к RADOS и позволяет
создать свой собственный интерфейс к хранилищу кластера Ceph.
Блочное устройство Ceph (Ceph Block Device,
известное также как RADOS block device, RBD)
предоставляет блочное хранилище, которое может отображаться, форматироваться и монтироваться в точности
как любой другой диск в сервере. Блочное устройство Ceph имеет функциональность корпоративных хранилищ, такую как
динамичное выделение и моментальные снимки.
Шлюз объектов Ceph (Ceph Object Gateway), также известный
как шлюз RADOS (RGW), обеспечивает RESTful интерфейс API совместимый с Amazon S3 (Simple Service Storage) и
хранилищами объектов OpenStack API (SWIFT). RGW также поддерживает множественных владельцев и службу проверки подлинности
OpenStack Keystone.
Сервер метаданных Ceph (MDS, Metadata Server отслеживает
метаданные файловой иерархии и сохраняет их только для CephFS. Блочное устройство Ceph и шлюз RADOS не требуют метаданных,
следовательно, они не нуждаются в демоне Ceph MDS. MDS не предоставляет данные непосредственно клиентам, тем самым устраняя
единую точку отказа в системе.
Файловая система Ceph(CephFS, Ceph File System ) предлагает POSIX-
совместимую распределенную файловую систему любого размера. CephFS опирается на CephFS MDS, т.е. метаданные, для хранения
иерархии. В настоящее время CephFS не готова к промышленной эксплуатации, однако она является идеальным кандидатом для
РОС тестирования. Ее развитие идет очень высоким темпами мы ожидаем, что она появится в промышленной эксплуатации
в кратчайшие сроки.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
{Прим. пер.: Это может показаться забавным, однако с некоторых пор стало возможным построение бесплатной среды виртуализации на основе гипервизора Hyper-V с бесплатной же системой хранения Storage Spaces, обладающей современными функциональностью и мощностью сопоставимыми, например, с Ceph. Хотя она и ограничена в масштабировании применением аппаратных технологий SAS/ FC. Остаётся дождаться смещения Storage Spaces Direct (S2D) в сферу халявного применения, чтобы имеющаяся в Непосредственно подключаемых пространствах хранения Программно определяемая шина хранения (Software Storage Bus), заменяющая собой SAS/FC, смогла составить конкуренцию системам хранения уровня Ceph!} |
Ceph RADOS (RADOS, Reliable Autonomic Distributed Object Store)
является сердцем системы хранения Ceph, которая также называется кластером хранения Ceph. RADOS обеспечивает для Ceph
различные характеристики, включающие в себя распределенное хранение объектов, высокую доступность, надежность, отсутствие
единой точки отказа, самовосстановление, самоуправление и тому подобное. В результате уровень RADOS имеет особое значение в
архитектуре хранения Ceph. Методы доступа Ceph, такие как RBD, CephFS, RADOSGW и librados, все работают поверх уровня RADOS.
Когда кластер Ceph получает запрос на запись от клиента, алгоритм CRUSH вычисляет местоположение и определяет где должны быть записаны данные. Эта информация затем передается уровню RADOS для дальнейшей обработки. На основании наборов правил CRUSH RADOS распределяет данные по всем узлам кластера в виде небольших объектов. Наконец, эти объекты сохраняются в OSD.
Будучи настроенным с фактором репликаций более одного RADOS, тем самым, обеспечивает мероприятия по сохранности данных. В то же время она реплицирует объекты, создает копии и сохраняет их в различных зонах отказов. Однако, для более индивидуальной настройки и повышения надежности вы должны выполнить тонкую настройку вашего набора правил для приведения их в соответствие вашим потребностям и требованиям среды.
Помимо хранения и репликации объектов в кластере, RADOS также гарантирует непротиворечивость состояния объектов. В случае возникновения несоответствия объектов производится восстановление по остальным копиям объектов. Эта операция выполняется автоматически и прозрачна для пользователя, обеспечивая тем самым для Ceph самоуправляемость и самовосстановление. Если вы проанализируете диаграмму архитектуры Ceph, то вы увидите, что она имеет две части, а именно, RADOS как нижнюю часть, которая является полностью внутренней для кластера Ceph без какого бы то ни было непосредственного интерфейса с клиентами, и верхней части, которая имеет все клиентские интерфейсы.
RADOS хранит данные в форме объектов внутри пулов. Давайте взглянем на пулы следующим образом:
# rados lspools
Вы получите вывод результатов, подобный показанному на следующем моментальном снимке:
[root@ceph-node1 /]# rados lspools data metadata rbd [root@ceph-node1 /]#
Проверьте список объектов в пуле при помощи следующей команды:
# rados -p metadata ls
Проверьте загруженность кластера следующей командой:
# rados df
Вывод результатов может отличаться, а может нет, от приводимого нами моментальном снимке:
[root@ceph-node1 ~]# rados df pool name category KB objects clones degraded unfound rd data - 0 0 0 0 0 0 metadata - 0 0 0 0 0 0 rbd - 0 0 0 0 0 0 total used 328196 total avail 46756168 total space 47084364 [root@ceph-node1 ~]#
RADOS состоит из двух основных составляющих, OSD и мониторов. Теперь мы более детально обсудим эти компоненты.
OSD Ceph является одним из самых важных строительных блоков кластера хранения данных Ceph. Оно сохраняет фактические данные на физических накопителях всех узлов кластера в виде объектов. Основную часть работы внутри кластера Ceph осуществляют демоны Ceph OSD. Они являются реальными рабочими лошадками, которые хранят данные пользователей. Теперь мы обсудим значение и обязанности демона Ceph OSD.
Ceph OSD хранит все клиентские данные в виде объектов и предоставляет те же данные клиентам при получении от них запросов. Кластер Ceph состоит из множества OSD. Для любой операции чтения или записи клиент запрашивает у мониторов карты кластера, а после этого он могут непосредственно взаимодействовать с OSD для выполнения операций ввода/вывода, без вмешательства монитора. Это делает процесс транзакции данных быстрым, поскольку создающие данные клиенты могут напрямую записывать данные на OSD, которые хранят данные без каких-либо дополнительных слоев обработки данных. Такой метод механизм хранения-данных-и-их-получения является относительно уникальным в Ceph по сравнению с другими решениями для хранения данных.
Основные особенности Ceph, в том числе надежность, выполнение балансировки, восстановления и согласованности привносятся OSD. Основываясь на настроенных размерах репликаций, Ceph обеспечивает надежность за счет тиражирования каждого объекта несколько раз по узлам кластера, что делает объекты весьма доступными и отказоустойчивыми. Каждый объект в OSD имеет одну первичную копию и несколько вторичных копий, которые разбросаны по остальным OSD. Поскольку Ceph является распределенной системой, а объекты распределены по нескольким OSD, каждый OSD выступает первичным OSD для некоторых объектов, и в то же время, он становится вторичным OSD для других объектов. Вторичный OSD остается под контролем основного OSD; однако, они способны стать первичным OSD. Начиная с редакции Ceph Firefly (0.80) был добавлен новый механизм защиты данных, известный как кодирование стирания. Мы подробно ознакомимся с кодированием стирания в последующих главах.
В случае сбоя диска демон Ceph OSD интеллектуально обменивается данными с другими равноправными OSD для выполнения операции восстановления. В течение этого времени хранящие реплицированные копии отказавших объектов вторичные OSD повышают ранг до первичных, и одновременно в ходе операции восстановления OSD создаются новые копии вторичных объектов, причем это полностью прозрачно для клиентов. Данные функции делают кластер Ceph надежным и согласованным. Типичная реализация кластера Ceph создает OSD демон для каждого физического диска в узле кластера, что является рекомендуемой практикой. Тем не менее, OSD поддерживает гибкое развертывание одного OSD на диск, на хост, или на том RAID. Большинство реализаций кластера Ceph в среде JBOD использует один OSD демон на один физический диск.
Ceph OSD состоит из физического диска, файловой системы Linux поверх него, и службы Ceph OSD. Файловая система
Linux существенна для демона OSD Ceph, поскольку она поддерживает расширенные атрибуты
(XATTRs, extended attributes). Такие расширенные атрибуты
файловые предоставляют демону Ceph OSD внутреннюю информацию о состоянии объекта, моментальных снимках,
метаданных и ACL, которая помогает в управлении данными. Посмотрите на следующую диаграмму:
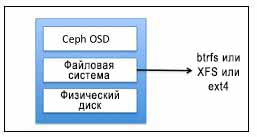
Ceph OSD работает поверх физического диска, имеющего допустимый раздел Linux. Раздел Linux может быть либо Btrfs (файловая система B-деревьев), XFS или ext4. Выбор файловой системы является одним из основных критериев для выполнения эталонного тестирования вашего кластера Ceph. В отношении Ceph, эти файловые системы отличаются друг от друга различными свойствами:
-
Btrfs: OSD, с файловой системой Btrfs на нижнем уровне обеспечивает наилучшую производительность по сравнению с OSD на основе файловых систем XFS и ext4. Одним из основных преимуществ использования Btrfs является ее поддержка копирования при записи и перезаписываемые моментальные снимки, которые очень выгодны в ситуации, когда дело доходит до подготовки и клонирования виртуальных машин. Она также поддерживает прозрачное сжатие и всеобъемлющие контрольные суммы, а также включает в себя управление многими устройствами в файловой системе. Btrfs поддерживает эффективные XATTR и встроенные данные для малых файлов, обеспечивает интегрированное управление томами поддерживающее SSD, а также имеет особенности требующиеся для онлайнfsck. Однако, несмотря на эти новые возможности, Btrfs в настоящее время не готова к промышленному использованию, но является хорошим кандидатом для тестового развертывания. -
XFS: Это надежная, зрелая и очень стабильная файловая система, а следовательно, рекомендуется для использования в промышленных кластерах Ceph. Поскольку Btrfs не готова к промышленному использованию, XFS является наиболее часто используемой файловой системы в системах хранении Ceph и рекомендуется для OSD. Тем не менее, при сравнении с Btrfs XFS располагается ниже. XFS имеет проблемы с производительностью при масштабировании метаданных. Кроме того, XFS является файловой системой с журналированием, то есть, каждый раз, когда клиент отправляет данные на запись в кластер Ceph, они вначале записываются в пространство журналирования, а затем в файловую систему XFS. Это увеличивает издержки записи одних и тех же данных в два раза, и, таким образом, делает производительность XFS более медленной по сравнению с Btrfs, которая не использует журналы. -
ext4: Четвертая расширяемая файловая система также является журналируемой файловой системой, которая является готовой к промышленному использованию файловой системой для Ceph OSD; однако, она не настолько популярна как XFS. С точки зрения производительности ext4 не сопоставима с BtrfsCeph OSD делает использование расширенных атрибутов основой файловой системы для различных форм внутренних состояний объектов и метаданных. XATTRs позволяют хранить дополнительную информацию, связанную с объектами в виде
xattr_nameиxattr_value, и, таким образом, обеспечивают способ маркировки объектов бОльшей информацией метаданных. Файловая система Ext4 не обеспечивает достаточной емкости для XATTRs из-за ограничений на количество байтов для хранения XATTRs, что делает ее менее популярной среди выбираемых файловых систем. С другой стороны, Btrfs и XFS имеет относительно большие пределы XATTRs.
Для OSD Ceph использует журналируемые файловые системы, такие как Btrfs и XFS. Перед фиксацией данных на устройстве хранения, Ceph вначале записывает данные в отдельную область хранения, называемую журналом, которая является меньшим разделом размера буфера, либо на том же шпиндельном диске, либо на отдельном шпиндельном диске, или на отдельном твердотельном диске (SSD), или даже просто файлом в файловой системе. При подобном механизме Ceph первоначально записывает все в журнал, а затем разгружает в хранилище, как показано на следующей диаграмме:
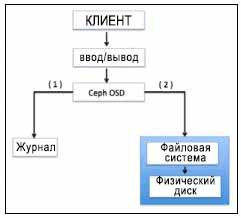
Журнал выгружается во внешнее хранилище путем синхронизации, по умолчанию выполняемой каждые пять секунд. Обычным размером для журнала является емкость в 10 ГБ, но чем больше размер раздела, тем лучше. Ceph использует журналы для скорости и согласованности. Журнал позволяет Ceph OSD выполнять малые записи быстро; случайные записи вначале вначале выполняются последовательным образом в журнал, а затем сбрасываются в файловую систему. Это позволяет файловой системе объединять операции записи на диск. Относительное увеличение производительности наблюдается, когда журналы создаются в разделах твердотельных дисков. При таком подходе все записи клиентов вначале осуществляются в суперскоростные журналы SSD, а затем сбрасываются на шпиндельные диски.
Использование твердотельных дисков в качестве журналов для OSD поглощает всплески рабочей нагрузки. Однако, если ваши журналы медленнее чем ваши устройства постоянного хранения, это может стать ограничительным фактором в производительности вашего кластера. В качестве рекомендации, вы не должны превышать соотношение OSD к журналу в 4 или 5 OSD на диск журнала при использовании внешнего твердотельного диска для журналов. Превышение указанного количества OSD на журнальный диск может создать узкое место в производительности для вашего кластера. К тому же, если отказывает ваш диск журнала, который обслуживает множество OSD под управлением файловой системы XFS или ext4, вы потеряете OSD и его данные.
Это является случаем, при котором Btrfs имеет преимущество; в случае отказа журнала в файловой системе на основе Btrfs, она откатывает назад по времени, приводя к минимальным потерям данных или совсем избегая их. Btrfs является файловой системой копирования-при-записи, что означает, что если содержимое блока изменено, то измененный блок записывается отдельно, таким образом, старый блок остается нетронутым. В случае происшествия с журналом, данные остаются доступными, поскольку старое содержание все еще доступно. Для дополнительной информации по Btrfs, посетите https://btrfs.wiki.kernel.org.
До сих пор мы обсуждали использование физических дисков для Ceph OSD. Однако, реализации кластеров Ceph также используют в своей основе RAID для OSD. Мы не рекомендуем вам использовать RAID для хранения ваших данных в кластере Ceph по целому ряду причин, которые перечисляются ниже:
-
Создание RAID с последующей репликацией поверх него является источником головной боли. По умолчанию, Ceph выполняет внутренние репликации для защиты данных; создание RAID на тех же реплицируемых данных не дает никаких преимуществ. Это, в конечном счете, добавит дополнительный уровень защиты данных и увеличит сложность. В RAID массиве, если вы утрачиваете диск, операции восстановления требуют дополнительного диска того же типа перед тем как они могут стартовать. Дополнительно, мы должны ожидать завершения записи всех утраченных данных на новый диск. Перенос тома данных RAID занимает огромное количество времени, а также ухудшает производительность по сравнению с методом распределенной репликации. Таким образом, вам не следует делать RAID при наличии репликаций. Однако, если в системе имеется RAID контроллер, вам следует использовать все дисковые устройства как RAID 0.
Для целей защиты данных Ceph полагается на репликацию вместо RAID. Преимущество, во-первых, заключается в том, что вам не требуются избыточные диски или диски ровно той же емкости в случае наступления события отказа диска в системе хранения. Для восстановления утраченных данных используется сетевая среда кластера и друге узлы. Во время выполнения операции восстановления, основанной на вашем уровне репликаций и группах размещения, в восстановлении данных участвуют практически все узлы вашего кластера, что делает операцию восстановления существенно более быстрой, поскольку в процессе восстановления участвует гораздо бОльшее количество дисков.
На производительность кластера Ceph существенное влияние может оказывать RAID со случайными операциями ввода/вывода, при RAID 5 и 6 она будет просто очень низкой.
|
| Замечание |
|---|---|
|
Существуют случаи применения, при которых RAID может быть полезным. Например, если у вас существует очень большое количество дисков на одно хосте, и вы должны запускать по демону для каждого, вы можете подумать о создании тома RAID путем объединения некоторого количества дисков с последующим запуском OSD поверх такого тома RAID. Это уменьшит количество демонов OSD по сравнению с количеством физических дисков. Например, если у вас есть насыщенный узел с 64 физическими дисками при низком значении системной оперативной памяти в 24ГБ, рекомендуемая конфигурация OSD, будет требовать 128 ГБ оперативной памяти (2 ГБ на один физический диск) для машин с 64 физическими дисками. Поскольку вы не имеете достаточной емкости системных ресурсов для OSD, вы можете рассмотреть возможность создания групп RAID для ваших физических дисков (шесть RAID групп с 10 физическими дисками на RAID группу плюс четыре запасных диска) и после этого запустить OSD для этих шести групп RAID. Таким образом, вам потребуется примерно 12 ГБ оперативной памяти, которыми вы располагаете. Недостатком такого подхода будет то, что в случае отказа OSD, вы потеряете данные на всех 10 дисках, (во всей группе RAID), что является большим риском. Следовательно, по возможности пытайтесь избегать групп RAID для OSD. |
Ниже приводится команда проверки состояния OSD для отдельного узла:
# service ceph status osd
[root@ceph-node1 ~]# service ceph status osd
===== osd. 2 ===
osd.2: running {"version":"0.72.2"}
=== osd.l ===
osd.1: running {"version":"0.72.2"}
=== osd.O =
osd.O: running {"version":"0.72.2"}
[root@ceph-node1 ~]#
Приводимая далее команда проверяет состояние всего кластера. Имейте в виду, что для того, чтобы
управлять всем кластером OSD из одного узла, файл ceph.conf
должен иметь информацию обо всех OSD с именами их хостов. Для достижения этой цели вы должны обновлять файл
ceph.conf. Это понятие объясняется в
последующих главах.
# service ceph -a status osd
[root@ceph-node1 ~]# service ceph -a status osd
== osd. 2 ===
osd.2: running {"version”:"0.72.2"}
=== osd.1 ===
osd.1: running {"version":"0.72.2"}
=== osd.0 ===
osd.O: running {"version”:"0.72.2"}
=== osd.3 ===
osd.3: running {"version":"0.72.2"}
=== osd.4 ===
osd.4: running {"version":"0.72.2"}
== osd. 5 ===
osd.5: running {"version":"0.72.2"}
=== osd.6 ===
osd.6: running {"version":"0.72.2"}
=== osd.7 ===
osd.7: running {"version":"0.72.2"}
=== osd.8 ===
osd.8: running {"version":"0.72.2"}
[root@ceph-node1 ~]# _
Следующая команда проверяет ID OSD:
# ceph osd ls
Далее следует команда для проверки карты OSD и их состояния:
# ceph osd stat
Приводимая ниже команда проверяет дерево OSD:
# ceph osd tree
Как это следует из названия, мониторы Ceph отвечают за контроль состояния работоспособности всего кластера. Это демоны, которые поддерживают режим членства в кластере путем сохранения важной информации о кластере, состояния одноранговых узлов, а также информации о настройках кластера. Монитор Ceph выполняет свои задачи поддерживая главную копию {Прим. пер.: карты(?)} кластера. Карта кластера содержит карты монитора, OSD, PG, CRUSH и MDS. Все эти карты в совокупности известны как карта кластера. Давайте бросим беглый взгляд на каждую из этих карт:
-
Карта монитора: Она содержит полную информацию об узле монитора, которая включает в себя ID кластера Ceph, имя хоста монитора, а также IP адрес монитора с номером порта. Она также хранит текущий период (epoch) для создания карты и информацию о последнем изменении. Вы можете проверить карту вашего монитора выполнив:# ceph mon dump
-
Карта OSD(устройства хранения объектов): Она хранит некоторые общие поля, такие как ID кластера, период (epoch) создания карты OSD и информацию о последнем изменении; а также информацию, относящуюся к пулам, такую как имена пулов, ID пулов, тип, уровень репликаций и группу размещения. Она также хранит такую информацию OSD, как количество, состояние, вес, интервал последней очистки и информацию о хосте OSD. Вы можете сверить свою карту устройства хранения объекта, выполнив:# ceph osd dump
-
Карта PG(групп размещения): Она содержит информацию о версии группы размещения, временной метки, последнем периоде (epoch) карты OSD, полном соотношении и близком к полному соотношению. Она также содержит отслеживание ID каждой группы размещения, количества объектов, состояний, отпечатков состояний, наборов рабочего состояния и действия OSD и, наконец, детали очистки. Для контроля карты групп размещения выполните:# ceph pg dump
-
Карта CRUSH(управляемых масштабируемым хешированием репликаций): Она содержит информацию о ваших устройствах хранения кластера, иерархию домена отказов и определенных для домена отказов правил при сохранении данных. Для проверки карты управляемых масштабируемым хешированием репликаций выполните следующую команду:# ceph osd crush dump
-
Карта MDS(сервера метаданных): Она хранит информацию о текущем периоде (epoch) карты MDS, времени создания и изменения карты, ID пула данных и метаданных, количестве серверов метаданных кластера и состоянии MDS. Для сверки состояния карты сервера метаданных выполните:# ceph mds dump
Монитор Ceph не хранит данные на клиентах и не обслуживает их данные, скорее, он предоставляет обновления карт кластера клиентам и другим узлам кластера. Клиенты и узлы кластера периодически сверяются с мониторами на предмет самых последних карт кластера.
Мониторы являются легкими демонами, которые не требуют огромных системных ресурсов. Для большинства реализаций будет достаточно сервера нижнего уровня с низкой стоимостью с достойными процессором, оперативной памятью и гигабитным Ethernet. Узел монитора должен иметь достаточную емкость диска для хранения журналов кластера, включая журналы OSD, MDS и монитора. Обычный работоспособный кластер создает журналы с размерами протоколов от нескольких МегаБайт до нескольких Гигабайт; однако потребность к емкости резко возрастает для кластера при детальном/ отладочном уровне. Для хранения журналов должно быть предоставлено несколько ГБ дискового пространства.
|
| Замечание |
|---|---|
|
Важно быть уверенным, что системный диск далек от заполнения, в противном случае кластеры могут сталкиваться с проблемами. Рекомендуются планируемая политика ротации, а также регулярный мониторинг использования файловой системы, в особенности для мониторов с увеличенными отладочными подробностями, которые могут приводить к возникновению огромных журналов со средней скоростью 1 ГБ в час. |
Обычный кластер Ceph содержит более одного узла монитора. Архитектура со множеством мониторов создает кворум и обеспечивает согласованность для распределенного принятия решений в кластере с использованием алгоритма Paxos {Прим. пер.: https://ru.wikipedia.org/wiki/Алгоритм_Паксос, https://github.com/kostja/lectures/blob/master/10.paxos.txt}. Количество мониторов в вашем кластере должно быть нечетным числом; абсолютный необходимый минимум состоит из одного узла монитора, а рекомендуемым числом является три. Поскольку мониторы работают в кворуме, более половины общего числа узлов мониторов должно быть всегда доступно чтобы избежать проблем раздвоения сознания, которые наблюдаются в других системах. Это причина, по которой рекомендуется нечетное число мониторов. Из всех этих мониторов кластера один из них выступает в роли ведущего. Другие узлы мониторы имеют право стать ведущими, если монитор- лидер становится недоступным. Находящийся в промышленной эксплуатации кластер должен иметь по крайней мере три узла мониторов для обеспечения высокой доступности.
[root@ceph-node1 ceph]# ceph daemon mon.ceph-node1 mon_status
{ "name”: "ceph-node1",
"rank": 0,
"state": "leader",
"election_epoch": 34,
"quorum": [
0,
1,
2],
"outside-quorum": [],
"extra_probe_peers": [
"192.168.57.102:6789\/0",
"192.168.57.103:6789\/O"],
"sync_provider": [],
"monmap": { "epoch": 9,
"fsid": "ffa7c0e4-6368-4032-88a4-5fb6a3fb383c",
"modified": "2014-04-15 23:16:08.649712",
"created": "0.000000",
"mons": [
{ "rank": 0,
"name": "ceph-node1",
"addr": "192.168.57.101:6789\/0"},
{ "rank": 1,
"name": "ceph-node2",
"addr": "192.168.57.102:6789\/0"},
{ "rank": 2,
"name": "ceph-node3",
"addr": "192.168.57.103:6789\/0"}]}}
[rootOceph-node1 ceph]#
Предыдущий вывод результатов демонстрирует ceph-node1
в качестве нашего начального монитора и ведущего в кластере. Вывод результатов также объясняет состояние кворума
и другие подробности монитора.
Если у вас существуют бюджетные ограничения или вы осуществляете хостинг малого кластера Ceph, демоны монитора могут работать на тех же узлах, что и OSD. Однако при такой реализации мы рекомендуем использовать бОльшие процессоры, оперативную память и системные диски для хранения журналов монитора, если вы планируете запускать службы монитора и OSD на одном общем узле.
Для промышленной среды уровня предприятия мы рекомендуем использовать выделенные узлы монитора. Если вы потеряете узел OSD, вы все еще сможете осуществлять связь с вашим кластером если достаточно мониторов работает на отдельных машинах. На этапе планирования кластера также должно быть рассмотрено физическое расположение в стойках. Вы должны рассредоточить ваши узлы монитора во всех имеющихся у вас областях отказов, например, различные коммутаторы, источники электропитания и физические стойки. Если вы имеете множество центров данных с единой высокоскоростной сетевой средой, ваши узлы монитора должны быть в различных центрах данных.
Для проверки состояния службы монитора выполните следующую команду:
# service ceph status mon
Существует множество способов ознакомления с состоянием монитора, например такие:
# ceph mon stat # ceph mon_status # ceph mon dump
Взгляните на следующий скриншот:
[root@ceph-node1 -]# ceph mon stat
e9: 3 mons at {ceph-node1=192.168.57.101:6789/0,ceph-node2=192.168.5
7.102:6789/0,ceph-node3=192.168.57.103:6789/0}, election epoch 152,
quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3
[root@ceph-node1 ~]#
[root@ceph-node1 ~]# ceph mon_status
{"name":"ceph-node1","rank":0,"state":"leader","election_epoch":152,
"quorum":[0,1,2],"outside_quorum":[],"extra_probe_peers":[],"sync_pr
ovider":[],"monmap":{"epoch":9,"fsid":"ffa7c0e4-6368-4032-88a4-5fb6a
3fb383c","modified":"2014-04-15 23:16:08.649712","created":"0.000000
","mons":[{"rank":0,"name":"ceph-node1","addr":"192.168.57.101:6789\
/0"},{"rank":1,"name":"ceph-node2","addr":"192.168.57.102:6789\/0"},
{"rank":2,"name":"ceph-node3","addr":"192.168.57.103:6789\/0"}]}}
[root@ceph-node1 ~]#
[root@ceph-node1 ~]# ceph mon dump
dumped monmap epoch 9
epoch 9
fsid ffa7c0e4-6368-4032-88a4-5fb6a3fb383c
last_changed 2014-04-15 23:16:08.649712
created 0.000000
0: 192.168.57.101:6789/0 mon.ceph-node1
1: 192.168.57.102:6789/0 mon.ceph-node2
2: 192.168.57.103:6789/0 mon.ceph-node3
[root@ceph-node1 ~]#
librados является естественной библиотекой C, которая позволяет приложениям напрямую работать с RADOS, минуя другие уровни интерфейса для взаимодействия с кластером Ceph. librados является библиотекой для RADOS, которая предлагает богатую поддержку API, которая позволяет приложениям выполнять прямые и одновременные запросы к кластерам без HTTP заголовков. Приложения имеют возможность расширять свои собственные протоколы для получения доступа к RADOS через соединения librados. Аналогичные библиотеки доступны,чтобы расширить поддержку для C++, Java, Python, Ruby и PHP. librados выступает в качестве основы для других служебных интерфейсов, которые строятся поверх собственного интерфейса librados, который включает в себя блочные устройства Ceph, файловую систему CephFS и шлюз Ceph RADOS. librados поддерживает богатые подмножества API, эффективное хранение ключ / значение внутри объекта. API поддерживает транзакции с единым объектом-атомом путем совместного обновления данных, ключей и атрибутов. Межклиентское взаимодействие осуществляется через объекты.
Прямое взаимодействие с кластерами RADOS через библиотеку librados резко повышает производительность, надежность и эффективность приложений. librados предлагает очень мощный библиотечный набор, который может предоставить дополнительные преимущества облачным решениям Платформа-как-Служба (PaaS) и Программное-обеспечение-как-служба (SaaS).
Блочные хранилища являются одним из наиболее распространенных форматов для хранения данных в корпоративных средах. Блочные устройства Ceph известны также как блочные устройства RADOS (RBD, RADOS block device). Они предоставляют решения блочного хранения физическим гипервизорам и виртуальным машинам. Драйвер Ceph RBD был интегрирован в ядро Linux основной линии (2.6.39 и выше) и поддерживается QEMU/ KVM, обеспечивая бесшовный доступ к блочному устройству Ceph.
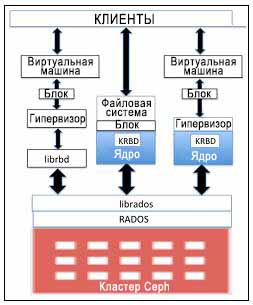
Хосты Linux расширяют полную поддержку Ядра RBD (KRBD, Kernel RBD)
и карт блочных устройств Ceph с применением librados. RADOS затем сохраняет объекты блочных устройств Ceph
по всем кластерам распределенным образом. Будучи включенным в состав карты на хосте Linux, блочное устройство Ceph
может использоваться как сырой (RAW) раздел или может быть помечен в файловой системе с последующим монтированием.
С самого начала Ceph был тесно интегрирован в облачные платформы, подобные OpenStack. Для Cinder и Glance, которые являются программами томов и образов для OpenStack, Ceph предоставляет сервера блочных устройств для хранения томов виртуальных машин и образов операционных систем. Эти тома и образы являются динамично выделяемыми (thin provisioning) {Прим. пер.: http://en.wikipedia.org/wiki/Thin_provisioning, http://habrahabr.ru/post/170389/}. Должны сохраняться только измененные объекты; это помогает сохранять в OpenStack значительное пространство хранения. Свойства Ceph копирования-при-записи (copy-on-write {Прим. пер.: при изменении новых данных эти данные вначале копируются в новую область}) и мгновенного клонирования (instant cloning) помогают OpenStack помогают раскручивать сотни экземпляров виртуальных машин за меньшее время. RBD также поддерживает моментальные снимки, тем самым быстро сохраняя состояние виртуальной машины, которое в последующем может быть клонировано для создания виртуальной машины того же типа и использоваться для восстановления временных точек. Ceph работает как обычный сервер для виртуальных машин, и таким образом помогает виртуальным машинам осуществлять миграцию, поскольку все виртуальные машины могут осуществлять доступ к кластеру хранения Ceph. Контейнеры виртуализации, такие как QEMU, KVM и XEN могут быть настроены для загрузки виртуальных машин с томов, хранящихся в кластере Ceph.
RBD использует библиотеки librbd для достижения преимуществ RADOS и обеспечения надежного, полностью распределенного хранилища блоков на основе объектов. Когда клиент записывает данные в RBD, библиотеки librbd преобразовывают блоки данных в объекты и осуществляют их репликацию по всему кластеру, тем самым обеспечивая повышенные производительность и надежность. RBD поверх уровня RADOS поддерживает эффективное обновление объектов. Клиенты могут осуществлять операции записи, добавления и усечения с существующими объектами. Это делает RBD оптимальным решением для томов виртуальных машин и обеспечивает частые записи на их виртуальные диски.
Ceph RBD затмевает и заменяет дорогостоящие решения SAN для хранения данных, предоставляя возможности корпоративного класса, такие как динамичное выделение, копирование-при-записи моментальных снимков и клонирования, реверсивных снимков, доступных только для чтения, а также поддерживает облачные платформы, такие как OpenStack и CloudStack. В последующих главах мы узнаем больше о блочных устройствах Ceph.
Шлюз объектов Ceph, также известный как шлюз RADOS, является прокси, который преобразовывает запросы HTTP в запросы RADOS и наоборот, предоставляя объектное хранилище RESTful, которое является совместимым с S3 и Swift. Объектное хранилище Ceph использует демон шлюза объектов Ceph (radosgw) для взаимодействия с библиотекой librgw и кластером Ceph, librados. Он реализован как модуль FastCGI при помощи libfcgi, и может использоваться любым FastCGI- совместимым веб- сервером. Хранилище объектов Ceph поддерживает три интерфейса:
-
S3 совместимый: Он предоставляет Amazon S3 RESTful API- совместимый интерфейс к кластерам хранения Ceph. -
Swift совместимый: Он предоставляет OpenStack Swift API- совместимый интерфейс к кластерам хранения Ceph. Шлюз объектов Ceph может быть использован как замена для Swift в кластере OpenStack. -
API администратора: Он позволяет выполнять администрирование вашего кластера Ceph посредством HTTP RESTful API
Следующая диаграмма показывает различные методы доступа, которые используют шлюз RADOS и librados для хранения объектов.
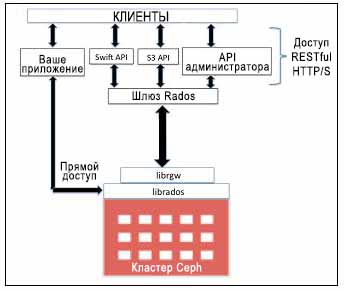
Шлюз объектов Ceph имеет свое собственное управление пользователями. И S3, и Swift API используют общее пространство имен внутри кластера Ceph, следовательно вы можете записывать данные одним API, а получать их другим. Для быстрой обработки он может использовать память для эффективного кэширования метаданных. Также вы можете использовать более одного шлюза и оставлять их под управлением балансировщика нагрузки для эффективного управления нагрузкой на ваше хранилище объектов. Улучшение производительности достигается за счет разбиения больших объектов REST на меньшие по размеру объекты RADOS. Взамен S3 и Swift API, ваше приложение может обойти шлюз RADOS и получить прямой одновременный доступ к librados, т.е. к кластеру Ceph. Это может быть эффективно использовано в индивидуальных корпоративных приложениях, которые требуют с точки зрения хранилища экстремальной производительности, путем удаления дополнительных уровней. Ceph допускает прямой доступ к своему кластеру. Это поднимает над другими решениями хранения данных, которые являются жесткими и имеют ограничения в интерфейсе.
Ceph MDS является сокращением для сервера метаданных ион требуется только для файловой системы Ceph (CephFS) и других методов хранения блоков. Хранение на основе объектов не требует служб MDS. Ceph MDS работает как демон, который позволяет клиентам монтировать файловую систему POSIX любого размера. MDS не предоставляет клиенту напрямую никаких данных; предоставление данных осуществляется OSD. MDS обеспечивает совместно используемую, согласованную файловую систему с интеллектуальным уровнем кэширования; следовательно, резко сокращая чтения и запись. MDS расширяет свои преимущества в направлении разделения динамичных поддеревьев и отдельных MDS для фрагментов метаданных. Он является динамичным по своей природе; демоны могут присоединяться и уходить, а также быстро поглощать отказавшие узлы.
MDS является единственным компонентом Ceph, который пока не готов к промышленной эксплуатации; существующие в настоящее время сервера метаданных не могут пока масштабироваться и пока поддерживается только один сервер метаданных. Большое количество вопросов и ответов свидетельствуют о том, что он готовится стать готовым к промышленному использованию; мы можем ожидать некоторых новостей очень скоро.
MDS не хранит локальные данные, что очень полезно при некоторых реализациях. Если демон MDS пропадает, мы можем запустить его снова в любой системе, имеющей доступ к кластеру. Демоны сервера метаданных могут настраиваться как активные или пассивные. Первичный MDS демон становится активным, а остальные переходят в режим ожидания. В случае отказа первичного демона второй узел берет управление в свои руки и выдвигается в активное состояние. Для еще более быстрого восстановления вы можете указать, что резервный узел должен следовать за одним из ваших активных узлов, что позволит иметь в оперативной памяти те же данные для соответствующего кэширования.
Для выполнения настройки Ceph MDS для файловой системы Ceph, вамследует иметь работающий кластер Ceph. В предыдущей главе мы развернули кластер Ceph. Мы воспользуемся темже кластером для развертывания MDS. Настройка MDS относительно проста, для этого:
-
Воспользуйтесь
ceph-deployна машинеceph-node1для настройки MDS:# ceph-deploy mds create ceph-node2
-
Проверьте состояние вашего кластера Ceph и найдите запись
mdsmap. Вы увидите, что вы заново настроили узел MDS:[root@ceph nodel ceph]# ceph -s cluster ffa7c0e4-6368-4032-88a4-5fb6a3fb383c health HEALTH_OK monmap e9: 3 mons at {ceph-node1-192.168.57.101:6789/0,ceph-node2=192.168.57.102:6789/0, ceph-node3=192.168.57.103:6789/0}, election epoch 76, quorum 0,1,2 ceph-node1,ceph-node2,ceph -node3 mdsmap e25: 1/1/1 up (0=ceph-node2=up:active} osdmap e28l: 9 osds: 9 up, 9 in pgmap v603: 192 pgs, 3 pools, 9470 bytes data, 21 objects 345 MB used, 45635 MB / 45980 MB avail 192 active+clean
CephFS предоставляет POSIX- совместимую файловую систему поверх RADOS. Она использует демон MDS, который управляет ее метаданными и хранит их отдельно от данных, что помогает уменьшить сложность и увеличивает надежность. CephFS наследует свойства RADOS и предоставляет динамичную ребалансировку для данных.
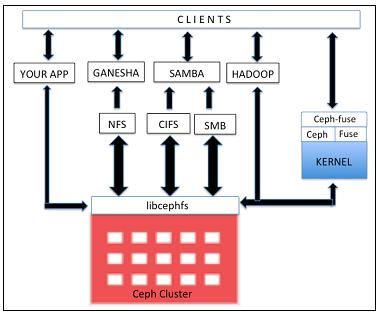
Библиотеки libcephfs играют важную роль в поддержке ее множественной реализации клиентов.
Она имеет естественную поддержку драйвера ядра Linux, таким образом клиент может использовать
естественное монтирование при помощи команды mount.
Она имеет тесную интеграцию с SAMBA и поддержку для CIFS и SMB. CephFS расширяет свою поддержку
файловых систем в пространстве пользователей (FUSE, fiesystems in userspace) при помощи
модулей cephfuse. Она также
допускает прямое взаимодействие приложений с кластером RADOS с использованием библиотек libcephfs.
CephFS становится популярной в качестве замены для Hadoop HDFS. HDFS имеет единственный узел имен, который влияет на ее масштабируемость. В отличие от HDFS, CephFS может быть реализована поверх множества MDS в активно- активном режиме, таким образом, достигая высокой доступности и высокой производительности при отсутствии единой точки отказа. В последующих главах мы сосредоточимся на реализации CephFS.
С самого начала, Ceph разрабатывалась чтобы быть мощным единым решением хранения, снабженным функционалом блочных устройств Ceph, хранилищ объектов Ceph и файловой системы Ceph из единого кластера Ceph. При формировании кластера Ceph использует такие компоненты, как мониторы, OSD и MDS, которые являются отказоустойчивыми, высоко масштабируемыми и высоко производительными. Ceph использует уникальный подход для хранения данных на физических дисках. Любой тип данных, будь то блочные устройства, хранимые объекты или файловая система Ceph, нарубаются в форме малых объектов и затем сохраняются в динамично вычисляемом месте. Карты монитора хранят информацию и снабжают ею узлы кластера и обновления клиентов. Такой механизм позволяет Ceph выделяться из общей массы и предоставлять высоко масштабируемые, надежные и высокопроизводительные решения хранения.