Глава 7. Настройка производительности Hyper-V
"Догадки это путь к провалу. Начните с хорошей основы, имеющей MAP (Microsoft Assessment and Planning Toolkit) и знания своих потребностей. Следуёте наилучшему практическому опыту данной книги чтобы избежать основных проблем производительности. А также применяйте на практике мониторинг своих хостов и рабочих нагрузок с тем, чтобы вы могли быстро исправлять их в случае появления."
Эйдан Финн - MVP Hyper-V
Содержание
- Глава 7. Настройка производительности Hyper-V
- Измерение производительности
- Настройка производительности
- Эталонное тестирование Hyper-V
- Hyper-V для виртуальных рабочих мест
- Распространённые ошибки настройки
- Выводы
По окончанию основной настройки всех компонентов Hyper-V, самое время для дополнительной настройки производительности.
Существуют следующие темы, которые мы обсудим в данной главе:
-
Измерение производительности
-
Настройка производительности и руководство по определению размеров для:
-
Аппаратных средств
-
Системы хранения/ сетевой среды
-
Роли сервера Hyper-V
-
-
Эталонное тестирование
-
Настройка виртуализации клиента и виртуальных GPU
Перед тем как мы приступим к настройке производительности, необходимо получить представление о текущей ситуации. Многие случаи установления размера для настроек Hyper-V, которые, казалось бы, были основаны на некоторых произвольных внушающих доверие оценках без осознания текущего положения дел или грядущих потребностей. Наиболее лучший подход к определению размеров настроек Hyper-V состоит в применении инструментария MAP (Microsoft Assessment and Planning Toolkit), который мы уже обсуждали в Главе 1, Ускорение развёртывания Hyper-V. MAP собирает счётчики производительности всех присущих настройке Hyper-V компонентов. Так как он используется для определения размеров вашего Hyper-V, он также может применяться аналогичным образом для для создания базоваого уровня производительности вашей настройки Hyper-V. Он также может быть получен при помощи Microsoft SCOM (System Center Operations Manager). Если вы уже имеете на своём месте SCOM, этот инструмент может рассматриваться как более предпочтительный перед MAP. Отсылаем вас к Главе 8, Управление при помощи системного центра и Azure за дополнительными подробностями.
Оба инструмента непрерывно считывают счётчики производительности с хостов Hyper-V и их ВМ и архивируют их в некоторой базе данных. Выполняйте эти задач непрерывно некоторое время - я рекомендую целый месяц - для установления адекватного базового уровня. За это время вы соберёте минимальные, максимальные и средние счётчики производительности ваших систем. Минимальные размеры не дадут вам информации о реальных размерах; однаако средние значения предоставят великолепную информацию для базового уровня, в то время как максимальные значения позволят вам определить показатели пиковой производительности ваших систем.
Реальное значение также может быть взято из 95- процентилей значений {значений, составляющих 95% замеров} для счётчиков производительности ЦПУ, оперативной памяти, дисков и сетевых устройств для планировния основного базового уровня. Значение в 95 процентилей было проверено на практике в качестве надёжного источника для измерения производительности и установления размеров.
Те же самые счётчики производительности, которые применяются инструментарием MAP и SCOM для создания
подобных отчётов, могут отслеживаться вручную и настраиваться с применением Windows
Performance Monitor (perfmon.exe).
{Прим. пер.: рекомендуем также Zabbix.}
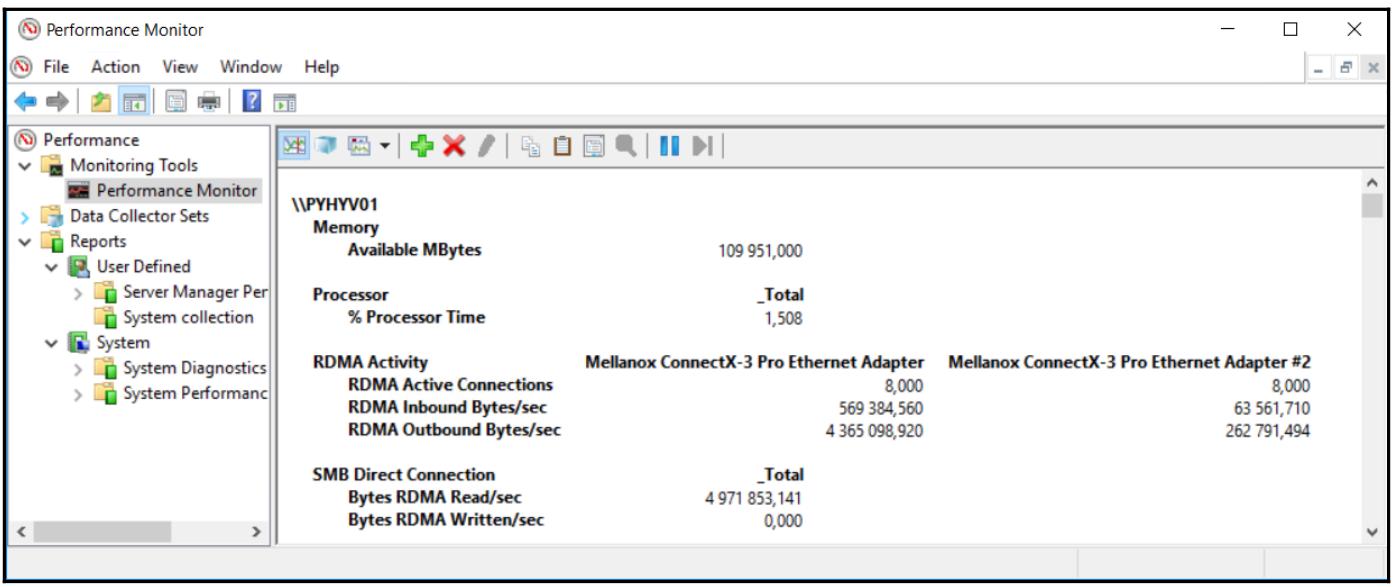
Давайте рассмотрим самые важные счётчики производительности для Hyper-V; вы можете их легко получить из
perfmon.exe.
Последующие основные счётчики важны на уровне хоста, если не оговорено иное, однако большинство из них может также быть использовано на уровне вашей ВМ.
Производительность диска
Наличие достаточной ёмкости в вашей системе важно, однако, как мы видели ранее, хранилища в центре обработки
данных основываются на IOPS. Существует два важных счётчика производительности сообщающих о том, что у вас
нет достаточной доступной производительности IOPS: \Logical Disk(*)\Avg. sec/Read
и \Logical Disk(*)\Avg. sec/Write.
Они замеряют латентность дисковой ваших систем проистекающую из недостаточности IOPS. Если система хранения предоставляет достаточно IOPS, значения латентности для производительности чтения и записи хранилища не должно выходить за пределы 15 миллисекунд.
Латентность диска между 15 и 25 миллисекундами или даже выше может вызывать отрицательное воздействие на производительность ваших ВМ и приложений, а когда латентность диска превосходит 25 миллисекунд, это гарантированно вызывает отрицательное влияние. Высокая латентность дисков является причиной номер один для медленной производительности Hyper-V, поскольку архитектура IOPS хранилищ часто находится в запущенном состоянии.
Применяйте индивидуальные счётчики дисков для фильтрации этих настроек на определённый уровень диска. Будьте осведомлены об использовании логических дисков из SAN или NAS, так как этот счётчик получает значение только от логического диска целиком, а не от индивидуальных физических дисков. {Прим. пер.: рекомендуем ознакомиться со сведениями Главы 8, Производительность нашего перевода "ZFS для профессионалов", содержащей множество тем являющихся общими не только для ZFS, но и для всех современных систем хранения.}
Производительность памяти
Для проверки достаточно или нет оперативной памяти доступно внутри ВМ или на уровне вашего хоста Hyper-V воспользуйтесь следующими двумя счётчиками производительности:
-
\Memory\Available Mbytes: измеряет общий объём оперативной памяти доступной для выполняющихся активных процессов. Убедитесь, что по крайней мере 15 процентов от общего объёма установленной оперативной памяти являются доступными. Если этого не наблюдается, добавьте ещё оперативной памяти в этот физический хост или виртуальную машину. Если вы используете динамичную память внутри виртуальной машины, убедитесь что вы увеличили её буфер чтобы сделать больше доступной оперативной памяти доступной для такой виртуальной машины. -
\Memory\Pages/sec: этот счётчик замеряет общее соотношение того насколько часто осуществляется доступ к вашему диску для разрешения аппаратных прерываний (hard page faults). Для достижения этого операционная система разгружает содержимое оперативной памяти на свои диски, что наиболее сильным образом оказывает воздействие на общую производительность. Убедитесь что этот счётчик остаётся ниже значения в 500 страниц в секунду; в противном случае это прямой индикатор того, что ваша система нуждается в большем объёме оперативной памяти.
Производительность сетевой среды
Опять же, здесь имеются два самых важных счётчика производительности для измерения общей производительности сетевой среды Hyper-V:
-
\Network Interface(*)\Bytes Total/sec: этот счётчик замеряет общий объём текущего использования сетевой среды. Вычтите полученное значение из общей доступной пропускной способности сетевой среды и убедитесь что вы получите по крайней мере 20 процентов остающейся полосы пропускания сетевой среды доступной. -
Network Interface(*)\Output Queue Length: замеряет общую латентность в отправке сетевых пакетов в виде потоков, которые находятся в ожидании на NIC хоста. Эта очередь должна всегда быть нулевой; значение больше одного является признаком деградации сетевой производительности.
Для измерения общего использования сети в гостевой операционной системе применяйте счётчик
\Hyper-V Virtual Network Adapter(*)\Bytes/sec для определения того,
какие виртуальные сетевые адаптеры потребляют наибольшую сетевую нагрузку.
Производительность RDMA и непосредственного SMB
Если вы реализовали решение на основе SMB 3, вам следует интересоваться своими счётчиками производительности RDMA и SMB 3:
-
\RDMA Activity: эти счётчики показывают вам глабальную активность относящуюся к RDMA. Вы можете видеть, например, общее число входящих и исходящих байт/ секунду RDMA, общее число активных соединений и тому подобное. -
\SMB Direct Connection: эти счётчики замеряют информацию, относящуюся к непосредственному (Direct) SMB, например, общее число прочитанных или записанных байт RDMA в секунду.
Производительность процессора
Заключительные, но отнюдь не последние, здесь представлены два основных счётчика производительности для измерения производительности ЦПУ на общем уровне хоста:
-
\Processor(*)\% Processor Time: этот счётчик доступен только на уровне всего хоста и замеряет общее использование ЦПУ. Значение этого счётчика не должно превосходить 80 процентов в хорошем базовом уровне производительности. -
\Hyper-V Hypervisor Logical Processor(_Total)\% Total Run Time: данный счётчик используется на общем уровне хоста для оценки процессора гостевой операционной системы.
Для индикации общей мощности ЦПУ используемой в данном хосте самом по себе, применяйте счётчик
\Hyper-V Hypervisor Root Virtual Processor - % Total Run Time .
Вы уже прочитали о счётчике \Hyper-V Hypervisor Logical Processor(_Total)\% Total Run Time
на уровне всего хоста. Существует ещё один другой счётчик, очень похожий на этот:
\Hyper-V Hypervisor Virtual Processor(_Total)\% Total Run Time.
Он также работает на уровне всего хоста, однако он замеряет воздействие общего числа виртуальных процессоров, которые вы передали каждой виртуальной машине, а не воздействие логических процессоров на уровне всего хоста. Это позволяет вам получать информацию значительного размера. Если значение вашего логического процессора является высоким, однако значение счётчика виртуального процессора является низким, это означает, что вы выделили для ВМ больше vCPU чем у вас физически доступно.
Счётчик \Hyper-V Hypervisor Virtual Processor(*)\%Guest Run Time
позволяет вам определять какие vCPU потребляются ресурсами логических ЦПУ чтобы находить подходящих
кандидатов для переразмещения.
После установления базового уровня счётчиков производительности, наступило время для их интерпретации. Значения для сетевой среды, дисков и оперативной памяти объясняют себя сами, поэтому давайте перейдём сразу к подробностям размеров ЦПУ.
Если значение счётчика логического процессора низкое, а значение счётчика виртуального процессора высокое, это означает, что вы можете добавить больше vCPU к своим виртуальным машинам, так как логические процессоры всё ещё доступны.
Теоретически не существует реального верхнего предела тому сколько виртуальных ЦПУ вы можете назначать виртуальным машинам. Microsoft рекомендует не выходить за пределы 8 виртуальных ЦПУ на физическое ядро ЦПУ для серверных рабочих нагрузок и не более чем 12 виртуальных ЦПУ на физическое ядро ЦПУ для рабочих нагрузок VDI. Однако, не существует предела поддержки и в то же время существуют сценарии с низкой загруженностью при которых эти рекомендации могут быть превышены.
Мой реальный жизненный опыт при работе со счётчиками производительности и базовыми уровнями состоит в применении соотношения 1 : 4 для промышленных рабочих нагрузок как высеченное на камне правило и соотношение 1 : 12 для рабочих нагрузок тестирования/ VDI в качестве размеров базового уровня.
Имейте в виду, что виртуальная машина с четырьмя vCPU может быть в действительности медленнее чем та же самая ВМ, иеющая только два vCPU, так как ожидание для четырёх доступных потоков (threads) в вашем хосте может оказаться продолжительнее чем ожидание для двух. Это именно та причина, по которой вам следует подключать только необходимое число vCPU к виртуальным машинам, а также избегать переполнения на своём гостевом уровне.
Windows Server с Hyper-V оптимизирован для производительности, а также для зелёных ИТ в своих настройках по умолчанию. Достижение обеих целей в одно и то же время является компромиссом. Это компромисс для применения близкой к наилучшей производительности при её необходимости и в то же время сохранения наибольшей мощности незадействованной по возможности. Hyper-V поддерживает целый ряд опций сохранения мощности, таких как парковка ядер ЦПУ или изменение частот процессоров, но не все из имеющихся. В хостах Hyper-V не возможны режимы приостановки (standby) и засыпания (hibernation). Я рекомендую подход зелёных-ИТ. Приблизительно две трети от общей стоимости сервера в его типичном жизненном цикле, генерируется из стоимостей операционных расходов, таких как требующиеся для систем обеспечения энергоснабжением и отвода тепла, и только треть относится на начальную стоимость вашего серверного оборудования самого по себе. Поэтому сохранение мощности очень важный показатель при работе в инфраструктуре ИТ.
Я наблюдал, что Hyper-V проигрывает в некоторых эталонных замерах в сравнении с другими продуктами виртуализации и, в редких случаях, я вынужден был идти на компромиссы в угоду такому ориентированному на зелёные ИТ подходу. Существует возможность изменить такое поведение по умолчанию направленное на опции по энергосбережению для хостов Hyper-V и вытащить несколько самых последних процентов производительности из Hyper-V.
Установка Windows Server, будь то на физическом, или на виртуальном уровне, по умолчанию применяет сбалансированную схему потребления энергии. После переключения этого плана производительности на высокую производительность я увидел лучшую производительность и более низкую латентность в хостах Hyper-V с разницей примерно в 10 процентов. На уровне гостевой ОС (где изменение этих опции потребления мощности не имеет никакого эффекта), я обнаружил рост производительности баз данных SQL до 20 процентов в лучшую сторону при использовании плана энергопотребления с высокой производительностью для лежащих в основе хостов.
Я рекомендую применять следующие практические наработки:
-
Оставляйте хосты Hyper-V, используемые для лабораторных, тестовых целей и применения с низкой загруженностью в установленном по умолчанию сбалансированном плане энергопотребления.
-
Переключите имеющийся план энергопотребления обычно нагруженных промышленных хостов на высокопроизводительный.
-
Оставляете план энергопотребления для своих гостевых ВМ сбалансированным.
-
Кроме того, при выполнении эталонного тестирования в соревновании с прочими парнями, убедитесь что вы имеете установленными в высокопроизводительный режим настройки энергопотребления.
-
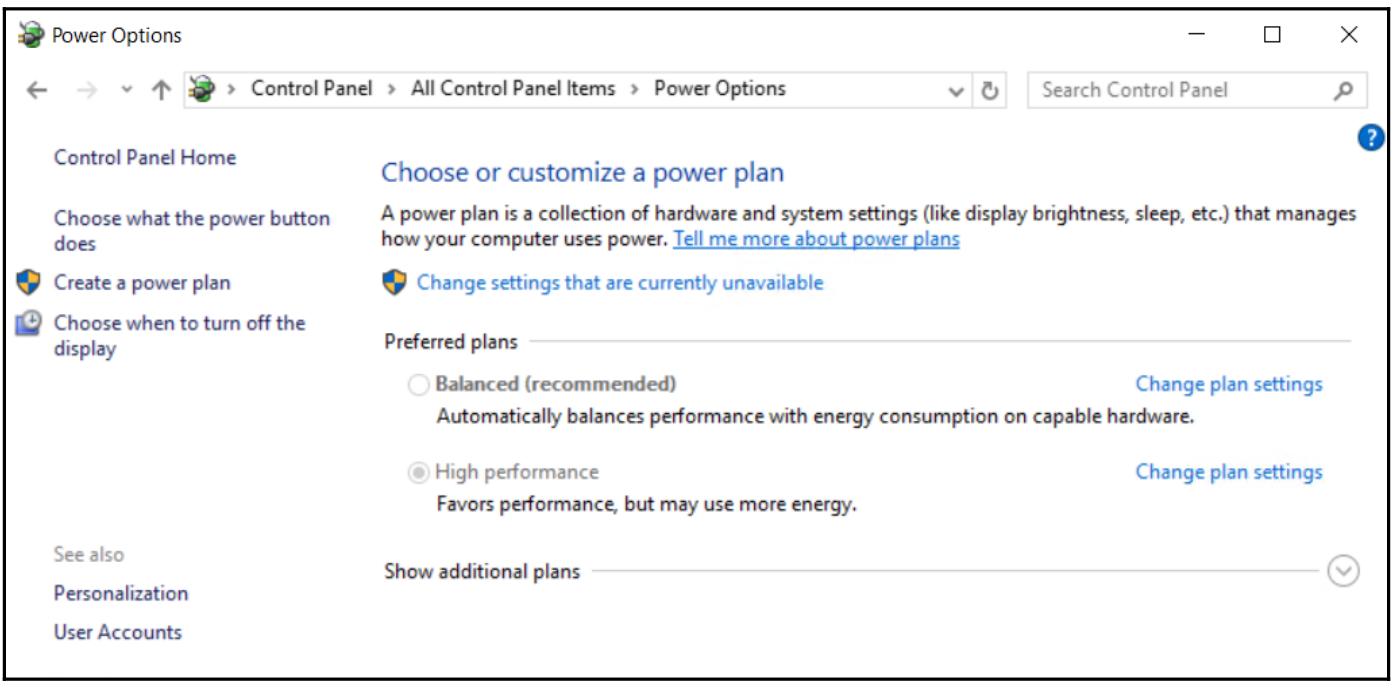
Измените свой план энергопотребления для данного хоста Hyper-V на высокопроизводительный запустив оболочку верхнего уровня и выполнив в ней следующую команду:
POWERCFG.EXE /S SCHEME_MIN
Не поддайтесь искушению запутаться; SCHEME_MIN относится не к
минимальной производительности, а к сбережению электроэнергии. Он имеет всегда включёнными турбированные
частоты ЦПУ и запрещает парковку ядер.
После выполнения этого GUI представит следующие настройки, отображённые на снимке экрана ниже:
Для возврата к схеме сбалансированного энергопостребления воспользуйтесь:
POWERCFG.EXE /S SCHEME_BALANCED
Вне зависимости от того какой план энергопоптребления вы применяете, убедитесь что вы применяете высокоэффективные блоки питания и вентиляторы с изменяемой скоростью вращения в своих серверах для по- возможности большего сохранения электроэнергии и денег.
Существуют также другие доступные опции для получения большей производительности ваших хостов Hyper-V, начинающихся с аппаратных функций и перемещающиеся к настройкам от гипервизора и драйвера до тюнинга приложений и сценариев использования. Давайте начнём с аппаратных параметров путём выбора высокопроизводительного оборудования для нашего хоста Hyper-V.
Добавление большего числа ЦПУ и ядер, также как и выбор процессоров с преимуществами гиперпоточности (HyperThreading) для наивысшего соотношения ВМ которое наш хост сможет обрабатывать. Выбор ЦПУ с большим объёмом кэша улучшит общую производительность Hyper-V. Что касается начала 2016, Intel предлагал ЦПУ с 55МБ интеллектуального кэша, однако его стоимость составляла приблизительно 7,000USD, что далеко выходит за экономное решение основного потока ЦПУ Inel для виртуализации. {Прим. пер.: см. Главу 8, Планирование промышленного применения и настройка производительности Ceph нашего перевода Ceph Cookbook с таблицей рекомендуемых в апреле 2016г (действительны в ноябре 2016г) Intel цен для их покупки крупными партиями. Приведенная там ссылка на xls- файл содержит более полные цифровые данные с выделением цветом для целей OSD Ceph.}
Применение ЦПУ с SLAT (Second Level Address Translation, преобразования адресов второго уровня) не является обязательным для серверов операционных систем (для клиентских операционных систем это так), однако настоятельно рекомендуется. SLAT также требуется для рабочих нагрузок VDI. Добавление опцйи SLAT, таких как EPT (Extended Page Tables) или NPT (Nested Page Tables) увеличивает общую производительность Hyper-V. Если пойти ещё дальше, выбирайте ЦПУ с более высокой частотой. ЦПУ Intel Xeon E7v3 предоставляет частоту до 3.2ГГц с опциональным автоматическим увеличением до 3.5ГГц на ядро. Ядро с двойной частотой обычно даёт лучшую производительность чем два ядра с одинарной частотой. Множество ядер не предоставляют исключительного масштабирования; они дают дают меньшее масштабирование если включена гиперпоточность (hyper-threading), так как гиперпоточность основана на совместном использовании ресурсов одного того же ядра. {Прим. пер.: можно поспорить с такой однозначностью: существует множество наборов задач, которые существенно выигрывают при большем числе потоков даже при меньших тактовых частотах. В качестве первого приходящего на ум примера можно привести HTTP- сервера.}
На сегодняшний день существуют только два производителя ЦПУ с поддержкой для Hyper-V - это Intel и Amd. Я тестировал оба и не был в состоянии определить преимущества производительности каждого из них, поэтому выбирайте производителя по своему выбору/ стоимости. По моему опыту Amd предлагает слегка большую производительность за евро/ доллар, хотя большинство моих потребителей Hyper-V используют стандартные настройки Intel для всех рабочих нагрузок. Только убедитесь, что не смешиваете обоих производителей в своих решениях и вы будете счастливы. {Прим. пер.: к сожалению, по состоянию на 2016г вынуждены констатировать два существенных цифровых недостатка (помимо имеющего место быть несколько худшего сопровождения по причинам меньшего объёма продаж) у Amd. Это отсутствие поддержки PCI Express v.3.0 и меньшее число Flops на ядро при одной и той же тактовой частоте.}
Что касается оперативной памяти, вы уже изучили, что файл подкачки страниц не требует никаких специальных настроек. Кроме того, объём оперативной памяти, необходимой хосту Hyper-V определяется и настраивается автоматически, поэтому вы можете сосредоточиться на потребностях определённых виртуальных машин в их настройках оперативной памяти. В гиперконвертгентном сценарии будьте аккуратны с оперативной памятью, которая будет использоваться для виртуальных машин и для хранения, в особенности когда вы реализуете большой кэш хранения. В таком сценарии для каждых 10ТБ кэша будет использоваться 10ГБ оперативной памяти.
Больше не применяйте устаревшие слоты PCI в своих серверах; PCIe предлагает значительно расширенную производительность. Убедитесь что вы применяете слоты PCIe v.3.0 и выше для 10- гигибитных Ethernet адаптеров на своих серверных материнских платах чтобы не ограничивать производительность на этом физическом уровне. {Прим. пер.: полоса пропускания PCIe v.3.0 x8 (8 lane) превышеает 63Gb/s или 7.87ГБ/с.}
Если у вас имеется достаточное число слотов адаптеров доступное в вашей серверной системе, применяйте множество NIC в нескольких слотах вместо единой NIC с множеством портов для достижения оптимальной производительности и отказоустойчивости.
Параметры настройки сетевого оборудования
Правильный выбор сетевого оборудования для ваших хостов Hyper-V может помочь поднять вашу общую производительность ВМ. Существуют различные доступные аппаратные функции для поддержки вашего хоста Hyper-V. Вы уже читали об SMB Direct (непосредственном SMB) с возможностями RDMA сетевых карт, но существует также намного больше возможностей разгрузки.
Масштабирование принимающей стороны (RSS)
RSS (Receive Side Scaling, масштабирование принимающей стороны) является технологией драйвера NIC, которая позволяет эффективное распределение обработки приёма сетевой среды по множеству ЦПУ в многопроцессорных системах. В основном это подразумевает то, что всякий раз, когда вы не используете RSS, все ваши запросы к ЦПУ на управление сетевой обработки Hyper-V доставляются на самое первое ядро ЦПУ. Даже если у вас имеется четыре физических ЦПУ с 12 ядрами каждый и разрешена гиперпоточность, только самое первое ядро принимает эти запросы. Если вы используете полосу пропускания сети быстрее 4ГБ/с существует высокая вероятность того, что вы получите провал производительности в случае отсутствия RSS. Поэтому убедитесь, что она доступна для вашей NIC, а также в вашем драйвере NIC и активирована. В этом случае такие сетевые запросы (прерывания) будут распределяться по всем доступным ядрам ЦПУ.
RSS доступна только в самом физическом хосте, но не внутри виртуальных машин. Windows Server 2012 R2 предложил решение для этого - Bold D-VMQ (Dynamic Virtual Machine Queue, динамичные очереди виртуальных машин). При включённой D-VMQ на вашем хосте, вы можете применять RSS на своих виртуальных машинах.
Чтобы убедиться, что ваши адаптеры подготовлены для D-VMQ, проверьте через PowerShell:
Get-NetAdapterVmq -Name NICName
Включение vRSS на одной ВМ через PowerShell:
Enable-NetAdapterRSS -Name NICName
В Windows Server 2012 R2, vRSS не работает на виртуальных NIC, подключённых к виртуальному коммутатору в вашем разделе управления хоста. Благодаря SET, описанному в Главе 5, Практический опыт сетевой среды, мы можем усилить vRSS на ваш раздел управления. Однако, при использовании SET не доступны некоторые свойства, например, SR-IOV (Single root I/O virtualization, единый корень виртуализации ввода/ вывода). Поэтому вы должны сделать выбор что из них лучше для ваших целей. Для использования vRSS в ваших ВМ необходимо применять D-MVQ на уровне хоста.
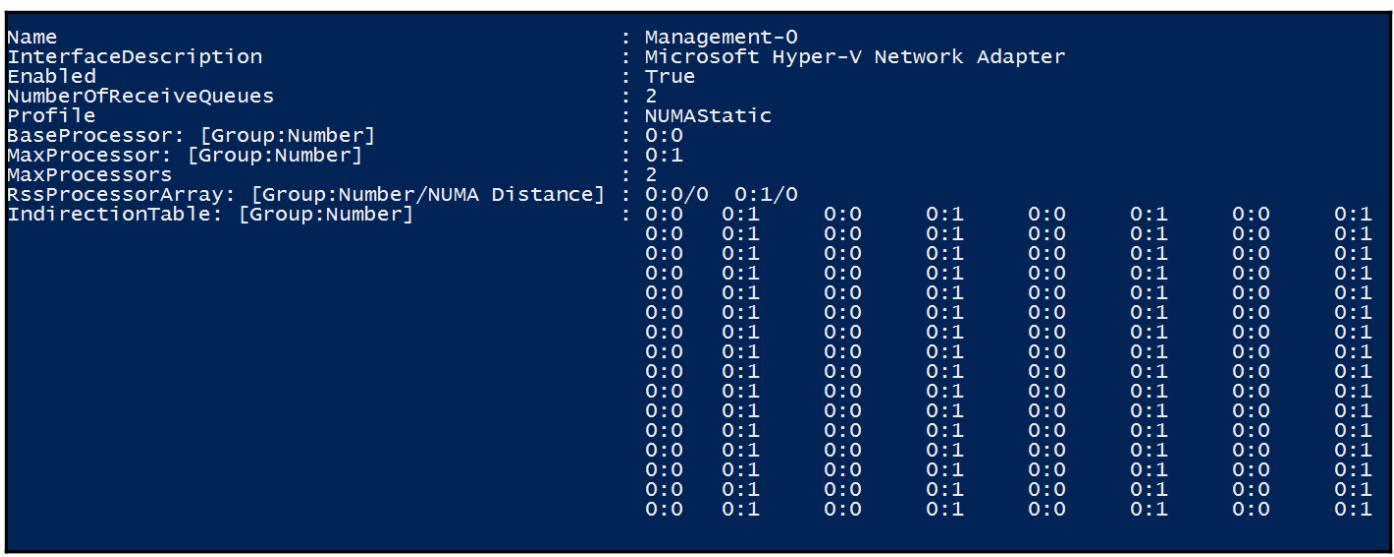
Следующий снимок экрана отображает гостей Hyper-V с поддержкой vRSS:
Виртуализация единого корня ввода/ вывода
SR-IOV (Single Root IO Virtualization, виртуализация единого корня ввода/ вывода) является другой великолепной возможностью в сетевой среде Hyper-V. Она позволяет вашим устройствам PCIe, таких как, NIC, представлять себя как множество устройств, например, для виртуальных машин. Представляйте себе это как виртуализацию PCIe. Это работает только в том случае, если поддерживается на физическом уровне (сетевая плата), на системном уровне сервера (BIOS- {правильнее FirmWare}), а также в Hyper-V. SR-IOV предлагает большую производительность чем VMQ, так как он применяет DMA (Direct memory access, прямой доступ к памяти) для непосредственного взаимодействия между вашим физическим NIC и вашей виртуальной машиной. Все прочие стороны сетевой среды Hyper-V пропускаются, поэтому нет вовлечённости групповых NIC, виртуальных коммутаторов и прочих технологий поверх них. Это делает возможной чрезвычайно низкую латентность и будет великолепной опцией, в то время как сетевая виртуализация Hyper-V вызывает воздействие ЦПУ через RSS без DMQ в противном случае. Однако, это также подразумевает, что если вы применяете группирование NIC, такие NIC не могут применяться для SR-IOV и отсутствует vSwitch в промежутке, который делал возможным поддержку Уровня обслуживания и прочего управления. SR-IOV совместим с миграцией в реальном времени и прочими свойствами Hyper-V, которые не вовлечены в сетевую виртуализацию.
В моей практике SR-IOV является великолепным выбором когда обрабатываются ВМ с низкой латентностью и высокой полосой пропускания (например, взаимодействие VoIP) и должна применяться в обычных моделях сетевых сред, без SR-IOV не предоставить достаточной производительности сетевой среды. Однако её не следует применять в качестве опции по умолчанию, поскольку она понижает возможности управления.
Существует великолепная серия блогов про SR-IOV от Джона Ховарда из Microsoft, доступных по адресу http://bit.ly/1uvyagL.
Прочие возможности разгрузки
Вычисление контрольных сумм в ваших NIC может разгрузить вычисление и проверку контрольных сумм для обрабатываемых TCP и UDP, а также для адаптеров IPv4 и IPv6. Эта функциональность должна быть доступной и активирована на всех ваших используемых в Hyper-V сетевых адаптерах.
При применении шифрования сетевого обмена при помощи IPSec вам следует использовать разгрузку IPSec; в противном случае вы будете наблюдать 20- 30 процентный провал производительности на своих ЦПУ Hyper-V. Однако вы должны применять IPSec только когда стандарты безопасности вашей компании говорят вам об этом, в противном случае оставляйте её выключенной.
Кадры jumbo являются другой прекрасной опцией для поддержки ускорения обмена; однако для надлежащей
работы они требуют повсеместной настройки. В физическом NIC хоста Hyper-V настройте кадры jumbo в
соответствии с размером вашего пакета. Например, рекомендуется для большинства NIC Intel устанавливать MTU
в значение 9014 байт. В то время как кадры jumbo не нуждаются ни в какой настройке в вашем Hyper-V
vSwitch, они должны быть настроены на портах физического коммутатора, а также в NIC гостевых ОС.
После настройки вы легко можете проверить свои настройки применив команду ping
с гигантскими размерами пакета:
ping -f -l 8500 192.168.1.10
Будет хорошей практикой включать кадры jumbo если они поддерживаются всеми звеньями ваше цепочки. Они также совместимы с большей частью сетевых свойств Hyper-V, такими как RSS, к тому же я настоятельно рекомендую чтобы вы также включали их при использовании хранилищ iSCSI.
Существуют прочие функции разгрузки, такие как RSC (Receive-Segment Coalescing, объединённое получение сегмента), которое понижает число заголовков IP; однако они не привносят дополнительных заметных преимуществ производительности в ВМ Hyper-V и кроме того не достаточно разъясняются. Более того, это свойство разгрузки не поддерживается во встроенном группировании коммутации (Switch Embedded Teaming).
За дополнительными подробностями об этих свойствах или прочих расширенных настройках производительности, связанных с сетевой средой Hyper-V посетите раздел Windows Server Performance Tuning Guidelines, который можно найти по адресу http://bit.ly/1rNpTkR.
Применение IPv6 с Hyper-V
Другой часто задаваемый вопрос касается использования современного IP протокола, IPv6. Он по умолчанию включён в Windows Server 2016 с Hyper-V и вам лучше оставить это в таком состоянии. Могут возникнуть непредвиденные проблемы, происходящие после запрета IPv6.
Однако, если ваши сетевые стандарты предписывают вам запретить IPv6, это может быть сделано на вашем хосте Hyper-V, а также на всех ВМ. Если вы решите запретить IPv6, делайте это исключительно в вашем реестре. Мы добавим соответствующий ключ реестра через PowerShell:
New-ItemProperty "HKLM:\SYSTEM\CurrentControlSet\Services\Tcpip6\Parameters" `
- Name "DisabledComponents" `
-Value 0xffffffff -PropertyType "DWord"
Затем перезагрузите свою системы. Не применяйте никакие другие методы для отключения IPv6, такие как убирание флажка в позиции для отметки свойств TCP IP сетевого адаптера; я наблюдал проблемы, возникающие после этого.
Я видел много пользователей запрещающих IPv6 через свой реестр, и некоторые из них имели проблемы с прочими ролями, такими как Windows Server RRAS. Однако я не встречал ни одного пользователя, испытавшего проблемы с ролью Hyper-V при отключении IPv6 через реестр. Таким образом, вы будете в порядке с такими настройками, но они всё ещё не рекомендуются Microsoft.
В излагавшихся ранее главах мы получили обзор великолепных возможностей хранения возможных с Hyper-V. Давайте сосредоточимся на некоторых дополнительных настройках производительности для хранилищ. Вы уже видели, что динамическое расширение жёстких дисков является великолепным вариантом для гибкости, в особенности в комбинации с динамичным выделением (thin provisioning), которое поддерживается Hyper-V на уровне программного обеспечения и на уровне оборудования. Hyper-V имеет некоторые специальные свойства для обратных действий, когда данные удалены. Важно проинформировать подсистему хранения, что предварительно занятые блоки в настоящее время доступны для повторного применения. Если этого не происходит, ваша физическая система хранения рассматривает себя переполненной данными, в то время как на логическом уровне она может быть наполовину пустой. В наихудшем варианте у вас не будет возможности осуществлять запись на незаполненный диск. Windows Server с Hyper-V использует стандартные функции Trim и Unmap.
Они включены по умолчанию и не нуждаются в каких- либо настройках, однако вам следует убедиться, что используемое вами хранилище в состоянии работать с функциями Trim/Unmap для максимизации эффективности хранения. Только Hyper-V-SCSI, информированные (enlightened) IDE и виртуальные контроллеры FC позволяют доставлять команду Unmap со стороны гостя в стек виртуального хранения хоста. Со стороны виртуальных жёстких дисков только отформатированные под VHDX виртуальные диски поддерживают команды Unmap от гостевых ОС. Это дополнительный повод применять файлы VHDX. Если вы работаете с первым поколением ВМ, убедитесь что вы применяете для данных и приложений небольшие системные разделы с IDE-подключением и VHDX файл на контроллере SCSI.
Windows Server с Hyper-V делает возможной большое разнообразие фоновых заданий для консолидации и оптимизации хранилища, например, задания по дедупликации и дефрагментации. Чтобы обеспечить безошибочность выполнения этих заданий, убедитесь, что вы оставляете свободными по крайней мере 10 процентов от всех дисков, включая совместно используемые в кластере тома.
Разгружающий обмен данными
ODX (Offloaded Data Transfer, разгружающий обмен данными) является великолепным способом ускорения обмена данными. Если вы используете хранилище с возможностями ODX, Windows Server с Hyper-V проверит перед запуском задания не будет ли более быстрым подход, при котором ваши данные копируются в вашем программном стеке. Он передаст маркер (token) в вашу подсистему хранения копирующую источник в получатель и, если оба маркера получаются систмой хранения с поддержкой ODX, задание будет выполнено на обеспечиваемом аппаратурой уровне. Если источник и получатель оказываются в одной системе, никакие данные не будут копироваться; вместо этого будет создана всего за несколько мгновений новая ссылка на те же самые блоки.
Стек хранения Hyper-V также выполняет операции ODX в процессе работы по обслуживанию VHD такие, как слияние дисков после удаления моментальных снимков.
ODX включен по умолчанию; однако опять же, он поддерживается только на виртуальных жёстких дисках, которые подключены к контроллеру SCSI. Контроллер IDE не поддерживает эти функции. Кроме того, если ваша подсистема хранения не поддерживает ODX для Windows Server 2016, вам следует выключить её с применением реестра через PowerShell, поскольку я наблюдал проблемы при такой комбинации:
Set-ItemProperty HKLM:\SYSTEM\CurrentControlSet\Control\FileSystem `
-Name "FilterSupportedFeaturesMode" `
-Value 1
Затем, после установки данного ключа, перезагрузите систему.
Даже если подсистема хранения поддерживает ODX, убедитесь, что вы её протестировали перед промышленным использованием.
Существуют некоторые дополнительные опции настройки производительности Hyper-V и его ВМ; данные параметров описываются в настоящем разделе.
Настройка таймаута выключения
Если вы используете кластер Hyper-V и отправляете команду shutdown
на один из его узлов, этот узел автоматически запустит миграцию в реальном масштабе времени всех исполняющихся
на нём ВМ чтобы освободить этот узел. Если вы отправите команду shutdown
на работающий обособленно хост, он попытается остановить все свои ВМ. Однако, может оказаться возможным, что
узел кластера запустит перезагрузку когда операции миграции в реальном времени и останова ВМ ещё находятся в
процессе исполнения. Такое время останова хоста может быть настроено через реестр. Выполните следующую
последовательность:
-
Откройте
regedit -
Переместитесь в
HKLM\Cluster\. -
Измените значение
ShutdownTimeoutInMinutesв соответствии с вашими потребностями. -
После установки значения ключа перезагрузите свою систему.
Можно провести некоторые эксперименты для поиска верного значения для вашего случая; я обычно устанавливаю его больше чем на 10 минут.
После успешной установки некоторого базового уровня для Hyper-V важно создать тестирование вашего окружения Hyper-V на постоянной основе. Применяйте MAP и SCOM для мониторинга производительности общих счётчиков производительности {Прим. пер.: или Zabbix}, однако я рекомендую чтобы вы время от времени применяли что общий уровень производительности ваших приложений находится в согласованном состоянии.
Каким видом эталонного тестирования вы воспользуетесь определяется вашей рабочей нагрузкой. Я настоятельно рекомендую стандартные эталонные тесты, которые применяют некую базу данных и какой- то уровень приложений. Первичным эталонным тестом для этого является пакет тестирования SAP SD. Если вы являетесь пользователем SAP, это вариант, которого стоит придерживаться. Вы можете найти блог- публикации о рекомендуемых эталонных тестах SAP Hyper-V по адресу http://bit.ly/1nMVSQw.
Если вы не применяете SAP или прочие ERP системы с этим типом эталонного тестирования, вы можете применять
другие эталонные тесты. Я настоятельно рекомендую PassMark Performance
Test, который доступен для 30- дневного пробного использования по адресу
http://bit.ly/UFd2Ff, так как он предлагает эталонное
тестирование, которое использует все наши обсуждаемые ресурсы оборудования. Я также рекомендую
SQLIO
для тестирования хранилища и соединений с хранилищем, доступный по адресу http://bit.ly/1obVdIV. Если вы хотите применять виртуализацию рабочих мест, вы можете
воспользоваться пакетом эталонного тестирования Login
VSI; дополнительную информацию ищите по ссылке
http://bit.ly/1pt2roe. Чтобы завершить тему,
Microsoft выпустил набор Powershell для оценки вашего общего IOPS для всего решения хранения. Этот инструмент
называется VM Fleet. За дополнительной
информацией отсылаем вас к адресу http://bit.ly/2bfhPJU.
Все результаты этих эталонных тестов совместимы с другими настройками Hyper-V, а также с прочими платформами виртуализации, которые не применяют счётчики производительности Hyper-V.
Большую часть времени Hyper-V используется для размещения виртуальных машин с установленными серверными операционными системами. Hyper-V также предлагает богатые возможности для размещения виртуальных рабочих мест, однако, поскольку необходимо специальное лицензирование, Hyper-V VDI реализации встречаются не очень часто. Этот тематический раздел cоcредоточен на применении Hyper-V с виртуальными рабочими местами и его настройками для клиентских операционных систем.
Имейте в виду, что развёртывание VDI, в большинстве случаев, не экономичнее чем развёртывание сеансов хостов удалённых рабочих мест (Terminal Services, терминальных служб), однако может предложить стандартизованную архитектуру с центральным пунктом управления.
Чтобы создать инфраструктуру размещения для виртуальных рабочих мест, воспользуйтесь своим менеджером сервера в существующем Windows Server 2016. Мастер Add Roles имеет на борту полный мастер развёртывания VDI. Конечно, в качестве альтернативы, вы можете использовать PowerShell для установки полной среды VDI:
New-RDVirtualDesktopDeployment -ConnectionBroker VDI01.int.homecloud.net `
-WebAccessServer VDI02.int.homecloud.net `
-VirtualizationHost VDI03.int.homecloud.net
Также существует прекрасное сквозное решение PowerShell доступное для реализации сценария VDI в некоторой лаборатории, а также для изучения всех необходимых для настройки вашего VDI cmdlet PowerShell.
VDI SK (The Virtual Desktop Infrastructure Starter Kit) создан Виктором Арзейтом из Microsoft и доступен в галерее Technet по ссылке http://bit.ly/1pkILFP.
Настройка быстрого запуска устанавливает все необходимые ответственные за VDI службы в едином экземпляре операционной системы; это не рекомендуется в любом случае. В обоих случаях для VDI необходимо развёртывание рабочих мест на виртуальной основе. Настройте свой целевой сервер для каждой из ваших рабочих нагрузок VDI:
-
Remote Desktop Connection Broker: посредник соединений RD соединяет или переустанавливает соединение устройства клиента к клиенту VDI (виртуальной машине)
-
Remote Desktop Web Access: сервер веб- доступа RD делает возможным для пользователей соединяться со своими клиентами VDI через коллекции сеансов и коллекции виртуальных рабочих мест, применяя веб- браузер
-
Remote Desktop Session Host: хост сеансов RD является хостом Hyper-V со включённым VDI.
После ввода имён серверов, вся последующая настройка будет выполняться менеджером сервера/ PowerShell без какой либо необходимости настроек вручную.
Если у вас уже имеется готовая среда Hyper-V, запустите создание шаблона ВМ для VDI. Установите новую ВМ Hyper-V с необходимой клиентской операционной системой по вашему выбору (я настоятельно рекомендую по крайней мере Windows 8.1 из- за её усиленных свойств VDI) в качестве золотого образа.
После завершения установки Windows, включающей все необходимые обновления и инструментов поддержки, которые вы желаете иметь на каждом клиенте VDI, выполните Sysprep с опцией OOBE/generalize и выберите останов своей системы:
C:\Windows\System32\Sysprep\Sysprep.exe /OOBe /Generalize /Shutdown /Mode:VM
Применение нового переключателя /Mode:VM делает возможной более
быстрое исполнение sysprep, так как для виртуальных машин присутствует намного меньше необходимого
распознавания оборудования, поскольку вы применяете оду и ту же среду виртуализации.
Скопируйте ВМ источника и определите её путь в следующем сценарии.
Для создания новой коллекции виртуальных рабочих мест воспользуйтесь следующим сценарием PowerShell:
New-RDVirtualDesktopCollection -CollectionName demoPool -PooledManaged `
-VirtualDesktopTemplateName WinGold.vhdx `
-VirtualDesktopTemplateHostServer VDI01 `
-VirtualDesktopAllocation @{$Servername = 1} `
-StorageType LocalStorage `
-ConnectionBroker VDI02 `
-VirtualDesktopNamePrefix msVDI
![[Совет]](/common/images/admon/tip.png) | Совет по лицензированию |
|---|---|
|
Microsoft применяет специальные лицензии для VDI (лицензии VDA). Если у вас уже есть хосты Hyper-V, охваченные редакциями центра данных Windows Server (datacenter editions), может быть более экономичным для вас применять только ВМ однопользовательского сервера (single-user-server) вместо ВМ действительного клиента (real-client). |
Некоторые технические описания (white papers) по великолепной производительности VDI доступны в проекте VRC по ссылке http://bit.ly/1nwr9aK; они замеряют воздействие антивирусов или Microsoft Office на среду VDI.
RDP (Remote Desktop Protocol) Microsoft, доступный в настоящее время в Версии 8.1 или старше, предлагает великолепные возможности, включая RemoteFX. Малоизвестным фактом является то, что оригинальный клиент RDP доступен для широкого диапазона платформ, включая Windows 7, Windows 8, Windows 8.1, Windows RT, Windows Phone, а также для Android и Apple iOS.
RemoteFX предлагает некоторые великолепные свойства вокруг соединений RDP и почти все они могут применяться без специальных графических адаптеров. RemoteFX включён по умолчанию и предлагает такие функции как мультисенсорность, адаптивная графика, а также оптимизация WAN. Новый RDP клиент также предлагает дополнительную функциональность такую, как автоматическое определение сетевой среды и RDP over UDP.
RemoteFX способен определять содержимое по умолчанию и загружать его с приоритетами. Первым загружается текст, затем загружаются ваши изображения, а последними видео и дополнительно загружаемые на экран баннеры. Наличие этих возможностей делает RDP не только более эффективным, но также улучшает ощущаемую пользователем производительность.
Свойства RemoteFX могут быть настроены через групповые политики следующим образом:
-
Откройте редактор управления групповыми политиками (Group Policy Management Editor) и переместитесь в ComputerConfiguration | AdministrativeTemplates | WindowsComponents | Remote Desktop Services | Remote Desktop Session Host | Remote Session Environment:
-
- Поправьте свои настройки Configure image quality for RemoteFX Adaptive Graphics.
- Измените их со значения по умолчанию Midium на High или Lossless, если вы хотите применять более качественную графику. Это будет потреблять большую полосу пропускания.
-
- В том же самом пути измените свои настройки Configure RemoteFX Adaptive Graphics.
- Выберите RemoteFX для оптимизации между масштабируемостью сервера или использованием полосы пропускания.
-
- В том же самом пути измените свои настройки Configure compression for RemoteFX data.
- Выберите одно из Optimize to use less memory (что потребует больше сетевых возможностей) или Optimize to use less network bandwidth (что требует больше памяти), тем самым балансируя между памятью и полосой пропускания сети и не применяйте RDP-compression algorithm. Настоятельно рекомендуется применять опцию понижения необходимой полосы пропускания сети.
-
- Измените настройки установки Limit maximum color depth.
- Выберите 32 бита на пиксель. По моему опыту это предлагает наилучшую производительность.
-
Перезагрузите свои сервера.
![[Замечание]](/common/images/admon/note.png)
Замечание Эти GPO должны быть привязаны к вашим хостам виртуализации, а не к виртуальным рабочим местам или ВМ RDSH, которые исполняются поверх этих хостов виртуализации.
Существуют также прочие доступные групповые политики, однако установленные для них значения по умолчанию, для большего числа применений, достаточно хороши.
Другим способом ускорения производительности RDP является добавление мощного GPU в ваш сервер. Профессиональные графические адаптеры, ранее известные только в игровых ПК и рабочих станциях CAD {/CAE}, теперь доступны для клиентов VDI и ВМ RDSH.
RemoteFX был расширен в Windows Server 2016. Теперь RemoteFX поддерживает ВМ 2го поколения (Gen 2), разрешение 4K, OpenGL и OpenCL API, а Microsoft улучшил производительность.
Вам необходимо выбрать GPO, которая поддерживает DirectX 11.0 или выше, а также применяет драйвер WDDM 1.2 или выше. Убедитесь, что вы проверили снова каталог Windows Server на RemoteFX GPU. Я имел хороший опыт с адаптерами nVidia GRID относительно производительности и совместимости. Также убедитесь, что ваше оборудование сервера хоста Hyper-V совместимо с работой профессиональных GPU. Обычные серверные GPU предлагают очень ограниченную производительность и используют только несколько МБ оперативной памяти. GPU RemoteFX предлагают великолепную производительность и поставляются с гигабайтами графической оперативной памяти. Если вы хотите делать больше в своих ВМ VDI или сеансах RDSH, чем просто просматривать веб- страницы или редактировать офисные файлы; RFX GPU может оказаться верной опцией. Она подходит для воспроизведения full HD видео или редактирования CAD {/CAE} моделей внутри виртуальной машины. При помощи Hyper-V в Windows Server 2016 вы даже можете совместно применять один GPU в различных виртуальных машинах. Чтобы добавить GPU к виртуальной машине примените следующий cmdlet PowerShell:
Add-VMRemoteFx3dVideoAdapter -VMName VM01
Чтобы определить разрешающую способность, которую вы применяете внутри своей ВМ, воспользуйтесь следующим cmdlet PowerShell:
SET-VMRemoteFx3dVideoAdapter -VMName VM01 -MaximumResolution 1920x1200
При использовании адаптеров RemoteFX с ВМ VDI будет хорошей практикой рассчитывать возрастающее использование оперативной памяти. ВМ Windows 10 должны быть развёрнуты с возможностью использовать до 4ГБ ОЗУ. В сценариях vGPU с nonRemoteFX, 2ГБ ОЗУ будет достаточно в большинстве сценариев. Клиенты VDI с Windows 10 хорошо работают с динамической оперативной памятью и двумя ядрами ЦПУ, следовательно, это должно быть установкой по умолчанию. Я часто наблюдал рабочие нагрузки VDI развёрнутые с дисками приращений (differencing disks). Это не является оптимальным с точки зрения производительности, а кроме того, это ночной кошмар, так как VMM не может работать с дисками приращений. Намного лучшим вариантом является использование динамичных файлов VHDX и активировать встроенную дедупликацию Windows, которую мы изучали в Главе 4, Практический опыт хранилищ.
Во всех остальных отношениях, виртуальные машины, которые исполняют рабочие нагрузки VDI являются совсем другим букетом ВМ Hyper-V.
В некоторых инфраструктурах, в которых я работал над решением проблем производительности и стабильности, я видел одни и те же неправильные настройки повторяющиеся многократно. В данном разделе я попытаюсь описать общие ошибки настроек, которые я наблюдал.
Первая общая ошибка, которую я наблюдаю в развёртываниях Hyper-V, заключается в недооценке этапа проектирования. Большинство проектов, в которые я был вовлечён, не начинались с изучения существующей среды. Как вы можете узнать о необходимом количестве ЦПУ, памяти и хранилищ, если вы не проинспектировали текущую инфраструктуру? Если вы не проверите существующее окружение, ваша новая инфраструктура Hyper-V может не соответствовать требованиям или быть слишком большой (а также черезчур затратной) по отношению к вашим потребностям. Прежде чем покупать аппаратные средства, выполните инструментарий Microsoft Assessment and Planning для вычисления необходимого числа ядер, памяти и ёмкости хранения. После проведения вычислений вы можете добавить дополнительные ресурсы для обработки последующих дополнительных ВМ.
Например, в настоящее время у вас имеется инфраструктура с 500 ВМ, каждая из которых потребляет 2 vCPU, 8ГБ ОЗУ и 60ГБ хранилища. Предположим, вы хотите консолидацию в соотношении 4 : 1. Для вычисления числа необходимых ресурсов мы можем следовать такой формуле:
-
Ядра:
((500 ВМ x 2 vCPU) / консолидирующее соотношение 4) = 250 Ядер -
Оперативная память:
500 ВМ x 8 ГБ = 4000 ГБ -
Хранилище:
500 ВМ x 60 ГБ = 30 ТБ
Теперь у нас имеется требующиеся значения для поддержки текущих рабочих нагрузок. Но что относительно нагрузок в будущем, которые придут в последующие три года? Для вычисления последующих нагрузок я делаю предположение, что ваша инфраструктура будет обрабатывать на 25% больше ВМ. Давайте проведём вычисления вновь:
-
Ядра:
250 Ядер x 25% = 312.5, округляемые до 320 ядер -
Оперативная память:
4000 ГБ x 25% = 5ТБ -
Хранилище:
30 ТБ x 25% = 37.5, округляемые до 40ТБ
Для ресурсов вычислений и памяти нам потребуется соответственно 320 ядер и 5ТБ оперативной памяти в случае отказа узла в вашем кластере. Для такого проекта я выбираю Intel Xeon E5-2660v4, который имеет 14 ядер. Так как все сервера имеют два ЦПУ, каждый из них будет иметь 28 ядер. Таким образом, мне нужно всего 384 ядер для поддержки отказа одного узла. Для расчёта общего числа серверов вы можете применить следующую формулу:
-
Число серверов:
348 Ядер / 28 ядер в сервере = 12.42, округляемые до 13 серверов
Теперь, когда у нас имеется общее число серверов, мы можем вычислить сколько оперативной паммяти мы имеем для реализации в каждом сервере:
-
ОЗУ на сервер:
((5000 ГБ / 13 + 5000 ГБ) /13 = 414 ГБ
Эта формула учитывает отказ одного узла. Начало формулы вычисляет необходимый объем памяти на один сервер. Затем это значение добавляется к общему объёму памяти и делится на общее число узлов. Так как не существует возможности реализовать 414ГБ памяти в реальном сервере, предыдущее значение должно быть округлено вверх до 512ГБ (16 x 32 ГБ памяти). Для семейства Intel Xeon v4, общее число линеек памяти должно быть кратно четырём (Quad Channel) для достижения наилучшей производительности.
Таким образом, для реализации нашего примера вам необходимо 13 серверов, состоящих из двух процессоров Intel Xeon E5-2660v4 и 16 * 32ГБ ОЗУ.
Я видел некоторые проекты, в которых участники группы (teaming) полагались на один и тот же сетевой адаптер. Некоторые сетевые адаптеры могут иметь два или даже четыре контроллера. Это означает, что вы можете подключать столько кабелей, сколько у вас есть контроллеров. Однако, если вы добавляете все сетевые контроллеры в одну и ту же группу, это не будет вам гарантировать высокую доступность в случае проблем с оборудованием. Если существуют проблемы на PCB вашего сетевого адаптера или в шине PCI-E, все связанные с ними адаптеры будут отключены.
Это именно та причина, по которой я рекомендую для промышленной среды приобретать по крайней мере два различных сетевых адаптера. Если вам необходимо два 40ГБ NIC, приобретайте два одинарных контроллера и затем группируйте их. Это правило верно для всех сетевых адаптеров и всех HBA для подключения к SAN.
Другая ошибка, которую я наблюдаю, связана с группированием NIC различных моделей сетевых адаптеров. Я рекомендую не делать этого из- за нестабильности такого вида настроек. Объединяйте в одну группу только одинаковые сетевые адаптеры (одну и ту же модель с одним и тем же встроенным программным обеспечением).
В качестве завершения, избегайте создания нескольких виртуальных коммутаторов и предпочитайте усиливать сетевую конвергенцию. Давайте задумаемся о DMZ и локальной сети. Отдельный виртуальный коммутатор легко может обрабатывать обе сетевые среды если вы настраиваете физический коммутатор с режимом поддержки транков. С другой стороны, если вы создадите несколько виртуальных коммутаторов, вам потребуется несколько NIC и управление станет менее гибким.
В некоторых средах я наблюдал сетевые адаптеры, выделенные для iSCSI в группы. Не существует никаких преимуществ применения таких настроек перед MPIO (вводом/ выводом со множеством путей). MPIO обрабатывает высокую доступность и расщепляет рабочие нагрузки iSCSI по всем NIC iSCSI. Поэтому я не использую группирование NIC в данном случае. {Прим. пер.: рекомендуем обзор Множества путей SAS в нашем переводе ZFS для профессионалов.}
Относительно HBA FC, я наблюдал некоторых пользователей, которые смешивали обмен хранилища Hyper-V и применение NPIV. Это не является проблемой, однако я не рекомендую смешивать обмен вашего хранилища и NPIV в одном HBA для подключения LUN к ВМ.
На протяжении всего жизненного цикла инфраструктуры Hyper-V множество людей могут работать с ОС Hyper-V. Иногда они могут иметь некоторые проблемы и устанавливать инструменты на узле общего кластера. Иногда, из- за нехватки времени, некоторые обновления устанавливаются на одном узле, а на других нет. Каждый узел из общего кластера не имеет все те же самые ошибки.
Прежде всего, избегайте установки инструментов на сервер. Отдавайте предпочтение перемещаемым инструментам (таким как SysInternal) для проблем поиска неисправностей. Если вы устанавливаете некоего агента на сервер, этот агент должен быть развёрнут на каждом узле.
Далее, каждый узел в кластере должен иметь один и тот же уровень обновлений. Это означает, что каждый узел должен иметь одни и те же применённые к нему обновления. Если вы будете следовать такой наилучшей практике, ваш кластер будет более надёжным. Это правило не относится только к обновлениям Microsoft, но также и ко всему встроенному программному обеспечению (firmware) и драйверам. Обновлениями Microsoft можно управлять через WSUS, SCCM или SCVMM.
Чтобы избежать установки дополнительных инструментов и ограничить общее число обновлений для их применения, я рекомендую вам устанавливать ваши узлы Hyper-V в режиме установки ядра. Некоторое программное обеспечение препятствует использованию установки в режиме ядра. В таком случае, вам придётся выбрать развёртывание ваших узлов в полном режиме. Однако, если ничто не препятствует установке в режиме ядра, предпочитайте именно этот режим. После того, как вы осуществили свой выбор, не смешивайте различные режимы установки в одном и том же кластере.
К концу данной главы вы реализовали множество возможных оптимизаций для своей среду Hyper-V и вам не следует бояться промышленного применения вашей наладки. Вы подгоните свои серверное оборудование, хранилища и сетевую среду, а также настройки роли Hyper-V под сценарии оптимального применения.
В Главе 8, Управление при помощи системного центра и Azure вы получите дополнительную информацию об управлении хостами Hyper-V, их виртуальными машинами, а также всей структурой при помощи комплекта управления Microsoft, системного центра (System Center). Вы также получите дополнительные сведения о развёртывании, мониторинге, резервном копировании и автоматизации Hyper-V.