Глава 6. Работа с процессами в Python
Содержание
Данная глава является самой первой из трёх глав по применение совместной обработки посредством многопроцессного программирования в Python.
Мы рассмотрели различные образцы процессов, используемых в совместном и параллельном программировании. В этой главе вы получите введение в формальное
определение процесса, а также модуль Python multiprocessing. Данная глава пройдёт некоторыми наиболее
распространёнными способами работы с процессами с применением API этого модуля multiprocessing, такими как
класс Process, класс Pool и инструментами межпроцессного взаимодействия,
такими как класс Queue. Эта глава также рассмотрит ключевые отличия между многопоточностью и множеством
процессов в совместном программировании.
В данной главе будут рассмотрены следующие темы:
-
Само понятие процесса в контексте совместного программирования в информатике
-
Основы API модуля Python
multiprocessing -
Как осуществлять взаимодействие с процессами и те расширенные функции, которые предоставляет модуль
multiprocessing -
Как модуль
multiprocessingподдерживает взаимодействие между процессами -
Основные ключевые отличия между многопроцессностью и многопоточностью при совместном програмировании
{Прим. пер.: тем, кому интересно ознакомиться с новой реализацией параллельности в Python, появившейся начиная с версии 3.9, подчинённым интерпретатором, рекомендуем наш перевод Внутреннее устройство CPython Энтони Шоу, изданной в январе 2021 RealPython.}
Вот перечень предварительных требований для данной главы:
-
Убедитесь что на вашем компьютере уже установлен Python 3
-
Выгрузите необходимый репозиторий из GitHub
-
На протяжении данной главы мы будем работать с вложенной папкой, имеющей название
Chapter06 -
Ознакомьтесь со следующими видеоматериалами Code in Action
В сфере информатики, некий процесс исполнения является каким- то экземпляром определённой компьютерной программы, или программного обеспечения, которое подлежит исполнению со стороны операционной системы. Некий процесс содержит как собственно код программы, так и его текущие операции и взаимодействия с прочими сущностями. В зависимости от операционной системы, сама реализация процесса может выполняться из множества потоков исполнения, которые могут исполнять инструкции совместно или параллельно.
Важно отметить, что некий процесс не эквивалентен какой- то программе компьютера. В то время как некая программа являет собой просто какой- то статичный набор инструкций (код программы), некий процесс является вместо этого реальным исполнением таких инструкций. Это также означает, что одна и та же программа может быть запущена одновременно путём порождения множества процессов. Эти процессы исполняют тот же самый код из одной родительской программы.
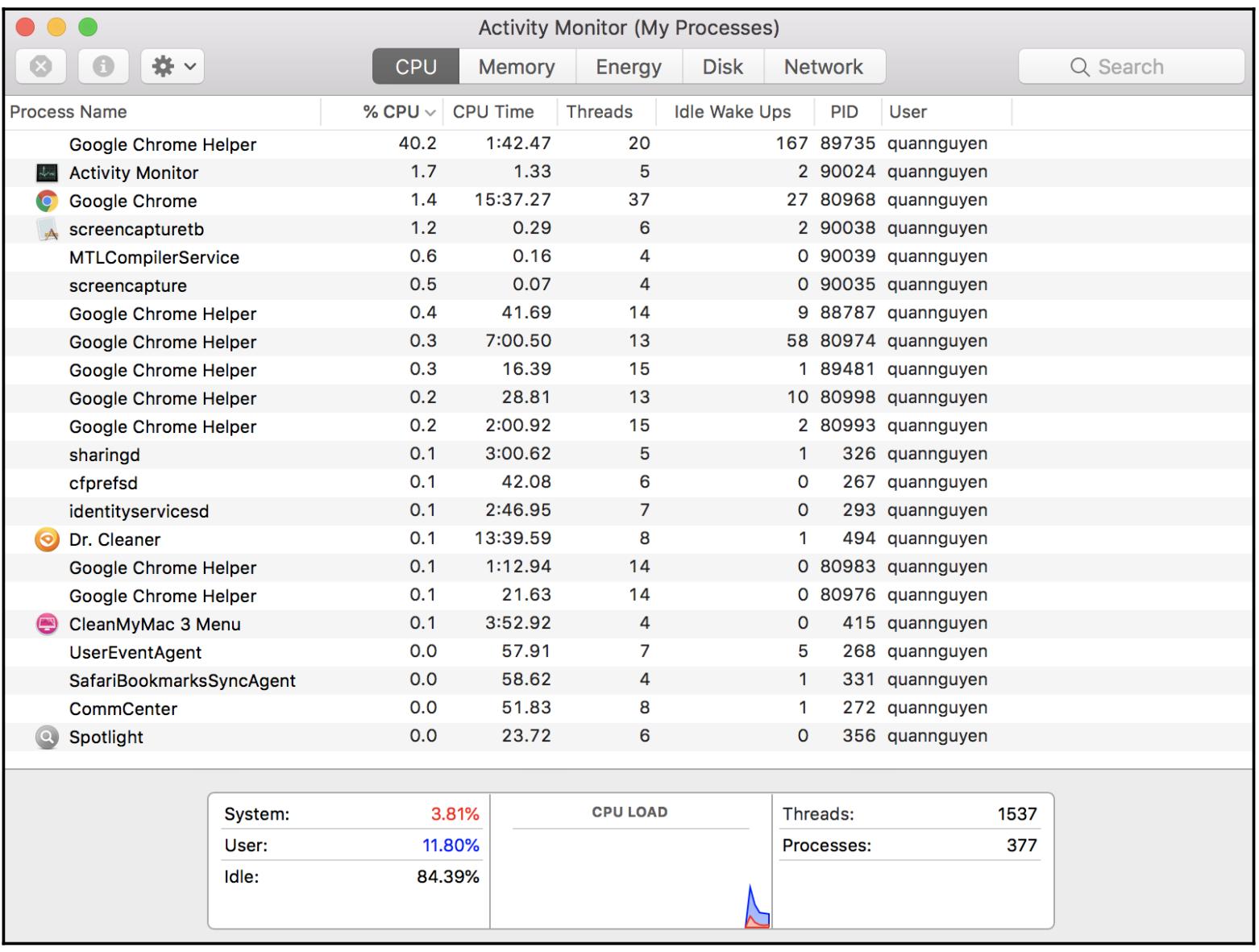
Например, интернет браузер Google Chrome обычно управляет неким процессом с названием Google Chrome Helper в качестве его основной программы чтобы снабжать веб просмотр и прочие процессы помощью в различных целях. Самый простой способ увидеть различные процессы вашей системы состоит в запуске и управлении, вовлекающим в себя использование Task Manager для Windows, Activity Monitor для iOS и System Monitor для операционных систем Linux.
Ниже приводится экранный снимок моего Activity Monitor. В этом списке можно обнаружить множество процессов с названием Google Chrome Helper. В колонке PID (что является сокращением от process ID) сообщается значение уникального идентификатора, который имеет каждый такой процесс:
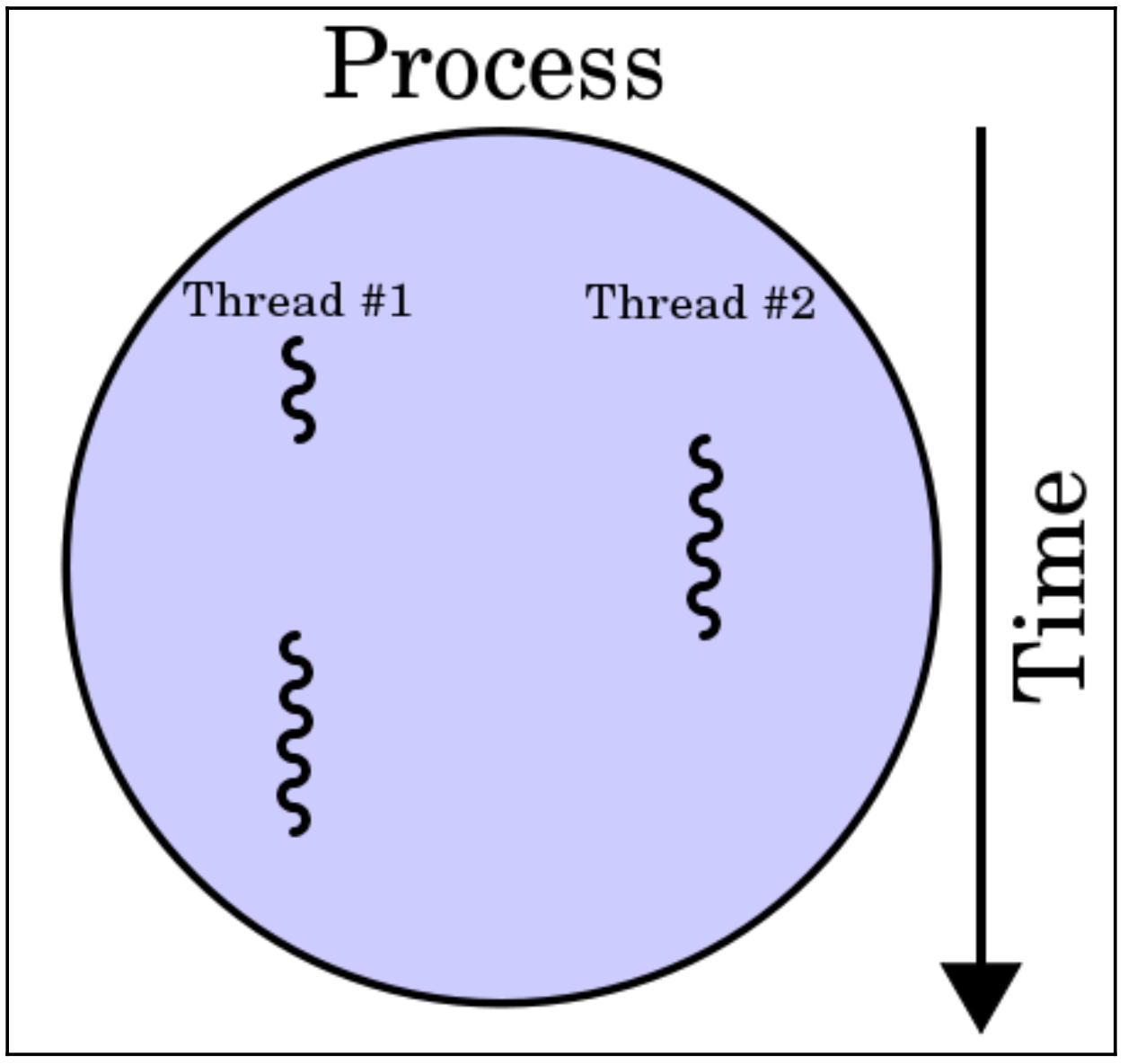
Одной из самых распространённых ошибок, которую делают программисты при разработке совместных или параллельных приложений состоит в путанице имеющейся структуры и функций процессов и потоков. Как мы уже видели в Главе 3, Работа с потоками в Python, некий поток является наименьшим элементом программного кода и обычно он является каким- то компонентом процесса. Более того, внутри одного и того же процесса может быть реализовано более одного потока для доступа и совместного использования памяти и прочих ресурсов, в то время как различные процессы не взаимодействуют таким образом. Такая взаимосвязь отображена на следующей схеме:
Поскольку некий процесс является элементом большего размера нежели поток, он также и более сложен и составлен из большего числа программных компонент. Некий процесс, таким образом, также требует больших ресурсов, в то время как для потока это не так и иногда он именуется процессом с малым весом. В типичном процессе вычислительной системы имеется целый ряд основных ресурсов, отображаемых следующим списком:
-
Некий образ (или копия) того кода, который подлежит исполнению из своей родительской программы.
-
Память, связанная с неким экземпляром программы. Она должна содержать исполняемый код, входные и выходные данные для этого конкретного процесса, стек вызовов для управления событиями программы ии же некую кучу, которая содержит вырабатываемые вычислениями данные и используемые данным процессом на протяжении времени исполнения.
-
Дескрипторы для тех ресурсов, которые выделены этому конкретному процессу со стороны ео операционной системы. Мы видели некий пример этого - файловые дескрипторы - в Главе 4, Применение оператора with в потоках.
-
Компоненты безопасности некоторого определённого процесса, а именно, самого владельца этого процесса и его полномочия, а также допустимые операции.
-
Собственно состояние процессора, также именуемое контекстом данного процесса. Данные такого контекста некоторого процесса часто находятся в регистрах процессора, той оперативной памяти, которая используется этим процессором или в регистрах управления, используемых его операционной системой для управления самим процессом.
Так как каждый процесс имеет некое выделенное ему состояние, процессы поддерживают больше информации о состоянии нежели потоки; множество процессов внутри некоего процесса, в свою очередь, совместно используют состояния процесса, память и прочие разнообразные ресурсы. По аналогичным причинам, процессы взаимодействуют друг с другом исключительно через предоставляемые системой методы межпроцессного взаимодействия, в то время как потоки способны запросто взаимодействовать друг с другом путём разделения ресурсов.
Кроме того, переключение контекста - определённое действие по сохранению текущего состояния данных какого- то процесса или потока для прерывания исполнения некоторой задачи и возобновления её позднее - требует больше времени между различными процессами, чем между различными потоками внутри того же самого процесса. Тем не менее, несмотря на то, что мы уже наблюдали, что взаимодействие между потоками требует тщательной синхронизации памяти для гарантии правильной обработки данных, за счёт того что между отдельными процессами имеется взаимодействия, для процессов требуется менше синхронизации памяти, если они совсем не обходятся без таковой.
Многозадачность в информатике является распространённым понятием. При многозадачности некая операционная система просто переключается между различными процессами на высокой скорости создавая видимость что эти процессы исполняются одновременно, даже несмотря на то, что обычно имеет место исполнение только одного процесса в единственном ЦПУ (CPU, central processing unit) в определённый момент времени. В противоположность этому, метод множества процессов применяет более одного ЦПУ для исполнения какой- то задачи.
Хотя имеется ряд различных способов применения данного термина многопроцессности, в нашем контексте совместного исполнения и параллелизма многопроцессность относится к исполнению множества совместных процессов в операционной системе, при которой каждый процесс исполняется в отдельном ЦПУ, в противоположность тому что только отдельный процесс исполняется в определённый момент времени. По самой природе данного процесса операционной системе требуется иметь два или более ЦПУ чтобы иметь возможность реализовать задачи с множеством процессов, так как ей требуется поддерживать много процессоров в одно и то же время и делить их между задачами соответствующим образом.
Эта взаимосвязь показана на следующей схеме:
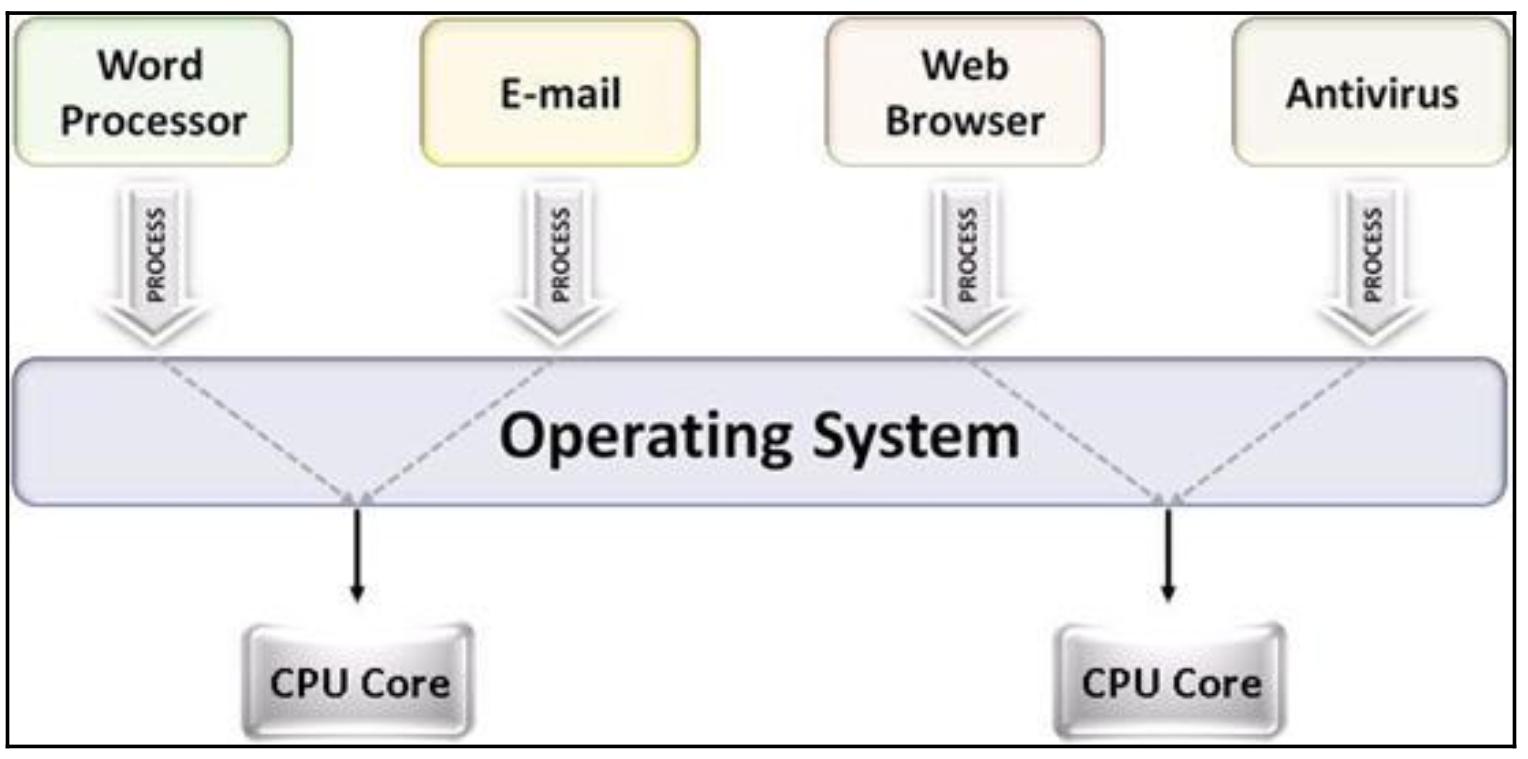
Мы уже видели в Главе 3, Работа с потоками в Python что многопоточность разделяет нечто аналогично определению многопроцессности. Многопоточность означает, что используется только один процессор, а сама система переключается между задачами в пределах этого процессора (что также именуется разделением времени, квантованием времени - time slicing), в то время как многопроцессность как правило выражается в реальном совместном/ параллельном исполнении множества процессов с применением множества процессоров.
Приложения со множеством процессов приобретают всё растущую популярность на полях совместного и параллельного программирования. Вот перечисление некоторых причин:
-
Более быстрое время исполнения: Как мы уже знаем, правильная совместная обработка всегда предоставляет дополнительные ускорения вашим программам при условии что некоторые части способны исполняться независимо.
-
Освобождение от синхронизации: Учитывая тот факт, что отдельные процессы не разделяют ресурсы между собой в некотором приложении со множеством процессов, а разработчики часто вынуждены тратить своё время на координацию таких совместных ресурсов и синхронизировать их, в отличии от приложений со множеством процессов, где не требуются усилия для гарантии корректной обработки данных.
-
Безопасность при крушениях: Поскольку процессы не зависят друг от друга как в терминах вычислительных процедур, так и в отношении ввода/ выода, отказ одного из процессов не оказывает воздействия на исполнение другого в программе со множеством процессов, при должной обработке. Это подразумевает, что программисты могут быть в состоянии порождать большое число процессов (которые всё ещё способна обрабатывать их система) и получаемые шансы крушения всего приложения целиком при этом не растут.
Сказав всё это, стоит также сказать и о недостатках применения множества процессов, которые следует учитывать и которые перечислены далее:
-
Требуется множество процессоров: И снова, многопроцессность требует наличия у операционной системы более одного ЦПУ. Даже хотя хотя множество процессоров достаточно распространено в вычислительных системах в наши дни, если у вас нет в наличии более одного, тогда данная реализация множества процессов будет невозможной.
-
Время и пространство обработки: Как уже упоминалось ранее, имеется множество сложных компонентов, вовлекаемых в реализацию некоего процесса и его ресурсов. Следовательно, это требует значительного времени вычисления и мощности чтобы порождать и управлять процессами сравнительно к тем же задачам с потоками.
Для иллюстрации примера запуска множества процессов в операционной системе давайте рассмотрим быстрый пример на Python. Давайте
остановимся на своём файле Chapter06/example1.py, отображаемом ниже:
# Chapter06/example1.py
from multiprocessing import Process
import time
def count_down(name, delay):
print('Process %s starting...' % name)
counter = 5
while counter:
time.sleep(delay)
print('Process %s counting down: %i...' % (name, counter))
counter -= 1
print('Process %s exiting...' % name)
if __name__ == '__main__':
process1 = Process(target=count_down, args=('A', 0.5))
process2 = Process(target=count_down, args=('B', 0.5))
process1.start()
process2.start()
process1.join()
process2.join()
print('Done.')
В этом файле мы намерены вернуться обратно к своему примеру обратного отсчёта, который мы уже рассматривали в
Главе 3, Работа с потоками в Python, когда мы рассматривали понятие потоков. Наша функция
count_down() получала некую строку в качестве идентификатора процесса и какой- то диапазон задержки.
Затем она выполняла обратный отсчёт от 5 до 1, засыпая между итерациями на то число секунд, которое было определено в её параметре
delay. Данная функция также выводила на печать при каждой итерации некое сообщение с идентификатором
соответствующего процесс.
Как мы уже говорили в Главе 3, Работа с потоками в Python, основным моментом, демонстрируемым данным
примером является демонстрация природы одновременности исполнения отдельных задач в одно и то же самое время. причём на этот раз проходя
отличными процессами с применением класса Process из модуля multiprocessing.
В своей основной программе мы инициализируем одновременно два процесса чтобы реализовать два одновременных отдельных обратных отсчёта на основе времени.
После запуска данного сценария Python вы получите некий вывод, который должен быть аналогичен следующему:
> python example1.py
Process A starting...
Process B starting...
Process B counting down: 5...
Process A counting down: 5...
Process B counting down: 4...
Process A counting down: 4...
Process B counting down: 3...
Process A counting down: 3...
Process B counting down: 2...
Process A counting down: 2...
Process A counting down: 1...
Process B counting down: 1...
Process A exiting...
В точности как и ожидалось, данный вывод сообщает нам, что эти два обратных отсчёта исполнялись одновременно; вместо того, чтобы завершить первый обратный отсчёт и после этого запустить второй, наша программа исполняла эти два обратных отсчёта почти одновременно. Даже несмотря на то, что процессы более затратны и содержат больше дополнительных накладных расходов нежели потоки, многопроцессность также показывает двойное улучшение в смысле скорости исполнения программы в сравнении с предыдущей.
Помните, что при множественности потоков мы наблюдаем явление, при котором получаемый порядок вывода на печать меняется при различных запусках данной программы. В частности, иногда процесс B может обгонять процесс A в процессе своего обратного отсчёта и завершаться до процесса A, даже если он и инициализировался позднее. Именно это, опять же, прямое воздействие реализации и запуска двух процессов, которые исполняют одну и ту же функцию практически одновременно. Запуская данный сценарий много раз вы будете наблюдать, что скорее всего для вас выводятся различные результаты в смысле порядка выполняемого обратного отсчёта и завершения таких обратных отсчётов.
Модуль multiprocessing является одной из самых распространённых реализаций многопроцессного программирования в
Python. Он предлагает методы для порождения процессов и взаимодействия с ними при помощи API аналогичного API модуля
threading (как мы обнаружили уже это с методами start() и
join() в своём предыдущем образце). Согласно его документации на вебсайте, данный метод допускает как локальную, так
и удалённую совместные обработки и действенно избегает global interpreter lock
(GIL) в Python (которая будет обсуждаться более подробно в
Главе 15, Глобальная блокировка интерпретатора) применяя субпроцессы вместо потоков.
В модуле multiprocessing процессы обычно порождаются в классе Process
и управляются им. Каждый объект Process представляет некое действие, которое исполняет какой- то отдельный
процесс. Для удобства объект класса Process эквивалентен методам и API, которые можно отыскать в соответствующем
классе threading.Thread.
В частности, применяя объектно- ориентированный подход программирования, класс Process из
multiprocessing предоставляет следующие ресурсы:
-
run(): Данный метод исполняется при инициализации и запуске нового процесса. -
start(): Этод метод запускается и инициализируется вызывая объектProcessпосредством запроса соответствующего методаrun(). -
join(): Данный метод ожидает завершения данного вызываемого объектаProcessпрежде чем продолжить исполнение оставшейся части программы. -
isAlive(): Метод возвращает Булево значение, указывающий исполняется ли в настоящий момент данный объект вызоваProcess. -
name: Этот атрибут содержит собственно название данного объекта вызоваProcess. -
pid: Данный атрибут содержит идентификатор процесса вызываемого объектаProcess. -
terminate(): Метод прекращает исполнение данного объекта вызоваProcess.
Как вы могли видеть в предыдущем примере, при инициализации некоего объекта Process мы можем
передать параметры в какую- то функцию и исполнить её в отдельном процессе, определив саму target (для такой
целевой функции) и параметры args (в качестве аргументов целевой функции). Отметим также, что можно переопределить
установленный по умолчанию конструктор Process() и реализовать свою собственную функцию
run().
Поскольку он является основным игроком в модуле multiprocessing и в совместной обработке Python в целом,
мы рассмотрим вначале класс Process в своём следующем разделе снова.
В модуле multiprocessing класс Pool в основном применяется для
реализации некоего пула процессов, каждый из которых будет заботиться о задачах, поставляемых некому объекту Pool.
Обычно класс Pool более удобен нежели класс Process, в особенности
если необходимо упорядочивать данные, получаемые от ваших совместных приложений.
В частности, мы видели, что получаемый порядок завершения для различных элементов в списке с большой долей вероятности изменяется, будучи помещённым в некую функцию совместной обработки когда вы запускаете свою программу снова и снова. Это приводит к трудностям при упорядочении получаемого вывода данной программы относительно изначальному порядку получаемых ею данных на входе. Одним из возможных решений является создание кортежей процессов и их выводов с последующей их сортировкой по идентификатору процессов.
Данная задача решается обсуждаемым классом Pool: имеющиеся методы Pool.map()
и Pool.apply() следуют соглашениям традиционных методов Python map()
и apply(), гарантируя, что все возвращаемые значения упорядочиваются в точности в том порядке, как они
поступают на вход. Тем не менее, эти методы блокируют свою основную программу до тех пор, пока процесс не завершит обработку. Вследствие этого,
класс Pool также имеет функции map_async() и
apply_async() для лучшего обслуживания одновременной обработки и параллелизма.
Класс Process предоставляет ряд способов более простого взаимодействия с процессами в программе совместной
обработки. В данном разделе мы изучим параметры управления различными процессами посредством определения значения текущего процесса, ожидания и
прекращения процесса.
Определение значения текущего процесса
Работа с процессами порой весьма сложная и тем самым требует значительной отладки. Один из основных методов отладки какой- то программы состоит
в идентификации того процесса, который столкнулся с ошибкой. В качестве напоминания, в нашем предыдущем примере обратного отсчёта мы передали
некий параметр name в свою функцию count_down() для определения
того где находится каждый процесс на протяжении конкретного обратного отсчёта.
Однако нет необходимости для каждого объекта Process иметь некий параметр
name (с каким- то значением по умолчанию), которое можно изменять. Процесс именования является наилучшим способом
оставлять на глазу исполняемые процессы нежели передавать некий идентификатор в свою целевую функцию саму по себе (как мы это делали ранее), в
особенности в приложениях с различными типами процессов, исполняемыми в одно и то же время. Одной из мощных функций, предоставляемых модулем
multiprocessing является его метод current_process(), который вернёт
тот объект Process, который в настоящий момент исполняется в любой точке программы. Это иной способ
эффективно и без усилий отслеживать запущенные процессы.
Давайте рассмотрим это более подробно при помощи некоего примера. Перейдите к файлу Chapter06/example2.py,
который показан в следующем коде:
# Chapter06/example2.py
from multiprocessing import Process, current_process
import time
def f1():
pname = current_process().name
print('Starting process %s...' % pname)
time.sleep(2)
print('Exiting process %s...' % pname)
def f2():
pname = current_process().name
print('Starting process %s...' % pname)
time.sleep(4)
print('Exiting process %s...' % pname)
if __name__ == '__main__':
p1 = Process(name='Worker 1', target=f1)
p2 = Process(name='Worker 2', target=f2)
p3 = Process(target=f1)
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
В этом примере у нас имеются две функции пустышки, f1() и f2(),
каждая из которых выводит на печать название того процесса, которые исполнял данную функцию до и после сна в течении заданного промежутка времени.
В нашей основной программе мы выполнили инициализацию трёх отдельных процессов. Первые два мы озаглавили Worker 1
и Worker 2, а самый последний мы целенаправленно оставили пустым, чтобы предоставить ему устанавливаемое по
умолчанию название (то есть, 'Process-3'). После запуска данного сценария вы должны получить вывод аналогичный
такому:
> python example2.py
Starting process Worker 1...
Starting process Worker 2...
Starting process Process-3...
Exiting process Worker 1...
Exiting process Process-3...
Exiting process Worker 2...
Мы можем обнаружить что наш current_process() успешно помог нам выполнить доступ к верному процессу,
который исполнил все функции и наш третий процесс, которому было назначено по умолчанию соответствующее название
Process-3. Другой способ отслеживать все запущенные в вашей программе процессы это просматривать соответствующие
индивидуальные идентификаторы процессов при помощи модуля os. Давайте рассмотрим некий видоизменённый пример
из файла Chapter06/example3.py, как это показано в следующем коде:
# Chapter06/example3.py
from multiprocessing import Process, current_process
import time
import os
def print_info(title):
print(title)
if hasattr(os, 'getppid'):
print('Parent process ID: %s.' % str(os.getppid()))
print('Current Process ID: %s.\n' % str(os.getpid()))
def f():
print_info('Function f')
pname = current_process().name
print('Starting process %s...' % pname)
time.sleep(1)
print('Exiting process %s...' % pname)
if __name__ == '__main__':
print_info('Main program')
p = Process(target=f)
p.start()
p.join()
print('Done.')
Наше особое внимание для этого примера это функция print_info(), которая применяет функции
os.getpid() и os.getppid() для идентификации данного текущего процесса
с помощью его идентификатора процесса. В частности, os.getpid() возвращает сам идентификатор процесса, а
os.getppid() (который доступен только в системах Unix) возвращает значение идентификатора его
родительского процесса. Ниже мой вывод после запуска данного сценария:
> python example3.py
Main program
Parent process ID: 14806.
Current Process ID: 29010.
Function f
Parent process ID: 29010.
Current Process ID: 29012.
Starting process Process-1...
Exiting process Process-1...
Done.
Значение идентификатора процесса может меняться от системы к системе, однако их относительное взаимодействие должно оставаться тем же самым.
В частности, в моём выводе мы можем видеть, что в то время как идентификатором для основной программы был 29010,
идентификатором его родительского процесса было значение 14806. Воспользовавшись
Activity Monitor я выполнил проверку иным способом и подключил его к своему Терминалу
и профилю Bash, что имеет смысл сделать, так как я запустил этот сценарий Python из своего Терминала. На приводимом ниже снимке экрана вы можете видеть
отображаемые результаты:

Помимо своей основной программы мы можем также вызвать print_info() внутри своей функции
f(), у которой идентификатором процесса было значение 29012.
Мы также можем обнаружитьЮ что тем процессом, который запустил исполнение нашей функции f()
на самом деле является наш основной процесс, идентификатором которого являлось значение 29010.
Ожидание процесса
Зачастую мы бы хотели дождаться завершения исполнения всех своих процессов одновременной обработки прежде чем перейти к следующему разделу своей программы.
Как уже упоминалось ранее, класс Process из модуля multiprocessing
предоставляет надлежащий модуль join() для реализации некоего способа ожидания пока какой- то процесс не
завершит свои задачи и не выйдет.
Тем не менее, порой разработчики желают реализовывать процессы, которые запускаются в фоновом режиме и не блокируют свою основную программу для выхода. Такое предписание обычно применяется когда для основной программы нет простого способа сообщить будет ли правильно прервать определённый процесс в некое заданное время, либо когда выход из основной программы без завершения её исполнителя не оказывает воздействия на конечный результат.
Такие процессы именуются процессами демонов. Класс
Process также предоставляет некий простой параметр для определения того будет ли некий процесс являться
демоном посредством соответствующего атрибута daemon, который принимает Булево значение. Значением по
умолчанию для такого атрибута daemon является False, следовательно
установка его в значение True превратит такой процесс в некоего демона. Давайте рассмотрим это подробнее,
воспользовавшись примером из файла Chapter06/example4.py, который показан в следующем коде:
# Chapter06/example4.py
from multiprocessing import Process, current_process
import time
def f1():
p = current_process()
print('Starting process %s, ID %s...' % (p.name, p.pid))
time.sleep(4)
print('Exiting process %s, ID %s...' % (p.name, p.pid))
def f2():
p = current_process()
print('Starting process %s, ID %s...' % (p.name, p.pid))
time.sleep(2)
print('Exiting process %s, ID %s...' % (p.name, p.pid))
if __name__ == '__main__':
p1 = Process(name='Worker 1', target=f1)
p1.daemon = True
p2 = Process(name='Worker 2', target=f2)
p1.start()
time.sleep(1)
p2.start()
В этом примере у нас имеется некая функция с длительным временем жизни (представленная f1(), у которой период
сна составляет 4 секунды) и более быстрая функция (которая представляется f2()
с периодом засыпания всего на 2 секунды). У нас таже имеются два отдельных процесса, которые перечисляются
следующим списком:
-
Процесс
p1, который является процессом демона, который назначен для исполненияf1(). -
Процесс
p2, который является процессом демона, который назначен для исполненияf2().
В своей основной программе мы запускаем оба процесса без вызова соответствующего метода join() в любой из них
в самом конце этой программы. Так как процесс p1 обладает длительным временем жизни, он скорее всего не завершит
своего исполнения прежде чем завершится p2 (который является более быстрым процессом из этих двух). Мы также
знаем, что p1 является процессом демона, следовательно наша программа должна выполнить выход до того как
завершит исполнение. После запуска данного сценария Python ваш вывод должен быть похож на такой:
> python example4.py
Starting process Worker 1, ID 33784...
Starting process Worker 2, ID 33788...
Exiting process Worker 2, ID 33788...
И снова, даже несмотря на то, что идентификаторы процессов могут отличаться когда вы сами запустите данный сценарий, общий формат получаемого
вывода будет тем же самым. Как мы можем видеть, получаемый вывод согласуется с тем что мы обсуждали: оба процесса,
p1 и p2, были проинициализированы и запущены нашей основной
программой, причём сама эта программа прекратила исполнение после выхода соответствующего процесса, не являющегося демоном не дожидаясь пока
этот процесс демона закончит своё исполнение.
Данная возможность прекращения своей основной программы без обязанности дожидаться определённой задачи, которая является обрабатывающим демоном, на самом деле чрезвычайно полезно. Тем не менее, мы порой желаем дождаться исполнения процессов демона предписанное число раз прежде чем выполнить выход; таким образом, если соответствующее предписание данной программы допускает некое время ожидания до исполнения своего процесса, мы бы могли завершить некий процесс, потенциально являющийся демоном, вместо его преждевременного завершения.
Такое комбинирование процесса демона и соответствующего метода join() из модуля
multiprocessing может помочь нам реализовать такое решение, в частности, учитывая что пока наш метод
join() блокирует на неопределённое время исполнение нашей программы (или, по крайней мере, пока не завершится
соответствующая задача), также имеется возможность передать некий параметр таймаута для определения необходимого числа секунд на выполнение ожидания
перед выходом. Давайте рассмотрим некую изменённую версию своего предыдущего примера в Chapter06/example5.py.
Обладая теми же самыми функциями f1() и f2() в своём следующем примере,
мы меняем тот способ, при помощи которого мы обрабатываем свой процесс демона в основной программе:
# Chapter06/example5.py
if __name__ == '__main__':
p1 = Process(name='Worker 1', target=f1)
p1.daemon = True
p2 = Process(name='Worker 2', target=f2)
p1.start()
time.sleep(1)
p2.start()
p1.join(1)
print('Whether Worker 1 is still alive:', p1.is_alive())
p2.join()
Вместо прекращения без ожидания своего процесса демона, в данном примере мы вызываем метод join() для
обоих процессов: мы даём одну секунду для p1 на завершение, в то время как мы блокируем свою основную программу
пока не завершится p2. Если p1 не завершит исполнение после этой одной секунды,
наша основная программа продолжит исполнять то что в ней осталось, в то время как мы видим, что p1 - или
Worker 1 - всё ещё жива. После исполнения данного сценария Python ваш вывод будет похож на такой:
> python example5.py
Starting process Worker 1, ID 36027...
Starting process Worker 2, ID 36030...
Whether Worker 1 is still alive: True
Exiting process Worker 2, ID 36030...
Мы видим, что p1 на самом деле всё ещё жив, в то время как основная программа проследовала далее после
ожидания одной секунды.
Прекращение процесса
Метод terminate() из обсуждаемого класса multiprocessing.Process
предлагает некий способ быстрого прекращения процесса. При вызове данного метода не будут исполняться обработчики выхода, завершающие положения или
аналогичные ресурсы, предписанные в соответствующем классе Process или некотором перекрывающем классе.
Однако процессы потомки не будут прекращены. Такие процессы именуются сиротскими процессами
(orphaned).
Хотя на прекращение процессов иногда и смотрят неодобрительно, такое отношение порой неизбежно, так как некие процессы общаются с ресурсами
межпроцессного взаимодействия, такими как блокировки, семафоры, конвейеры, или очереди и принудительный останов таких процессов вызовет разрушение
такого ресурса или его недоступность для прочих процессов. Однако, если имеющиеся в вашей программе процессы никогда не взаимодействуют с упомянутыми
выше ресурсами, такой метод terminate() достаточно полезен, в частности, когда некий процесс кажется не отвечающим,
или участвующим во взаимной блокировке.
Один из моментов, который следует отметить при применении метода terminate(), состоит в том, что даже
несмотря на то, что соответствующий объект Process действенно уничтожается после вызова данного метода, важно
что вы вы также вызываете в этом методе также и join(). Поскольку состояние
alive объекта Process порой не обновляется немедленно после соответствующего
метода terminate(), данная практика даёт своей системе в фоновом режиме возможность реализовать обновление
самого себя в ответ на прекращение своих процессов.
В то время как блокировки являются одним из наиболее распространённых примитивов синхронизации, которые применяются для взаимодействия между потоками, конвейеры и очереди являются основным способом взаимодействия между различными процессами. В частности, они предоставляют возможности обмена сообщениями для обеспечения взаимодействия между процессами - конвейеры для взаимодействия между двумя процессами, а очереди для множества поставщиков и потребителей.
В этом разделе мы изучим применение очередей, в частности класса Queue из обсуждаемого модуля
multiprocessing. Имеющаяся реализация класса Queue в действительности
сохраняет и поток, и процесс, причём мы уже видели применение очередей в Главе 3,
Работа с потоками в Python. Посредством объекта Queue могут передаваться любые пригодные к маринованию
объекты Python; в данном разделе мы будем применять очереди для передачи сообщений взад и вперёд между процессами.
Применение какой- то очереди сообщений для взаимодействия между процессами является более предпочтительным чем владение совместными ресурсами поскольку, если определённые процессы неверно управляют и разрушают совместные память и ресурсы, в то время как эти ресурсы подлежат совместному использованию, тогда будут иметься многочисленные нежелательные и не предсказуемые последствия. Однако, если некий процесс потерпел неудачу корректной обработки своего сообщения, прочие сообщения в этой очереди останутся не тронутыми. Демонстрируемая ниже схема показывает имеющиеся отличия в архитектуре между применением очереди и совместных ресурсов (в частности, памяти) при взаимодействии между процессами:
Рисунок 6-5
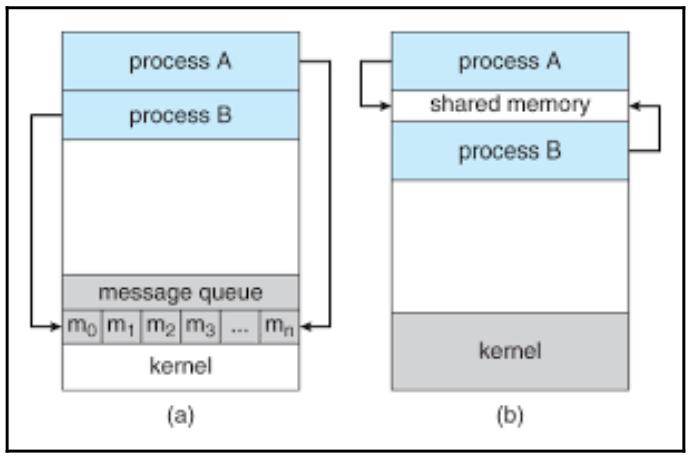
пример решения, вовлекаемого в использование очереди сообщений и совместных ресурсов для взаимодействия между процессами
Прежде чем мы погрузимся в пучину кода своего примера на Python, для начала нам следует обсудить в частности как мы применяем некий объект
Queue в своём приложении со множеством процессов. Допустим у нас имеется некий класс
worker, который исполняет тяжёлые вычисления и не требует значительных ресурсов для совместного использования
и взаимодействия. Всё же эти экземпляры исполнителей всё ещё требуют наличия возможности время от времени в процессе своего исполнения принимать
информацию.
Именно здесь вступает в дело некая очередь: когда мы помещаем всех своих исполнителей в некую очередь. В то же самое время у нас будет также иметься некоторое число выполнивших инициализацию процессов, каждый из которых будет проходить данную очередь и обрабатывать одного исполнителя. Оглядываясь назад на приведённую ранее схему, мы можем обнаружить, что имеется два отдельных процесса, которые продолжают выхватывать и обрабатывать сообщения из очереди.
В объекте Queue мы будем использовать два основных метода, которые приведены в следующем списке:
-
get(): Этот метод возвращает следующий элемент в вызываемом объектеQueue -
put(): Данные метод добавляет передаваемый ему параметр в качестве некоторого дополнительного элемента в сам вызываемый объектQueue
Давайте рассмотрим образец сценария, показывающего пример использования некоторой очереди в Python. Переместитесь к своему файлу
Chapter06/example6.py и откройте его, что показано в приводимом далее коде:
# Chapter06/example6.py
import multiprocessing
class MyWorker():
def __init__(self, x):
self.x = x
def process(self):
pname = multiprocessing.current_process().name
print('Starting process %s for number %i...' % (pname, self.x))
def work(q):
worker = q.get()
worker.process()
if __name__ == '__main__':
my_queue = multiprocessing.Queue()
p = multiprocessing.Process(target=work, args=(my_queue,))
p.start()
my_queue.put(MyWorker(10))
my_queue.close()
my_queue.join_thread()
p.join()
print('Done.')
В этом сценарии у нас имеется некий класс MyWorker, который получает в некотором числе
x параметр и выполняет некое вычисление на его основе (в данном случае это всего лишь вывод на печать
этого числа). В своей основной функции мы инициализируем некий объект Queue из модуля
multiprocessing и добавляем какой-то объект MyWorker со значением
числа 10в нём. У нас также имеется соответствующая функция work(),
которая при её вызове получит самый первый элемент из данной очереди и обработает его. Наконец, у нас есть процесс, чья задача состоит в
вызове такой функции work().
Данная структура спроектирована с целью передачи некоторого сообщения - в данном случае какого- то объекта
MyWorker - в один отдельный процесс. Основная программа затем ожидает завершения исполнения такого процесса.
После запуска данного сценария ваш вывод должен походить на такой:
> python example6.py
Starting process Process-1 for number 10...
Done.
Как уже упоминалось ранее, наша цель состоит в обладании структурой, в которой существует несколько процессов постоянно запускающих исполнителей
из некоторой очереди и, когда некий процесс завершает выполнение одного исполнителя, тогда он подхватывает нового. Для этого мы будем применять
некий подкласс Queue с названием JoinableQueue, который будет
предоставлять свои дополнительные методы task_done() и join(), как
это определено в данном списке:
-
task_done(): Данный метод сообщает нашей программе что вызываемый объектJoinableQueueзавершён. -
join(): Этот метод выполняет блокирование до тех пор, пока все элементы в его вызываемом объектеJoinableQueueне будут обработаны.
Теперь основная цель здесь, опять же, состоит в наличии некоего объекта JoinableQueue, содержащего
все те задачи которые должны быть исполнены - мы именуем это своей очередью задач - а также неким числом процессов. До тех пор пока в нашей
очереди задач имеются элементы (сообщения), имеющиеся процессы будут в свою очередь на исполнение такие элементы. У нас также будет иметься
некий объект Queue для сохранения всех результатов возвращаемых из исполняемых процессов - мы будем
называть её очередью результатов.
Перейдём к своему файлу Chapter06/example7.py и переключимся на рассмотрение класса
Consumer и класса Task, которые отображены в следующем коде:
# Chapter06/example7.py
from math import sqrt
import multiprocessing
class Consumer(multiprocessing.Process):
def __init__(self, task_queue, result_queue):
multiprocessing.Process.__init__(self)
self.task_queue = task_queue
self.result_queue = result_queue
def run(self):
pname = self.name
while not self.task_queue.empty():
temp_task = self.task_queue.get()
print('%s processing task: %s' % (pname, temp_task))
answer = temp_task.process()
self.task_queue.task_done()
self.result_queue.put(answer)
class Task():
def __init__(self, x):
self.x = x
def process(self):
if self.x < 2:
return '%i is not a prime number.' % self.x
if self.x == 2:
return '%i is a prime number.' % self.x
if self.x % 2 == 0:
return '%i is not a prime number.' % self.x
limit = int(sqrt(self.x)) + 1
for i in range(3, limit, 2):
if self.x % i == 0:
return '%i is not a prime number.' % self.x
return '%i is a prime number.' % self.x
def __str__(self):
return 'Checking if %i is a prime or not.' % self.x
Приводимый класс Consumer, который является неким переопределением подкласса имеющегося класса
multiprocessing.Process, составляет логику нашей обработки, которая получает некую очередь задач и
какую- то очередь результатов. Будучи запущенным, каждый объект Consumer получает следующий элемент из
своей очереди задач, исполняет его и наконец вызывает task_done() и помещает возвращаемые результаты в
его очередь результатов. Каждый элемент в такой очереди задач является в свою очередь представителем соответствующего класса
Task, чья основная функциональность состоит в первичной проверке его параметра
x. Так как один экземпляр нашего класса Consumer взаимодействует с
одним экземпляром соответствующего класса Task, он также выводит на печать некое вспомогательное
сообщение для нас чтобы легче отслеживать какой из потребителей какую из задач исполняет.
Давайте продвинемся далее и рассмотрим свою основную программу, которая отображается таким кодом:
# Chapter06/example7.py
if __name__ == '__main__':
tasks = multiprocessing.JoinableQueue()
results = multiprocessing.Queue()
# spawning consumers with respect to the
# number cores available in the system
n_consumers = multiprocessing.cpu_count()
print('Spawning %i consumers...' % n_consumers)
consumers = [Consumer(tasks, results) for i in range(n_consumers)]
for consumer in consumers:
consumer.start()
# enqueueing jobs
my_input = [2, 36, 101, 193, 323, 513, 1327, 100000, 9999999, 433785907]
for item in my_input:
tasks.put(Task(item))
tasks.join()
for i in range(len(my_input)):
temp_result = results.get()
print('Result:', temp_result)
print('Done.')
Как мы уже сказали ранее, мы создали в своей основной программе некую очередь задач и очередь результатов. Мы также создали какой-то перечень
объектов Consumer и запустили их все; общее число созданных процессов соответствует общему числу ЦПУ,
доступных в нашей системе. Далее, из некоего списка входных данных, которые требуют тяжёлых вычислений в нашем классе
Task, мы инициализируем некий объект Task для каждого входного данного и
помещаем их все в свою очередь задач. На этот момент наши процессы - наши объекты Consumer -
начнут исполнять эти задачи.
Наконец, в самом финале своей основной программы мы вызываем join() в своей очереди задач для гарантии
того,что все элементы были выполнены и выводим на печать результаты, обходя циклом свою очередь результатов. После исполнения данного сценария ваш вывод
должен походить на такой:
> python example7.py
Spawning 4 consumers...
Consumer-3 processing task: Checking if 2 is a prime or not.
Consumer-2 processing task: Checking if 36 is a prime or not.
Consumer-3 processing task: Checking if 101 is a prime or not.
Consumer-2 processing task: Checking if 193 is a prime or not.
Consumer-3 processing task: Checking if 323 is a prime or not.
Consumer-2 processing task: Checking if 1327 is a prime or not.
Consumer-3 processing task: Checking if 100000 is a prime or not.
Consumer-4 processing task: Checking if 513 is a prime or not.
Consumer-3 processing task: Checking if 9999999 is a prime or not.
Consumer-2 processing task: Checking if 433785907 is a prime or not.
Result: 2 is a prime number.
Result: 36 is not a prime number.
Result: 193 is a prime number.
Result: 101 is a prime number.
Result: 323 is not a prime number.
Result: 1327 is a prime number.
Result: 100000 is not a prime number.
Result: 9999999 is not a prime number.
Result: 513 is not a prime number.
Result: 433785907 is a prime number.
Done.
Всё кажется работающим, но если мы приглядимся внимательнее к тем сообщениям, которые наши процессы вывели на печать, мы заметим, что
большая часть задач исполнялась либо Consumer-2, либо Consumer-3, а
Consumer-4 выполнил только одну задачу, в то время как Consumer-1
отказал вообще в исполнении. Что здесь происходит?
По существу, когда один из наших потребителей - допустим Consumer-3 - завершил исполнение некоторой
задачи, он пытается отыскать другую задачу для исполнения сразу после этого. В большинстве случаев он получит приоритет перед остальными потребителями
так как он уже исполнялся нашей основной программой. Поэтому в то время как Consumer-2 и
Consumer-3 постоянно завершали исполнение своих задач и прихватывали на исполнение прочие задачи,
Consumer-4 смог "выдавить" из себя это всего один раз, в то время как
Consumer-1 отказался это делать вовсе.
Запуская данный сценарий снова и снова, вы заметите некий аналогичный тренд: только один или два потребителя исполняют большую часть задач, в то время как прочие отказывают в этом. Такое положение дел нежелательно для нас, так как данная программа не использует все доступные процессы, которые были созданы в самом начале этой программы.
Чтобы решить данную проблему, была разработана некая техника для останова потребителей от немедленного получения следующего имеющегося элемента в нашей очереди задач, получившая название ядовитой пилюли. Основная мысль состоит в том, что после установки своих реальных задач в имеющуюся очередь задач, мы также добавляем некую задачу пустышку, которая содержит значения "stop" и которая заставит текущего потребителя задержаться и позволит прочим потребителям получать следующие имеющиеся элементы в этой очереди задач первыми; это поясняет название "ядовитой пилюли".
Для реализации этой техники нам необходимо добавить в своё значение tasks в нашей основной программе
особых объектов, по одному на потребителя. Кроме того, в нашем классе Consumer также требуется реализация
особой логики для обработки таких специальных объектов. Давайте рассмотрим свой файл example8.py
(некую модификацию версии нашего предыдущего примера, содержащую соответствующую реализацию техники ядовитой пилюли), в частности в нашем классе
Consumer и в нашей основной программе, как это отображено в следующем коде:
# Chapter06/example8.py
class Consumer(multiprocessing.Process):
def __init__(self, task_queue, result_queue):
multiprocessing.Process.__init__(self)
self.task_queue = task_queue
self.result_queue = result_queue
def run(self):
pname = self.name
while True:
temp_task = self.task_queue.get()
if temp_task is None:
print('Exiting %s...' % pname)
self.task_queue.task_done()
break
print('%s processing task: %s' % (pname, temp_task))
answer = temp_task.process()
self.task_queue.task_done()
self.result_queue.put(answer)
class Task():
def __init__(self, x):
self.x = x
def process(self):
if self.x < 2:
return '%i is not a prime number.' % self.x
if self.x == 2:
return '%i is a prime number.' % self.x
if self.x % 2 == 0:
return '%i is not a prime number.' % self.x
limit = int(sqrt(self.x)) + 1
for i in range(3, limit, 2):
if self.x % i == 0:
return '%i is not a prime number.' % self.x
return '%i is a prime number.' % self.x
def __str__(self):
return 'Checking if %i is a prime or not.' % self.x
if __name__ == '__main__':
tasks = multiprocessing.JoinableQueue()
results = multiprocessing.Queue()
# spawning consumers with respect to the
# number cores available in the system
n_consumers = multiprocessing.cpu_count()
print('Spawning %i consumers...' % n_consumers)
consumers = [Consumer(tasks, results) for i in range(n_consumers)]
for consumer in consumers:
consumer.start()
# enqueueing jobs
my_input = [2, 36, 101, 193, 323, 513, 1327, 100000, 9999999, 433785907]
for item in my_input:
tasks.put(Task(item))
for i in range(n_consumers):
tasks.put(None)
tasks.join()
for i in range(len(my_input)):
temp_result = results.get()
print('Result:', temp_result)
print('Done.')
Наш класс Task остаётся тем же самым, что и в нашем предыдущем примере. Мы можем обнаружить что
:нашей ядовитой пилюлей является значение None: в своей основной программе мы добавляем в
None значения числа, равного общему числу потребителей, которых мы породили в своей очереди задач;
в своём классе Consumer, если текущая подлежащая исполнению задача содержит значение
None, тогда объект данного класса будет выводить на печать некое сообщение с указанием на ядовитую пилюлю,
вызовет task_done() и завершит исполнение.
Запустите этот сценарий, ваш вывод должен походить на такой:
> python example8.py
Spawning 4 consumers...
Consumer-1 processing task: Checking if 2 is a prime or not.
Consumer-2 processing task: Checking if 36 is a prime or not.
Consumer-3 processing task: Checking if 101 is a prime or not.
Consumer-4 processing task: Checking if 193 is a prime or not.
Consumer-1 processing task: Checking if 323 is a prime or not.
Consumer-2 processing task: Checking if 513 is a prime or not.
Consumer-3 processing task: Checking if 1327 is a prime or not.
Consumer-1 processing task: Checking if 100000 is a prime or not.
Consumer-2 processing task: Checking if 9999999 is a prime or not.
Consumer-3 processing task: Checking if 433785907 is a prime or not.
Exiting Consumer-1...
Exiting Consumer-2...
Exiting Consumer-4...
Exiting Consumer-3...
Result: 2 is a prime number.
Result: 36 is not a prime number.
Result: 323 is not a prime number.
Result: 101 is a prime number.
Result: 513 is not a prime number.
Result: 1327 is a prime number.
Result: 100000 is not a prime number.
Result: 9999999 is not a prime number.
Result: 193 is a prime number.
Result: 433785907 is a prime number.
Done.
На этот раз, заодно с тем, что мы наблюдаем выводимые на печать сообщения о ядовитых пилюлях, наш вывод также отображает намного лучшее распределение относительно тог как какие потребители исполняют какие задачи.
В области информатики некий процесс является экземпляром особой вычислительной программы или программного обеспечения, которое исполняется имеющейся операционной системой. Некий процесс содержит как код программы, так и её текущие активности и взаимодействия с прочими сущностями. Для реализации доступа и разделения памяти или прочих ресурсов в рамках одного и того же процесса могут быть реализованы более одного потока, в то время как различные процессы не взаимодействуют таким образом.
В обсуждаемом контексте совместной обработки и параллелизма, множественность процессов относится к конкретному исполнению одновременных процессов
из некоторой операционной системы, в которой каждый процесс исполняется в каком- то отдельном ЦПУ, что абсолютно отличается от отдельного процесса
исполняемого в заданный момент времени. Модуль multiprocessing в Python предоставляет мощный и гибкий API для
порождения процессов и управления ими в приложениях со множеством процессов. Он также допускает сложные технологии для межпроцессного взаимодействия
через его класс Queue.
В своей следующей главе мы обсудим более передовые функции Python - снижение числа операций - а также как это поддерживается в многопроцессном программировании.
-
Что такое процесс? В чём состоят ключевые отличия между процессами и потоками?
-
Что такое многопроцессность? В чём состоят ключевые отличия между многопроцессностью и многопоточностью?
-
Какие варианты API предоставляются модулем
multiprocessing? -
В чём состоят ключевые отличия между классом
Processи классомPoolиз модуляmultiprocessing? -
Какие имеются варианты для определения значения текущего процесса в какой- то программе Python?
-
Что такое процесс демона? В ч1м состоит их цель в терминах ожидания процессов в некоторой программе со множеством процессов?
-
Как вы завершаете процесс? Почему порой приемлемо прекращать процессы?
-
Каковы способы снабжения межпроцессного взаимодействия в Python?
Для получения дополнительных сведений вы можете воспользоваться следующими ссылками:
-
Наш перевод 2 издания Python Parallel Programming Cookbook, Джанкарло Законне, Packt Publishing Ltd, сентябрь 2019
-
Learning Concurrency in Python: Build highly efficient, robust, and concurrent applications, Элиот Форбс, Packt Publishing Ltd, 2017
-
Python Module of The Week. "Communication Between Processes", содержит функции, которые вы можете применять для определения текущего процесса.