Глава 15. Глобальная блокировка интерпретатора
Содержание
Одним из основных игроков в параллельном программировании Python выступает GIL (Global Interpreter Lock , Глобальная блокировка интерпретатора). В данной главе мы обсудим само её определение, а также основные цели имеющейся GIL и того как она оказывает влияние на параллельные приложения в Python. Также будут рассмотрены основные проблемы, которые GIL предлагает для систем совместной обработки Python и те дебаты, которые ведутся вокруг её реализации. Наконец, мы упомянем некоторые соображения, о которых следует задумываться программистам и разработчикам Python и о том как взаимодействовать с существующей GIL.
Данная глава рассмотрит следующие вопросы:
-
Некое краткое введение в GIL: что её породило и основные проблемы, которые она вызывает
-
Усилия, предпринимаемые в Python для удаления/ исправления GIL
-
Как действенно работать с GIL в параллельных программах Python
{Прим. пер.: тем, кому интересно внутреннее устройство GIL и почему она всё- же позволяет ускорять одновременное выполнение потоков, рекомендуем наш перевод Внутреннее устройство CPython Энтони Шоу, изданной в январе 2021 RealPython. Тут же вы можете ознакомиться с новой реализацией параллельности в Python, появившейся начиная с версии 3.9, подчинённым интерпретатором.}
{Прим. пер.: ещё одним существенным моментом внутреннего устройства Python выступают сборка мусора и подсчёт ссылок, которые предоставляют элегантное, но весьма затратное решение (как в отношении ресурсов, так и в отношении времени исполнения), существует подход к ускорению кода без применения сборки мусора в программах на Rust, которые способны интегрироваться с кодом Python, что описывается в нашем переводе Ускоряем ваш Python при помощи Rust Максвелл Флиттон, Packt, 2022. Написание кода на Rust может стать хорошей альтернативой расширениям на C или C++.}
Вот перечень предварительных требований для данной главы:
-
Убедитесь что на вашем компьютере уже установлен Python 3
-
Вам следует иметь установленными OpenCV и NumPy для вашего дистрибутива Python 3
-
Выгрузите необходимый репозиторий из GitHub
-
На протяжении данной главы мы будем работать с вложенной папкой, имеющей название
Chapter15 -
Ознакомьтесь со следующими видеоматериалами Code in Action
Сам GIL достаточно популярна в сообществе параллельного программирования Python. Будучи разработанной как блокировка, которая будет допускать только один поток для доступа и управления со стороны интерпретатора Python в любой определённый момент времени, GIL в Python часто известна как печально известная GIL, которая препятствует многопоточным программам достижения их полностью оптимальной скорости. В этом разделе мы обсудим ту концепцию, которая стоит за GIL, а также её цели: зачем она была разработана и реализована и то как она воздействует на многопоточное программирование в Python.
Прежде чем мы ринемся в особенности GIL и её последствия, давайте рассмотрим те проблемы, с которыми сталкивались разработчики ядра Python в ранние дни Python и что породило необходимость самой GIL. В частности, существует существенная разница между программированием на Python и программированием на прочих популярных языках программирования относительно управления объектами в имеющемся пространстве оперативной памяти.
Например, в программном языке C++ некая переменная на самом деле какое- то местоположение в имеющемся пространстве оперативной памяти в котором будет записано некое значение. Такая установка ведёт к тому факту, что при назначении некоторого определённого значения переменной не являющейся указателем, данный язык программирования действенно копирует это определённое значение в данное местоположение оперативной памяти (то есть в саму переменную). Кроме того, когда некоей переменной назначается другая переменная (которая не является указателем), само местоположение оперативной памяти последней переменной будет скопировано в местоположение первой; никакой связи между этими двумя переменными не будет поддерживаться после данного назначения.
С другой стороны Python рассматривает некую переменную просто как некое название, в то время как реальные значения его переменных изолированы в некоторой другой области в имеющемся пространстве памяти. Когда некое значение назначается какой- то переменной, эта переменная действенно получает некую ссылку на то самое местоположение в имеющемся пространстве памяти, где содержится это значение (даже хотя сам термин ссылки не применяется в том же самом смысле, как это имеет место в случае ссылки C++). Управление памятью в Python таким образом фундаментально отличается от той модели помещения некоторого значения в пространстве оперативной памяти, которое мы наблюдаем в C++.
Это означает, что при исполнении некоторой операции назначения Python просто взаимодействует со ссылками и переключается между ними - вместо того чтобы делать это со значениями. Кроме того, по этой же причине множество переменных может ссылаться на одно и то же значение, а изменения выполняемые одной переменной отражаются во всех прочих связанных переменных.
Давайте проанализируем это свойство Python. Если вы уже выгрузили необходимый код данной книги с её страницы GitHub,
пройдите далее и переместитесь в каталог Chapter15. Давайте рассмотрим следующий
файл Chapter15/example1.py:
# Chapter15/example1.py
import sys
print(f'Reference count when direct-referencing: {sys.getrefcount([7])}.')
a = [7]
print(f'Reference count when referenced once: {sys.getrefcount(a)}.')
b = a
print(f'Reference count when referenced twice: {sys.getrefcount(a)}.')
###########################################################################
a[0] = 8
print(f'Variable a after a is changed: {a}.')
print(f'Variable b after a is changed: {b}.')
print('Finished.')
В этом примере мы рассматриваем управление соответствующим значением [7]
(некий список из одного элемента: целого значения 7). Мы уже упомянули, что
значения в Python хранятся независимо от переменных, а управление значениями в Python просто ссылается на переменные
для соответствующих значений. Имеющийся в Python метод sys.getrefcount()
получает некий объект и возвращает значение счётчика всех ссылок, которые связаны с данным объектом. В нашем случае
мы вызываем sys.getrefcount() три раза: для самого реального значения,
[7]; для переменной a, которой
назначено это значение; и, наконец, для переменной b, которой назначена
переменная a.
Кроме того мы изучаем сам процесс мутации этого значения применяя некую ссылающуюся на него переменную и получаемые
в результате значения всех тех переменных, которые связаны с этим значением. В частности, мы изменяем самый первый
элемент данного списка через переменную a и выводим на печать
получаемые значения обеих переменных, a и b.
Запустите этот сценарий и вы получите следующее:
> python3 example1.py
Reference count when direct-referencing: 1.
Reference count when referenced once: 2.
Reference count when referenced twice: 3.
Variable a after a is changed: [8].
Variable b after a is changed: [8].
Finished.
Как вы можете видеть, этот вывод согласуется с тем что мы обсуждали: для самого первого вызова функции
sys.getrefcount() имеется только одно значение счётчика для ссылки на значение
[7], и эта ссылка была создана когда мы напрямую сослались на неё; после того как
мы назначили данный список переменной a, его значение составило две ссылки, так
как a теперь ассоциирована с этим значением; наконец, когда
a было назначено b, на
[7] дополнительно ссылается и b и
значением счётчика теперь является три.
В получаемом выводе из второй части программы мы можем видеть, что после того как мы изменили то значение, на которое
ссылалась переменная a, вместо значения переменной a
мутацию претерпело [7]. Как результат, переменная b,
которая также ссылалась на то же самое значение, что и a также получила
изменение своего значения.
Следующая схема иллюстрирует данный процесс. В программах Python переменные (a
и b) просто представляют ссылки на свои реальные значения (объекты) и некоторый
оператор назначения (скажем, a = b) выдаёт инструкцию Python, чтобы тот имел две
переменные, ссылающиеся на один и тот же объект ( в противоположность копированию реального значения в другое местоположение
в памяти, как это делается в C++).
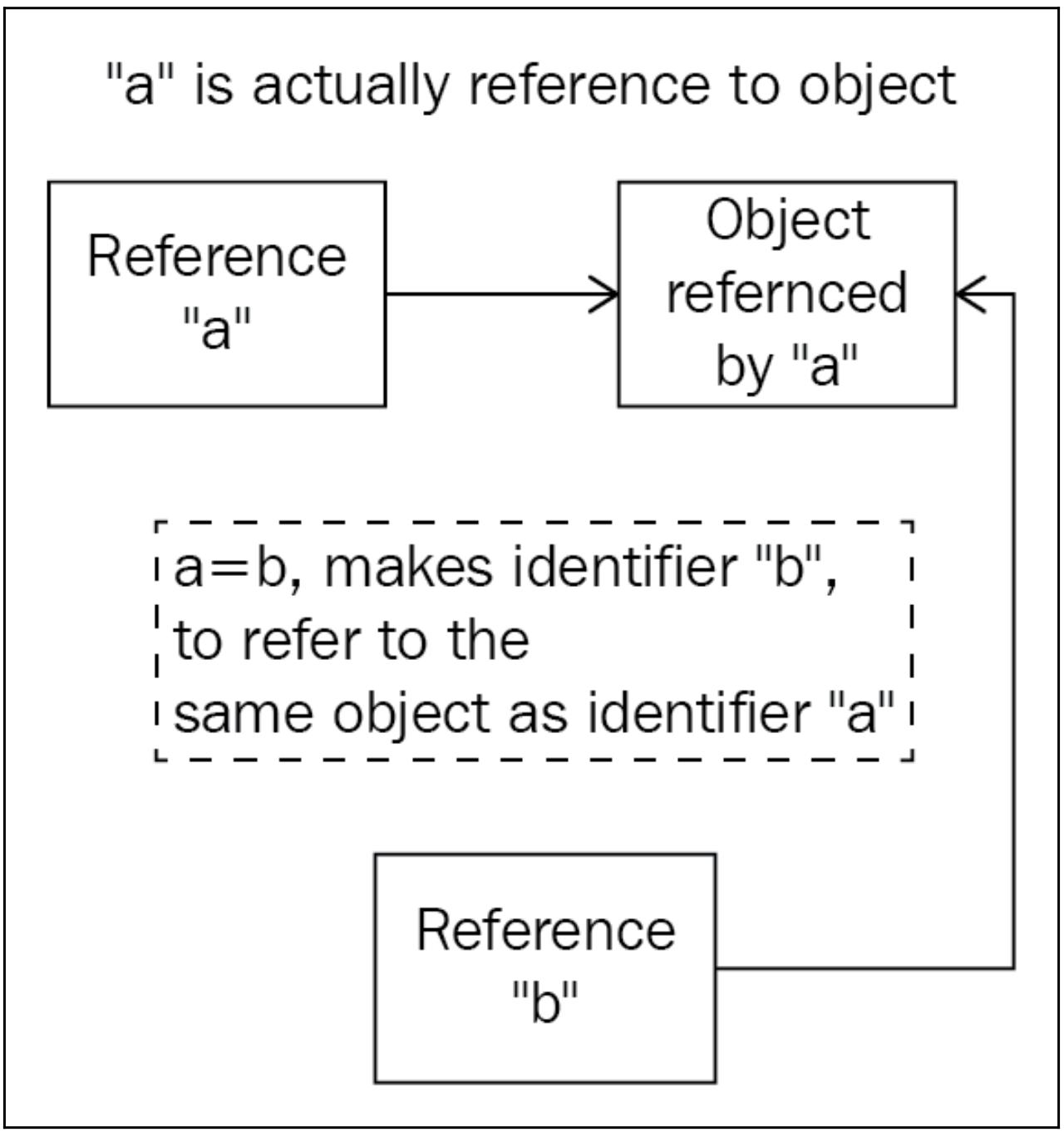
Имея в виду реализацию памяти и управление переменными, мы можем обратить внимание на то, что ссылки на некое определённое значение в Python постоянно изменяются в программе и тем более крайне важно отслеживать число ссылок для какого- то значения.
Теперь, применяя то, что вы изучили в Главе 14, Условия состязательности, вы должны знать, что в программе совместной обработки такой счётчик ссылок является совместно применяемым ресурсом, которому требуется защита от условий состязательности. Иными словами, данный счётчик ссылок является некоторым критическим разделом, который, если его небрежно обрабатывать, будет иметь результатом некую неверную интерпретацию того сколько переменных ссылаются на некое определённое значение. Это будет вызывать утечки памяти, которые превратят программы Python в достаточно неэффективные и даже могут освобождать некую память, на которую на самом деле ссылаются некоторые переменные, утрачивая это значение навсегда.
Как вы это уже изучали в нашей предыдущей главе, неким решением для гарантии того что условие состязательности не будет происходить в отношении определённого разделяемого ресурса состоит в размещении некоторой блокировки на таком ресурсе, которая действенно допускает максимум лишь единственному потоку доступ к данному ресурсу в любой определённый момент времени внутри некоторой программы совместной обработки. Мы также обсуждали, что если в некоторой программе совместной обработки размещается достаточное число блокировок, такая программа станет целиком последовательной и никакая дополнительная скорость не будет получена за счёт реализации одновременной обработки.
Имеющаяся GIL является решением для предыдущих двух проблем, выступая в роли одной единственной блокировки для всего исполнения Python целиком. Данная GIL для начала должна быть получена любой инструкцией Python, которая хочет исполниться (связанные с ЦПУ задачи), предотвращая появление условия состязательности для всех счётчиков ссылок.
На ранних стадиях разработки языка Python также предлагались и иные решения для обсуждаемой нами проблемы, однако именно GIL оказалась наиболее действенной и простой и продолжает оставаться таковой и до сих пор. Так как имеющаяся GIL обладает малым весом и является всеобъемлющей блокировкой всего исполнения Python, для гарантирования целостности прочих критических разделов и удержания накладных расходов производительности Python в минимальном значении, не требуется реализация никаких иных блокировок.
Интуитивно ясно, что при охране блокированием всех связанных с ЦПУ задач в Python программа совместной обработки не будет
способна стать полностью многопоточной. Имеющаяся GIL действенно препятствует связанным с ЦПУ задачам исполняться параллельно
в множестве потоков. Для осознания данного эффекта давайте рассмотрим некий пример Python; перейдите к следующему
файлу Chapter15/example2.py:
# Chapter15/example2.py
import time
import threading
COUNT = 50000000
def countdown(n):
while n > 0:
n -= 1
###########################################################################
start = time.time()
countdown(COUNT)
print('Sequential program finished.')
print(f'Took {time.time() - start : .2f} seconds.')
###########################################################################
thread1 = threading.Thread(target=countdown, args=(COUNT // 2,))
thread2 = threading.Thread(target=countdown, args=(COUNT // 2,))
start = time.time()
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print('Concurrent program finished.')
print(f'Took {time.time() - start : .2f} seconds.')
В этом примере мы сравниваем скорость исполнения некоторой определённой программы в Python для исполнения последовательно и
совместно, при помощи многопоточности. В частности, у нас имеется некая функция с названием countdown(),
которая имитирует некую задачу тяжело загружающую ЦПУ, которая получает некое число, n,
и пошагово уменьшает его пока оно не станет нулём или отрицательным. Затем мы вызываем
countdown() для 50 000 000 снова как некую последовательную программу.
Наконец, мы вызовем эту функцию дважды, причём каждую в отдельном потоке для 25 000 000, что в точности составляет половину
от 50 000 000; это является многопоточной версией нашей программы. Мы также отслеживаем время, которое понадобится Python
исполнить и последовательную, и многопоточную программу.
Теоретически многопоточная версия данной программы должна занимать половину длительности последовательной версии, так как данная задача была действенно разделена на две половины и запущена параллельно в двух потоках которые мы создали. Однако, производимый данной программой вывод предлагает обратное. Ниже приведён вывод, который я получил запустив этот сценарий:
> python3 example2.py
Sequential program finished.
Took 2.80 seconds.
Concurrent program finished.
Took 2.74 seconds.
В противоположность тому что мы предполагали, наша версия совместной обработки обратного отсчёта потребовала почти столько же времени, сколько и её последовательная версия; многопоточность не предложила никакого существенного ускорения нашей программе. Именно это является прямым эффектом наличия GIL, охраняющего ограниченные ЦПУ задачи, так как множеству потоков не разрешается совместное исполнение. Порой некая многопоточная программа может потребовать даже более длительного времени исполнения нежели их последовательный конкурент, так как она имеет дополнительные накладные расходы получения и высвобождения GIL.
Несомненно это значительная проблема для многопоточности и для параллельного программирования на Python в целом, так как пока некая программа содержит инструкции, ограниченные ЦПУ, эти инструкции фактически будут последовательными при исполнении такой программы. Тем не менее, те инструкции, которые не завязаны исключительно на ЦПУ происходят вне GIL и, таким образом, они не подвержены воздействию GIL (например инструкции, ограниченные вводм/ выводом).
Вы уже узнали, что GIL устанавливает существенные ограничения на наши многопоточные программы в Python, в особенности для ограниченных ЦПУ задач. По этой причине многие разработчики Python начали рассматривать GIL в негативном свете и термин "тот самый печально известный GIL" начал приобретать популярность; неудивительно, что кое- кто даже стал защищать полное удаление GIL из самого языка Python.
Фактически выдающимися пользователями Python было предпринято множество попыток удаления GIL. Тем не менее, GIL настолько глубоко вросла в реализацию самого языка, а выполнение большинства библиотек и пакетов, которые не обеспечивают безопасность потока, настолько зависит GIL, что удаление GIL на практике вызовет ошибки а также проблемы обратной несовместимости для ваших программ Python. Большое число разработчиков и исследователей Python пыталось полностью опустить GIL при исполнении Python, но большинство имеющихся расширений C, которые сильно зависят от функциональностей GIL, перестают работать.
В наши дни существуют прочие жизнеспособные решения для решения обсуждаемых проблем; иными словами, GIL во всех отношениях заменим. Тем не менее, большинство таких решений содержат настолько большой объём сложных инструкций, что на практике они снижают получаемую производительность последовательных и ограниченных вводом/ выводом программ, которые составляют значительное процентное соотношение существующих приложений Python. Интересно, что создатель Python, Гвидо ван Россум, также прокомментировал эту тему в своей статье "Улалить GIL не просто":
Я был бы двумя руками за набор исправлений Py3k, только если бы это не уменьшало производительность однопоточных программ (а также многопоточных, ограниченных вводом/ выводом программ).
К сожадению, ни одна из альтернатив GIL не предлагает достижения этой просьбы. Имеющаяся GIL остаётся некоей встроенной частью самого языка Python.
Существует несколько способов работы с GIL в ваших приложениях Python, которые будут рассмотрены далее.
Это, скорее всего, наиболее популярный и самый простой способ перехитрить GIL и достичь оптимальной скорости в программе совместной обработки. Поскольку имеющаяся GIL препятствует только множеству потоков для одновременного исполнения задач, ограниченных ЦПУ, обработка процессами на множестве ядер системы, когда каждый из них обладает своим собственным пространством оперативной памяти, имеет полный иммунитет от GIL.
В частности, рассмотрим свой предыдущий пример обратного отсчёта и давайте сравним значения производительности для ограниченной
ЦПУ программы при её реализации в последовательном, многопоточном и многопроцессном видах. Перейдите к нашему файлу
Chapter15/example3.py; самая первая часть этой программы идентична тому что мы видели
ранее, однако в самом конце мы добавили некую реализацию решения со множеством процессов для своей задачи обратного отсчёта начиная с
50 000 000 при помощи двух обособленных процессов:
# Chapter15/example3.py
import time
import threading
from multiprocessing import Pool
COUNT = 50000000
def countdown(n):
while n > 0:
n -= 1
if __name__ == '__main__':
#######################################################################
# Sequential
start = time.time()
countdown(COUNT)
print('Sequential program finished.')
print(f'Took {time.time() - start : .2f} seconds.')
print()
#######################################################################
# Multithreading
thread1 = threading.Thread(target=countdown, args=(COUNT // 2,))
thread2 = threading.Thread(target=countdown, args=(COUNT // 2,))
start = time.time()
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print('Multithreading program finished.')
print(f'Took {time.time() - start : .2f} seconds.')
print()
#######################################################################
# Multiprocessing
pool = Pool(processes=2)
start = time.time()
pool.apply_async(countdown, args=(COUNT//2,))
pool.apply_async(countdown, args=(COUNT//2,))
pool.close()
pool.join()
print('Multiprocessing program finished.')
print(f'Took {time.time() - start : .2f} seconds.')
После запуска этой программы я получил такой вывод:
> python3 example3.py
Sequential program finished.
Took 2.95 seconds.
Multithreading program finished.
Took 2.69 seconds.
Multiprocessing program finished.
Took 1.54 seconds.
Всё ещё остаётся минимальным отличие в скорости между последовательной и многопоточной версиями данной программы. Тем не менее, наша версия со множеством процессов оказалась способной урезать почти наполовину время её исполнения; так как процессы имеют достаточно тяжёлый вес, инструкции множества процессов содержат значительные накладные расходы, которые и объясняют почему получаемая время исполнения нашей программы со множеством процессов не составила в точности половину от последовательной версии программы.
Существуют собственные расширения Python, написанные на C/ C++ и, следовательно, способные избегать ограничения, устанавливаемые GIL; одним из примеров является самый популярный пакет научных вычислений Python, NumPy. Внутри таких расширений могут выполняться высвобождения GIL вручную, так что получаемое выполнение может просто обходить блокировку. Однако эти высвобождения должны быть тщательно реализованы и сопровождаться повторным подтверждением GIL, прежде чем выполнение вернётся к основному исполнению Python.
GIL присутствует только в CPython, который на данный момент является наиболее распространённым интерпретатором для данного языка, и построен на C. Однако есть и другие интерпретаторы для Python, такие как Jython (написанный на Java) и IronPython (написанный на C++), и это можно применять для исключения GIL и его влияния на многопоточные программы. Имейте в виду, что эти интерпретаторы не так широко используются, как CPython, и некоторые пакеты и библиотеки могут быть несовместимы с одним или даже с обоими из них.
Хотя GIL в Python предлагает простое и интуитивно понятное решение для одной из наиболее сложных проблем в этом языке, он также сам по себе возбуждает ряд проблем, относящихся к возможности исполнять множество потоков в программе на Python для обработки задач, ограниченных ЦПУ. Для удаления GIL из самой основной реализации Python было предпринято множество попыток, однако ни одна из них не оказалась способной достичь этого при сопровождении той же эффективности обработки не ограничивающихся ЦПУ задач в той же степени что и GIL.
В Python для предоставления работы с имеющейся GIL доступно множество методов. В целом, несмотря на то что она обладает дурной славой в сообществе программирования Python, GIL оказывает воздействие только на определённую часть всей экосистемы Python и может рассматриваться как необходимое зло, которое является черезчур важным чтобы быть удалённым из самого языка. Разработчикам Python необходимо изучать сосуществование с GIL и работать с ним в своих программах совместной обработки.
В своих последних главах мы обсудили некоторые из наиболее общеизвестных и самых распространённых проблем параллельного программирования в Python. В самом окончательном разделе данной книги мы рассмотрим некоторые из наиболее продвинутых функциональностей совместной обработки, предоставляемых Python. В нашей следующей главе вы изучите проектирование свободных от блокирования и основанных на блокировках структур данных.
-
К чему сводятся отличия в управлении памятью между Python и C++?
-
Какую проблему решает GIL для Python?
-
Какие задачи создаёт GIL для Python?
-
В чём заключаются основные подходы перехитрить имеющийся GIL в программах Python?
Для получения дополнительных сведений вы можете воспользоваться следующими ссылками:
-
What is the Python Global Interpreter Lock (GIL)?, Абхинав Аджитсэйрия
-
The Python GIL Visualized, Дэйв Бизли
-
It isn't Easy to Remove the GIL, Гвидо ван Россум
-
Parallel Programming with Python, Ян Пэйлач, Packt Publishing Ltd, 2014
-
Learning Concurrency in Python: Build highly efficient, robust, and concurrent applications, Эллиот Форбс, Packt Publishing Ltd, 2017