Глава 1. Расширенное введение в одновременность и параллельное программирование
Содержание
- Глава 1. Расширенное введение в совместное и параллельное программирование
Эта первая глава Mastering Concurrency in Python представит некий обзо того чем является параллельное программирование (в противоположность последовательному программированию). Мы вкратце обсудим те различия между программами, которые могут выполнены параллельно, а какие нет. Мы пройдёмся по истории инженерии и программированию параллельной обработки, а также мы предоставим ряд примеров того как параллельное программирование может применяться в наши дни. Наконец, мы представим некое краткое введение в тот подход, который будет использоваться в данной книге, включая основные контуры структуры глав и подробные инструкции как выгружать предлагаемый код и создать некую рабочую среду Python.
Эта глава покрывает следующие темы:
-
Понятие параллельной обработки
-
Почему некоторые программы не могут быть сделаны параллельными и как отличать их от тех, которые можно сделать такими
-
История параллельной обработки в науке о вычислениях: как она используется в этой индустрии в наши дни и что можно ожидать в будущем
-
Особые темы, которые будут рассматриваться во всех разделах/ главах этой книги
-
Как настроить среду Python и как проверять/ выгружать код с GitHub
Ознакомьтесь со следующими видеоматериалами чтобы посмотреть Код в Действии: http://bit.ly/2TAMAeR.
Существует оценка что объём данных, который требуется обрабатывать вычислительными программами удваивается каждые два года. International Data Corporation (IDC), например, делает оценку, что к 2020 году на Земле будет 5 200 ГБ данных на человека. При столь ошеломительном объёме данных возникают ненасытные требования к вычислительным мощностям и, хотя каждый день разрабатываются и используются многочисленные вычислительные технологии, параллельное программирование продолжает оставаться одним из наиболее важных способов действенной и тщательной обработки данных.
Хотя кого- то может и отпугивать появление слова "параллелизм", стоящее за этим понятие достаточно понятно интуитивно, причём оно является достаточно распространённым, даже и не в контексте программирования. Однако это вовсе не означает что такие параллельные программы настолько же просты как и последовательные; их на самом деле намного сложнее создавать и понимать. Тем не менее, как только будет достигнута правильная и эффективная параллельная структура, как вы увидите впоследствии, значительно улучшится время исполнения.
Возможно наиболее очевидным способом осознать параллельное программирование это сопоставить его с последовательным программированием. В то время как некая последовательная программа постоянно располагается в некий момент временем в одном месте, при параллельном программировании различные компоненты являются независимыми или частично независимыми и, следовательно, в одно и то же время (поскольку исполнение одного компонента не зависит от результата другого). Следующая схема иллюстрирует базовые отличия между этими двумя типами:
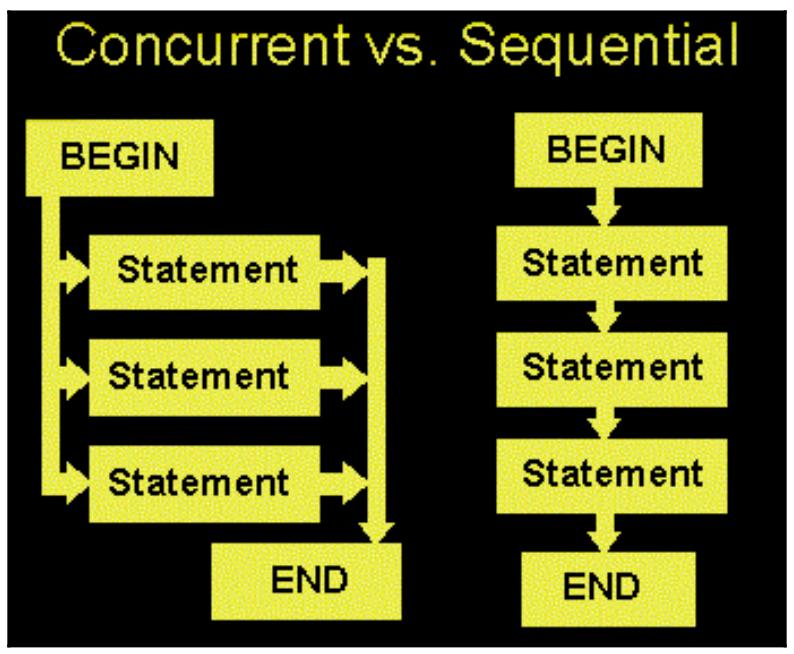
Одним из немедленно получаемых преимуществ параллельной обработки является улучшение времени исполнения. Опять же, так как некоторые задачи являются независимыми и таким образом могут завершаться одновременно, для выполнения такой программы целиком вашему компьютеру требуется меньше времени.
Давайте по- быстрому рассмотрим некий пример. Допустим, что у нас имеется некая простая функция, которая проверяет является ли некое неотрицательное число простым следующим образом:
# Chapter01/example1.py
from math import sqrt
def is_prime(x):
if x < 2:
return False
if x == 2:
return True
if x % 2 == 0:
return False
limit = int(sqrt(x)) + 1
for i in range(3, limit, 2):
if x % i == 0:
return False
return True
Кроме того, допустим что у нас имеется некий перечень достаточно больших целых (1013 до 1013 + 500)
, и мы желаем проверить являются ли каждое из них простым путём применения нашей предыдущей функции:
input = [i for i in range(10 ** 13, 10 ** 13 + 500)]
Некий последовательный подход будет простой передачей одного числа за другим в нашу функцию is_prime()
следующим образом:
# Chapter01/example1.py
from timeit import default_timer as timer
# sequential
start = timer()
result = []
for i in input:
if is_prime(i):
result.append(i)
print('Result 1:', result)
print('Took: %.2f seconds.' % (timer() - start))
Скопируйте этот код или выгрузите его из соответствующего репозитория GitHub и запустите его (воспользовавшись командой python
example1.py). Самый первый раздел вашего вывода будет чем- то аналогичным такому:
> python example1.py
Result 1: [10000000000037, 10000000000051, 10000000000099, 10000000000129, 10000000000183, 10000000000259, 10000000000267, 10000000000273, 10000000000279, 10000000000283, 10000000000313, 10000000000343, 10000000000391, 10000000000411, 10000000000433, 10000000000453]
Took: 3.41 seconds.
Вы можете отметить, что эта программа потребовала около 3.41 секунды на обработку всех чисел; вскоре мы вернёмся
к этому числу. Теперь нам также будет полезно убедиться в том насколько тяжело трудился наш компьютер при исполнении данной программы. Откройте
приложение Монитора активности в своей операционной системе и запустите свой сценарий Python снова; следующий снимок экрана отображает мои результаты:

Очевидно, что мой компьютер работал не слишком усердно, поскольку имелось почти 83% простоя.
Теперь давайте посмотрим сможет ли на самом деле параллельность помочь нам улучшить нашу программу. Наша функция is_prime()
содержит много тяжёлых вычислений и, таким образом, является хорошим претендентом на параллельное программирование. Так как определённый процесс
передачи одного числа в нашу функцию is_prime() не зависит от другой передачи, мы потенциально можем применить
одновременность для своей программы следующим образом:
# Chapter01/example1.py
# concurrent
start = timer()
result = []
with concurrent.futures.ProcessPoolExecutor(max_workers=20) as executor:
futures = [executor.submit(is_prime, i) for i in input]
for i, future in enumerate(concurrent.futures.as_completed(futures)):
if future.result():
result.append(input[i])
print('Result 2:', result)
print('Took: %.2f seconds.' % (timer() - start))
Короче говоря, мы мы расщепляем свои задачи на различные, меньшие фрагменты и запускаем их одновременно. В данный момент вам не стоит беспокоиться о специфических особенностях данного кода, так как мы обсудим данное использование пула процессов в мельчайших подробностях позднее.
Когда я исполню эту функцию, полученное время исполнения было заметно лучше, причём мой компьютер также применял больше своих ресурсов, оставаясь простаивающим только 37%:
> python example1.py
Result 2: [10000000000183, 10000000000037, 10000000000129, 10000000000273, 10000000000259, 10000000000343, 10000000000051, 10000000000267, 10000000000279, 10000000000099, 10000000000283, 10000000000313, 10000000000391, 10000000000433, 10000000000411, 10000000000453]
Took: 2.33 seconds
Соответствующий вывод нашего приложения Монитора активности будет выглядеть как- то так:

На данный момент, если у вас имеется некий опыт параллельного программирования, вы можете быть удивлены тем, что совместность (concurrency) является
чем- то иным нежели параллелизм. Основное ключевое отличие между совместным и параллельным программированием состоит в том, что в параллельной
программе существует некое число потоков обработки (в основном ЦПУ и ядер), работающих независимо по одному каждый, причём могут иметься различные потоки
обработки (в основном потоки, threads), выполняющие доступ и использующие некий разделяемый ресурс в одно и
то же время в программах совместной работы.
Поскольку такой совместный ресурс может быть считан и перезаписан любым из различных потоков, требуется некая форма управления в те моменты времени, когда наши подлежащие исполнению задачи не целиком независимы друг от друга. Иными словами, для некоторых задач важно исполняться после иных чтобы гарантировать что их программа произведёт верные результаты.
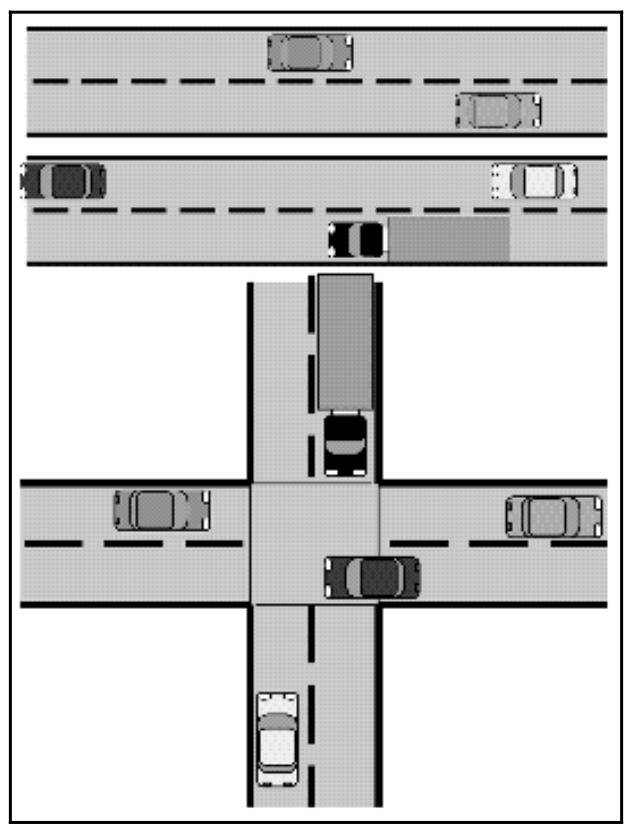
Наш предыдущий рисунок иллюстрирует основное отличие между совместностью и параллелизмом: в то время как в верхнем отсеке параллельные действия (в данном случае машин), которые не взаимодействуют друг с другом, могут исполняться в одно и то же время, в нижнем отсеке некоторым задачам приходится ждать завершения прочих чтобы они могли быть исполненными.
Позднее мы рассмотрим дополнительные примеры этих отличий.
{Прим. пер.: если контекст изложения не предполагает наличия факта совместной работы различных частей кода, мы будем себе позволять и далее переводить concurrency как параллельность или одновременность, следуя сложившейся традиции в русскоязычной терминологии. Когда же параллельность предполагает наличие неких механизмов согласования мы будем стараться употреблять при переводе concurrency совместную обработку. Concurrent programming, как правило, будет переводиться как параллельное программирование по причине сложившегося стереотипа.}
Быстрая метафора
Совместная работа - это достаточно сложное понятие чтобы его сразу полностью понять, поэтому давайте рассмотрим небольшую метафору для облегчения понимания одновременности и его отличий от параллелизма.
Хотя некоторые нейробиологи могут и не согласиться с таким подходом, давайте для краткости предположим, что различные части человеческого мозга отвечают за выполнение отдельных, исключительных действий и активностей частей тела. Например, левое полушарие мозга контролирует правую сторону тела и, следовательно, правую руку (и наоборот); или же одна часть мозга может отвечать за письмо, в то время как другая исключительно обрабатывает речевое общение.
Теперь давайте, в частности, представим первый пример. Если вы желаете переместить свою левую руку, правая сторона вашего мозга (и только эта правая сторона) обязана обработать такую команду на перемещение, что означает, что левая сторона вашего мозга свободна для обработки иной информации. Таким образом можно перемещать и применять совместно ваши левую и правую руки для выполнения различных вещей. Аналогично, имеется возможность писать и говорить в одно и то же время.
Именно это является параллелизмом: когда различные процессы не взаимодействуют и являются независимыми друг от друга. Запомните, что совместная работа не совсем похожа на параллелизм. Несмотря на то, что имеются случаи, когда процессы выполняются вместе, совместная работа также вовлекает общее использование одних и тех же ресурсов. Если параллелизм аналогичен применению левой и правой рук для независимых задач в одно и то же время, совместная работа может ассоциироваться с жонглированием, когда ваши две руки выполняют различные задачи одновременно, но они также взаимодействуют с одним и тем же объектом (в данном случае жонглёрскими шарами), а следовательно требуется некая координация между вашими двумя руками.
Не все программы разрабатываются одинаково: некоторые могут быть сделаны параллельными или совместно исполняемыми относительно просто, в то время как прочие по своей сути последовательны и таким образом не могут исполняться совместно или параллельно. Неким экстремальным примером первого являются ошеломительно параллельные программы, которые могут быть разделены на различные параллельные задачи между которыми имеется небольшая зависимость или нет её совсем, или же нет потребности во взаимодействии.
Распространённым примером ошеломительной параллельной программы является 3D рендеринг, обрабатываемый графическим процессором, при котором каждый кадр или пиксель могут обрабатываться независимо. Взлом пароля является другой ошеломляюще параллельной задачей, которая запросто может распределяться по ядрам ЦПУ. В последующих главах мы вывалим некое число аналогичных проблем, в том числе обработку изображений и вытаскивание веб данных, которые, интуитивно понятно, могут быть сделаны совместными/ параллельными, что даст в результате значительное улучшение времени исполнения.
В противоположность ошеломляюще параллельным задачам исполнение некоторых задач жёстко зависит от получаемых прочими результатов. Другими словами, эти задачи не являются независимыми и тем самым не могут быть сделаны параллельными или совместными. Более того, если мы бы попытались реализовать в эти программы совместное применение, это могло бы стоить гораздо большего времени исполнения для воспроизводства тех же самых результатов. Давайте вернёмся к своему более раннему примеру первичной проверки; ниже приводится вывод, который мы уже видели:
> python example1.py
Result 1: [10000000000037, 10000000000051, 10000000000099, 10000000000129, 10000000000183, 10000000000259, 10000000000267, 10000000000273, 10000000000279, 10000000000283, 10000000000313, 10000000000343, 10000000000391, 10000000000411, 10000000000433, 10000000000453]
Took: 3.41 seconds.
Result 2: [10000000000183, 10000000000037, 10000000000129, 10000000000273, 10000000000259, 10000000000343, 10000000000051, 10000000000267, 10000000000279, 10000000000099, 10000000000283, 10000000000313, 10000000000391, 10000000000433, 10000000000411, 10000000000453]
Took: 2.33 seconds.
Пристальнее вглядевшись, вы можете обнаружить, что полученные двумя методами результаты не являются идентичными; простые числа во втором результате являются неупорядоченными. (Напомним, что в своём втором методе для применения совместной работы мы предписали расщепление своих задач на различные группы для их одновременного исполнения, а порядок полученных результатов является тем порядком, в котором завершалась каждая задача.) Именно это является неким непосредственным результатом применения совместной работы в нашем втором методе: мы расщепили задачу на её исполнение своей программой в различных группах и наша программа обрабатывала эти задачи в таких группах в одно и то же время.
Поскольку задачи в различных группах исполнялись одновременно, в списке на входе имелись задачи, которые стояли позади прочих, но выполнились раньше этих
стоящих впереди задач. К примеру, простое число 10000000000183 идёт за
10000000000129 в нашем списке на вход, но было обработано ранее и, следовательно, идёт перед простым числом
10000000000129 в нашем списке вывода. На самом деле, если вы исполните эту программу снова и снова, получаемый второй
результат будет отличаться практически при каждом запуске.
Очевидно, что такая ситуация не желательна если тот результат, который бы мы хотели получить должен был бы быть в том же порядке, что мы имели изначально на входе. Конечно, в данном случае мы можем просто изменить полученный результат, воспользовавшись сортировкой какого- то вида, однако это будет стоить нам затрат дополнительного времени в самом конце, что сделает его даже более затратным чем первоначальный последовательный подход.
Некая концепция, которая обычно применяется для иллюстрации внутренне присущей последовательности некоторых задач это беременность: наличие нескольких женщин никогда не уменьшит продолжительность беременности. В отличии от параллельных или совместных задач, в которых увеличение числа обрабатывающих элементов улучшает общее время исполнения, добавление большего числа процессоров в задачи со врождённой последовательностью не даст выигрыша. Известными примерами с внутренне присущей упорядоченностью являются итеративные алгоритмы: метод Ньютона, итерационные задачи трёх тел или итерационные методы численного приближения {Прим. пер.: конечно- разностные решения дифференциальных уравнений эллиптического типа.}
Пример 2 - последовательные по своей сути задачи
Давайте рассмотрим быстрый пример.
Вычислим ƒ1000(3) с ƒ(x) = x2 + 1 и
ƒn+1(x) = ƒ(ƒn(x)).
Для сложных функций наподобии ƒ (когда относительно сложно отыскать некий общий вид
ƒn(x)), единственный очевидно разумный способ вычисления
ƒ1000(3) или аналогичных значений состоит в итеративном вычислении
ƒ2(3) = ƒ(ƒ(3)),
ƒ3(3) = ƒ(ƒ2(3)), ... ,
ƒ999(3) = ƒ(ƒ998(3)) и, наконец,
ƒ1000(3) = ƒ(ƒ999(3)).
Так как вычисление на самом деле ƒ1000(3) отнимет много времени, даже с применением компьютера,
мы рассмотрим в своём коде только ƒ20(3) (мой ноутбук начал перегреваться после
ƒ25(3)):
# Chapter01/example2.py
def f(x):
return x * x - x + 1
# sequential
def f(x):
return x * x - x + 1
start = timer()
result = 3
for i in range(20):
result = f(result)
print('Result is very large. Only printing the last 5 digits:', result % 100000)
print('Sequential took: %.2f seconds.' % (timer() - start))
Запустите его (или воспользуйтесь python example2.py); приводимый ниже код отображает полученный мной вывод:
> python example2.py
Result is very large. Only printing the last 5 digits: 35443
Sequential took: 0.10 seconds.
Теперь, если мы попытаемся применить совместную работу для данного сценария, единственный возможный путь состоял бы в применении цикла
for. Одно из решений может быть таким:
# Chapter01/example2.py
# concurrent
def concurrent_f(x):
global result
result = f(result)
result = 3
with concurrent.futures.ThreadPoolExecutor(max_workers=20) as exector:
futures = [exector.submit(concurrent_f, i) for i in range(20)]
_ = concurrent.futures.as_completed(futures)
print('Result is very large. Only printing the last 5 digits:', result % 100000)
print('Concurrent took: %.2f seconds.' % (timer() - start))
Полученный мной вывод отображён ниже:
> python example2.py
Result is very large. Only printing the last 5 digits: 35443
Concurrent took: 0.19 seconds.
Даже несмотря на то, что оба метода предоставляют один и тот же результат, наш совместный метод отнимает почти в два раза больше времени нежели последовательный
метод. Это обусловлено тем, что всякий раз когда порождается новый поток (из ThreadPoolExecutor), наша функция
conconcurrent_f(), внутри этого потока, требует дождаться обработки в предыдущем потоке значения переменной
result, а сама программа в целом, таким образом исполнялась, несмотря ни на что, последовательным образом.
Итак, в действительности в нашем втором методе не привлекалась никакая совместность при обработке, а полученная стоимость накладных расходов порождения новых потоков внесла значительное ухудшение в значение времени исполнения. Это один из примеров внутренне присущей последовательности задач, при которой совместная работа и параллелизм не следует применять в попытке улучшения времени исполнения.
Другим вариантом задуматься о последовательной обработке является понятие (из информатики) условия, имеющего название ограничений ввода/ вывода, при котором значение требуемого ему времени для завершения вычислений в основном определяется тем временем, которое тратится на ожидание завершения операций ввода/ вывода (I/O). Это условие появляется когда значение скорости с которой запрашиваются данные медленнее значения скорости с которой они потребляются, или, более кратко, больше времени тратится на запрос данных, нежели на их обработку.
При некотором состоянии ограниченности вводом/ выводом, основной ЦПУ глушит свои операции, ожидая данные для обработки. Это означает, что даже если такой ЦПУ быстрее обрабатывает данные, процессы имеют тенденцию не увеличивать скорость пропорционально росту скорости ЦПУ, так как они получают дополнительное сдерживание вводом/ выводом. При том что более быстрая скорость вычислений является основной первичной целью проектирования нового компьютера и процессора, состояния ограничения вводом/ выводом становятся нежелательными, но при этом всё более и более распространёнными в программах.
Как вы видите, существует ряд ситуаций в которых ваше приложение совместного программирования имеет результатом снижение скорости обработки и их следует избегать. Поэтому нам важно не рассматривать совместную обработку как некий золотой билет, который способен безусловно произвести лучшее время исполнения, а также понимать отличия между структурами программ, которые выигрывают от совместной обработки и которые не получают от неё преимуществ.
В наших последующих подразделах мы обсудим прошлое, настоящее и будущее совместной обработки.
Область параллельного программирования пользуется значительной популярностью с самых ранних дней науки о вычислениях. В этом разделе мы обсудим как начиналось параллельное программирование и эволюцию его истории, его текущее применение в данной отрасли, а также некие предсказания относительно того как совместная обработка будет применяться в будущем.
Понятие совместной обработки существует уже долгое время. Основная идея возникла в ранних работах с железными дорогами и телеграфом в девятнадцатом и начале двадцатого веков, причём некоторые термины даже дошли до наших дней (такие, как семафор, который указывает некую переменную, которая указывает на переменную, управляющую доступом к общему ресурсу в совместных программах). Одновременность впервые была применена для решения вопроса о том, как обрабатывать несколько поездов в одной и той же железнодорожной системе чтобы избежать столкновений и максимизировать эффективность, а также как обрабатывать множество обменов по фиксированному набору проводов в раннем телеграфе.
Значительная часть теоретических основ параллельного программирования фактически была заложена в 1960е. Самый ранний алгоритмический язык ALGOL 68, который впервые был разработан в 1959 {Прим. пер.: так в авторском тексте, на самом деле Алгол 68 был выпущен в 1968 году, а разрабатывался в 1964- 1968 годах и является совершенно другим языком, нежели выпущенный в 1958- 1959 годах Алгол 60, несмотря на некую преемственность языковых примитивов. Алгол 60 не имел никаких элементов параллельного программирования.}, содержал средства, которые выполняли поддержку совместного программирования. Академическое изучение параллелизма официально началось с основополагающей работы Эдсгера Дейкстры, который был пионером в области науки о вычислениях, наиболее известным благодаря алгоритму поиска пути, названному в его честь.
Эта плодотворная статья, рассматривается как самый первый документ в области параллельного программирования, в котором Дейкстра определил и разрешил проблему взаимного исключения. Взаимное исключение, которое является неким свойством управления одновременностью, предотвращающим состояние состязательности (что мы обсудим позднее), стало одной из самых обсуждаемых тем в параллельной обработке.
Тем не менее, после этого не было значительного интереса. {Прим. пер.: так в авторском тексте, на самом деле важной эпохой явился язык Ада, появившийся в начале 1980х, который привнёс понятия задач с их разделением на интерфейс и реализацию, оператор accept, защитников - guards, защищённые объекты, оператор select для неблокирующих вызовов, подпись в точках входа для согласованности, механизм рандеву и многое другое).} Начиная примерно с 1970 до ранних 2000, о процессорах говорилось, что они удваивают скорость исполнения каждые 18 месяцев. На протяжении этого периода программистам не было нужды заниматься параллельным программированием, поскольку всё, что им нужно было сделать чтобы их программы работали быстрее, это подождать. Однако в начале 2000-х произошла смена парадигмы в процессорном бизнесе; вместо того чтобы выпускать всё более большие и быстрые процессоры для компьютеров, производители стали сосредотачиваться на более медленных процессорах меньшего размера, которые помещались вместе в группы. Именно в это время компьютеры начали иметь процессоры со множеством ядер. {Прим. пер.: следует также обратить внимание на тот факт, что фактически отрасль упёрлась в проблему невозможности дальнейшего увеличения тактовой частоты, а в ближайшие годы мы станем свидетелями нового порога - предела миниатюризации элементов ЦПУ в одном слое материала процессора, обусловленного его размерами его атомов.}.
В наши дни среднестатистический компьютер имеет более одного ядра. Поэтому, если программист создаёт все свои программы как не применяющие параллелизм в каком- то виде, он обнаружит что его программы используют только одно ядро или один поток для обработки данных, в то время как остальной ЦПУ простаивает, не делая ничего (что мы уже наблюдали в своём разделе Пример 1 - проверка является ли неотрицательное число простым). Именно это является одной из причин недавнего рывка в развитии параллельного программирования.
Другой причиной для роста популярности параллельной обработки является увеличение области разработки графических, мультимедийных и основанных на веб приложений, в которых широко применяются приложения одновременности для решения сложных и многогранных задач. Например, параллельность является основным игроком в веб разработке: всякий выполняемый пользователем новый запрос превращается в свой собственный процесс (это именуется многопроцессностью; см. Главу 6, Работа с процессами в Python) или асинхронно координируется с прочими запросами (это называется асинхронным программированием; см. Главу 9, Введение в асинхронное программирование); если какой- либо из этих запросов требует доступа к некоему общему ресурсу (например, к базе данных), в котором могут быть изменены данные, следует принимать во внимание совместную обработку.
Рассматривая наши дни, в которые взрывообразный рост Интернета и совместного использования данных происходит каждую секунду, совместная обработка становится ещё более важной чем раньше. Текущее применение параллельного программирования придаёт особое значение корректности, производительности и надёжности.
Некоторые совместные системы, например, операционные системы или систему управления базами данных являются в целом спроектированными для независимой работы, включая автоматическое восстановление после сбоев, а также внезапных остановок. Как уже упоминалось ранее, совместные системы применяют общие ресурсы и таким образом они требуют некий вид семафоров в своей реализации для управления доступом к таким ресурсам и его координацией.
Параллельное программирование достаточно повсеместно распространено в области разработки программного обеспечения. Вот некоторые примеры, в которых присутствует совместная обработка:
-
Совместная обработка играет важную роль в большинстве современных языков программирования: C++, C#, Erlang, Go, Java, Julia, JavaScript, Perl, Python, Ruby, Scala и тому подобных.
-
Опять- таки, поскольку почти все компьютеры в наши дни имеют более одного ядра в своём ЦПУ, настольные приложения требуют наличия возможности пользоваться преимуществами этой вычислительной мощности для предоставления на самом деле хорошо спроектированного программного обеспечения.
-
Выпущенный в 2011 iPhone 4S имел ЦПУ с двумя ядрами, поэтому разработчики мобильных приложений также оказались подключёнными к параллельным приложениям.
-
Что касается видеоигр, два основных игрока на текущем рынке это Xbox 360, который является системой со множеством ЦПУ и PS3 Sony, которая является существенно многоядерной системой.
-
Даже в текущей итерации $35 Raspberry Pi строится на примерно четырёхядерной системе..
-
Имеется оценка, что в среднем Google обрабатывает 40 000 запросов на поиск каждую секунду, что эквивалентно 3.5 миллиардов поисков в день и 1.2 триллиона поисков в год во всём мире. Помимо наличия массивных машин с невероятной вычислительной мощностью, одновременность является наилучшим способом обработки такого количества запросов.

Большой процент современных данных и приложений хранится в определённом облаке. Так как вычислительные экземпляры в этом облачном решении относительно малы в размере, почти каждое веб приложение таким образом усиливается совместной обработкой, обрабатывая различные небольшие задания одновременно. По мере того, как оно получает больше клиентов и должно обрабатывать больше запросов, хорошо спроектированное веб приложение может просто применять больше серверов, придерживаясь всё той же логики; это соответствует упоминавшемуся ранее свойству устойчивости к сбоям (робастности).
Даже во всё более популярных отраслях искусственного интеллекта и науки о данных значительные успехи отчасти были достигнуты именно благодаря доступности высокопроизводительных графических карт (GPU), которые применяются в качестве механизмов параллельных вычислений. Во всех значимых конкурсах на крупнейшем сайте по науке о данных (www.kaggle.com/), почти все получившие приз решения имеют некий вид применения GPU на этапе процесса обучения. Благодаря огрмному количеству данных, которые следует обрабатывать моделям Больших данных, совместная обработка обеспечивает действенное решение. Некоторые алгоритмы ИИ даже предназначены для разделения входных данных на более мелкие части и их независимой обработки, что является великолепной возможностью применять параллелизм ждля достижения лучшего времени обучения модели.
В наши дни пользователи компьютера/ интернета ожидают моментального вывода, вне зависимости от того какие приложения они применяют и разработчики зачастую сталкиваются с задачей предоставления наилучшей скорости для своих приложений. С точки зрения применения, распараллеливание продолжает оставаться одним из основных игроков в той области программирования, которая предоставляет уникальные и инновационные решения данных проблем. Как уже упоминалось ранее, будь то проектирование видеоигр, мобильных приложений, настольного программного обеспечения или веб разработка, одновременное исполнение является, есть и будет оставаться вездесущей в будущем.
Принимая во внимание необходимость поддержки распараллеливания в приложениях, кое- кто может утверждать, что параллельное программирование может стать стандартным в академических кругах. Несмотря на то, что особые темы в совместной обработке и параллелизме обсуждаются в курсах по науке о вычислениях, углублённые, сложные предметы параллельного программирования (как теоретически, так и прикладные) будут реализовываться на курсах бакалавриата и магистратуры для лучшей подготовки студентов к той отрасли, в которой совместная обработка применяется ежедневно. Курсы информатики по построению систем совместной обработки изучению потоков данных, а также анализу совместно обрабатываемых и параллельных структур являются только началом.
Кое- кто может скептически рассматривать будущее параллельного программирования. Некоторые могут говорить что совместная обработка в действительности относится к анализу зависимостей: подобласти той теории вычислений, которая анализирует ограничения порядка выполнения между операторами/ инструкциями и определяет будет ли безопасно для некоторой программы переупорядочить или распараллелить свои операторы. Кроме того, поскольку очень небольшое число программистов на самом деле понимает совместную обработку и все её сложности, потребуется толчок для компиляторов, совместно с сопровождением со стороны операционной системы для того чтобы взять на себя всю ответственность за фактическую реализацию совместной обработки в конкретных программах, которые они компилируют по своему усмотрению.
В частности, в будущем программистам не придётся заботиться о концепциях и проблеммах параллельного программирования, и в этом даже не будет нужды. Некий алгоритм, реализуемый на уровне компилятора должен просматривать саму компилируемую программу, анализировать её операьоры и инструкции, производить некий граф зависимостей для определения оптимального порядка исполнения для этих операторов и инструкций и применять совместную обработку/ параллелизм там где они подходят и являются действенными. Короче говоря, сочетание небольшого числа программистов, понимающих системы совместной обработки и способных с ними действенно работать, а также возможность автоматизации проектирования одновременной обработки приведут к снижению интереса к параллельному программированию.
В конце концов, только время покажет то ожидает параллельное программирование в будущем. Мы, программисты, можем только наблюдать за тем, как совместная обработка используется в настоящее время в реальном мире и определять стоит ли его изучать или нет: что, как мы видим в данном случае так и есть. Более того, даже несмотря на наличие жёсткой взаимосвязи между проектирование параллельных программ и анализом зависимостей, лично я рассматриваю параллельное программирование как более запутанный и сложный процесс, который с большим трудом поддаётся автоматизации.
Параллельное программирование на самом деле очень сложное и очень трудно понимается верным образом, но это также и означает, что полученные в процессе освоения знания дадут преимущества и окажутся полезными для всех программистов и я полагаю, что это достойная причина изучения совместной обработки. Возможность анализа имеющихся проблем ускорения программ, реструктуризация ваших программ в различные независимые задачи и координация этих задач для использования одних и тех же ресурсов являются основными навыками, которые приобретают программисты при работе с совместной обработкой, а знания этих тем помогут им также и в прочих задачах программирования.
Python является одним из наиболее популярных языков программирования и на это имеются веские причины. Этот язык поставляется с многочисленными библиотеками и средами сопровождения, которые способствуют высокопроизводительным вычислениям, будь то разработка программного обеспечения, веб- разработка, анализ данных или машинное обучение. Тем не менее, среди разработчиков имелись дискуссии, критикующие Python, которые зачастую вращаются вокруг его GIL (Global Interpreter Lock - Глобальной блокировки интерпретатора) и проистекающей из неё сложности реализации совместных и параллельных программ.
В то время как совместная обработка и параллелизм на самом деле ведут себя не так как в прочих распространённых языках программирования, всё же имеется возможность для программистов реализовывать программы Python, которые исполняются совместно или параллельно и достигают значительного ускорения своих программ.
Mastering Concurrency in Python послужит выразительным введением в различные передовые концепции совместной инженерной разработки и программирования на Python. Данная книга также предоставит подробный обзор того как совместная обработка и параллелизм применяются в приложениях реального мира. Это идеальное сочетание теоретического анализа и практических примеров, которые снабдят вас полным пониманием теорий и методов относительно программирования совместной обработки в Python.
Эта книга будет подразделена на шесть основных разделов. Она начинается с основной идеи, стоящей позади совместной обработки и параллельного программирования - история, как они применяются в данной отрасли в наши дни и, наконец, математического анализа ускорения, которое потенциально может предоставлять совместная обработка. Кроме того, самый последний раздел в этой главе (который является нашим следующим разделом) рассмотрит инструкции относительно того как следовать имеющимся образцам кодов из этой книги, в том числе настройку среды Python в вашем собственном компьютере, выгрузке/ клонированию содержащегося в этой книге кода из GitHub, а также запускать все примеры на вашем компьютере.
Следующие три раздела обсудят три основных подхода реализации в программировании совместной обработки, соответственно: потоки, процессы и асинхронный ввод/ вывод. Эти разделы содержат теоретические понятия и принципы для каждого из перечисленных подходов, имеющийся синтаксис и различные функциональности, которые язык Python предоставляет для их поддержки, обсуждение наилучших практических приёмов для их расширенного применения, а также проекты из реальной практики, которые напрямую применяют эти концепции для решения задач повседневной жизни.
Пятый раздел представит читателю введение в некоторые из наиболее распространённых проблем, с которыми сталкиваются инженеры и программисты при параллельном программировании: взаимная блокировка, зависание и состояние состязательности. Читатели изучат теоретические основы и то, что вызывает каждую из проблем, проанализируют и реплицируют их в Python и, наконец, реализуют потенциальные решения. Самая последняя глава в этом разделе обсудит вышеупомянутый GIL, который является специфичным именно для языка Python. Я обсужу основную интегрирующую роль GIL в экосистеме Python, некоторые вызовы, которые GIL бросает параллельному программированию и как реализовывать действенные пути обхода.
В самом последнем разделе данной книги мы поработаем с различными передовыми приложениями программирования совместной обработки на Python. Эти приложения будут содержать архитектуру свободную от блокировок и структуры данных совместно обработки на основе блокирования, модели памяти и операции атомарных типов, а также как построить с нуля некий сервер, который поддерживает обработку одновременных запросов. Этот раздел также обсудит наилучшие практические приёмы при тестировании, отладке и планировании приложений совместной обработки Python.
На протяжении данной книги вы приобретёте существенные навыки для работы с программами совместной обработки, просто следуя приводимым обсуждению, примерам кода и практическим проектам. Вы начнёте понимать основы наиболее важных понятий в параллельном программировании, как их реализовывать в программах Python и как применять это знание для расширения приложений. К концу Mastering Concurrency in Python вы получите уникальное сочетание интенсивных теоретических знаний относительно совместной обработки и практические навыки различных приложений параллельности в языке программирования Python.
Как уже упоминалось ранее, одна из сложностей, с которой сталкиваются разработчики при работе с совместной обработкой в языке программирования Python (в частности, CPython - эталонной реализации Python, написанной на C), это GIL. Механизм GIL является средством взаимной блокировки, которое защищает доступ к объектам Python, предотвращая одновременное исполнение кодов байт Python во множестве потоков. Такая блокировка необходима в основном по той причине, что управление памятью CPython не является ориентированной на многопоточное исполнение (not thread-safe). CPython использует счётчик ссылок при реализации своего управления памятью. Это в результате приводит к тому факту, что множество потоков могут выполнять доступ и исполнять код Python одновременно; такая ситуация является нежелательной и она может вызывать неверную обработку данных и мы говорим что такой тип управления памятью не является ориентированным на многопоточное управление. Для решения данной проблемы и существует GIL, как свидетельствует его название, некая блокировка, которая допускает всего лишь один поток для доступа к коду и объектам Python. Тем не менее, это также означает, что для реализации в CPython программ со множеством потоков разработчики обязаны знать о GIL и обходить его. Именно по этой причине много кто имеет проблемы при реализации систем совместной обработки в Python.
Итак, зачем мы вообще применяем Python для совместной обработки? Даже несмотря на то, что GIL не позволяет программам CPython со множеством потоков получать все преимущества мультипроцессорных систем в определённых ситуациях, большая часть операций с блокировкой или длительным исполнением, такие как ввод/ вывод, обработка изображений, а также перемалывание чисел в NumPy происходят вне имеющегося GIL. Таким образом, сам GIL становится потенциальным узким местом только для программ со множеством потоков, которые тратят значительное время внутри GIL. Как вы увидите в последующих главах, многопоточность всего лишь является неким видом программирования совместной обработки и хотя GIL и бросает определённые вызовы для программ CPython с многопоточностью, которые допускают более чем одному потоку осуществлять доступ к общим ресурсам, прочие формы параллельного программирования не имеют данной проблемы. Например, приложения со множеством процессов, которые не разделяют никакие общие ресурсы между процессами, такие как ввод/ вывод, обработка изображений или перемалывание чисел NumPy могут бесшовно работать с GIL. Мы обсудим сам GIL и его место в экосистеме Python более подробно в Главе 15, Глобальная блокировка интерпретатора.
Помимо этого, Python получил всё растущую популярность в сообшестве программирования. Благодаря дружелюбному к пользователю синтаксису и общей читабельности, всё больше и больше людей полагают, что применять Python в своей разработке относительно просто, будь то новичок, изучающий новый язык программирования, пользователи со средним уровнем подготовки в поиске для имеющихся современных функциональных возможностей Python, или опытные программисты, применяющие Python для решения сложных задач. Существуют оценки, что разработка кода Python может оказываться до 10 раз более быстрой, чем кодирование C/C++.
Большое число применяющих Python разработчиков добились в результате мощного, всё ещё продолжающего рост сообщества. Каждый день разрабатываются и выпускаются библиотеки и пакеты на Python, снабжая различные задачи и технологии. В настоящее время язык Python поддерживает невероятно широкий диапазон программирования - а именно, разработку программного обеспечения, GUI рабочих мест, проектирование видеоигр, веб- и интернет- разработку, а также научные и численные вычисления. В последние годы Python также вырос как один из топовых инструментов в науке о данных, Больших данных, а также машинном обучении, соревнуясь с долговременным игроком в этой области, R.
Огромное число доступных в Python инструментов разработки побудило всё большее число разработчиков начинать программированть на Python, что делает Python ещё более популярным и простым в применении; Я называю это заколдованным кругом Python. Дэвид Робинсон, научный руководитель DataCamp написал некий блог относительно невероятного роста Python и назвал его наиболее популярным языком программирования.
Тем не менее, Python является медленным, по крайней мере медленнее прочих пользующихся популярностью языков программирования. Это обусловлено тем, что Python является языком с динамической типизацией, интерпретирующим, в котором значения хранятся не в плотных буферах, а в разбросанных объектах. Это прямой результат читабельности и удобства применения Python. К счастью, существуют различные варианты того, как заставить вашу программу Python работать быстрее, причём параллелизм является одним из самых сложных среди них; и именно это мы собираемся освоить в данной книге.
Прежде чем мы двинемся дальше, давайте пройдём по некому числу описаний относительно того как настроить необходимые инструменты, которые вы будете применять в этой книге. В частности, мы обсудим сам процесс получения дистрибутива Python для вашей системы и подходящей среды разработки, а также как выгружать тот код, который применяется в примерах, содержащийся во всех главах данной книги.
Давайте рассмотрим собственно процесс получения некоего дистрибутива Python для вашей системы и соответствующей среды разработки:
-
Все разработчики могут получить свой собственный дистрибутив Pyton c https://www.python.org/downloads/.
-
Даже несмотря на то, что поддерживаются и сопровождаются обе версии, и Python 2, и Python 3, на протяжении всей этой книги мы будем применять Python 3.
-
Для данной книги гибким вариантом будет IDE (integrated development environment, интегрированная среда разработки). Хотя технически возможно разрабатывать приложения Python при помощи минимального текстового редактора, такого как Notepad или TextEdit, обычно намного проще читать и писать код при помощи IDE, целенаправленно разработанного под Python. Они включают в свой состав: IDLE, PyCharm, Sublime Text и Atom.
Для получения того, кода, который применяется на протяжении всей этой книги вы можете выгрузить репозиторий с GitHub, который содержит все примеры и код проекта, описываемые в книге:
-
Для начала посетите https://github.com/PacktPublishing/Mastering-Concurrency-in-Python.
-
Для выгрузки соответствующего репозитория просто кликните по кнопке Clone or download в правом верхнем углу своего окна. Выберите Download ZIP для выгрузки необходимого сжатого репозитория на свой компьютер:
-
Распакуйте выгруженный файл для создания искомой нами папки. Эта папка должна иметь название
Mastering-Concurrency-in-Python.

Внутри полученной папки будут расположены отдельные папки, озаглавленные ChapterXX, указывающие ту главу,
которая содержит соответствующий код в этой папке. К примеру, папка Chapter03 содержит все примеры и код проекта,
обсуждаемые в Главе 3, Работа с потоками в Python. В каждой вложенной папке имеются различные сценарии
Python; по мере того как вы проходите каждый образец кода из этой книги, вы определите какой именно сценарий запускать по конкретному указателю в каждой
из глав.
Теперь вы изучили азы понятий совместного и параллельного программирования. Всё это относится к проектированию и структурному программированию команд и инструкций с тем, чтобы разные разделы вашей программы могли исполняться неким действенным образом, и в то же время совместно применять те же самые ресурсы. Поскольку когда некоторые команды и инструкции исполняются одновременно сберегается время, параллельное программирование предоставляет значительное улучшение времени исполнения программы при сопоставлении с традиционным последовательным программированием.
Тем не менее, при проектировании какой- то параллельной программы следует принимать во внимание различные факторы. В то время как существуют особые задачи, которые могут быть запросто разбиты на независимые разделы, которые могут исполняться параллельно (ошеломляюще параллельные задачи), прочие требуют различных видов координации между имеющимися командами программы, с тем, чтобы такие совместные ресурсы могли применяться правильно и эффективно. Также имеются и задачи с внутренне присущей им последовательной обработкой, в которых никакие совместная обработка и параллелизм не могут применены для получения ускорения программы. Вам следует знать такие фундаментальные отличия между этими задачами с тем, чтобы вы могли аккуратно проектировать свои программы совместной обработки.
В последнее время произошёл сдвиг парадигмы, который облегчил реализацию совместной обработки в большинстве сторон существующей вселенной программирования. Теперь совместную обработку можно обнаружить повсеместно: настольные и мобильные приложения, видео игры, веб- и интернет- разработка, ИИ и так далее. Совместная обработка всё ещё растёт и, как ожидается, продолжит расти и в будущем. Поэтому для любого опытного программиста крайне важно понимать совместную обработку и относящиеся к ней концепции, а также знать как интегрировать эти понятия в свои приложения.
С другой стороны Python является одним из наиболее (если не самый) популярных языков программирования. Он предоставляет варианты в большинстве подотраслей программирования. Объединение совместной обработки и Python таким образом является одной из наиболее важных тем для изучения и освоения в программировании.
В нашей следующей главе, Закон Амдала, мы обсудим насколько значительны возможные улучшения для ускорения, которые предоставляются нашей программе совместной обработкой. Мы проанализируем основную формулу Закона Амдала, обсудим её последствия и рассмотрим примеры Python.
-
Какая основная идея стоит за совместной обработкой и почему она плодотворна?
-
Что составляет отличия программирования совместной обработки и последовательное программирование?
-
В чём основная разница между программированием совместной обработки и параллельным программированием?
-
Может ли всякая программа быть превращена в совместную или параллельную?
-
Что представляют из себя задачи с ошеломительной параллельностью?
-
Что такое задачи с врождённой последовательностью?
-
Что понимается под ограничением со стороны ввода/ вывода?
-
Как совместная обработка в настоящее время применяется в реальном мире?
Для получения дополнительных сведений вы можете воспользоваться следующими ссылками:
-
Наш перевод 2 издания Python Parallel Programming Cookbook, Джанкарло Законне, Packt Publishing Ltd, сентябрь 2019
-
Learning Concurrency in Python: Build highly efficient, robust, and concurrent applications, Elliot Forbes, Packt Publishing Ltd, 2017.
-
The historical roots of concurrent engineering fundamentals. IEEE Transactions on Engineering Management 44.1 (1997): 67-78, by Robert P. Smith.
-
Programming language pragmatics, 4th ed., Michael Lee Scott, Morgan Kaufmann, 2015 {Прим. пер.: в библиографии автора ссылка на первое издание 2000 года.}