Глава 9. Избыточность в Windows Server 2019
Содержание
- Глава 9. Избыточность в Windows Server 2019
- Балансировка сетевой нагрузки
- Настройка и балансировка нагрузки веб- сайта
- Отказоустойчивая кластеризация
- Уровни кластера
- Настройка отказоустойчивого кластера
- Последние улучшения кластера в Windows Server
- S2D (Storage Spaces Direct)
- Выводы
- Вопросы
Помножай это на два. Эту фразу я слышу постоянно когда планирую массовую раскрутку для работы. Я уверен, что вы поступаете так же. Всякий раз когда вы массово раскручиваете новую технологию, вы желаете спланировать такую раскрутку очень тщательно. Определяйте какие серверы вам нужны, где они должны быть размещены и как должна быть настроена сетевая среда для этих парней. А потом, когда всё сказано и сделано по планированию - о да, мне нужно всего этого по два, на случай если что- то сломается. Мы живём в мире постоянно работающих технологий. Падение служб неприемлемо, особенно если мы размещаем облачные или частные облачные службы. На самом деле, любое приложение или служба, от которых зависит выполнение своей работы пользователями, являются критически важными и требуют 100% времени работы, либо чертовски близко к тому. Проблема с избыточностью состоит в том, что это быстро сказывается, да не просто делается. Возможно когда-то наступит день когда нам явится магическая кнопка Нажмите сюда, чтобы сделать ваш сервер избыточным - но это будет не сегодня {Прим. пер.: и не в нашем районе}. Нам необходимо понимать доступные нам технологии, которые предоставляют избыточность в наших системах. Эта глава расскажет нам кое-что об этих технологиях. Данная книга сосредоточена на Server 2019, применяемом на вашей площадке, поэтому те технологии, которые мы обсуждаем здесь и сейчас будут теми технологиями, которые мы сможем применять в своих локальных центрах обработки данных на всамделишных (физических или виртуальных) серверах, за которые вы несёте ответственность при их построении, настройке и сопровождении. Да, облака могут предоставить нам некие магические варианты масштабируемости и избыточности, однако это слишком просто и нам даже не нужно знать как это работает. Когда же мы используем свои собственные серверы в своих собственных стенах, как мы можем добавить некое увеличение надёжности в свои собственные системы?
В данной главе мы рассмотрим следующие темы:
-
Балансировка нагрузки сетевой среды (NLB)
-
Настройка балансировки нагрузки вебсайта
-
Отказоустойчивая кластеризация
-
Уровни кластеризации
-
Настройка отказоустойчивой кластеризации
-
Улучшения кластеризации в Windows Server
-
Непосредственно подключаемые Пространства хранения (S2D, Storage Spaces Direct)
Очень часто, когда я слышу как люди обсуждают избыточность своих серверов, обсуждение содержит множество экземпляров слова кластер. Например, "Если мы настроим некий кластер для предоставления избыточности для этих серверов..." или "Наш основной вебсайт выполняется в кластере...". Хотя это и замечательно, что имеется некоторый вид применяемой в нашей системе эластичности, к которой имеет отношение данное обсуждение, зачастую это тот случай, когда кластеризация вовсе не вовлечена в процесс на самом деле. Когда мы углубляемся в подробности того как настроены их системы, мы обнаруживаем, что всю работу за них осуществляет NLB (Network Load Balancing, Балансировка сетевой нагрузки). Далее в этой главе мы обсудим действительную кластеризацию, но вначале я бы хотел начать с более общего подхода, которые делает множество служб избыточными. NLB распределяет обмен вашего уровня TCP/IP, что означает, что сами операционные системы сервера не полностью не имеют информации о том, что могут полагаться друг на друга, а избыточность собственно предоставляется на самом сетевом уровне. Это - NLB против кластеризации - может определённо вводить в заблуждение, так как даже сам Microsoft иногда ссылается на что- то как на кластер, хотя на самом деле применяется NLB для возможности осуществления таких соединений. Прекрасным примером является DirectAccess. Когда у вас есть два или более сервера DA соединённых в один массив, имеются документы TechNet и даже места внутри самой консоли, которые называют это кластером. Однако в действительности здесь нет отказоустойчивой кластеризации, та технология под капотом, которая осуществляет поток соединений к обоим этим узлам, в действительности Балансировка сетевой нагрузки Windows (Windows NLB, Windows Network Load Balancing).
Скорее всего вы слышали некоторые имена на рынке аппаратной балансировки нагрузок - F5, Cisco, Kemp, Barracuda. Это выделенные коробки, которые могут брать направленный к определённому имени или получателю обмен и интеллектуально расщеплять этот обмен между двумя или более серверами приложений. Хотя это обычно наиболее надёжный способ, которым вы можете устанавливать NLB, он также и наиболее затратный и делающий всё окружение более сложным. Одна из функциональностей, предлагаемых этими парнями, которую не может предоставлять Балансировка сетевой нагрузки Windows, это прекращение SSL или разгрузка SSL, как мы порой называем её. Такое специализированное приспособление способно принимать обмен вебсайта от применяющего SSL компьютера пользователя и расшифровывать пакеты прежде чем отправлять их по своему пути на соответствующий веб сервер. Таким образом сам веб сервер выполняет меньшую работу, так как ему нет необходимости тратить циклы ЦПУ на шифрование и дешифрование пакетов. Однако, сегодня мы совсем не собираемся говорить об аппаратной балансировке сетевой нагрузки, вместо этого мы обсудим те же самые возможности NLB, которые предоставляются прямо из самого Windows Server 2019. {Прим. пер.: рекомендуем также ознакомится с наш переводом Книги рецептов NGINX Дерека ДеДжонге.}
На протяжении многих лет я обнаруживаю, что для некоторых людей идея Балансировки сетевой нагрузки на самом деле
является карусельным (round- robin) DNS. Позвольте мне привести пример этого. Скажем, у вас имеется работающий вебсайт
корпоративной сети (интранета), к которому все ваши пользователи осуществляют повседневные запросы. Это делает
существенным то, что вы бы хотели предоставлять некоторую избыточность такой системе и по этой причине вы настраиваете
два веб сервера, на тот случай, если один из них упадёт. Однако в случае падения одного из них вы не желаете чтобы
требовались выполняемые вручную шаги по отсечению отказавшего сервера в пользу дополнительного, вы хотите чтобы это
происходило автоматически. На уровне DNS это возможно путём создания двух DNS записей хоста (A), которые имеют одно и то
же имя, однако указывают на два различных IP адреса. Если Server01
выполняется на 10.10.10.5, а Server02
исполняется на 10.10.10.6, вы можете создать две DNS записи, причём обе с именем
INTRANET так, чтобы одна запись хоста указывала на
10.10.10.5, а вторая запись хоста на 10.10.10.6.
Это предоставит карусельный DNS, однако никакую не балансировку нагрузки в действительности. То, что по существу будет
происходить когда компьютер клиента будет запрашиватьINTRANET,
DNS будет предоставлять им один или другой IP адрес для соединения. DNS не заботится о том, работает ли в действительности
этот вебсайт, он просто выдаёт ответ с неким IP адресом. Так что вы даже могли бы настроить это для работы и оно выглядит
работающим без сбоев, потому что вы можете обнаружить, что клиенты соединяются с обоими серверами, и с
Server01, и с
Server02, которые заблаговременно предупреждены.
Если возникает событие отказа какого- либо сервера, у вас будет всё ещё достаточное число всё ещё работающих клиентов, а
также большое число клиентов, которые несомненно получат сообщение Page cannot be
displayed (Страница не может быть отображена), когда DNS решит отправить их к IP адресу того сервера, который
в настоящий момент не работает.
Балансировка сетевой нагрузки намного умнее данного варианта. В случае падения одного из узлов в некотором массиве NLB, обмен осуществляемый на совместно используемый IP адрес будет направляться только на тот узел, который всё ещё включён. Вскоре мы получим возможность увидеть это воочию, когда мы настроим NLB в корпоративном вебсайте для наших собственных нужд.
Балансировка сетевой нагрузки изначально разрабатывалась для приложений stateless
(без состояния), другими словами, приложения, которые не требуют долговременно хранимого положения или состояния
соединения. В приложении без состояния каждый выполняемый данным приложением запрос может цепляться
Server01, а затем переключаться на
Server02 без прерывания самого
приложения. Некоторые приложения (такие как вебсайты) обрабатываются так очень хорошо, а некоторые нет.
Веб службы (IIS) определённо получают большинство преимуществ от такой избыточности, предоставляемой Балансировкой сетевых соединений. NLB достаточно просто настраивается и предоставляет полную избыточность для вебсайтов, которые вы должны исполнять на своих Windows Servers, причём без необходимости в каких- либо дополнительных затратах.
Другая роль, которая обычно взаимодействует с NLB - это роль удалённого доступа. В особенности, DirectAccess может применять встроенную в Windows Балансировку сетевой нагрузки для предоставления вам избыточной среды терминальных серверов удалённого доступа. При настройке применения балансировки нагрузки для DirectAccess, сразу не является очевидным что вы применяете встроенное в вашу операционную систему свойство NLB, так как вы настраиваете все установки балансировки нагрузки изнутри Консоли управления Удалённым доступом (Remote Access Management Console) вместо имеющейся консоли NLB. Когда вы проходите через мастер Управления Удалённым доступом для установления балансировки нагрузки, данная консоль Удалённого доступа на самом деле обращается к механизму NLB внутри данной операционной системы и выполняет её настройку, таким образом именно её алгоритмы и транспортные механизмы являются используемыми DirectAccess частями для расщепления обмена между множеством серверов.
Одна из лучших частей использования NLB состоит в том, что вы можете вносить изменения в среду без воздействия на
существующие узлы. Хотите добавить новый сервер в имеющийся массив NLB? Нет проблем.
Накатите его без какого- либо времени простоя. Необходимо выполнить работы по сопровождению какого-
либо сервера? Даже здесь нет проблем. NLB может быть остановлен на определённом узле, на самом деле он
действительно предназначен для NIC, поэтому вы можете исполнять различные режимы NLB на различных NIC на определённом
сервере. Вы можете запросить NLB остановиться на определённом NIC, удаляя этот сервер из массива на это время. А что ещё
лучше, если вам требуется какое- то время перед остановкой этого сервера, вы можете выполнить команду
drain-stop (дренажирования, осушающего останова) вместо немедленной остановки.
Это позволяет завершится обычным образов всем имеющимся в настоящий момент сеансам сетевых соединений на данном сервере.
Никакие новые сеансы при этом не будут протекать через данный NIC, который вы останавливаете дренажным способом, а старые
сеансы испарятся своим чередом со временем. Как только все сеансы на данном сервере завершатся, вы сможете выдернуть его
и проводить на нём работы по сопровождению.
Тот способ, которым NLB применяет IP адресацию, является важной для понимания концепцией.
Прежде всего, все NIC в сервере, которые готовятся под то чтобы они стали частью массима балансировки сетевых нагрузок
обязаны иметь назначпенными им статические IP адреса. NLB не работает с адресацией DHCP. В мире NLB некий статический
адрес в NIC имеют название DIP
(Dedicated IP Address, Выделенного IP адреса).
Такие DIP являются уникальными для NIC, что очевидно означает, что каждый сервер имеет свой собственный DIP.
Например, в моей среде WEB1
работает с DIP адресом 10.10.10.40, а мой сервер WEB2
имеет DIP 10.10.10.41.
Каждый сервер размещает один и тот же вебсайт, причём со своим установленным в настоящий момент соответствующим DIP. Что
важно понимать, так это то, что когда между этими двумя серверами устанавливается NLB, я должен удерживать эти персональные
DIP для каждой из коробок, но я буду также создавать совершенно новые IP адреса, которые будут совместно использоваться этими
двумя серверами. Эти IP адреса называются VIP
(Virtual IP Address, Виртуальными IP адресами). Когда мы через
какое- то время будем знакомиться с настройкой NLB, я воспользуюсь для своего VIP IP адресом
10.10.10.42, который до этого момента не применялся в моеё сетевой среде.
Вот краткая хема IP адресов, которые я собираюсь применять при настройке своей Балансировки сетевой
нагрузки:
-
WEB1 DIP = 10.10.10.40 -
WEB2 DIP = 10.10.10.41 -
Shared VIP = 10.10.10.42
При настройке моей записи DNS для intranet.contoso.local, которая является именем
моего вебсайта, я создам только единственную запись хоста (A), и она укажет на мой VIP
10.110.0.42.
Вкратце, мы находимся в реальной настройке своей балансировки нагрузки и будем принимать некоторые решения внутри этого интерфейса. Одно из основных решений состоит в том какой режим NLB мы хотим применять. По умолчанию принят Unicast (Одноадресный) и это вариант, который я вижу в основном числе компаний, настраивающих свою NLB - возможно просто потому что так принято по умолчанию и они никогда не задумываются об его изменении. Давайте потратим всего минуту и обсудим здесь каждый из возможных вариантов, чтобы убедиться, что вы можете выбрать наиболее соответствующий потребностям вашей сетевой среды.
Unicast
Здесь мы начинаем проникать в сердцевину того, как NLB распределяет пакеты по различным хостам. Так как у нас нет физического балансировщика нагрузки, который вначале принимает весь обмен, а затем принимает решение куда его отправлять, как наши серверы балансировки нагрузки принимают решение кто какой пакет потока получит?
Чтобы ответить на этот вопрос, нам необходимо вернуться слегка назад и обсудить то, как на самом деле протекает обмен
внутри вашей сетевой среды. Когда вы открываете браузер на своём компьютере и посещаете HTTP://WEB1,
DNS определяет, например, IP адресу значение 10.10.10.40. Когда обмен попадает на
ваш коммутатор и нуждается в последующей отправки куда- то, коммутатор должен принять решение о том, куда должен
проследовать обмен с 10.10.10.40. Вы можете быть знакомы с MAC адресами.
Каждый NIC имеет некий MAC адрес, и когда вы назначаете некий IP адрес для какого- то NIC, он регистрирует свой собственный
MAC адрес и IP в своём собственном сетевом оборудовании. Эти MAC адреса сохраняются внутри некоторой таблицы ARP, которая
является расположенной в большинстве коммутаторов, маршрутизаторов и межсетевых экранов таблицей. Когда моему серверу
WEB1 был назначен IP адрес
10.10.10.40, он регистрирует свой MAC адрес, как соответствующий
10.10.10.40. Когда обмену необходимо протекать на
WEB1, имеющийся коммутатор учитывает,
что тому обмену, который предназначен для 10.10.10.40, следует идти на
такой- то NIC с определённым MAC адресом и выстреливает его соответствующим образом.
Поэтому в мире NLB, когда вы отправляете обмен на отдельный IP адрес, который разделяется между множеством NIC, как это обрабатывается на уровне MAC? Ответ для одноадресного NLB состоит в том, что данные физические адреса MAC подменяются неким виртуальным MAC адресом, а этот MAC назначается всем NIC внутри массива NLB. Это означает, что пакеты, протекающие на этот MAC адрес должны доставляться на все такие NIC, тем самым, на все эти серверы, которые содержатся в данном массиве. Если вы думаете об этом, как о звучащем как о том, что производится большой объём работы бесполезного сетевого обмена по его перемещению внутри коммутатора, вы будете правы.
Самое лучшее в одноадресном режиме состоит в том, что в большинстве случаев он работает без необходимости выполнять некие специальные настройки в ваших коммутаторах или прочем сетевом оборудовании. Вы настраиваете эту установку NLB и она обрабатывает всё остальное. Обратной стороной одноадресного режима является то, что из- за существования одного и того же MAC адреса на всех этих узлах это может вызывать некие проблемы взаимодействия между узлами. Другими словами, сервера, в которых включён NLB будут иметь сложности во взаимодействии с IP адресами друг друга. Если вам на самом деле требуется, чтобы эти веб- серверы имели возможность общаться друг с другом непрерывно и надёжно, самое простое решение состоит в установке отдельного NIC на каждый из таких серверов и применение такого NIC для данного взаимодействия внутри массива при том, что первичные NIC остаются настроенными на NLB обмен.
Другой обратной стороной для одноадресного режима является то, что он создаёт некоторое неуправляемое заполнение коммутатора. Коммутаторы не способны изучать постоянный маршрут для виртуального адреса MAC, так как он нам необходим для доставки на все узлы в нашем массиве. Так как каждый перемещаемый в такой виртуальный MAC пакет отправляется вниз по всем проспектам коммутатора с тем, чтобы он мог достичь все свои NIC, в которых требуется эта доставка, они имеют потенциал переполнить ваши коммутаторы. Если вы беспокоитесь об этом или имеете жалобы от ваших сетевых парней о переполнении коммутаторов, вы должны захотеть проверить режимы со множеством адресов (multicast) для своего кластера NLB.
Некий альтернативный метод для управления переключением потоков unicast состоит в получении креативности при помощи VLAN в ваших коммутаторах. Если вы планируете некий NLB массив серверов и желаете гарантировать что коммутируемый обмен, вырабатываемый этим массивом не будет воздействовать на прочие системы в вашей сетевой среде, вы несомненно можете создать некую небольшую VLAN в своём коммутаторе и подключать в такую VLAN лишь свои NIC с включённым NLB. Тем самым, при возниконовении планируемого потока, он будет ударяться лишь в небольшое число портов внутри вашей VLAN, вместо того чтобы сегментировать свой путь по всему коммутатору целиком.
Multicast
Выбор multicast (многоадресного) режима для вашего NLB приносит некий положителный эффект и некую головную боль. Положительная сторона состоит в том, что он добавляет дополнительные MAC адреса для каждого NIC. Каждый участник NLB затем имеет два MAC адреса, первоначальный и ещё один, создаваемый механизмом NLB. Это позволяет коммутаторам и сетевому оборудованию более простые заания по изучению всех маршрутов и отправлять обмен их правильным получателям без переполнения пакетами потока. Чтобы выполнить это, вам необходимо сообщить своим коммутаторам какой MAC адрес должен получать этот обмен NLB, в противном случае вы вызовете переполнение коммутатора, как и в случае с одноадресным режимом. Сообщение вашим коммутаторам какие MAC нуждаются в таком подключении требует регистрации в ваших коммутаторах и создании некоторых статических записей ARP для улаживания этого. Для любой компании с выделенными сетевым парнями, как правило экспертами в оборудовании Cisco, это не вызовет проблем. Если вы не знакомы с изменением таблиц ARP и добавлением статических маршрутов, это может быть слегка неприятным выполнить их правильную настройку. В конце концов, многоадресный режим в целом лучше одноадресного, однако он может быть приносящим больше административной головной боли. Моё предпочтение всё ещё склоняется к одноадресному режиму, в особенности в малом бизнесе. Я видел его применяемым во множестве различных сетевых сред без каких- либо проблем, и к тому же следование одноадресным режимом означает, что вы можете оставить программирование коммутаторов в стороне.
Multicast IGMP
Самым лучшим, но не всегда доступным, является многоадресный режим с IGMP (Multicast with Internet Group Membership Protocol). Многоадресный IGMP действительно помогает создавать множество шлюзов коммутируемого потока, но он работает только в коммутаторах, поддерживающих отслеживание IGMP. Это означает, что такой коммутатор имеет возможность заглядывать вовнутрь пакетов с множественными адресами для определения куда он в точности должен следовать. Таким образом, когда одноадресный режим создаёт по своей природе некоторое дополнительное наполнение коммутаторов, многоадресный режим может помочь уменьшать этот объём, а IGMP может подготовить такое снижение к ещё меньшим значениям.
Тот режим NLB, который вы выбираете, во многом зависит от имеющегося у вас сетевого оборудования. Если ваши серверы имеют только один NIC, попробуйте воспользоваться многоадресным режимом, иначе вы получите проблемы внутри массива. С другой стороны, если ваши коммутаторы и маршрутизаторы не поддерживают многоадресные таблицы, у вас нет выбора - одноадресный режим будет вашей единственной возможностью для настройки Балансировки сетевой нагрузки Windows.
Хватит болтовни, самое время настроить это для себя и попробовать. У меня имеются два веб сервера, работающие
в моей лаборатории, WEB1 и
WEB2. Оба они применяют IIS для
размещения корпоративного вебсайта. Моя цель состоит в предоставлении их своим пользователям с единой записью
DNS для взаимодействия с ними, однако заставляя весь этот обмен расщепляться между этими двумя серверами при
помощи некоторой реальной балансировки нагрузки. Последуйте совместно с приводимыми ниже шагами и сделайте это
возможным.
Перво- наперво нам необходимо убедиться, что WEB1
и WEB2
готовы к выполнению Балансировки сетевой нагрузки (NLB), так как оно не устанавливается по умолчанию. NLB является свойством,
доступным в Windows Server 2019, и вы добавляете в точности так же как и остальные свойства, выполняя это при помощи
мастера Добавления ролей и свойств (Add roles and features).
Добавьте это свойство на все сервера, которые вы желаете сделать частями своего массива NLB:
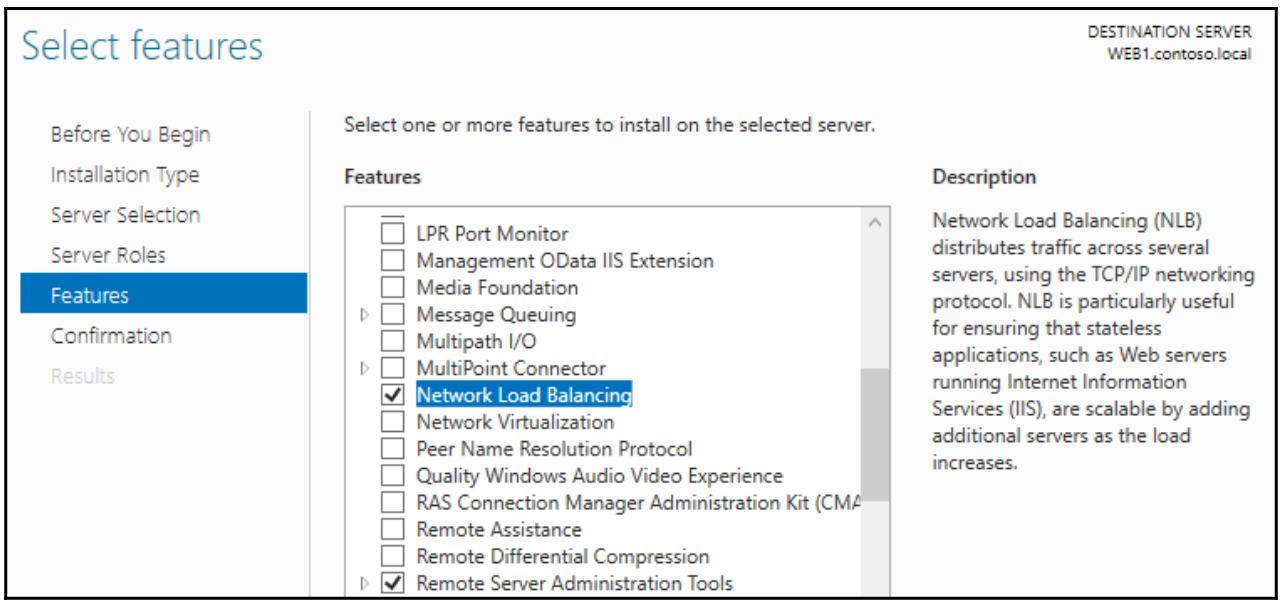
Включение поддержки MAC адресов в ВМ
Помните, когда мы обсуждали одноадресный NLB, как физические MAC адреса имеющихся NIC подменялись виртуальными MAC адресами, которые применялись для взаимодействия массива NLB? Да, виртуальным машинам это не нравится. Если вы осуществляете балансировку нагрузок физических серверов с физическими NIC, вы можете пропустить этот раздел. Однако многие из вас будут исполнять веб сервера, которые являются ВМ. Будут ли они размещаться под Hyper-V, VMware или какой- либо другой технологией виртуализации, существуют дополнительные опции в настройках самих этих виртуальных машин, которые вам придётся выполнить, чтобы эта ваша ВМ успешно соглашалась с такой подменой адресации MAC.
Название таких настроек будет как- то созвучно строке Enable MAC Address Spoofing (Включение подстановки MAC адреса), хотя определённое имя этой функции может отличаться в зависимости от применяемой вами технологии виртуализации. Эта настройка должна выглядеть как простая флаговая кнопка, которую вы должны включить чтобы заставить работать подстановку MAC надлежащим образом. Убедитесь, что вы сделали это для всех виртуальных NIC, на которых вы будете применять NLB. Имейте ввиду, что эта настройка выполняется для установки каждой NIC индивидуально. Если у вас в некой ВМ множество NIC, убедитесь, что вы сделали это для всех NIC, если вы планируете их все в балансировке нагрузки.
Чтобы сделать эти изменения, вам необходимо остановить эти ВМ, поэтому я сейчас остановлю свои серверы
WEB1 и
WEB2. Теперь найдите необходимую флаговую кнопку
и включите её. Так всё используемое мной основывается на технологии Microsoft, я, конечно же, применяю в качестве своей
платформы Hyper-V для своих виртуальных машин в моей лаборатории. Внутри Hyper-V, если я кликну правой кнопкой по своему
серверу WEB1 и проследую в настройки его ВМ, я
могу кликнуть по своему сетевому адаптеру чтобы увидеть различные части, которые можно изменять в виртуальном NIC
WEB1. И там имеется флаговая кнопка
Enable spoofing of MAC addresses
(Включение подстановки MAC адреса). Просто кликните по ней чтобы включить, и это все ваши настройки:
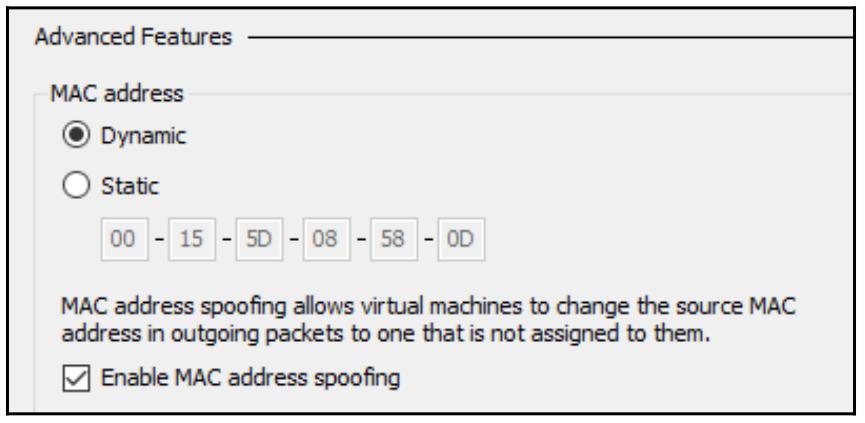
Если Enable spoofing of MAC addresses выделена серым цветом, помните, что данная машина должна быть полностью остановлена, прежде чем появится данная опция. Остановите её, затем откройте соответствующие Settings и посмотрите ещё раз. теперь эта опция должна быть доступна для выбора.
Давайте суммируем где мы находимся на текущий момент. У меня имеются два веб сервера,
WEB1 и
WEB2,
причём они оба в настоящее время имеют один и тот же IP адрес. Каждый сервер имеет установленный IIS, который размещает
отдельный вебсайт. Я включил на каждом из них подстановку MAC адреса и я только что завершил настройку свойства Балансировки
сетевой нагрузки на каждом из веб серверов. Теперь у нас имеются все необходимые части для того чтобы сделать возможной
настройку NLB и получения расщепления такого веб обмена между обоими серверами.
Я буду работать с WEB1 для реального
осуществления настройки Балансировки сетевой нагрузки. Зарегистрируемся на нём и теперь мы получаем уведомление, что у нас
имеется новый инструмент в данном перечне Средств (Tools),
которые доступны в Диспетчере сервера под названием Network Load Balancing Manager
(Диспетчер Балансировки сетевой нагрузки). Пройдём далее и откроем эту консоль. Когда у вас имеется открытый
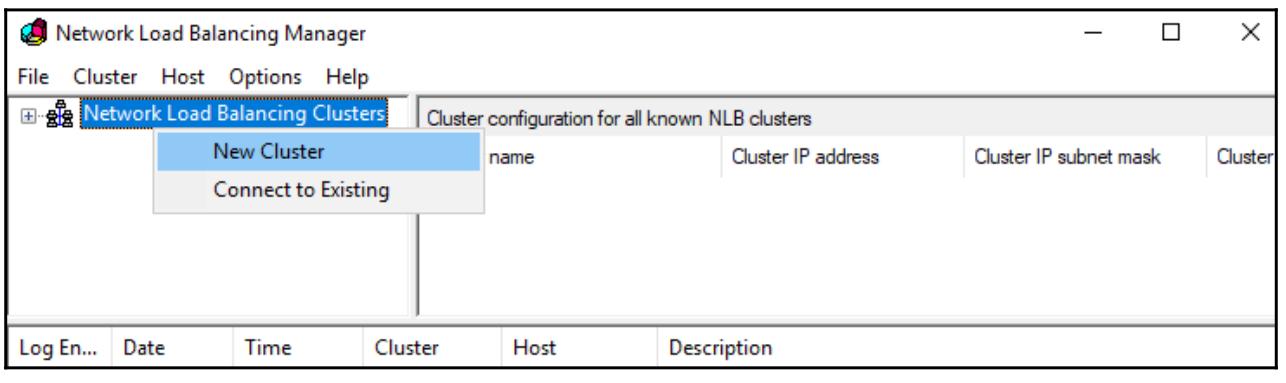
Диспетчер NLB, кликните правой кнопкой по Network Load Balancing Clusters
(Балансировка сетевой нагрузки кластеров) и выберите New Cluster
(Новый кластер), как это показано ниже на снимке экрана:
Когда вы создадите новый кластер, важно отметить, что в настоящий момент в этом кластере не имеется ни одной машины.
Даже сам сервер, на котором мы выполняем эту консоль не добавился автоматически в этот кластер, мы должны не забыть поместить
его вручную в данный экран. Поэтому вначале я собираюсь набрать в поле имени свой сервер
WEB1 и кликнуть
Connect. После осуществления этого Диспетчер NLB опросит
WEB1 на предмет NIC и выдаст мне перечень
доступных NIC из которых я могу потенциально настроить NLB:
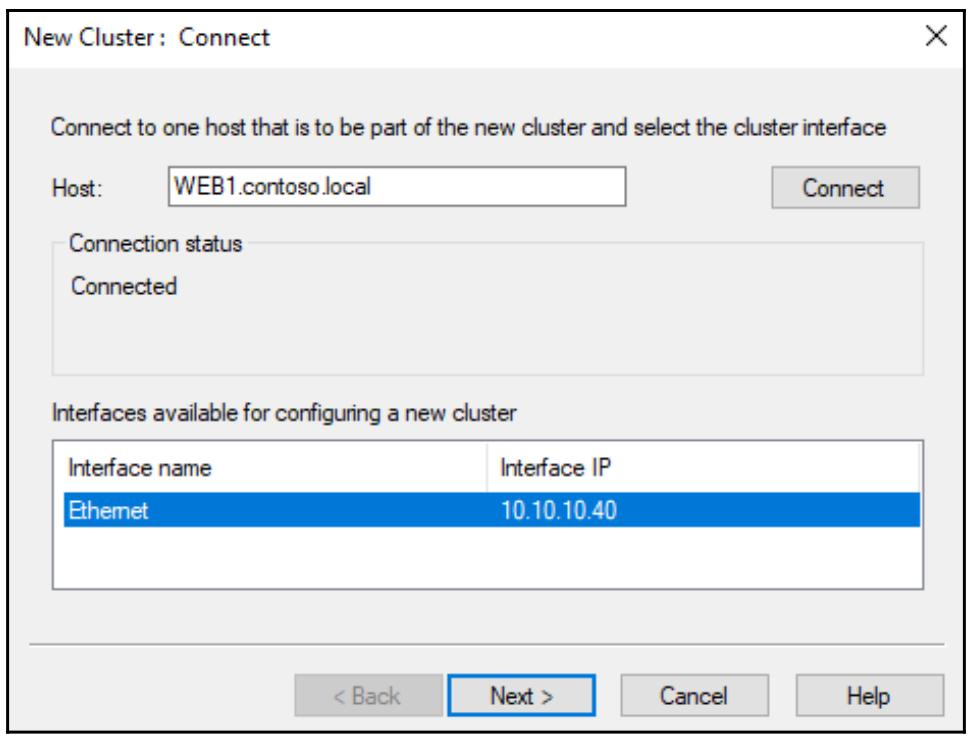
Так как в этом сервере у меня имеется только один NIC, я просто оставляю его выбранным и кликаю по
Next. Следующий экран предоставляет мне возможность ввода
дополнительных IP адресов для WEB1, однако так
как мы исполняем только один IP адрес, я оставляю этот экран как есть и снова кликаю
Next.
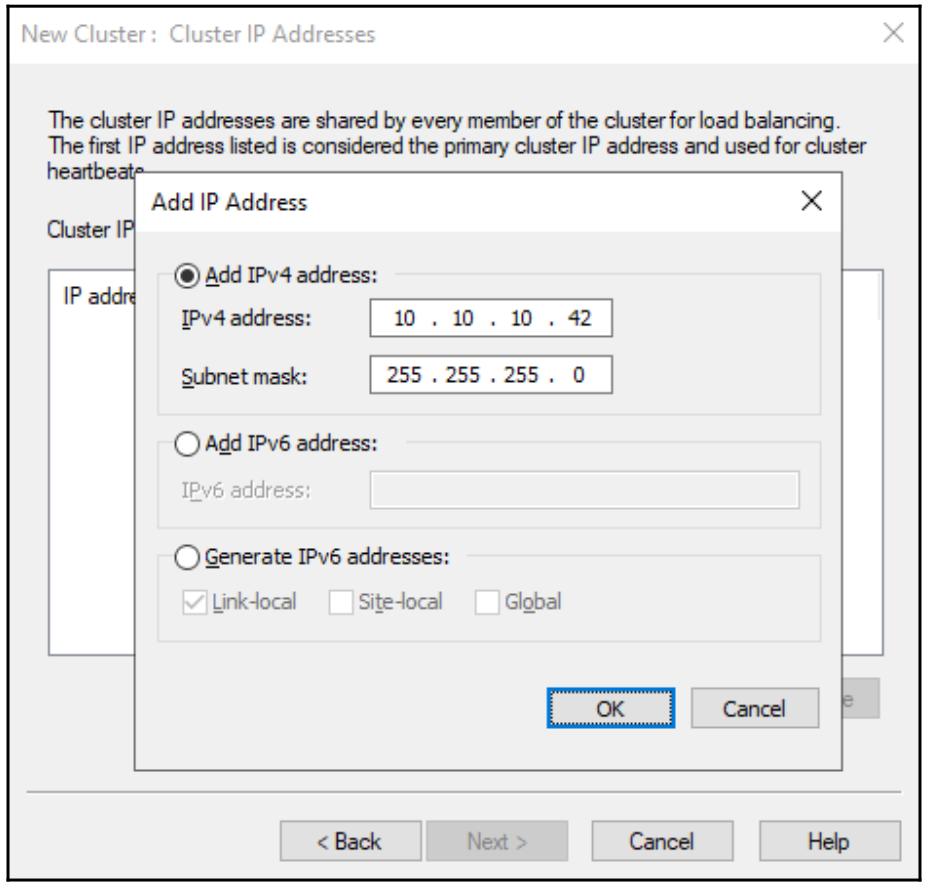
Теперь мы перемещаемся к экрану, запрашиваещему у нас ввод IP адресов Кластера. Это уже Виртуальные IP адреса (VIP,
Virtual IP Addresses), которые мы собираемся прменять для взаимодействия с таким кластером NLB. Как было постулирвано ранее,
мой VIP для данного вебсайта должен быть 10.10.10.42, поэтому я кликаю по кнопке
Add… и ввожу этот IPv4 адрес вместе с соответствующей маской
подсети:
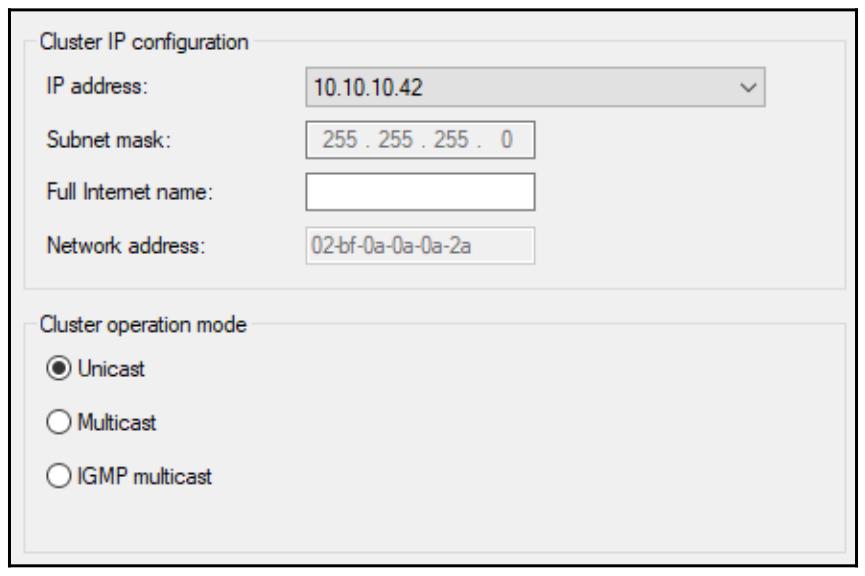
Ещё один клик по кнопке Next и мы можем теперь увидеть опцию, для которой мы хотим выполнить Cluster operation mode (Режим работы кластера). В зависимости от ваших настроек сетевой среды выберите, соотвественно, между Unicast, Multicast и IGMP multicast:
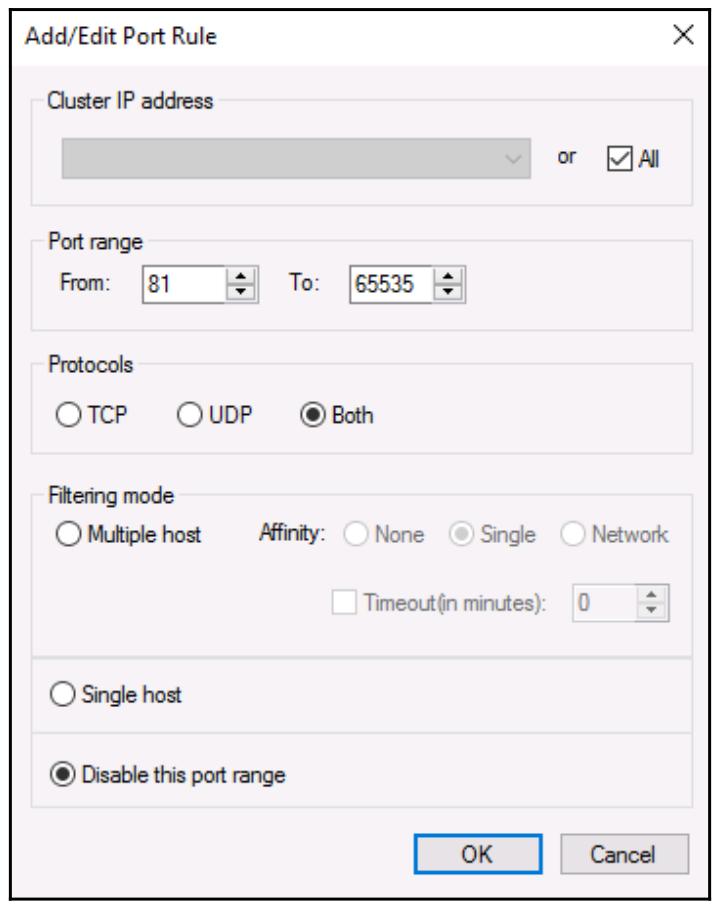
Следующий экран вашего мастера NLB предоставит вам настройку Port Rules (Правил порта). По умолчанию имеется единственное правило, которое сообщает NLB о необходимости выполнять балансировку нагрузки дюбого входящего обмена для любого порта, однако вы можете изменить это по своему желанию. Я не видел большого числа людей, определяющих здесь в данном поле правила для распределения по определённым получателям, однако одним отличным свойством в данном экране является возможность запрещать определённые диапазоны портов.
Этот фрагмент может быть очень полезным, если вы желаете блокировать нежелательный обмен на имеющемся уровне NLB.
Например, приводимый далее снимок экрана отображает настройки, которые будут блокировать порты
81 и выше от их проброса через имеющийся механизм NLB:
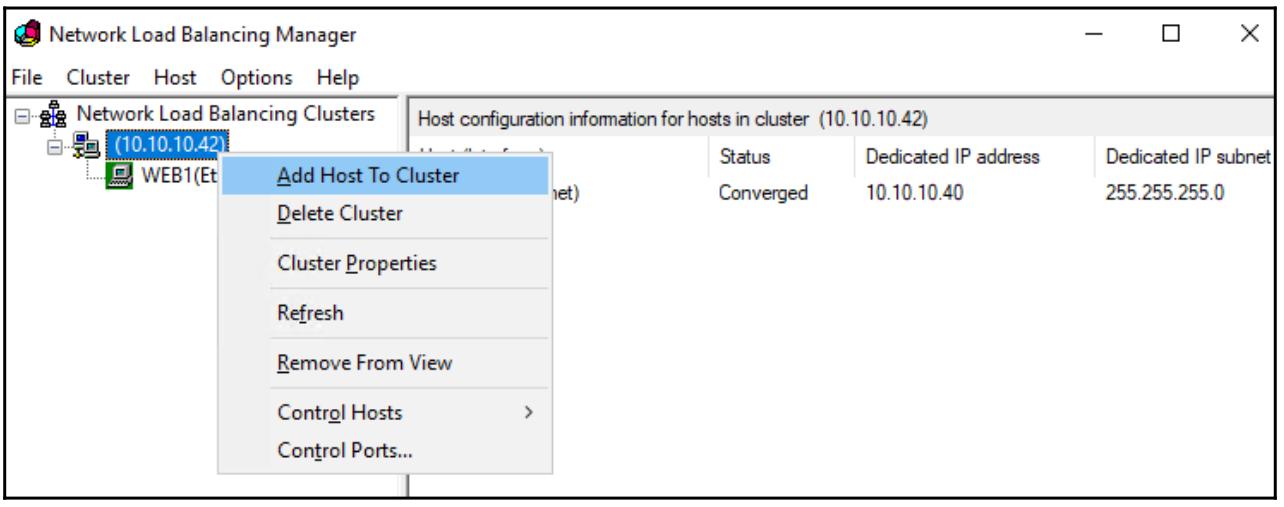
Завершите этот мастер и вы создали теперь некий NLB кластер! Однако, на данный момент времениу нас имеется заданной только
информация о нашем VIP и о сервере WEB1.
Мы пока не установили ничего для WEB2.
Пройдите далее и кликните правой кнопкой по своему новому кластеру и выберите Add Host
To Cluster (Добавить хост к кластер):
Введите имя нашего сервера WEB2
и кликните по Connect и прогуляйтесь по данному мастеру чтобы
добавить второй узел NLB WEB2 в ваш кластер. Когда
оба узла добавлены в этот кластер, наш массив балансировки сетевой нагрузки, или кластер, включён и готов к применению. Если
вы заглянете вовнутрь имеющихся свойств NIC своих веб серверов и кликните по имеющейся там кнопке
Advanced внутри свойств TCP/IP v4, вы можете увидеть, что наш
новый адрес IP кластера 10.10.10.42 был добавлен к этим NIC:
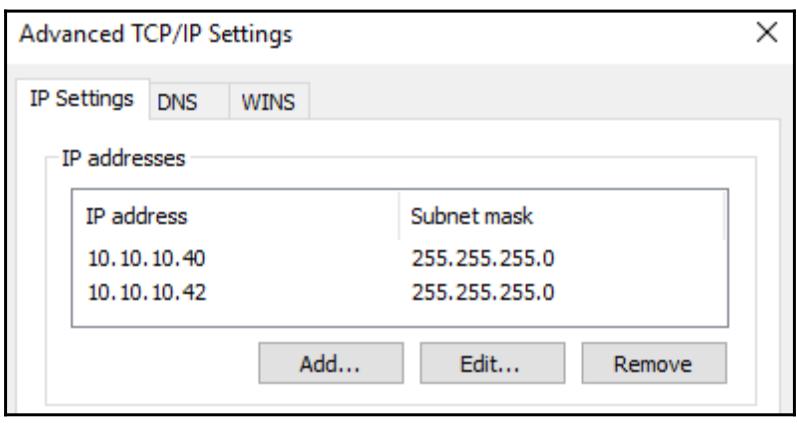
Весь обмен, который предназначен для IP адреса 10.10.10.42, теперь начинает
расщепляться между этими двумя узлами, однако прямо сейчас имеющиеся вебсайты, которые работают на наших серверах
WEB1 и
WEB2 настроены на работу только с выделенными IP
адресами 10.10.10.40 и 10.10.10.41, поэтому
нам необходимо проверить и отрегулировать это далее.
Всего лишь один быстрый шаг внутри IIS в каждом из наших веб серверов должен настроить данный вебсайт отвечать по
соответствующему IP адресу. Теперь, когда настройка данного NLB была осуществлена и мы получили подтвержение, что наш
новый VIP адрес 10.10.10.42 был добавлен в соответствующие NIC, мы можем
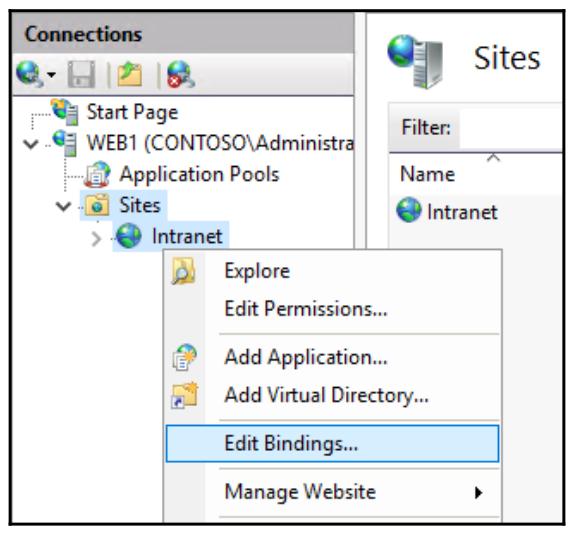
использовать этот IP адрес для связывания вебсайта. Откройте консоль управления IIS и раскройте папку
Sites так, чтобы вы могли видеть свойства своего вебсайта.
Кликните правой кнопкой по имени этого сайта и выберите Edit
Bindings…:
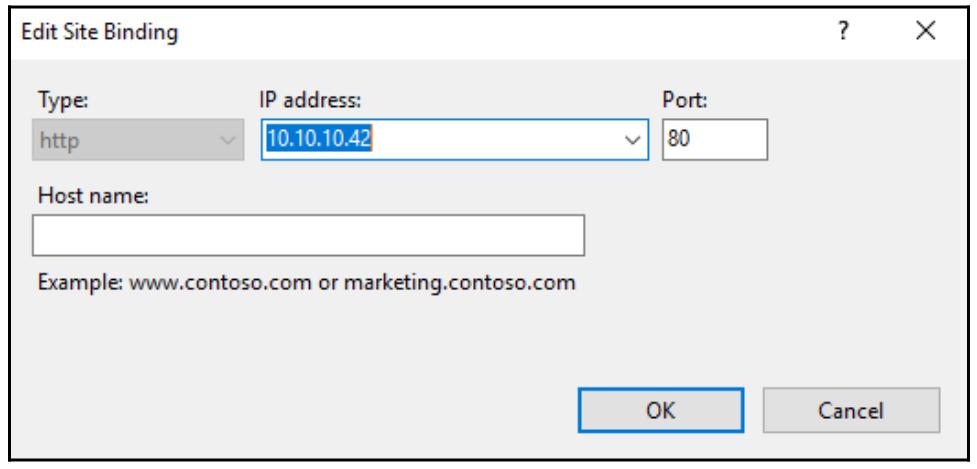
Находясь внутри Site Bindings, выберите ту связь, которую вы
желаете обрабатывать и кликните кнопку Edit…. Этот
корпоративный вебсайт всего лишь простой сайт HTTP, поэтому я собираюсь выбрать своё связыванеи HTTP для данного
изменения. Связывание в настоящий момент настроено на 10.10.10.40 для
WEB1 и на 10.10.10.41
для WEB2. Это означает, что данный вебсайт
отвечает только на обмен, который поступает на данные IP адреса. Всё что мне нужно сделать, это развернуть вниз
IP address для данного нового VIP, который установлен в
значение 10.10.10.42. После выполнения этого изменения и нажатия на
OK, данный вебсайт моментально начинает отвечать на обмен,
приходящий на данный IP адрес 10.10.10.42:
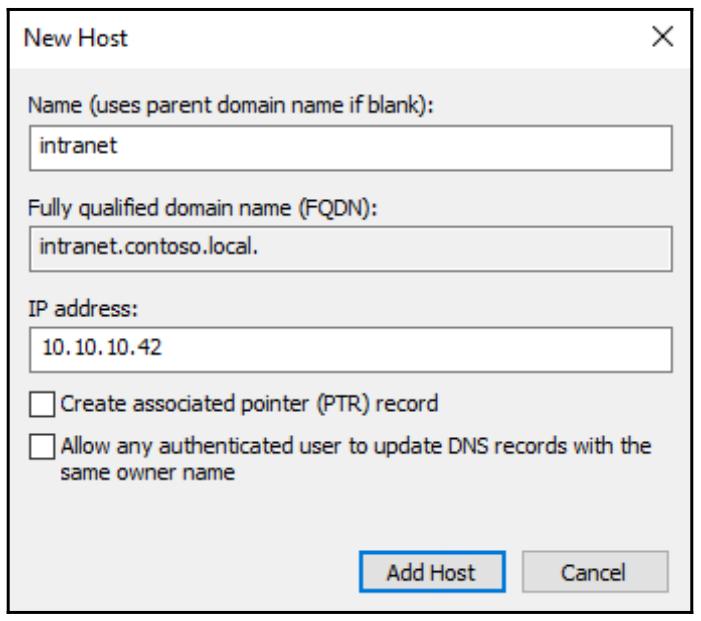
Теперь мы переходим к самому последнему фрагменту всей мозаики - DNS. Помните, мы хотим чтобы пользователи имели
возможность просто вводить http://intranet в своих веб- браузерах чтобы переходить на
этот новый NLB вебсайт, поэтому нам необходимо настроить соответствующим образом запись Host (A) DNS. Этот процесс в
точности тот же, что и для любой другой записи хост DNS, просто создайте её и укажите
intranet.contoso.local на 10.10.10.42:
NLB настроен? - Проверьте.
Связывание IIS изменено? - Проверьте.
Запись DNS создана? - Проверьте.
Мы готовы проверить все эти моменты. Если я открою браузер Интернет на каком- либо компьютере клиента и
просмотрю http://intranet, я могу увидеть этот вебсайт:
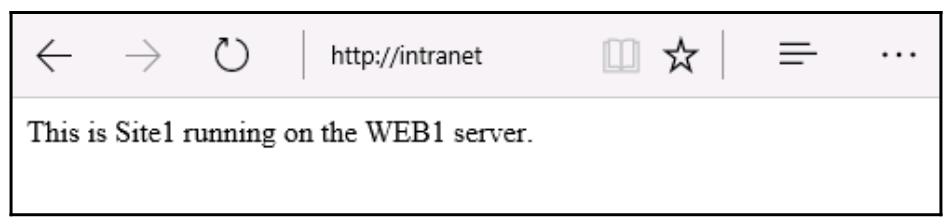
Однако как мы можем определить, что данная балансировка нагрузки в реальности выполняется?
Если я продолжу обновлять данную страницу, или выполню просмотр с другого клиента, я продолжу доступ к http://intranet
и имеющийся механизм NLB от случая к случаю будет принимать решение что новый запрос следует отправлять к
WEB2 вместо
WEB1. Когда это произойдёт, я тогда получу вместо
предыдущей такую страницу:
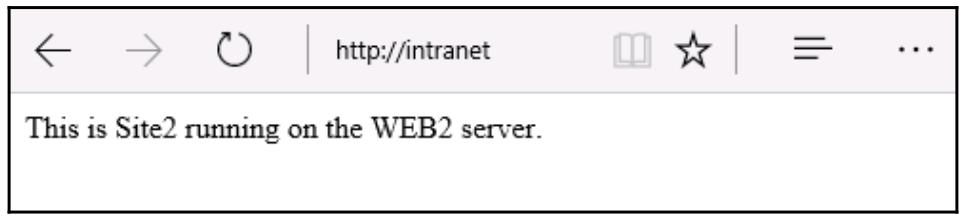
Как вы можете видеть, я изменил содержимое на WEB1
и WEB2 чтобы иметь возможность делать отличие
между различными узлами, исключительно для целей данной проверки. Если это реальный промышленный корпоративный вебсайт, я
бы хотел быть уверенным, что содержимое обоих сайтов было в точности одни и тем же, чтобы у пользователей не было
возможности иметь информацию о наличии NLB - всё что им нужно знать, это то, что данный вебсайт является доступным и
работающим, причём постоянно.
Ранее у нас имелось небольшое обсуждение о том, как коммутаторы хранят кэшируемую информацию ARP, что уменьшает то время, которое требуется данным коммутаторам при принятии решения куда должны протекать пакеты. Когда вы назначаете некому NIC какой- то адрес IP, имеющийся MAC адрес данного NIC связывается с соответствующим IP адресом внутри таблицы ARP в определённом фрагменте сетевого оборудования. Коммутаторы, маршрутизаторы, межсетевые экраны - все эти инструменты имеют то, что мы называем некоторой таблицей ARP, следовательно, и они имеют набор данных в этой таблице, который называется кэшем ARP.
При настройке NLB, в особенности в режиме одного адреса (unicast), MAC адрес ваших NIC замещается новым, виртуальным MAC адресом. Иногда имеющиеся коммутаторы и сетевое оборудование очень быстро захватывают данное изменение и они связывают такой новый MAC адрес с его новым IP адресом и всё работает просто великолепно. Однако я полагаю, что при настройке NLB следующее правило в целом верно: Чем умнее и более дорогостояще ваше оборудование, тем тупее оно становится при настройке NLB. Что я имею ввиду под этим, так это то, что сетевое оборудование может продолжать сохранять всю имеющуюся старую информацию MAC адресов, которая имеется в его таблице ARP, и при этом не проводить обновления для отражения имеющейся новой MAC адресации.
Как это выглядит в реальной жизни? Сетевой обмен перестаёт следовать к- или от- этих NIC. Иногда, когда вы устанавливаете NLB и она включает себя, весь сетевой обмен вдруг замерзает и останавливается к- или от- этих сетевых интерфейсов. Что необходимо делать для исправления данной ситуации? Иногда вы можете подождать её разрешения, в пределах нескольких минут, часов, а порой и дней, пока ваши коммутаторы сбросят старую информацию ARP и позволят новым MAC зарегистрировать себя здесь. Что можно сделать чтобы ускорить этот процесс? Сбросить имеющийся ARP кэш.
Процедура выполнения этого будет различной в зависимости от вида того сетевого оборудования, с которым вы работаете - является ли оно коммутатором или маршрутизатором, какую торговую марку оно имеет, какая у него модель и тому подобное. Но любой из этих парней должен иметь такую возможность, и она должна иметь название, созвучное обнулению имеющейся таблицы ARP. Когда вы осуществите эту функцию в своём оборудовании, это очистит данную ARP таблицу, освободится от старой информации, которая вызвала ваши проблемы и позволит новым MAC адресам зарегистрировать себя соответствующим образом в данной новой таблице.
Я просто хочу обратить внимание на это событие при настройке вами NLB, только если обнаружится прекращение поступления обмена на ваш сервер. Скорее всего это вызвано тем, что кэш ARP застрял в одном или большем числе фрагментов сетевого оборудования, которое пытается направлять весь обмен к- и от- вашего сервера.
Мы установили, что Балансировка сетевой нагрузки является великолепным решением для приложений, не запоминающих состояния и при этом первичным примером были вебсайты, которые вы пожелаете сделать высокодоступными. А что с остальными ролями или свойствами серверов, которые вы пожелаете сделать избыточными? Да, противоположностью для не запоминания состояний (stateless) является учёт состояния соединения (statefull), поэтому что мы можем предоставить для высокой доступности фрагментов технологий с запоминанием состояния соединения?
Отказоустойчивая кластеризация (Failover clustering) предоставляет такой уровень возможностей и может применяться в случаях, когда узлы внутри этого кластера осуществляют доступ к совместно используемым данным. Именно это является ключевым фактором для способа разработки отказоустойчивой кластеризации, что имеющееся применяемое всеми узлами кластера хранилище должно совместно использоваться и предоставлять доступ всем узлам, которым это требуется. Существует множество различных ролей и служб, которые могут получить преимущества от отказоустойчивой кластеризации, однако имеется четыре определённые технологии, которые составляют основу кластеров, исполняющихся в современных центрах обработки данных - Hyper-V, файловые службы, Exchange и SQL. Если вы работаете с любой из этих технологий, а имеется шанс что вы работаете сразу со всеми ними, вам необходимо изучить возможности высокой доступности, которые могут быть предоставлены вам инфраструктурой, использующей отказоустойчивую кластеризацию.
Хотя отказоустойчивая кластеризация предоставляемая Windows Server Microsoft встроена и имеет возможность очень хорошо работать прямо из коробки со многими ролями и службами, важно отметить, что вы можете устанавливать отказоустойчивую кластеризацию также и для не-Microsoft приложений. Приложения сторонних производителей, которые работают под Windows Server в вашей среде, или даже выращенное в домашних устовиях приложение, которое было построено на дому, могут также получить преимущества от отказоустойчивого кластера. раз это приложение использует совместное хранилище, и вы можете определить те задачи, которые одно должно быть способным выполнять для данных приложений со стороны инструментов кластерного администрирования - как запускать эту службу, как останавливать эту службу, как отслеживать состояние такой службы и тому подобное - вы можете взаимодействовать с такими персональными службами и приложениями из отказоустойчивого кластера и предоставлять некоторую основную избыточность практически для любого типа приложений.
Один из самых мощных примеров отказоустойчивой кластеризации высвечивается при объединении кластеризации с Hyper-V. Существует возможность построить два или более серверов Hyper-V, соединить их все вместе в кластер и предоставить им возможность каждому размещать все имеющиеся виртуальные машины, которые хранятся в этой виртуальной среде. Предоставляя всем этим серверам хоста Hyper-V доступ к одному и тому же совместно используемому хранилищу, в котором сохраняются все виртуальные жёсткие диски, и настраивая отказоустойчивую кластеризацию между всеми этими узлами, вы можете создавать невероятно мощные и отказоустойчивые решения виртуализации для своей компании. Если сервер Hyper-V отключается, все ВМ, которые работали на этом хосте Hyper-V перенесутся на другой сервер хоста Hyper-V и раскрутят себя вместо этого там.
После минимального прерывания в обслуживании на время раскрутки этих ВМ, всё возвращается назад в рабочее состояние автоматически, без какого бы то ни было административного вмешательства. Что ещё лучше, как насчёт тех случаев, когда вам надо внести исправления или ещё как- нибудь вывести некий сервер хоста из рабочего состояния для работ по его обслуживанию? Вы можете легко заставить свои ВМ работать на другом сервере участнике данного кластера, причём они осуществят миграцию в реальном масштабе времени на этот сервер, так что будет нулевой простой, а затем вы вольны удалить данный узел для работ по его техническому обслуживанию и закончить работу на нём в свободное время до последующего его ввода в данный кластер. Раз мы применяем виртуальные машины и серверы для всех видов рабочих нагрузок, разве не было бы замечательно, если бы вы имели возможность избавить себя от любых единых точек отказа внутри такой среды виртуализации? Это именно то, что может предоставить отказоустойчивая кластеризация.
Балансировка нагрузки виртуальных машин
На практике кластер Hyper-V не только имеет возможность быстрого самостоятельного восстановления в случае отказа некого узла сервера Hyper-V, но теперь у нас также имеется некая логика интеллектуальной балансировки нагрузки, работающей совместно с такими кластерными службами. Если ваш кластер Hyper-V испытывает перегрузку виртуальными машинами, имеет смысл добавить ещё узел в этот кластер, предоставив данному кластеру больше возможностей и вычислительной мощности. Но после того как такой узел добавлен, сколько работы потребуется для сдвига части имеющихся ВМ на этот новый узел кластера?
Нисколько! Поскольку у вас имеется включённой балансировка нагрузки ВМ, веса данного кластера будут вычисляться автоматически, а рабочие нагрузки ВМ будут мигрировать в реальном масштабе времени, причём без времени простоя, на лету, с целью лучшего распределения имеющейся работы по всем узлам кластера, включая и полученный новый сервер. Балансировка нагрузки ВМ может исполняться и оцениваться по запросу, всякий раз когда вы посчитаете это необходимым, или же может быть настроена на автоматический запуск, выполняя анализ среды каждые 30 минут, автоматически принимая решение следует ли перемещать какие- либо рабочие нагрузки.
Кластеризация файловых серверов была доступна достаточно давно; это было одним из изначальных намерений, стоящим за выпуском кластеризации. Первоначально была полезна только применительно к документам и обычным файлам, другими словами, когда обладающим знаниями сотрудникам требуется повседневный доступ к файлам и папкам, а вам желателен доступ к этим файлам с высокой доступностью. На сегодняшний день такая кластеризация файловых серверов общего назначения работают в активно- пассивном сценарии. Когда несколько серверов сгруппированы сообща кластером для файлового доступа общего назначения, только один из этих узлов файловых серверов выступает активным и предоставляется в некий момент ролзователю. Только при возникновении времени его простоя данного узла его роль перекидывается прочим участникам кластера.
Горизонтальное масштабирование файлового сервера
В то время как кластеризации файлового сервера и великолепна при обычном доступе к файлам и папкам, она не была достаточно всеобъемлющей в плане обработки открытых или непрерывно изменяемых файлов. Первейшим примером таких файлов выступают файлы виртуальных жёстких дисков. К счастью, размещение рабочих нагрузок прикладных данных подобных этим именно то, для чего разработан Горизонтально масштабируемый файловый сервер (SOFS, Scale-Out File Server). Если вы планируете размещать виртуальные машины при помощи Hyper-V, вы определённо пожелаете ознакомиться с возможностями отказоустойчивой кластеризации, которые доступны для применения со службами Hyper-V. Более того, если вы собираетесь использовать кластеризованный хостинг Hyper-V, тогда вы несомненно пожелаете ознакомиться с Горизонтально масштабируемым файловым сервером как с технологией инфраструктуры для поддержки такой среды Hyper-V с высокой доступностью. Горизонтально масштабируемый файловый сервер (SOFS) помогает поддерживать отказоустойчивую кластеризацию, предоставляя файловые серверы с возможностью наличия работающими множества узлов (активный - активный), которые продолжают оставаться постоянно соединёнными друг с другом. Таким образом, что в случае отказа одного из серверов остальные немедленно доступны перекрыть возникающий зазор, причём без процесса отсекания, который приводит к времени простоя. Это важно при рассмотрении различий между хранением статических данных, таких как документы, и хранением файлов виртуальных жёстких дисков для доступа к ним со стороны ВМ. Ваши ВМ имеют возможность оставаться в рабочем состоянии в процессе выхода из строя некоторого файлового сервера при применении Горизонтально масштабируемого файлового сервера, что достаточно невероятно!
Поверх концепции отказоустойчивой кластеризации важно понимать, что имеются различные уровни, на которых может приносить вам преимущества кластеризация. Имеются два различных уровня, на которых вы можете применять построение кластеров: чтобы произвести впечатление на своих друзей по HA вы можете тот или иной подход и воспользоваться всего одним из этих уровней отказоустойчивой кластеризации, либо вы можете объединять оба.
Кластеризация на уровне приложений обычно включает в себя установку отказоустойчивой кластеризации на виртуальные машины. Использование ВМ не является тяжёлым требованием, но при этом является наиболее общим способом установки. Вы можете смешивать и подгонять виртуальные машины с физическими серверами в средах кластеризации, пока каждый из серверов соответствует имеющимся критериям установки. Такой режим приложений кластеризации полезен когда вы имеете исполняющиеся внутри своей опреационной системы определённые службы или роли, которые вы бы хотели иметь избыточными. Представляйте для себя это в большей степени как возможность микрокластеризации, при которой вы на самом деле защищаетесь и делаете одну определённую компоненту своей операционной системы избыточной посредством другого узла сервера, который способен перехватывать возникающую слабину, в случае отказа вашего первичного сервера.
Если кластеризация приложения является представителем микромира, то кластеризация на уровне хоста является представителем макромира. Наилучшие пример, который я могу привести, это именно тот, с которого большинство администраторов начинают в первую очередь при отказоустойчивой кластеризации, Hyper-V. Давайте допустим, что у вас имеются два физических сервера, которые оба размещают в вашей среде виртуальные машины. Вы желаете объединить в совместный кластер эти серверы с тем, чтобы все имеющиеся размещаемые на этих серверах Hyper-V ВМ имели возможность получать избыточность от этих двух физических серверов. Если отказывает сервер Hyper-V целиком, второй из них имеет возможность раскрутить те ВМ, которые исполнялись на своём вышедшем из строя первичном узле, и после минимального прерывания в обслуживании ваши ВМ, которые размещают реальные службы возвращаются в сторй и продолжают свою работу, являясь доступными для пользователей и тех приложений, в которые они проникли.
Оба этих упомянутых выше режима кластеризации несомненно могут объединяться воедино для ещё лучшей и более выразительной истории высокой доступности. Давайте позволим этому примеру рассказать о себе самостоятельно. Если у вас имеются два сервера Hyper-V, причём каждый подготовлен для работы с последовательностями виртуальных машин. Вы применяете кластеризацию хостов между этими серверами, поэтому если физическая коробка отказывает, другая восполняет имеющийся зазор. Это само по себе великолепно, однако вы интенсивно используете SQL, и вы желаете иметь уверенность что SQL сам по себе также имеет высокую доступность. Вы можете исполнять две виртуальные машины, причём каждая из них является SQL сервером, и настроить отказоустойчивую кластеризацию прикладного уровня между этими двумя ВМ специально для имеющихся служб SQL. Таким образом, если что- то происходит с одной из виртуальных машин, вам не придётся выполнять работы по обработке отказа для резервной копии сервера Hyper-V, вместо этого ваша проблема может быть решена вторым физическим сервером. Не имелось никакой необходимости в полномасштабном приобретении Hyper-V второго физического сервера, но вы всё же применяли отказоустойчивую кластеризацию для того чтобы иметь уверенность, что SQL всегда в рабочем состоянии.Это первичный пример кластеризации поверх кластеризации, и рассуждая в таком направлении мы можем начать достаточно созидательно предоставлять различные способы, которыми мы можем применять кластеризацию в вашей сетевой среде.
Когда у вас настроена отказоустойчивая кластеризация, множество узлов остаются в постоянном взаимодействии друг с другом. Таким образом, если один из них падает, им немедленно это становится известно, и они могут перебрасывать службы на другой узел, чтобы привнести их назад в рабочее состояние. Отказоустойчивая кластеризация применяет регистрацию для отслеживания многих установок на узле. Эти идентификаторы синхронно хранятся между узлами, поэтому в случае падения одного из них такие необходимые настройки разрушаются по всем оставшимся серверам и следующему узлу в кластере сообщается о необходимости раскрутить некие приложения, ВМ или рабочие нагрузки, которые размещались на упавшем первичной коробке. Может присутствовать некая небольшая загрузка в обслуживании пока раскручиваются эти компоненты на выбранном новом узле, однако все эти процессы полностью автоматизированы и не требуют ручного вмешательства, сводя время простоя до минимума.
Если вам требуется вырезать службы с одного узла на другой в качестве запланированного события, такого как внесение исправлений или технического обслуживания, для этого даже имеется ещё лучшая версия. Применяя процесс, имеющий название Миграции в реальном времени (Live Migration), вы имеете возможность перекидывать ответственность на второй сервер с нулевыми значениями простоя. Таким образом вы можете выводить узлы из своего кластера для их обслуживания или внесения исправлений в их безопасность, либо по какой ещё причине, причём без воздействия на пользователей или время работы системы на всём её пути. Миграция в реальном масштабе времени особенно полезна для кластеров Hyper-V, гда вам часто приходится вручную принимать решение на каком узле размещаются ваши ВМ для выполнения работы на другом узле или узлах.
Во многих кластерах присутствует идея кворума. Это означает, что если данный кластер расщепляется, например, когда останавливается какой- то узел, либо множество внезапно ставшими недоступными узлов из- за сетевого отключения какого-то вида, в таком случае для определения какой из сегментов кластера является тем, который всё ещё продолжает работу, применяется логика кворума. Когда у вас имеется некий крупный кластер, распространяющийся на множество подсетей внутри некой сетевой среды, тогда порой на имеющемся сетевом уровне происходит отделение узлов кластера друг от друга, причём обе стороны данного кластера осознают что не могут продолжать общение с прочими участниками кластера, тогда обе стороны данного кластера будут автоматически предполагать, что им следует теперь отвечать за рабочие нагрузки данного кластера.
Настройки кворума сообщают данному кластеру сколько отказов узлов может произойти перед тем как предпринять необходимые действия. При том что весь кластер знает настройку кворума, это может помочь в предоставлении ответов на подобные вопросы относительно того какой из разделов данного кластера является первичным при возникновении расщепления кластера. Во многих случаях кластеры предоставляют кворум, который полагается на некого стороннего участника, именуемого Свидетелем (witness). Как и предполагает его название, такой Свидетель отслеживает текущее состояние всего кластера и помогает в принятии решения относительно того когда и где необходимо производить восстановление после отказа. Я упоминаю об этом здесь в предверии обсуждения нами новых кластерных возможностей, встроенных в Server 2019, одна из которых состоит в неком улучшении в том плане, что такие Свидетели работают в средах небольшого размера.
Имеется большой объём информации, которую следует получить и ознакомиться с ней если вы намерены создавать достаточно крупные кластеры для настройки кворума и Свидетелей. Если вы заинтересованы в дополнительном изучении, обратитесь к https://docs.microsoft.com/en-us/windows-server/storage/storage-spaces/understand-quorum/
Мы собираемся потратить несколько минут на настройку небольшого кластера из серверов с тем, чтобы вы
могли ознакомиться с инструментами управления и моментами, с которыми следует соприкасаться при осуществлении
этого. К текущему моменту я откатил назад все настройки NLB на своих серверах
WEB1 и
WEB2,
которые я устанавливал ранее, так что теперь они опять на данный момент простые веб серверы и опять же нет
никакой избыточности между ними. Давайте настроим свой первый отказоустойчивый кластер и добавим оба этих
сервера в кластер.
У нас уже имеются два работающих сервера с установленной на них Windows Server 2019. Ничего специального на этих серверах не настроено, но мне нужно добавить на оба роль Служб файлов (File Server), так как в конечном счёте я намерен применять их в качестве кластера файловых серверов. Ключевым здесь является то, что по возможности вам следует иметь здесь серверы примерно одинаковые, с уже установленными ролями, которые вы собираетесь применять внутри данного кластера.
Ещё одно замечание на протяжении данной фазы построения состоит в том, что если это возможно, то наилучшим применением при кластеризации для серверов участников, располагающихся в одном и том же кластере, будет их размещение в одной и той же Организации (OU) из Active Directory. Причина для этого двоякая: во- первых, это обеспечивает вам одни и те же GPO, применяемые к этим множествам серверов при попытке сделать их настройки по возможности идентичными.
Во- вторых, в процессе создания такого кластера будут создаваться автоматически некоторые объекты, причём они будут создаваться в AD, а когда серверы участники расположены в одной и той же OU, эти новые объекты будут создаваться также в этой OU. Очень часто для того, чтобы видеть все связанные с ними объекты в AD, всем работающим в кластере участникам необходимо быть частью одной и той же OU, а самой этой OU быть выделенной для данного кластера:

Теперь, когда наши серверы включены и работают, мы хотим пройти далее и установить возможности кластеризации на каждый из них. отказоустойчивая кластеризация (Failover Clustering) является свойством внетри Windows Server, поэтому откройте мастер добавления ролей и свойств (Add roles and features) и добавьте его во все свои узлы кластера:
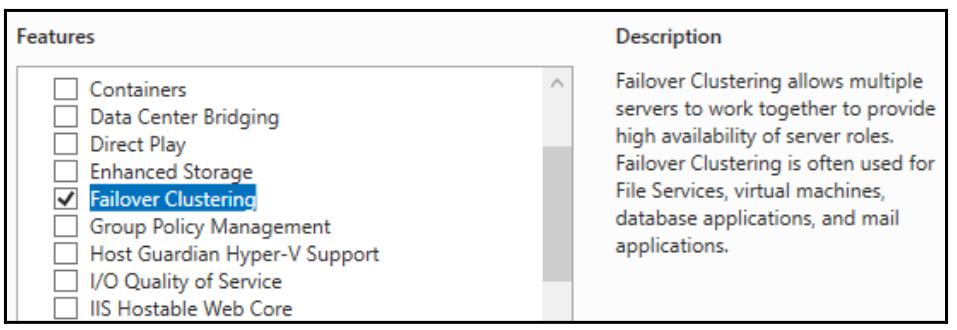
Как и в случае с большинством ролей и свойств, которые могут быть установлены в Windows Serever 2019, после реализации
вы обнаружите консоль управления для него внутри меню Средства (Tools)
Диспетчера сервера. Теперь загляните вовнутрь WEB1,
я могу видеть, что мне стал доступен для нажатия Диспетчер отказоустойчивого кластера
Failover Cluster Manager. Я собираюсь открыть этот инструмент
и начать работать с настройкой своего первого кластера в этом интерфейсе управления:
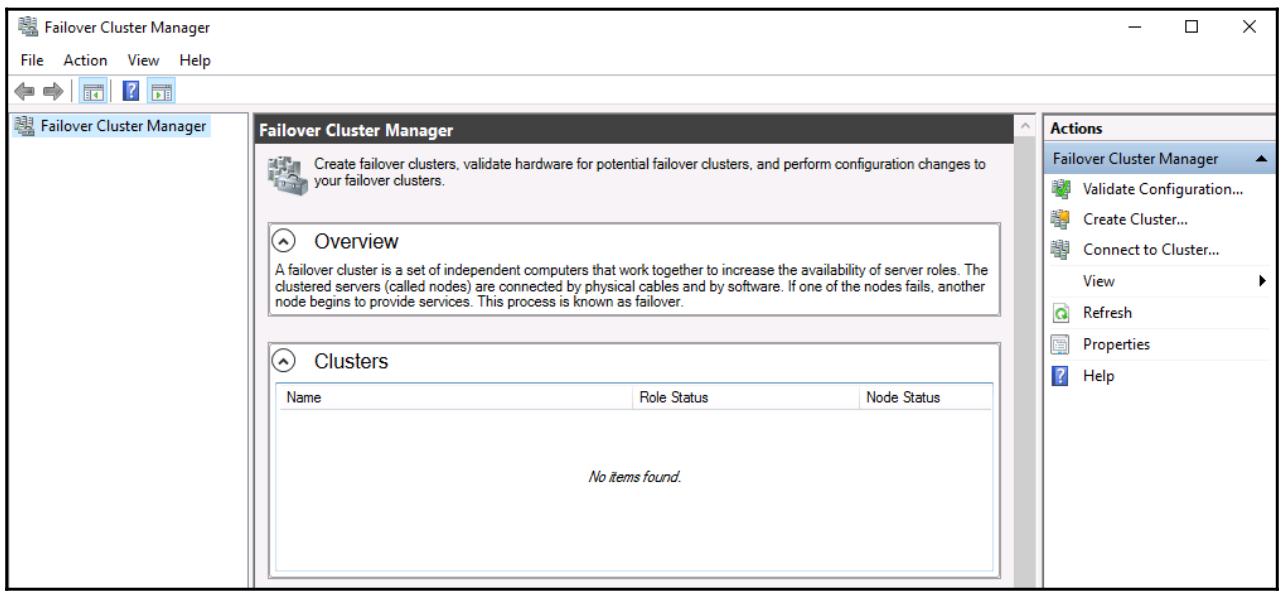
Внутри Диспетчера отказоустойчивого кластера (Failover Cluster Manager), вы заметите некий перечень доступных для запуска задач в разделе Управление (Management) данной консоли, рядом с самой серединой вашего экрана:
Прежде чем вы настроите сам этот кластер или добавите в него какие- либо узлы, мы должны для начала выполнить проверку наших настроек оборудования. Отказоустойчивая кластеризация является достаточно сложным набором технологий и имеется множество моментов, при которых их неверная настройка или несовместимость могут криво настроить весь кластер. Очевидно, что вы собираетесь создать кластер для надёжного резервирования, но даже простейшая ошибка в настройке ваших серверов участников может вызвать проблемы, которых будет достаточно чтобы отказ такого узла не приводил в результате к автоматическому восстановлению, что влечёт за собой провал главной цели. Чтобы все ваши "T" пересекались пунктиром с "I", имеется некоторая очень многосторонняя проверка допустимости, встроенная в ваш Диспетчер отказоустойчивого кластера. Это некий вид встроенного анализатора лучших практических приёмов. Эти проверки могут быть выполнены в любой момент, прежде чем данный кластер построен или после того как он проработал в промышленном варианте на протяжении лет. На самом деле, даже если вам придётся открыть вариант поддержки (support case) Microsoft, скорее всего, самое первое что они попросят вас, это будет как раз выполнение инструментария Проверки правильности настроек (Validate Configurations) и просьба просмотреть их вывод.
Чтобы начать наш процесс допустимости, пройдите далее и кликните по ссылке с названием Validate
Configurations…. Теперь вы запускаете мастер, который позволит нам выбрать фрагменты, которые являются
фрагментами вашей технологии кластера, которые мы собираемся проверить на правильность. Повторим, мы должны заставить нашу
централизованную технологию управления Microsoft задуматься и осознать, что данный
мастер не имеет представления и не заботится о том, что он исполняется на одном из тех серверов участников, которые я
намереваюсь сделать частью общего кластера.
Мы должны определить все узлы серверов, которые мы бы хотели просканировать для проверок правильности,
поэтому в своём случае я собираюсь сообщить ему что я бы хотел проверить свои серверы
WEB1 и
WEB2:
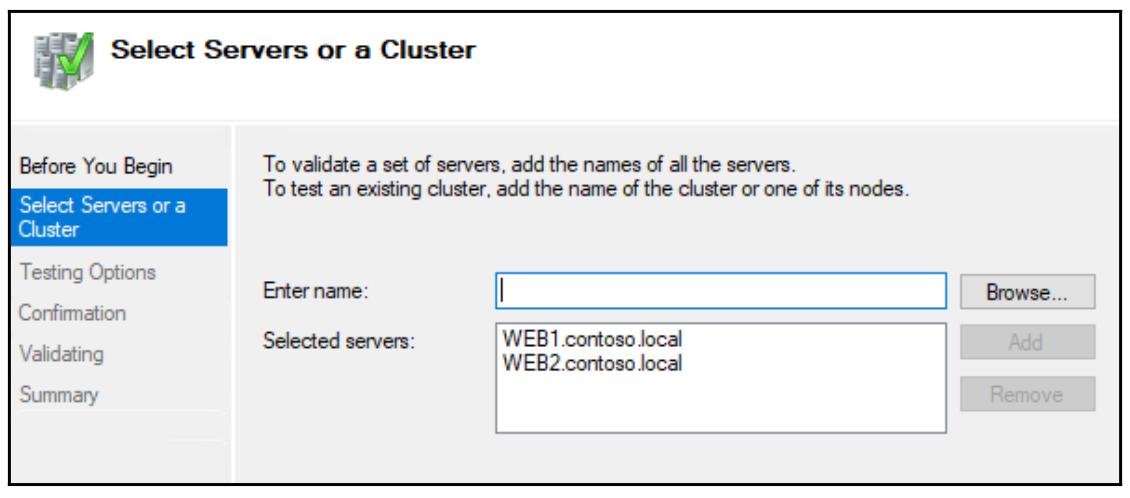
Экран Testing Options позволяет вам выбрать радио кнопку Исполнения только выбранных мной тестов (Run only tests I select) и у вас далее будет возможность исполнять только определённые выбираемые вами тесты проверки правильности. Обычно, когда вы настраиваете совершенно новый кластер, вы захотите выполнить все эти тесты чтобы быть уверенным что всё измерено правильно. В промышленных системах, однако, вы можете выбирать ограниченное число тестов для исполнения. Это, в частности, так в отношении тестов Хранилища (Storage), так как они могут временно отключать ваш кластер при работе этих тестов, а вы не хотели бы вмешиваться в ваши промышленные службы, если вы работаете в рамках запланированного окна технического обслуживания:

Так как я настраиваю совершенно новый кластер, я собираюсь позволить исполнение всех имеющихся тестов. Поэтому я оставлю выбранной рекомендуемую опцию для исполнения всех тестов (Run all tests) и продолжить:
Когда все тесты завершатся, вы увидите окончательный вывод их результатов. Вы можете кликнуть по кнопке View Report… чтобы просмотреть дополнительные подробности всего что выполнено. Имейте в виду, что имеются три уровня прохождения/ отказов. Зелёное это хорошо, а красное плохо, однако жёлтое это что-то навроде это будет работать, но оно не является наилучшим вариантом. Например, у меня есть только один NIC в каждом из моих серверов и мой мастер распознает, что несомненно имеется проблема с резервированием во всех отношениях, мне необходимо иметь по крайней мере два. Он позволит такое падение и продолжит работу, но предупредит меня, что я мог бы выполнить улучшение, добавив второй NIC в каждый из своих узлов.
Между прочим, если вам придётся зарегистрироваться как администратору, как и мне, у вас не будет возможности открыть такой отчёт проверки правильности, так как браузер Edge не имеет полномочий для запуска под учётной записью администратора. Это прекрасная встроенная в Windows Server 2016 проверка безопасности, и позор мне делать что- либо с учётной записью администратора, однако, здорово - это же проверочная лаборатория.
Если вы обнаружите, что вы не можете просматривать по какой- то причине данный отчёт, вы сможете обнаружить этот отчёт
внутри C:\Windows\Cluster\Reports, скопируйте его на свой локальный компьютер и
откройте его там:
Помните, что вы можете вернуться к процессу валидации в любой момент для проверки ваших настроек, воспользовавшись задачей Validate Configurations… внутри своего Диспетчера отказоустойчивого кластера.
Этап проверки правильности может занять некоторое время если у вас имеется множество результатов, которые подлежать исправлению прежде чем процесс будет продложен. Однако когда вы получите своб проверку валидации чистой, вы наконец готовы к построению самого кластера. Для этого кликните следующее действие, которое доступно нам в нашей консоли Диспетчера отказоустойчивого кластера - Создать кластер (Create Cluster…).
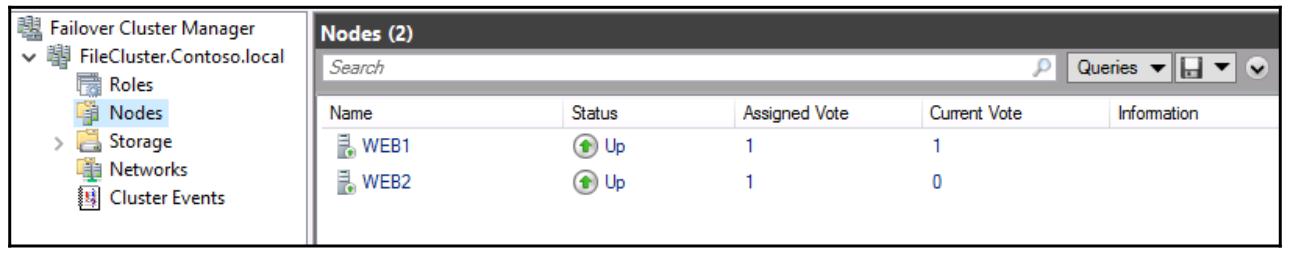
Повторим, для начала мы должны определить какие серверы мы хотим иметь частью данного нового кластера, поэтому я
собираюсь снова ввести свои серверы WEB1 и
WEB2. После этого у нас не так много информации
для ввода о находящемся в кластере, но одно из самых ключевых мест информации содержится в экране Точки доступа для
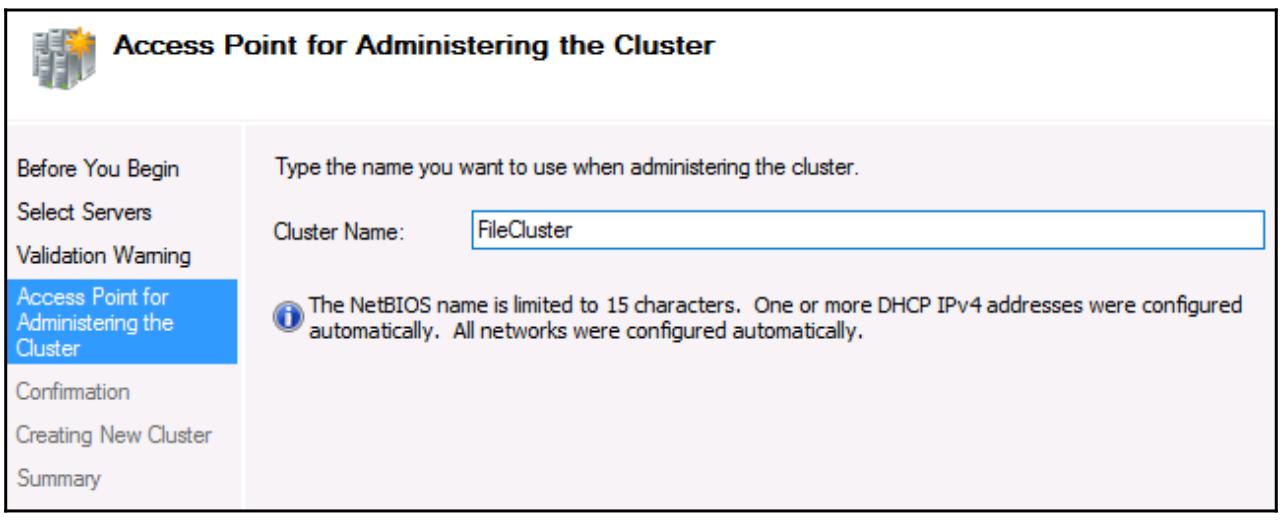
администрирования кластером (Access Point for Administering the Cluster).
Именно здесь мы определяем уникальное имя, которое будет использоваться нашим кластером и совместно применяться всеми
серверами участниками. Оно имеет название Объекта имени кластера (CNO,
Cluster Name Object), и по завершению настройки вашего кластера
вы будете видеть это имя, отображаемое в виде объекта внутри Active Directory:
После завершения данного мастера, вы теперь сможете видеть новый кластер внутри интерфейса Диспетчера отказоустойчивого кластера, а также иметь возможность углубляться в более спуцифические функции внутри этого кластера. Существует ещё одно действие для вещей таких как Configure Role…, которое будет важным для настройки реальных функций, которые данный кластер собирается выполнять, а также Add Node…, которое является вашим местом для включения дополнительных серверов участников в данный кластер в его дальнейшем пути:
Свойство построения кластеров присутствует уже продолжительное время, но постоянно совершенствуется. В двух последних выпусках LTSC, Server 2016 и Server 2019, были внесены некие крупные изменения и добавления в построение отказоутсойчивых кластеров. Некоторые из этих изменений, которые мы будем обсуждать, первоначально были представлены в 2016, а следовательно они не являются совершенно новыми, но они всё ещё значимы для того способа, которым мы обрабатываем кластеры в Server 2019, а следовательно они также упоминаются здесь.
При настройке кворума для отказоустойчивого кластера, вплоть до Server 2019, кластер из трёх узлов требовал три сервера, так как Свидетелю для кластера требовалось располагаться в некого вида совместном ресурсе свидетельства, обычно в обособленном файловом сервере.
Начиная с Server 2019, такое свидетельство теперь может быть неким простым USB устройством и его даже не обязательно подключать к некому Windows Server! Имеется множество фрагментов оборудования сетевой среды (коммутаторы, маршрутизаторы и тому подобное), которое способно принимать носители хранения на основе USB, а подключаемый к такому сетевому устройству USB носитель теперь будет достаточен чтобы отвечать требованиям Свидетельства кластера. Именно это составляет выигрыш для кластеризации в малых окружениях.
В Windows Server 2019 було выполнено значительное число улучшений для построения отказоустойчивых кластеров. Предыдущие версии для аутентификации обмена внутри кластера полагались на NTLM (New Technology LAN Manager), однако большое число компаний активно предпринимают шаги по отключению применения NTLM (по крайней мере ранних версий) внутри своих сетевых сред. Отказоустойчивое построение кластеров теперь может выполнять взаимодействие внутри кластера с применением Kerberos и сертификатов для удостоверения такого сетевого обмена, что устраняет потребность в NTLM.
Другой проверкой безопасности/ надёжности, которая реализовывалась при установке некого Свидетельства отказоустойчивого кластера на совместном файловом ресурсе, состояло в блокировании хранимого внутри DFS Свидетельства. Никогда не поддерживалось создание некого Свидетельства внутри совместного ресурса DFS, но консоль ранее позволяла вам делать это, что означает, что некоторые компании выполнили именно это и заплатили за это определённую цену, так как подобное способно создавать проблемы со стабильностью кластера. Инструменты управления кластером были обновлены для проверки наличия пространства имён DFS при создании Свидетеля и более не допускают такого наличия.
Могу ли я настраивать отказоустойчивую кластеризацию по подсетям? Иными словами, если у меня имеется первичный центр обработки данных, а я также арендую пространство в CoLo по мере развития, либо у меня имеется другой центр обработки данных в моей стране существуют ли возможности для меня настроить кластеризацию между узлами, которые физически разделены? Здесь имеется быстрый и простой ответ: да, отказоустойчивой кластеризации всё равно! В точности также, как если бы эти серверные узлы располагались прямо рядом друг с другом, кластеризация может получать преимущества от множества площадок, каждая из которых размещает свои собственные узлы кластера, и перемещать службы взад и вперёд по этим площадкам.
Исторически у нас имелась единственная возможность установления отказоустойчивой кластеризации между узлами, которые были объединены в один и тот же домен. Windows Server 2016 привнёс возможность выйти за рамки этого ограничения, и мы можем даже строить кластер без Active Directory замешенного во что бы то ни было. В Server 2016 и Server 2019 вы можете, конечно, всё ещё создавать кластеры, в которых все узлы присоединены к одному и тому же домену, и мы ожидаем, что это всё ещё будет верным для большинства имеющихся установок. Однако, если у вас имеются серверы, которые присоединены к различным доменам, вы можете сейчас устанавливать кластеризацию между такими узлами, более того, серверы- участники в некотором кластере могут теперь быть членами рабочей группы и им даже совсем не нужно присоединяться к какому- нибудь домену.
Хотя это и расширяет имеющиеся возможности отказоустойчивой кластеризации, это также приводит к паре ограничений. При применении многодоменной кластеризации или кластеризации с рабочей группой, вы будете ограничены исключительно применением в качестве интерфейса PowerShell. Если вы применяете для взаимодействия со своими кластерами один из инструментов GUI, вам необходимо задуматься над этим. Вам также будет необходимо создавать локальные учётные записи пользователей, которые могут применяться кластеризацией и предоставлять их каждому из узлов этого кластера, а эти учётные записи пользователей должны иметь права администраторов для данных серверов.
Междоменная миграция кластеров
Хотя установка кластеризации для множества доменов и была возможна на протяжении ряда лет, миграция кластеров с одного домена AD в другой не являлась неким вариантом. Начиная с Server 2019 это изменилось. При построении кластеров со множеством доменов у нас имеется большая гибкость, которая включает и миграцию кластеров между такими доменами. Данная возможность поможет администраторам продвигать проекты приобретения компаний и консолидации доменов.
Эта новая возможность, предоставляемая нам в 2016, имеет слегка странное название, но на самом деле очень крутая функция. Это нечто разработанное для того чтобы помочь тем из нас, кто применял отказоустойчивую кластеризацию для того чтобы улучшать своё окружение. Если вы работаете с кластером в настоящее время, и этот кластер является Windows Server 2012 R2, это определённо то, что вы ищете. Круговое обновление операционной системы кластера (Cluster Operating System Rolling Upgrade) делает для вас возможным обновление операционных системы ваших узлов кластера с Server 2012 R2 до Server 2016, а затем и на Server 2019, причём без простоя. Больше нет необходимости останавливать какую- либо из служб в ваших рабочих нагрузках Hyper-V или Горизонтально масштабируемых файловых серверов, которые применяют кластеризацию, вы просто применяете такой процесс кругового обновления и в конце него все ваши узлы кластера работают с новой Windows Server, причём их кластер всё ещё активен и даже никто не знает что же произошло. Конечно, кроме вас.
Это значительно отличается от предыдущего процесса обновления, при котором чтобы перенести ваш кластер на Server 2012 R2, требовалось отключать весь кластер, вводить новые узлы под управлением 2012 R2 и затем повторно устанавливать весь кластер. Это сопровождалось большим временем простоя и значительной головной болью чтобы получить уверенность что всё прошло гладко по возможности.
Хитрость, которая делает возможной такое бесшовное обновление состоит в том, что сам по себе кластер продолжает работать
под функциональным уровнем (FL, functional level) 2012 R2 пока вы не выполните команду для его перескока к функциональному
уровню Server 2016. Пока вы не выполните эту команду, кластеризация работает под самым старым FL, даже на имеющихся новых
узлах, которые вы ввели под управлением операционной системы Server 2016. по мере обновления ваших узлов по одному за раз,
все остальные узлы, которые всё ещё активны в остающемся в рабочем состоянии кластере и продолжают обслуживать своих
пользователей и приложения, так что все системы работают как обычно с точки зрения рабочих нагрузок как для серверов 2012
R2, однако выполняя это на функциональном уровне 2012 R2. Это называется смешанным режимом. Он позволяет вам снимать даже
самую последнюю коробку 2012 R2, изменить её на 2016, а потом повторно ввести её, причём никто не будет знать об этом. Затем,
когда все обновления ОС будут завершены, исполняется команда PowerShell Update-ClusterFunctionalLevel
для перескока на следующий уровень функционирования и вы получаете кластер Windows Server 2016, который бесшовно обновился
с нулевым временем простоя.
Как вы можете успешно подразумевать из его названия, Эластичность виртуальной машины (Virtual Machine Resiliency является улучшением) в кластеризации, которая предоставляет определённые преимущества кластерам серверов Hyper-V. Во времена кластеризации Server 2012 R2 не было чем- то необычным иметь некоторые проблемы взаимодействия внутри массива или внутри кластера. Это иногда выглядело как отказ перехода, что означало, что кластер полагал, что некий узел перешёл в автономный режим, в то время, как он когда этого на самом деле не было, а также приводило к отказу, который иногда вызывал большее время простоя, чем если бы шаблоны распознавания для реального отказа просто бы оказывались слегка лучшими. Хотя для большей части кластеризации и отказоустойчивости узлов кластера это работало успешно, нет предела для совершенства. Это именно то, чему посвящена Эластичность виртуальной машины. Теперь вы можете настраивать варианты для эластичности, предоставляя возможность более конкретного определения того, какого именно поведения должны придерживаться ваши узлы в процессе отказов узла кластера. Вы можете определять такие вещи, как Уровень эластичности (Resiliency Level), который сообщает данному кластеру как ему обрабатывать отказы. Вы также можете установить свой собственный период эластичности (Resiliency Period), промежуток времени, в течение которого эти ВМ могут работать в изолированном состоянии.
Другое изменение состоит в том, что неработоспособные узлы кластера теперь помещаются в некий карантин на определяемое администратором время. Им теперь не разрешается присоединяться назад в кластер пока они не определены как жизнеспособные и отбывшие свой срок ожидания, что предотвращает ситуации такие как узел, который застрял на цикле перезагрузки неосмотрительно подключается назад в данный кластер и вызывает непрерывные проблемы своими периодическими падениями и подъёмами.
Реплика хранения (SR, Storage Replica) является новым способом синхронизации данных между серверами. Она является технологией репликации данных, которая предоставляет возможность репликации данных между серверами на блочном уровне, даже между различными физическими площадками. Реплики хранения сами по себе являются новой формой резервирования в Windows Server 2016, которую мы ранее не наблюдали в своём мире Microsoft; в прошлом нам приходилось полагаться на инструменты сторонних производителей для такого вида возможностей. Реплика хранения также важна для обсуждения прямо на задах отказоустойчивой кластеризации, потому что SR является секретным соусом, который делает возможным проведение отказоустойчивой кластеризации для множественных площадок. Когда у вас имеется потребность размещать узлы кластера во множестве различных физических мест, вам необходим способ для того, чтобы быть уверенным что все данные, используемые даными узлами кластера непрерывно синхронизуются с тем, чтобы отказоустойчивость действительно была возможной. Такой поток данных предоставляется репликой хранения.
Одним из самых замечательных моментов относительно SR состоит в том, что он в конце концов делает возможным некое решение от единственного производителя, коим, естественно, выступает Microsoft, для предоставления единой технологии и программного обеспечения для хранения и построения кластеров. Оно также равнодушно к оборудованию, предоставляя вам возможность применять ваши собственные предпочтения для носителей хранения данных.
SR означает тесную интеграцию и одну из поддерживаемых технологий основательной среды, устойчивой к отказам. На самом деле, имеющийся графический интерфейс для SR расположен внутри программного обеспечения Диспетчера отказоустойчивого кластера - но конечно же настраивается также через PowerShell - поэтому убедитесь что вы рассматриваете Отказоустойчивую кластеризацию и SR как давайте жить дружно для своей среды.
В Windows Server 2019 теперь обновлён тот момент, что SR теперь доступен внутри Server 2019 редакции Standard! (Изначально он требовал Datacenter, что было запретительным для ряда реализаций.) Администрирование SR теперь доступно изнутри нового WAC (Windows Admin Center, Центра администрирования Windows).
{Прим. пер.: Существует три различных варианта которые вы можете выбрать для осуществления Реплики хранения, вот краткое изложение каждой из них чтобы вы могли определить что будет работать в вашей среде, более подробное изложение см. в Реализация Реплик хранения в нашем переводе Курса подготовки к экзамену 70-740, вышедшей в январе 2017 книги Крейга Заккера.}
S2D является кластерной технологией, но я привожу её именно здесь, обособленно от общего построения отказоустойчивых кластеров, так как S2D составляет центральный компонент SDDC (software-defined data center, Программно- управляемого центра обработки данных), а за последние несколько лет так много внимания уделялось улучшениям, что он на самом деле достоин собственной категории.
В своей сердцевине S2D являетс неким способом построения чрезвычайно эффективной и надёжной централизованной, основанной на сетевой среде платформы хранения, причём целиком построенной на Windows Server. При обслуживании в точности тех же самых общих целей (файлового хранения), что и традиционные устройства NAS или SAN, S2D применяет совершенно иной подход, при котором он не требует некого специализированного оборудования, ни каких бы то ни было особых кабелей или подключений между имеющимися узлами в своём кластере S2D.
Всё что вам требуется для построения S2D, это Windows Server; чем быстрее, тем лучше, но они могут быть обычными, повседневными серверами. Эти серверы должны соединяться посредством сетевой среды, но здесь нет никаких особых требований; они просто все вместе подключены к некой сетевой среде, в точности как все прочие серверы в вашем окружении. После того как у вас имеются запущенными серверы, вы можете воспользоваться технологиями построения кластера или новым WAC для соединения этих серверов воедино в массивы S2D.
S2D выступает частью общей истории Гиперконвергентной инфраструктуры (HCI, Hyper-Converged Infrastructure) и является великолепным способом предоставления чрезвычайно быстрого и защищённого хранилища для чего угодно, а в особенности для рабочих нагрузок подобных кластерам серверов Hyper-V. Как вы уже знаете, при построении кластера серверов Hyper-V его узлам необходим доступ к совместному хранилищу в котором будут располагаться файлы жёстких дисков виртуальных машин. S2D является наилучшим способом такого централизованного хранилища.
S2D берёт имеющиеся у серверов узлов вашего кластера S2D жёсткие диски и сочетает всё их пространство воедино в программно- определяемые пулы хранения. Такие пулы хранения настраиваются с возможностями кэширования и даже со встроенным равнодушием к отказам. Очевидно что вы не желаете останова отдельного узла S2D или даже отдельного жёсткого диска, вызывающих икоту вашего решения S2D, и Microsoft, естественно, не хочет чтобы такое происходило. Поэтому когда вы группируете серверы и все их жёсткие диски воедино в такие большие пулы хранения S2D, они автоматически настраиваются с избыточностью по всем таким дискам с тем чтобы при отключении отдельных компонентов не приводило в результате к утрате данных или даже к замедлению системы.
S2D является наилучшей платформой хранения как для SOFS, так и для кластеров Hyper-V.
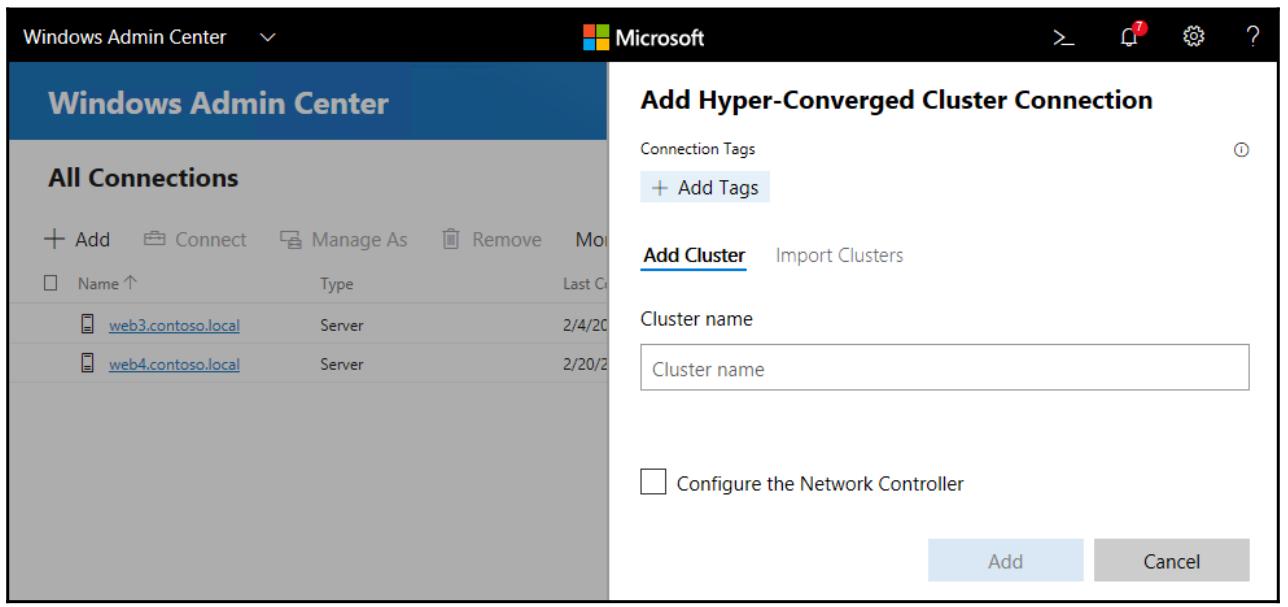
Хотя S2D на основе Server 2016 настраивался в основном через PowerShell (что к сожалению означает, что очень многие администраторы даже и не попробовали её пока), Windows Server 2019 привнёс нам новый набор инструментов WAC, а WAC теперь содержит встроенные параметры для настройки некой среды S2D:
S2D является одной из тех технологий, которая гарантирует свою собственную книгу, однако те кто ищут способа опробовать её или начать работать с этой поразительной технологией долны начать с https://docs.microsoft.com/en-us/windows-server/storage/storage-spaces/storage-spacesdirect-overview.
{Прим. ещё одной ложкой дёгтя является требование наличия лицензии Datacenter. Тем для кого это является существенным денежным препятствием в освоении данной технологии, рекомедуем рассмотреть возможность применения Ceph в тех же самых серверах узлов. Советуем свой перевод 2 издания Полного руководства Ceph Ника Фиска для знакомства с этой технологией, имеющей возможность установки из кода с открытым исходным кодом. Также готовы предоставить вам услуги по консалтингу, настройке и сопровождению обеих SDDC технологий хранения.}
Для тех, кто уже знаком с основными понятиями S2D и кто желает узнать что же нового или отличного имеется в особенностях Server 2019, вот некоторые улучшения, которые привнесены самой новой версией обсуждаемой операционной системы:
-
Улучшенное применение томов ReFS (File System): теперь у нас имеются функции дедупликации и сжатия располагающихся в S2D томов ReFS.
-
Свидетельство USB: Мы уже обсуждали его кратко, применительно к кластеру S2D использование Свидетельства делает возможным наличие только двух узлов, а вы теперь можете применять некий ключ USB подключённым в часть сетевого оборудования, вместо того чтобы запускать для целей свидетельства третий узел.
-
WAC: WAC теперь содержит инструменты и функциональность для определения и упралвения кластерами S2D. Это упрощает адаптацию того народа, который не переполнен знакомством с PowerShell.
-
Улучшенная ёмкость: Мы теперь имеем возможность размещения в кластере Петабайтов.
-
Улучшенная скорость: Хотя S2D и была достаточно быстрой начиная с самой первой версии, в Server 2019 у нас имеются некие действенные улучшения. На конференции Ignate последнего года microsoft выставил некий кластер S2D из 8 узлов, который имел возможность достигать 13 000 000 IOPS. ХМ!
Избыточность является критически важным компонентом для того способа, которым мы планируем строить серверную инфраструктуру в наши дни. Windows Server 2019 имеет некоторые мощные возможности построения прямо внутри себя, которые вы можете применять в ваших собственных средах, причем уже сегодня! Я надеюсь, что набрав дополнительную информацию как о Балансировке сетевых нагрузок, так и об отказоустойчивой кластеризации, вы получите возможности расширения своей организации применяя эти методы и расширяя пределы бесперебойной работы ваших служб. На мой взгяд, если и имеется какой- либо путь продолжения данной главы, так это начать построение вашего собственного HCI с применением S2D {Ceph} и отказоустойчивой кластеризации для того чтобы создавать собственную элластичность в вашей инфраструктуре Hyper-V. Гиперконвергентность буквально изменит способ вашей работы и предоставит вам некий душевный покой, который вы даже не могли себе представить возможным в некотором мире, имеющим цель работы в течение 99.999% времени. В своей следующей главе мы рассмотрим PowerShell.
-
Какая из технологий лучше подходит для превращения вашего веб сервера в более устойчивый - Балансировка сетевой нагрузки или Построение отказоустойчивого кластера?
-
Что означают сокращения DIP и VIP в Балансировке сетевой нагрузки?
-
Перечислите три режима Баланисровки сетевой нагрузки.
-
Является ли Балансировка сетевой нагрузки в Windows Server 2019 ролью или свойтсвом?
-
Какие роли наиболее часто применяются совместно с построением отказоустойчивого кластера?
-
Какой вид небольшого устройства теперь может применяться в качестве Свидетельства некого кворума (совершенно нового для Server 2019)?
-
Истина или ложь - Storage Spaces Direct требуют применения жёстких дисков SSD.