Руководство по вопросам проектирования программно определяемого хранилища
Содержание
- Руководство по вопросам проектирования программно определяемого хранилища
- Обзор вопросов проектирования
- Этап 1: Определение требований хранилища
- Этап 2: Просмотр структуры и внесение необходимых изменений
- Этап 3: Работа с поставщиком аппаратных ресурсов Пространств хранения над завершением проекта
- Этап 4: Подготовка к размещению решения
- Последующие этапы
- Добавление А: Выбор инструментов развёртывания и управления
Обновлён на английском языке: 23 мая 2016 (перевод 30 ноября 2016).
Применимо к: Windows Server 2012 R2
Данное руководство детализирует последовательность, которой следует придерживаться для создания решения хранения данных, отвечающего индивидуальным требованиям вашей организации. Руководство использует электронные таблицы расчёта проекта Программно-определяемого хранилища для записи требований, а также вычисления конфигурации оборудования и программных средств.
Для кого предназначено данное руководство? Для ИТ-специалистов в малых, средних и крупных организациях, отвечающих за проектирование решения хранения данных, обеспечивающих виртуализированные или любые другие рабочие нагрузки.
Как это руководство поможет вам? Вы можете применять это руководство и электронные таблицы Калькулятора проектирования Программно- определяемого хранилища для проектирования решения хранения, которое использует Пространства хранения (Storage Spaces) и функциональность Горизонтально- масштабируемого файлового сервера (SOFS, Scale-Out File Server) Windows Server 2012 R2 совместно с эффективными в стоимостном отношении серверами и совместно используемыми полками хранения SCSI (SAS).
Пространства хранения является программно определяемой технологией хранения, которая позволяет вам виртуализировать хранилища, группируя SSD и жёсткие диски в пулы, а затем создавая высоко- производительные и отказоустойчивые виртуальные диски, называемые Пространствами хранения, из доступной ёмкости в ваших пулах. Затем вы можете разместить Совместно используемые в кластере тома (CSV, Cluster Shared Volumes) и разделяемые файлы на таких виртуальных дисках, которые в свою очередь размещают данные для ваших рабочих нагрузок (см. Рисунок 1)
Рисунок 1
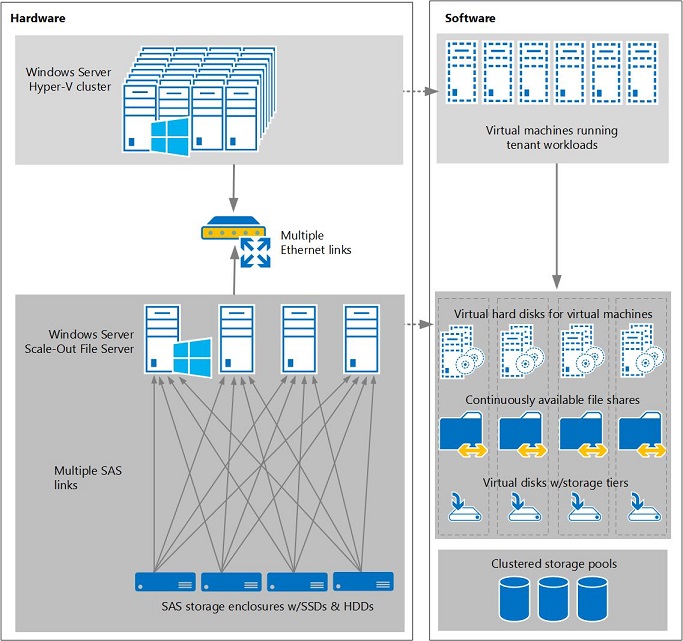
Архитектура Программно определяемого хранилища, использующего Пространства хранения с помощью полок хранения SAS
Где можно найти лежащую в основе технологии информацию? В приведённых ниже материалах предоставлена информация, лежащая в основе Пространств хранения, а также общие указания по проектированию связной архитектуры виртуализации, включающие ресурсы для вычислений, сетевой среды и хранилищ:
Это руководство совместно с электронные таблицы Калькулятора проектирования Программно- определяемого хранилища предоставляют набор этапов для проектирования решения хранения на основе Пространств хранения. Скорее всего, вы будете возвращаться назад и проходить повторно по некоторым из этих этапов по мере усовершенствования вашего проекта, общения с вашим поставщиком аппаратных средств, покупки оборудования и достижения готовности к размещению.
Вот что мы рассматриваем в данном руководстве:
Если вы желаете сразу перескочить к проектированию решения, воспользуйтесь закладкой QuickDesign в электронной таблице Калькулятора проектирования программно- определяемого хранилища, отображённую на Рисунке 2 для выбора шаблона решения, которое придерживается практики выбора рекомендуемых решений. Для настройки проекта, отвечающего вашим определённым потребностям, воспользуйтесь закладкой AdvancedDesign этой таблицы для выбора шаблона и после этого настройте его согласно требованиям следующего этапа.
Рисунок 2
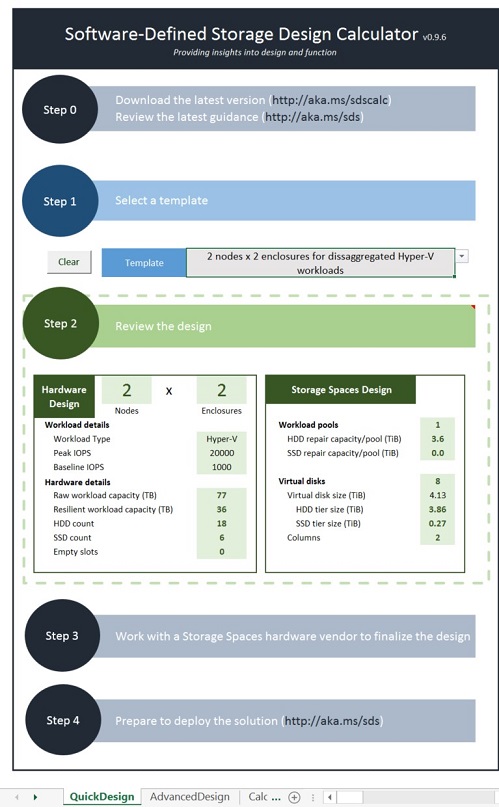
Закладка Быстрого проекта вашего калькулятора проектирования Программно- определяемого хранилища
Первый этап при проектировании решения хранения состоит в определении ваших рабочих нагрузок (приложений, серверов и клиентов) с последующим определением ваших требований к хранилищу.
Описание вашей рабочей нагрузки включает в себя ряд подзадач: выявление самой нагрузки, определение характеристик производительности, принятие решения о необходимом вам объёме, а также о том будете ли вы хранить резервные копии ваших данных рабочей нагрузки в том же самом хранилище, в котором идёт основная работа.
Подзадача 1а: Выявление вашей нагрузки
Начните с определения той нагрузки, для которой вы хотите предоставить данноехранилище и того, будет ли она выполняться с Горизонтально масштабируемыми файловыми серверами (SOFS).
-
Для каких работ вы собираетесь применять данное хранилище? В своей закладке AdvancedDesign электронной таблицы Калькулятора проектирования Программно определяемого хранилища вначале воспользуйтесь списком Template для определения того, сколько узлов кластера и полок хранения использовать в начальном черновом проекте (таблица добавит дополнительные полки в ваш проект в случае такой необходимости, а вы также можете добавлять узлы). Затем воспользуйтесь полем Role (отображённом на Рисунке 3) для определения того, для какой роли сервера вы хотите сделать сервер. Например, вы можете пожелать выполнить хранилище для некоторого массива служб и приложений, работающих на виртуальных машинах Hyper-V, которые могут вызывать в общем случае нагрузку Hyper-V общего назначения.
-
Является ли ваша нагрузка работающей с Горизонтально масштабируемым файловым сервером (SOFS)? Кластеры Горизонтально масштабируемого файлового сервера (SOFS, Scale-Out File Server) делают для вас возможным создание непрерывно доступных совместных файловых ресурсов которые будут устойчивыми к отказам и способными выполнять балансировку нагрузки между узлами без сбрасывания SMB3 сетевых соединений. Это увеличивает время непрерывной работы без сбоев и позволяет вам масштабировать производительность путём добавления узлов кластера.
Hyper-V, сервер Microsoft SQL Server, информационный сервер Microsoft Internet (IIS), а также библиотека System Center Virtual Machine Manager (VMM) умеют хорошо выполнять совместную работу с непрерывно доступными общими ресурсами в Горизонтально масштабируемом файловом сервере (SOFS). Если у вас имеются другие рабочие нагрузки, может оказаться, что они не оптимизированы под SOFS (например, общие файлы, поддерживающие информацию рабочих данных).
Если ваши рабочие нагрузки требуют хранения общих файлов, однако не поддерживают SOFS, вы можете применять Файловый сервер для обычного применения (File Server for general use) кластерного типа, хотя и без получения преимуществ масштабирования и непрерывной доступности SOFS. Из- за ограничений в масштабировании, такие кластеры Фалового сервера общего применения обычно проектируются для работы в кластере с двумя узлами.
Для получения дополнительной информации отсылаем вас к cale-Out File Server for Application Data Overview.
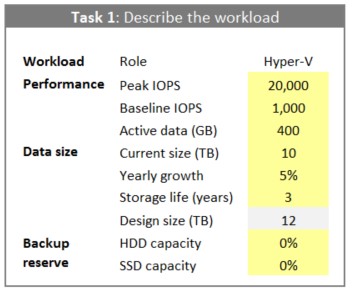
Подзадача 1b: Определение характеристик производительности вашей нагрузки
Хотя производители хранилищ и любят обсуждать сколько IOPS (input/output operations per second) предоставляет их хранилище (в качестве одного из примеров отсылаем вас к Achieving Over 1-Million IOPS from Hyper-V VMs in a Scale-Out File Server Cluster Using Windows Server 2012 R2), эти значения обычно представляют сценарий наилучшего варианта с использованием высоко оптимизированных условий, которые зачастую далеки от ваших рабочих ситуаций.
Для более полезного сравнения будет полезным понимать характеристики производительности существующих у вас нагрузок. Чем лучше вы знаете свои нагрузки, тем более содержательный разговор вы можете вести со своим поставщиком оборудования. Вы также найдёте информацию, которая будет полезной при проектировании пулов хранения и виртуальных дисков с тем, чтобы обеспечить достаточные производительность и ёмкость. А позже, когда вы настроите своё новое решение хранения, вы будете способны применять эти данные для тестирования производительности вашего хранилища с использованием синтетически создаваемых нагрузок, которые будут близки характеристикам ваших существующих нагрузок.
Мониторинг производительности базовой рабочей нагрузки
Чтобы иметь представление о производительности имеющихся у вас рабочих нагрузок, затратьте некоторое время на следующие показатели (обычно получаемые при помощи Windows Performance Monitor):
-
Peak и baseline IOPS - Воспользуйтесь полями Peak IOPS и Baseline IOPS таблицы Калькулятора проекта Программно определяемого хранилища для того чтобы записать сколько фрагментов данных ваша рабочая нагрузка в настоящее время осуществляет в одну секунду (выровняйте значение IOPS чтобы более или менее соответствовать вашему новому решению). Вы можете наблюдать его в мониторе производительности (Performance Monitor) при помощи счётчика Logical Disk > Disk Transfers/sec.
-
Peak throughput - Сколько данных передаётся в одну секунду? Вы можете измерить это значение в мониторе производительности счётчиками Logical Disk > Disk Reads Bytes/sec и Disk Writes Bytes/sec.
-
Queue depth - Сколько операций ввода/ вывода ожидают в очереди своей обработки? В мониторе производительности вы можете измерить это значение счётчиком Logical Disk > Avg. Disk Queue Length.
-
Maximum latency - Сколько времени требует каждая операция ввода/ вывода (передача)? В мониторе производительности это счётчики Logical Disk > Avg. Disk sec/Read и Avg. Disk sec/Write.
-
Active data (working I/O) set - Воспользуйтесь полем Active data вашей таблицы для записи того, сколько ваших данных нагрузки активно изменяются. У нас нет счётчиков производительности для этого, поэтому вместо этого поразмыслите о показателях вашей рабочей нагрузки - например, размер базы данных влияет на то, сколько данных являются активными в нагрузках сервера SQL.
-
Demand variation over time - Какие пиковые нагрузкиважны для наблюдения? Например, обмен регистраций утром в понедельник или обмен в конце каждого месяца.
-
Minimum required throughput for backups - Если вы намереваетесь применять свой кластер хранения для резервного копирования собственных данных, какая пропускная способность требуется для сохранения ваших резервных копий актуальными?
Не обязательный мониторинг подробных показателей ввода/ вывода
Кроме этого будет полезным взглянуть на некоторые дополнительные параметры нагрузок вашего ввода/ вывода:
-
I/O (block) size - Каков размер фрагментов данных в обмене вашей нагрузки? Вы можете наблюдать этот показатель в мониторе производительности счётчиками Logical Disk > Avg. Disk Bytes/Read и Avg. Disk Bytes/Write.
-
Read and write ratio - Как подразделяются чтения и записи в вашей нагрузке? В мониторе производительности за это ответственны счётчики Logical Disk > Disk Reads/sec и Disk Writes/sec.
-
Random and sequential ratio - Как подразделяются произвольные и последовательные операции ввода/ вывода в смежных блоках данных? Например, базы данных обычно выполняют произвольные выборки для разбросанных блоков данных, в то время как чтение или запись больших файлов или потоковых данных имеют результатом последовательные операции ввода/ вывода в соседних блоках данных. Не существует никаких счётчиков монитора производительности для определения того являются ли операции ввода/ вывода случайными или последовательными - вы скорее всего имеете оценку на основе собственных знаний о своей нагрузке.
-
Encryption - используете ли вы сейчас шифрование или требуется ли вам оно в будущем (такое как шифрование дисков Bitlocker) или шифрование на- лету (шифрование SMB3)? Шифрование уменьшает производительность, поэтому большинство потребителей полагаются на физическую безопасность для своих кластеров хранения и связанную с ними сетевую инфраструктуру.
Вы можете ограничить воздействие шифрования на производительность разрешив его только в тех томах и общих ресурсах, которые требуют расширенной безопасности, а осуществляя мониторинг после развёртывания подтверждать адекватность производительности испытываемым вами нагрузок.
Подзадача 1c: Принятие решение о том, какая ёмкость вам требуется
Чтобы принять решение о том, какая ёмкость вам нужна, рассмотрите следующие факторы:
-
Current size - Применяйте поле Current size таблицы Калькулятора проектирования Программно определяемого хранилища для записи начального размера данных, которые вы собираетесь хранить.
-
Yearly growth rate - Воспользуйтесь полем Yearly growth вашей таблицы для записи скорости роста ваших данных.
-
Storage lifetime - Используйте поле Storage life вашей таблицы для записи того как долго вы хотите чтобы хранилище тянуло до последнего, прежде чем вы добавите ёмкость.
![[Замечание]](/common/images/admon/note.png)
Замечание Когда подходит время покупать дополнительные хранилища, мы рекомендуем добавлять другой кластер хранения и связанные с ним полки хранения (которые вместе мы будем называть устройством масштабирования хранилища). Хотя это может и казаться привлекательным добавить дисков или полок в существующий кластер, такое поведение может вызвать нарушение периодов гарантийного срока, снижения производительности и конфигураций, которые не поддерживают осведомлённости о них полок.
Подзадача 1d: Принятие решение о том, будете ли вы хранить резервные копии в том же самом хранилище
Желаете ли вы использовать свой кластер хранения для записи резервных копий данных дополнительно к вашим первичным данным? Многи пользователи применяют отдельный сервер или кластер для резервных копий, однако сохранение резервных копий в том же самом решении может уменьшить объём закупаемого вами оборудования.
Если вы хотите использовать своё решение для первичных данных и резервных копий, определите какую ёмкость HDD и SSD запасти для резервных копий - этот объём обычно помещается в свой собственный пул хранения.
-
HDD capacity % for backups - Воспользуйтесь полем HDD capacity % таблицы Калькулятора проектирования Программно определяемого хранилища для записи ёмкости HDD в процентах, которую вы хотите запасти для хранения резервных копий или поместите 0%, если вы будете применять другую систему для хранения резервных копий. Типичное значение состоит в запасе в 33% от вашей общей ёмкости HDD при резервных копиях, сохраняемых в виртуальных дисках которые применяют вариант с двойными контрольными суммами и дедупликацией данных.
-
SSD capacity % for backups - Используйте поле SSD capacity % таблицы Калькулятора проектирования Программно определяемого хранилища для записи ёмкости HDD в процентах, которую вы хотите запасти для хранения резервных копий или поместите 0%, если вы будете применять другую систему для хранения резервных копий.
Если у вас имеется большой объём данных для резервного копирования, добавляйте 4 небольших SSD на свой пул для каждых 16- 32 HDD (в зависимости от того, насколько вы желаете увеличить производительность записи) и установите тип использования своих SSD в
Journalприменив командуSet-PhysicalDisk -Usage Journal. Если вы не применяете полку с информированностью, вы можете добавлять диски в соотношении 3 SSD на 12- 24 HDD. Так как производительность последовательной записи SSD обычно "всего" в 2 - 4 раза больше аналогичной для жёстких дисков NL SAS, ваши диски журнала вероятно могут стать узким местом общей производительности если у вас общее количество имеющихся у вас жёстких дисков больше чем в четыре раза превосходит диски журнала SSD. Однако, производительность записи обычно достаточно хороша для большей части рабочих нагрузок при соотношении SSD к HDD в пропорции 1 : 8.Замечание Пространства хранения используют два типа журналов записи - журнал данных 1ГБ (кэш отложенной щаписи, write-back cache) и 256МБ журнал контрольных сумм, который применяется только в пространствах контрольных сумм. Журналы разделяются по физическим дискам с применением зеракльного типа отказоустойчивости и применяют то же самое число копий данных что и связанный с ними виртуальный диск. Например, виртуальный диск с двойной контрольной суммой (dual- parity) должен применять скрытое тройное зеркало для хранения 1ГБ кэша отложенной записи и 256МБ журнала контрольных сумм с тремя копиями данных, потребляя 3.75ГБ (1.25ГБ x 3 копии данных) прсотранства на дисках журнала. так как журналы настолько невелики, эти журналы SSD могут быть меньше, нежели ваши прочие SSD (100ГБ более чем достаточно).
Хотя может показаться привлекательной попытка применять избыток ёмкости SSD не используемой вашими журналами, обычно это не стоит тех усилий. Например, если вы оставите свой SSD журнала в наборе пула для настроек Автоматического применения, виртуальные диски без многоуровневого хранения (содержащие пространства контрольных сумм) будут распространять свои данные как по HDD, так и по SSD. Однако, производительность виртуального диска ограничена самыми медленными дисками в пуле (игнорируя SSD, применяемые для кэширования отложенной записи и многоуровневого хранения). Такие виртуальные диски без многоуровневого хранения, которые чередуют данные между SSD и HDD не будут хоть сколько- то быстрее чем если бы они были просто размещены на HDD. Более того, чередование данных по SSD журнала может потреблять слишком много ёмкости SSD, уменьшая размеры журнала и тем самым нанося вред производительности.
В Windows Server 2012 R2 вы скорее всего захотите использовать рассредоточенную (disaggregated) архитектуру хранения со включённым многоуровневым хранением, однако вот некоторые дополнительные ложащиеся в основу факты:
-
Архитектура решения - в Windows Server 2012 R2 Пространства хранения применяют рассредоточенную архитектуру хранения для большинства рабочих нагрузок, включая виртуальные рабочие нагрузки. При помощи рассредоточенной архитектуры рабочие нагрузки работают на отдельном сервере и осуществляют доступ к хранилищу в сервере или кластере Пространств хранения через сетевые соединения с использованием протокола SMB.
Рассредоточенная архитектура позволяет вам масштабировать ваши рабочие нагрузки независимо от вашего хранилища, поэтому если один из этих элементов растёт со скоростью, отличающейся от другого, у вас нет необходимости зацикливаться на покупке и хранилища и вычислительного сервера в одно и то же время - вы покупаете только то, что нужно вам. Это также делает возможным слияние воедино ёмкости хранения и производительности, так что вы в конечном итоге не столкнётесь с избытком ёмкости и производительности не доступными к применению рабочими нагрузками, которым они требуются в данный момент. Рассредоточенная архитектура также полезна при использовании Дедупликации данных и пространств контрольных сумм в качестве устройств назначения для резервного копирования, поскольку Дедупликация данных требует дополнительных вычислительных ресурсов, которые вы можете не захотеть отбирать от своих рабочих нагрузок.
Однако некоторые производители также предлагают решения Пространств хранения которые применяют гиперконвергентные архитектуры. При использовании гиперконвергентной архитектуры виртуальные рабочие нагрузки выполняются непосредственно на том же самом сервере или кластере, который содержит это хранилище. Гиперконвергентные решения могут уменьшать стоимость, в особенности для решений малого масштаба, исключает потребность во втором сервере или кластере, а также то, что ваши вычислительные возможности и ёмкость хранилища растут с подобными скоростями.
-
Модель хранения - В Windows Server 2012 R2 подсистема Пространств хранения использует общие диски SAS и полки в кластерах во всех узлах совместно использующих одни и те же диски и полки хранения.
-
Уровни хранения - Уровни хранения улучшают производительность перемещая данные с более частым обращением на хранилище SSD, при этом оставляя основную массу ваших данных на более крупных и менее затратных HDD. Если вам требуется наивысший уровень производительности, перейдите на к решению с хранением данных только на SSD (all-SSD), для балансировки между производительностью и ёмкостью применяйте уровни хранения; если ёмкость является вашей первичной целью, уменьшите или полностью исключите свой уровень SSD. {Прим. пер.: в Windows Server 2016 появилась возможность применения Виртуальных дисков с множественной отказоустойчивостью в рамках S2D (Непосредственно подключаемых пространств хранения).}
Насколько важно время непрерывной работы для вашего хранилища? Насколько ненавидит ваша команда заменять оборудование посреди ночи? При проектировании своего хранилища на уровнях кластера, пула и виртуального диска рассмотрите эти вопросы.
Подзадача 3a: Проектирование отказоустойчивости кластера
Рассмотрите следующие факторы отказоустойчивости кластера:
-
Cluster nodes - Воспользуйтесь полем Node count в таблице Калькулятора проектирования Программно определяемого хранилища для регулировки общего числа узлов кластера в вашем проекте. Большинство пользователей начинают процесс проектирования с кластера из двух узлов, а затем добавляют узлы, если они предвидят большую нагрузку. Например, вы можете посчитать, что у вас имеется слишком большая нагрузка, чтобы выполнять её на одном узле в процессе отказа одного из узлов или работ по сопровождению, поэтому выбираете три узла. Пулы хранения могут оставаться в рабочем состоянии с одним узлом кластера, в то время как вы получаете свидетельство кластера, что по крайней мере 50% всех физических дисков в в вашем пуле хранения дисков доступны.
Отметим, что кластеры с пятью или более узлами могут быть трудными для подключения каждой полки хранения с отказоустойчивыми соединениями, причём при этом могут возникать узкие места производительности, которые будут ограничивать получение дополнительной производительности, хотя некоторые производители предоставляют творческие решения для подобных ограничений. {Прим. пер.: необходимость подобных креативных решений снимается в Windows Server 2016 применением Непосредственно подключаемых пространств хранения (S2D) с их Программно управляемой шиной хранения на базе стандартных сетевых архитектур (прежде всего Ethernet) взамен использования шин SAS и FC.}
-
SAS connections и MPIO - Примените поле MPIO в таблице для определения того, будут ли соединения SAS избыточными между всеми узлами и подключаемыми полками хранения. Если у вас имеется более одного соединения с каждой полкой хранения, вы можете включить Ввод/ вывод со множеством путей (MPIO, Multipath I/O) для предоставления избыточности и увеличения пропускной способности между узлами хранения и полками хранилищ. {Прим. пер.: желающим ознакомиться с проблемами множественностей путей рекомендуем раздел Множество путей SAS нашего перевода ZFS для профессионалов.}
Обычным является применение одного или двух SAS HBA (не RAID адаптеров), причём с двумя портами каждый и кабелями на основе для предоставления каждому узлу доступа к каждой полке хранения. Отметим, что Пространства хранения не поддерживают применения коммутаторов SAS, хотя расширители SAS в полках хранения прекрасно подходят.
-
Network adapters, ports, and cables - Сколько отказов сетевых адаптеров, портов и кабелей вы хотите допускать? Обычным является применение одного или двух сетевых адаптеров с двумя портами в сумме и двух кабелей на узел для получения избыточности и производительности, однако некоторые потребители могут выбрать использование большего числа для увеличения полосы пропускания или поддержки других сетевых конфигураций.
Если вы используете своё хранилище для поддержки Hyper-V или других рабочих нагрузкой с высокими значениями полосы пропускания, на других серверах, вам скорее всего потребуется, как минимум два 10GbE порта на узел кластера с поддержкой RDMA для предоставления достаточной полосы пропускания и отказоустойчивости. {Прим. пер.: более корректный, нежели RDMA термин в данном контексте - RoCE, RDMA over Converged Ethernet или iWARP. Желающих ознакомиться с деталями настройки множества портов (групповые сервера) отсылаем к разделу Построение таблицы маршрутизации в нашем переводе Полного руководства Windows Server 2016. Также отметим незначительную разницу в стоимости между 10GbE и 25GbE адаптерами по состоянию на конец 2016г, а также возможность объединения до 4х узлов двухпортовыми адаптерами (например, начиная с Mellanox Connrct X®5), без использования выделенного коммутатора.} Если вам необходимо обеспечить маршрутизацию обмена RDMA между подсетями, вы также можете выбрать сетевое оборудование iWARP. Для получения дополнительной информации см. Deploy SMB Direct with Ethernet (iWARP) Network Adapters.
-
Network switches - Сколько отказов сетевых коммутаторов вы будете считать допустимым? Типичным является выбор решения с двумя коммутаторами для вашего центра обработки данных, который поддерживает обмен между вашим кластером хранения и вашим Hyper-V или прочими потребителями данных хранилища.
Если вы применяете избыточные сетевые соединения, вы вероятно пожелаете два 10GbE коммутатора для взаимодействия между вашим кластером хранения и рабочими нагрузками, которые основаны на его данных. Коммутаторы также должны все технологии, необходимые для надлежащей производительности ваших сетевых адаптеров - например, вы можете захотеть использовать кадры jumbo, а RoCEv2 потребует одной или более VLAN, а также управления приоритетами потока (PFC, priority flow control). Вероятно, вам также понадобится один или два 1GbE коммутаторов для взаимодействия с интерфейсом безголового управления узлами сервера (BMC) для подготовке к работе голого железа. {Прим. пер.: отсылаем к соответствующему разделу для ознакомления с подробностями Параметров настройки сетевого оборудования. Повторим тезисы о незначительной разнице в стоимости между 10GbE и 25GbE адаптерами по состоянию на конец 2016г, а также о возможности объединения до 4х узлов двухпортовыми адаптерами (например, начиная с Mellanox Connrct X®5), без использования выделенного коммутатора.}
Подзадача 3b: Проектирование отказоустойчивости пула хранения
Пространства хранения берут все ваши диски и SSD и помещают их в один или несколько пулов хранения, из которых вы можете вырезать виртуальные диски. По умолчанию возвращение виртуального диска к его полной отказоустойчивости после отказа диска требует замены всех отказавших дисков. Или вы можете спроектировать некоторую дополнительную ёмкость чтобы не приходилось заменять диски посреди ночи.
Воспользуйтесь следующими разделами для определения как отказоустойчивости работать в вашем пуле (пулах) хранения:
-
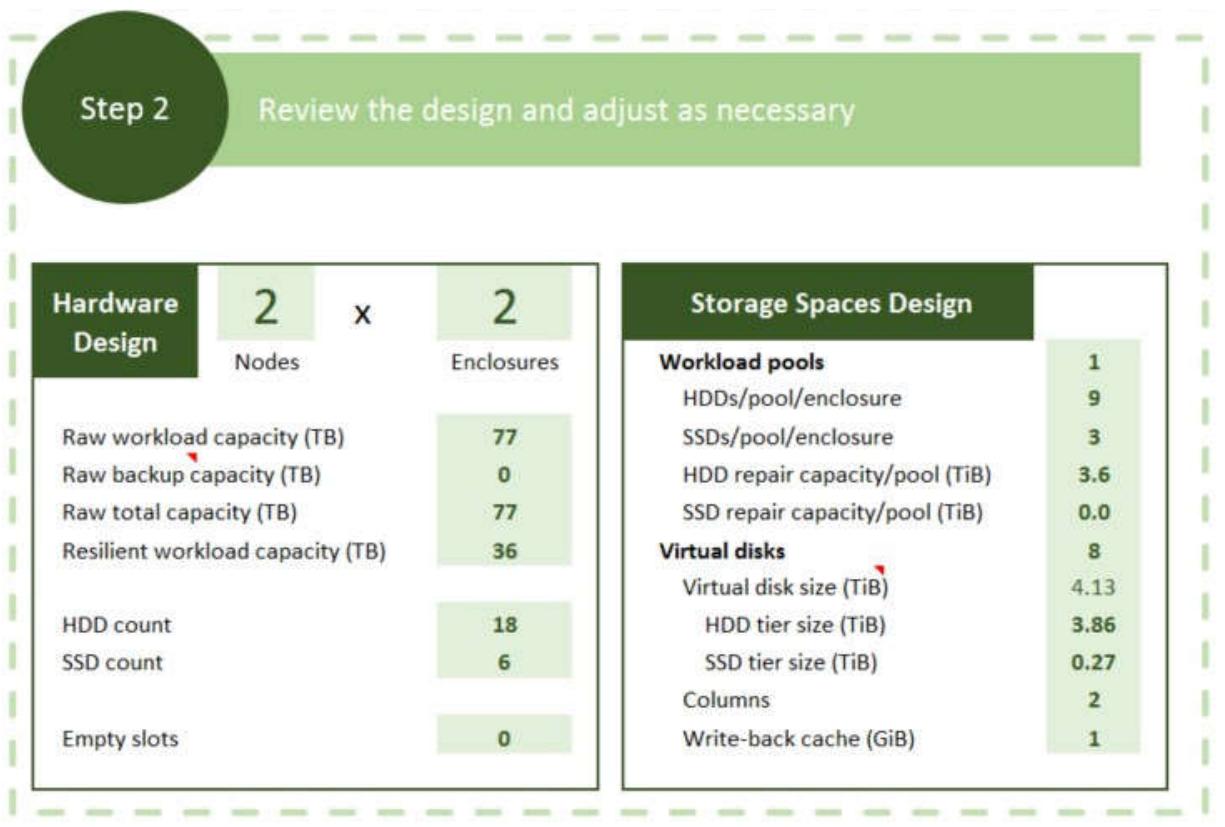
Число пулов - Используйте поле Workload pools в таблице Калькулятора проектирования Программно- определяемого хранилища для определения того сколько пулов применять для ваших рабочих нагрузок (без резервного копирования). Пулы хранения являются управляемыми и отказоустойчивыми доменами, поэтому увеличение их общего числа означает больше пулов для управления и пространства настроенного внутри для восстановления виртуального диска, однако это также ограничивает воздействие отказов диска только для виртуальных дисков внутри этого пула, как это показано в Таблице 1.
Обычно вы будете применять один пул пока у вас не будет более 84 дисков, что является максимальным рекомендуемым числом дисков на пул кластера хранения. Если вы включите в пул большее число дисков, это может повлечь увеличению числа восстановлений до момента вызывающего отказ ввода/ вывода
Таблица 1.1 - Количество пулов и устойчивость к отказам Число пулов Тип зеркала Перегрузка отказоустойчивостью Устойчивость к отказам пула(1) Устойчивость к отказам системы(2) 1
Двойное
50%
1 диск
1 диск
Двойное
67%
2 диска
2 диска
2
Двойное
50%
1 диск
2 диска
Тройное
67%
2 диска
4 диска
3
Двойное
50%
1 диск
3 диска
Тройное
67%
2 диска
6 дисков
4
Двойное
50%
1 диск
4 диска
Тройное
67%
2 диска
8 дисков
(1)Общее число дисков, которое может быть утрачено в Пуле до того, как потеря данных коснётся размещаемых Виртуальных дисков
(2)Общее число дисков во всей системе хранения (при условии равномерности их отказов) до того, как потеря данных коснётся размещаемых Виртуальных дисков
Автоматически восстанавливаемые отказы SSD - Примените поле SSDs to repair в своей таблице для определения того, какое число отказов SSD в пуле вы хотите автоматически восстанавливать, что затем вычислит вам какой объём зарезервировать в ваших пулах. Вычисление сложное, поэтому пока вы для своей забавы вы не выведите формулу, мы предлагаем вам применять для вычислений данную таблицу. Обычно у вас достаточно места в соответствующей полке для восстановления данных всех отказавших дисков плюс некоторый дополнительный запас. Отметим, что если у вас есть меньше копий данных чем полок, общий возвращаемый объём уменьшается, так как все данные в отказавшем диске могут быть восстановлены в двух полках вместо одной.
Реализации небольшого масштаба часто не создают внутри никакой ёмкости SSD, в то время как применения большего размера часто настраиваются внутри SSD для восстановления одного отказавшего диска на пул, что также может уменьшить максимальное число столбцов - дисков по которым происходит чередование данных - для ваших виртуальных дисков на один.
Автоматически восстанавливаемые отказы HDD - Воспользуйтесь полем HDDs to repair в своей таблице для определения того, сколько отказов HDD вы хотите автоматически восстанавливать в пуле, которая затем вычислит ёмкость необходимую для резерва в ваших пулах.
Реализации небольшого масштаба часто создают внутри достаточную ёмкость HDD для восстановления одного отказавшего диска на пул, в то время как установки большего масштаба могут резервировать ёмкость для трёх или более восстановлений на пул. Отметим, что виртуальные диски используют одно и то же число столбцов для обоих уровней хранения, причём максимальное число столбцов определяется по уровню с наименьшим значением (обычно это уровень SSD).
Горячий резерв - Горячее резервирование работает в Windows Server 2012 и является простым для проектирования, однако медленнее чем применение свободного пространства для восстановления виртуальных дисков и не экономит много (если это вообще имеет место) ёмкости, поэтому му не рекомендуем его для Windows Server 2012 R2.
Если вы решите применять горячее резервирование для восстановления полной отказоустойчивости после отказа одного диска добавлением дисков в этот пул, установите тип выделения в значение hot spare для одного HDD и одного SSD на пул, или на полку (если вы применяете информированность полок).
Замечание В Windows Server 2012 R2 время для восстановления виртуального диска после его отказа зависит от объёма ёмкости свободного пространства пула, которое вы установите дополнительно. Если вы установите дополнительно достаточное пространство HDD в своём пуле (представленное в вашей таблице полем HDDs to repair ) для автоматического восстановления только одного отказавшего HDD (на полку при использовании информированности полки), все восстановления, за исключением первого, происходят с той же скоростью, что и в случае с применением горячего резерва. Первое автоматическое восстановление быстро записывается на множество дисков в вашей полке с имеющимся отказавшим диском, однако последующие восстановления записывают только на один диск, так как только вновь заменённый диск имеет достаточное избыточное пространство. Для получения более быстрых времён восстановления - обычно это важно только для HDD с уровнями кэширования - устанавливайте дополнительно достаточный объём свободного пространства в своём пуле для одновременного автоматического восстановления двух или трёх отказавших HDD на полку и заменяйте диски после отказа первого диска. Восстановление первого диска всё ещё самое быстрое, однако последующие восстановления обычно осуществляют запись одновременно на по крайней мере два из трёх HDD если вы заменили отказавшие HDD после первого отказа и ваш новый диск не является следующим отказавшим диском.
Подзадача 3c: Проектирование отказоустойчивости виртуального диска
Существует три фактора, которые определяют как вы создаёте отказоустойчивые виртуальные диски из пространства пула:
-
Компоновка Хранилища - Воспользуйтесь полем Layout в своей таблице Калькулятора проектирования Программно- определяемого хранилища для определения схемы своего хранилища (а также копий данных, которые обсуждаются далее). Пространства хранения предоставляют три первичных схемы хранения (также называемых типами отказоустойчивости, resiliency types), которые управляют тем как осуществлять отказоустойчивость ваших данных:
-
Mirror (зеркало) - Записывает чередующиеся данные по множеству дисков и при этом также записывает одну или две дополнительные копии этих данных. Зеркало аналогично массиву RAID 1 или RAID 10 и осуществляет балансировку производительности и ёмкости.
Используйте зеркалирование для большей части рабочих нагрузок- это поможет защитить ваши данные от отказов дисков и предоставляет великолепную производительность, в особенности когда вы добавляете SSD в свой пул хранения и применяете многоуровневое хранение.
-
Parity (контрольная сумма) - Записывает чередующиеся данные по множеству дисков и при этом также записывает одну или две копии информации контрольных сумм. Применение контрольных сумм во многом аналогично массиву RAID 5 (или RAID 6, если вы применяете двойные контрольные суммы), а также оптимизирует ёмкость в за счёт затрат на производительность записи.
Применяйте схему с контрольными суммами для рабочих нагрузок архивирования и потоковой информации или для прочих рабочих нагрузок, в которых вы желаете максимизировать ёмкость и вы готовы согласиться с более низкой производительностью записи. Пространства контрольных сумм имеют те же ограничения что и массивы RAID5 и RAID6 - они имеют хорошую производительность чтения, однако намного более медленны для записи, в особенности при произвольных записях малых блоков. Такие замедления записи ещё более ощутимы при двойных контрольных суммах, хотя вы можете значительно улучшить их путём добавления SSD дисков журналов (схватывается в поле Backup reserve > SSD capacity вашей таблицы). {Прим. пер.: существенную помощь здесь сможет оказать аппаратная разгрузка вычисления контрольных сумм в ASIC, уже реализованная, например Mellanox. Ждём её применения на уровне программного обеспечения!}
-
Simple (однократная) - Записывает чередующиеся данные по множеству дисков без какой- либо записи дополнительных копий или контрольных сумм. Во многом похоже на массив RAID 0 - предоставляет максимальную производительность и ёмкость, однако не обеспечивает никакой отказоустойчивости.
Так как однократная запись не предоставляет никакой защиты от отказов дисков, применяйте её только когда вам нужна наивысшая производительность и ёмкость и вы готовы к потере данных или их повторному созданию в случае отказов дисков. Вы также можете применять однократную запись когда ваши приложения предоставляют собственную защиту данным.
-
-
Копии данных - Схемы с зеркалированием или контрольными суммами делают для вас возможным определять хотите ли вы две или три копии своих данных, защищая вас от одного или двух одновременных отказов. Реализации с большим числом дисков и наличием критически важных данных обычно применяют три копии данных для дополнительной защиты, хотя это приводит к некоторому уменьшению производительности в сравнении с вариантом двух копий.
Отметим, что восстановление пространств после отказа диска с контрольными суммами потребует большего времени, нежели вариант с зеркалированными пространствами, так как данные должны восстанавливаться из информации контрольных сумм, что может увеличить вероятность отказа второго диска до завершения процесса восстановления. Такое время восстановления возрастает по мере роста размеров диска, следовательно если вы хотите применять схему с контрольными суммами, а ваши диски больше 1ТБ, вы вероятно захотите применять двойные контрольные суммы для минимизации вероятности утраты данных в случае отказа двух дисков в быстрой последовательности. {Прим. пер.: рекомендуем ознакомиться с организацией Удаляющего кодирования Ceph, если вы хотите получить дополнительные сведения по работе с контрольными суммами. Также отметим, что по умолчанию в системах хранения крупного масштаба, аналогичных Ceph применяется схема, ориентированная на отработку отказа двух копий данных.}
-
Информированность полки - Используйте поле Enclosure awareness в своей таблице для определения того, включить ли информированность полки, делая каждую полку доменом отказа. Информированные полки хранят копии ваших данных в различных полках с тем, чтобы в случае отказа некоторой полки целиком ваши виртуальные диски оставались доступными.
Хранение копий в отдельных полках может уменьшить общее число дисков, к которым осуществляется одновременный доступ (общее число столбцов) на виртуальный диск, так как данные чередуются только по дискам, расположенным в пределах этой полки, в отличии от варианта с дисками во всём пуле. Хотя это и может уменьшить абсолютную пропускную способность для определённого виртуального диска, производительность во всём пуле обычно остаётся высокой, так как доступ к виртуальным дискам может осуществляться одновременно. Применение числа столбцов в количестве 4- 6 обычно даёт наилучший баланс пропускной способности и латентности для рабочих нагрузок с виртуализацией.
Таблица 2 - Максимальная устойчивость к отказам без разрушения виртуальных дисков, которые имеют включённой информированность полок Тип отказоустойчивости Три полки Четыре полки Одинарная запись
Не поддерживаются
Не поддерживаются
Двойное зеркало
1 полка; или 1 диск*
1 полка; или 1 диск*
Тройное зеркало
1 полка +1 диск*; или 2 диска*
1 полка +1 диск*; или 2 диска*
Одинарная контрольная сумма
Не поддерживаются
Не поддерживаются
Двойная контрольная сумма
Не поддерживаются
1 полка +1 диск*; или 2 диска*
* - на пул
-
Число виртуальных дисков на узел - Примените поле Virtual disks/node в своей таблице для определения того, сколько виртуальных дисков использовать на один узел. За один раз доступ может осуществляться только к одному виртуальному диску, поэтому чтобы разделять нагрузку по узлам кластера, создайте виртуальные диски в количестве, помноженном на общее число узлов кластера. Большее число виртуальных дисков на узел более равномерно реализует балансировку, в том числе при отказах в кластере с тремя или четырьмя узлами. 2- 4 виртуальных диска на узел (равномерно разделённые по пулам) являются обычным диапазоном для начальных значений, хотя вам может понадобиться увеличить это значение чтобы предотвратить чрезмерное разрастание виртуальных дисков в размерах.
Следующая задача состоит в определении того, какой размер применять полкам хранения и дискам, а также во взвешивании требований к ЦПУ и оперативной памяти.
-
Полки хранения - Запишите общее число слотов дисков, которое использует ваша полка хранения и заполнять ли все слоты дисками в полях Disk slots и Fill all slots электронной таблицы Калькулятора проектирования Программно определяемого хранилища. Увеличение общего размера числа вмещаемых полкой необходимых вам дисков обычно приводит к экономии средств, а в последствии вы добавите вторую, третью и четвёртую полки, равномерно распределяя диски по полкам (и, скорее всего, заполняя каждую полку).
-
Типы SSD и HDD - Какая скорость вращения (для HDD) и модель диска соответствуют вашим требованиям ёмкости и производительности и поддерживаются вашим производителем оборудования? Обычно пользователи применяют HDD near line (почти постоянно работающие, NEAR onLINE) 7200rpm в совокупности с SSD и уровнями хранения - SSD предоставляют большую часть производительности, в то время как ваши HDD обеспечивают основную ёмкость.
-
Размер HDD - Запишите размер своих HDD в поле HDD size в своей таблице. Проверьте вместе со своим поставщиком оборудования что в точности он предлагает, однако обычно диски самого большого размера дают самую лучшую стоимость за ТБ и достаточную производительность для вашего уровня HDD. {Прим. пер.: не совсем так - как правило, диски самой большой ёмкости имеют более высокий параметр стоимости одного ТБ в сравнении с аналогичными моделями на один два шага ниже в размере, например в начале декабря 2016 оптовые цены cо складе в Москве одного из производителей дисков в ценах одного и того же поставщика находятся в следующей пропорции: 4-6-8-10ТБ/ 245-276-394-500$ подробнее.}
Совместно с теми значениями, которые вы ввели ранее, размеры HDD определят сколько HDD использует ваше решение для получения нужной вам ёмкости. Общая ёмкость и суммарное число HDD затем будут отображены в разделе Hardware Design вашей рабочей таблицы, обсуждаемой на Этапе 2.
-
Размер SSD - Запишите размер своих SSD в поле SSD size своей электронной таблицы - общее число SSD в вашем решении определяет абсолютную производительность вашего хранилища (за счёт расширения того числа SSD, которое может быть доступным одновременно), хотя общая ёмкость ваших уровней SSD определяет какой объём данных может быть доступен на скоростях SSD. Если у вас имеется больше активных данных, чем вмещают в себя уровни SSD, активные данные перетекают на ваши уровни HDD, увеличивая задержки и уменьшая время ответа ваших рабочих нагрузок, а также объём нагрузки, который вы можете добавлять. Отметим, что общее число SSD на пул обычно ограничивает максимальное число столбцов для ваших виртуальных дисков, что оказывает воздействие на общую производительность обоих уровней. {Прим. пер.: сервера 2016 позволяют иметь дополнительный уровень NVMe.}
-
Соотношение SSD/HDD - Воспользуйтесь полем SSD/HDD ratio в своей электронной таблице для записи соотношения SSD к HDD в вашем проекте. При определении размеров решения Пространств хранения, уточните общее число и размер HDD в вашем решении на основе того, какая ёмкость вам необходима, затем уточните размер ваших SSD на основании того какая производительность вам необходима и того, сколько активных данных у вас имеется. Соотношение SSD к HDD является удобным способом увеличения или уменьшения общей производительности вашего решения. Значение 25% SSD является обычным для предоставления хорошего баланса производительности и ёмкости, однако вы можете регулировать это значение для увеличения производительности или снижения стоимости.
-
Процессор - Если ваше решение содержит сетевые адаптеры с поддержкой RDMA, которые обрабатывают сетевой обмен напрямую, может оказаться, что ваши узлы хранения не нуждаются в более производительных процессорах, хотя производительность Дедупликации данных может изменяться в зависимости от ваших процессоров. Для узлов кластера обычным являются ЦПУ с шестью ядрами. {Прим. пер.: подробнее, см. выбор ЦПУ для OSD Ceph.}
-
Оперативная память - Оперативная память в узлах кластера хранения применяется при Дедупликации данных (если вы её используете) и при некоторых видах его кэширования, хотя, скорее всего, вы не будете применять кэш CSV (обычно он является наиболее жадным в отношении оперативной памяти в кластерном файловом сервере). 64ГБ оперативной памяти является обычным выбором для узлов кластера {Прим. пер.: см. также обсуждение объёмов памяти при выборе узлов OSD Ceph, при выборе алгоритмов кэширования для ZFS, а также Потребности дедупликации в памяти для ZFS. Несмотря на отличие этих систем хранения они применяют схожие методы, так что подробности в приведённых ссылках могут обогатить вас дополнительным пониманием обсуждаемой темы.}
-
Версии встроенного ПО и драйвера - Какие версии встроенного ПО (firmware) и драйверов рекомендуются вашими поставщиками оборудования для каждого из имеющихся у вас компонентов? Важно применять версии, которые указываются как лишённые проблем при масштабировании и под нагрузкой, а не просто полагаться на те драйверы, которые содержатся в вашей версии Windows Server.
Когда вы пройдёте через задачи 1 Этапа данной статьи и Калькулятор проектирования Программно определяемого хранилища выдаст вам рекомендации по проектированию для вашего оборудования и программного обеспечения. Рисунок 4 показывает такой пример.
Следующие разделы переходят к некоторым подробностям моментов проектирования, которые принимаются во внимание в электронной таблице.
Здесь описывается что спроектировал для ваших виртуальных дисков Калькулятор Программно- определяемого хранилища:
-
HDD and SSD repair capacity - Общая ёмкость которую вы определили внутри каждого пула для восстановления вычисляется на основании того, сколько дисковых отказов в пуле и полке вы хотите автоматически восстанавливать. Эта ёмкость уменьшает общий объём пространства SSD и HDD, доступный на каждом из уровней для ваших виртуальных дисков.
-
Number of virtual disks - Чем больше общее число виртуальных дисков, тем больше затрат требуется для размещения этих виртуальных дисков и управления ими. Однако, что осуществлять равномерную балансировку по всем узлам кластера, вам следует иметь по крайней мере два виртуальных диска на узел (четыре или более типично для решений большего масштаба).
Если у вас в пуле имеются SSD, каждый виртуальный диск получает свой собственный кэш отложенной записи (write- back) 1ГБ, следовательно даже хотя увеличение общего числа виртуальных дисков съест некоторую ёмкость вашего уровня SSD, это также может предоставить небольшую поддержку ускорения производительности записи.
-
Virtual disk size - В настоящее время мы рекомендуем создавать виртуальные диски которые имеют размер 10ТБ или меньше для максимизации надёжности при больших масштабах под нагрузкой.
-
HDD and SSD tier sizes - При определении размеров уровней хранения (и при увеличении размера ваших виртуальных дисков), ваша электронная таблица берёт общий объём пространства SSD в вашем пуле, вычитает общий объём, ёмкости для запаса под восстановление отказавших SSD и для кэширования отложенной записи, а затем делится то что осталось на общее число виртуальных дисков, которое вы хотите создать. Это же выполняется аналогичным образом для вычисления ёмкости HDD.
Отметим, что балансировка нагрузки SMB предполагает, что ваши виртуальные диски идентичны (или по крайней мере симметричны) по всем кластерным узлам, поэтому если вам нужно создавать множество типов виртуальных дисков, создавайте каждый со множителем общего числа узлов кластера с тем, чтобы нагрузка могла балансироваться более равномерно.
-
Column count - Пространства хранения (Storage Spaces) записывают данные на множество дисков фрагментами, называемыми полосами (stripe). Общее число дисков в полосе называется количеством столбцов (column count).
Увеличение числа столбцов увеличивает общее число физических дисков, по которым может чередоваться виртуальный диск, что увеличивает пропускную способность и IOPS для такого виртуального диска. Однако, это также может увеличить латентность. По этой причине вы можете оптимизировать общую производительность применяя множество виртуальных дисков со значением 3-4 столбцов (при использовании зеркалирования) или семи столбцов при использовании пространств контрольных сумм, что является значениями, применяемыми в вашей электронной таблице. Производительность всего кластера остаётся высокой, так как множество виртуальных дисков используется одновременно, навёрстывая уменьшение числа столбцов.
Если вы хотите получить автоматическое восстановление виртуальных дисков после отказа некоторого диска, вы не можете применять максимальное число столбцов, которое допускает ваше оборудование - даже если оно соответствует рекомендуемому числу столбцов 3- 4. Вместо этого ваша электронная таблица уменьшает общее число столбцов на значение отказавших SSD, которое вы бы хотели чтобы пул был бы в состоянии автоматически восстанавливать (обычным значением в проекте является один отказ SSD). Уровень HDD применяет то же самое значение числа столбцов, что и уровень SSD, поэтому если вы определите, что вы желаете автоматического восстановления после отказа трёх HDD, например, ваша электронная таблица установит внутри большую ёмкость HDD в пуле, что обычно не влияет в дальнейшем на общее число столбцов.
Таблица 3 предоставляет формулы для вычисления числа столбцов (в предположении, что у вас имеется меньше SSD чем HDD, а также что вы временно не учитываете никакие SSD применяемые для дисков журнала), однако ваша электронная таблица сделает это гораздо легче. Округлите полученный результат вниз до ближайшего целого значения. Опять же, повторим: мы рекомендуем следовать правилу не более 3- 4 столбцов для зеркалирования и семи для пространств контрольных сумм.
Таблица 3 - Вычисление общего числа столбцов для виртуальных дисков Тип отказоустойчивости При информированности полок Без информированности полок Зеркалирование
Столбцы = (Число SSD / Число пулов / Число полок) - Число отказавших дисков для автоматического восстановления
Столбцы = (Число SSD / Число пулов / Число копий данных) - Число отказавших дисков для автоматического восстановления
Контрольная сумма
Столбцы = (Число полок x 2) - 1*
Столбцы = (Число SSD / Число пулов) - Число отказавших дисков для автоматического восстановления
* для пространств контрольных сумм с информированными полками, число дисков должно составлять по крайней мере значение двух плюс общее число отказавших дисков, подлежащее автоматической замене.
Замечание При использовании информированности полок, будьте аккуратны и не применяйте число столбцов большее, чем общее число SSD в полке на пул (в допущении что у вас имеется меньше SSD, нежели HDD). Калькулятор Программно- определяемого хранилища учитывает это для вас.
-
Write-back cache size - Увеличение размера кэша отложенной записи обычно предоставляет небольшое (если оно имеет место) улучшение производительности, и может повлечь за собой слишком большое увеличение времени восстановления после отказа при работе под нагрузкой. Это именно то, почему мы рекомендуем следовать значению по умолчанию в 1ГБ, даже если вы применяете SSD в качестве дисков журнала для пространств контрольных сумм и имеете избыточную ёмкость SSD.
Помимо того, что вы создали виртуальные диски для своих данных и для резервного копирования, вы, вероятно, можете пожелать создать маленький виртуальный диск для его применения в кворуме кластера самого кластера хранения или для других кластеров (через подписи совместно используемого файла). Калькулятор проектирования Программно- определяемого хранилища не проектирует ваш виртуальный диск кворума кластера, однако это просто сделать - просто следуйте перечню:
-
Size - 1ГБ является минимумом; значение превышающее 10ГБ может быть пустой тратой дискового пространства если только вы не используете его для большого числа кластеров. Отметим, что Пространства хранения округляют вверх размер вашего виртуального диска до множителя в 1ГБ помноженному на ваше число столбцов, следовательно скорее всего у вас имеется 4ГБ или такой минимальный размер виртуального диска.
-
Resiliency type - Вы можете применять либо двойное, либо тройное зеркалирование для своего диска кворума - если вы воспользуетесь VMM для создания своего кластера, вы получите тройное зеркало.
-
Storage tiers - Диск кворума вашего кластера маленький и не требует большой производительности, поэтому нет необходимости в создании уровней его хранения - вы просто потратите впустую ёмкость SSD.
-
Witness disk type - Раз вы создали такой виртуальный диск, вы можете использовать его в качестве диска подписей в кластерах, которые имеют SAS соединения с совместно используемыми полками, или подписи общих файлов для других кластеров, которые не могут осуществлять прямой доступ к совместно используемому хранилищу.
![[Совет]](/common/images/admon/tip.png)
Совет Если вы используете настройки по умолчанию при создании виртуального диска кворума своего кластера, данные чередуются по всем дискам в вашем пуле, включая небольшие значения в ваших SSD. Если вы хотите вручную определить только HDD вашего пула при создании такого виртуального диска, воспользуйтесь Windows PowerShell для создания такого виртуального диска, конвейеризуя только свои объекты PhysicalDisk для HDD в имеющемся пуле для исполняемого cmdlet New-Volume.
После прохода через этапы 1-2 в данной статье, и в Калькуляторе проектирования Программно- определяемого хранилища, у вас имеется ряд рекомендаций, которые вы можете обсудить с поставщиком аппаратного решения. Когда вы выбрали оборудование, вы можете отрегулировать свои значения в своей таблице Этапа 1, чтобы привести её в точное соответствие закупаемому оборудованию.
Теперь также хорошее время поболтать с вашим поставщиком оборудования о том, какого размера сектора его диски применять. Совсем недавно все диски применяли для хранения данных сектора в 512 байт. Сегодня SSD и HDD обычно используют для хранения данных физические сектора 4кБ (эти диски называются дисками с расширенным форматом), однако могут представлять сектора с логическим размером 512 байт операционной системе для обратной совместимости (они также имеют название 512e дисков, так как они эмулируют сектора в 512 байт). Если операционные системы и приложения в ваших виртуальных машинах поддерживают натуральные диски с секторами 4кБ (а наиболее последние версии таковы), вы получите оптимальную производительность если все диски являются натуральными дисками 4K вместо дисков 512e. Натуральные диски 4K применяют физические и логические сектора 4кБ и являются более быстрыми в сравнении с дисками 512e, так как им нет нужды эмулировать сектора 512 байт, что влияет на производительность дополнительными операциями чтения при записи (известном как читай-изменяй-записывай). {Прим. пер.: Подробнее о связанных с этим проблемах, в том числе при выравнивании разделов, см. наш перевод Обзора технологии Расширенного формата жёстких дисков Ильи Крутова, IBM.})
Совет Для промышленного применения мы рекомендуем приобретать всё оборудование у производителя, который протестировал и поддерживает это оборудование в качестве интегратора решений с Пространствами хранения. Примером такого решения является Microsoft Cloud Platform (CPS) Powered by Dell. Также важно следовать всем рекомендациям производителя о том, чьи диски и какие версии встроенного ПО использовать.
Когда вы будете готовы разместить хранилище с Пространствами хранения, существуют некоторые настройки, которые вам следует пересмотреть на основании нашего понимания Пространств хранения (Storage Sapces) с крупномасштабных средах, как это описано в следующих задачах.
Вот перечень некоторых настроек, которые вам необходимо принимать во внимание при регулировках на каждом узле кластера:
-
Обновления Windows - мы выпускали и выпускаем критически важные обновления для Windows и компонентов Пространств хранения на основании крупномасштабных тестирований, поэтому важно применять обновления Windows для узлов кластера на постоянной основе - мы рекомендуем ежемесячно.
-
Обновления восстановлений реестра Пространств хранения - Существуют некоторые выполняемые вручную шаги которые вы должны выполнять для обновления конкретного способа обновлений виртуальных дисков Пространств хранения - для получения дополнительной информации обратитесь к Optimize Storage Spaces repair settings on Scale-Out File Servers.
-
Уведомление Windows file-delete (trim/unmap) - Хотя в Windows и встроена поддержка для уведомления об удалении файла (выдающая команды trim для очистки хранилища SSD), мы рекомендуем выключить уведомление Windows file-delete на использующих Пространства хранения серверах. Чтобы сделать это из запускаемого приглашения командной строки, выполните следующую команду на всех узлах вашего кластера:
Fsutil behavior set DisableDeleteNotify 1 -
Настройки MPIO (Multipath I/O) - Если вы используете множественные соединения SAS к вашей полке хранилища, включите MPIO на всех узлах вашего кластера с тем, чтобы Пространства хранения могли взаимодействовать с полками по множеству кабелей. Вы также пожелаете установить глобальную политику MPIO - политикой по умолчанию является Round Robin (карусельная), однако согласно нашим внутренним тестам, Least Blocks (наименьшие блоки) предоставляют увеличение производительности в большинстве случаев.
Чтобы достичь предела производительности вы также можете установить политику персональную SSD в Round Robin (что будет иметь результатом применение для HDD Least Blocks и Round Robin для SSD). Чтобы устанавливать политику MPIO для конкретных SSD применяйте команду
Mpclaim.exeна каждом узле для настройки политики MPIO для отдельных SSD. Например, чтобы установить политику MPIO в Robin Round (представленную в MPclaim значением 2) для диска 10, примените в вызываемом приглашении командной строки такую команду:Mpclaim -l -d 10 2. -
Кэши физического диска - В некоторых случаях оставление включённым кэширование отложенной записи (write- back) может снизить производительность, поэтому мы рекомендуем выключать его на всех дисках. Чтобы сделать это, воспользуйтесь инструментарием
Diskcache.exe, как это описано в заметке Microsoft Knowledge Base 811392.
Существует несколько настроек пула и тома, которые важно выполнить:
-
Как выводить утраченные физические диски - Чтобы включить Пространства хранения на применение дополнительной ёмкости пула для восстановления виртуальных дисков после отказа физического диска воспользуйтесь cmdlet Set-StoragePool для установки политики
RetireMissingPhysicalDisksв значениеAlways.Если вы предпринимаете нечто, что может влиять на связь со множеством дисков, например, замена поддона для нескольких дисков, установите эту политику в значение
Neverна время выполнения действий технического обслуживания. Если ваше окружение использует диски с горячей заменой, оставьте политику настроенной в значениеAuto. -
Стоит ли разрешать в томах большие FRS (File Record Segment, сегменты записи файла) - Чтобы сделать возможным надлежащее расширение больших файлов
.vhdx, существуют новые рекомендации для форматирования томов. При форматировании томов, которые будут размещать очень большие файлы, такие как.vhdxболее чем 1ТБ, применяйте cmdlet Format-Volume с параметрами-AllocationUnitSize 64KB –UseLargeFRSдля форматирования томов с элементами размещения NTFS размером 64кБ и включите поддержкуFRS. -
Применять ли для ваших пулов хранения логические секторы 4кБ - Чтобы продолжать поддержку совместимости с более ранними приложениями, Пространства хранения используют для виртуальных дисков сектора 512 байт, если в вашем пуле отсутствуют какие- либо диски с натуральными 4K при его создании (см. Таблицу 4). Однако вы не можете добавлять диски с натуральными 4K в пул, который применяет для виртуальных дисков сектора 512 байт, следовательно, если вы думаете, что вы сможете добавлять в этот пул диски с натуральными 4K (например, при замене отказавших дисков), создавайте пулы с логическими секторами 4кБ, даже если вы ещё не имеете никаких дисков с натуральными 4K.
Чтобы проверить размеры сектора, применяемого вашими физическими дисками, воспользуйтесь следующей командой Windows PowerShell:
Get-PhysicalDisk | Sort-Object SlotNumber | Select-Object SlotNumber, FriendlyName, Manufacturer, Model, PhysicalSectorSize, LogicalSectorSize | Format-Table.Чтобы создать пул хранения с логическими секторами 4кБ, применяйте cmdlet New-StoragePool с параметром
–LogicalSectorSizeDefault 4096для принудительного применения вашим пулом логических секторов 4кБ при их создании.
{Прим. пер.: Подробнее о связанных с этим проблемах, в том числе при выравнивании разделов, см. наш перевод Обзора технологии Расширенного формата жёстких дисков Ильи Крутова, IBM.})Таблица 4 - Применяемые Windows Server для различных типов дисков размеры секторов по умолчанию Тип диска в пуле Размер физического сектора диска Размер логического сектора диска Размер логического сектора Пространств хранения Размер физического сектора .vhdx Размер логического сектора .vhdx натуральные 512 (старые диски)
512 байт
512 байт
512 байт
512 байт
512 байт
512e*
4 кБ
512 байт
512 байт
512 байт
512 байт
натуральные 4K (или замес из натуральных 4K и 512e*)
4 кБ
4 кБ и (512 байт если у вас имеются только диски 512e
4 кБ
4 кБ
512 байт
* вы также можете иметь подмешанными натуральные диски 512 - мы опускаем это в целях упрощения.
-
Использовать ли логические сектора 4кБ для файлов .vhdx - По умолчанию, Hyper-V применяет для виртуальных жёстких дисков
.vhdxлогические сектора 512 байт для поддержки совместимости с более ранними приложениями, даже если лежащие в основе пул хранения и диски применяют сектора 4 кБ (см. Таблицу 4). Hyper-V по существу создаёт виртуальные диски 512e. Однако, в наши дни большинство приложений поддерживают логические сектора 4 кБ, поэтому если у вас применяются пулы с логическими секторами 4 кБ, вы можете оптимизировать производительность создав с таким же успехом файлы.vhdxс логическими секторами 4 кБ.Чтобы создать файл
.vhdxс логическими секторами 4 кБ, воспользуйтесь следующим примером:New-VHD -Path C:\ClusterStorage\Volume1\sharedvhdx.vhdx -SizeBytes 200GB -PhysicalSectorSizeBytes 4KB -LogicalSectorSizeBytes 4KB.Для получения дополнительной информации о Расширенном формате дисков смотрите Understanding the Impact of Large Sector Media for IT Pros, Hyper-V Support for Large Sector Disks Overview и Advanced Format (4K) Disk Compatibility Update {Прим. пер.: также предлагаем наш перевод Обзора технологии Расширенного формата жёстких дисков Ильи Крутова, IBM.})
Замечание Если ваш пул хранения применяет логические сектора 4 кБ, однако у вас имеются совместно используемые файлы
.vhdx, которые по умолчанию применяют логические секторы 512 байт, вы можете увидеть следующую ошибку при инициализации общего файла.vhdx:The request could not be performed because of an I/O device error(Запрос не может быть выполнен из- за ошибки ввода/ вывода устройства). Чтобы решить эту проблему установите исправление, включённое в заметку Microsoft Knowledge Base 3025091. -
Применять ли множество источников при восстановлении виртуальных дисков (политика repair - ранее политика rebuild) - Если вы применяете свободное пространство пула для восстановления виртуальных дисков после отказов физических дисков, по умолчанию восстановление будет копировать данные параллельно со множества дисков в одно и то же время, уменьшая время требующееся для полного восстановления отказоустойчивости. Если вы хотите минимизировать воздействие на прочие операции ввода/ вывода в процессе восстановления, вы можете вместо этого включить последовательное восстановление, которое копирует за раз одну платину (область диска). Однако, последовательного восстановления обычно недостаточно для поддержания хорошей производительности.
Большинство SAS SSD оптимизируют своё восстановление и время жизни устройства без помощи со стороны операционной системы и нам приходилось наблюдать возрастание задержек SSD в процессе исполнения команд trim из операционной системы, что приводило к снижению производительности. Мы продолжим своё сотрудничество с производителями SSD а также с поставщиками аппаратных решений наших Пространств хранения для обеспечения наилучшего поведения между Windows и флеш- памятью и обновим эту страницу в случае изменения ситуации.
-
Должно ли ваше хранилище иметь избыточные источники электропитания - Если ваши узлы хранения и полки имеют избыточные блоки питания и источники энергоснабжения (такие, как источники бесперебойного электропитания - UPS, uninterruptable power supply - или обслуживание от множества поставщиков электричества), вы можете применять Windows PowerShell для включения переключателя IsPowerProtected в своих пулах хранения, что увеличит производительность записи за счёт запрета операций отложеной записи на дисковом уровне, полагаясь на то, что диск всегда завершит эту операцию.
Однако, включение IsPowerProtected приведёт к разрушению данных если узел или полка утратят энергоснабжение в процессе выполнения операции записи, что делает критически важным гарантию избыточности и надёжности энергоснабжения.
В зависимости от вашей рабочей нагрузки вы можете пожелать включить Дедупликацию данных или кэш CSV:
-
Дедупликация данных - Если у вас имеются рабочие нагрузки, которые совместимы с Дедупликацией данных, например, резервное копирование, библиотеки VHD, а также размещения VDI, вы можете включить дедупликацию на соответствующих виртуальных дисках.
Для получения дополнительной информации ознакомьтесь с Plan to Deploy Data Deduplication и Large scale Virtual Desktop Infrastructure deployment using Windows Server 2012 R2 with Storage Tiers and Data Deduplication.
-
CSV (Cluster shared volumes, общие тома) и совместно используемые файлы - Для минимизации административных накладных расходов и упрощения балансировки нагрузки ваших общих ресурсов и узлов кластера, вы обычно желаете создавать отдельный CSV на виртуальный диск, а также отдельный непрерывно доступный общий файл на CSV.
-
Кэш CSV - Вы можете выделить системную память на своих узлах кластера для кэширования CSV, что может улучшить производительность чтения в рабочих нагрузках подобных Hyper-V. Однако, кэширование CSV не применяется виртуальными дисками с многоуровневым хранением (которые, скорее всего, являются вашими первичными дисками данных), или виртуальными дисками, которые применяют Дедупликацию данных (которые вероятно являются вашими дисками резервного копирования), что может ничего не оставить для применения вашего кэша CSV... Если вы найдёте причину для применения кэширования CSV в своём кластере хранения - может быть у вас есть много виртуальных дисков которые не используют многоуровневое хранение - самый максимум всего кэша CSV который вы должны использовать в Windows Server 2012 R2 составляет 64ГБ.
Когда вы завершите этапы данной статьи, вы будете иметь проект для своего оборудования и программного обеспечения решения хранения. Раз вы сотрудничаете со своим поставщиком оборудования для завершения построения аппаратуры и последующих регулировок своего решения программного обеспечения на основании вашего окончательного выбора оборудования, самое время разместить Windows Server и создать ваши пулы хранения, виртуальные диски и общие файлы.
Для получения дополнительной информации о развёртывании Пространств хранения ознакомьтесь с Deploy Clustered Storage Spaces.