Глава 17. Модели памяти и операции атомарных типов
Содержание
Те соображения, которые следует принимать во внимание при программировании процессов совместной обработки, а также вытекающие из них проблемы, связаны с тем как Python управляет своей памятью. Следовательно глубокое понимание того как переменные и значения хранятся и как на них осуществляются ссылки в Python не только поможет выявлять ошибки нижнего уровня, которые влекут за собой сбои в программе совместной обработки, но также помогут оптимизировать ваш параллельный код. В данной главе мы подробно рассмотрим модель памяти Python, а также её атомарные типы, в частности их места в экосистеме совместной обработки Python.
В данной главе будут рассмотрены следующие вопросы:
-
Модель памяти Python, её компоненты, которые сопровождают выделение памяти на различных уровнях, а также общую философию управления памятью в Python
-
Собственно определение атомарных операций, ту роль, которую они играют в программировании совместной обработки и как их применять в Python
Вот перечень предварительных требований для данной главы:
-
Убедитесь что на вашем компьютере уже установлен Python 3
-
Вам следует иметь установленными OpenCV и NumPy для вашего дистрибутива Python 3
-
Выгрузите необходимый репозиторий из GitHub
-
На протяжении данной главы мы будем работать с вложенной папкой, имеющей название
Chapter17 -
Ознакомьтесь со следующими видеоматериалами Code in Action
Вы можете помнить краткое обсуждение относительно методов управления памятью в Python из Главы 15, Глобальная блокировка интерпретатора. В этом разделе мы более глубоко рассмотрим модели памяти Python сопоставляя механизмы её управления по отношению с механизмами Java и C++, а также обсудим как это соотносится с имеющимися практиками программирования совместной обработки в Python.
Данные Python хранятся в памяти определённым образом. Для получения глубокого понимания на высоком уровне относительно того как обрабатываются данные в программах совместного обслуживания нам для начала требуется окунуться глубже в имеющуюся теоретическую структуру выделения памяти в Python. В этом разделе мы обсудим как выделяются данные в некоей частной куче (heap), а также как эти данные обрабатываются росредством диспетчера памяти Python - некоей всеохватывающей сущности, которая обеспечивает необходимую целостность данных.
Диспетчер памяти Python состоит из ряда компонентов, которые взаимодействуют с различными логическими объектами и сопровождают различные функциональные возможности. Например, один из компонентов обрабатывает выделение памяти на нижнем уровне посредством взаимодействия с имеющимся диспетчером памяти операционной системы, в которой запущен Python и он именуется распределителем сырой памяти (raw memory allocator).
На самом верхнем уровне также имеется ряд иных распределителей памяти, которые взаимодействуют с уже упомянутой частной кучей объектов и значений. Эти компоненты имеющегося диспетчера памяти Python обрабатывают выделения специфичные для объектов, которые исполняют операции с памятью, особенные для конкретных типов данных и объектов; целые значения должны обрабатываться и управляться иными распределителями, нежели те, которые управляют строками, или же словарями либо кортежами. Так как операции сохранения и считывания различаются между этими типами данных, эти распределители памяти различных специфических объектов реализуются для получения дополнительной скорости, принося в жертву некое пространство обработки.
На один шаг ниже упомянутого ранее распределителя памяти находятся распределители самой системы из стандартной библиотеки C (в предположении что вашим рассматриваемым интерпретатором Python выступает CPython). Порой именуемые как распределители общего назначения, ути написанные на C логические объекты отвечают за помощь распределителю сырой памяти при взаимодействии со своим диспетчером памяти операционной системы.
Полная модель описанного ранее диспетчера памяти Python может быть проиллюстрирована следующей схемой:

Мы должны изучать основные общие процессы выделения памяти в Python, поэтому в данном разделе давайте задумаемся о том как данных сохраняются в Python и кк выполняются ссылки к ним. Многие программисты обычно представляют себе имеющуюся в Python модель памяти как некую графовую модель объекта с некоей меткой в каждом узле и всем рёбрами, имеющими направление - если коротко, это некий помеченный направленный граф объектов. Такая модель памяти впревые была введена в обиход вторым старейшим из компьютерных языков программирования, Lisp (первоначально именовавшимся LISP).
Его часто рассматривается как ориентированный граф, так как его модель памяти отслеживает свои данные и переменные исключительно посредством указателей: значением каждой переменной является указатель, причём он моежет указывать на некий символ, какое- то число, либо некую подпрограмму. Тем самым эти указатели выступают направленными рёбрами в определённом объекте графа, а реальные значения (символы, числа, подпрограммы) являются узлами такого графа. Приводимая ниже схема является неким упрощением такой модели памяти Lisp на его ранних стадиях:
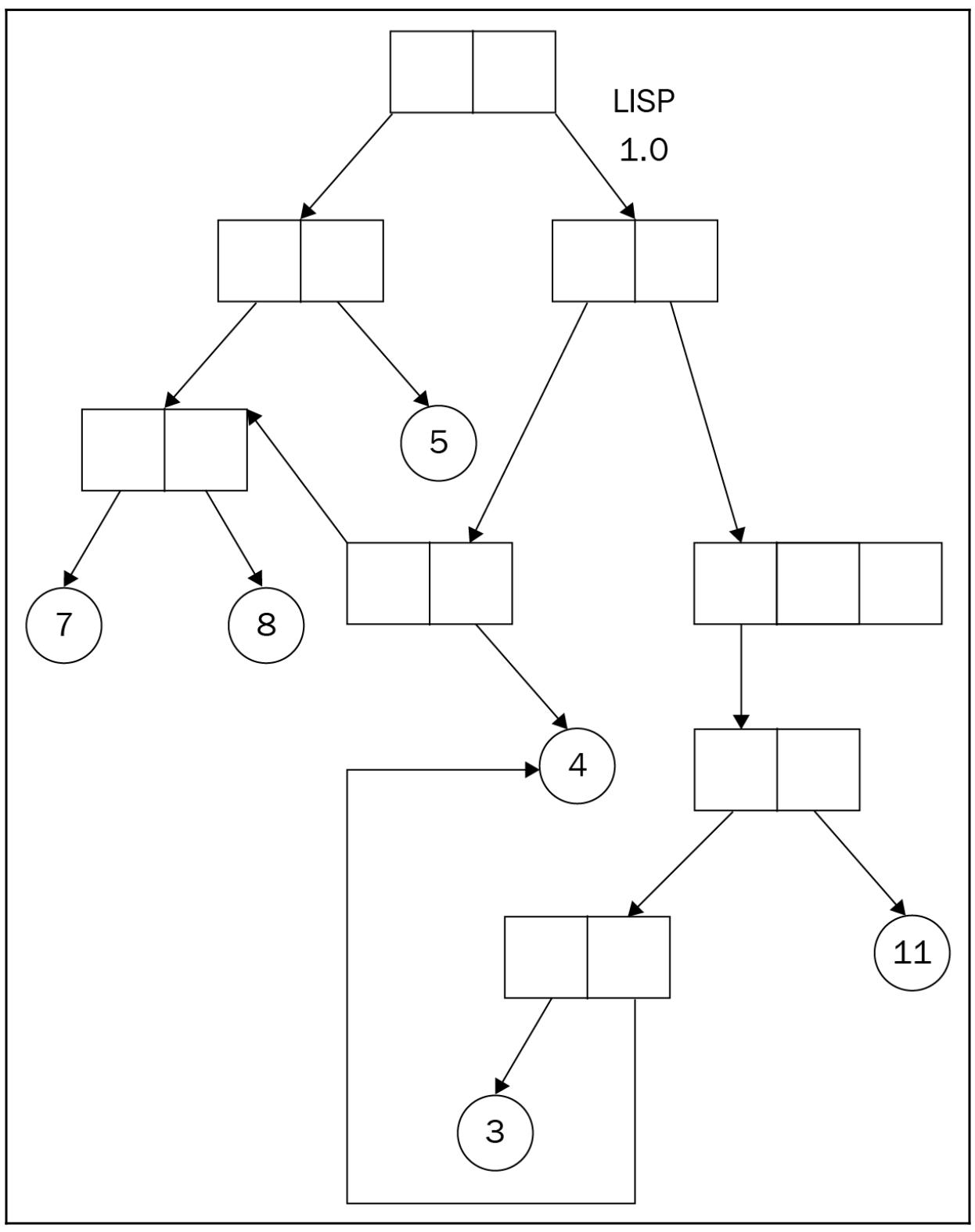
С такой моделью памяти объекта графа привносится ряд преимущественных характеристик для управления памятью. Прежде всего, данная модель предлагает значительную степень гибкости относительно повторного использования: имеется возможность, причём это достаточно просто, записать некую структуру данных или какой- то набор инструкций для одного типа объекта, а затем также повторно использовать его в других видах. В противоположность этому, C является неким языком программирования, который применяет различные модели памяти, которые не предлагают такой гибкости, а его программистам обычно требуется тратить значительное время на повторную запись тех же самых структур данных и алгоритмов для различных видов типов данных и объектов.
Другим видом гибкости этого является то, что данная предоставляемая модель памяти являет тот факт, что на всякий объект может ссылаться любое число указателей (или неограниченное число переменных) и следовательно он может видоизменяться каждым из них. Мы уже наблюдали имеющееся воздействие этой характеристики в некоем образце программы в Главе 15, Глобальная блокировка интерпретатора, когда две переменные ссылаются на один и тот же (изменяемый) объект (что достигается тем, что одна переменная присваивается другой) и одна переменная успешно видоизменяет данный объект по своей ссылке, тогда это изменение также отражается через ссылку вашего второго объекта.
Как уже обсуждалось в Главе 15, Глобальная блокировка интерпретатора, это не походит на управление памятью в C++. Например, в случае когда некоторой переменной (которая не является указателем или ссылкой) присваивается некое конкретное значение, этот язык программирования скопирует такое определённое значение в то местоположение в памяти, которое содержит ваша первоначальная переменная. Кроме того, некая переменная присваивается иной переменной, значение из местоположения в памяти последней будет скопировано в местоположение предыдущей; никакой взаимосвязи в дальнейшем эти две переменные не поддерживают после выполненного присвоения.
Однако кое- кто утверждает, что это фактически может быть неким недостатком при программировании, в особенности при программировании совместной обработки, так как не скоординированные попытки видоизменения какого- то разделяемого объекта могут повлечь за собой нежелательные результаты. Будучи искушённым программистом Python, вы также могли заметить, что данный тип ошибки (когда некая переменная одного заданного типа ссылается на некий объект другого, несовместимого типа) достаточно распространён при программировании в Python. Это также непосредственный результат данной модели памяти, потому что, опять же, некий ссылочный указатель может указывать на что угодно.
Имея в виду обсуждённые теоретические основы имеющейся в Python модели памяти, какое воздействие мы можем ожидать от них на общую экосистему программирования совместной обработки в Python? К счастью, имеющаяся в Python модель памяти работает в пользу параллельного программирования в том смысле, что она позволяет думать и рассуждать о совместной обработке более простым образом и намного более интуитивно понятно. В частности, Python реализует свою модель памяти и исполняет свои программы именно так, как мы обычно и ожидаем.
Для понимания этого преимущества, которым обладает Python, давайте вначале рассмотрим совместную обработку в языке программирования Java. Для достижения наилучшей производительности в смысле скорости в параллельных программах (в частности, в многопоточных программах), Java позволяет ЦПУ перестраивать тот порядок, в котором исполняются определённые, содержащиеся в коде Java, операции. Такая перестановка, однако, производится произвольным образом, поэтому мы не можем простым образом обосновать получаемый порядок просто исходя из имеющейся упорядоченной последовательности того кода, который исполняется множеством потоков. Это влечёт за собой тот факт, что если некая программа совместной обработки на Java исполняется неким не предусмотренным образом, её разработчику придётся потратить значительное время на определение текущего порядка исполнения данной программы чтобы выловить ошибку в своей программе.
В отличии от Java Python имеет свою модель памяти структурированной таким образом, чтобы сопровождать установленную согласованность последовательности его инструкций. Это означает, что то порядок, в котором выстроены инструкции в коде на Python определяет тот порядок, в котором они исполняются - никакого произвольного перестроения имеющегося кода и, следовательно, никакого неожиданного поведения от ваших программ совместной обработки. Тем не менее, поскольку имеющееся перестроение в совместной обработке с Java реализовано для достижения лучшей скорости его программ, это означает, что Python приносит в жертву свою производительность для сохранения простоы своего исполнения и большей интуитивной понятности.
Другой важной темой, относящейся к управлению памятью являются атомарные операции. В данном подразделе мы исследуем само определение того что такое быть атомарным в программировании, ту роль, которую атомарные операции имеют в контексте программирования совместной обработки, а также, наконец, как применять атомарные операции при программировании на Python.
Давайте вначале исследуем реальные характеристики для того чтобы быть атомарным. Если некая операция атомарна при программировании совместной обработки, тогда она не может быть прервана никакими прочими логическими объектами из этой программы на протяжении своего исполнения; некая атомарная операция также может называться линеаризуемой, неразложимой или не прерываемой. Исходя из самой природы условий состязательности и того что обычно она присутствует в программах совместной обработки, совершенно очевидно заключить, что атомарность является желательной характеристикой для программы, так как она гарантирует необходимую целостность имеющихся совместных данных, а также защищает их от не скоординированных видоизменений.
Сам термин "атомарности" указывает на тот факт, что некая атомарная операция проявляется одномоментно для остальной части программы, в которой она содержится. Это означает, что данная операция должна быть исполнена неким слитным образом, без прерываний. Наиболее общий метод реализации атомарности, как вы вероятно могли догадаться, состоит во взаимном исключении, или блокировках. Блокировки, как мы уже видели, требуют взаимодействия с неким разделяемым ресурсом для получения его одним потоком или процессом за раз, тем самым защищая данное взаимодействие одного потока/ процесса от его прерывания и потенциального разрушения другими соперничающими потоками или процессами.
Если некий программист допускает для некоторых из своих операций быть неатомарными, им также требуется допускать для этих операций быть достаточно аккуратными и гибкими (в смысле взаимодействия и видоизменения данных) с тем, чтобы никакие ошибки не происходили в результате их прерывания иными операциями. Тем не менее, если бы имело место неправильное и ошибочное поведение при прерывании подобных операций во время их исполнения, их программисту было бы достаточно сложно в действительности воспроизвести и отладить такое поведение.
Одним из основных элементов в обсуждаемом контексте атомарных операций Python, безусловно, является GIL; имеются дополнительные распространённые неверные представления, а также сложности относительно той роли, которую играет GIL в атомарных операциях.
К примеру, относительно самого определения атомарных операций, кое- кто пытается утвержлать, что все операции в Python на самом деле атомарные, поскольку имеющаяся GIL на самом деле требует исполнять потоки согласованным образом, причём только один способен исполняться в каждый конкретный момент времени. По существу это ложное утверждение. То требование существующего GIL, что только один поток Python может исполнять код Python в некий определённый момент времени не влечёт за собой присутствия атомарности для всех операций Python; одна операция всё ещё может прерываться другой, причём ошибки всё ещё могут происходить по причине неверной обработки и разрушения совместных данных.
На неком нижнем уровне сам интерпретатор Python обрабатывает необходимое переключение между потоками в какой- то
программе совместной обработки Python. Это процесс выполняется в отношении байтовых кодов инструкций, которые компилируются
в код Python и который интерпретируется и исполняется машинами. В частности, Python поддерживает некую фиксированную
частоту того насколько часто его интерпретатор должен переключаться с одного активного потока на другой и эта частота может
устанавливаться с применением встроенного метода sys.setswitchinterval(). Любые
атомарные операции могут прерываться в процессе их исполнения такми событием переключения потока.
В Python 2 установленным по умолчанию значением для данной частоты является 1 000 инструкций байтового кода, что означает, что после того как поток успешно исполнить 1 000 инструкций байтового кода, имеющийся интерпретатор Python выберет из других активных потоков, которые ожидают своего исполнения. Если имеется хотя бы один ожидающий поток, управляющий интерпретатор заставит исполняемый в настоящий момент времени поток освободить имеющуюся GIL и заставит этот поток ожидать его и тем самым запускает исполнение своего следующего потока.
В Python 3 значение частоты фундаментально иное. Тот элемент, который применяется для значения частоты теперь основывается на времени, в частности, секундах. Со значением по умолчанию в 15 миллисекунд такая частота определяет, что если некий поток исполнялся по крайней мере то количество времени, эквивалентное этому пороговому значению, тогда имеет место событие переключения этого потока (совместно с высвобождением и получением имеющейся GIL) как только данный поток завершит соответствующее исполнение своей текущей инструкции байтового кода.
Как уже упоминалось ранее, некая операция может быть прервана в процессе своего исполнения если тот поток, который её исполняет проходит предел своего исполнения (к примеру, 15 миллисекунд в Python 3 по умолчанию), причём в этот момент данная операция обязана завершить свою текущую инструкцию байтового кода и вернуть обратно имеющуюся GIL другому ожидающему потоку. Это означает, что событие переключения потока имеет место только между инструкциями байтового кода.
В Python существуют операции, которые могут исполняться в одной единственной инструкции байтового кода и тем самым атомарны по своей природе без соответствующей помощи внешних механизмов, таких как взаимное исключение. В частности, если некая операция в потоке завершает своё исполнение в одном единственном байтовом коде, она не может быть прервана соответствующим событием переключения потока, так как такое событие имеет место после завершения соответствующей инструкции байтового кода. Эта характеристика врождённой атомарности очень полезна, поскольку она позволяет тем операциям, которые обладают ею, свободно исполнять свои инструкции даже если не был применён никакой метод синхронизации, в то же время обеспечивая то, что они не будут прерваны и не получат свои данные испорченными.
Сопоставление атомарность и не атомарности
Важно отметить, что для программистов может оказаться удивительным изучать какие операции в Python являются атомарными, а какие нет. Кое- кто может предположить, что так как простые операции требуют меньше байтового кода чем сложные, такие более простые операции, скорее всего, должны быть врождённо атомарными. Тем не менее, это не имеет места, и единственный способ определить без сомнений какие операции являются атомарными врождённо состоит в выполнении дальнейшего анализа.
В соответствии с документацией Python 3 (которую можно отыскать по ссылке), некие примеры врождённой атомарности включают в себя:
-
Добавление некоторого предварительно определённого объекта в конец списка
-
Расширение некого списка другим списком
-
Выборка элемента из некоторого списка
-
"Выталкивание" (Popping) из какого- то списка
-
Сортировка некоего списка
-
Назначение переменной другой переменной
-
Назначение переменной какому- то атрибуту некоего объекта
-
Создание новой записи для какого- то словаря
-
Обновление некоего словаря другим словарём
А вот некоторые операции, которые не являются врождённо атомарными:
-
Инкрементальное увеличение некоего целого значения, в том числе при помощи
+= -
Обновление некоторого элемента в каком- то списке по ссылке другого элемента в этом списке
-
Обновление некоторого элемента в каком- то словаре по ссылке другого элемента в этом словаре
Имитация в Python
Давайте проанализируем имеющееся отличие между некими атомарной и не атомарной операциями в какой- то реальной
программе совместной обработки Python. Если у вас уже имеется код для данной книги, выгруженный с соответствующей страницы
GitHub, проследуйте далее и переместитесь в папку Chapter17. В качестве такого
примера мы рассматриваем свой файл Chapter17/example1.py:
# Chapter17/example1.py
import sys; sys.setswitchinterval(.000001)
import threading
def foo():
global n
n += 1
n = 0
threads = []
for i in range(1000):
thread = threading.Thread(target=foo)
threads.append(thread)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(f'Final value: {n}.')
print('Finished.')
Прежде всего мы сбрасываем значение частоты переключения потока своего интерпретатора Pyhon в значение 0.000001 секунды - это для того, чтобы иметь наличие событие переключения потока более часто чем обычно и тем самым усилить любое условие состязательности, которое может иметь место в нашей программе.
Основная суть нашей программы состоит в увеличении приращением простого глобального счётчика (n)
в 1 000 обособленных потоков, причём каждый увеличивает значение счётчика один раз через соответствующую функцию
foo(). Так как значение счётчика изначально проинициализировано в 0,
если программа исполнена верно, мы бы должны были иметь, что наш счётчик по окончанию такой программы сохраняет значение 1 000.
Однако, мы знаем что наш оператор инкрементального приращения, который мы используем в своей функции
foo() (+=) не является атомарной операцией,
что означает, что он может быть прерван неким событием переключения потока при его применении к некоторой глобальной
переменной.
После исполнении данного сценария много раз мы можем наблюдать, что в нашем коде по- существу присутствует условие состязательности. Это иллюстрирует неверное значение сч1тчика, которое менее чем 1 000. Например, я получил в выводе следующее:
> python3 example1.py
Final value: 998.
Finished.
Это находится в соответствии с тем, что мы обсуждали ранее, то есть, так как наш оператор +=
не является атомарным, он требует иного механизма синхронизации чтобы обеспечить требуемую целостность тех данных, с которыми
происходит совместное взаимодействие множества потоков. Давайте теперь проведём имитацию того же самого эксперимента с некоторой
операцией, о которой мы знаем что она атомарна, в частности добавление некоторого
предварительно определённого объекта в конец списка.
В своём файле Chapter17/example2.py мы имеем следующий код:
# Chapter17/example2.py
import sys; sys.setswitchinterval(.000001)
import threading
def foo():
global my_list
my_list.append(1)
my_list = []
threads = []
for i in range(1000):
thread = threading.Thread(target=foo)
threads.append(thread)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(f'Final list length: {len(my_list)}.')
print('Finished.')
Вместо какого- то глобального счётчика у нас теперь имеется некий глобальный список, который изначально был пустым.
Наша новая функция foo() теперь получает этот глобальный список и добавляет в его конец
целое значение 1. Вся оставшаяся часть данной программы всё ещё создаёт и исполняет
1 000 обособленных потоков, причём каждый из них вызывает по разу соответствующую функцию foo().
В самом конце программы мы выведем общую длину своего глобального списка чтобы определить был ли соответствующий список
видоизменён 1 000 раз. В частности, если длина этого списка менее чем 1 000, мы будем знать, что в нашем коде имелось условие
состязательности, аналогично тому, что мы наблюдали в своём предыдущем примере.
Поскольку наш метод list.append() является атомарной операцией, тем не менее,
это гарантирует что никакого условия состязательности нет при вызове нашей функции foo()
и взаимодействии с имеющимся глобальным списком. Это иллюстрирует получаемая длина данного списка по окончанию нашей программы.
Не имеет значения сколько раз мы исполнили данную программу, наш список вскгда будет иметь длину 1 000:
> python3 example2.py
Final list length: 1000.
Finished.
Даже хотя некоторые операции в Python являются врождённо атомарными, может оказаться достаточно сложным сказать будет ли данная операция являться атомарной сама по себе или нет. Так как конкретное приложение не атомарных операций на совместных данных может приводить к условиям состязательности, а тем самым к ошибочным результатам, всегда рекомендуется чтобы программисты применяли механизмы синхронизации чтобы обеспечить требуемую целостность разделяемых данных в программе совместной обработки.
В этой главе мы изучили ту структуру, которая лежит в основе модели памяти Python, а также как сам язык управляет своими значениями и переменными в контексте программирования совместной обработки. Принимая во внимание как структурировано и организовано управление памятью в Python, умозаключения о поведении некоторой программы совместной обработки может быть существенно проще чем аналогичные размышления в ином языке программирования. Такая простота понимания и отладки программ совместной обработки в Python, тем не менее, также получается с неким снижением производительности.
Атомарные операции являются инструкциями, которые не могут быть прерванными в процессе их исполнения. Атомарность является желательной характеристикой операций совместной обработки, так как гарантирует безопасность данных, разделяемых между различными потоками. В то время как в Python существуют операции с врождённой атомарностью, для гарантии полной атомарности некоторой определённой операции всегда рекомендуются механизмы синхронизации, такие как блокирование.
В своей следующей главе мы рассмотрим как построить некий сервер совместной обработки с нуля. На протяжении этого процесса мы дополнительно изучим реализацию протоколов взаимодействия, а также применение совместной обработки к некоторому существующему приложению Python.
-
Каковы основные компоненты диспетчера памяти Python?
-
Чем имеющаяся модель памяти Python походит на помеченный ориентированный граф?
-
В чём состоят преимущества и недостатки модели памяти Python в отношении разработки приложений совместной обработки на Python?
-
Что представляют из себя атомарные операции и почему они желательны в программировании совместной обработки?
-
Приведите три примера врождённо атомарных операций Python.
Для получения дополнительных сведений вы можете воспользоваться следующими ссылками:
-
The memory models that underlie programming languages, К. Дж.Сайтэйкер
-
Grok the GIL: How to write fast and thread-safe Python, Э. Джесс Джайрью Дэйвис
-
Thread Synchronization Mechanisms in Python Фредрик Ландх
-
Memory Management, Документация Python
-
Concurrency, Документация Jython
-
Memory management in Python, Ану Б. Наир