Глава 3. Работа с потоками в Python
Содержание
В Главе 1, Расширенное введение в совместное и параллельное программирование, вы увидели
некий пример потоков, применяемых в совместной обработке и параллельном программировании. В этой главе вы получите некое введение в собственно
формальное определение потока, а также модуль threading из Python. . Мы рассмотрим некое число способов
работы с потоками в какой- то программе на Python, в том числе такие действия как создание новых потоков, синхронизацию потоков а также работу
при помощи многопоточными очередями с приоритетами, причём на конкретных примерах. Мы также обсудим основное понятие блокировки при
синхронизации потоков, а также мы реализуем некое многопоточное приложение с блокированием для лучшего понимания преимуществ синхронизации
потоков.
В этой главе будут обсуждены такие темы:
-
Собственно понятие потока в обсуждаемом контексте программирования совместной обработки в информатике
-
Базовый API модуля
threadingв Python -
Как создавать новый поток при помощи модуля
threading -
Концепция блокирования и как применять различные механизмы блокировки для синхронизации потоков
-
Основное понятие очереди в обсуждаемом контексте программирования совместной обработки и как применять модуль
Queueдля работы с объектами очереди в Python
Вот перечень предварительных требований для данной главы:
-
Убедитесь что на вашем компьютере уже установлен Python 3
-
Выгрузите необходимый репозиторий из GitHub
-
На протяжении данной главы мы будем работать с вложенной папкой, имеющей название
Chapter03 -
Ознакомьтесь со следующими видеоматериалами Code in Action
В области информатики, некий поток исполнения является наименьшим элементом команд программирования (кода), который какой- то планировщик (обычно как часть операционной системы) может обрабатывать, а также управлять им. В зависимости от конкретной операционной системы реализация потоков и процессов (которые мы обсудим в своей следующей главе) меняется, но поток является обычно является неким элементом (компонентом) в каком- то процессе.
Внутри одного и того же процесса может буть реализовано более одного потока, скорее всего исполняющихся совместно и осуществляющих доступ/ разделяя одни и те же ресурсы. Потоки в одном и том же процессе совместно используют все последующие инструкции (свой код) и контекст (те значения, на которые ссылаются их переменные в любой определённый момент).
Основным ключевым отличием между этими двумя понятиями состоит в том, что некий поток обычно компонент какого- то процесса. Таким образом, один процесс может содержать множество потоков, которые могут исполняться одновременно. Потоки также обычно допускают совместное применение ресурсов, таких как память и данные, в то время как процессы крайне редко делают это. Короче говоря, некий поток является каким- то независимым компонентом вычислений, который аналогичен процессу, однако сам поток внутри некоего процесса может разделять адресное пространство и, тем самым, и собственно данные такого процесса:
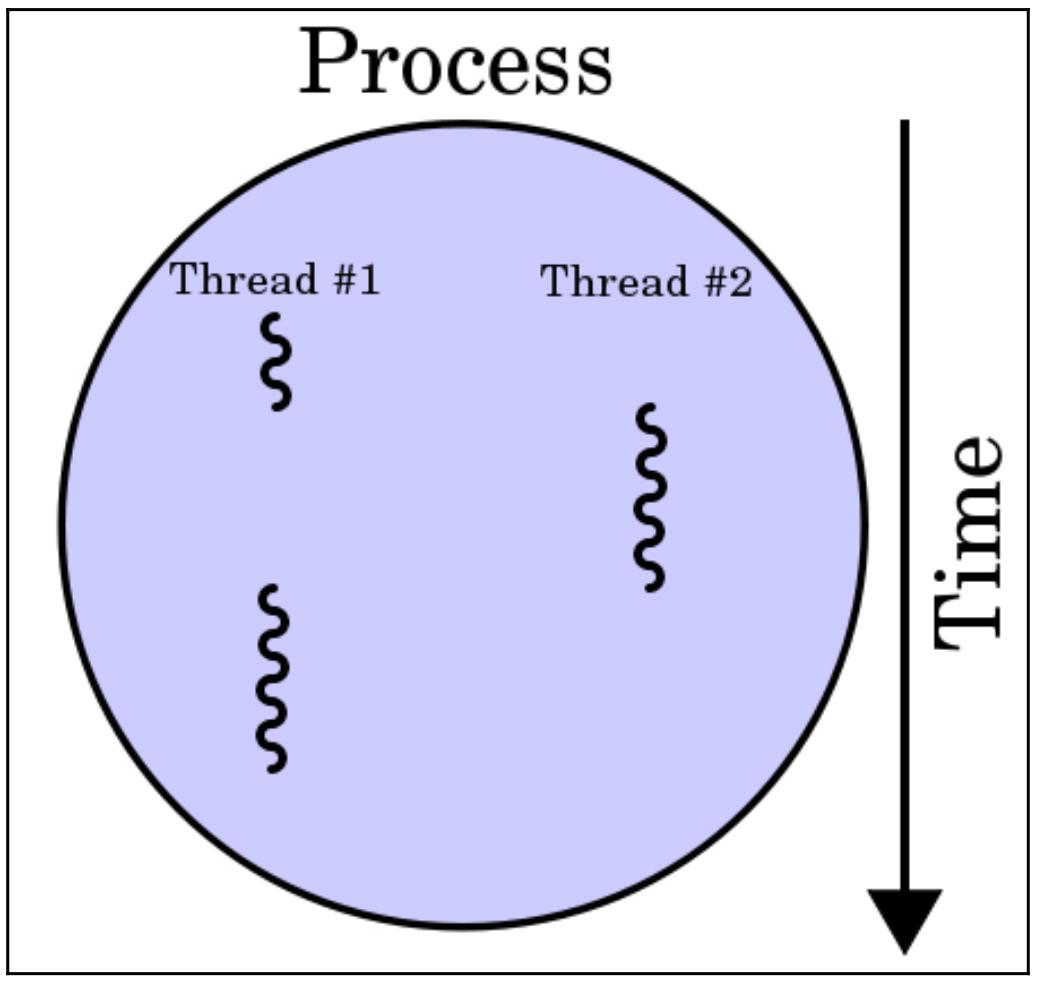
Первые упоминания о применении потоков для переменного числа задач в мультипрограммировании OS/360, которая является снятой с производства системой пакетной обработки, датируемые 1967 годом после её разработки IBM. В то время разработчики именовали потоки задачами, а сам термин поток стал популярным позднее и приписывается Виктору А. Высоцкому, математику и научному сотруднику в области вычислений, который был директором- основателем Исследовательской лаборатории Digital в Кембридже.
В информатике одиночный поток аналогичен традиционной последовательной обработке, исполняющей некую отдельную команду в определённый момент времени. С другой стороны, многопоточность реализует более одного потока существующими и исполняющимися в каком- то отдельном процессе, причём одновременно. За счёт разрешения множеству потоков осуществлять доступ к совместным ресурсам/ контекстам и исполняться независимо, такая техника может помогать приложениям ускоряться в своём исполнении независимых задач.
Многопоточность изначально может достигаться двумя способами. В системах с единственным процессором, многопоточность обычно реализуется путём деления времени, техники, которая позволяет имеющемуся ЦПК переключаться между различным программным обеспечением, запущенным в различных потоках. При разделении времени, сам ЦПУ переключает своё исполнение настолько быстро и настолько часто, что пользователи обычно воспринимают что их программное обеспечение запущено параллельно (например, когда вы открываете две различные программы в одно и то же время в каком- то компьютере с единственным процессором):
В противоположность системам с единственным процессором, системы со множеством процессоров или ядер способны легко реализовывать многопоточность, причём исполняя каждый поток в каком- то отдельном процессоре или ядре и при этом одновременно. Кроме того, неким вариантом является и разделение времени, так как такие системы со множеством процессоров и множеством ядер могут иметь только один процессор/ одно ядро для переключения между задачами - хотя обычно это не самый практичный приём.
Многопоточные приложения имеют ряд преимуществ по сравнению с обычными последовательными приложениями; некоторые из них таковы:
-
Более быстрое время исполнения: Одним из основных преимуществ совместной обработки при многопоточности является достигаемое ускорение. Отдельные потоки в одной и той же программе мугут исполняться совместно или параллельно, когда они достаточно независимы друг от друга.
-
Быстрота отклика: Некая программа с единственным потоком за раз может обрабатывать только один кусочек ввода; тем самым, если её основной поток исполнения блокируется в какой- то задаче с длительным временем исполнения (например, некая часть ввода, которая требует интенсивных вычислений и обработки), вся программа целиком не будет способна продолжить прочий ввод и, следовательно, будет казаться замёрзшей. Применяя отдельные потоки для осуществления вычислений и оставаясь исполняемой для получения ввода другого пользователя в то же самое время, некая многопоточная программа может предоставлять гораздо лучшую отзывчивость.
-
Эффективность в потреблении ресурсов: Как уже упоминалось ранее, множество потоков внутри одного и того же процесса могут совместно разделять одни и те же ресурсы и осуществлять к ним доступ. Вследствие этого, многопоточные программы могут обслуживать и обрабатывать множество запросов клиентов к данным для совместной обработки, используя значительно меньше ресурсов чем это потребовалось бы при применении однопотоковых или многопроцессных программ. Это также ведёт к более быстрому взаимодействию между потоками.
При этом многопточные программы также имеют и свои собственные недостатки, а именно:
-
Крушения: Даже хотя некий процесс может содержать множество потоков, отдельная недопустимая операция в пределах одного потока может отрицательно сказываться на имеющейся обработке всех прочих потоков в этом процессе и может вызывать в результате крушение всей программы целиком.
-
Синхронизация: Даже хотя разделение одних и тех же ресурсов может выступать неким преимуществом над обычным последовательным программированием или программами с множеством процессов, для такого совместного использования ресурсов также требуется аккуратное рассмотрение подробностей с тем, чтобы совместные данные вычислялись правильно и их обработка была корректной. Интуитивно непонятные проблемы, которые могут быть вызваны небрежной координацией потоков включают в свой состав взаимные блокировки, зависания и состояние конкуренции, каждое из которых будет обсуждено в последующих главах.
Чтобы продемонстрировать само понятие запуска множества потоков в одном и том же процессе, давайте рассмотрим некий быстрый пример на Python.
Если у вас уже имеется выгруженным с нашей страницы в GitHub необходимый код для данной книги, проследуйте далее и переместитесь в папку
Chapter03. Давайте рассмотрим приводимый далее файл
Chapter03/my_thread.py:
# Chapter03/my_thread.py
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name, delay):
threading.Thread.__init__(self)
self.name = name
self.delay = delay
def run(self):
print('Starting thread %s.' % self.name)
thread_count_down(self.name, self.delay)
print('Finished thread %s.' % self.name)
def thread_count_down(name, delay):
counter = 5
while counter:
time.sleep(delay)
print('Thread %s counting down: %i...' % (name, counter))
counter -= 1
В этом файле мы применяем соответствующий модуль threading мз Python в качестве необходимой основы для
своего класса MyThread. Кадлый объект из этого класса имеет некое
name и параметр delay. Имеющаяся функция
run(), которая вызывается как только некий новый поток инициализирован и запущен, печатает какое- то
стартовое сообщение и, в свою очередь, вызывает соответствующую функцию thread_count_down(). Данная функция
ведёт обратный отсчёт с 5 до 0, а между итерациями засыпает на несколько
секунд, которые определены определяемым параметром задержки.
Основной момент в данном примере состоит в том чтобы показать имеющуюся природу совместной обработки через одновременный запуск более одного объектов
из нашего класса MyThread. Мы знаем, что как только каждый поток запускается, также стартует и обратный отсчёт
на основе времени. В традиционной последовательной программе отдельный обратный отсчёт будет исполняться обособленно, по- порядку (то есть, какой- то
новый обратный отсчёт не начнётся, пока не завершится текущий). Как вы обнаружите, все отдельные обратные отсчёты для обособленных потоков исполняются
совместно.
Давайте рассмотрим следующий файл, Chapter03/example1.py:
# Chapter03/example1.py
from my_thread import MyThread
thread1 = MyThread('A', 0.5)
thread2 = MyThread('B', 0.5)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print('Finished.')
Здесь мы выполнили инициализацию и запустили совместно два потока, причём каждый из них имеет в качестве параметра delay
0.5 секунд. Воспользовавшись своим интерпретатором Python запустите этот сценарий. Вы должны получить
следующий вывод:
> python example1.py
Starting thread A.
Starting thread B.
Thread A counting down: 5...
Thread B counting down: 5...
Thread B counting down: 4...
Thread A counting down: 4...
Thread B counting down: 3...
Thread A counting down: 3...
Thread B counting down: 2...
Thread A counting down: 2...
Thread B counting down: 1...
Thread A counting down: 1...
Finished thread B.
Finished thread A.
Finished.
В точности, как и ожидалось, полученный вывод сообщает нам, что наши два обратных отсчёта для имеющихся потоков исполнялись совместно; вместо того чтобы завершить наш самый первый поток обратного отсчёта и затем запустить второй имеющийся поток обратного отсчёта, наша программа исполнила эти два обратных отсчёта почти в одно и то же время. Без включения каких- то накладных расходов и различных объявлений, такая методика организации потоков позволяет почти удвоить улучшение скорости для нашей предыдущей программы.
Имеется один дополнительный момент, который стоит принять во внимание в нашем предыдущем выводе. После самого первого обратного отсчёта под номером
5 мы можем заметить, что поток B в действительности обогнал поток A в исполнении, даже хотя мы и знаем, что поток A
был проинициализирован и запущен до потока B. Такое изменение на самом деле позволило потоку B завершиться ранее потока A. Это явление является
непосредственным результатом совместной работы при многопоточности; так как эти два потока были проинициализированы и запущены почти одновременно, имеется
большая вероятность что один поток опередит другой при исполнении.
Если вы запустили этот сценарий много раз, достаточно вероятно что вы получите отличающийся вывод в терминах порядка исполнения и завершения своих обратных
отсчётов. Ниже приводятся два фрагмента вывода, которые я получил запуская этот сценарий снова и снова. Самый первый вывод показывает некое единообразие и
неизменность порядка исполнения и завершения, при котором эти два обратных отсчёта были исполнены рука к руке. Второй же показывает некий вариант, при
котором поток A исполнился слегка быстрее чем поток B; даже завершившись до того, как поток B отсчитал число
1. Этот вариант вывода в дальнейшем проиллюстрирует тот факт, что наши потоки воспринимались и исполнялись со
стороны Python одинаково.
Следующий код показывает один возможный вывод нашей программы:
> python example1.py
Starting thread A.
Starting thread B.
Thread A counting down: 5...
Thread B counting down: 5...
Thread A counting down: 4...
Thread B counting down: 4...
Thread A counting down: 3...
Thread B counting down: 3...
Thread A counting down: 2...
Thread B counting down: 2...
Thread A counting down: 1...
Thread B counting down: 1...
Finished thread A.
Finished thread B.
Finished.
А вот ещё один возможный вывод:
> python example1.py
Starting thread A.
Starting thread B.
Thread A counting down: 5...
Thread B counting down: 5...
Thread A counting down: 4...
Thread B counting down: 4...
Thread A counting down: 3...
Thread B counting down: 3...
Thread A counting down: 2...
Thread B counting down: 2...
Thread A counting down: 1...
Finished thread A.
Thread B counting down: 1...
Finished thread B.
Finished.
Существует множество вариантов, когда дело доходит до реализации многопоточных программ в Python. Один из наиболее распространённых способов работы
с потоками в Python состоит в применении модуля threading. Прежде чем мы погрузимся в имеющуюся модель применения и
её синтаксис, вначале давайте изучим саму модель thread, которая первоначально была самым основным модулем
разработки на основе потока в Python.
Прежде чем приобрёл популярность модуль threading, первичным модулем разработки на основе потоков был
thread. Если вы используете более старые версии Python 2, имеется возможность применять этот модуль
"как есть". Тем не менее, согласно странице документации этого модуля, на самом деле этот модуль в Python 3 был переименован в
_thread.
Для тех читателей, которые работали с этим модулем thread для построения многопоточных приложений и
рассматривают возможность портации своего кода с Python 2 на Python 3, инструмент 2to3 может оказаться неким решением. Инструмент 2to3 обрабатывает
большинство выявленных несовместимостей между различными версиями Python, при этом производя синтаксический анализ получаемого исходного кода и
обходящего это исходное дерево для преобразования кода Python 2.x в код Python 3.x. Другой трюк для достижения преобразования состоит в изменении
своего импортируемого кода с import thread на import _thread as thread
в вашей программе Python.
Основным свойством данного модуля thread является его скорость и достаточность метода создания нового потока
для исполнения функций: соответствующей функции thread.start_new_thread(). Кроме того, для целей
синхронизации предоставляются простые объекты блокировки (например, взаимные исключения - mutexes и семафоры - semaphores).
Старый модуль thread рассматривался разработчиками Python как утративший актуальность на длительное время, в
основном, по причине его функций на достаточно низком уровне и ограничении применения. С другой стороны, модуль
threading строится поверх имеющегося модуля thread , предоставляя более
простые способы для работы с потоками посредством мощных API верхнего уровня. Пользователи Python на самом деле одобрили применение этого нового
модуля threading вместо модуля thread в своих программах.
Кроме того, сам модуль thread рассматривает каждый поток как некую функцию; когда вызывается
thread.start_new_thread(), она на самом деле получает некую отдельную функцию в качестве своего основного
аргумента чтобы породить некий новый поток. Тем не менее, новый модуль threading разработан с целью предоставления
дружественного пользователю интерфейса для тех, кто исходит из парадигмы объектно- ориентированного программного обеспечения, трактуя каждый создаваемый
поток как некий объект.
В дополнение ко всей функциональности для работы с потоками, которые предоставляет модуль thread, новый модуль
threading поддерживает ряд дополнительных методов, как то:
-
threading.activeCount(): Эта функция возвращает общее число активных в настоящий момент времени объектов потока в данной программе -
threading.currentThread(): Данная функция возвращает общее число объектов потока в данном текущем потоке, управляемых стороной вызова -
threading.enumerate(): Функция возвращает список всех активных в настоящий момент объектов потока в данной программе
Следуя парадигме разработки объектно- ориентированного программного обеспечения, новый модуль threading
также предоставляет некий класс Thread, который поддерживает необходимую объектно- ориентированную
реализацию потоков. В данном классе поддерживаются такие методы:
-
run(): Этот метод исполняется когда инициализируется и запускается некий новый поток -
start(): Данный метод запускает инициализированный вызывающий объекта потока, вызывая соответствующий методrun() -
join(): Такой метод ожидает завершения соответствующего вызывающего объекта потока прежде чем продолжить исполнение оставшейся части программы -
isAlive(): Данный метод возвращает Булево значение, указываюшее исполняется ли в данный момент вызывающий объект потока -
getName(): Этот метод возвращает собственно название данного вызывающего объекта потока -
setName(): Этот метод устанавливает соответствующее название данного вызывающего объекта потока
Предоставляя некий обзор нового модуля threading и его отличия от имеющегося старого модуля
thread в данном разделе, мы изучим ряд примеров создания новых потоков применяя эти инструменты в Python.
Как уже упоминалось ранее, новый модуль threading, вероятно, наиболее распространённый способ работы с
потоками в Python. Особые случаи требуют применения старого модуля thread, а может быть также и прочих
инструментов и нам важно быть способными выявлять такие ситуации.
В модуле thread для исполнения функций совместно создаются новые потоки. Как мы уже упоминали, основным способом
для выполнения этого является применение функции thread.start_new_thread():
thread.start_new_thread(function, args[, kwargs])
Когда вызывается эта функция, для исполнения той функции, которая определены в передаваемых параметрах, порождается новый поток, а когда данная функция
завершает своё исполнение, возвращается значение идентификатора созданного потока. Значением параметра function
является название подлежащей исполнению функции, а перечень параметров args (который обязан пыть списком или
кортежем) содержит те аргументы, которые должны быть переданы в данную определяемую функцию. Необязательный параметр
kwargs, с другой стороны, содержит некий отдельный словарь дополнительных аргументов с ключевыми словами.
После того осуществляется возврат из порождённой функции thread.start_new_thread(), этот поток также втихую
завершится.
Давайте взглянем на некий пример использования модуля thread в программе Python. Если вы уже выгрузили
необходимый для данной книги код с нашей страницы GitHub, пройдите далее и переместитесь в папку Chapter03
к файлу Chapter03/example2.py. В этом примере мы рассмотрим функцию
is_prime(), которую мы уже применяли в своих предыдущих главах:
# Chapter03/example2.py
from math import sqrt
def is_prime(x):
if x < 2:
print('%i is not a prime number.' % x)
elif x == 2:
print('%i is a prime number.' % x)
elif x % 2 == 0:
print('%i is not a prime number.' % x)
else:
limit = int(sqrt(x)) + 1
for i in range(3, limit, 2):
if x % i == 0:
print('%i is not a prime number.' % x)
print('%i is a prime number.' % x)
Вы можете заметить, что результатом её вычисления данной функции is_prime(X) является совершенной другой
способ возвращения полученного результата; вместо возврата true или
false для указания является ли параметр x простым числом, данная
функция is_prime() непосредственно выводит этот результат на печать. Как мы уже сказали ранее, наша функция
thread.start_new_thread() исполняет полученную параметром функцию посредством порождения нового потока, но на практике
она возвращает значение получаемого идентификатора потока. Выводя на печать получаемый результат нашей функции
is_prime() мы обходим задачу получения доступа к самому результату данной функции в потоке модуля
thread.
В самой основной части нашей программы мы организуем цикл по некоторому перечню потенциальных кандидатов быть простыми числами и будем вызывать свою
функцию thread.start_new_thread() для вычисляющей функции is_prime() и
каждого числа из данного перечня следующим образом:
# Chapter03/example2.py
import _thread as thread
my_input = [2, 193, 323, 1327, 433785907]
for x in my_input:
thread.start_new_thread(is_prime, (x, ))
Вы можете обратить внимание, что в данном файле Chapter03/example2.py присутствует строка кода для получения
ввода от клиента в самом конце:
a = input('Type something to quit: \n')
Теперь давайте прокомментируем эту самую последнюю строку. Потом, когда мы исполним всю программу Python целиком, будет казаться, что наша программа
завершилась без вывода на печать каких- нибудь результатов; другими словами, наша программа завершилась прежде чем могут завершить своё исполнение её
потоки. Это происходит по той причине, что когда некий новый поток порождается из функции thread.start_new_thread()
для обработки числа из нашего входного списка, сама программа продолжает обходить циклом все последующие числа в то время как такие вновь созданные потоки
исполняются.
Поэтому, ко времени, когда наш интерпретатор Python достигнет самого конца своей программы, если никакой поток не завершил исполнение (в нашем случае,
такими являются все эти потоки), такой поток будет проигнорирован и прекращён и никакой вывод при этом не будет отображён на печати. Тем не менее, время от
времени одним из выходных данных является 2 is a prime number, что является выведенным на печать результатом до завершения
данной программы, так как обрабатывающий число 2 поток имеет возможность завершиться до данного момента.
Самая последняя строка кода является иным обходным манёвром для нашего модуля thread на этот раз чтобы решить
указанную выше проблему. Эта строка удерживает нашу программу от выхода вплоть до ввода пользователем любого нажатия клавиши для завершения всех запущенных
потоков (то есть, чтобы завершить обработку всех имеющихся в перечне входа чисел). Удалите комментарий с самой последней строки и выполните этот файл, в
результате вы получите свой вывод, который будет похож на следующее:
> python example2.py
Type something to quit:
2 is a prime number.
193 is a prime number.
1327 is a prime number.
323 is not a prime number.
433785907 is a prime number.
Как вы можете отметить, строка Type something to quit, которая соответствует самой последней строке кода из нашей
программы, была выведена прежде чем мы получили вывод из функции is_prime(); это согласуется с тем фактом, что данная
строка исполняется прежде чем все прочие потоки завершили своё исполнение, в большинстве вариантов. Я указываю именно "в большинстве вариантов",
так как когда наш поток который обрабатывает самое первое данное на входе (число 2) завершает исполнение прежде
чем интерпретатор Python достигает самой последней строки, наш вывод порой может выглядеть аналогично следующему:
> python example2.py
2 is a prime number.
Type something to quit:
193 is a prime number.
323 is not a prime number.
1327 is a prime number.
433785907 is a prime number.
Теперь вы знаете как запускать некий поток при помощи модуля thread, а также вы знаете о его ограничениях
и применении потоков на низком уровне, помимо потребности рассмотрения интуитивно не понятного обходного манёвра при работе с ним. В данном
подразделе мы изучим более предпочтительный модуль threading и его преимущества над
thread по отношению к реализации многопоточных программ в Python.
Чтобы создать и выполнить индивидуальную настройку какого- то нового потока при помощи нового модуля threading,
существуют определённые шаги, которые должны быть следующими:
-
В вашей программе определите некий подкласс общего класса
threading.Thread -
Внутри полученного подкласса перепишите установленный по умолчанию метод
__init__(self [,args])для добавления необходимых индивидуальных аргументов в этот класс -
Внутри этого же подкласса перепишите установленный по умолчанию метод
run(self [,args])для персонализации имеющегося поведения данного класса потоков при инициализации и запуске некоего нового потока
На самом деле вы уже видели некий пример в самом первом примере из данной главы. Чтобы напомнить, ниже приводится то что нам приходится применять
для индивидуализации какого- то подкласса threading.Thread для выполнения обратного отсчёта в пять шагов
с некой персональной задержкой между каждыми шагами:
# Chapter03/my_thread.py
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name, delay):
threading.Thread.__init__(self)
self.name = name
self.delay = delay
def run(self):
print('Starting thread %s.' % self.name)
thread_count_down(self.name, self.delay)
print('Finished thread %s.' % self.name)
def thread_count_down(name, delay):
counter = 5
while counter:
time.sleep(delay)
print('Thread %s counting down: %i...' % (name, counter))
counter -= 1
В своём следующем примере мы рассмотрим свою задачу выявления является ли задаваемое число простым. В этот раз мы реализуем некую многопоточную
программу Python посредством нового модуля threading. Перейдите в папку Chapter03
к файлу example3.py. Давайте вначале сосредоточимся на своём подклассе
MyThread:
# Chapter03/example3.py
import threading
class MyThread(threading.Thread):
def __init__(self, x):
threading.Thread.__init__(self)
self.x = x
def run(self):
print('Starting processing %i...' % x)
is_prime(self.x)
Всякий экземпляр нашего класса MyThread имеет некий параметр с названием x,
определяющий число- кандидат на то чтобы быть простым. Как вы можете заметить, когда инициализируется и запускается некий экземпляр этого класса
(а точнее, в функции run(self)), наша функция is_prime(), которая является
той же самой функцией проверки является ли число простым, которую мы применяли в своём предыдущем примере, причём с указанным параметром
x, а перед этим в нашей функции run() для указания на начало данного процесса
также выводится на печать некое сообщение.
В своей основной программе мы всё ещё имеем всё тот же список на вход для проверки на принадлежность к простым числам. Мы намерены пройти по всем
числам из этого перечня, порождая и запуская некий новый экземпляр данного класса MyThread с этим числом и
дописывая этот экземпляр MyThread в некий отдельный список. Такой список созданных потоков необходим по той
причине, поскольку после этого нам придётся вызвать метод join() для всех этих потоков, который удостоверит все эти
потоки успешно завершили своё исполнение:
my_input = [2, 193, 323, 1327, 433785907]
threads = []
for x in my_input:
temp_thread = MyThread(x)
temp_thread.start()
threads.append(temp_thread)
for thread in threads:
thread.join()
print('Finished.')
Отметим, что в отличии от того случая когда мы применяли старый модуль thread, на этот раз нам нет нужды
изобретать какой- то обходной манёвр чтобы гарантировать что все потоки успешно завершили своё исполнение. Опять же, это делается указанным методом
join(), который предоставляется новым модулем threading. Это всего
лишь один пример из множества преимуществ применения более мощного API верхнего уровня нового модуля threading,
относительно использования традиционного модуля thread.
Как вы видели в наших предыдущих примерах, новый модуль threading имеет множество преимуществ над своим
предшественником, традиционным модулем thread, с точки зрения функциональности и вызовов API верхнего уровня.
Даже хотя кое- кто рекомендует искушённым разработчикам Python знать как реализовывать многопоточные приложения при помощи обоих модулей, скорее всего,
для работы с потоками Python вы будете применять именно модуль threading. В данном разделе мы рассмотрим
использование модуля threading при синхронизации потоков.
Прежде чем мы перепрыгнем к некому реальному примеру на Python, давайте изучим само понятие синхронизации в информатике. Как вы уже видели в предыдущих главах, порой нежелательно иметь все порции программы исполняемыми параллельно. Фактически, в наиболее современных совместных программах, даже внутри некоторой совместной части, также необходима некая форма координации между различными потоками/ процессами.
Синхронизация потоков/ процессов является неким понятием из информатики, которое определяет различные механизмы гарантии того, что за раз не более одной одновременно исполняемого потока/ процесса может обработать и исполнить некую определённую часть кода; такая часть кода именуется критическим разделом и мы будем обсуждать его более подробно когда будем рассматривать распространённые проблемы при параллельном программировании в Главе 12, Взаимные блокировки и в Главе 13, Зависание.
В некоторой конкретной программе, когда какой- то поток осуществляет доступ/ исполняет соответствующий критический раздел данной программы, все прочие потоки обязаны дожидаться пока этот поток не завершит исполнение. Наиболее типичной целью синхронизации потоков является избежание потенциальной противоречивости данных при организации доступа множеством потоков разделяемых ими ресурсов; позволяя только одному потоку исполнять данный критический раздел вашей программы за раз чтобы гарантировать что в многопоточном приложении не произойдёт никаких конфликтов с данными. {Прим. пер.: пример, иллюстрирующий такой конфликт, приводится в нашем переводе раздела Ресторан Серийных ботов книги Asyncio в Python 3 Цалеба Хаттингха.}
Один из наиболее общих путей применения синхронизации потоков состоит в реализации некоторого механизма блокировки. В нашем модуле
threading, класс threading.Lock предоставляет некий образец и
интуитивно понятного подхода по созданию блокировок и работе с ними. Его основное использование включает в себя такие методы:
-
threading.Lock(): Этот метод инициализирует и возвращает некий объект блокировки. -
acquire(blocking): При вызове данного метода все имеющиеся потоки будут запущены синхронно (то есть, только один поток может исполнять данный критический раздел в определённый момент времени):-
Необязательный аргумент
blockingпозволяет нам определять должен ли данный текущий поток выполнять ожидание чтобы получить данную блокировку. -
Когда
blocking = 0, данный текущий поток не дожидается данной блокировки и просто возвращает0, если такая блокировка не может быть получена этим потоком или1в противоположном случае. -
Когда
blocking = 1, данный текущий поток выполняет блокирование и дожидается пока эта блокировка не освободится и получает её после этого.
-
-
release(): При вызове данного метода его блокирование высвобождается.
Давайте рассмотрим некий конкретный пример. В этом примере мы будем просматривать свой файл Chapter03/example4.py.
Мы вернёмся обратно к своему примеру обратного отсчёта от пяти до одного, который уже рассматривали в самом начале данной главы; улучите момент
чтобы чтобы вернуться назад и вспомнить постановку задачи. В данном примере мы отрегулируем свой класс MyThread
следующим образом:
# Chapter03/example4.py
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name, delay):
threading.Thread.__init__(self)
self.name = name
self.delay = delay
def run(self):
print('Starting thread %s.' % self.name)
thread_lock.acquire()
thread_count_down(self.name, self.delay)
thread_lock.release()
print('Finished thread %s.' % self.name)
def thread_count_down(name, delay):
counter = 5
while counter:
time.sleep(delay)
print('Thread %s counting down: %i...' % (name, counter))
counter -= 1
В противоположность самому первому примеру из этой главы, класс MyThread применяет некую блокировку объекта
(имя переменной которого имеет название thread_lock) внутри своей функции
run(). В частности, данный объект блокировки получается сразу перед вызовом функции
thread_count_down() (то есть когда начинается обратный отсчёт), а высвобождается этот блокируемый объект сразу
после её завершения. Теоретически, данная спецификация позволит изменять то поведение наших потоков, которое мы видели в самом первом примере; вместо
одновременного имеющегося обратного отсчёта наша программа теперь исполняет имеющиеся потоки по отдельности, и каждый последующий обратный отсчёт будет
иметь место после предыдущего.
Наконец, мы проинициализируем свою переменную thread_lock а также запустим два отдельных экземпляра класса
MyThread:
thread_lock = threading.Lock()
thread1 = MyThread('A', 0.5)
thread2 = MyThread('B', 0.5)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print('Finished.')
Вывод будет таким:
> python example4.py
Starting thread A.
Starting thread B.
Thread A counting down: 5...
Thread A counting down: 4...
Thread A counting down: 3...
Thread A counting down: 2...
Thread A counting down: 1...
Finished thread A.
Thread B counting down: 5...
Thread B counting down: 4...
Thread B counting down: 3...
Thread B counting down: 2...
Thread B counting down: 1...
Finished thread B.
Finished.
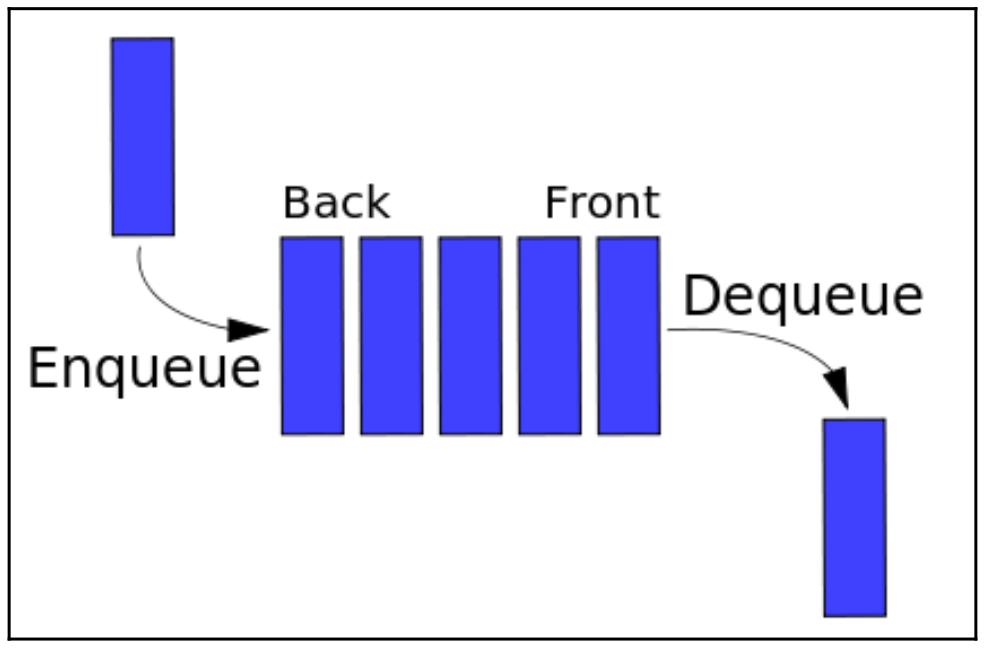
Широко применяемым как в не параллельном, так и в совместном программировании понятием информатики является применение очередей. Некая очередь является абстрактной структурой данных, которая является коллекцией различных элементов для сопровождения некоего установленного порядка; эти элементы могут быть иными объектами в какой- то программе.
Очереди являются интуитивно понятной концепцией, которая легко может быть соотнесена с повседневной практикой, например, когда вы стоите к стойке в одну линию в аэропорту. В реальной цепочке из людей вы наблюдаете следующее:
-
Люди обычно встают с одной стороны этой цепочки и покидают её с другой стороны.
-
Если персона A поступает в эту цепь перед персоной B, то персона A также покинет эту цепь до персоны B (если только у персоны B не более высокий приоритет).
-
Когда все разместятся в самолёте, в данной очереди никого не останется. Иными словами, данная цепь будет пустой.
В информатике очередь работает в значительной степени аналогичным образом:
-
Элементы могут добавляться в самый конец определённой очереди; эта задача называется постановкой в очередь (enqueue).
-
Элементы также могут удаляться из самого начала такой очереди; такая задача именуется извлечением из очереди (dequeue).
-
В очереди FIFO (First In First Out, первый пришёл- первый ушёл) тот элемент, что добавляется первым, также будет и удалён первым (отсюда и название, FIFO). Это является противоположностью другой распространённой структуре данных в информатике, именуемой стеком, в котором самый последний добавляемый элемент удаляется первым. Что также именуется как LIFO (Last In First Out, последний пришёл - первый ушёл).
-
Если внутри некоторой очереди были удалены все элементы, такая очередь будет пустой и не будет никакого способа удалять и далее элементы из такой очереди. Аналогично, если данная очередь достигает максимальной ёмкости по числу элементов, которые она может содержать, нет никакого способа добавлять какие бы то ни было элементы в данную очередь:
Модуль queue в Python предоставляет некую простую реализацию такой структуры данных очереди. Каждая очередь
из имеющегося класса queue.Queue может содержать определённое количество элементов и может иметь следующие методы
в качестве своего API верхнего уровня:
-
get(): Данный метод возвращает следующий элемент вызывая объектqueueи удаляя его из этого объектаqueue -
put(): Этот метод добавляет новый элемент в данный вызываемый объектqueue -
qsize(): Этот метод возвращает общее число текущих элементов в данном вызываемом объектеqueue(то есть его размер). -
empty(): Такой метод возвращает некое Булево значение, указывающее является ли вызываемый объектqueueпустым. -
full(): Данный метод возвращает некое Булево значение, указывающее является ли вызываемый объектqueueзаполненным.
Обсуждаемое понятие очереди даже ещё более распространено в подобласти совместного программирования, в особенности когда нам необходимо реализовать некое фиксированное число потоков в нашей программе для взаимодействия с переменным числом совместных ресурсов.
В своих предыдущих примерах мы изучили назначение некой определённой задачи какому- то новому потоку. Это означает, что общее число задач,
которое необходимо обработать будет диктовать общее число потоков, которое следует породить нашей программе (Например, в своём файле
Chapter03/example3.py мы имели пять чисел в качестве наших входных данных и мы, следовательно, создали пять потоков -
каждый взял по одному числу из входных данных и обработал его.)
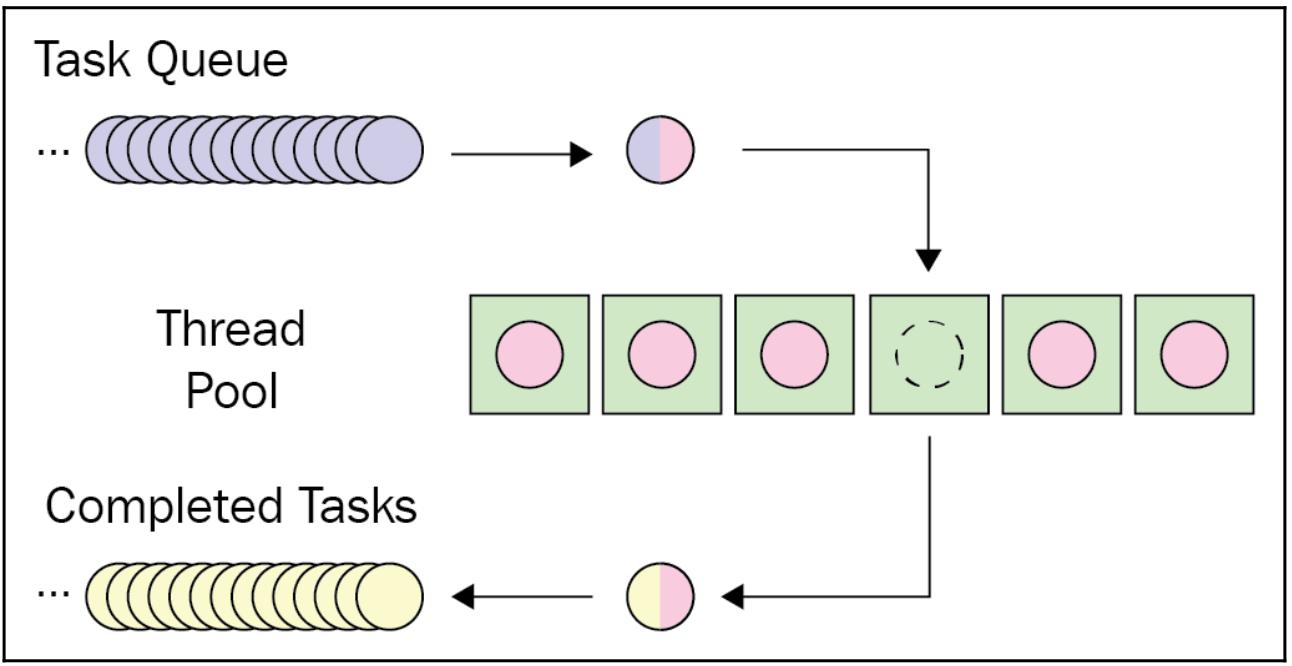
Порой не желательно иметь столько же потоков, сколько задач у нас имеется для обработки. Скажем, у вас имеется большое число подлежащих обработки, тогда было бы достаточно не эффективно порождать то же самое число потоков и иметь каждый поток исполняющим только одну задачу. Может дать больше преимуществ наличие фиксированного числа потоков (обычно именуемого неким пулом потоков), который мог бы работать с имеющимися задачами на основе кооперации.
Здесь на сцену выходит понятие очереди. У нас есть возможность спроектировать некую структуру, в которой наш пул потоков не будет сохранять какую бы то ни было информацию относящуюся к задачам, которые ему следует исполнять, а вместо этого сами задачи хранятся в некоторой очереди (иными словами, создают очередь задач), и соответствующие элементы из этой очереди будут питать персональных участников имеющегося пула потоков. По мере того как выбранная задача завершается неким участником нашего пула потоков, если присутствующая очередь задач всё ещё содержит подлежащие обработке элементы, тогда следующий элемент из этой очереди будет отправлен в тот поток, который только что освободился.
Приводимая ниже схема иллюстрирует такую настройку:
Давайте рассмотрим быстрый пример на Python чтобы проиллюстрировать этот момент. Перейдите к соответствующему файлу
Chapter03/example5.py. В этом примере мы будем рассматривать задачу вывода всех положительных множителей некоторых
элементов в заданном списке положительных целых. Мы всё ещё придерживаемся своего класса MyThread, но
с некими настройками:
# Chapter03/example5.py
import queue
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name):
threading.Thread.__init__(self)
self.name = name
def run(self):
print('Starting thread %s.' % self.name)
process_queue()
print('Exiting thread %s.' % self.name)
def process_queue():
while True:
try:
x = my_queue.get(block=False)
except queue.Empty:
return
else:
print_factors(x)
time.sleep(1)
def print_factors(x):
result_string = 'Positive factors of %i are: ' % x
for i in range(1, x + 1):
if x % i == 0:
result_string += str(i) + ' '
result_string += '\n' + '_' * 20
print(result_string)
# setting up variables
input_ = [1, 10, 4, 3]
# filling the queue
my_queue = queue.Queue()
for x in input_:
my_queue.put(x)
# initializing and starting 3 threads
thread1 = MyThread('A')
thread2 = MyThread('B')
thread3 = MyThread('C')
thread1.start()
thread2.start()
thread3.start()
# joining all 3 threads
thread1.join()
thread2.join()
thread3.join()
print('Done.')
Тут имеется много на что стоит посмотреть, поэтому давайте разобьём эту программу на части меньшего размера. Во- первых, давайте рассмотрим свою ключевую функцию:
# Chapter03/example5.py
def print_factors(x):
result_string = 'Positive factors of %i are: ' % x
for i in range(1, x + 1):
if x % i == 0:
result_string += str(i) + ' '
result_string += '\n' + '_' * 20
print(result_string)
Эта функция берёт некий параметр, x, затем выполняет итерации по всем положительным числам между
1 и своим значением чтобы проверить является ли это число неким множителем
x. В конце выводится на печать форматированное сообщение, которое содержит всю необходимую информацию,
которая накопилась в нашем цикле.
В нашем новом классе MyThread, после того как некий новый экземпляр проинициализирован и запущен, будет
вызвана соответствующая функция process_queue(). Эта функция вначале попытается получить следующий
требуемый элемент из существующего объекта очереди, который содержится в переменной my_queue неким
образом без блокировки посредством вызова соответствующего метода get(block=False). Если произошла некая
исключительная ситуация queue.Empty (что указывает на то, что данная очередь не содержит значений), тогда мы
завершаем исполнение данной функции. В противном случае мы просто передаём тот элемент, что мы только что получили, в свою функцию
print_factors().
# Chapter03/example5.py
def process_queue():
while True:
try:
x = my_queue.get(block=False)
except queue.Empty:
return
else:
print_factors(x)
time.sleep(1)
Переменная my_queue определяется в нашей основной функции как некий объект Queue
из модуля queue, который содержит все элементы в своём перечне input_:
# setting up variables
input_ = [1, 10, 4, 3]
# filling the queue
my_queue = queue.Queue(4)
for x in input_:
my_queue.put(x)
В оставшейся части своей основной программы мы просто инициируем и запускаем такие отдельные потоки пока все они не завершат свои соответствующие исполнения. В данном случае мы остановились на создании только трё потоков для имитации своей архитектуры, которую мы обсудили выше - некое фиксированное число потоков обработки очереди на входе, чьё число элементов может изменяться независимым образом:
# initializing and starting 3 threads
thread1 = MyThread('A')
thread2 = MyThread('B')
thread3 = MyThread('C')
thread1.start()
thread2.start()
thread3.start()
# joining all 3 threads
thread1.join()
thread2.join()
thread3.join()
print('Done.')
Запустите эту программу и получите следующий вывод:
> python example5.py
Starting thread A.
Starting thread B.
Starting thread C.
Positive factors of 1 are: 1
____________________
Positive factors of 10 are: 1 2 5 10
____________________
Positive factors of 4 are: 1 2 4
____________________
Positive factors of 3 are: 1 3
____________________
Exiting thread C.
Exiting thread A.
Exiting thread B.
Done.
В этом примере мы реализовали ту структуру, которую обсудили ранее: очередь задач, которая хранит все подлежащие исполнению задачи и некий пул потоков (потоки A?\, B и C), которые взаимодействуют с имеющейся очередью для обработки её элементов.
Все элементы в некоторой очереди обрабатываются в том порядке, в котором они были добавлены в эту очередь; иными словами, самый первый добавленный в очередь элемент покидает эту очередь первым (FIFO). Даже хотя такая абстрактная структура данных и имитирует реальную жизнь во многих случаях, в зависимости от самого приложения и его целей, порой нам требуется переопределять/ изменять имеющийся порядок стоящих в очереди элементов динамически. Именно в такой ситуации удобным становится понятие очереди с приоритетами.
Абстрактная структура данных очереди с приоритетами аналогична уже обсуждённой структуре данных очереди (и даже вышеупомянутому понятию стека), но каждый имеющийся в некоторой очереди с приоритетами элемент, как предвосхищает её название, имеет некий связанный с ним приоритет; говоря иначе, когда некий элемент добавляется в очередь с приоритетами, требуется определить его приоритет. В отличии от обычной очереди, принцип выборки из очереди с приоритетами полагается на значение приоритета имеющихся элементов: те элементы, у которых приоритет выше, обрабатываются ранее конкурентов с меньшим приоритетом.
Данная концепция очереди с приоритетами используется в разнообразных различных приложениях - а именно, управлении полосой пропускания, алгоритме Дейкстры, алгоритмах наилучшего первого поиска, и тому подобных. Каждое из таких приложений обычно применяет систему очков с конечным числом значений/ функцию определения значения приоритета её элементов. Например, при управлении полосой пропускания, приоритетный обмен, такой как обмен в потоках реального масштаба времени, обрабатывается с наименьшей задержкой и наименьшей вероятностью отказа. В алгоритмах наилучшего поиска, которые применяются для нахождения кратчайшего пути между двумя определёнными узлами графа, реализуется очередь с приоритетами для отслеживания не обследованных маршрутов; маршруты с более короткой оценочной длиной имеют более высокий приоритет в такой очереди.
Некое исполнение потока является самым малым элементом программирования команд. В информатике многопоточные приложения позволяют множеству потоков существовать внутри одного и того же процесса одновременно для реализации одновременной обработки и параллелизма. Многопоточность предоставляет различные преимущества во время исполнения, в виде способности к отклику, а также относительно действенности применения ресурсов.
Модуль threading в Python 3. который обычно рассматривается в качестве покрывающего более ранний модуль
thread, предоставляет эффективный, мощный и при этом представленный верхним уровнем API для работы с потоками
при реализации многопоточных приложений в Python, включая варианты для порождения новых потоков динамически, а также для синхронизации потоков
посредством различных механизмов.
Очереди и очереди с приоритезацией являются важными структурами данных в отрасли информатики, причём они являются существенным понятием в синхронной обработке и параллельном программировании. Они делают возможным для многопоточных приложений действенно исполнять и аккуратно завершать свои потоки, гарантируя то, что разделяемые ресурсы обрабатываются особым образом и при этом динамически.
В своей следующей главе мы обсудим более современные функции Python, оператор with и то, как он дополняет
использование многопоточного программирования в Python.
-
Что такое поток? В чём состоит ключевое отличие потока от процесса?
-
В чём состоят варианты, предоставляемые модулем
threadв Python? -
Что предлагают параметры, предлагаемые модулем
threadingиз Python? -
В чём состоит процесс создания новых потоков через модули
threadиthreading? -
Что стоит за основной идеей синхронизации потоков при помощи блокировки?
-
Что составляет процесс реализации синхронизации потоков с применением блокировки в Python?
-
В чём основная идея структуры данных очереди?
-
Что является основным приложением очередей для совместного программирования?
-
Что составляет центральное отличие между обычными очередями и очередями с приоритетами?
Для получения дополнительных сведений воспользуйтесь следующими ссылками:
-
Наш перевод 2 издания Python Parallel Programming Cookbook, Джанкарло Законне, Packt Publishing Ltd, сентябрь 2019
-
Learning Concurrency in Python: Build highly efficient, robust, and concurrent applications, Элиот Форбс, Packt Publishing Ltd, 2017
-
Real-time concepts for embedded systems, Кинг Ли и Кэролайн Яо, CRC Press, 2003