Глава 7. Мониторинг Ceph
{Прим. пер.: рекомендуем сразу обращаться к нашему переводу 2 издания вышедшего в феврале 2019 Полного руководства Ceph Ника Фиска}
Содержание
- Глава 7. Мониторинг Ceph
- В чём заключается важность мониторинга Ceph
- Что подлежит мониторингу
- Состояния PG - хорошо, плохо и опасно
- Мониторинг Ceph при помощи collectd
- Выводы
Когда вы работаете с неким кластером Ceph важно отслеживать его жизнеспособность и производительность. Выполняя наблюдение за Ceph вы можете быть уверенным, что ваш кластер исполняется полностью жизнеспособным и к тому же иметь возможность быстро реагировать на любые проблемы, которые могут возникать. Перехватывая и строя графики счётчиков производительности вы также будете иметь все данные, требующиеся для регулировки Ceph и наблюдения за за воздействием ваших регулировок на данный кластер.
В данной главе мы изучим следующие темы:
-
Почему важно выполнять мониторинг Ceph
-
Как отслеживать жизнеспособность Ceph
-
За чем следует наблюдать
-
Все состояния PG и что они означают
-
Как осуществлять перехват и счётчики производительности Ceph посредством collectd
-
Пример диаграмм с применением Graphite
Наиболее важная причина для наблюдения за Ceph состоит в получении гарантий того, что данный кластер работает в некотором жизнеспособном состоянии. Если Ceph не работает в жизнеспособном состоянии, что может быть вызвано неким отказом диска или по какой- либо ещё причине, ваши шансы утраты обслуживания или потери данных возрастают. Хотя Ceph высоко автоматизирован в отношении восстановления при различных ситуациях, существенно быть осведомлённым о том что происходит и когда требуется ручное вмешательство.
Мониторинг не просто заключается в определении отказов, наблюдение за прочими измерениями, такими как используемое дисковое пространство в точности так же существенно, как знание о том когда отказал диск. Если ваш кластер Ceph заполнится, он прекратит приём запросов на операции ввода/ вывода и не будет способен производить восстановление после отказов OSD в дальнейшем.
Наконец, мониторинг и всех операционных систем, и замеров производительности Ceph может помочь вам высвечивать проблемы производительности или определять возможности регулировок.
Простым ответом будет всё, либо столько, сколько вы можете. Вы никогда не можете предсказать какой сценарий может быть навязан вам и вашему кластеру и наличие правильного мониторинга и системы предупреждений на своём месте могут означать разницу между постепенной обработкой ситуации или наличием полномасштабного отключения. Некий перечень подлежащих мониторингу моментов в порядке убывания важности таковых.
Наиболее важная вещь для захвата является состоянием жизнеспособности Ceph. Основные сообщаемые элементы
состоят в повсеместных состояниях жизнеспособности данного кластера, будь то
Health_OK, Health_Warning или
Health_Critical. Наблюдая за этими состояниями, вы получаете уведомления
в любой момент времени когда Ceph сам по себе понимает что что-то идёт не так. Кроме того, вы также можете
пожелать захватывать все состояния имеющихся групп размещения и число деградировавших объектов, они могут
предоставить дополнительную информацию с тем, чтобы вы начали беспокоиться без необходимости реальной
регистрации в сервере Ceph и применять имеющийся набор инструментов Ceph для проверки текущего состояния.
Также настоятельно рекомендуется чтобы вы захватывали текущее состояние исполняющей программное обеспечение Ceph операционной системы а также состояние всего обеспечивающего их работу аппаратных средств. Перехват таких вещей как использование ЦПУ и оперативной памяти оповестит вас о возможном истощении ресурсов прежде чем это станет потенциально критичным. Кроме того, долговременные тенденции этих данных могут помочь вам планировать выбор аппаратных средств для Ceph. Также настоятельно рекомендуется наблюдение за перехватом отказов оборудования, такого как диски, источники питания и вентиляторы. Большая часть серверного оборудования избыточна и может быть не очевидно без наблюдения, что оно работает в деградировавшем состоянии. Кроме того, наблюдение за сетевыми соединениями с тем, чтобы быть уверенным что оба NIC доступные в связанной конфигурации работают, тоже является хорошей идеей.
Также неплохой мыслью является тестирование жизнеспособности всех дисков с применением комплектов инструментов интеллектуального (smart) наблюдения. Они могут помочь выявлению отказавших дисков или тех, которые работают с необычно высоким уровнем ошибок. Для SSD вы также можете измерять их скорость износа элементов флеш -памяти, что является хорошей индикацией того что данный SSD скорее всего откажет. Наконец, наличие возможности улавливания температуры всех дисков позволит вам быть уверенным, что ваши серверы не перегреваются.
Поскольку Ceph полагает, что та сетевая среда, поверх которой он работает, будет надёжной, может давать преимущества наблюдение за сетевыми устройствами на предмет ошибок и проблем с производительностью. Большая часть сетевых устройств может опрашиваться через SNMP для получения таких данных. Кроме того, применение кадров jumbo, вы можете подумать над тем, чтобы создать некий автоматизированный мониторинг ping для непрерывной проверки того, что кадры jumbo работают правильно в вашей сетевой среде. Вы никогда не знаете когда неожиданные изменения могут повлиять на способность вашей сетевой среды обмениваться пакетами jumbo, что приводит к путанице, поскольку вам кластер Ceph может внезапно оказаться поставленным в тупик.
осуществляя наблюдение за счётчиками производительности как самой операционной системы, так и Ceph, вы вооружаете себя богатством знаний, дающих лучшее понимание того, как ваш кластер Ceph работает. Если позволяет хранилище, будет лучше улавливать столько измерений сколько возможно; вы никогда не знаете какие из получаемых измерений окажутся полезными. Достаточно часто бывает так, что измерение, которое ранее считалось не связанным с данной проблемой внезапно проливает свет на реальную причину. В этом отношении обычный подход наблюдения только за ключевыми измерениями является очень ограничивающим.
Большинство агентов наблюдения, которые работают под Linux позволят вам улавливать большие массивы замеров от потребляемых ресурсов в используемую файловую систему. Стоит потратить время на то, чтобы проанализировать какие метрики вы можете собирать и настроить это надлежащим образом. некоторые из таких агентов наблюдения также имеют встраиваемые модули (plugins) для Ceph, которые могут вытаскивать счётчики производительности из различных компонентов Ceph, таких как узлы OSD и MON.
Каждая группа размещения в Ceph имеет одно или более состояний назначаемых ей; обычно вы хотите видеть все свои PG
с выставленным в них active+clean. Понимание того что означает каждое
состояние может помочь нам определить что происходит с PG и нужно ли вам предпринимать действие.
Все следующие состояния отображают некую жизнеспособную работу кластера, нет необходимости предпринимать какие- либо действия.
Активное состояние
Состояние active означает, что группа размещения полностью
жизнеспособна и имеет возможность принимать запросы клиентов.
Чистое состояние
Состояние clean означает, что объекты PG реплицируют правильное
число раз и все в согласованном состоянии.
Очистка и глубокая чистка
Очистка (scrubbing) означает, что Ceph проверяет согласованность ваших данных и это обычный фоновый процесс. Очистка сама по себе это именно то, где Ceph проверяет что все объекты и соответствующие метаданные присутствуют. Когда Ceph выполняет глубокую промывку, он сравнивает само содержимое объектов и их реплик на согласованность.
Все следующие состояния отображают, что Ceph не полностью жизнеспособен, однако это не должно немедленно приводить к каким- либо проблемам.
Несогласованное состояние
Данное состояние inconsistent означает, что в процессе очистки
Ceph обнаружил один или более объектов, которые не согласуются со своими репликами. Ознакомьтесь с разделом поиска
неисправностей далее в этой книге по поводу того как обрабатывать эти ошибки.
{Прим. пер.: также см. Проверка Групп размещения (PG) Ceph на непротиворечивость в фоновом режиме и способы
восстановления данных.}
Состояния заполнения, ожидания заполнения, восстановления, ожидания восстановления
Все эти состояния (backfilling,
backfill_wait, recovering и
recovery_wait states) означают, что Ceph выполняет копирование или
миграцию данных с одного OSD на другой. Это может возможно означать, что данная PG имеет число копии менее
желаемого числа. Если оно находится ещё и в состоянии ожидания, то это объясняется дросселированием на каждом
OSD, Ceph ограничивает общее число одновременных операций для снижения воздействия на операции клиентов.
Состояние деградации
Состояние degraded означает, что PG отсутствует или имеет устаревшие
копии одного или более объектов. Это обычно будет исправлено определённым процессом восстановления/
заполнения (recovery/backfill).
Пересоставление карты
Для того чтобы перейти в активное состояние, PG в настоящее время соответствует неким различным OSD или наборам OSD. Это скорее всего произойдёт когда OSD остановлен (down), но ещё пока не был восстановлен в оставшиеся имеющиеся OSD.
Данное состояние (ugly) не является одним из тех, которые вы желаете обнаружить. Если вы увидите одно из перечисленных ниже состояний, оно скорее всего будет означать, что доступ клиента к кластеру нарушен и пока данная ситуация не будет разрешена, может случиться утрата данных.
Незавершённое состояние
Состояние incomplete означает, что Ceph не способен обнаружить какую бы
то ни было имеющую силу копию объекта внутри PG по всем OSD которые в настоящее время работают (up) в данном
кластере. Это может быть той по причине, что данного объекта просто нет там, или все доступные объекты пропущены
более новыми записями, которые могли выполниться на недоступные в настоящее время OSD.
Состояние останова
Аналогично incomplete, в состоянии
down для данной PG может не хватать объектов, которые, как известно,
могут располагаться на недоступных OSD.
Состояние чрезмерной заполненности
backfill_toofull - Ceph пытается восстановить ваши данные, однако
ваши диски OSD слишком заполнены и не могут продолжать заполнение. Для исправления данной ситуации
требуются дополнительные OSD.
Ранее в данной главе мы обсудили, что по всей вашей инфраструктуре Ceph должен осуществляться мониторинг. Хотя мониторинг с выдачей предупреждений выходит за рамки данной книги, мы сейчас рассмотрим улавливание всех замеров производительности Ceph при помощи colletd, сохранения их в Graphite, а затем в конце концов создадим некую инструментальную панель с диаграммами при помощи Grafana. Такие перехваченные измерения могут затем применяться в последующих главах чтобы помочь с регулировкой вашего кластера Ceph.
Мы построим такую инфраструктуру мониторинга на одном из ваших узлов монитора в нашем тестовом кластере. В некотором промышленном кластере настоятельно рекомендуется чтобы вы выделили под это свой собственный сервер. {Прим. пер.: рекомендуем также консолидацию, например, с Zabbix.}
Graphite является базой данных временных последовательностей, которая исключительна для хранения больших количеств измерений и имеет зрелый язык запросов, который можно применять в приложениях для манипуляций с рассматриваемыми данными.
Вначале нам необходимо установить все необходимые пакеты Graphite:
sudo apt-get install graphite-api graphite-carbon graphite-web
Предыдущая команда предоставит вам следующий вывод:
Измените файл схемы хранения /etc/graphite/storage-schemas.conf и
поместите в него следующее:
[carbon]
pattern = ^carbon\.
retentions = 60:90d
[default_1min_for_1day]
pattern = .*
retentions = 60s:1d
И теперь мы можем создать необходимую базу данных Graphite следующей командой:
sudo graphite-manage syncdb
Предыдущая команда предоставит вам следующий вывод:

Установите пароль для своего пользователя root, когда он будет запрошен:
sudo apt-get install apache2 libapache2-mod-wsgi
Предыдущая команда предоставит вам следующий вывод:
Чтобы прекратить конфликт установленного по умолчанию сайта apache с имеющейся в Graphite веб службой, нам необходимо запретить его, выполнив приводимую ниже команду:
sudo a2dissite 000-default
Предыдущая команда предоставит вам следующий вывод:

Теперь мы можем скопировать настройки apache graphite в имеющееся окружение apache:
sudo cp /usr/share/graphite-web/apache2-graphite.conf /etc/apache2/sites-available
sudo a2ensite apache2-graphite
Предыдущая команда предоставит вам следующий вывод:

Перезапустите данную службу apache:
sudo service apache2 reload
Мы изменим файл репозитория apt и добавим в него репозиторий для Graphana:
sudo nano /etc/apt/sources.list.d/grafana.list
Поместите в данный файл следующую строку и сохраните его:
deb https://packagecloud.io/grafana/stable/debian/ jessie main
Теперь выполните приведённую ниже команду для получения необходимого ключа
gpg и обновления всего списка пакетов:
curl https://packagecloud.io/gpg.key | sudo apt-key add –sudo apt-get update
Установите grafana при помощи такой команды:
sudo apt-get install grafana
Предыдущая команда предоставит вам следующий вывод:
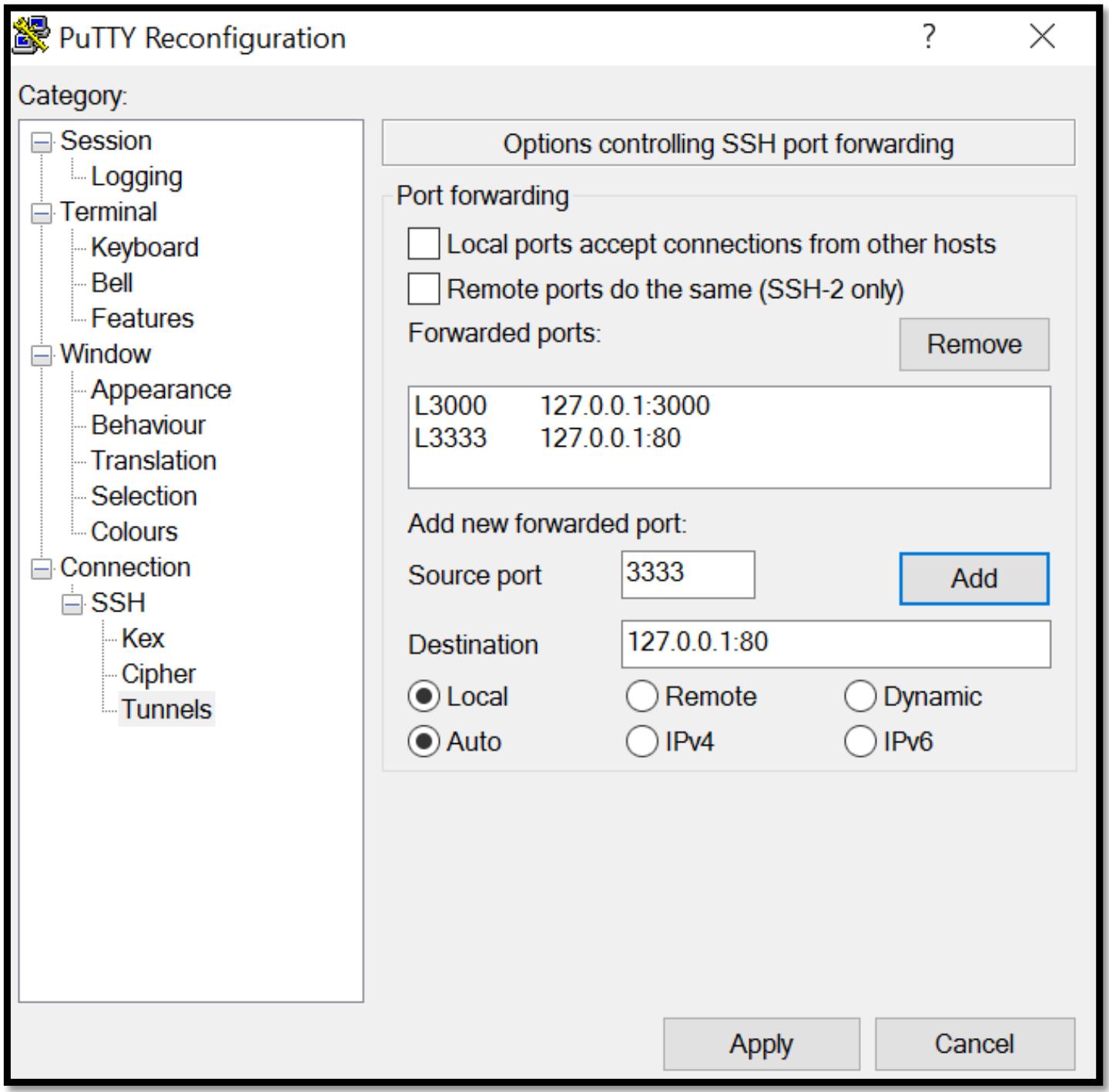
При помощи стандартной настройки Vagrant вы не будете в состоянии соединиться с данным портом HTTP,
предоставляемым Grafana. Для получения доступа к Grafana нам понадобится пробросить порт посредством
ssh port 3000 в нашу локальную машину.
Некий пример с использованием PuTTY показан на приведённом ниже снимке экрана:
Теперь воспользуйтесь http://localhost:3000 в строке URL, и вы
должны попасть на домашнюю страницу Grafana. Переместитесь к источнику данных и затем позвольте настроить
Grafana для опроса только что установленной сборки Graphite:
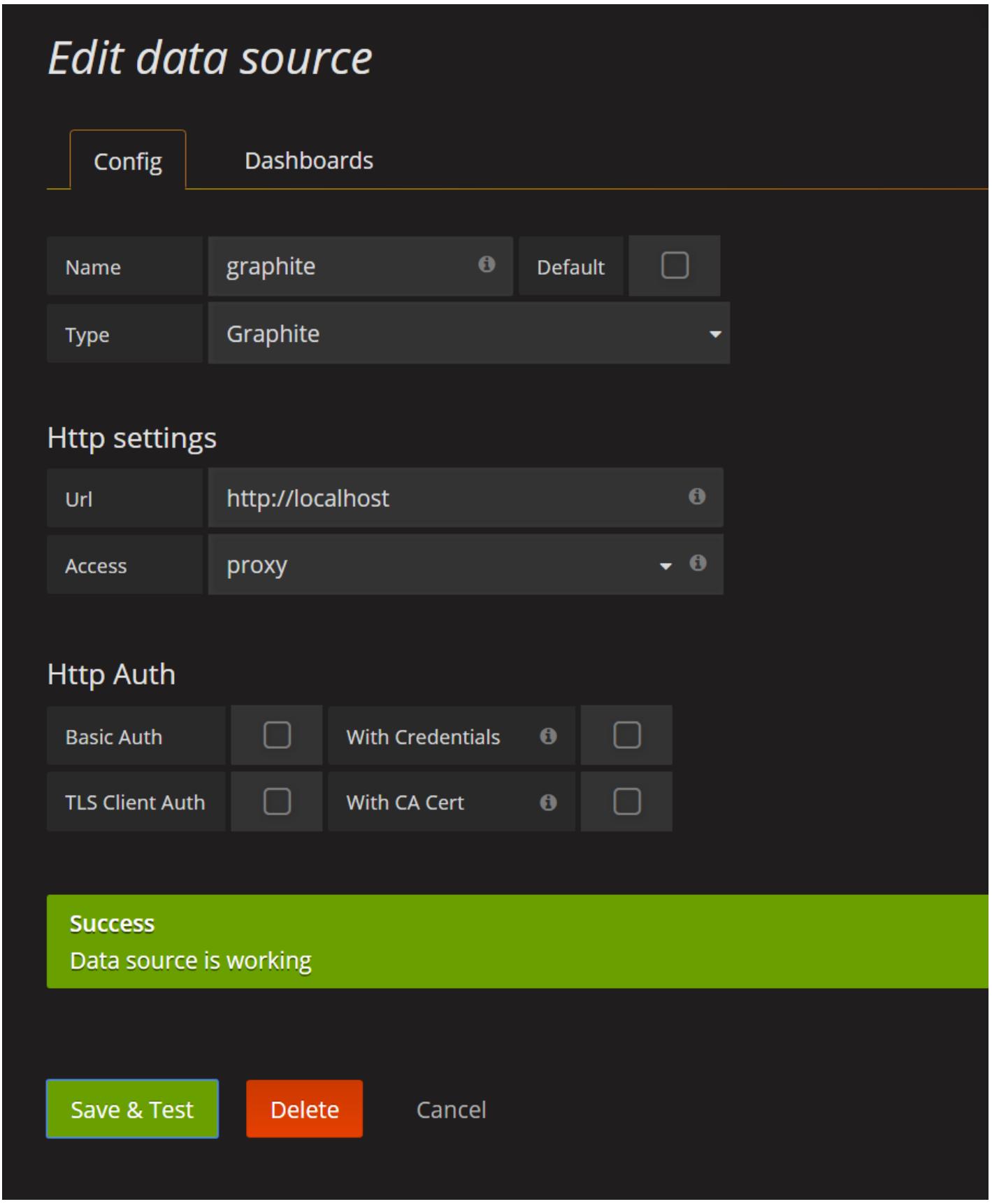
Если вы получили зелёный прямоугольник успеха когда вы кликнули по кнопке Save & Test, значит вы успешно установили и настроили Graphite и Grafana.
Теперь, когда у нас есть блестящая установка Graphite и Grafana для просмотра, нам требуется поместить некие данные чтобы иметь возможность выработать некие диаграммы. collectd является хорошо оформленным набором инструментов, который способен выводить измерения в Graphite. Само ядро приложения collectd чрезвычайно минимальное и оно рассчитывает на последовательности подключаемых модулей для сбора измерений и пересылку их для хранения в приложения подобные Graphite.
Прежде чем мы приступим к сбору измерений со своих узлов Ceph, давайте установим collectd в той же самой ВМ, в которой мы установили Graphite и Grafana. Мы сделаем это чтобы лучше понимать collectd и сам процесс, требующийся для его настройки. Затем мы применим Ansible для установки и настройки collectd во всех узлах Ceph, что и составляет рекомендуемый подход если это раскручивается в некой промышленной среде. Мы исполняем такой код:
sudo apt-get install collectd-core
Предыдущая команда предоставит вам следующий вывод:
Это установит collectd и основной набор встраиваемых модулей для запроса стандартных ресурсов операционной системы. В приведённом ниже местоположении имеется некий пример сохранённых настроек:
/usr/share/doc/collectd-core/examples/collectd.conf
Он перечисляет все основные подключаемые модули и примеры вариантов настроек. Неплохо просмотреть этот файл чтобы изучить различные встраиваемые модули и их параметры настроек. Для данного примера, однако, мы начнём с некоторого пустого файла настроек и установим некоторые основные ресурсы:
-
Создайте некий новый файл настроек
collectdпри помощи следующей команды:sudo nano /etc/collectd/collectd.conf -
Добавьте в него это:
Hostname "ansible" LoadPlugin cpu LoadPlugin df LoadPlugin load LoadPlugin memory LoadPlugin write_graphite <Plugin write_graphite> <Node "graphing"> Host "localhost" Port "2003" Protocol "tcp" LogSendErrors true Prefix "collectd." StoreRates true AlwaysAppendDS false EscapeCharacter "_" </Node> </Plugin> <Plugin "df"> FSType "ext4" </Plugin> -
Перезапустите службу
collectdпри помощи приведённой далее команды:udo service collectd restart -
Теперь переместитесь обратно в Grafana и просмотрите все элементы меню его инструментальной панели. Кликните по кнопке в средней части для создания некоторой новой инструментальной панели:
-
Выберите Graph для добавления новой диаграммы в данной инструментальной панели. Появится некий пример новой диаграммы, который мы захотим изменить заменив одной из своих собственных диаграмм. Для этого кликните по заголовку этой диаграммы и появится всплывающее меню:
-
Кликните по
Editчтобы пройти в экран редактирования ваших приспособлений (widget) диаграмм. Здесь мы можем удалить поддельные изображённые данные выбрав иконку dustbin (мусорного ведра), как это показано в следующем блоке с тремя иконками:
-
Теперь в ниспадающем меню измените источник данных данной панели на тот источник graphite, который мы недавно добавили и кликните по кнопке
Add query.
-
Появится блок запроса поверх изменяемой панели, он также имеет блок меню с тремя кнопками, как и появлявшийся ранее. Здесь мы можем переключиться в режим изменения данного редактира запроса кликнув по кнопке с тремя горизонтальными линиями:
Опция
Toggle Edit Modeпереключает данный редактор запроса между режимом клика и выбора, в котором вы можете изучить все доступные измерения и построить базовый запрос, а также режим текстового редактора. Режимы клика и выбора полезны если вы не знаете названий измерений и хотите создавать только базовые запросы. Для более сложных запросов требуется текстовый редактор.Вначале мы сделаем некий запрос для своей диаграммы при помощи режима основного редактора, а затем переключимся в текстовый режим для оставшейся части данной главы, чтобы вам было проще копировать все запросы из данной книги.

Вначале давайте изобразим свою загрузку той системы ВМ, в которой мы установили collectd:

Она теперь предоставляет некую полученную ранее диаграмму, отображаемую при загрузке системы.
Кликнув далее по символу +,
вы можете расширить свой запрос с применением различных функций к имеющимся данным. Это можно применять для
совместного добавления множества источников данных, либо для нахождения среднего значения. Мы изучим это далее
в данной главе, когда мы начнём мастерить некие запросы для анализа производительности Ceph. Прежде чем мы
продолжим, давайте теперь переключим редактор запроса в текстовый режим чтобы увидеть как выглядит данный
запрос:

Вы можете видеть, что каждый лист данного дерева измерений отделяется точкой. Именно так работает язык запросов Graphite.
Теперь, когда мы получили подтверждение, что наш стек наблюдения установлен и работает правильно, давайте применим Ansible для развёртывания collectd на все наши узлы Ceph с тем, чтобы мы могли наблюдать за ними.
Переключимся на каталог ansible:
cd /etc/ansible/roles
git clone https://github.com/fiskn/Stouts.collectd
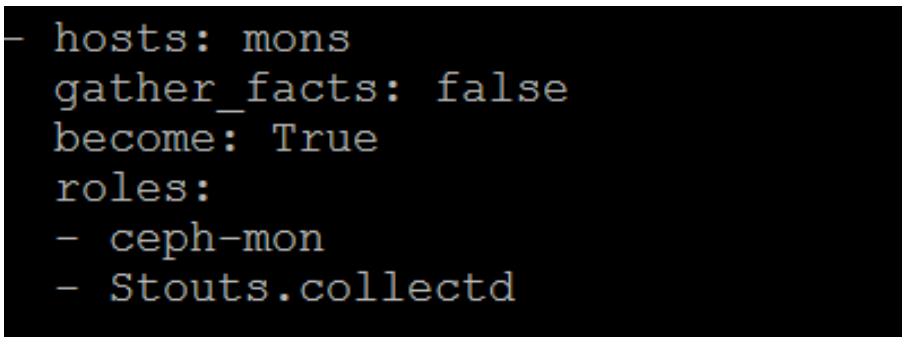
Измените свой файл Ansible site.yml и добавьте роль
colectd в планы для ваших mon
и osd так, чтобы они выглядели следующим образом:
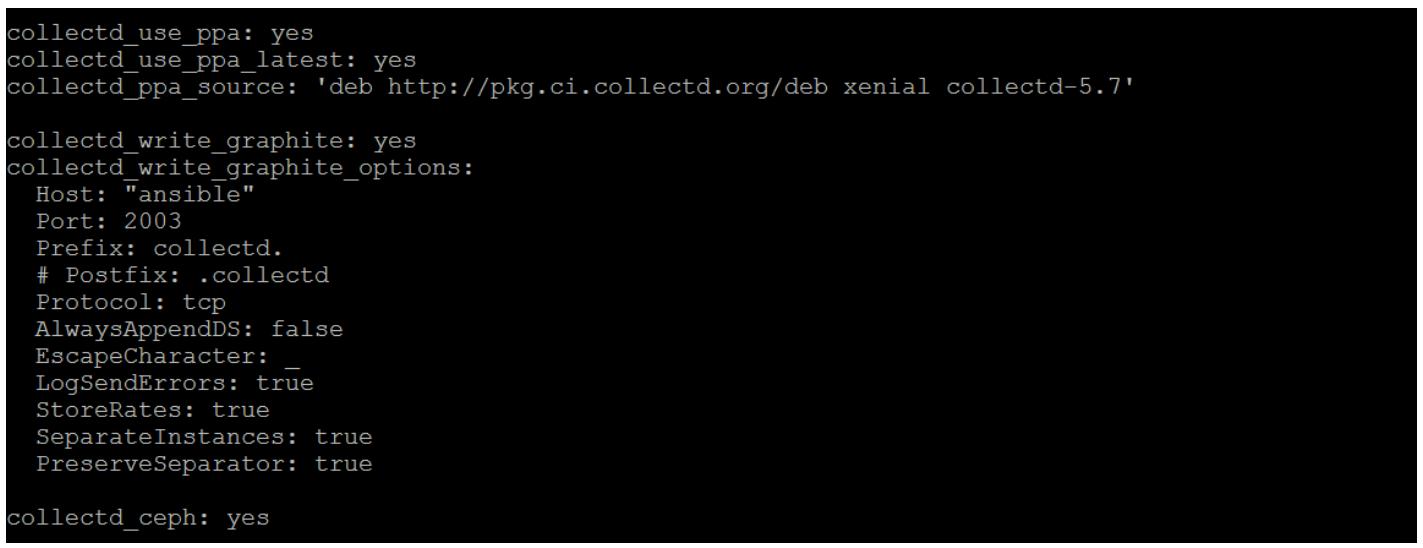
Измените group_vars/all с тем, чтобы внести следующее:
Теперь исполните план site.yml:
ansible-playbook -K site.yml
Предыдущая команда предоставит вам следующий вывод:
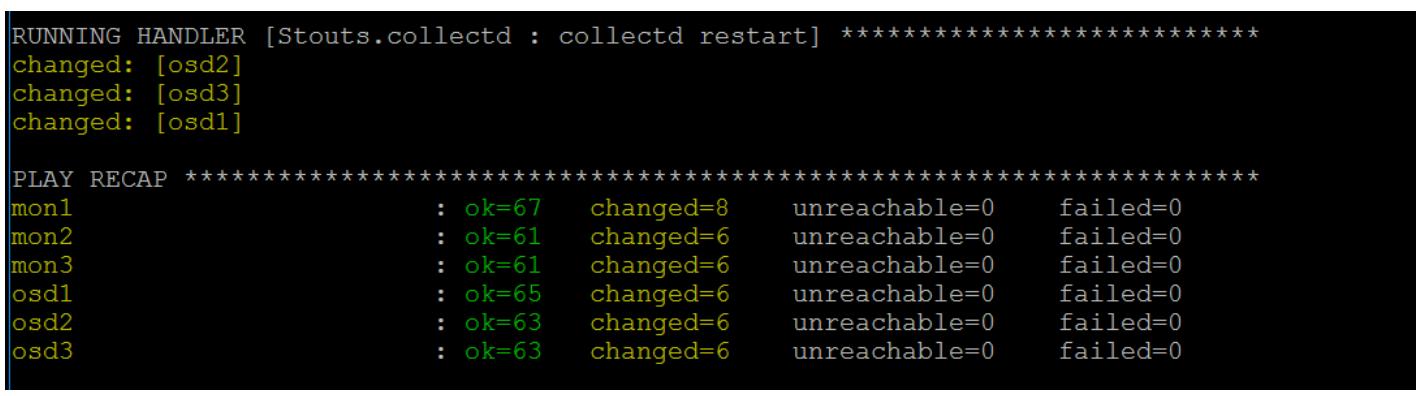
Вы должны увидеть в строке состояния в самом конце, что Ansible равернул collectd
на всех ваших узлах Ceph и имеет настроенными встроенные модули Ceph collectd.
В Grafana вы теперь должны иметь возможность видеть свои узлы Ceph отображаемыми как доступные измерения (metrics).
Ниже приводится один из наших узлов монитора:
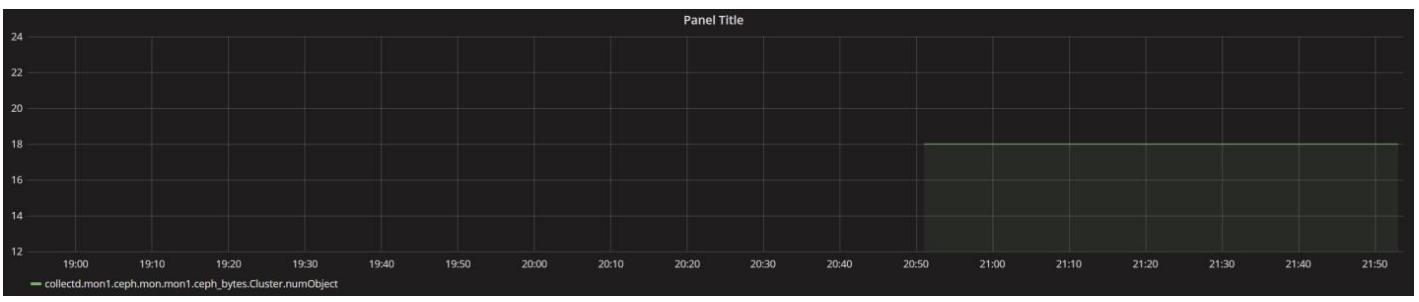
Например, мы теперь можем создать некую диаграмму, отображающую общее число хранимых в нашем кластере Ceph объектов. Создайте некую новую диаграмму в Grafana и введите следующий запрос:
collectd.mon1.ceph.mon.mon1.ceph_bytes.Cluster.numObject
Это представит диаграмму, подобную следующей:
Вам предлагается потратить некоторое время на просмотр всех доступным измерений чтобы вы были знакомы с ними, прежде чем перейдёте к следующему разделу.
Хотя вы можете создавать некоторые очень полезные диаграммы простым выбором персональных показателей, благодаря объединённой совместной мощности функций Graphite по обращению с этими измерениями можно создавать диаграммы, которые предложат намного больше подробностей внутри вашего кластера Ceph. Последующие запросы Graphite полезны для создания общих диаграмм, а также хорошая отправная точка для создания ваших собственных персональных запросов.
Число OSD Up и In
Очень удобно иметь возможность быстро окидывать взглядом некую инструментальную панель и видеть сколько OSD
являются Up и In. Два следующих
запроса показывают эти значения:
maxSeries(collectd.mon*.ceph.mon.mon*.ceph_bytes.Cluster.numOsdIn)
maxSeries(collectd.mon*.ceph.mon.mon*.ceph_bytes.Cluster.numOsdUp)
Отметим применение функции maxSeries, которая позволяет вытаскивать
данные из ваших узлов mon и выдавать самые высокие значения.
Отображение наиболее отклоняющихся от нормы OSD
Благодаря тому способу, которым CRUSH помещает PG в каждом OSD, никогда не будет иметься исключительного баланса PG из расчёта на OSD. Следующий запрос создаст диаграмму, которая отобразит 10 самых отклонившихся OSD с тем, чтобы вы могли видеть их, если сбалансированность была бы предпочтительной. У нас имеется следующий код:
mostDeviant(10,collectd.osd*.df.var-lib-ceph-osd-ceph- *.df_complex.used)
Общее число IOP по всем OSD
Здесь применяется функция sumSeries и символы группировки для
собирания воедино всех измерений op от каждого из OSD:
mostDeviant(10,collectd.osd*.df.var-lib-ceph-osd-ceph- *.df_complex.used)
Также имеются счётчики с названиями opR и
opW, которые отобразят вам индивидуально, соответственно операции
чтения и записи.
Общее значение MBps по всем OSD
Аналогично, также имеются счётчики, которые отображают MBps для каждого OSD, так же как аналогичные
счётчики op; также может быть применена известная нам функция
sumSeries. У нас получается такой код:
mostDeviant(10,collectd.osd*.df.var-lib-ceph-osd-ceph- *.df_complex.used)
Ёмкость и использованность кластера
Два следующих запроса отображают общую ёмкость в байтах данной кластера и общее число используемых байт. Они могут применяться для создания круговых диаграмм в Grafana для изображения процентного соотношения задействованного пространства. Отметим, что эти счётчики показывают сырую ёмкость до репликаций:
maxSeries(collectd.mon*.ceph.mon.mon*.ceph_bytes.Cluster.osdBytes)
maxSeries(collectd.mon*.ceph.mon.mon*.ceph_bytes.Cluster.osdBytesUsed)
Среднее значение латентности
Два следующих запроса отображают могут быть полезны для отображения диаграммы средней латентности в вашем кластере. Большие размеры операций ввода/ вывода увеличат значение средней латентности, чем больше операция ввода/ вывода, тем длиннее процесс. Раз так данная диаграмма не даст ясной картины латентности ваших кластеров если со временем изменяется средний размер операций ввода/ вывода. У на имеется следующий код:
averageSeries(collectd.osd*.ceph.osd.*.ceph_latency.Osd.opWLatency)
averageSeries(collectd.osd*.ceph.osd.*.ceph_latency.Osd.opRLatency)
Хотя стандартный встраиваемый модуль collectd Ceph выполняет хорошую работу по сбору всех счётчиков производительности Ceph, ему не хватает всех необходимых данных для того, чтобы вы могли получить полное представление о работоспособности и производительности вашего кластера. В данном разделе будет показано как применять дополнительные персональные встраиваемые модули для сбора всех состояний PG, статистику производительности по пулам и более реалистичные показатели латентности:
-
Перескочите на один из ваших узлов
monприменив SSH и клонируйте следующий репозиторий git:git clone https://github.com/grinapo/collectd-ceph -
Создайте некий каталог
cephвнутри каталогаcollectd/plugins:sudo mkdir -p /usr/lib/collectd/plugins/ceph -
Скопируйте весь каталог
pluginsвusr/lib/collectd/plugins/cephвоспользовавшись следующей командой:sudo cp -a collectd-ceph/plugins/* /usr/lib/collectd/plugins/ceph/ -
Теперь создайте некий новый файл настроек
collectdчтобы включить встраиваемые модули:sudo nano /etc/collectd/collectd.conf.d/ceph2.conf -
Поместите внутри него следующие настройки и сохраните его в требующемся новом файле:
<LoadPlugin "python"> Globals true </LoadPlugin> <Plugin "python"> ModulePath "/usr/lib/collectd/plu Import "ceph_pool_plugin" Import "ceph_pg_plugin" Import "ceph_latency_plugin" <Module "ceph_pool_plugin"> Verbose "True" Cluster "ceph" Interval "60" </Module> <Module "ceph_pg_plugin"> Verbose "True" Cluster "ceph" Interval "60" </Module> <Module "ceph_latency_plugin"> Verbose "True" Cluster "ceph" Interval "60" TestPool "rbd" </Module> </Plugin>Данный встраиваемый модуль латентности применяет стенд (bench) RADOS для определения латентности вашего кластера; это означает, что он на самом деле исполняет стенд RADOS и будет записывать данные в ваш кластер. Значение параметра
TestPoolопределяет необходимую цель для данной стендовой команды RADOS. Более того, рекомендуется чтобы в промышленном кластере для такого применения вы бы создавали отдельный пул небольшого размера.![[Совет]](/common/images/admon/tip.png)
Совет Если вы пытаетесь применять такой дополнительный встраиваемый модуль в выпусках Ceph Kraken и старше, вам будет необходимо изменить имеющийся файл
ceph_pg_plugin.pyи изменить название переменной в строке 71 сfs_perf_statнаperf_stat. -
Перезапустите службу
collectd:service collectd restartСреднее значение латентности кластера теперь может быть получено следующим запросом:
collectd.mon1.ceph-ceph.cluster.gauge.avg_latency
Данный параметр основывается на выполнении записей по 64кБ и поэтому в отличии от измерений OSD он не будет изменяться в зависимости от имеющегося среднего размера операций ввода/ вывода клиента.
В данной главе мы изучили всю важность наблюдения за вашим кластером Ceph и поддерживающей его инфраструктуры. Вам также должны получить хорошее понимание различных компонентов, которые вам необходимо наблюдать и некие примеры инструментов, котрые могут быть задействованы. Мы рассмотрели некоторые из состояний PG, которые в соединении с решением мониторинга позволяют вам понимать текущее состояние вашего кластера Ceph. Наконец, мы развернули высоко масштабируемую систему наблюдения, содержащую collectd, Graphite и Grafana, которые позволят вам создать профессиональный просмотр инструментальной панели для отображения всех состояний и производительности вашего кластера Ceph.