Глава 4. Сбор данных
Содержание
- Глава 4. Сбор данных
Теперь, когда у вас имеется соответствующая размерам вашей среды установка Zabbix, вы можете захотеть на самом деле запустить её мониторинг. Хотя совершенно просто определить какие хосты или приложения, физические или какие- либо ещё вы можете пожелать подвергнуть мониторингу, может оказаться не сразу не ясным какие реальные замеры вы должны выполнять в них. Метрики, которые вы можете определять на хосте называются элементами (item), а данная глава обсудит их основные свойства и характеристики. Первая часть по большей части является теоретической и будет сосредоточена на следующем:
-
Элементы в качестве метрик, а не для проверок состояния
-
Поток данных и направленность для элементов
-
Улавливающие элементы как средство контроля над вашим потоком данных
Затем мы переместимся к более практическим и специфичным методам и обсудим как настраивать элементы для сбора данных со следующих источников данных:
-
Баз данных и ODBC в качестве источников
-
Приложений Java, консоли JMX, агентов SNMP {Прим. пер.: а также, например, через протокол MQTT}
-
SSH мониторинга
-
Элементов IPMI
-
Мониторинга веб- страниц
-
Агрегирующих и вычисляемых элементов
Одно из самых важных свойств, которое выделяет Zabbix из прочих решений мониторинга заключается в том, что его главный режим взаимодействия с объектами мониторинга сосредотачивается на сборе исходных данных вместо получения предупреждений или обновлений состояний. Другими словами, многие приложения мониторинга имеют рабочий поток (или его видоизменения) отображаемый следующей схемой:

Иными словами, агент или любой другой датчик мониторинга не просто для выполнения измерения, но также и для включения некоего вида принятия решения о состоянии о проведённом измерении перед его отправкой на вашу главную серверную компоненту для дальнейшей обработки.
С другой стороны, основной рабочий поток Zabbix едва уловимо, но при этом очень существенно, отличается, что отображает следующая схема:

В этом случае агент или датчик мониторинга запрашивается только для измерений с последуюшей отправкой выполненных измерений на серверную компоненту для хранения в конечном итоге для дальнейшей обработки.
Эти данные не связываются каким- либо определённым решением о срабатывании спускового механизма (trigger), а именно: пропустить/ отвергнуть, хорошо/ предостережение/ ошибка или любые другие возможные варианты, а вместо этого удерживаются на вашем сервере как отдельная точка данных или измерений. Если это допустимо, например, для численных данных, они также сохраняются агрегированном и обобщающем динамику формате в виде минимума, максимума и среднего на протяжении различных периодов времени. Сохранение данных отличается от логики принятия решений, однако помещение всего в одно место снабжает Zabbix двумя отличительными преимуществами.
Первое состоит в том, что вы можете использовать Zabbix для сбора данных о вещах, которые не связаны непосредственно с возможными предостережениями и действиями, которые вы должны предпринимать, однако относятся к общей производительности и поведению системы. Классическим примером является коммутатор со множеством портов. Вас могут не интересовать предостережения об аномальном обмене в отдельном порту (так как может быть также непросто определять аномальный обмен по отдельному порту без наличия информации о контексте), однако вас может интересовать сбор замеров обмена как на уровне порта, так и на уровне коммутатора для установления базового уровня, определения узких мест, или планирования расширения вашей сетевой инфраструктуры. Аналогичный случай может рассматриваться при использовании ЦПУ и ядер, ёмкости хранилища, одновременного числа пользователей для данного приложения и тому подобного. В своих простейших вариантах применения, Zabbix может даже использоваться для сбора применяемых данных и визуализации их в различных графиках и диаграммах, без касательства его мощных свойств триггеров (запускающих механизмов) и согласования, и по прежнему оставаться исключительным вкладом вашего времени и ресурсов.
Говоря о механизме запуска (triggering), второе большое преимущество наличия полной, централизованной базы данных исходной информации, в противовес отдельным замерам (или, в лучшем случае, лишь несколькими измерениями одного и того же элемента), состоит в том, что для каждого триггера (запускающего механизма) и схемы принятия решений вы можете использовать выгоду от всей базы данных измерений для точного определения типа события, которое вы хотите отслеживать и получать о нём предупреждения. У вас нет нужды полагаться на отдельное измерение; вам даже не нужно полагаться на самое последнее измерение плюс несколько предыдущих для того же самого элемента с того же самого хоста. На самом деле вы можете сопоставлять что угодно с чем угодно ещё в вашей базе данных истории элементов. Это свойство настолько мощное, что мы выделяем ему целую главу, и вы можете непосредственно перейти к следующей если это то, о чём вы хотите прочитать. Было бы достаточно сказать, что вся эта мощь основывается на том факте, что в Zabbix полностью разделяются все функции сбора данных от логики запуска (trigger logic) и функций действия.
Таким образом, в Zabbix элемент представлен отдельной метрикой - отдельным источником данных и измерениями. Существует множество видов внутренних элементов Zabbix даже без рассмотрения индивидуальных пользовательских, которые вы можете определить применяя внешние сценарии. В данной главе мы изучим некоторые менее очевидные, но очень интересные из перечня таких элементов. Вы увидите как иметь отношения с базами данных, как интегрировать нечто чуждое в виде ловушек SNMP в образе мышления Zabbix, как агрегировать существующие элементы вместе для представления кластеров наблюдения, и тому подобное. Так как вы заложите прочную основу в разумном и стратегическом определении элемента и сборе данных, вы сможете уверенно полагаться на неё для развития управления своими событиями и функциями визуализации данных, с которыми вы ознакомитесь в последующих главах.
Элемент Zabbix можно понимать по его самым необходимым частям - идентификатору, типу данных и связанному хосту. Эти элементы обычно являются наиболее полезными для всех остальных компонентов Zabbix. Идентификатор (обычно это имя и связанный ключ элемента) и его сопутствуюший хост применяются для отличия отдельного элемента между тысячами, которые могут быть определены в среде мониторинга. Тип данных важен чтобы Zabbix знал как сохранять данные, как их визуализировать (текстовые данные не могут отображаться графиками, например) и, что наиболее важно, какой вид функций можно к ним применять для дальнейших моделей запуска и обработки.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Имя элемента является описательной меткой, которая подразумевается лёгкой для прочтения, в то время как ключ элемента следует определённому синтаксису и в точности определяет метрику, которую мы хотим измерять. |
Двумя очень важными элементами, которые являются общими для всех элементов являются история (и обобщённая динамика, trend) периода сохранности и тип элемента. Мы уже видели в Главе 1, Развёртывание Zabbix, как сохраняемая история напрямую воздействует на размер вашей базы данных мониторинга, как делать её оценку, и как сводить баланс между производительностью и доступностью данных. С другой стороны, тип элемента является существенным, поскольку сообщает Zabbix как данные элемента в действительности становятся доступными вашему серверу, что, другими словами, означает как Zabbix намеревается собирать данные: через агента, запрос SNMP, внешний сценарий и так далее.
Как вы вероятно уже знаете, существует достаточное количество различных типов элементов. Хотя достаточно просто понять разницу между элементом SSH и элементом ODBC, также важно понимать как данные преодолевают путь между сервером и его датчиками, а также то, являются ли они агентом Zabbix, датчиком со стороны сервера или внешней проверкой какого- либо рода. С этой точки зрения, мы сначала сосредоточимся на нашем агенте Zabbix и разнице между пассивным и активным элементами.
Прежде всего, активная и пассивная концепции должны пониматься с точки зрения агента, а не сервера. Помимо этого, они служат для иллюстрации компонентов, которые инициируют соединение для отправки и получения информации о настройках и данные мониторинга, как это отображено на следующей схеме:
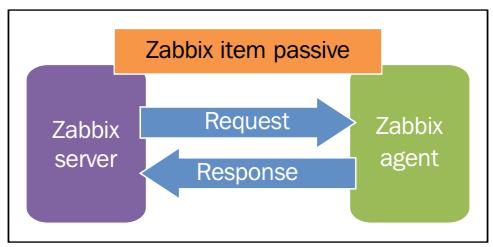
Таким образом, стандартный элемент Zabbix рассматривается как пассивный с точки зрения агента. Это означает, что именно стороной сервера является задание опрашивать своего агента, причём в определённые для этого элемента временные интервалы, с целью немедленного получения нужных замеров и отчётов обратно. В терминах сетевых операций, вашим сервером инициируется и сбивается выделенное соединение, в то время как агент находится в состоянии прослушивания.
С другой стороны, в случае с активным элементом Zabbix, именно сам агент выполняет задание запрашивать свой сервер о том какие подлежащие мониторингу данные он должен собирать и в какие интервалы. Затем он выполняет согласно расписанию свои собственные измерения и соединяется для их отсылки назад на свой сервер для дальнейшей обработки. В терминах сетевых операций в данный процесс вовлечены следующие два различных сеанса:
-
Агент запрашивает свой сервер об элементах и интервалах для мониторинга
-
Агент отправляет такие данные мониторинга, которые собираются на его сервере
В отличие от стандартных пассивных элементов, ван необходимо выполнить настройку агента таким образом,
чтобы он знал с каким сервером он должен соединяться для целей настройки и обмена данными. Естественно, это
определяется в конкретном файле zabbix_agentd.conf для каждого
агента; просто установите ServerActive на конкреное имя хоста или
определённый IP адрес вашего сервера Zabbix и задайте в RefreshActiveChecks
необходимое значение секунд, которое агент должен ожидать перед проверкой есть ли какие либо новые или
изменённые определения элемента. Следующая схема отображает это:
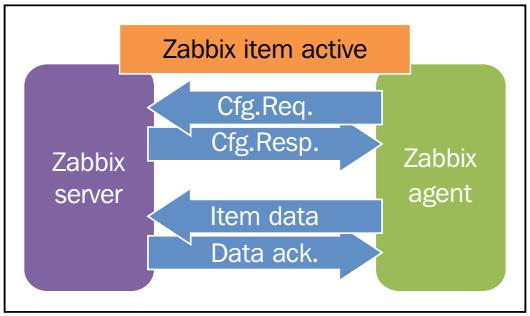
В отличие от инициации обычного сетевого соединения, основная разница между пассивным и активным элементами состоит в том, что в последнем случае невозможно определять гибкие интервалы мониторинга. В случае пассивного элемента вы можете определять различные интервалы мониторинга на основании времени суток и дня недели. Например, вы можете проверять доступность сервера управления идентификацией каждую минуту на протяжении рабочих часов и каждые 10 минут ночью. С другой стороны, если вы используете активный элемент, вы застрянете всего лишь с одним вариантом интервала мониторинга.
Возможно, вы также отметили выходящую за рамки пассивности схожесть между вашими активными и пассивными элементами, а также схожесть между функциональностью и свойствами активных и пассивных прокси Zabbix.
На самом деле, мы можем выбирать между активными и пассивными элементами во многом таким же самым образом и по тем же самым причинам, как мы выбирали между активными или пассивными прокси в Главе 2, Распределённый мониторинг для разгрузки некоторых заданий расписания серверов и работы с охватом ограничений и пределов вашей сетевой среды и маршрутизации или настроек межсетевого экрана.
Конечно,существует основная разница между прокси и агентами. Не является фактом, что прокси может получать данные мониторинга с большого числа хостов, в то время как агент теоретически (но не практически, несомненно, существует возможность растягивать его функциональность с использованием пользовательских элементов, которые основываются на сценариях или внешних приложениях) ограничен в средствах мониторинга только тем хостом, на котором он установлен.
Когда речь идёт о потоке данных, основной разницей является то, что режим работы прокси- сервера применяется для всех тех хостов и элементов, которыми управляет этот прокси. На самом деле он не заботится о природе тех элементов, которые подлежат мониторингу со стороны прокси. Однако, когда активный прокси собирает свои данные (будь то данные от активных или пассивных элементов агентов, внешних сценариев, SNMP, SSH и тому подобного), он всегда будет инициировать все соединения со своим сервером. Аналогичное происходит и с пассивным прокси; не имеет значения будут ли все имеющиеся у него элементы для мониторинга активными или пассивными. Он всегда будет ожидать от своего основного сервера запросов для обновления настроек и измерений.
С другой стороны активный или пассивный элемент это просто один элемент из множества. Хост может определяться смесью активных и пассивных элементов; поэтому вы можете предполагать, что агент будет всегда инициировать все свои соединения с сервером. Чтобы сделать это, все полагающиеся на этого агента ваши элементы должны быть определены как активные, включая появляющиеся в будущем.
Крайней версией активного элемента, которая всё ещё основывается на протоколе Zabbix является элемент ловушки (trapper item) Zabbix. Выделяясь среди всех прочих типов элементов, элемент ловушки не имеет интервала мониторинга определяемого на уровне сервера. Другими словами, сервер будет знать определён ли элемент ловушки, его тип данных, связанный с ним конкретный хост, а также период сохранности как для истории, так и для обобщённых динамик (trend). Однако он никогда не будет управлять по расписанию проверками для такого элемента и не будет передавать информацию о своём расписании и интервале мониторинга какому- либо прокси или агенту. Поэтому он настроен на определённое снятие показаний управляемое по расписанию неким образом с последующей отправкой полученной информации о собранных данных на свой сервер.
Улавливающие элементы, до некоторой степени, являются противоположностью внешних проверок Zabbix с точки
зрения потока данных. Как вы вероятно уже знаете, вы определяете тип элемента внешней проверки когда вы желаете,
чтобы сервер выполнял внешний сценарий для сбора измерений вместо опроса агента (Zabbix, SNMP и тому подобных).
Это может настоятельно потребовать дополнительных расходов производительности сервера, поскольку такой подход
создаёт новую ветвь процесса для каждого внешнего сценария, который он должен выполнить, а затем дождаться
отклика. По мере того, как число сценариев растёт, это может существенно замедлять работу сервера до того
момента, когда накопится значительное число просроченных проверок в то время как он занят исполнением
сценариев. Чрезвычайно простой и примитивный, но всё ещё эффективный вариант обработки этой проблемы
(естественно, помимо уменьшения числа внешних сценариев настолько большого, насколько это возможно) состоит
в преобразовании всех элементов внешних проверок в улавливающие элементы, следующие исполнению по тому же
расписанию, что и те же самые применяемые для внешних проверок сценарии через crontab или любое другое
средство планирования, и изменить сами эти сценарии таким образом, чтобы они использовали
zabbix_sender для взаимодействия от ваших измеряемых данных к их
серверу. Когда мы обсудим протокол Zabbix в Главе 8,
Обработка внешних сценариев, вы увидите приличное число примеров такой наладки.
Это краткая сводка классифицированных по типу соединения типов элементов с предложением альтернативы,
если пожелаете по любой причине, для другого подхода. Как вы можете увидеть,
Zabbix Trapper зачастую единственно возможная, хотя и неуклюжая и
топорная, альтернатива если вам совершенно необходимо поменять тип соединения. Отметим, что в приводимой ниже
таблице термин Passive подразумевает, что данное соединение инициируется
его сервером, а Active означает, что данное соединение инициируется там,
где применяется прибор. Хотя это может казаться противоречащим здравому смыслу, это на самом деле не связано
с аналогичными терминами в их применении к прокси и агентам, что отображено в следующей таблице:
| Тип элемента | Направление | Альтернатива |
|---|---|---|
Агент Zabbix |
Пассивный |
Агент Zabbix (активный) |
Агент Zabbix (активный) |
Активный |
Агент Zabbix |
Простая проверка |
Пассивная |
Ловушка Zabbix |
Агент SNMP |
Пассивный |
Ловушка Zabbix (ловушки SNMP по своей природе совершенно отличны) |
Ловушка SNMP |
Активная |
нет |
Внутренний элемент Zabbix |
нет (данные о самом по себе сервере) |
нет |
Ловушка Zabbix |
Активная |
Зависит от самой природы подлежащих мониторингу данных |
Агрегат Zabbix |
нет (используемые данные уже доступны в базе данных) |
нет |
Внешняя проверка |
Пассивная |
Ловушка Zabbix |
Монитор базы данных |
Пассивная |
Ловушка Zabbix |
Агент IPMI |
Пассивная |
Ловушка Zabbix |
Агент SSH |
Пассивная |
Ловушка Zabbix |
Агент TELNET |
Пассивная |
Ловушка Zabbix |
Агент JMX |
Пассивная |
Ловушка Zabbix |
Вычисляемый элемент |
нет (используемые данные уже находятся в базе данных) |
нет |
В последующих нескольких параграфах мы углубимся в некоторые более сложные и интересные типы элементов.
Zabbix предлагает способ опроса любой базы данных с применением запросов SQL. Получаемый от этой базы данных результат сохраняется в качестве определённого значения элемента и, как обычно, может иметь связанные с ним механизмы запуска (триггеры). Подобная функциональность полезна по многих приложениях. Это даёт вам вариант мониторинга конкретных подключённых в настоящий момент к базе данных пользователей, общее число присоединившихся к вашему веб- порталу пользователей, или просто получать метрики из механизма СУБД.
ODBC является уровнем - уровнем трансляции между СУБД
(Системой управления базой данных, DBMS - Database Management System) и вашим приложением. Ваши приложения
используют функции ODBC через связанный с ними менеджер драйвера ODBC. Драйвер ODBC был реализован и разработан
в согласии с большинством мировых производителей СУБД для предоставления возможности их базам данных
взаимодействовать с данным уровнем. Файл настройки определяет вашему драйверу загружать все параметры его
соединений для каждого DSN (Data Source Name,
имени источника данных), а все DSN пронумерованы и определены внутри этого файла. DSN также предоставляет
свою функциональность для представления всей базы данных в читаемом человеком формате. Файл DSN должен
быть защищён. В предлагаемой наладке допустимо применять различные учётные записи для вашего сервера Zabbix,
что делает вещи более простыми. Поскольку существует только один сервер Zabbix, единственный нуждающийся в
доступе к этому файлу пользователь это пользователь сервера Zabbix. Данный файл должен находиться о владении
такого пользователя и быть не доступным для чтения прочими. DSN содержатся в файле
odbc.ini в каталоге ect.
Уделите внимание защите этого файла и предотвратите доступ прочих людей к данному файлу, поскольку он содержит
пароли.
Существует две версии доступных ODBC с открытым исходным кодом - unixODBC и iODBC. Zabbix может применять их обе, однако прежде чем мы сможем ими воспользоваться, первая вещь, которую необходимо сделать, это позволить Zabbix применять ODBC и установить свой уровень unixODBC. Существует два способа сделать это: один состоит в применении менеджера пакетов, а другой представляет собой старый вариант загрузки исходных кодов и их компиляции (на момент написания книги самая последняя стабильная версия 2.3.2):
$ wget ftp://ftp.unixodbc.org/pub/unixODBC/unixODBC-2.3.2.tar.gz
$ tar zxvf unixODBC-2.3.2.tar.gz
$ cd unixODBC-2.3.2
$ ./configure --prefix=/usr --sysconfdir=/etc
$ make
$ make install
|
| Совет |
|---|---|
|
Если вы находитесь в 64- разрядной операционной системе, вам следует определить 64- разрядную
версию библиотек при помощи |
Местоположением являются /usr/bin для исполняемых
файлов и /usr/lib или /usr/lib64
для библиотек в зависимости от той версии, которую вы установили.{Прим. пер.:
Подробнее см. наш перевод Главы 16, Введение в компиляцию программного обеспечения из исходного кода на C книги
Брайана Варда "Как работает Linux".}
Если вы интересуетесь установкой unixODBC посредством менеджера пакетов, вам нужно выполнить следующую команду от имени root:
$ yum -y install unixODBC unixODBC-devel
Установка драйверов базы данных
unixODBC поддерживает широкий и практически полный перечень баз данных. Поддерживается большинство из следующих широко распространённых баз данных:
-
MySQL
-
PostgreSQL
-
Oracle
-
DB2
-
Sybase
-
Microsoft SQL Server (через FreeTDS)
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Полный перечень поддерживаемых unixODBC баз данных доступен по ссылке Глава http://www.unixodbc.org/drivers.html. |
Драйверы ODBC MySQL
Сейчас, если вы предварительно установили unixODBC посредством менеджера пакетов, вы можете следовать той же процедуре, например, в Red Hat при помощи следующей команды:
$ yum install mysql-connector-odbc
В противном случае они также доступны в виде пакета; вам необходимо только загрузить соотвествующий
пакет, например, mysql-connector-odbc-5.1.13-linux-glibc2.5-x86-64bit.tar.gz.
Затем раскрыть этот пакет и скопировать содержимое его каталогов /usr/lib/odbc
и /usr/lib64/odbc/ следующим образом:
$ tar xzf mysql-connector-odbc-5.1.13-linux-glibc2.5-x86-64bit.tar.gz
$ mkdir /usr/lib64/odbc/
$ cp /usr/src/ mysql-connector-odbc-5.1.13-linux-glibc2.5-x86-64bit/lib/*/usr/lib64/odbc/
Теперь вы можете проверить все ли необходимые библиотеки присутствуют в вашей системе при помощи команды
ldd.
Это можно сделать в 32- разрядной операционной системе следующей командой:
$ ldd /usr/lib /libmyodbc5.so
А в 64- разрядной системе команда слегка отличается:
$ ldd /usr/lib64 /libmyodbc5.so
Если ничто не помечается как Not Found, это означает, что все
необходимые библиотеки найдены и вы можете продолжить; в противном случае вам нужно проверить что
пропущено и исправить это.
Все установленные драйверы ODBC перечислены в /etc/obcinst.ini;
для MySQL 5 этот файл содержит следующее:
[mysql]
Description = ODBC for MySQL
Driver = /usr/lib/libmyodbc5.so
Setup = /usr/lib/libodbcmyS.so
64- битная система должна содержать следующее:
mysql]
Description = ODBC for MySQL
Driver64 = /usr/lib64/libmyodbc5.so
Setup64 = /usr/lib64/libodbcmyS.so
|
| Замечание |
|---|---|
|
Для ознакомления со всеми доступными опциями ODBC отсылаем вас к официальной документации, доступной по ссылке http://dev.mysql.com/doc/refman/5.1/en/connector-odbc-info.html. |
Источники данных определяются в вашем файле odnc.ini. Вам необходимо
создать файл со следующим содержимым:
[mysql-test]
# This is the driver name as specified on odbcinst.ini
Driver = MySQL5
Description = Connector ODBC MySQL5
Database = <db-name-here>
USER= <user-name-here>
Password = <database-password-here>
SERVER = <ip-address-here>
PORT = 3306
|
| Совет |
|---|---|
|
Существует возможность настройки ODBC с использованием безопасного SSH соединения, однако вам необходимо создать сертификат и настроить обе свои стороны (ODBC и сервер) чтобы разрешить его. Отсылаем вас к официальной документации за деталями. |
Драйверы ODBC PostgreSQL
Чтобы получить через ODBC доступ к базе данных PostgreSQL, вам необходимо установить соответствующий драйверы. Они будут использоваться сервером Zabbix для отправки запросов к любой базе данных PostgreSQL через её протокол ODBC.
Официальные драйверы ODBC для PostgreSQL доступны по ссылке http://www.postgresql.org/ftp/odbc/versions/src/
Для работы с базой данных PostgreSQL выполните следующие шаги:
-
Вы можете загрузить, скомпилировать и установить свой драйвер
psqlODBCпри помощи следующих команд:$ tar -zxvf psqlodbc-xx.xx.xxxx.tar.gz $ cd psqlodbc-xx.xx.xxxx $ ./configure $ make $ make install -
Сценарий настройки принимает различные опции; некоторые из наиболее важных следующие:
--with-libpq=DIR postgresql path --with-unixodbc=DIR path или непосредственно файл odbc_config (default:yes) --enable-pthreads= thread-safe driver when available (не для всех платформ) -
В качестве альтернативы вы здесь можете даже выбрать пакеты rpm и затем выполнить следующую команду:
$ yum install postgresql-odbc -
Имея в наличии скомпилированный и установленный драйвер ODBC, вы можете создать файл
/etc/obcinst.iniили, если у вы выполняли установку с rpm, просто убедитесь что этот файл существует со следующим содержимым:[PostgreSQL] Description = PostgreSQL driver for Linux Driver = /usr/local/lib/libodbcpsql.so Setup = /usr/local/lib/libodbcpsqlS.so Driver64 = /usr/lib64/psqlodbc.so Setup64 = /usr/lib64/libodbcpsqlS.so -
Теперь может быть выполнен
odbcinstпередачей шаблона этой команде:$ odbcinst -i -d -f template_filepsqlЗамечание ODBC поддерживает шифрованную регистрацию с
md5, но не поддерживаетcrypt. Имейте в виду, что только сама регистрация шифруется после login. ODBC отправляет все запросы как обычный текст. Начиная с версии 08.01.002,psqlODBCподдерживает зашифрованные SSL соединения, что защитит ваши данные. -
Так как драйвер
psqlODBCподдерживает потоки (threads), вы можете изменять уровень последовательного упорядочивания для каждого элемента драйвера. Таким образом, например, содержимоеodbcinst.iniбудет следующим:[PostgreSQL] Description = PostgreSQL driver for Linux Driver = /usr/local/lib/libodbcpsql.so Setup = /usr/local/lib/libodbcpsqlS.so Threading = 2 -
Теперь вам нужно настроить ваш файл
odbc.ini. Вы также можете применить здесьodbcinst, предоставив ему шаблон или текстовый редактор следующим образом:$ odbcinst -i -s -f template_file -
Вы должны иметь внутри вашего
odbc.iniчто-то аналогичное следующему:[PostgreSQL] Description = Postgres to test Driver = /usr/local/lib/libodbcpsql.so Trace = Yes TraceFile = sql.log Database = <database-name-here> Servername = <server-name-or-ip-here> UserName = <username> Password = <password> Port = 5432 Protocol = 6.4 ReadOnly = No RowVersioning = No ShowSystemTables = No ShowOidColumn = No FakeOidIndex = No ConnSettings =
Драйверы ODBC Oracle
Oracle является другой широко применяемой базой данных и также предоставляет драйвер ODBC. Ниже приводится описание как установить Oracle ODBC, так как http://www.unixodbc.org не содержит достаточной информации об этом.
-
Первое что следует сделать, это получить Instant Client с веб-сайта Oracle. Oracle предоставляет ряд клиентов в виде
rpmиtar.gz, что отображено в следующих командах:$ rpm –I oracle-instantclient11.2-basic-11.2.0.1.0-1.i386.rpm oracle-instantclient11.2-odbc-11.2.0.1.0-1.i386.rpm oracleinstantclient11.2-sqlplus-11.2.0.1.0-1.i386.rpm
Затем вам нужно настроить некоторые переменные окружения следующим образом:
$ export ORACLE_HOME=/usr/lib/oracle/11.2/client
$ export ORACLE_HOME_LISTNER=/usr/lib/oracle/11.2/client/bin
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH :/usr/lib/oracle/11.2/client/lib
$ export SQLPATH=/usr/lib/oracle/11.2/client/lib
$ export TNS_ADMIN=/usr/lib/oracle/11.2/client/
Теперь вам необходимо настроить свой файл /etc/odbcinst.ini.
Данный файл должен иметь следующее содержание:
[Oracle11g]
Description = Oracle ODBC driver for Oracle 11g
Driver = /usr/lib/oracle/11.2/client/lib/libsqora.so.11.1
В файле odbc.ini элементы DSN необходимо настроить
следующим образом:
[ORCLTEST]
Driver = Oracle 11g ODBC driver
ServerName = <enter-ip-address-here>
Database = <enter-sid-here>
DSN = ORCLTEST
Port = 1521
Вы можете как обычно проверить своё соединение при помощи следующей команды:
$ isql -v ORCLTEST
+---------------------------------------+
| Connected! |
| |
| sql-statement |
| help [tablename] |
| quit |
+---------------------------------------+
Теперь с вашим ODBC соединением всё хорошо.
Файлы настройки unixODBC
К настоящему моменту вы сделали доступными соединения к наиболее распространённым базам данных. Чтобы
проверить соединение вы можете выполнить их тестирование при помощи isql
следующим образом:
-
Если вы не определили имя своего пользователя и его пароль внутри файла
odbc.ini, они могут быть переданы в ваш DSN при помощи следующего синтаксиса:$ isql <DSN> <user> <password> -
Иначе, если всё уже определено, вы просто можете проверить соединение следующей командой:
$ isql mysql-test -
Если всё пройдёт нормально, вы должны увидеть следующий вывод:
+---------------------------------------+ | Connected! | | | | sql-statement | | help [tablename] | | quit | | | +---------------------------------------+ SQL>Замечание Если вы получите некое сообщение об ошибке от unixODBC, такое как
Data source name not foundиno default driver specified, убедитесь что переменные окруженияODBCINIиODBCSYSINIуказывают на правильный файлodbc.ini. Например, если ваш файлodbc.iniнаходится в каталоге/usr/local/etc, окружение должно быть настроено следующим образом:export ODBCINI=/usr/local/etc/odbc.ini export ODBCSYSINI=/usr/local/etc -
Если DSN представляет проблемы, может оказаться полезной такая команда:
$ isql -v <DSN>
Это делает доступным режим с детализацией (verbose mode), который очень полезен при отладке.
Полезно знать, что odbc.ini является общим файлом, следовательно
вы будете иметь там все свои записи unixODBC.
Компиляция Zabbix с ODBC
Теперь, если вы соединены с подлежащей мониторингу целевой базой данных, самое время скомпилировать ваш сервер Zabbix с поддержкой ODBC выполнив следующие шаги:
|
| Замечание |
|---|---|
|
Если ваш Zabbix уже установлен и работает, не выполняйте команду |
-
Сейчас вы можете получить командную строку
configureсо всеми параметрами, описанными в Главе 1, Развёртывание Zabbix, добавив следующим образом параметр--with-unixodbc:$ ./configure --enable-server -–with-postgresql --with-net-snmp --with-libcurl --enable-ipv6 --with-openipmi --enable-agent --with-unixodbc -
В строках вывода вы должны увидеть следующее:
checking for odbc_config... /usr/local/bin/odbc_config checking for main in -lodbc... yes checking whether unixodbc is usable... yes -
Это подтверждает, что все необходимые вам двоичные файлы найдены и могут использоваться. Когда фаза настройки хавершена, вы можете выполнить следующую команду:
$ make -
Когда она завершится, просто снимите резервную копию своего предыдущего установленного файла
zabbix_serverи скопируйте на его место новую версию.После запуска
zabbix_serverобратите внимание на файл протокола, вы должны увидеть в нём следующее:****** Enabled features ****** SNMP monitoring: YES IPMI monitoring: YES WEB monitoring: YES Jabber notifications: YES Ez Texting notifications: YES ODBC: YES SSH2 support: YES IPv6 support: YES ******************************
Это означает, что всё прошло успешно.
Элементы монитора базы данных
Теперь самое время воспользоваться функциональностью ODBC. Чтобы сделать это, вам необходимо создать
элемент с типом Database monitor,
как это показано на следующем снимке экрана:
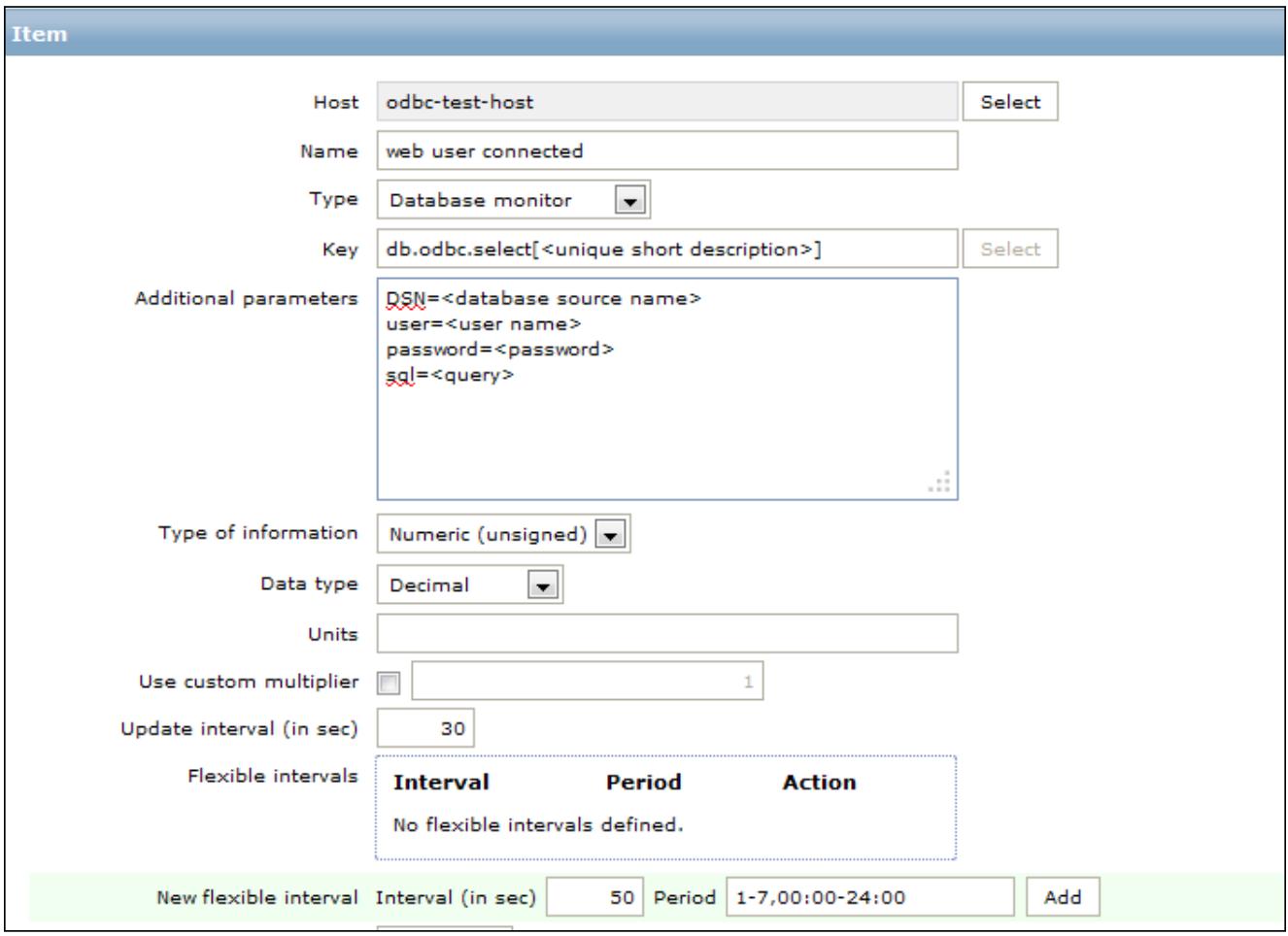
Элемент, в котором будут сохраняться получаемые значения идентифицируется ключом эkемента (itm key) следующим образом:
db.odbc.select[<unique short description>]
<unique short description> является строкой, которая должна быть
уникальной и может быть какой вы захотите. Наш пример таков:
db.odbc.select[web_user_connected_on_myapp]
Внутри поля Additional parameters вам надлежит определить следующее:
DSN=<database source name>
user=<user name>
password=<password>
sql=<query>
Если DNS должен присутствовать внутри /etc/odbc.ini и хранятся ли
ваши имя пользователя и пароль в определении DSN или нет может быть определено здесь. В последней строке вам
необходимо определить запрос SQL.
Некоторые соображения о запросах SQL ODBC
Ниже приводятся некоторые ограничения на использование и подлежащие рассмотрению предметы для запроса SQL:
-
SQL должен начинаться с оператора select
-
SQL не может содержать никаких разрывов строк
-
Запрос должен возвращать только одно значение
-
Если запрос возвращает множество колонок, будет прочтена только первая
-
Если запрос возвращает множество строк, будет прочтена только первая колонка первой строки
-
Макросы не будут замещаться (например,
{HOSTNAME}) -
Команда SQL должна начинаться с символа в нижнем регистре, то есть,
sql= -
Запрос должен быть завершён до общего таймаута
-
Запрос должен возвращать в точности определённый тип; иначе элемент не будет поддерживаться
Как вы можете заметить, существуют лишь небольшие ограничения которые вы можете принять. В частности, вы не можете выполнять функцию, если эта функция возвращает только одно значение {Прим. пер.: так в тесте. Нам кажется, правильно будет: Более одного значения?} Вы не можете исполнять хранимые процедуры; вы можете исполнять только select данных. Кроме того, запрос не может содержать никаких разрывов строк, следовательно длинные и сложные запросы не будет просто прочесть. {Прим. пер.: до определённой степени эту проблему можно решить при помощи представлений.}
Далее перечислены некоторые другие подлежащие рассмотрению элементы:
-
Если запрашиваемая база данных чрезвычайно загружена, она может отвечать с некоторой задержкой (ваша регистрация также может испытывать определённую задержку вызываемую большой нагрузкой)
-
Каждый запрос выполняет регистрацию
-
Если база данных прослушивается по
127.0.0.1, соединение может иметь проблемы -
Если вы используете прокси, они также должны быть скомпилированы с поддержкой вашего unixODBC
Если вы рассматриваете базу данных, которая будет испытывать большую загруженность, не надо иметь пул представленный для накладных расходов, в этом нет необходимости. Кроме того, в этом случае возможна ситуация, при которой простое получение соединения потребует от вас ожидания на более чем пять секунд.
Упомянутые ранее 5 секунд не являются случайным значением; на самом деле, таймаут соединения определяется при открытии некоторого соединения. В процессе его инициализации вам необходимо определить ваше ожидаемое время таймаута до того момента, как считать соединение невозможным.
Zabbix определяет этот таймаут следующей командой:
src/libs/zbxdbhigh/odbc.c
В 130й строке данного файла у нас имеется определение значение таймаута соединения для Zabbix в следующем виде:
SQLSetConnectAttr(pdbh->hdbc, (SQLINTEGER)SQL_LOGIN_TIMEOUT,
(SQLPOINTER)5, (SQLINTEGER)0);
Именно (SQLPOINTER)5 устанавливает
SQL_LOGIN_TIMEOUT в значение 5 секунд. Если ваша база данных не отвечает
на протяжении 5 секунд, вы получите в файле протокола следующее сообщение об ошибке:
[ODBC 3.51 Driver]Can't connect to MySQL server on 'XXX.XXX.XXX.XXX' (4)]
(2003).
|
| Совет |
|---|---|
|
В случае |
Zabbix версии 2.0 имеет внутреннюю поддержку для мониторинга приложений, применяющих JMX. Исполнитель, который выполняет мониторинг приложений JMX это демон Java, называемый шлюзом Java Zabbix. В основном, он выступает в качестве шлюза. Когда Zabbix желает узнать значение счётчика JMX, он просто запрашивает шлюз JMX и этот шлюз выполняет всю работу для Zabbix. Все запросы выполняются с применением API управления JMX Oracle.
Шлюз Java Zabbix находится в очень ранней стадии разработки и, таким образом, предоставляет великолепную функциональность при всё ещё испытывает некоторые трудности.
Отличительной особенностью данного метода является то, что приложению требуется только его запуск со своей включённой удалённой консолью JMX и не требуется никакой реализации или расширения класса или написания нового кода для обработки запроса Zabbix, потому что все запросы являются стандартом JMX.
Вариантом по умолчанию включения консоли JMX является запуск приложения Java со следующими параметрами:
-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port=<put-your-port-number-here>
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.ssl=false
С помощью данных параметров вы собираетесь настроить интерфейс JMX на стороне приложения. Как обычно, вам необходимо определить некий порт, свой метод аутентификации и вариант шифрования.
Такая базовая наладка является простейшим и самым лёгким способом, однако, к сожалению, она не является самой гарантированной и наиболее безопасной настройкой.
Теперь, когда вы собираетесь открыть дверь в своём приложении, вы в основном подвергаете своё приложение
риску для безопасности. Консоль JMX, в большинстве широко распространённых серверных приложений, не только
точка для получения значений от своих счётчиков, но также и что- то, что является намного более сложным.
Обычно, при открытой консоли на некоем сервере приложений, вы можете развёртывать приложение. Запуская его,
останавливая его и выполняя тому подобное, вы можете понимать что хакер способен разворачивать, а также запускать
приложение или вызывать проблему на уже работающих приложениях. Консоль JMX может вызываться из определённого
зацикленного серверного приложения с применением методов post и
get. Добавление вредоносного содержимого в раздел
HEAD какой- либо веб- страницы приводит в результате к тому, что
сервер, имеющий консоль является именно тем что не будет безопасным и легко подвергается взлому, что является
самым слабым местом в вашей инфраструктуре. Если серверное приложение скомпрометировано, вся ваша сетевая
среда становится потенциально раскрытой, а вам необходимо предостерегаться всего такого. Это может быть сделано
при помощи следующих шагов:
-
Самое первое, что необходимо сделать, это разрешить аутентификацию следующим образом:
-Dcom.sun.management.jmxremote.authenticate=true -
Теперь нам необходимо определить файл, который будет содержать ваш пароль следующим образом:
-Dcom.sun.management.jmxremote.password.file=/etc/java-6-penjdk/management/jmxremote.passwordСовет Существуют потенциальные проблемы безопасности с аутентификацией по паролю для удалённых соединений JMX. Когда определённый клиент получает свой удалённый разъём из не обеспеченного безопасностью реестра RMI (условие по умолчанию), в случае любых атак со злоумышленником в роли посредника (MITM), атакующий может запустить фальшивый реестр RMI на целевом сервере непосредственно перед первоначальным и запустить его и, тем самым, может затем воровать пароли клиентов.
-
Другая полезная вещь, которую следует сделать заключается в профилировании своих пользователей, определив следующий параметр:
-Dcom.sun.management.jmxremote.access.file=/etc/java-6-penjdk/management/jmxremote.access -
Файл
access, например, должен содержать что-то аналогичное следующему:monitorRole readonly controlRole readwrite -
Файлы паролей должны быть следующими:
monitorRole <monitor-password-here> controlRole <control-password-here>> -
Теперь, чтобы избежать воровства паролей вам следует включить SSL следующим образом:
-Dcom.sun.management.jmxremote.ssl=true -
Эти параметры в результате связываются со следующими:
-Djavax.net.ssl.keyStore=<Keystore-location-here> -Djavax.net.ssl.keyStorePassword=<Default-keystorepassword> -Djavax.net.ssl.trustStore=<Trustore-location-here> -Djavax.net.ssl.trustStorePassword=<Trustore-password-here> -Dcom.sun.management.jmxremote.ssl.need.client.auth=trueЗамечание Параметр
-Dбудет записан в своём файле запуска вашего приложения или сервера приложения, поскольку, после такой настройки ваш запускающий файл будет содержать чувствительные данные (ваши паролиkeyStoreиtrustStore) которые подлежат защите и не должны читаться из других учётных записей в той же самой группе или прочими пользователями.
Для компиляции шлюза Java следуйте таким шагам:
-
Прежде всего вам необходимо установить требующиеся пакеты:
$ yum install java-devel -
Затем вам необходимо выполнить следующую команду:
$ ./configure --enable-java -
Вы должны получить следующий вывод:
Enable Java gateway: yes Java gateway details: Java compiler: javac Java archiver: jar -
Это отображает то, что ваш шлюз Java готовится ко включению и компиляции после применения следующей команды:
$ make && make install -
Обычно структура каталога будет содержать следующий файл - ваш шлюз Java:
bin/zabbix-java-gateway-2.0.5.jar -
vfs.zfs.vdev.cache.size="10M" -
Необходимые для вашего шлюза библиотеки таковы:
lib/logback-classic-0.9.27.jar lib/logback-core-0.9.27.jar lib/android-json-4.3_r3.1.jar lib/slf4j-api-1.6.1.jar -
Вот два файла настроек:
lib/logback-console.xml lib/logback.xml -
Сценарии для запуска и останова вашего шлюза следующие:
shutdown.sh startup.sh -
Вот общий файл сценария, берущий исходные коды из сценариев запуска и останова который содержит следующие настройки:
settings.sh -
Теперь, если вы сделали доступным свой SSL соединение, вам нужно включить такой же уровень безопасности на вашем шлюзе Java Zabbix. Чтобы выполнить это, вам нужно добавить следующий параметр в ваш сценарий запуска:
Djavax.net.ssl.* -
Когда всё налажено, вам необходимо определить следующее внутри настроек вашего сервера Zabbix:
JavaGateway=<ip-address-here> JavaGatewayPort=10052Замечание Если вы пожелаете использовать свой шлюз Java с вашего прокси, вам необходимо настроить как
JavaGateway, так иJavaGatewayPropertiesв своём файле настроек прокси. -
Так как по умолчанию Zabbix не запускает никакой регистратор (poller) Java, вам требуется определить их тоже таким образом:
StartJavaPollers=5 -
Сразу как сделаете это, перезапустите свой сервер или прокси Zabbix.
vfs.zfs.vdev.cache.size="10M" -
Теперь вы окончательно можете запустить шлюз Java Zabbix выполнив команду
startup.sh.
Все регистрации будут доступны в /tmp/zabbix_java.log с уровнем
подробностей "info".
|
| Совет |
|---|---|
|
Так как шлюс Java Zabbix использует библиотеку Здесь вы также можете изменить все свои параметры
|
Если вам необходимо отлаживать некую проблему шлюза Java Zabbix, другой полезный момент, который следует
знать, заключается в том, что вы можете запускать шлюз Java в режиме консоли. Чтобы выполнить это, вам просто
нужно закрыть комментарием переменную PID_FILE, содержащуюся в
settings.sh. Если ваш сценарий
startup.sh не найдёт параметр PID_FILE,
он запустит шлюз Java в режиме приложения консоли, а Logback вместо пержнего будет использовать файл
lib/logback-console.xml. Такой файл настройки, кроме того что включит
ваш протокол консоли, даже изменит ваш уровень регистраций на отладочный (debug). Тем не менее, если
вы ищите дополнительные подробности о протоколировании в шлюзе Java Zabbix, вы можете напрямую перейти к
руководству пользователя SLF4J доступному по ссылке http://www.slf4j.org/manual.html.
Теперь наступило время создать выполняющий мониторинг JMX хост с соответствующими элементами JMX мониторинга. Чтобы сделатьэто, внутри настроек вашего хоста вам необходимо добавить интерфейс JMX и адрес, как это отображается на нашем следующем снимке экрана:
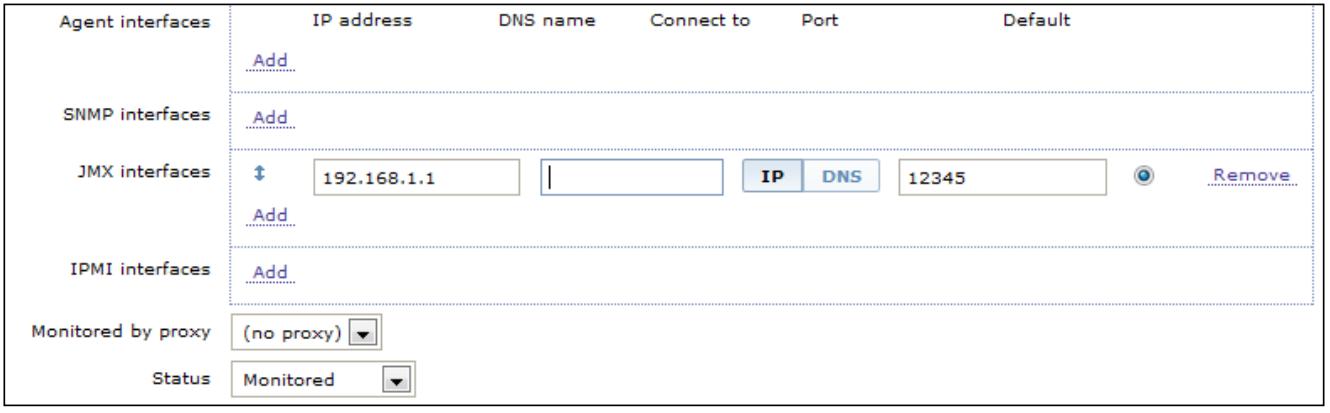
Когда вы выполните это для каждого своего счётчика JMX, который вы хотите получать, вам необходимо определить некий элемент с типом JMX agent. Внутри определения данного агента JMX вам необходимо определить своё имя пользователя, пароль, а также строку запроса JMX. Ключ JMX составляется следующим образом:
-
Имя объекта MBean
-
Имя атрибута, то есть имя атрибута MBean
Приводимый ниже снимок экрана отображает окно настроек вашего Item:
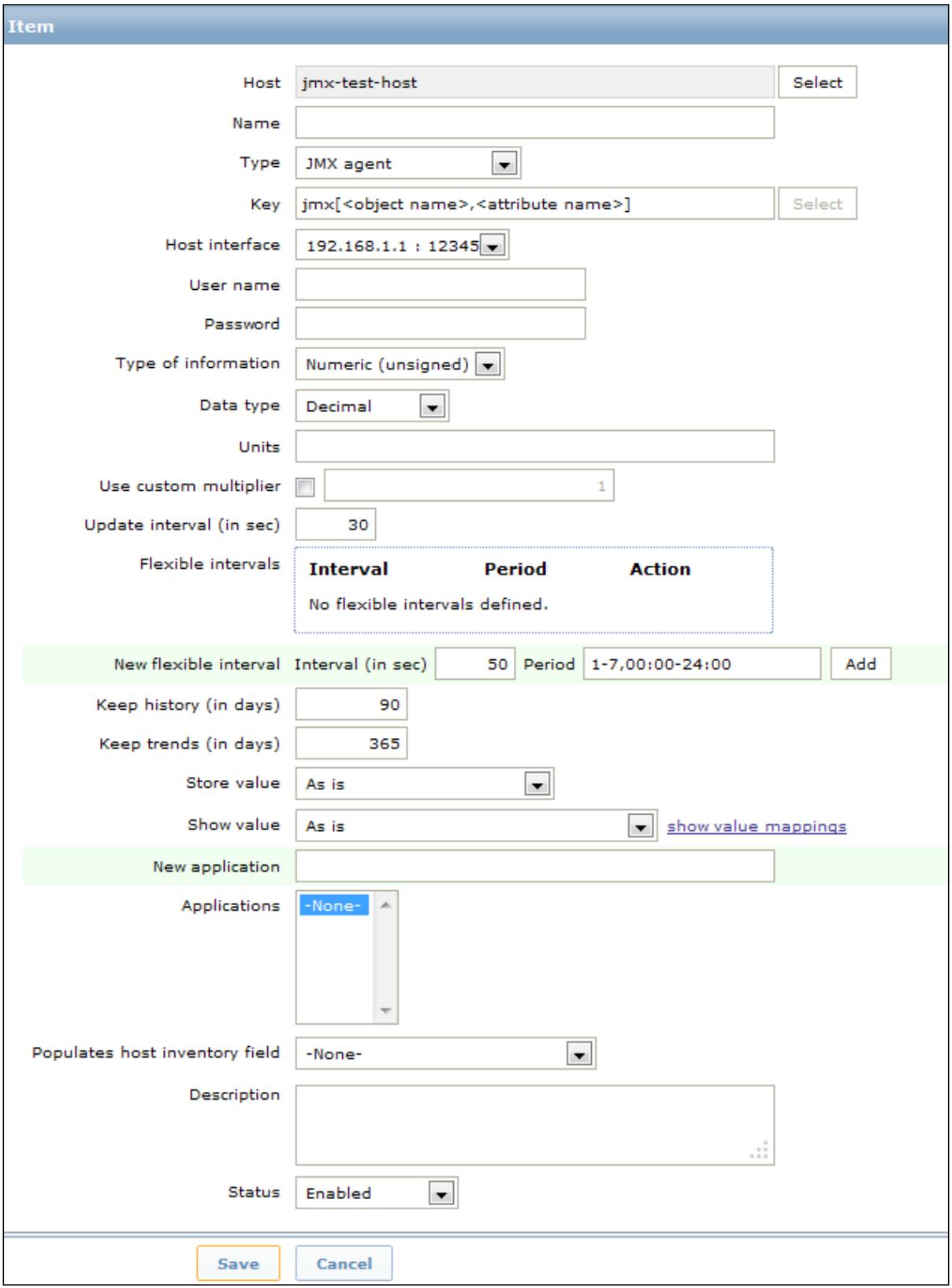
Data type в этом окне настроек позволяет
нам сохранять целые значения без знака (например, 0 или
1) в виде чисел или Булевых значений (таких как
true или false).
Детализация ключей JMX
MBean является совершенно простой строкой определяемой в вашем приложении Java. Прочие компоненты, тем не менее, являются слегка более сложными; атрибут может возвращать базовые типы данных или составные данные.
Базовыми типами данных являются простейшие типы, такие как целые и строки. Например, вы можете иметь следующий запрос:
jmx[com.example:Type=Test,weight]
Он будет возвращать измеренный вес, выражаемый в виде численного значения с плавающей запятой.
Если атрибут возвращает составные данные, это слегка усложняется, но обрабатывается так как поддерживаются точки. Например, вы можете иметь перо, которое имеет два значения представляющих цвет и остающиеся чернила, обычно разделяемых точкой, как это показано в следующем коде:
jmx[com.example:Type=Test,pen.remainink]
jmx[com.example:Type=Test,pen.color]
Теперь, если у вас имеется имя некоего атрибута которое содержит точку в своём имени, например,
all.pen, вам необходимо экранировать эту точку, как это отображено
в следующем коде:
jmx[com.example:Type=Test,all\.pen.color]
Если ваше имя атрибута также содержит обратную косую черту (\),
она нуждается в двойном экранировании, как это отображается в приводимом ниже коде:
jmx[com.example:Type=Test,c:\\utility]
Если имя объекта или имя атрибута содержит пробелы или запятые, его необходимо брать в двойные кавычки:
jmx[com.example:type=Hello,""c:\\documents and settings""]
Проблемы JMX и соображения о них
К сожалению, поддержка JMX не является гибкой и индивидуально настраиваемой какой она должна быть; по крайней мере, на момент написания данной книги JMX всё ещё имела ряд проблем.
Например, из собственного персонального опыта я знаю, что JBoss, который является одним из наиболее
широко распространённых используемых серверов приложений, не подлежит успешному выполнению запросов.
Терминал (endpoint) JMX в настоящее время жёстко закодирован в JMXItemChecker.java
следующим образом:
"service:jmx:rmi:///jndi/rmi://" + conn + ":" + port + "/jmxrmi"
Некоторые приложения применяют различные терминалы (endpoint) для своих консолей управления JMX. JBoss является одним из таких. Терминалы не настраиваются ни на хосте, ни в интерфейсе, а также вы не можете добавлять параметр для определения этого терминала в своём окне настроек хоста.
Тем не менее, идущее развитие действительно активное и вещи становятся всё лучше и усиливаются с каждым днём. На данный момент состояние таково, что имеющийся шлюз Java Zabbix нуждается в некоторых улучшениях. К тому же текущая реализация шлюза Java Zabbix страдает от рабочих нагрузок; если у вас имеется более 100 элементов JMX на хост, ваш шлюз нуждается в периодических перезапусках. Вполне вероятно, что вы столкнётесь с некоторыми ошибками следующего рода:
failed: another network error, wait for 15 seconds
За этим следует:
connection restored
Помимо этого, присутствует ещё одна подлежащая рассмотрению сторона: в сценарии реального мира может так случаться, что у вас имеется множество JMX работающих на одних и тех же хостах. В этом случае вам необходимо настраивать каждый порт создающий множество элементов и псевдонимы хостов, по одному для каждого сетевого интерфейса; хорошо, подобный сценарий может быть решён с помощью низкоуровневого обнаружения и требует большого объёма избыточной работы по ручной настройке. Принципиальным является то, что реализующие инфраструктуру мониторинга Zabbix знают не только все сильные моменты данного продукта, но также минусы и ограничения. Разработчики могут выбирать, хотят ли они что- то развивать самостоятельно, применяя альтернативу с открытым исходным кодом, пытаться устранять возможные проблемы, или запросить у команды Zabbix новой функциональности или исправлений.
SNMP (Simple Network Monitoring Protocol) может не оказаться настолько простым, как это предлагается его названием; он фактически является стандартом для многих приборов и приложений. Он не толко вездесущ - он зачастую является единственным разумным способом которым кто-то может извлекать свою информацию мониторинга из сетевых коммутаторов, полок дисковых устройств, батарей UPS и тому подобного.
Схема базовой архитектуры для мониторинга SNMP действительно прямолинейна. Каждый подлежащий мониторингу хост или прибор выполняет агента SNMP. Этот агент может быть запрошенным неким устройством (будь то просто программа из командной строки для выполнения запросов вручную или сервер мониторинга, подобный Zabbix) и отсылает назад информацию по любой метрике, которую он должен делать доступной или даже изменять предварительно настроенные установки на самом данном хосте в виде отклика на команду настройки с опрашивающего устройства. Более того, этот агент не просто пассивный пассивная сущность, которая просто отвечает на команды get и set, но ткже может отсылать предостережения и предупреждения в качестве ловушки SNMP на предварительно определённый хост в случае возникновения некоторого специфичного условия.
Предметы несколько усложняются, когда мы подходим к определению метрик. В отличие от обычных элементов Zabbix, или любых других систем мониторинга, метрика SNMP является частью огромной иерархии, дерево метрик, которое охватывает производителей аппаратных средств и разработчиков программного обеспечения идентифицируется нектороым видом кода. Этот уникальный идентификатор метрики называется OID и отождествляет как сам объект, так и его положение в общем дереве иерархии SNMP.
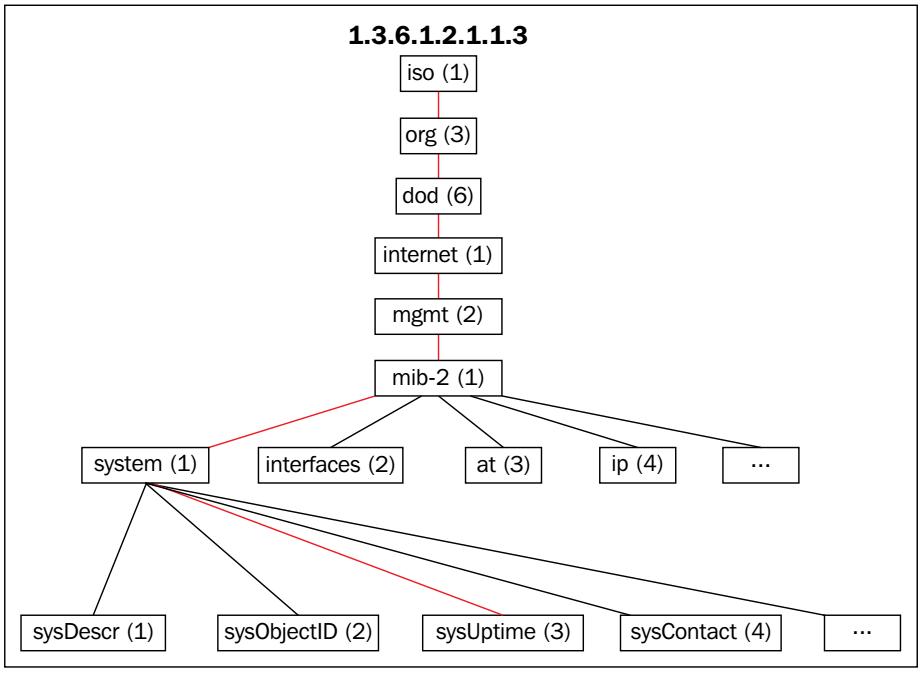
OID и его значения являются реальным содержимым, которое пропускается в сообщениях SNMP. Хотя они и наиболее эффективно с точки зрения сетевого обмена, OID также должны транслироваться во что- то применимое и понимаемое людьми. Это выполняется при помощи распределённой базы данных, называемой MIB (Management Information Base). MIB являются естественными текстовыми файлами, которые описывают определённые подразделения общего дерева OID с текстовым описанием своих OID, их типов данных, а также читаемых человеком строчных идентификаторов.
MIB даёт нам знать, например, что OID 1.3.6.1.2.1.1.3
относится к времени безотказной работы определённой системы агента работающего на какой- либо машине.
Его значение выражается в виде целого в сотых долях секунд и может обчно называться как
sysUpTime. Следующая схема
отображает это:
Как вы можете видеть, это совершенно отличается от способа которым работают агенты Zabbix, причём сразу и как в терминах протокола соединения, так и определения элемента и организации. Тем не менее, Zabbix предоставляет средства для трансляции из OID SNMP в элементы Zabbix - если вы скомпилировали для своего сервера поддержку SNMP, будет существовать возможность создавать очереди SNMP естественным образом и при помощи пары инструментов поддержки также будет возможно обрабатывать улавливатели (trap) SNMP.
Конечно, это естественная функциональность если вам необходимо осуществлять мониторинг приборов которые поддерживают только SNMP и вообще не имеют возможности установки естественного агента на сетевом устройстве (коммутатор, маршрутизатор и так далее), полки дисковых массивов и тому подобное. Однако ниже приведены причины, которые могут послужить вам реальной основой для выбора SNMP в качестве основного протокола мониторинга в вашей сетевой среде и полностью освободиться от агентов Zabbix:
-
У вас может отсутствовать потребность в большом количестве сложных или индивидуальных метрик помимо тех, которые уже предоставляются операционной системой сегмента OID SNMP. Вы, скорее всего, уже настроили мониторинг SNMP для своего сетевого оборудования и если вам требуются только простые метрики, такие как время безотказной работы, загрузка ЦПУ, свободная память и тому подобные о вашего среднего хоста, может оказаться более простым положиться на SNMP для них вместо внутреннего агента Zabbix. Таким образом, вам никогда не придётся бепокоиться о развёртывании агента и его обновлениях - вы просто позволите серверу Zabbix осуществлять контакт с удалёнными агентами Zabbix и получать ту информацию, которая вам нужна.
-
Протокол SNMP и номера портов хорошо известны практически всем имеющимся продуктам. Если вам необходимо отсылать информацию мониторинга по сетевым средам, может оказаться более простым положится на протокол SNMP вместо вашего протокола Zabbix. Это может быть по той причине, что обмен по вашим UDP портам
161и162уже разрешён или потому что может быть проще запросить у сетевого администратора разрешить доступ к хорошо известным протоколам, вместо относительно менее известного. -
Функции SNMP версии 3 имеют встроенную поддержку аутентификации и безопасности. Это означает, что в отличие от вашего протокола Zabbix, как вы уже видели в Главе 2, Распределённый мониторинг, сообщения SNMPv3 будут иметь большую целостность, конфиденциальность и достоверность. Хотя Zabbix поддерживает все три версии SNMP, настоятельно рекомендуется применять Версию 3 везде, где это возможно, так как она единственная имеет возможности реадьной безопасности. В противоположность ей, Версии 1 и 2 имеют только простую отсылку строк внутри сообщений, что является очень тонким уровнем безопасности. {Прим. пер.: версия 3 Zabbix снимает остроту этого положения, поскольку имеет встроенную поддержку шифрования обмена и аутенификации.}
-
Хотя могут существовать хорошие основания для применения мониторинга SNMP в вашей установке настолько много, насколько это возможно, существует ещё пара сильных причин придерживаться вашего агента Zabbix. Агент Zabbix имеет ряд очень полезных встроенных метрик, которые могут быть необходимы пользовательским расширениям при реализации через агента SNMP. Например, если вы хотите осуществлять мониторинг файла протокола с автоматической поддержкой ротации регистраций и опускать устаревшие данные, вам просто необходимо определить ваш ключ
logrt[]для активного элемента Zabbix. Та же самая вещь применима применяется если вы хотите наблюдать за определённой контрольной суммой, размером определённого файла или свойством Performance Monitor операционной системы Windows и тому подобному. Во всех этих случаях, ваш агент Zabbix является самым непосредственным и простым выбором. -
Агент Zabbix имеет встроенную возможность обнаружения многих видов ресурсов, которые доступны в данном хосте и сообщать о них назад своему серверу, который будет по очереди автоматически создавать элементы и запускающие механизмы (триггеры) и уничтожать их когда указанные ресурсы более являются недоступными. Это означает, что при наличии агента Zabbix вам будет доступно делать возможным для сервера создвать соответствующие элементы для каждого ЦПУ хоста, смонтированной файловой системы, числа сетевых интерфейсов и тому подобного. Хотя возможно определять правила обнаружения низкого уровня на основе SNMP, часто проще полагаться на агента Zabbix для этого вида функциональности.
Итак, ещё раз, вы должны выдерживать баланс различных особенностей каждого решения с целью найти наиболее подходящее для вашей среды. Однако, вообще говоря, вы могли бы выполнить следующие общие оценки: если у вас имеются простые показатели, но вы нуждаетесь в сильной безопасности, следуйте SNMP v3; если у вас имеется сложный мониторинг или потребности в автоматизированном обнаружении и вы можете освободиться от сильной защищённости (или готовы дополнително работать над её получением, как это объясняется в Главе 2, Распределённый мониторинг), следуйте агенту и протоколу Zabbix.
Тем не менее, существует ряд подлежащих исследованию сторон, когда дело доходит до мониторинга SNMP Zabbix. Вначале мы обсудим простые запросы SNMP, а затем поговорим о ловушках SNMP.
Элемент мониторинга SNMP совершенно прост в настройке. Основным представляющим интерес местом
является то, что несмотря на то, что вы применяете OID
SNMP, который позволяет вам получать ваши измерения, вам всё ещё необходимо определять
некоторое уникальное имя для вашего элемента и, что более важно, некий уникальный ключ элемента.
Имейте в виду, что ключ элемента используется во всех выражениях Zabbix, которые определяют триггеры,
вычисляемые элементы, действия и тому подобное. Поэтому попробуйте придерживаться коротких и простых
имён, хотя и легко узнаваемых. В качестве примера, давайте предположим, что вы хотите определить показатели
для входящего обмена сетевого порта номер 3 некоторого прибора, его OID будет
1.3.6.1.2.1.2.2.1.10.3, в то время как вы можете вызывать свой
ключ как что-то подобное port3.ifInOctects, как это отображено
на следующем снимке экрана:
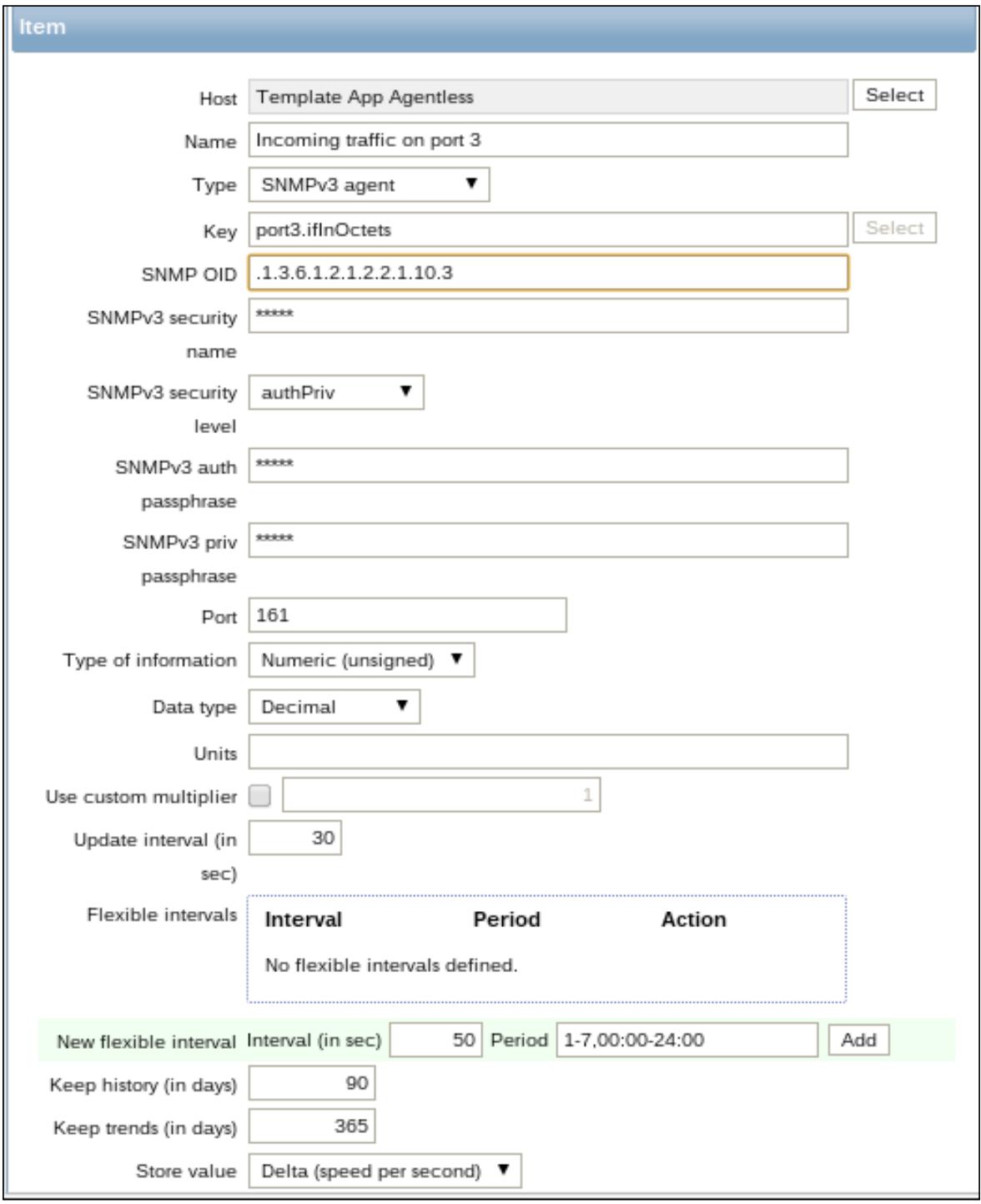
Если вы ещё не имеете своих элементов SNMP определённых в виде шаблона, простейший способ получить их
состоит в том, чтобы применить инструментарий snmpwalk для
непосредственного запроса к тому хосту, для которого вы хотите осуществлять мониторинг и получить информацию
о доступных OID и их типах данных.
Например, следующая команда применяется для получения всего дерева объектов с устройства по
адресу 10.10.15.19:
$ snmpwalk -v 3 -l AuthPriv -u user -a MD5 -A auth -x DES -X priv -m ALL 10.10.15.19
|
| Совет |
|---|---|
|
Вам необходимо заменить строку |
SNMP агент н вашем хосте будет отвечать списком всех его OID. Ниже приводится часть из того, что вы можете получить:
HOST-RESOURCES-MIB::hrSystemUptime.0 = Timeticks: (8609925)
23:54:59.25HOST-RESOURCES-MIB::hrSystemDate.0 = STRING: 2013-7-
28,9:38:51.0,+2:0
HOST-RESOURCES-MIB::hrSystemInitialLoadDevice.0 = INTEGER: 393216
HOST-RESOURCES-MIB::hrSystemInitialLoadParameters.0 = STRING: "root=/dev/sda8 ro"
HOST-RESOURCES-MIB::hrSystemNumUsers.0 = Gauge32: 2
HOST-RESOURCES-MIB::hrSystemProcesses.0 = Gauge32: 172
HOST-RESOURCES-MIB::hrSystemMaxProcesses.0 = INTEGER: 0
HOST-RESOURCES-MIB::hrMemorySize.0 = INTEGER: 8058172 KBytes
HOST-RESOURCES-MIB::hrStorageDescr.1 = STRING: Physical memory
HOST-RESOURCES-MIB::hrStorageDescr.3 = STRING: Virtual memory
HOST-RESOURCES-MIB::hrStorageDescr.6 = STRING: Memory buffers
HOST-RESOURCES-MIB::hrStorageDescr.7 = STRING: Cached memory
HOST-RESOURCES-MIB::hrStorageDescr.8 = STRING: Shared memory
HOST-RESOURCES-MIB::hrStorageDescr.10 = STRING: Swap space
HOST-RESOURCES-MIB::hrStorageDescr.35 = STRING: /run
HOST-RESOURCES-MIB::hrStorageDescr.37 = STRING: /dev/shm
HOST-RESOURCES-MIB::hrStorageDescr.39 = STRING: /sys/fs/cgroup
HOST-RESOURCES-MIB::hrStorageDescr.53 = STRING: /tmp
HOST-RESOURCES-MIB::hrStorageDescr.56 = STRING: /boot
Скажем, допустим вы интересуетесь размером памяти своей системы. Чтобы получить для неё OID мы
повторно выполним команду snmpwalk применив опцию
fn для переключателя -O.
Это сообщит snmpwalk о необходимости отображать полный OID в
численном формате. Мы также ограничим этот запрос к необходимому нам OID, как полученному из предыдущего
вывода:
$ snmpwalk -v 3 -l AuthPriv -u user -a MD5 -A auth -x DES -X priv -m ALL -O fn 10.10.15.19 HOST-RESOURCES-MIB::hrMemorySize.0
.1.3.6.1.2.1.25.2.2.0 = INTEGER: 8058172 KBytes
И вот, мы получили его. OID, который мы должны помещать в наши определения элемента это:
1.3.6.1.2.1.25.2.2.0
Ловушки SNMP слегка чудные, если их сравнивать со всеми прочими типами элементов Zabbix. В отличие от других элементов, ловушки SNMP выдают не отчёты о простых замерах, а некоторое событие какого- то типа. Другими словами, они являются определённым результатом некоего вида проверки или вычисления, выполняемого агентом SNMP и отсылаемого на сервер мониторинга в виде отчёта о состоянии. Ловушка SNMP может выполняться при каждой перезагрузке хоста, при падении интерфейса, разрушении диска или потери ИБП питания и сохранении сервера в работающем состоянии с использованием его батарей.
Такой вид информации противоречит основному предположению Zabbix, т.е. что элемент является простой метрикой не связанной напрямую со специфичным событием. С другой стороны, может не существовать другого способа получать сведения об определённых ситуациях кроме как через какую-то ловушку SNMP либо потому что не существует связанного показателя (например, рассмотрим конкретное событие сервер был выключен), дибо из-за того, что данное устройство имеет единственным вариантом передачи своего состояния такую гирлянду объектов и ловушек SNMP.
Таким образом, ловушки относительно ограничивают применение Zabbix, поскольку вы не можете ничего делать кроме как выстроить простой запускающий механизм (триггер) каждой ловушки и затем сообщать о подобном событии (нет особого смысла в построении графиков или вычисляемых элементов на их основе). Тем не менее, они могут оказаться существенными для полного решения мониторинга.
Для эффективного управления ловушками SNMP, Zabbix необходима пара вспомогательных инструментов:
демон snmptrapd для
действительной обработки соединений с агентами SNMP и определённый вид сценария для корректной
компоновки каждой ловушки и пробрасывания её в сервер Zabbix для дальнейшей обработки.
Процесс snmptrapd
Если у вас скомпилирована поддержка SNMP в сервере Zabbix, вы уже имеете установленным полный
комплект SNMP, который содержит демон SNMP, демон ловушек SNMP, а также кучу утилит, таких как
snmpwalk и snmptrap.
Если вдруг окажется, что на самом деле у вас не установлен комплект SNMP, следующая команда должна позаботиться об этом:
# yum install net-snmp net-snmp-utils
Подобно тому, как сам сервер Zabbix имеет кучу демонов процессов, которые прослушивают его порт
10051 для входящих соединений (от агентов, прокси и узлов),
snmptrapd является демоном процесса, который прослушивает UDP порт
162 для ловушек входного потока, поступающего от удалённых агентов
SNMP.
Будучи установленным, snmptrapd считывает свои параметры настройки
из файла snmptrapd.conf, который обычно находится в каталоге
/etc/snmp/. Самый минимум настроек для
snmptrapd.conf требует только определения строки сообщества в случае
версий SNMP 1 и 2 следующим образом:
authCommunity log public
В качестве альтернативы, определение какого- либо пользователя и уровня частного доступа при наличии SNMP версии 3 выглядит так:
createUser -e ENGINEID user MD5 auth DES priv
|
| Совет |
|---|---|
|
Вам необходимо создать отдельную строку |
С такой минимальной настройкой snmptrapd будет сам по себе
ограничен в протоколировании уловленного в syslog. Хотя от может иметь возможность выделять подобную
информацию и отсылать её в Zabbix, проще сообщить snmptrapd то,
как он должен обрабатывать перехваченную информацию. В то время как демон не имеет сам по себе возможностей
обработки, он может выполнить любую команду или приложение либо с использованием директивы
trapHandle, либо при помощи усиления от встроенной функциональности
perl. Последнее гораздо эффективнее, так как демон не имеет возможности
выполнять ответвление нового процесса и ожидать окончания его выполнения, поэтому рекомендуется именно оно,
если вы планируете принимать значительное число уловленного. Просто добавьте следующую строку в
snmptrapd.conf:
perl do "/usr/local/bin/zabbix_trap_receiver.pl";
|
| Совет |
|---|---|
|
Вы можете получить сценарий |
Когда он будет запущен повторно, демон snmptrapd будет исполнять
сценарий perl по вашему выбору для обработки каждого приёма от
ловушки. Как вы вероятно поняли, ваше задание не завершается здесь - вам всё ещё необходимо определить как
обрабатывать такие ловушки в своём сценарии и находить способ отсылки результатов работы на свой сервер Zabbix.
Мы обсудим оба этих момента в следующем разделе.
Обработчик внутренних прерываний perl
Сценарий perl, включённый в дистрибутив Zabbix работает в качестве
транслятора из формата ловушки SNMP в измерения элемента Zabbix. Для каждой принимаемой ловушки он будет
компоновать данные в соответствии с определёнными в этом сценарии правилами и будет выводить полученные
результаты в файл регистрации. Сервер Zabbix, в противоположность, будет наблюдать за указанным файлом
протокола и обрабатывать каждую новую строку как элемент ловушки SNMP, в основном ставя в соответствие
содержимому этой строки любого улавливающего элемента (trap item), определённого для соответствующего
хоста. Давайте рассмотрим как всё работает проглядев данный сценарий perl
сам по себе и пояснив его логику:
#!/usr/bin/perl
#
# Zabbix
# Copyright (C) 2001-2013 Zabbix SIA
#
#########################################
#### ABOUT ZABBIX SNMP TRAP RECEIVER ####
#########################################
# This is an embedded perl SNMP trapper receiver designed for
# sending data to the server.
# The receiver will pass the received SNMP traps to Zabbix server
# or proxy running on the
# same machine. Please configure the server/proxy accordingly.
#
# Read more about using embedded perl with Net-SNMP:
# http://net-snmp.sourceforge.net/wiki/index.php/Tut:Extending_snmpd_using_perl
Этот первый раздел содержит только информацию о лицензии и краткое описание данного сценария. Ничего такого,
о чём стоит упомянуть, кроме простого напоминания - убедитесь, что ваш исполняемый perl
имеет правильную ссылку в первой строке или измените её надлежащим образом.
#################################################
#### ZABBIX SNMP TRAP RECEIVER CONFIGURATION ####
#################################################
$SNMPTrapperFile = '/tmp/zabbix_traps.tmp';
$DateTimeFormat = '%H:%M:%S %Y/%m/%d';
Просто установите $SNMPTrapperFile на соответствующий путь к тому
файлу, в котором вы желаете регистрировать всё уловленное им и установите параметр
SNMPTrapperFile в вашем файле zabbix_server.conf
на то же значение. Раз уж вы в нём, также установите $SNMPTrapperFile
в значение 1 в zabbix_server.conf
чтобы этот сервер запустил мониторинг указанного файла.
$DateTimeFormat с другой стороны, должен соответствовать формату вашей
реальной ловушки SNMP, которую вы получаете от своих удалённых агентов. В основном установленное по умолчанию
значение верно, однако найдите время проверить это и изменить в случае необходимости.
Следующий раздел содержит реальную логику данного сценария. Обратим внимание на то, что большая часть
логики содержится в подпрограмме, именуемой zabbix_receiver.
Эта подпрограмма будет вызываться и исполняться с тем чтобы завершить данный сценарий, однако полезно
разобраться в деталях:
###################################
#### ZABBIX SNMP TRAP RECEIVER ####
###################################
use Fcntl qw(O_WRONLY O_APPEND O_CREAT);
use POSIX qw(strftime);
sub zabbix_receiver
{
my (%pdu_info) = %{$_[0]};
my (@varbinds) = @{$_[1]};
Демон snmptrapd будет исполнять данный сценарий и передавать
то уловленное, что он только что получил. Данный сценарий, наоборот, вызывает свою подпрограмму, которая
будет немедленно распространять информацию данной ловушки в два списка - первый аргумент назначается на
хэш %pdu_info, а второй на массив
@varbinds:
# open the output file
unless (sysopen(OUTPUT_FILE, $SNMPTrapperFile,
O_WRONLY|O_APPEND|O_CREAT, 0666))
{
print STDERR "Cannot open [$SNMPTrapperFile]:
$!\n";
return NETSNMPTRAPD_HANDLER_FAIL;
}
Здесь ваш сценарий откроет файл вывода или любезно не выполнит это если каким-то образом не сможет.
Следующий шаг заключается в выделении имени хоста (или IP адреса) того агента, который отсылает уловленное.
Эта информация сохраняется определённом нами ранее в хэше %pdu_info:
# get the host name
my $hostname = $pdu_info{'receivedfrom'} || 'unknown';
if ($hostname ne 'unknown') {
$hostname =~ /\[(.*?)\].*/;
$hostname = $1 || 'unknown';
}
Теперь мы готовы построить реальное уведомляющее сообщение ловушки SNMP. Первая часть нашего вывода
будет использоваться Zabbix для распознавания наличия новой ловушки (путём поиска строки
ZBXTRAP и получения сведений о том, к какому из подлежащих мониторингу
хостов данная ловушка относится). Имейте в виду, что IP адрес или имя хоста устанавливаемые здесь должны
соответствовать значению адреса SNMP в вашей настройке хоста, так как набор, используемый интерфейсом
Zabbix.Это значение должно быть установлено даже если оно идентично главному IP/ имени хоста для данного
хоста. Когда сервер Zabbix определил правильный хост, он отбросит данную часть уведомления ловушки:)
# print trap header
# timestamp must be placed at the beginning of the first line (can be omitted)
# the first line must include the header "ZBXTRAP [IP/DNS address] "
* IP/DNS address is the used to find the corresponding SNMP trap items
# * this header will be cut during processing (will not appear in the item value)
printf OUTPUT_FILE "%s ZBXTRAP %s\n",
strftime($DateTimeFormat, localtime), $hostname;
После заголовка с уведомлением, данный сценарий выведет оставшуюся часть уловленного, принятого данным агентом SNMP:
# print the PDU info
print OUTPUT_FILE "PDU INFO:\n";
foreach my $key(keys(%pdu_info))
{
printf OUTPUT_FILE " %-30s %s\n", $key,
$pdu_info{$key};
}
Оператор printf в предыдущем коде пройдёт циклом по хэшу
%pdu_info и выведет каждую пару ключ-значение:
# print the variable bindings:
print OUTPUT_FILE "VARBINDS:\n";
foreach my $x (@varbinds)
{
printf OUTPUT_FILE " %-30s type=%-2d value=%s\n"",
$x->[0], $x->[2], $x->[1];
}
close (OUTPUT_FILE);
return NETSNMPTRAPD_HANDLER_OK;
}
Второй оператор printf, printf
OUTPUT_FILE " %-30s type=%-2due=%s\n", $x->[0], $x->[2], $x->[1];,
выведет всё содержимое массива @varbinds по одному. Данный
массив это единственное, что содержит реальные значения, получаемые из отчёта обсуждаемой ловушки.
Когда мы выполним эту часть, файл журнала закрывается и выполнение нашей подпрограммы завершается
неким сообщением о выходе:
NetSNMP::TrapReceiver::register("all", \&zabbix_receiver) or
die "failed to register Zabbix SNMP trap receiver\n";
print STDOUT "Loaded Zabbix SNMP trap receiver\n";
Последние несколько строчек сценария устанавливают вашу подпрограмму zabbix_receiver
в качестве реального обработчика ловушки и выдаёт обратный ответ о своей корректной настройке. Когда обработчик
ловушки запускает наполнение своего файла журнала zabbix_traps.log, вам
необходимо определить соответствующие элементы Zabbix.
Как вы уже видели, первая часть строки регистрации используется получателем ловушки Zabbix для установления
соответствия с отвечающим ему хостом. Вторая часть соответствует вышеупомянутому определению RegExp элемента
ловушки SNMP хоста, а также его содержимое добавляется к каждой соответствующему значению истории элемента.
Это означает, что если вы хотите иметь начальный элемент ловушки для данного хоста, вам необходимо настроить
элемент ловушки SNMP с ключом snmptrap["coldStart"], что
показывается на следующем снимке экрана:
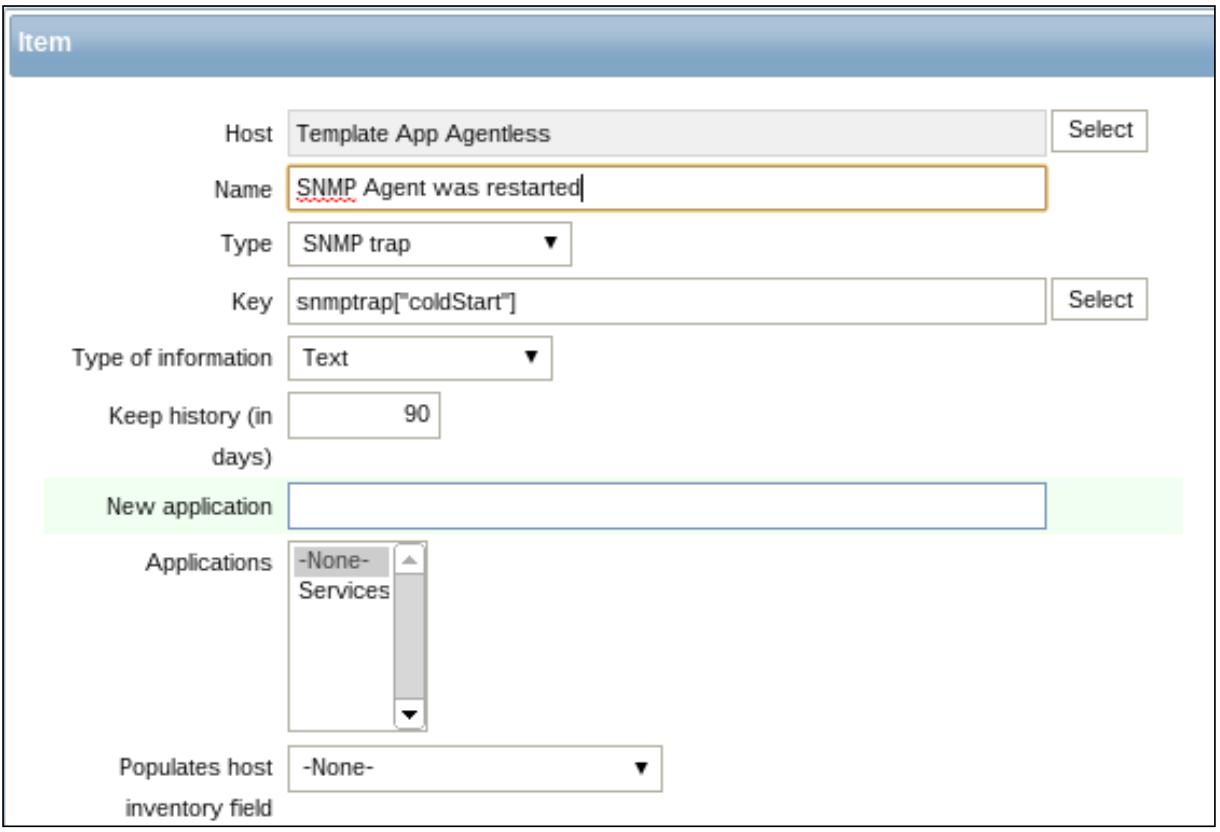
Начиная с этого момента, вы имеете возможность видеть содержимое обсуждавшейся ловушки в своей истории данных элемента.
Функции мониторинга SSH, предоставляемые Zabbix, в силу возможности их запуска сервером и к тому же свободности от агента, очень полезны. Эта особенная функциональность представляет большую ценность, так как позволяет нам выполнять удалённые команды на устройстве, которое не поддерживает агентов Zabbix. Такая функциональность изготавливается на заказ для всех вариантов применения, причём, по причинам дальнейшей поддержки, мы не можем устанавливать агента Zabbix. Некоторые случаи из практического опыта таковы:
-
Имеющие собственную специфику аппараты стороннего производителя, в которые вы не имеете возможности устанавливать программное обеспечение
-
Имеющие выполненные на заказ или закрытые операционные системы устройства
Замечание Чтобы иметь возможность выполнения проверок SSH, Zabbix нуждается в настройке с поддержкой SSH2; в этом случае минимально поддерживаемой
libssh2является версия 1.0.0.
SSH проверки поддерживают два различных способа аутентификации:
-
SSH с именем пользователя и паролем
-
Аутентификация на основе файла ключа
Для применения аутентификации по паре имя пользователя/ пароль у нас нет необходимости выполнять некие специальные настройки; достаточно иметь скомпилированный Zabbix с поддержкой SSH2.
Для применения аутентификации по ключу, первая вещью подлежащей настройке является
zabbix_server.conf; в частности, нам необходимо изменить
следующий элемент:
# SSHKeyLocation=
SSHKeyLocation=/home/zabbixsvr/.ssh
Когда это сделано, вам необходимо перезапустить ваш сервер Zabbix от имени root следующей командой:
$ service zabbix-server restart
Теперь мы можем окончательно создать новую пару ключей SSH выполнив следующую команду с правами root:
$ sudo -u zabbix ssh-keygen -t rsa -b 2048
Generating public/private rsa key pair.
Enter file in which to save the key (/home/zabbix/.ssh/id_rsa):
Created directory '/home/zabbix/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/zabbix/.ssh/id_rsa.
Your public key has been saved in /home/zabbix/.ssh/id_rsa.pub.
The key fingerprint is:
a9:30:a9:ce:c6:22:82:1d:df:33:41:aa:df:f3:e4:de zabbix@localhost.localdomain
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| |
| .. . |
| +o S |
| ...o.. |
|.o.+ .... |
|=o= ..=o . |
|ooo.. .*+ E |
+-----------------+
Теперь на этом удалённом хосте вам необходимо создать выделенную ограниченную учётную запись, так
как мы хотим не расширять свою систему, а только осуществлять её мониторинг, а затем мы можем окончательно
скопировать свои ключи. В следующем нашем примере мы собираемся создать свою учётную запись
zabbix_mon на обсуждаемом удалённом хосте:
$ sudo -u zabbix ssh-copy-id zabbix_mon@<remote-host-ip>
Теперь мы можем проверить всё ли идёт хорошо просто запустив удалённое соединение при помощи:
$ sudo -u zabbix ssh zabbix_mon@<remote-host-ip>
Сейчас, если всё было настроено надлежащим образом, мы будем иметь некий сеанс со своим удалённым хостом.
Наконец, мы можем определить индивидуальный элемент для выборки своего вывода uname –a
и затем мы извлекаем версию ядра в качестве элемента. Всё это отображено на приводимом ниже снимке экрана:
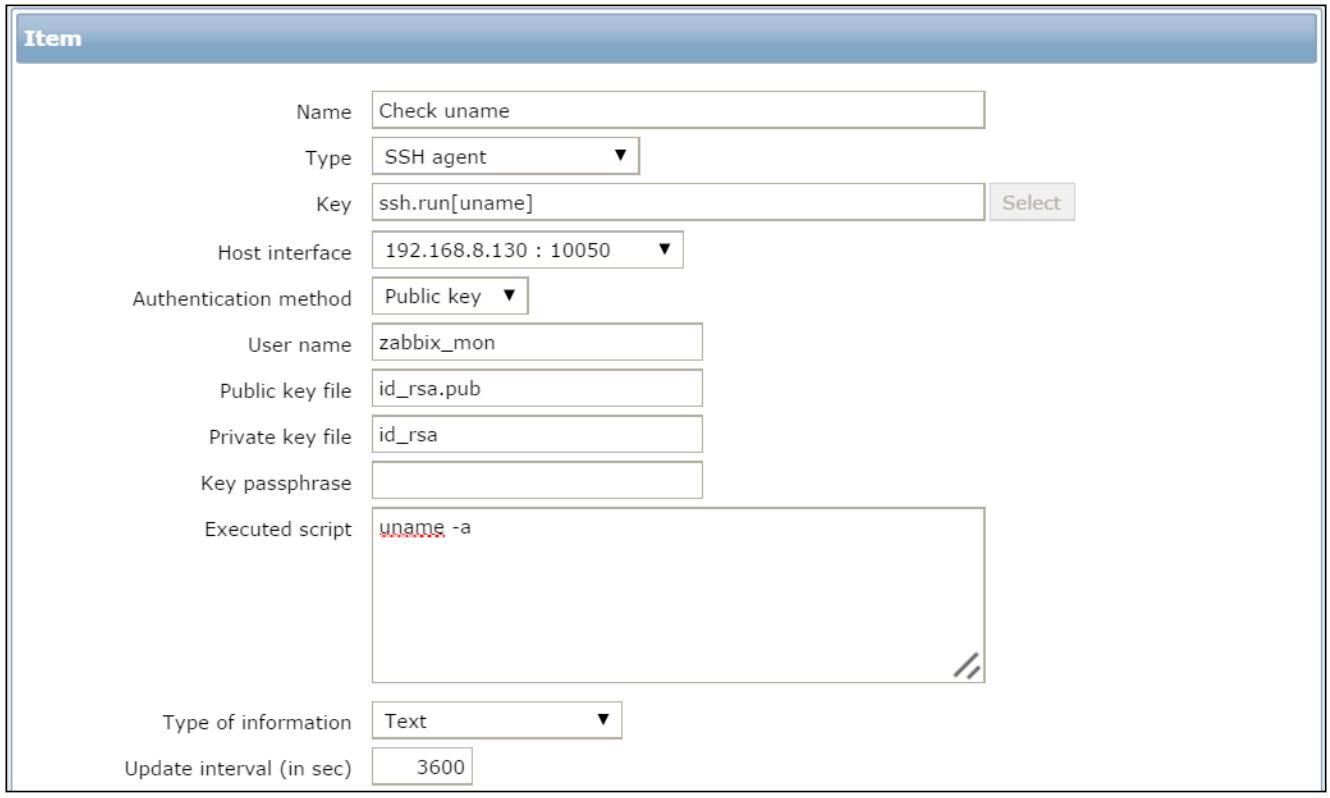
Он требует некоторого объяснения; во- первых, существует возможность чтобы libssh2
урезать вывод до 32кБ, в этом случае лучше иметь это в виду. К тому же лучше всегда использовать полностью
определённый путь для всех описанных команд. Здесь также стоит рассмотреть то, что SSH может добавлять задержку
и тем самым замедлять весь процесс. Все эти соображения остаются в силе для проверок агентом
Telnet. Его отрицательной стороной является, конечно, отсутствие шифрования
и лишённый безопасности протокол. Кроме того, как вы знаете, он поддерживает только аутентификацию по
имени пользователя и паролю. В особенности, если вы собираетесь применять Telnet, принципиально, хотя и не
критично, иметь учётную запись только на чтение для проверок Telnet.
В наши дни вы легко можете осуществлять мониторинг состояния и доступность ваших устройств с помощью
IPMI. Несомненно, основным требованием здесь является то, чтобы ваше устройство
поддерживало Intelligent Platform Management
Interface (IPMI, интеллектуальный
интерфейс управления платформой). IPMI является спецификацией аппаратного уровня, то есть
программно независимо, что означает, что оно никоим образом
не увязывается с BIOS {Прим. пер.: более точно FirmWare} и
операционной системой. Одно интересное свойство стостит в том, что интерфейс IPMI может быть доступен
даже когда его система находится в состоянии с отключённым электропитанием. Это возможно благодаря
повсеместно встроенному обеспечивающему IPMI устройству, именно отдельное устройство, потребляющие
существенно меньшую мощность существует независимо от любых прочих печатных плат или программного
обеспечения. На текущий момент IPMI полностью поддерживается большинством производителем серверов и
говоря о серверах, мы обычно представляем их по платам управления: HP ILO, IBM RSA, Sun SSP, Dell
RDAC и тому подобным. {Прим. пер.: Наличие поддержки IPMI вообще можно
до некоторой степени считать основным показателем, отделяющим серверы от настольных систем общего
пользования.}
Если вы захотите узнать подробности того как работает IPMI, поскольку это стандарт разработанный Intel {Прим. пер.: не принижая роль Intel в качестве основного драйвера IPMI, хотелось бы поправить эту неточность: Первая спецификация интерфейса представлена 16 сентября 1998 года совместно корпорациями Intel, Dell, NEC и Hewlett-Packard. В настоящее время действует 2я редакция стандарта, совместно поддерживаемая более чем 200 производителями.} Вы можете найти его документацию по ссылке http://www.intel.com/content/www/us/en/servers/ipmi/ipmi-specifications.html.
Очевидно, что для выполнения проверки IPMI, вам необходимо иметь скомпилированный Zabix с поддержкой
IPMI --with-openipmi, пожалуйста, ознакомьтесь с этим вопросом в
Главе 1, Развёртывание Zabbix.
IPMI применяет для иалога протокол запрос-ответ поверх основанного на сообщениях интерфейсе со всеми вашими компонентами устройств, однако наиболее интересно то, что помимо получения измерений или доступа к энергонезависимому системному журналу событий, вы даже имеете возможность получать данные со всех установленных в вашем аппаратном средстве датчиков.
Прежде всего, вам необходимо убедиться что вы установили все требующиеся пакеты; в противном случае вы можете установить их при помощи следующей команды, выполняемой от имени root:
$ yum install ipmitool OpenIPMI OpenIPMI-libs
Теперь мы уже, например, можем получать замеры температуры при помощи IPMI, воспользовавшись следующей командой:
$ ipmitool sdr list | grep Temp
Ambient Temp | 23 degrees C | ok
CPU 1 Temp | 45 degrees C | ok
CPU 2 Temp | disabled | ns
CPU 3 Temp | disabled | ns
CPU 4 Temp | disabled | ns
Отметим, что в предыдущем примере мы получили три строки disabled,
поскольку эти разъёмы ЦПУ являются незаполненными. Как вы можете увидеть, мы можем быстро выбирать через
свой интерфейс IPMI все необходимые внутренние параметры. Теперь, интересно посмотреть все наши возможные
состояния, которые могут приниматься для нашего IPMI ID, которым является CPU 1
Temp, заметьте, пожалуйста, что поскольку IPMI ID содержит пробелы. нам необходимо применять
нотацию с двойными кавычками:
$ ipmitool event "CPU 1 Temp" list
Finding sensor CPU 1 Temp... ok
Sensor States:
lnr : Lower Non-Recoverable
lcr : Lower Critical
lnc : Lower Non-Critical
unc : Upper Non-Critical
ucr : Upper Critical
unr : Upper Non-Recoverable
Это все доступные состояния для CPU 1 Temp. Итак, IPMI
является простым, доступным только для чтения протоколом, но вы можете даже выполнять эмуляцию ошибок
или настроек параметров. Сейчас мы собираемся эмулировать низкотемпературный порог, просто посмотрите
как это работает. Выполнив следующую команду, мы можем эмулировать считывание -128
градусов по Цельсию:
$ ipmitool event "CPU 1 Temp" "lnc : Lower Non-Critical"
Finding sensor CPU 1 Temp... ok
0 | Pre-Init Time-stamp | Temperature CPU 1 Temp | Lower Non-critica l | going low | Reading -128 < Threshold -128 degrees C
Теперь мы можем быстро проверить, что это было зарегистрировано в вашем журнале системных событий при помощи:
$ ipmitool sel list | tail -1
1c0 | 11/19/2008 | 21:38:22 | Temperature #0x98 | Lower Non-critical going low
|
| Совет |
|---|---|
|
Это один из наилучших неразрушающих тестов, который мы можем выполнить чтобы убедиться, что вы осознаёте необходимость профилирования учётной записи IPMI на доступность только для чтения. |
Для настройки учётной записи IPMI, у вас, естественно, имеется два варианта:
-
Воспользоваться самим интерфейсом управления (RDAC, ILO, RS и т.п.)
-
Применять инструменты ОС и затем OpenIPMI
Прежде всего, лучше изменить пароль root по умолчанию; вы можете выполнить это при помощи:
$ ipmitool user set password 2 <new_password>
Здесь мы выполнили сброс значения пароля по умолчанию для вашей учётной записи root, которая имеет
ID пользователя, равный 2.
Теперь важно создать учётную запись пользователя Zabbix, которая может опрашивать фактические данные и при этом не иметь права на перезапуск сервера или изменение каких- либо настроек.
В следующей строке мы создаём пользователя Zabbix с ID пользователя 2;
проверьте, пожалуйста, нет ли у вас уже пользователя с этим идентификатором в вашей системе. Прежде всего
определим login пользователя данной командой от имени root:
$ ipmitool user set name 3 zabbix
Затем установим связанный с ним пароль:
$ ipmitool user set password 3
Password for user 3:
Password for user 3:
Теперь нам нужно предоставить Zabbix требующиеся полномочия:
$ ipmitool channel setaccess 1 3 link=on ipmi=on callin=on privilege=2
Активируем эту учётную запись:
$ ipmitool user enable 3
Убедимся, что всё хорошо:
$ ipmitool channel getaccess 1 3
Maximum User IDs : 15
Enabled User IDs : 2
User ID : 3
User Name : zabbix
Fixed Name : No
Access Available : call-in / callback
Link Authentication : enabled
IPMI Messaging : enabled
Privilege Level : USER
Только что созданный нами пользователь имеет имя zabbix и
он имеет полномочия уровня USER. В любом случае, эта учётная
запись не позволяет доступ через вашу сеть; чтобы включить эту учётную запись, нам необходимо
активировать аутентификацию MD5 для доступа LAN для данной группы пользователей:
$ ipmitool lan set 1 auth USER MD5
Мы можем проверить это воспользовавшись:
$ ipmitool lan print 1
Set in Progress : Set Complete
Auth Type Support : NONE MD5 PASSWORD
Auth Type Enable : Callback :
: User : MD5
: Operator :
: Admin : MD5
: OEM :
Теперь мы можем наконец выполнять удалённые запросы с сервеа Zabbix напрямую при помощи такой команды:
$ ipmitool –U Zabbix –H <ip-of-IPMI-host-here> -I lanplus sdr list | grep Temp
Ambient Temp | 23 degrees C | ok
CPU 1 Temp | 45 degrees C | ok
CPU 2 Temp | disabled | ns
CPU 3 Temp | disabled | ns
CPU 4 Temp | disabled | ns
Сейчас мы готовы использовать свой сервер Zabbix для получения элементов IPMI.
Когда вы ищете показатели IPMI, наиболее трудная часть состоит в настройке того, что было только что выполнено.
В Zabbix наладка совершенно проста. Прежде всего, нам нужно убрать комментарий со следующей строки в
zabbix_server.conf:
# StartIPMIPollers=0
Измените данное значение на что- нибудь разумное для величины количества интерфейсов IPMI, для которых вы хотите выполнять мониторинг. В любом случае, это не критично; наиболее важная часть состоит во включении регистратора (poller) IPMI Zabbix,который по умолчанию выключен. В данном примере мы используем:
StartIPMIPollers=5
Теперь нам необходимо перезапустить Zabbix от имени root выполнив:
$ service zabbix-server restart
Теперь мы можем окончательно переключиться на веб- интерфейс и начать добавлять элементы IPMI.
Первый шаг состоит в настройке параметров вашего IPMI на уровне хоста с последующим переходом в Configuration | Host. Здесь нам необходимо добавить Configuration | Host, наш связанный порт, как это отображается на следующем экранном снимке:

Затем нам необходимо переключиться на свою закладку IPMI, которая является тем местом, в котором расположены оставшиеся параметры настройки.
В закладке IPMI для
Authentication algorithm выберите
MD5, как это первоначально было сделано для
нашего примера настройки, в качестве уровня Privilege
выберите User. В поле
Username вы можете написать
Zabbix, а в Password
вы можете ввести пароль, который вы определили в процессе настройки, как это показано на следующем
снимке:
Теперь мы можем добавить свой элемент и набрать IPMI agent. Как и для предыдущего примера, элемент, который мы собираемся получать это CPU 1 Temp, а его Type имеет значение Numeric (float). Снимок ниже отображает это:
Настройка IPMI на стороне Zabbix является незамысловатым процессом; тем не менее, если вы применяете различные версии OpenIPMI? пожалуйста, имейте в виду, что существуют известные проблемы с OpemIPMI версии 2.0.7, и что Zabbix не работает должным образом с этой версией. Для выполнения его работы требуется версия 2.0.14 или последующие. В некоторых устройствах, таких как сетевые датчики температуры, которые имеют только одну карту интерфейса, что логично, та же самая карта будет распространять и его интерфейс IPMI. Если это ваш случай, пожалуйста, не забудьте настроить её на тот же самый IP адрес что и ваше устройство. Другой важный момент, который следует знать об IPMI, состоит в том, что именование дискретных датчиков изменялось между OpenIPMI 2.0.16, 2.0.17, 2.0.18 и 2.0.19. Таким образом, лучше проверить правильность использования имён вашей версии OpenIPMI, которую вы развернули в своём сервере Zabbix.
В наши дни и времена веб- приложения являются практически вездесущими. Некоторые виды вебсайтов или коллекций вебстраниц обычно являются конечным продуктом или службой сложной структуры, которая охватывает различные базы данных, серверы приложений, веб- серверы, прокси, балансировщики сетевых сред и сетевое оборудование, а также многое другое. Когда дело доходит до мониторинга их работы, имеет смысл просто сделать ещё один шаг вперёд и наблюдать за окончательным сайтом или веб- страницей помимо всех серверных средств, обеспечивающих обсуждаемую страницу. Выгода от того что будут приходить предупреждения и уведомления довольно ограничена, так как отказ в доступе к веб странице определённой критичное событие. Однако они вряд ли дадут какое- либо понимание того, что является действительной проблемой если вы правильно не настроите измерения и триггеры на стороне сервера. С другой стороны, это может оказаться важным для сбора данных о производительности веб- сайта. Для того чтобы предвидеть возможные проблемы, обосновывать отчётность SLA, а также планировать обновление аппаратных и программных средств.
Одним из больших преимуществ веб- мониторинга Zabbix является его концепция сценария. Вы можете определить отдельный веб- сценарий, который состоит из множества простых этапов, причём каждый последующий строится на основании предыдущего и вместе они представляют общий набор данных. Более того, каждое такое определение включает в себя автоматическое создание содержательных элементов и графиков, причём и те и другие как на уровне всего сценария (общая производительность), так и на уровне отдельного этапа (локальная производительность). Это делает возможным не только осуществлять мониторинг отдельной веб- страницы, но также имитировать весь веб- сеанс таким образом, что каждый компонент некоторого веб- приложения будет способствовать общему окончательному результату. Отдельный сценарий может быть очень сложным и требовать великое множество элементов, которые в конечном итоге будет сложно отслеживать и группировать совместно. Это та причина, по которой веб- мониторинг в Zabbix имеет свои собственные закладку настроек и интерфейс, отдельные от обычных элементов, и это то самое место, в котором вы можете настраивать мониторинг на некотором верхнем уровне.
|
| Замечание |
|---|---|
|
Для осуществления веб- мониторинга сервер Zabbix должен быть первоначально настроенным с
поддержкой |
Веб- сценарии поддерживают простые HTTP/HTTPS, BASIC, NTLM, аутентификацию на основе форм, cookies, заполнение полей форм, а также проверки содержания страниц помимо ответов наблюдаемого кода HTTP.
При всей своей мощности, веб- сценарии также страдают от ряда ограничений, когда дело доходит до осуществления мониторинга современного Веб.
Прежде всего, не поддерживается JavaScript, поэтому вы не можете имитировать полный сеанс AJAX в точности, как если бы реальный пользователь осуществлял бы его. Это также означает, что в данном сценарии не могут выполняться какие- либо виды автоматических перезагрузок страницы.
Более того, хотя вы и можете осуществлять заполнение форм, вам необходимо знать наперёд как имя обследуемого поля, так и его содержание. Если какая- либо из них создаётся динамически при переходе с одной страницы на другую (поскольку многие страницы ASP.NET должны хранить информацию о сеансе), вы не будете иметь возможности применять её на последующих этапах.
Это может казаться незначительными ограничениями, однако они могут оказаться весьма важными если вам необходимо осуществлять мониторинг какого- либо сайта, который в значительной степени основывается на разработке клиентской стороны (JavaScript и дружественных ему средств) или динамичных маркерах (tokens) и полям форм. Реальность состоит в том, что растущее число веб- приложений или инфраструктур используют одну или более из этих функций.
Тем не менее, даже при этих ограничениях возможности веб- мониторинга Zabbix доказывают свою очень большую пользу и мощность инструментов, которыми вы можете в полной мере воспользоваться, в особенности, если вы выдаёте на гора в качестве окончательного результата конвейера IT великое множество веб- страниц.
{Прим. пер.: существенную помощь при работе с динамическими веб- страницами могут оказывать современные методики анализа (scraping), например, описываемые в книге Ryan Mitchell Web Scraping with Python. Мы рассматриваем возможность её перевода.}
Для создания веб- сценария вам необходимо пройти через Configuration | Host, а затем кликнуть на Create scenario. Вы увидите окно, отображаемое на следующем снимке экрана:
В рамках этой формы вы можете определить параметры, отличные от обычно применяемых, такие как Name, Application и Update interval, который представляет частоту исполнения нашего сценария. Может быть определено даже имя нашего Agent и число Retries. Если уж вы определяете пользователя Agent, которого вы хотите применять, Zabbix будет работать как выбранный браузер представляя себя в качестве определённого вами браузера. Рассматривая Retries, важно знать, что Zabbix не будет повторять некий шаг в случае неверного отклика или ошибки в строке запроса.
Другой важный и новый раздел это Headers. В нём вы можете определять заголовки, которые будут отсылаться когда Zabbix исполняет запрос.
|
| Замечание |
|---|---|
|
Индивидуальные заголовки подерживаются начиная с Zabbix 2.4. В этом поле мы можете применять макрос
|
Существует три метода аутентификации, поддерживаемые веб- мониторингом; вы можете увидеть их в соответствующей закладке Authentication, как это отображено на приводимом ниже снимке экрана:
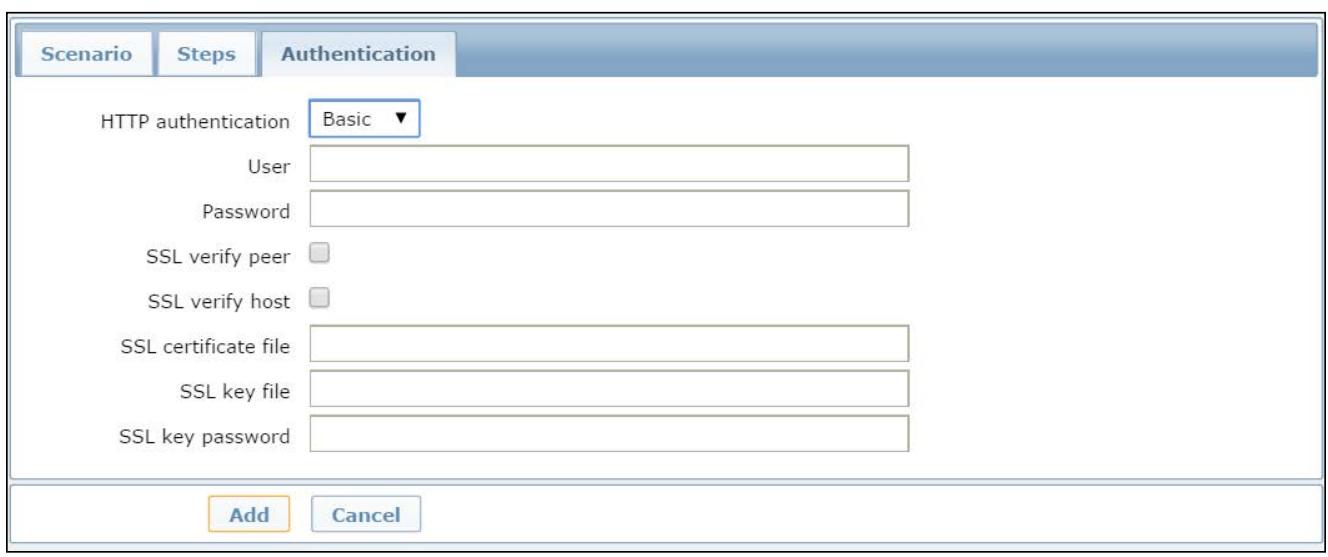
Этими методами являются базовый, NTLM и на основе формы. Первые два достаточно прямолинейные и нуждаются в простом определении на уровне вашего сценария. Аутентификация NTLM предоставит два дополнительных поля для ввода имени пользователя и пароля. Начиная с Zabbix 2.2 мы теперь должны полностью поддерживать применение пользовательских макросов в полях имени пользователя и пароля. К тому же, в этой закладке мы даже имеем возможность включить проверку SSL. Флаговая кнопка SSL verify peer включает проверку сертификата вашего веб- сервера, а флаговая кнопка SSL verify host применяется для проверки поля Common Name или поля Subject Alternate Name сертификата вашего веб сервера. Флаговая кнопка SSL certificate file применяется для аутенитификации со стороны клиента; здесь вам необходимо определить файл сертификата PEM. Если сертификат PEM содержит даже частный (private) ключ, вы можете избежать этого указав свой относительный ключ в SSL key file или SSL key password.
|
| Замечание |
|---|---|
|
Местоположение сертификата может быть настроено в главном файле настроек,
|
Оба поля, SSL certificate file и
SSL key file поддерживают макрос
HOST.*.
Возвращаясь назад к аутентификации, нам необходимо также отобразить аутентификацию на основе форм, которая полагается на возможность вашего клиента (в данном случае сервера Zabbix) сохранять cookies сеанса, и который запускается (triggered), когда обсуждаемый клиент заполняет форму данными аутентификации. При определении сценария вам необходимо выделять этап просто для такой аутентификации. Чтобы узнать какое поле формы вам необходимо заполнить, просмотрите источник HTML той страницы, которая содержит эту форму аутентификации. В следующем примере мы рассмотрим страницу аутентификации Zabbix. Каждая форма будет слегка отличаться, однако общая структура по большей части будет той же самой (в нашем случае для болеьшей краткости показывается только форма регистрации):
<form action="index.php" method="post">
<input type="hidden" name="request" class="input hidden" value="" />
<!-- Login Form -->
<div>Username</div>
<input type="text" id="name" name="name" />
<div>Password</div>
<input type="password" id="password" name="password" />
<input type="checkbox" id="autologin" name="autologin" value="1" checked="checked" />
<input type="submit" class="input" name="enter" id="enter" value="Sign in" />
</form>
Вы должны принять во внимание имеющиеся теги ввода и опции их имён, так как это те поля формы, которые вы собираетесь
отсылать на сервер для аутентификации. В данном случае ваше имя пользователя называется
name, поле пароля именуется как
password и, наконец, поле подстановки называется
enter и имеет определённое значение
Sign in.
Теперь мы готовы создать сценарий; затем мы определим свой сценарий как это отображается на нашем следующем снимке экрана:
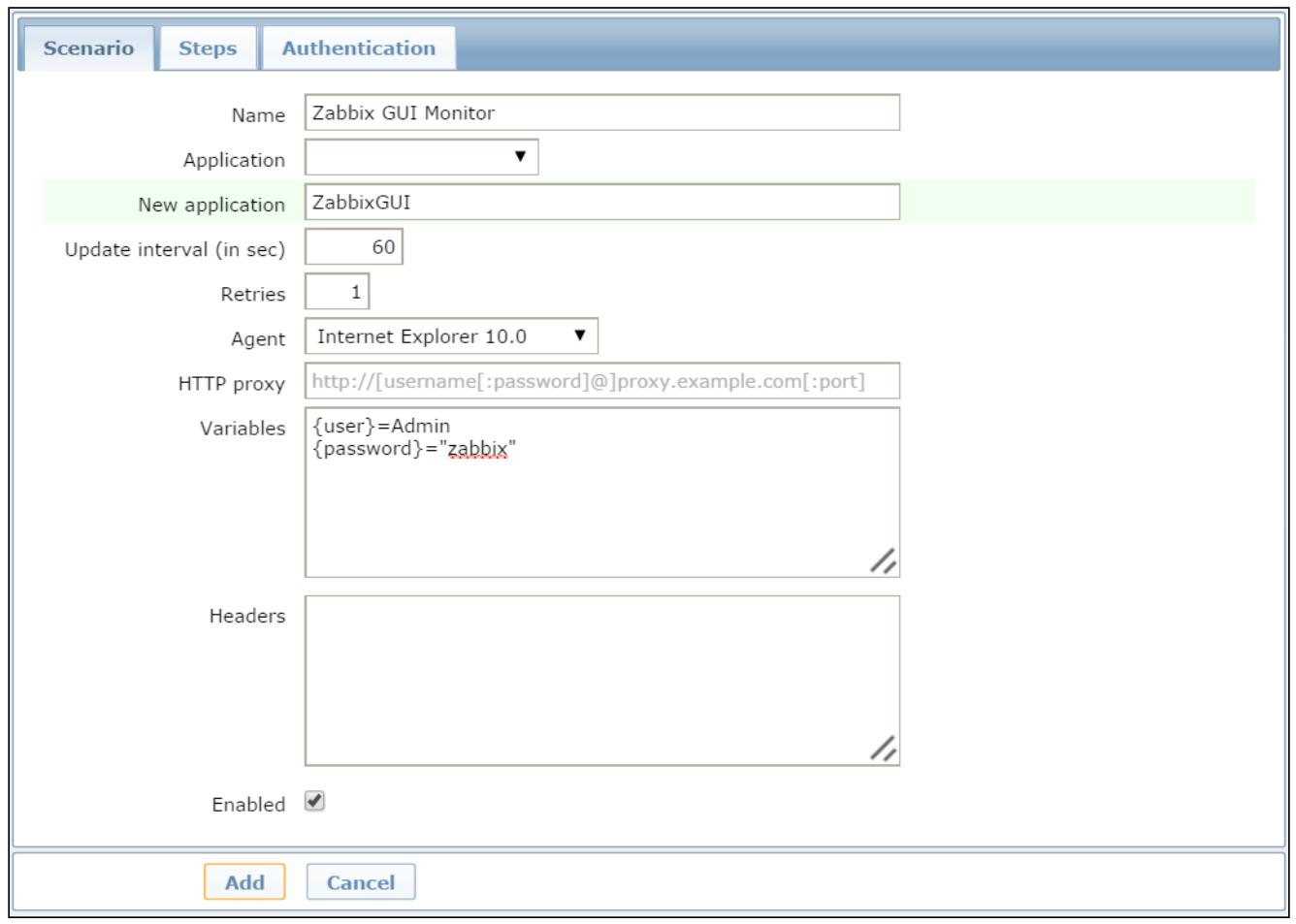
Как вы можете увидеть, в поле Variables мы можем определить две переменные, которые мы собираемся использовать на последующих этапах и в дальнейшем на этапе аутентификации. Это полезное свойство, так как оно позволяет нам делать различные определения в своём сценарии.
Следующая вещь, которую необходимо выполнить это собственно аутентификация, после чего нам необходимо добавить один этап в свой сценарий, как это отображено на нашем следующем снимке экрана:
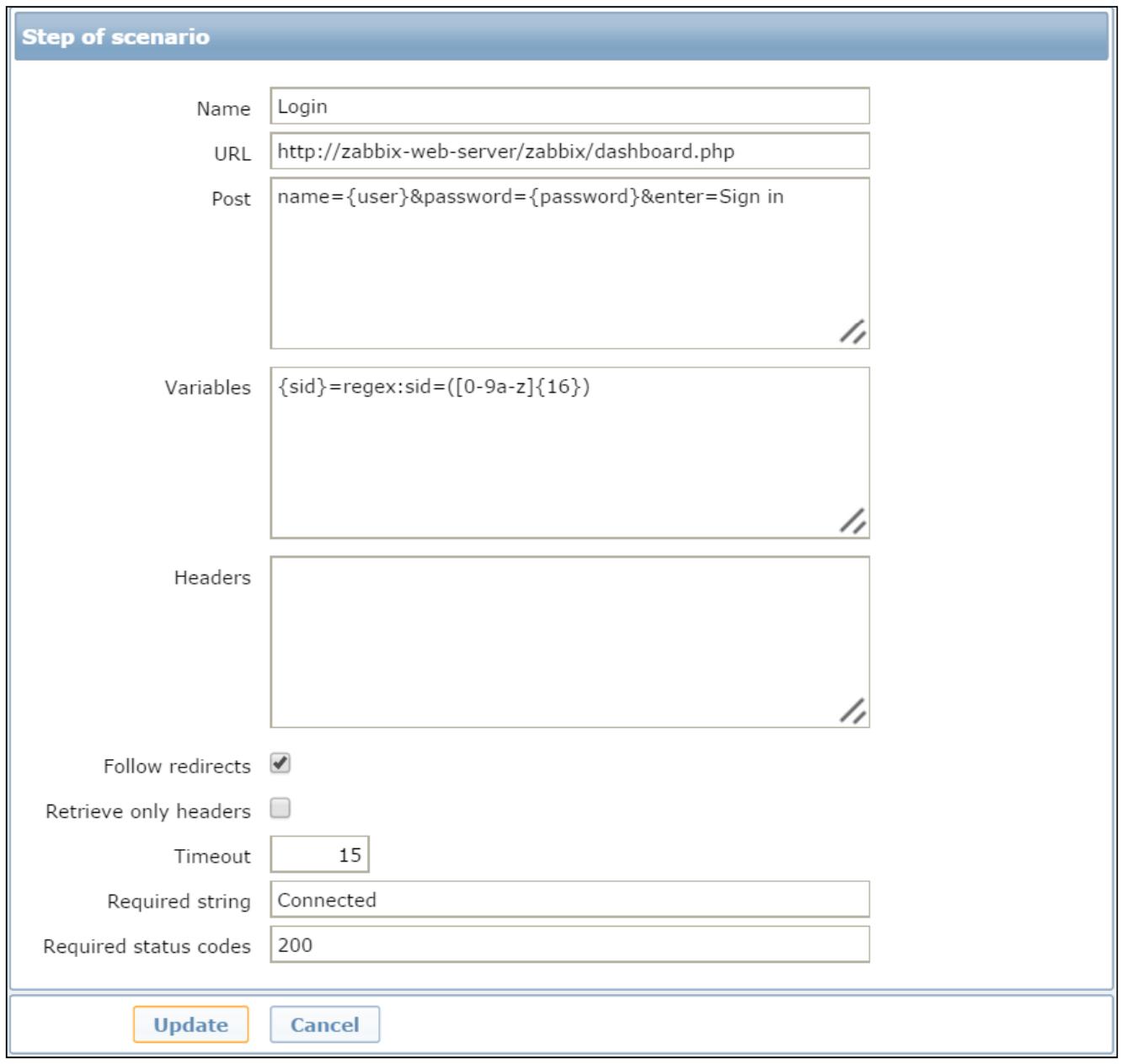
Отметьте, пожалуйста, применение предварительно определённых переменных
{user} и
{password}. В качестве необходимой строки мы можем применять
Connected, которая появляется непосредственно в сноске когда вы
подсоединены и, конечно, Required status codes
будет 200. В этом примере мы определяем новую переменную которая
представляет маркер (token) аутентификации. Эта переменная будет использоваться в процессе выхода и будет
заполняться принимаемыми данными. Начиная с этого момента каждый URL, который вы проверяете, или каждая
форма, которую вы заполняете, будет иметь контекстом сеанс с выполненной аутентификацией, предполагая,
конечно, что регистация была успешной.
|
| Замечание |
|---|---|
|
Начиная с Zabbix 2.4, каждый определяемы этап поддерживает веб- перенаправление. Если соответствующие
флаговые окна отмечены Zabbix, установите опцию cURL |
Одна распространённая ошибка при веб- мониторинге стостоит в том, что часть аутентификации при запуске сценария принимается во внимание, однако зачастую в процессе окончания забывают о корректном завершении сеанса. Если вы не закроете сеанс с вебсайтом, в зависимости от вида используемой для отслеживания системы, от которой отключился пользователь, а также от активных сеансов, может возникнуть целый ряд проблем.
Активные сеансы обычно находятся в диапазоне от нескольких минут до нескольких дней. Если вы осуществляете мониторинг числа зарегистрированных пользователей, а таймауты ваших сеансов находятся в наиболее длительной стороне вашего спектра, каждый сценарий регистрации добавлял бы к общему числу активных пользователей представляемых элементами вашего наблюдения. Если вы не выполняете непосредственно завершение сеанса по его окончанию, вы, по крайней мере, можете закончить замерами мониторинга, которые в действительности не заслуживают доверия, и они показали бы множество активных сессий, которые в действительности являются просто проверками наблюдения.
В случае наихудшего сценария ваш менеджер идентификации и сервер аутентификации могут оказаться неспособными обрабатывать огромное число несуществующих сеансов и могут внезапно прекратить работу, приводя всю вашу инфраструктуру к полному параличу. Мы можем заверит вас, что это не гипотетическая ситуация, а эпизоды из реальной практики, которые случались в собственном опыте автора.
Во всяком случае, вы несомненно не допустите ошибку, добавляя шаг завершения сеанса (logout) в каждый веб-
сценарий, который выполняет регистрацию (log in). Вы убедитесь, что ваши действия мониторинга не будут вызывать
непредвиденных проблем и, по меньшей мере, вы также будете тестировать правильную работу своих процедур
демонтажа сеанса. Этапы завершения сеанса также обычно абсолютно просты, так как они обычно выполняют запрос
GET к корректному URL. В нашем случае интерфейса Zabbix вы создали бы
следующий завершающий этап (который показан на снимке экрана ниже) перед окончанием своего сеанса:
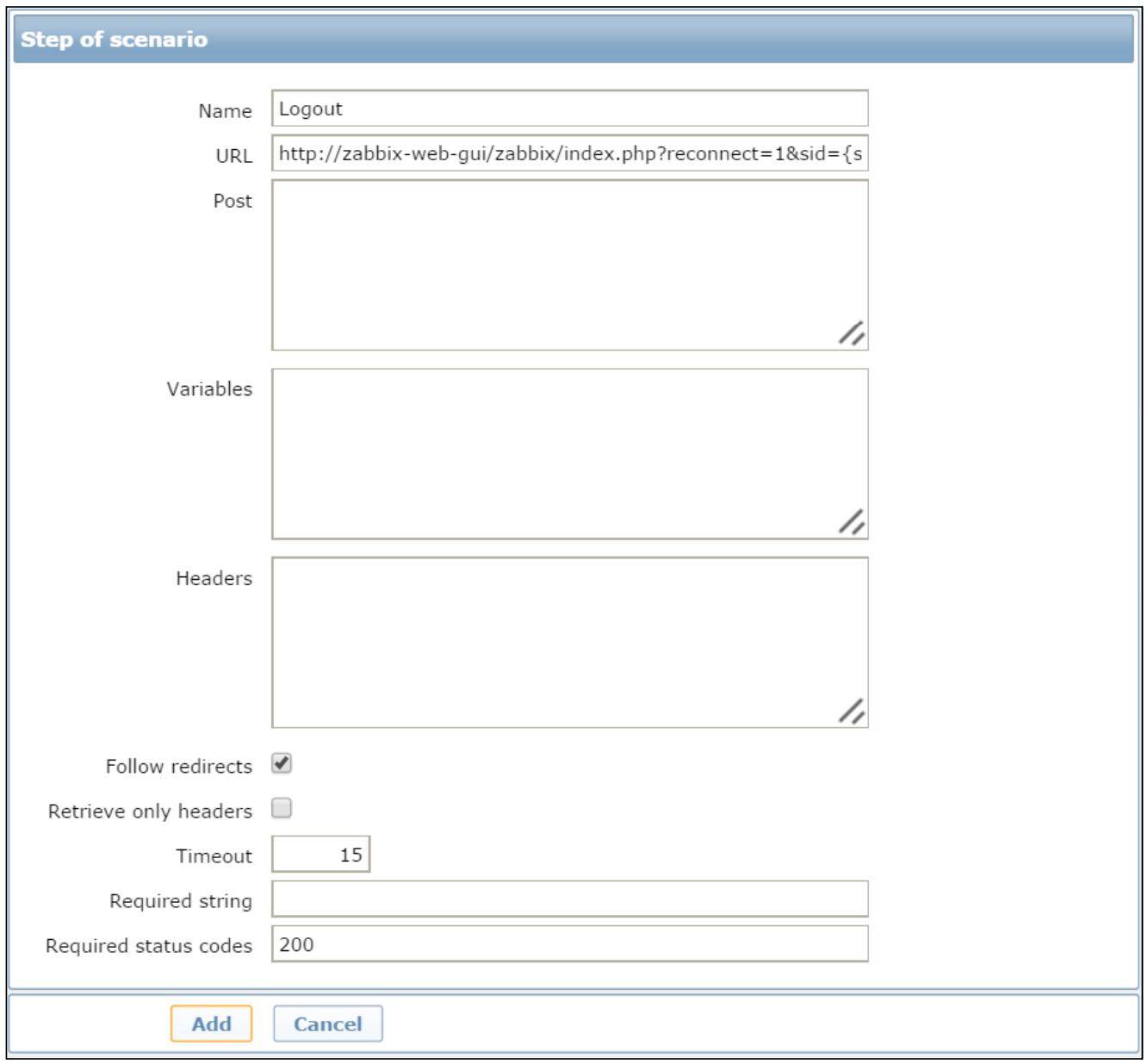
Когда вы определите этот этап завершения сеанса, ваш сценарий будет выглядеть аналогично следующему экранному снимку:
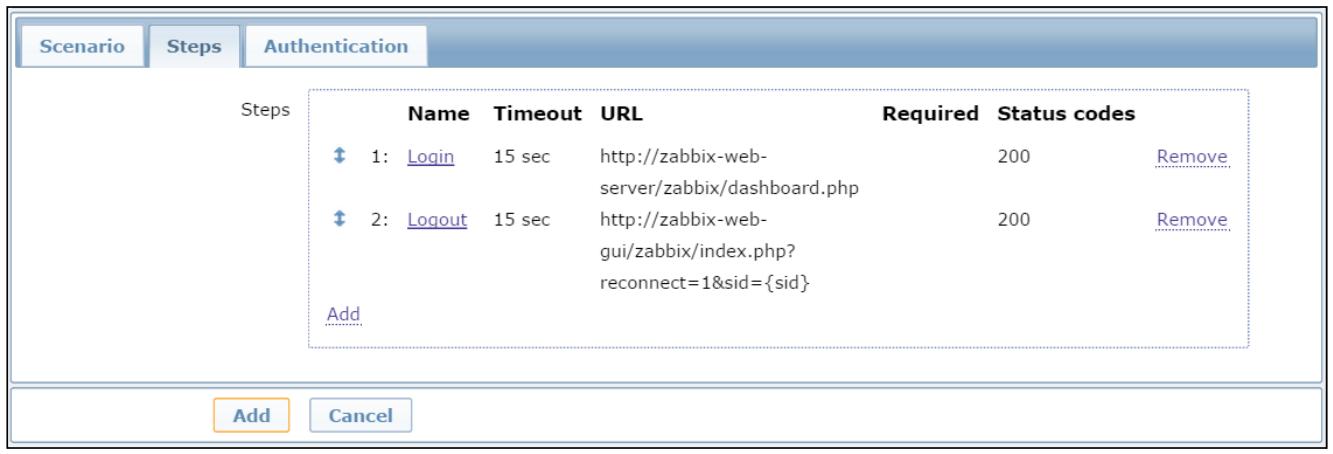
Отметьте, пожалуйста, наличие применения переменной {sid} в вашей
строке завершения сеанса. К тому же в данном примере мы воспользовались zabbix-web-gui.
Очевидно, что это необходимо заменить вашим собственным веб- сервером.
Более того, примите во внимание, чтобы каждый новый сеанс использовал небольшой объём вычислительных ресурсов будь то дисковое пространство или оперативная память. Если вы создаёте большое число сеансов за короткий промежуток времени, в результате частых проверок вы можете завершить работу значительной деградацией производительности вебсайта. Таким образом, позаботьтесь о:
-
Включении в свой сценарий всех необходимых этапов
-
Избежании дублированных сценариев для простых проверок
-
Всегда определять этап завершения сеанса (logout)
-
Иметь в виду, что частота проверок должна иметь разумное значение и не оказывать влияния на сам мониторинг системы
Помимо этого важно знать, что не можете пропускать этапы, включённые в ваши веб- сценарии. Все они выполняются в предопределённом порядке. К тому же, если вам необходим более подробный журнал, вы можете увеличить его в работающем в реальном времени регистраторе HTTP воспользовавшись следующей командой:
$ zabbix_server –R log_level_increase="http poller"
В качестве последнего совета, имейте в виду, что вся история, для которой мы осуществляем мониторинг элементов составляет 30 дней и проводится для 90 обобщённых динамик (trend).
До сих пор каждый описываемый в данной главе компонент мог рассматриваться как средство получения простых данных замеряемых как отдельные точки данных. Фактически внимание данной главы было сосредоточено на наладке Zabbix для извлечения видов данных отличающихся от того, что мы в действительности собираем. Это было обусловлено с одной стороны тем, что корректная наладка критична для эффективных сбора и мониторинга, в то время как с другой стороны, пригодность данной метрики широко варьируется в различных средах и установках в зависимости от конкретных потребностей которые вы можете иметь.
Однако, когда подходит время агрегировать и вычислять элементы, вещи начинают становиться более интересными. Оба типа совсем не полагаются на зондирование и измерения; вместо этого они строятся на существующих значениях элемента для обеспечения совершенно нового уровня внутренней структуры и детальной проработки на основе собранных в вашем окружении данных.
Это один из моментов, при котором философия Zabbix отсоединённых замеров и переключающей логики в действительно окупается, так как в противном случае она была бы чрезвычайно громоздкой для достижения аналогичной функциональности и, несомненно, приводила бы к значительным накладным расходам.
В общем случае эти два типа имеют следующие свойства:
-
Они оба не выполняют замеров никакого вида (на основе агентов, внешних, SNMP, JMX или каких ещё), однако напрямую запрашивают базу данных Zabbix для обработки существующей информации.
-
Хотя они и должны быть связаны с определённым хостом, потому что наши данные Zabbix так организованы, они освобождены от соединения по сравнению с обычным элементом. Фактически вы можете назначить агрегированный элемент для любого хоста вне зависимости от особенностей элемента, хотя обычно яснее и проще если вы определяете один или более простых выделенных хостов которые будут содержать агрегированные и вычисляемые элементы потому что так они могут быть проще найдены и так проще на них ссылаться.
-
Агрегированные и вычисляемые элементы работают только с численными типами данных - не существует никакого резона в запросе общей суммы или среднего значения кучи текстовых фрагментов.
Представляя простейший из обсуждаемых здесь двух типов, агрегируемые элементы могут выполнять различные виды вычислений над особенным элементом, который определён для каждого хоста в группе. Для каждого хоста в данной группе агрегированный элемент будет получать предписанные данные элемента (основываясь на заданной функции), а заетм применять групповую функцию ко всем собранным данным. Результатом будет определённое значение агрегированного измерения элемента в определённый момент времени, которое было вычислено.
Для построения агрегированного элемента вам необходимо в начале идентифицировать группу хостов в которой
вы заинтересованы, а затем определить свой элемент, совместно представляемый всеми хостами этой группы,
который будет формировать основу ваших вычислений. Например, скажем, вы сосредоточены на своих серверах
веб- приложений и вы желаете знать нечто об активных сеансах своих установок Tomcat. В этом случае группа
могла бы быть чем-то навроде Tomcat Servers, а её ключом элемента был
бы jmx["Catalina:type=Manager,path=/,host=localhost",activeSessions].
Далее вам необходимо решить как вы хотите извлекать данные элемента каждого хоста. Это обусловлено тем,
что вы не ограничены только последним значением, а можете выполнять различные виды предварительных вычислений.
Исключением является функция last, которая, тем не менее, просто
извлекает самое последнее значение из истории данного элемента, все остальные функции принимают период времени
в качестве следующего аргумента.
| Функция | Описание |
|---|---|
|
Это среднее значение за определённый период времени |
|
Это сумма всех значений за определённый период времени |
|
Это минимальное значение, записанное за определённый период времени |
|
Это максимальное значение, записанное за определённый период времени |
|
Это самое последнее записанное значение |
|
Это число значений записанных за определённый период времени |
То что вы теперь имеете, так это куча значений, которые всё ещё нуждаются быть собранными вместе. Следующая таблица объясняет задания функции группировки:
| Функция | Описание |
|---|---|
|
Это среднее значение всех собранных значений |
|
Это сумма значение всех собранных значений |
|
Это сумма значение всех собранных значений |
|
Это минимальное значение в коллекции |
|
Это максимальное значение в коллекции |
Теперь, когда вы знаете обо всех компонентах агрегированного элемента, вы можете построить его ключ; соответствующий синтаксис таков:
groupfunc["Host group","Item key",itemfunc,timeperiod]
|
| Совет |
|---|---|
|
Часть |
Продолжая с нашим примером, скажем, мы интересуемся сбором среднего числа сеансов в вашем сервере приложений Tomcat за каждый час. В этом случае ключ элемента будет выглядеть следующим образом:
grpavg["Tomcat servers",
"jmx["Catalina:type=Manager,path=/,
host=localhost",activeSessions]", avg, 3600]
|
| Совет |
|---|---|
|
Вы также можете применять |
Применяя ту же самую группу и аналогичный элемент, вы могли бы также захотеть узнать пиковые значения одновременного числа сеансов по всем серверам
Этот тип элемента построен на понятиях функций элемента изложенных в предыдущих параграфах и
выводит его на новый уровень. В отличие от агрегированных элементов, при использовании вычисляемых вы
не ограничены определённой группой хостов, и что более важно, вы не ограничены отдельным ключём элемента.
При использовании вычисляемых элементов вы можете применять любые функции, доступные для определения триггеров
к любому элементу в вашей базе данных и комбинировать различные вычисления элемента с использованием
арифметических операций. Как и в случае прочих типов элемента, которые имеют дело с особенными частями
данных, ключ объекта вычисляемого элемента не используется для реального определения вашего источника
данных, однако всё ещё необходим чтобы он был уникальным, чтобы вы могли ссылаться на этот элемент в триггерах,
графиках и действиях. Действительное определение элемента содержится в поле formula
и, как вы можете себе представить, согласно вашим потребностям оно может быть как простым так и весьма
мудрёным.
Оставаясь в рамках примера нашего сервера Tomcat, вы можете иметь вычисляемый элемент который даёт вам общую пропускную способность приложения для данного сервера следующим образом:
last(jmx["Catalina:type=GlobalRequestProcessor,name=http-8080",bytesReceived]) +
last(jmx["Catalina:type=GlobalRequestProcessor,name=http-8080",bytesSent]) +
last(jmx["Catalina:type=GlobalRequestProcessor,name=http-8443",bytesReceived]) +
last(jmx["Catalina:type=GlobalRequestProcessor,name=http-8443",bytesSent]) +
last(jmx["Catalina:type=GlobalRequestProcessor,name=jk-8009",bytesReceived]) +
last(jmx["Catalina:type=GlobalRequestProcessor,name=jk-8009",bytesSent])
В качестве альтернативы вы можете интересоваться соотношением между своими активными сеансами и вашим макимальным значением разрешённых сеансов и таким образом, позже, вы можете определить запускающий механизм (триггер) на основе процентного значения вместо абсолютного следующим образом:
100*last(jmx["Catalina:type=Manager,path=/,host=localhost",activeSessions]) /
last(jmx["Catalina:type=Manager,path=/,host=localhost",maxActiveSessions])
Как было определено ранее, у вас нет необходимости придерживаться одного хоста в любых своих вычислениях.
Ниже приводится как вы можете оценивать каждые 3 минуты среднее число очередей в своей базе данных для отдельного сеанса на сервере приложений:
avg(DBServer:mysql.status[Questions], 180) /
avg("Tomcatserver:Catalina:type=Manager,path=/,host=localhost",activeSessions], 180)
Единственное ограничение для вычисляемых элементов состоит в том, что не существует простых функций групп, как это имеется в случае с агрегируемыми элементами. Поэтому, хотя вычисляемые элементы существенно более мощная и гибкая версия агрегируемых элементов, вы всё ещё не можете освободиться от агрегируемых элементов, так как они необходимы вам для связанных с группами функций.
Несмотря на это ограничение, как вы легко можете себе представить, не существует предела когда дело доходит до вычисляемых элементов. Совместно с агрегируемыми элементами они являются идеальным инструментом для мониторинга производительности группы хостов, таких как кластеры и гриды, или для корреляции различных измерений на различных хостах, котрые вносят вклад в общую производительность отдельной службы.
Испольуете ли вы их для анализа производительности и планирования ёмкости, или в качестве основы для сложных и интеллектуальных механизмов запуска (триггеров), или же для обеих ситуаций, разумное применение агрегированных и вычисляемых элементов поможет вам сделать вам большую часть вашей установки Zabbix.
В этой главе мы погрузились в различные аспекты определения элемента в Zabbix. На данный момент вы должны понимать основную разницу между элементом Zabbix и объектом мониторинга или прочими продуктами и то, почему подход Zabbix сбора простых, первоначальных данных вместо наблюдения за событиями является очень мощным. Вы также должны знать все входы и выходы своих потоков обмена данными мониторинга и то, как воздействовать на их основе на ваши потребности и вашу среду. Вам должно быть комфортно перемещаться между стандартными агентами Zabbix при сборе данных и вы должны быть способны настраивать свой сервер для сбора данных из различных источников - запросов к базам данных, агентов SNMP, агентов IPMI, веб- страниц, консолей JMX и тому подобного.
Наконец, вы должны, скорее всего, ухватить огромные возможности подразумеваемые двумя мощными типами элемента - агрегированными и вычисляемыми.
В следующей главе вы изучите то, как представлять и визуализировать всё собранное вами богатство данных при помощи графиков, карт и экранов.