Глава 16. Разработка параллельных структур данных, основанных на блокировании и отсутствии взаимных исключений
Содержание
- Глава 16. Разработка параллельных структур данных, основанных на блокировании и отсутствии взаимных исключений
- Технические требования
- Параллельные структуры данных в Python на основе блокировок
- Свободные от взаимного исключения параллельные структуры данных в Python
- Построение простых структур данных
- Выводы
- Вопросы
- Дальнейшее чтение
В этой главе мы проанализируем подробности проектирования и реализации двух общих типов структур данных при программировании совместной обработки: основанных на блокировании и свободных от семафоров. Будут рассмотрены принципиальные отличия между этими двумя структурами данных, а также их соответствующие применения при программировании совместной обработки. На протяжении данной главы также предоставляется некий анализ необходимого компромисса между точностью и скоростью программ совместной обработки. Применяя такой анализ читатели смогут применять то же самое сопоставление компромисса для своих собственных приложений совместной обработки.
Эта глава охватывает следующие темы:
-
Обычные проблемы структур данных на основе блокировок и пути их решения
-
Подробный анализ того как реализовывать структуру данных на основе блокирования
-
Основная идея, стоящая за структурами данных без семафоров, а также их преимущества и недостатки в сопоставлении со структурами данных на основе блокировок
-
Подробный анализ того как реализовывать структуры данных, освобождённые от семафоров
Вот перечень предварительных требований для данной главы:
-
Убедитесь что на вашем компьютере уже установлен Python 3
-
Вам следует иметь установленными OpenCV и NumPy для вашего дистрибутива Python 3
-
Выгрузите необходимый репозиторий из GitHub
-
На протяжении данной главы мы будем работать с вложенной папкой, имеющей название
Chapter16 -
Ознакомьтесь со следующими видеоматериалами Code in Action
В предыдущих главах, которые рассматривали применение блокировок, вы ознакомились с тем, что блокировки не блокируют ничего; некий иллюзорный механизм, реализуемый в структуре данных на самом деле не избавляет внешние программы от доступа к их структурам данных в одно и то же время, просто обходя размещённые блокировки. Одним из решений этой проблемы является встраивание самой блокировки в конкретную структуру данных с тем, чтобы было невозможно игнорировать определённую блокировку внешними объектами реального мира.
В своём первом разделе данной главы мы обсудим теоретические основы стоящие за последующими особенностями применения блокировок и структур данных с блокированием. В частности, мы проанализируем сам процесс разработки некоторого совместно используемого счётчика, который может безопасно исполняться различными потоками, с применением блокировок (или семафоров) как необходимого механизма синхронизации.
Давайте смоделируем столкновение с проблемой при помощи наивной реализации без блокировки некоторого класса счётчика в
программе совместной обработки. Если вы уже выгрузили необходимый код для данной книги с её страницы в GitHub, пройдите
далее и переместитесь в папку Chapter16.
Давайте рассмотрим файл Chapter16/example1.py - и в частности, класс
LocklessCounter:
# Chapter16/example1.py
import time
class LocklessCounter:
def __init__(self):
self.value = 0
def increment(self, x):
new_value = self.value + x
time.sleep(0.001) # creating a delay
self.value = new_value
def get_value(self):
return self.value
Это некий простой счётчик, который имеет атрибут с названием value, который
содержит текущее значение данного счётчика, назначаемое значением 0 при первой
инициализации данного экземпляра счётчика. Имеющийся метод increment() данного
класса получает некий аргумент, x, и увеличивает имеющееся текущее значение вызываемого
объекта LocklessCounter на x. Отметим, что
мы создали некую небольшую задержку внутри своей функции increment() между самим
процессом вычисления получаемого нового значения данного счётчика и процессом присвоения этого нового значения самому
объекту счётчика. Данный класс также имеет некий метод с названием get_value(),
который возвращает текущее значение самого вызываемого счётчика.
Достаточно очевидно почему данная реализация нашего класса LocklessCounter
может создать некое условие состязательности в какой- то программе совместной обработки: пока один поток пребывает в середине
увеличения совместно используемого счётчика, другой поток также может получить доступ к этому счётчику для выполнения того же
метода increment() и то изменение значения счётчика, которое делается самым первым потоком
может быть переписано потоком, выполняющим второе изменение.
Чтобы освежить графическое представление, следующая схема отображает некое условие состязательности, которое может произойти в ситуации со множеством доступов и изменений некоторого совместного ресурса в одно и то же время процессами или потоками:
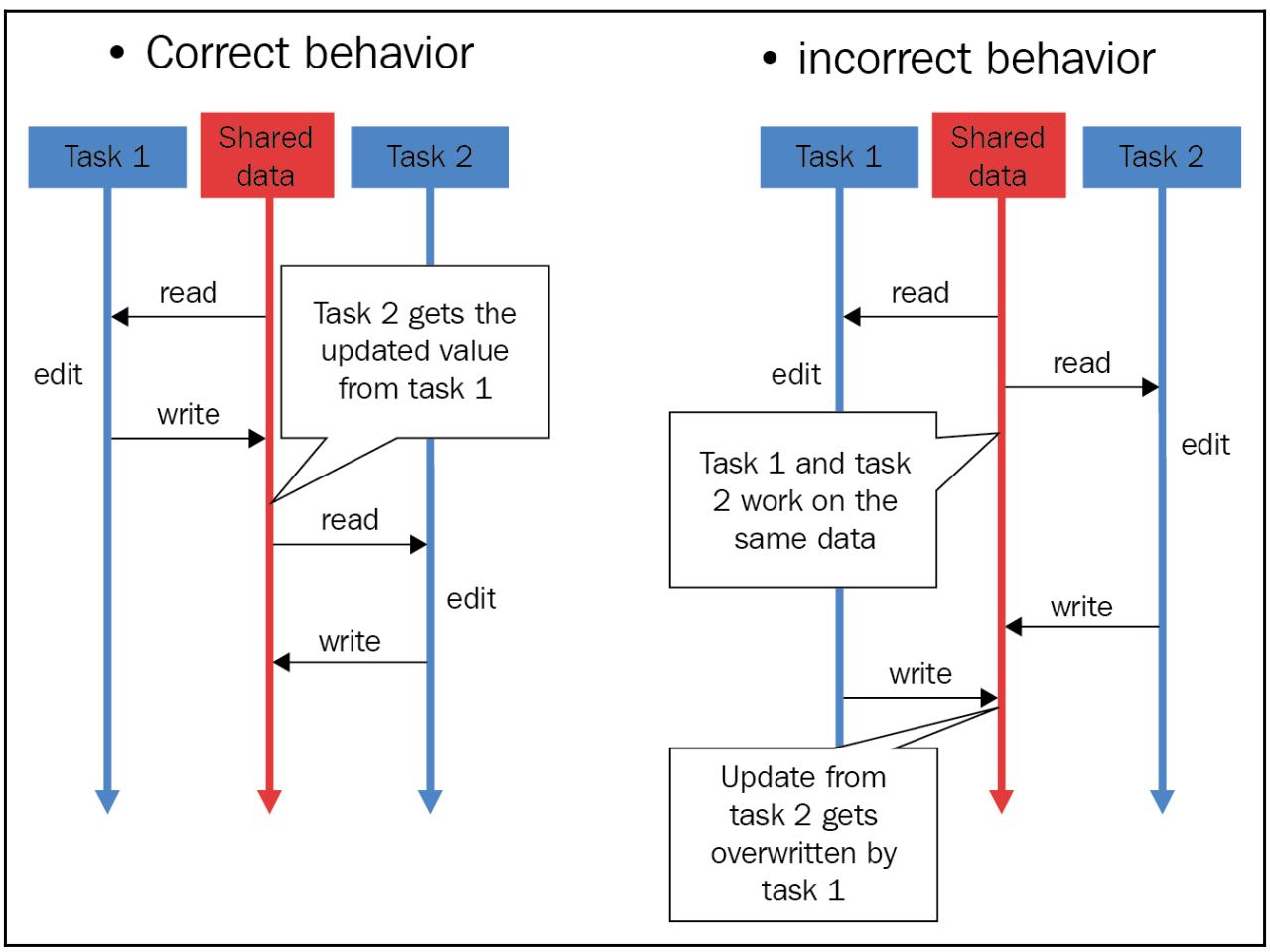
Для имитации данного условия состязательности в своей основной программе мы включаем в общей сложности три потока для увеличения разделяемого счётчика 300 раз:
# Chapter16/example1.py
from concurrent.futures import ThreadPoolExecutor
counter = LocklessCounter()
with ThreadPoolExecutor(max_workers=3) as executor:
executor.map(counter.increment, [1 for i in range(300)])
print(f'Final counter: {counter.get_value()}.')
print('Finished.')
Модуль concurrent.futures предлагает нам простой способ высокого уровня для
планирования некоторой задачи посредством пула потоков. В частности, после инициализации некоторого совместного объекта
счётчика мы объявляем переменную executor как некий пул из трёх потоков
(с применением диспетчера контекста), и этот исполнитель вызывает соответствующий метод increment()
для данного разделяемого счётчика 300 раз, причём всякий раз увеличивая текущее значение данного счётчика на
1.
Эти задачи должны выполняться в трёх потоках из имеющегося пула при помощи метода map()
из класса ThreadPoolExecutor. По завершению данной программы мы просто выводим на
печать окончательное значение своего объекта счётчика. Приводимый ниже код отображает то что получил я после запуска данного
сценария:
> python3 example1.py
Final counter: 101.
Finished.
Хотя и имеется возможность получения различных значений для данного счётчика при исполнении рассматриваемого сценария
в вашей системе, чрезвычайно низка вероятность того, что вашим окончательным значением на самом деле окажется правильное
значение, 300. Кроме того, если вы исполняете это сценарий снова и снова, достаточно вероятно получение различных значений для
данного счётчика, что иллюстрирует не детерминированную природу этой программы. И опять же, раз некоторые потоки переписывали
получаемые изменения, совершаемые прочими потоками, некоторые увеличения теряются в процессе исполнения, что имеет
результатом тот факт, что значение счётчика было успешно увеличено в данном случае только 101
раз.
Основная цель хорошей совместно обрабатываемой структуры данных с блокировкой состоит в наличии её внутренней
реализации внутри своего класса атрибутов и методов с тем чтобы внешние функции и программы не имели возможности
обходить такие блокирования и выполнять доступ к разделяемым объектам совместной обработки в одно и то же время. Для своей структуры
данных счётчика мы будем добавлять некий дополнительный атрибут данного класса, который будет хранить сам объект
lock, который соответствует текущему значению данного счётчика. Рассмотрим приводимую далее
новую реализацию такой структуры данных в файле Chapter16/example2.py:
# Chapter16/example2.py
import threading
import time
class LockedCounter:
def __init__(self):
self.value = 0
self.lock = threading.Lock()
def increment(self, x):
with self.lock:
new_value = self.value + x
time.sleep(0.001) # creating a delay
self.value = new_value
def get_value(self):
with self.lock:
value = self.value
return value
В данной реализации структуры данных нашего счётчика некий объект lock
также инициализирует атрибут экземпляра LockedCounter при инициализации
этого экземпляра. Кроме того, при всяком обращении к значению счётчиком некоторого потока, будь то с целью чтения
(соответствующий метод get_value()), или для обновления
(метод increment()), необходимо получить сам атрибут lock
чтобы гарантировать что никакой иной поток также не осуществляет доступ к нему. Это осуществляется при помощи диспетчера
контекста с соответствующим атрибутом lock.
Теоретически, данная реализация должна для нас разрешить имеющуюся проблему условия состязательности. В своей основной программе мы реализуем тот же самый пул потоков, который мы применяли в своём предыдущем примере. Будет создан некий разделяемый счётчик, а также 300 раз будет выполнено увеличение (по одному в каждом конкретном элементе) среди трёх различных потоков:
# Chapter16/example2.py
from concurrent.futures import ThreadPoolExecutor
counter = LockedCounter()
with ThreadPoolExecutor(max_workers=3) as executor:
executor.map(counter.increment, [1 for i in range(300)])
print(f'Final counter: {counter.get_value()}.')
print('Finished.')
Запустим данный сценарий и получаемый вывод, производимый данной программой должен быть аналогичен такому:
> python3 example2.py
Final counter: 300.
Finished.
Как вы можете видеть, проблема условия состязательности была успешно разрешена: наше окончательное значение получаемого
счётчика равно 300, что соответствует в точности общему числу выполненных нами изменений.
Более того, не имеет значения как много раз вы запустите эту программу снова, получаемое значение данного счётчика всегда будет
оставаться равным 300. В настоящий момент у нас есть работающая, правильная структура
данных для счётчиков совместной обработки.
Одной из сторон, которая существенна для конкретного приложения совместной обработки является масштабируесть. Под масштабируемостью мы подразумеваем значения изменений в производительности при росте общего числа задач, подлежащих обработке. Андрэ Б. Бонди, основатель и президент Software Performance and Scalability Consulting, LLC, определяет масштабируемость как "возможность системы, сетевой среды или процесса обрабатывать растущий объём работы или его потенциал увеличения для соответствия такому росту."
При программировании совместных систем масштабируемость является важным понятием, которое позволяет учитывать потребности; количество возрастающей работы при программировании совместной обработки обычно является числом подлежащих исполнению задач, а также общее число активных процессов и потоков для исполнения этих задач. Например, фазы проектирования, реализации и тестирования некоего приложения совместной обработки обычно вовлекает достаточно небольшой объём вычислений для содействия действенной и быстрой разработке. Это означает, что некое типичное приложение совместной обработки будет обрабатывать значительно больше вычислений в ситуациях реальной жизни, которые не происходят на стадии самой разработки. Именно поэтому некий анализ масштабируемости является критически важным для хорошо спроектированных приложений совместной обработки.
Однако исключительной масштабируемости фактически невозможно достичь в большинстве случаев из- за существенных накладных расходов при создании потоков и процессов. При этом если производительность программы совместной обработки не ухудшается существенным образом по мере увеличения количества активных процессов, тогда мы можем согласиться с присутствующей масштабируемостью. Сам термин значительное ухудшение сильно зависит от типов задач, за исполенение которых отвечает данная программа совместной обработки, а также от того какова величина допустимого снижения произвидительности в программе.
В данном виде анализа мы будем рассматривать некий двумерный график, представляющий размер масштабирования данной программы
совместной обработки. Ось x обозначает общее число активных потоков или процессов
(и опять же, каждый из них отвечает за исполнение фиксированного числа вычислений на протяжении всей программы); ось
y обозначает значение скорости данной программы для различного числа активных потоков
или процессов. При рассмотрении данного графика у нас будет иметься тендеция роста; чем больше процессов/ потоков имеет данная
программа, тем больше времени (скорее всего) потребуется для исполнения данной программы. Исключительная масштабируемость,
с другой стороны, будет транслироваться в некую горизонтальную линию, так как никакого дополнительного времени не требуется при
росте общего числа потоков/ процессов.
Следующая схема является неким примером такого графика для анализа масштабируемости:

В нашем предыдущем графике ось x указывает общее число исполняемых потоков/
процессов, а ось y указывает общее время исполнения (в секундах, в данном случае).
Различные графики показывают размер масштабируемости определённой установки (самой операционной системы в комбинации с множеством
ядер).
Чем круче наклон графика, тем хуже соответствующая модель совместной обработки масштабируется с увеличением числа потоков/ процессов. Например, некая горизонтальная линия (тёмно синяя и самая нижняя в данном случае) означает идеальную масштабируемость, в то время как жёлтый (самый верхний) график указывает на нежелательную масштабируемость.
Теперь давайте рассмотрим величину масштабирования нашей текущей структуры данных счётчика - в частности, в зависимости от изменения числа активных потоков. У нас имеется три потока прибавления единицы совместного счётчика для 300 раз; таким образом, в своём анализе масштабируемости мы будем иметь ситуацию, при которой каждый из активных потоков прибавляет единицу к разделяемому счётчику 100 раз при изменении общего числа активных потоков в нашей программе. Следую обсуждённой выше процедуре масштабирования мы рассмотрим как производительность (скорость) данной программы, которая применяет рассматриваемую структуру данных счётчика изменяется при увеличении общего числа потоков.
Рассмотрим следующий файл Chapter16/example3.py:
# Chapter16/example3.py
import threading
from concurrent.futures import ThreadPoolExecutor
import time
import matplotlib.pyplot as plt
class LockedCounter:
def __init__(self):
self.value = 0
self.lock = threading.Lock()
def increment(self, x):
with self.lock:
new_value = self.value + x
time.sleep(0.001) # creating a delay
self.value = new_value
def get_value(self):
with self.lock:
value = self.value
return value
n_threads = []
times = []
for n_workers in range(1, 11):
n_threads.append(n_workers)
counter = LockedCounter()
start = time.time()
with ThreadPoolExecutor(max_workers=n_workers) as executor:
executor.map(counter.increment,
[1 for i in range(100 * n_workers)])
times.append(time.time() - start)
print(f'Number of threads: {n_workers}')
print(f'Final counter: {counter.get_value()}.')
print(f'Time taken: {times[-1] : .2f} seconds.')
print('-' * 40)
plt.plot(n_threads, times)
plt.xlabel('Number of threads'); plt.ylabel('Time in seconds')
plt.show()
В нашем предыдущем сценарии мы всё ещё будем применять ту же самую реализацию своего класса
LockedCounter, которую мы применяли в своём предыдущем примере. В своей основной
программе мы тестируем это класс с различным числом активных потоков; в частности, мы выполняем итерации в цикле
for для получения общего числа потоков от 1 до 10. Для каждой итерации мы
инициализируем некий разделяемый счётчик и создаём некий пул потоков для обработки соответствующего числа задач - в данном
случае добавление единицы к разделяемому счётчику 100 раз для каждого потока.
Мы также отслеживаем общее число активных потоков, а также того времени, которое требуется для данного пула потоков для завершения своих задач на каждой итерации. Именно это выступает в качестве наших данных для общего процесса анализа масштабируемости. Мы выводим на печать эти данные и вычерчиваем график масштабируемости, который аналогичен к тому, что мы видели на своём предыдущем примере графика.
Приводимый далее код показывает мой вывод при исполнении данного сценария:
> python3 example3.py
Number of threads: 1
Final counter: 100.
Time taken: 0.15 seconds.
----------------------------------------
Number of threads: 2
Final counter: 200.
Time taken: 0.28 seconds.
----------------------------------------
Number of threads: 3
Final counter: 300.
Time taken: 0.45 seconds.
----------------------------------------
Number of threads: 4
Final counter: 400.
Time taken: 0.59 seconds.
----------------------------------------
Number of threads: 5
Final counter: 500.
Time taken: 0.75 seconds.
----------------------------------------
Number of threads: 6
Final counter: 600.
Time taken: 0.87 seconds.
----------------------------------------
Number of threads: 7
Final counter: 700.
Time taken: 1.01 seconds.
----------------------------------------
Number of threads: 8
Final counter: 800.
Time taken: 1.18 seconds.
----------------------------------------
Number of threads: 9
Final counter: 900.
Time taken: 1.29 seconds.
----------------------------------------
Number of threads: 10
Final counter: 1000.
Time taken: 1.49 seconds.
----------------------------------------
Кроме того приведём полученный мной график масштабируемости:
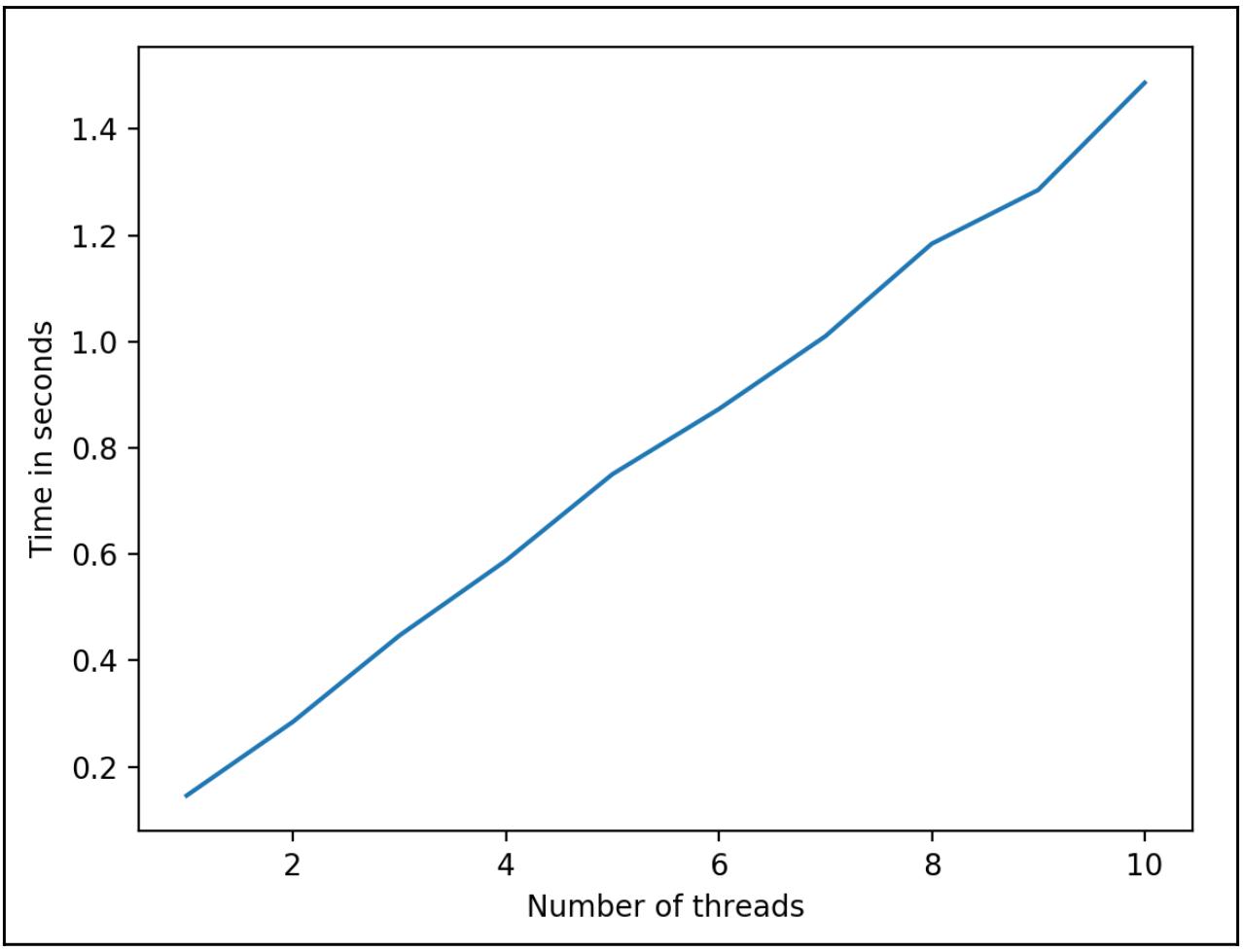
Даже если ваш собственный вывод отличается в конкретных продолжительностях для каждой итерации, сама тенденция масштабируемости должна быть относительно той же самой; иными словами, ваш график масштабируемости должен иметь тот же самый наклон, что и предыдущий график. Как вы можете видеть из того вида вывода, который мы получили, даже хотя счётчик при всех итерациях и имел правильное значение, текущая масштабируемость нашей структуры данных счётчика крайне нежелательна: по мере того как всё больше потоков добавляется в нашу программу для выполнения всё большего числа задач, значение производительности данной программы уменьшается, причём почти линейно.
Интуитивно понятно, что эта константа масштабирования является результатом нашего механизма блокирования: так как только один поток способен осуществлять доступ и увеличивать на единицу значение совместного счётчика в некий определённый момент времени, чем больше увеличений нашей программе предстоит исполнить, тем больше времени потребуется для завершения всех задач увеличения. Самым большим недостатком применения блокировок в качестве механизма является именно второй: блокировки способны исполнять некую программу совместной обработки (и снова, самый первый недостаток состоит в том, что блокировки в действительности ничего не блокируют).
Учитывая сложность проектирования и реализации верной, но быстрой, основанной на блокировке структуры данных совместной обработки, разработка действенно масштабируемых механизмов блокирования является популярной темой исследований в области информатики и уже было предложено множество подходов к решению стоящей перед нами проблемы. В данном разделе мы обсудим один из них: приблизительные счётчики.
Основная мысль стоящая за аппроксимацией счётчиков
Давайте вернёмся к размышлению относительно своей программы совместной обработки и той причине, почему такая блокировка выступает против достижения нами хорошей производительности в терминах скорости: все имеющиеся активные потоки в нашей программе взаимодействуют с одним и тем же разделяемым счётчиком, который в свою очередь может взаимодействовать только с одним потоком за раз. Основное решение данной проблемы состоит в изоляции такого взаимодействия с неким счётчиком обособленными потоками. В частности, получаемое значение того счётчика, который мы отслеживаем не будет представляться только единственным больше не разделяемым счётчиком; вместо этого мы будем применять множество локальных счётчиков, по одному для каждого потока/ процесса дополнительно к тому совместному глобальному счётчику, который у нас уже имелся изначально.
Основная идея, стоящая за таким подходом, заключается в том чтобы распределить необходимые вычисления (увеличение на единицу самого разделяемого глобального счётчика) между прочим счётчиками нижнего уровня. Когда некий активный поток исполняется и желает увеличить на единицу значение глобального счётчика, вначале ему придётся увеличить на единицу его соответствующий локальный счётчик. Взаимодействие с индивидуальными локальными счётчиками, в отличии от выполнения этого в отдедьным, совместно используемым счётчиком, имеет гораздо лучшую масштабируемость, так как только один поток осуществляет доступ и обновляет каждый локальный счётчик; иными словами, не существует раздора между различными потоками при взаимодействии с такими локальными счётчиками.
Поскольку всякий поток взаимодействует со своим соответствующим локальным счётчиком, такие локальные счётчики обязаны
взаимодействовать с имеющимся глобальным счётчиком. В частности, каждый локальный счётчик будет периодически запрашивать блокировку
для своего глобального счётчика и увеличивать его в соответствии со своим текущим значением; например, если некий
локальный счётчик содержал шесть пожеланий увеличения на единицу своего глобального счётчика, он выполнит это увеличением на шесть
и вернёт своё собственное значение обратно в ноль. Именно поэтому все сообщаемые от своих локальных счётчиков приращения
относятся к общему значению их глобального счётчика, что подразумевает, что если некий локальный счётчик содержит значение
x, значение глобального счётчика следует прирастить на его значение
x.
Вы можете представить себе эту архитектуру в виде некоей простейшей сети, причём её глобальный счётчик расположен в самом центральном узле, в то время как все локальные счётчики будут расположены в заднем узле. Всякий тыльный узел взаимодействует со своим центральным узлом, отправляя своё значение в этот центральный узел и в результате сбрасывая своё значение обратно в ноль. Следующая схема выступает дополнительной иллюстрацией такого дизайна:

Как мы уже обсуждали ранее, когда все активные потоки взаимодействовали с одним и тем же счётчиком на основе блокировки, никакой дополнительной скорости невозможно было достичь при преобразовании этой программы в совместно исполняемую, поскольку само исполнение между отдельными потоками не может накладываться одно на другое. Теперь при наличии одного обособленного объекта счётчика для каждого потока, каждый поток имеет возможность обновлять свой соответствующий локальный счётчик независимо и одновременно, создавая перекрытие, которое в результате приведёт к лучшей производительности в отношении скорости нашей программы и сделает эту программу более масштабируемой.
Название такой технологии, аппроксимирующие счётчики, проистекает из того факта, что получаемое значение нашего глобального счётчика просто является приближением к некоторому верному значению. В частности, получаемое значение глобального счётчика вычисляется исключительно на основе значений локальных счётчиков, и оно становится более точным при каждом увеличении значения глобального счётчика на величину одного из локальных счётчиков.
Тем не менее, в данной конструкции присутствует некое определение, которое требует большего внимания. Как часто локальным счётчикам следует взаимодействовать со своим глобальным счётчиком и обновлять его значение? Естественно, это не может происходить со скоростью каждого увеличения на единицу (увеличение значения глобального счётчика при каждом приращении на единицу локального счётчика), так как это было бы эквивалентно применению одной совместной блокировки, причём с ещё более значительными накладными расходами (за счёт локальных счётчиков).
Для обозначения частоты запросов применяется численный показатель с названием порогового значения S; в частности, порог S определяется как верхняя граница получаемого значения локального счётчика. Поэтому, если некий локальный счётчик инкрементально наращивается до значения, превышающего эту величину, он обязан обновить свой глобальный счётчик и сбросить своё значение в ноль. Чем меньше пороговое значение S, тем более часто значения локальных счётчиков обновляют свой глобальный счётчик, и тем ниже будет масштабируемость нашей программы, но получаемое значение нашего глобального счётчика будет более актуальным. И наоборот, чем больше порог S, тем менее часто обновляется значение общего глобального счётчика, но при этом у нашей программы будет лучше значение производительности.
Таким образом, имеется некий компромисс значения точности некоторого объекта аппроксимации объекта счётчика и величины масштабируемости некоторой программы совместной обработки при помощи этой структуры данных. Аналогично прочим распространённым компромиссам в информатике и программировании, для оптимального порогового значения S необходимой структуры данных приблизительного счётчика можно определить соответствующее значение только путём индивидуальных экспериментов и проверок.
Реализация аппроксимирующих счётчиков в Python
Имея на уме приблизительные счётчики, давайте попробуем реализовать их структуру данных на Python, построив свою
предыдущую архитектуру для таких счётчиков на основе блокировок. Рассмотрим следующий файл Chapter16/example4.py,
- в частности класс LockedCounter и класс
ApproximateCounter:
# Chapter16/example4.py
import threading
import time
class LockedCounter:
def __init__(self):
self.value = 0
self.lock = threading.Lock()
def increment(self, x):
with self.lock:
new_value = self.value + x
time.sleep(0.001) # creating a delay
self.value = new_value
def get_value(self):
with self.lock:
value = self.value
return value
class ApproximateCounter:
def __init__(self, global_counter):
self.value = 0
self.lock = threading.Lock()
self.global_counter = global_counter
self.threshold = 10
def increment(self, x):
with self.lock:
new_value = self.value + x
time.sleep(0.001) # creating a delay
self.value = new_value
if self.value >= self.threshold:
self.global_counter.increment(self.value)
self.value = 0
def get_value(self):
with self.lock:
value = self.value
return value
В то время как класс LockedCounter остаётся тем же самым, чем он и был в
нашем предыдущем примере (этот класс был использован для реализации наших объектов глобального счётчика), именно класс
ApproximateCounter, который содержит необходимую реализацию для логики наших
аппроксимирующих счётчиков, которую мы обсудили ранее, является предметом нашего интереса. Вновь инициализируемый объект
ApproximateCounter будет определён с начальным значением
0, причём он также будет иметь некую блокировку, так как также является структурой
данных на основе блокирования. Самыми важными атрибутами объекта ApproximateCounter
являются тот глобальный счётчик, который необходимо выдавать в отчёте и величина порогового значения, которая определяет
параметры скорости с которой он выдаёт сообщения своему соответствующему глобальному счётчику. Как уже упоминалось ранее,
в данном случае мы просто выбираем 10 в качестве некоторого произвольного значения
для величины порога.
В своём методе increment() из класса ApproximateCounter
мы также можем обнаружить ту же самую логику инкрементальных приращений: этот метод получает параметр с названием
x и увеличивает имеющееся значение данного счётчика на x,
при размещении блокировки на этот вызываемый объект аппроксимирующего счётчика. Кроме того, этот метод также должен проверить
будет ли вновь приращиваемое значение этого счётчика преодолевать его пороговую величину; если это произошло, он добавит
к значению своего глобального счётчика то число, которое эквивалентно текущему значению его локального счётчика, а само значение
этого локального счётчика будет сброшено обратно в 0. Метод
get_value(), который применяется для возврата текущего значения счётчика в данном
классе тот же самый, что мы наблюдали и ранее.
Теперь давайте проведём проверку и сопоставим величину масштабирования своей новой структуры данных в нашей основной программе. Во- первых мы восстановим все данные для соответствующего масштабирования нашей старой структуры данных счётчика с единственной блокировкой:
# Chapter16/example4.py
from concurrent.futures import ThreadPoolExecutor
# Previous single-lock counter
single_counter_n_threads = []
single_counter_times = []
for n_workers in range(1, 11):
single_counter_n_threads.append(n_workers)
counter = LockedCounter()
start = time.time()
with ThreadPoolExecutor(max_workers=n_workers) as executor:
executor.map(counter.increment,
[1 for i in range(100 * n_workers)])
single_counter_times.append(time.time() - start)
В точности как и в своём предыдущем примере, мы применяем некий объект ThreadPoolExecutor
для совместной обработки задач, причём в отдельных потоках, в то же самое время отслеживая продолжительность, требующуюся для
завершения каждой итерации; здесь нет ничего удивительного. Далее мы вырабатываем те же самые данные с соответствующими числами
активных потоков в своих итерациях соответствующего цикла for следующим
манером:
# New approximate counters
def thread_increment(counter):
counter.increment(1)
approx_counter_n_threads = []
approx_counter_times = []
for n_workers in range(1, 11):
approx_counter_n_threads.append(n_workers)
global_counter = LockedCounter()
start = time.time()
local_counters = [ApproximateCounter(global_counter) for i in range(n_workers)]
with ThreadPoolExecutor(max_workers=n_workers) as executor:
for i in range(100):
executor.map(thread_increment, local_counters)
approx_counter_times.append(time.time() - start)
print(f'Number of threads: {n_workers}')
print(f'Final counter: {global_counter.get_value()}.')
print('-' * 40)
Давайте потратим какое- то время на анализ своего предыдущего кода. Во- первых, у нас имеется некая внешняя функция
thread_increment(), которая получает некий счётчик и увеличивает его на 1;
эта функция будет применяться для переделки кода впоследствии, для индивидуализации приращений наших локальных
счётчиков.
Снова мы будем выполнять итерации посредством цикла for для анализа значения
производительности этой новой структуры данных при изменениии числа активных потоков. Внутри каждой итерации мы вначале
инициализируем некий объект LockedCounter в качестве своего глобального счётчика,
совместно с неким списком локальных счётчиков, которые выступают экземплярами соответствующего класса
ApproximateCounter. Все они ассоциированы с тем же самым глобальным счётчиком
(который мы передали в своём методе инициализации), поскольку им требуется выдавать отчёты в один и тот же счётчик.
Затем, аналогично тому как мы выполняли планирование задач для множества потоков, мы применяем некий диспетчер
контекста для создания пула потоков, внутри которого мы будем распределять имеющиеся задачи (увеличения значений локальных
счётчиков) через некий встраиваемый цикл for. Та причина, по которой мы проходим
циклом через другой for состоит в имитации общего числа задач, согласующегося с теми,
что мы реализовывали в своём предыдущем примере, а также в распределении этих задач по всем имеющимся локальным счётчикам
для совместной обработки. Также мы выводим на печать получаемое окончательное значение своего глобального счётчика при
каждой итерации, чтобы удостоверяться что наша новая структура данных работает правильно.
Наконец, в своей основной программе мы будем вырисовывать точки значений данных, которые вырабатываются в соответствующих
двух циклах for, чтобы проводить сопоставление этих двух структур данных посредством их
соответствующих значений производительности:
# Chapter16/example4.py
import matplotlib.pyplot as plt
# Plotting
single_counter_line, = plt.plot(
single_counter_n_threads,
single_counter_times,
c = 'blue',
label = 'Single counter'
)
approx_counter_line, = plt.plot(
approx_counter_n_threads,
approx_counter_times,
c = 'red',
label = 'Approximate counter'
)
plt.legend(handles=[single_counter_line, approx_counter_line], loc=2)
plt.xlabel('Number of threads'); plt.ylabel('Time in seconds')
plt.show()
Запустите этот сценарий и самый первый вывод, который вы получите будет содержать ваши следующие индивидуальные
окончательные значения соответствующих глобальных счётчиков в нашем втором цикле for:
> python3 example4.py
Number of threads: 1
Final counter: 100.
----------------------------------------
Number of threads: 2
Final counter: 200.
----------------------------------------
Number of threads: 3
Final counter: 300.
----------------------------------------
Number of threads: 4
Final counter: 400.
----------------------------------------
Number of threads: 5
Final counter: 500.
----------------------------------------
Number of threads: 6
Final counter: 600.
----------------------------------------
Number of threads: 7
Final counter: 700.
----------------------------------------
Number of threads: 8
Final counter: 800.
----------------------------------------
Number of threads: 9
Final counter: 900.
----------------------------------------
Number of threads: 10
Final counter: 1000.
----------------------------------------
Как вы можете видеть, все полученные из ваших глобальных счётчиков окончательные значения являются правильными, подтверждающими что наша структура данных работает ожидаемым образом. Кроме того, вы получите некий график, похожий на такой:

Наша синяя линия указывает значения изменений в скорости структуры данных с единственным счётчиком, в то время как соответствующая красная линия указывает изменения структуры данных аппроксимирующего счётчика. Как вы можете наблюдать, даже хотя значение производительности нашего аппроксимирующего счётчика несколько ухудшается по мере увеличения общего числа потоков (благодаря накладным расходам таким, как создание индивидуальных локальных счётчиков и распределения растущего числа задач инкрементального добавления), наша новая структура данных имеет высокую масштабируемость, в особенности при сравнении с нашей предыдущей структурой данных счётчика с единственной блокировкой.
Ряд соображений относительно проектирования аппроксимации счётчиков
Одним из моментов, на который вы могли обратить внимание, состоит в том, что даже хотя только один поток взаимодействует
с отдельным локальным счётчиком, его структура данных всё еще имеет некий атрибут lock
при своей инициализации. Это происходит по той причине, что фактически имеется возможность разделять одни и те же локальные
счётчики по множеству потоков. Существуют ситуации при которых будет неэффективным создание одного локального счётчика для
каждого активного потока, поэтому разработчики могут иметь вместо этого два или более совместно использующими один и тот
же локальный счётчик, а индивидуальные счётчики смогут всё ещё выдавать отчёты в тот же самый глобальный счётчик.
Например, предположим, что у нас имеются 20 потоков, исполняемых в некоторой программе совместной обработки счётчиков; мы можем иметь всего лишь 10 локальных счётчиков для отчётов в один глобальный счётчик. Из этого мы можем заключить, что данная установка будет иметь более низкий уровень масштабируемости чем та, которая имела бы индивидуальные локальные счётчики для каждого потока, однако значительным преимуществом данного подхода является то, что он использует меньшее пространство памяти и избегает части накладных расходов создания большего числа локальных счётчиков.
Существует и иная возможная вариация того пути, которым может разрабатываться некая программа которая использует аппроксимирующие счётчики. Вместо наличия только одного уровня локальных счётчиков, мы можем также реализовать частично- глобальные счётчики, в которые выдают отчёты локальные счётчики и которые, в свою очередь, выдают отчёты в те глобальные счётчики, которые находятся на один уровень выше чем они сами. При применении соответствующей структуры данных счётчика, сам разработчик не только вынужден определять, как уже обсуждалось ранее, некий подходящий порог выдачи отчётов, но к тому же он или она вынуждены оптимизировать общее число потоков, связываемых с одним отдельным локальным счётчиком, а также общее число уровней в нашем проекте.
Предыдущий подраздел завершил наше обсуждение проектирования структуры данных совместной обработки на основе блокировки на Python, а также вовлечённые в это сложности. Теперь мы перейдём к одному подходу в теоретическом проектировании структур данных совместной обработки, свободных от семафоров.
Сам термин свободных от взаимного блокирования (семафоров, mutex-free) в структурах данных параллельного программирования указывает на отсутствие какого бы то ни было механизма для защиты целостности такой структуры данных. Это не означает что такая структура данных просто пренебрегает наличием защищённости своих данных; вместо этого обсуждаемая структура данных должна реализовывать иные механизмы синхронизации. В этом разделе мы проанализируем такой механизм, который известен как чтение- копирование- обновление, а также обсудим как применять его к некоторой структуре данных Python.
В противоположность структуре данных с блокированием имеются структуры данных без блокировок. Здесь мы будем обсуждать их определение и те причины, по которым почему такие характеристики, которые требуют полной свободы от блокирования на самом деле невозможны в Python, и почему самое ближнее чего мы можем достичь это получить их свободными от семафоров.
В отличие от структур данных на основе блокировок, некая структура данных, которая является свободной от блокирования не только не предоставляет никакого механизма блокировки (как это в случае структур данных без семафоров - mutex-free), но также требует чтобы каждый заданный поток или процесс не мог бы выполнять ожидание бесконечно долго. Это означает, что если успешно реализовать некую структуру данных без блокирования, использующие такую структуру данных приложения никогда не будут сталкиваться с проблемами взаимных блокировок и зависаний. По этой причине свободные от блокировок структуры данных имеют широкое поле применения и более продвинутая технология в программировании совместной обработки, а следовательно они значительно сложнее в реализации.
На самом деле такую характеристику, как свободу от блокировки, невозможно реализовать в Python (или, чтобы быть конкретнее, в интерпретаторе CPython). Как вы возможно уже предвосхитили, это происходит по причине наличия той самой GIL, которая препятствует более чем одному потоку исполняться в конкретном ЦПУ в некий определённый момент времени. Для получения дополнительных сведений относительно GIL перейдите к Главе 15, Глобальная блокировка интерпретатора и ознакомьтесь с подробным анализом самой GIL, если вы этого ещё не сделали. В целом, наличие полностью свободной от блокировки структуры данных реализуемой в CPython логически невозможно.
Тем не менее, это не означает, что программирование совместной обработки в Python не способно извлекать преимуществ из самой архитектуры структур данных, свободных от блокирования. Как уже упоминалось ранее, безсемафорные структуры данных Python (которые могут рассматриваться как некое подмножество структур данных свободных от блокировок) целиком доступны для реализации. На самом деле структуры данных без семафоров всё ещё приводят к успешному предотвращению проблем с взаимными блокировками и зависаниями. Тем не менее, они не могут полностью получать преимущества чистого исполнения без блокировок, которое имело бы результатом лучшую скорость.
В своих последующих подразделах мы рассмотрим индивидуальную структуру данных в Python, проанализируем саму проблему, которая возникает при применении совместной обработки и, наконец, попытаться применим некую свободную от семафоров логику к лежащей в основе структуре данных.
Та структура данных, которую мы начинаем реализовывать, походит на некую сетевую среду узлов, в которой один из них является первичным узлом. Кроме того, каждый узел содержит некий ключ и значение для данного узла. Вы можете представлять себе эту структуру данных как некий словарь Python (иными словами, некое множество ключей и значений соответственно собранные воедино парами), однако одна из этих пар ключей и значений именуется первичным узлом в данной сетевой среде.
Неким хорошим способом визуализации такой структуры данных является анализ ситуации в которой применяется эта структура данных. Допустим, что вас попросили реализовать определённый запрос, обрабатывающий логику некоего востребованного вебсайта, который, к тому же распространённая цель для атак DOS (denial of service, отказа в обслуживании). Так как достаточно высока возможность что это вебсайт будет достаточно часто падать несмотря на усилия вашей команды кибербезопасности, некий подход, который вы можете предпринять чтобы гарантировать клиентам данного вебсайта всё ещё иметь возможность доступа состоит в сопровождении более чем одной копии такого вебсайта в дополнение к самому основному вебсайту на вашем сервере.
Эти копии эквивалентны в любом случае эквивалентны своему основному вебсайту и следовательно ваш основной вебсайт может быть полностью заменён одной из копий в любой момент времени. Теперь когда падает некий основной вебсайт в результате DoS атаки, вы, будучи администратором этого сервера, можете запросто позволить своему основному вебсерверу отключиться и переключить его адрес на новый основной вебсайт с одной из тех копий, которые вы имеете готовыми. Все клиенты такого вебсайта тем самым не испытают никаких сложностей или несогласованностей при доступе данных к вашему вебсайту, так как все копии идентичны своему основному вебсайту, почившему в бозе. Серверы которые не реализуют такой механизм, с другой стороны, скорее всего вынуждены тратить некое время на восстановление после DoS атак (изоляцию атакующих, построение вновь всех прерванных или разрушенных данных и тому подобного).
Теперь мы можем установить связь между таким способом администрирования и вышеупомянутой структурой сетевых данных. Фактически, сетевая структура данных по- существу является некоей абстракцией данного метода на верхнем уровне; обсуждаемая структура данных является неким множеством узлов или пар значений (адрес самого вебсайта и его данных в нашем предыдущем случае), при этом отслеживаемый первичный первичный узел, который также может быть заменён любым другим узлом (после того как основной сайт подвергся атаке, обращающиеся к вашему вебсайту клиенты направляются на новый вебсайт). Мы будем называть такую обработку обновлением лидера в своей структуре данных, что отображено на следующей схеме:
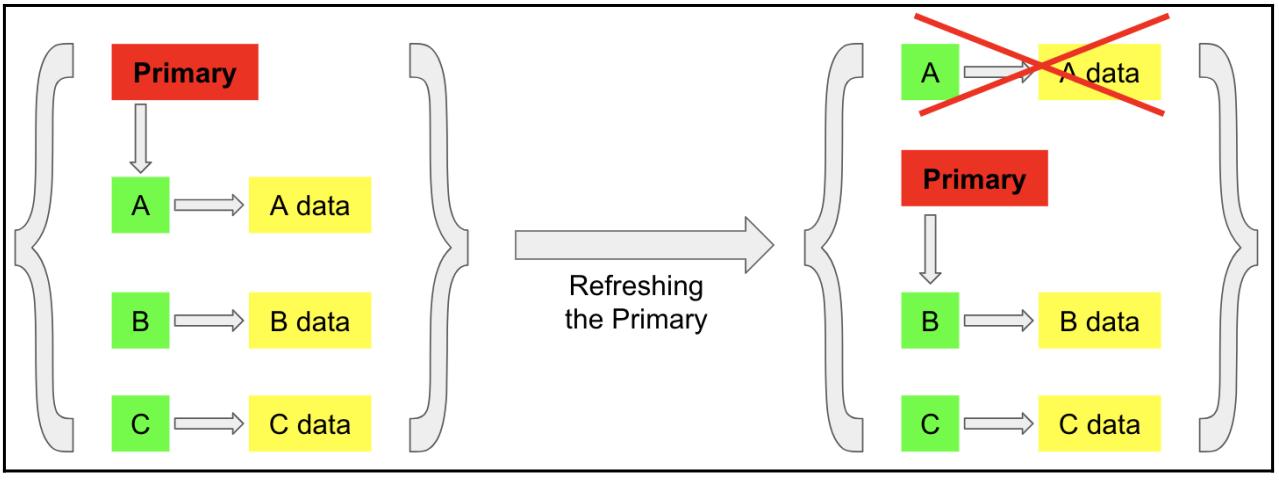
На своей предыдущей схеме мы имеем три отдельных заметки данных в своей сетевой структуре данных (отображаемых как
некий словарь, выделяемый парой фигурных скобок): ключ A,
указывающий на некие данные; ключ B, указывающий на
свои собственные данные; и, наконец, ключ C, также
указывающий на его собственные данные. Кроме того, у нас имеется некий указатель, отмечающий первичный ключ нашего сетевого
словаря (лидера), который указывает на ключ A.
Как только имеет место обновление первичного ключа, мы прекращаем отслеживать ключ
A (который выступает в роли нашего первичного ключа)
и того чем он владеет, а затем получаем соответствующий указатель лидера, показывающий на другой узел в нашей сетевой среде
(в данном случае, ключ B).
Давайте рассмотрим некую начальную реализацию такой структуры данных в Pythonю Перейдите к следующему нашему файлу
Chapter16/network.py:
# Chapter16/network.py
import time
from random import choice
class Network:
def __init__(self, primary_key, primary_value):
self.primary_key = primary_key
self.data = {primary_key: primary_value}
def __str__(self):
result = '{\n'
for key in self.data:
result += f'\t{key}: {self.data[key]};\n'
return result + '}'
def add_node(self, key, value):
if key not in self.data:
self.data[key] = value
return True
return False
# precondition: the object has more than one node left
def refresh_primary(self):
del self.data[self.primary_key]
self.primary_key = choice(list(self.data))
def get_primary_value(self):
primary_key = self.primary_key
time.sleep(1) # creating a delay
return self.data[primary_key]
Этот файл содержит необходимый класс Network, который реализует
ту логику, которая обсуждалась нами ранее. После инициализации, каждый экземпляр данного класса получает по крайней
мере один узел в данной сетевой среде (сохраняемый в атрибуте data), именно он
выступает в роли первичного узла; мы также применяем структуру данных словаря Python для реализации такой сетевой
архитектуры. Каждый объект помимо этого должен отслеживать значение ключа своих первичных данных, который сохраняется в
его атрибуте primary_key.
В данном классе у нас также имеется некий метод add_node(), который применяется
для добавления какого- то нового узла данных в некий сетевой объект; отметим, что каждый узел обязан иметь некий ключ и
какое- то значение. Вспомним свой пример веб администрирования - это соответствует некому интернет адресу и тем данным,
которые имеются у данного вебсайта. Данный класс также имеет метод refresh_primary(),
который имитирует процесс восстановления его лидера (и который удаляет имеющуюся ссылку на свои предыдущие первичные
данные и псевдослучайным образом выбирает некий новый первичный узел из всех остающихся узлов). Держите в уме то соображение,
что основным предварительным условием для данного метода является то, что данный вызываемый объект обязан иметь по крайней
мере остающимися два узла.
Наконец, у нас имеется некий метод средства доступа с названием get_primary_value(),
который возвращает само значение того первичного ключа вызываемого сетевого объекта, на который будет выставлен указатель.
Здесь мы добавляем небольшую задержку в своё исполнение данного метода для имитации того условия состязательности, которое может
происходить при использовании такой безыскусной структуры данных. (Кроме того, мы переписываем определённый по умолчанию метод
__str__() для более простой отладки.)
Теперь давайте вернёмся к своему файлу Chapter16/example5.py, в котором мы импортируем
эту структуру данных и применяем её в некоторой программе совместной обработки:
# Chapter16/example5.py
from network import Network
import threading
def print_network_primary_value():
global my_network
print(f'Current primary value: {my_network.get_primary_value()}.')
my_network = Network('A', 1)
print(f'Initial network: {my_network}')
print()
my_network.add_node('B', 1)
my_network.add_node('C', 1)
print(f'Full network: {my_network}')
print()
thread1 = threading.Thread(target=print_network_primary_value)
thread2 = threading.Thread(target=my_network.refresh_primary)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(f'Final network: {my_network}')
print()
print('Finished.')
Прежде всего мы реализуем некий функциональный вызов print_network_primary_value(),
который осуществляет доступ и получает значение первичных данных некоторого сетевого объекта, который также является
глобальной переменной, воспользовавшись уже упомянутым методом get_primary_value().
В своей основной программе мы затем инициализируем некий сетевой объект с каким- то начальным узлом, с
A в качестве значения ключа и 1 как
данных этого узла (этот узел также автоматически становится первичным узлом). Затем мы добавляем два
дополнительных узла в эту сетевую среду: B, указывающий на
1 и C, указывающий на
1, соответственно.
Теперь выполнены инициализация и запуск двух потоков, самый первый, который вызывает функцию
print_network_primary_value() для вывода значения текущих первичных данных нашей
сетевой среды. Второй вызывает метод refresh_primary() из своего сетевого объекта.
Мы также выводим на печать текущее состояние своего сетевого объекта в разных точках на протяжении своей программы.
Достаточно просто определить то условие состязательности, которое скорее всего произойдёт в этом месте: так как самый первый поток пытается получить доступ к своим первичным данным, в то время как имеющийся второй поток пытается обновить имеющиеся в нашей сети данные (по существу, в данный момент удалить текущие первичные данные), самый первый поток скорее всего вызовет некую ошибку при своём исполнении. В частности, ниже приведён мой вывод после исполнения данного сценария:
> python3 example5.py
Initial network: {
A: 1;
}
Full network: {
A: 1;
B: 1;
C: 1;
}
Exception in thread Thread-1:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/threading.py", line 917, in _bootstrap_inner
self.run()
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/threading.py", line 865, in run
self._target(*self._args, **self._kwargs)
File "example5.py", line 7, in print_network_primary_value
print(f'Current primary value: {my_network.get_primary_value()}.')
File "/Users/quannguyen/Documents/python/mastering_concurrency/ch16/network.py", line 30, in get_primary_value
return self.data[primary_key]
KeyError: 'A'
Final network: {
B: 1;
C: 1;
}
Finished.
В точности как мы и обсуждали, мы столкнулись с KeyError, которая получена в
результате того факта, что пока самый первый поток получал значение имеющегося первичного ключа, этот ключ и сами
первичные данные были уже удалены из существующей структуры данных в результате исполнения нашего второго потока. Приводимая
дапее схема дополнительно иллюстрирует этот момент:

Как вы видели в предыдущих главах, мы применяем свою функцию time.sleep()
в нашем исходном коде соответствующей структуры данных чтобы гарантировать возникновение условия состязательности. В
большинстве случаев получаемое исполнение будет достаточно быстрым чтобы могла возникнуть некая ошибка, хотя само
условие состязательности всё ещё имеется тут, а именно оно и является той проблемой в нашей текущей структуре данных,
которую нам предстоит разрешить.
Корнем условия состязательности, с которым мы столкнулись, как мы знаем, является тот факт, что тот сетевой объект,
с которым мы работаем, разделяется между различными потоками, которые изменяют и считывают имеющиеся данные из
обсуждаемой структуры данных в одно и то же время. В частности, второй поток из нашей программы изменил имеющиеся данные
(вызвав метод refresh_primary()), в то время как наш первый поток считывал те же
самые данные.
Очевидно, что мы можем просто применить блокировку в качестве механизма синхронизации для этой структуры данных. Однако, мы знаем, что такие задачи получения и высвобождения блокировки вносят некую стоимость, которая становится существенной по мере того, как эта структура данных широко используется по всей системе. Так как популярные веб-сайты и системы (а именно, MonoDB) применяют такую абстракцию для проектирования и построения структуры своих серверов, весьма высокий уровень обмена сделает очевидной имеющуюся стоимость применения блокировок и приведёт к снижению имеющейся производительности. Реализация некоей вариации какой- то аппроксимирующей структуры данных могло бы помочь в решении данной проблемы, но трудности такой реализации могут оказаться слишком сложными для последующего выполнения.
Тем самым мы останавливаемся перед своей целью применения свободного от семафоров подхода в качестве своего механизма синхронизации - в данном случае RCU (read- copy- update, чтение- копирование- обновление). Чтобы защитить целостность вашей структуры данных, RCU, по существу, является неким механизмом синхронизации, который создаёт и поддерживает иную версию необходимой структуры данных в том случае, когда некий поток или процесс запрашивает доступ на чтение или запись к ней. Посредством изоляции самого взаимодействия между имеющейся структурой данных и потоками/ процессами внутри некоторой отдельной копии, RCU гарантирует что не произойдёт никаких конфликтов. После того, как некий поток или процесс изменяет имеющуюся информацию в той копии соответствующей структуры данных, на которую он назначен, это обновление может затем выдавать сообщение своей первоначальной структуре данных.
Если кратко, когда имеется запрос к некоторой совместно используемой структуре данных со стороны потоков или процессов (процесс считывания), ей требуется возвращать некую свою копию, вместо того чтобы допускать таким потокам/ процессам выполнять доступ к её собственным данным (процесс копирования); наконец, если имеются некие изменения в такой копии этой структуры данных, они должны быть обновлены обратно в рассматриваемую разделяемую структуру данных (процесс обновленгия).
RCU чрезвычайно полезен для структур данных, которым приходится обрабатывать отдельных корректоров и множество
читателей одновременно, что является типичным случаем тех сетевых серверов, которые мы обсуждали ранее (множество клиентов
постоянно осуществляют доступ и запрашивают данные, но только изредка, периодически, происходят атаки). Но как это применить
к нашей текущей сетевой структуре данных? Теоретически, метод средства доступа нашей структуры данных (а именно, метод
get_primary_value()), который, опять- таки, корень получаемого условия состязательности,
требует создания какой- то копии имеющейся структуры данных перед считыванием этих данных из какого- то потока. Данная
спецификация реализуется в методе средства доступа в нашем следующем файле
Chapter16/concurrent_network.py:
# Chapter16/concurrent_network.py
from copy import deepcopy
import time
class Network:
[...]
def get_primary_value(self):
copy_network = deepcopy(self)
primary_key = copy_network.primary_key
time.sleep(1) # creating a delay
return copy_network.data[primary_key]
Здесь мы применяем встроенный метод deepcopy из своего модуля копирования,
который возвращает обособленную копию нашей сетевой среды в некотором ином расположении памяти. Затем мы только
считываем полученные в этой копии данные своего сетевого объекта, а не самого своего первоначального объекта.
Этот процесс иллюстрируется следующей схемой:
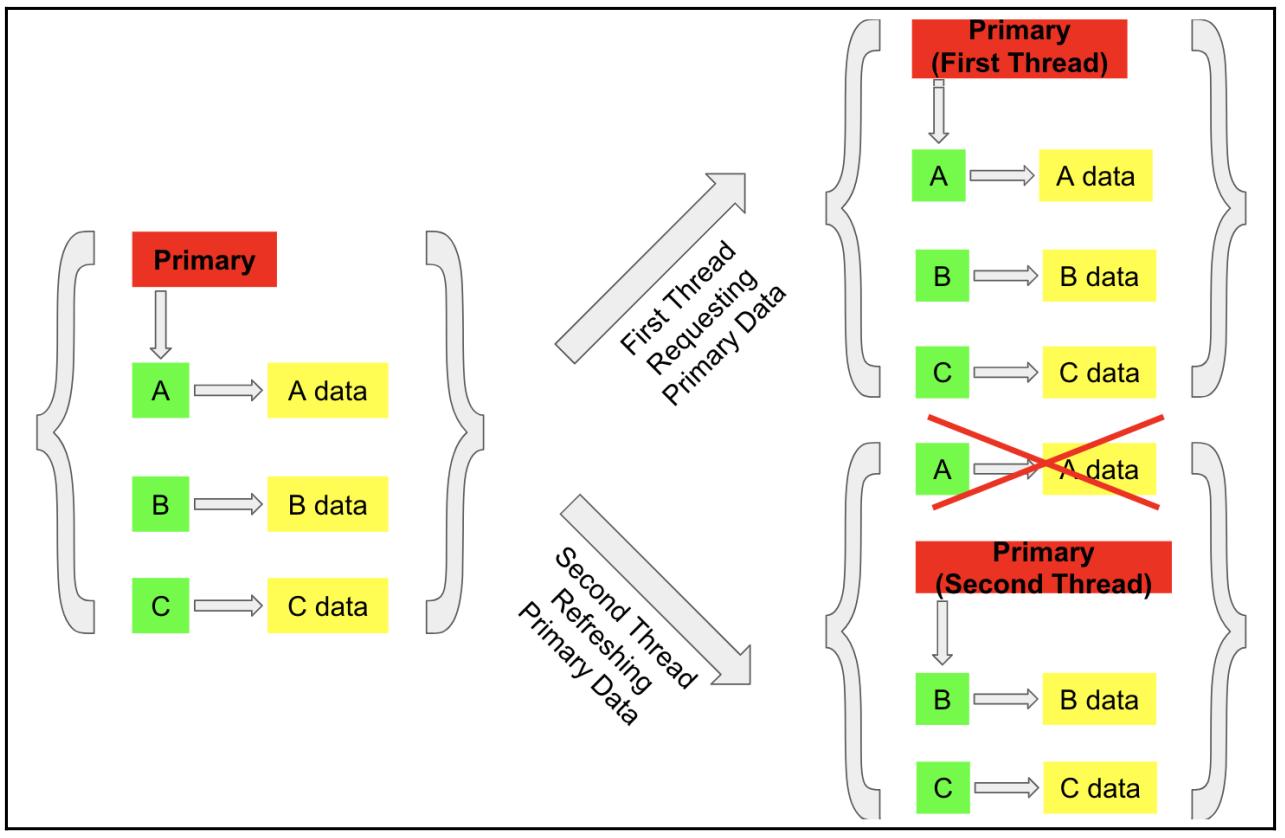
В своей предыдущей схеме мы можем видеть что никакой конфликт не происходит относительно данных, так как два потока
теперь имеют дело с различными копиями рассматриваемой структуры данных. Давайте рассмотрим эту реализацию в действии
в своём файле Chapter16/example6.py, который содержит те же самые инструкции, что и
наш предыдущий файл example5.py (инициализация некоего сетевого объекта, вызов
одновременный двух потоков - один для доступа к имеющимся первичным данным нашей сети, а другой для обновления тех же
самых первичных данных), только теперь наша программа использует нашу новую структуру данных из соответствующего
файла concurrent_network.py.
После исполнения данного сценария ваш вывод должен быть таким же, как приводимый ниже:
> python3 example6.py
Initial network: {
A: 1;
}
Full network: {
A: 1;
B: 1;
C: 1;
}
Current primary value: 1.
Final network: {
B: 1;
C: 1;
}
Finished.
Как вы можете видеть, данная программа не только получает верные значения своих первичных данных в первом потоке
без каких- либо ошибок, но она также содержит правильную сеть по окончанию данной программы (без предварительно
удалённого узла с ключом A). Наш метод RCU
на самом деле решает обозначенную проблему условия состязательности без применения каких бы то ни было механизмов
блокирования.
Один из моментов, который вы скорее всего уже заметили, состоит в том, что RCU также можно применять для нашего примера счётчика из предыдущего раздела книги. Это действительно так, и RCU, и аппроксимирующие счётчики являются обоснованными подходами к задаче со счётчиками, а на вопрос о том, какой из них является наилучшим решением для конкретной задачи совместной обработки можно ответить только с помощью эмпирического, практического анализа, например, анализа масштабируемости.
На протяжении данной главы мы работали с неким числом простых структур данных совместной обработки, таких как счётчики и сетевые среды. По этой причине мы имеем возможность на самом деле дойти до основания тех проблем, с которыми сталкиваются программы совместной обработки, которые применяют такие структуры данных, а также имели возможность выполнить анализ во всю глубину того как улучшать их структуры и архитектуру.
По мере того как вы работаете с более сложными структурами данных совместной обработки в своих вычислениях и проектах, вы обнаружите что их построение и структуры, а также сопровождающие их проблемы, по своей сути, фундаментально аналогичны тем, что мы наблюдали в проанализированных нами структурах данных. Понимая истинную архитектуру, лежащую в основе рассматриваемых структур данных, а также и сам корень проблем, которые могут возникать в тех программах, которые их применяют, вы можете опираться на эти знания и разрабатывать структуры данных, которые являются более сложными в инструкциях, но выступающие эквивалентами в логике.
В этой главе мы изучили теоретические отличия между структурами данных на основе блокировок и без семафоров: структуры данных на основе блокировок применяют механизмы блокирования для защиты необходимой целостности данных, в то время как свободные от семафоров нет. Мы проанализировали имеющиеся проблемы условий состязательности, которые могут происходить в плохо спроектированных структурах данных и рассмотрели как их разрешать при обеих ситуациях.
В своём примере структуры данных счётчика на основе блокировки с совместной обработкой мы продумали соответствующую архитектуру аппроксимирующих счётчиков, а также улучшенную масштабируемость, которую может предлагать такой подход. В своём анализе сетевой структуры данных совместной обработки мы изучили технику RCU, которая изолирует инструкции чтения от инструкций обновления, имея целью сопровождение целостности своей структуры данных совместной обработки.
В своей следующей главе мы рассмотрим иной набор современных понятий в параллельном программировании на Python: модели памяти и операции атомарного типа. Вы дополнительно изучите управление памятью Python, а также определение и применения атомарных типов.
-
В чём состоит основной подход к решению той проблемы что блокировки ничего не блокируют?
-
Опишите основную концепцию масштабируемости в нашем контексте параллельного программирования.
-
Как упрощённый механизм блокирования воздействует на размеры масштабирования программы совместной обработки?
-
Что представляют из себя аппроксимирующие счётчики и как они на самом деле помогают в решении задачи масштабирования программ совместной обработки?
-
Возможны ли свободные от блокирования структуры данных в Python? Почему?
-
Что представляет из себя свободная от семафоров структура данных и в чём её отличие от структуры данных совместной обработки, свободной от блокировки?
-
Что такое техника RCU и какие проблемы она разрешает для структур данных совместной обработки без семафоров?
Для получения дополнительных сведений вы можете воспользоваться следующими ссылками:
-
Operating systems: Three easy pieces, Арпачи- Дюссо Ремзи Х. и Арпачи- Дюссо Андре К., Vol. 151. Wisconsin: Arpaci-Dusseau Books, 2014
-
The Secret Life of Concurrent Data Structures, Микаэль Шпийгель
-
What is RCU, fundamentally? Linux Weekly News (LWN. net) (2007), Поль Э. МакКинни и Джонатан Волпоул
-
Wasp's Nest: The Read-Copy-Update Pattern in Python, Э. Джесси Джайриу Дэйвис
-
Characteristics of scalability and their impact on performance, proceedings of the second international workshop on software and performance (WOSP) '00. p. 195, Андре Б. Бонди