Глава 9. Тонкая настройка Ceph
Содержание
Хотя установленные по умолчанию настройки Linux и Ceph будут вероятно предоставлять разумную производительность благодаря многолетним исследованиям и тонкой юстировке разработчиков, скорее всего администраторы Ceph могут пожелать попытаться и выжать дополнительную производительность из имеющегося у них оборудования. Тонкая регулировка и операционной системы, и Ceph может реализовать получение прироста производительности. В Главе 1, Планирование Ceph вы изучили то, как выбирать оборудование для кластера; теперь давайте изучим как собрать большую его часть.
В данной главе мы изучим следующие темы:
-
Латентность и её природу
-
Важность наличия возможности наблюдать все результаты регулировок
-
Ключевые параметры регулировок, на которые вам следует обратить внимание
При проведении эталонных расчётов вы в конечном итоге замеряете необходимые результаты латентности (задержек). Все прочие виды замеров эталонного тестирования, включая IOPS, MBps или даже измерения приложений более высокого уровня в конечном сроке проистекают из значений латентности в этом запросе.
IOPS являются общим числом запросов на операции ввода/ вывода выполняющихся в секунду; общая латентность каждого запроса напрямую воздействует на число возможных IOPS и может быть обнаружена в данной формуле:

IOPS = 1 секунда / Латентность
Некая средняя латентность в 2 миллисекунды на запрос будет иметь результатом, грубо говоря, 500 IOPS, в предположении, что каждый запрос представляется неким синхронным образом:
1 / 0.002 = 500
MBps это просто общее число IOPS помноженное на средний размер операции ввода/ вывода:
500 IOPS * 64 kB = 32 000 kBps
Вам должно быть ясно, что когда вы выполняете эталонное тестирование, вы на самом деле в конечном результате измеряете некую латентность. По этой причине любые регулировки которые вы выполняете, должны быть проведены для повсеместной латентности каждого запроса на операцию ввода/ вывода.
Прежде чем мы перейдём к просмотру того, как выполнять эталонное тестирование различных компонентов вашего кластера Ceph, и разнообразные доступные параметры регулировок, нам для начала необходимо разобраться с различными источниками задержек для некоторой типовой операции ввода/ вывода. Раз мы можем разбить каждый источник латентности на его собственные категории, тогда становится возможным выполнять эталонное тестирование каждого из них с тем, чтобы могли надёжно отслеживать как положительный, так и отрицательный эффект на каждом этапе.
Следующая схема отображает некий пример запроса на запись Ceph со всеми основными источниками латентности:
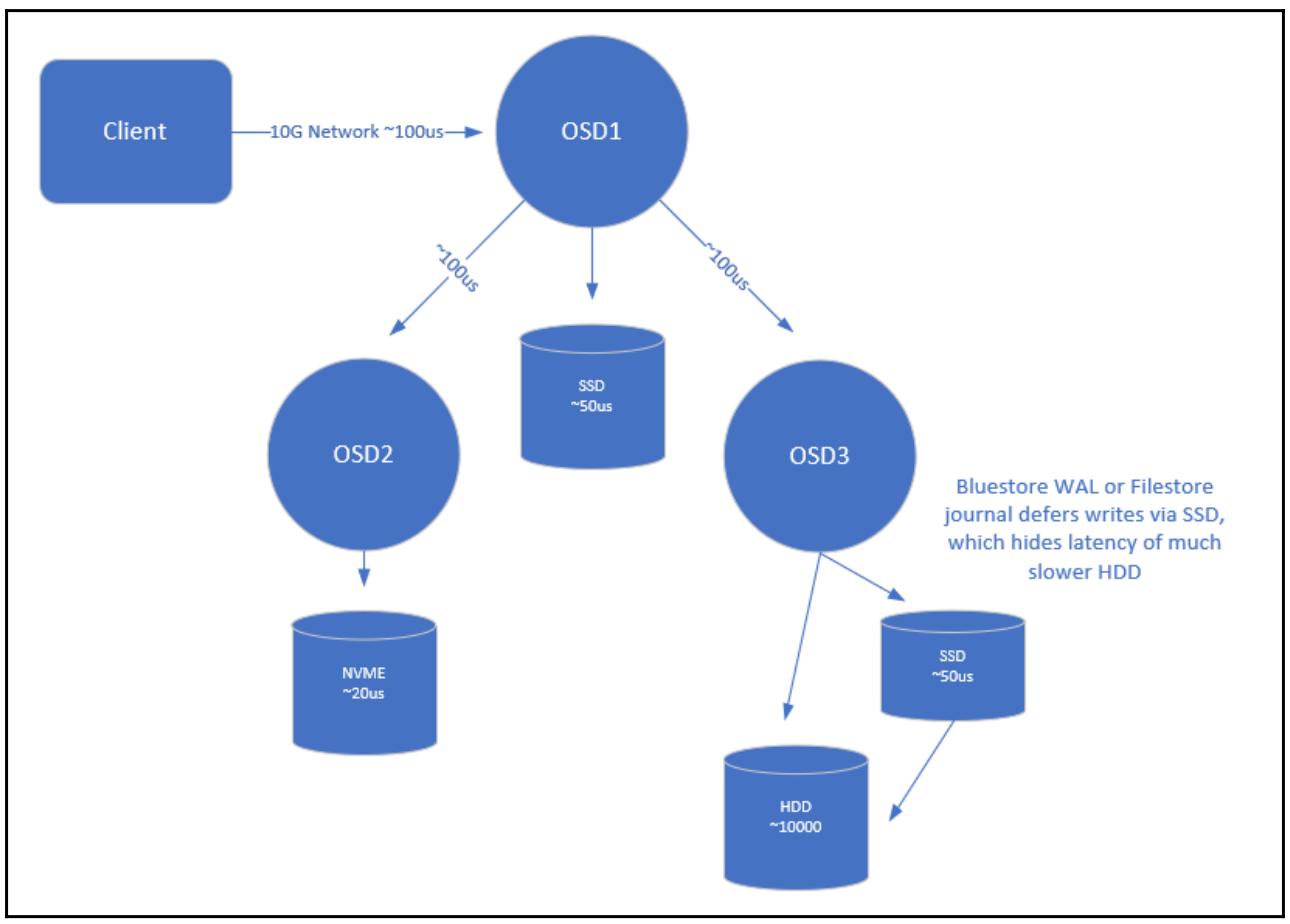
Начиная с самого клиента, мы можем обнаружить что в среднем, имеется вероятность примерно 100 микросекунд
потери латентности на её общение со своим первичным OSD. При сетевой среде 1G значение этой латентности может
быть порядка 1 миллисекунды. Мы можем удостовериться в этом значении воспользовавшись либо
ping, либо iperf для замера
средней задержки прохождения кадров между двумя узлами.
Из предыдущей формулы мы можем увидеть, что при сетевой среде 1G даже если имеются прочие источники задержек, максимально синхронные операции ввода/ вывода на запись будут порядка 1000 IOPS.
Хотя сам клиент привносит некую латентность своими руками, она минимальна в сравнении со всеми прочими источниками и, поэтому, она не содержится в данной схеме.
Далее, все OSD, которые исполняют код Ceph вносят латентность в процессе данного запроса. Достаточно сложно поместить точные значения напротив каждого, однако они являются результатом скорости данного ЦПУ. Более быстрый ЦПУ с более высокой частотой будет проходить через путь данного кода быстрее, снижая латентность. Ранее в этой книге мы отметили, что первичный OSD будет отправлять запросы на два других OSD в своём наборе реплик. Оба они будут обрабатываться одновременно, поэтому имеется минимальное увеличение латентности, исходящее от двукратного до трёхкратного при репликации, в предположении что лежащие в основе диски в состоянии справляться с данной нагрузкой.
Имеется также некий другой дополнительный сетевой тычок между первичным и реплицируемыми OSD, который привносит латентность в каждый запрос.
Раз первичный OSD фиксирует данный запрос в своём журнале, и должен получать уведомления обратно от всех OSD реплик, тогда они в свою очередь должны делать то же самое, он может затем отправить уведомление обратно клиенту и может представить свой следующий запрос операции ввода/ вывода.
Что касается самого журнала, в зависимости от типа применяемого носителя значение фиксации латентности может меняться. SSD NVMe будут иметь тенденцию обслуживать запросы в диапазоне 10-20 микросекунд, в то время как SSD на основе SATA/ SAS обычно обслуживают запросы в диапазоне 50- 100 микросекунд. Устройства NVMe также имеют тенденцию располагать более согласованным профилем латентности с неким увеличением имеющейся глубины очереди, что делает их идеальными для вариантов, когда множество дисков могут применять некий отдельный журнал. {Прим. пер.: отметим также что одно устройство NVMe допускает до 65 636 одновременных очередей, в отличие от единственной очереди в устройствах с AHCI подробнее...} В дальнейшем пути появляются жёсткие диски, которые измеряются десятками миллисекунд, хотя они и обладают достаточной устойчивостью с точки зрения задержек при увеличении общего размера операций ввода/ вывода.
Должно быть очевидным, что для малых, но высокопроизводительных рабочих нагрузок, именно латентность жёстких дисков будет доминировать в общем значении латентности и, таким образом, для них более предпочтительными должны быть SSD, причём лучше с NVMe.
В конечном итоге, хорошо спроектированный и настроенный кластер Ceph в комбинации со всеми такими составляющими должен в среднем позволять обслуживание запросов записей 4кБ в рамках 500- 700 микросекунд.
Эталонное тестирование (benchmarking) является важным инструментом с тем, чтобы иметь возможность увидеть эффект ваших усилий по регулировке, а также определить те пределы, на которые способен ваш кластер. Однако, важно чтобы ваше эталонное тестирование отражало тот тип рабочих нагрузок, которые в обычных условиях имеются в вашем кластере Ceph. Будет бесполезно регулировать ваш кластер Ceph с тем, чтобы он был превосходным в больших последовательных чтениях и записях если вы в конце концов выполнять на нём высокочувствительные к латентности базы данных OLTP. Если это возможно, вам следует пробовать и включать некое эталонное тестирование, которое на самом деле применяет то же самое программное обеспечение, которое вы используете в рабочих нагрузках в реальной жизни. Снова, как и в примере с конкретной базой данных OLTP, попытайтесь посмотреть имеются ли эталонные тесты для программного обеспечения вашей базы данных, которые предоставят наиболее точные результаты.
Далее мы приводим перечень средства, которые являются рекомендуемым набором инструментария эталонного тестирования чтобы вы могли приступить к нему.
-
Fio: Гибкий инструмент тестирования операций ввода/ вывода, Fio, позволяет вам эмулировать разнообразные сложные шаблоны ввода/ вывода посредством своих расширенных возможностей настроек. Он имеет встраиваемые модули (plugin) как для локальных блочных устройств, так и для RBD, что означает, что вы можете проводить тестирование RBD вашего кластера Ceph либо напрямую, или монтируя его через имеющийся драйвер ядра RBD Linux.
-
Sysbench: Sysbench имеет набор тестов OLTP MySQL, которые эмулируют некое приложение OLTP.
-
Ping: Не преуменьшайте значение скромного инструмента ping; помимо того, что он способен продиагностировать многие проблемы сетевой среды, сообщаемое им время в оба конца является удобной справкой для по поводу задержек соединений сетевой среды.
-
iPerf: iPerf позволяет вам проводить последовательности сетевых тестов для определения общей полосы пропускания между двумя серверами.
Имеется целый ряд областей, в которых нам необходимо эталонное тестирование нашей сетевой среды чтобы быть способными понимать все ограничения и гарантировать что нет пробелов в настройках.
Стандартный кадр ethernet составляет 1500 байт, в то время как кадр jumbo обычно имеет 9000 байт. Такое увеличение размера кадра снижает имеющиеся накладные расходы отправки данных. Если вы настраиваете свою сетевую среду на работу с некими кадрами jumbo, самым первым моментом, который необходимо проверить это то, что они правильно настроены во всех ваших серверах и сетевых устройствах. Если кадры jumbo настроены неверно, Ceph будет проявлять странное случайное поведение которое очень сложно отследить; по этой причине очень существенно чтобы кадры jumbo были настроены правильно убедиться что всё работает до того как вы начнёте развёртывать Ceph поверх вашей сетевой среды.
Чтобы убедится, что кадры jumbo работают правильно, вы можете применить ping
для отправки пакетов с установленным флагом don't
fragment (не разбивать):
ping -M do -s 8972 <destination IP>
Эту команду необходимо выполнить на всех ваших узлах, чтобы быть уверенным, что они выполняют ping друг к другу при помощи кадров jumbo. В случае отказа изучите эту проблему и разрешите её перед развёртыванием Ceph. Также будет неверно автоматизировать это тестирование, поскольку дальнейшие изменения сетевой среды могут прервать это поведение, а диагностика неверной настройки кадров jumbo поверх Ceph практически невозможна.
Следующей проверкой, которую необходимо предпринять, является замер времени прохождения кадра в обе стороны при помощи инструментария ping. Применение его параметра размера пакета вновь, но с применением флага запрета разбивки, сделает возможной проверку времени прохода в две стороны пакетов c определёнными размерами вплоть до 64кБ, что является максимальным размером пакета IP.
Вот пример результата тестирования между двумя хостами в сетевой среде с 10GBase-T:
-
32В = 85 миллисекунд
-
4kВ = 112 миллисекунд
-
16kВ = 158 миллисекунд
-
64kВ = 248 миллисекунд
Как вы видите, пакеты большего размера воздействуют на время пути в обе стороны; именно это является одной из причин почему операции ввода/ вывода большего размера будут казаться уменьшающими IOPS в Ceph.
Наконец, давайте проверим общую полосу пропускания между двумя хостами чтобы убедиться, мы получили ли мы ожидаемую производительность или нет.
Выполните iperf -s на своём сервере который исполняет роль сервера
iPerf:

Затем запустите iperf -c <address of iperf server>:
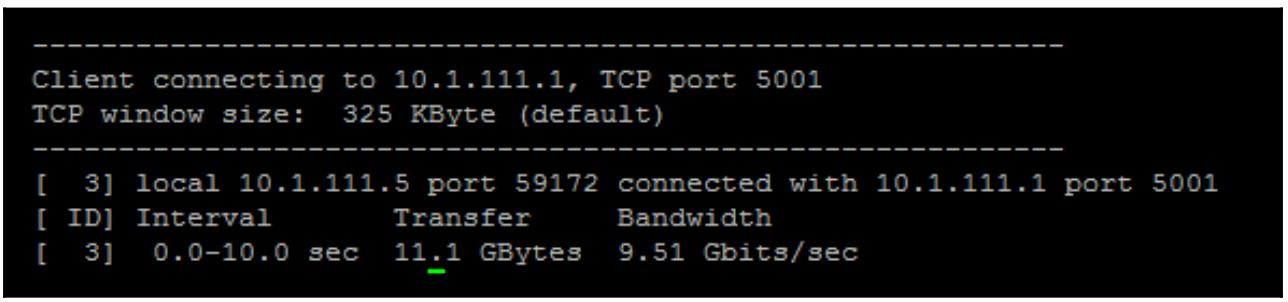
Как мы можем увидеть в этом примере, два хоста соединяются через некую сетевую среду 10G и получают значения близкие к теоретическому максимуму пропускной способности. Если вы не увидите правильной пропускной способности, тогда исследуйте свою сетевую среду, включая настройку хоста, которую необходимо выполнить.
Хорошей идеей является понимание основной производительности всех жёстких дисков и SSD в вашем кластере Ceph, поскольку это позволит вам предсказать общую производительность вашего кластера Ceph. Чтобы провести эталонное тестирование всех дисков в вашем кластере, будет применён инструментарий fio.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
В случае работы в режиме с записью, будьте аккуратнее с применением fio. Если вы определите некое блочное устройство, fio со счастливым видом выполнит запись поверх всех данных, которые имеются на этом диске. |
Fio является сложным средством со множеством вариантов настроек. Для целей данной главы мы сосредоточимся на применении его для выполнения эталонного тестирования базового чтения и записи:
-
Установите инструментарий fio на некий узел OSD Ceph:
apt-get install fioПредыдущая команда предоставит вам следующий вывод:
-
Теперь создайте некий новый файл и поместите в него следующие настройки fio:
[global] ioengine=libaio randrepeat=0 invalidate=0 rw=randwrite bs=4k direct=1 time_based=1 runtime=30 numjobs=1 iodepth=1 filename=/test.fio size=1G
Предыдущая настройка fio будет выполнять некую проверку записи случайным образом по 4кБ в отдельном потоке на
протяжении 30 секунд. Она создаст некий 1ГБ файл test.fio в основном
корне вашей файловой системы. Если вы пожелаете иметь целью непосредственно блочное устройство, просто установите
соответствующее имя файла на это блочное устройство; однако обращаем внимание на приведённое выше предостережение,
что fio перезапишет все данные на этом блочном устройстве.
Отметим, что данное задание установлено для применение направленности, поэтому имеющийся страничный кэш не ускорит никаким образом никакие операции ввода/ вывода.
Чтобы исполнить задание fio просто сделайте вызов fio с конкретным
именем файла, в котором вы сохранили все предыдущие настройки:
fio <filename>
Предыдущая команда предоставит вам следующий вывод:
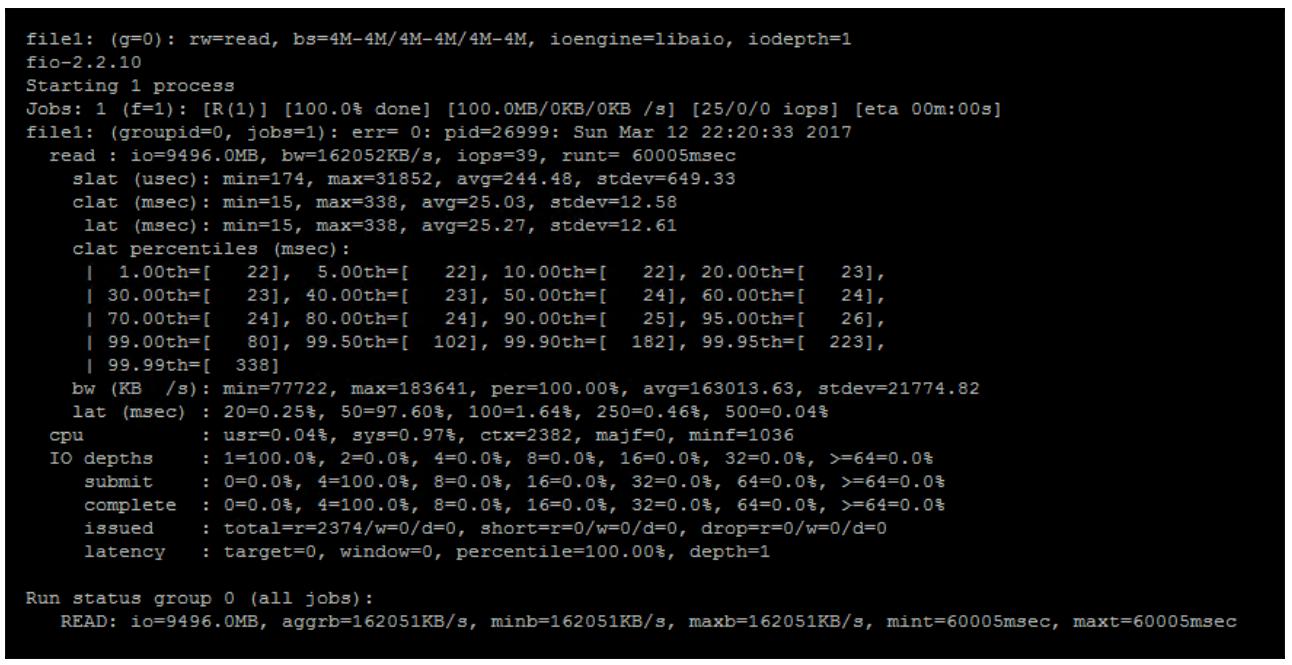
Когда данное задание осуществится, fio предоставляет вывод, аналогичный приведённому на снимке экрана выше. Вы можете видеть, что данное задание fio исполнилось в среднем с 39 IOPS и 162 MBps, а средняя латентность составляла 25 миллисекунд. Также имеется разбивка латентности по процентным соотношениям, которая может быть полезной для понимания распределения латентности по всему запросу.
Имеется также разбивка по процентилям, которая может оказаться полезной для понимания распределения летентности в самом запросе.
Хорошей идеей является понимание основной производительности всех жёстких дисков и SSD в вашем кластере Ceph, поскольку это позволит вам предсказать общую производительность вашего кластера Ceph. Чтобы провести эталонное тестирование всех дисков в вашем кластере, будет применён инструментарий fio.
|
| Совет |
|---|---|
|
В случае работы в режиме с записью, будьте аккуратнее с применением fio. Если вы определите некое блочное устройство, fio со счастливым видом выполнит запись поверх всех данных, которые имеются на этом диске. |
Fio является сложным средством со множеством вариантов настроек. Для целей данной главы мы сосредоточимся на применении его для выполнения эталонного тестирования базового чтения и записи:
-
Установите инструментарий fio на некий узел OSD Ceph:
apt-get install fioПредыдущая команда предоставит вам следующий вывод:
-
Теперь создайте некий новый файл и поместите в него следующие настройки fio:
[global] ioengine=libaio randrepeat=0 invalidate=0 rw=randwrite bs=4k direct=1 time_based=1 runtime=30 numjobs=1 iodepth=1 filename=/test.fio size=1G
Предыдущая настройка fio будет выполнять некую проверку записи случайным образом по 4кБ в отдельном потоке на
протяжении 30 секунд. Она создаст некий 1ГБ файл test.fio в основном
корне вашей файловой системы. Если вы пожелаете иметь целью непосредственно блочное устройство, просто установите
соответствующее имя файла на это блочное устройство; однако обращаем внимание на приведённое выше предостережение,
что fio перезапишет все данные на этом блочном устройстве.
Отметим, что данное задание установлено для применение направленности, поэтому имеющийся страничный кэш не ускорит никаким образом никакие операции ввода/ вывода.
Чтобы исполнить задание fio просто сделайте вызов fio с конкретным
именем файла, в котором вы сохранили все предыдущие настройки:
fio <filename>
Предыдущая команда предоставит вам следующий вывод:
Когда данное задание осуществится, fio предоставляет вывод, аналогичный приведённому на снимке экрана выше. Вы можете видеть, что данное задание fio исполнилось в среднем с 39 IOPS и 162 MBps, а средняя латентность составляла 25 миллисекунд. Также имеется разбивка латентности по процентным соотношениям, которая может быть полезной для понимания распределения латентности по всему запросу.
Следующим этапом является эталонное тестирование самого уровня RADOS. Это снабдит вас комбинированным значением, включающим производительность всех дисков, сетевой среды совместно с накладными расходами самого кода Ceph, а также дополнительными репликациями копий данных.
Инструменты командной строки RADOS имеют встроенную команду эталонного тестирования, которая по умолчанию инициирует 16 потоков, причём все они пишут 4МБ объекты. Чтобы выполнить данное тестирование RADOS исполните следующую команду:
rados -p rbd bench 10 write
Она исполнит эталонное тестирование записи на протяжении 10 секунд:
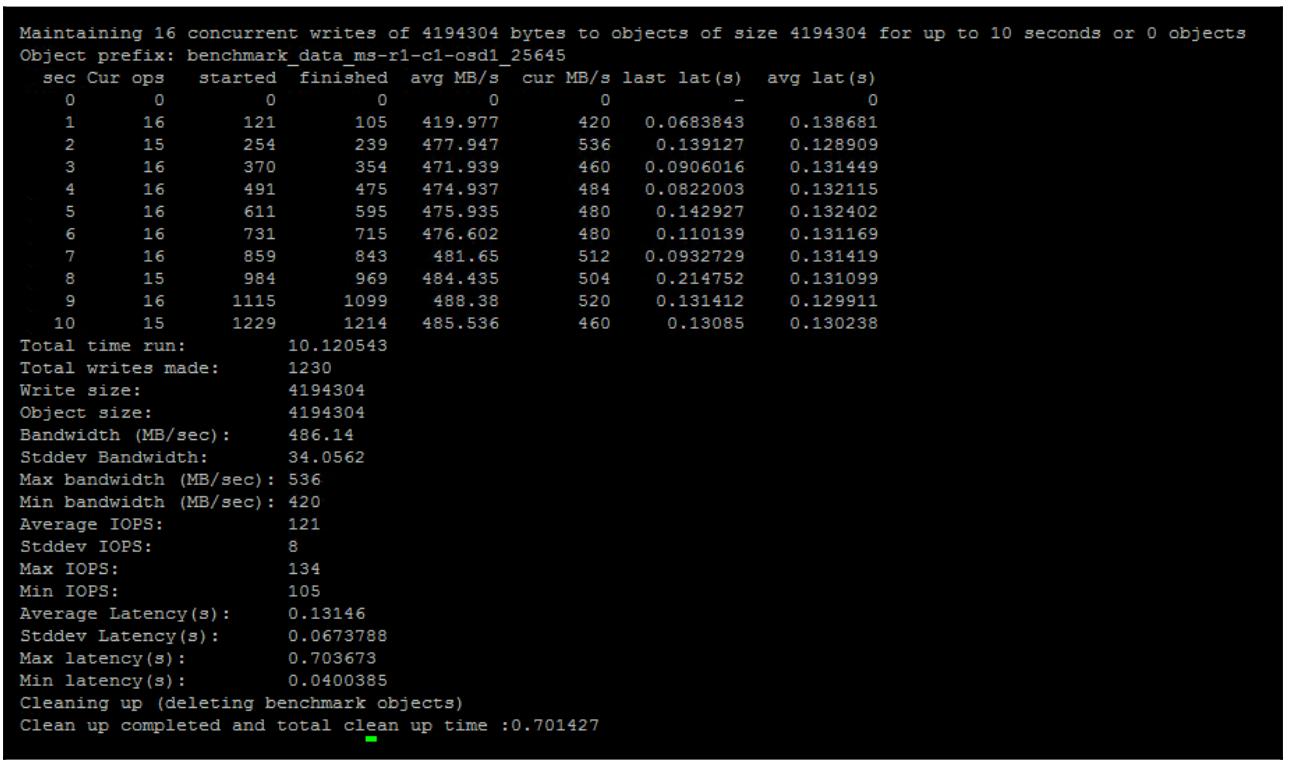
Из предыдущего примера можно увидеть, что данный кластер способен поддерживать полосу пропускания для записи
около 480MBps. Данный вывод также снабжает вас латентностью и прочими полезными значениями. Отметим, что по
окончанию тестирования, инструмент автоматически удаляет все объекты, созданные как часть данной эталонной
проверки. Если вы желаете применить другой инструмент RADOS для проведения эталонного тестирования чтения,
тогда вам необходимо определить опцию --no-cleanup чтобы оставить
все эти объекты на месте, а затем исполнить эталонное тестирование вновь с типом проверки определённым как
seq вместо write. Затем вам
после всего понадобится вручную выполнить очистку от эталонных объектов.
Наконец, мы протестируем общую производительность RBD применяя свой любимый инструмент fio вновь. Он протестирует весь стек программных и аппаратных средств, а его результаты будут очень близки к тому, что клиенты ожидали бы наблюдать. Настроив fio на эмуляцию определённых приложений клиентов, мы также можем получить ощущение от ожидаемой производительности этих приложений.
Чтобы проверить производительность некоторого RBD, мы воспользуемся механизмом RBD fio, который позволит fio общаться напрямую с самим образом RBD. Создайте новую настройку fio и поместите в неё следующее:
[global]
ioengine=rbd
randrepeat=0
clientname=admin
pool=rbd
rbdname=test
invalidate=0
rw=write
bs=1M
direct=1
time_based=1
runtime=30
numjobs=1
iodepth=1
Как вы можете здесь заметить, в отличие от настроек эталонного тестирования диска, вместо механизма
libaio данный файл настроек теперь применяет механизм
rbd. При применении данного механизма
rbd вам также понадобится определить сам пул RADOS и определённого
пользователя cephx, который имеется в данном пуле RADOS, который вы
настроили.
Затем исполните задание fio для проверки производительности вашего RBDL:
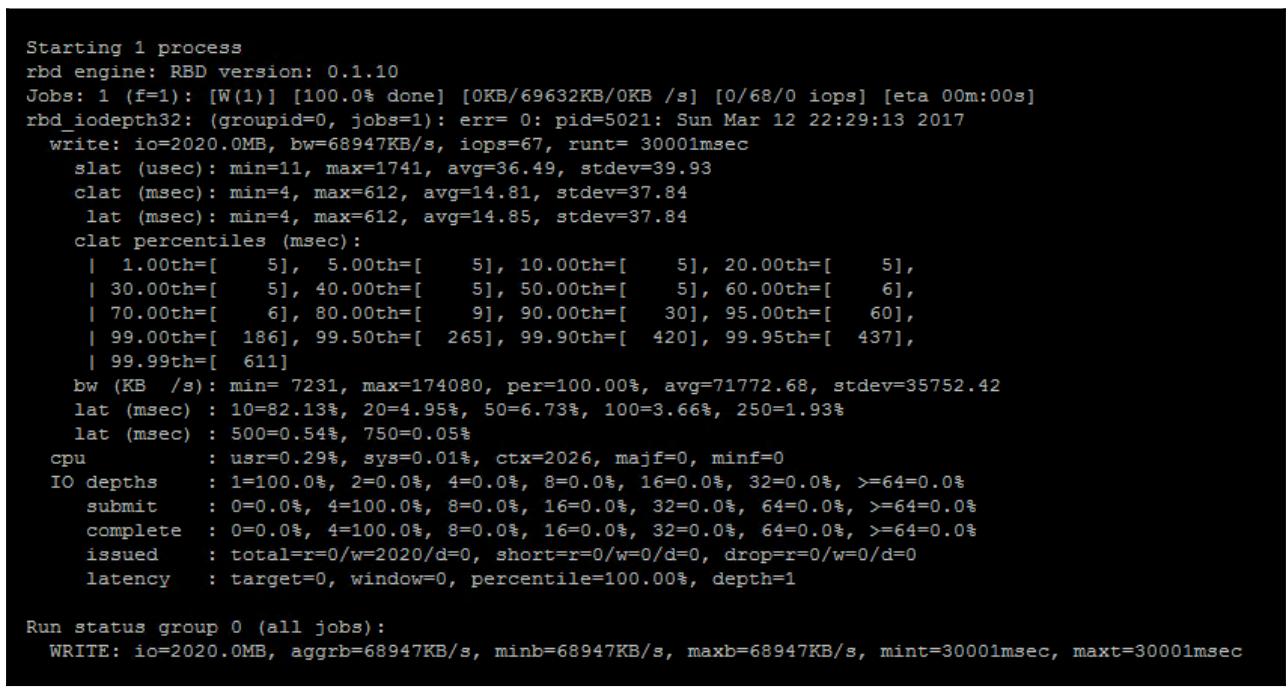
Как вы можете определить из предыдущего вывода, наш инструмент fio непосредственно применяет имеющийся механизм RBD, передавая все требования для монтирования некого RBD в операционную систему Linux прежде чем он сможет выполнить тестирование.
Регулировка вашего кластера Ceph позволит вам получить лучшую производительность и вынести больше преимуществ от своего оборудования. В данном разделе мы рассмотрим рекомендуемые варианты регулировок Ceph. Важно понимать, что путём выполнения регулировок всё что вы делаете, это уменьшаете число узких мест. Если вы управляете снижением достаточного числа узких мест в одной области, они могут просто переместиться в другую область. Вы всегда где- то имеете узкие места и в конце концов вы достигаете того момента, когда вы просто достигли пределов того что может предоставлять конкретное оборудование. Таким образом, основная цель состоит в снижении числа узких мест в программном обеспечении и операционной системе чтобы высвободить целиком весь имеющийся потенциал вашего оборудования.
Поскольку Ceph является программно определяемым для хранения, его производительность сильно подвержена влиянию имеющихся в его узлах OSD ЦПУ. Более быстрый ЦПУ означает что весь код Ceph может работать быстрее и будет проводить меньше времени на обработке каждого запроса операции ввода/ вывода. Результатом будет меньшая латентность на операцию ввода/ вывода. что, если все лежащие в его основе хранилища могут это обслуживать, снизит значимость ЦПУ в качестве узкого места и даст более высокую общую производительность. В Главе 1, Планирование Ceph мы осведомили вас, что процессоры с с большим числом ГГц должны предпочитаться по соображениям производительности; однако имеются дополнительные соображения относительно высокого числа ядер ЦПУ когда они превышают определённое для данного задания значение.
Чтобы понять это, нам необходимо рассмотреть краткую историю архитектуры ЦПУ. На протяжении ранних 2000, все ЦПУ имели архитектуру с единственным ядром, которое постоянно работало на одной и той же частоте и не поддерживало множество режимов с меньшей мощностью. По мере их продвижения к более высоким частотам, а также когда стартовало разделение на ядра, стало очевидно, что не все ядра имели бы возможность работать на максимальной частоте на протяжении всего времени. Общий объём создаваемого всем пакетом ЦПУ тепла был просто гигантским. Быстро перескочим в сегодняшние дни, и всё это продолжает оставаться верным - не существует такой штуки как ЦПУ с 20 ядрами с частотой 4ГГц; он создавал бы слишком много тепла чтобы быть реализованным.
Однако те способные парни, которые разрабатывают ЦПУ пришли к решению, при котором допустимо каждому ядру работать на отличной от прочих частоте, а также которое допускает ему самостоятельно запитывать себя вплоть до состояний сна. Такой ЦПУ имеет намного более низкие тактовые частоты, однако способен для определённого общего числа ядер задействовать турбированный режим, при котором возможны более высокие частоты. Обычно присутствует постепенное снижение топовой турбированной тактовой частоты по мере роста общего числа активных ядер для сохранения выхода тепла ниже определённого порогового значения. Если запущен процесс с небольшим числом потоков, данный ЦПУ пробуждает пару ядер и разгоняет их до максимально высокой частоты для достижения наилучшей производительности в отдельном потоке. В ЦПУ Intel различные уровни частот называются P- состояниями, а уровни сна именуются C- состояниями.
Всё это звучит как некий исключительный пакет: некий ЦПУ, который в состоянии покоя едва ли потребляет какую мощность, но когда возникает потребность, он может турбированно ускорить небольшое число ядер для достижения высоких тактовых частот. К сожалению, как и со всеми вещами в жизни, не существует такого момента как свободный запуск. Имеются некоторые накладные расходы для данного подхода, которые пагубно воздействуют на чувствительные к имеющимся задержкам приложениям, причём Ceph в их числе.
Существует две основные проблемы для данного подхода, которые воздействуют на чувствительные к задержкам приложения. Первая состоит в том, что для пробуждения из спящего состояния некоторому ядру требуется определённое время. Чем глубже уровень сна, тем больше займёт его пробуждение. Данное ядро должно повторно инициализировать определённые моменты прежде чем будет готово к использованию. Вот некоторый список для ЦПУ Intel E3-1200 v5; более ранние процессоры могут быть несколько хуже:
-
POLL = 0 микросекунд
-
C1-SKL = 2 микросекунды
-
C1E-SKL = 10 микросекунд
-
C3-SKL = 70 микросекунд
-
C6-SKL = 85 микросекунд
-
C7s-SKL = 124 микросекунд
-
C8-SKL = 200 микросекунд
Мы можем видеть, что в наихудшем случае пробуждение ядра из самого глубокого сна может потребовать до 200 микросекунд. Когда вы рассматриваете что некая отдельная операция ввода/ вывода Ceph может потребовать пробуждения нескольких потоков в нескольких узлах ЦПУ, такой выход задержек может начинать на самом деле добавляться. Хотя P- состояния, от которых зависит частота ядра не влияют на производительность в той же мере сильно, как это имеет место для задержек выхода C- состояний, текущая тактовая частота не увеличивается моментально до максимальной скорости как только оно начинает применяться. Это означает, что при некотором низком использовании все ядра ЦПУ могут работать только при небольших значениях ГГц. А это приводит ко второй проблеме, которая состоит в планировщике самого Linux.
Linux имеет информацию о том какие ядра активны и в каком C- состоянии и P- состоянии работает каждое ядро. Он может полностью управлять поведением каждого ядра. К сожалению, планировщик Linux не принимает во внимание никакую из такой имеющейся информации, а вместо этого он предпочитает попытаться и равномерно балансирует потоки по ядрам. ЧТо это означает, так это то, что при низком применении все имеющиеся ядра ЦПУ будут проводить своё основное время в их наинизшем C- состоянии и будут работать на некоторой низкой частоте. Из- за некоторого низкого использования, это может воздействовать на задержки для малых операций ввода/ вывода в 4- 5 раз, что является существенным воздействием.
Пока Linux не будет иметь осведомлённый о потребляемой мощности планировщик, который будет учитывать то, какие ядра уже активные и планировать потоки в них, наилучший имеющийся подход состоит в том, чтобы заставить данный ЦПУ уходить в состояние сна только до определённого C- состояния, а также заставить его работать на самой высокой частоте всё время. Это на самом деле увеличивает общее энергопотребление, однако в самых последних моделях ЦПУ оно слегка сократилось. По этой причине должно быть понятно почему рекомендуется подбирать размер вашего ЦПУ под вашу рабочую нагрузку. Работа некоторого сервера с 40 ядрами на высоких C- состояниях и с высокими частотами будет потреблять много мощности.
Чтобы заставить Linux сбрасывать вниз только до C- состояния C1, добавьте в свои настройки GRUB следующее:
intel_idle.max_cstate=1
Некоторые дистрибутивы Linux имеют какой- то производительный режим при котором он работает с ЦПУ на
максимальной частоте. Однако, получить эту информацию можно только вручную и это эхо значения через
sysfs. Прикрепив следующее в своём
/etc/rc.local установит все ваши ядра в работу на их максимальной
частоте после загрузки:
/sys/devices/system/cpu/intel_pstate/min_perf_pct
После того как вы перезапустите свой узел OSD, эти изменения вступят в действие. Подтвердите это исполнив данные команды:
sudo cpupower monitor
Как уже упоминалось ранее в данной главе, перед тем как выполнить эти изменения, проведите некое оценочное эталонное тестирование, а затем выполните его вновь после всего, чтобы вы могли понять что получили данными изменениями.
Самые последние версии Ceph содержат некую функциональность автоматической регулировки для OSD BlueStore.
Такие автоматические регулировки работают над анализом использования кэшей OSD и выравнивают пороговые значения
кэширования для OSD, RocksDB и кэширования данных в зависимости от текущих состояний попадания в кэш. Они также
ограничивают общую сумму этих кэшей чтобы попытаться ограничивать общее использование памяти для ограничения
установок значения переменной osd_memory_target, которое по умолчанию
устанавливается в значение 4 ГБ.
Очевидно, что если у вас в узле меньше оперативной памяти и он, следовательно, не способен предоставить 4ГБ
для каждого OSD, это число следует уменьшить во избежание исчерпывания оперативной памяти данным узлом. Однако, если
у узла Ceph достаточно памяти, рекомендуется увеличить значение переменной osd_memory_target
чтобы позволить Ceph максимально применять всю установленную память. Когда OSD и RocksDB будет выделен достаточный
объём памяти, вся дополнительная память будет применяться для кэширования данных и это поможет гораздо более эффективному
обслуживанию верхних процентилей операций ввода/ вывода при чтении. Имеющийся в настоящее время алгоритм автоматической
регулировки довольно медленный и требует некоторого времени для своего наращивания, поэтому следует отвести не менее 24- 48
часов на определение полного воздействия изменения значения переменной
osd_memory_target.
Отложенные записи WAL
BlueStore может выполнять записи с журналированием в WAL RocksDB и сбрасывать их с задержкой, что позволяет объединять и упорядочивать запись. Это может привнести значительное улучшение производительности в кластерах, которые применяют шпиндельные диски с устройствами на основе флеш- памяти для RocksDB.
По умолчанию, если ваш OSD определён как шпиндельный HDD, записи меньшие или равные 32 кБ записываются в имеющемся WAL
OSD получателя и после этого подтверждение отправляется обратно его клиенту. Это контролируется значением переменной
bluestore_prefer_deferred_size_hdd; данное значение может быть скорректировано, если
выявлено что ваша рабочая нагрузка также выиграет от задержек записей большего размера через установленный WAL для
получения более низких задержек и более высоких IOPS. Следует также подумать о нагрузке записи в устройство флеш- памяти,
в котором установлен WAL, как в отношении полосы пропускной способности, так и из сооброжений износа числа записей.
Настройки BlueStore также могут ограничивать число записей в очереди до принудительного их сброса в соответствующий OSD
для очистки данного диска; это контролируется значением переменной bluestore_deferred_batch_ops
и по умолчанию установлено в 64. Увеличение данного значения может увеличивать
общую пропускную способность, но также приводит к риску того, что диск будет тратить слишком много времени и увеличит
среднее значение латентности.
Практически во всех случаях BlueStore превосходит файловое хранилище и устраняет целый ряд ограничений, поэтому рекомендуется обновить кластер до BlueStore. Однако для полноты ниже мы приводим элементы, которые можно настраивать для повышения производительности файлового хранилища если ваш кластер всё ещё работает с ним.
Загруженность кэша VFS
Как и обязывает название, все объекты файлового хранилища занимаются хранением объектов RADOS в виде файлов в некоторой стандартной файловой системе Linux. В большинстве случаев это XFS. Поскольку каждый объект хранится как некий файл, на каждом диске будут вероятно сотни тысяч, если не миллионов файлов. Некий кластер Ceph состоит из 8 ТБ дисков и применяется для рабочих нагрузок RBD. Предположим, данные RBD состоят из стандартных 4 МБ объектов, тогда число объектов на диск может составлять примерно 2 миллиона.
Когда некоторое приложение запрашивает Linux прочесть или записать некий файл в файловой системе, следует знать имеется ли на диске этот файл. Чтобы определить такую локализацию, это потребует проследовать по всей структуре записей каталога и inodes. Каждый из таких поисков потребует доступа к диску если только всё это не кэшировано в оперативной памяти. Это может повлечь к ухудшению производительности в некоторых случаях если такие объекты, которые подлежат чтению или записи не получали доступа в течение какого- то времени и, следовательно, не кэшированы. Такие штрафы намного выше в кластерах шпиндельных дисков в сравнении с кластерами на основе SSD благодаря воздействию случайных чтений.
По умолчанию Linux предпочитает кэшировать данные в виде страниц кэша в противовес кэшированию inodes и записей каталогов. Во многих случаях в Ceph это в точности до наоборот тому, что в действительности желательно иметь на месте. К счастью, имеются регулируемые ядра, которые позволяют вам сообщать Linux о необходимости предпочесть inodes страничному кэшированию; это может управляться следующей установкой sysctl:
vm.vfs_cache_pressure
Если некоторое низкое значение устанавливает какое- то предпочтение для кэширования inodes и записей каталога, не устанавливайте его в ноль. Установка нуля сообщает своему ядру не сбрасывать старые записи даже в случае условий недостатка памяти и может иметь вредное воздействие. Рекомендуется значение 1.
WBThrottle и/или nr_requests
Файловое хранилище использует для записи буферизованные операции ввода/ вывода; это привносит целый ряд преимуществ если журнал файлового хранения находится на более быстром носителе. Запросы клиентов получают уведомления как только данные записаны в журнал, а затем сбрасываются на сам диск данных в более позднее время пользуясь стандартной функциональностью Linux. Это делает возможным для OSD шпиндельных дисков предоставлять латентность записи аналогичную SSD при записях малыми пакетами. Такая задержанная отложенная запись также позволяет самому ядру перестраивать запросы операций ввода/ вывода к диску с надеждой либо слить их воедино, либо позволить имеющимся головкам диска выбрать некий более оптимальный путь поверх своих пластин. Конечный эффект состоит в том, что вы можете выжать слегка больше операций ввода/ вывода из каждого диска чем это было бы возможно при прямых или синхронных операциях ввода/ вывода.
Однако, возникает определённая проблема если объём приходящих записей в данный кластер Ceph будут опережать все возможности лежащих в основе дисков. При таком сценарии общее число находящихся в рассмотрении операций ввода/ вывода в ожидании записи на диск могут неконтролируемо расти и иметь результатом очереди операций ввода/ вывода, заполняющую весь диск и очереди Ceph. Запросы на чтение воздействуют в особенности плохо, так как они застревают между запросами записи, которые могут требовать нескольких секунд для сброса на основной диск.
Для победы над этой проблемой Ceph имеет встроенный в файловое хранение механизм дросселирования отложенной записи (writeback) с названием WBThrottle. Он разработан для ограничения общего объёма операций ввода/ вывода отложенной записи, которые могут выстраиваться в очередь и начинать свой процесс сброса раньше чем чем это произошло бы естественным образом за счёт включения самим ядром. К сожалению, тестирование демонстрирует, что установленные по умолчанию значения всё ещё могут не урезать имеющееся поведение до уровня, который может уменьшать такое воздействие на латентность операций чтения. Регулировка может изменить это поведение и уменьшить общие длины очередей записи и сделать возможным не сильным такое воздействие. Однако имеется некий компромисс: уменьшая общее максимальное число разрешённых к постановке в очередь записей, вы можете снизить возможность самого ядра максимизировать свою эффективность упорядочения поступающих запросов. Стоит немного задуматься что вам более необходимо для вашего конкретного случая применения, рабочих нагрузок и регулировать под соответствие им.
Чтобы управлять глубиной такой очереди отложенной записи, вы можете либо уменьшать общее максимальное количество невыполненных операций ввода/ вывода, применяя установки WBThrottle, либо уменьшая максимальное значение для невыполненных операций на самом блочном уровне своего ядра. И то, и другое могут эффективно управлять одним и тем же поведением и именно ваши предпочтения будут в основе реализации данной настройки.
Также следует отметить, что имеющаяся в Ceph система приоритетов операций является более эффективной для более коротких запросов на дисковом уровне. При сокращении общей очереди к данному диску основное местоположение нахождения в очереди перемещается в Ceph, где он имеет большее управление над тем какой приоритет имеет операция ввода/ вывода. Рассмотрим следующий пример:
echo 8 > /sys/block/sda/queue/nr_requests
Начиная с выпуска ядра Linux 4.10 было введено новое свойство, которое устраняет приоритеты операций ввода/ вывода с отложенной записью; это существенно снижает нехватки записи для Ceph и стоит изучить возможен ли переход на ядро 4.10.
Дросселирование очереди файлового хранилища
При установленных по умолчанию настройках, по мере заполнения некоторого диска его очередь к диску начинает постепенно подсаживаться. Затем сама очередь файлового хранения также начинает проседать. Вплоть до этого момента операции ввода/ вывода всё ещё принимаются настолько быстро, насколько их способен принимать имеющийся журнал. Как только данная очередь файлового хранения просела, и/ или сам WBThrottle получил удар, операции ввода/ вывода будут внезапно остановлены пока данные очереди не откатятся ниже установленных пороговых значений. Такое поведение приводит к большому числу всплесков и, скорее всего, промежуткам с низкой производительностью при которых запросы прочих клиентов будут испытывать высокие задержки.
Чтобы снизить подобную зубчатость файлового хранилища при заполнении дисков имеются некоторые дополнительные параметры настроек, которые вы можете установить для постепенного обратного дросселирования операций по мере заполняемости очереди вместо ограничения его около жёсткого предела.
filestore_queue_low_threshhold
Выражается в виде процентного соотношения между 0.0
и 1.0. Ниже данного порогового значения не выполняется никакое
дросселирование.
filestore_queue_high_threshhold
Выражается в виде процентного соотношения между 0.0
и 1.0. Дросселирование выполняется между самым нижним и верхним
пороговыми значениями посредством введения некоторой задержки для каждой операции ввода/ вывода, причём
она линейно увеличивается от 0 до
filestore_queue_high_delay_multiple/filestore_expected_throughput_ops
А затем, начиная с максимального порогового значения до максимального дросселирование будет выполняться
со скоростью, определяемой
filestore_queue_max_delay_multiple/filestore_expected_throughput_ops.
Обе эти скорости дросселирования применяют именно те настройки, которые ожидаются быть вычисленными для всего
диска с целью введения правильной задержки. Имеющиеся переменные delay_multiple
присутствуют там чтобы сделать возможным увеличение этих задержек если очередь перейдёт через верхнее пороговое
значение.
filestore_expected_throughput_ops
Должно быть установлено в значение ожидаемой производительности IOPS для лежащих в основе исполняемого OSD дисков.
filestore_queue_high_delay_multiple
При нахождении между нижним и верхними порогами, данный множитель применяется для вычисления правильного количества вводимых задержек.
filestore_queue_max_delay_multiple
Выше определённого максимального размера очереди данный множитель используется для вычисления ещё большей задержки с надеждой прекращения переполнения данной очереди.
Расщепление PG
Некая файловая система имеет какой- то придел значения числа файлов, которое может храниться в одном каталоге прежде чем начнётся деградация производительности при запросе списка всего содержимого. Так как Ceph хранит на каждом диске миллионы объектов, который всего лишь являются файлами, он расщепляет все файлы между наследуемыми структурами каталогов для ограничения общего числа файлов, помещаемых в каждый из каталогов. По мере роста общего числа объектов в данном кластере то же самое происходит с общим числом файлов в каждом каталоге. Когда общее число файлов в этих каталогах превосходит данные пределы, Ceph расщепляет такой каталог на последующие подкаталоги и переносит все объекты в них. Такая операция может иметь значительные штрафы производительности при её возникновении. Более того, XFS пытается помещать свои файлы в одном и том же каталоге поближе друг к другу на данном диске. При возникновении расщепления групп размещения (PG) может происходить фрагментация данной файловой системы XFS, что приводит к последующей деградации производительности.
По умолчанию Ceph выполняет расщепление некоторой PG когда она содержит 320 объектов. Некий 8 ТБ диск в кластере Ceph настраивается исходя из рекомендованного числа PG на OSD, которое скорее всего будет иметь около 5000 объектов на группу размещения. Эта PG должна проходить через определённые операции расщепления в своём жизненном цикле, что имеет результатом более глубокую и сложную структуру каталогов.
Как уже упоминалось ранее в разделе интенсивного применения кэша VFS, чтобы избежать затратных ступенчатых поисков, само ядро пытается кэшировать её. Такой результат расщепления PG означает, что имеется большее число каталогов для кэширования и может не хватать оперативной памяти для кэширования всего, что есть в наличии, что приводит к более плохой производительности.
Некий общий подход к данной задаче состоит в увеличении допустимого числа файлов в каждом из каталогов путём установки параметров настройки следующим образом:
filestore_split_multiple
а также такой установки
filestore_merge_threshold
Согласно приводимой ниже формуле, вы можете установить при каком пороговом значении Ceph будет расщеплять некую PG:

Следует проявить осмотрительность. Хотя увеличение данного порогового значения уменьшит возникновения расщеплений PG и также снизит сложность имеющейся структуры каталогов, когда некоторое расщепление группы размещения всё же происходит, ему придётся разделять намного больше объектов. Чем больше общее число объектов, подлежащее расщеплению, тем большее воздействие мы имеем на производительность и можем даже получить выход OSD по тайм ауту. Именно это является неким компромиссом частоты расщеплений и времени расщепления; имеющиеся по умолчанию значения могут быть слегка в консервативной стороне, в особенности для дисков большого размера.
Удвоение или утроение имеющегося порога расщепления, скорее всего, может быть сделано безопасно без излишнего его изучения; большие значения следует проверять с имеющимся кластером под нагрузкой операций ввода/ вывода прежде чем размещать их в промышленной реализации.
Очистка (Scrabbing) является способом, которым Ceph проверяет, что все хранящиеся в RADOS объекты являются согласованными, а также для защиты от битовой деградации (bit rot) или прочей порчи. Очистка может быть обычной или глубокой в зависимости от установок расписания. При обычной очистке Ceph считывает все объекты для определённой группы размещения (PG) и сравнивает все копии, чтобы убедиться их размеры и атрибуты находятся в соответствии. Глубокая очистка продвигается на шаг глубже и сравнивает реальное содержимое данных всех объектов. Это создаёт намного больше операций ввода/ вывода чем простая процедура очистки. Обычная очистка выполняется ежедневно, в то время как глубокая очистка из- за дополнительной нагрузки ввода/ вывода делает попытку своего осуществления на еженедельной основе.
Несмотря на отсутствие приоритетности, очистка производит некоторое воздействие на операции ввода/ вывода клиента и, следовательно, присутствует масса настроек OSD, которые можно тонко подстраивать для направления Ceph тем, как ему следует осуществлять данную очистку.
Параметры настроек OSD osd _scrub_begin_hour и
osd _scrub_end_hour определяют то окно, когда Ceph попытается и
спланирует очистку. По умолчанию, это установки для разрешения проведения очистки на протяжении периода
в 24 часа. Если ваши нагрузки выполняются только днём, вы можете пожелать отрегулировать времена запуска
и окончания очистки, чтобы сообщить Ceph что вы желаете выполнять очистку только вне времён пиковых
нагрузок.
Следует отметить, что в момент осуществления некое окно соблюдается только если данная PG не вывалилась за пределы своего максимального интервала очистки. Если это случилось, тогда она продолжит очистку вне зависимости от установок временного окна. Максимальные значения и для обычной, и для глубокой очисток установлены в одну неделю.
Ceph имеет возможность выставлять приоритетность для определённых операций над остальными, имея в виду идею, что операции клиентского ввода/ вывода должны предшествовать всем опреациям восстановления, очистки и обрезки моментальный снимков. Днные приоритеты управляются приведёнными ниже параметрами настроек:
osd client op priority
osd recovery op priority
osd scrub priority
osd snap trim priority
Здесь чем выше само значение, тем выше его приоритет. Определённые по умолчанию значения работают достаточно успешно и не следует сильно требовать их изменения. Однако могут иметься некоторые преимущества в понижении имеющегося приоритета операций очистки и восстановления для ограничения их воздействия на основной объём операций ввода/ вывода клиента. Таким образом настройка длины самой очереди в предыдущем разделе может быть необходима для достижения максимума преимуществ.
Сетевая среда является центральным компонентом любого кластера Ceph, причём её производительность будет обычно влиять на общую производительность всего кластера. 10GbE следует рассматривать в качестве минимума, 1GbE сеть не предоставит требуемую латентность для какого бы то ни было высоко производительного кластера Ceph. Имеется целый ряд регулировок, которые могут помочь в улучшении общей производительности сетевой среды путём снижения задержек и повышения пропускной способности.
Самый первый момент, подлежащий рассмотрению это желаете ли вы применять кадры jumbo, используемые в MTU с длиной 9000 вместо 1500; причём все запросы операций ввода/ вывода смогут отправляться с применением меньших кадров Ethernet. Поскольку всякий кадр Ethernet имеет небольшие накладные расходы, увеличение максимума кадра Ethernet до 9000 может помочь. На практике выручка обычно менее 5% и подлежит взвешиванию в сопоставлении с неудобствами проверять что все устройства настроены верно.
Следующие установки параметров в вашем sysctl.conf рекомендуются
для максимизации сетевой производительности.
#Сетевые буферы
net.core.rmem_max = 56623104
net.core.wmem_max = 56623104
net.core.rmem_default = 56623104
net.core.wmem_default = 56623104
net.core.optmem_max = 40960
net.ipv4.tcp_rmem = 4096 87380 56623104
net.ipv4.tcp_wmem = 4096 65536 56623104
#Максимум соединений и незавершённых операций
net.core.somaxconn = 1024
net.core.netdev_max_backlog = 50000
#Опции регулировок TCP
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 10
#Не применяйте медленный старт на простаивающих соединениях TCP
net.ipv4.tcp_slow_start_after_idle = 0
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Если вы применяете для своего кластера Ceph ipv6, убедитесь что используете подходящие параметры ipv6 sysctl. |
|
| Замечание |
|---|---|
|
{Прим. пер.: Для максимального применения полосы пропускания сетевой среды можете воспользоваться RDMA, если это позволяют ваши сетевые интерфейсы, подробнее см. Приложение A: Ceph поверх RDMA из перевода первого издания.} |
Имеется целый ряд общих параметров системы, которые рекомендуется отрегулировать для лучшего
соответствия требованиям производительности Ceph. В ваш файл /etc/sysctl.conf
можно добавить приводимые ниже установки:
# Убедитесь что ваша система имеет достаточно свободной оперативной памяти на протяжении всего времени:
vm/min_free_kbytes = 524288
# Увеличьте установленный максимум для разрешённых процессов:
kernel.pid_max=4194303
# Максимальное число обработчиков файлов (file handles):
fs.file-max=26234859
Драйвер RBD ядра Linux позволяет вам напрямую устанавливать соответствие RBD Ceph в виде стандартных блочных устройств Linux и применять их тем же самым образом, что и все прочие устройства. Обычно соответствие RBD ядру требует минимальных настроек, однако в некоторых особых случаях может оказаться необходимой регулировка.
Прежде всего рекомендуется применять ядро, которое настолько новое, насколько это возможно, так как более новый ядра будут иметь лучшую поддержку RBD и, в определённых ситуациях, улучшать производительность.
Глубина очереди
Начиная с ядра 4.0, драйвер RBD применяет blk-mq, который
спроектирован чтобы предлагать лучшую производительность чем более ранние системы очередей. По умолчанию,
максимум невыполненных запросов в RBD возможен при использовании blk-mq
равного 128. Для большинства случаев этого более чем достаточно; однако, если ваши рабочие нагрузки
требуют использовать всю мощность некоторого большого кластера Ceph, тогда вы можете обнаружить, что наличие
всего 128 незавершённых запросов может быть недостаточным. Имеется некая опция, которая может быть
определена при установке соответствия ваших RBD для увеличения этого значения и может быть установлена
далее.
Упреждающее чтение
По умолчанию, RBD будет настроен с неким 128 кБ упреждающим чтением. Если ваша рабочая нагрузка в основном содержит большие последовательные чтения, тогда вы можете значительно ускоряться в производительности увеличивая данное значение упреждающего чтения. В ядрах вплоть до 4.4, имелось ограничение, при котором значения упреждающего чтения выше 2 МБ игнорировались. В большинстве систем хранения это не являлось некоторой проблемой, так как размеры чередований должны быть ниже 2 МБ. Поскольку упреждающее чтение больше чем данный размер чередования, все ваши диски будут вовлечены и производительность возрастёт.
По умолчанию некий RBD Ceph чередуется по объектам в 4 МБ и, следовательно, некий RBD может иметь какую- то порцию размеров в 4 МБ и размер чередования = 4 МБ * Число OSD во всём кластере. таким образом, при размере упреждающего чтения ниже 4 МБ, большую часть времени упреждающее чтение будет вносить очень незначительное улучшение в производительность и вы скорее всего обнаружите, что производительность чтения бьётся за превышение значения отдельного OSD.
В ядре 4.4 или выше вы можете установить необходимое значение упреждающего чтения намного выше и получить производительность чтения в сотнях МБ во втором диапазоне.
Существует два основных показателя определяющих производительность CephFS - скорость доступа к метаданным и скорость доступа к данным, хотя в большинстве случаем они оба вносят свой вклад в запросы доступа.
Важно понимать, что после того как в CephFS необходимые метаданные были получены для некоторого файла, чтение самих данных файла на самом деле не требуют никаких иных последующих операций с метаданными до тех пор пока этот файл не будет закрыт его клиентом. Аналогично, при записи файлов, метаданные обновляются только после того как изменённые данный сброшены определённым клиентом. Следовательно, для крупных, последовательных операций ввода/ вывода действия с метаданными скорее всего будут составлять всего лишь незначительную часть общего ввода/ вывода в кластере.
Аналогично, файловые системы CephFS, которые имеют дело с большим числом непрерывно открываемых и закрываемых множеством небольших файлов клиентов, операции с метаданными будут играть намного более значимую роль в определении общей производительности. Кроме того, метаданные применяются для сопровождения информации клиента относительно окружающей его файловой системы, например, предоставления перечней каталога.
Обработка производительности пула данных CephFS должна производиться аналогично с всеми прочими требованиями производительности Ceph в данной главе, поэтому относительно целей обсуждения данного раздела мы сосредоточимся на производительности метаданных.
Производительность метаданных определяется двумя факторами: значением скорости считывания/ записи метаданных через пул метаданных RADOS, а также значением скорости с которой MDS способны обрабатывать запросы клиента. Во- первых, давайте убедимся что наш пул метаданных расположен на устройстве хранения с флеш- памятью, так как это снизит латентность запросов к метаданным по крайней мере на порядок величины, если не более. Тем не менее, как это уже обсуждалось ранее в разделе Латентность данной главы, величина латентности, вносимая распределённой платформой сетевого хранения также может оказывать воздействие на производительность метаданных.
Для обработки некоторых видов таких задержек наши MDS имеют концепцию локального кэширования для обработки запросов к
горячим метаданным. По умолчанию, некий MDS резервирует 1 ГБ оперативной памяти для применения в качестве кэша, а говоря в
целом, чем больше оперативной памяти вы выделяете, тем лучше. Это резервирование контролируется значением переменной
mds_cache_memory_limit. Увеличивая общий объём памяти, который MDS способен
применять в качестве кэша, мы снижаем то число запросов, которое нам приходится выполнять к его пулу RADOS, а само местоположение
этой оперативной памяти будет снижать задержки доступа к метаданным.
Будет существовать некий момент, при котором добавление дополнительной оперативной памяти будет приносить очень незначительный вклад.Это может происходить либо по причине того, что достаточно велик размер имеющегося кэша, либо достигнуто то число запросов, которое способен обрабатывать данный MDS.
Относительно последующего момента, сам процесс MDS является однопоточным и следовательно всегда наступит некий случай, когда общее число запросов к метаданным вызывает то, что MDS потребляет 100% отдельного ядра ЦПУ и не поможет никакое дополнительное кэширование или SSD. Текущей рекомендацией будет попытаться исполнять ваш MDS с самой высокой из доступных частот ЦПУ. Для целей такого применения идеальным будет четырёхядерный Xeon E3, зчастую получающий близкие к 4 ГГц частоты при достаточно разумных стоимостях. По сравнению с некоторыми ЦПУ Xeon с более низкими частотами, часто имеющими гораздо большее число ядер, значение получаемой производительности почти удваивается при гарантии применения быстрых ЦПУ.
Если вы приобрели самые быстрые из доступных ЦПУ и выяснили что отдельный MDS всё ещё продолжает оставаться узким местом, самое последнее действие к которому вам стоит прибегнуть состоит в начале развёртывания множества активных MDS с тем, чтобы ваши запросы MDS разделялись по множеству MDS.
Когда применяется хранение в пулах RBD с удаляющим кодированием, для поддержания наилучшей производительности вам следует попытаться везде где это только возможно производить чередующиеся записи. Когда некий пул удаляющего кодирования выполняет полную запись с полным чередованием, сама эта операция может быть осуществлена отдельным вводом/ выводом и не потребует значительных штрафов, вызываемых циклом чтение- изменение- запись при частичных записях.
Сами клиенты RBD могут обладать некой интеллектуальностью когда они будут вызывать RADOS, и тем самым записывать команды целиком если они определяют что ввод/ вывод клиента верхнего уровня полностью переписывает объект. Убедитесь что та файловая систем, которая расположена поверх RBD, отформатирована с правильным выравниванием числа полос чередования для обеспечения того что вырабатывается настолько много полных записей, насколько это возможно.
Некий пример форматирования файловой системы XFS в каком- то RBD для пула EC 4 + 2 таков:
mkfs.xfs /dev/rbd0 -d su=1m,sw=4
Это выдаст указание XFS выравнивать выделения, кторые бы наилучшим образом подходили для кусочков 4 x 1 МБ, которые создают объект 4 МБ в неком пуле удаляющего кодирования 4 + 2.
Кроме того, в случае использования, который требует прямого монтирования RBD в неком сервере Linux вместо того чтобы
делать это через виртуальную машину QEMU/ KVM, будет также целесообразно рассмотреть возможность применения
rbd-nbd. Этот клиент RBD пространства пользователя применяет librbd, в то время как
клиент ядра RBD всецело полагается на представленный в запущенном ядре код.
Это означает не только то, что вы можете воспользоваться самыми последними свойствами, которые могут быть не представлены в исполняемом ядре, но также имеет дополнительную функциональность кэширования с отложенной записью. Такое кэширование с отложенной записью намного лучше осуществляет задания соединения записей в объект полного размера нежели это способен выполнять клиент ядра и тем самым повлечёт меньшие накладные расходы производительности. Держите на уме, что предоставляемое в librbd кэширование с отложенной записью не является удерживаемым, а тем самым, никакие синхронизирующие записи не дадут никаких преимуществ.
Хотя в строгом смысле и не относится к опции регулировки производительности, обеспечение ровного распределения PG по всему вашему кластеру является существенной задачей, которую подлежит выполнить в процессе самой ранней стадии развёртывания вашего кластера. Поскольку Ceph применяет CRUSH для псевдо- случайного определения местоположения данных, он не всегда будет сбалансирует группы размещения (PG) по всем OSD. Некий кластер несбалансированный кластер Ceph будет не в состоянии получить все преимущества имеющейся сырой ёмкости, так как большая часть обладающих чрезмерной подпиской OSD на самом деле станут пределом для общей ёмкости.
Неравномерно сбалансированный кластер будет означать, что некоторое большее число запросов будет иметь целью те OSD, которые содержат большее число групп размещения. Эти OSD затем поместят неестественную заоблачную производительность на данный кластер, в особенности, если данный кластер состоит из OSD на шпиндельных дисках.
Для повторной балансировки PG по некоторому кластеру Ceph вы просто должны поменять веса всех OSD с тем, чтобы CRUSH выровнял сколько в нём должно храниться PG. Важно отметить, что по умолчанию, вес всякого OSD равен 1, причём вы не можете изменить вес недозагруженного OSD выше 1 чтобы увеличить его использование. Единственный вариант состоит в снижении значений веса для перегруженных OSD, что должно переместить PG на менее используемые OSD.
Также важно понимать, что существует разница между самим весом CRUSH некоторого OSD и данным значением повторного взвешивания (reweight value). Данное значение повторного взвешивания применяется в качестве переопределения для исправления неверного применения алгоритма CRUSH. Команда reweight влияет только на данное OSD и не оказывает воздействия на веса во всей пачке (например, в хосте), в которой оно участвует. Оно также сбрасывается в значение 1.0 при перезапуске данного OSD. Хотя это и может мешать, важно понимать что все последующие изменения свойств в имеющемся кластере состоящие в увеличении общего числа PG или добавлении дополнительных OSD, скорее всего сделают любое значение повторного взвешивания неверным. Таким образом, повторное взвешивание OSD не должно рассматриваться как некая одноразовая операция, а её следует иметь в виду как нечто что постоянно выполняется и будет выравнивать все изменения в вашем кластере.
Чтобы повторно взвесить некоторое OSD просто воспользуйтесь следующей командой:
Ceph osd reweight <osd number> <weight value 0.0-1.0>
После её исполнения Ceph начнёт засыпку для перемещения PG на свои вновь назначенные OSD.
Конечно, поиск по всем вашим OSD и попытка определить те OSD, которые нуждаются во взвешивании, а затем исполнение данной команды для каждого из них были бы слишком длительным процессом. К счастью, имеется другой инструмент Ceph, который может автоматизировать большую часть данного процесса:
ceph osd reweight-by-utilisation <threshold> <max change> <number of OSDs>
Эта команда сравнит все имеющиеся в вашем кластере OSD и изменит веса повторных взвешиваний всех верхних
N OSD, где N
управляется самым последним параметром, и который является превышением имеющегося порогового значения. Вы
также можете ограничить предел общего максимума изменений, применяемых к каждому OSD определив второй параметр:
0.05 или 5%
обычно является неким рекомендуемым числом.
Также имеется команда test-reweight-by-utilization, которая позволит
вам увидеть как будет выглядеть исполнение команды до её реального выполнения.
Хотя эти команды безопасны для применения, имеется ряд моментов, которые необходимо учитывать перед их исполнением:
-
Она не имеет понятия о различных пулах в различных OSD. Если, скажем для примера, у вас есть некий уровень SSD и некий уровень HDD, ваша команда
reweight-by-utilizationвсё ещё будет пытаться и сбалансирует данные по всем OSD. Если ваш уровень SSD не настолько заполнен как уровень HDD, данная команда не будет работать как ожидалось. Если вы желаете выполнить балансировку OSD, ограниченных некоторой отдельной пачкой, рассмотрите версию сценария с данной командой, созданной в Cern. -
Имеется возможность повторно взвесить весь кластера до такой степени, что CRUSH будет не в состоянии определить размещение для некоторых PG. Если останавливается восстановление и одна или более PG остаются в переназначенном состоянии, тогда скорее всего именно это и произошло. Просто увеличьте или сбросьте все значения повторного взвешивания чтобы исправить это.
Раз вы ознакомились с применением данной команды, имеется возможность вставить её в расписание через
cron с тем, чтобы ваш кластер оставался в более сбалансированном
состоянии автоматически.
Начиная с выпуска Luminous был добавлен некий новый модуль под названием балансировщика Ceph. Этот новый модуль постоянно работает в фоновом режиме для оптимизации распределения PG и обеспечения того что в вашем кластере Ceph доступна максимальная ёмкость.
Модуль балансировщика Ceph может применять два метода балансировки распределения данных. Первый является crush-compat; этот метод применяет некое поле дополнительного веса для выравнивания весов всех OSD. Основным преимуществом метода crush-compat является обратная совместимость с более ранними клиентами. Другой метод имеет название upmap; upmap может достигать намного более гранулированного соответствия PG чем это возможно при crush-compat, так как он применяет новые возможности в имеющейся карте OSD для оказание воздейтсвия на установление соответствия PG. Обратной стороной, вытекающей из этих новых возможностей, является то что клиенты Ceph должны исполнять выпуск Luminous или новее.
Для включения балансировщика Ceph просто исполните две следующие команды:
ceph mgr module enable balancer
ceph balancer on
Вы обнаружите, что Ceph запустит заполнение (backfill), так как PG выполнят переназначение на новые OSD для балансировки использования имеющегося пространства; это будет продолжаться до тех пор, пока этот балансировщик Ceph не снизит имеющиеся расхождения загруженности OSD.
Теперь вы должны иметь обширные знания того, как регулировать некий кластер Ceph для максимизации производительности и достижения более низкой латентности. Применяя эталонное тестирование вы должны теперь иметь возможность выполнять тестирования до и после чтобы подтверждать, что те вещи, которые вы совершили, достигли желаемого результата. Не вредно также просмотреть всю официальную документацию Ceph чтобы получить лучшее представление о некоторых прочих параметрах настройки, которые могут дать преимущества вашему кластеру.
Вы также изучили некоторые из тех ключевых сторон, которые воздействуют на производительность Ceph и того как её регулировать, например, частоту и состояния сна ЦПУ. Обеспечение того что ваша инфраструктура кластера Ceph работает с показателями своей максимальной производительности гарантирует что вы сможете работать с ним наилучшим образом.
В своей следующей главе мы обсудим множество уровней и то как это можно применять для повышения производительности соединяя воедино различные технологии дисков.
-
Является ли распределение PG по умолчанию единообразным?
-
Почему полное чередование записи в неком пуле удаляющего кодирования является предпочтительным?
-
Для более низких значений задержек какой тип ЦПУ является более предпочтительным?
-
Какие три фактора в наибольшей степени оказывают воздействие на задержки?
-
Какой инструмент автоматизации может применяться для балансировки используемого пространства в вашем кластере?