Глава 13. Установка Proxmox промышленного уровня
Содержание
- Глава 13. Установка Proxmox промышленного уровня
- Определение промышленного уровня
- Калибровка ЦПУ и памяти
- Промышленный кластер Ceph
- Жидкостное охлаждение
- Реальные сценарии Proxmox
- Сценарий 1 - академический институт
- Сценарий 2 - кластер многоуровневого хранения в кластере Proxmox
- Сценарий 3 - виртуальная инфраструктура для поставщика служб с множеством владельцев
- Сценарий 4 - встроенная виртуальная среда для компании разработчика ПО
- Сценарий 5 - виртуальная инфраструктура для общественной библиотеки
- Сценарий 6 - виртуальная инфраструктура многоэтажного офиса с виртуальными рабочими местами
- Сценарий 7 - виртуальная инфраструктура для гостиничного хозяйства
- Сценарий 8 - виртуальная инфраструктура для организации геологических изысканий
- Выводы
До сиз пор мы видели в этой книге внутреннюю работу Proxmox. Теперь мы знаем как надлежащим образом собрать всецело работающий кластер Proxmox. Мы обсудили Ceph - надёжную и избыточную систему совместного хранения - и как мы можем соединить её с кластером Proxmox. Также мы видели что такое виртуалтная сеть и как она работает с кластером Proxmox.
В данной главе мы собираемся выяснить какие компоненты играют решающую роль в превращении кластера Proxmox в готовый к промышленному применению с многоуровневым резервированием, хорошей производительностью и стабильностью. Мы собираемся осветить следующие темы:
-
Определение промышленного уровня
-
Ключевые моменты сборки промышленного уровня
-
Требования к оборудованию начального уровня и продвинутого уровня
На протяжении этой главы вы увидите, что мы воспользовались самостоятельно построенными пользователями аппаратными решениями вместо готовых бренд- серверов. Цель этого состоит в том, чтобы показать вам какой вид конфигураций оборудования можно использовать готового к применению общедоступного оборудования для урезания стоимости при построении стабильно работающего кластера Proxmox. Все показанные в этой главе примеры конфигураций не являются теоретическими сценариями, а взяты из различных работающих в обслуживании кластеров. Используйте информацию из этой главы исключительно как руководство, с тем чтобы вы могли выбрать подобающее оборудование для своей среды и уложиться в рамки бюджета.
Промышленный уровень является сценарием, при котором среда кластера компании всецело функционирует и активно обслуживает своих пользователей или клиентов на постоянной основе. Она больше не рассматривается как платформа для изучения Proxmox или пробная платформа для тестирования на ней различных вещей. Сборка промышленного уровня требует более изощрённого планирования и подготовки, потому что когда наладка завершена и кластер введён в эксплуатацию, он не может быть просто выведен полностью из рабочего состояния в момент уведомления, когда пользователи зависят от него. Надлежащим образом спланированная сборка промышленного уровня может сократить часы и дни головной боли. Если вы до сих пор изучаете Proxmox, вы возможно захотите наладить оборудование на стороне, чтобы попрактиковаться на нём для того чтобы отшлифовать своё мастерство перед тем как попытаться собрать промышленный уровень. В данной главе мы собираемся рассмотреть некоторые ключевые компоненты или характеристики среды промышленного уровня.
Следующие ключевые компоненты, обусловленные требованиями стабильности и производительности следует иметь в виду пр планировании наладки кластера для промышленного уровня:
-
Стабильное и масштабируемое оборудование
-
Избыточность для резервирования
-
Текущая нагрузка в сопоставлении с будущей
-
Бюджет
-
Простота
-
Отслеживание инвентаризации оборудования
Надёжное и масштабируемое оборудование
Стабильное оборудование означает минимальный простой. Без качественного оборудования не будет необычным наличие случайных отказов аппаратуры в среде кластера, вызывающих массивные нежелательные простои. Очень важно выбрать бренд оборудования с хорошей репутацией и придерживаться его. Например, компоненты серверного уровня Intel широко известны своей великолепной стабильностью и поддержкой. Это верно, что вы платите больше за продукты Intel. AMD также является великолепным выбором. Однако статистически известно, что оборудование на основе AMD имеет больше проблем со стабильностью. Для чувствительных к бюджету корпоративных сред мы можем смешивать и оборудование на основе Intel, и на основе AMD в одном и том же кластере. Так как Proxmox предоставляет возможности полной миграции, мы можем иметь узлы Intel, работающие всё время, в то время как узлы AMD работают только как перехватывающие управление при отказах. Это уменьшает стоимость без сокращения стабильности. На протяжении данной главы мы будем в основном придерживаться оборудования на основе Intel. Под конец данной главы мы рассмотрим несколько проверенных кластеров на базе AMD чтобы дать вам некоторые идеи как сделать жизнеспособными AMD в кластерных средах AMD.
При выборе между Intel и AMD, помимо стабильности, следующий два фактора также являются влияющими на принятие решения:
-
Стоимость электроэнергии
-
Выделяемое тепло
ЦПУ Intel потребляют меньше энергии и выделяют намного меньше тепла при работе чем их конкуренты AMD. Увеличенное тепловыделение в серверах AMD означает увеличение требований для охлаждения, тем самым увеличивая и счета на коммунальные услуги. По своей архитектуре ЦПУ AMD потребляют намного больше Ватт на один ЦПУ, что напрямую вызывает более высокое тепловыделение.
Другим решающим фактором оборудования является масштабирование и доступность. Компоненты используемой в серверах аппаратуры должны быть легко доступны когда возникает потребность в их замене. Применение сложных для поставки компонентов, даже если они более экономичны в стоимостном отношении, только продлевает время простоя, когда что-то должно быть заменено. Общей практикой является использование идентичного оборудования для групп серверов, основываясь на их рабочей нагрузке. Это делает более простым управление, а также позволяет в случае необходимости произвести быструю замену, имея под рукой склад. Очень трудно иметь дело со средами, в которых кластер собирается воедино из всех возможных видов различных торговых марок, моделей и конфигураций.
Избыточность
Необходимости наличия резервирования на различных уровнях не может не уделяться достаточного внимания. Избыточность должна присутствовать на различных уровнях компонентов.
Уровень узла
Уровень резервирования узла обычно включает избыточные блоки питания, сетевые платы, RAID и тому подобное. Резервирование ограничено в узле самом по себе. При избыточных блоках питания узел может быть подключён к двум различным источникам электропитания, тем самым гарантируя непрерывность работы при отказах энергоснабжения. Всегда применяйте зеркалированные SSD устройства в качестве устройств операционной системы. Это гарантирует вам что операционная система сама по себе будет работать без прерываний даже если одно из устройств полностью откажет.
Уровень вспомогательного оборудования
Чтобы узлы вашего кластера оставались в рабочем состоянии при утрате энергоснабжения, нам необходимо обеспечить некоторый вид резервного электропитания либо посредством UPS, либо генератора или большим запасом батарей {Прим. пер.: в требованиях Tier и ANSI/TIA-942 также присутствуют рекомендации по независимым источникам электроснабжения.}
Уровень сетевой среды
Резервированность уровня сетевой среды включает в себя сетевую инфраструктуру, такую как коммутаторы и кабели. Применяя множество коммутаторов и множество сетевых путей мы можем гарантировать что связь в сети не будет прервана в случае отказа коммутатора или кабеля. Применение управляемых коммутаторов 3 уровня, например, стекируемых коммутаторов, является правильным решением для создания полностью резервированных сетевых путей.
Уровень отвода тепла
Надлежащее охлаждение при наличии резервного плана для непрерывного отвода тепла при событии, что система теплоотвода (HVAC) выйдет из строя, часто является недооценённой. В зависимости отобщего числа серверных узлов, коммутаторов, и тому подобного, всякая сетевая среда производит огромное количество тепла {Прим. пер.: с точки зрения термодинамики кпд вычислительной техники равен нулю: она не производит никакой механической работы, вся потребляемая энергия в конечном счёте выделяется в тепло}. Если не обеспечена избыточность, отказ системы охлаждения может иметь результатом при отказе чрезмерное выделение тепла компонентами. Будь то воздушная или жидкостная система охлаждения, должна существовать непрерывность работы системы отвода тепла для предотвращения каких- бы то ни было разрушений. Разрушение компонентов также означает потерю связности и увеличение стоимости.
Уровень системы хранения
Система хранения играет важную роль в любой виртуальной среде и заслуживает того же самого уровня внимания к резервированию как и ваш остальной кластер. Нет никакого смысла в реализации резервирования для всех узлов хостов Proxmox, сетевой среды или источника питания при размещении образов виртуальных дисков на едином хранилище NAS без какого- либо резервирования. Если отказывает единственный узел хранения, даже когда он рассматривается как совместно используемое хранилище, все хранимые в нём ВМ будут полностью недоступными. В промышленной среде критичным является применение систем хранения корпоративного уровня, такие как Ceph, Gluster и тому подобных. {Прим. пер.: появление в январе 2016 Репликаций в общедоступных версиях ZFS также выводит её на данный уровень.}
Сопоставление текущей нагрузки с ростом в будущем
При проектировании кластера вы всегда должны помнить о дальнейшем росте, по крайней мере, на предсказуемое будущее. Клстер корпоративного уровня должен иметь возможность роста и адаптации к возрастающим рабочим нагрузкам и вычислительным требованиям. По меньшей мере, планируйте его таким образом, что вы не превысите свои ресурсы в пределах нескольких месяцев своего развития. И кластер Proxmox, и кластер Ceph, оба имеют возможность роста в любой момент до любого размера. Это предоставляется возможностью простого добавления новых аппаратных узлов для расширения размера кластера и увеличения ресурсов, требующихся для виртуальных машин.
При предоставлении конфигурации памяти вашего узла принимайте во внимание нагрузку восстановления после сбоев. Вероятно, вам понадобится иметь доступной 50 процентов ёмкости для отказа одного узла. Если отказывают два узла в кластере из трёх узлов, вы возможно захотите чтобы каждая машина использовала только 33 процента доступной памяти. Например, допустим все шесть узлов в кластере имеют 64ГБ памяти, из которых 60ГБ потребляются постоянно всеми виртуальными машинами. В случае отказа узла 1 у нас не будет возможности провести миграцию всех виртуальных машин с узла 1 на оставшиеся 5 узлов, так как на них недостаточно оперативной памяти. Мы только можем добавить другой запасной узел и провести миграцию всех виртуальных машин с отказавшего узла. Однако мы должны быть уверены, что у нас достаточно разъёмов электропитания чтобы хотя бы подключить этот новый узел.
Бюджет
Соображения бюджета всегда играли определённую роль в принятии решения безотносительно от того с каким сетевым окружением мы имеем дело. Реальный факт заключается в том, что настройка может быть адаптирована практически под любой бюджет при некотором искусном и изобретательном планировании. Администраторы часто вынуждены работать с очень ограниченными бюджетами. Будем надеяться, что данная глава поможет вам вам ту утерянную нить для увязывания бюджета с соответствующими аппаратными компонентами. При применении обычного оборудования вместо полностью брендированных серверов мы легко можем собрать полный кластер Proxmox в рамках очень ужатого бюджета. Proxmox очень хорошо работает с качественными общедоступными аппаратными компонентами. {Прим. пер.: не можем удержаться от ехидства и не поделиться совместимостью несовместимого из нашей практики последних лет. Компания Huawei известна своими достижениями в области телекома с показателями надёжности в пять девяток и выше. Как говорят их инженеры, накопленный компанией опыт позволяет за счёт использования элементной базы уровня телекома (>99.999) достигать высоких качественных показателей надёжности и для своих серверов, блейд- систем, а также систем хранения. Об этом, например, свидетельствуют численные данные диапазонов допустимых рабочих температур, гарантирующих 24x7x режим работы с температурой воздуха на входе в систему +35°С при допустимости часовых тепловых нагрузок до +60°С почти для всего диапазона оборудования. Всё поставляемое ими оборудование проходит 100% выходное тестирование, в том числе, и по температурным показателям. При этом нам удаётся в сотрудничестве с Huawei делать стоимостные предложения, сопоставимые с ценой нашего собственного самосбора. Рекомендуем ознакомиться с нашими презентациями по блейд- системам E9000 (выигрыш в стоимости до 50% в сравнении с обычными 1U/2U/4U решениями) и СХД OceanStore (с сентября 2016г доступны обладающие полной функциональностью СХД нижнего уровня 2200/2600 V3 со стоимостью начиная с <10000USD). Что касается серверов основной линейки, мы предлагаем модели RH1288/ RH2288/ RH5288 (соответственно: 1U/2U/4U, 4 считается плохой цифрой конца в китайском понимании, подлежащей замене) со стоимостью базовых моделей от <2000USD с последующим линейным commodity- ростом стоимости при расширении их памятью, дисками и адаптерами, обращайтесь на mdl.ru для получения подробностей (+7-495-956-3499).}
Простота
О простоте часто забывают в сетевых средах. По большей части это просто получается само собой. Если мы не заботимся о простоте, мы очень быстро можем сделать сеть сложной без необходимости этого. Смешивая аппаратные RAID с программными RAID, размещая RAID внутри другого RAID или посредством настройки с многими дисками для защиты ОС, мы можем вызвать падение производительности любого кластера до почти не используемой или до нестабильного состояния. И Proxmox, и Ceph, оба могут работать на широком спектре общедоступного оборудования, в том числе на серверах с обычными аппаратными средствами. Например, просто выбрав настольный компьютер уровня i7 вместо сервера уровня Xeon мы можем отрубить половину стоимости, и в то же время предоставить стабильную и простую сьорку кластера - до тех пор, пока не появятся особенные потребности для настройки со многими Xeon. {Прим. пер.: всё- таки в нашем понимании, сервер должен поддерживать IPMI, настоятельно рекомендуем даже при выборе однопроцессорных решений не лишать себя возможности удалённого контроля за работой своего оборудования, раз уж мы говорим о промышленном применении! Это потребует дополнительных затрат немногим больше 100USD на узел.}
Отслеживание перечня оборудования
Администратор должен иметь доступ к ключевой информации об применяемом в сетевой среде оборудовании: такой информации, как бренд, модель и серийный номер компонентов оборудования; когда оно приобреталось; кто был производителем; когда оно подлежит замене и тому подобной. Надлежащее отслеживание системы может сохранить массу времени в случае, когда потребуется получить эту информацию. Поскольку все компании разнятся, подобные системы отслеживания тоже могут быть разнообразными. Однако ответственность за получение данной информации полностью ложится на менеджера сети или её администратора. Если нет никакой системы, простого создания электронной таблицы может оказаться достаточным для отслеживания всей информации об аппаратных средствах.
Выбор аппаратных средств
На выбор аппаратных средств оказывают влияние различные факторы, такие как намеревается данный кластер поддерживать множество виртуальных машин с меньшими ресурсами или же он будет обслуживать несколько виртуальных машин с высокими потребностями в ресурсах. Кластер сосредоточенный на большом числе виртуальных машин нуждается в наличии гораздо большего числа процессорных ядер, поэтому наша цель будет заключаться в размещении в каждом узле столько ядер, сколько мы можем. В то время, как для настраиваемого на работу с небольшим числом виртуальных машин кластера нам нужно иметь большой объём памяти. Таким образом, система с меньшим числом ядер, но большим объёмом памяти является более подходящей в этом случае. В то же время, кластер может быть нацелен на оба типа и создавать гибридную кластерную среду. Гибридное окружение обычно начинается с наладки оборудования начального уровня и в последствии, по мере роста компании и доступности бюджета большего размера, дозревает до настройки более совершенных аппаратных средств. Например, небольшая компания может запустить свою кластерную инфраструктуру на стабильном оборудовании уровня настольных систем, а затем постепенно замещать его платформами серверного уровня, подобными Xeon, для соответствия расширению компании.
Когда приходит время создавать виртуальная среда, часто задаётся вопрос сколько ЦПУ и какой объём оперативной памяти будут необходимы каждому узлу и сколько их выделять на каждую виртуальную машину. Это один из тех вопросов, которые остаются без ответа, так как их ответ сильно меняется от одной среды к другой. Однако, существует несколько отметок, которые нужно хранить в памяти во избежание избыточного и недостаточного выделения.
Это факт, что мы будем часто перерасходывать память намного быстрее чем ЦПУ для определённого Proxmox или любого другого узла хоста. Исходя из использования каждой ВМ на ваших узлах Proxmox, мы можем определить требования к оперативной памяти и ЦПУ для данного узла. В данном разделе мы собираемся пройтись по факторам, которые помогут нам принять решение о потребности в ЦПУ и ОЗУ.
Узлы со множеством разъёмов всегда будут иметь лучшую производительность чем односокетные, невзирая на число ядер на ЦПУ. Они работают намного эффективнее распределяя рабочую нагрузку ВМ. Это справедливо как для архитектуры Intel, так и для архитектуры AMD {Прим. пер.: а также SPARC, ARM}. Если позволяет бюджет узел с четырьмя разъёмами предоставит максимум производительности в сравнении с любыми другими конфигурациями сокетов узла. {Прим. пер.: можно не останавливаться на 4х: 16 и 32 сокета в одном хосте ещё лучше, раз уж бюджет позволяет! Также советуем обратить внимаие на сопоставление стоимостей ядер различных ЦПУ в нашем переводе "Книги рецептов Ceph" Крана Сингха.}
Одной из основных разниц между Intel и AMD является hyper-threading. В AMD все ядра ЦПУ являются реальными ядрами, в то время как ЦПУ Intel имеют hyper-threading, который создаёт два виртуальных ядра для физического ядра. Другой достаточно часто задаваемый вопрос состоит в том разрешать или нет hyper-threading. Сотни отчётов и тестирований приводят к мысли, что лучше будет оставлять его для самых новых серверов Intel. Боязнь деградации производительности из- за hyper-threading больше не действует, так как они прошли сквозь десятилетия разработки и все существовавшие по началу проблемы были разрешены. Кроме того, не стоит все ядра с hyper-threading пересчитывать как реальные ядра, поскольку они всё-таки виртуальные. При подсчёте общего числа доступных в узле ядер принимайте консервативный подход и считайте меньше чем у вас есть ядер в в доступности {Прим. пер.: при инвентаризации всегда нужно быть слегка прапорщиком!}
Виртуальная машина полностью отличается от физической машины и она и требует трактовать её как таковую. Она не потребляет ЦПУ и оперативную память так, как это делает физический узел. Хорошая практика состоит в том, чтобы всегда очень скупо предоставлять ресурсы ЦПУ и памяти, а затем увеличивать их по мере того, как вы следите за производительностью приложений. Это позволит вашей ВМ эффективно использовать выделенные ресурсы, что в конечном итоге сделает в узле эффективной работу всех ВМ. Предоставляя избыточные ресурсы ЦПУ и памяти для всех ВМ в вашем узле, мы утопим производительность узла, поскольку все узлы будут сражаться за получение большего процессорного времени. Всегда начинайте с одного виртуального ЦПУ (vCPU) для большей части своих ВМ. Стартуйте с двух vCPU для затратных в процессорном времени ВМ, таких как сервера баз данных, сервера обмена сообщениями и тому подобных. Наблюдайте за ресурсом этой ВМ и выравнивайте его соответствующим образом. Быстрым способом просмотра того, какая ВМ использует больше ЦПУ или памяти будет вариант с меню Datacenter или Node Search. Следующий снимок экрана отображает перечень всех элементов в нашем примере кластера с наивысшим потреблением ЦПУ:
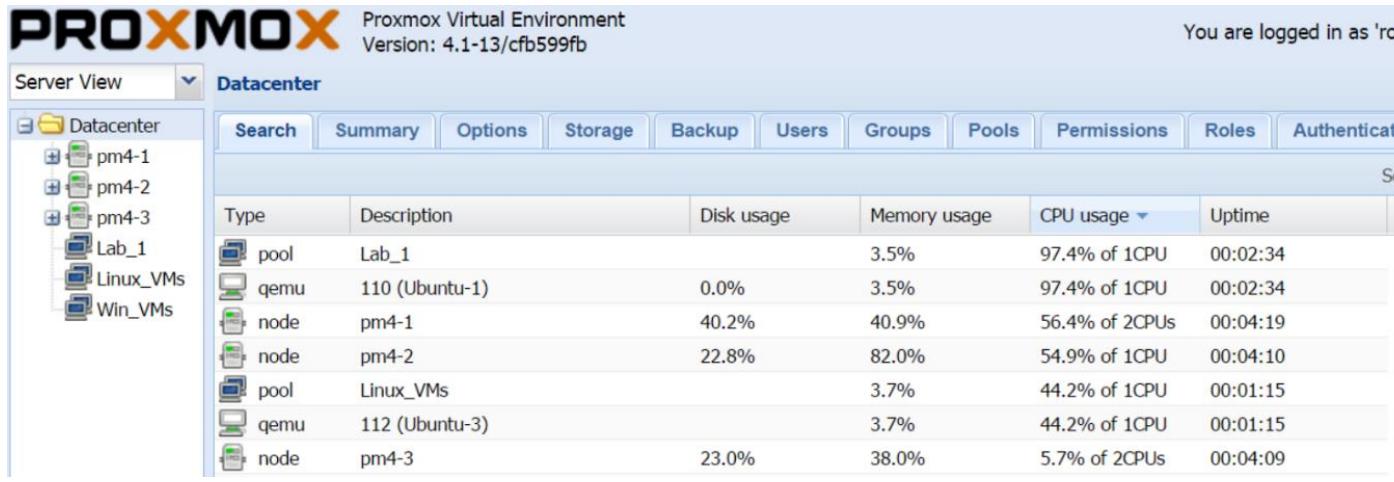
При выделении vCPU для отдельной ВМ никогда не превышайте общее число ядер в данном узле. Это приведёт к падению производительности всего вашего узла и всех ВМ в нём. Имейте в виду, что в виртуальной среде большее значение ЦПУ или памяти для виртуальной машины не означает лучшую производительность.
Всегда убеждайтесь в том, что каждый узел Proxmox в кластере имеет аналогичные ресурсы ЦПУ и ОЗУ. Если некоторые узлы чаще других завершаются безуспешно, попытка перемещения или миграции ВМ с узла с большим объёмом ресурсов на узел с меньшими ресурсами вызовет проблему. Узел с меньшими ресурсами будет не способен обрабатывать все ВМ, тем самым приводя к более длительному простою в процессе отказа узла. Эта проблема может быть компенсирована при использовании комбинации нескольких узлов с большим объёмом ресурсов и большего числа узлов с меньшими ресурсами.
Как упоминалось на протяжении всей этой книги, Ceph является очень эластичной распределённой системой хранения, которая хорошо сочетается на пару с Proxmox. для хранения образов виртуальных дисков. Существует ряд ключевых факторов, которые делают кластер Ceph хорошим выбором для виртуальной среды промышленного уровня.
Когда мы обращаемся к узлу или кластеру Ceph, мы можем забыть про RAID на аппаратной основе. Вместо этого мы должны думать об RAID со многими узлами или кластерном RAID. Это происходит по причине распределённой природы Ceph и того как данные распределяются по всем имеющимся в кластере дискам вне зависимости от того, на каком узле этот диск находится. Применяя Ceph мы больше не должны заботиться об отказах диска на определённом узле. Производительность Ceph максимальна когда он получает доступ к каждому диску напрямую без какого- либо RAID между ними. Если мы вынуждены размещать диски в RAID на узле, мы действительно привнесём значительный вред и изымем всё, что делает Ceph великолепным. Однако мы всё ещё можем использовать интерфейсные карты RAID для реализации конфигурации JBOD или для возможности подключения большого числа устройств к узлу. {Прим. пер.: В любом случае HBA адаптеры более предпочтительны. К числу недостатков некоторых RAID JBOD можно отнести тот факт, что RAID контроллеры порой предоставляют JBOD доступ эмулируя его через процессор RAID, что всё так же лишает нас прямого доступа к дисковому устройству. Например, нам могут продолжать оставаться недоступными функции S.M.A.R.T. параметры геометрии, предоставляемые контроллером самого диска. Подробнее, например, см. раздел Контроллеры RAID в переводе книги М.В.Лукаса и А.Джуда ZFS.}
Входящие данные для кластера Ceph осуществляют запись в журнал перед тем как они передаются на сами OSD. Поэтому выделенные устройства наподобие SDD значительно увеличат скорость записи, поскольку они могут достигать значительного превосходства в скорости записи над стандартными SATA или SAS дисками. {Прим. пер.: а к тому же, если они обладают ещё и интерфейсом NVM, полностью открывающий возможности одновременного доступа в ячейкам памяти в различных адресных доменах одного устройства, без какого-то ни было! Подробнее, см: NVMe.} Даже самый быстрый диск корпоративного уровня с 15000rpm и близко не приближается к производительностям SSD. {Подробнее: Топовые характеристики устройств хранения, март 2016.} При выборе SSD для журнала Ceph стоит уделить внимание выбираемым бренду и модели.
Не все SSD будут показывать хорошую производительность для журнала Ceph. В настоящее время единственными SSD, которые могут выдерживать безжалостную нагрузку Ceph при обеспечении великолепной скорости записи и защиты от потери электропитания являются Intel DC S3700 или S3500. Также существуют прочие SSD, которые также могут хорошо работать, однако упомянутые выше имеют намного более длительный промежуток жизни. {Прим. пер.: не умаляя достоинств оборудования Intel, утверждение слишком категоричное. Готовы предоставить более широкий перечень подходящих устройств при соблюдении ваших бюджетных ограничений! К тому же вопрос о совокупной стоимости дисков за определённый период эксплуатации при их должной замене при выходе из строя тоже весьма дискуссионный вопрос.} Встроенная защита при потере электропитания {в указанных устройствах Intel} также предотвращает разрушение данных Журнала. Посетите следующую ссылку со статьёй о том как тестировать пригодные для Ceph SSD и перечень возможных SSD для применения в вашем кластере Ceph: http://www.sebastien-han.fr/blog/2014/10/10/ceph-how-to-test-if-yourssd-is-suitable-as-a-journal-device/.
Вместо стандартных SATA SSD мы также можем использовать SSD на основе PCI, котрые могут предоставлять исключительное увеличение производительности в сравнении со стандартными SATA SSD. Если существует ограничение дисковых отсеков для выделенных SSD, то это великолепный выбор. Следующая ссылка определяет SSD Intel PCI-e, который может рассматриваться в качестве журнала Ceph: http://www.intel.com/content/www/us/en/solid-state-drives/solidstate-drives-750-series.html {Прим. пер.: есть ещё много достойных представителей PCI-e SSD, однако они уходят на второй план в сравнении с устройствами, имеющими интерфейс NVMe. Повторим ссылку на раздел NVMe в книге М.В. Лукаса Advanced ZFS, дающий содержательный обзор с цифровыми данными о преимуществах обработки множественных очередей в SSD устройствах с данным новым интерфейсом. Также отметим, что современные производители серверного оборудования уже обеспечивают поддержку NVMe устройств, при этом предоставляя возможность не занимать не только дисковые отсеки, но и станлартные слоты PCI-e, предоставляя свободные разъёмы на материнской плате. Например, уже упоминавшиеся в данной главе сервера Huawei RH1288/2288/5288 по состоянию на осень 2016г уже доступны к заказу с поддержкой NVMe устройств.}.
В то же время Ceph может быть использован и без выделенного SSD устройства. Мы можем настроить OSD Ceph на хранение журнала на том же самом шпиндельном диске. Однако из- за низкой скорости механических устройств мы увидим высокие времена ожидания ввода/ вывода в таких узлах Proxmox {Прим. пер.: так в оригинале, правильнее Ceph}. Применение SATA и SAS дисков корпоративного уровня уменьшит это время ожидания ввода/ вывода, но не так сильно как выделенный SSD.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Никогда не размещайте выделенный журнал, будь то SSD или HDD, на RAID любого вида. Это уменьшит производительность журнала, что в результате повлияет на общую производительность Ceph. {Прим. пер.: также задали вопрос автору об его отношении к зеркалированию устройств журнала, сообщим об его ответе.} |
Наличие обильной пропускной способности сетевой среды является критичным для Ceph или любого другого хранилища. Чем большая полоса пропускания выделена, тем лучше преимущества получат производительность и латентность ВМ. Отметим, что когда применяется выделенный журнал, например SSD, значительно возрастают требования к пропускной способности сетевой среды, поскольку в кластере Ceph перемещается больше данных для репликации и распределения. В кластерах, в которых используется SSD в качестве выделенного журнала, для сетевой среды кластера Ceph не должна применяться гигабитная сеть. По крайней мере, 10GbE могла бы быть идеальной сетью. Мы также можем применять Infiniband в качестве альтернативного сетевого решения при более низком бюджете. Если ничего из этого недоступно, тогда множественные сцепленные гигабитные сети также будут работать. При одном гигабитном соединении сетевая среда становится узким местом, вызывающим обширное падение производительности кластера.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
{ Прим. пер.: Стоит также отметить появление в 2016г практически у всех производителей сетевого оборудования 25GbE коммутаторов, происхождение которых просто объясняется арифметикой деления нацело 100GbE. Что касается перспектив применения Infiniband. Несмотря на то, что сетевые адаптеры основного производителя оборудования данного сегмента (Mellanox) способны поддерживать оба стека протоколов (и Ethernet, и Infiniband), информация последних лет от персонала Mellanox, как и сама линейка развития их коммутаторов, говорят о том, что разветвление в сфере коммутаторов можно считать свершившимся процессом. Вся мощь аппаратной поддержки систем хранения оборудованием коммутаторов всецело переходит в зону ответственности коммутаторов Ethernet, поэтому для организации сетевой среды СХД в перспективе стоит ориентироваться именно на 10/25/100/200GbE. На текущий момент флагманом здесь является линейка коммутаторов SN2700/2410/2100 от Mellanox. При поддержке инженеров Mellanox мы собираемся подготовить обзор, посвящённый новым технологиям Mellanox, привносимых ими в технологию обмена данных в распределённых системах хранения. Пока рекомендуем пользоваться информацией пресс- релизов и технических спецификаций этого производителя или обращаться к нам за консультациями. (Неполный перечень: RoCE/ разгрузка ASIC EC/ NVM fabric/ поддержка ACL, LACP Bypass, sFlow, VRF, Forwarding Table, VXLAN, NVGRE, MPLS, GENEVE, NSH, ASAP, SR-IOV и т.д.; функционал PIM-SM, TACACS+, CLI (NCLU), Netq (сетевая ОС Cumulus Linux)/ безкоммутаторное объединение сетевыми адаптерами доменов из 4х узлов...) Пример нашего решения 2016г высокоскоростной низколатентной коммутации 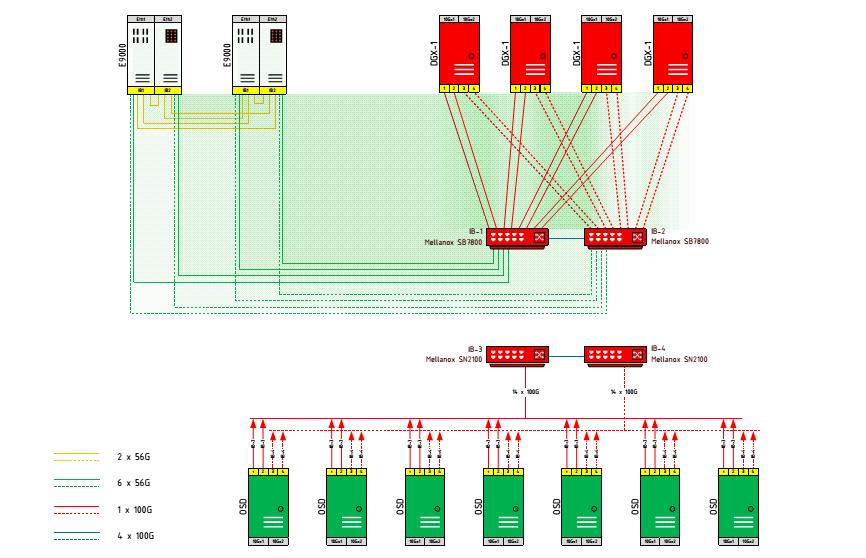 На схеме отображены только высокоскоростные низколатентные сетевые соединения. Помимо этого, все входящие в состав блоки имеют сетевую среду 10/25GbE для управления, общего доступа и прочих сетевых функций. } |
К тому же, синхронизация кластера Ceph должна выполняться в своей собственной выделенной сетевой среде, в то время как общедоступная сетевая среда интерфейса Ceph должна быть другой. Ceph использует кластерную сетевую среду для фиксации всех синхронизаций между OSD. Это предотвращает от ненужной загрузки общедоступной сети, так как именно только серверы являются в ней единственным источником запросов к данным в хранилище Ceph.
При данном решении оборудование компьютера охлаждается с применением для теплообмена жидкости вместо воздуха. Жидкость 1000 раз лучше отводит тепло в сравнении с воздухом. Мы можем эффективно удалять тепло прямо с оборудования ИТ и отводить его за пределы наших средств гораздо более простым способом. Жидкостное охлаждение снимает многие преграды работы больших систем отвода тепла путём вентиляции (HVAC), тем самым экономя значительные затраты и значительно уменьшая шум. Жидкостное охлаждение не требует никаких внутренних вентиляторов и таким образом мы можем увеличивать плотность серверов в 10 раз. За жидкостным охлаждением большое будущее, поскольку всё больше и больше средств ИТ реализуют свой полный потенциал. При применении жидкостного охлаждения мы также можем снизить наше энергопотребление - значительно снижая выбросы углекислого газа в атмосферу. На рынке присутствуют различные доступные решения жидкостного охлаждения.
Оборудование ИТ полностью погружается в минеральное масло. Горячее масло прокачивается в теплообменник жидкость- жидкость, в котором ваше тепло отбирается прочь с применением воды {Прим. пер.: или другого общеупотребимого теплоносителя: фреона, этиленгликоля и т.п.} во внешнюю охлаждающую систему. Вода и масло никогда не вступают в прямой контакт и всего лишь обмениваются теплом. Это не только самое эффективное с точки зрения стоимости решение жидкостного охлаждения на сегодняшний день, но также и самое сложное, поскольку требует погружения серверов в масло. Оно также требует больше места, поскольку все стойки нуждаются в дополнительной оснастке. Однако такое дополнительное пространство легко может быть компенсировано увеличением плотности, исчисляемой в узлах на объём. В настоящее время пионером в этой технологии является Green Revolution Cooling { Прим. пер.: в РФ и СНГ компания Immers.} Посетите следующие ссылки с их официальными сайтами и впечатляющее видео, демонстрирующее данную технологию в действии:
Существует также другая технология, о которой стоит упомянуть здесь, которая аналогична погружной, однако в ней погружение изолировано в самом узле сервера. Решение жидкостного охлаждения имеет уникальный подход заполнения герметизированного серверного шасси минеральным маслом для отвода тепла. Посетите следующую ссылку для ознакомления с данным подходом: http://www.liquidcoolsolutions.com/?page_id=86.
Аналогично погружному масляному охлаждению, это тоже полная погружная технология в которой вместо минерального масла используется жидкость, разработанная 3M Novec. Главное преимущество данного варианта заключается в нулевом загрязнении. В отличие от масла, данная жидкость не налипает ни на какое оборудование и совсем не требует никаких теплообменников и насосов для перемещения жидкостей внутри себя. Данная жидкость закипает при температуре 60 градусов Цельсия. Когда пар нагревает холодную спираль в верху контейнера, он опять конденсируется в жидкость и капает назад вниз в резервуар. Единственный насос нужен для прокачки воды сквозь охлаждающую спираль, таким образом требуется только половина оборудования, обычно необходимого для охлаждения на основе масла. Посетите следующую ссылку для ознакомления с видео- презентацией данной технологии: https://www.youtube.com/watch?v=a6ErbZtpL88.
В данном подходе тепло отводится прямо с источника тепла, каковым являются ЦПУ и память, при помощи охлаждающих пластин и жидкостного охладителя, например, воды или любого другого охлаждающего агента. Поскольку никакое оборудование не погружается, данная технология может применяться в существующей инфраструктуре при существенной модификации при увеличении в то же время плотности узлов на стойку. Это далеко не уникальная технология, поскольку такой тип решения жидкостного охлаждения применялся на протяжении ряда лет. Решения жидкостного охлаждения потребительского класса применяют подобные готовые к применению технологии. Для настольных решений жидкостного охлаждения известным производителем для пользователей рабочих станций является Asetek. Посетите их официальный сайт при помощи следующей ссылки: http://www.asetek.com/.
Другой производитель жидкостного охлаждения с прямым контактом, о котором стоит упомянуть здесь это CoolIT Systems. Они также применяют подход охлаждающих пластин для отвода тепла с оборудования посредством жидкого теплоносителя. Некоторые из их решений могут быть реализованы прямо в стойке в качестве стандартно устанавливаемых охлаждающих модулей без необходимости наличия иметь некое оборудование для воды или градирни. Для получения дополнительной информации по данному решению посетите следующую ссылку:http://www.coolitsystems.com/.
{Прим. пер.: уже отмечавшееся в наших комментариях в данной главе решение Huawei E9000 обладает одной из самых высоких плотностей (64 процессора Xeon в 12U) в данном классе. Поэтому не удивительно, что в 2016г появилась модификация данного решения с жидкостным охлаждением, готовое к применению практически "из коробки".}
Вооружившись всеми теми знаниями, которые мы собрали из предыдущих глав этой книги, теперь мы готовы соединить все кусочки воедино для формирования сложной виртуальной среды практически для любого сценария, который к нам поступит. Некоторый приводимый в следующем разделе набор сценариев для построения сетевых сред использует Proxmox для различных отраслей. В конце данной главы мы найдём сетевые схемы для каждого из сценариев, приведённых в первой части данной книги.
Некоторые сценарии были взяты из реальных промышленных сред, в то время как часть является теоретическими для демонстрации того, насколько сложные сетевые среды могут быть доступны при помощи Proxmox. Вы можете брать эти модели и применять их в том виде, как они представлены или изменять их, чтобы сделать даже лучше.
Мы надеемся, что воспользовавшись этими моделями вы начнёте видеть Proxmox с совершенно новой точки зрения и будете полностью готовы с любым уровнем виртуальной инфраструктуре, которая бросит вам вызов.
|
| Совет |
|---|---|
|
При анализе данных сценариев имейте в виду что приводимые в данной главе решения и схемы являются одним из множества способов, которыми может быть собрана ваша сетевая инфраструктура. Чтобы подогнать эти схемы к ограничениям данной книги, возможно, были опущены некоторые не являющиеся жизненно необходимыми компоненты. Все сетевые среды и идентификационная информация являются вымышленными. |
Сетевые схемы отображают взаимосвязь между компонентами в пределах описываемой инфраструктуры, таких как виртуальная среда, кластер или узлы, а также общая сетевая связь. Они также представляют виртуальные сетевые компоненты, такие как связанные друг с другом мосты, сегментация сетевой среды и тому подобное.
Данный сценарий представлен для типичного академического института со множеством сетевых сред и множеством кампусов, а также большим количеством построенных установок, причём как частных, так и общедоступных сетей.
-
Сетевая изоляция для защищённости чувствительных данных.
-
Возможность иметь в наличии централизованное управление для сетевой инфраструктуры.
-
Профессорский состав должен присутствовать в отдельной сети Wi-Fi, доступной только им. Данная сеть Wi-Fi должна давать возможность профессорам регистрироваться в главном сервере кампуса для получения его файлов для лекций.
-
Студенты должны иметь Wi-Fi доступ в кампусе и проводное соединение с Internet в своих общежитиях. Эти подсети должны быть отделены от основной сетевой среды кампуса.
-
Библиотека должна находиться в отдельной подсети со своим собственным сервером.
-
Учебные классы, административные офисы, а также профессорский состав должны присутствовать в в главной изолированной сетевой среде. Профессора должны иметь возможность получать свои файлы с файлового сервера в на компьютеры в учебных классах во время лекций.
Ключевые требования:
Это сценарий для типичной сетевой среды кампуса академического института. Благодаря Proxmox мы можем всё основное серверное оборудование и виртуальное окружение в одном месте для обладания централизованным управлением. В данной сетевой среде присутствуют пять подсетей:
| Подсеть | Описание сетевой среды |
|---|---|
|
Проводная сетевая среда для общежития. Межсетевой экран предоставляет DHCP. Эта подсеть не должна проходить сквозь основную сетевую среду. |
|
Студенческий и общедоступный Wi-Fi в кампусе. Межсетевой экран предоставляет DHCP. Эта подсеть не должна проходить сквозь основную сетевую среду. |
|
Главная административная и профессорская сетевая среда. Частный Wi-Fi для профессоров является расширением данной сети чтобы сделать доступным для профессорского состава получение их файлов беспроводным образом. Все учебные классы также находятся в данной сети для предоставления доступа профессоров к файлам внутри учебных классов. |
|
Кластер хранения данных. |
|
Подсеть библиотеки. DHCP предоставляется виртуальным сервером библиотеки. Этот сервер
обслуживает только библиотеку. Для соединения определённой виртуальной машины со зданием
библиотеки используется отдельная локальная сеть ( |
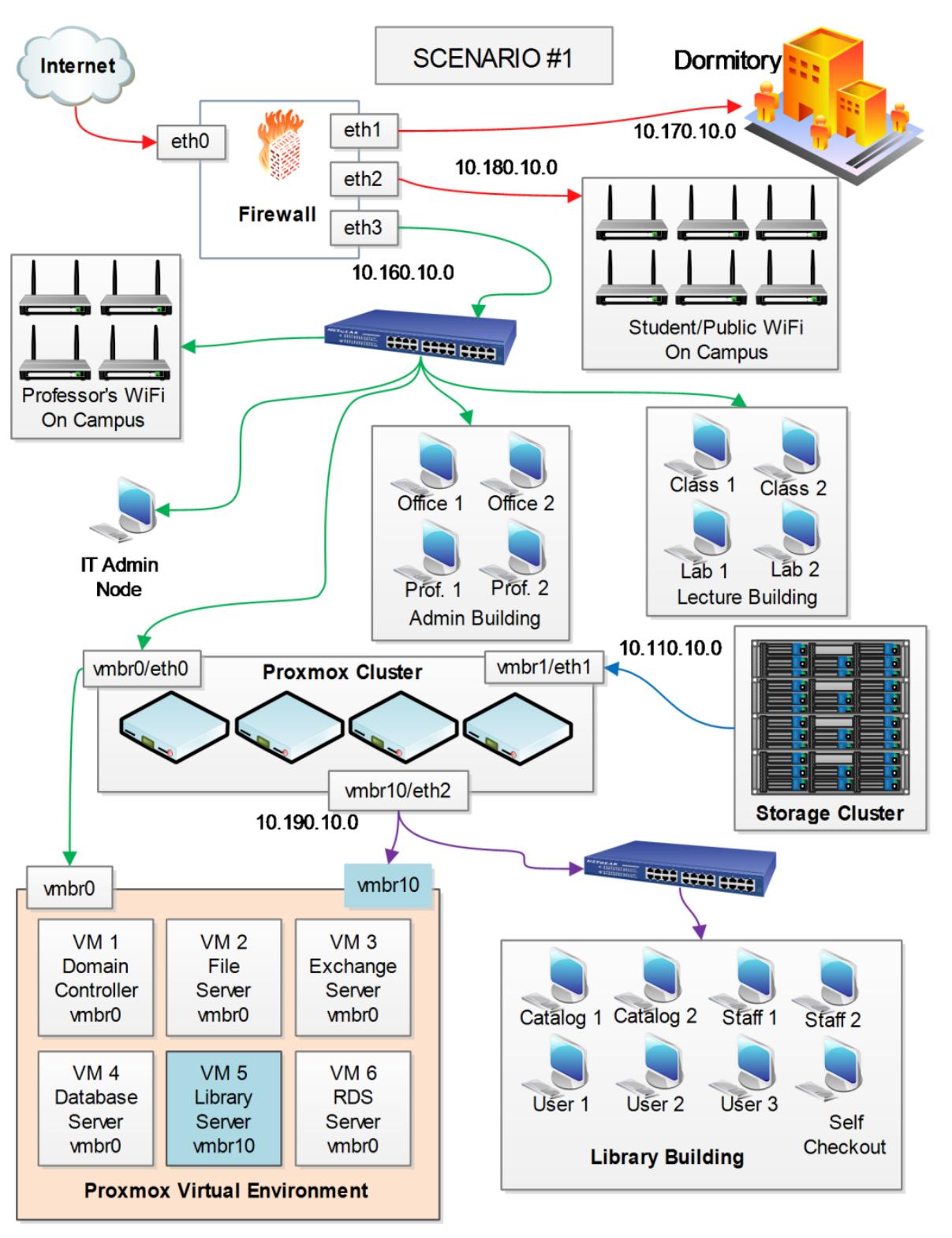
-
Необходимость разделения кластеров хранения для SSD, гибридных HDD и HDD.
-
Кластеры хранения должны находиться в отдельных подсетях.
-
Хранилище должно быть распределённым при наличии высокой доступности и большой масштабируемости.
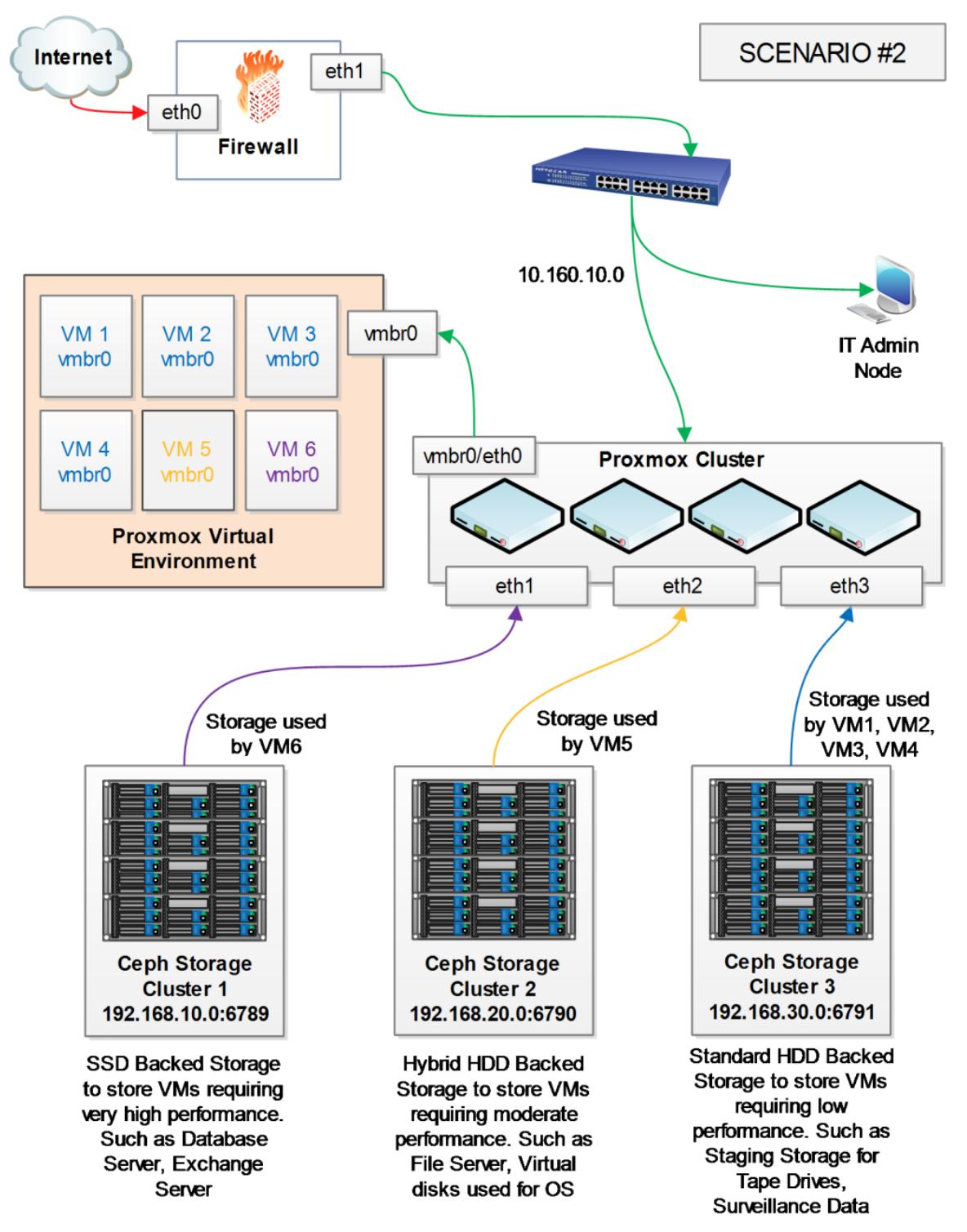
Ключевые требования:
Для данного сценария каждый узел Proxmox должен иметь, по крайней мере, четыре сетевых интерфейсных платы: три для соединения с тремя подсетями кластеров хранения и одну для соединения с виртуальной средой. Данный пример создан для предоставления доступа для шести виртуальных машин к трём имеющим различную производительность хранилищам. Ниже приводятся три кластера Ceph и их категории производительности:
| Подсеть | Описание сетевой среды |
|---|---|
|
Кластер CEPH |
|
Кластер CEPH |
|
Кластер CEPH |
|
Это основная подсеть для всех виртуальных машин. |
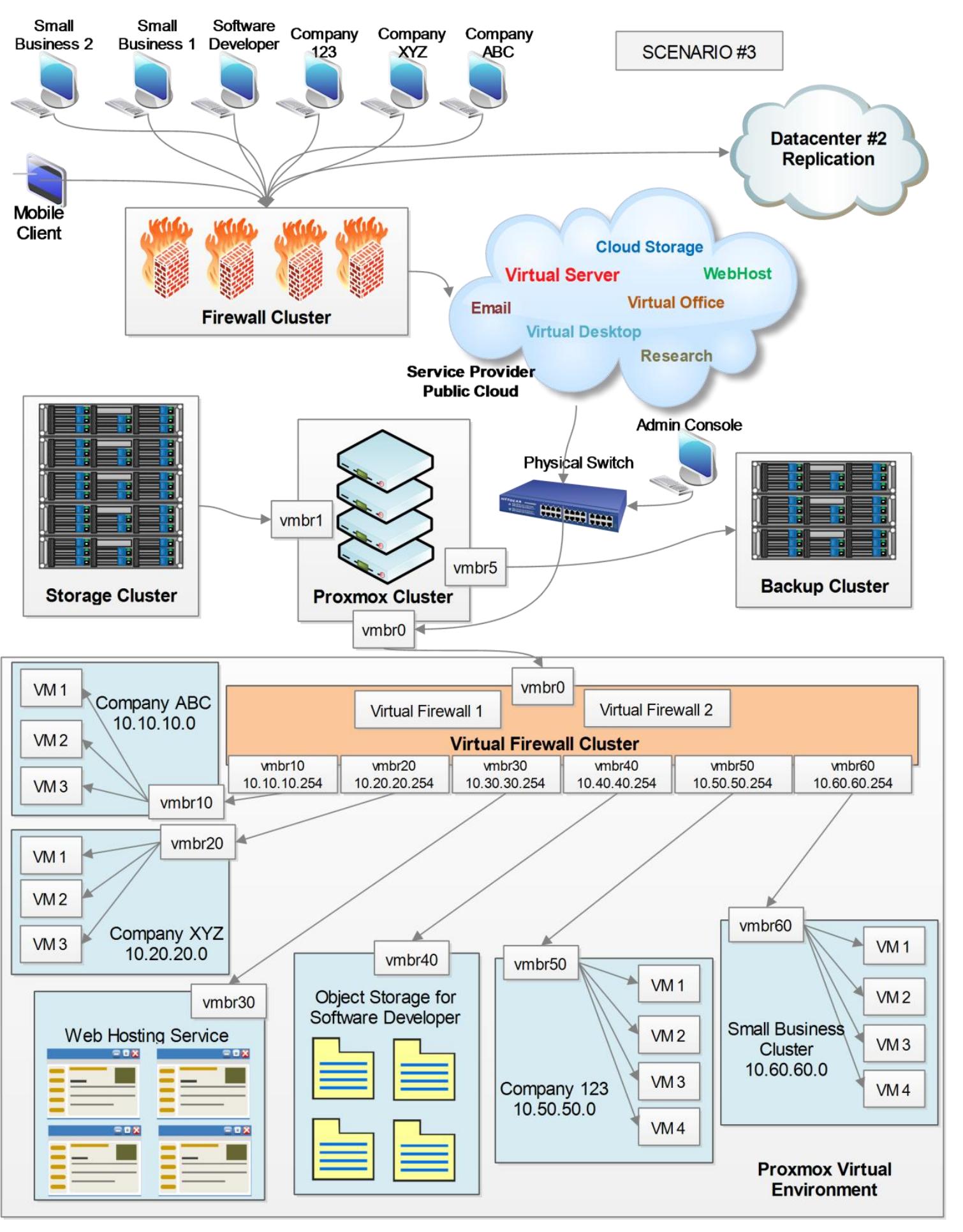
Многоуровневая инфраструктура очень типична для центров данных стремя различными уровнями клиентов на основе SLA с различными требованиями к производительности системы хранения:
-
Для Граничных межсетевых экранов должен присутствовать кластер межсетевого экрана.
-
Каждая клиентская сетевая среда должна быть полностью изолирована друг от друга.
-
Для резервного копирования необходим отдельный кластер хранения.
-
Клиенты пользователей должны иметь возможность доступа к виртуальным рабочим местам своей компании через RDP.
-
Должна иметься в наличии возможность управления полосой пропускания для связи с интернетом клиентских сетевых сред.
-
Репликация всех данных в другой центр обработки данных.
Ключевые требования:
В данном сценарии для разделения обмена между всеми сетевыми средами клиентов применяются виртуальные
межсетевые экраны и виртуальные мосты. Виртуальный межсетевой экран имеет семь виртуальных сетевых интерфейсов
для соединения шести сетевых сред клиентов в пределах общей виртуальной среды и для предоставления связи с
WAN. Полоса пропускания Internet управляется посредством виртуального межсетевого экрана для каждого vNIC.
Виртуальный межсетевой экран соединяется с WAN через главный виртуальный мост vmbr0. Кластер Proxmox имеет девять виртуальных мостов:
| Подсеть | Описание сетевой среды |
|---|---|
|
Главный виртуальный мост для предоставления соединения с виртуальным межсетевым экраном. |
|
Соединяет главный кластер хранения. |
|
Соединяет кластер хранения для резервного копирования. |
|
Мост для компании ABC с подсетью |
|
Мост для компании XYZ с подсетью |
|
Мост для контейнеров LXC для размещения экземпляров веб- служб. |
|
Мост для экземпляров хранилищ объектов, используемых разработчиками программного обеспечения. |
|
Мост для компании 123 с подсетью |
|
Мост для виртуального кластера малого бизнеса. |
Каждый мост соединяет виртуальные машины клиентов компании вместе и создаёт изолированную внутреннюю сеть для соответствующих клиентов:
-
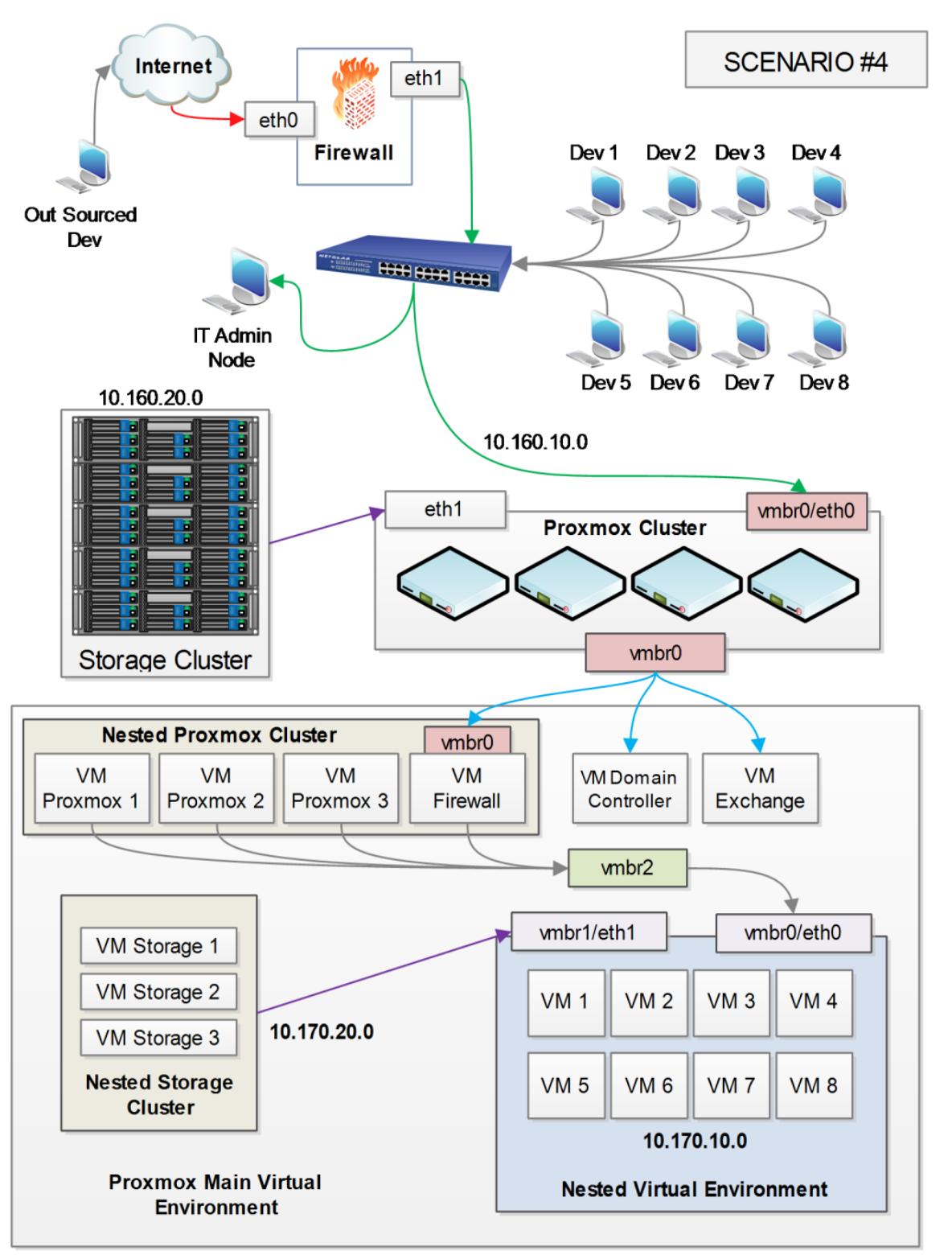
Разработчики должны иметь вложенное виртуальное окружение для тестирования программного обеспечения.
-
Работающие на стороне разработчики должны иметь доступ к вложенному виртуальному окружению с применением RDP.
-
Разработчики должны иметь контроль над созданием и удалением виртуального кластера.
-
Клиенты пользователей должны иметь возможность доступа к виртуальным рабочим местам своей компании через RDP.
-
Вложенное виртуальное окружение должно быть полностью изолированным от главной сетевой среды компании.
Ключевые требования:
В данном сценарии внутри главного кластера создаётся вложенный виртуальный кластер Proxmox в основном для целей тестирования программного обеспечения компанией, разрабатывающей программное обеспечение. Поскольку виртуальные кластеры могут создаваться и убираться в любой момент времени, это уменьшает стоимость и время сборки целиком оборудования и процесса наладки. Для прямого обмена между вложенной и основной виртуальными средами применяется виртуальный межсетевой экран. Все разработчики осуществляют доступ к своим вложенным виртуальным машинам путём перенаправления порта RDP. СТоронним разработчикам также требуется соединение с вложенной виртуальной средой с применением RDP. Главный межсетевой экран осуществляет перенаправление порта в виртуальный межсетевой экран. После этого виртуальный межсетевой экран выполняет перенаправление порта во вложенные виртуальные машины. В данном примере используются четыре подсети:
| Подсеть | Описание сетевой среды |
|---|---|
|
Это главная подсеть компании. Весь персонал, включая разработчиков, находится в этой подсети. |
|
Подсеть главного кластера хранения. Она соединяется с главным кластером через
|
|
Подсеть вложенного кластера. Она изолирована от главного кластера при помощи
|
|
Подсеть вложенного кластера хранения. |
Для создания вложенного кластера Proxmox используются виртуальные машины ВМ Proxmox 1, ВМ Proxmox 2 и ВМ Proxmox 3, в то время как виртуальные машины ВМ Storage 1, ВМ Storage 2 и ВМ Storage 3 используются для вложенного кластера хранения:
-
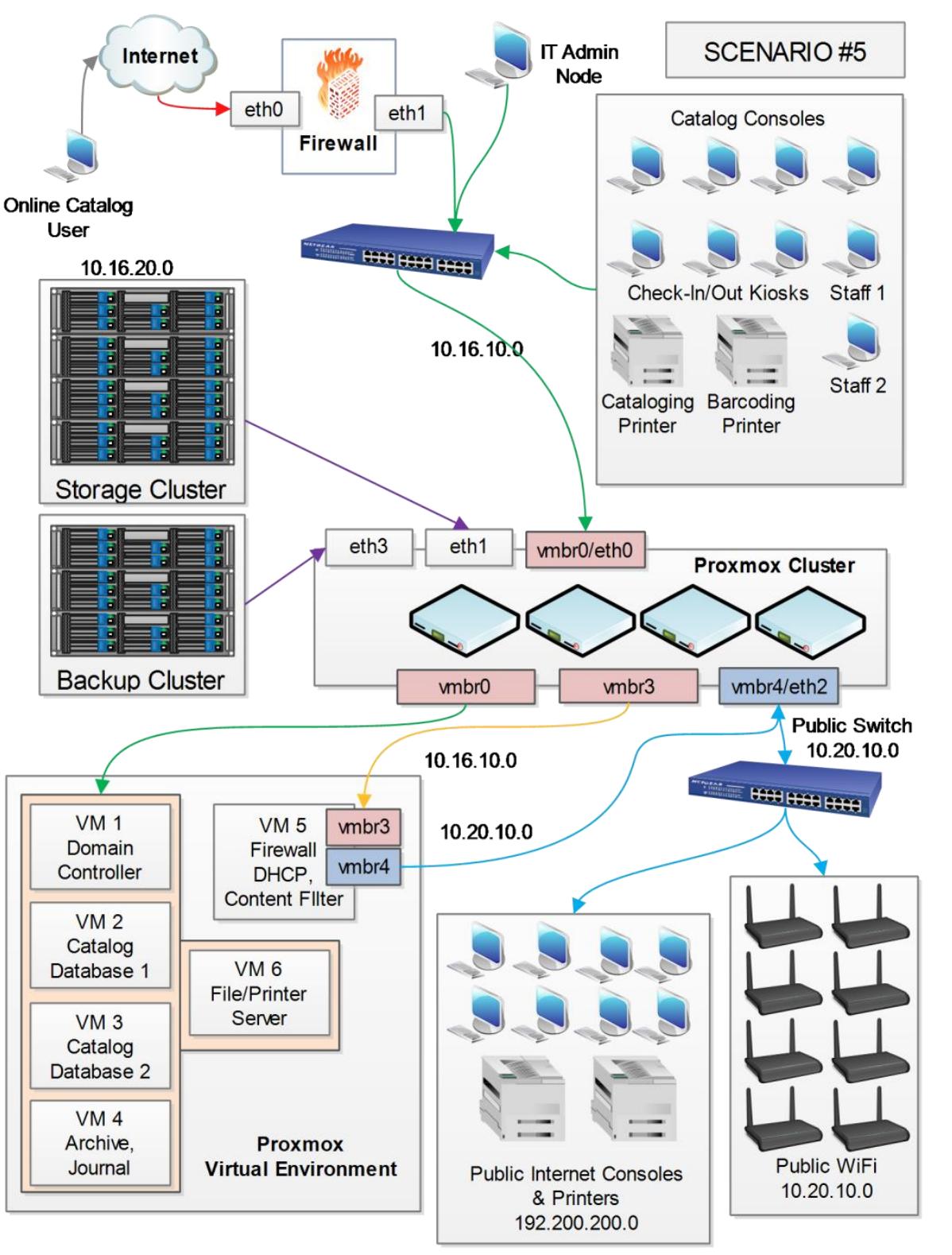
Консоли каталога должны присутствовать в отдельной подсети наряду с главной подсетью администрирования.
-
Общедоступный Wi-Fi и консоли для общедоступного использования интернета должны находиться в одной и той же отдельной подсети.
-
Киоски для самостоятельной регистрации запросов и выдачи книг и носителей.
-
Онлайн доступ к каталогу данной библиотеки.
-
Общедоступный обмен интернета должен мониториться на предмет обнаружения любых политик использования интернета.
-
Общедоступные компьютеры должны иметь доступ к печати.
Ключевые требования:
Это типичный сценарий для сетевой системы общественной библиотеки. Поскольку общественная библиотека является публичным местом с доступам к компьютерам для общедоступного применения, очень важно изолировать чувствительные сетевые среды. В нашем примере сетевая среда изолируется посредством двух подсетей: :
| Подсеть | Описание сетевой среды |
|---|---|
|
Главная подсеть только для персонала библиотеки и защищённых консолей таких как Каталог, Киоск, принтеры персонала, а также самостоятельной регистрации запросов и выдачи. |
|
Это общедоступная подсеть для публичного Wi-Fi, консолей интернет, а также принтеров с платёжной системой. |
Сетевая среда 10.20.10.0 контролируется, управляется и изолируется
с использованием виртуального межсетевого экрана VM5. Этот
виртуальный межсетевой экран имеет два vNIC, один для соединения с WAN через
vmbr3 и другой для соединения с выделенным NIC на узле
Proxmox через vmbr4. Eth2
узла Proxmox соединяется с отдельным коммутатором LAN только для подключения общедоступных
устройств. Виртуальный межсетевой экран предоставляет возможность мониторинга обмена в интернете для
отслеживания любых нарушений политики библиотеки по использованию интернета.
Каждый узел Proxmox имеет четыре платы сетевого интерфейса eth0,
eth1, eth2 и
eth3, а кластер имеет три виртуальных моста
vmbr0, vmbr2 и
vmbr4. Главное хранилище кластера присоединяется к узлу
Proxmox через eth1, а кластер резервного копирования
через eth3:
-
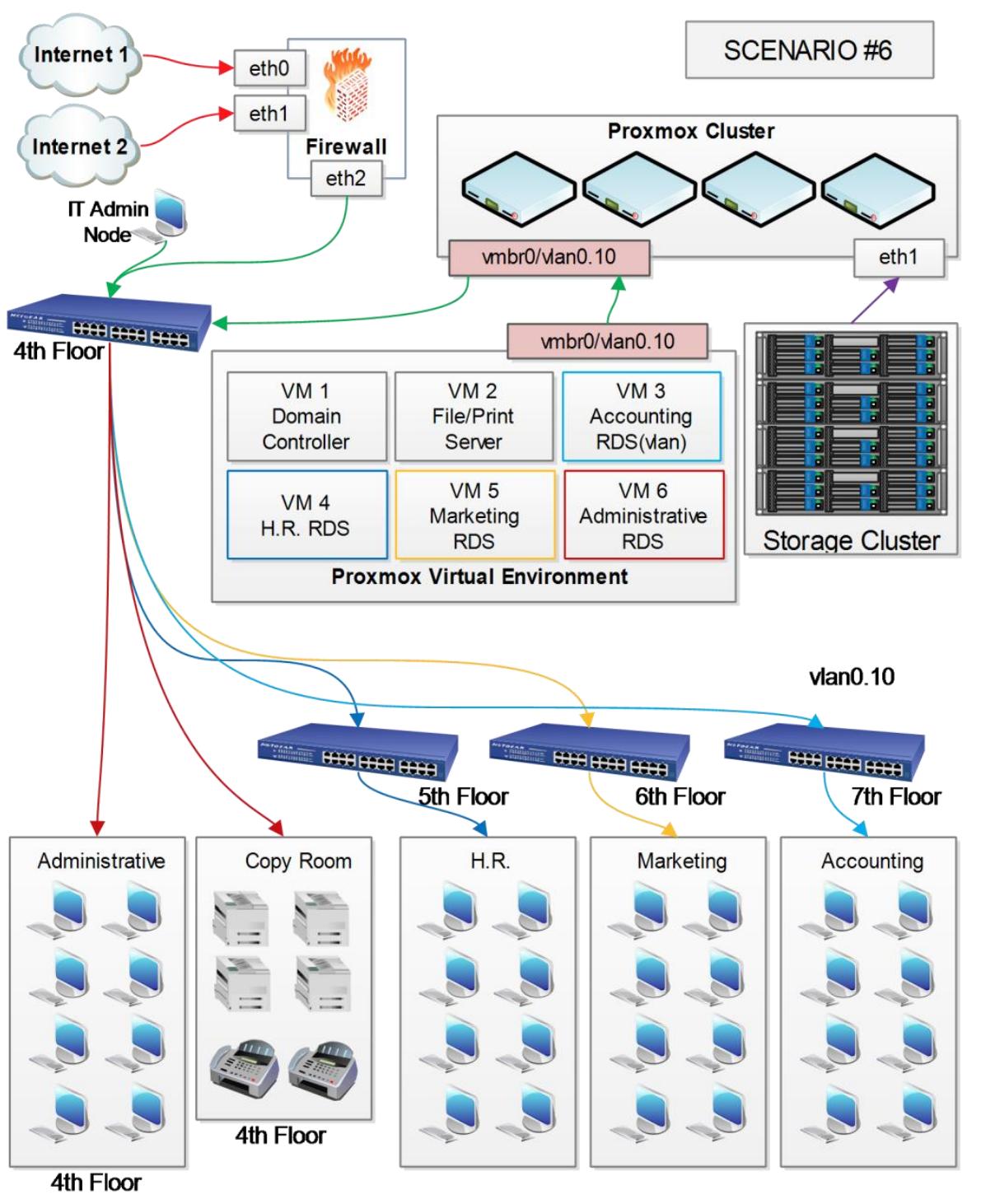
Все работники должны быть оснащены виртуальными удалёнными рабочими местами.
-
Резервированное подключение к интернету.
-
Каждое подразделение должно иметь свой собственный сервер удалённого доступа.
-
Данные о сетевом обмене подразделения учётных записей должны направляться только в это подразделение.
Ключевые требования:
Это обычный сценарий для офисного здания, в котором подразделения находятся на различных этажах этого здания. Так как подразделение учётных записей требует изоляции данных, мы собираемся применить мы собираемся применить для изолирования их данных vLAN. Административные офисы, комната копирования, а также главное серверное помещение расположены на 4м этаже. Подразделение кадров (HR) находится на 5м этаже, маркетинг на 6м, а департамент учётных записей на 7м этаже. 5й, 6й и 7й этажи имеют свои собственные коммутаторы локальной сети. Поэтому мы с лёгкостью можем воспользоваться vLAN для других этажей, если возникнет такая необходимость. Нам нужно настроить только vLAN на коммутаторе 4го этажа.
Каждый узел Proxmox имеет два сетевых интерфейса. eth1
служит для соединения кластеров хранения, а eth0 предназначен
для соединения всех виртуальных машин с их подразделениями. vlan0.10
применяется для выделения обмена учётными записями только напрямую на 71 этаж.
Все подразделения персонала применяют виртуальные рабочие места при помощи RDP. Виртуальный сервер каждого подразделения работает как сервер удалённых рабочих мест и главный сервер подразделения:
-
Централизованное управление инфраструктурой ИТ.
-
Выделенный безопасный доступ Wi-Fi для гостей.
-
Весь персонал имеет удалённые рабочие места для ежедневной работы.
-
Система видеонаблюдения должна быть интегрирована с виртуальным окружением.
Ключевые требования:
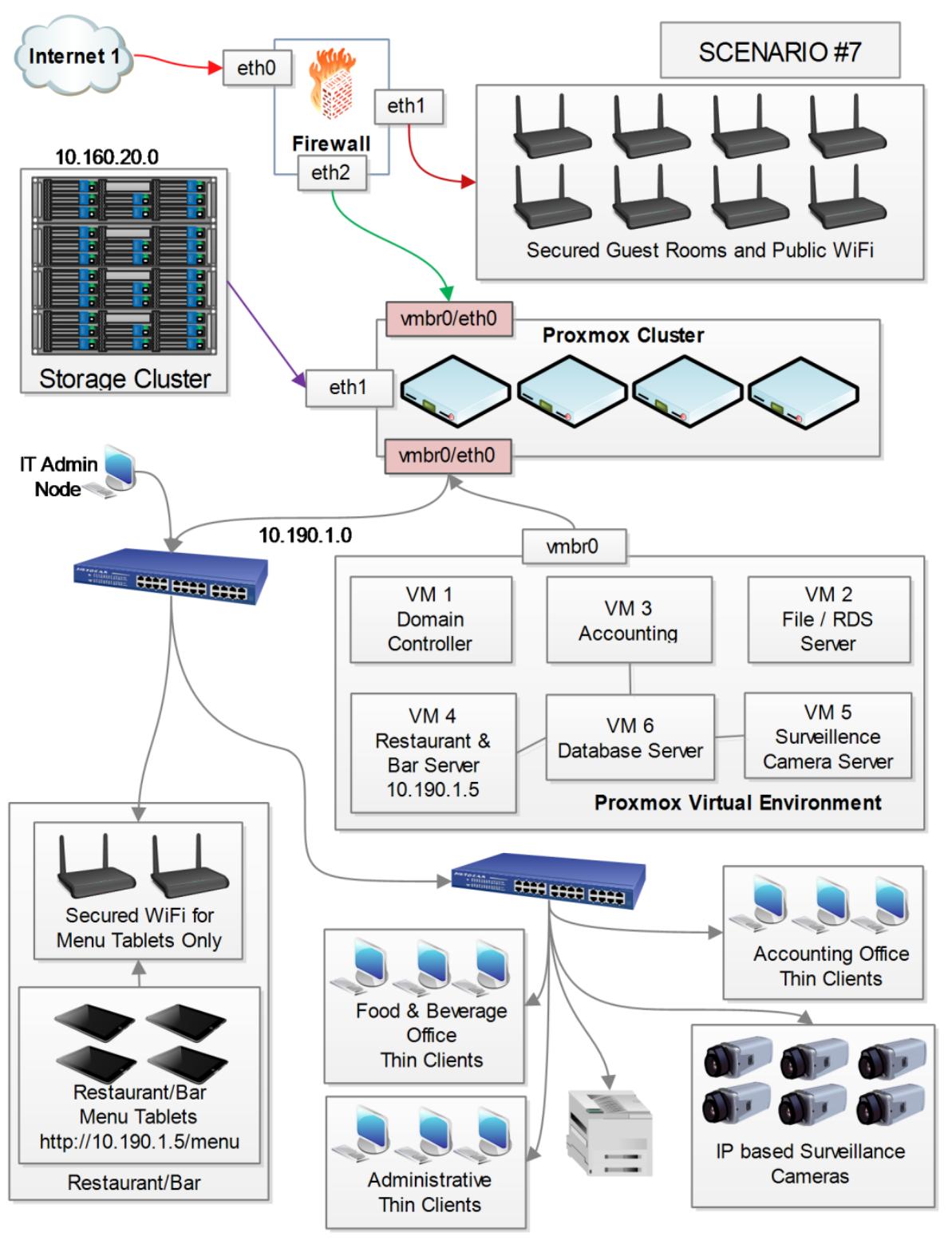
Это сценарий для типичного гостиничного заведения с собственным рестораном. Данный пример использует центральный виртуальный сервер базы данных для хранения всей информации. Хотя это и необычный способ соединения всех подразделений с единственной базой данных (включая систему видеонаблюдения), вполне допустимо единое решение всё-в-одном для снижения стоимости накладных расходов управления. При обычном сценарии, для обработки различных подразделений применяется отдельное программное обеспечение без переносимости данных. В данном примере универсальное программное обеспечение управления соединяет все подразделения с единой базой данных и индивидуализирует интерфейс пользователя для каждого подразделения.
Безопасная Wi-Fi интернет связь без фильтрации предоставляется для всех гостей. DHCP предоставляется
непосредственно межсетевым экраном. Безопасный частный Wi-Fi настраивается для планшетов ресторанного
меню. Все планшеты меню соединяются только с виртуальным сервером ресторана или бара с IP
10.190.1.5. Все тонкие клиенты подразделения и видео- камеры наблюдения
на базе IP соединяются с главной подсетью сетевой среды 10.190.1.0:
-
Полевые изыскатели должны представлять свои рабочие заказы со своих мобильных устройств через соединения VPN.
-
Выделенный безопасный доступ Wi-Fi для гостей.
-
Должна присутствовать отказоустойчивая инфраструктура сетевой топологией множества площадок.
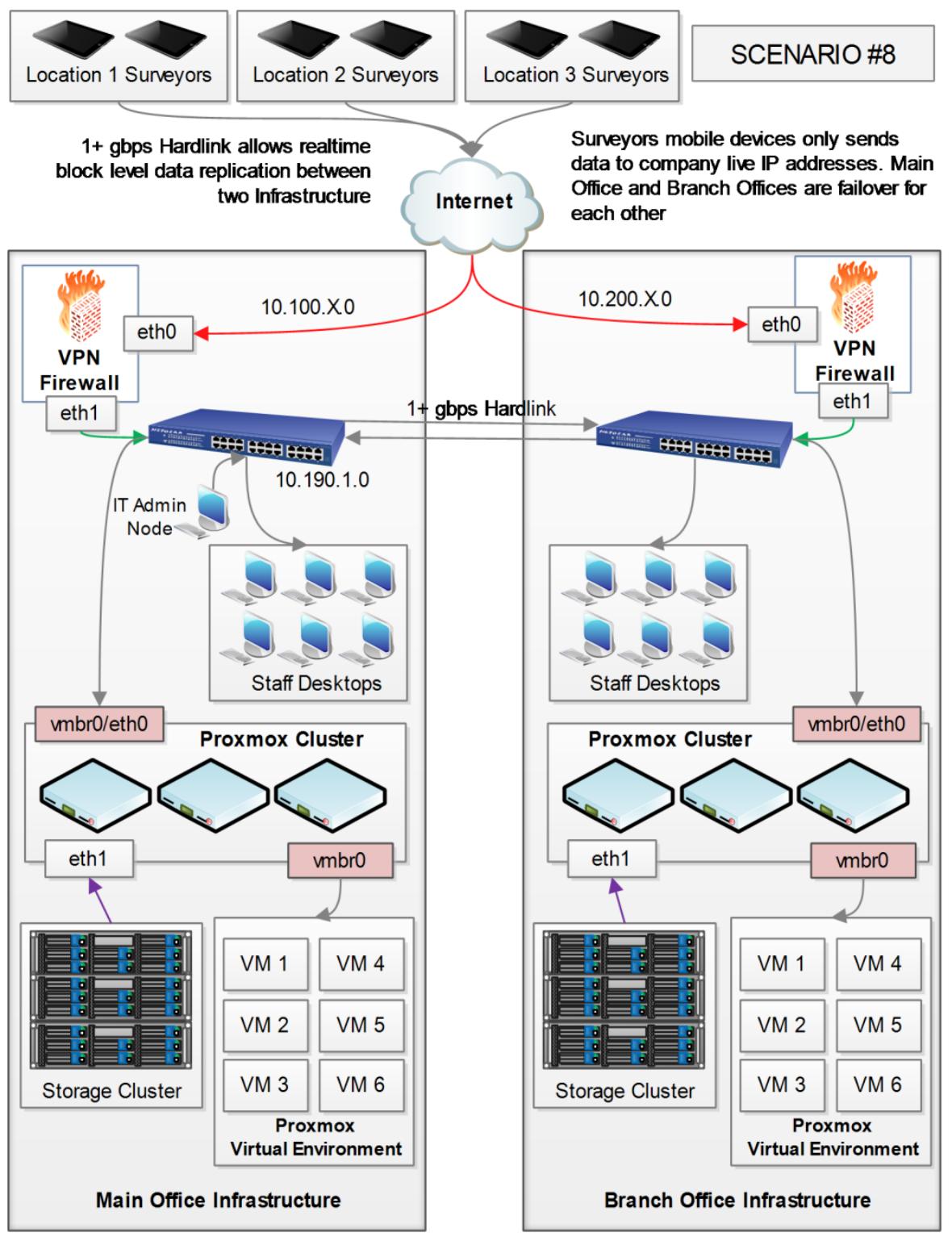
Ключевые требования:
При данном сценарии геологическая исследовательская компания имеет головной офис и отделения соединяются 1+ Gbps кабельными сетевыми соединениями. Каждый офис имеет идентичную настройку инфраструктуры. Все изыскатели применяют мобильные устройства подобные планшетам в своей исследовательской деятельности. Программное обеспечение исследователя автоматически определяет какой IP офиса доступен и отправляет данные в инфраструктуру данного офиса. Все данные реплицируются на уровне блоков между офисами в реальном времени.
Если инфраструктура одного из офисов становится недоступной, персонал может просто продолжать работу с подобной инфраструктурой из другого офиса:
Виртуальные среды являются очень гибкими, поэтому не существует единственной- сетевой- среды- соответствующей- всем- конфигурациям. Каждая сетевая среда будет уникальной. Описанные в данной главе компоненты и требования являются простым руководством для того как выбирать правильный подход для планирования сборки Proxmox промышленного уровня. Мы рассмотрели некоторые требования настройки промышленного уровня, а также мы изучили как надлежащим образом выделять ресурсы ЦПУ и оперативной памяти как для узла Proxmox, так и для виртуальной машины самой по себе. Мы также обсудили как дать хранилищу Ceph лучшие возможности предоставления резервирования наряду с производительностью. Наконец, мы рассмотрели как эффективно охлаждать оборудование путём дополнительных преимуществ жидкостного охлаждения, тем самым увеличивая плотность вычислительных узлов на стойку при одновременной экономии энергопотребления.
Также мы рассмотрели некоторые реальные сценарии Proxmox в действии в различных отраслях. Как мы надеемся, это поможет вам в вашем поиске обнаружения того исключительного баланса между производительностью и бюджетом, которого страстно желают все сетевые администраторы.
В следующей главе мы собираемся рассмотреть некоторые происшествия из реальной жизни и то, как обнаруживать неисправности в кластерном окружении Proxmox. Подобные проблемы были взяты из ежедневной работы кластеров и промышленных сред.