Глава 4. Сетевая среда libvirt
Содержание
- Глава 4. Сетевая среда libvirt
- Основы построения физической и виртуальной сетевой среды
- Построение виртуальной сетевой среды
- Применение сетевой среды пространства пользователя при помощи устройств TAP и TUN
- Реализация построения моста Linux
- Настройка Open vSwitch
- Основы SR-IOV и его использование
- Основы macvtap
- Выводы
- Вопросы
- Дальнейшее чтение
В сетевой среде NAT libvirt (и просто чтобы не забыть
что мы об этом упомянули, именно так по умолчанию настраивается наша сетевая
среда), наша виртуальная машина расположена позади некого коммутатора libvirt в режиме NAT. Представляете себе это
как будто я обладаю неким интернет подключением в сценарии @home - это в точности
то чем обладает большинство из нас: наша частная сетевая среда за неким
общедоступным IP адресом. Это означает, что наше устройство для доступа в Интернет (к примеру, DSL модем) подключено
к общедоступной сетевой среде (Интернету) и получает некий общедоступный IP адрес в виде части этого процесса.
С нашей стороны сетевой среды мы обладаем своей собственной подсетью (например,
10.10.10.0/24, или чем- то навроде этого) для всех своих устройств, которые мы
бы желали подключить к Интернету.
Теперь давайте преобразуем это в некий пример виртуальной сетевой среды, это означает, что наша виртуальная машина способна взаимодействовать со всем, что подключено к имеющейся физической сетевой среде через IP адрес хоста, но не наоборот. Чтобы нечто имело возможность обмениваться данными с нашей виртуальной машиной позади коммутатора NAT, наша виртуальная машина обязана инициировать это взаимодействие (или же мы обязаны настроить некую переадресацию портов), но это не относится к нашему случаю).
Наша следующая схема поможет лучше пояснить о чём мы говорим:
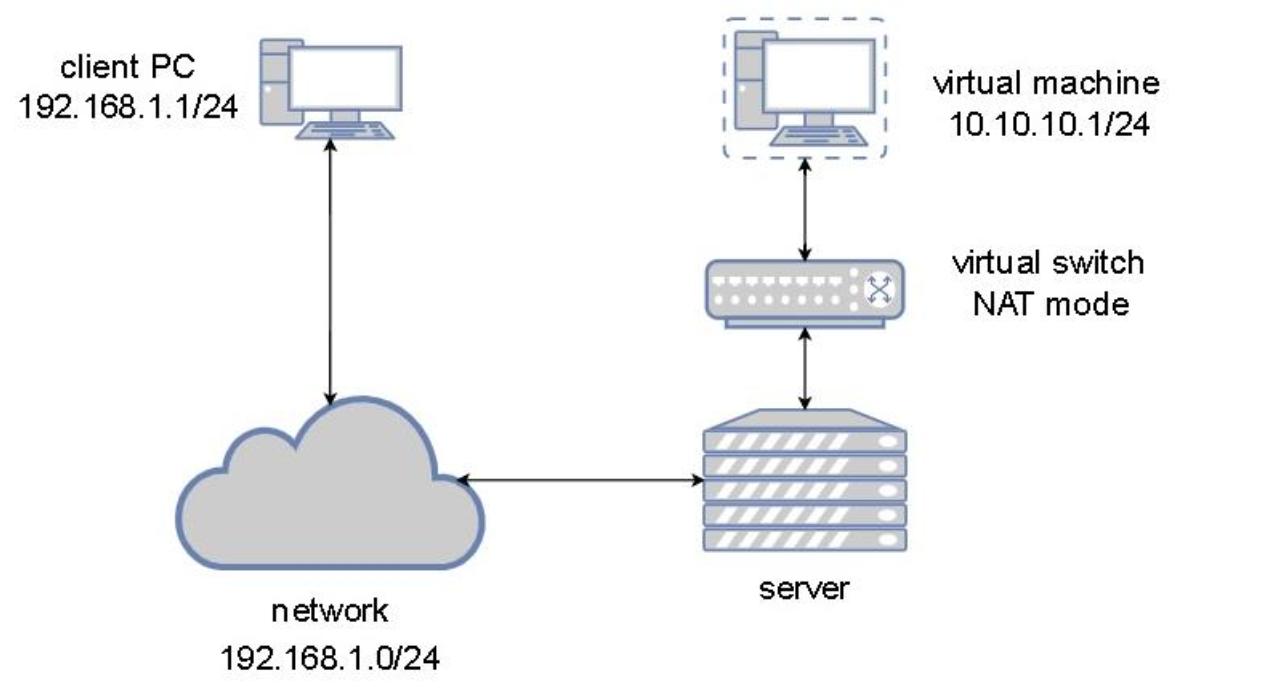
С точки зрения самой виртуальной машины, она беззаботно пребывает в совершенно обособленном сегменте сетевой
среды (отсюда адреса IP 10.10.10.1 и
10.10.10.2) и применяет некий виртуальный сетевой коммутатор в качестве шлюза
для доступа к внешним сетям. Это не должно быть связано с какой бы то ни было дополнительной маршрутизацией, ибо именно
это одна из тех причин, по которой мы пользуемся NAT - для упрощения маршрутизации оконечных узлов.
Второй тип построения сети это сетевая среда с маршрутизацией, что по существу означает, что наша виртуальная машина напрямую подключается к имеющейся физической сетевой среде через некий виртуальный коммутатор. Это подразумевает, что наша виртуальная машина пребывает в той же самой сетевой среде Уровней 2/3, что и её физический хост. Этот тип сетевого подключения применяется очень часто, поскольку сплошь и рядом нет необходимости обладать какой- то обособленной сетевой средой NAT для доступа к вашим виртуальным машинам в ваших же сетевых средах. В некотором смысле, это просто всё усложняет, в особенности по той причине, что вам необходимо настроить маршрутизацию, чтобы знать о сети NAT, которую вы применяете для своих виртуальных машин. При применении режима с маршрутизацией наша виртуальная машина пребывает в том же самом сегменте сетевой среды что и следующее далее физическое сетевое устройство. Приводимая далее схема сообщает тысячи слов о маршрутизируемых сетевых средах:
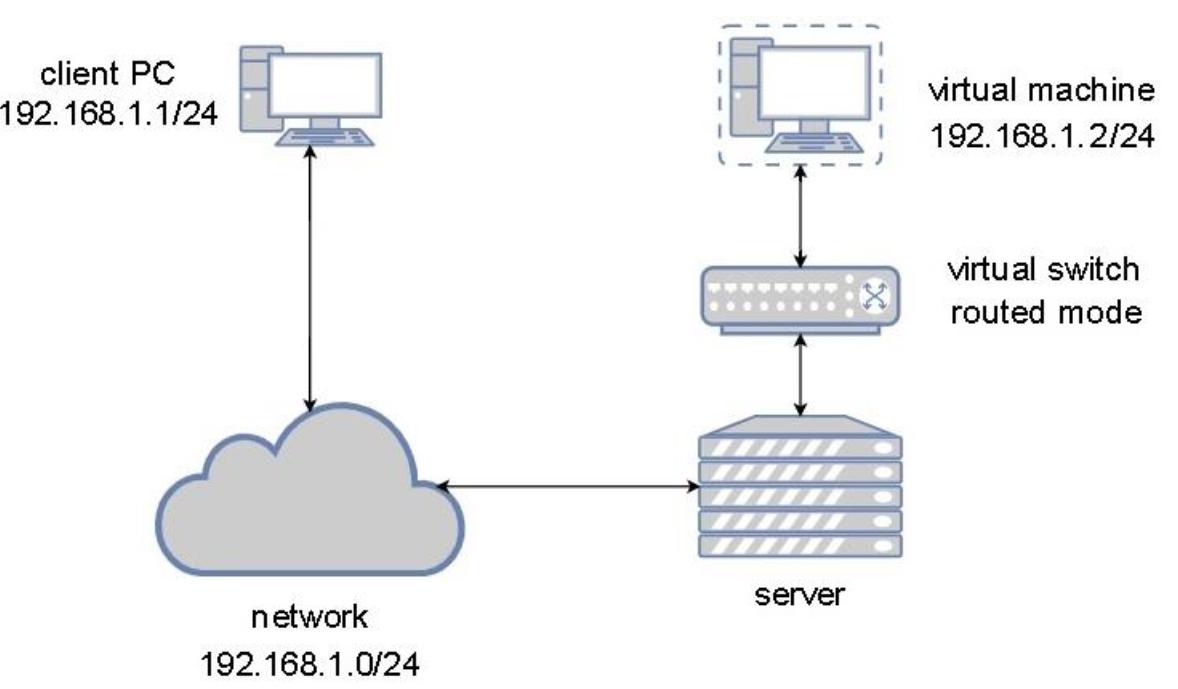
Теперь, когда мы рассмотрели два наиболее распространённых типов сценариев построения виртуальных сетей, настало время для третьей, которая покажется слегка невразумительной. Когда мы настроим некий виртуальный коммутатор без каких бы то ни было восходящих подключений (uplink, что подразумевает, что они не обладают никакими подключёнными к ним физическими сетевыми картами), тогда такой виртуальный коммутатор вовсе не способен отправлять никакой сетевой обмен. Всё что остаётся, это взаимодействие внутри границ самого этого коммутатора, откуда и проистекает его название изолированного. Давайте создадим теперь такую иллюзорную сетевую среду.
В этой ситуации подключённые к одному и тому же изолированному виртуальные машины способны взаимодействовать друг с другом, однако они не способны взаимодействовать с чем бы то ни было за пределами того хоста, в котором они запущены. Ранее, для определения этой ситуации мы применяли слово глухой (obscure), но в действительности это не так - в некоторых случаях он идеален для особых видов изолированного обмена, поскольку он даже не получает соответствующей физической сетевой среды.
Подумайте об этом варианте - допустим, у вас имеется виртуальная машина, которая размещает какой- то веб сервер, к примеру, исполняет WordPress. Вы создаёте два виртуальных коммутатора: один запускает сетевую среду с маршрутизацией (непосредственно подключённый к физической сети), а другой является изолированным. Таким образом, вы можете настроить свою виртуальную машину WordPress с двумя виртуальными сетевыми картами, причём первая подключена к сетевому коммутатору с маршрутизацией, а вторая соединена с изолированным виртуальным коммутатором. WordPress требуется некая база данных, а потому вы создаёте другую виртуальную машину и настраиваете её на применение исключительно внутреннего виртуального коммутатора. Следовательно, вы применяете такой изолированный виртуальный коммутатор для изоляции обмена между своим веб сервером и его сервером баз данных с тем, чтобы WordPress подключался к своему серверу баз данных через такой коммутатор. Что вы получаете при настройке своей виртуальной машины таким образом? Вы обладаете приложением с двумя уровнями, причём наиболее важная часть такого веб приложения (база данных) недоступна из внешнего мира. Это может показаться неплохой идеей, не так ли?
Изолированные виртуальные сети используются и во многих прочих связанных с безопасностью ситуациях, но это просто в качестве некого примера, в котором мы запросто можем осознать их назначение.
Давайте опишем свою изолированную сетевую среду на следующей схеме:
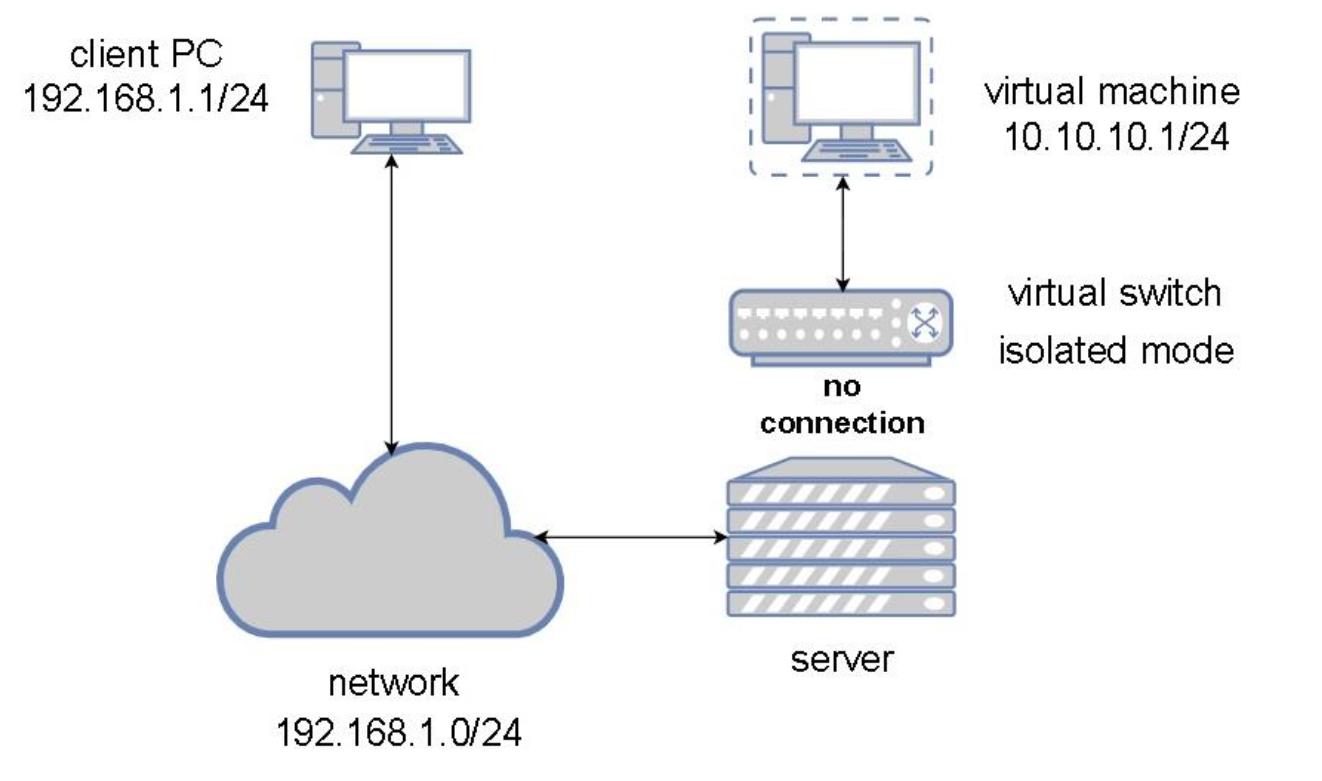
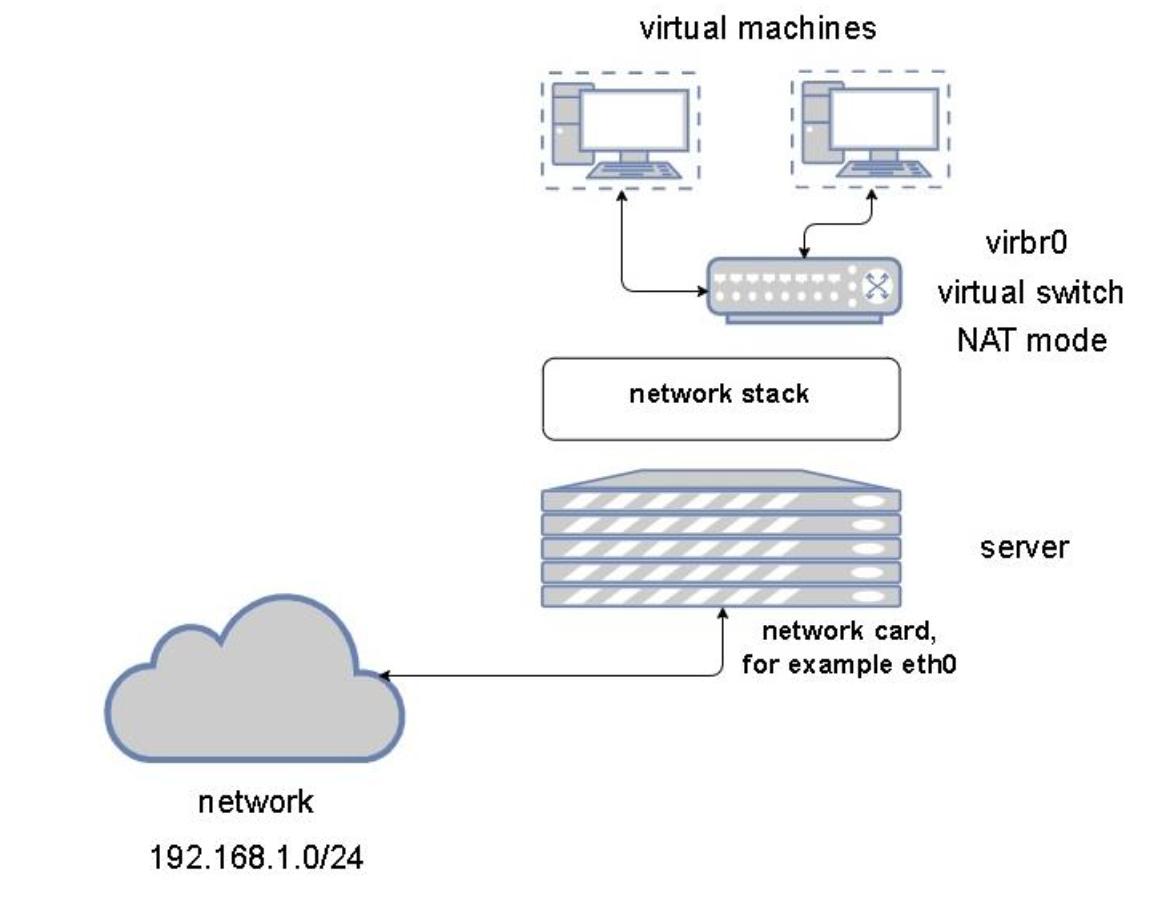
В своей предыдущей главе (Главе 3, Установка гипервизора KVM, libvirt и oVirt) из этой книги мы упоминали сетевую среду по умолчанию (default) и мы скзали, что мы намерены поговорить о ней чуть позже. Сейчас это выглядит как возможность сделать это, ибо у нас имеется достаточно сведений для описания того, что из себя представляет устанавливаемая по умолчанию сетевая среда.
Когда мы установили все необходимые библиотеки и утилиты KVM, как мы это сделали в Главе 3, Установка гипервизора KVM, libvirt и oVirt, сразу после установки мы получили некий установленный по умолчанию и настроенный виртуальный коммутатор. Основная причина этого проста - он наиболее дружелюбен для пользователя и предварительно настроен, а потому пользователи могут просто приступить к созданию виртуальных машин и их подключению к имеющейся по умолчанию сетевой среде, которую пользователи также ожидают иметь настроенной. В точности то же предпринимает vSphere VMware (коммутатор по умолчанию имеет название vSwitch0), а Hyper-V запрашивает у нас в процессе развёртывания самый первый виртуальный коммутатор (который мы на самом деле можем пропустить и настроить его позднее). А потому, это всего лишь хорошо известный, стандартный, установившийся подход, который позволяет нам быстрее запускать создание наших виртуальных машин.
Устанавливаемый по умолчанию коммутатор работает в режиме NAT с активным сервером DHCP и опять- таки, для этого имеется простая причина - гостевые операционные системы, по умолчанию, настроены на конфигурирование DHCP, что означает, что наша только что созданная виртуальная машина готова вытащить устанавливаемые сетевые ресурсы, требующиеся для настройки IP. Тем самым, наша ВМ получает все необходимые сведения о сетевых настройках и мы можем начинать её применять сразу.
Следующая схема показывает что представляет собой сетевая среда по умолчанию:
Теперь давайте изучим как настраивать эти понятия построения сетевой среды с нуля и из GUI. Мы также рассматриваем эту процедуру как некий порядок действий, который требуется выполнять упорядочено:
-
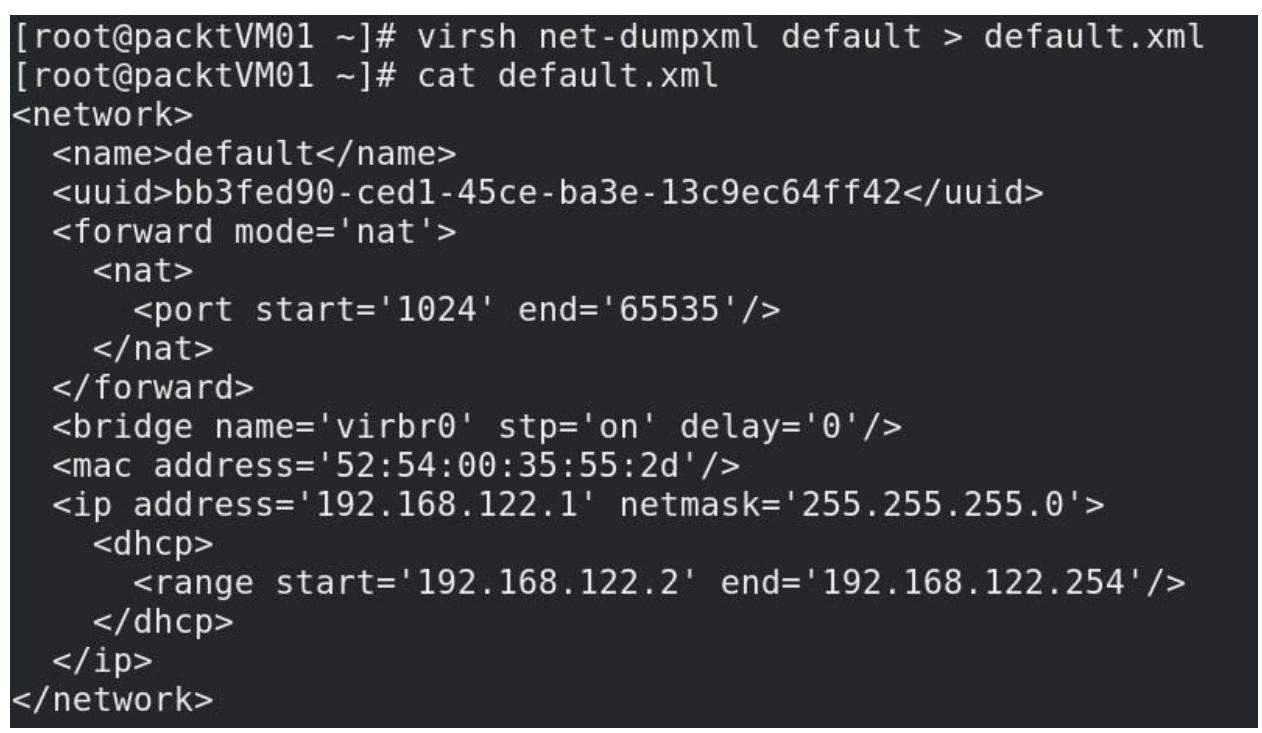
Давайте начнём с настройки своей сетевой среды по умолчанию в XML с тем, чтобы мы могли применять его как шаблон для создания некой новой сети:
-
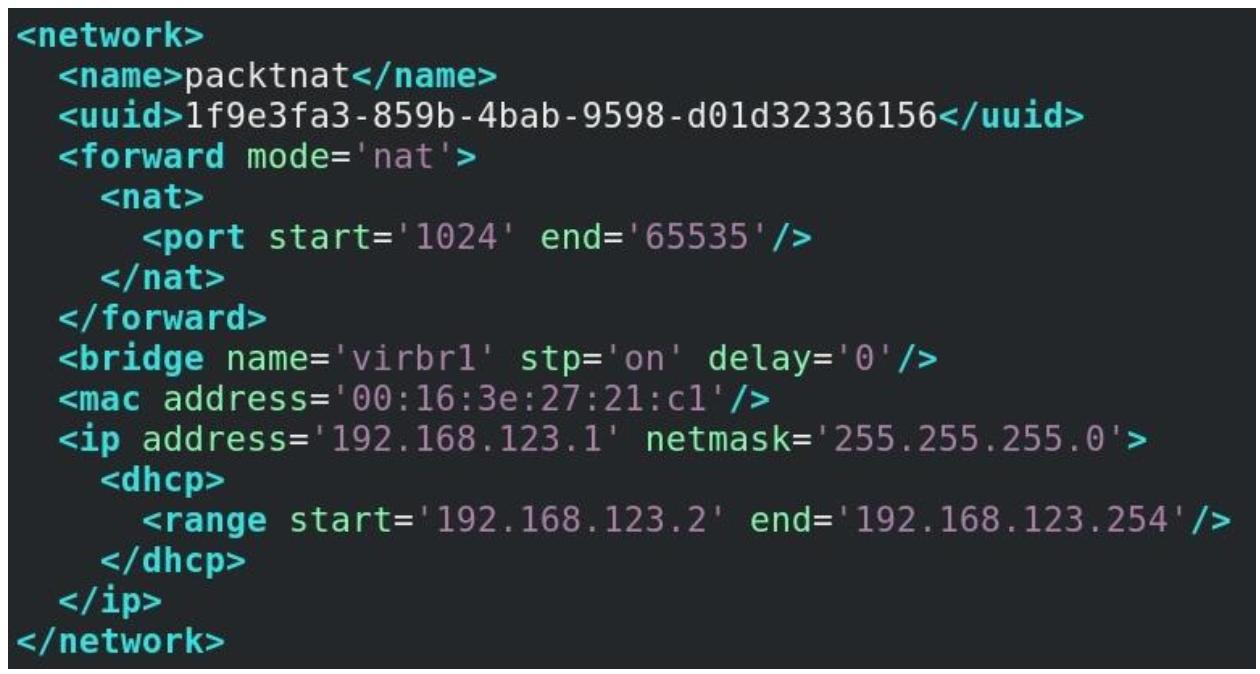
Теперь давайте скопируем этот файл в новый файл с названием
packtnat.xml, внесём в него изменения и затем применим его для создания новой виртуальной сетевой среды NAT. Тем не менее, прежде чем мы выполним это, нам потребуется выработать две вещи - некий новый объект UUID (для своей новой сети) и какой- то уникальный MAC адрес. Новый UUID может быть произведён из нашей оболочки при помощи командыuuidgen, однако производство MAC слегка более замысловато. А потому мы воспользуемся стандартным предлагаемым Red Hat методом, доступным на веб сайте Red Hat. Применив этот самый первый, доступный по указанной ссылке, фрагмент кода создайте некий новый MAC адрес (допустим,00:16:3e:27:21:c1).Воспользовавшись командой
dnf(ранее yum), установите python2:> dnf -y install python2Убедитесь что вы исправили свой XML файл с тем, чтобы он отражал те моменты, которые мы настроили для некого нового моста (
virbr1). Теперь мы можем завершить эту настройку своего файла XML сетевой среды новой виртуальной машины:
Наш следующий шаг импортирует эти настройки.
-
Для импорта этих настроек и создания своей собственной виртуальной сетевой среды, её запуска и превращения её в постоянно действующую, а также проверки того, что всё загружено верно, мы можем воспользоваться командой
virsh:> virsh net-define packtnat.xml > virsh net-start packtnat > virsh net-autostart packtnat > virsh net-list
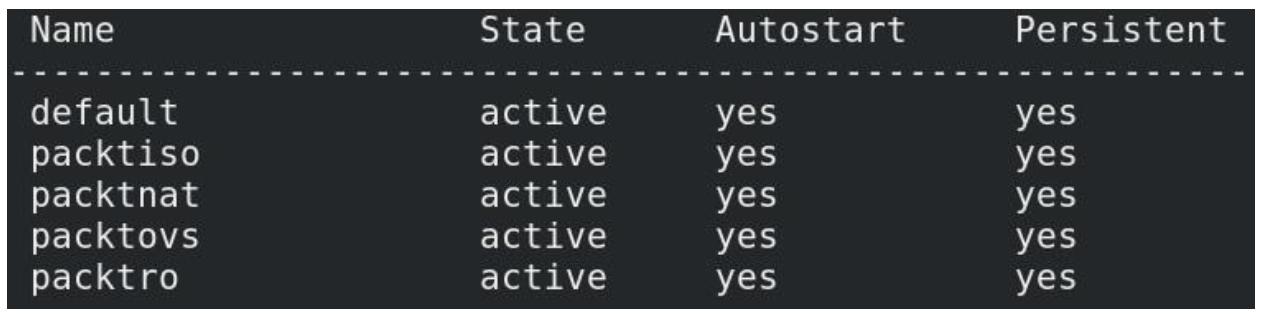
Принимая во внимание, что мы не удалили свою сетевую среду по умолчанию, наша последняя команда выдаст следующий вывод:
Рисунок 4-7

Применение virsh net-list для проверки того, какими виртуальными сетями мы обладаем в своём хосте KVM
Теперь давайте создадим две дополнительные виртуальные сети - сеть с мостом и изолированную сетевую среду. И
снова, давайте для создания обеих этих сетей в качестве шаблонов воспользуемся файлами. Имейте в виду, что для того
чтобы иметь возможность создания сетевой среды с мостом нам потребуется некий физический сетевой адаптер, а потому
нам потребуется для этой цели в своём сервере обладать доступным физическим адаптером. В нашем сервере такой
интерфейс носит название ens224, в то время как интерфейс с названием
ens192 применяется для установленной по умолчанию сетевой среды libvirt.
Итак, давайте создадим два файла настроек с названиями packtro.xml
(для нашей сетевой среды с маршрутизацией) и packtiso.xml (для нашей
изолированной сети):
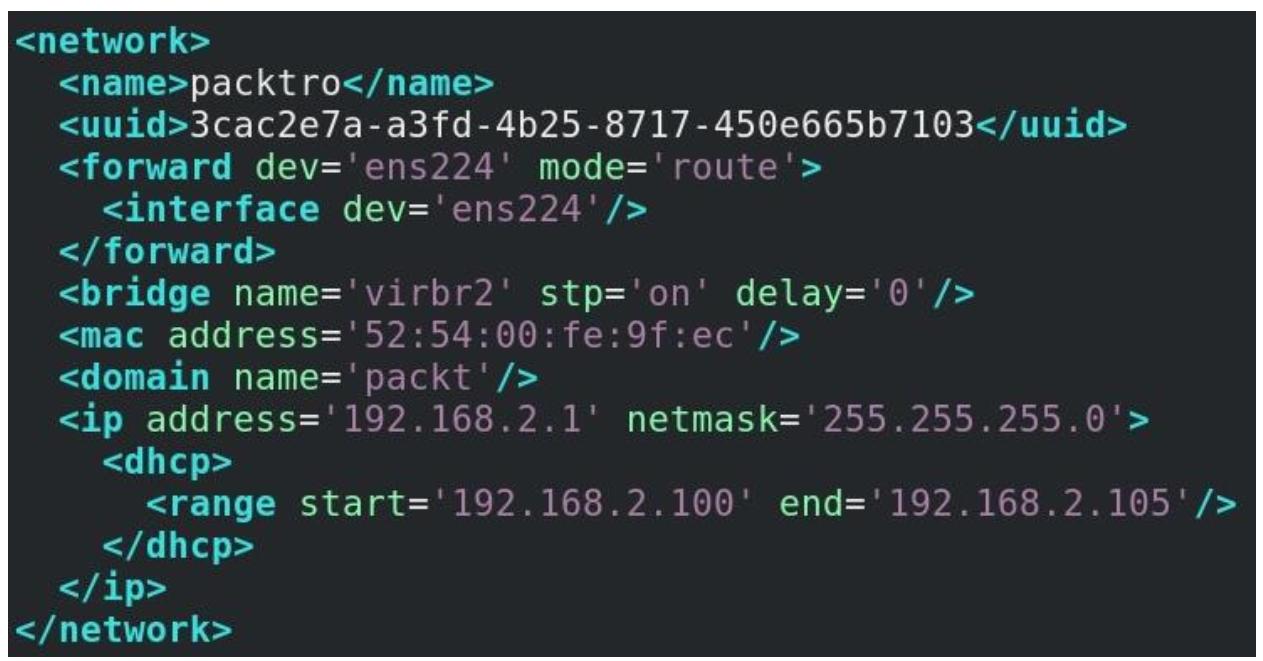
В этой конкретной настройке мы пользуемся ens224 в качестве восходящего
подключения (uplink) для своей виртуальной сетевой среды с маршрутизацией, которая пользуется той же самой подсетью
(192.168.2.0/24), что и её физическая сеть, к которой подключён
ens224.
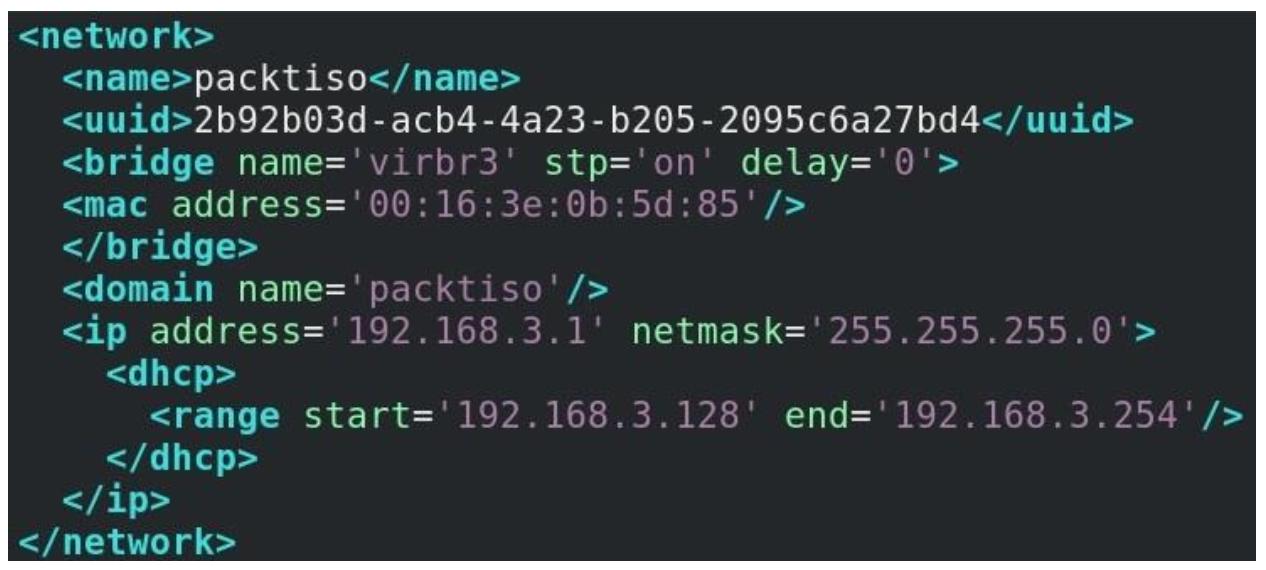
Просто чтобы осветить основы, мы запросто можем настраивать всё это при помощи GUI Диспетчера Виртуальных машин, поскольку это приложение также обладает неким мастером для создания виртуальных сетей. Однако когда мы говорим о сетевых средах большего размера, импорт XML это более простой процесс, даже когда мы забываем о том факте, что множество хостов виртуализации вовсе не обладают установленными в них GUI.
До сих пор мы обсуждали виртуальные сети с общей точки зрения хоста. Однако существует два других подхода к
этому вопросу- при помощи виртуальной машины как некого объекта к которому мы можем добавлять некую виртуальную
карту и её подключения к какой- то виртуальной сети. Для этой цели мы можем применять
virsh. Итак, просто в качестве некого примера, мы можем подключить свою
виртуальную машину с названием MasteringKVM01 к некой изолированной
виртуальной сетевой среде:
> virsh attach-interface --domain MasteringKVM01 --source isolated --type network --model virtio --config --live
Существуют и прочие понятия, которые позволяют подключать виртуальные машины к некой физической сетевой среде и некоторые из них мы обсудим позднее в данной главе (например, SR-IOV). Тем не менее, теперь, когда мы рассмотрели основные подходы для подключения виртуальных машин к некой физической сетевой среде при помощи виртуального коммутатора/ моста, нам потребуется получить чуть больше технических навыков. Дело в том, что имеются дополнительные понятия, относящиеся к подключению виртуальных машин к виртуальному коммутатору, например, TAP и TUN, которые мы и рассмотрим в своём следующем разделе.
В Главе 1, Основы виртуализации KVM мы пользовались
командой virt-host-validate для выполнения неких предполётных проверок с
точки зрения готовности нашего хоста к виртуализации KVM. В качестве части этого процесса некоторые из этих проверок
содержат контроль наличия следующих устройств:
-
/dev/kvm: Установленные драйверы KVM создают с своём хосте некое символьное устройство/dev/kvmдля обеспечения прямого аппаратного доступа к виртуальным машинам. Отсутствие этого устройства означает, что такая ВМ не будет способна получать доступ к физическому оборудованию, хотя оно и включено в BIOS и это значительно снижает производительность такой ВМ. -
/dev/vhost-net: В вашем хосте будет создано символьное устройство/dev/vhost-net. Это устройство служит неким интерфейсом для настройки конкретного экземпляраvhost-net. Отсутствие такого устройства значительно снижает сетевую производительность создаваемой виртуальной машины. -
/dev/net/tun: Это другое специальное символьное устройство для создания устройств TUN/ TAP с целью обеспечения сетевого подключения некой виртуальной машины. Такое устройство TUN/ TAP будет объясняться в последующих главах. На данный момент просто уясните, что обладание таким символьным устройством важно для надлежащей работы виртуализации KVM.
Давайте сосредоточимся на этом последнем устройстве, устройстве TUN, которое обычно дополняется неким устройством TAP.
До сих пор все рассматриваемые нами понятия содержали некий вид связности с какой- то физической сетевой картой
с исключением в виде изолированных виртуальных сетевых сред. Однако даже некая изолированная виртуальная сеть это просто
некая виртуальная сетевая среда для наших виртуальных машин. Что произойдёт когда у нас присутствует тот случай,
когда нам требуется чтобы наше взаимодействие происходило в конкретном пространстве пользователя, например между
запущенными в неком сервере приложениями? Будет бесполезно делать вставки из неких понятий виртуальных коммутаторов
или обычных мостов, поскольку это просто привнесло бы дополнительные накладные расходы. Именно по этой причине в дело
вступают устройства TUN/ TAP, предоставляя поток пакетов для программ пространства пользователя. Достаточно просто,
некое приложение может открыть /dev/net/tun и воспользоваться функцией
ioctl() для регистрации сетевого устройства в самом ядре что, в свою очередь,
представит его как устройство tunXX или tapXX. Когда это приложение закрывает соответствующий файл, исчезают и
все созданные сетевые устройствва и маршруты (как это объясняется в документации
tuntap.txt ядра). Итак, это всего лишь некий вид виртуального сетевого
интерфейса для операционной системы Linux, поддерживаемого самим ядром Linux - вы можете добавить к нему некий IP
адрес и маршруты с тем, чтобы через него мог проходить такой обмен из вашего приложения, вместо обычного
сетевого устройства.
TUN эмулирует некое устройство L3 через создание коммуникационного туннеля, что- то подобное туннелю точка- точка. Оно активируется когда драйвер tuntap настраивается в режиме tun. При его активации все получаемые вами из некого дескриптора (который настраивается самим приложением) данные будут представлять сведения в виде обычных пакетов IP (в большинстве вариантов применения). Кроме того, когда вы отправляете данные, они записываются в это устройство TUN как обычные пакеты IP. Этот тип взаимодействия порой применяется при тестировании, разработке и отладке для целей эмуляции.
Интерфейс TAP в целом эмулирует некое устройство L2 Ethernet. Он активируется когда установленный драйвер tuntap настроен в режиме tap. При его активации, в отличии от того что происходит с интерфейсом TUN (Уровень 3), вы получаете сырые пакеты Ethernet 2 Уровня, включая пакеты ARP/ RARP и всё прочее. По существу, мы говорим о неком виртуальном соединении Ethernet 2 Уровня.
Эти понятия (в особенности TAP) используются в libvirt/ QEMU, поскольку применяя эти типы конфигураций мы можем
создавать подключения из своего хоста к некой виртуальной машине - к примеру, без соответствующего моста/ коммутатора.
Фактически мы способны настроить все необходимые детали для интерфейса TUN/ TAP, а затем приступить к развёртыванию
виртуальных машин, которые подключены непосредственно к этим интерфейсам применяя параметры
kvm-qemu. Итак, это достаточно интересная концепция, которая обладает своим
местом и в мире виртуализации. В особенности это интересно когда мы приступаем к созданию мостов Linux.
Давайте создадим некий мост и затем добавим в него какое- то устройство TAP. Прежде чем мы сделаем это, мы должны быть
уверены что модуль моста загружен в наше ядро. {Прим. пер.: некоторые полезные технические
приёмы работы с мостами Linux описаны в нашем переводе Книги рецептов
виртуализации KVM Константина Иванова. Для установки пакета bridge-utils в CentOs 8 вполне сгодится его реализация
из CentOs 7: dnf install
http://mirror.centos.org/centos/7/os/x86_64/Packages/bridge-utils-1.5-9.el7.x86_64.rpm.}
Давайте начнём:
-
Если он не загружен, воспользуйтесь
modprobe bridgeдля загрузки этого модуля:# lsmod | grep bridgeДля создания моста с названием
testerвыполним следующую команду:# brctl addbr testerДавайте посмотрим был ли создан наш мост:
# brctl show bridge name bridge id STP enabled interfaces tester 8000.460a80dd627d noНаша команда
brctl showотобразит все доступные мосты в нашем сервере, помимо некоторых основных сведений, таких как значение ID этого моста, состояние STP (Spanning Tree Protocol) и все подключённые к нему интерфейсы. В нашем случае мостtesterне имеет никаких подключённых к его виртуальным портам интерфейсов. -
Мост Linux также будет отображаться как некое сетевое устройство. Чтобы просмотреть подробности нашего моста
tester, воспользуйтесь командойip:# ip link show tester 6: tester: <BROADCAST,MULTICAST>mtu 1500 qdiscnoop state DOWN mode DEFAULT group default link/ether 26:84:f2:f8:09:e0 brdff:ff:ff:ff:ff:ffВы также можете воспользоваться
ifconfigдля проверки и настройки установок своей сетевой среды для моста Linux;ifconfigотносительно просто читать и понимать, но она не настолько богата функциональными возможностями какip:# ifconfig tester tester: flags=4098<BROADCAST,MULTICAST>mtu 1500 ether26:84:f2:f8:09:e0txqueuelen 1000 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Наш мост Linux
testerтеперь готов. Давайте создадим и добавим к нему устройство TAP. -
Прежде всего убедимся что наш модуль устройства TUN/ TAP загружен в установленное ядро. Если это не так, вы уже знаете как его добыть:
# lsmod | greptun tun 28672 1Для создания некого устройства с названием
vm-vnicвыполните следующую команду:# ip tuntap add dev vm-vnic mode tap # ip link show vm-vnic 7: vm-vnic: <BROADCAST,MULTICAST>mtu 1500 qdiscnoop state DOWN mode DEFAULT group default qlen 500 link/ether 46:0a:80:dd:62:7d brdff:ff:ff:ff:ff:ffТеперь у нас имеется мост с названием
testerи некое устройство tap с названиемvm-vnic. Давайте добавим вtestervm-vnic:# brctl addif tester vm-vnic # brctl show bridge name bridge id STP enabled interfaces tester 8000.460a80dd627d no vm-vnic
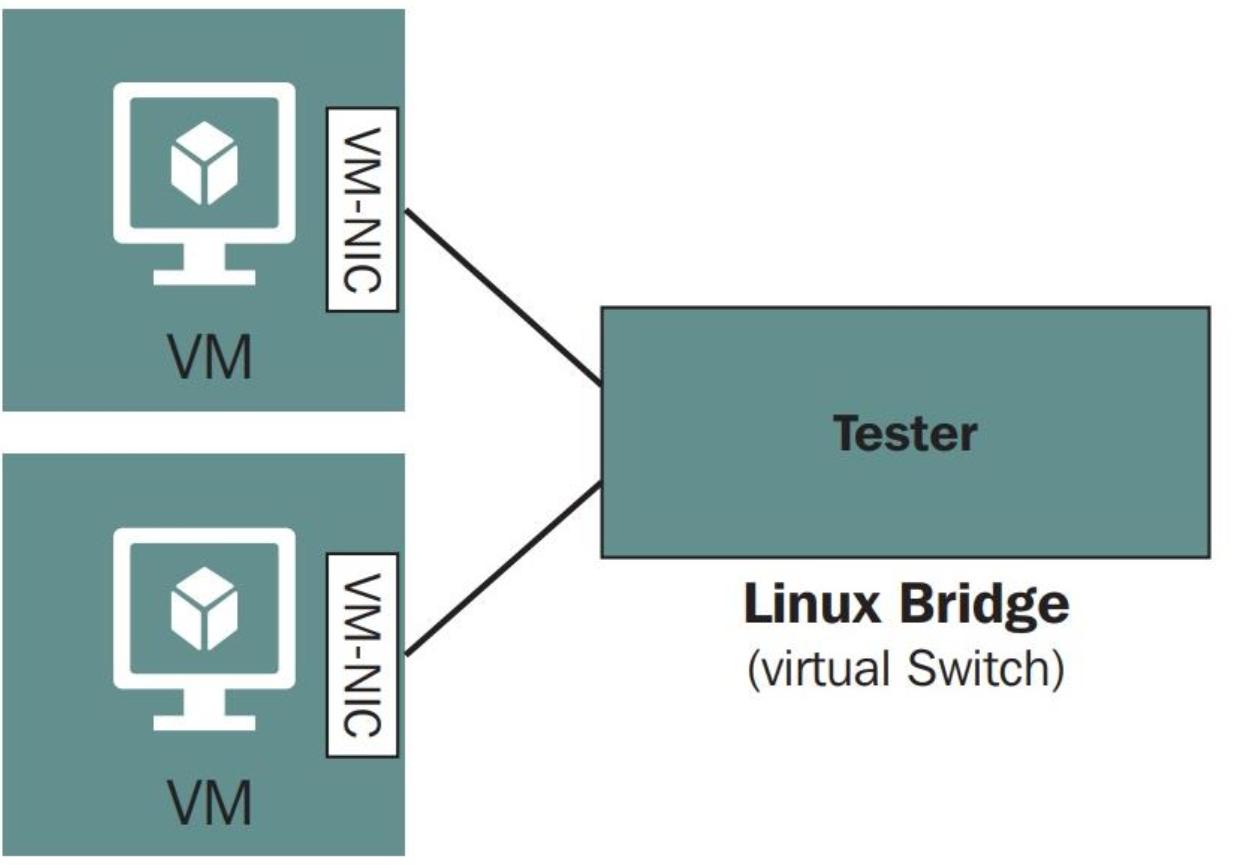
Теперь vm-vnic способно действовать в качестве соответствующего
интерфейса между вашей виртуальной машиной и мостом tester, который,
в свою очередь, позволяет имеющимся виртуальным машинам взаимодействовать с прочими виртуальными машинами,
которые добавляются к этому мосту:
Вам также может потребоваться удалить все те объекты и настройки, которые мы создали в своей предыдущей процедуре. Давайте выполним это пошагово через командную строку:
-
Вначале нам надлежит удалить устройство tap
vm-vnicиз своего мостаtester:# brctl delif tester vm-vnic # brctl show tester bridge name bridge id STP enabled interfaces tester 8000.460a80dd627d noПосле того как
vm-vnicбыл удалён из общего моста, удалите его устройство tap с помощью командыip:# ip tuntap del dev vm-vnic mode tap -
Затем удалите сам мост
tester:# brctl delbr tester
Это те же самые шаги, которые libvirt выполняла в самом сервере при осуществлении отключения сетевой среды для виртуальной машины. Мы хотим чтобы вы основательно разобрались с этой процедурой прежде чем двинуться дальше. Теперь, когда мы рассмотрели мост Linux, настало время продвинуться к более передовому понятию с названием Open vSwitch.
Представим себе на секунду, что вы работаете в небольшой компании, которая имеет от трёх до четырёх хостов KVM, пару подключаемых к сети устройств хранения (NAS) для размещения их 15 виртуальных машин и что вы работали в этой компании с самого начала. А потому вы всё это наблюдали: эта компания приобретала какие- то серверы, сетевые коммутаторы, а также устройства хранения и вы являлись частью небольшой команды персонала, который отстраивал эту среду. После 2 лет этого процесса вы знаете что всё это работает, просто в обслуживании и не причиняет вам больших страданий.
Теперь представим себе жизнь вашего приятеля, работающего на более крупную корпоративную компанию, которая обладает 400 хостами KVM и близка к управлению 2 000 виртуальных машин, осуществляя те же самые задания, которые вы выполняете в комфортном кресле своего офиса в вашей небольшой компании.
Вы представляете себе, что ваш приятель способен управлять его или её средой применяя те же самые инструменты, которыми пользуетесь вы? XML файлы для настройки сетевого коммутатора, развёртывание сервера с загружаемого USB устройства, настройки всего и вся вручную и обладания временем для выполнения всего этого? Вам это кажется возможным?
В такой второй ситуации имеются две основные проблемы:
-
Сам масштаб этой среды. Это самое очевидное. По причине имеющегося размера среды вам требуется некий подход, который будет управляться централизованно, вместо того чтобы выполнять это на уровне хоста, скажем как те виртуальные коммутаторы, которые мы обсуждали до сих пор.
-
Политики компании: Они, как правило, некое соответствие, которое исходит из максимально возможной стандартизации конфигурации. Теперь мы могли бы согласиться с тем, что мы имели бы возможность составить сценарий некоторых обновлений настроек через Ansible, Puppet или чего-то в этом же роде, но что толку? Нам придётся создавать новые конфигурационные файлы, новые процедуры и новые рабочие книги всякий раз, когда нам требуется вносить изменения в сетевую среду KVM. А крупные компании не одобряют этого.
Итак, то что нам требуется, это некий централизованный объект построения сети, который можно накладывать на множество хостов и который предлагает согласованность настроек. В этом контексте согласованность настроек предлагает нам гигантское преимущество - все вносимые нами в объект этого типа изменения будут реплицироваться во все хосты, которые выступают участниками такого централизованного объекта построения сетевой среды. Иными словами, то что нам требуется, это Open vSwitch (OVS). Для тех из вас, кто знает толк в построении сетевых сред на основе VMware, мы можем воспользоваться приблизительной метафорой - Open vSwitch для основанных на KVM средах аналогичен тому, чем выступает vSphere Distributed Switch для сред на базе VMware.
В терминах технологий OVS поддерживает следующее:
-
Изоляцию VLAN (IEEE 802.1Q)
-
Фиольтрацию обмена
-
Привязку с LACP (протоколом управления агрегированием каналов) или без оного
-
Различные перекрывающиеся сетевые среды - VXLAN, GENEVE, GRE, STT и тому подобные
-
Поддержку 802.1ag
-
Netflow, sFlow и тому подобное
-
(R)SPAN
-
OpenFlow
-
OVSDB
-
Построение очерёдности обмена и его совместное использование
-
Поддержку Linux, FreeBSD, NetBSD, Windows и Citrix (а также хостинг прочих)
Теперь, когда мы перечислили некоторые из поддерживаемых технологий, давайте обсудим тот способ, которым работает Open vSwitch.
Прежде всего давайте обсудим архитектуру собственно Open vSwitch. Сама реализация Open vSwitch разбивается вниз на две части: модуль ядра Open vSwitch (горизонт данных, data plane) и инструменты пространства пользователя. Поскольку приходящие пакеты данных должны обрабатываться настолько быстро, насколько это возможно, имеющийся горизонт данных Open vSwitch был помещён в имеющееся пространство ядра:
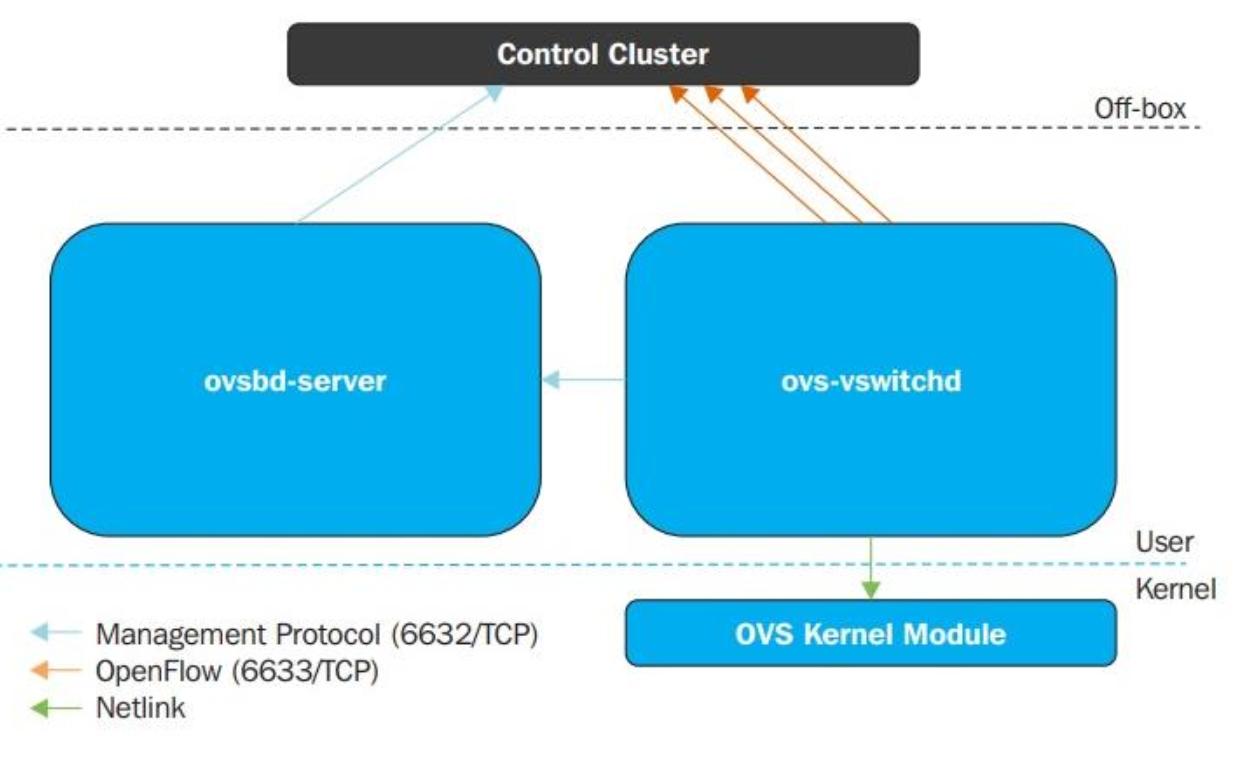
Путь к самим данным (модулю ядра OVS) применяет сокет netlink для взаимодействия с установленным демоном vswitchd, который реализует любое число коммутаторов OVS в вашей локальной системе и управляет ими.
Open vSwitch не обалдает неким определённым контроллером SDN (программно определяемой сетевой среды), который он применяет для целей управления, аналогично распределённому коммутатору VMware vSphere и NSX, которые обладают vCenter и различными компонентами NSX для управления их возможностями. В OVS основной момент состоит в том, чтобы применять чей- то ещё контроллер SDN, который затем взаимодействует с ovs-vswitchd при помощи протокола OpenFlow. Имеющийся сервер ovsdb поддерживает базу данных таблицы коммутации, а внешние клиенты способны взаимодействовать с этим сервером ovsdb при помощи JSON-RPC; JSON это определённый формат данных. Имеющаяся база данных ovsdb в настоящее время содержит около 13 таблиц, причём эта база данных сохраняется после перезапуска.
Open vSwitch работает в двух режимах: обычном и потоковом режимах. Эта глава в первую очередь сосредоточится на том как привносить некое подключение ВМ KVM к мосту Open vSwitch в обособленном/ обычном режиме и мы предоставим краткое введение в потоковый режим при помощи контроллера OpenDaylight:
-
Обычный (Normal) режим: Коммутация и отправка обрабатываются мостом OVS. В этом режиме OVS действует как некий обучаемый коммутатор L2. Данный режим особенно полезен при настройке для вашей цели нескольких перекрывающихся сетевых сред, вместо того чтобы манипулировать соответствующим потоком коммутаций.
-
Потоковый (Flow) режим: В потоковом режиме для определения в какой порт надлежит отправлять конкретные полученные пакеты применяется таблица потока имеющегося моста Open vSwitch. Все эти потоки управляются неким внешним контроллером SDN. Добавление или удаление соответствующего потока управления требует применения некого контроллера SDN, который управляет имеющимся мостом или при помощи команды
ctl. Этот режим позволяет больший уровень абстракции и автоматизации; соответствующий контроллер SDN выставляет необходимый REST API. Наше приложение может пользоваться этим API для непосредственного манипулирования потоками моста для удовлетворения потребностей сетевой среды.
Давайте перейдём к практической стороне и изучим как установить Open vSwitch в CentOS 8:
-
Самая первая вещь, которую нам следует сделать, так это сообщить системе использовать надлежащие репозитории. В данном случае нам требуется разрешить репозитории с названиями
epelиcentos-release-openstack-trainМы сделаем это при помощи командыyum{Прим. пер.: на самом деле, в CentOS 8 это синоним дляdnf:}# yum -y install epel-release # yum -y install centos-release-openstack-train -
Нашим следующим шагом будет установка
openvswitchиз репозитория Red Hat:# dnf install openvswitch -y -
После этого процесса установки нам требуется проверить что всё работает через проверку запуска и включения службы Open vSwitch и запуска команды
ovs-vsctl -V:# systemctl start openvswitch # systemctl enable openvswitch # ovs-vsctl -VСамая последняя команда должна вам выбросить в вывод определение версии Open vSwitch и её схемы DB. В нашем случае это Open vSwitch
2.11.0и схема DB7.16.1. -
Теперь, когда мы успешно установили и запустили Open vSwitch, настало время настроить его. Давайте выберем некий сценарий развёртывания, при котором мы намерены применять Open vSwitch как новый виртуальный коммутатор для своих виртуальных машин. В своём сервере у нас имеется другой физический интерфейс с названием
ens256, который мы собираемся применять в качестве восходящего подключения для своего виртуального коммутатора Open vSwitch. Мы также намерены очистить настройкиens256, сконфигурировать некий IP адрес для своего OVS, и запустить этот OVS при помощи следующих команд:# ovs-vsctl add-br ovs-br0 # ip addr flush dev ens256 # ip addr add 10.10.10.1/24 dev ovs-br0 # ovs-vsctl add-port ovs-br0 ens256 # ip link set dev ovs-br0 up -
Теперь, когда всё настроено, но не на постоянной основе, нам необходимо сделать эти настройки неизменными. Это означает настройку некоторого конфигурационного файла сетевого интерфейса. Итак, пройдём в
/etc/sysconfig/network-scriptsи создадим два файла. Один из них назовёмifcfg-ens256(для своего восходящего интерфейса):DEVICE=ens256 TYPE=OVSPort DEVICETYPE=ovs OVS_BRIDGE=ovs-br0 ONBOOT=yesДругой файл поименуем как
ifcfg-ovs-br0(для своего OVS):DEVICE=ovs-br0 DEVICETYPE=ovs TYPE=OVSBridge BOOTPROTO=static IPADDR=10.10.10.1 NETMASK=255.255.255.0 GATEWAY=10.10.10.254 ONBOOT=yes -
Мы не настраивали это просто для показа, а потому нам потребуется убедиться что наши виртуальные машины KVM также способны пользоваться им. Это означает - снова - что нам потребуется создать некую виртуальную сетевую среду KVM, которая намерена пользоваться OVS. К счастью, мы уже имели дело с файлами XML виртуальной сетевой среды KVM (убедитесь в разделе Сетевая среда изолированной Libvirt), а следовательно это не должно стать проблемой. Давайте назовём свою сетевую среду
packtovs, а соответствующий ей файл XMLpacktovs.xml. Он должен содержать следующее:<network> <name>packtovs</name> <forward mode='bridge'/> <bridge name='ovs-br0'/> <virtualport type='openvswitch'/> </network>
Итак, теперь, когда у нас имеются определение виртуальной сетевой среды и некий файл XML, который служит для определения, запуска и автоматического старта этой сети, мы можем выполнять свои обычные действия:
# virsh net-define packtovs.xml
# virsh net-start packtovs
# virsh net-autostart packtovs
Если мы оставим всё как то было при создании наших виртуальных сетей, вывод из virsh
net-list должен выглядеть следующим образом:
Итак, всё что осталось, так это подцепить ВМ в нашу только что созданную сеть на основе OVS с названием
packtovs и мы дома. В качестве альтернативы мы могли бы просто создать новый
и подключить его к этому конкретному интерфейсу, воспользовавшись полученными в Главе 3, Установка гипервизора KVM, libvirt и oVirt знаниями. Итак, давайте выполним следующую
команду, в которой изменены всего два параметра (--name и
--network):
# virt-install --virt-type=kvm --name MasteringKVM03 --vcpus 2 --ram 4096 --os-variant=rhel8.0 --cdrom=/var/lib/libvirt/images/CentOS-8-x86_64-1905-dvd1.iso --network network:packtovs --graphics vnc --disk size=16
После того как установка этой виртуальной машины выполнена, мы подключены к виртуальной сети
packtovs на основе OVS, а наша виртуальная машина может применять её. Допустим,
требуются дополнительные настройки и что нам требуется помечать тегом обмен, поступающий их этой виртуальной машины при
помощи VLAN ID 5. Запустим вашу виртуальную машину и воспользуемся следующим
набором команд:
# ovs-vsctl list-ports ovs-br0
ens256
vnet0
Эта команда сообщает нам, что мы применяем порт ens256 как восходящее
подключение и что наша виртуальная машина, MasteringKVM03 использует виртуальный
порт сети vnet0. Мы можем применять пометку VLAN для этого порта при помощи такой
команды:
# ovs-vsctl set port vnet0 tag=5
Нам надлежит отметить некоторые дополнительные относящиеся к администрированию и управлению OVS команды, поскольку они выполняются через CLI. Итак, вот некоторые наиболее применяемые команды CLI администрирования OVS:
-
#ovs-vsctl show: Очень удобная и часто применяемая команда. Она сообщает какова запущенная в данный момент конфигурация этого коммутатора. -
#ovs-vsctl list-br: Перечисляет мосты, которые настроены в Open vSwitch. -
#ovs-vsctl list-ports <bridge>: Отображает все названия всех имеющихся портов вBRIDGE. -
#ovs-vsctl list interface <bridge>: Отображает все названия всех имеющихся интерфейсов вBRIDGE. -
#ovs-vsctl add-br <bridge>: Создаёт мост в базе данных этого коммутатора. -
#ovs-vsctl add-port <bridge> : <interface>: Привязывает некий интерфейс (физический или виртуальный) к мосту данного Open vSwitch -
#ovs-ofctl и ovs-dpctl: Эти две команды используются для администрирования и мониторинга записей потока. Вы знаете что OVS управляет двумя видами потоков: OpenFlows и Datapath. Первый управляется в панели управления, в то время как второй является потоком на основе ядра.#ovs-ofctlобщается с модулем OpenFlow, в то время какovs-dpctlобщается с модулем Ядра.
Ниже приводятся образцы наиболее применимых вариантов для каждой из этих команд:
-
#ovs-ofctl show <bridge>: Отображает краткие сведения относительно самого коммутатора, включая значение номера порта для соответствия названию порта. -
#ovs-ofctl dump-flows <bridge>: Опрашивает таблицы OpenFlow. -
#ovs-dpctl show: Выводит на печать основные сведения относительно всех имеющихся логических путей данных, именуемых мостами, представленными в этом коммутаторе. -
#ovs-dpctl dump-flows: Отображает тот поток, что кэширован в пути данных. -
#ovs-appctl: Эта команда предлагает некий способ отправки команд в запущенный Open vSwitch и получения сведений, которые не выставляются непосредственно командойovs-ofctl. Это нож швейцарской армии устранения неисправностей OpenFlow. -
#ovs-appctl bridge/dumpflows <br>: Опрашивает таблицы потока и предоставляет прямое подключение для ВМ из тех же самых хостов. -
#ovs-appctl fdb/show <br>: Перечисляет выученные пары MAC/VLAN.
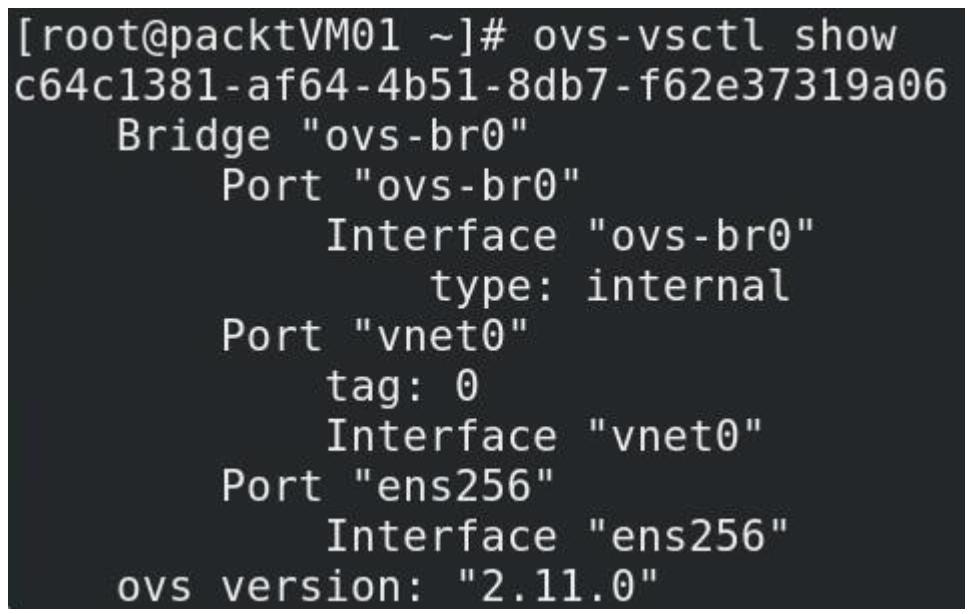
Вы также всегда можете воспользоваться командой ovs-vsctl show для
получения сведений относительно самих настроек вашего коммутатора OVS:
К предмету Open vSwitch мы намерены вернуться в Главе 12, Горизонтальное масштабирование KVM посредством OpenStack, поскольку мы погрузимся глубже в своё обсуждение распространения Open vSwitch по множеству хостов, в особенности при том что будем иметь на уме тот факт, что мы желаем иметь возможность охватывать свои перекрывающиеся облачные сети (на основе GENEVE, VXLAN, GRE или аналогичных протоколов) по множеству хостов и площадок.
Как вы можете представить, Open vSwitch это просто удобное понятие для libvirt или OpenStack - он также может применяться для разнообразия прочих ситуаций. Давайте рассмотрим одну их них, которая может оказаться важной для тех, кто ищет интеграции с VMware NSX или NSX-T.
Давайте лишь поясним здесь несколько основных терминов и взаимосвязей. VMware NSX это некая технология на основе SDN, которая может применяться в разнообразных случаях:
-
Соединение центров обработки данных и расширения облачных перекрывающихся сетевых сред за рамки центров обработки данных.
-
Разнообразных ситуаций восстановления после чрезвычайных ситуаций. NSX может выступать большой подмогой для восстановления после происшествий в средах со множеством площадок, а также для интеграции с разнообразными внешними службами и устройствами, которые могут составлять часть такого сценария (PAN Пало Альто).
-
Согласованная микро сегментация между площадками выполняется верным способом на уровне сетевых карт самой виртуальной машины.
-
Для целей безопасности, начиная с различных типов поддерживаемых технологий VPN для соединения площадок и конечных пользователей вплоть до распределённых межсетевых экранов, вариантов гостевого самоанализа (антивирусов и обнаружения вредоносного ПО), вариантов сетевого самоанализа (IDS/ IPS) и тому подобного.
-
Для балансировки нагрузки, причём вплоть до Уровня с разгрузкой SSL, постоянными сеансами, высокой доступностью, правилами приложений и прочим.
Да, приём VMware с SDN (NSX) и Open vSwitch выглядят конкурирующими технологиями, однако в действительности имеется большое число клиентов, которые желают применять оба. Именно тут интеграция VMware с OpenStack, а также интеграция NSX с хостами KVM на основе Linux (с применением Open vSwitch и дополнительных агентов)становятся действительно удобными. просто для дальнейшего объяснения этих моментов - имеются вещи, которые выполняет NSX и которые требуют интенсивного применения технологий на основе Open vSwitch - аппаратной интеграции VTEP через базу данных Open vSwitch, расширения сетевых сред GENEVE на узлы VM при помощи интеграции Open vSwitch/NSX и многое иное.
Представьте себе, что вы работаете на поставщика услуг - предоставляющего облачные службы, обычно, интернет провайдера, любой вид компании, у которой имеются большие сетевые среды с множеством сетевой сегментации. Имеется большое число поставщиков служб, применяющих VMware's vCloud Director для предоставления облачных служб конечным пользователям и компаниям. Тем не менее, по причине потребностей рынка, эти среды часто требуется расширять для включения AWS (для дополнительных сценариев роста инфраструктуры через имеющиеся общедоступные облачные решения) или OpenStack (для создания сценариев гибридного облачного решения). Когда у нас нет возможности в обладании взаимодействием между такими решениями, у нас не было бы варианта по применению этих обоих предложений одновременно. Однако с точки зрения сетевой среды, стоящие в основе сети это NSX или NSX-T (которые на самом деле применяют Open vSwitch).
На протяжении многих лет было понятно, что будущее за средами со множеством облачных решений, а такие типы интеграции привлекут большее число клиентов, причём они пожелают воспользоваться такими достижениями при разработке собственной облачной службы. Последующие разработки, к тому же, скорее всего будут содержать (и уже частично включают) интеграцию с Docker, Kubernetes и/ или OpenShift, чтобы обладать возможноть управления контейнерами в той же самой среде.
Имеется также ряд более экстремальных образцов использования оборудования - в нашем примере вы говорим о сетевых картах на шине PCI Express - путём их расчленения. В настоящее время наши пояснения этого понятия с названием SR-IOV намерено ограничиваться сетевыми картами, но мы расширим это понятие в Главе 6, Устройства и протоколы Виртуальных устройств отображения, когда мы начнём обсуждать совместное деление на части GPU для целей виртуальных машин. Итак, давайте обсудим практический пример использования SR-IOV на сетевой карте Intel, которая поддерживает это.
Понятие SR-IOV это нечто, что мы упоминали уже в Главе 2,
KVM в качестве решения виртуализации. Применяя SR-IOV мы способны разбивать на
части ресурсы PCI (например, сетевые карты) на виртуальные функции PCI и вставлять их в виртуальную
машину. Если мы воспользуемся этим понятием для сетевых карт, обычно мы делаем это с единственной целью - чтобы мы
могли избегать применение ядра операционной системы и стека сетевой среды при доступе к карте сетевого интерфейса
из нашей виртуальной машины. Чтобы мы могли сделать это, нам требуется аппаратная поддержка, а потому нам следует
проверить, действительно ли наша сетевая карта поддерживает её. В физическом сервере мы можем воспользоваться
командой lspci для выделения сведений атрибутов для наших устройств PCI и далее
grep -нуть Single Root I/O Virtualization
как строку чтобы попытаться обнаружить является ли наше устройство совместимым с этим. Вот некий пример из нашего
сервера:

![[Замечание]](/common/images/admon/note.png) | Важное замечание |
|---|---|
|
Будьте внимательными при настройке SR-IOV. Вам требуется обладать сервером, который поддерживает её, устройство, которое поддерживает её и вам следует убедиться что вы включили функциональность SR-IOV в BIOS. Затем вам следует иметь в виду, что существуют серверы, которые обладают только особыми слотами, которые предназначены под SR-IOV. Тот сервер, которым пользуемся мы (HP Proliant DL380p G8) обладает тремя слотами PCI-Express, назначенными под CPU1, однако SR-IOV работает лишь в слоте #1. Когда мы вставим свою карту в слот #2 или #3, мы получим сообщение BIOS, что SR-IOV не будет работать в этом слоте и что нам следует переместить нашу карту в слот, который поддерживает SR-IOV. Итак, будьте любезны убедиться что вы внимательно прочитали документацию своего сервера и вставили совместимое с SR-IOV в правильный слот PCI-Express. |
В этом конкретном случае это сетевой адаптер Intel 10 Гигабит с двумя портами, который мы можем применять чтобы выполнить SR-IOV. Эта процедура не так уж и сложна и она требует от нас выполнения следующих шагов:
-
Освободиться от своего предыдущего модуля.
-
Зарегистрировать его в модуле
vfo-pci, который доступен в стеке ядра Linux. -
Настроить некого гостя, собирающего воспользоваться им.
Итак, что вам надлежит сделать, так это выгрузить тот модуль, который в настоящее время применяет ваша сетевая
карта при помощи modprobe -r. Далее вы загрузите его снова, но назначая некий
дополнительный параметр. В нашем конкретном сервере, используемому нами нашему двухпортовому адаптеру Intel (X540-AT2)
были назначены сетевые устройства ens1f0 и ens1f1.
Поэтому, давайте воспользуемся ens1f0 в качестве примера настройки SR-IOV в момент
запуска:
-
Самое первое что нам следует сделать (в качестве общего соображения), так это выяснить какой модуль ядра применяет наша сетевая карта. Для этого нам необходимо выполнить следующую команду:
# ethtool -i ens1f0 | grep ^driverВ нашем случае тот вывод, что мы получаем, таков:
driver: ixgbeНам надлежит отыскать дополнительные доступные параметры для этого модуля. Для этого мы можем воспользоваться командой
modinfo(мы интересуемся лишь частьюparmиз этого вывода):# modinfo ixgbe ….. Parm: max_vfs (Maximum number of virtual functions to allocate per physical function – default iz zero and maximum value is 63.К примеру, мы применяем здесь модулем
ixgbeи мы можем сделать следующее:# modprobe -r ixgbe # modprobe ixgbe max_vfs=4 -
Затем мы можем воспользоваться имеющейся системой
modprobeчтобы превратить эти изменения в постоянные при перезагрузках, создав некий файл в/etc/modprobe.dс названиемixgbe.confи добавить в него следующую строку:options ixgbe max_vfs=4
Это предоставит нам до четырёх виртуальных функций, которые мы можем применять внутри своих виртуальных машин. Теперь, наша следующая задача, которую нам требуется разрешить, это как запускать свой сервер с активным SR-IOV в момент загрузки. Имеется несколько вовлекаемых в это шагов, итак, давайте приступим:
-
В строку запуска ядра по умолчанию и в настройку ядра по умолчанию нам требуется добавить параметры
iommuиvfs. Поэтому, откройте/etc/default/grubи измените строкуGRUB_CMDLINE_LINUX, добавив в неёintel_iommu=on(илиamd_iommu=onкогда вы используете систему AMD), а такжеixgbe.max_vfs=4. -
Нам необходимо перенастроить
grubдля применения этих изменений, а потому нам необходимо воспользоваться следующей командой:# grub2-mkconfig -o /boot/grub2/grub.cfg -
Порой даже этого недостаточно, а потому нам потребуется настроить необходимые параметры ядра, такие как максимальное число виртуальных функций и свой параметр
iommuдля их использования в нашем сервере. Это приводит нас к такой команде:# grubby --update-kernel=ALL --args="intel_iommu=on ixgbe.max_vfs=4"
После перезапуска мы должны получить возможность наблюдать свои виртуальные функции. Наберите следующую команду:
# lspci -nn | grep "Virtual Function"
Вы должны получить некий вывод, который выглядит следующим образом:

Мы должны иметь возможность обнаружения этих виртуальных функций из libvirt и мы можем проверить это через
команду virsh. Давайте попробуем это (мы используем grep 04 по той причине, что идентификатор нашего устройства начинается с 04, что
видно на нашем предыдущем изображении; мы обрезали этот вывод только для важных записей):
# virsh nodedev-list | grep 04
……
pci_0000_04_00_0
pci_0000_04_00_1
pci_0000_04_10_0
pci_0000_04_10_1
pci_0000_04_10_2
pci_0000_04_10_3
pci_0000_04_10_4
pci_0000_04_10_5
pci_0000_04_10_6
pci_0000_04_10_7
Самые первые два устройства это наши физические функции. Остающиеся восемь устройств (два порта, помноженные на
четыре функции) это наши виртуальные устройства (с pci_0000_04_10_0 по
pci_0000_04_10_). Теперь мы выведем дам этих устройств применив команду
virsh nodedev-dumpxml pci_0000_04_10_0:
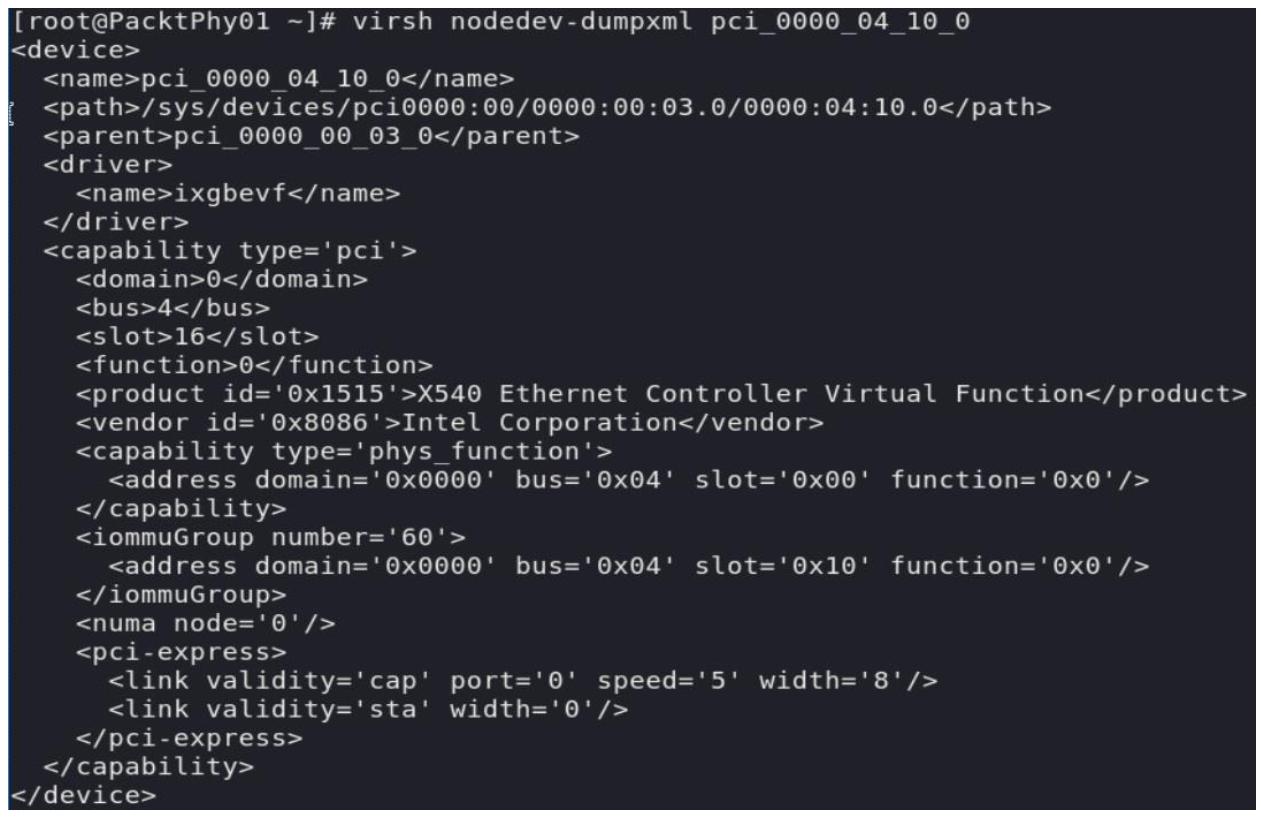
Итак, когда у нас имеется работающая виртуальная машина, которую мы бы желали настроить для применения этого,
нам пришлось бы создать XML файл с определением, который выглядит примерно так: (мы назовём его
packtsriov.xml):
<interface type='hostdev' managed='yes' >
<source>
<address type='pci' domain='0x0000' bus='0x04' slot='0x10' function='0x0'>
</address>
</source>
</interface>
Конечно же, domain, bus, slot и function должны указывать в точности вашу VF. Далее мы можем воспользоваться
командой virsh для подключения этого устройства к нашей виртуальной машине
(скажем, MasteringKVM03):
# virsh attach-device MasteringKVM03 packtsriov.xml --config
Когда мы воспользуемся virsh dumpxml
<driver name='vfio'/> помимо
прочих сведений, которые мы настроили на своём предыдущем шаге (типа адреса, домена, шины, слота, функции).
Наша виртуальная машина не должна иметь проблем при использовании этой виртуальной функции в качестве сетевой карты.
Теперь настало время обсудить другое понятие, которое очень сильно полезно в построении сетей KVM: macvtap. Это более новый драйвер, который должен упростить нашу виртуальную сетевую среду, полностью удаляя драйверы tun/ tap единым модулем.
Этот модуль работает как сочетание модулей tap и macvlan. Мы уже поясняли что делает модуль tap. Модуль macvlan позволяет нам создавать виртуальные сети, которые мы прикалываем к некому физическому сетевому интерфейсу (обычно мы называем этот интерфейс нижним или устройством). Комбинирование tap и macvlan делает для нас возможным выбор между четырьмя различными режимами действий, именуемыми VEPA (Virtual Ethernet Port Aggregator), мостом, частным и пробросом.
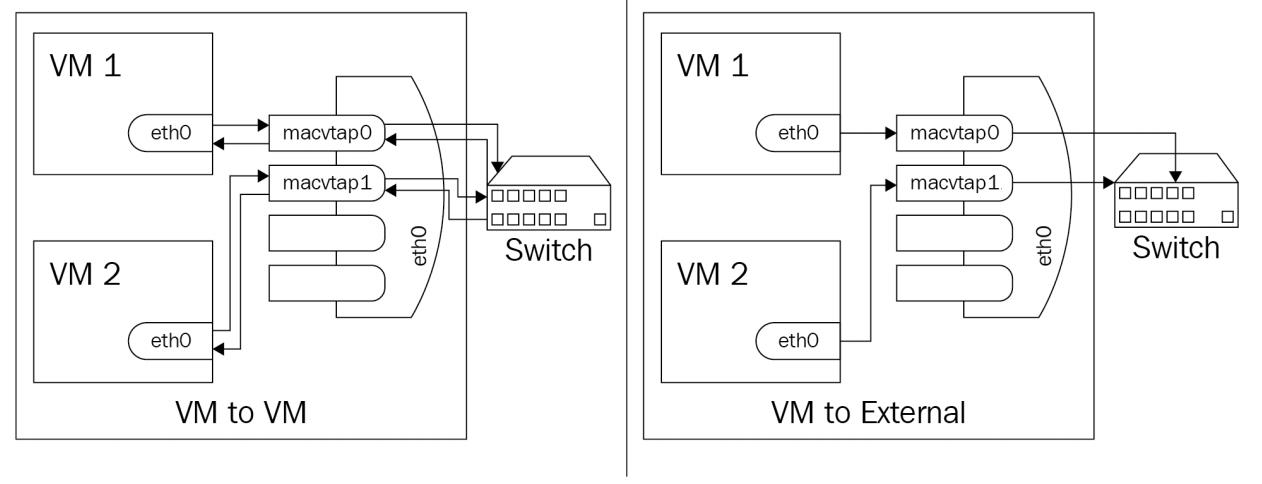
Когда мы применяем режим VEPA (режим по умолчанию, наш физический коммутатор обязан поддерживать VEPA сопровождая
режим hairpin (шпильки, также именуемый отражающей ретрансляцией - reflective
relay). Когда некое нижнее устройство получает данные из macvlan в режиме VEPA,
этот обмен всегда отправляется в имеющееся выше по потоку устройство, что означает что обмен всегда проходит через
некий внешний коммутатор. Основное преимущество этого режима состоит в том факте, что сетевой обмен между
виртуальными машинами становится видимым во внешней сетевой среде, что может быть полезным по различным причинам.
Вы можете проверить как сетевой поток работает по следующей последовательности схем:
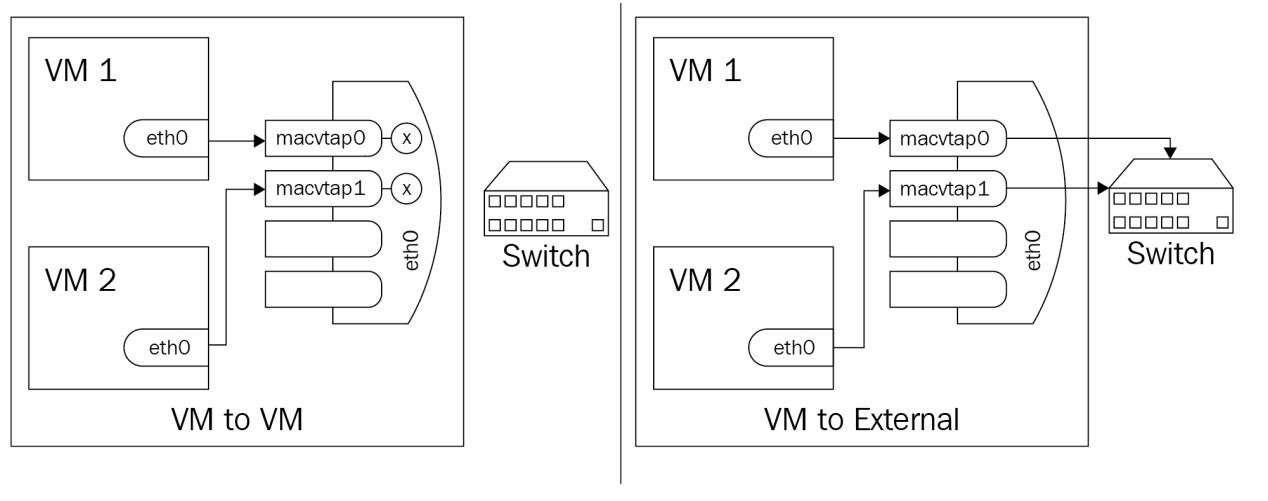
В частном режиме всё аналогично VEPA в том, что всё приходит в некий внешний коммутатор, но в отличие от VEPA, обмен доставляется только тогда, когда он отправляется через внешний маршрутизатор или коммутатор. Вы можете применять этот режим когда желаете изолировать подключённые к конечным точкам виртуальные машины друг от друга, но не от внешней сетевой среды. Если это очень похоже на ситуацию частной VLAN, то вы совершенно правы:
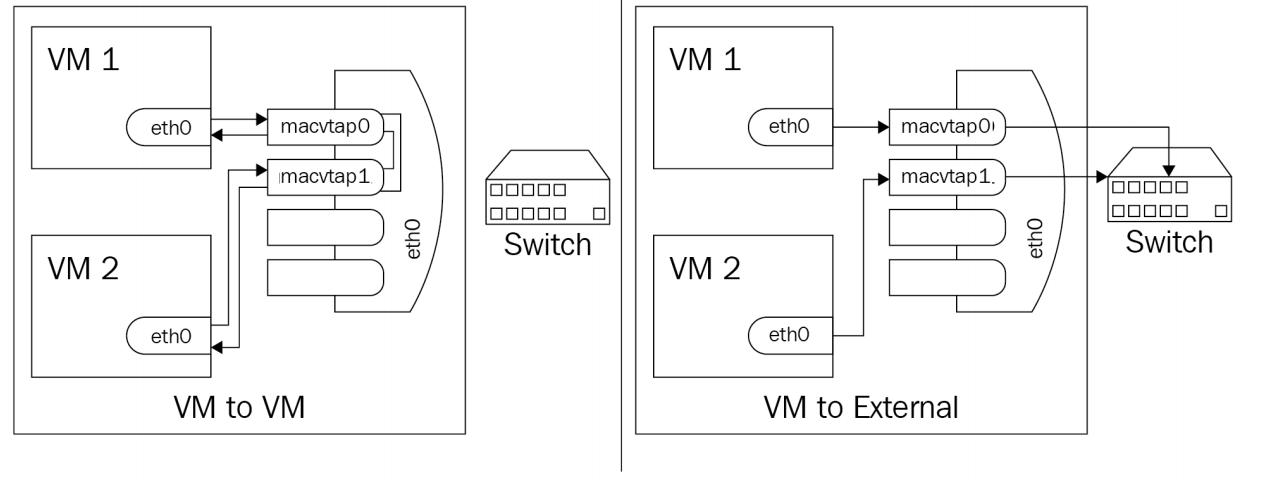
В режиме моста полученные вашим macvlan данные, подлежащие переходу в другой macvlan в том же самом нижнем устройстве, отправляются непосредственно в свою цель, причём не внешним образом, а затем отправляется обратно. Это очень похоже на то, что выполняет NSX VMware когда предполагается что происходит обмен данными между виртуальными машинами в разных сетях VXLAN, но в одном и том же хосте:
В режиме проброса мы в целом говорим о ситуации SR-IOV, при котором мы применяем некую VF или физическое устройство напрямую в наш интерфейс macvtap. Основное ключевое отличие состоит в том, что отдельный сетевой интерфейс может передаваться лишь отдельному гостю (соотношение 1:1):
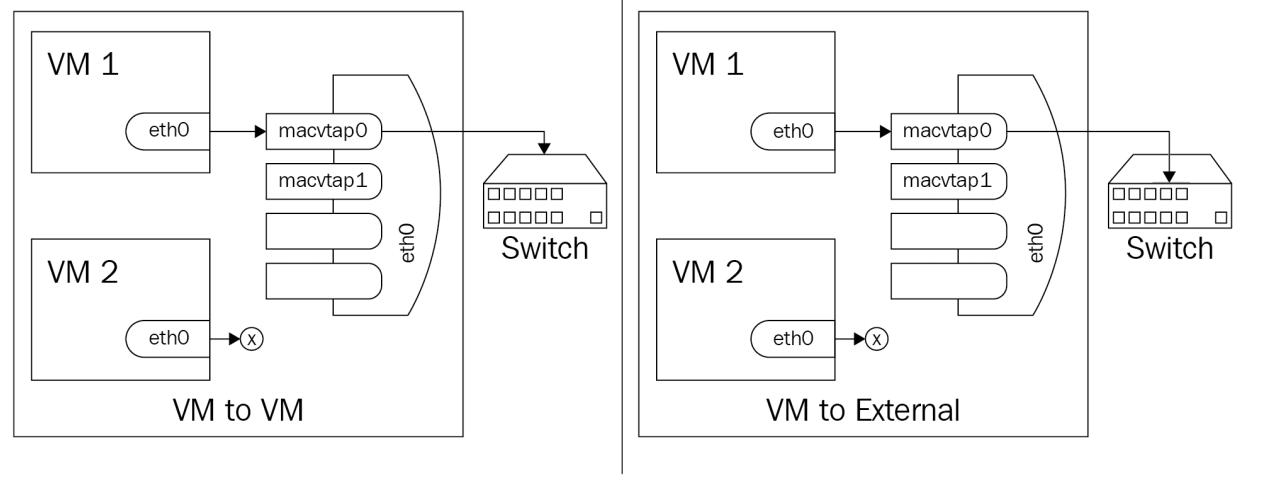
В Главе 12, Горизонтальное масштабирование KVM посредством OpenStack и в Главе 13, Горизонтальное масштабирование KVM посредством AWS мы объясним почему виртуальные и перекрывающиеся сети (VXLAN, GRE, GENEVE) ещё более важны для сетевых сред облачных решений, поскольку мы расширим свою локальную среду на основе KVM до облачного решения либо через OpenStack, либо через AWS.
В этой главе мы рассмотрели основы построения виртуальных сетевых сред в KVM и пояснили почему виртуальные сети такая гигантская часть виртуализации. Мы глубоко погрузились в файлы настройки и их параметры, так как это будет предпочтительным методом администрирования в более крупных средах, в особенности когда речь идёт о виртуальных сетях.
Обратите особое внимание на все этапы настройки и особенно на ту часть, которая связана с применением команд virsh для управления настройкой сети и для конфигурирования Open vSwitch и SR-IOV. Основанные на SR-IOV понятия широко применяются в средах, чувствительных к задержкам, чтобы предоставлять сетевые услуги с минимально возможными накладными расходами и задержками, поэтому это понятие очень важно для различных корпоративных сред, связанных с финансовым и банковским сектором.
Теперь, когда мы рассмотрели все необходимые сетевые сценарии (некоторые из которых будут рассматриваться и позднее в данной книге), настало время задуматься о следующей теме нашего виртуального мира. Мы уже обсудили ЦПУ и память, а также сетевые среды, а это означает, что у нас остался четвёртый столп виртуализации: хранилище. Этим вопросом мы займёмся в своей следующей главе.
-
Почему так важно чтобы виртуальные коммутаторы одновременно принимали подключения от множества виртуальных машин?
-
Как виртуальные коммутаторы работают в режиме NAT?
-
Как виртуальные коммутаторы работают в режиме маршрутизатора?
-
Что представляет собой Open vSwitch и для каких целей мы можем применять его в виртуальных и облачных сред?
-
Опишите различия между интерфейсами TAP и TUN.
Для получения дополнительных сведений относящихся к рассмотренному нами в этой главе воспользуйтесь, пожалуйста, следующими ссылками:
{Прим. пер.: Технология PCI Express 3.0 Майк Джексон, Рави Бадрак}