Глава 1. Основы виртуализации
Содержание
Эта книга поясняет основы виртуализации и поможет вам создавать ваши собственные инфраструктуры контейнеров, подобные Docker, но в облегчённой версии. Прежде чем мы приступим к этому процессу, нам потребуется разобраться с тем, как само ядро Linux поддерживает виртуализацию и как собственно развитие ядра Linux и ЦПУ способствует развитию виртуальных машин в плане производительности, что в свою очередь повлекло к созданию контейнерных технологий.
Цель данной главы состоит в том, чтобы пояснить что представляет из себя виртуальная машина (ВМ) и что происходит под капотом. Мы также рассмотрим некоторые основы гипервизоров, которые дают возможность запуска виртуальной машины в системе.
До наступления эры виртуализации единственный путь полной подготовки физических серверов пролегал через ИТ. Это был дорогостоящий и трудоёмкий процесс. Одним из недостатков такого метода был тот, что такие ресурсы машины как ЦПУ, память и диски оставались не полностью используемыми. Для обхода этого начало набирать обороты понятие виртуализации.
История виртуализации восходит к 1960-м годам, когда Джим Рымарчик, который был проргаммистом в IBM приступил к виртуализации мейнфреймов IBM. Для внутреннего использования IBM разработал мейнфрейм CP-40. Эта система эволюционировала в CP-67, в которой применялась технология нескольких разделов для одновременного запуска нескольких приложений. {Прим. пер.: авторы перевода застали систему виртуальных машин на серии мейнфреймов IBM 360/370 в их исполнении в серии ЕС ЭВМ.} В конце концов пришёл Unix, который позволял запускать несколько программ на оборудовании x86. Тем не менее, оставалась проблема переносимости. В ранние 90-е Sun Microsystems представила Java, которая позволила расправить крылья парадигме "написанное один раз запускать повсеместно". Теперь пользователь мог написать некую программу на Java, которая могла запускаться на широком диапазоне аппаратных архитектур. Java осуществила это, вводя промежуточный код (носящий название кода байт), который затем можно было бы выполнять с среде времени выполнения Java в различных аппаратных архитектурах. Это знаменовало появление виртуализации на уровне процессов, посредством которой среда времени исполнения виртуализировала соответствующий уровень POSIX.
В 1990-е в дело вмешалась VMware и запустила собственную модель виртуализации. Она была связана с виртуалтзацией фактического оборудования, такого как ЦПУ, память, диски и тому подобное. Это означало, что поверх программного обеспечения VMware (также носящего название гипервизор), мы способны запускать собственно операционные системы (именуемые гостевыми). Это означало, что разработчики не были ограничены запуском лишь программ Java, но были способны запускать любую программу, предназначенную для работы в своей гостевой операционной системе. Примерно в 2001 году VMware запустила свои серверы ESX и GSX. GSX был гипервизором 2 типа, а потому ему требовалась некая подобная Windows оперционная система для запуска гостей. ESX являл собой гипервизор 1 типа, который позволял гостевым ОС запускаться непосредственно поверх такого гипервизора.
Виртуализация предоставляет абстракцию поверх реально имеющихся ресурсов, которые мы бы желали виртуализировать. Тот уровень, на котором применяется такая абстракция, изменяет сам способ того как выглядят различные технологии виртуализации.
На верхнем уровне имеются две основные технологии виртуализации, основывающиеся на своём уровне абстракции.
-
На основе Виртуальных Машин (ВМ)
-
На сонове контейнеров
Помимо этих двух техник виртуализации имеются и прочие технологии, например, юникёрны (unikernels), которые являются облегчёнными ВМ с единственной целью. IBM в настоящее время предпринимает попытки запускать юникёрны в качестве процессов в таких проектах как Nabla. {Прим. пер.: начиная с версии 2004 Windows 10 (build 18917) также поддерживает запуск облегчённых ВМ Linux (WSL 2, Подсистемы Windows для Linux 2 типа), подробнее см. наш перевод изданной в сентябре 2020 книги Изучаем подсистемы Windows для Linix Прэйтика Сингха.} В данной книге мы в основном рассматриваем виртуализацию лишь на основе ВМ и контейнеров.
Такой подход на основе ВМ выполняет виртуализацию всей ОС целиком. Те абстракции, которые предоставляются в соответствующую ВМ, это виртуальные устройства такие как виртуальные диски, виртуальные ЦПУ и виртуальные NIC {Прим. пер.: а также виртуальные GPU и т.д.}. Иначе говоря, мы можем постулировать, что это полная ISA (instruction set architecture, архитектура набора инструкций); например, ISA x86.
При помощи виртуальных машин множество ОС способно совместно использовать ресурся одного и того же оборудования, причём с виртуальным представлением каждого из таких ресурсов, доступных для своей ВМ. Например, такая ОС в своей виртуальной машине (также именуемой гостевой) способны продолжать операции ввода/ вывода на неком диске (в данном случае это какой- то виртуальный диск), полагая что именно они являются единственной ОС в данной физической машине (также носящей название хоста), хотя в действительности они разделяют его со множеством виртуальных машин, а также с ОС самого хоста.
ВМ очень схожи с прочими процессами в ОС своего хоста. ВМ исполняется в неком аппаратно изолированном виртуальном адресном пространстве и на более низком уровне привилений, чем ОС их хоста. Самое основное отличие между неким процессом и какой- то ВМ состоит в ABI (Application Binary Interface, Двоичном интерфейсе приложения), выставляемом самам хостом в соответствующую ВМ. В случае некого процесса такой выставляемый ABI конструируется подобно сетевым сокетам, FD (дескрипторам файлов) и тому подобному, в то время как в окончательно завершённой виртуализации ОС, её ABI будет обладать неким виртуальным диском, виртуальным ЦПУ, виртуальными сетевыми картами, и так далее.
Такая форма виртуализации на выполняет абстракцию своего оборудования, а вместо этого применяет технологии внутри своего ядра Linux для изоляции путей доступа к различным ресурсам. Она высекает некие логические границы внутри одной и той же операционной системы. В качестве примера, мы получаем отдельную корневую файловую систему, отдельное дерево процессов, отдельную сетевую подсистему, и так далее.
Для виртуализации самой ОС применяется специальная порция программного обеспечения, носящего название гипервизора. Гипервизор сам по себе облдает двумя частями:
-
Virtual Machine Monitor (VMM) (Монитор Виртуальной Машины): Используется для отделения и эмуляции набора привилегированных инструкций (которые может исполнять лишь само ядро его операционной системы).
-
Device model (Модель Устройства): Используется для виртуализации имеющихся устройств ввода/ вывода.
Поскольку в некой виртуальной машине соответствующее оборудование не доступно напрямую (хотя в некоторых случаях это может иметь место {Прим. пер.: проброс оборудования или его частей, разделяемых на аппаратном уровне}), имеющийся VMM отлавливает привилегированные инструкции, которые запрашивают доступ к оборудованию (например,к диску/ сетевой карте) и исполняют эти инструкции от имени такой виртуальной машины.
Такой VMM обязан соответствовать трём свойствам (Popek and Goldberg, 1973):
-
Изоляция: Обязан изолировать госткй (ВМ) друг от друга.
-
Эквивалентности: Должен вести себя точно так же, как при виртуализации, так и без неё. Это означает, что мы запускаем большинство (почти все) инструкции в имеющемся физическом оборудовании без какой бы то ни было трансляции, и тому подобного.
-
Производительность: Обязано выполняться так же хорошо, как это делалось бы без какой бы то ни было виртуализации. Это опять- таки означает, что имеющиеся издержки запуска некой ВМ минимальны.
Некоторые функциональные возможности VMM таковы:
-
Не позволяет доступ ВМ к привилегированным состояниым; то есть, такие вещи как манипулирование значением состояния регистров хоста не допускаются из соответствующей ВМ. Имеющийся VMM будет всегда отлавливать и эмедировать подобные вызовы.
-
Обрабатывает исключительные состояния и прерывания. Когда некий сетевой вызов (то есть запрос) испускается изнутри некой виртуальной машины, он будет отловлен в имеющемся VMM и сэмулирован им. По получению отклика от физической сетевой среды/ NIC, физический ЦПУ выработает некое прерывание и доставит его в реальную виртуальную машину, которой оно предназначено.
-
Обрабатывает виртуализацию ЦПУ запуская большинство инструкций естественным образом (внутри соответствующего виртуального ЦПУ этой ВМ) и отлавливая лишь определённые привилегированные инструкции. Это означает, что производительность почти такова, как если бы родной код выполнялся бы напрямую на физическом оборудовании.
-
Обрабатывает устновленный в памяти ввод/ вывод осуществляя трансляцию своих вызовов в сответствующую виртуальную память своего гостя, относящуюся к устройству, в реальную память физического устройства. Для этого установленный VMM обязан контролировать все соответствия физической памяти (Гостевой физической памяти в физическую память Хоста). Более детально мы обсудим это в последующем разделе данной главы.
Модель устройства соответствующего гипервизора обрабатывает установленную виртуализацию ввода/ вывода опять же через отлавливание и эмуляцию с последующей доставкой прерываний обратно в конкретную виртуальную машину.
Одним из критически важных вызовов при виртуализации является то как преврщать память в виртуальную. Получаемая гостевая ОС должна обладать тем же поведением, что и ОС без виртуализации. Это означает, что наша гостевая ОС должна быть слана так, то по крайней мере она считает что управляет своей памятью.
В случае виртулизации нашей гостевой ОС не может быть предоставлен прямой доступ к имеющейся физической памяти. Что это означает, так это то, то что наша гостевая ОС не способна манипулировать аппаратными таблицами страниц, ибо это могло пы приводить к получению таким гостем контроля над своей физической системой.
Прежде чем мы окунёмся в то как управляться с этим, потребуется некое базовое понимание виртуализации памяти, даже в контексте взаимодействия с обычными ОС и оборудованием.
Конкретная ОС снабжает свои процессы неким виртуальным представлением памяти; всякий доступ к установленой физической памяти перехватывается и обрабатывается имеющейся аппаратной компонентой, носящей название MMU (Memory Management Unit, Диспетчер памяти). Сама ОС устанавливает значение регистра CR3 (через привилегированную инструкцию) и имеющийся MMU применяет эту запись для прохождения по соответствующим таблицам памяти для определения физического соответствия. Сама ОС также заботится об изменении такого соответствия когда происходит выделение или высвобождение физической памяти.
Теперь, в случае виртуальных гостей, их поведение должно быть аналогичным. Такой гость не должен получать прямого доступа к физической памяти, а вместо этого должен перехватываться и обрбатываться имеющимся VMM.
В целом, при исполнении некой гостевой ОС имеются вовлечёнными три абстракции памяти:
-
Гостевая виртуальная память: Это именно то, что видно самому процессу гостевой ОС в качестве пространства исполнения.
-
Гостевая физическая память: Это то, что видит гостевая ОС
-
Системная физическая память: Это то, что наблюдает VMM.
Для обработки этого имеются два возможных подхода:
-
Таблицы теневых страниц
-
Вложенные таблицы страниц с аппаратной поддержкой
В случае теневых таблиц страниц, Гостевая виртуальная память ставится в соответствие напрямую Системной Физической памяти через VMM хоста. Это улучшает производителность путём исключения одного дополнительного уровня трансляции. Однако этот подход обладает недостатками. Когда в таблице гостевых страниц имеется изменение, необходимо обновлять таблицы теневых страниц. Это подразумвает, что для обработки в VMM должны иметься некая ловушка и эмуляция. Имеющийся VMM может выполнять это помечая свои гостевые страницы доступными лишь для чтения. Тем самым, любые попытки записи его гостевой ОС вызовут перехват и VMM сможет затем обновить свои теневые страницы.
Для данной задачи Intel и AMD предоставляют решение через аппаратные расширения. Intel предоставляет нечто, носящее название EPT (Extended Page Table, Расширенной таблицы страниц), что делает возможным для MMU проходить по двуи таблицам страниц.
Первый проход заключается в соответствии из Гостевой Виртуальной в Гостевую Физическую память,а второй проход выполняет соответстиве из Гостевой Физической в Системную Физическую память. Поскольку все трансляции теперь происходят на аппаратном урове, нет необходимости пддержки теневых страниц таблиц. Гостевые таблицы страниц сопровождаются самой гостевой ОС,а все прочие таблицы боддерживаются VMM хоста.
При использовании теневых таблиц страниц, значения кэша TLB (translation look-aside buffer, буфера предыстории процесса, являющегося частью MMU) необходимо сбрасывать при переключении контекста, то есть при запуске другой ВМ. Тогда как в случае EPT оборудование представляет некий идентификатор ВМ через соответствующий идентификатор адресного пространства, что означает, что TLB способен обладать соответствиями для различных ВМ одновременно, что является ускорением производительности.
Прежде чем мы рассмотрим виртуализацию ЦПУ, было бы познавательно разобраться как в архитектуре x86 строятся кольца защиты.Такие кольца делают возможным для ЦПУ защищать память и контролировать права, а также определять какой код исполняется на каком уровне.
Архитектура x86 пользуется понятием колец защиты. Само ядро исполняется в наиболее привилегированном режиме, Кольце 0, а соответствующее пространство пользователя, используемое для выполнения процесов запускается в Кольце 3.
Имеющееся оборудование требует, чтобы все привилегированные инструкции исполнялись в Кольце 0. Когда в Кольце 3 предпринимается любая попытка запуска некой привилегированной инструкции, имеющийся ЦПУ вырабатывает отказ. Ядро хоста регистрирует обработчики отказов и, на основании типа отказа, вызыввается некий обработчик отказа. Соответствующий обработчик отказа выполняет контроль корректности этой ошибки и обрабатывает её. Если проверка корректности прошла, этот обработчик ошибок управляется с этим исполнением от имени самого процесса. В случае виртуализации на основе ВМ, такая ВМ запускается как некий процесс в ОС самого хоста, а потому если этот отказ не будет обработан, будет уничтожена вся ВМ целиком.
На верхнем уровне привилегированные инструкции из 3 Кольца контролируются неким регистром сегмента кода через
надлежащий бит CPL (code privilege level, уровень привилегированности кода). Все вызовы из Кольца 3 управляемо
пропускаются в Кольцо 0. Например, некой подобной syscall инструкции
(из пространства пользователя) может выполняться какой- то системный вызов, который, в свою очередь, устанавливает
значение верного уровня CPL и испольняет необходимый код ядра с более высоким уровнем полномочий. Любая попытка
непосредственного вызова еода с высокими полномочиями из более верхнего кольца приводит к аппаратному отказу.
Та же самае концепция применяется к некой виртуальной ОС. В этом случае соответствующий гость понижается в полномочиях и запускается в Кольце 1, а процесс этого гостя запускается в Кольце 3. VMM хоста сам по себе исполняется в Кольце 0. Для всех полностью виртуальных гостей все любые привилегированные инструкции должны улавливаться и эмклироваться. Именно VMM эмулирует такую перехваченную инструкцию. Помимо таких привилегированных инструкций, секретные инструкции также подлежат перехвату и эмуляции через VMM хоста.
Более ранние версии ЦПУ x86 не обладали возможностями иртуализации, что подразумевает, что не все секретные инструкции являются привилегированными. Такие инструкции, как SGDT, SIDT и ряд прочих, могут выполняться в Кольце 1 без их перехвата. Это может оказаться пагубным при запуске некой гостевой ОС, поскольку такой код позволяет соответствующему гостю заглядывать в структуры данных ядра хоста. Эту проблему можно решать двумя способами:
-
Двоичная трансляция в случае полной виртулизации
-
Паравиртуализацией в случае гипервызовов XEN
В этой ситуации соответствующая гостевая ОС применяется без каких бы то ни было изменений. Соответствующие инструкции отлавливаются и эмулируются для надлежащей целевой среды. Это вызывает большое число накладных расходов, поскольку должно перехватываться большое число инструкций в соответствующем хосте/ гипервизоре с последующей эмуляцией.
Во избежание относящихся к двоичной трансляции проблем при использовании полной виртулизации мы применяем паравиртуализацию, при которой соответствующий гость осведомлён, что он запущен в виртуальной среде и его взаимодействие с хостом оптимизировано для избегания затратного отлавливания. Например, код драйвера устройства изменяется и расщепляется на две части. Одна из них выступает в качестве серверной (которая располагается в самом гипервизоре), а другая выступает интерфейсом, который пребывает в госте. Сам гость и драёверы хоста теперь взаимодействуют поверх буферов колец. Соответствующий буфер кольца получает выделение в памяти этого гостя. Теперь этот гость способен накапливать/ агрегировать данные внутри своего буфера кольца и осуществлять один гипервызов (то есть вызов к своему гипервызору, также именуемый толчком, kick) для передачи сигнала что все данные готовы опустошения. Это избегает затратных перехватов из соответствующего гостя их хостом и приводит к выигрышу в производительности.
В 2005 x86 окончательно превратились в поддерживающие виртуализацию. Они ввели ещё одно дополнительное кольцо, именуемое Кольцом -1, которое также носит название режим корня VMX (virtual machine extensions, расширения виртуальной машины). Необходимый VMM запускается в режиме корня VMX, а все гости исполняются в не корневом режиме.
Это означает, что все гости могут запускаться в Кольце 0 и, для большинства инструкций нет ловушек. Необходимые для выполнения привилегированные/ секретные инструкции исполняются через VMM в режиме корня через соответствующую ловушку. Мы называем такие переключения Выходами ВМ (VM Exits, то есть установленный VMM приступает к исполнению инструкций из соответствующего гостя) и Входами ВМ (VM Entries, соответствующая ВМ получает управление из установленного VMM).
Помимо этого, такие допускающие виртуализацию ЦПУ управляют некой структурой данных, именуемой
VMCS (VM control structure, Управляющая структура ВМ) и именно она обладает состоянием соответствующей ВМ
и её регистров. Надлежащий ЦПУ применяет эти сведения на протяжении Входов и Выходов в ВМ. Такая структура
VMCS подобна task_struct, той структуре данных, которая применятеся
для предствления процесса. Один указатель VMCS указывает на активную в данный момент VMCS. Когда имеется
некое прерывание для VMM хоста, VMCS предоставляет значение состояния всех регистров этого гостя, например,
причину выхода и т.п..
У аппаратной виртуализации имеются два преимущества:
-
Отсутствие двоичной трансляции
-
Никаких изменений ОС
Основная проблема заключается в том, что Входы и Выходы ВМ свё ещё тяжёлые вызовы, вовлекающие в себя большое число циклов ЦПУ, поскольку должно сохраняться и восстанавливаться полное состояние ВМ. На соуращение необходимого числа циклов на Входы и Выходы были направлены значительные усилия. Применение драйверов паравиртуализации способствкет смягчению части этих проблем с производительностью. Подробности мы поясняем в своём следующем разделе.
Обычно в целом имеются две модели виртуализации ввода/ вывода:
-
Полная виртуализация
-
Паравиртуализация
При полной виртуализации соответствующий гость не осведомлён о том, что он запущен в некотором гипервизоре и ОС этого гостя не нуждается ни в каких изменениях для запуска в гипервизоре. Всякий раз, когда такой гость выполняет вызовы ввода/ вывода, они перехватываются в его гипервизоре и сам гипервизор выполняет этот ввод/ вывод в соответствующем устройстве.
В данном случае ОС соответствующего гостя осведомлена о том, что она запущена в виртуальной среде и для заботы о необходимом вводе/ выводе в соответствующем госте загружены специальные драйверы. Соответствующие системные вызовы для ввода/ вывода заменяются гипервызовами.
Рисунок 1-1 отображает различия между паравиртуализацией и полной виртуализацией.
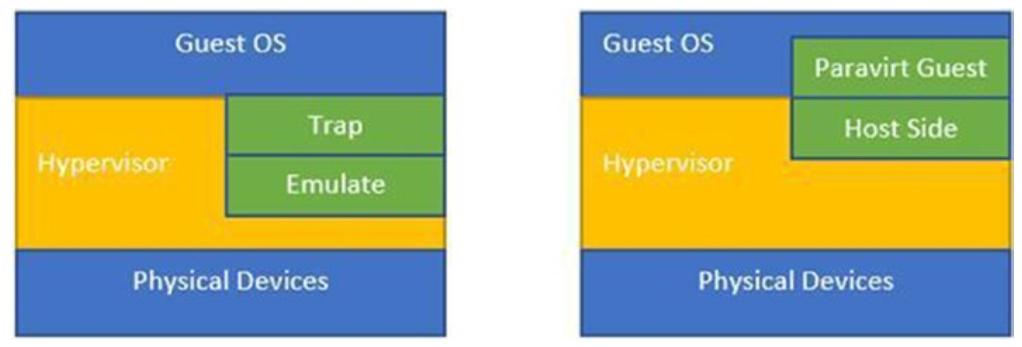
При сценарии паравиртуализации, драйверы соответствующей стороны гостя носят название драйверов интерфейса (frontend), а драйверы стороны хоста именуются драйверами сервера (backend). Для реализации драйверов паравиртуализации стандартом выступает Virtio. Соответствующие драйверы интерфейса сетевых устройств и ввода/ вывода гостевой стороны реализуются на основе стандарта Virtio и такие драйверы интерфейса осведомлены о том, что они запущены в некой виртуальной среде. Они работают в тандеме с серверными драйверами Virtio своего гипервизора. Такой механизм работы драйверов интерфейса и сервера способствуют достижению высокой производительности сетевых и дисковых операций и является основной причиной для большинства преимуществ производительности, которыми обладает паравиртуализация.
Как уже упоминалось, соответствующие драйверы интерфейса в гостях реализуют некий общий набор взаимодействий, который предписывается стандартом Virtio. Когда из соответствующего процесса в госте должен выполняться некий вызов ввода/ вывода, этот драйвер вызывает API своего драйвера интерфейса и этот драйвер передаёт пакеты данных в надлежащий драйвер сервера через виртуальную очередь (virtqueue).
Драйверы сервера могут работать двумя путями:
-
Они могут применять эмуляцию QEMU, что означает, что QEMU эмулирует соответствующие вызовы необходимого устройства через системные вызовы из пространства пользователя. Это подразумевает, что гипервизор позволяет программам QEMU соответствующего пространства пользователя выполнять реальные обращения к устройству.
-
Они могут применять механизм vhost, в то же время избегая эмуляции QEMU, вместо этого реальные вызовы устройства выполняет ядро самого гипервизора.
Как уже упоминалось, взаимодействие между драйверами интерфейса и сервера Virtio осуществляются через абстракции виртуальной очереди. Соответствующая виртуальная очередь предоставляет для взаимодействия некий API, который делает возможным заполнять очередь буфера и разгружать её. В зависимости от типа драйвера, они могут использовать ноль или более очередей. В случае сетевого драйвера он применяет две виртуальные очереди - одну очередь для запросов,а вторую для получаемых пакетов. В случае блочного драйвера Virtio, он применяет лишь одну виртуальную очередь.
Рассмотрим такой пример некого потока сетевых пакетов, когда соответствующий гость желает отправить некоторые данные через сетевую среду:
-
Гость выполняет инициализацию сетевого пакета, записываемого через ядро соответствующего гостя.
-
Соответствующие драйверы паравиртуализации (Virtio) в госте принимают эти буферы и помещают их в необходимую виртуальную очередь (
tx). -
Сервером этой виртуальной очереди выступает поток исполнителя и именно он получает эти буферы.
-
Полученные буферы затем записываются в файловый дескриптор устройства ответвления. Это устройство ответвления можно подключить к программному мосту, например, к мосту OVS или Linux.
-
Обратная сторона этого моста имеет некий физический интерфейс, который затем выводится через установленный физический уровень.
В данном примере, когда гость получает пакеты в очередь tx, ему
требуется некий механизм информирования стороны самого хоста что у того имеются пакеты для обработки. В Linux
имеется интересный механизм с названием eventfd, который применяется для
уведомления своей стороны хоста, что имеются некие события. Сам хост отслеживает изменения
eventfd.
Некий аналогичный механизм применяется для отправки пакетов обратно соответствующему гостю.
Как вы могли видеть в предыдущих разделах, индустрия оборудования навёрстывает пространство виртуализации и
предоставляет всё больше и больше аппаратной виртуализации, будь они предназначены для ЦПУ (введение нового
кольца), а также инструкций vt-x, или же в отношении памяти (расширенные
таблицы страниц).
Аналогично, для виртуализации ввода/ вывода, оборудование обладает неким механизмом с названием устройства управления памятью (memory management unit, MMU) ввода/ вывода, которое аналогично устройству управления памяти ЦПУ, но предназначено лишь для основанной на вводе/ выводе памяти. Это понятие аналогично MMU ЦПУ, однако здесь доступ к памяти перехватывается и ставится в соответствие разным гостям. Гостям устанавливается соответствие к различной физической памяти и доступ контролируется самими оборудованием MMU ввода/ вывода. Это предоставляет ту изоляцию, которая необходима для доступа к устройству.
Данная функциональная возможность может применяться совместно с чем- то, имеющим название SRIOV (single root I/O virtualization, виртуализацией ввода/ вывода с единственным корнем), которая позволяет неким совместимым с SRIOV устройствам разбиваться на множество виртуальных функций. Самая основная мысль состоит в обходе самого гипервизора в пути данных и применении некого механизма проброса (pass-through), в то время как ВМ напрямую взаимодейтсвует с соответствующими устройствами. Подробности SRIOV выходят за пределы тем данной книги. Заинтересованный читатель может проследовать по приводимым ниже ссылкам для получения дополнительных сведений.
https://blog.scottlowe.org/2009/12/02/what-is-sr-iov/
https://fir3net.com/Networking/Protocols/what-is-sr-iov-single-root-i-o-virtualization.html
{Прим. пер.: также см.наш перевод главы по этой теме из книги Технология PCI Express 3.0 Майка Джексона, Рави Бадрака}.