Глава 5. Компоновка повторно используемого содержания и ролей Ansible
{Прим. пер.: рекомендуем сразу обращаться к нашему более полному переводу 3 издания вышедшего в марте 2019 существенно переработанного и дополненного Полного руководства Ansible Джеймса Фримана и Джесса Китинга}
Содержание
- Глава 5. Компоновка повторно используемого содержания и ролей Ansible
Для многих проектов может быть достаточно простого, одиночного плейбука Ansible. По мере того как время идёт и проекты растут, добавляются дополнительные файлы плейбуков и переменных, а файлы задач могут расщепляться. Прочие проекты внутри некоторой организации могут пожелать повторно применять некое имеющееся содержимое; либо сами проекты добавляются в имеющееся дерево каталога, либо всё желательное содержимое может копироваться во множество проектов. По мере того как растёт сложность и размер ваших вариантов применения, очень желательно нечто большее чем некая неопределённая организация полезных плейбуков, файлов задач и файлов переменных. Создание такой иерархии может быть внушающей страх и это способно пояснить почему многие применения Ansible начинаются с простых и всего лишь перерастают в некую лучшую организацию когда разбросанные файлы становятся громоздкими и трудными для сопровождения. Осуществление такой миграции может быть затруднительной и способно потребовать повторного написания значительных частей плейбуков, что может ещё больше задержать усилия реорганизации.
В данной главе мы обсудим все имеющиеся наилучшие практические навыки для смешивания, повторного применения и хорошей организации содержимого внутри Ansible. Изучаемые в данной главе уроки помогут разработчикам проектировать содержимое Ansible для хорошего роста внутри имеющегося проекта, избегая потребности в сложном повторном проектировании работы впоследствии. Ниже приводится набросок того что мы обсудим:
-
Задачи, обработчики, переменные и плейбуки, включая основные понятия
-
Роли (структуры, значения по умолчанию, зависимости)
-
Проектирование верхнего уровня плейбуков для применения ролей (тегов и прочих недостающих в ролях вещей)
-
Совместное применение ролей в проектах (зависимости через репозитории подобные git, galaxy)
Самым первым шагом в понимании того как действенно организовывать некую структуру проекта Ansible является овладение понятием вложения файлов. Такое действие вложения файлов позволяет содержимому определяться в особом для некоторой темы файле, который может быть включённым (вложенным) в другие файлы один раз или более в рамках какого- то проекта. Такая функциональность включения поддерживает имеющуюся концепцию Не повторять себя самого (DRY, Don't Repeat Yourself).
Файлы задач являются файлами YAML, которые определяют одну или
более задач. Эти задачи не связаны напрямую в какие бы то ни было воспроизведение или плейбук; они присутствуют
просто как некий список задач. На эти файлы могут ссылаться плейбуки или другие файлы задач посредством
имеющегося оператора include. Данный оператор принимает некий путь к
какому- то файлу задач и, как мы усвоили в Главе 1, Архитектура
системы и проектирование Ansible, такой путь может быть относительным для того файла, который применяет
эту ссылку.
Для демонстрации того, как применять такой оператор include чтобы
включать задачи, давайте создадим некое простое воспроизведение, которое включает некий файл задач с какими то
задачами отладки внутри него. Вначале мы напишем свой файл плейбука, и мы озаглавим его
includer.yaml:
---
- name: task inclusion
hosts: localhost
gather_facts: false
tasks:
- name: non-included task
debug:
msg: "I am not included"
- include: more-tasks.yaml
Затем мы создадим в некотором каталоге, который содержит includer.yaml
файл more-tasks.yaml:
---
- name: included task 1
debug:
msg: "I am the first included task"
- name: included task 2
debug:
msg: "I am the second included task"
Теперь мы исполним свой плейбук чтобы посмотреть на его вывод:
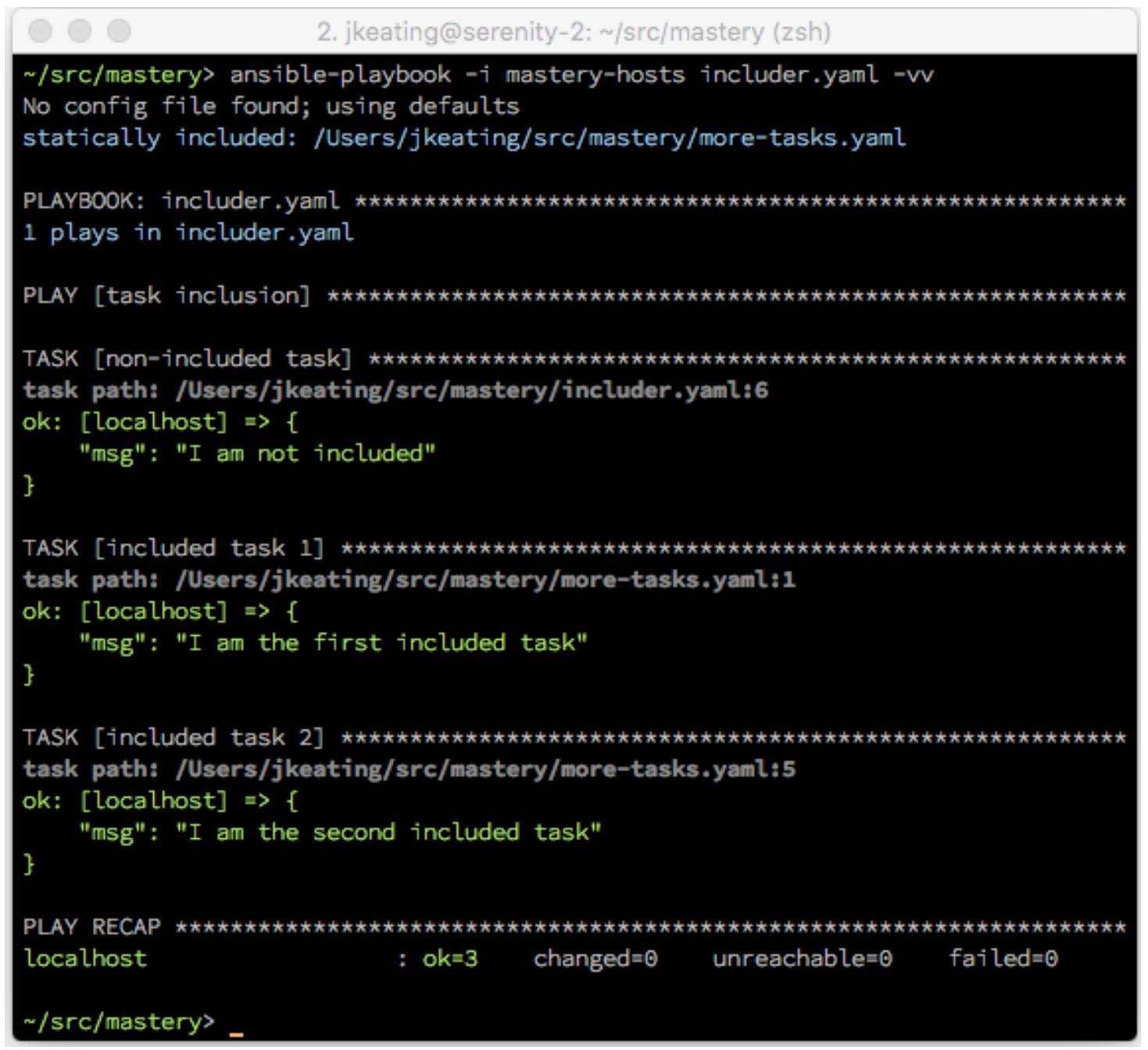
Мы можем отчётливо видеть свои задачи из исполнения данного файла include.
Поскольку этот оператор includeбыл применён внутри данного
раздела воспроизведения задач, эти включённые задачи были исполнены внутри данного воспроизведения. На самом
деле если мы должны были добавить некую задачу в своё воспроизведение после данного оператора
include, мы бы увидели, что имеющийся порядок исполнения следует
так, как если бы эти задачи из данного включённого файла имелись в том месте, где был применён сам оператор
include:
tasks:
- name: non-included task
debug:
msg: "I am not included"
- include: more-tasks.yaml
- name: after-included tasks
debug:
msg: "I run last"
Если мы исполним свой видоизменённый плейбук, мы увидим тот порядок задач, который мы ожидаем:
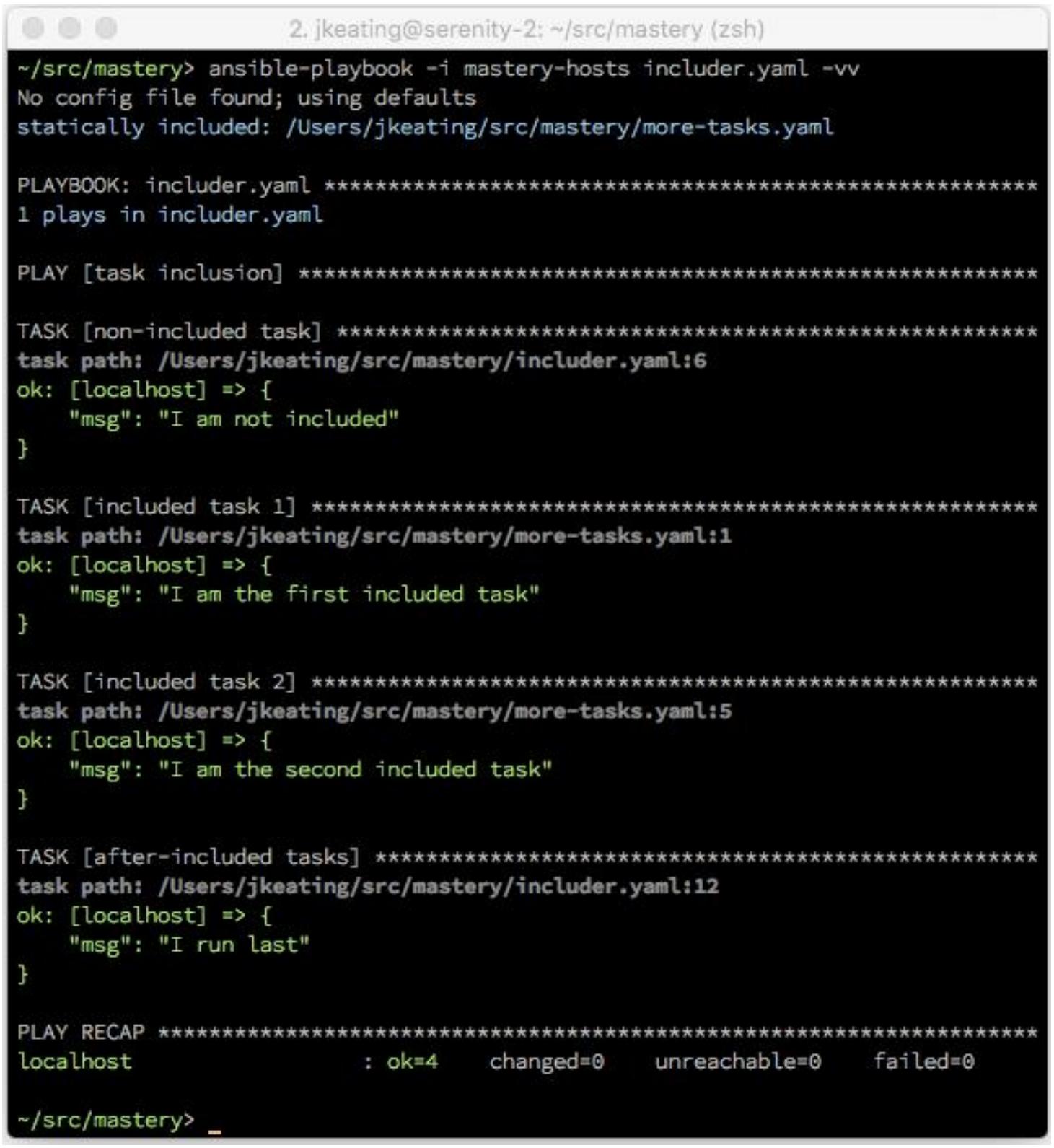
Разбивая такие задачи на их собственные файлы мы можем включать их множество раз или во множество плейбуков. Если нам когда- то придётся изменить одну из этих задач, нам только нужно изменить некий отдельный файл вне зависимости от того из какого числа мест имеются ссылки на этот файл.
Передача значений переменных во включённые задачи
Порой мы желаем разделить некий набор задач, но иметь эти задачи действующими слегка отличным образом в
зависимости от переменных данных. Наш оператор include позволяет
нам определять и переписывать переменные данные во время их включения. Такая сфера данного определения
имеется только внутри определяемых файлов включения задач (и всех прочих файлов, которые могут включаться в
них). Чтобы проиллюстрировать такую возможность, давайте создадим некий новый сценарий при котором нам
нужно выполнить touch {Прим. пер.: изменить время последнего изменения или создать
файл} для пары файлов, причём каждый из них в своём собственном пути каталога. Вместо написания двух
задач файлов для каждого файла (один для создания такого каталога и другой для контакта с самим файлом), мы
создадим некий файл задачи с обеими задачами который будет применять имена переменных в теле задач. Затем мы
включим этот файл задачи дважды, причём каждый раз передадим в него разные данные. Вначале мы проделаем это
с имеющимся файлом задач files.yaml:
---
- name: create leading path
file:
path: "{{ path }}"
state: directory
- name: touch the file
file:
path: "{{ path + '/' + file }}"
state: touch
Далее мы создадим необходимое воспроизведение чтобы включить тот файл задач, который мы только что создали, совместно с этим передав переменные данные для переменных определённого пути и файла:
---
- name: touch files
hosts: localhost
gather_facts: false
tasks:
- include: files.yaml vars:
path: /tmp/foo
file: herp
- include: files.yaml vars:
path: /tmp/foo
file: derp
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Предоставляемое при включении файлов определения переменных может быть либо в виде встроенного формата
|
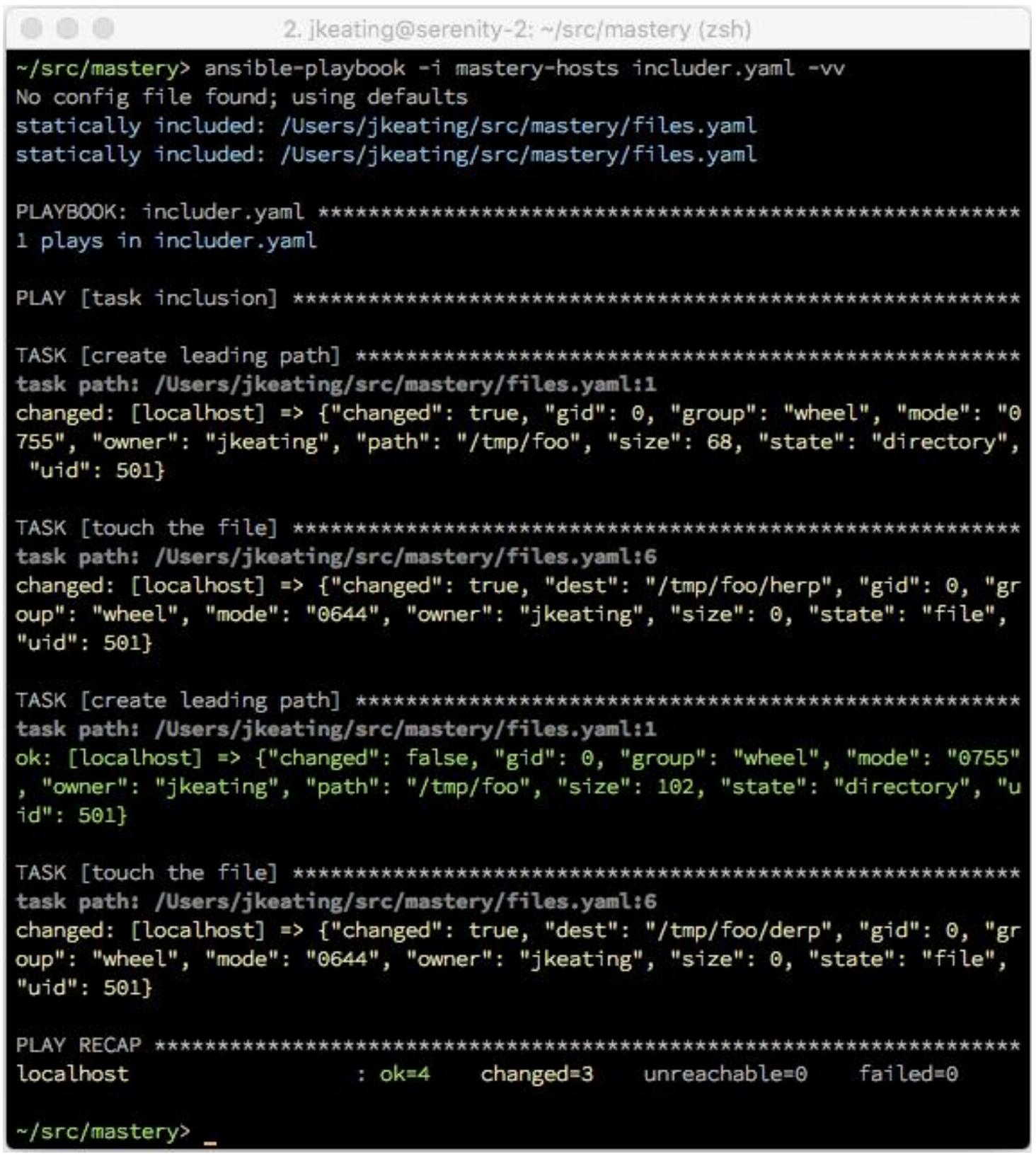
Когда мы выполним этот плейбук, мы увидим выполненными четыре задачи, по две задачи из
files.yaml дважды. При этом наш второй набор должен иметь результатом только
одно изменение, так как его путь один и тот же в обоих наборах:
Передача сложных данных во включённые задачи
Когда желательна передача сложных данных во включаемые задачи, например, некий список или хэш, может применяться альтернативный синтаксис при включении такого файла. Давайте повторим свой последний вариант, только на этот раз вместо включения своего файла задачи дважды мы включим его один раз и передадим некий хэш необходимых путей и файлов. Для начала мы поработаем над своим файлом задач:
---
- name: create leading path
file:
path: "{{ item.value.path }}"
state: directory
with_dict: "{{ files }}"
- name: touch the file
file:
path: "{{ item.value.path + '/' + item.key }}"
state: touch
with_dict: "{{ files }}"
Теперь мы видоизменим свой плейбук чтобы предоставлять необходимый хэш
files в некотором отдельном выражении
include:
---
- name: touch files
hosts: localhost
gather_facts: false
tasks:
- include: files.yaml
vars:
files:
herp:
path: /tmp/foo
derp:
path: /tmp/foo
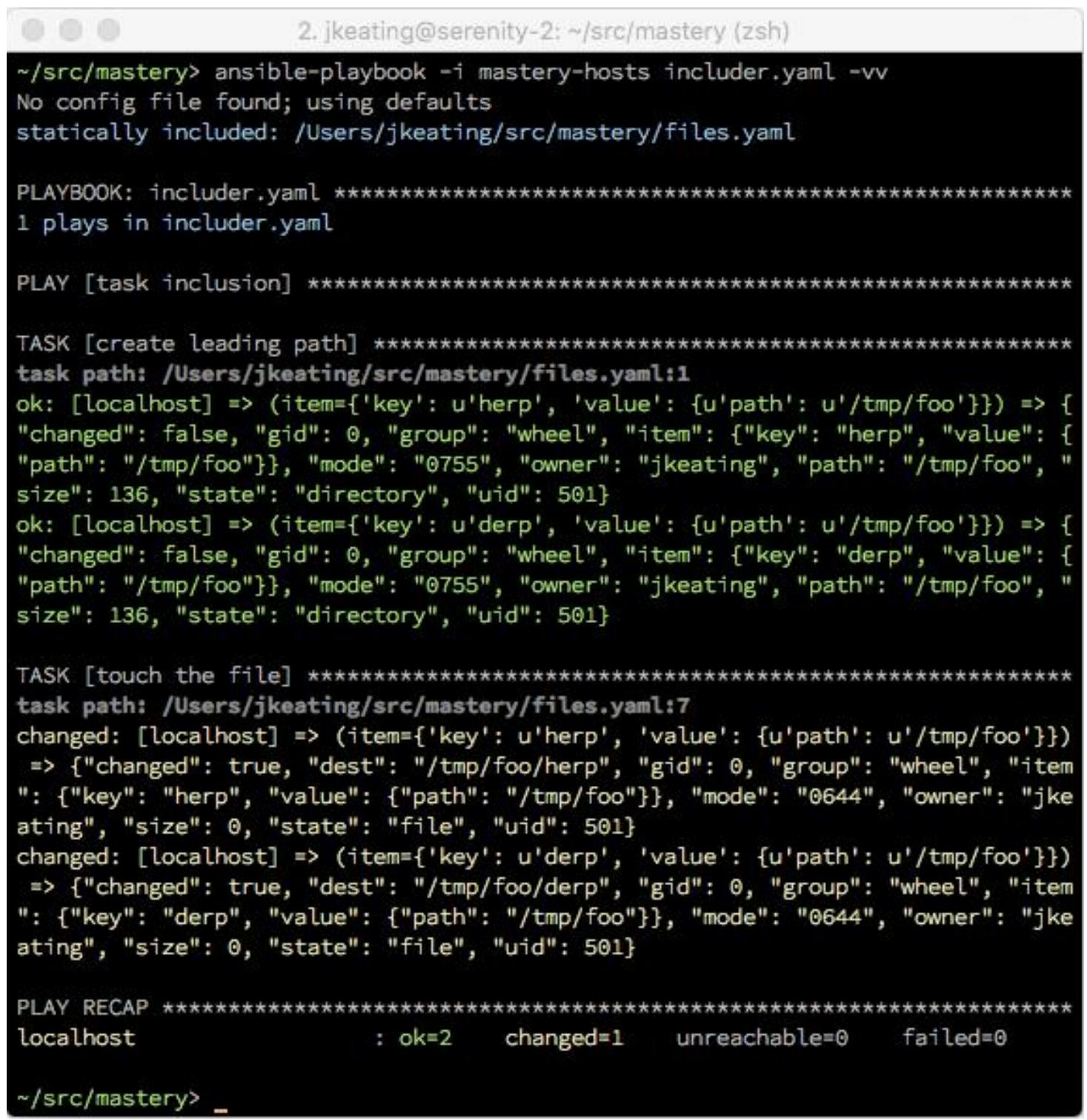
Если мы исполним эти новый плейбук и файл задач, мы должны видеть аналогичный, но слегка отличающийся вывод,
причём его конечный результат состоит в определённом каталоге /tmp/foo,
уже имеющемся на своём месте и необходимыми двумя файлами herp и
derp для выполнения с ними команды touch:
Такое применение передачи в виде некоторого хэша данных позволяет для вашего растущего набора сущностей
создание выражений в вашем главном плейбуке без роста общего числа выражений
include.
Условные включения задач
Аналогично передаче данных во включаемые файлы, в них также могут передаваться и условные зависимости.
Это осуществляется присоединением некоторого выражения when в
ваш оператор включения. Такое условие не должно вызывать Ansible выполнять конкретную проверку для определения
того следует или нет включать данный файл; место этого оно указывает Ansible добавить такую условную
зависимость в каждую без исключения задачу внутри данного включаемого файла (а также во все прочие файлы,
которые может включать обсуждаемый файл).
|
| Замечание |
|---|---|
|
Не существует возможности условного включения файла. Файлы всегда будут включены; однако, некоторая задача может применяться к каждой задаче внутри в соответствии с условной зависимостью. |
Давайте продемонстрируем это изменив свой первый пример, который включает простые выражения отладки. Мы добавим некоторую условную зависимость и передадим её совместно с некоторыми данными для применения такой зависимости. Для начала давайте изменим свой плейбук:
---
- name: task inclusion
hosts: localhost
gather_facts: false
tasks:
- include: more-tasks.yaml
when: item | bool vars:
a_list:
- true
- false
Затем модифицируем more-tasks.yaml для цикла по имеющейся
переменной a_list внутри каждой задачи:
---
- name: included task 1
debug:
msg: "I am the first included task"
with_items: "{{ a_list }}"
- name: include task 2
debug:
msg: "I am the second included task"
with_items: "{{ a_list }}"
Теперь давайте выполним этот плейбук и рассмотрим свой новый вывод:
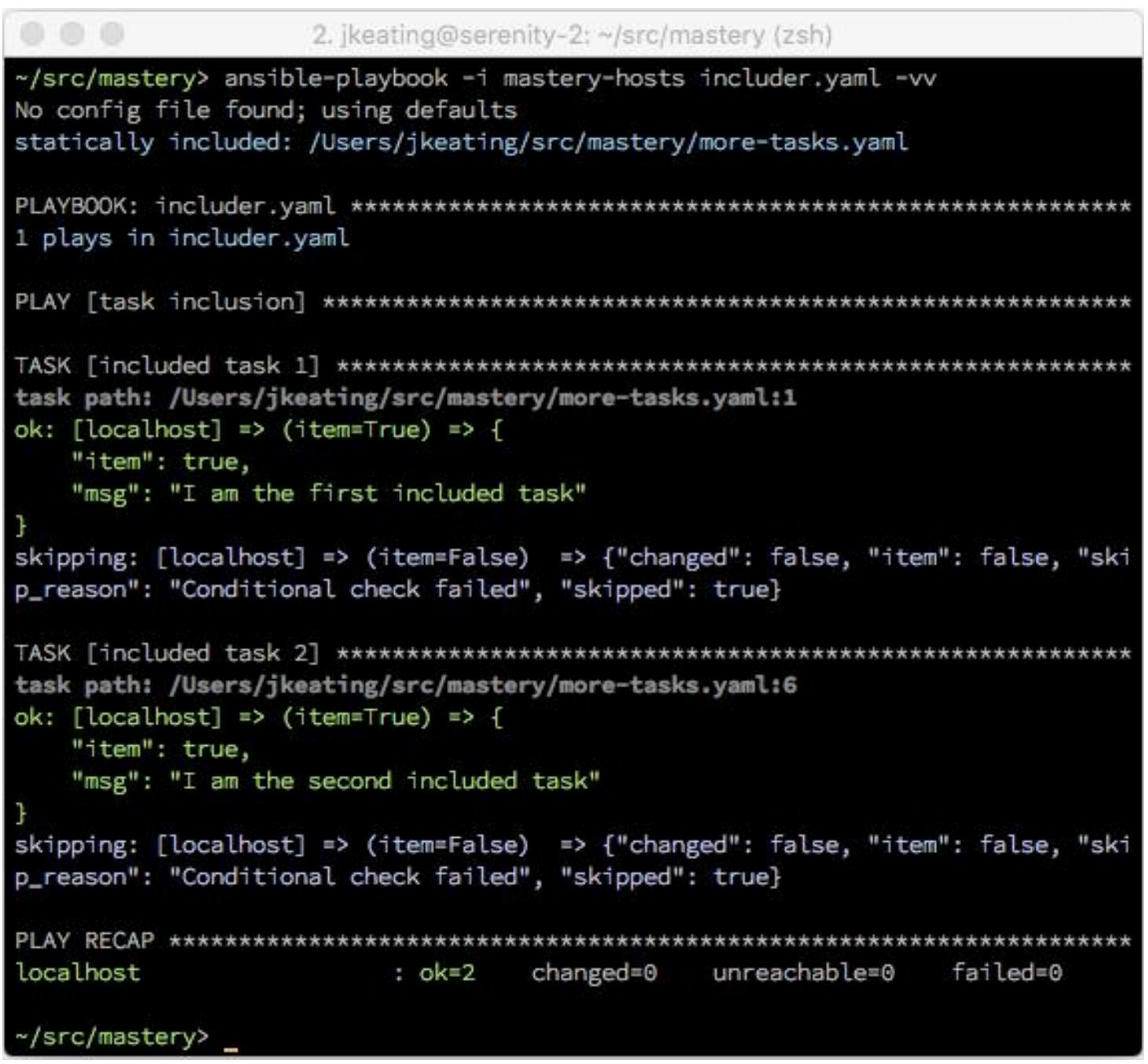
Мы можем видеть некую пропускаемую итераций в каждой из задач, а именно, ту итерацию, в которой данный
элемент вычисляет Булево значение false. Важно помнить, что все хосты будут находить значение всех включённых
задач. Не имеется никакого способа повлиять на то, чтобы Ansible не включил некий файл для какого- то
подмножества хостов. Самое большое, для каждой из задач внутри некоторой иерархии включения может быть
применена некая условная зависимость с тем, чтобы эти включённые задачи могли бы быть пропущены. Единственный
метод для включения задач на основе фактов хостов состоит в применении подключаемого метода действия
group_by для создания динамических групп на основании фактов хостов.
Затем вы можете предоставлять таким группам их собственные воспроизведения для включения особых задач.
Данное упражнение оставляем самому читателю.
Помеченные включения задач
При включении файлов задач имеется возможность пометить все эти задачи внутри данного файла. Для определения
одного или более тегов используется ключ tags для его применения ко всем
имеющимся задачам внутри данной включаемой иерархии. Такая возможность пометки на момент включения может
предохранять сам данный файл задач лишённым статичности относительно того как эти задачи должны помечаться и
может позволить включение некоторого набора задач множество раз, но при этом с различными передаваемыми данными
и тегами.
|
| Замечание |
|---|---|
|
Теги могут быть определены в определённом выражении |
Давайте создадим некую простую демонстрацию чтобы проиллюстрировать как могут применяться теги. Мы начнём с некоторого плейбука, который включает некий файл задач дважды, причём всякий раз с неким отличным именем тега и другими переменными данными:
---
- name: task inclusion
hosts: localhost
gather_facts: false
tasks:
- include: more-tasks.yaml vars:
data: first
tags: first
- include: more-tasks.yaml vars:
data: second
tags: second
Теперь мы обновим more-tasks.yaml для выполнения чего- нибудь с
предоставляемыми данными:
---
- name: included task
debug:
msg: "My data is {{ data }}"
Если мы выполним этот плейбук без выбора тегов, мы увидим эту задачу исполненной дважды:
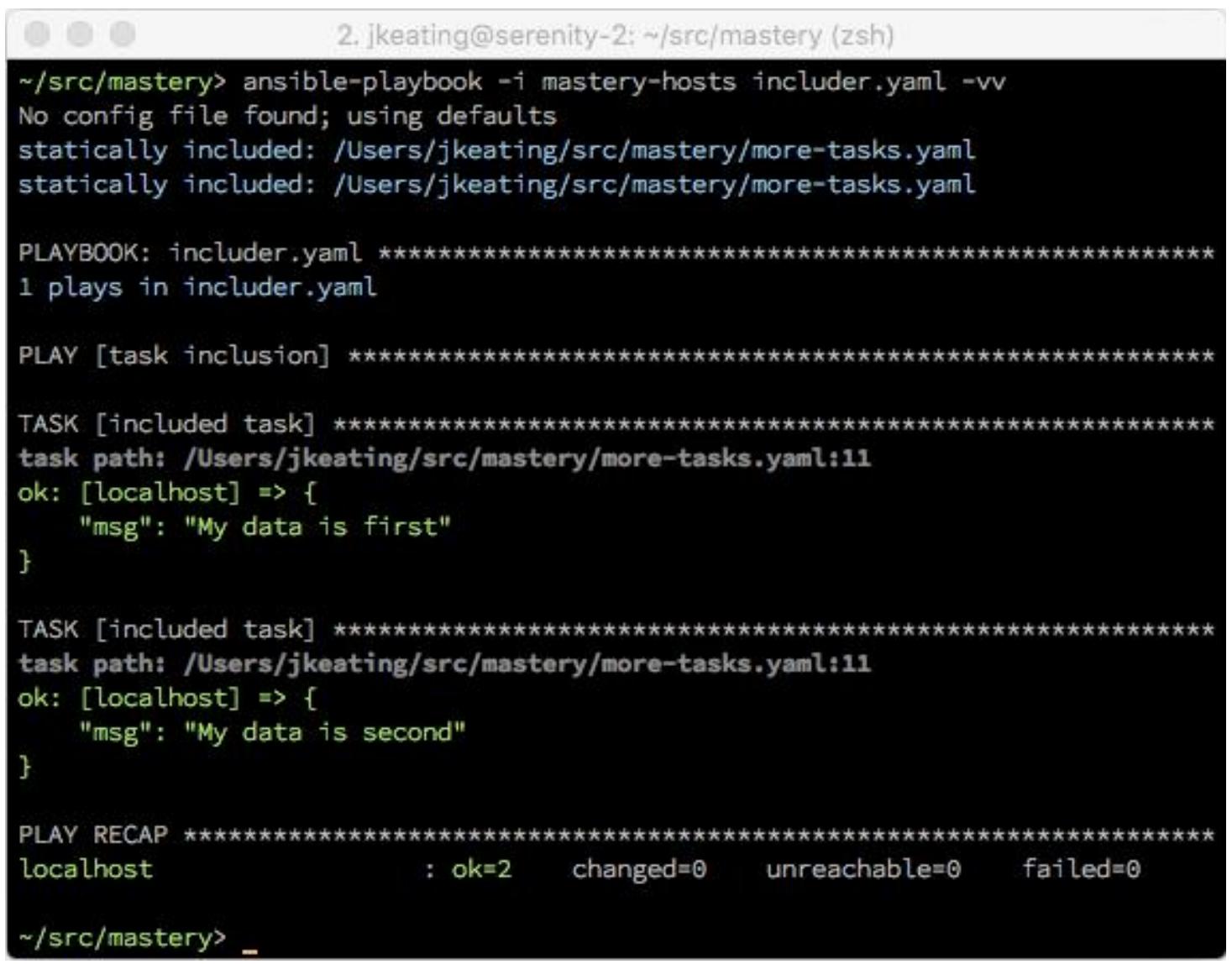
Теперь, если мы выберем какой тег исполнять, допустим, второй через видоизменение наших аргументов
ansible-playbook, мы должны увидеть что только будет исполнена только это
вхождение нашей включённой задачи:
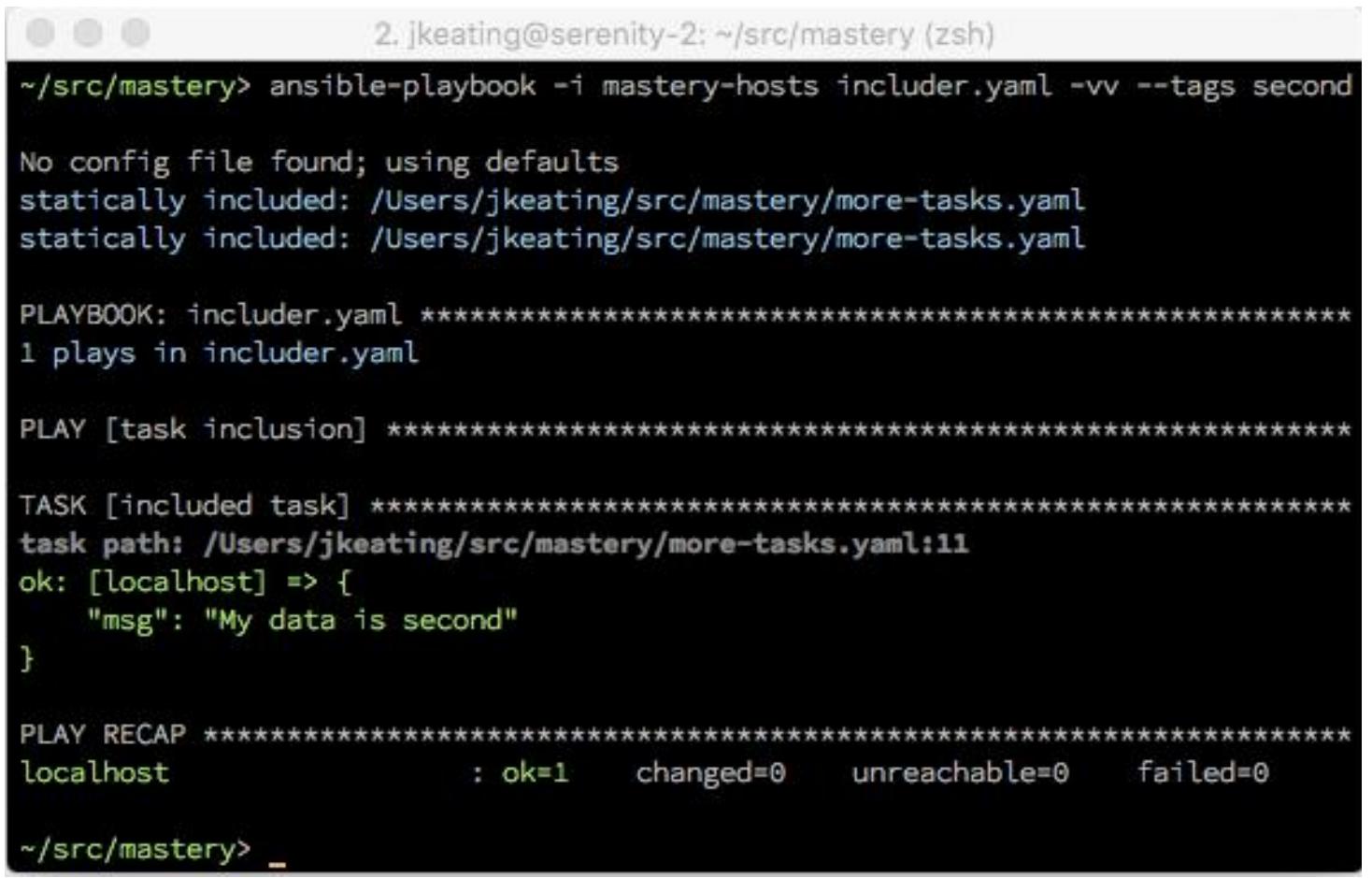
Наш пример использует аргумент командной строки --tags для указания
того какую помеченную задачу исполнить. Некий другой аргумент, --skip-tags,
позволяет выразить обратное действие, а именно: какие помеченные задачи не исполнять.
Включения задач могут объединяться также с циклами. При добавлении некоторого цикла
with_ в какое- то включение задач, все задачи внутри этого файла будут
исполнены с той переменной item, которая придерживает место для текущего
значения данного цикла. Весь включаемый файл целиком будет повторно исполняться пока такой цикл не обойдёт
все элементы. Давайте обновим свой пример воспроизведения чтобы продемонстрировать это:
- name: task inclusion
hosts: localhost
gather_facts: false
tasks:
- include: more-tasks.yaml
with_items:
- one
- two
Нам также нужно обновить свой файл more-tasks.yaml чтобы
применить свой item цикла:
---
- name: included task 1
debug:
msg: "I am the first included task with {{ item }}"
- name: included task 2
debug:
msg: "I am the second included task with {{ item }}"
После выполнения мы можем сказать, что задачи 1 и 2 исполнены по одному разу для каждого
item в данном цикле:
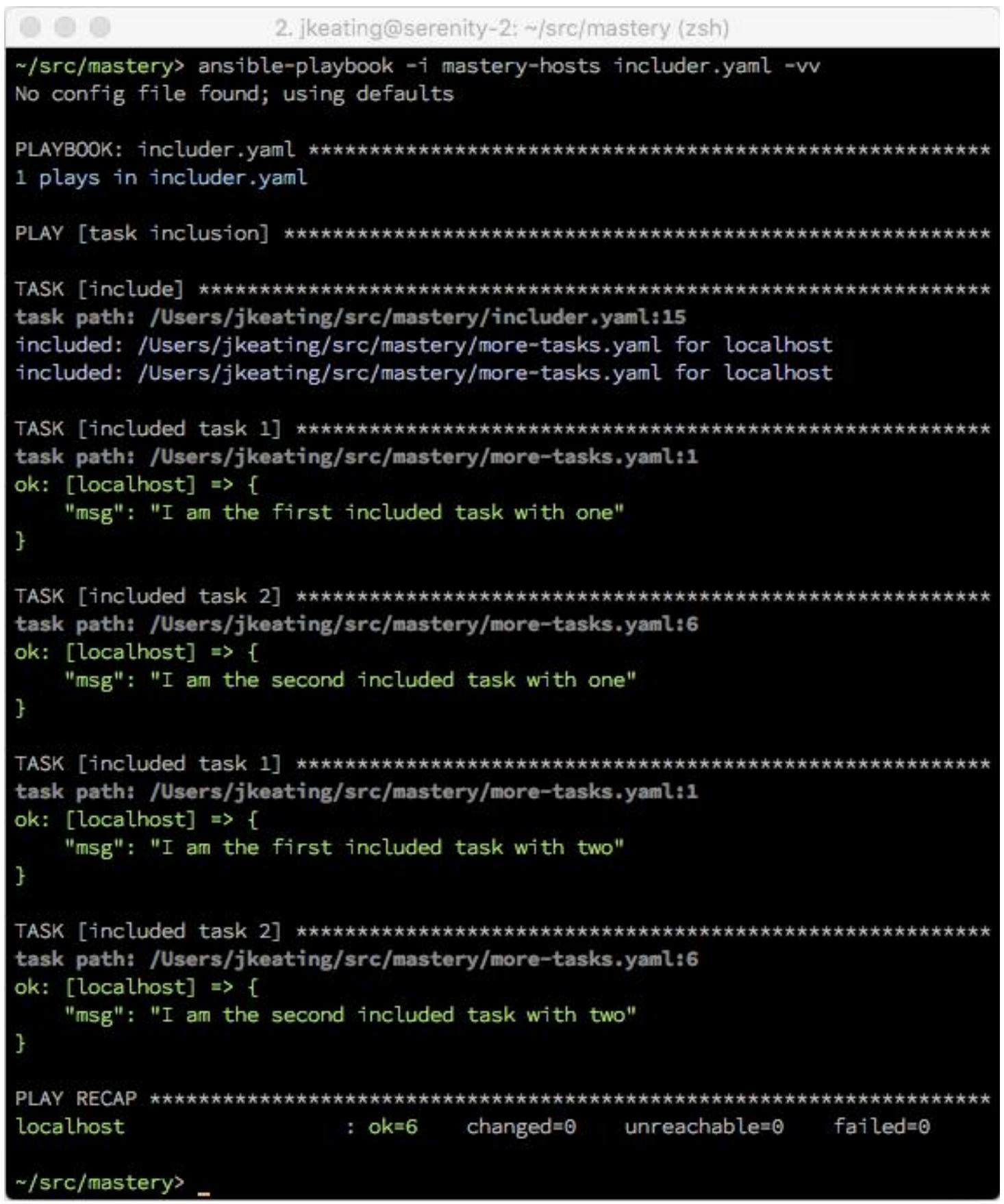
Цикличность при включении является неким мощным понятием, однако оно привносит одну сложность. Что если внутри
данного включаемого файла имелись задачи, которые имеют свои собственные циклы? Будет иметься некое противоречие
определяемой переменной item, приводящее к неожиданным результатам. По
этой причине в версии Ansible 2.1 было добавлено свойство loop_control.
Помимо прочих вещей, эта функциональность предоставляет некий метод именования той переменной, которая применяется
в конкретном цикле вместо определённой по умолчанию переменной item.
Применяя такую функциональность, мы можем различать те item, которые
поступают извне данного включения от всех item, используемых внутри
данного включения. Чтобы продемонстрировать это мы добавим некое управление loop_var
в своё внешнее включение:
- include: more-tasks.yaml
with_items:
- one
- two
loop_control:
loop_var: include_item
Внутри more-tasks.yaml мы будем иметь некую задачу со своим собственным
циклом, применяющим имеющийся include_item и свою локальную переменную
item:
---
- name: included task 1
debug:
msg: "I combine {{ item }} and {{ include_item }}"
with_items:
- a
- b
После исполнения мы видим, что задача 1 исполнилась дважды для
каждого включённого цикла и что применены две обе имеющиеся переменный цикла:
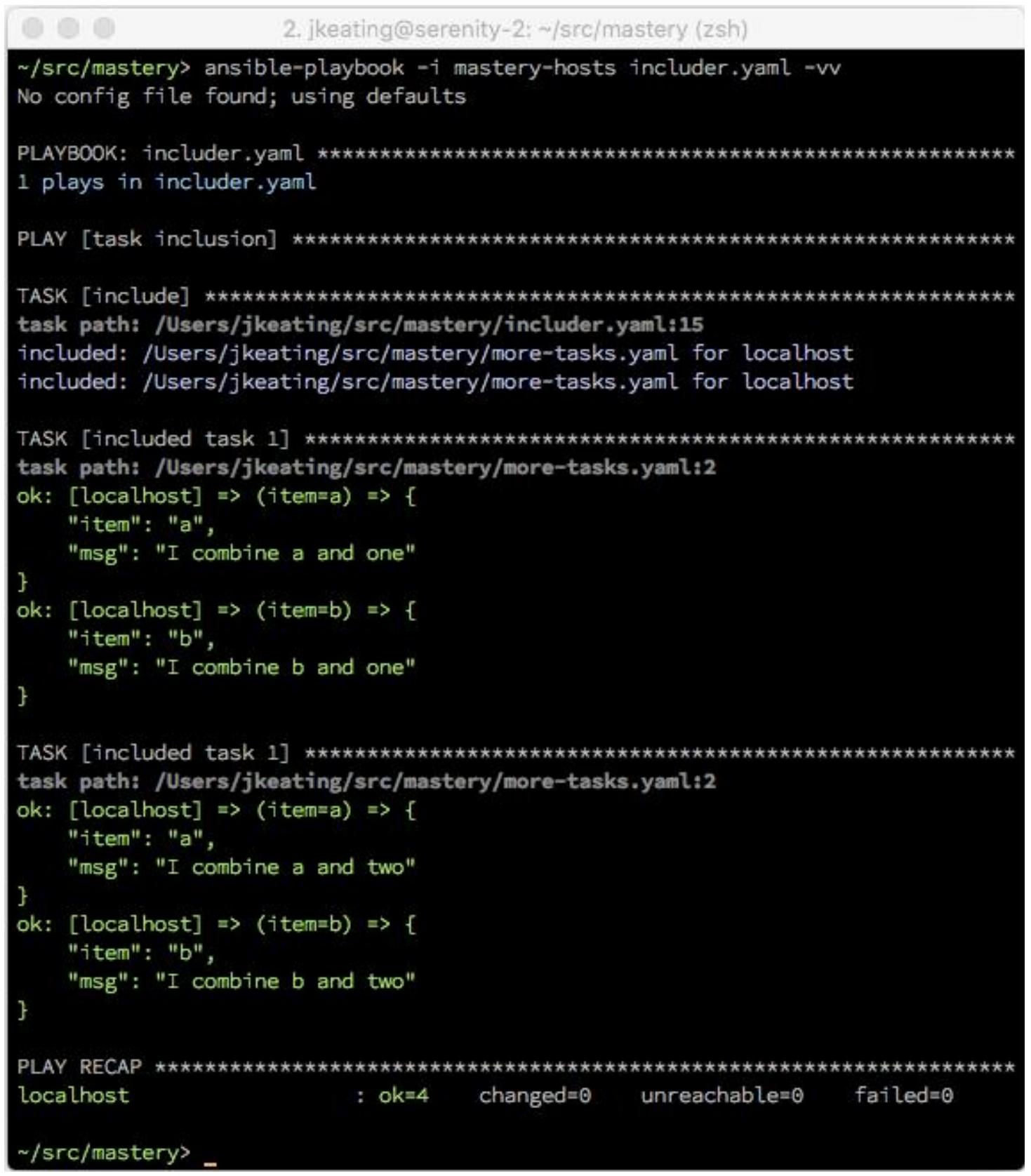
Кроме того также имеется другое управление циклом, такое как label,
которое определит что показывается на экране в выводе данной задачи для данного значения
item (что полезно для предотвращения приведения в беспорядок вашего
экрана большими структурами данных) и pause, предоставляя возможность
pause (простановки) на некоторое определённое число секунд между каждым
циклом.
Обработчики в сущности являются задачами. Они являются неким набором потенциальных задач, включаемых посредством
уведомлений от прочих задач. Раз они являются таковыми, задачи обработчика могут включаться в точности как
это можно делать с обычными задачами. Оператор include допустим внутри
определённого блока handlers.
В отличии от включений задач переменные данные не могут передаваться при включении задач обработчика. Однако, имеется возможность подключать некую условную зависимость в какому- то включению обработчика чтобы применять такое условие для всех обработчиков внутри данного файла.
Давайте создадим некий пример для демонстрации. Вначале мы создадим некий плейбук, имеющий какую- то задачу, которая всегда будет изменяться и которая включает некий файл задач обработчика и присоединяет отдельную условную зависимость к этому включению:
---
- name: touch files
hosts: localhost
gather_facts: false
tasks:
- name: a task
debug:
msg: "I am a changing task"
changed_when: true
notify: a handler
handlers:
- include: handlers.yaml
when: foo | default('true') | bool
|
| Замечание |
|---|---|
|
При оценивании некоторой переменной, которая может быть определена за пределами какого- то плейбука,
лучше применять имеющийся фильтр |
Затем мы создадим handlers.yaml для определения своих задач
обработчика:
---
- name: a handler
debug:
msg: "handling a thing"
Если исполнить этот плейбук без предоставления каких- либо последующих данных, мы должны обнаружить включение своего обработчика:
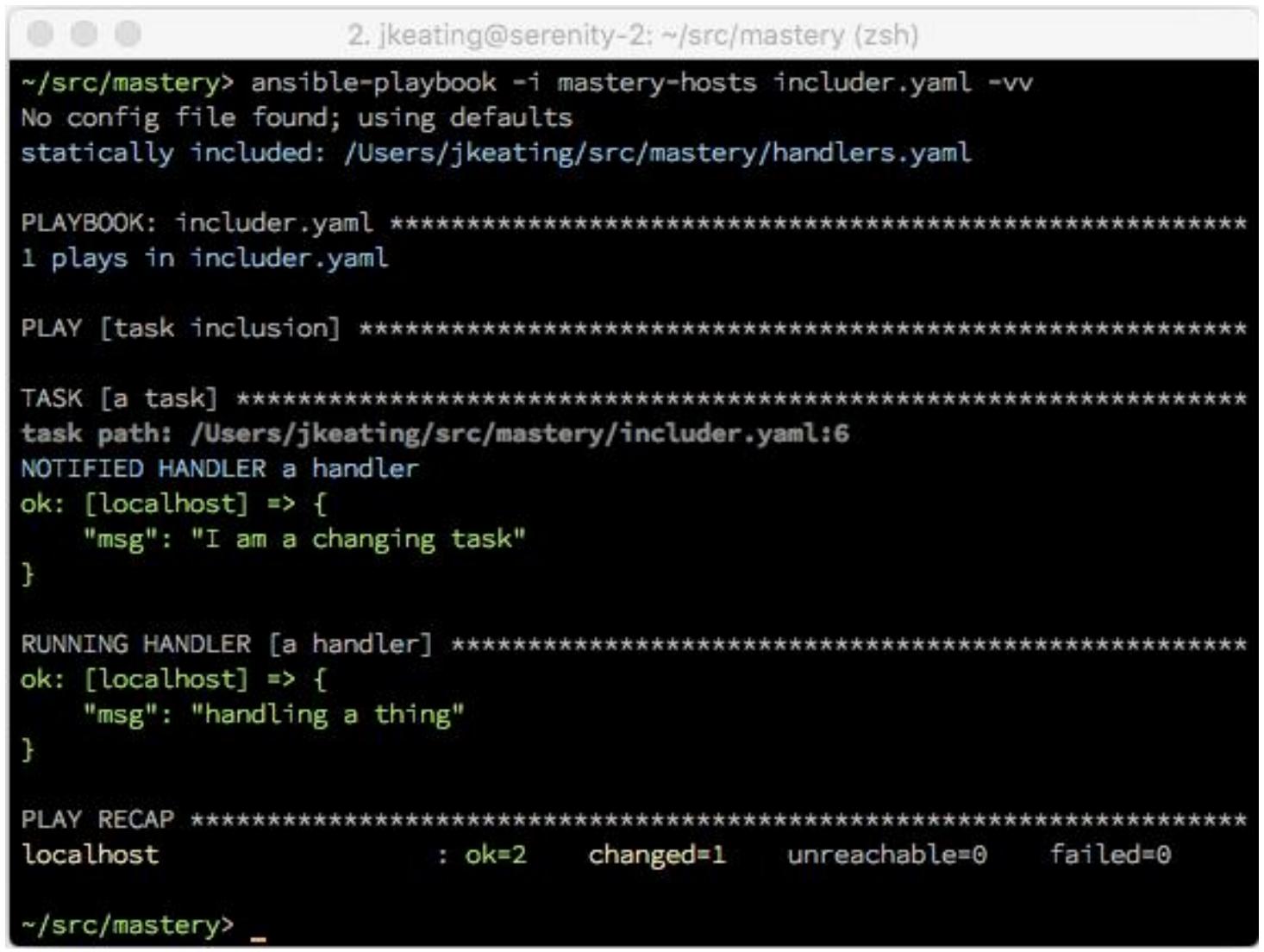
Теперь давайте выполним этот плейбук вновь; на это раз мы определим foo
значением false и как некую extra-var для своих аргументов исполения
ansible-playbook:
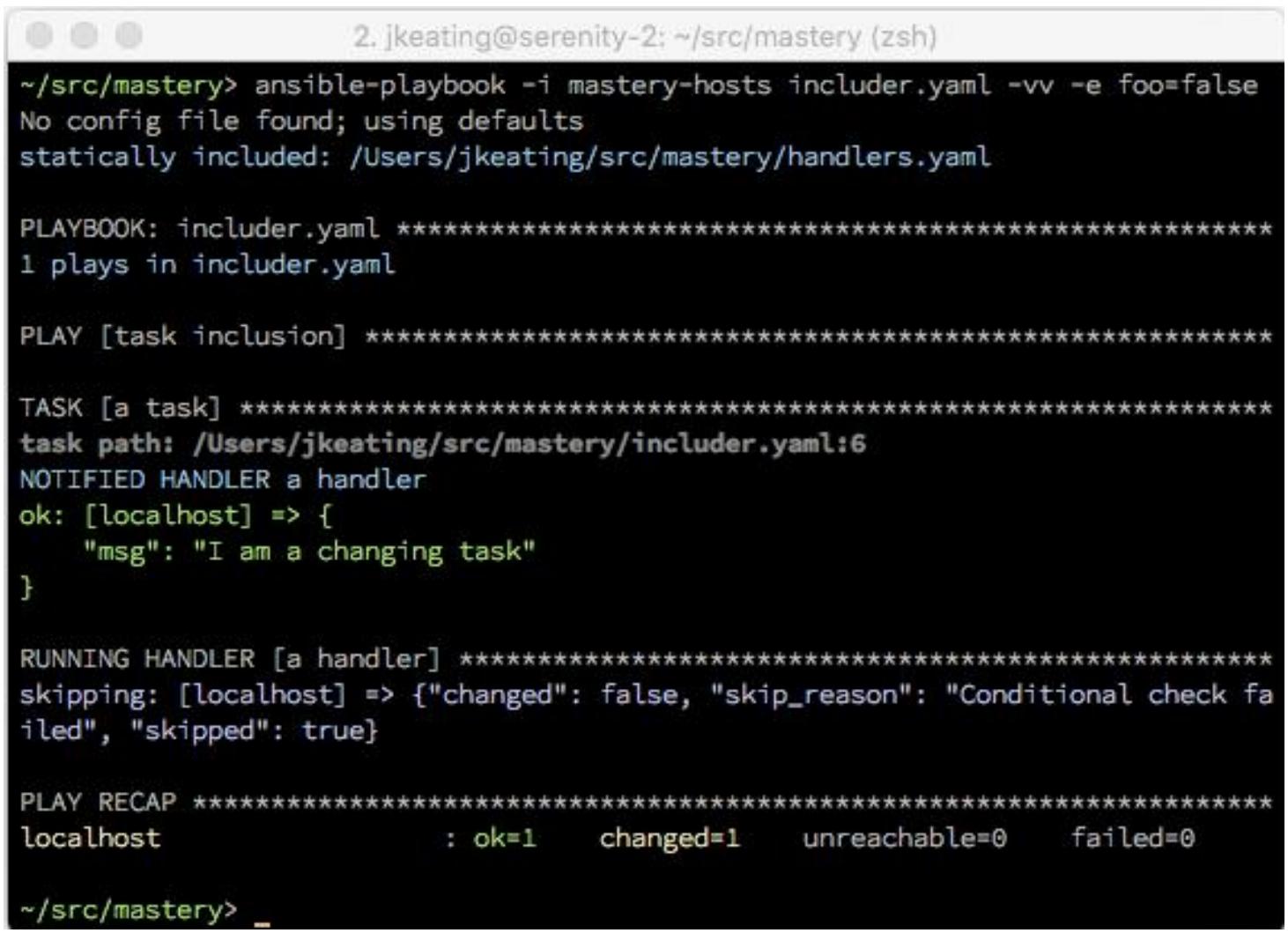
На этот раз, поскольку foo оценивается как
false, наш включаемый обработчик пропускается.
Переменные также могут разделяться на загружаемые файлы. Это позволяет совместно применять переменные во множестве воспроизведений или плейбуков, либо включать переменные данные, которые располагаются за пределами каталога данного проекта (например, секретные данные). Файлы переменных являются простыми файлами в формате YAML, предоставляющими ключи и значения. В отличии от файлов включения задач, включения переменных не могут включать и далее дополнительные файлы.
Переменные могут включаться тремя различными способами; через vars_files,
через include_vars или посредством
--extra-vars (-e).
vars_files
Ключ vars_files является директивой воспроизведения. Он определяет
некий перечень файлов для считывания с целью загрузки переменных данных. Эти файлы считываются и синтаксически
разбираются в тот момент, когда выполняется синтаксический анализ самого рассматриваемого плейбука. В точности
как и для включаемых задач и обработчиков, имеющийся путь является относительным в рассматриваемому файлу для
искомого файла ссылки.
Вот некий пример воспроизведения, которое загружает переменные из некоторого файла:
---
- name: vars
hosts: localhost
gather_facts: false
vars_files:
- variables.yaml
tasks:
- name: a task
debug:
msg: "I am a {{ name }}"
Теперь нам нужно создать variables.yaml в том же самом каталоге что
и наш плейбук:
name: derp
Исполнение нашего плейбука отобразит, что значение этой именованной переменной надлежащим образом
получено из исходного кода в нашем файле variables.yaml:
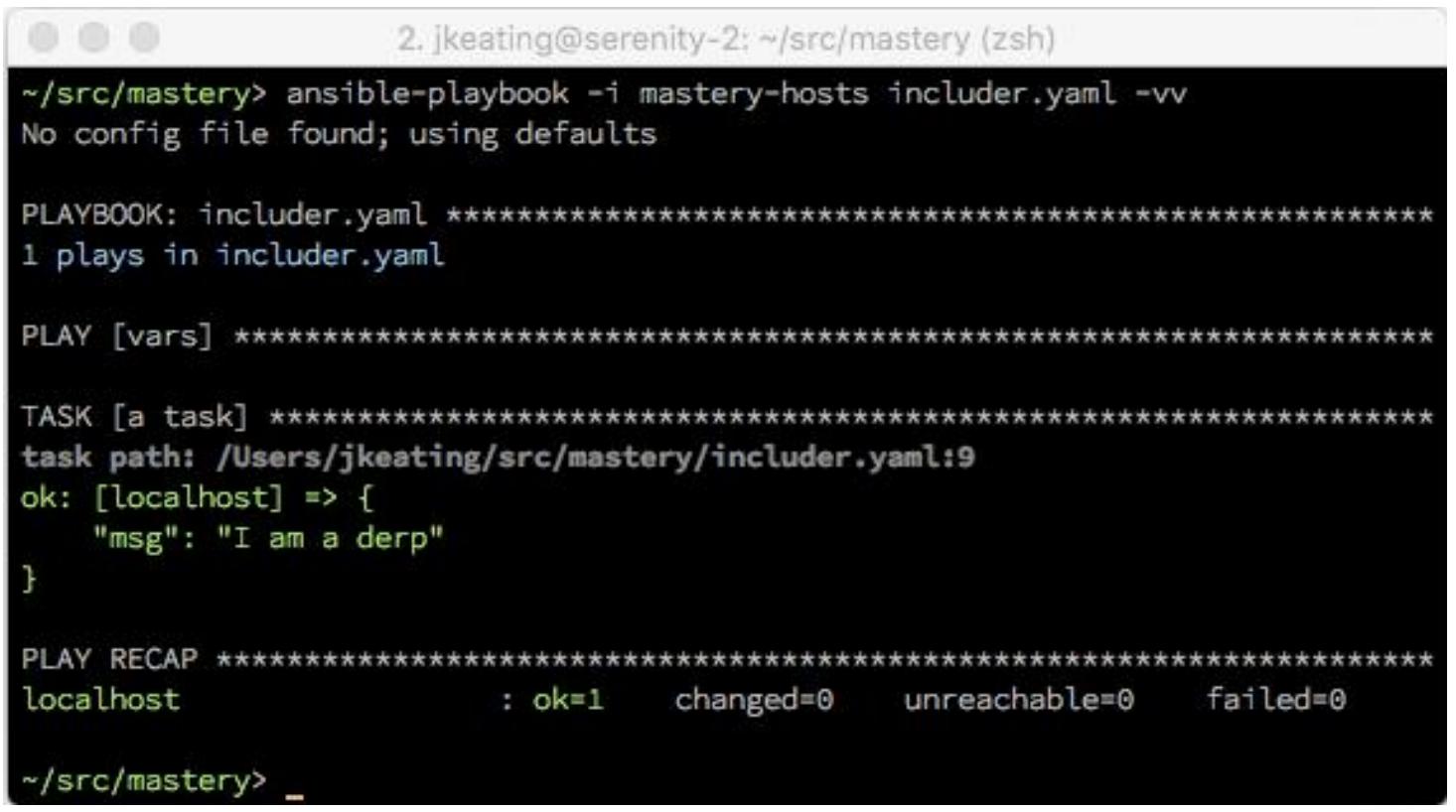
Динамические включения vars_files
При определённых обстоятельствах может быть желательным параметризировать имеющиеся файлы переменных, подлежащие загрузке. Это возможно сделать благодаря применению переменной в качестве части самого названия файла; однако эта переменная должна иметь некоторое значение, определённое на момент синтаксического анализа рассматриваемого плейбука, в точности как и при применении переменных в названиях задач. Давайте обновим свой пример воспроизведения для загрузки некоего переменного файла на основании тех данных, которые предоставляются на момент исполнения:
---
- name: vars
hosts: localhost
gather_facts: false
vars_files:
- "{{ varfile }}"
tasks:
- name: a task
debug:
msg: "I am a {{ name }}"
Теперь, когда мы выполним этот плейбук, мы предоставим определённое значение для
varfile с помощью аргумента -e:
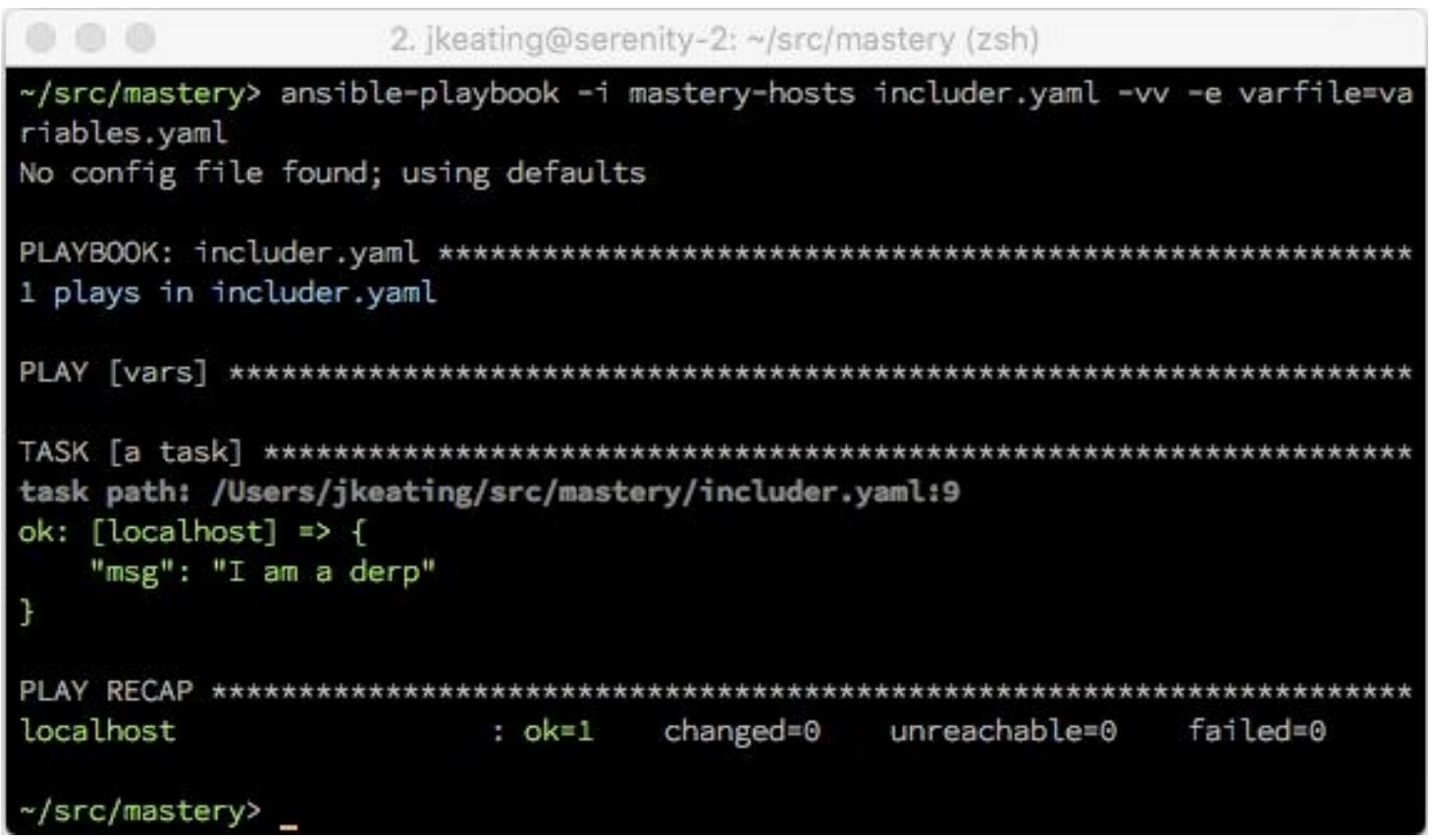
Дополнительно к необходимости определения самого значения переменной на момент исполнения, сам подлежащий
загрузке файл также должен иметься во время исполнения. Даже если некая ссылка на какой- то файл является
четвёртым воспроизведением вниз по отдельному плейбуку и такой файл сам по себе создаётся в имеющемся первом
воспроизведении, если такой файл не существует на момент исполнения,
ansible-playbook выдаст сообщение об ошибке.
include_vars
Нашим вторым методом для включения переменных данных из файлов является имеющийся модуль
include_vars. Этот модуль загрузит переменные в виде некого действия
задачи и будет выполнен на каждом хосте. В отличии от большинства модулей, этот модуль исполняется локально на
самом хосте Ansible; вследствие этого все пути всё ещё являются относительными к самому файлу исполняемого
воспроизведения. Так как все загрузки переменных выполняются как некая задача, оценка переменных в данном
имени файла происходит при исполнении такой задачи. Переменные данные в этом file name
могут быть особенными для хоста и определяться к некоторой предыдущей задаче. Кроме того, этот файл сам по себе
не должен существовать на момент исполнения; он может быть также создан какой- то предыдущей задачей. Это
очень мощная и гибкая концепция, которая может влечь за собой очень динамичные плейбуки при надлежащем
применении.
Прежде чем мы двинемся далее, давайте продемонстрируем некое простое применение
include_vars изменив наше имеющееся воспроизведение чтобы загрузить
определённый файл переменных в качестве задачи:
---
- name: vars
hosts: localhost
gather_facts: false
tasks:
- name: load variables
include_vars: "{{ varfile }}"
- name: a task
debug:
msg: "I am a {{ name }}"
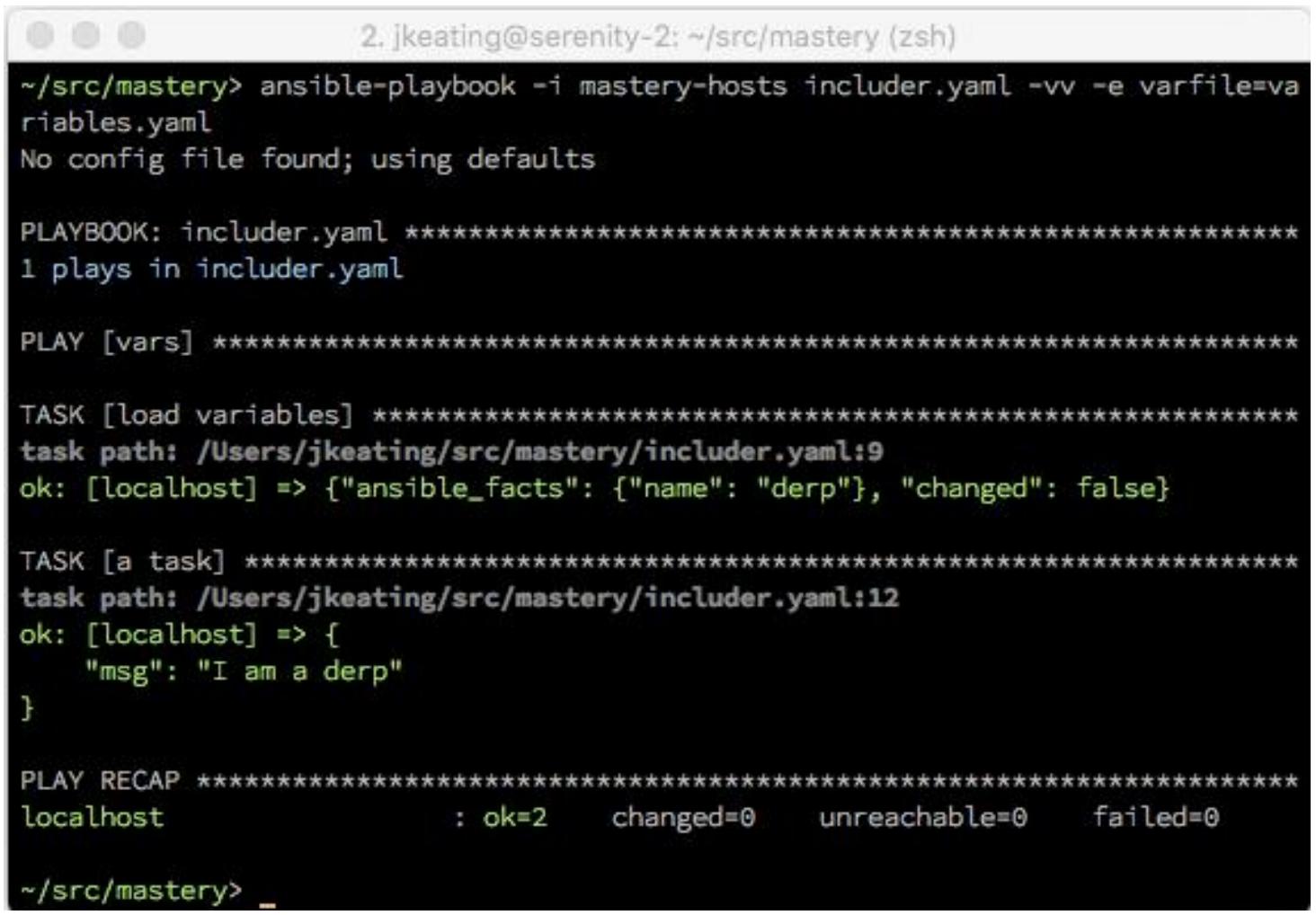
Иполнение этого плейбука оста1тся тем же самым и наш вывод только слегка отличается от предыдущих итераций:
В точности как и для остальных задач, для загрузки более одного файла в отдельной задаче могут применяться
цикличность. Это в особенности действенно при использовании специального цикла
with_first_found для итераций по некоторому списку всё более общих имён
файлов пока не будет загружен искомый файл. Давайте продемонстрируем это изменив своё воспроизведение для
применения собранных фактов хоста чтобы предпринять попытку и загрузить некий файл переменных, специфичный для
определённого дистрибутива, особенного для конкретного семейства дистрибутива или, в конце концов, некоторого
файла по умолчанию:
---
- name: vars
hosts: localhost
gather_facts: true
tasks:
- name: load variables
include_vars: "{{ item }}"
with_first_found:
- "{{ ansible_distribution }}.yaml"
- "{{ ansible_os_family }}.yaml"
- variables.yaml
- name: a task
debug:
msg: "I am a {{ name }}"
Исполнение должно выглядеть очень похоже на предыдущие прогоны, только на этот раз мы обнаружим созданную фактами задачу и мы не передаём совместно никакие дополнительные данные при данном исполнении:
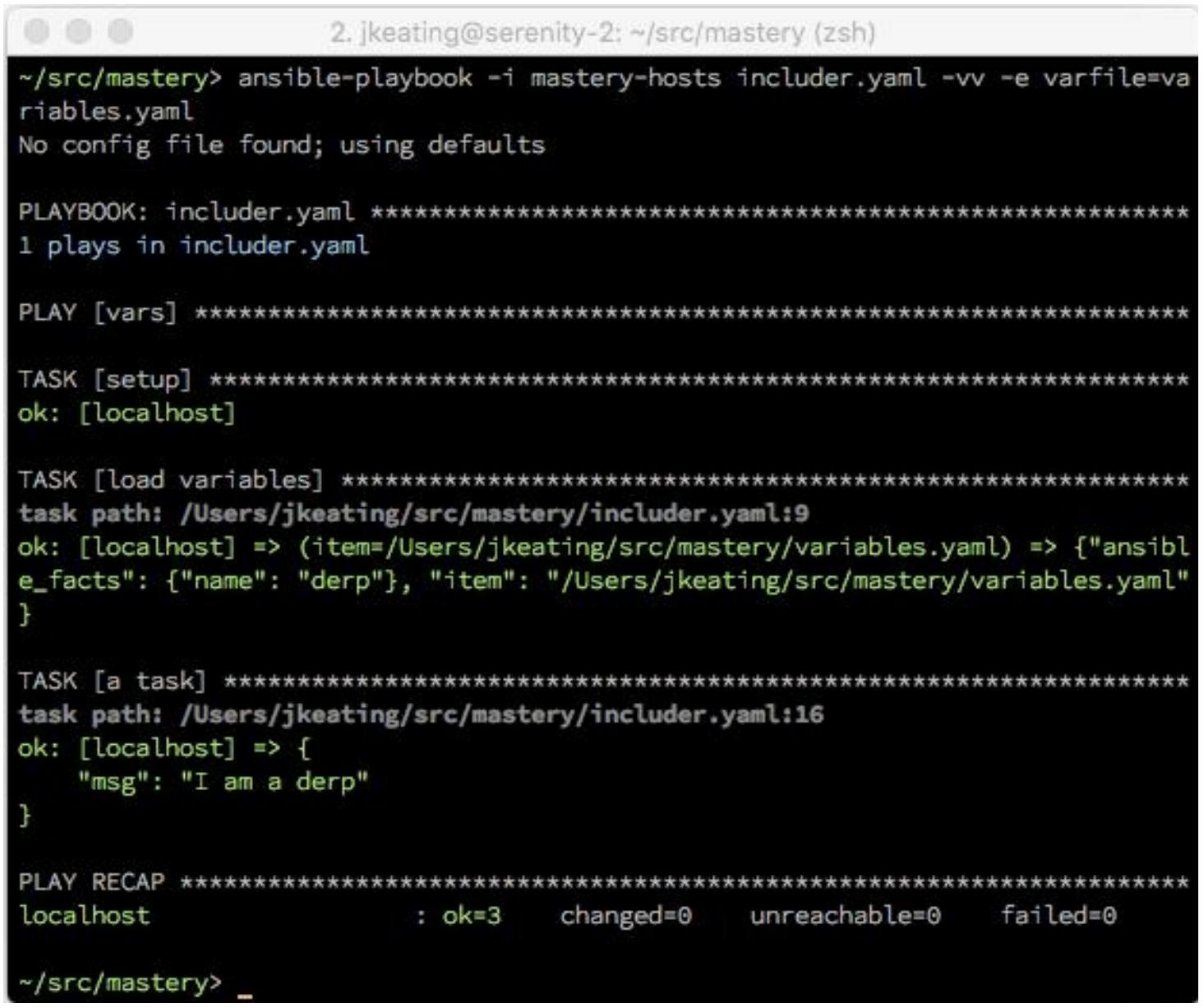
Из данного вывода мы также можем видеть какой файл был определён для загрузки. В данном случае был загружен
variables.yaml, поскольку два прочих файла не существуют. Такая
практика общеупотребима для загрузки переменных, которые являются особенными для операционной системы данного
хоста в запросе. Переменные для различных операционных систем могут быть записаны в соответствующим образом
именованных файлах. Применяя определённую переменную ansible-distribution,
которая заполняется полученными фактическими данными, файлы переменных, которые используют значения
ansible-distribution как часть своего имени могут загружаться при помощи
аргумента with_first_found. В некотором файле может быть предоставлен
какой- то набор переменных по умолчанию, который не применяет никаких переменных данных в качестве защиты от
неисправностей.
extra-vars
Самый последний метод загрузки переменных данных из некоторого файла состоит в ссылке на некий путь файла при
помощи аргумента --extra-vars (или -e)
для ansible-playbook. Обычно этот аргумент ожидается в виде некоторого набора
данных key=value; однако, если представляется некий путь файла и он имеет
префикс с символом @, Ansible считает весь файл целиком для загруки
переменных данных. Давайте видоизменим один из своих более ранних примеров в котором мы применяли
-e и вместо определения некой переменной прямо в командной строке мы
включим определённый файл переменных который уже написан нами:
---
- name: vars
hosts: localhost
gather_facts: false
tasks:
- name: a task
debug:
msg: "I am a {{ name }}"
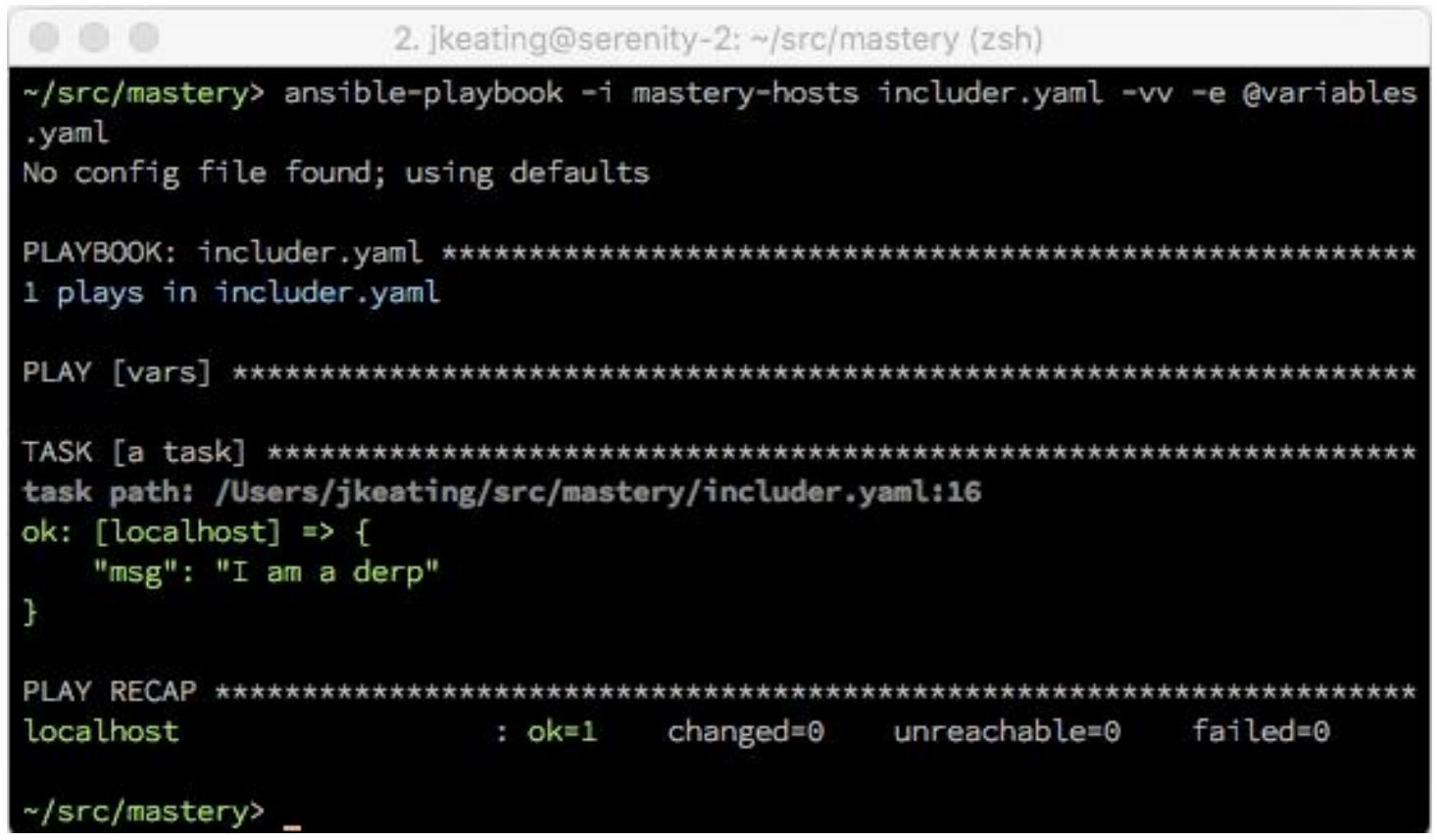
Когда мы предоставим некий путь после имеющегося символа @, такой
путь является относительным для нашего текущего рабочего каталога, причём вне зависимости от того где
располагается сам этот плейбук. Давайте исполним наш плейбук и предоставим некий путь к
variables.yaml:
|
| Замечание |
|---|---|
|
При включении некоторого файла переменных с определённым аргументом
|
Файлы плейбука могут включать прочие файлы плейбуков целиком. Такая конструкция может быть полезной для связывания воедино нескольких независимых плейбуков в какой- то больший, более выразительный плейбук. Включение плейбука слегка более примитивное чем включение задач. Вы не можете выполнять подстановку переменных при включении некоторого плейбука, вы не можете применять условные зависимости и вы не можете применять теги ни в каоком виде. Такие подлежащие включению файлы плейбуков также должны существовать на момент исполнения.
Разобравшись с функционированием имеющихся включений переменных, задач, обработчиков и плейбуков мы можем переместиться к более продвинутой теме Ролей. Роля выходят за рамки основной структуры нескольких плейбуков небольшого числа разделённых файлов для ссылки. Роли предоставляют некую структуру для полностью независимых или взаимно зависимых коллекций переменных, задач, файлов, шаблонов и модулейю Каждая роль обычно ограничена определённой темой или желаемым конечным результатом, причём все необходимые шаги для достижения этого результата либо внутри самой этой роли, либо в иных ролях, перечисленных как зависимости. Сами по себе роли не являются плейбуками. Не имеется никакого способа напрямую исполнять какую- то роль. Роли не имеют установок для какого хоста эта роль будет применена. Тем клеем, который связывает все хосты из вашего учёта ресурсов с ролями, которые должны применяться к этим хостам, являются плейбуки верхнего уровня.
Роли имеют структурную схему на уровне своей файловой системы. Такая структура существует для предоставления автоматизации по включению задач, обработчиков, переменных, модулей и зависимостей ролей. Данная структура также позволяет легко ссылаться на файлы и шаблоны из любого места в рамках такой роли.
Все роли располагаются в некотором подкаталоге архива какого- то плейбука, в своём каталоге
roles/. Конечно, это настраивается посредством имеющегося общего
ключа настройки roles_path, однако давайте останемся с этим определением
по умолчанию. Каждая роль сама по себе некое дерево каталога. Именем роли является само название каталога внутри
roles/. Каждая роль имеет некое число подкаталогов со специальным
значением, которое работает когад некая роль применяется к какому- то набору хостов.
Некая роль может содержать все эти элементы или всего лишь один из них. Опущенные элементы просто игнорируются. Некоторые роли существуют просто чтобы предоставить общие обработчики по некоторому проекту. Прочие роли существуют как некая отдельная точка зависимости, которая в свою очередь зависит от ряда прочих ролей.
Задачи
Сам файл задачи является основной плотью некоторой роли. Если существует
roles/<role_name>/tasks/main.yaml,
все имеющиеся там задачи и все прочие файлы, которые они включают будут встроены в данное воспроизведение и
исполнятся.
Обработчики
Аналогично задачам, обработчики автоматически загружаются из
roles/<role_name>/handlers/main.yaml,
если этот файл существует. На эти обработчики могут ссылаться любые задачи внутри данной роли, или любые задачи
внутри любой другой роли, которая перечисляется этой ролью в качестве зависимости.
Переменные
Существует два вида переменных, которые могут быть определены в некоторой роли. Имеются переменные роли,
загружаемые из roles/<role_name>/vars/main.yaml, а также
существуют значения по умолчанию роли, которые загружаются из
roles/<role_name>/defaults/main.yaml.
Основная разница между vars и defaults
имеет отношение к порядку приоритета. Дл подробного описания имеющегося порядка отсылаем вас к
Главе 1, Архитектура системы и проектирование Ansible.
Определения по умолчанию роли являются самым нижним порядком переменных. Буквально, любое прочее определение
некоторой переменной будет более предпочтительно в сравнении с с некоторым значением по умолчанию роли. Значения
по умолчанию роли можно представлять как держатель места для реальных данных, некоторой справкой какие переменные
могут заинтересовать какого- то разработчика при определении особых для площадки значений. Переменные роли, с другой
стороны, имеют некий высший порядок приоритета. Пременные роли могут переназначаться, однако обычно они применяются
когда на один и тот же набор данных ссылаются более одного раза внутри какой- то роли. Если этот набор данных должен
быть переопределён некими значениями локальной площадки, тогда такая переменная должна быть перечислена в имеющихся
значениях по умолчанию этой роли вместо того чтобы быть представленной в переменных этой роли.
Модули и встраиваемые модули
Некая роль может включать персональные модули также как и встраиваемые модули. Хотя сам проект Ansible
достаточно хорош в отношении просмотра и принятия представленных модулей, имеются определённые случаи при
которых может быть нежелательным или даже незаконным представление некоторого персонального модуля вверх
проекта. В таких случаях предоставление определённого модуля с конкретной ролью может быть наилучшим вариантом.
Модули могут загружаться из roles/<role_name>/library/ и
могут применяться любой задачей в данной роли или любой последующей роли. Представленные в таком пути модули
перепишут все прочие копии того же самого названия модуля в любом прочем месте в данной файловой системе,
что может быть неким способом распространять дополнительную функциональность в некий модуль ядра прежде чем эта
функциональность будет принята в восходящем потоке проекта и выпущена с некоторой новой версией Ansible.
Аналогично, встраиваемые модули часто применяются для настройки поведения Ansible неким способом, который имеет смысл для какой- то особенной среды и не подходит для сотоварищей в восходящем потоке проекта. Встраиваемые модули могут распространяться как часть некоторой роли, что может быть проще чем установка в явном виде встраиваемых модулей на каждом хосте, который будет действовать как некий управляющий хост Ansible. Вcтраиваемые модули автоматически загружаются если они обнаружены внутри какой- то роли в одном из следующих подкаталогов:
-
action_plugins -
lookup_plugins -
callback_plugins -
connection_plugins -
filter_plugins -
strategy_plugins -
cache_plugins -
test_plugins -
shell_plugins
Зависимости
Роли могут выражать некую зависимость от другой роли. Общей практикой является установка всех ролей звисящими
от некоторой общей роли, такой как задачи, обработчики, модули и тому подобноею Эти роли могут зависеть только
от того, что должно быть определено только один раз. Когда Ansible обрабатывает некую роль для некоего набора
хостов, он вначале просматривает все зависимости, которые определены в
roles/<role_name>/meta/main.yaml.
Если какие- либо из них определены, эта роль будет обрабатываться и все задачи внутри будут исполнены (после
проверки также и всех перечисленных внутри зависимостей) пока, прежде чем запустятся задачи данной начальной
роли, не будут завершены все зависимости. Более глубоко мы опишем зависимости роли позже в данной главе.
Файлы и шаблоны
Модули задачи и обработчиков могут иметь относительные ссылки внутри
roles/<role_name>/files/.
Такое имя файла может предоставляться без какого бы то нибыло префикса и будет иметь источником
roles/<role_name>/files/<file_name>.
Относительные префиксы также допускаются при доступе к файлам внутри подкаталогов
roles/<role_name>/files/.
Такие модули как template, copy
и script могут также получать преимущества этого.
Аналогично, применяемые модулем template шаблоны могут иметь ссылки
относительно roles/<role_name>/templates/.
Данный код примера использует некий относительный путь для загрузки своего шаблона
derp.j2 из полного пути
roles/<role_name>/templates/herp/derp.j2:
- name: configure herp
template:
src: herp/derp.j2
dest: /etc/herp/derp.j2
Собираем всё вместе
Для иллюстрации того как может выглядеть полная структура роли, вот некоторый пример с названием
demo:
roles/demo
├── defaults
│ └── main.yaml
├── files
│ └── foo
├── handlers
│ └── main.yaml
├── library
│ └── samplemod.py
├── meta
│ └── main.yaml
├── tasks
│ └── main.yaml
├── templates
│ └── bar.j2
└── vars
└── main.yaml
При создании некоторой роли требуются не все каталоги или файлы. Обрабатываться будут только те файлы, которые присутствуют.
Как уже устанавливалось, роли могут зависеть от других ролей. Эти взаимосвязи имеют название
dependencies и они описываются в файле
meta/main.yaml некоторой роли. Этот файл ожидает какого- то хэша
данных верхнего уровня с неким ключом dependencies; все данные внутри
являются неким списком ролей:
---
dependencies:
- role: common
- role: apache
В данном примере Ansible полностью обработает вначале роль common
(и все зависимости, которые она может выражать), прежде чем продолжит со второй ролью
apache и затем в конце концов запустит задачи своей роли.
Зависимости могут иметь ссылки по имени без какого бы то ни было префикса если присутствуют внутри той
же самой структуры каталога или располагаются внутри имеющихся настроенными
roles_path. В противном случае для указания местоположения роли могут
применяться полные пути:
role: /opt/ansible/site-roles/apache
При выражении некоторой зависимости имеется возможность передачи данных совместно с такой зависисомтью. Эти данные могут быть переменными, тегами или даже условными зависимостями.
Переменные зависимости ролей
Передаваемые совместно с перечнем зависимостей переменные будут переписывать значения для соответствующих
переменных, определяемых в defaults/main.yaml или
vars/main.yaml. Это может быть полезным для использования некоей общей
роли подобной роли apache в качестве зависимости при предоставлении
особенных данных, таких как какой порт открывать в имеющемся межсетевом экране или какой модуль
apache включать. Переменные выражаются как дополнительные ключи для
данного перечисления роли. Давайте обновим свой пример чтобы добавить простые и сложные переменные в наши две
зависимости:
---
dependencies:
- role: common
simple_var_a: True
simple_var_b: False
- role: apache
complex_var:
key1: value1
key2: value2
short_list:
- 8080
- 8081
При предоставлении переменных данных зависимости имеется два зарезервированных имени, которые не могут
применяться в качестве переменных роли: tags и
when. Первое используется для передачи данных тегов в некую роль, а
второе для передачи условных зависимостей в эту же роль.
Тэги
Теги могут применяться для всех имеющихся задач, обнаруженных внутри некоторой зависимости роли. Эти функции
во многом аналогичны тому способу, ктором теги могут применяться для включения файлов задач, как это
описывалось ранее в данной главе. Их синтаксис простой; ключ tags
может быть неким отдельным элементом или каким- то списком. Для демонстрации давайте добавим некие теги в свой
пример списка зависимости:
---
dependencies:
- role: common
simple_var_a: True
simple_var_b: False
tags: common_demo
- role: apache
complex_var:
key1: value1
key2: value2
short_list:
- 8080
- 8081
tags:
- apache_demo
- 8080
- 8181
Как и в случае с добавлением тегов во включаемые файлы задач, все те задачи, которые обнаружены внутри некоторой зависимости (и любой зависимости внутри этой иерархии) получат предоставляемые марекры (теги).
Условные зависимости ролей
Хотя и невозможно предотвратить текущую обработку некоторой зависимости роли с помощью некоторого условия,
имеется возможность пропуска всех имеющихся задач внутри какой- то иерархии зависимости роли применив
некое условие к какой- то зависимости. Это также отражает всю функциональность включения задач с условиями.
Для выражения этого условия применяется ключ when. И вновь мы
увеличим свой пример добавив некую зависимость для демонстрации имеющегося синтаксиса:
---
dependencies:
- role: common
simple_var_a: True
simple_var_b: False
tags: common_demo
- role: apache
complex_var:
key1: value1
key2: value2
short_list:
- 8080
- 8081
tags:
- apache_demo
- 8080
- 8181
when: backend_server == 'apache'
Роли не являются воспроизведениями. У них нет какого- либо представления о том на каких хостах задачи этой роли должны исполняться, какие методы соединения применять, работать или нет последовательно или любое иное поведение воспроизедения, описанное в Главе 1, Архитектура системы и проектирование Ansible. Роли должны применяться внутри некоторого воспроизведения внутри какого- то плейбука, в котором могут быть выражены все эти заключения.
Чтобы применить некую роль внутри какого- то воспроизведения применяется оператор
when. Этот оператор ожидает некий список ролей для применения к имеющимся
хостам в этом воспроизведении. Во многом как и с описанием зависимостей роли, при определении применяемых ролей,
вместе с ними могут передаваться данные, такие как переменные, теги и условия. Его синтаксис в точности
такой же.
Для демонстрации применения ролей внутри некоторого воспроизведения давайте создадим какую- то простую роль
и применим её в простом плейбуке. Вначале даввайте построим такую род с названием
simple, которая будеи иметь неую отдельную задачу
debug в
roles/simple/tasks/main.yaml, печатающую то значение некоторой переменной
по умолчанию роли, которая определена в roles/simple/defaults/main.yaml.
Во- первых давайте поработаем с самим файлом задачи:
---
- name: print a variable
debug:
var: derp
Далее мы напишем свой файл по умолчанию в какой- то единственной переменной,
derp:
---
derp: herp
Для исполнения такой роли мы запишем некий плейбук с единственным воспроизведением для применения этой
роли. Мы вызовем свой плейбук roleplay.yaml, причём он расположен
в том же самом уровне каталога, что и сам каталог roles/:
---
- hosts: localhost
gather_facts: false
roles:
- role: simple
|
| Замечание |
|---|---|
|
Если с этой ролью не предоставляются никакие данные, может применяться некий альтернативный синтаксис, который всего лишь перечисляет все роли для применения вместо отображённого нами хэша. Однако, для согласованности, как мне кажется, будет лучше всегда применять один и тот же синтаксис в рамках одного проекта. |
Мы повторно применим свой список ресурсов mastery-hosts из
предыдущих глав и выполним свой плейбук:
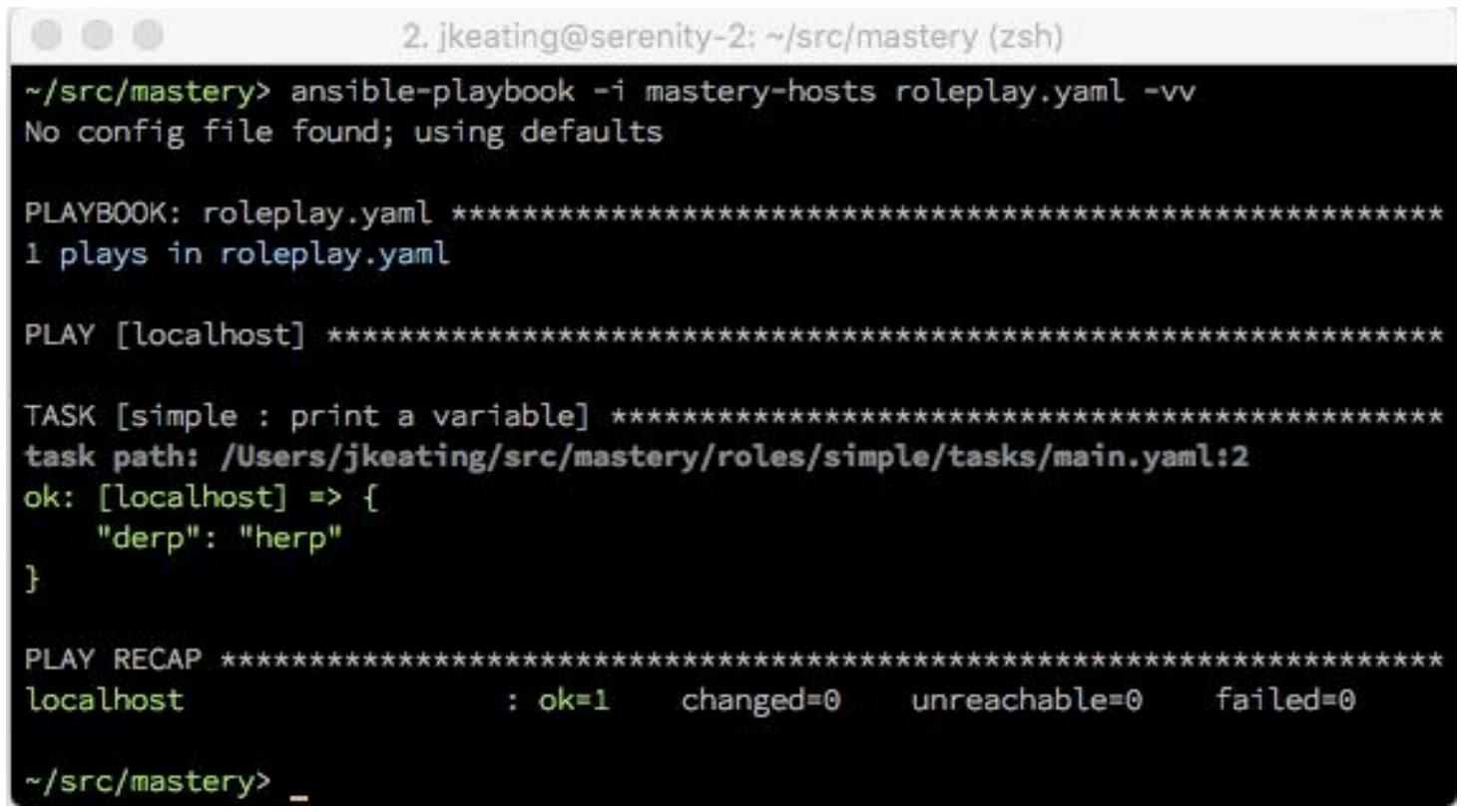
Благодаря магии ролей имеющееся значение переменной derp было
автоматически загружено из значений роли по умолчанию. Конечно, мы можем переопределить такое значение по
умолчанию при применении данной роли. Давайте изменим свой плейбук и применим некое новое значение для
derp:
---
- hosts: localhost
gather_facts: false
roles:
- role: simple
derp: newval
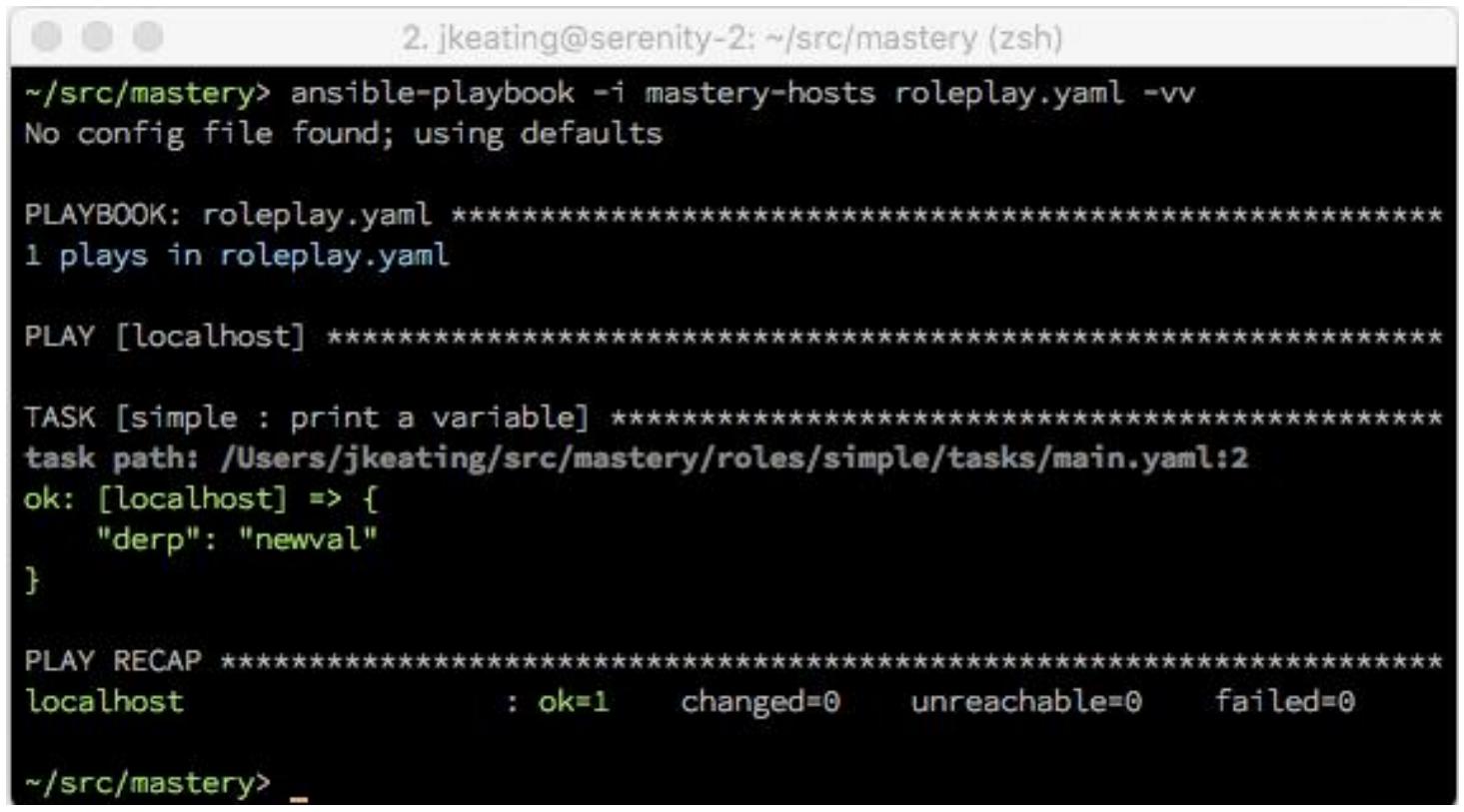
На этот раз, при нашем исполнении мы обнаружим в качестве значения для
derp newval:
Внутри некоторого отдельного воспроизведения может применяться множество ролей. Ключ
roles: ожидает некий перечень значений. Для применения большего числа ролей
просто добавьте дополнительные:
---
- hosts: localhost
gather_facts: false
roles:
- role: simple
derp: newval
- role: second_role
othervar: value
- role: third_role
- role: another_role
Смешанные роли и задачи
Обработчики для некоторого воспроизведения мелькают во множестве мест. Если имеется некий блок
pre_tasks, обработчики вспыхивают после исполнения всех
pre_tasks. Затем исполняются блоки
roles и tasks
(первыми роли, затем задачи в зависимости от того порядка, в котором они записаны в данном плейбуке), после чего
вновь вспыхнут обработчики. Наконец, если имеется блок post_tasks,
обработчики мелькнут снова после того как исполнится post_tasks.
Конечно, обработчики могут мигнут в любой момент времени с вызовом
meta: flush_handlers. Давайте расширим свой
roleplay.yaml чтобы продемонстрировать все различные разы, когда могут
включаться обработчики:
---
- hosts: localhost
gather_facts: false
pre_tasks:
- name: pretask
debug:
msg="a pre task"
changed_when: true
notify: say hi
roles:
- role: simple
derp: newval
tasks:
- name: task
debug:
msg: "a task"
changed_when: true
notify: say hi
post_tasks:
- name: posttask
debug:
msg: "a post task"
changed_when: true
notify: say hi
handlers:
- name: say hi
debug:
msg="hi
Мы также заменим свой пример задачи роли чтобы также отметить обработчик
say hi:
---
- name: print a variable
debug:
var: derp
changed_when: true
notify: say hi
|
| Замечание |
|---|---|
|
Это работает только потому, что наш обработчик |
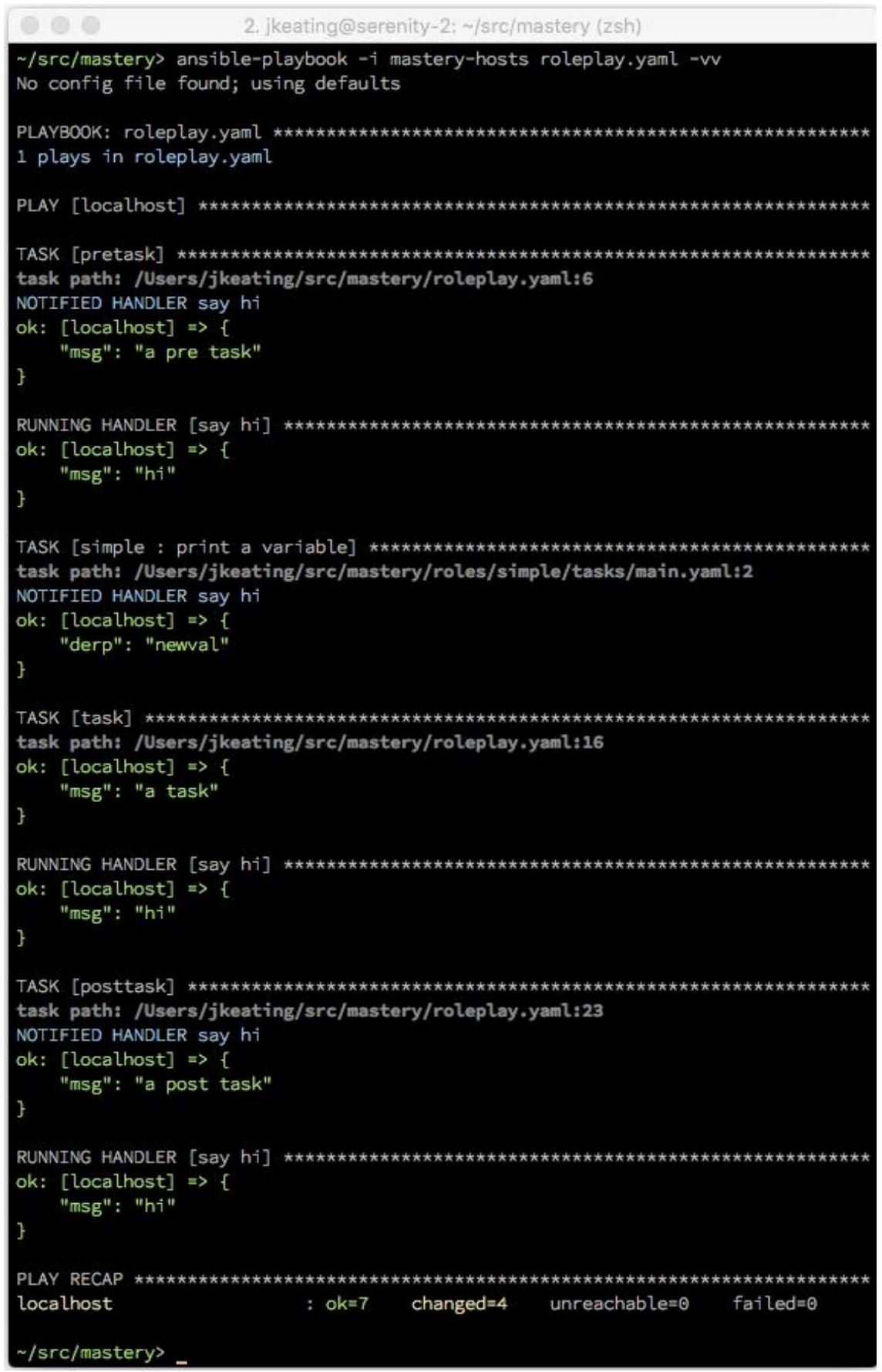
Исполнение нашего плейбука должно иметь результатом вызов имеющегося обработчика
say hi суммарно три раза: один раз для
pre_tasks, один раз для
roles и tasks, а также один раз
для post_tasks:
Хотя тот порядок, в котором pre_tasks,
roles, tasks и
post_tasks записаны в воспроизведении не влияет на тот порядок, в котором
эти разделы исполняются, лучше записывать их именно в том порядке, в котором они выполняются. Именно этот
визуальный сигнал чтобы помочь запомнить данный порядок и избежать путаницы при последующем прочтении
данного плейбука.
Включения ролей
Для Ansible версии 2.2 в качестве некоторого предварительного технического предложения сделан доступным
новый подключаемый модуль действия,include_role. Этот
подключаемый модуль применяется в некоторой задаче для включения и исполнения некоторой целой роли напрямую из
какой- то задачи. Это интересная концепция которая всё ещё находится в состоянии оценки и нет гарантии что
она останется доступной в последующих выпусках. Следует избегать данную функциональность с целью
надёжности.
Одним из преимуществ применения ролей является имеющаяся возможность совместно применять такие роли по воспроизведениям, плейбукам, целым пространствам проекта и даже по всем организациям. Роли разрабатываются чтобы они были самостоятельными (или ясно отражать зависимость ролей), поэтому они могут существовать вне некоторого пространства проекта в котором располагается тот плейбук, который применяет данную роль. Роли могут быть установленными в совместно применяемых путях в некотором хосте Ansible или они могут распространяться через управление исходными кодами.
Ansible Galaxy
Ansible Galaxy является общеупотребимым
хабом для поиска и совместного применения ролей Ansible. Этот вебсайт може посетить любой чтобы пройтись по
имеющимся ролям и обзорам; плюс пользователи, которые создают некую регистрацию могут предоставлять обзоры
тех ролей, которые они проверили. Роли из Galaxy могут выгружаться при помощи утилиты
ansible-galaxy, предоставляемой в Ansible.
Эта утилита ansible-galaxy может соединяться с вебсайтом Ansible Galaxy
и устанавливать роли из него. Данная утилита по умолчанию устанавливает роли в
/etc/ansible/roles. Если настроен
roles_path или если предоставляется с помощью
--roles-path (или -p)
некий путь времени исполнения, все роли будут установлены там вместо этого. Если какая- то роль была установлена
в roles_path или предоставленный путь,
ansible-galaxy может перечислить её и также показывать информацию о ней.
Для демонстрации применения ansible-galaxy давайте воспользуемся им
чтобы установить некую роль чтобы управлять known_hosts для
ssh из Ansible Galaxy, требующего
username.rolename, поскольку множество пользователей могут выгружать
роли с одним и тем же именем. В данном случае нам нужна роль docker_ubuntu
от определённого пользователя angstwad:
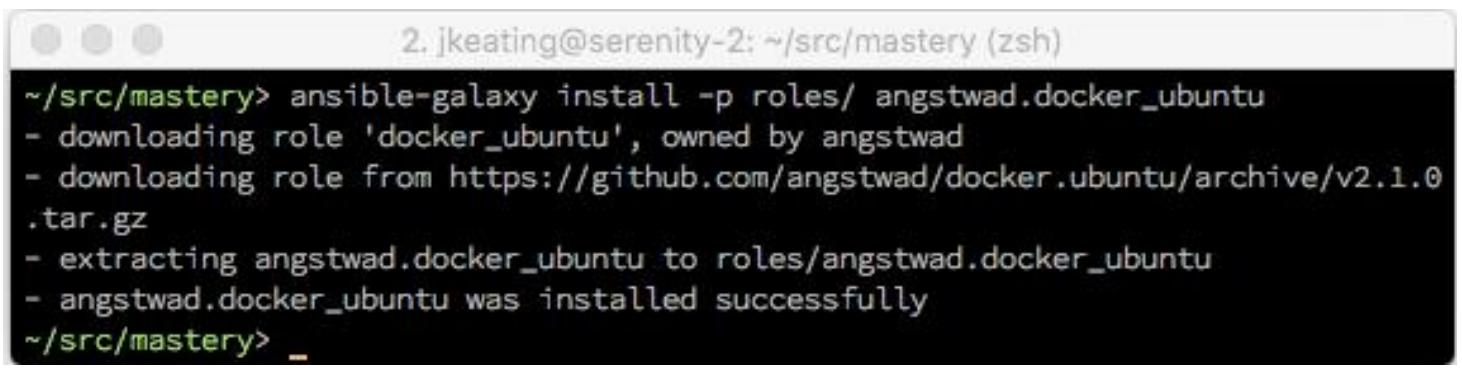
Теперь мы можем воспользоваться этой ролью по ссылке angstwad.docker_ubuntu
в некотором воспроизведении или другом блоке зависимостей ролей. Мы также можем перечислить её и получить
информацию о ней воспользовавшись своей утилитой ansible-galaxy:
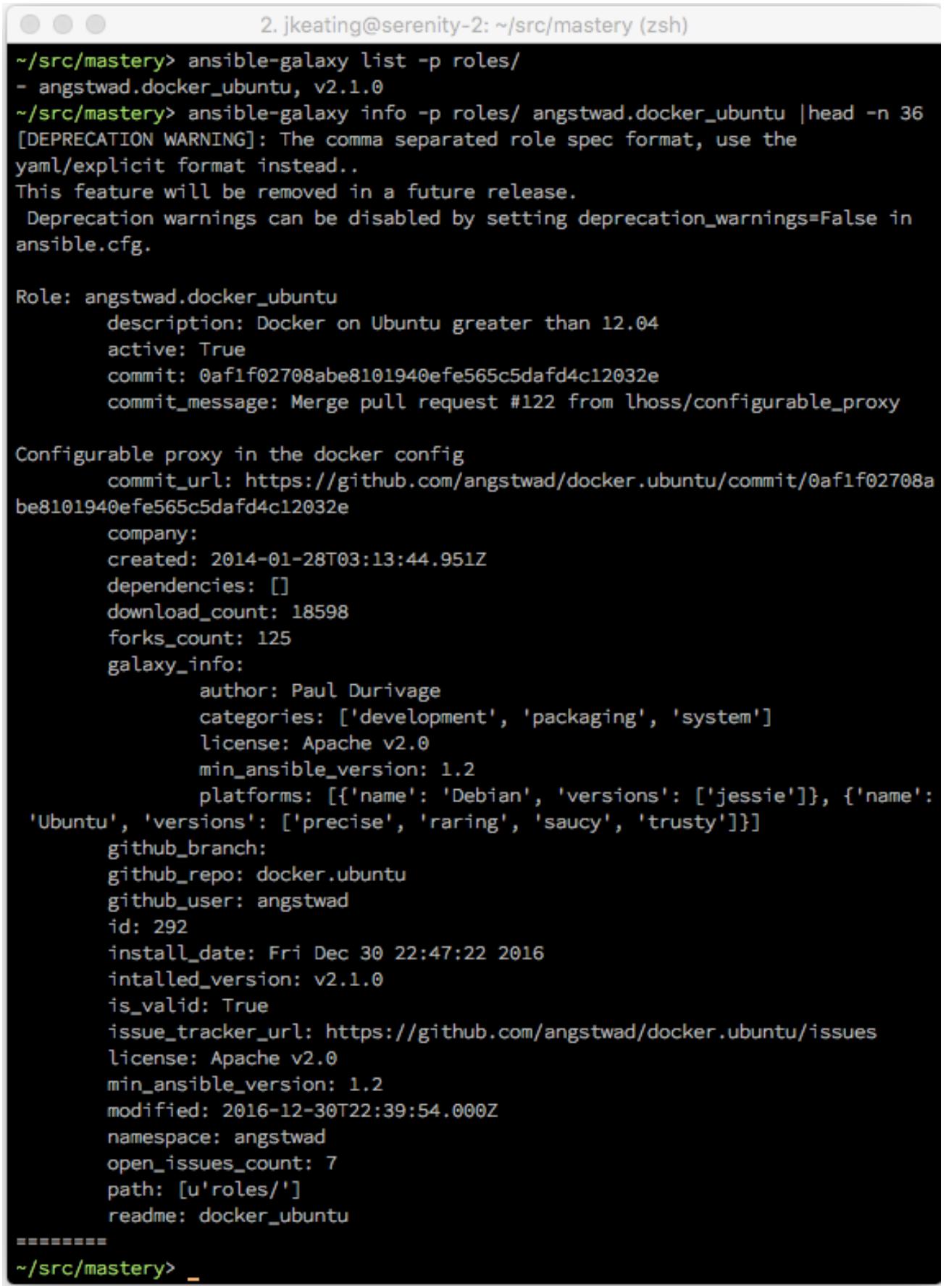
Наш вывод ограничен сверху 37 строками во избежание отображения всего содержимого
README.md. некоторые из данных, подлежащих отображению этой командой
информации располагаются в самой роли, в файле meta/main.yaml.
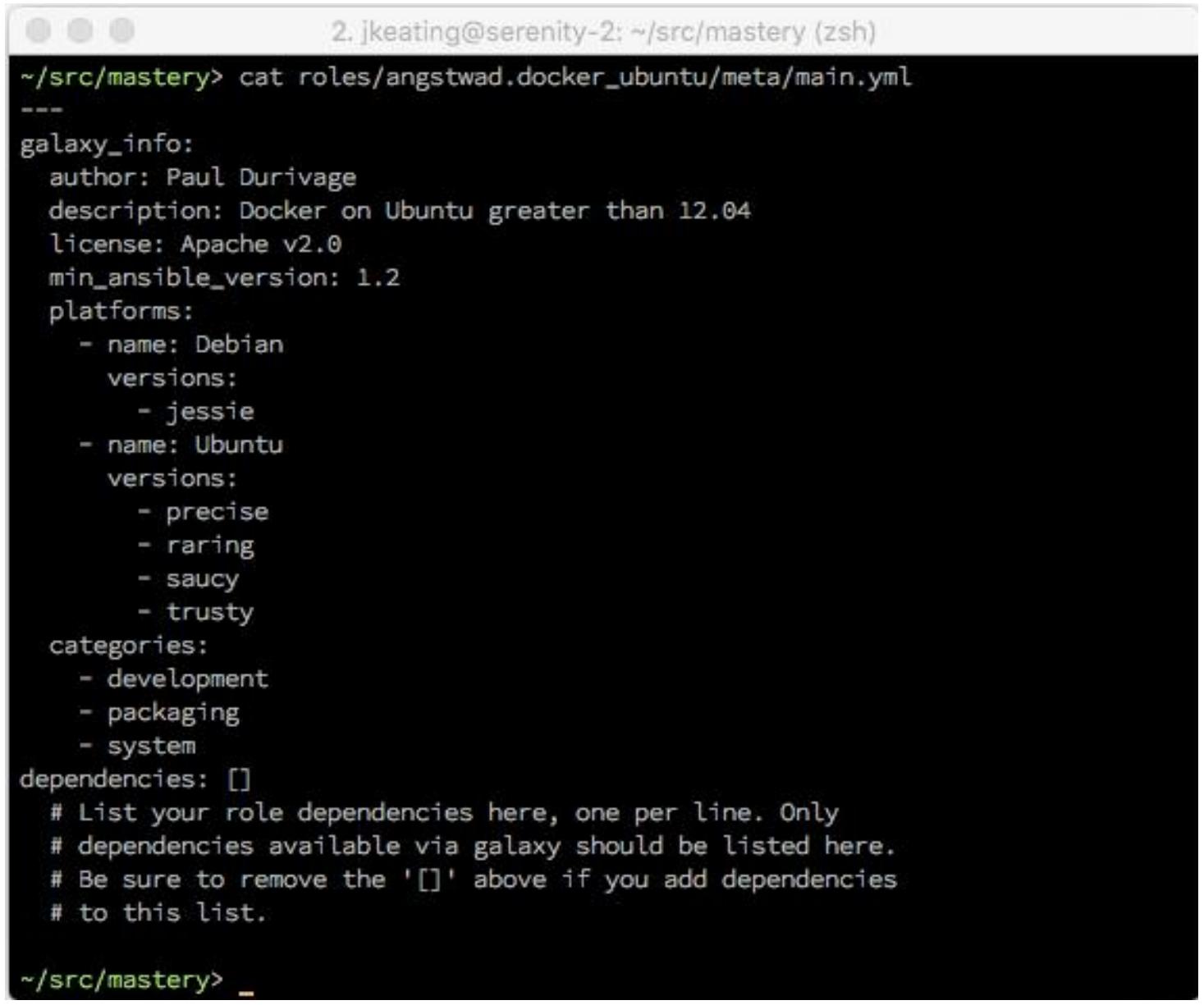
Изначально мы увидели только информацию о зависимостях в данном файле и возможно не было смысла называть
данный каталог meta, однако теперь мы видим что в этом файле также
располагаются прочие метаданные:
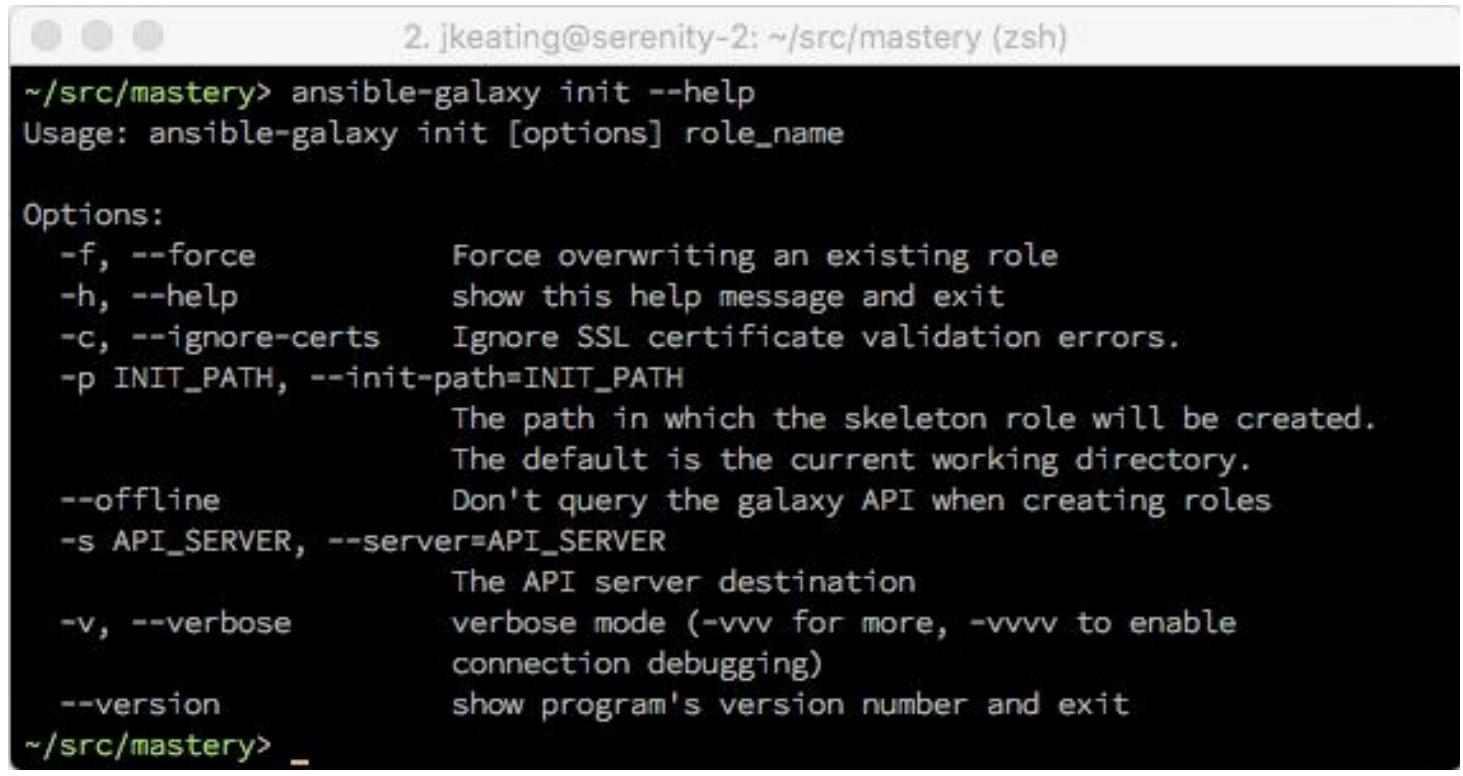
Данная утилита ansible-galaxy также может помочь с созданием новых
ролей. имеющийся метод init создаст некий скелет дерева каталога для
такой роли помимо того, что заполнит имеющийся файл meta/main.yaml
заполнителем места для связанных с Galaxy данных. Этот метод init
получает некое разнообразие параметров, что отражено в его справочной информации:
Давайте продемонстрируем данную возможность создав некую новую роль в своём рабочем каталоге с названием
autogen:
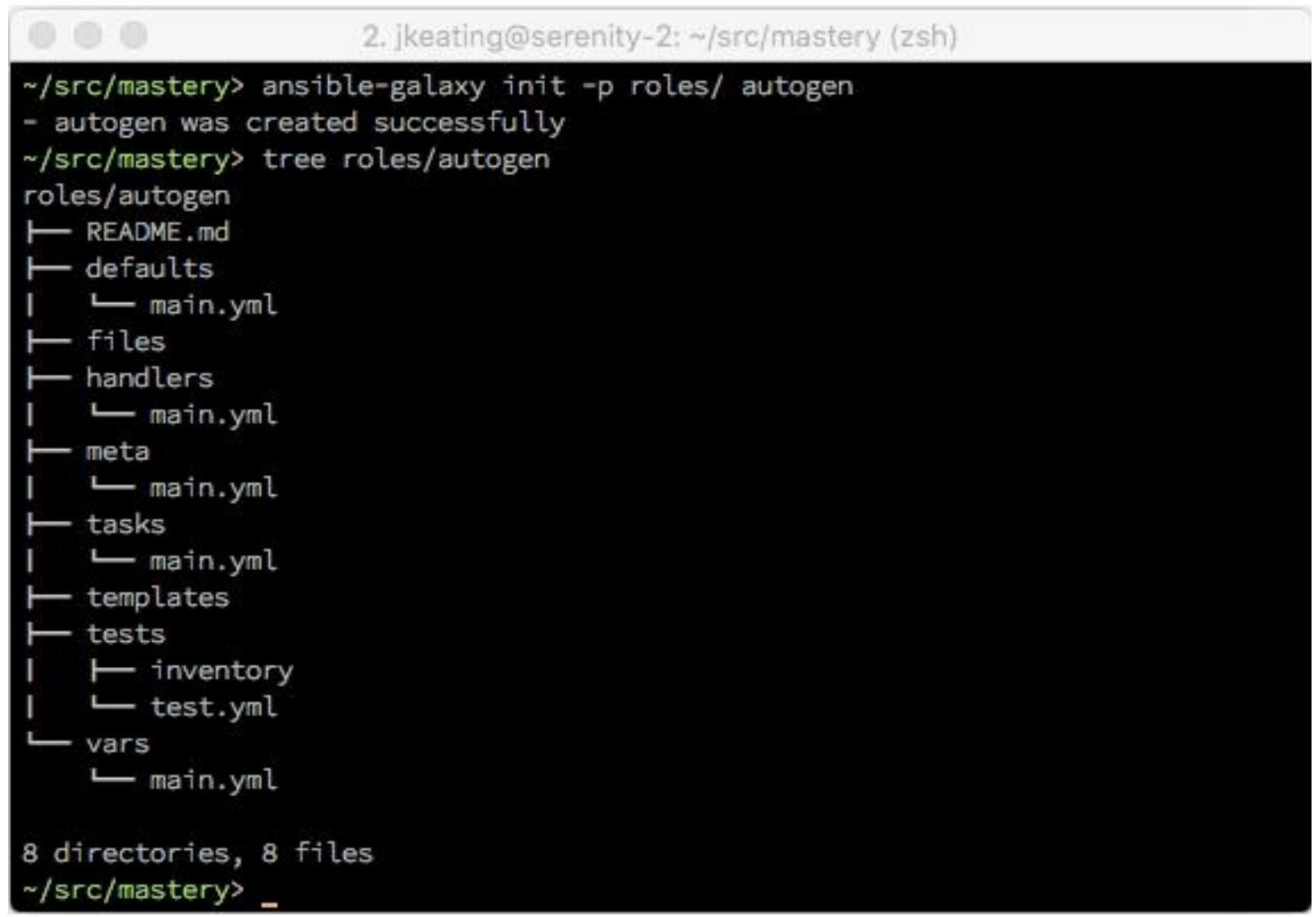
Для ролей, которые не пригодны для Ansible Galaxy, напроимер, те роли, которые связаны с внутренними
системами, ansible-galaxy может выполнять установку напрямую с
некоторого URL git. Вместо простого предоставления названия роли для установки таким методом, вместо этого
может быть предоставлен некий полный URL git с необяательным параметром версии. Например, если мы желаем
установить свою роль foowhiz с нашего сервера git, мы можем просто
сделать следующее:

Без указания информации о версии , будет применена ветвь master.
Без данных назввания, такое имя будет определено из самого URL. Чтобы предоставить некую версию, добавьте в
конец запятую и строку с номером версии, которую поймёт этот git, например, как некий тег или название
ветви, например, v1:

Некое название для такой роли может быть добавлен с другой запятой, которая следует после определения строкового имени. Если вам нужно предоставить некое имя, но вы не желаете указывать какую бы то ни было версию, для места версии всё же требуется пустой слот. Например:

Роли также могут устанавливаться напрямую из tarball, а также путём предоставления URL к такому tarball в месте полного URL git или имени некоторой роли для доставки с Ansible Galaxy.
Когда нам нужно устанавливать много ролей для какого- то проекта, имеется возможность определять множество
ролей для выгрузки и установки в некотором файле с форматом YAML, который заканчивается
.yaml (или .yml). Имеющийся
формат данного файла позволяет вам определять множество ролей из большого числа источников и сохраняет
вашу возможность определять версии и названия роли. Кроме того, может перечисляться метод управления
источником кода (в настоящее время поддерживаются только git и
hg):
---
- src: <name or url
version: <optional version>
name: <optional name override>
scm: <optional defined source control mechanism>
Чтобы установить все роли из некоторого файла воспользуйтесь параметром
--roles-file (-r) со
своим методом установки:

Ansible предоставляет определённую возможность делить содержимое логически на раздельные файлы. Эта
возможность помогает разработчикам проекта не повторять один и тот же код снова и снова. Роли внутри Ansible
проводят эту возможность на шаг далее и обёртывают некоторой магией сами пути имеющегося содержимого.
Роли имеют возможность настройки, повторного использования, переносимости и совместного использования блоков
функциональности. Ansible Galaxy существует ккак некий хаб сообщества для того чтобы разработчики могли найти,
отранжировать и совместно применять роли. Инструмент командной строки ansible-galaxy
предоставляет некий метод взаимодействия с Ansible Galaxy или прочими механизмами совместных ресурсов. Такие
возможности и инструменты помогают с организацией и использованием общего кода.
В своей следующей главе мы охватим различные стратегии разработки и обновления и те свойства Ansible, которые полезны для каждой стратегии.