Глава 8. Планирование промышленного применения и настройка производительности Ceph
В данной главе мы охватим такие рецепты:
-
Динамика ёмкости, производительности и стоимости
-
Выбор аппаратных и программных компонентов Ceph
-
Рекомендации Ceph и настройка производительности
-
Удаляющее кодирование Ceph
-
Создание пула с удаляющим кодированием
-
Многоуровневое кэширование Ceph
-
Создание пула для многоуровневого кэширования
-
Создание уровня кэша
-
Настройка уровня кэша
-
Тестирование уровня кэша
Содержание
- 8. Планирование промышленного применения и настройка производительности Ceph
- Введение
- Динамика ёмкости, производительности и стоимости
- Выбор аппаратных и программных компонентов Ceph
- Рекомендации Ceph и настройка производительности
- Удаляющее кодирование Ceph
- Создание пула с удаляющим кодированием
- Многоуровневое кэширование Ceph
- Создание пула для многоуровневого кэширования
- Создание уровня кэша
- Настройка уровня кэша
- Тестирование уровня кэша
В этой главе мы изучим некоторые очень интересные концепции относительно Ceph. Они содержат рекомендации по аппаратным и программным средствам, настройку производительности компонентов Ceph (т.е. Ceph MON, OSD), а также клиентов, включая тюнинг ОС. Наконец мы узнаем об удаляемом кодировании и многоуровневом кэшировании, охватив различные технологии обоих.
Ceph является определяемым программным обеспечением решением хранения, которое разработано для работы на общедоступных аппаратных средствах. Такая возможность Ceph делает её гибким и экономичным решением, которое подгоняется под ваши потребности. Поскольку вся интеллектуальность Ceph содержится в её программном обеспечении, она требует хорошего набора аппаратных средств для выполнения общей упаковки которая является великолепным решением.
Выбор аппаратных средств Ceph требует тщательного планирования на основе ваших потребностей хранения и имеющихся у вас вариантов применения. Организациям необходима оптимизация аппаратных конфигураций, которая позволяет им начиная с малого масштабироваться до нескольких петабайт. Следующая схема представляет ряд факторов, которые применяются для определения оптимальной конфигурации для вашего кластера Ceph:
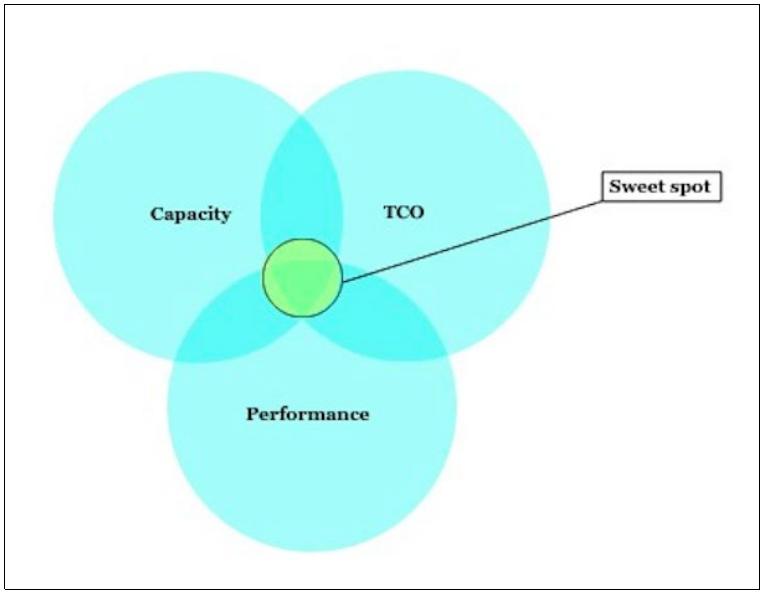
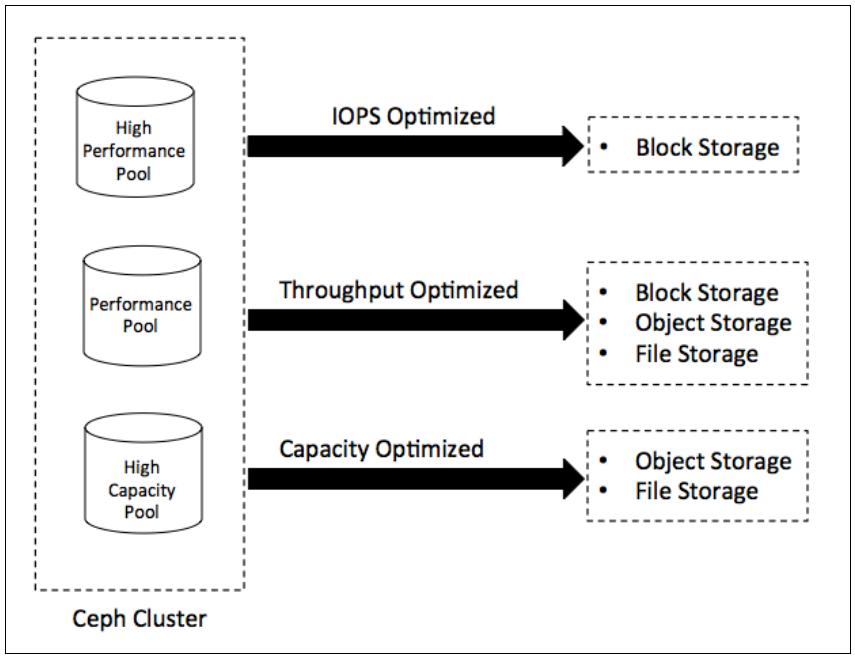
Различные организации имеют различные рабочие нагрузки, которые обычно требуют некоторых общих компромиссов между производительностью, ёмкостью и ТСО. Ceph является универсальным хранилищем, то есть, оно может предоставлять хранение Файлов, Блоков и Объектов в одном и том же кластере. Ceph также способен предоставлять различные типы пулов хранения в пределах одного и того же кластера, которые предназначены для различных рабочих нагрузок. Может существовать множество способов определения ваших потребностей в хранении; следующая схема один из вариантов их определения:
-
IOPS Optimized (оптимизированные под IOPS): Основным моментом такого типа конфигурация является наивысшая IOPS (количество операций ввода/ вывода в секунду) при низкой TCO (совокупной стоимости владения) операции ввода/ вывода (IO). Обычно реализуется с применением для хранения высокопроизводительных узлов, содержащих самые быстрые диски SSD, PCIe SSD, NVMe и тому подобного. Обычно применяется для хранения блоков, однако вы можете применять их и для других рабочих нагрузок, нуждающихся в высоких IOPS.
-
Throughput Optimized (оптимизированные под пропускную способность): Их изюминка состоит в наивысшей пропускной способности при её низкой стоимости. Они обычно реализуются с применением дисков SSD и PCIe SSD для ведения журналов OSD с физически дублированной сетевой средой высокой пропускной способности. В основном применяются для блочных устройств. Если ваши варианты применения требуют высокопроизводительного хранения объектов или файлов, то вам следует рассмотреть такой вариант.
-
Capacity Optimized (оптимизированные под ёмкость): Его привлекательная сторона заключается в низкой стоимости за ТБ и низкой стоимости из расчёта на юнит стойки или физическое пространство центра обработки данных. Оно также известно как экономичное хранилище, хранилище с низкой стоимостью, а также как архивное/ долговременное хранилище, и оно обычно реализуется с применением плотных серверов, наполненных шпиндельными дисками, обычно от 36 до 72 физических дисков на сервер с ёмкостью физических дисков 4 или 6ТБ. Они обычно применяются как хранилища объектов или файловых систем большой ёмкости с низкой стоимостью. Это хорошие претенденты на применение удаляющего кодирования для максимизации используемой ёмкости.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
{Прим. пер.: Это может показаться забавным, однако с некоторых пор стало возможным построение бесплатной среды виртуализации на основе гипервизора Hyper-V с бесплатной же системой хранения Storage Spaces, обладающей современными функциональностью и мощностью сопоставимыми, например, с Ceph. Хотя она и ограничена в масштабировании применением аппаратных технологий SAS/ FC. Остаётся дождаться смещения Storage Spaces Direct (S2D) в сферу халявного применения, чтобы имеющаяся в Непосредственно подключаемых пространствах хранения Программно определяемая шина хранения (Software Storage Bus), заменяющая собой SAS/FC, смогла составить конкуренцию системам хранения уровня Ceph!} |
Как уже упоминалось ранее, выбор аппаратных средств Ceph требует тщательного планирования на основе вашей среды и потребностей в хранении. Тип аппаратных компонентов, сетевая инфраструктура и архитектура кластера являются некоторыми критичными факторами, которые вы должны рассматривать на начальном этапе планирования хранилища Ceph. Не существует золотого правила для выбора оборудования Ceph, поскольку такой выбор зависит от различных факторов, таких как бюджет, производительность в соотношении к ёмкости, или и то и другое, уровень отказоустойчивости и ваш вариант применения.
Ceph не зависит от аппаратных средств; организации вольны выбирать любое оборудование по своему усмотрению основываясь на их бюджете, требованиях к производительности/ ёмкости или способам применения. Они получают полное управление над их кластером хранения и лежащей в его основе инфраструктуре. Кроме того, одним из основных преимуществ Ceph является то, что она поддерживает разнородное оборудование. Вы можете мешать торговые марки при создании инфраструктуры кластера Ceph. Например, при построении своего кластера Ceph вы можете смешивать оборудование от различных производителей, таких как HP, Dell, Supermicro и так далее {Fujitsu, Huawei, Inspur, Mdl...}, а также даже уже имеющееся в наличии оборудование, что может приводить к значительной экономии средств. {Прим. пер.: не следует, однако, забывать об усложнении технической поддержки и сопровождения при росте вашего зоопарка.}
Вам следует иметь в виду, что выбор для Ceph управляется рабочими нагрузками, которые вы планируете размещать в вашем кластере хранения, вашей среде и используемой вами функциональности. В данном рецепте мы изучим некоторые основные практические подходы по выбору оборудования для вашего кластера Ceph. {Прим. пер.: см. также наш перевод официальных Рекомендаций по оборудованию Ceph.}
Ваш демон монитора Ceph поддерживает карты вашего кластера и не обслуживает никакие данные клиентов, следовательно он легковесен и не имеет очень сильных требований к процессору. В большинстве случаев средний одноядерный процессор выполнит работу монитора Ceph. Сдругой стороны, MDS Ceph слегка более требователен к ресурсам. Ему требуется значительно более мощный ЦПУ с четырьмя ядрами или даже больше. Для небольшого кластера Ceph или для среды проверки концепции вы можете совмещать мониторы Ceph с прочими его компонентами, такими как OSD, Radosgw или даже MDS Ceph. Для окружений с размером от среднего и выше, вместо совместного использования мониторы Ceph должны размещаться на выделенных машинах. {Прим. пер.: с точки зрения единообразия и взаимозаменяемости стоит рассмотреть и возможность применения однотипных ЦПУ!}
Демон OSD требует достаточный объём вычислительной мощности, так как он обслуживает данные клиентов. Для оценки требований к ЦПУ для OSD Ceph важно знать сколько OSD будет размещать данный сервер. Обычно рекомендуется чтобы каждый демон OSD располагал как минимум одним ГГц на ядро ЦПУ. Вы можете применять следующую формулу для оценки потребностей ЦПУ OSD:
((разёмы ЦПУ * число ядер на разъём ЦПУ * тактовая частота ЦПУ в ГГц) / число OSD) >=1
Например, сервер с одним сокетом ЦПУ, 6 ядрами по 2.5ГГц должен быть достаточно хорош для 12 OSD Ceph, причём каждый OSD получит примерно 1.25ГГц
вычислительной мощности: ((1*6*2.5)/12)= 1.25.
-
Процессор Intel® Xeon® E5-2620 v3 (2.40 ГГц, 6 ядер)
1 * 6 * 2.4= 14.4предполагает, что его достаточно для узла Ceph с общим числом OSD до 14. -
Процессор Intel® Xeon® E5-2680 v3 (2.50 ГГц, 12 ядер)
1 * 12 * 2.5= 30предполагает, что его достаточно для узла Ceph с общим числом OSD до 30.
Если вы планируете применять функциональность удаляющего кодирования (erasure coding, EC), будет более выгодным получить более мощные ЦПУ, поскольку работа удаляющего кодирования требует больших вычислительных потребностей.
![[Совет]](/common/images/admon/tip.png) | Совет переводчика |
|---|---|
|
{Cтоит воздерживаться от применения в одном кластере ЦПУ разных поколений (например Intel® Xeon® E5-2620 v3 и Intel® Xeon® E5-2620 v2) и, тем более, разных производителей (Intel/ Amd) или даже архитектур (x86/ ARM/ Sparc/ Power). Это может стать причиной проблем с применяемым программным обеспечением, а также существенно осложнит возможности миграции и сопровождения. Если уж деваться некуда, необходимо убедиться в совместимости применяемого вами в режиме совместимости кода.} |
|
| Замечание переводчика |
|---|---|
|
{Ядра многих современных ЦПУ поддерживают Hyper-threading (гиперпоточность), позволяющую демонам разделять ядро на аппаратном уровне. Хотя эта технология, как правило, проигрывает в производительности от долей процента до нескольких процентов по сравнению с работой ядра при выключенной гиперпоточности, не стоит сбрасывать со счетов эту возможность для аппаратной изоляции демонов с прицелом на повышение высокой доступности. Испытывающий проблемы OSD будет конкурировать за ресурс с нормально работающими OSD и даже может "подвешивать" их, разделение ресурсов на аппаратном уровне способно помогать в подобной ситуации.} |
31 марта 2016 Intel объявил о начале приёма заказов на новую линейку процессоров Intel® Xeon® E5-2600 v4, совместимых с v3 (необходимо обновление firmware материнской платы). Ждём новый чипсет материнских плат для PCIe 4.0.
| Наименование | Число ядер Рекомендуемое число OSD |
Расчётная мощность | Рекомендуемая цена Cтоимость OSD |
|---|---|---|---|
|
22
|
145Вт |
$4 115
|
|
18
|
145Вт |
$2 702
|
|
14
|
120Вт |
$1 745
|
|
12
|
105Вт |
$1 166
|
|
10
|
90Вт |
$939
|
|
10
|
85Вт |
$667
|
|
8
|
85Вт |
$417
|
|
8
|
85Вт |
$310
|
|
12
|
120Вт |
$1745
|
|
10
|
105Вт |
$1166
|
|
8
|
85Вт |
$667
|
|
6
|
85Вт |
$417
|
|
6
|
85Вт |
$213
|
Рекомендуемая розничная цена (РРЦ) представляет собой рекомендуемую цену для продуктов Intel. Цены указаны для прямых клиентов Intel, обычно для заказов партий из 1000 шт. и могут быть изменены без уведомления. Налоги, расходы на доставку и прочие расходы не включены. Цены могут отличаться для других типов упаковки и объёмов поставок, а также могут действовать условия специальных акций. Если продаётся в оптовой партии, цена относится к единице продукции. Указание рекомендуемых розничных цен не является официальной ценовой офертой Intel. Обратитесь к своему представителю Intel, чтобы получить официальное подтверждение цены. | |||
Демонам монитора и метаданных требуется обслуживать свои данные быстро, следовательно они должны иметь достаточно памяти для более быстрой работы. Практический способ - необходимо иметь 2ГБ или более памяти на экземпляр демона- этого должно быть достаточно и для MDS Ceph, и для монитора. MDS Ceph сильно зависят от кэширования данных; так как им необходимо обслуживать данные быстро, им необходимо достаточно оперативной памяти. Чем больше оперативной памяти для для MDS Ceph, тем лучше будет производительность CephFS.
Для OSD обычно требуется приличный объём физической памяти. При средней рабочей нагрузке 1ГБ памяти на экземпляр демона OSD должно быть достаточно; однако с точки зрения производительности 2ГБ на демон OSD будет хорошим выбором, а ещё больший объём также поможет при восстановлении и будет лучше для кэширования. Эта рекомендация предполагает, что вы применяете один демон для одного физического диска. Если вы применяете более одного физического диска на OSD, ваши требования к памяти также возрастут. Обычно больший объём физической памяти это хорошо, поскольку в процессе восстановления кластера значительно повышается потребление оперативной памяти. Следует знать, что потребление памяти OSD увеличится, если вы учитываете сырую ёмкость лежащего в основе физического диска. Поэтому требования OSD для 6ТБ диска будут больше чем в случае 4ТБ диска. Вам следует принимать такое решение разумно, с тем, чтобы оперативная память не стала узким местом в производительности вашего кластера.
|
| Совет переводчика |
|---|---|
|
{Для увеличения пропускной способности обмена ЦПУ и оперативной памяти современные системы применяют более одного канала памяти на разъём процессора. Серверы с процессорами Intel® Xeon® E5-2600 v2 использовали, как правило, 3 канала памяти, а процессоры Intel® Xeon® E5-2600 v3 4 канала памяти. Для достижения максимальных значений пропускной способности необходимо полностью заполнять канал однотипными модулями памяти.} |
{Прим. пер.: современные процессоры Intel® Xeon® E5-2600 v3 применяют память DDR4 SDRAM, согласно
спецификации имеющую
предел пропускной способности 25.6ГБ/c на канал. С учётом потерь на взаимодействие модулей памяти, это около 100ГБ/c при эффективной
частоте 3.2ГГц, что даёт оценку времени обмена данными в 1ТБ порядка 10 секунд. Имеющаяся на рынке в марте 2016г
работает с эффективной частотой 2.133ГГц, что допускает предел пропускной способности порядка 68ГБ/с и оценку времени обмена данными
с объёмом в 1ТБ порядка 15
секунд. Стоимость оперативной памяти очень сильно подвержена биржевым колебаниям. Точнее всего их динамику
отслеживает ресурс http://dramexchange.com/ (оценка стоимости для
больших партий снизу). Приведём пример методики оценки текущей стоимости памяти для 16ГБ модуля M393A2G40DB1 производства Samsung. Согласно спецификации,
этот модуль памяти содержит 36 кристаллов 4Gb (1Gx4) 2133МГц. Биржевая стоимость 4Gb DDR4 DRAM в марте 2016 составляет порядка $2
(см. строка "DDR4 4Gb 512Mx8 2133 MHz" на http://dramexchange.com/). Разброс стоимости доступного на рынке модуля памяти составит от
$2 * 36 * [1.5-2],
где [1.5-2] - оценка коэффициента пересчёта. Т.е. рыночная стоимость такого
модуля памяти будет в пределах $110-$140. Проверяем по amazon.com: $126.5 на момент
проверки. Согласен, данная методика даёт слишком большой разброс, однако она позволяет следить за динамикой при часто возникающих
турбулентных процессах на рынке памяти.}
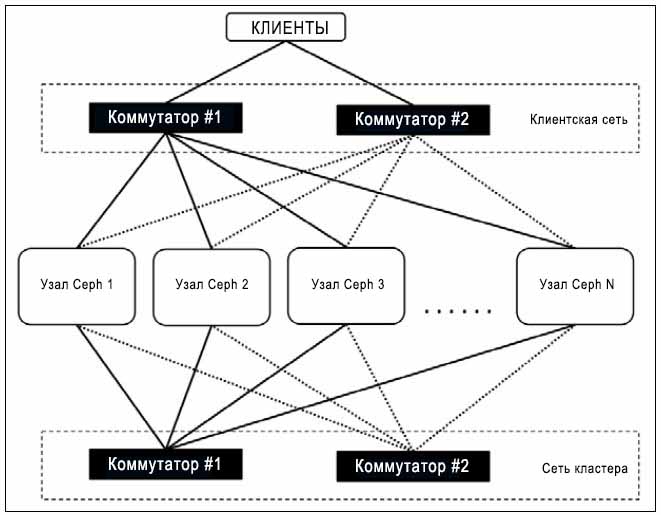
Ceph является распределённой системой хранения и он в большой степени полагается на лежащую в его основе сетевую инфраструктуру. Если вы планируете, чтобы ваш кластер Ceph был надёжным и производительным, убедитесь что у вас имеется спроектированная для него сетевая среда. Рекомендуется чтобы все узлы кластера имели две избыточные раздельные сетевые среды для обмена внутри самого кластера и для клиентов.
Для небольшой проверки концепции или для тестирования будет достаточно кластера Ceph из нескольких узлов с сетевой средой, работающей на 1Gbps. Если у вас имеется кластер с размером выше среднего (несколько десятков узлов), вам следует думать о применении сетевой среды с пропускной способностью 10Gbps или выше. На момент восстановления/ ребалансировки сетевая среда играет решающую роль. Если у вас имеются хорошие соединения с пропускной способностью сетевой среды 10Gbps или выше, ваш кластер будет восстанавливаться быстро, в противном случае это займёт определённое время. Поэтому, с точки зрения производительности, Дублированная сеть с 10Gbps или выше будет хорошим параметром. Хорошо спроектированный кластер Ceph применяет две раздельные сетевые среды: одну для сетевой среды кластера (внутренняя сеть) и другую для сетевой среды клиентов (внешняя сеть); обе эти сетевые среды должны быть физически разделены прямо начиная с вашего сервера вплоть до сетевого коммутатора и всё в промежутке, как показано на следующей схеме:
{Прим. пер.: Часто в качестве бонуса в наличии имеется некая сеть на встроенных в материнские платы 1GbE адаптерах. Эту сеть мы рекомендуем выделять в третью, административную, способную работать с оборудованием на уровне IPMI и выполнять другие административные функции (например, функциональность Ограждения /Fencing/ для предоставления высокой доступности и управление прочими системами контроля оборудования). Причём, обращаем внимание на возможность наличия дублирования функциональности IPMI в других имеющихся в наличии сетевых средах, в том числе с выделением полосы пропускания (очень сильно зависит от производителя конкретного оборудования). За дополнительными консультациями обращайтесь к нашим специалистам.
Для завершения обсуждения наших "хотелок" в плане сетевых сред отметим, что вынесение сетевой среды ребалансировки, наполнения и восстановления в отдельную физическую сеть делает более прогнозируемым поведение как внешней, так и внутренней сетей.}
В отношении вашей сетевой среды другой темой дискуссий является обсуждение того, что лучше применять: сетевую среду Ethernet или Infiniband, или, более определённо: сеть 10GbE, 40GbE или ещё больших пропускных способностей. Это зависит от ряда факторов, таких как рабочая нагрузка, размер вашего кластера Ceph, плотность и число узлов OSD Ceph и тому подобное. В некоторых реализациях я видел как пользователи применяли и 10GbE и 40GbE сетевые среды в Ceph. В этом случае их кластеры Ceph относились к уровню нескольких Петабайт и нескольких сотен узлов, причём они применяли 10GbE в качестве клиентской сети, а внутренняя сетевая среда имела более высокую пропускную способность и более низкую латентность 40GbE. Тем не менее, стоимость сетевых сред Ethernet стремительно падает; основываясь на вашем варианте применения, вы можете определять тип сетевой среды, которой вы хотите обладать.
{Прим. пер.: На протяжении последних лет я неустанно рассказывал своим заказчикам о несомненных преимуществах 56/100G IB перед 10/40/100GbE, пока не наткнулся на препятствие, которое представители Mellanox объяснили исключительно требованиями спецификации Infiniband. А именно: невозможность объединять в транки несколько линий IB для повышения пропускной способности как на аппаратном уровне, так и на уровне программного управления каналом (драйверы, etc.). Понятно, что это можно выполнить на более высоком уровне, например, на прикладном. Но это сродни забиванию гвоздей микроскопом.}
{Прим. пер.: приведём таблицу экономичных коммутаторов различных производителей, применяемых
нами (или которые мы бы рады были применить в ваших решениях) для построения сетей в кластерах:
Allied Telesis AT-DC2552XS/L3 48x SFP+ 10GbE 4x QSFP+ 40GbE 1.28Tbps 952.32 Mpps $16 0001 Allied Telesis AT-XS916MX(T/S) 12x/4x Base-T 10GbE 4x/12 SFP+ 10GbE 320Gbps 238 Mpps - Brocade VDX 6940-144S 96*10GbE SFP+ 4*100GbE QSFP+ 2.88Tbps 2.16 Bpps ? Dell Z9100-ON/ S6100-ON 32x 100GbE / 64x 50GbE / 64x/32x 40GbE (S6100/Z9100) /128x SFP+ 25GbE /128x SFP+ 10GbE 6.4Tbps 4.4 Bpps ~$50 000/ Dell S6000-ON 96x SFP+ 10GbE 8x QSFP+ 40GbE / 32x QSFP+ 40GbE 1.44Tbps 1 080 Mpps ?1 Dell S4048-ON 48x SFP+ 10GbE 6x QSFP+ 40GbE 1.44Tbps 1 080 Mpps ?1 Dell N4064F 48x SFP+ 10GbE 4x QSFP+ 40GbE 1.28Tbps 952 Mpps $15 0001 Dell N4032F 24x SFP+ 10GbE 2x QSFP+ 40GbE 0.64Tbps 476 Mpps $9 9001 Dlink DXS-1210-12SC 10x SFP+ 10GbE + 2x Base-T/SFP+ 10GbE 0.24Tbps 178.56 Mpps $1 5001 Edge-Core AS5610-52X (ONIE) WhiteBox 48x 10GbE SFP+ 4x 40GbE QSFP+ 1.28 Tbps 960 Mpps $5 1001 Edge-Core AS6701-32X (ONIE) WhiteBox 20x 40GbE SFP+ (+ 12x 40GbE через слоты расширения) 2.56 Tbps 1.92 Bpps $7 9001 Huawei CE6851-48S6Q-HI 48*10GbE SFP+ 6*40GbE QSFP+ 1.44Tbps 1 080Mpps $16 0001 Huawei S6720-54C-EI-48S-AC 48*10GbE SFP+/SFP 2*40GbE QSFP+ 2.56Tbps 1 080Mpps $16 0001 Huawei S6720-30C-EI-24S-AC 24*10GbE SFP+/SFP 2*40GbE QSFP+ 2.56Tbps 720Mpps $12 8001 Huawei CE7850-32Q-EI 32*40GbE QSFP+ - 2.56Tbps 1 440Mpps $32 0001 Huawei CE8860-4C-EI 4 слота обслуживания x(8x100GbE QSFP28/ 6.4Tbps 2 976Mpps $40 0001 Huawei S12804S 4 слота до 36x 40GbE (2016Q3: 100GbE) 40/80Tbps 17 280 Mpps $69 6241 Juniper OCX1100-48SX 48x 10GbE SFP+ 6x 40GbE портов QSFP+ 1.44Bbps 1 080 Mpps $32 0001 Juniper QFX5100-24Q 24x 40GbE QSFP+ 2.56Tbps 1.44Bpps $40 0001 Juniper QFX5200-32С 32x40GbE QSFP+/ 28QSFP 3.2Tbps 2.44Bpps $35 0001 Mellanox SN2700 до 32x 40/56/100GbE или 64x 10/25GbE или 64x 50GbE 6.4Tbps 4 770 Mpps - Mellanox SN2410 48x 25GbE 8x 100GbE 6.4Tbps 4 770 Mpps - Mellanox SB7790-E 10/20/40/56/100G 4X IB 36x QSFP28 портов 7.2Tbps 7 020 Mpps $22 0091 Mellanox SX6036F 10/20/40/56 4X IB 36x QSFP 4.032 Tbps ? $15 3731 Mellanox SX1024 48x 10GbE SFP+ 12x/4x 40GbE QSFP+ 2.0 Tbps 3 Mpps Mellanox SX1012 12x 40/56GbE SFP+ портов 2.0 Tbps 3 Bpps $11 4251 Mellanox SX6015F 18x QSFP+ FDR 56G 2.0 Tbps 3 Bpps $11 9951 Mellanox SX6005F 12x QSFP+ FDR 56G 1.3 Tbps 1.5? Bpps $5 3611 Mellanox SX6005T 12x QSFP+ FDR10 40G 1.3 Tbps 1.5? Bpps $6 6521 Mellanox SX6005T 12x QSFP+ FDR10 40G 1.3 Tbps 1.5? Bpps $6 6521
1 Стоимостные оценки приводятся по прайс- листам
рекомендованных производителями цен при не сопоставимых
условиях и поэтому не могут служить основанием для сравнения цен различных
производителей в пределах этой таблицы! Сопоставлять в пределах таблицы можно исключительно цены одного производителя!
}
Наименование
Число основных портов
/портов расширенияОбщая производ. коммутации
/производ. передачиРекоменду- емая цена
Важно: см. сноску
1
~$60 0001
16x 40GE QSFP+/
24x 25GE SFP28/
24x 10GE SFP+)
При наличии необходимости сопоставления цен различных производителей под конкретный проект
обращайтесь к нашим специалистам!
{Прим. пер.: приведём таблицу оценки времён, необходимых для обмена данных объёмом в 4ТБ (условно говоря,
выход из строя 6ТБ диска в системе с "приличной" загруженностью):
10GbE 55 минут 25GbE 22 минуты 40GbE 14 минут 56G IB 10 минут
PCIe v.3 8x lane 8+2/3 минут 100GbE/ IB 5.5 минут
PCIe v.3 16x lane 4+1/3 минуты
}
Скорость обмена
Оценка необходимого времени
{ Прим. пер.: Следует иметь в виду, что устройства сетевого обмена имеют большой объем функционала, позволяющий сделать вашу жизнь легче. Это и объединение каналов в "транки", и различные виды поддержки RDMA (например, RDMA over Converged Ethernet), а также, Mellanox анонсировал аппаратную поддержку Erasure Coding в своих ASIC ConnectX-4. Следовательно в августе 2016 можно ждать новые драйверы Infiniband и Mellanox Ethernet с аппаратной поддержкой EC для Ceph, освобождающей от этой задачи ЦПУ узлов (подробности по возможности асинхронной работы таких методик). Большой интерес также представляет инициатива 25GbE. Помимо снижения стоимости пропускной способности и повышения ее общедоступного нижнего порога для сетевой среды кластера Ceph (c 10GbE на 25GbE), она улучшает арифметику деления ядра сети: 100 делится на 25 без остатка! Стоит отметить, что 25GbE уже - 31 марта 2016 - доступны к заказу! Повторим: они призваны заменить собой 10GbE. В качестве лёгкого отстутпления от темы: все мы пользуемся WiFi, следовательно и добравшееся своими 2.5/5GbE до стандарта Ethetrnet- сообщество радует нас!}
Производительность и экономичность для кластеров Ceph совместно сильно зависят от эффективного выбора носителей для хранения.
Вам следует понимать вашу рабочую нагрузку и возможные требования перед выбором носителей хранения для вашего кластера Ceph.
Ceph применяет носители хранения двумя способами: часть Ceph ведущая журналы и часть данных Ceph. Как объяснялось в предыдущих
главах, каждая операция write в Ceph является в настоящее время двухшаговым процессом.
Когда OSD получает запрос на запись объекта, он вначале записывает этот объект в журнальную часть OSD в его активном наборе и
отправляет подтверждение write клиентам. Вскоре после этого журнальные данные
синхронизируются с разделом данных. Следует знать, что репликации также являются важным фактором в процессе исполнения
write. Коэффициент (factor) репликаций обычно является компромиссом между надёжностью,
производительностью и совокупной стоимостью владения (TCO). В этом случае вся производительность кластера вращается вокруг
разделов журнала и данных OSD.
Если рабочая нагрузка сосредоточена вокруг производительности, то рекомендуется применять для журналов SSD. При использовании SSD
вы можете получить значительное улучшение за счёт уменьшения времени доступа и латентности write.
Для использования SSD в качестве журнала мы создаём множество логических разделов на каждом физическом SSD так, что каждый логический
раздел SSD (журнал) соответствует одному разделу OSD. В этом случае ваш раздел данных размещается на шпиндельном диске и имеет собственный
журнал в более быстром разделе SSD. Следующая схема иллюстрирует такую конфигурацию:
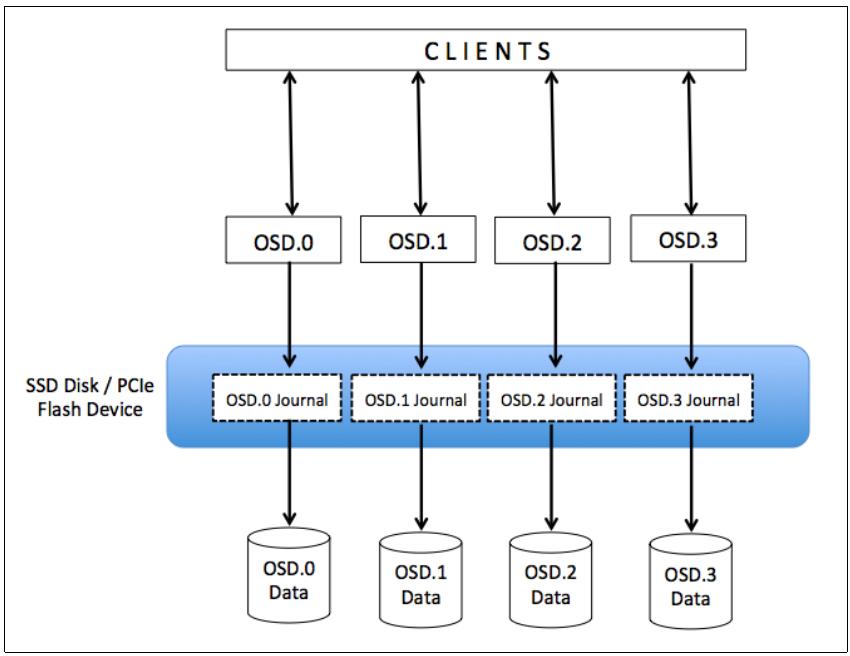
При подобном типе компоновки вам следует иметь в виду, что не следует перегружать SSD хранением множества журналов свыше их пределов. Обычно для большинства вариантов применения должно быть достаточно размера журнала от 10 до 20ГБ, если у вас SSD большего размера вы можете создавать устройства журнала большего размера; в этом случае не забывайте увеличивать максимальный и минимальный интервалы синхронизации сохранения файлов для OSD.
Двумя наиболее распространёнными типами энергонезависимых быстрых устройств хранения применяемыми в Ceph являются SATA или SAS SSD и PCIe или NVMe SSD. Для получения хорошей производительности ваших SATA/ SAS SSD, ваше соотношение SSD к OSD должно быть 1 : 4, т.е. один SSD применяется совместно 4мя дисками данных OSD. При использовании вами флеш- устройств PCIe или NVMe, в зависимости от производительности, соотношение SSD к OSD может варьироваться от 1 : 12 до 1 : 18, т.е. одно флеш- устройство разделяется между дисками данных в количестве от 12 до 18.
Тёмной стороной применения одного SSD для нескольких журналов состоит в том, что если вы теряете ваш SSD, размещающий множество журналов, все те OSD, которые связанные с этим OSD выйдут из строя и вы можете утратить ваши данные. Однако вы можете преодолеть эту проблему применяя RAID 1 в для ведения журнала, что, однако, приведёт к повышению стоимости вашего хранилища. К тому же стоимость за гигабайт примерно в 10 раз выше по сравнению с HDD {Прим. пер.: спорное утверждение, см. приводимые ниже справочные данные по состоянию на март 2016.} Поэтому, если вы строите кластер с SSD, вы увеличиваете стоимость за Гигабайт для вашего кластера Ceph. Однако, если вы ищете пути значительного улучшения производительности вашего кластера Ceph, инвестиции в SSD для журналов будут достойны внимания.
Мы получили сведения о журналах SSD и понимании того вклада, который они вносят в улучшение вашей производительности
write. Однако, если вы не беспокоитесь о значительном улучшении производительности, а стоимость
за ТБ является для вас решающим фактором для вас, то вам следует рассмотреть настройку раздела данных журнала на том же самом
дисковом устройстве. Это означает, что вы будете выделять на вашем большом шпиндельном диске несколько ГБ для журнала OSD и применять
оставшееся пространство того же диска для данных OSD. Такой вид установки может оказаться не столь производительным как аналогичная
установка на основе SSD журнала, однако совокупная стоимость за ТБ будет значительно ниже.
OSD являются реальными рабочими лошадками, хранящими все ваши данные. В промышленной среде Вам следует применять для вашего кластера Ceph жёсткие диски класса предприятия, облака или архива. Обычно жесткие диски уровня настольных компьютеров не очень хорошо подходят для промышленного кластера Ceph. Причина состоит в том, что в кластере Ceph несколько сот вращающихся жёстких дисков установлены очень близко и комбинация вибраций от вращения может стать проблемой для жёстких дисков уровня настольных компьютеров. Это увеличивает скорость отказа диска и может ухудшать общую производительность. Жёсткие диски корпоративного уровня намеренно имеют многие другие конструктивные решения для обработки вибраций и при этом они сами по себе генерируют очень малые уровни вибрации. Кроме того, их среднее время безотказной работы (MTBF) значительно выше чем показатели жёстких дисков уровня настольных решений.
{Прим. пер.: более дорогостоящие жёсткие диски имеют на управляющем контроллере несколько датчиков ускорений и схему управления обратной связью с системой позиционирования блока головок над считывающими дорожками, которые до определённой степени компенсируют внешние вибрации. Не следует также пренебрегать и прочими конструктивными особенностями шасси при размещении ваших шпиндельных устройств, позволяющих снижать уровень вибраций. Однако вибрации - не единственный фактор, вносящий различия между шпиндельными дисками с низкой стоимостью и дисками, предназначенными для работы в режиме 24x7. К таковым можно отнести качество применяемых подшипников, материалов корпуса, их уровня теплопроводности, устойчивости к перепадам температур и тем же вибрациям, применяемая элементная база и многие другие конструктивные решения, нагляднее...}.
Другим подлежащим рассмотрению моментом для диска данных OSD Ceph является интерфейс, то есть SATA или SAS. Жёсткие диски NL-SAS имеют дублированные порты SAS 12Гб/с и они обычно более высоко производительны чем интерфейсы жёстких дисков SATA 6Гб/c с одиночным портом. Кроме того, дублированные порты SAS предоставляют отказоустойчивость и допускают одновременные чтение и запись. Дополнительным фактором устройств SAS также является то, что они имеют более низкое значение невосстановимых ошибок чтения (unrecoverable read errors, URE) в сравнении с устройствами SATA. Чем ниже уровень URE, тем меньше ошибок очистки и операций по восстановлению групп размещения. {Прим. пер.: см. также обзор ETegro SAS vs SATA, для справки: значения URE для современных дисков составляют величины порядка 10-15 - 10-16.}
Плотность ваших узлов OSD также является важным фактором для производительности кластера, используемого пространства и совокупной стоимости владения. Обычно лучше иметь большее число меньших узлов чем несколько узлов с большой ёмкостью, но эта тема всегда открыта для обсуждений. Вам следует выбирать плотность вашего OSD узла таким образом, чтобы один узел должен быть меньше чем 10% общего размера вашего кластера.
Например, в кластере Ceph с размером 1ПБ вам следует избегать применения узлов OSD 4x 250ТБ, в которых каждый узел содержит 25% ёмкости кластера. Вместо этого вы можете располагать узлами OSD 13x 80ТБ, в которых размер каждого узла меньше 10% от ёмкости всего кластера. Однако это может увеличить вашу стоимость совокупного владения и может оказывать воздействие на прочие факторы планирования вашего кластера.
{Прим. пер.: приведём таблицу топовых характеристик устройств хранения некоторых производителей, применяемых
нами (или которые мы бы рады были применить в ваших решениях) для построения OSD в кластерах:
HGST HUH7210 10ТБ 256МБ/ 7200rpm/ 3.5" 249 - - 4.16мс Seagate ST8000NM 8ТБ 256МБ/ 7200rpm/ 3.5" 237 165 380 4.16мс HGST HUC1018 1.8ТБ 128МБ/ 10Krpm/ 2.5" 247 - - 2.85мс Seagate ST1800MM 1.8ТБ 128МБ/ 10Krpm/ 2.5" 241 - - 2.9мс HGST HUC1560 0.6ТБ 128МБ/ 15Krpm/ 2.5" 271 - - <2.0мс Seagate ST600MP 0.6ТБ 128МБ/ 15Krpm/ 2.5" 233 - - 2.0мс Seagate ST2000NT 2.0ТБ 128МБ/ 7200rpm/ 2.5" 136 - - 4.16мс HGST SN100 3.2ТБ NVMe/ PCIe SSD 3000/ 1600 743000 140000 512мкс HGST FlashMaxII/III 4.8ТБ/ 2.2ТБ eMLC/ PCIe SSD 2200/ 1400 531000/ 269000 59000/ 51000 19/22мкс HGST SSD800MH 0.8ТБ eMLC/ 2.5" 1100/ 765 130000 110000 - Seagate ST1600FM 1.6ТБ eMLC/ 2.5" 1900/ 625 200000 80000 115мкс бытовой SSD .96ТБ MLC/ 2.5" 560/ 455 79000 75000 -
}
Наименование серии
макс. ёмкость
осн. характеристикиМакс. скорость обмена МБ/с
чтение/ записьМакс. IOPS
чтение/ записьЛатентность
{ Прим. пер.: по состоянию на март 2016г стоимость NL SATA/SAS дисков начинается от 50$/ТБ, общедоступные MLC диски могут предоставлять Терабайт за стоимость менее $500, для eMLC дисков стоимость Терабайта начинается от $2000. Интересным представляется обсуждение проблемы необходимости eMLC (Enterprise Multi-level cell, многоуровневые ячейки памяти). Один из производителей бытовых SSD на основе MLC NAND, предоставил нам информацию о количестве гарантируемых им циклов перезаписи, на основании которой мы пришли к выводу, что исходя из пропускной способности этого устройства на запись нам потребуется 3 месяца для выполнения полной последовательной записи всего диска указанное число раз в режиме 24 x 7. В любом случае, мы предоставляем расширенную гарантию на замену SSD диска в случае его выхода из строя по причине израсходованием ресурса количества перезаписи в течение гарантийного срока. За подробностями обращайтесь к нашим специалистам!}
{ Прим. пер.: Достаточно простой и внятный обзор NVMe, нового интерфейса для систем хранения, приводится в новой книге М.В.Лукаса и А.Джуда ZFS для профессионалов (Mastery FreeBSD: Advanced ZFS). В частности, становятся понятными неудачи ранних тестирований NVMe: см., например, озор тестирования NVMe Андрея Кожемяко на iXBT.
Действительно, NVMe представляет собой совершенно новый интерфейс, призванный заменить собой SAS/SATA/SCSI для безшпиндельных устройств хранения. Вот некоторые основные преимущества NVMe:
-
Он полностью отказывается от представления данных в виде головки-цилиндры-сектора.
-
Вместо единственной очереди для AHCI, к тому же ограниченной 32-64 командами, NVMe поддерживает до 64k очередей по 64k команд в каждой! Это позволяет максимально загружать работой все имеющиеся в накопителе ячейки памяти с макимально доступным уровнем параллелизма!
-
Он выделяет пространство имён, делая возможной раздельную работу с ним и относящимися к нему данными. В NVMe уровня предприятия заявлена функциональность множественности разделяемых пространств имён, что предоставит дополнительные возможности роста производительности!
Исходя из этого, становится понятным, что новые интерфейсы устройств требуют новых подходов для построения оптимальных режимов работы. Прежде всего необходима грамотная организация достаточного числа (для организации загруженности NVMe устройства) очередей. А именно: предлагается создавать не менее одной очереди на чтения и одной очереди на запись для каждого доступного ядра ЦПУ. Следующий этап лежит в оптимозации размера блока. Для NVMe предначертано спецификацией применение блоков с максимально возможными размерами. Уже эти два мероприятия быстро дают выход на пики производительности, как это демонстрируют М.В.Лукас и А.Джуд в своей новой книге, см. наш перевод.}
{Прим. пер.: приведём таблицу оценки времён, необходимых для обмена данных объёмом в 4ТБ (условно говоря, выход из строя 6ТБ диска в системе с "приличной" загруженностью):
| Скорость обмена | Оценка необходимого времени |
|---|---|
HDD 130МБ/с |
9 часов |
HDD 240МБ/с |
5 часов |
SSD 455МБ/с |
2.5 часа |
SATA 6G |
1.5 часа |
SAS 12G |
45 минут |
SSD 2200МБ/с |
30 минут |
NVMe 3000МБ/с |
23 минуты |
PCIe v.3 8x lane |
8+2/3 минут |
PCIe v.3 16x lane |
4+1/3 минуты |
}
Ceph является определяемой программным обеспечением системой, которая работает поверх операционной системы на основании Linux. Ceph поддерживает большинство основных дистрибутивов Linux. На текущий момент допустимым выбором операционной системы для работы кластера Ceph являются RHEL, CentOS, Fedora, Debian, Ubuntu, OpenSuse и SLES. Что касается версии ядра Linux, рекомендуется чтобы вы выполняли равёртывание Ceph на последних редакциях ядра Linux. Мы также рекомендуем развёртывать её на редакциях с долговременной поддержкой (LTS, long-term support). На момент написания этой книги рекомендовались версии ядра Linux v3.16.3 или более поздние в качестве хорошей отправной точки. {Прим. пер.: на момент перевода рекомендуется применять ядро Linux v4.1.4 или более поздние.} Хорошей идеей будет заглянуть на http://docs.ceph.com/docs/master/start/os-recommendations. Согласно документации, CentoS 7 и Ubuntu 14.04 являются дистрибутивами 1 уровня, для которого выполнены исчерпывающие функциональные, регрессивные и нарузочные испытания соответствия на постоянной основе и, несомненно, RHEL является наилучшим выбором, если вы применяете продукт enterprise Red Hat Ceph Storage.
Демон OSD Ceph работает поверх файловой системы, которой может быть XFS, EXT4 или даже Btrfs. Однако выбор правильной файловой системы является критическим моментом, поскольку демоны OSD основываются на стабильности и производительности лежащей в их основе файловой системы. Помимо стабильности и производительности файловая система также предоставляет расширенные атрибуты (XATTR, extended attributes), преимуществами которых пользуются демоны OSD Ceph. XATTR предоставляют внутреннюю информацию о состоянии объекта, снимках, метаданны[, а также ACL вашему демону Ceph, который помогает в управлении данными.
Вот почему лежащая в основе файловая система должна предоставлять достаточную ёмкость для XATTR. Btrfs предоставляет значительно
больше метаданных xattr, которые хранятся с файлом. XFS имеет относительно большой предел (64kB),с которым большинство приложений
не столкнётся, однако ext4 слишком мал для применения. Если вы применяете файловую систему ext4 для вашего OSD Ceph, вы всегда
должны добавлять filestore xattr use omap = true в последующие настройки вашего файла
ceph.conf. Выбор файловой системы чрезвычайно важен для промышленных рабочих нагрузок,
а в отношении Ceph данные файловые системы отличаютсядруг от друга следующим:
-
XFS: Является надёжной, зрелой и очень стабильной файловой системой, которая рекомендуется для промышленного использования в кластерах Ceph. Тем не менее, XFS находится ниже при сравнении с Btrfs. XFS имеет некоторые проблемы с производительностью при масштабировании метаданных. Кроме того, XFS является файловой системой с журналированием, то есть, когда клиент отправляет данные для записи в кластер Ceph, они вначале записываются в пространство журнала, а уже потом в файловую систему XFS. Это в два раза увеличивает накладные расходы на запись и тем самым делает выполнение XFS медленнее в сравнении с Btrfs, которая не применяет журналы. Однако, благодаря своей надёжности и стабильности XFS является наиболее популярной и рекомендуемой файловой системой для реализаций Ceph.
-
Btrfs: OSD с файловой системой Btrfs в его основе предоставляет наилучшую производительность в сравнении с OSD на основе файловых систем XFS и ext4. Одним из основных преимуществ применения Btrfs состоит в её поддержке копирования при записи и снимков с поддержкой записи. При применении файловой системы Btrfs Ceph применяет параллельное ведение журналов, иными словами: Ceph записывает данные в соответствующий журнал OSD и собственно данные OSD одновременно, что является существенным усилением для производительности
write. Она также поддерживает прозрачные сжатие и всеобъемлющие контрольные суммы, а также она объединяет управление множеством устройств в файловой системе. Она также имеет привлекательный функционал FSCK в реальном масштабе времени. Тем не менее, Btrfs в настоящее время не готова к промышленному применению, однако является хорошим претендентом для тестового развёртывания. -
Ext4: Четвёртая расширенная файловая система также является файловой системой с журналированием, которая является готовой к промышленному применению для OSD Ceph. Однако она не так популярна как XFS. С точки зрения производительности ext4 находится далеко от Btrfs.
В этом рецепте мы изучим некоторые параметры настройки для кластера Ceph. Такие параметры всего кластера опеределяются в вашем
файле настроек кластера Ceph, следовательно, когда запускается какой-то демон Ceph, он будет соблюдать соответствующие настройки.
По умолчанию именем файла настроек является файл с именем ceph.conf, который размещён в каталоге
/etc/ceph. Этот файл настроек имеет раздел глобальных установок, а также некоторые разделы для
каждого типа служб. При запуске каждого типа служб он применяет заданные в разделе [global]
настройки, а также специфичные для определённого демона разделы. Файл настроек Ceph имеет различные разделы, что отображено на
следующем снимке экрана:
[global]
fsid = {UUID}
public network = 192.168.0.0/24
cluster network = 192.168.0.0/24
osd pool default pg num = 128
[mon]
[mon.alpha]
host = alpha
mon addr = 192.168.0.10:6789
[mds]
[mds.alpha]
host = alpha
[osd]
osd recovery max active = 3
osd max backfills = 5
[osd.0]
host = delta
[osd.1]
host = epsilon
[client]
rbd cache = true
[client. radosgw.gateway]
host = ceph-radosgw
Теперь мы обсуждаем роль каждого раздела файла настроек.
-
Global section: Общий раздел файла настроек вашего кластера начинается с ключевого слова
[global]. Все определённые в этом разделе настройки применяются ко всем демонам в данном кластере Ceph. Ниже приводятся параметры, определяемые в разделе[global].public network = 192.168.0.0/24
-
раздел Monitor section: Определённые в разделе
[mon]файла настройки в разделе конфигураций применяются ко всем демонам монитора Ceph в вашем кластере. Определённые в этом разделе параметры переопределяются параметрами, определёнными в разделе[global]. Далее приводится пример параметров, обычно определяемых в вашем разделе[mon].mon initial members = ceph-mon1
-
Раздел OSD: Настройки, определяемые в разделе
[osd]применяются ко всем демонам OSD в вашем кластере OSD. Определяемые в этом разделе настройки аналогичны установкам, перезаписывающим аналогичные настройки, определённые в разделе в разделе[global]. Далее приводится пример установок в данном разделе:osd mkfs type = xfs
-
Раздел MDS: Настройки, определяемые в разделе
[mds]применяются ко всем демонам MDS в вашем кластере Ceph. Определяемые в этом разделе настройки переопределяют аналогичные настройки, определённые в разделе в разделе[global]. Далее приводится пример установок в данном разделе:mds cache size = 250000
-
Раздел Client: Настройки, определяемые в разделе
[client]применяются ко всем вашим клиентам Ceph. Определяемые в этом разделе настройки переопределяют аналогичные настройки, определённые в разделе в разделе[global]. Далее приводится пример установок в данном разделе:rbd cache size = 67108864
В следующем рецепте мы изучим некоторые советы по тонкой настройке производительности вашего кластере Ceph. Настройка производительности является безбрежной темой требующей понимания Ceph а также других компонентов стека хранения. Не существует серебряной пули для настройки производительности. Тюнинг во многом зависит от лежащих в основе инфраструктуры и среды.
Общие параметры должны быть определены в разделе [global] вашего файла настроек
кластера Ceph:
-
network: вам рекомендуется применять две физически разделённые сетевые среды для вашего кластера Ceph, которые называются соответственно общедоступной (public) и кластерной (cluster) сетевыми средами. Ранее в этой главе мы уже обсуждали потребность в двух различных сетевых средах. Давайте теперь разберёмся как мы можем определять их в настройках Ceph.-
Общедоступная сетевая среда: для определения общедоступной сетевой среды применяется такой синтаксис:
public network = {public network / netmask}:public network = 192.168.100.0/24
-
Сетевая среда кластера: для определения общедоступной сетевой среды применяется такой синтаксис:
cluster network = {cluster network / netmask}:cluster network = 192.168.1.0/24
-
-
max open files: Если этот параметр находится на месте и кластер Ceph запускается, он устанавливает максимальное число дескрипторов открытых файлов на уровне ОС. Это предотвращает выход демонов OSD за установленные пределы для дескрипторов файлов. Значением по умолчанию для этого параметра является0{Прим. пер.: без ограничения}; вы можете установить его в значение 64- битного целого:max open files = 131072
-
osd pool default min size: это уровень репликаций при состоянии деградации. Он устанавливает минимальное число реплик для объектов в пуле которые должны подтверждать операцию клиентовwrite. По умолчанию установлено значение0{Прим. пер.: все}:osd pool default min size = 1
-
osd pool default pgиosd pool default pgp: Убедитесь что ваш кластер реалистичное число групп размещения. Рекомендуемое значение групп размещения на OSD равно 100. Для вычисления числа групп размещений применяйте следующую формулу:(Total number of OSD * 100)/number of replicas.Для варианта с 10 OSD при 3 репликах значение для PG должно быть равно
(10*100)/3 = 333:osd pool default pg num = 128 osd pool default pgp num = 128
Как мы уже объясняли ранее, значения PG и PGP должны устанавливаться одинаковыми. Ваши значения PG и PGP очень сильно зависят от размера кластера. Приведённые ранее настройки не должны повредить ваш кластер, однако вы можете пересмотреть эти значения перед применением. Вам следует знать, что эти параметры не изменяют число PG и PGP для существующих пулов; они применяются при создании нового пула без задания значений для PG и PGP.
-
osd pool default min size: Это значение уровня репликаций в деградировавшем состоянии, которое должно быть установлено в значение ниже чемosd pool default size. Оно устанавливает минимальное число реплик для объектов пула и тем самым сможет подтверждать операцииwriteдаже при деградации кластера. Если текущее значение минимального размера не соответствует установленному значению, Ceph не будет подтверждатьwriteклиенту:osd pool default min size = 1
-
osd pool default crush rule: Набор правил CRUSH по умолчанию для применения при создании пула:osd pool default crush rule = 0
-
Запрет ведения журналов в памяти: Каждая подсистема имеет уровень ведения журналов для выдаваемых ею регистрационных записей, и они ведутся в оперативной памяти. Мы можем устанавливать различные значения для каждой из этих подсистем устанавливая уровень файла журнала и уровень памяти для отладочного ведения журналов по шкале от 1 до 20, где 1 это краткий (terse), а 20 - подробный (verbose). Первой установкой является уровень журнала, а второй - уровень памяти. Вы можете разделять их прямым слешем (/):
debug_<subsystem> = <log-level>/<memory-level>.Установленные по умолчанию значения обычно приемлемы для вашего кластера, пока вы не замечаете, что уровень регистрируемых в памяти записей журналов влияет на вашу производительность или потребление памяти. В этом случае вы можете попробовать запретить ведение журналов в памяти. Для запрета установленных по умолчанию значений ведения журналов в памяти добавьте следующие параметры:
debug_lockdep = 0/0 debug_context = 0/0 debug_crush = 0/0 debug_buffer = 0/0 debug_timer = 0/0 debug_filer = 0/0 debug_objecter = 0/0 debug_rados = 0/0 debug_rbd = 0/0 debug_journaler = 0/0 debug_objectcatcher = 0/0 debug_client = 0/0 debug_osd = 0/0 debug_optracker = 0/0 debug_objclass = 0/0 debug_filestore = 0/0 debug_journal = 0/0 debug_ms = 0/0 debug_monc = 0/0 debug_tp = 0/0 debug_auth = 0/0 debug_finisher = 0/0 debug_heartbeatmap = 0/0 debug_perfcounter = 0/0 debug_asok = 0/0 debug_throttle = 0/0 debug_mon = 0/0 debug_paxos = 0/0 debug_rgw = 0/0
Настройка параметров монитора должна выполняться в разделе [mon] вашего файла настройки
кластера Ceph:
-
mon osd down out interval: Определяет число секунд, которое Ceph ожидает прежде чем пометить OSD Ceph как "down" и "out" если они не отвечают. Этот параметр понадобится когда ваши узлы OSD претерпят аварию и перезагрузятся самостоятельно или после некоторого краткосрочного сбоя в сетевой среде. Вы не захотите чтобы ваш кластер приступал к перебалансировке сразу при возникновении проблемы, а скорее подождёте несколько минут и посмотрите не исправится ли эта проблема:mon_osd_down_out_interval = 600
-
mon allow pool delete: Во избежание случайного удаления пула Ceph установите этот параметр в значениеfalse. Это может быть полезно если у вас много администраторов управляющих кластером Ceph и вы не хотите принимать никакие риски для данных клиента:mon_allow_pool_delete = false
-
mon osd min down reporters: OSD демон Ceph может сообщать MON о своих одноранговых OSD в случае их отключения; по умолчанию это значение равно1. При помощи этого параметра вы можете изменять минимальное число демонов OSD Ceph необходимое для генерации отчёта об отключении OSD Ceph монитору Ceph. В большом кластере рекомендуется иметь это значение выше установленного по умолчанию; значение3должно быть приемлемым:mon_osd_min_down_reporters = 3
В этом рецепте мы дадим представление об общей настройке параметров OSD, которые должны определяться в разделе
[osd] вашего файла настройки кластера Ceph:
Общие установки OSD
Следующие настройки позволяют демону OSD Ceph определять тип файловой системы, параметры монтирования, а также некоторые другие полезные установки:
-
osd mkfs options xfs: При создании OSD Ceph применит эти параметры xfs для создания своей файловой системы OSD:osd_mkfs_options_xfs = "-f -i size=2048"
-
osd mount options xfs: Предоставляет параметры монтирования файловой системы xfs для OSD. Когда Ceph монтирует некое OSD, она будет использовать следующие параметры для монтирования файловой системы OSD:osd_mount_options_xfs = "rw,noatime,inode64,logbufs=8,logbsize=256k,delaylog,allocsize=4M"
-
osd max write size: Максимальный размер данных в мегабайтах, которые OSD может записывать за раз:osd_max_write_size = 256
-
osd client message size cap: Наибольшее сообщение клиентских данных в байтах, допускаемое в оперативной памяти:osd_client_message_size_cap = 1073741824
-
osd map dedup: Удалять дублирующиеся записи в карте OSD:osd_map_dedup = true
-
osd op threads: Число потоков для обслуживания работы демона OSD Ceph. Установка значения в0запрещает его. Увеличение данного значения может увеличить скорость обработки запросов:osd_op_threads = 16
-
osd disk threads: Число потоков дисков которые применяются для выполнения фоновой работы интенсивного дискового обмена такого как очистка (scrubbing) и подрезка снимка (snap trimming):osd_disk_threads = 1
-
osd disk thread ioprio class: Применяется совместно сosd_disk_thread_ioprio_priority. Эта регулировка может изменять класс расписаний вашего ввода/ вывода дискового потока и может работать только с планировщиками CFQ. Возможными значениями являютсяidle,beилиrt:-
idle: Ваши дисковые потоки будут иметь более низкий приоритет чем прочие потоки в ваших OSD. Это полезно когда вы хотите замедлить свою очистку в некотором OSD, который занят обработкой клиентских запросов. -
be: Дисковые потоки имеют тот же приоритет, что и прочие потоки в этом OSD. -
rt: Дисковые потоки будут иметь больший приоритет чем все прочие потоки. Это полезно когда очень нужна очистка и она может иметь приоритет за счёт работы клиента.osd_disk_thread_ioprio_class = idle
-
osd disk thread ioprio priority: Применяется совместно с
osd_disk_thread_ioprio_class. Эта регулировка может изменять приоритет вашего планировщика
ввода/ вывода дискового потока от 0 (наивысший) до
7 (наинизший). Если все OSD на данном хосте находятся в классе
idle и соперничают за ввод/ вывод и не выполняют много операций, этот параметр может быть
применён для замедления приоритета потока диска одного OSD до 7, таким образом, что другой
OSD с приоритетом 0 может выполнить очистку быстрее. Как и
osd_disk_thread_ioprio_class, это также работает только с планировщиком CFQ ядра Linux.
osd_disk_thread_ioprio_priority = 0
Установки журнала OSD
Демоны OSD Ceph поддерживают следующие настройки журнала:
-
osd journal size: Значение Ceph этого параметра по умолчанию равно0; вам следует применять параметрosd_journal_sizeдля установки размера журнала. Размер журнала должен быть по крайней мере удвоенным произведением ожидаемой скорости диска и максимального интервала сохранения файлов. Если вы используете журналы SSD, обычно хорошо создавать журналы более 10ГБ и увеличивать минимальный/ максимальный интервал синхронизации сохранения файлов:osd_journal_size = 20480
-
journal max write bytes: Максимальное число байт, которое журнал может записать за раз:journal_max_write_bytes = 1073714824
-
journal max write entries: Максимальное число элементов, которое журнал может записать за раз:journal_max_write_entries = 10000
-
:journal queue max ops: Максимальное число разрешённых в очереди журнала операций в данное время:journal_queue_max_ops = 50000
-
:journal queue max bytes: Максимальное число байт разрешённых в очереди журнала в данное время:journal_queue_max_bytes = 10485760000
-
journal dio: Разрешение операций прямого ввода/ вывода в журнал. Требует установления в значениеtrueпараметраjournal block align:journal_dio = true
-
journal aio: Разрешает применение libaio для асинхронной записи в журнал. Требует установленияjournal dioв значениеtrue:journal_aio = true
-
journal block align: Блочно выравнивает операцииwrite. Требуется дляdioиaio.
Установки сохранения файлов OSD
Существует несколько установок сохранения файлов, которые могут быть настроены для ваших демонов OSD Ceph:
-
filestore merge threshold: Разрешает применение libaio для асинхронной записи в в ваш журнал. Требует чтобыjournal dioбыл установлен в значениеtrue:filestore_merge_threshold = 40
-
filestore split multiple: Максимальное число файлов в подкаталоге перед расщеплением на два дочерних каталога:filestore_split_multiple = 8
-
filestore op threads: Число потоков операций файловой системы которые выполняются одновременно:filestore_op_threads = 32
-
filestore xattr use omap: Применяет карту объектов для XATTRS (расширенных атрибутов). Требует установки в значениеtrueдля файловой системыext4:filestore_xattr_use_omap = true
-
filestore sync interval: Чтобы создать непротиворечивую точку фиксации, сохранение файлов требует заморозить операцииwriteи выполнить операциюsyncfs(), которая синхронизирует данные журнала с данными раздела и тем самым освободит этот журнал. Более частое выполнение операций синхронизации уменьшает объём данных, сохраняемых в журнале. В этом случае журнал становится недоиспользованным. Настройка на менее частые синхронизации позволяет файловой системе лучше объединять малые записи и мы можем получить улучшение производительности. Следующие параметры определяют минимальный и максимальный периоды между двумя синхронизациями:filestore_min_sync_interval = 10 filestore_max_sync_interval = 15
-
filestore queue max ops: Максимальное число операций, которое сохранений файлов может принять перед блокированием новых операций для их присоединения к очереди:filestore_queue_max_ops = 2500
-
filestore queue max bytes: Максимальное число байт в одной операции:filestore_queue_max_bytes = 10485760
-
filestore queue committing max ops: Максимальное число операций, которое может фиксировать сохранение файлов:filestore_queue_committing_max_ops = 5000
-
filestore queue committing max bytes: Максимальное число байт, которое может фиксировать сохранение файлов:filestore_queue_committing_max_bytes = 10485760000
Установки восстановления OSD
Эти установки должны применяться когда вам нужна производительность вместо восстанавливаемости или наоборот. Если ваш кластер Ceph испытывает проблемы с жизнеспособностью и находится в процессе восстановления, вы можете не получать его обычной производительности, поскольку OSD будут заняты восстановлением. Если вы всё же предпочитаете производительность над восстанавливаемостью, вы можете уменьшить приоритет восстановления для сохранения меньшей занятости OSD восстановлением. Вы также можете устанавливать эти значения если вы хотите более быстрого восстановления вашего кластера, помогая OSD выполнять восстановление быстрее.
-
osd recovery max active: Число активных запросов восстановления на OSD на определённый момент времени:osd_recovery_max_active = 1
-
osd recovery max single start: Применяется совместно сosd_recovery_max_active. Чтобы понять механизм, предположим, чтоosd_recovery_max_single_startустановлено в значение1, аosd_recovery_max_activeравно3. В данном случае это означает, что OSD запустит максимально одну операцию восстановления за раз, в то время, когда активны в сумме три операции:osd_recovery_max_single_start = 1
-
osd recovery op priority: Установка приоритета для операции восстановления. Чем ниже число,тем выше приоритет восстановления:osd_recovery_op_priority = 50
-
osd recovery max chunk: Максимальный размер порции восстановления данных в байтах:osd_recovery_max_chunk = 1048576
-
osd recovery threads: Число потоков, необходимое для восстановления данных:osd_recovery_threads = 1
Установки заполнения OSD
Настройки наполнения OSD позволяют устанавливать операции заполнения на более низкую приоритетность чем read
и write
.
-
osd max backfills: Максимальное число заполнений разрешённое к или от одного OSD:osd_max_backfills = 2
-
osd backfill scan min: Минимальное число объектов на сканирование заполнения:osd_backfill_scan_min = 8
-
osd backfill scan max: Максимальное число объектов на сканирование заполнения:osd_backfill_scan_max = 64
Установки очистки OSD
Очистка OSD важна для поддержки целостности данных, однако она может уменьшать производительность. Вы можете выравнивать следующие установки для увеличения или уменьшения операций очистки:
-
osd max scrubs: Максимальное число одновременных операций очистки для одного демона OSD Ceph:osd_max_scrubs = 1
-
osd scrub sleep: Время в секундах которое очистка выжидает между двумя последовательными чистками:osd_scrub_sleep = .1
-
osd scrub chunk min: Минимальное число фрагментов данных с которыми OSD должно выполнять:osd_scrub_chunk_min = 1
-
osd scrub chunk max: Максимальное число фрагментов данных с которыми OSD должно выполнять очистку:osd_scrub_chunk_max = 5
-
osd deep scrub stride: Размерreadв байтах при выполнении глубокой очистки:osd_deep_scrub_stride = 1048576
-
osd scrub begin hour: Самый ранний час, когда очистка может быть начата. Применяется совмесно сosd_scrub_end_hourдля определения временного окна очистки:osd_scrub_begin_hour = 19
-
osd scrub end hour: Самый поздний час, когда очистка может выполняться. Работает совмесно сosd_scrub_begin_hourдля определения временного окна очистки:osd_scrub_end_hour = 7
Настройка клиента
Параметры настройки клиента должны быть определены в разделе [client] вашего файла настроек Ceph.
Обычно этот раздел [client] также должен присутствовать в файле настроек Ceph, размещённом на узле
клиента:
-
rbd cache: Разрешает кэширование для RADOS Block Device (RBD):rbd_cache = true
-
rbd cache writethrough until flush: Запускается в режимеwrite-throughи переключается наwritebackпосле принятия первого запроса на сброс:rbd_cache_writethrough_until_flush = true
-
rbd concurrent management ops: Число одновременных операций управления которые могут выполняться вrbd:rbd_concurrent_management_ops = 10
-
rbd cache size: Размер кэшаrbdв байтах:rbd_cache_size = 67108864 #64M
-
rbd cache max dirty: Предел в байтах, при котором кэш должен переключаться наwriteback. Должен быть меньше чемrbd_cache_size:rbd_cache_max_dirty = 50331648 #48M
-
rbd cache target dirty: Изменение получателя перед тем, как кэш начнёт записывать данные в лежащее в основе хранилище:rbd_cache_target_dirty = 33554432 #32M
-
rbd cache max dirty age: Число секунд, которое изменённые данные могут находиться в кэше перед запускомwriteback:rbd_cache_max_dirty_age = 2
-
rbd default format: Применяет второй форматrbd, который поддерживается librbd и ядром Linux начиная с версии 3.11. Добавляет поддержку для клонирования и более просто расширяется, допуская больше функциональности в будущем:rbd_default_format = 2
Настройка операционной системы
В предыдущих рецептах мы рассматривали параметры настройки для Ceph MON, OSD и клиентов. В данном рецепте мы рассмотрим ряд общих параметров настройки, которые могут быть применены к операционной системе.
-
kernel pid max: Это параметр ядра Linux который отвечает за максимальное число потоков и идентификаторов процессов. По умолчанию ядро Linux относительно небольшое значениеkernel.pid_max. Вам следует настроить этот параметр на большее значение на узлах Ceph размещающих множество OSD, обычно, более 20 OSD. Эта установка поможет породить множество потоков для более быстрого восстановления и перебалансировки. Для применения этого параметра выполните следующую команду от имени пользователя root:# echo 4194303 > /proc/sys/kernel/pid_max
-
file max: Максимальное число открытых файлов в системе Linux. Обычно неплохо иметь большее значение этого параметра:# echo 26234859 > /proc/sys/fs/file-max
-
Jumbo frames: Фреймы Ethernet с более чем 1500 байт полезной информации MTU называются фреймами Jumbo. Разрешение таких фреймов во всех используемых Ceph и для кластера, и для клиентов интерфейсах сетевой среды должно улучшать пропускную способность и общую производительность сети.
Фреймы Jumbo должны быть разрешены на хосте а также стороне коммутатора сетевой среды, в противном случае несоответствие в размере MTU приведёт к потере пакетов. Для разрешения фреймов jumbo в вашем интерфейсе
eth0выполните следующую команду:# ifconfig eth0 mtu 9000
Кроме того, вы должны сделать это для других интерфейсов, которые принимают участие в сетевой среде Ceph. Чтобы сделать эти замены постоянными, вам следует добавить эти настройки в файл конфигурации интерфейса.
-
Disk read_ahead: Параметрread_aheadускоряет операцию дисковогоreadпредварительной выборкой данных и загрузкой их в оперативную память. Установка относительно более высокого значенияread_aheadдаёт преимущество клиентам, выполняющим операции последовательногоread.Давайте предположим, что диск
vdaявляется RBD, который смонтирован на узле клиента. Воспользуйтесь следующей командой для проверки его значенияread_ahead, которое является установленным по умолчанию в большинстве случаев:# cat /sys/block/vda/queue/read_ahead_kb
Чтобы установить
read_aheadв большее значение, то есть 8МБ для RBDvda, выполните следующую команду:# echo "8192" > /sys/block/vda/queue/read_ahead_kb
Настройка
read_aheadприменяется на клиентах Ceph которые используют смонтированные RBD. Для получения повышения производительностиreadвы можете установить его на несколько МБ, в зависимости от ваших аппаратных средств, причём на всех устройствах RBD. -
Virtual memory: Из-за сильно загруженного профиля ввода/ вывода применение подкачки может повлечь в целом к получению недоступности сервера. Для высоких рабочих нагрузок ввода/ выода рекомендуется более низкое значение
swappiness. Установитеvm.swappinessв ноль в/etc/sysctl.confдля предотвращения подобного:echo quot;vm.swappiness=0" >> /etc/sysctl.conf
-
min_free_kbytes: Определяет минимальное число килобайт оставляемых свободными в файловой системе. Вы можете сохранить от 1 до 3% общей системной памяти свободной применивmin_free_kbytesс помощью выполнения следующей команды:# echo 262144 > /proc/sys/vm/min_free_kbyt
-
I/O Scheduler: Linux предоставляет нам возможность выбора планировщика ввода/ вывода и он также может быть изменён без перезагрузки. Он предоставляет три параметра для планировщиков ввода/ вывода, а именно:-
Deadline: Планировщик ввода/ вывода Deadline заменяет CFQ как применяемый по умолчанию в Red Hat Enterprise Linux 7 и его производных, а также в Ubuntu Trusty. Планировщик Deadline предпочитает чтение перед записью посредством применения отдельных очередей ввода/ вывода для каждого. Этот планировщик удобен для большинства вариантов применения, однако в особенности для тех, при которых операции
readпроисходят чаще операцийwrite. Выстроенные в очередь запросы на ввод/ вывод сортируются в пакетыreadиwriteа затем планируются для выполнения в порядке возрастания LBA. Пакетыreadимеют преимущество перед пакетамиwriteпо умолчанию, поскольку приложения более вероятно блокируют ввод/ выводread. Для рабочих нагрузок OSD Ceph планировщик ввода вывода Deadline выглядит многообещающим. -
CFQ: Планировщик полностью справедливых очередей (CFQ, Completely Fair Queuing) был планировщиком по умолчанию в Red Hat Enterprise Linux (4, 5 и 6) и его производных. Планировщик по умолчанию применяется только к устройствам, определяемым как диски SATA. Планировщик CFQ делит процессы натри различных класса: реального времени (real time), наилучших усилий (best efforts) и незанятых (idle). Процессы в классе реального времени всегда выполняются до процессов класса наилучших усилий, которые, в свою очередь, всегда выполняются до процессов класса незанятых. Это означает, что процессы класса реального времени могут заморозить время ЦПУ и для процессов наилучших усилий, и для незанятых процессов. По умолчанию процессы назначаются в класс наилучших усилий.
-
Noop: Планировщик Noop реализует алгоритм простейшего планирования первый- пришёл- первый- выполнен (FIFO, first-in first-out). Запросы объединяются в общий блок уровня простым кэшем последнего попадания. Он может быть наилучшим планировщиком для систем с ограниченными возможностями ЦПУ, использующими быстрые хранилища. Для SSD планировщик ввода/ вывода Noop может уменьшить латентность ввода/ вывода и увеличить пропускную способность, а также исключить затраты ЦПУ на переупорядочение запросов ввода/ вывода. Этот планировщик обычно хорошо работает с SSD, виртуальными машинами и даже с платами NVMe. Таким образом, планировщик ввода/ вывода Noop может быть хорошим выбором для дисков SSD, применяемых для журналов SSD.
Выполните следующую команду для определения планировщика ввода/ вывода дискового устройства
sdaпо умолчанию. Планировщик по умолчанию должен быть заключён в []:# cat /sys/block/sda/queue/scheduler
Измените планировщика ввода/ вывода дискового устройства
sdaпо умолчанию на Deadline:# echo deadline > /sys/block/sda/queue/scheduler
Измените планировщика ввода/ вывода дискового устройства
sdaпо умолчанию на Noop:# echo noop > /sys/block/sda/queue/scheduler
-
-
I/O Scheduler queue: Размер очереди по умолчанию установлен в значение128. Очередь планировщика сортируется и записывается с целью оптимизации последовательного ввода/ вывода и уменьшения времени позиционирования. Изменение глубины очереди до1024может увеличить соотношение выполняемого дисками последовательного ввода/ вывода и улучшить общую пропускную способность.Для проверки глубины планирования блочного устройства
sdaвоспользуйтесь следующей командой:# cat /sys/block/sda/queue/nr_requests
Для увеличения глубины планирования до
1024примените:# echo 1024 > /sys/block/sda/queue/nr_requests
В Ceph механизмом защиты данных по умолчанию являются репликации. Он испытан и является одним из самых популярных методов защиты данных. Однако изнанкой репликаций является то, что она требует удвоения вашего объёма пространства хранения для предоставления избыточности. Например, если вы планируете построить решение хранения с 1ПБ используемой ёмкости с фактором репликаций равным трём, то вам понадобится 3ПБ сырой ёмкости хранения для 1ПБ используемой ёмкости, то есть, 200% или более. Таким образом, при механизме репликаций значительно возрастает стоимость за гигибайт системы хранения. Для небольшого кластера вы можете игнорировать накладные расходы репликаций, однако для больших сред они становятся значительными.
Начиная с редакции Ceph Firefly был введён другой метод защиты данных, называемый удаляющим кодированием (erasure coding).
Этот метод защиты данных совершенно отличается от метода репликаций. Он гарантирует, защищённость данных разбиением каждого
объекта на фрагменты меньшего размера, называемые порциями данных (data chunk), и в конце концов сохраняя все эти порции в
различных зонах отказа (failure zone) кластера Ceph. Концепция удаляющего кодирования вращается вокруг уравнения
n = k + m. Что объясняется так:
-
k: Это число фрагментов, на который поделён оригинальный объект; также называется порциями данных. -
m: Это дополнительный код, добавляемый к первоначальным порциям данных, для обеспечения защиты данных; также называемые порциями кодирования Для более простого понимания, вы можете рассматривать их как уровень вашей надёжности. -
n: Это общее число порций, создаваемое в процессе кодирования.
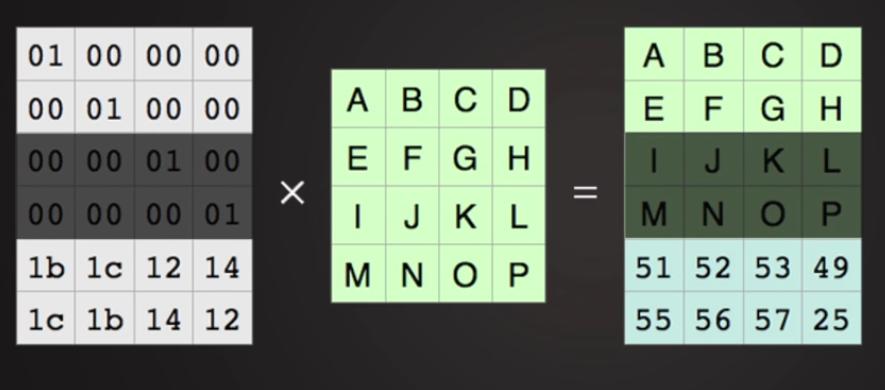
{ Прим. пер.: Метод удаляющего кодирования основывается на
методе Рида- Соломона, демонстрирующегося в видео
Примера удаляющего кодирования Рида- Соломна.
Вкратце, в виде слайдшоу (один элемент данных является байтом):
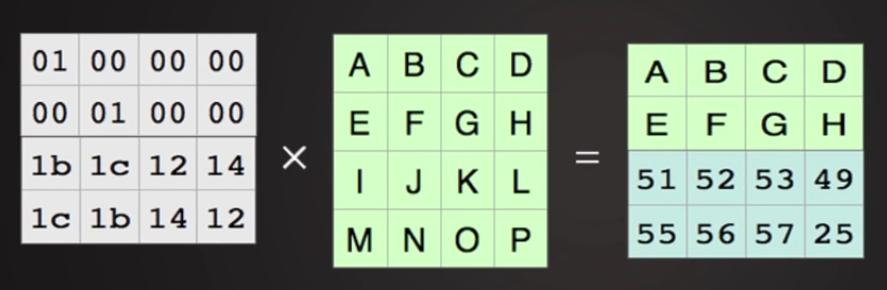
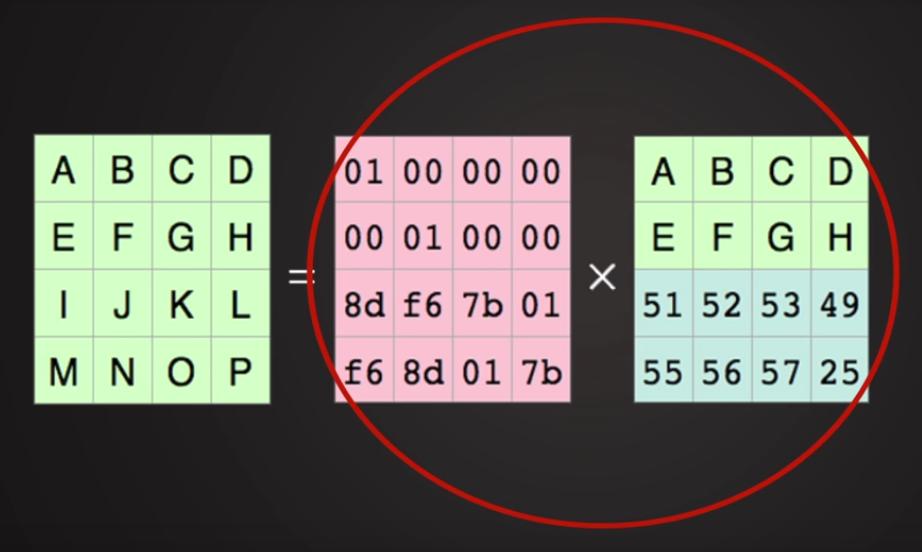
Рисунок 8.7. Теперь воспользуемся магией математики. Рисунок 8.11. Единичная матрица: Рисунок 8.12. Умножим единичную матрицу на исходные данные: Рисунок 8.14. Вернёмся к нашим фрагментам:
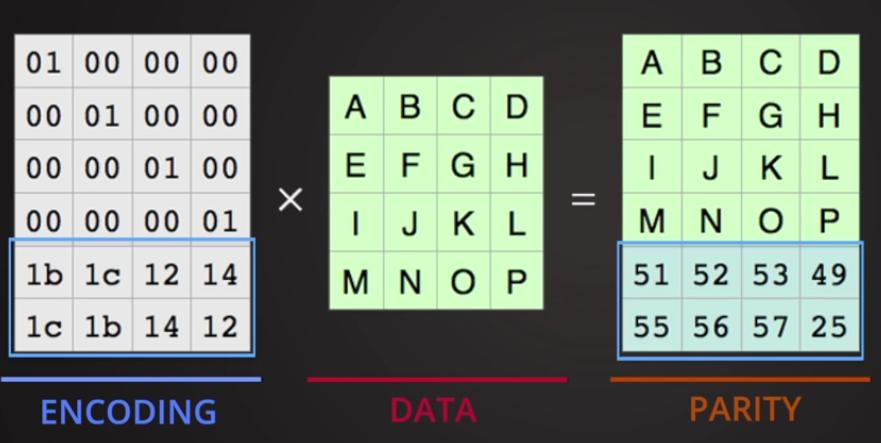
Перемножим две матрицы: кодирующую и исходные данные для получения дополнительных кодированных данных
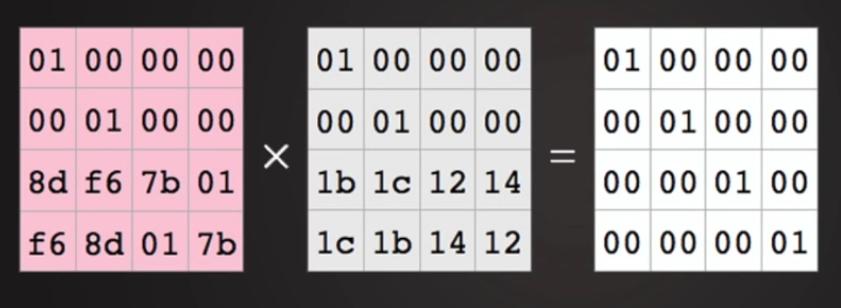
Вспоминаем матричную алгебру: розовая матрица является обратной для нашей кодирующей матрицы.
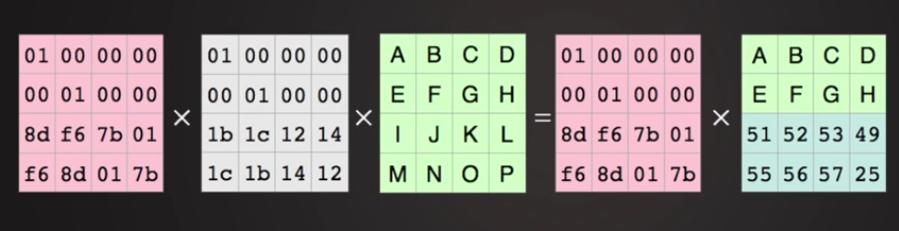
Учитываем результат умножения Рисунка 8.10.
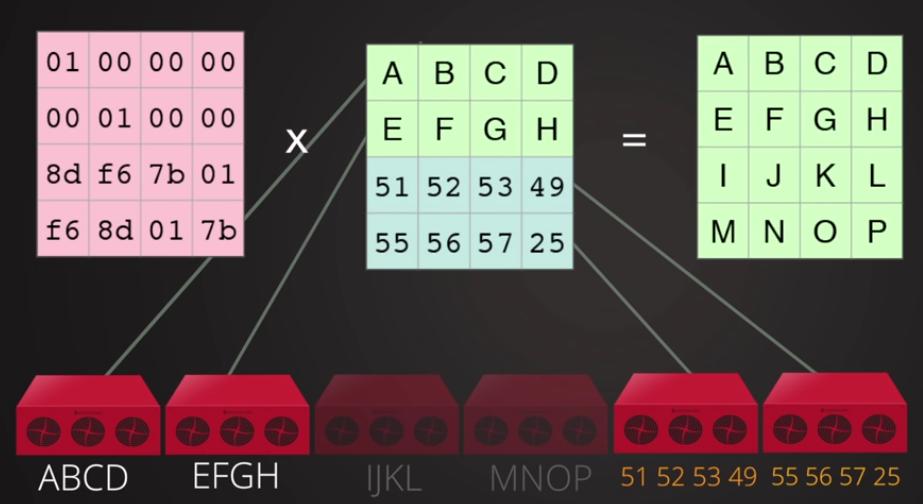
и наложим на них нашу матричную алгебру. Утратив две средние порции мы всё ещё восстанавливаем исходные данные!
Можно проверить: это сохраняется при утрате ЛЮБЫХ двух порций.
}
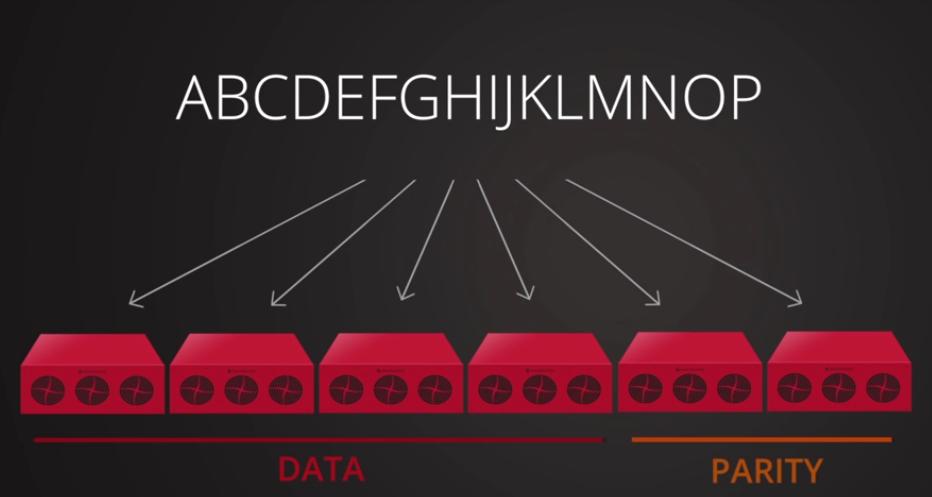
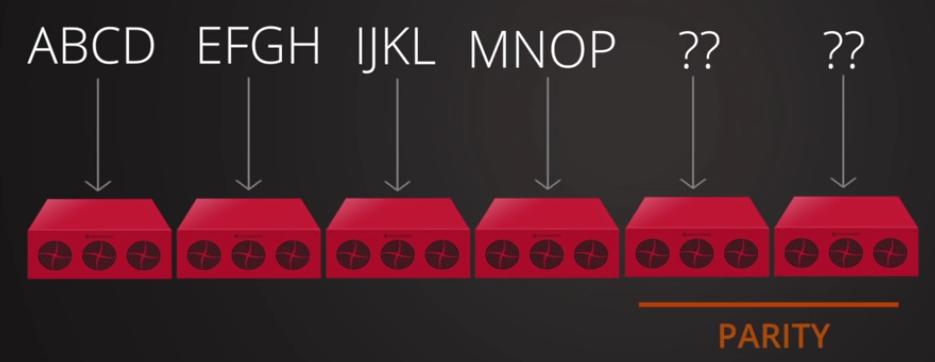
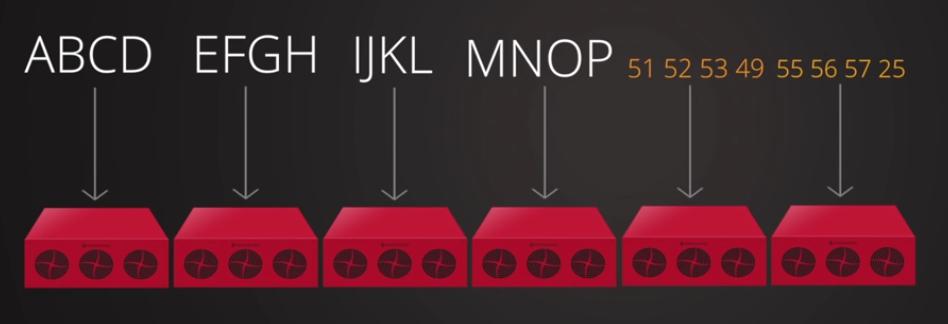
Основываясь на приведённом ранее уравнении, каждый объект в пуле удаляющего кодирования будет сохраняться в виде
k + m порций, причём каждая порция сохраняется в уникальном OSD с действующим набором.
Таким образом, все ваши порции объекта распределяются по всему кластеру Ceph предоставляя более высокую степень надёжности.
Теперь давайте обсудим некоторые полезные термины, относящиеся к удаляющему кодированию:
-
Восстановление(Recovery): На момент восстановления нампонадобятся любыеkпорций (chunk) из {имевшихся}nдля восстановления ваших данных. -
Уровень отказоустойчивости(Reliability level): При удаляющем кодировании Ceph может вынести утрату доmпорций. -
Соотношение кодирования (r)(Encoding Rate): Может быть определено согласно формулеr = k / n, где r меньше 1. -
Необходимый обёъм хранения(Storage required): Может быть определено согласно формуле1 / r.
Для лучшего понимания этих терминов давайте рассмотрим пример. Пул Ceph создаётся с пятью OSD на основе правила
erasure code (3, 2). Каждый сохраняемый в пуле объект буедет делиться на
множество и кодировать порции в соответствии с формулой: n = k + m.
Положим 5 = 3 + 2, тогда n = 5, k = 3,
а m = 2. Таким образом, каждый объект будет делиться на три порции данных и к
нему будут добавляться две дополнительные порции удаляющего кодирования, делая в сумме пять порций, которые будут распределённо
сохраняться в пяти OSD пула удаляющего кодирования кластера Ceph. При возникновении отказа для построения исходного файла нам
нужно (k порций), три фрагмента из пяти
(n порций) для восстановления. Таким образом, мы можем допустить
отказ любых (m) двух OSD, поскольку данные могут быть восстановлены с
применением трёх OSD.
-
Соотношение кодирования(Encoding Rate, r) = 3 / 5 = 0.6 < 1 -
Необходимый обёъм хранения(Storage required) = 1 / r = 1 / 0.6 = 1.6 размеров исходного файла.
Давайте предположим, что существует файл размером 1ГБ. Для хранения этого файла в кластере Ceph в пуле удаляющего кодирования (3, 5) вам понадобится 1.6ТБ пространства хранения, причём он предоставит вам хранение файла устойчивое к отказам двух OSD.
В отличие от метода репликаций, при котором если файл хранится в пуле с репликациями, то для предоставления устойчивости пула к отказу двух OSD, Ceph понадобится пул с размеров реплики 3, что в конечном итоге потребует 3ГБ пространства хранения для надёжного хранения файла размером в 1ГБ. Таким образом, мы можем уменьшить стоимость хранения приблизительно на 40 процентов с применением функциональности удаляющего кодирования Ceph при получении тойже отказоустойчивости, что и в случае репликаций.
Пулы удаляющего кодирования требуют меньшее пространство хранения по сравнению с пулами репликаций, однако, такое сбережение пространства хранения происходит за счёт стоимости производительности, поскольку процесс удаляющего кодирования подразделяет каждый объект на множество более мелких порций данных и некоторых вычисляемых порций перемешиваемых с этими порциями данных. В конечном итоге эти порции сохраняются в различных зонах отказа (failure zone) кластера Ceph. Весь этот механизм требует немного больше вычислительной мощности от узлов OSD. Более того, на момент восстановления декодирование порций данных также требует множества вычислений. Поэтому вы можете найти механизм хранения данных удаляющим кодированием несколько более медленным чем механизм репликаций. Удаляющее кодирование во многом зависит от вариантов использования и вы можете получить очень многого от удаляющего кодирования на основании требований вашего хранения данных.
{Прим. пер.: Ситуация с требованиями к ресурсам ЦПУ со стороны удаляющего кодирования стремительно меняется. Перечислим некоторые технологии решающие эту проблему:
-
SHEC, Shingled Erasure Code(Черепичное удаляющее кодирование, см. обзор ниже , а также переводы рабочих материалов и статьи авторов метода) позволяет применять вычисления к частям сохраняемых объектов, что в разы снижает накладные расходы на вычисления при сохранении уровня эффективности использования пространства на тех же значениях, что и при оригинальном удаляющем кодировании. -
Lazy Means Smart(Интеллектуальные средства задержки, см. переводы рабочих материалов) позволяет снижать в разы нагрузку на пропускную способность сети и вычисления за счёт группирования дисковых операций. -
Аппаратная поддержка EC в ConnectX-4анонсированная 02 февраля 2016 позволит практически полностью решить проблему загрузки ЦПУ удаляющим кодированием подробнее ...
}
Ceph предоставляет нам параметры выбора встраиваемого модуля (плагина) удаляющего кодирования при создании профиля вашего удаляющего кодирования. {Прим. пер.: вы легко можете создать свой собственный встраиваемый модуль.} Можно создать множество профилей удаляющего кодирования, причём вкаждом случае можно использовать различные встраиваемые модули. Для удаляющего кодирования Ceph поддерживает следующие модули:
-
Jerasure erasure code plugin: Встраиваемый модуль Jerasure является наиболее общим и гибким. Он также является применяемым по умолчанию для пула удаляющего кодирования Ceph. Встраиваемый модуль Jerasure инкапсулирует библиотеку Jerasure. Jerasure применяет технику кода Рида Соломона. Следующая схема иллюстрирует
Jerasure Code (3, 2). Как уже объяснялось, вначале данные делятся на три порции и добавляются две вычисляемые (coded) порции, а в конце концов они сохраняются в своей уникальной зоне отказа (failure zone) вашего кластера Ceph:
Применяя встраиваемый модуль Jerasure, при сохранении удаляюще кодированного объекта во множестве OSD, восстановление из одного OSD требует чтения из всех остальных. Например, если Jerasure настроен с
k = 3иm = 2, потеря одного OSD потребует чтения из пяти OSD для восстановления, что не очень эффективно в процессе регенерации. -
Locally repairable erasure code plugin: Поскольку удаляющее кодирование Jerasure (Рида Соломона) было не эффективно для восстановления, оно было улучшено методом локальных вычислений, так что новый метод называется
Locally repairable erasure code (LRC). Встраиваемый модуль локального восстанавливающего удаляющего кодирования создаёт локально вычисляемые порции, которые способны восстанавливать применяя меньше OSD, что делает его эффективным для восстановления.Для его лучшего понимания давайте предположим, что мы настроили LRC с
k = 8,m = 4иl = 4(locality, близость), он создаёт дополнительные вычисляемые порции для всех четырёх OSD. Когда утрачивается отдельное OSD, может быть восстановлено только четыре OSD вместо одиннадцати, как это было в случае с Jerasure.
Локальные восстанавливающие коды спроектированы для уменьшения вашей полосы пропускания при восстановлении в случае утраты отдельного OSD. Как было показано выше, локально вычисляемая порция (L) генерируется длякаждых четырёх порций данных (K). Когда теряется K3, вместо восстановления всех [(K+M)-K3] порций, то есть 11 фрагментов, при использовании Локального восстанавливающего кода будет достаточно провести восстановление из порций K1, K2, K4 и L1.
-
Shingled erasure code plugin: Локальные восстанавливающие коды оптимизированы для одиночных отказов OSD. При множественных отказах OSD накладные расходы на восстановление при LRC становятся больше, так как они не имеют глобальных вычислений (global parity, M) для восстановления. Давайте ещё раз рассмотрим предыдущий сценарий и предположим, что утрачено множество порций данных, K3 и K4. Для восстановления потерянных порций с применением LRC необходимо проводить восстановление из K1, K2, L1 (ваша локально вычисляемая порция) и M1 (ваша глобально вычисляемая порция). Таким образом, LRC включает в себя накладные расходы с множеством отказов дисков.
Для решения этой проблемы был предложен SHEC (
Shingled Erasure Code). Встраиваемый модуль SHEC инкапсулирует множество библиотек SHEC и позволяет Ceph восстанавливать данные более эффективно чем Jerasure и LRC. Цель SHEC состоит в эффективной обработке множественных отказов дисков. Применяя этот метод, диапазон вычислений для локальных кодов был смещён и вычисляемые коды перекрывают друг друга (как черепицы или дранки на крыше), предоставляя достаточную живучесть (durability).Давайте рассмотрим это на примере,
SHEC (10,6,5), гдеk = 10(порции данных),m = 6(вычисляемые порции), аl = 5(диапазон вычислений, locality). В этом случае схема представления SHEC выглядит следующим образом:
Эффективность восстановления является одной из самых выдающихся функциональностей SHEC. Он минимизирует количество чтений данных с диска в процессе восстановления. Если утрачены порции K6 и K9, SHEEC воспользуется для восстановления вычисляемыми (parity) порциями M3 и M4, а также порциями данных K5, K7,K8 и K10. Это показано на следующей схеме:
При множественных отказах дисков, ожидается, что SHEC будет проводить восстановление более эффективно чем прочие методы. Время восстановления SHEC было на 18.6% быстрее чем в случае применения кода Соломона при двух отказах дисков. {Прим. пер.: подробнее см. наш перевод статьи авторов метода}
-
ISA-I erasure code plugin: Встраиваемый модуль Intelligent Storage Acceleration (ISA, интеллектуального ускорения хранилищ) инкапсулирует библиотеку ISA. ISA-I был оптимизирован для платформ Intel с применением специфичных для платформ Intel инструкций и, тем самым, работает исключительно на архитектурах Intel. ISA может применяться водной из двух форм Рида Соломона, а именно, Вандермонда или Коши.
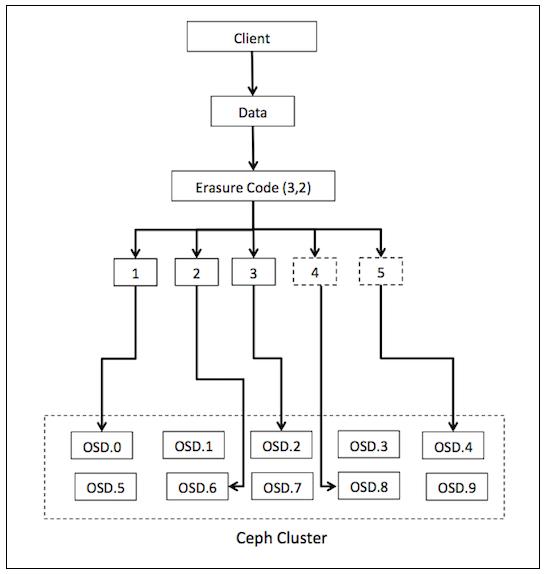
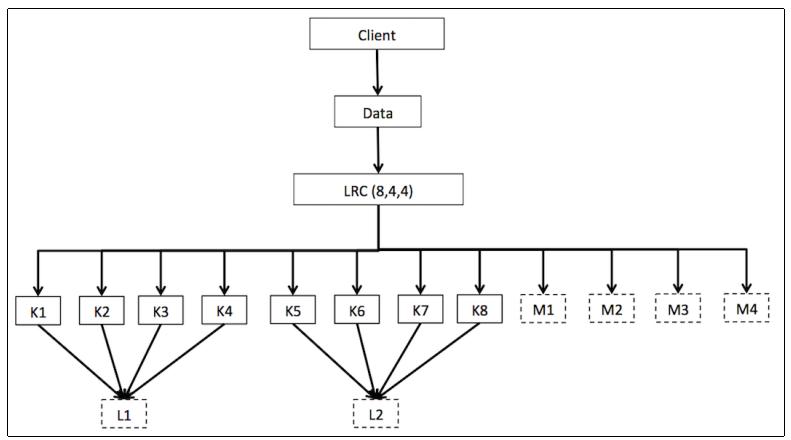
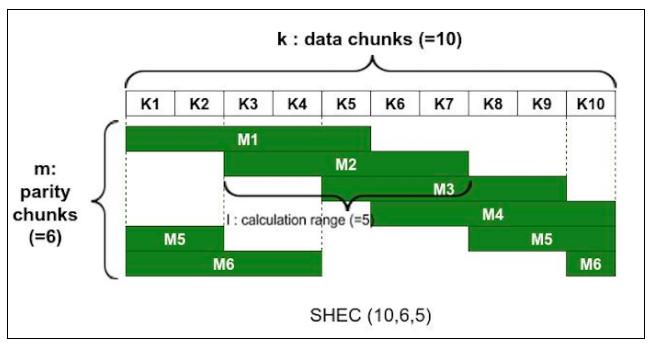
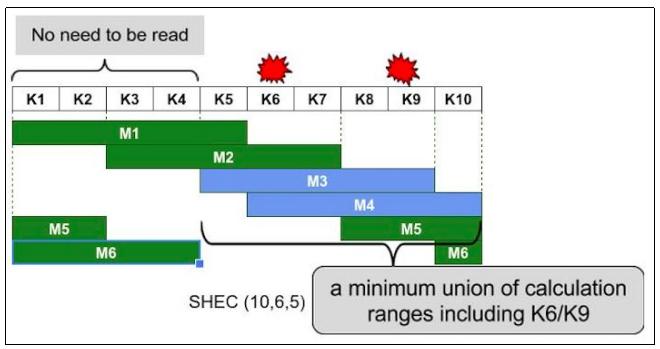
Удаляющее кодирование реализуется посредством создания пула Ceph с типом erasure. Этот
базируется на профиле удаляющего кодирования, который определяет характеристики удаляющего кодирования. Вначале мы создадим профиль
удаляющего кодирования, а затем, на основании этого профиля, мы создадим пул удаляющего кодирования.
-
Приводимая в этом рецепте команда создаст профиль удаляющего кодирования с именем
EC-profile, который будет иметь характеристикиk = 3иm = 2, которые являются числом порций данных и вычислений соответственно. Таким образом, каждый сохраняемый в пуле объект будет делиться на 3 (k) порции данных и 2 (m) дополнительные добавляемые к ним кодируемые порции, создавая итого 5 (k + m) порций. В конце концов эти 5 (k + m) порций распространяются по различным OSD зон отказа (failure zone).-
Создайте профиль удаляющего кодирования:
# ceph osd erasure-code-profile set EC-profile rulesetfailure-domain=osd k=3 m=2
-
Отобразите список профилей:
# ceph osd erasure-code-profile ls
-
Получите содержимое профиля удаляющего кодирования:
# ceph osd erasure-code-profile get EC-profile [root@ceph-node1 ~]# ceph osd erasure-code-profile set EC-profile rulesetfailure-domain=osd k=3 m=2 [root@ceph-node1 ~]# ceph osd erasure-code-profile ls EC-profile default [root@ceph-node1 ~]# ceph osd erasure-code-profile get EC-profile directory=/usr/1ib64/ceph/erasure-code k=3 m=2 plugin=jerasure rulesetfailure-domain=osd technique=reed_sol_van [root@ceph-node1 ~]#
-
-
Создайте пул типа
erasure, который основан на созданном нами на 1 шаге профиле удаляющего кодирования:# ceph osd pool create EC-pool 16 16 erasure EC-profile
Проверьте состояние только что созданного пула; вы должны увидеть, что размер пула равен 5 (
k + m), т.е. размерerasure5. Следовательно, данные будут записываться в 5 различных OSD:# ceph osd dump | grep -i EC-pool [root@ceph-node1 ~]# ceph osd pool create EC-pool 16 16 erasure EC-profile pool 'EC-pool' created [root@ceph-node1 ~]# ceph osd dump | grep EC-pool pool 47 'EC-pool' erasure size 5 min_size 3 crush_ruleset 3 object_hash rjenkins pg_num 16 pgp_num 16 last_change 4504 flags hashpspool stripe_width 4128 [root@ceph-node1 ~]#
-
Давайте добавим какие- нибудь данные в только что созданный пул Ceph. Для этого мы создадим фиктивный файл,
hello.txt, и добавим этот файл в пулEC-pool.[root@ceph-node1 ~]# echo "Hello Ceph" >> hello.txt [root@ceph-node1 ~]# cat hello.txt Hello Ceph [root@ceph-node1 ~]# rados -p EC-pool ls [root@ceph-node1 ~]# rados -p EC-pool put objectl hello.txt [root@ceph-node1 ~]# rados -p EC-pool ls object1 [root@ceph-node1 ~]#
-
Для проверки правильной работы пула удаляющего кодирования мы проконтролируем карту OSD для
EC-poolиobject1.[root@ceph-node1 ~]# ceph osd map EC-pool object1 osdmap e4601 pool 'EC-pool' (47) object 'objectl' -> pg 47.bac5debc (47.c) -> up ([5,3,2,8,0], p5) acting ([5,3,2,8,0], p5) [root@ceph-node1 ~]#
Если вы изучите приведённый выше вывод, вы отметите, что
object1сохранён в группе размещения47.c, которая в свою очередь хранится вEC-pool. Вы также отметите, что группа размещения хранится в пяти OSD, а именно, вosd.5,osd.3,osd.2,osd.8иosd.0. Если вы вернётесь к 1 шагу, вы вспомните, что мы создали наш профиль удаляющего кодирования(3, 2). Это объясняет почемуobject1хранится в пяти OSD.На данном этапе мы выполнили сборку пула удаляющего кодирования в кластере Ceph. Теперь мы намеренно попытаемся разрушить OSD чтобы увидеть как себя ведёт пул удаляющего кодирования когда недоступны OSD.
-
Теперь мы попытаемся сломать
osd.5иosd.3один за другим.Замечание Это необязательный шаг и вам не следует выполнять его в вашем промышленном кластере Ceph. Кроме того, номера OSD могут отличаться в вашем кластере, если понадобится, замените их.
Сломаем
osd.5и проверим карту OSD дляEC-poolиobject1. Вы должны отметить, чтоosd.5заменён случайным числом,2147483647, что означает, чтоosd.5больше не доступен для этого пула:# ssh ceph-node2 service ceph stop osd.5 # ceph osd map EC-pool object1 [root@ceph-node1 ~]# ssh ceph-node2 service ceph stop osd.5 === osd.5 === Stopping Ceph osd.5 on ceph-node2...kill 23469...kill 23469...done [root@ceph-node1 ~]# ceph osd map EC-pool object1 osdmap e4603 pool 'EC-pool' (47) object 'objectl' -> pg 47.bac5debc (47.c) -> up ([2147483647,3,2,8,0], p3) acting ([2147483647,3,2,8,0], p3) [root@ceph-node1 ~]#
-
Аналогично сломаем ещё один OSD, а именно,
osd.3и просмотрим карту OSD дляEC-poolиobject1. Вы отметите, что как и в случае сosd.5,osd.3также будет замещён тем же случайным числом,2147483647, что означает, чтоosd.3также больше не доступен для этогоEC-pool:# ssh ceph-node2 service ceph stop osd.3 # ceph osd map EC-pool object1 [rootcdceph-node1 ~]# ssh ceph-node2 service ceph stop osd.3 === osd.3 === Stopping Ceph osd.3 on ceph-node2...kill 22954...kill 22954...done [root@ceph-node1 ~]# ceph osd map EC-pool object1 osdmap e4605 pool 'EC-pool' (47) object 'objectl' -> pg 47.bac5debc (47.c) -> up ([2147483647,2147483647,2,8,0], p2) acting ([2147483647,214748 3647,2,8,0], p2) [root@ceph-node1 ~]#
-
Теперь
EC-poolработает на трёх OSD, что является требуемым минимумом для такой сборки пулаerasure. Как уже обсуждалось ранее,EC-poolпотребует любые три порции для чтения данных. Теперь мы имеем оставшимися только три порции, а именноosd.2,osd.8иosd.0и мы всё ещё имеем доступ к данным. Давайте проверим это прочитав наши данные:# rados -p EC-pool ls # rados -p EC-pool get object1 /tmp/object1 # cat /tmp/object1 [root@ceph-node1 ~]# rados -p EC-pool is object1 [root@ceph-node1 ~]# rados -p EC-pool get object1 /tmp/object1 [root@ceph-node1 ~]# cat /tmp/object1 Hello Ceph [root@ceph-node1 ~]#
Функциональность удаляющего кодирования в основном пользуется преимуществами надёжной архитектуры Ceph. Когда Ceph обнаруживает недоступность любой зоны отказа, он запускает свои базовые операции восстановления. Во время операции восстановления пулы
erasureперестраивают себя декодируя отказавшие порции на новые OSD, а после этого они автоматически делают все порции доступными. -
В последних двух обсуждавшихся шагах мы намеренно разрушили
osd.5иosd.3. После всего этого Ceph запустит восстановление и регенерирует утраченные порции на различные OSD. Когда операция восстановления завершится, нам следует проверить нашу карту OSD дляEC-poolиobject1. Мы будем поражены увидев свои новые идентификаторы OSD, например,osd.7иosd.4. И, таким образом, пулerasureстановится жизнеспособным без административного вмешательства.[root@ceph-node1 ~]# ceph osd stat osdmap e4645: 9 osds: 7 up, 7 in; 336 remapped pgs [root@ceph-node1 ~]# ceph osd map EC-pool object1 osdmap e4645 pool 'EC-pool' (47) object 'objectl' -> pg 47.bac5debc (47.c) -> up ([7,4,2,8,0], p7) acting ([7,4,2,8,0], p7) [root@ceph-node1 ~]#
Как и удаляющее кодирование, функциональность многоуровневого кэширования (cache tiering) также была введена в Ceph в редакции Firefly. Уровни кэша снабжают клиентов Ceph лучшей производительностью ввода/ вывода для подмножеств ваших данных, сохраняемых на уровне кэша. Многоуровневое кэширование создаёт пул поверх самых быстрых дисков, обычно SSD. Такой кэширующий пул должен быть размещён перед обычным пулом, с реплиукациями или удаляющим кодированием, таким образом, чтобы все операции клиентского ввода/ вывода вначале обрабатывались бы кэширующим пулом; позже эти данные сбрасываются в существующие пулы данных. Клиенты обладают высокой производительностью своего кэширующего пула, а их данные прозрачно записываются в обычные пулы. Следующая схема иллюстрирует многоуровненвое кэширование Ceph:
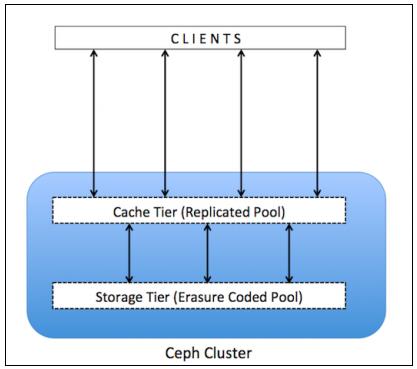
Уровень кэша строится поверх дорогостоящих, самых быстрых SSD/ NVMe, таким образом он снабжает клиентов наилучшей
производительностью ввода/ вывода. Уровень кэша имеет в основе уровень хранения, который выполнен на HDD с типом репликаций или
удаляющего кодирования. Все запросы ввода/ вывода клиентов приходят на уровень кэширования и получают самый быстрый отклик вне
зависимости будет это read или write; самый быстрый уровень
кэша обслуживает ваш запрос клиента. На основе ваших политик, которые мы создали для уровня кэша, он сбрасывает все свои данные
на лежащий в его основе уровень хранения, так что он может кэшировать новые запросы от клиентов. Вся миграция данных между уровнями
кэша и хранения происходит автоматически и является прозрачной для клиентов. Агент многоуровневого кэширования обрабатывает миграцию
данных между уровнем кэша и уровнем хранения. Администраторы имеют возможность настраивать то как такая миграция осуществляется.
Существует два основных сценария.
Когда многоуровневое кэширование настроено на режим writeback (отложенной записи), клиенты
Ceph записывают свои данные в имеющийся пул уровня кэша, то есть, в самый быстрый пул и, следовательно, получают подтверждение
моментально. Основываясь на политике сброса/ выселения, которую вы установили для вашего уровня кэша, данные мигрируют с уровня кэша
на уровень хранения и в конечном счёте удаляются со своего уровня кэширования агентом многоуровневого кэширования. В процессе
операции клиента read данные вначале пересылаются с уровня хранения на уровень кэширования
агентом многоуровневого кэширования а затем предоставляются клиентам. Данные сохраняются в своём уровне кэширования пока они не
становятся неактивыми или неиспользуемыми (cold). Уровень кэширования с режимом writeback
идеален для изменяемых данных, таких как редактирование фото и видео, транзакционных данных и тому подобного. Режим
writeback идеален для изменяемых данных.
Когда многоуровневое кэширование настроено в режиме read-only, оно работает только
для клиентских операций read. Операции write не
обслуживаются в этом режиме и они сохраняются на уровне хранения. Когда клиент выполняет операцию read,
агент многоуровневого кэширования копирует запрашиваемые данные с уровня хранения на свой уровень кэширования. Основываясь
на политике которую вы настроили для своего уровня кэширования, просроченные объекты удаляются с уровня кэширования. Такой подход
идеален для множества клиентов с потребностями чтения больших объёмов аналогичных данных, например, содержимого социальных медиа.
Неизменяемые данные являются хорошими претендентами для уровня кэширования доступного только для чтения.
Для получения наилучших результатов функциональности многоуровневого кэширования Ceph вамследует применять более быстрые диски,
такие как SSD и делать быстрый кэширующий пул поверх медленного/ обычного пула выполненного на шпиндельных дисках. В
Главе 7. Ceph под колпаком мы рассматривали процесс создания пулов на
специфических OSD путём модификации карты CRUSH. Чтобы собрать уровень кэшав вашей среде вам вначале необходимо
изменить вашу карту CRUSH и создать набор правил для своих дисков SSD. Поскольку мы уже обсуждали это ранее, мы воспользуемся
тем же набором правил для SSD, который базируется на osd.0,
osd.3 и osd.6. Поскольку это тестовая сборка, нам
не нужно иметь настоящие SSD, мы предположим, что OSD 0, 3 и 6 являются SSD и создадим пул кэша поверх них, как показано на
следующей схеме:
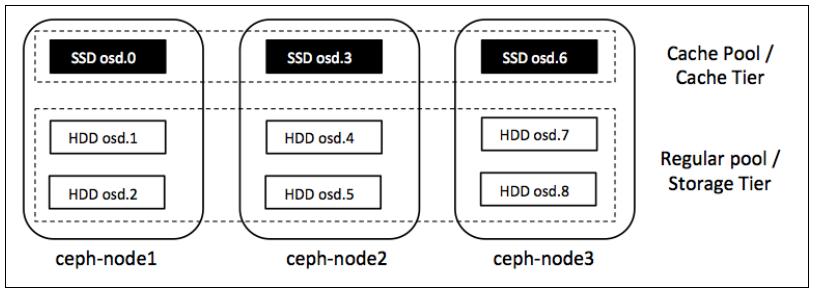
Давайте проверим нашу компоновку CRUSH применив команду ceph osd crush rule ls, как показано на
следующем снимке экрана. У нас уже есть правила CRUSH SSD пула, которые мы создали в Главе
7. Ceph под колпаком. Вы можете получить дополнительную информацию выполнив команду ceph osd crush rule dump
ssd-pool:
[root@ceph-node1 ~]# ceph osd crush rule ls [ "replicated_ruleset", "ssd-pool", "sata-pool", "EC-pool" ] [rootgceph-node1 ~]#
-
Создайте новый пул с именем
cache-poolи установитеcrush_rulesetв значение1, таким образом ваш новый пул будет создан на дисках SSD:# ceph osd pool create cache-pool 16 16 # ceph osd pool set cache-pool crush_ruleset 1 [root@ceph-node1 ~]# ceph osd pool create cache-pool 16 16 pool 'cache-pool' created [root@ceph-node1 ~]# ceph osd pool set cache-pool crush_ruleset 1 set pool 48 crush_ruleset to 1 [root@ceph-node1 ~]#
-
Убедитесь что ваш пул создан правильно, что означает, что он всегда должен сохранять все свои объекты в
osd.0,osd.3иosd.6:-
Выведите содержимое списка
cache-pool; так как это новый пул, он не должен иметь содержимого:# rados -p cache-pool ls
-
Добавьте временный объект в ваш
cache-pool, чтобы проверить что он сохраняет объект в правильных OSD:# rados -p cache-pool put object1 /etc/hosts # rados -p cache-pool ls
-
Проверьте карту OSD в отношении
cache-poolиobject1; он должен храниться вosd.0,osd.3иosd.6:# ceph osd map cache-pool object1
-
Наконец, удалите объект:
# rados -p cache-pool rm object1 [root@ceph-node1 ~]# rados -p cache-pool ls [root@ceph-node1 ~]# rados -p cache-pool put object1 /etc/hosts [root@ceph-node1 ~]# rados -p cache-pool ls object1 [root@ceph-node1 ~]# ceph osd map cache-pool object1 osdmap e4767 pool 'cache-pool' (48) object 'objectl' -> pg 48.bac5debc (48.c) -> up ([3,6,0], p3) acting ([3,6,0], p3) [root@ceph-node1 ~]# rados -p cache-pool rm object1 [root@ceph-node1 ~]# rados -p cache-pool is [root@ceph-node1 ~]#
-
-
Также смотрите Создание уровня кэша в этой главе.
В этом рецепте мы создадим пул, cache-pool
EC-pool
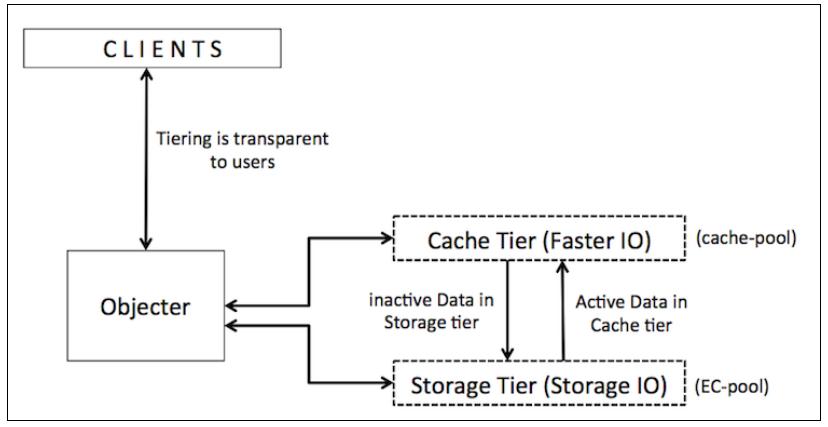
writeback
EC-pool
-
Создайте уровень кэша, который будет ассоциировать пулы хранения с пулами кэша. Синтаксис таков:
ceph osd tier add <storage_pool> <cache_pool>:# ceph osd tier add EC-pool cache-pool
-
Установите режим кэширования либо как
writeback, либо какread-only. В нашей демонстрации мы применяемwriteback, а синтаксис такой:ceph osd tier cachemode <cache_pool> writeback:# ceph osd tier cache-mode cache-pool writeback
-
Чтобы направить все запросы клиентов из стандартного пула в пул кэша, установите перекрытие (overlay) пула с применением следующего синтаксиса:
ceph osd tier set-overlay <storage_pool> <cache_pool>:# ceph osd tier set-overlay EC-pool cache-pool [root@ceph-node1 ~]# ceph osd tier add EC-pool cache-pool pool 'cache-pool' is now (or already was) a tier of 'EC-pool' [root@ceph-node1 ~]# ceph osd tier cache-mode cache-pool writeback set cache-mode for pool 'cache-pool' to writeback [root@ceph-node1 ~]# ceph osd tier set-overlay EC-pool cache-pool overlay for 'EC-pool' is now (or already was) 'cache-pool' [root@ceph-node1 ~]#
-
Проверяя подробности пула, вы заметите, что
EC-poolимеетtier,read_tierиwrite_tierустановленные в значение48, что является идентификатором пула для вашегоcache-pool. Аналогично, дляcache-poolустановки будут:tier_ofназначено на47, аcache_modeустановлен какwriteback. Все эти установки подразумевают, что пул кэша настроен правильно:# ceph osd dump | egrep -i "EC-pool|cache-pool" [root@ceph-node1 ~]# ceph osd dump | egrep "EC-poollcache-pool" pool 47 'EC-pool' erasure size 5 min_size 3 crush_ruleset 3 object_hash rjenkins pg_num 16 pgp_num 16 last_change 4770 lfor 4770 flags hashpspool tiers 48 read_tier 48 write_tier 48 stripe_width 4128 pool 48 'cache-pool' replicated size 3 min_size 2 crush_ruleset 1 object_hash rjenkins pg_num 16 pgp_num 16 last_change 4770 flags hashpspool,incomplete clones tier of 47 cache node writeback stripe width 0 [root@ceph-node1 ~]#
Уровень кэша имеет некоторые необязательные параметры настройки, которые определяют политику вашего уровня кэша. Такая политика
уровня кэша требуется для сбрасывания данных с уровня кэша на уровень хранения в случае writeback
(отложенной записи). В случае с уровнем кэша только для чтения, она перемещает данные с уровня хранения на уровень кэша. В данном
рецепте я пытаюсь продемонстрировать уровень кэша в режиме writeback. Здесь приводятся
некоторые установки, которые вам следует настроить для вашей промышленной среды с отличными значениями на основании ваших требований:
-
Для промышленного развёртывания вам следует применять структуру данных 'bloom filters':
ceph osd tier add <storage_pool> <cache_pool>:# ceph osd pool set cache-pool hit_set_type bloom
-
hit_set_countопределяет какой период времени в секундах должен охватывать каждый набор попадания в кэш, аhit_set_periodсколько таких наборов попаданий должно удерживаться:# ceph osd pool set cache-pool hit_set_count 1 # ceph osd pool set cache-pool hit_set_period 300
-
target_max_bytesявляется максимальным значением в байтах, после которого агент многоуровневого кэширования начинает сбрасывать/ выселять объекты из пула кэша, аtarget_max_objectsопределяет количество объектов, по достижению которых агент многоуровневого кэширования начинает сбрасывать/ выселять объекты из пула кэша:# ceph osd pool set cache-pool target_max_bytes 1000000 # ceph osd pool set cache-pool target_max_objects 10000 [root@ceph-node1 ~]# ceph osd pool set cache-pool hit_set_type bloom set pool 48 hit_set_type to bloom [root@ceph-node1 ~]# ceph osd pool set cache-pool hit_set_count 1 set pool 48 hit_set_count to 1 [root@ceph-node1 ~]# ceph osd pool set cache-pool hit_set_period 300 set pool 48 hit_set_period to 300 [root@ceph-node1 ~]# ceph osd pool set cache-pool targetmax_bytes 1000000 set pool 48 targetmax_bytes to 1000000 [root@ceph-node1 ~]#
-
Разрешите
cache_min_flush_ageиcache_min_evict_age, которые являются временем в секундах, которое агент многоуровневого кэширования принимает для сброса и выселения объектов из уровня кэша вуровень хранения:# ceph osd pool set cache-pool cache_min_flush_age 300 # ceph osd pool set cache-pool cache_min_evict_age 300 [root@ceph-node1 ~]# ceph osd pool set cache-pool target_max_objects 10000 set pool 48 target_max_objects to 10000 [root@ceph-node1 ~]# ceph osd pool set cache-pool cache_min_flush_age 300 set pool 48 cachemin_flush_age to 300 [root@ceph-node1 ~]# ceph osd pool set cache-pool cache_min_evict_age 300 set pool 48 cache_min_evict_age to 300 [root@ceph-node1 ~]#
-
Разрешите
cache_target_dirty_ratio, что является процентом пула кэша содержащего модифицированные (dirty) объекты до того,как агент многоуровневого кэширования сбросит их на уровень хранения: :# ceph osd pool set cache-pool cache_target_dirty_ratio .01
-
Включите
cache_target_full_ratio, что является процентом пула кэша, содержащего не изменённые обекты до того,как агент многоуровневого кэширования сбросит их на уровень хранения:# ceph osd pool set cache-pool cache_target_full_ratio .02
Когда вы выполните эти шаги, настройка многоуровневого кэширования должна завершится и вы можете начинать добавлять к ней рабочую нагрузку:
-
Создайте временный файл размером 500МБ который будет использован для записи в ваш
EC-poolи который в конечном счёте будет записан вcache-pool:# dd if=/dev/zero of=/tmp/file1 bs=1M count=500 [root@ceph-node1 ~]# ceph osd pool set cache-pool cache_target_dirty_ratio .01 set pool 48 cache_target_dirty_ratio to .01 [root@ceph-node1 ~]# ceph osd pool set cache-pool cache_target_full_ratio .02 set pool 48 cache_target_full_ratio to .02 [root@ceph-node1 ~]# dd if=/dev/zero of=/tmp/file1 bs=1m count=500 500+0 records in 500+0 records out 524288000 bytes (524 MB) copied, 5.81312 s, 90.2 MB/s [root@ceph-node1 ~]#
Так как наш уровень кэша готов, в процессе операций write клиенты будут видеть то, что
всё записывается в их обычные пулы, но на самом деле это записывается вначале в пулы кэша, а уже потом на основании политики данных
уровня кэширования оно сбрасывается на уровень хранения. Такая миграция данных прозрачна для клиента.
-
В предыдущем рецепте мы создали тестовый файл 500МБ с именем
/tmp/file1; теперь мы поместим этот файл вEC-pool:# rados -p EC-pool put object1 /tmp/file1
-
Поскольку
EC-poolсвязан уровнями сcache-pool, файл с именемfile1не должен быть записан на своём первом шаге вEC-pool, однако, он будет записан в нашcache-pool. Для проверки этого выведите список каждого пула для получения имён объектов. Примените команду даты для отслеживания времени и изменений:# rados -p EC-pool ls # rados -p cache-pool ls # date [root@ceph-node1 ~]# rados -p EC-pool put objectl /tmp/file1 [root@ceph-node1 ~]# rados -p EC-pool ls [root@ceph-node1 ~]# rados -p cache-pool ls object1 [root@ceph-node1 ~]# [root@ceph-node1 ~]# date Sun Sep 14 02:14:58 EEST 2014 [root@ceph-node1 ~]#
-
Через 300 секунд (поскольку мы настроили
cache_min_evict_ageна значение300секунд), агент многоуровневого кэширования проведёт миграциюobject1изcache-poolв нашEC-poolиobject1будет удалён изcache-pool:# rados -p EC-pool ls # rados -p cache-pool ls # date [root@ceph-node1 ~]# date Sun Sep 14 02:27:41 EEST 2014 [root@ceph-node1 ~]# rados -p EC-pool ls object1 [root@ceph-node1 ~]# rados -p cache-pool ls [root@ceph-node1 ~]#
Если вы пристальнее вглядитесь вшаги 2 и 3, вы отметите, что данные мигрировали из
cache-poolвEC-poolпосле определённого промежутка времени, причём это абсолютно прозрачно для наших пользователей.