Глава 4. Ceph изнутри
В данной главе мы рассмотрим следующие пункты:
-
Объекты Ceph
-
Алгоритм CRUSH
-
Группы размещения
-
Пулы Ceph
-
Управление данными Ceph
Содержание
Теперь вы очень хорошо разбираетесь в архитектуре Ceph и ее основных компонентах; далее мы сосредоточимся на том, как Ceph выполняет свою магию в фоновом режиме. Существует несколько элементов, которые работают под прикрытием и составляют основу кластера Ceph. Давайте узнаем о них подробнее.
Объект обычно содержит в себе компоненты данных и метаданных, которые связаны вместе и снабжены глобальным уникальным идентификатором (ID). Такой уникальный идентификатор гарантирует, что не существует никакого другого объекта с таким же идентификатором объекта во всем кластере хранения и, таким образом, гарантирует уникальность объекта.
В отличие от основанного на файлах хранилища, в котором файлы ограничены в размере, объекты могут достигать огромных размеров, а также снабжаться метаданными переменного размера. В объектах данные хранятся совместно с обильными метаданными, запоминающими информацию о контексте и содержании данных. Метаданные хранилища объектов позволяют пользователям соответствующим образом управлять и осуществлять доступ к неструктурированным данным. Рассмотрим следующий пример хранения записи о пациенте в виде объекта:
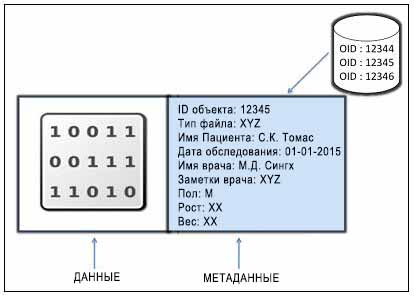
Объект не ограничен никаким типом или объемом метаданных; это снабжает вас гибкостью добавления
индивидуальных типов в метаданные и, таким образом, дает вам полное владение вашими данными.
Он не использует иерархию каталогов или древовидную структуру для хранения; более того, он использует
линейное адресное пространство содержащее миллиарды объектов без какой- либо запутанности.
Объекты могут храниться локально, или они могут быть географически разделены в пространстве линейных адресов,
то есть в прилегающих пространствах хранилища. Такой механизм хранения помогает объектам уникально представлять
себя во всем кластере. Любые приложения могут получать данные из объектов на основе их ID объекта через
использование вызовов RESTful API. Аналогичным образом работают URL в интернете, ID объекта предоставляет
уникальный указатель на объект. Такие объекты хранятся в устройствах хранения на основе объектов
(OSD, Object Storage Device) в виде репликаций,
которые обеспечивают высокую доступность. Когда кластер хранения получает от клиента запрос на
запись данных, он сохраняет данные как объект. Демон OSD затем записывает данные в файл в файловой
системе OSD.
Каждый элемент данных в Ceph хранится в виде объекта внутри пула. Пул Ceph является логическим разделом для хранения объектов, что обеспечивает организованный способ хранения. Позже в данной главе мы узнаем больше подробностей о пулах. А сейчас мы обсудим объекты, которые являются наименьшей единицей хранения данных в Ceph. После развертывания кластера Ceph, он создает некоторые пулы хранения по умолчанию в качестве пулов данных, метаданных и RBD (блочного устройства RADOS). После развертывания MDS (сервера метаданных) на одном из узлов Ceph, он создает создает объекты внутри пула метаданных, которые требуются CephFS для надлежащей функциональности. Поскольку ранее в нашей книге мы уже развернули кластер, давайте исследуем эти объекты:
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
Начиная с редакции Ceph Giant, которая является следующей редакцией после Firefly, пулы метаданных и данных не будут создаваться по умолчанию пока вы не настроите для своего кластера MDS. Единственным пулом по умолчанию будет пул RBD. |
-
Проверьте состояние вашего кластера Ceph с применением следующей команды в
pgmap. Вы найдете три пула и некоторые объекты:# ceph -s
[root@ceph-node1 ceph]# ceph -s cluster ffa7c0e4-6368-4032-88a4-5fb6a3fb383c health HEALTH_OK monmap e9: 3 mons at {ceph-node1=192.168.57.101:6789/0,ceph-node2=192.168.57.102:6789/0, ceph-node3=192.168.57.103:6789/0}, election epoch 76, quorum 0,1,2 ceph-node1,ceph-node2,ceph -node3 mdsmap e25: 1/1/1 up {0=ceph-node2=up:active} osdmap e281: 9 osds: 9 up, 9 in pgmap v603: 192 pgs, 3 pools, 9470 bytes data, 21 objects 345 MB used, 45635 MB / 45980 MB avail 192 active+clean -
Выведите список имён пулов вашего кластера Ceph с помощью следующей команды. Она покажет вам пулы по умолчанию, поскольку вы не создавали пока никаких пулов. Здесь будут перечислены три пула.
# rados lspools
[root@ceph-node1 /]# rados 1 spools data metadata rbd [root@ceph node1 /]#
Наконец, выведите список объектов из пула метаданных. Вы найдете в этом пуле созданные системой объекты:
# rados -p metadata ls
[root@ceph-node1 /]# rados -p metadata ls 1.00000000.inode 100.00000000 100.00000000.inode 1.00000000 2.00000000 200.00000000 200.00000001 600.00000000 601.00000000 602.00000000 603.00000000 604.00000000 605.00000000 606.00000000 607.00000000 608.00000000 609.00000000 mds0_inotable mds0_sessionmap mds_anchortable mds_snaptable [root@ceph-node1 /]#
За последние три десятилетия механизмы хранения усложнили хранимые данные и их метаданные. Метаданные, которые являются данными о данных, содержат информацию, например такую как местоположение где данные реально хранятся в наборе узлов хранения и дисковых массивов. При каждом добавлении новых данных в систему хранения вначале обновляются их метаданные сведениями о том, где физически будут сохранены данные, после чего происходит реальное сохранение данных. Этот процесс хорошо себя зарекомендовал на практике когда мы оперируем с небольшими объёмами данных в масштабах от гигабайт до нескольких терабайт информации, однако что можно сказать в случае хранения данных уровня петабайт или экзабайт? Определённо данный механизм не будет приемлем для хранилищ в будущем. Более того, он создаёт единую точку отказа для вашей системы хранения. К сожалению, если вы теряете метаданные вашего хранилища, вы теряете все ваши данные. Следовательно, крайне важно оберегать любыми средствами центральные данные в сохранности от происшествий, либо путём хранения множества копий на одном узле, либо путём репликации данных и метаданных целиком для бОльшей степени отказоустойчивости. Такое сложное управление метаданными является узким местом при масштабировании систем хранения, а также пр достижении высокой доступности и производительности.
Ceph совершил революцию, когда вышел на рынок систем хранения данных и управления ими. Он применяет
алгоритм Управляемых масштабируемым хешированием репликаций (CRUSH,
Controlled Replication Under Scalable Hashing), интеллектуальный механизм
распределения данных. Алгоритм CRUSH является одним из бриллиантов в короне Ceph; он является ядром
всего механизма хранения данных Ceph. В отличие от традиционных систем которые полагаются на хранение и
управление централизованными метаданными / индексными таблицами, Ceph использует алгоритм CRUSH для
детерминированного (предопределённого) вычисления того, где должны быть записаны данные или откуда их
необходимо считывать. Вместо хранения метаданных, CRUSH вычисляет метаданные по запросу, тем самым
удаляя все ограничения, с которыми сталкиваются метаданные при традиционных подходах.
Механизм CRUSH работает таким образом, что нагрузка вычислений метаданных распределена и выполняется только при возникновении необходимости в них. Процесс вычисления метаданных также известен как нахождение (lookup) CRUSH, а имеющаяся в настоящее время вычислительная аппаратура достаточно мощна для быстрого и эффективного выполнения операций нахождения CRUSH. Уникальным моментом в нахождении CRUSH является то, что он системно- независим. Ceph предоставляет клиентам достаточную гибкость для выполнения по запросу вычисления метаданных, то есть, осуществления нахождения CRUSH на своих собственных системных ресурсах, тем самым исключая централизованное местоположение.
Для выполнения операций чтения-и-записи в кластере Ceph, первоначально клиенты общаются с монитором Ceph и получают копию карты кластера. Карта кластера помогает клиентам знать состояние и конфигурацию кластера Ceph. Данные преобразуются в объекты с именами/ идентификаторами объектов и пулов. Затем объекты хешируются номером группы размещения для создания окончательной группы размещения (PG, placement group) внутри необходимого пула Ceph. Вычисленная группа размещения затем следует найденным CRUSH для определения местоположения первичного OSD (устройства хранения объектов) для сохранения или получения данных. После вычисления точного идентификатора OSD, клиент взаимодействует с OSD напрямую и выполняет операцию с данными. Все эти операции вычислений выполняются клиентами, следовательно они не влияют на производительность кластера. Когда данные записаны на первичное OSD, этот же узел выполняет операцию нахождения CRUSH и вычисляет местоположение для вторичных групп размещения (PG) и OSD, тем самым выполняя репликацию данных в кластере для высокой доступности. Рассмотрим следующий пример нахождения CRUSH и размещения объекта в OSD.
Прежде всего к имени объекта и номеру группы размещения кластера применяется хеш- функция и степень (основание) идентификатора пула; таким образом создается идентификатор группы размещения, PGID. Затем по этому PGID выполняется нахождение CRUSH для поиска первичного и вторичных OSD для записи данных.
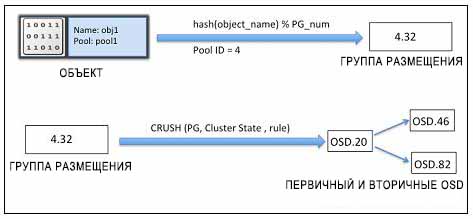
CRUSH полностью осведомлён об инфраструктуре и является абсолютно настраиваемым со стороны пользователя; он устанавливает вложенную иерархию для всех компонентов вашей инфраструктуры. Список устройств CRUSH обычно содержит диск, узел, стойка, ряд, коммутатор, цепь электропитания, зал, центр обработки данных и тому подобное. Эти компоненты известны как зоны отказа или сегменты (bucket) CRUSH. Карта CRUSH содержит перечень доступных сегментов для преобразования устройств в физические местоположения. Она также содержит список правил, которые сообщают CRUSH как выполнять репликацию данных для различных пулов Ceph. Следующая диаграмма даст вам представление о том, как выглядит CRUSH в вашей физической инфраструктуре:
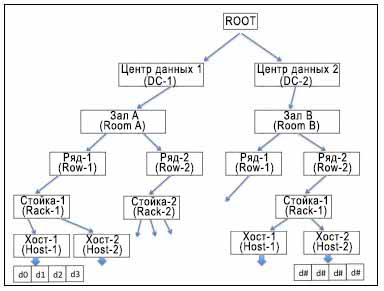
В зависимости от вашей инфраструктуры CRUSH распределяет данные и их реплики по всем этим зонам отказа таким образом, чтобы они были сохранены и доступны даже в случае отказов некоторых компонентов. Это то, как CRUSH удаляет проблемы единых точек отказа из вашей инфраструктуры хранения, которая собрана из общедоступного оборудования и, тем не менее, гарантирует высокую доступность. CRUSH равномерно записывает данные по всем дискам кластера, что повышает производительность и надёжность и заставляет все диски принимать участие в работе кластера. Он гарантирует, что все диски кластера используются в равной мере вне зависимости от их ёмкости. Для осуществления этого CRUSH присваивает веса каждому OSD (устройству хранения объектов). Чем выше вес OSD, тем большую физическую ёмкость хранения он имеет, и CRUSH будет записывать на такое OSD больше данных. Следовательно, в среднем, OSD с меньшим весом заполняются примерно в той же пропорции, что и OSD с бОльшим весом.
В случае отказа любого компонента из зоны отказа Ceph ожидает по умолчанию 300 секунд перед тем, чтобы пометить
OSD вышедшим из строя, после чего начинает операцию восстановления. Этой установкой можно управлять при помощи
параметра mon osd down out interval в файле настроек Ceph.
Во время операции восстановления Ceph запускает регенерацию утраченных данных, которые размещались отказавшем узле.
Поскольку CRUSH выполняет репликацию данных на различные диски, во время восстановления используются такие реплицированные копии данных. CRUSH пытается перемещать минимальные объёмы данных в процессе выполнения операций восстановления и разрабатывает новую схему кластера, делая Ceph устойчивым к отказам даже после выхода из строя некоторых компонентов.
Когда в кластер добавляется новый хост или диск, CRUSH запускает операцию повторной балансировки, в процессе
которой он перемещает данные с существующих хостов/ дисков на новые хосты/ диски. Ребалансировка выполняется для
сохранения заполненности дисков в одной пропорции, что увеличивает производительность кластера и сохраняет его
работоспособность. Например, если кластер Ceph содержит 2000 OSD (устройств хранения объектов) и добавляется новая
система с 20 новыми OSD, будет перемещён только один процент данных в процессе выполнения операции повторной балансировки,
причём все существующие OSD будут выполнять работу по перемещению данных одновременно, помогая операции быстро
завершиться. Однако для кластеров Ceph, находящихся под высокой нагрузкой рекомендуется добавлять новые OSD
со значением параметра веса 0 и затем плавно увеличивать
их вес до наивысшего значения, соответствующего их размеру. При таком подходе новое OSD будет прилагать меньшую
нагрузку повторной балансировки на кластеры Ceph и избежит проблемы уменьшения производительности.
Когда мы развернули Ceph с использованием ceph-deploy,
команда создала карту CRUSH по умолчанию для нашей конфигурации. Карта CRUSH по умолчанию идеальна при тестировании
и в среде песочницы, однако если вы планируете разворачивать кластер Ceph в большой промышленной среде, вам
следует проанализировать возможность разработки индивидуальной карты CRUSH для вашей среды. Следующий процесс
поможет вам скомпилировать новую карту CRUSH:
-
Выделите вашу существующую карту CRUSH. При помощи параметра
-oCeph выведет в указанный вами файл скомпилированную карту CRUSH:# ceph osd getcrushmap -o crushmap.txt
-
Декомпилируйте вашу карту CRUSH. При помощи параметра
-dCeph декомпилирует вашу карту CRUSH и выведет в файл, указанный в-o:# crushtool -d crushmap.txt -o crushmap-decompile
-
Отредактируйте карту CRUSH любым редактором:
# vi crushmap-decompile
-
Скомпилируйте новую карту CRUSH:
# crushtool -c crushmap-decompile -o crushmap-compiled
-
Установите новую карту CRUSH в кластер Ceph:
# ceph osd setcrushmap -i crushmap-compiled
Индивидуальная настройка компоновки кластера является одним из самых важных шагов к построению прочного и надёжного
кластера хранения Ceph. Одинаково важно установить кластерное оборудование в отказоустойчивой зоне
и включить его в высоко доступную схему с точки зрения перспективы программного обеспечения Ceph. Развёртыванию
Ceph по умолчанию ничего не известно о компонентах, не имеющих обратной связи, таких как стойки, ряды, центры обработки
данных. После проведения начальной установки нам необходимо выполнить индивидуальные настройки схемы компоновки в
соответствии с нашими требованиями. Например, если вы выполните команду
ceph osd tree, она уведомит вас только о том, что она имеет
хосты и OSD, перечисленные под root, что является
поведением по умолчанию. Давайте попробуем разместить эти хосты по стойкам:
-
Выполните
ceph osd treeдля получения имеющейся в настоящее время схемы кластера:[root@ceph node1 ~]# ceph osd tree # id weight type name up/down reweight -1 0 root default -2 0 host ceph-node1 0 0 osd.O up 1 1 0 osd.l up 1 2 0 osd.2 up 1 -3 0 host ceph-node2 3 0 osd.3 up 1 4 0 osd.4 up 1 S 0 osd.5 up 1 -4 0 host ceph-node3 6 0 osd.6 up 1 7 0 osd.7 up 1 8 0 osd.8 up 1
-
Добавьте несколько стоек в компоновку вашего кластера Ceph:
# ceph osd crush add-bucket rack01 rack # ceph osd crush add-bucket rack02 rack # ceph osd crush add-bucket rack03 rack
-
Переместите каждый хост в определенную стойку:
# ceph osd crush move ceph-node1 rack=rack01 # ceph osd crush move ceph-node2 rack=rack02 # ceph osd crush move ceph-node3 rack=rack03
-
Теперь переместите все стойки в root default:
# ceph osd crush move rack03 root=default # ceph osd crush move rack02 root=default # ceph osd crush move rack01 root=default
-
Проверьте вашу новую компоновку. Вы заметите, что все ваши хосты теперь размещены в определённых стойках. Таким образом вы можете индивидуально настраивать вашу компоновку CRUSH для приведения в соответствие с физическим размещением установленного оборудования:
[root@ceph-node1 ~]# ceph osd tree # id weight type name up/dcwn reweight -1 0 root default -7 0 rack rack03 -4 0 host ceph-node3 6 0 osd.6 up 1 7 0 osd.7 up 1 8 0 osd.8 up 1 -6 0 rack rack02 -3 0 host ceph-node2 3 0 osd.3 up 1 4 0 osd.4 up 1 5 0 osd.5 up 1 -5 0 rack rack01 -2 0 host ceph-nodel 0 0 osd.O up 1 1 0 osd.l up 1 2 0 osd.2 up 1
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
{Прим. пер.: чтобы полностью использовать полосу пропускания SSD, они должны расщепляться примерно между 5 OSD (по опыту Mirantis), для включения такой возможности вам необходимо удалить OSD, созданные на этих SSD при установке, разделить каждый SSD на пять разделов и создать на них OSD. см., например, раздел 6.1 Эталонной архитектуры для компактного облачного решения с применением Mirantis OpenStack 9.1 и оборудования Dell EMC.} |
Когда кластер Ceph получает запросы на хранение данных, он разделяет их на разделы, называемые
группами размещения (PG, placement groups).
Тем не менее, данные CRUSH сначала разбиваются на набор объектов и на основании хеш- операций с именами объектов,
уровнями репликаций и общего числа групп размещения в системе создаются идентификаторы групп размещения.
Группа размещения является логической коллекцией объектов, которые реплицируются в OSD (устройства хранения объектов)
для обеспечения надёжности в системе хранения. В зависимости от уровня репликаций в вашем пуле Ceph, с каждой
группой размещения выполняется репликация распространяемая на более чем одно OSD в кластере Ceph. Вы можете
рассматривать группу размещения как логический контейнер, хранящий множество объектов таким образом, что этот
логический контейнер отображается на множество OSD. Группы размещения имеют важное значение для масштабируемости и
производительности системы хранения Ceph.
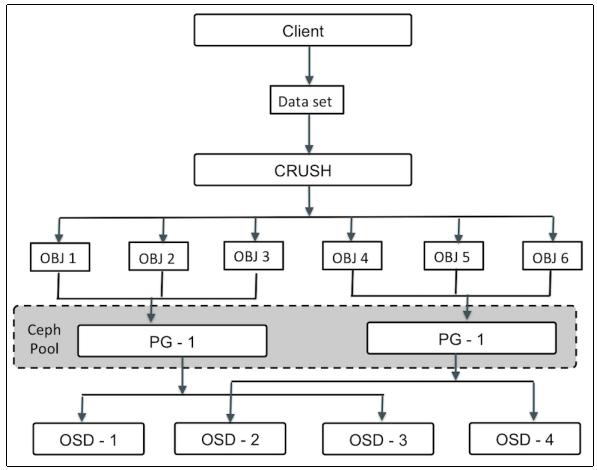
Без групп размещения было бы трудно управлять и отслеживать десятки миллионов объектов, которые реплицируются и распространяются на сотни OSD. Управление этими объектами без групп размещения также имело бы в результате перерасход вычислительных ресурсов. Вместо индивидуального управления каждым объектом, система должна управлять группами размещения с большим количеством объектов в каждой. Это делает Ceph более управляемой и менее сложной функционально. Каждая группа размещения требует определённое количество системных ресурсов, процессоров и оперативной памяти, поскольку каждая группа размещения должна управлять множеством объектов. Число групп размещения в кластере должно быть тщательно рассчитано. Обычно увеличение числа групп размещения в вашем кластере уменьшает нагрузку на OSD, однако прирост всегда должен выполняться регулируемым образом. Рекомендуется от 50 до 100 групп размещения на OSD. Это позволяет избегать высокой загруженности ресурсов узла OSD. По мере возникновения потребности увеличения данных, вам необходимо увеличивать масштаб вашего кластера регулируя число групп размещения. Когда устройства добавляются в кластер или удаляются из него, большинство групп размещения остаются в работе; CRUSH управляет перемещение групп размещения в кластерах.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
PGP |
Принятие решения о правильном числе групп размещения является важным этапом при построении кластеров хранения Ceph корпоративного уровня. Группы размещения могут в определённой степени улучшать или ухудшать производительность системы хранения.
Формула для вычисления общего числа групп размещения для кластера Ceph следующая:
Total PGs = (Total_number_of_OSD * 100) / max_replication_count
Результат должен быть округлён вверх до ближайшего числа степени 2. Например, если кластер Ceph имеет 160 OSD и число репликаций равно 3, то общее число групп размещения получается 5333.3, и, округляя его вверх до ближайшей степени 2 мы получаем конечное значение 8192 PG.
Мы также должны провести вычисления для того, чтобы найти общее число PG на пул в кластере Ceph. Формула для такого вычисления следующая:
Total PGs = ((Total_number_of_OSD * 100) / max_replication_count) / pool count
Мы рассмотрим тот же пример, который мы использовали ранее. Общее число OSD равно 160, уровень репликаций 3, а общее число пулов равно трём. Исходя из этих предположений, формула выдаёт 1777.7. Наконец, округляя значение вверх до степени 2 мы получаем 2048 PG на пул.
Важно сбалансировать число PG на пул с числом PG на OSD чтобы уменьшить вероятность изменений значений PG на OSD и избежать процесса восстановления, который является медленным.
Если вы управляете кластером Ceph, в определённый момент времени вам может потребоваться изменение значений PG и PGP для вашего пула. Прежде чем приступить к изменению PG и PGP, давайте разберёмся с тем, что такое PGP.
PGP это группы размещения для целей расположения (Placement Group for Placement purpose), которое должно
оставаться равным общему числу групп размещения (pg_num).
Если вы увеличивает число групп размещения для пула Ceph, то есть pg_num,
то вы должны также увеличить pgp_num до того же
целочисленного значения, равного pg_num, следовательно
кластер начнет процесс ребалансировки. Скрытый механизм ребалансировки можно пояснить следующим образом.
Значение pg_num определяет число групп размещения, которое
отображается на OSD (устройства хранения объектов). Когда значение pg_num
увеличивается для любого пула, каждая PG этого пула разделяется пополам, однако они все по прежнему отображаются на свои
родительские OSD. До этого момента времени Ceph не начинает ребалансировку. Теперь, когда вы увеличиваете значение
pgp_num для того же самого пула, PG начинают миграцию с родительских
на некоторые другие OSD и начинается ребалансировка. Таким образом, PGP играет важную роль в ребалансировке кластера.
Теперь давайте узнаем как изменить pg_num и
pgp_num:
-
Получите текущие значения числа PG и PGP:
# ceph osd pool get data pg_num # ceph osd pool get data pgp_num
[root@ceph-node1 /]# [root@ceph-node1 /]# ceph osd pool get data pg_num pg_num: 64 [root@ceph-node1 /]# ceph osd pool get data pgp_num pgp_num: 64 [root@ceph-node1 /]#
-
Определите уровень репликаций выполнив следующую команду и получив значение для
rep size:# ceph osd dump | grep size
[root@ceph node1 /]# ceph osd durp grep -i size pool 3 'rbd' rep size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 452 owner 0 pool 4 'data' rep size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 454 owner 0 pool 5 ’metadata' rep size 2 min_size 1 crush ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 456 owner 0 [root@ceph-node1 /]#
-
Вычислите новое число групп размещения для нашей установки с использованием {следующих значений}:
Total OSD = 9, Replication pool level (rep size) = 2, pool count = 3
Основываясь на предыдущей формуле мы получаем значение числа групп размещения для каждого пула равным
150, округление вверх до ближайшей степени 2 дает нам256. -
Изменяем PG и PGP для пула {данных}:
# ceph osd pool set data pg_num 256 # ceph osd pool set data pgp_num 256
[root@ceph-node1 /]# ceph osd pool set data pg_num 256 set pool 6 pg_num to 256 [root@ceph-node1 /]# [root@ceph-nodel /]# ceph osd pool set data pgp_num 256 set pool 6 pgp_num to 2S6 [root@ceph-node1 /]#
-
Аналогично изменяем значения PG и PGP для пулов метаданных и RBD (блочного устройства RADOS, Безотказного автономного распределённого хранилища объектов - Reliable Autonomic Distributed Object Store)):
[root@ceph-node1 /]# ceph osd pool get data pg_num pg_num: 256 [root$ceph-node1 /]# ceph osd pool get data pgp_num pgp_num: 256 [root@ceph-node1 /]# ceph osd pool get metadata pg_num pg_num: 256 [root@ceph-node1 /]# ceph osd pool get metadata pgp_num pgp_num: 256 [rootQceph-node1 /]# ceph osd pool get rbd pg_num pg_num: 256 [rootOceph node1 /]# ceph osd pool get rbd pgp_num pgp_num: 256 [root@ceph-node1 /]#
Демон Ceph OSD выполняет равноправные операции обмена (peering operation) состояний всех объектов и их метаданных для конкретных групп размещения, которые включают в себя согласование межу хранящими группу размещения OSD (устройствами хранения объектов). Кластер хранения Ceph сохраняет множество копий любых объектов во множестве PG (групп хранения), которые затем записываются в множестве OSD. Эти OSD называются первичными, вторичными, третичными и т.д. Действующий (acting) набор относится к группе OSD, ответственной за PG. Первичный OSD называется первым OSD из действующего набора и он отвечает за операции равноправного обмена для каждой PG со своими вторичными / третичными OSD. Первичное OSD является единственным OSD, которое принимает записывает операции от клиента. Находящееся в рабочем состоянии OSD остаётся в действующем состоянии. Ели вдруг первичное OSD выходит из строя, оно сначала удаляется из набора включённых (up); вторичное OSD повышается до первичного OSD. Ceph восстанавливает PG отказавшего OSD новым OSD и добавляет его в наборы включённых (up) и действующих (acting) для обеспечения высокой доступности.
В кластере Ceph определённое OSD может быть первичным OSD для некоторой PG, и в то же самое время быть вторичным или третичным OSD для другой PG.
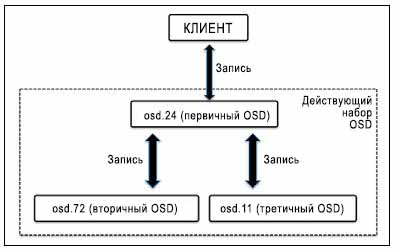
В предыдущем примере действующий набор содержит три OSD (osd.24, osd.72
и osd.11). Из них
osd.24 является первичным OSD, а
osd.72 и osd.11
являются вторичным и третичным OSD, соответственно. Поскольку osd.24
является первичным OSD, оно заботится о равноправных операциях обмена для всех PG, существующих на этих трёх OSD.
Таким образом Ceph гарантирует, что PG всегда доступны и непротиворечивы.
Концепция пула не является новой для систем хранения. Системы хранения уровня предприятий управляются путём создания определённых пулов; Ceph также обеспечивает лёгкое управление хранением посредством пулов хранения. Пул Ceph является логическим разделом для хранения объектов. Каждый пул в Ceph поддерживает определённое число групп размещения (PG), которые, в свою очередь, содержат ряд объектов, которые отображаются в OSD по всем кластерам. Следовательно, каждый отдельный пул распределён по всем узлам кластера и это обеспечивает устойчивость. Начальное развёртывание Ceph создаёт пулы по умолчанию на основании ваших требований; вам настоятельно рекомендуется создавать пулы отличные от тех, которые создаются по умолчанию.
Пул обеспечивает доступность данных за счет создания желаемого числа копий объектов, то есть, реплик или
кодов удаления. Свойство кода удаления EC, erasure coding
было добавлено в Ceph совсем недавно, начиная с редакции Ceph Firefly. Код удаления является методом защиты данных,
при котором данные разбиваются на фрагменты, кодируются, а затем сохраняются распределённым образом. Ceph, будучи
распределённым по собственной природе, использует EC удивительно хорошо.
Во время создания пула мы можем определить размер реплик {Прим. пер.:
из приводимых ниже примеров станет понятнее применение термина размер в применении к числу реплик: фактически это размер
набора OSD в группе размещения}; значением по умолчанию является
2. Уровень репликации пула очень гибок; в любой момент времени
мы можем изменить его. При создании пула мы также можем определить правила кода удаления, которые обеспечивают
тот же уровень надёжности, но требуют меньшего объёма пространства по сравнению с методом репликаций.
|
| Замечание |
|---|---|
|
Пул может быть создан либо с репликациями, либо с кодом удаления, но не с обоими одновременно. |
Пул Ceph отображается наборами правил CRUSH при записи данных в пул; он идентифицируется набором правил CRUSH для размещения объектов и их реплик внутри кластера. Набор правил CRUSH снабжают пулам Ceph новыми возможностями. Например, мы можем создавать быстрый пул, также известный как пул кэширования, поверх дисковых устройств SSD, или гибридный пул из дисковых устройств SSD и SAS или SATA.
Пулы Ceph также поддерживают функциональность моментальных снимков. Мв можем воспользоваться командой
ceph osd pool mksnap для создания моментального снимка
определённого пула, и мы можем восстановить его при необходимости. Кроме того, пул Ceph позволяет нам установить
права владения и правила доступа к объектам. Идентификатор пользователя может быть назначен на владение пулом.
Это очень полезно при определённых условиях, когда мы должны обеспечить ограниченный доступ к пулу.
|
| Замечание |
|---|---|
|
{Прим. пер.: Это может показаться забавным, однако с некоторых пор стало возможным построение бесплатной среды виртуализации на основе гипервизора Hyper-V с бесплатной же системой хранения Storage Spaces, обладающей современными функциональностью и мощностью сопоставимыми, например, с Ceph. Хотя она и ограничена в масштабировании применением аппаратных технологий SAS/ FC. Остаётся дождаться смещения Storage Spaces Direct (S2D) в сферу халявного применения, чтобы имеющаяся в Непосредственно подключаемых пространствах хранения Программно определяемая шина хранения (Software Storage Bus), заменяющая собой SAS/FC, смогла составить конкуренцию системам хранения уровня Ceph!} |
Выполнение операций с пулом Ceph одна из повседневных работ для администратора Ceph. Ceph предоставляет
богатый инструментарий cli для создания пулов и
управления ими. В следующем разделе мы узнаем о работе с пулами Ceph.
Для создания пула требуется имя пула, число PG и PGP, а также тип пула, который может быть либо реплицируемым, либо удаляемым. Значение по умолчанию - реплицируемый. Давайте начнём создание пула:
-
Создадим пул
web-servicesсо значением128для чисел PG и PGP. Приводимая команда создаст пул с репликациями, поскольку это параметр по умолчанию.# ceph osd pool create web-services 128 128
-
Перечень пулов может быть получен двумя способами. Однако вывод результатов третьей команды снабжает нас бОльшим объёмом информации, такой как идентификатор пула, размер репликаций, набор правил CRUSH, а также числами PG и PGP:
# ceph osd lspools # rados lspools # ceph osd dump | grep -i pool
[root@ceph-node1 /]# ceph osd dump | grep -i pool pool 3 'rbd' rep size 2 mir_size 1 crush_ruleset 0 object_hash rjenkins pg_nun 256 pgp_num 256 last_change 428 owner 0 pool 5 'metadata' rep size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_nun 256 pgp_num 256 last_change 476 owner 0 pool 6 'data' rep size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 256 pgp_num 256 last_change 470 owner 0 pool 8 'web-services' rep size 2 min_size 1 crush_ruleset 0 object_hasb rjenkins pg_num 128 pgp_num 128 last_change 503 owner 0 [root@ceph-node1 /]#
-
Значение по умолчанию для размера репликаций при создании пула Ceph для Ceph Emperor или более {ранних} редакций является
2; мы можем изменить значение размера репликаций с использованием следующей команды:# ceph osd pool set web-services size 3 # ceph osd dump | grep -i pool
[root@ceph-node1 /]# ceph osd pool set web-services size 3 set pool 8 size to 3 [root@ceph-node1 /]# [root@ceph-node1 /]# ceph osd dump | grep -i pool pool 3 'rbd' rep size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 256 pgp_num 256 last_change 478 owner 0 pool S 'metadata' rep size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 256 pgp_num 256 last_change 476 owner 0 pool 6 'data' rep size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 256 pgp_num 256 last_change 470 owner 0 pool 8 'web-services' rep size 3 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 128 pgp_num 128 last_change 505 owner 0
Замечание Для Ceph Emperor и более ранних редакций значение размера репликаций для пула по умолчанию было
2; это значение по умолчанию было изменено на3начиная с Ceph Firefly. -
Переименуйте пул следующим образом:
# ceph osd pool rename web-services frontend-services # ceph osd lspools
-
Пулы Ceph поддерживают моментальные снимки; мы можем восстановить объекты из моментального снимка в случае отказа. В следующем примере мы создадим в пуле объект и затем сделаем моментальный снимок пула. После этого мы умышленно удалим объект из пула и попытаемся восстановить объект из моментального снимка:
# rados –p frontend-services put object1 /etc/hosts # rados –p frontend-services ls # rados mksnap snapshot01 -p frontend-services # rados lssnap -p frontend-services # rados -p frontend-services rm object1 # rados -p frontend-services listsnaps object1 # rados rollback -p frontend-services object1 snapshot01 # rados -p frontend-services ls
[root@ceph-node1 /]# [root@ceph-node1 /]# [root@ceph-node1 /]# rados -p frontend-services put object1 /etc/hosts [root@ceph-node1 /]# rados -p frontend-services ls object1 [root@ceph-node1 /]# rados mksnap snapshot01 -p frontend-services created pool frontend-services snap snapshot01 [root@ceph-node1 /]# rados lssnap -p frontend-services 5 snapshot01 2014.05.12 13:20:58 1 snaps [root@ceph-node1 /]# rados -p frontend-services rm object1 [root@ceph-node1 /]# [root@ceph-node1 /]# rados -p frontend-services listsnaps object1 object1: cloneid snaps size overlap 5 5 237 [] [root@ceph-node1 /]# rados rollback -p frontend-services object1 snapshot01 rolled back pool frontend-services to snapshot snapshot01 [root@ceph-node1 /]# rados -p frontend-services ls object1 [root@ceph-node1 /]# [root@ceph-node1 /]# _
-
Удаление пула удаляет также и все его моментальные снимки. После удаления пула вам следует удалить наборы правил CRUSH, если вы их создавали вручную. Если вы создавали пользователей с полномочиями исключительно для пула, который больше не существует, вам следует также проанализировать удаление таких пользователей:
# ceph osd pool delete frontend-services frontend-services -- yes-i-really-really-mean-it
Управление данными внутри кластера Ceph включает в себя все компоненты, которые мы обсуждали до сих пор. Координация между этими компонентами даёт Ceph мощность для обеспечения надёжной и отказоустойчивой системы хранения. Управление данными начинается как только клиент записывает данные в пул Ceph. Сразу после того, как клиент записал данные в пул Ceph, данные сначала записываются в первичное OSD (устройство хранения объектов){. Далее,} основываясь на размере репликаций пула, первичное OSD выполняет репликацию тех же данных на свои вторичное и третичное{, а также, возможные последующие} и ожидает от них подтверждения. Как только вторичное и третичное OSD завершают запись данных, они посылают сигнал подтверждения первичному OSD и, наконец, первичное OSD возвращает подтверждение клиенту, утверждая завершение операции записи.
Таким образом Ceph непрерывно сохраняет каждую операцию записи и обеспечивает доступность данных из своих реплик в случае возникновения отказов. Давайте теперь рассмотрим как данные сохраняются в кластере.
-
Вначале мы создадим тестовый файл, пул Ceph и установим репликации пула на
3копии:# echo "Hello Ceph, You are Awesome like MJ" > /tmp/helloceph # ceph osd pool create HPC_Pool 128 128 # ceph osd pool set HPC_Pool size 3
-
Поместим в этот пул какие-нибудь данные и проверим его содержимое:
# rados -p HPC_Pool put object1 /tmp/helloceph # rados -p HPC_Pool ls
-
Теперь файл был сохранен в пул Ceph. Как вы знаете, все в Ceph сохраняется в форме объектов, которые помещаются в группы размещения (PG) а эти группы размещения располагаются во множестве OSD. Теперь рассмотрим эту концепцию на практике:
# ceph osd map HPC_Pool object1
Эта команда покажет вам карты OSD для
object1, который находится внутриHPC_Pool:[root@ceph-node1 /]# ceph osd map HPC_Pool object1 osdmap e566 pool ’HPC_Pool' (10) object 'object1' -> pg 10.bac5debc (10.3c) -> up [0,6,3] acting [0,6,3] [root@ceph-node1 /]#
- Давайте обсудим вывод результатов этой команды:
-
osdmap e566: Это идентификатор версии карты OSD, или OSD epoch 556. -
pool 'HPC_Pool' (10): Это имя пула Ceph и идентификатор пула. -
pg 10.bac5debc (10.3c): Это номер группы размещения, т.е.object1который находится в PG10.3c. -
up [0,6,3]: Это набор включённых (up) OSD, который содержитosd.0,osd.6иosd.3. Поскольку пул имеет уровень репликаций, установленный в значение3, каждая PG будет содержать три OSD. Это также означает, что все три содержащиеся в PG10.3cOSD работают. Это упорядоченный список OSD, который соответствует для конкретных OSD в конкретных периодах (epoch), как это указано в карте CRUSH. Обычно это ровно то, что содержит набор действующих PG. -
acting [0,6,3]:osd.0,osd.6,osd.3являются действующим набором. Причёмosd.0является первичное OSD,osd.6это вторичное OSD иosd.3третичное OSD. Этот набор действующих OSD является упорядоченным списком, который соответствует определённым OSD.
-
-
Найдите физическое местоположение каждого из этих OSD. Вы обнаружите, что OSD
0,6и3физически разделены в хостахceph-node1,ceph-node3иceph-node2соответственно:[root@ceph-node1 ~]# ceph osd tree * id weight type name up/down reweight -1 0 root default -7 0 rack rack03 -4 0 host ceph-node3 6 0 osd.6 up 1 7 0 osd.7 up 1 8 0 osd.8 up 1 -6 0 rack rack02 -3 0 host ceph-node2 3 0 osd.3 up 1 4 0 osd.4 up 1 5 0 osd.5 Up 1 -5 0 rack rack01 -2 0 host ceph-node1 0 0 osd.O up 1 1 0 osd.1 Up 1 2 0 osd.2 Up 1
-
Теперь зарегистрируемся на одном из этих узлов чтобы проверить на каких OSD расположены реальные данные. Вы обнаружите, что
object1сохранен в PG10.3снаceph-node2, в разделеsdb1, который являетсяosd.3; заметим, что указанные идентификаторы PG ID и OSD ID могут быть другими в вашей установке:# ssh ceph-node2 # df -h | grep -i ceph-3 # cd /var/lib/ceph/osd/ceph-3/current # ls -l | grep -i 10.3c # cd 10.3c_head/ # ls -l
[root@ceph-node1 /]# ssh ceph-node2 Last login: Wed May 14 12:45:59 2014 from ceph-node1 [root@ceph-node2 ~]# df -h | grep -i ceph-3 /dev/sdb1 5.0G 54m 5.OG 2% /var/lib/ceph/osd/ceph-3 [root@ceph-node2 ~]# cd /var/lib/ceph/osd/ceph-3/current [root@ceph-node2 current]# ls -l | grep -i 10.3c drwxr-xr-x. 2 root root 38 May 14 12:06 10.3c_head [root@ceph-node2 current]# cd 10.3c_head/ [root@ceph-node2 10.3c_head]# ls -1 total 64 -rw-r--r--. 1 root root 35 May 14 12:06 object1__head_BAC5DEBC__a [root@ceph-node2 10.3c_head]#
Таким образом Ceph сохраняет каждый объект данных реплицируемым образом в различных областях отказов. Такой интеллектуальный механизм является ядром управления данных Ceph.
В данной главе мы изучили внутренние компоненты Ceph, включающие в себя объекты, алгоритм CRUSH, группы размещения и пулы, а также как они взаимодействуют друг с другом для обеспечения высоких показателей надёжности и масштабируемости для кластера хранения. Эта глава основывается на практическом подходе для данных компонентов, следовательно вы можете понять каждый их бит.Мы также показываем как данные сохраняются в кластере, прямо начиная с того момента , как они приходят в виде запроса на запись в пул Ceph вплоть до того,как они достигают правильной файловой системы OSD (устройство хранения объектов) и сохраняются в виде объектов. Мы рекомендуем вам повторить эти практические примеры, на вашем тестовом кластере; это даст вам более обширное понимание того, как Ceph сохраняет свои данные с высокой степенью реплицированности в легко доступной форме. Если вы являетесь системным администратором, вам следует сосредоточиться на обнаружении пулов Ceph и карт CRUSH, как это упоминалось в данной главе. Это то, что ожидается от системных администраторов как до, так и после подготовки кластера. В следующей главе мы узнаем о планировании оборудования кластера Ceph и различных методах его установки, а после этого с модернизацией кластера Ceph и его масштабированием.